生成视频传播
The problem of generative video propagation, as addressed in this paper, is rooted in the broader field of computer vision, specifically within the domain of video generation and editing.
背景与学术渊源
本文所探讨的生成视频传播问题,根植于更广泛的计算机视觉领域,特别是在视频生成与编辑的范畴内。历史上,核心挑战在于如何将对单个帧(或稀疏帧集)所做的修改,一致且逼真地传播到整个视频序列。视频传播的早期方法,源于在修改后的视频内容中保持时间连贯性和视觉合理性的必要性,主要依赖于传统计算机视觉技术,如光流 [9, 44]、深度估计 [6, 55]、辐射场 [33] 和图集 [20, 24]。随着对能够以最小人工干预处理复杂、逼真场景的先进视频编辑工具的需求日益增长,这一特定问题的出现和演变也随之加速。
促使作者开发新框架的先前方法的根本局限性或“痛点”源于几个关键问题。传统方法常常容易在视频持续时间内发生误差累积,导致后期帧的质量下降和不一致。这使得它们鲁棒性较差,并限制了它们在不同视频内容上的泛化能力。许多现有技术也特定于任务,这意味着一个为某种类型编辑(例如,移除对象)训练的模型,需要进行大量重新训练或完全不同的模型才能处理另一项任务(例如,替换背景)[28, 31, 34, 61]。这种缺乏统一框架的情况是一个主要的瓶颈。尽管最新的基于扩散的视频编辑模型功能强大,但它们也有其自身的局限性。许多模型主要设计用于改变外观,而不是对对象形状进行实质性修改或处理复杂的背景修改。它们通常需要对每个单独的帧进行密集掩码标注,这是一个劳动密集且耗时的过程,使得实时或大规模应用不切实际。例如,I2VEdit [34] 等方法通过为每个视频片段学习运动 LoRA 来引入计算复杂性。其他方法,如 ReVideo [31],涉及用黑色方块遮挡输入视频的部分区域,这无意中移除了重要信息,并限制了它们处理复杂背景编辑和大形状修改的能力。作者的动机是克服这些局限性,提出一个统一的、生成式的框架,该框架能够无缝、鲁棒地传播各种编辑,而无需进行特定任务的重新训练或密集掩码输入,从而显著简化视频编辑过程。
直观的领域术语
以下是论文中的几个专业术语,用零基础读者的直观、日常类比进行解释:
-
生成视频传播 (Generative Video Propagation):想象一下你在制作定格动画电影。你雕刻了第一个场景,然后决定给你的黏土角色添加一顶小帽子。“生成视频传播”就像拥有一个神奇的、超级聪明的助手,它在看到你编辑过的第一个场景后,会自动重新雕刻所有后续场景,确保帽子始终出现在角色身上,与角色自然地移动,并完美地融入电影中,而无需你触摸每一帧。它以一种“生成式”(创造性、逼真)的方式将你最初的编辑“传播”到整个视频中。
-
图像到视频 (I2V) 生成模型 (Image-to-Video (I2V) Generation Model):将其视为一个极富想象力的故事讲述者。你给这位故事讲述者一张照片(“图像”)和一个关于接下来会发生什么的简短描述,它就能从中构思并创作出一个完整的短视频序列。例如,你给它一张静止的湖面照片,并说“让水面轻轻泛起涟漪”,它就会生成一个湖面泛起逼真涟漪的视频。在这篇论文中,这个故事讲述者被用来根据编辑过的第一帧来生成视频的其余部分。
-
选择性内容编码器 (SCE) (Selective Content Encoder (SCE)):想象一位非常细心的图书管理员。你给这位图书管理员两个版本的书:原版和其中你高亮了某些句子的版本。这位图书管理员的工作是只记住并保留你未高亮的原书中所有部分,同时故意忽略高亮的部分。它“选择性地编码”原始内容,专注于那些应保持不变的部分,以便生成模型随后可以填充编辑过的部分,而不会弄乱书的其余部分。
-
区域感知损失 (RA Loss) (Region-Aware Loss (RA Loss)):想象你在给一个学生的艺术项目打分,该项目有两个部分:绘画和着色。“区域感知损失”就像一个评分系统,它确保你对绘画(视频中未更改的部分)和着色(编辑过的部分)都给予同等的关注,即使其中一个部分小得多或看起来不那么重要。它确保模型在保留原始内容和准确传播编辑方面都表现良好,防止它过度关注一个部分而牺牲另一个部分。
符号表
| 符号 | 描述 |
|---|---|
问题定义与约束
核心问题表述与困境
本文解决了生成视频传播的复杂问题,旨在将对第一帧的编辑无缝应用于整个视频序列,同时保持逼真性和一致性。
输入/当前状态:
起点是一个原始视频 $V = \{v_1, v_2, ..., v_T\}$,包含 $T$ 帧,以及一个经过编辑的单帧 $v'_1$。这个 $v'_1$ 是对原始第一帧 $v_1$ 应用任意编辑的结果。现有的视频编辑方法通常存在几个局限性:它们通常需要对每一帧进行密集掩码标注,依赖于光流或深度图等辅助输入进行运动引导,或者需要为每个特定的编辑任务或视频片段进行重新训练。许多方法也仅限于特定类型的编辑,如外观变化,并且在显著的形状修改或复杂的背景变化方面存在困难。
输出/目标状态:
期望的终点是一个新的、经过编辑的视频 $V' = \{v'_1, v'_2, ..., v'_T\}$。对于每个后续帧 $v'_t$(其中 $t \in \{2, ..., T\}$),目标是确保在 $v'_1$ 中引入的修改能够准确且逼真地传播到整个视频。同时,视频中所有未编辑的区域必须在外观和运动方面与原始内容保持完全一致。该框架应普遍适用于各种视频编辑任务——包括对象移除、插入、替换、跟踪和外绘——而无需特定任务的数据或显式的运动线索,如光流。
缺失环节或数学鸿沟:
确切的缺失环节是一个统一的、生成式的框架,该框架能够有效地分离视频中已编辑和未编辑的区域,并将编辑从单帧编辑传播到整个序列。这必须在保持未编辑区域原始内容的同时,在已编辑区域生成新的、物理上合理的 Pika [2] 的内容,跨越各种复杂和复杂的编辑场景。数学上,本文旨在定义一个生成函数 $G$ 和一个选择性内容编码器 $E$,使得编辑后的帧 $v'_t$(对于 $t \in \{2, ..., T\}$)可以通过 $v'_t = G(E(V), v'_1, t)$ 生成。在这里,$E(V)$ 必须选择性地仅编码来自原始视频 $V$ 的未更改信息,允许 $G$(一个图像到视频生成模型)专注于将已编辑内容从 $v'_1$ 传播到后续帧。挑战在于设计 $E$ 和 $G$ 以协同工作,在没有显式每帧引导的情况下实现这种分离和一致传播。
