生成ビデオ伝播
The problem of generative video propagation, as addressed in this paper, is rooted in the broader field of computer vision, specifically within the domain of video generation and editing.
背景と学術的系譜
本稿で扱う生成ビデオ伝播の問題は、コンピュータビジョン、特にビデオ生成および編集の広範な分野に根差している。歴史的に、中心的な課題は、単一フレーム(または疎なフレーム群)に加えられた変更を、ビデオシーケンス全体にわたって一貫性があり、現実的に伝播させることであった。ビデオ伝播の初期のアプローチは、変更されたビデオコンテンツにおける時間的整合性と視覚的妥当性を維持する必要性から生まれたものであり、主に光学フロー [9, 44]、深度推定 [6, 55]、放射場 [33]、アトラス [20, 24] といった従来のコンピュータビジョン技術に依存していた。最小限の手作業で複雑で現実的なシナリオを処理できる高度なビデオ編集ツールの需要の高まりが、この特定の問題の出現と進化を推進してきた。
著者らが新しいフレームワークを開発する動機となった、従来のアプローチの根本的な限界または「ペインポイント」は、いくつかの主要な問題に起因する。従来のメソッドは、ビデオの持続時間中にエラーが蓄積しやすく、後続のフレームの品質低下や不整合につながることが多かった。これにより、ロバスト性が低下し、多様なビデオコンテンツに対する汎化能力が制限された。また、多くの先行技術はタスク固有であり、ある種類の編集(例:オブジェクト除去)のために訓練されたモデルは、別のタスク(例:背景置換)のために大幅な再訓練または完全に異なるモデルを必要とした [28, 31, 34, 61]。統一されたフレームワークの欠如は、大きなボトルネックであった。より最近の拡散ベースのビデオ編集モデルは強力であるものの、それらも独自の制約を持っていた。多くは、オブジェクトの形状に実質的な変更を加えたり、複雑な背景の変更を処理したりするよりも、主に外観の変更を目的として設計されていた。それらはしばしば、各フレームごとに密なマスクラベリングを必要としたが、これは労働集約的で時間のかかるプロセスであり、リアルタイムまたは大規模なアプリケーションを非現実的なものにしていた。例えば、I2VEdit [34] のような手法は、各ビデオクリップに対してモーションLoRAを学習する必要があることで計算の複雑さを増大させた。ReVideo [31] のような他のアプローチは、入力ビデオの一部を黒い正方形でマスクすることを含んでいたが、これは意図せず重要な情報を削除し、複雑な背景編集や大規模な形状変更を処理する能力を制限した。著者らの動機は、タスク固有の再訓練や密なマスク入力を必要とせずに、多様な編集をシームレスかつロバストに伝播できる統一された生成フレームワークを提案することで、これらの限界を克服し、ビデオ編集プロセスを大幅に簡素化することであった。
直感的なドメイン用語
この論文からの専門用語をいくつか、ゼロベースの読者向けに直感的な日常の類推で翻訳する。
-
生成ビデオ伝播 (Generative Video Propagation): クレイアニメーション映画を制作していると想像してください。最初のシーンを粘土で作り、次に粘土キャラクターの1人に小さな帽子を追加することにしました。「生成ビデオ伝播」とは、編集された最初のシーンを見た後、魔法のように非常に賢いアシスタントが、後続のすべてのシーンを自動的に再彫刻し、帽子が一貫してキャラクターに現れ、自然にキャラクターと一緒に動き、映画に完全に統合されているように見えるようにするようなものです。これは、すべてのフレームに触れることなく、あなたの最初の編集をビデオ全体に「生成的」(創造的、現実的)な方法で「伝播」させます。
-
画像からビデオ (I2V) 生成モデル (Image-to-Video (I2V) Generation Model): これは非常に想像力豊かな物語作家だと考えてください。この物語作家に1枚の写真(「画像」)と次に何が起こるかの簡単な説明を与えると、彼らはそこから短いビデオシーケンス全体を考案して作成できます。例えば、静止した湖の写真を与えて「水を穏やかに波立たせて」と言うと、彼らは現実的な波のある湖のビデオを生成します。この論文では、この物語作家は、編集された最初のフレームに基づいて、ビデオの残りの部分を生成するために使用されます。
-
選択的コンテンツエンコーダー (Selective Content Encoder, SCE): 非常に注意深い図書館員を想像してください。この図書館員に本の2つのバージョンを与えます。元の本と、あなたが特定の文章にハイライトを付けたバージョンです。この図書館員の仕事は、あなたがハイライトしなかった元の本のすべての部分を記憶し、保持するだけで、ハイライトされたセクションを意図的に無視することです。それは元のコンテンツを「選択的にエンコード」し、変更されないことに焦点を当てるため、生成モデルは残りの本を台無しにすることなく、編集された部分を埋めることができます。
-
領域認識損失 (Region-Aware Loss, RA Loss): 学生の美術プロジェクトを採点していると想像してください。プロジェクトには2つの部分があります。描画と絵画です。「領域認識損失」は、描画(ビデオの変更されていない部分)と絵画(編集された部分)の両方に同等の注意を払うことを保証する採点システムのようなものです。これは、モデルが元のコンテンツを維持することと編集の正確な伝播の両方でうまく学習することを保証し、一方を犠牲にして一方に集中しすぎるのを防ぎます。
記法表
| 記法 | 説明 |
|---|---|
問題定義と制約
コア問題定式化とジレンマ
本論文は、生成ビデオ伝播の複雑な問題に取り組み、現実性と一貫性を維持しながら、最初のフレームの編集をビデオシーケンス全体にシームレスに適用することを目指している。
入力/現在の状態:
出発点は、$T$ フレームからなる元のビデオ $V = \{v_1, v_2, ..., v_T\}$ と、単一の変更された最初のフレーム $v'_1$ である。この $v'_1$ は、元の最初のフレーム $v_1$ に適用された任意の編集の結果である。既存のビデオ編集手法は、通常、いくつかの限界に悩まされている。それらはしばしば、各フレームの密なマスクラベリングを必要としたり、モーションガイダンスのために光学フローや深度マップのような補助入力を利用したり、または各特定の編集タスクやビデオクリップごとに再訓練を必要としたりする。多くは、外観変更のような特定の種類の編集に限定されており、実質的な形状変更や複雑な背景変更には苦労する。
出力/目標状態:
望ましい終点は、新しい変更されたビデオ $V' = \{v'_1, v'_2, ..., v'_T\}$ である。各後続フレーム $v'_t$ ($t \in \{2, ..., T\}$) について、目標は、$v'_1$ で導入された変更がビデオ全体にわたって正確かつ現実的に伝播されることを保証することである。同時に、ビデオの編集されていないすべての領域は、外観とモーションの両方において、元のコンテンツと完全に一貫している必要がある。このフレームワークは、タスク固有のデータや光学フローのような明示的なモーションキューを必要とせずに、オブジェクト除去、挿入、置換、追跡、およびアウトペインティングを含む、幅広いビデオ編集タスクに一般的に適用可能であるべきである。
欠落しているリンクまたは数学的ギャップ:
