Генеративное распространение видео
Проблема генеративного распространения видео, рассматриваемая в данной статье, коренится в более широкой области компьютерного зрения, в частности, в области генерации и редактирования видео.
Предыстория и академическая родословная
Проблема генеративного распространения видео, рассматриваемая в данной статье, коренится в более широкой области компьютерного зрения, в частности, в области генерации и редактирования видео. Исторически основная задача заключалась в последовательном и реалистичном распространении изменений, внесенных в один кадр (или разреженное множество кадров), на всю видеопоследовательность. Ранние подходы к распространению видео, возникшие из необходимости поддерживать временную согласованность и визуальную правдоподобность в измененном видеоконтенте, в основном опирались на традиционные методы компьютерного зрения, такие как оптический поток [9, 44], оценка глубины [6, 55], поля излучения [33] и атласы [20, 24]. Растущий спрос на сложные инструменты редактирования видео, способные обрабатывать сложные, реалистичные сценарии с минимальными ручными усилиями, стимулировал появление и развитие этой конкретной проблемы.
Фундаментальное ограничение или «болевая точка» предыдущих подходов, побудившая авторов разработать новую структуру, проистекает из нескольких ключевых проблем. Традиционные методы часто были склонны к накоплению ошибок на протяжении всего видео, что приводило к снижению качества и несогласованности в более поздних кадрах. Это делало их менее надежными и ограничивало их обобщающую способность для разнообразного видеоконтента. Многие предыдущие методы также были специфичными для задач, что означало, что модель, обученная для одного типа редактирования (например, удаления объектов), требовала значительного переобучения или совершенно другой модели для другой задачи (например, замены фона) [28, 31, 34, 61]. Отсутствие единой структуры было основным препятствием. Более современные модели редактирования видео на основе диффузии, хотя и мощные, также имели свои ограничения. Многие были разработаны в первую очередь для изменения внешнего вида, а не для внесения существенных изменений в формы объектов или обработки сложных изменений фона. Они часто требовали плотного маскирования для каждого отдельного кадра, что является трудоемким и времязатратным процессом, делая приложения в реальном времени или крупномасштабные приложения непрактичными. Например, такие методы, как I2VEdit [34], вводили вычислительную сложность, требуя изучения LoRA движения для каждого видеоклипа. Другие подходы, такие как ReVideo [31], включали маскирование частей входного видео черными квадратами, что непреднамеренно удаляло значительную информацию и ограничивало их способность обрабатывать сложные фоновые редактирования и большие изменения формы. Мотивацией авторов было преодоление этих ограничений путем предложения единой генеративной структуры, которая могла бы беспрепятственно и надежно распространять разнообразные редактирования без необходимости специфического для задач переобучения или плотных входных масок, тем самым значительно упрощая процесс редактирования видео.
Интуитивные термины предметной области
Вот несколько специализированных терминов из статьи, переведенных в интуитивно понятные, повседневные аналогии для читателя с нулевым уровнем знаний:
-
Генеративное распространение видео: Представьте, что вы снимаете фильм в технике пластилиновой анимации. Вы лепите первую сцену, затем решаете добавить крошечную шляпу одному из ваших пластилиновых персонажей. «Генеративное распространение видео» похоже на наличие волшебного, суперумного помощника, который, увидев вашу отредактированную первую сцену, автоматически перелепливает все последующие сцены, гарантируя, что шляпа последовательно появляется на персонаже, естественно движется вместе с ним и выглядит идеально интегрированной в фильм, без необходимости трогать каждый отдельный кадр. Он «распространяет» ваше первоначальное редактирование по всему видео в «генеративном» (творческом, реалистичном) стиле.
-
Модель генерации «изображение-в-видео» (I2V): Думайте об этом как о высококреативном рассказчике. Вы даете этому рассказчику одну фотографию («изображение») и краткое описание того, что должно произойти дальше, и он может придумать и создать из этого целую короткую видеопоследовательность. Например, вы даете ему фотографию неподвижного озера и говорите: «сделай так, чтобы вода мягко рябила», и он генерирует видео озера с реалистичными волнами. В этой статье этот рассказчик используется для генерации остальной части видео на основе отредактированного первого кадра.
-
Селективный кодировщик контента (SCE): Представьте себе очень внимательного библиотекаря. Вы даете этому библиотекарю две версии книги: оригинал и одну, где вы выделили определенные предложения. Задача этого библиотекаря — только запомнить и сохранить все части оригинальной книги, которые вы не выделили, сознательно игнорируя выделенные разделы. Он «селективно кодирует» оригинальный контент, фокусируясь на том, что должно остаться неизменным, чтобы генеративная модель затем могла заполнить отредактированные части, не испортив остальную часть книги.