痛苦的权衡或困境:
先前的研究人员陷入了一个根本性的权衡:
1. 逼真性与一致性 vs. 泛化性与灵活性:实现高度逼真且时间上一致的编辑传播(特别是对于复杂的更改,如大形状修改或背景变化)通常以牺牲泛化性为代价。在一致性方面表现出色的方法通常依赖于显式的运动表示(例如,光流)或每个任务的微调,这使得它们灵活性较差并需要特定输入。相反,更通用的生成模型通常在保持细粒度一致性和避免随时间产生的伪影方面存在困难。改进一个方面(例如,允许实质性的形状变化)通常会破坏另一个方面(例如,时间连贯性或阴影等效果的逼真性)。
2. 计算效率 vs. 质量与范围:许多现有方法要么涉及计算密集型过程(如所有帧的密集掩码标注或每个视频的微调),要么产生质量和编辑范围有限的结果。困境在于如何在不产生高昂计算成本或需要大量手动干预的情况下实现高质量、多样化的视频编辑。
约束与失败模式
生成视频传播问题由于几个严苛的、现实的约束而变得异常困难:
- 时间一致性与误差累积:确保编辑在数百帧中平滑且一致地传播,而不会累积误差,这是一个重大挑战。即使是微小的失真也可能导致后期帧出现明显的“鬼影效应”、闪烁或质量下降,尤其是在处理复杂运动或长视频序列时。
- 已编辑与未编辑区域的分离:模型必须准确识别并保留未编辑区域的原始内容,同时为已编辑区域生成新内容。这种分离至关重要;失败可能导致原始对象出现在已编辑区域,或对视频未更改部分产生意外修改。
- 处理多样化和复杂的编辑:框架需要支持广泛的编辑任务,包括带有相关效应(阴影、反射)的对象移除、具有独立且物理上合理运动的对象插入以及背景替换。每项任务在内容生成和运动连贯性方面都带来了独特的挑战。
- 缺乏特定任务的数据:为每一种可想象的视频编辑任务创建大规模、配对的视频数据集成本过高且耗时。这种数据稀疏性迫使依赖于合成数据生成,这本身就带来了模型能否很好地泛化到真实世界视频并避免学习合成伪影的挑战。
- 计算和内存限制:处理高分辨率视频序列和生成具有复杂内容的新帧需要大量的计算资源。此类模型的训练和推理需要强大的 GPU 和大量内存,使得实时甚至近实时性能成为一个重大障碍。
- 缺乏显式的运动线索:与依赖光流或深度图的传统方法不同,该框架旨在在没有此类显式运动引导的情况下运行。这一约束给生成模型带来了更大的负担,使其能够隐式地理解和合成合理的运动,而这本身就非常困难。
- 不可微分的现实世界物理学:在生成框架中准确建模和传播阴影、反射和真实对象交互等物理效应是具有挑战性的,因为这些现象复杂且不易用可微分函数表示。
为什么选择这种方法
选择的必然性
作者决定在其 GenProp 框架中基于生成式图像到视频 (I2V) 模型进行构建,这不仅仅是偏好,而是由现有方法固有的局限性驱动的战略必需。传统视频传播方法,通常依赖于光流、深度图或图集,从根本上不适合通用生成视频传播的问题。这些方法容易随时间累积误差,泛化能力有限,并且至关重要的是,缺乏处理各种编辑任务而无需大量重新训练或特定任务修改的泛化能力。它们通常在一个定义明确的任务上表现出色,但在面对通用性需求时则会失效。
“顿悟”时刻,尽管没有明确陈述为单一事件,但可以从论文对最先进技术 (SOTA) 的关键评估中推断出来。即使是先进的基于扩散的视频编辑模型,虽然功能强大,但主要侧重于文本引导的外观变化或需要繁琐的逐案微调。它们在实质性形状修改、复杂背景编辑或插入对象的物理合理运动方面存在困难。例如,Revideo [31] 等方法依赖于用黑色方块遮挡输入视频的部分区域,这本质上移除了关键信息,并限制了它们处理复杂背景编辑或大形状修改的能力。其他方法,如 I2VEdit [34],通过为每个视频片段需要运动 LoRA 来引入计算复杂性。人们意识到,没有现有方法提供一个统一的、通用的框架,该框架能够将各种第一帧编辑(移除、插入、替换、跟踪、多重编辑)传播到整个视频序列,同时保持逼真性和一致性,而无需密集掩码标注或辅助运动预测。I2V 模型生成能力,经过精心设计和增强后,是唯一可行的方法来整体解决这一多方面挑战。
比较优势
GenProp 的定性优势源于其结构设计,该设计直接解决了先前方法的不足之处。与依赖光流等显式运动线索的传统方法不同,GenProp 利用了 I2V 模型固有的生成能力。这消除了困扰基于光流的方法的误差累积问题,从而在更长的视频序列中实现了显著更鲁棒和一致的传播。
一个关键的结构优势是选择性内容编码器 (SCE)。该组件允许 GenProp 选择性地编码来自原始视频未更改部分的特征,而 I2V 模型则将其生成能力集中在传播已编辑区域。这种分离对于在未编辑区域保持一致性至关重要,这是其他方法可能无意中改变稳定区域的常见失败点。此外,掩码预测解码器 (MPD),通过辅助头进行训练,指导模型准确识别和关注需要修改的区域,从而提高编辑的精度并改善注意力图的质量(如图 3 所示)。
也许最显著的定性飞跃是 GenProp 的通用性和灵活性。它支持广泛的复杂视频编辑任务——从带有阴影和反射等逼真效果的完整对象移除,到背景替换,再到具有物理合理运动的对象插入,甚至跟踪对象及其相关效果——所有这些都在一次推理运行中完成,并且无需特定任务的重新训练。这与先前 SOTA 方法形成鲜明对比,后者通常是针对一项任务专门设计的,或者需要对每一帧进行密集掩码标注。GenProp 的传播方法在推理时不需要任何掩码输入,极大地简化了编辑过程并减少了人工干预。这种结构优势使其具有压倒性的优势,提供了一个真正统一且通用的视频编辑解决方案。
与约束的对齐
GenProp 框架实现了问题严苛要求与其独特架构属性之间非凡的“结合”。让我们考虑关键约束:
- 逼真性:问题要求传播的更改看起来自然且逼真。GenProp 通过利用预训练的I2V 生成模型作为其核心,完美地实现了这一点。这些模型本质上设计用于生成高保真、逼真的视频内容,确保编辑后的序列保持视觉合理性。
- 一致性:未更改的区域必须与原始视频保持相同,编辑必须在时间上保持一致。这通过选择性内容编码器 (SCE) 来解决,它显式地保留了原始视频未编辑部分的信息。区域感知损失 (RA Loss) 通过分离修改和未修改区域的损失,进一步加强了这一点,惩罚稳定区域的更改,同时鼓励已编辑区域的准确传播。这确保了在没有预期编辑的区域忠实地保留了原始内容。