正確な欠落リンクは、ビデオの変更された領域と変更されていない領域を効果的に分離し、単一の編集された最初のフレームからシーケンス全体への変更を伝播できる、統一された生成フレームワークである。これは、変更されていない領域で元のコンテンツを維持し、編集された領域で新しい物理的に妥当なコンテンツを生成しながら、多様で複雑な編集シナリオ全体で達成されなければならない。数学的には、本論文は、変更されたフレーム $v'_t$ ($t \in \{2, ..., T\}$) が $v'_t = G(E(V), v'_1, t)$ によって生成されるような生成関数 $G$ と選択的コンテンツエンコーダー $E$ を定義することを目指している。ここで、$E(V)$ は元のビデオ $V$ からの変更されていない情報のみを選択的にエンコードする必要があり、$G$(画像からビデオへの生成モデル)が後続フレームへの編集されたコンテンツの伝播に焦点を当てることを可能にする。課題は、$E$ と $G$ を協調して設計し、明示的なフレームごとのガイダンスなしにこの分離と一貫した伝播を達成することである。
痛みを伴うトレードオフまたはジレンマ:
以前の研究者は、根本的なトレードオフに囚われていた。
1. 現実性と一貫性 vs. 一般性と柔軟性: 編集の非常に現実的で時間的に一貫した伝播(特に大規模な形状変更や背景変更のような複雑な変更の場合)を達成することは、しばしば一般性の犠牲を伴う。一貫性に優れる方法は、通常、明示的なモーション表現(例:光学フロー)またはタスクごとのファインチューニングに依存しており、それらを柔軟性に欠け、特定の入力を必要とするものにしている。逆に、より一般的な生成モデルは、細かい一貫性を維持し、時間の経過とともにアーティファクトを回避するのに苦労することが多い。一方の側面(例:実質的な形状変更を許可する)を改善すると、通常はもう一方(例:効果(影など)の時間的コヒーレンスまたは現実性)が壊れる。
2. 計算効率 vs. 品質と範囲: 多くの既存のアプローチは、計算集約的なプロセス(全フレームの密なマスクラベリングやビデオごとのファインチューニングなど)を含むか、または限定された品質と編集範囲の結果を生成するかのいずれかである。ジレンマは、法外な計算コストや広範な手作業介入を必要とせずに、高品質で多様なビデオ編集を達成する方法である。
制約と失敗モード
生成ビデオ伝播の問題は、いくつかの厳しい現実的な制約により、信じられないほど困難である。
- 時間的整合性とエラー蓄積: 編集が数百フレームにわたってスムーズかつ一貫して伝播され、エラーが蓄積しないことを保証することは、大きな課題である。特に複雑なモーションや長いビデオシーケンスを扱う場合、わずかな不整合でさえ、後続のフレームで顕著な「ゴースト効果」、ちらつき、または品質低下につながる可能性がある。
- 編集領域と未編集領域の分離: モデルは、未編集領域の元のコンテンツを正確に特定して維持し、同時に編集された領域のために新しいコンテンツを生成しなければならない。この分離は非常に重要である。ここで失敗すると、編集された領域に元のオブジェクトが再出現したり、変更されていないビデオの部分に意図しない変更が生じたりする可能性がある。
- 多様で複雑な編集の処理: フレームワークは、関連効果(影、反射)を伴うオブジェクト除去、独立した物理的に妥当なモーションを伴うオブジェクト挿入、および背景置換を含む、幅広い編集タスクをサポートする必要がある。各タスクは、コンテンツ生成とモーションコヒーレンスの点で独自の課題を提示する。
- タスク固有データの不足: 考えられるすべてのビデオ編集タスクに対して、大規模なペアビデオデータセットを作成することは、法外に高価で時間がかかる。このデータ不足により、合成データ生成に依存せざるを得なくなるが、これはモデルが実世界のビデオにうまく汎化し、合成アーティファクトを学習するのを回避する上で独自の課題をもたらす。
- 計算およびメモリの制限: 高解像度ビデオシーケンスの処理と複雑なコンテンツを持つ新しいフレームの生成には、かなりの計算リソースが必要である。このようなモデルの訓練と推論には、強力なGPUと十分なメモリが必要であり、リアルタイムまたはほぼリアルタイムのパフォーマンスが大きなハードルとなる。
- 明示的なモーションキューの不在: 光学フローや深度マップに依存する従来のメソッドとは異なり、このフレームワークは、そのような明示的なモーションガイダンスなしで動作することを目指している。この制約は、生成モデルに、本質的に困難である、妥当なモーションを暗黙的に理解し合成する負担をより大きくかける。
- 非微分可能な現実世界の物理: 生成フレームワーク内で、影、反射、および現実的なオブジェクト相互作用のような物理効果を正確にモデル化し伝播することは、これらの現象が複雑で微分可能な関数で容易に表現できないため、困難である。
なぜこのアプローチなのか
選択の必然性
著者らがGenPropフレームワークのために生成画像からビデオへの (I2V) モデルを基盤として構築するという決定は、単なる好みではなく、既存のアプローチの固有の限界によって推進された戦略的な必要性であった。光学フロー、深度マップ、またはアトラスに依存する従来のビデオ伝播メソッドは、一般的な生成ビデオ伝播の問題には根本的に適していなかった。これらのメソッドはエラーを時間とともに蓄積しやすく、ロバスト性が限られており、そして決定的に、広範な再訓練またはタスク固有の変更なしに多様な編集タスクを処理する汎化能力を欠いていた。それらは通常、単一の明確に定義されたタスクで優れているが、汎用性の必要性に直面すると崩壊する。
「ひらめき」の瞬間は、単一のイベントとして明示的に述べられていないものの、最先端 (SOTA) の厳密な評価から推測できる。強力な拡散ベースのビデオ編集モデルでさえ、主にテキストガイドによる外観変更に焦点を当てていたか、または面倒なケースごとのファインチューニングを必要とした。それらは実質的な形状変更、複雑な背景編集、または挿入されたオブジェクトの物理的に妥当なモーションに苦労した。例えば、Revideo [31] のようなメソッドは、入力ビデオの一部を黒い正方形でマスクすることに依存していたが、これは本質的に重要な情報を削除し、複雑な背景編集や大規模な形状変更を処理する能力を制限した。他のもの(I2VEdit [34] など)は、ビデオクリップごとにモーションLoRAを必要とすることで計算の複雑さを増大させた。認識されたのは、現実性と一貫性を維持しながら、ビデオシーケンス全体にわたって多様な最初のフレーム編集(除去、挿入、置換、追跡、複数の編集)を伝播できる統一された一般的なフレームワークを提供する既存のメソッドはなかったということである。密なマスク注釈や補助モーション予測を必要とせずに。I2Vモデルの生成能力は、慎重に設計され拡張された場合、この多面的な課題を全体的に解決するための唯一の実行可能な道であった。
比較優位性
GenPropの定性的な優位性は、その構造設計に由来しており、それは直接的に以前のメソッドの欠点を解決している。光学フローのような明示的なモーションキューに依存する従来のメソッドとは異なり、GenPropはI2Vモデルの固有の生成能力を活用する。これにより、フローベースのメソッドを悩ませるエラー蓄積の問題が排除され、より長いビデオシーケンスにわたって大幅にロバストで一貫した伝播が得られる。
重要な構造的利点は、選択的コンテンツエンコーダー (SCE) である。このコンポーネントにより、GenPropは元のビデオの変更されていない部分からの特徴を選択的にエンコードできる一方、I2Vモデルは変更された領域の伝播に生成能力を集中させる。この分離は、他のメソッドが安定した領域を意図せず変更する可能性がある一般的な失敗点である、編集されていない領域の一貫性を維持するために不可欠である。さらに、マスク予測デコーダー (MPD) は、補助ヘッドで訓練され、モデルが変更が必要な領域を正確に特定して焦点を当てるようにガイドする。これにより、編集の精度が向上し、注意マップの品質が向上する(図3に示す)。
おそらく最も重要な定性的な飛躍は、GenPropの一般性と柔軟性である。それは、単一の推論実行内で、タスク固有の再訓練を必要とせずに、現実的な効果(影や反射など)を伴う完全なオブジェクト除去、背景置換、物理的に妥当なモーションを伴うオブジェクト挿入、さらにはオブジェクトとその関連効果の追跡を含む、幅広い複雑なビデオ編集タスクをサポートする。これは、しばしば1つのタスクに特化していたり、すべてのフレームに密なマスクラベリングを必要としたりした以前のSOTAメソッドとは対照的である。GenPropの伝播ベースのアプローチは、推論中にマスク入力を全く必要としないため、編集プロセスが大幅に簡素化され、手作業の労力が削減される。この構造的利点は、真に統一された多用途なビデオ編集ソリューションを提供することで、圧倒的に優れている。