-
Регионально-ориентированная потеря (RA Loss): Представьте, что вы оцениваете художественный проект студента, состоящий из двух частей: рисунка и живописи. «Регионально-ориентированная потеря» — это как система оценки, которая гарантирует, что вы уделяете одинаковое внимание как рисунку (неизмененные части видео), так и живописи (отредактированные части), даже если одна часть намного меньше или кажется менее важной. Она гарантирует, что модель учится хорошо выполнять как сохранение оригинального контента, так и точное распространение редактирований, предотвращая чрезмерную концентрацию на одном за счет другого.
Таблица обозначений
| Обозначение | Описание |
|---|---|
Определение проблемы и ограничения
Основная постановка задачи и дилемма
Статья посвящена сложной проблеме генеративного распространения видео, направленной на бесшовное применение редактирования первого кадра ко всей видеопоследовательности при сохранении реализма и согласованности.
Входные данные / Текущее состояние:
Отправной точкой является оригинальное видео $V = \{v_1, v_2, ..., v_T\}$, состоящее из $T$ кадров, и один измененный первый кадр $v'_1$. Этот $v'_1$ является результатом произвольного редактирования, примененного к оригинальному первому кадру $v_1$. Существующие методы редактирования видео обычно страдают от нескольких ограничений: они часто требуют плотного маскирования для каждого кадра, полагаются на вспомогательные входные данные, такие как оптический поток или карты глубины, для управления движением, или требуют переобучения для каждой конкретной задачи редактирования или видеоклипа. Многие из них также ограничены определенными типами редактирования, такими как изменения внешнего вида, и испытывают трудности со значительными изменениями формы или сложными изменениями фона.
Выходные данные / Целевое состояние:
Желаемым конечным результатом является новое, измененное видео $V' = \{v'_1, v'_2, ..., v'_T\}$. Для каждого последующего кадра $v'_t$ (где $t \in \{2, ..., T\}$) цель состоит в том, чтобы гарантировать, что модификация, введенная в $v'_1$, точно и реалистично распространяется по всему видео. Одновременно все неизмененные области видео должны оставаться полностью согласованными с оригинальным контентом как по внешнему виду, так и по движению. Структура должна быть универсально применима к широкому спектру задач редактирования видео, включая удаление объектов, вставку, замену, отслеживание и аутпейнтинг, без необходимости специфических для задач данных или явных указаний на движение, таких как оптический поток.
Отсутствующее звено или математический пробел:
Точным недостающим звеном является единая генеративная структура, которая может эффективно разделять измененные и неизмененные области видео и распространять изменения из одного отредактированного первого кадра на всю последовательность. Это должно быть достигнуто при сохранении оригинального контента в неизмененных областях и генерации нового, физически правдоподобного контента в измененных областях, в разнообразных и сложных сценариях редактирования. Математически, статья стремится определить генеративную функцию $G$ и селективный кодировщик контента $E$ таким образом, чтобы измененные кадры $v'_t$ для $t \in \{2, ..., T\}$ могли быть получены как $v'_t = G(E(V), v'_1, t)$. Здесь $E(V)$ должен селективно кодировать только неизмененную информацию из оригинального видео $V$, позволяя $G$ (модели генерации «изображение-в-видео») сосредоточиться на распространении измененного контента из $v'_1$ на последующие кадры. Задача заключается в разработке $E$ и $G$ для синергетической работы для достижения этого разделения и последовательного распространения без явного пошагового руководства.
Болезненный компромисс или дилемма:
Предыдущие исследователи оказались в ловушке фундаментального компромисса:
1. Реализм и согласованность против универсальности и гибкости: Достижение высокореалистичного и временно согласованного распространения редактирований (особенно для сложных изменений, таких как большие изменения формы или фоновые изменения) часто достигается за счет универсальности. Методы, превосходящие по согласованности, обычно полагаются на явные представления движения (например, оптический поток) или пошаговую настройку для каждой задачи, что делает их менее гибкими и требующими специфических входных данных. И наоборот, более универсальные генеративные модели часто испытывают трудности с поддержанием детальной согласованности и избеганием артефактов с течением времени. Улучшение одного аспекта (например, допущение существенных изменений формы) обычно нарушает другой (например, временную когерентность или реализм эффектов, таких как тени).
2. Вычислительная эффективность против качества и масштаба: Многие существующие подходы либо включают вычислительно интенсивные процессы (такие как плотное маскирование для всех кадров или повидеовая настройка), либо дают результаты с ограниченным качеством и масштабом редактирования. Дилемма заключается в том, как достичь высококачественного, разнообразного редактирования видео без непомерных вычислительных затрат или необходимости обширного ручного вмешательства.