- 通用性与多功能性:解决方案必须处理广泛的视频编辑任务,而无需为每个任务重新训练。GenProp 通过其统一框架来实现这一点,该框架将第一帧编辑扩展到通用视频传播。至关重要的是,合成数据生成方案(复制粘贴、掩码填充、颜色填充)涵盖了训练期间的各种场景,使模型能够泛化到各种应用,如移除、插入、替换和跟踪,而无需在推理时进行特定任务的数据。
- 效率与简洁性:解决方案应避免繁琐的手动标注和易出错的中间表示。GenProp 消除了对所有帧进行密集掩码标注的需要,与许多传统方法甚至一些基于扩散的方法相比,这是一个重大的简化。它还绕过了对光流或深度图进行运动预测的依赖,从而避免了此类中间表示固有的误差累积。
- 复杂编辑:模型需要支持实质性的形状修改、独立的对象运动以及相关效果的移除。I2V 模型生成能力,结合 SCE 和 MPD 的精确引导,使 GenProp 能够处理这些复杂场景,例如具有独立运动的对象或对象(如阴影和反射)的移除,而传统方法通常无法做到这一点。
替代方案的拒绝
论文提供了拒绝替代方案的令人信服的理由,突出了它们对通用视频传播问题的根本局限性:
- 传统视频传播方法(光流、深度、图集):这些方法虽然是基础性的,但由于其鲁棒性有限、泛化能力差以及易于误差累积而被明确拒绝。它们通常是为单个任务设计的,并且需要为新应用重新训练,这使得它们对于统一框架来说不切实际。它们对显式运动线索的依赖使其在处理复杂、非刚性变形或重大场景变化时变得脆弱。
- 现有的基于扩散的视频编辑模型(例如,InsV2V、Pika、AnyV2V、ReVideo):虽然扩散模型功能强大,但它们现有的视频编辑实现存在不足。
- 许多模型仅限于改变外观,而不是精确地对对象形状进行实质性修改或处理复杂的背景编辑。
- 一些模型需要逐案微调(例如,I2VEdit 的运动 LoRA),增加了计算复杂性并减慢了过程。
- ReVideo [31] 等方法使用了黑色方块掩码,移除了关键信息,并严重限制了它们处理复杂背景编辑和大形状修改的能力,常常导致对象运动中的模糊边界和累积误差。
- 像 AnyV2V [27] 这样的免训练框架存在泛化能力有限的问题,并且在处理实质性形状变化或对象插入时遇到困难。Pika [2] 同样在处理重大形状变化或背景编辑时表现不佳。
- 依赖文本提示的方法(例如,InsV2V)常常受限于其训练数据,并且在处理复杂的、非外观的编辑时遇到困难。
- 传统修复流水线(例如,SAM-V2 + Propainter):对于对象移除等任务,这些级联方法被拒绝,主要是因为它们需要所有帧的密集掩码标注,这是一个劳动密集且易出错的过程,而 GenProp 完全避免了这一点。此外,Propainter 被证明在准确移除阴影和反射等对象效果方面存在困难,而 GenProp 由于其对物理规则的生成式理解而能够鲁棒地处理这些效果,这使得 GenProp 具有压倒性的优势。
- 用于跟踪的 SAM-V2:虽然 SAM-V2 [39] 在掩码跟踪方面非常出色,但它被指出由于其训练数据偏差而难以处理对象效果(反射、阴影)。GenProp 凭借其生成式预训练,对物理规则有更深入的理解,使其能够一致地跟踪这些相关效果。
总而言之,作者们得出结论,尽管这些替代方案的组成部分可能有用,但没有一个提供了在没有质量、效率或通用性方面重大妥协的情况下实现无缝、多样化视频传播所需的全面、鲁棒且通用的解决方案。GenProp 将选择性内容编码器、掩码预测解码器、区域感知损失和合成数据生成与强大的 I2V 模型相结合的创新集成,是克服这些集体局限性的唯一途径。
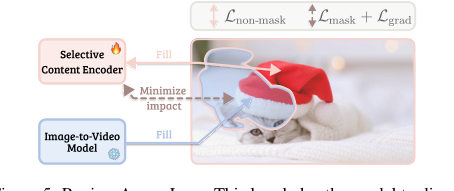 Figure 5. Region-Aware Loss. This loss helps the model to disen- tangle the edited region from the original content
Figure 5. Region-Aware Loss. This loss helps the model to disen- tangle the edited region from the original content
数学与逻辑机制
主方程
GenProp 的学习机制的核心体现在其区域感知损失中,该损失指导模型同时传播编辑并保留原始内容。虽然整体训练目标是最小化跨帧损失的总和,但单个帧的基本损失函数,它结合了所有关键组件,是:
$$ \mathcal{L} = \mathcal{L}_{\text{non-mask}} + \lambda \cdot \mathcal{L}_{\text{mask}} + \beta \cdot \mathcal{L}_{\text{grad}} + \gamma \cdot \mathcal{L}_{\text{MPD}} $$
这个主方程,以及将此损失随时间累加的整体训练目标,决定了模型如何学习执行生成视频传播。整体目标正式表述为:
$$ \min_{\mathcal{E}} \sum_{i=2}^{T} \mathcal{L}(G(E(V), v'_1, v_i), V_i) $$
其中 $\mathcal{E}$ 代表模型的可训练参数。
按项解剖
让我们逐一剖析主方程和整体目标的每个组成部分:
-
$\mathcal{L}$ (总区域感知损失):
- 数学定义:这是单个视频帧的总损失值,代表了与期望输出和行为偏差的总惩罚。
- 物理/逻辑作用:它作为优化器的主要信号,指示当前模型输出和内部状态有多“糟糕”。最小化 $\mathcal{L}$ 意味着改进模型在所有目标上的性能。
- 为何是加法? 作者使用加法是因为每个项代表模型必须满足的一个独立的目标或约束。通过将它们相加,模型被鼓励同时优化所有这些目标。如果一个项很高,总损失就会很高,表明在该特定方面需要进行调整。
-
$\mathcal{L}_{\text{non-mask}}$ (非掩码区域损失):