制約との整合性
GenPropフレームワークは、問題の厳しい要件と独自のアーキテクチャプロパティとの驚くべき「結婚」を達成している。主要な制約を検討してみよう。
- 現実性: 問題は、伝播された変更が自然で現実的に見えることを要求する。GenPropは、コアとして事前訓練されたI2V生成モデルを活用することで、完全に整合している。これらのモデルは、本質的に高忠実度で現実的なビデオコンテンツを生成するように設計されており、編集されたシーケンスが視覚的な妥当性を維持することを保証する。
- 一貫性: 変更されていない領域は元のビデオと同一でなければならず、編集は時間的に一貫していなければならない。これは、選択的コンテンツエンコーダー (SCE) によって対処され、ビデオの編集されていない部分からの情報を明示的に保持する。領域認識損失 (RA Loss) は、変更された領域と変更されていない領域の損失を分離し、安定した領域での変更を罰し、編集された領域での正確な伝播を奨励することにより、これをさらに強化する。これにより、元のコンテンツが意図された編集がない場所で忠実に維持されることが保証される。
- 一般性と汎用性: ソリューションは、各タスクの再訓練を必要とせずに、幅広いビデオ編集タスクを処理しなければならない。GenPropは、最初のフレーム編集を一般的なビデオ伝播に拡張する統一フレームワークを通じてこれを達成する。決定的に、合成データ生成スキーム(コピー&ペースト、マスク&フィル、カラーフィル)は、多様なシナリオを訓練中にカバーし、モデルが除去、挿入、置換、追跡などのさまざまなアプリケーションに、推論時にタスク固有のデータを必要とせずに汎化できるようにする。
- 効率性と簡潔性: ソリューションは、面倒な手作業の注釈やエラーを起こしやすい中間表現を回避すべきである。GenPropは、多くの従来型および一部の拡散ベースのメソッドよりも大幅な簡素化である、すべてのフレームに対する密なマスクラベリングの必要性を排除する。また、モーション予測のための光学フローや深度マップへの依存を回避し、それによって中間表現に固有のエラーの蓄積を回避する。
- 複雑な編集: モデルは、実質的な形状変更、独立したオブジェクトモーション、および関連効果の除去をサポートする必要がある。I2Vモデルの生成能力は、SCEおよびMPDからの正確なガイダンスと組み合わされて、GenPropが独立したモーションを持つオブジェクトや、オブジェクト除去と同時に影や反射のような複雑なシナリオを処理することを可能にする。これは、従来のメソッドがしばしば失敗することである。
代替案の却下
本論文は、一般的なビデオ伝播問題に対する根本的な限界を強調し、代替アプローチを却下する説得力のある理由を提供している。
- 従来のビデオ伝播メソッド(光学フロー、深度、アトラス): これらは基礎的であるが、ロバスト性、汎化能力、およびエラー蓄積への感受性が限られているため、明示的に却下される。それらはしばしば単一のタスクのために設計されており、新しいアプリケーションのために再訓練が必要であり、統一フレームワークには実用的ではない。明示的なモーションキューへの依存は、複雑な非剛体変形や実質的なシーン変更を扱う際にそれらを脆くする。
- 既存の拡散ベースビデオ編集モデル(例:InsV2V、Pika、AnyV2V、Revideo): 拡散モデルは強力であるが、ビデオ編集のための既存の実装は不十分であった。
- 多くは外観の変更に限定されており、オブジェクトの形状に実質的な変更を加えたり、複雑な背景編集を正確に処理したりすることはできなかった。
- 一部はケースごとのファインチューニング(例:I2VEditのモーションLoRA)を必要とし、計算の複雑さを増し、プロセスを遅くした。
- Revideo [31] のようなアプローチは、黒い正方形マスクを使用しており、これは重要な情報を削除し、複雑な背景編集や大規模な形状変更を処理する能力を著しく制限し、しばしばぼやけた境界線とオブジェクトモーションにおけるエラーの蓄積につながった。
- AnyV2V [27] のような訓練不要なフレームワークは、汎化能力が限られており、実質的な形状変更やオブジェクト挿入に苦労した。Pika [2] も同様に、実質的な形状変更や背景編集でパフォーマンスが悪かった。
- テキストプロンプト(例:InsV2V)に依存するメソッドは、訓練データによってしばしば制約され、複雑な非外観ベースの編集に苦労した。
- 従来のインペインティングパイプライン(例:SAM-V2 + Propainter): オブジェクト除去のようなタスクでは、これらのカスケードメソッドは、主にすべてのフレームに密なマスク注釈を必要とするという理由で却下された。これは労働集約的でエラーを起こしやすいプロセスであり、GenPropは完全に回避する。さらに、Propainterは、影や反射のようなオブジェクト効果を正確に除去するのに苦労することが示されており、GenPropは物理法則の生成的な理解により、これをロバストに処理する。
- 追跡のためのSAM-V2: SAM-V2 [39] はマスク追跡に優れているが、訓練データのバイアスによりオブジェクト効果(反射、影)に苦労することが指摘された。生成的な事前訓練を持つGenPropは、物理法則の優れた理解を示しており、SAM-V2がしばしば見逃すこれらの関連効果を一貫して追跡することを可能にする。
本質的に、著者らは、これらの代替案のコンポーネントは有用であったものの、品質、効率、または汎用性に大きな妥協をせずに、シームレスで多様なビデオ伝播に必要な包括的でロバストで一般的なソリューションを提供するものはなかったと結論付けた。強力なI2VモデルにSCE、MPD、RA Loss、および合成データ生成の新しい統合は、これらの集合的な限界を克服する唯一の方法であった。
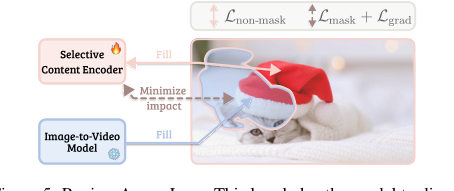 Figure 5. Region-Aware Loss. This loss helps the model to disen- tangle the edited region from the original content
Figure 5. Region-Aware Loss. This loss helps the model to disen- tangle the edited region from the original content
数学的および論理的メカニズム
マスター方程式
GenPropの学習メカニズムの核心は、編集の伝播と元のコンテンツの保持を同時に行うようにモデルをガイドする領域認識損失によってカプセル化されている。全体的な訓練目的はフレーム全体での損失の合計を最小化することであるが、すべての重要なコンポーネントを組み合わせた単一フレームの根本的な損失関数は次のとおりである。
$$ \mathcal{L} = \mathcal{L}_{\text{non-mask}} + \lambda \cdot \mathcal{L}_{\text{mask}} + \beta \cdot \mathcal{L}_{\text{grad}} + \gamma \cdot \mathcal{L}_{\text{MPD}} $$
このマスター方程式は、全体的な訓練目的とともに、モデルが生成ビデオ伝播を実行する方法を学習することを規定している。全体的な目的は正式には次のように述べられる。
$$ \min_{\mathcal{E}} \sum_{i=2}^{T} \mathcal{L}(G(E(V), v'_1, v_i), V_i) $$
ここで、$\mathcal{E}$ はモデルの訓練可能なパラメータを表す。
用語ごとの解剖
マスター方程式の各コンポーネントと全体的な目的を分解してみよう。
-
$\mathcal{L}$ (合計領域認識損失):