Ограничения и режимы отказа
Проблема генеративного распространения видео чрезвычайно сложна из-за нескольких суровых, реалистичных ограничений:
- Временная согласованность и накопление ошибок: Обеспечение плавного и последовательного распространения редактирований на сотни кадров без накопления ошибок является серьезной проблемой. Даже небольшие несогласованности могут привести к заметным «эффектам призрачности», мерцанию или деградации в более поздних кадрах, особенно при работе со сложными движениями или длинными видеопоследовательностями.
- Разделение измененных и неизмененных областей: Модель должна точно идентифицировать и сохранять оригинальный контент в неизмененных областях, одновременно генерируя новый контент для измененных областей. Это разделение имеет решающее значение; сбой здесь может привести к появлению оригинальных объектов в измененных областях или непреднамеренным изменениям в неизмененных частях видео.
- Обработка разнообразных и сложных редактирований: Структура должна поддерживать широкий спектр задач редактирования, включая удаление объектов с сопутствующими эффектами (тени, отражения), вставку объектов с независимым и физически правдоподобным движением и замену фона. Каждая задача представляет уникальные проблемы с точки зрения генерации контента и согласованности движения.
- Отсутствие специфических для задач данных: Создание крупномасштабных, парных видео наборов данных для каждой мыслимой задачи редактирования видео является непомерно дорогим и трудоемким. Эта нехватка данных заставляет полагаться на генерацию синтетических данных, что само по себе создает проблемы с обеспечением хорошей обобщающей способности модели на реальных видео и избеганием обучения на синтетических артефактах.
- Вычислительные и памятьные ограничения: Обработка видеопоследовательностей высокого разрешения и генерация новых кадров со сложным контентом требует значительных вычислительных ресурсов. Обучение и вывод для таких моделей требуют мощных GPU и значительной памяти, что делает производительность в реальном времени или даже близкую к реальному времени серьезным препятствием.
- Отсутствие явных указаний на движение: В отличие от традиционных методов, которые полагаются на оптический поток или карты глубины, эта структура стремится работать без такого явного руководства движением. Это накладывает более высокую нагрузку на генеративную модель для неявного понимания и синтеза правдоподобного движения, что по своей сути трудно.
- Недифференцируемая реальная физика: Точное моделирование и распространение физических эффектов, таких как тени, отражения и реалистичные взаимодействия объектов в генеративной структуре, является сложной задачей, поскольку эти явления сложны и нелегко представлены дифференцируемыми функциями.
Почему такой подход
Неизбежность выбора
Решение авторов построить основу GenProp на основе генеративной модели «изображение-в-видео» (I2V) было не просто предпочтением; это была стратегическая необходимость, обусловленная присущими ограничениями существующих подходов. Традиционные методы распространения видео, часто полагающиеся на оптический поток, карты глубины или атласы, были принципиально непригодны для задачи общего генеративного распространения видео. Эти методы склонны к накоплению ошибок с течением времени, демонстрируют ограниченную надежность и, что особенно важно, не обладают обобщающей способностью для обработки разнообразных задач редактирования без обширного переобучения или специфических для задач модификаций. Они обычно преуспевают в одной, четко определенной задаче, но терпят неудачу, когда сталкиваются с необходимостью универсальности.
«Эврика!» момент, хотя и не явно заявленный как единичное событие, может быть выведен из критической оценки авторами передовых достижений (SOTA). Даже передовые модели редактирования видео на основе диффузии, хотя и мощные, в основном фокусировались на изменении внешнего вида, управляемом текстом, или требовали громоздкой пошаговой настройки для каждого случая. Они испытывали трудности со значительными изменениями формы, сложными фоновыми редактированиями или физически правдоподобным движением вставленных объектов. Такие методы, как Revideo [31], например, полагались на маскирование частей входного видео черными квадратами, что по своей сути удаляло жизненно важную информацию и ограничивало их способность обрабатывать сложные фоновые редактирования или большие изменения формы. Другие, такие как I2VEdit [34], вводили вычислительную сложность, требуя LoRA движения для каждого видеоклипа. Осознание заключалось в том, что ни один существующий метод не предлагал единой, общей структуры, способной распространять разнообразные редактирования первого кадра (удаление, вставка, замена, отслеживание, множественные редактирования) по всей видеопоследовательности, сохраняя при этом как реализм, так и согласованность, без необходимости плотных масочных аннотаций или вспомогательных предсказаний движения. Генеративная мощь моделей I2V, при тщательном проектировании и дополнении, была единственным жизнеспособным путем для целостного решения этой многогранной задачи.
Сравнительное превосходство
Качественное превосходство GenProp обусловлено его структурным дизайном, который напрямую устраняет недостатки предыдущих методов. В отличие от традиционных подходов, которые полагаются на явные указания движения, такие как оптический поток, GenProp использует присущие генеративные возможности моделей I2V. Это устраняет проблему накопления ошибок, которая преследует методы, основанные на потоке, что приводит к значительно более надежному и последовательному распространению на более длинных видеопоследовательностях.