- 数学定义:$\mathcal{L}_{\text{non-mask}} = \mathbb{E}_{t \sim \mathcal{U}(1,T)} [\mathcal{L}_d((1 - m_t) \cdot v^{\text{out}}_t, (1 - m_t) \cdot v_t)]$。这是扩散均方误差 (MSE) 损失,$\mathcal{L}_d$,在生成输出 $v^{\text{out}}_t$ 和真实值 $v_t$ 之间计算,但仅限于掩码 $m_t$ 未覆盖的区域。
- 物理/逻辑作用:该项确保视频中在第一帧中未编辑的部分在整个序列中与原始视频内容保持一致。它充当保真度约束,防止对未编辑背景或对象的意外更改。
- 为何 $(1 - m_t) \cdot \text{frame}$? 与 $(1 - m_t)$ 进行逐元素乘法有效地“归零”了掩码(已编辑)区域,仅隔离了帧的未编辑部分以进行损失计算。这是一种精确地将一致性目标集中在特定区域的方法。
-
$\mathcal{L}_{\text{mask}}$ (掩码区域损失):
- 数学定义:$\mathcal{L}_{\text{mask}} = \mathbb{E}_{t \sim \mathcal{U}(1,T)} [\mathcal{L}_d(m_t \cdot v^{\text{out}}_t, m_t \cdot v_t)]$。这是扩散均方误差 (MSE) 损失,$\mathcal{L}_d$,在生成输出 $v^{\text{out}}_t$ 和真实值 $v_t$ 之间计算,但仅限于掩码 $m_t$ 覆盖的区域。
- 物理/逻辑作用:该项驱动模型准确生成已编辑内容,并传播从第一帧所做的修改。它确保更改在时间上被逼真地渲染并在修改区域内保持一致。
- 为何 $m_t \cdot \text{frame}$? 与 $\mathcal{L}_{\text{non-mask}}$ 类似,与 $m_t$ 进行逐元素乘法隔离了掩码(已编辑)区域,将生成目标专门集中在这些区域。
-
$\lambda$ ( $\mathcal{L}_{\text{mask}}$ 的权重):
- 数学定义:一个正标量系数(在论文中设置为 2.0)。
- 物理/逻辑作用:此超参数控制准确生成掩码(已编辑)区域相对于其他损失分量的相对重要性。较高的 $\lambda$ 值更强调正确传播编辑。
- 为何是乘法? 它缩放了 $\mathcal{L}_{\text{mask}}$ 对总损失的贡献,允许对不同目标之间的平衡进行微调。
-
$\mathcal{L}_{\text{grad}}$ (梯度损失):
- 数学定义:$\mathcal{L}_{\text{grad}} = \mathbb{E}_{t \sim \mathcal{U}(1,T)} [m_t \cdot ||\Delta f||^2]$,其中 $\Delta f = \frac{f(E(V + \delta)) - f(E(V))}{\delta}$ 是选择性内容编码器 (SCE) 特征 $f(E(V))$ 相对于输入视频 $V$ 中微小扰动 $\delta$ 的有限差分近似梯度。
- 物理/逻辑作用:这是分离的关键项。它惩罚 SCE,如果其输出特征在输入视频在掩码区域内受到微小扰动时发生显著变化。目标是强制 SCE 忽略已编辑部分,并仅专注于编码未更改的内容。这可以防止 SCE 无意中“重构”被移除的对象或干扰 I2V 模型在已编辑区域的生成任务。
- 为何 $||\Delta f||^2$? L2 范数的平方测量特征变化的大小。最小化此大小鼓励 SCE 的特征保持稳定且对掩码区域中的扰动不敏感。
- 为何 $m_t \cdot ||\Delta f||^2$? 掩码 $m_t$ 确保此梯度惩罚仅应用于已编辑区域,而这正是 SCE 理想情况下应该“盲目”的区域。
-
$\beta$ ( $\mathcal{L}_{\text{grad}}$ 的权重):
- 数学定义:一个正标量系数(在论文中设置为 1.0)。
- 物理/逻辑作用:此超参数控制梯度惩罚的强度,影响 SCE 被强制与已编辑区域分离的程度。
- 为何是乘法? 它缩放了 $\mathcal{L}_{\text{grad}}$ 对总损失的贡献。
-
$\mathcal{L}_{\text{MPD}}$ (掩码预测解码器损失):
- 数学定义:这是掩码预测解码器 (MPD) 预测的掩码与真实掩码 $m_t$ 之间的 MSE 损失。
- 物理/逻辑作用:这个辅助损失明确地训练 MPD 来准确识别修改区域。通过这样做,它为整个模型提供了关于编辑在哪里的清晰信号,这反过来有助于指导 I2V 模型的注意力和生成过程到正确的区域。它提高了注意力图的精度。
- 为何是 MSE? MSE 是回归任务的标准且有效的损失函数,包括像素级掩码值的预测。
-
$\gamma$ ( $\mathcal{L}_{\text{MPD}}$ 的权重):
- 数学定义:一个正标量系数(在论文中设置为 1.0)。
- 物理/逻辑作用:此超参数控制显式掩码预测任务的重要性。
- 为何是乘法? 它缩放了 $\mathcal{L}_{\text{MPD}}$ 对总损失的贡献。
-
$\mathbb{E}_{t \sim \mathcal{U}(1,T)}$ (时间步上的期望):
- 数学定义:在从 1 到 $T$ 均匀采样的 $t$ 时间步上的损失的平均值。
- 物理/逻辑作用:这确保了损失在整个视频序列的各种帧中被计算和考虑,从而促进了整个视频的时间一致性和泛化性。
- 为何是期望/均匀采样? 它提供了整个视频损失的稳健估计,防止模型过拟合到特定的帧或时间位置。
-
$\sum_{i=2}^{T}$ (帧上的求和):
- 数学定义:从 $i=2$ 到 $T$ 的每个帧的区域感知损失 $\mathcal{L}$ 的总和。
- 物理/逻辑作用:这将在训练期间将每帧损失聚合到整个视频序列的单个目标中。第一帧($i=1$)是输入的编辑帧,因此传播任务从第二帧开始。
- 为何是求和? 每个帧的损失对整体训练信号的贡献相等,确保模型学会了在整个视频中一致地传播编辑。
-
$G(E(V), v'_1, v_i)$ (生成的输出帧):
- 数学定义:图像到视频 (I2V) 生成模型 $G$ 的输出,以选择性内容编码器 $E(V)$ 的特征、修改后的第一帧 $v'_1$ 和原始第 $i$ 帧 $v_i$(用作 I2V 模型内部处理的参考,尽管真实值 $V_i$ 用于损失计算)为条件。