- 数学的定義: これは単一のビデオフレームの合計損失値であり、望ましい出力と動作からの逸脱に対する合計ペナルティを表す。
- 物理的/論理的役割: 最適化アルゴリズムの主要な信号として機能し、現在のモデルの出力と内部状態がどれほど「悪い」かを示す。$\mathcal{L}$ を最小化することは、その特定の側面におけるモデルのパフォーマンスを改善することを意味する。
- なぜ加算なのか? 著者らは加算を使用する。なぜなら、各項はモデルが満たさなければならない個別の目的または制約を表すからである。それらを合計することにより、モデルはこれらの目標すべてを同時に最適化するように奨励される。1つの項が高い場合、合計損失は高く、その特定の側面での調整の必要性を示唆する。
-
$\mathcal{L}_{\text{non-mask}}$ (非マスク領域損失):
- 数学的定義: $\mathcal{L}_{\text{non-mask}} = \mathbb{E}_{t \sim \mathcal{U}(1,T)} [\mathcal{L}_d((1 - m_t) \cdot v^{\text{out}}_t, (1 - m_t) \cdot v_t)]$。これは、生成された出力 $v^{\text{out}}_t$ とグラウンドトゥルース $v_t$ の間の拡散平均二乗誤差 (MSE) 損失 $\mathcal{L}_d$ であり、マスク $m_t$ でカバーされていない領域に対してのみ計算される。
- 物理的/論理的役割: この項は、最初のフレームで編集されなかったビデオの部分が、シーケンス全体を通して元のビデオコンテンツと一貫性を保つことを保証する。これは忠実性制約として機能し、編集されていない背景やオブジェクトの意図しない変更を防ぐ。
- なぜ $(1 - m_t) \cdot \text{frame}$ なのか? $(1 - m_t)$ との要素ごとの乗算は、マスクされた(編集された)領域を効果的に「ゼロアウト」し、損失計算のためにフレームの編集されていない部分のみを分離する。これは、特定の領域に整合性目標を集中させるための正確な方法である。
-
$\mathcal{L}_{\text{mask}}$ (マスク領域損失):
- 数学的定義: $\mathcal{L}_{\text{mask}} = \mathbb{E}_{t \sim \mathcal{U}(1,T)} [\mathcal{L}_d(m_t \cdot v^{\text{out}}_t, m_t \cdot v_t)]$。これは、生成された出力 $v^{\text{out}}_t$ とグラウンドトゥルース $v_t$ の間の拡散 MSE 損失 $\mathcal{L}_d$ であり、マスク $m_t$ でカバーされている領域に対してのみ計算される。
- 物理的/論理的役割: この項は、モデルが編集されたコンテンツを正確に生成し、最初のフレームに加えられた変更を伝播するように駆動する。変更が変更された領域内で現実的にレンダリングされ、時間的に一貫していることを保証する。
- なぜ $m_t \cdot \text{frame}$ なのか? $\mathcal{L}_{\text{non-mask}}$ と同様に、$m_t$ との要素ごとの乗算は、マスクされた(編集された)領域を分離し、生成目標をこれらの領域に具体的に集中させる。
-
$\lambda$ ($\mathcal{L}_{\text{mask}}$ の重み):
- 数学的定義: 正のスカラー係数(論文では2.0に設定)。
- 物理的/論理的役割: このハイパーパラメータは、他の損失成分と比較して、マスクされた(編集された)領域を正確に生成することの相対的な重要性を制御する。より高い $\lambda$ は、編集を伝播することの正確性をより重視する。
- なぜ乗算なのか? $\mathcal{L}_{\text{mask}}$ の合計損失への寄与をスケーリングし、異なる目的間のバランスの微調整を可能にする。
-
$\mathcal{L}_{\text{grad}}$ (勾配損失):
- 数学的定義: $\mathcal{L}_{\text{grad}} = \mathbb{E}_{t \sim \mathcal{U}(1,T)} [m_t \cdot ||\Delta f||^2]$、ここで $\Delta f = \frac{f(E(V + \delta)) - f(E(V))}{\delta}$ は、入力ビデオ $V$ の小さな摂動 $\delta$ に対する選択的コンテンツエンコーダー (SCE) の特徴 $f(E(V))$ の勾配の有限差分近似である。
- 物理的/論理的役割: これは分離のための重要な項である。SCEの出力特徴が、マスクされた領域内の入力ビデオがわずかに摂動された場合に大きく変化する場合にペナルティを与える。目標は、SCEが編集された部分を無視し、変更されていないコンテンツのみをエンコードすることに焦点を当てるように強制することである。これにより、SCEが意図せず削除されたオブジェクトを「再構築」したり、編集された領域でのI2Vモデルの生成タスクを妨害したりするのを防ぐ。
- なぜ $||\Delta f||^2$ なのか? 二乗L2ノルムは、特徴の変化の大きさを測定する。この大きさの最小化は、SCEの特徴が安定し、マスクされた領域の摂動に対して鈍感であることを奨励する。
- なぜ $m_t \cdot ||\Delta f||^2$ なのか? マスク $m_t$ は、この勾配ペナルティが編集された領域にのみ適用されることを保証する。これは、SCEが理想的には「盲目」であるべき場所である。
-
$\beta$ ($\mathcal{L}_{\text{grad}}$ の重み):
- 数学的定義: 正のスカラー係数(論文では1.0に設定)。
- 物理的/論理的役割: このハイパーパラメータは、勾配ペナルティの強度を制御し、SCEが編集された領域からエンコーディングを分離するようにどれだけ強く強制されるかに影響を与える。
- なぜ乗算なのか? $\mathcal{L}_{\text{grad}}$ の合計損失への寄与をスケーリングする。
-
$\mathcal{L}_{\text{MPD}}$ (マスク予測デコーダー損失):
- 数学的定義: これは、マスク予測デコーダー (MPD) によって予測されたマスクとグラウンドトゥルースマスク $m_t$ との間の MSE 損失である。
- 物理的/論理的役割: この補助損失は、MPDを明示的に訓練して、変更された領域を正確に特定させる。これにより、モデル全体に編集がどこにあるかについての明確な信号が提供され、ひいてはI2Vモデルの注意と生成プロセスを正しい領域にガイドするのに役立つ。注意マップの精度を向上させる。
- なぜ MSE なのか? MSEは、ピクセルごとのマスク値の予測を含む回帰タスクの標準的で効果的な損失関数である。
-
$\gamma$ ($\mathcal{L}_{\text{MPD}}$ の重み):
- 数学的定義: 正のスカラー係数(論文では1.0に設定)。
- 物理的/論理的役割: このハイパーパラメータは、明示的なマスク予測タスクの重要性を制御する。
- なぜ乗算なのか? $\mathcal{L}_{\text{MPD}}$ の合計損失への寄与をスケーリングする。
-
$\mathbb{E}_{t \sim \mathcal{U}(1,T)}$ (時間ステップに対する期待値):
- 数学的定義: $1$ から $T$ まで一様にサンプリングされた時間ステップ $t$ に対する損失の平均値。
- 物理的/論理的役割: これは、ビデオシーケンス全体にわたって損失が計算され、考慮されることを保証し、時間的整合性とビデオ全体にわたる汎化を促進する。
- なぜ期待値/一様サンプリングなのか? ビデオ全体にわたる損失のロバストな推定値を提供し、モデルが特定のフレームまたは時間位置に過剰適合するのを防ぐ。
-
$\sum_{i=2}^{T}$ (フレームに対する合計):
- 数学的定義: $2$ から $T$ までの各フレーム $i$ に対する領域認識損失 $\mathcal{L}$ の合計。