- 物理/逻辑作用:这是模型对修改视频的第 $i$ 帧的预测。它代表了在保持与原始视频未编辑部分一致性的同时传播第一帧编辑的结果。
-
$E(V)$ (选择性内容编码器特征):
- 数学定义:由选择性内容编码器 $E$ 从原始输入视频 $V$ 中提取的潜在特征。
- 物理/逻辑作用:该组件旨在编码原始视频未更改部分的信息。它为 I2V 模型提供上下文,指导其在未进行编辑的区域保留原始内容。
-
$v'_1$ (修改后的第一帧):
- 数学定义:视频的第一帧,已手动或合成编辑。
- 物理/逻辑作用:这充当传播的锚点。I2V 模型使用它作为起点来理解需要传播哪些更改。
-
$v_i$ (原始第 $i$ 帧):
- 数学定义:原始、未编辑视频序列 $V$ 的第 $i$ 帧。
- 物理/逻辑作用:在训练期间用作 I2V 模型的一部分输入,并在计算损失时用作未编辑区域的真实值。
-
$V_i$ (真实合成视频帧):
- 数学定义:合成视频序列 $V = \{V_1, V_2, ..., V_T\}$ 的第 $i$ 帧,该序列是通过将数据生成算子 $D$ 应用于原始视频生成的。
- 物理/逻辑作用:这是模型在训练期间的目标输出,代表传播后期望的修改视频帧。
分步流程
将 GenProp 想象成一个复杂的视频编辑工厂。以下是单个抽象数据点(视频帧)在训练期间如何通过其装配线:
- 原始视频摄入:一个原始视频序列,我们称之为 $V$,进入工厂。这个 $V$ 是一系列帧, $V_1, V_2, ..., V_T$。
- 合成编辑应用(数据生成):一个特殊的“编辑机器”(数据生成算子 $D$)获取 $V$ 并对其第一帧应用合成编辑,创建一个修改后的第一帧 $v'_1$。它还生成相应的真实修改帧 $V_2, ..., V_T$ 和二值掩码 $m_1, ..., m_T$,这些掩码精确地描绘了每帧中的编辑区域。这为我们提供了目标视频 $V' = \{v'_1, V_2, ..., V_T\}$。
- 内容编码(选择性内容编码器,SCE):整个原始视频 $V$ 被输入到“选择性内容编码器”($E$)。该编码器就像一个智能过滤器;它的工作是提取代表视频未更改内容的特征,并故意尝试忽略关于将要编辑的区域的任何信息。它正在学习对修改“视而不见”。
- 传播引擎(图像到视频模型):现在,对于每个后续帧 $i$(从 $2$ 到 $T$):
- 修改后的第一帧 $v'_1$(编辑的蓝图)被输入。
- 来自 $E(V)$ 的选择性编码特征(原始未编辑场景的上下文)被注入。
- 当前时间步 $i$ 也被提供。
- “图像到视频生成模型”($G$) 作为主要的传播引擎。它接收这些输入并生成其对修改视频的第 $i$ 帧的最佳猜测,我们称之为 $v^{\text{out}}_i$。这就是魔法发生的地方:来自 $v'_1$ 的编辑被传播,并以原始内容特征为指导。
- 掩码预测(掩码预测解码器,MPD):同时,一个“掩码预测解码器”(MPD)接收来自 I2V 模型的内部潜在表示,并尝试预测当前帧的掩码 $m_i$。这就像一个质量控制传感器,检查模型是否理解在哪里进行了编辑。
- 损失计算与反馈(区域感知损失):对于每个生成的帧 $v^{\text{out}}_i$:
- 一致性检查(非掩码损失):$v^{\text{out}}_i$ 的未编辑部分(由 $(1-m_i)$ 选择)与真实值 $V_i$ 的未编辑部分进行比较。这里的任何差异都会计入 $\mathcal{L}_{\text{non-mask}}$,促使模型保持原始内容不变。
- 编辑准确性检查(掩码损失):$v^{\text{out}}_i$ 的已编辑部分(由 $m_i$ 选择)与真实值 $V_i$ 的已编辑部分进行比较。这里的任何错误都会计入 $\mathcal{L}_{\text{mask}}$,推动模型准确传播更改。
- 编码器盲目性检查(梯度损失):一个特殊的“梯度传感器”检查 SCE 的特征是否会在输入掩码区域略微改变时发生变化。如果发生变化,则会增加 $\mathcal{L}_{\text{grad}}$,告诉 SCE 对编辑更加无动于衷。
- 掩码预测准确性检查(MPD 损失):MPD 预测的掩码与真实掩码 $m_i$ 进行比较,计入 $\mathcal{L}_{\text{MPD}}$。
- 总损失聚合:所有这些单独的损失组件($\mathcal{L}_{\text{non-mask}}$、$\mathcal{L}_{\text{mask}}$、$\mathcal{L}_{\text{grad}}$、$\mathcal{L}_{\text{MPD}}$)都被加权($\lambda, \beta, \gamma$)并相加,形成该帧的总区域感知损失 $\mathcal{L}$。此过程对从 $i=2$ 到 $T$ 的所有帧重复进行,并将所有这些每帧损失相加,得到整体目标。
- 参数调整:这个总目标值随后被发送给“优化器”,它就像工厂经理。它计算需要如何调整每个旋钮和拨盘(模型参数)以减小此总损失。这些调整是迭代进行的,在每次训练步骤中完善 SCE、I2V 模型和 MPD。
整个周期重复数百万次,逐步教会 GenProp 无缝传播编辑,同时保留视频的其余部分。
优化动力学
GenProp 通过梯度下降和精心设计的损失景观的复杂相互作用来学习和收敛。优化过程由最小化所有帧从 $i=2$ 到 $T$ 的区域感知损失 $\mathcal{L}$ 的总和来驱动。
-
基于梯度的学习:选择性内容编码器 (SCE)、图像到视频 (I2V) 生成模型和掩码预测解码器 (MPD) 的模型参数 ($\mathcal{E}$) 使用优化器(例如,如扩散模型常见的 Adam)进行迭代更新。这包括计算总损失相对于每个参数的梯度。这些梯度指示参数需要调整的方向和幅度以减小损失。学习率(例如,带有余弦衰减调度器和线性预热的 5e-5)控制这些调整的步长。还维护了模型参数的指数移动平均 (EMA),这通常通过平均噪声更新来提供更稳定的训练和更好的最终性能。梯度范数阈值 (0.001) 用于防止梯度爆炸并确保训练稳定性。
-
用于分离和一致性的损失景观塑形:区域感知损失 ($\mathcal{L}$) 的独特设计是塑造损失景观和指导模型学习的关键:
- 平衡区域优化:$\mathcal{L}_{\text{mask}}$ 和 $\mathcal{L}_{\text{non-mask}}$ 项创建了一个具有两个主要“山谷”的损失景观。一个山谷鼓励在已编辑区域内进行准确的生成,确保传播的更改是逼真的。另一个山谷促进在未编辑区域中对原始内容的高度保真度。通过对这些项进行加权(使用 $\lambda$),作者可以平衡模型的焦点,防止它要么忽略编辑,要么破坏原始背景。这个双重目标帮助模型导航一个复杂的景观,它必须同时创建新内容并保留现有内容。
- 强制 SCE 的选择性:$\mathcal{L}_{\text{grad}}$ 项尤其巧妙。通过惩罚 SCE,如果其特征在输入掩码区域被扰动时发生变化,它会在 SCE 输出相对于已编辑区域的损失景观中创建一个“平坦”区域。这迫使 SCE 学习一种不变于修改的表示,有效地使其对编辑“盲目”。这分离了 SCE 的角色(编码原始上下文)与 I2V 模型的角色(传播编辑),防止了鬼影或移除对象重新出现等问题。没有这个,SCE 可能会试图在所有地方重构原始内容,从而阻碍了更改的传播。
- 显式引导注意力:$\mathcal{L}_{\text{MPD}}$ 项为模型提供了明确的、监督式的信号来识别在哪里进行了编辑。这有助于 I2V 模型内部的注意力机制专注于正确的区域进行生成和修改。通过显式学习掩码,模型对已编辑和未编辑内容之间的“边界”有了更清晰的理解,从而实现了更精确的传播和更少的混淆。这个损失项有助于为需要修改的区域创建更清晰、更明确的损失景观边界。
-
迭代改进与收敛:经过多次迭代,模型会迭代地更新其参数。I2V 模型学会根据编辑过的第一帧和 SCE 的上下文生成越来越逼真且时间上一致的视频帧。SCE 学会从原始视频中提取鲁棒的、与编辑无关的特征。MPD 学会准确预测修改的区域。这种持续的反馈循环,在区域感知损失的指导下,将模型驱动到一个状态,在该状态下,它可以在整个视频序列中无缝传播各种第一帧编辑,同时保持对未编辑内容的高度保真度。当梯度变得非常小时,模型收敛,这表明进一步的参数更新带来的损失改进很小。
 Figure 1. GenProp. We propose a generative video propagation framework (GenProp), which can seamlessly propagate any first frame edit through the video. GenProp supports a wide range of video applications, including (a) complete object removal with effects such as shadows and reflections, (b) background replacement with realistic effects, (c) object insertion where inserted objects have physically plausible motion (i.e., blueberries falling while spoon goes up), (d) tracking of objects and their associated effects, and (e) multiple edits (outpainting, insertion, removal) at a single inference run
Figure 1. GenProp. We propose a generative video propagation framework (GenProp), which can seamlessly propagate any first frame edit through the video. GenProp supports a wide range of video applications, including (a) complete object removal with effects such as shadows and reflections, (b) background replacement with realistic effects, (c) object insertion where inserted objects have physically plausible motion (i.e., blueberries falling while spoon goes up), (d) tracking of objects and their associated effects, and (e) multiple edits (outpainting, insertion, removal) at a single inference run
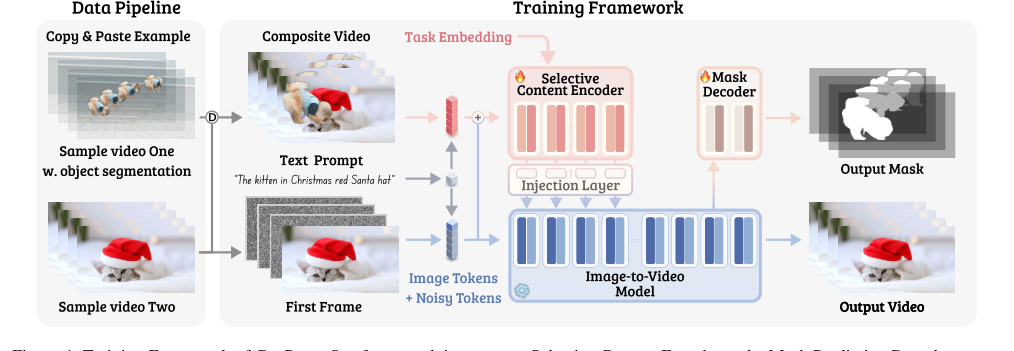 Figure 4. Training Framework of GenProp. Our framework integrates a Selective Content Encoder and a Mask Prediction Decoder on top of the I2V generation model, enforcing the model to propagate the edited region while preserving the content in the original video for all other regions. With synthetic data augmentations and task embeddings, our model is trained to propagate various changes in the first frame
Figure 4. Training Framework of GenProp. Our framework integrates a Selective Content Encoder and a Mask Prediction Decoder on top of the I2V generation model, enforcing the model to propagate the edited region while preserving the content in the original video for all other regions. With synthetic data augmentations and task embeddings, our model is trained to propagate various changes in the first frame
结果、局限性与结论
实验设计与基线
为了严格验证 GenProp 的能力,作者设计了一个全面的实验设置,利用了两种不同的基础视频生成模型:一种类似于 Sora [32] 的 DiT 架构和一种基于 Stable Video Diffusion (SVD) [5] 的 U-Net 架构。最终产生更优视频生成质量的 DiT 变体,经过训练,可以在 32、64 和 128 帧,以 12 和 24 帧/秒 (FPS) 的速率进行图像到视频 (I2V) 生成,基础分辨率为 360p。选择性内容编码器 (SCE) 和掩码预测解码器 (MPD) 组件在 I2V 模型保持冻结的情况下进行训练,确保 GenProp 的核心机制专注于传播编辑,而不是从头开始重新学习视频生成。
训练采用了 $5 \times 10^{-5}$ 的学习率,配合余弦衰减调度器和线性预热,以及用于稳定性的指数移动平均。梯度范数阈值设置为 0.001 以防止不稳定性。分类器自由引导 (CFG) 设置为 20。训练的一个关键方面是合成数据生成方案,该方案采用了各种增强比例(0.5、0.375、0.125)用于复制粘贴、掩码填充和颜色填充任务。区域感知 (RA) 损失对于分离已编辑和未编辑区域至关重要,其权重参数设置为:$\lambda = 2.0$、$\beta = 1.0$ 和 $\gamma = 1.0$。所有实验均在 32 或 64 个 NVIDIA A100 GPU 上进行,凸显了所需的显著计算资源。
GenProp 对比的“受害者”(基线模型)根据任务而异。对于通用视频编辑,它与 InsV2V [8]、AnyV2V [27]、Pika [2] 和 ReVideo [31] 进行了比较。对于对象移除,采用了 SAM-V2 [39](用于掩码跟踪)和 Propainter [64](用于修复)的级联流水线作为基线。对于对象跟踪,SAM-V2 [39] 是直接竞争对手。
定量评估在两个测试集上进行:
1. 经典测试集:包含 TGVE [51] 的 DAVIS [36] 数据集,使用“对象变化字幕”文本提示,侧重于对象替换和外观编辑。
2. 挑战性测试集:从 Pexels [1] 和 Adobe Stock [3] 中手动策划的 30 个视频集合,包含更复杂的场景,如大型对象替换、对象插入和背景替换。在此数据集上的编辑是使用商业照片编辑工具或特定基线方法(例如,Pika 的在线框选工具、ReVideo 的运动点提取)完成的。
GenProp 成功的决定性证据是通过以下几项指标衡量的:
- PSNRm:峰值信噪比,专门计算已编辑区域之外,以量化未更改内容的连贯性。
- CLIP-T:CLIP [38] 嵌入的已编辑帧和文本提示之间的余弦相似度,评估文本对齐度。
- CLIP-I:帧之间 CLIP [38] 特征的距离,衡量帧到帧的一致性。
- 用户研究:在 Amazon MTurk [45] 上进行的由 121 名参与者进行的人工评估,他们将 GenProp 的输出与基线和原始视频进行比较,并对指令的对齐度和整体视觉质量进行评判。
证据证明了什么
证据明确证明了 GenProp 的核心机制在实践中有效,将其确立为生成视频传播的领先框架。如表 1 所示,GenProp 在大多数指标上显著优于其他方法,尤其是在更具挑战性的挑战性测试集上。这不仅仅是渐进式改进;它证明了一种根本上更鲁棒、更通用的方法。
例如,在对象替换和背景替换(图 6a、6b)中,GenProp 展示了其无缝修改具有巨大形状差异和独立运动的对象,以及执行复杂背景编辑的能力。这直接解决了 InsV2V [8] 和 Pika [2] 等基线的主要局限性,它们由于依赖文本提示或有限的训练数据而在处理重大形状变化或对象插入方面遇到困难。AnyV2V [27] 也存在泛化能力有限的问题,而 ReVideo [31] 经常产生模糊的边界和来自其点跟踪机制的累积误差。GenProp 在无需对每一帧进行密集掩码标注的情况下处理这些复杂场景的能力,是其基于传播方法的证明。
在对象和效果移除(图 6c、6d)中,GenProp 不仅移除对象,还移除其相关效果(如阴影和反射),并逼真地重建大面积遮挡区域,表现出色。SAM+Propainter 基线虽然对于修复有效,但在移除这些细微效果方面存在困难,如表 2 中其较低的 CLIP-I 和用户偏好分数所示。GenProp 的统一方法,利用生成模型,本质上理解如何逼真地填充移除的区域,包括环境上下文。
对于实例对象和效果跟踪(图 6e),GenProp 即使在用纯色填充初始化的情况下,也展示了对对象及其相关效果的一致跟踪。虽然 SAM-V2 [39] 在实时跟踪方面更快,并且可以产生精确的掩码,但 GenProp 的视频生成预训练使其对物理规则有深刻的理解,使其能够跟踪 SAM-V2 由于其有限且有偏差的训练数据而经常错过的效果。这凸显了生成模型通过对场景动态的更深入理解来解决经典视觉任务的潜力。
消融研究进一步提供了 GenProp 关键组件有效性的无可辩驳的证据:
- 掩码预测解码器 (MPD) 显著提高了文本对齐度和一致性(表 3)。没有它,输出掩码通常会退化,导致对象移除不完整以及在传播区域与保留区域之间的混淆(图 7,第 1-2 行)。MPD 的显式监督有助于模型分离更改,并确保完全移除对象,即使存在严重遮挡。
- 区域感知损失 (RA Loss) 对于第一帧编辑的稳定和一致传播至关重要。没有 RA Loss,原始对象倾向于在后续帧中逐渐重新出现,阻碍了传播(图 7,第 3-5 行)。此损失确保已编辑区域稳定传播,而未更改区域保持一致。
- 颜色填充增强被证明是解决传播失败的关键因素,特别是对于大型形状修改。它显式地训练模型进行跟踪,引导其在整个序列中保持修改,从而实现诸如将女孩变成一只小猫之类的挑战性编辑(图 7,第 6-8 行)。