- 物理的/論理的役割: これは、訓練中にフレームごとの損失をビデオシーケンス全体に対する単一の目的関数に集計する。最初のフレーム ($i=1$) は入力編集フレームであるため、伝播タスクは2番目のフレームから始まる。
- なぜ合計なのか? 各フレームの損失は、全体的な訓練信号に等しく寄与し、モデルがビデオ全体にわたって編集を一貫して伝播することを学習することを保証する。
-
$G(E(V), v'_1, v_i)$ (生成出力フレーム):
- 数学的定義: 選択的コンテンツエンコーダー $E(V)$ からの特徴、変更された最初のフレーム $v'_1$、および元の $i$ 番目のフレーム $v_i$(I2Vモデルの内部処理の参照として使用されるが、損失計算にはグラウンドトゥルース $V_i$ が使用される)によって条件付けられた画像からビデオへの (I2V) 生成モデル $G$ の出力。
- 物理的/論理的役割: これは、変更されたビデオの $i$ 番目のフレームに対するモデルの推測である。これは、元のビデオの編集されていない部分との整合性を維持しながら、最初のフレーム編集を伝播した結果を表す。
-
$E(V)$ (選択的コンテンツエンコーダー特徴):
- 数学的定義: 選択的コンテンツエンコーダー $E$ が元の入力ビデオ $V$ から抽出した潜在特徴。
- 物理的/論理的役割: このコンポーネントは、元のビデオの変更されていない部分の情報をエンコードするように設計されている。これは、編集が行われなかった場所で元のコンテンツを維持するようにガイドするコンテキストをI2Vモデルに提供する。
-
$v'_1$ (変更された最初のフレーム):
- 数学的定義: 手動または合成的に編集されたビデオの最初のフレーム。
- 物理的/論理的役割: これは伝播のアンカーとして機能する。I2Vモデルは、伝播する必要がある変更内容を理解するための開始点としてこれを使用する。
-
$v_i$ (元の $i$ 番目のフレーム):
- 数学的定義: 元の編集されていないビデオシーケンス $V$ の $i$ 番目のフレーム。
- 物理的/論理的役割: 訓練中のI2Vモデルへの入力の一部として、および損失計算における未編集領域のグラウンドトゥルースとして使用される。
-
$V_i$ (グラウンドトゥルース合成ビデオフレーム):
- 数学的定義: 元のビデオにデータ生成演算子 $D$ を適用して生成された合成ビデオシーケンス $V = \{V_1, V_2, ..., V_T\}$ の $i$ 番目のフレーム。
- 物理的/論理的役割: これは、訓練中のモデルのターゲット出力であり、伝播後の望ましい変更されたビデオフレームを表す。
ステップバイステップフロー
GenPropを洗練されたビデオ編集工場として想像してください。ここでは、単一の抽象データポイント(ビデオフレーム)が訓練中の組み立てラインをどのように移動するかを示します。
- 元のビデオの取り込み: 元のビデオシーケンス $V$ が工場に入ります。この $V$ はフレームのシリーズ、$V_1, V_2, ..., V_T$ です。
- 合成編集の適用(データ生成): 特別な「編集マシン」(データ生成演算子 $D$)が $V$ を取り、その最初のフレームに合成編集を適用して、変更された最初のフレーム $v'_1$ を作成します。また、各フレームの編集領域を正確に区切る対応するグラウンドトゥルース変更フレーム $V_2, ..., V_T$ とバイナリマスク $m_1, ..., m_T$ も生成します。これにより、ターゲットビデオ $V' = \{v'_1, V_2, ..., V_T\}$ が得られます。
- コンテンツエンコーディング(選択的コンテンツエンコーダー、SCE): 元のビデオ全体 $V$ が「選択的コンテンツエンコーダー」($E$) に供給されます。このエンコーダーはスマートフィルターのようなもので、その仕事は、ビデオの変更されていないコンテンツを表す特徴を抽出することです。これは、編集される予定の領域に関する情報を意図的に無視しようとします。それは変更に「盲目」になることを学習しています。
- 伝播エンジン(画像からビデオモデル): 次に、各後続フレーム $i$($2$ から $T$ まで)について:
- 変更された最初のフレーム $v'_1$(編集の青写真)が入力されます。
- $E(V)$ からの選択的にエンコードされた特徴(元の未編集シーンのコンテキスト)が注入されます。
- 現在の時間ステップ $i$ も提供されます。
- 「画像からビデオ生成モデル」($G$) がメインの伝播エンジンとして機能します。これはこれらの入力を受け取り、変更されたビデオの $i$ 番目のフレームの最良の推測を生成します。これを $v^{\text{out}}_i$ と呼びます。ここで魔法が起こります:$v'_1$ からの編集が伝播され、元のコンテンツ特徴によってガイドされます。
- マスク予測(マスク予測デコーダー、MPD): 同時に、「マスク予測デコーダー」(MPD)は、I2Vモデルからの内部潜在表現を受け取り、現在のフレームのマスク $m_i$ を予測しようとします。これは品質管理センサーのようなもので、モデルが編集がどこにあるかを理解しているかを確認します。
- 損失計算とフィードバック(領域認識損失): 生成された各フレーム $v^{\text{out}}_i$ について:
- 整合性チェック(非マスク損失): $v^{\text{out}}_i$ の未編集部分($(1-m_i)$ で選択)は、グラウンドトゥルース $V_i$ の未編集部分と比較されます。ここで発生する不一致は $\mathcal{L}_{\text{non-mask}}$ に寄与し、モデルを元のコンテンツをそのまま維持するように引き寄せます。
- 編集精度チェック(マスク損失): $v^{\text{out}}_i$ の編集部分($m_i$ で選択)は、グラウンドトゥルース $V_i$ の編集部分と比較されます。ここで発生するエラーは $\mathcal{L}_{\text{mask}}$ に寄与し、モデルを正確に変更を伝播するように推進します。
- エンコーダー盲目チェック(勾配損失): 特別な「勾配センサー」は、入力マスク領域内がわずかに変更された場合にSCEの特徴が変化するかどうかをチェックします。変化する場合、それは $\mathcal{L}_{\text{grad}}$ に追加され、SCEに編集に対してさらに無関心になるように指示します。
- マスク予測精度チェック(MPD損失): MPDの予測マスクは、グラウンドトゥルースマスク $m_i$ と比較され、$\mathcal{L}_{\text{MPD}}$ に寄与します。
- 合計損失集計: これらの個々の損失コンポーネント($\mathcal{L}_{\text{non-mask}}$、$\mathcal{L}_{\text{mask}}$、$\mathcal{L}_{\text{grad}}$、$\mathcal{L}_{\text{MPD}}$)はすべて重み付けされ($\lambda$、$\beta$、$\gamma$)、そのフレームの合計領域認識損失 $\mathcal{L}$ を形成します。このプロセスは $i=2$ から $T$ までのすべてのフレームに対して繰り返され、これらのフレームごとの損失すべてが合計されて、全体的な目的が得られます。
- パラメータ調整: この合計目的値は「オプティマイザー」に送信され、これは工場のマネージャーのようなものです。それは、この合計損失を削減するために、各ノブとダイヤル(モデルパラメータ)をどのように調整する必要があるかを計算します。これらの調整は反復的に行われ、各訓練ステップでSCE、I2Vモデル、およびMPDを洗練させます。
このサイクル全体が何百万回も繰り返され、GenPropは編集をシームレスに伝播しながら、ビデオの残りの部分を維持することを徐々に学習します。
最適化ダイナミクス
GenPropは、勾配降下と慎重に形成された損失ランドスケープの洗練された相互作用を通じて学習し、収束します。最適化プロセスは、$i=2$ から $T$ までのすべてのフレームにわたる領域認識損失 $\mathcal{L}$ の合計である、合計目的関数を最小化することによって駆動されます。
-
勾配ベース学習: 選択的コンテンツエンコーダー (SCE)、画像からビデオ (I2V) 生成モデル、およびマスク予測デコーダー (MPD) のモデルパラメータ ($\mathcal{E}$) は、オプティマイザー(例:拡散モデルで一般的なAdam)を使用して反復的に更新されます。これには、合計損失の勾配を各パラメータに対して計算することが含まれます。これらの勾配は、損失を減少させるためにパラメータを調整する必要がある方向と大きさを指し示します。学習率(例:線形ウォームアップを伴うコサイン減衰スケジューラを備えた5e-5)は、これらの調整のステップサイズを制御します。モデルパラメータの指数移動平均 (EMA) も維持されており、これはしばしば、ノイズの多い更新を平均化することによって、より安定した訓練とより良い最終パフォーマンスにつながります。勾配ノルム閾値(0.001)は、勾配爆発を防ぎ、訓練の安定性を保証するために適用されます。
-
分離と整合性のための損失ランドスケープ形成: 領域認識損失 ($\mathcal{L}$) のユニークな設計は、損失ランドスケープを形成し、モデルの学習をガイドする鍵となります。
- バランスの取れた領域最適化: $\mathcal{L}_{\text{mask}}$ と $\mathcal{L}_{\text{non-mask}}$ の項は、2つの主要な「谷」を持つ損失ランドスケープを作成します。1つの谷は、編集された領域内での正確な生成を奨励し、伝播された変更が現実的であることを保証します。もう1つの谷は、元のコンテンツの忠実性を未編集領域で促進します。これらの項を $\lambda$ で重み付けすることにより、著者らはモデルの焦点をバランスさせ、編集を無視したり、元の背景を破損したりするのを防ぐことができます。この二重目的は、新しいコンテンツを作成し、既存のコンテンツを保持する必要がある複雑なランドスケープをモデルがナビゲートするのに役立ちます。
- SCEの選択性を強制する: $\mathcal{L}_{\text{grad}}$ 項は特に巧妙です。入力マスク領域が摂動された場合に特徴が変化する場合にSCEを罰することにより、編集された領域に関するSCEの出力の特徴に対して「平坦な」損失ランドスケープ領域を作成します。これにより、SCEは変更に対して不変な表現を学習することを強制され、実質的に編集に対して「盲目」になります。これにより、SCEの役割(元のコンテキストのエンコード)とI2Vモデルの役割(編集の伝播)が分離され、ゴーストや削除されたオブジェクトの再出現のような問題が防止されます。これがなければ、SCEはどこでも元のコンテンツを再構築しようとする可能性があり、変更の伝播を妨げる可能性があります。
- 注意のための明示的なガイダンス: $\mathcal{L}_{\text{MPD}}$ 項は、モデルがどこに編集があるかを特定するための明示的な教師あり信号を提供します。これにより、I2Vモデルの内部注意メカニズムが、生成と変更のための正しい領域に焦点を合わせるのに役立ちます。マスクを明示的に学習することにより、モデルは編集が必要な領域とそうでない領域の「境界」についてのより明確な理解を得て、より正確な伝播と混乱の減少につながります。この損失項は、変更が必要な領域の損失ランドスケープに、よりシャープで明確な境界を作成するのに役立ちます。
-
反復的な改善と収束: 多くの反復を通じて、モデルはパラメータを反復的に更新します。I2Vモデルは、SCEのコンテキストと編集された最初のフレームに基づいて、ますます現実的で時間的に一貫したビデオフレームを生成することを学習します。SCEは、元のビデオからロバストで編集に依存しない特徴を抽出することを学習します。MPDは、変更された領域を正確に予測することを学習します。領域認識損失によってガイドされるこの継続的なフィードバックループは、モデルを、元のコンテンツに対して高い忠実度を維持しながら、多様な最初のフレーム編集をビデオシーケンス全体にシームレスに伝播できる状態に駆動します。勾配が非常に小さくなり、パラメータ更新が損失の改善をほとんどもたらさないことを示すと、モデルは収束します。
 Figure 1. GenProp. We propose a generative video propagation framework (GenProp), which can seamlessly propagate any first frame edit through the video. GenProp supports a wide range of video applications, including (a) complete object removal with effects such as shadows and reflections, (b) background replacement with realistic effects, (c) object insertion where inserted objects have physically plausible motion (i.e., blueberries falling while spoon goes up), (d) tracking of objects and their associated effects, and (e) multiple edits (outpainting, insertion, removal) at a single inference run
Figure 1. GenProp. We propose a generative video propagation framework (GenProp), which can seamlessly propagate any first frame edit through the video. GenProp supports a wide range of video applications, including (a) complete object removal with effects such as shadows and reflections, (b) background replacement with realistic effects, (c) object insertion where inserted objects have physically plausible motion (i.e., blueberries falling while spoon goes up), (d) tracking of objects and their associated effects, and (e) multiple edits (outpainting, insertion, removal) at a single inference run
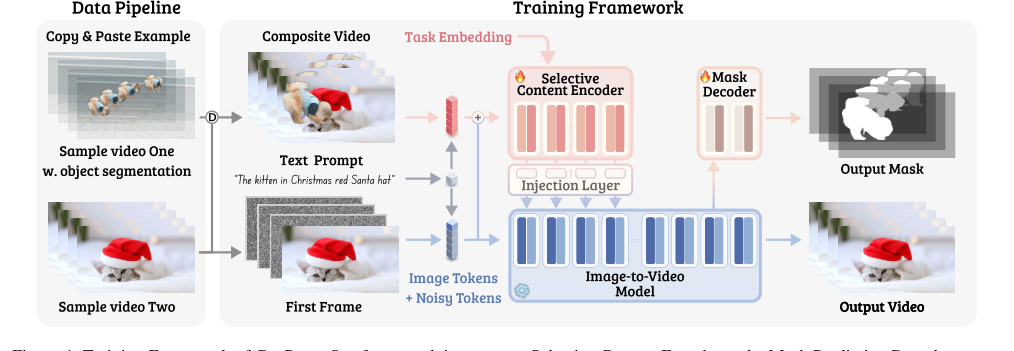 Figure 4. Training Framework of GenProp. Our framework integrates a Selective Content Encoder and a Mask Prediction Decoder on top of the I2V generation model, enforcing the model to propagate the edited region while preserving the content in the original video for all other regions. With synthetic data augmentations and task embeddings, our model is trained to propagate various changes in the first frame