总之,GenProp 的成功根植于其精心设计,利用了 I2V 模型、选择性内容编码器、掩码预测解码器和区域感知损失的生成能力,所有这些都通过一个多功能的合成数据生成管道进行训练。这种组合使其能够通过在各种具有挑战性的视频编辑任务中持续优于基线来无情地证明其数学声明。
局限性与未来方向
尽管 GenProp 在生成视频传播方面取得了重大进展,但承认其固有的局限性并考虑未来发展的途径至关重要。一个隐含的局限性是计算成本;在多个 NVIDIA A100 GPU 上进行训练表明,在消费级硬件上部署该模型以进行实时、高分辨率视频编辑可能仍然是一个挑战。此外,对合成数据的依赖,虽然能够实现多功能性,但可能会引入偏差或降低对与合成分布显著不同的极其新颖、未经策划的真实世界场景的泛化能力。论文还指出,传统的质量指标有时无法捕捉生成结果的逼真度,这需要用户研究,这表明在自动化、全面的评估方面存在差距。
展望未来,作者们明确计划将模型扩展到支持多于一个关键帧的编辑,这将显著增强其处理复杂、多阶段编辑工作流程的灵活性。他们还旨在发掘该框架可以支持的更多视频任务,这表明 GenProp 的底层生成能力具有未开发的潜力。
除了这些直接计划之外,还出现了几个讨论主题,以进一步发展和演进这些发现:
-
增强的用户控制和可解释性:虽然 GenProp 通过消除对密集掩码的需求来简化编辑过程,但如何集成更直观、更精细的用户控制来微调编辑?是否可以有一个“人在回路中”的系统,也许带有交互式反馈机制,允许用户在不重新引入传统方法的复杂性的情况下更精确地引导传播过程?探索使模型内部“推理”(例如,注意力图)对用户更具可解释性的方法也可以培养更大的信任和控制。
-
真实世界鲁棒性和数据稀缺性:当前框架从合成数据中受益匪浅。然而,真实世界的视频数据通常包含合成数据集未能完全捕捉的噪声、遮挡和不可预测的运动模式。未来的工作可以探索域适应技术或自监督学习策略,以提高 GenProp 对不受约束的“野外”视频的鲁棒性,可能减少对精心设计的合成数据的依赖。
-
生产的效率和可扩展性:为了更广泛的应用,优化 GenProp 以实现更快的推理和更低的内存占用至关重要。研究知识蒸馏、模型剪枝或更高效的架构设计等技术可以实现部署到边缘设备或实时处理更长、更高分辨率的视频。生成质量、速度和资源消耗之间的权衡是什么,以及如何为实际应用平衡这些权衡?
-
多模态集成和情境理解:视频本质上是多模态的。如何扩展 GenProp 以整合音频、文本描述(超越提示)或甚至 3D 场景信息,以创建更连贯、更具沉浸感的编辑?例如,编辑对象的运动可以自动触发相应的音效调整,或者理解场景的 3D 几何可以为插入的对象带来更物理上准确的交互和光照效果。
-
道德影响和负责任的 AI:随着生成视频编辑变得越来越复杂,创建高度逼真但经过操纵的内容的能力引发了重大的道德担忧。未来的讨论应主动解决如何负责任地开发和部署如此强大的工具,包括检测操纵内容的机制、建立明确的使用指南以及确保 AI 生成媒体的透明度。这对于这项技术对社会的长期影响至关重要。
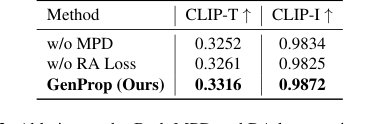 Table 3. Ablation study. Both MPD and RA loss can improve the success rate of editing and the quality of the output video
Table 3. Ablation study. Both MPD and RA loss can improve the success rate of editing and the quality of the output video
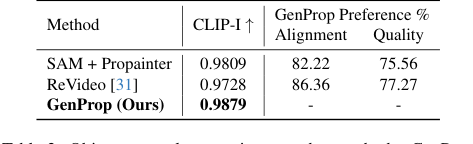 Table 2. Object removal comparison to other methods. GenProp outperforms baselines on consistency, alignment, and quality
Table 2. Object removal comparison to other methods. GenProp outperforms baselines on consistency, alignment, and quality
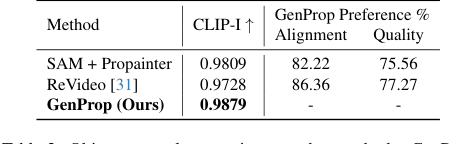 Table 1. Video editing benchmark compared to existing models. PSNRm measures the consistency outside the edited region. CLIP-T and CLIP-I measure text alignment and frame consistency. User study shows the percentage of users who preferred Ours over the compared method on alignment (left) and quality (right). GenProp significantly outperforms the other methods on the Challenging Set
Table 1. Video editing benchmark compared to existing models. PSNRm measures the consistency outside the edited region. CLIP-T and CLIP-I measure text alignment and frame consistency. User study shows the percentage of users who preferred Ours over the compared method on alignment (left) and quality (right). GenProp significantly outperforms the other methods on the Challenging Set
与其他领域的同构性
结构骨架
本质上,本文提出了一种机制,该机制选择性地将目标修改从初始状态传播到顺序数据结构,同时保持未修改区域的完整性。