Figure 4. Training Framework of GenProp. Our framework integrates a Selective Content Encoder and a Mask Prediction Decoder on top of the I2V generation model, enforcing the model to propagate the edited region while preserving the content in the original video for all other regions. With synthetic data augmentations and task embeddings, our model is trained to propagate various changes in the first frame
結果、限界、および結論
実験設計とベースライン
GenPropの能力を厳密に検証するために、著者らは、DiTアーキテクチャ(Sora [32] に類似)とStable Video Diffusion (SVD) [5] に基づくU-Netアーキテクチャという、2つの異なるベースビデオ生成モデルを活用した包括的な実験セットアップを設計した。最終的に優れたビデオ生成品質をもたらしたDiTバリアントは、32、64、および128フレームで、12および24フレーム/秒 (FPS) で、ベース解像度360pで画像からビデオ (I2V) 生成のために訓練された。選択的コンテンツエンコーダー (SCE) とマスク予測デコーダー (MPD) コンポーネントは、I2Vモデルが静止したままで訓練された。これにより、GenPropのコアメカニズムが、ビデオ生成を最初から再学習するのではなく、編集の伝播に焦点を当てることを保証した。
訓練は、学習率 $5 \times 10^{-5}$、コサイン減衰スケジューラと線形ウォームアップ、および安定性のための指数移動平均を伴って行われた。勾配ノルム閾値0.001が不安定性を防ぐために適用された。分類子フリーガイダンス (CFG) は20に設定された。訓練の重要な側面は、さまざまな拡張比率(0.5、0.375、0.125)のコピー&ペースト、マスク&フィル、カラーフィルタスクを使用した合成データ生成スキームであった。編集領域と未編集領域を分離するために不可欠な領域認識 (RA) 損失は、特定の重み付けパラメータ ($\lambda = 2.0$、$\beta = 1.0$、$\gamma = 1.0$) を使用した。すべての実験は、32または64のNVIDIA A100 GPUで実行され、必要なかなりの計算リソースを強調した。
GenPropが比較された「犠牲者」(ベースラインモデル)は、タスクによって異なった。一般的なビデオ編集については、InsV2V [8]、AnyV2V [27]、Pika [2]、およびReVideo [31] と比較された。オブジェクト除去については、SAM-V2 [39](マスク追跡用)とPropainter [64](インペインティング用)のカスケードパイプラインがベースラインとして機能した。オブジェクト追跡については、SAM-V2 [39] が直接の競合相手であった。
定量的評価は、2つのテストセットで実施された。
1. クラシックテストセット: オブジェクト置換と外観編集に焦点を当てた、「オブジェクト変更キャプション」テキストプロンプトを備えた、TGVE [51] のDAVIS [36] データセットで構成される。
2. 挑戦的なテストセット: Pexels [1] および Adobe Stock [3] から手動でキュレーションされた30本のビデオのコレクションで、大規模なオブジェクト置換、オブジェクト挿入、および背景置換のようなより複雑なシナリオを特徴とする。このセットでの編集は、商用写真編集ツールまたは特定のベースラインメソッド(例:Pikaのオンラインボクシングツール、ReVideoのポイント抽出)を使用して実行された。
GenPropの成功の決定的な証拠は、いくつかのメトリックを使用して測定された。
- PSNRm: ピーク信号対雑音比。編集領域外で計算され、変更されていないコンテンツの一貫性を定量化する。
- CLIP-T: CLIP [38] の埋め込みとテキストプロンプトのコサイン類似度。テキストアライメントを評価する。
- CLIP-I: フレーム間のCLIP [38] 特徴間の距離。フレーム間の一貫性を測定する。
- ユーザー調査: Amazon MTurk [45] で121人の参加者によって実施された人間の評価。彼らはGenPropの出力をベースラインおよび元のビデオと比較し、指示への整合性と全体的な視覚品質を判断した。
証拠が証明すること
証拠は、GenPropのコアメカニズムが実際に機能すること、そしてそれを生成ビデオ伝播のための主要なフレームワークとして確立することを示している。表1に示すように、GenPropはほとんどのメトリックで他のメソッドを大幅に上回り、特に要求の厳しい挑戦的なテストセットで優れている。これは単なる漸進的な改善ではなく、根本的にロバストで汎用性の高いアプローチのデモンストレーションである。
例えば、オブジェクト置換と背景置換(図6a、6b)では、GenPropは、形状が大きく異なり独立したモーションを持つオブジェクトをシームレスに変更し、複雑な背景編集を実行する能力を示した。これは、テキストプロンプトへの依存や訓練データの制限により、実質的な形状変更やオブジェクト挿入に苦労するInsV2V [8] や Pika [2] のようなベースラインの主要な限界に直接対処している。AnyV2V [27] も汎化能力が限られており、ReVideo [31] はしばしばぼやけた境界線とポイント追跡メカニズムからのエラー蓄積を生成した。GenPropが、各フレームの密なマスクラベリングを必要とせずにこれらの複雑なシナリオを処理できることは、その伝播ベースのアプローチの証である。
オブジェクトと効果の除去(図6c、6d)では、GenPropはオブジェクトだけでなく、影や反射のような関連効果も除去し、大きな隠蔽領域を現実的に再構築することによって優れていた。SAM + Propainterベースラインは、インペインティングには効果的であったが、表2の低いCLIP-Iおよびユーザー選好スコアが示すように、これらの微妙な効果を除去するのに苦労した。GenPropの統一アプローチは、生成モデルを活用し、本質的に削除された領域を環境コンテキストを含めて、妥当に埋める方法を理解している。
インスタンスオブジェクトと効果の追跡(図6e)については、GenPropは、ソリッドカラーフィルで初期化された場合でも、オブジェクトとその関連効果の一貫した追跡を示した。SAM-V2 [39] はリアルタイム追跡には高速であり、正確なマスクを生成できるが、GenPropのビデオ生成での事前訓練は、物理法則の強力な理解を与え、SAM-V2がしばしば見逃す効果を追跡することを可能にする。これは、生成ベースモデルがより深いシーンダイナミクス理解で古典的なビジョンタスクに取り組む可能性を示している。
アブレーション研究はさらに、GenPropの主要コンポーネントの効果に関する否定できない証拠を提供した。
- マスク予測デコーダー (MPD) は、テキストアライメントと整合性の両方を大幅に改善した(表3)。それなしでは、出力マスクはしばしば劣化し、オブジェクト除去の不完全さや、伝播すべき領域と保持すべき領域についての混乱につながった(図7、行1-2)。MPDの明示的な監督は、モデルが変更を分離し、重度の隠蔽があっても完全なオブジェクト除去を保証するのに役立つ。
- 領域認識損失 (RA Loss) は、最初のフレーム編集の安定した一貫した伝播に不可欠であった。RA Lossなしでは、元のオブジェクトは後続のフレームに徐々に再出現する傾向があり、伝播を妨げた(図7、行3-5)。この損失は、変更されていない領域が一貫性を保つ間、変更された領域が安定して伝播されることを保証する。
- カラーフィル拡張は、特に大規模な形状変更に対する伝播失敗に対処するための重要な要因であることが証明された。それは、追跡のためにモデルを明示的に訓練し、シーケンス全体で変更を維持するようにガイドし、女の子が小さな猫に変わるような困難な編集を可能にする(図7、行6-8)。
要するに、GenPropの成功は、I2Vモデルの生成能力、選択的コンテンツエンコーダー、マスク予測デコーダー、および領域認識損失を活用した慎重な設計に根差しており、すべてが多用途な合成データ生成パイプラインで訓練されている。この組み合わせにより、多様で挑戦的なビデオ編集タスク全体で、品質、効率、または汎用性に大きな妥協をせずに、編集をシームレスに伝播することが可能になる。
限界と将来の方向性
GenPropは生成ビデオ伝播における大きな飛躍を示しているが、その固有の限界を認識し、将来の開発を検討することは重要である。1つの暗黙的な限界は計算コストである。複数のNVIDIA A100 GPUでの訓練は、コンシューマーグレードのハードウェアでリアルタイムの高解像度ビデオ編集にこのモデルを展開することが依然として課題である可能性を示唆している。さらに、合成データへの依存は、多様性を可能にする一方で、合成分布とは大きく異なる非常に新しい、キュレーションされていない実世界のシナリオへのバイアスを導入したり、汎化を低下させたりする可能性がある。論文はまた、従来の品質メトリックが生成された結果の現実性を捉えきれないことがあると指摘しており、ユーザー調査が必要になることを示唆している。これは、自動的で包括的な評価のギャップを示している。
今後、著者らは、より複雑で多段階の編集ワークフローの柔軟性を大幅に向上させる複数のキーフレーム編集をサポートするようにモデルを拡張することを明確に計画している。また、フレームワークでサポートできる追加のビデオタスクを発見することも目指しており、GenPropの基盤となる生成能力には未開発の可能性があることを示唆している。
これらの直接的な計画を超えて、これらの発見をさらに発展させ進化させるためのいくつかの議論トピックが登場する。
-
強化されたユーザー制御と解釈可能性: GenPropは密なマスクの必要性を排除することで編集プロセスを簡素化するが、より直感的で詳細なユーザー制御を統合して編集を微調整するにはどうすればよいか?従来のメソッドの複雑さを再導入することなく、ユーザーが伝播プロセスをより正確にガイドできる、インタラクティブなフィードバックメカニズムを備えた「人間参加型」システムを探索できるか?モデルの内部「推論」(例:注意マップ)をユーザーにより解釈可能にすることは、信頼と制御の向上を促進する可能性もある。
-
実世界のロバスト性とデータ不足: 現在のフレームワークは合成データから大きな恩恵を受けている。しかし、実世界のビデオデータは、合成データセットでは完全に捉えられていないノイズ、隠蔽、および予測不可能なモーションパターンをしばしば含んでいる。将来の研究では、GenPropの「in-the-wild」ビデオに対するロバスト性を向上させるためのドメイン適応技術または自己教師あり学習戦略を探索し、慎重に作成された合成データへの依存を減らす可能性がある。
-
生産のための効率性とスケーラビリティ: より広範な採用のために、推論の高速化とメモリフットプリントの削減のためにGenPropを最適化することが重要である。知識蒸留、モデルプルーニング、またはより効率的なアーキテクチャ設計などの技術を調査すると、エッジデバイスでの展開や、より長く高解像度のビデオのリアルタイム処理が可能になる可能性がある。生成品質、速度、およびリソース消費の間にはどのようなトレードオフがあり、実用的なアプリケーションのためにそれらをどのようにバランスさせることができるか?
-
マルチモーダル統合と文脈理解: ビデオは本質的にマルチモーダルである。GenPropをオーディオ、プロンプトを超えるテキスト説明、または3Dシーン情報を取り込んで、より一貫性のある没入型の編集を作成するように拡張するにはどうすればよいか?例えば、オブジェクトのモーションを編集すると、対応する効果音の調整が自動的にトリガーされる可能性があるか、またはシーンの3Dジオメトリを理解すると、挿入されたオブジェクトのより物理的に正確な相互作用と照明効果につながる可能性がある。
-
倫理的影響と責任あるAI: 生成ビデオ編集がますます洗練されるにつれて、非常に現実的だが操作されたコンテンツを作成する能力は、重大な倫理的懸念を引き起こす。将来の議論では、そのような強力なツールの責任ある開発と展開方法、操作されたコンテンツを検出するためのメカニズム、使用のための明確なガイドラインの確立、およびAI生成メディアにおける透明性の確保を積極的に検討する必要がある。これは、この技術の長期的な社会的影響にとって重要な側面である。
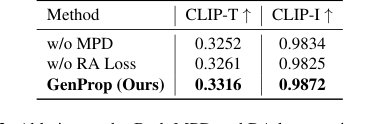 Table 3. Ablation study. Both MPD and RA loss can improve the success rate of editing and the quality of the output video
Table 3. Ablation study. Both MPD and RA loss can improve the success rate of editing and the quality of the output video
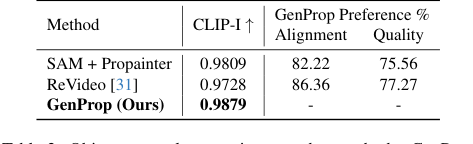 Table 2. Object removal comparison to other methods. GenProp outperforms baselines on consistency, alignment, and quality
Table 2. Object removal comparison to other methods. GenProp outperforms baselines on consistency, alignment, and quality
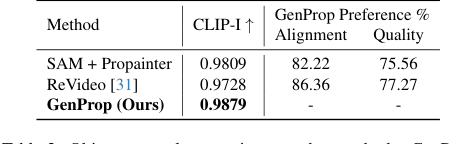 Table 1. Video editing benchmark compared to existing models. PSNRm measures the consistency outside the edited region. CLIP-T and CLIP-I measure text alignment and frame consistency. User study shows the percentage of users who preferred Ours over the compared method on alignment (left) and quality (right). GenProp significantly outperforms the other methods on the Challenging Set
Table 1. Video editing benchmark compared to existing models. PSNRm measures the consistency outside the edited region. CLIP-T and CLIP-I measure text alignment and frame consistency. User study shows the percentage of users who preferred Ours over the compared method on alignment (left) and quality (right). GenProp significantly outperforms the other methods on the Challenging Set
他の分野との同型性
構造的骨格
本論文は、本質的に、未変更領域の整合性を維持しながら、初期状態からシーケンシャルデータ構造全体にわたるターゲット変更を選択的に伝播するメカニズムを提示している。