Ключевым структурным преимуществом является селективный кодировщик контента (SCE). Этот компонент позволяет GenProp селективно кодировать признаки из неизмененных частей оригинального видео, в то время как модель I2V фокусирует свою генеративную мощь на распространении измененных областей. Это разделение имеет решающее значение для поддержания согласованности в неизмененных областях, что является распространенной точкой отказа для других методов, которые могут непреднамеренно изменять стабильные области. Кроме того, декодер предсказания маски (MPD), обученный с вспомогательной головкой, направляет модель на точное определение и фокусировку на областях, требующих модификации, повышая точность редактирования и улучшая качество карт внимания (как показано на Рисунке 3).
Пожалуй, самым значительным качественным скачком является универсальность и гибкость GenProp. Он поддерживает широкий спектр сложных задач редактирования видео — от полного удаления объектов с реалистичными эффектами, такими как тени и отражения, до замены фона, вставки объектов с физически правдоподобным движением и даже отслеживания объектов и связанных с ними эффектов — все это в рамках одного прогона вывода и без необходимости специфического для задач переобучения. Это резкий контраст с предыдущими методами SOTA, которые часто были специализированы для одной задачи или требовали плотного маскирования для каждого кадра. Подход GenProp, основанный на распространении, не требует входных масок при выводе, что значительно упрощает процесс редактирования и снижает ручные усилия. Это структурное преимущество делает его подавляюще превосходящим, предлагая поистине унифицированное и универсальное решение для редактирования видео.
Соответствие ограничениям
Структура GenProp достигает замечательного «брака» между суровыми требованиями задачи и ее уникальными архитектурными свойствами. Рассмотрим ключевые ограничения:
- Реализм: Задача требует, чтобы распространяемые изменения выглядели естественно и реалистично. GenProp идеально соответствует этому, используя предварительно обученную модель генерации I2V в качестве своей основы. Эти модели по своей сути предназначены для генерации высококачественного, реалистичного видеоконтента, гарантируя, что отредактированные последовательности сохраняют визуальную правдоподобность.
- Согласованность: Неизмененные области должны оставаться идентичными оригинальному видео, а редактирования должны быть временно согласованными. Это достигается с помощью селективного кодировщика контента (SCE), который явно сохраняет информацию из неизмененных частей видео. Регионально-ориентированная потеря (RA Loss) дополнительно усиливает это, разделяя потери для измененных и неизмененных областей, наказывая изменения в стабильных областях, одновременно поощряя точное распространение в измененных областях. Это гарантирует, что оригинальный контент добросовестно сохраняется там, где не предполагается никаких редактирований.
- Универсальность и гибкость: Решение должно поддерживать широкий спектр задач редактирования видео без необходимости переобучения для каждой из них. GenProp достигает этого благодаря своей единой структуре, которая распространяет редактирование первого кадра на общее распространение видео. Важно отметить, что схема генерации синтетических данных (копирование и вставка, маскирование и заполнение, цветовое заполнение) охватывает разнообразные сценарии во время обучения, позволяя модели обобщать различные приложения, такие как удаление, вставка, замена и отслеживание, без необходимости специфических для задач данных при выводе.
- Эффективность и простота: Решение должно избегать громоздких ручных аннотаций и подверженных ошибкам промежуточных представлений. GenProp устраняет необходимость плотного маскирования для всех кадров, что является значительным упрощением по сравнению со многими традиционными и даже некоторыми диффузионными методами. Он также обходит зависимость от оптического потока или карт глубины для предсказания движения, тем самым избегая накопления ошибок, присущих таким промежуточным представлениям.
- Сложные редактирования: Модель должна поддерживать существенные изменения формы, независимое движение объектов и удаление сопутствующих эффектов. Генеративная мощь модели I2V в сочетании с точным руководством от SCE и MPD позволяет GenProp обрабатывать эти сложные сценарии, такие как объекты с независимым движением или удаление теней и отражений вместе с основным объектом, что часто не удается традиционным методам.
Отклонение альтернатив
Статья предоставляет убедительные причины для отклонения альтернативных подходов, подчеркивая их фундаментальные ограничения для общей проблемы распространения видео:
- Традиционные методы распространения видео (оптический поток, глубина, атласы): Эти методы, хотя и являются основополагающими, явно отклоняются из-за их ограниченной надежности, обобщающей способности и подверженности накоплению ошибок. Они часто разработаны для одной задачи и требуют переобучения для новых приложений, что делает их непрактичными для единой структуры. Их зависимость от явных указаний движения делает их хрупкими при работе со сложными, нежесткими деформациями или значительными изменениями сцены.
- Существующие модели редактирования видео на основе диффузии (например, InsV2V, Pika, AnyV2V, ReVideo): Хотя диффузионные модели мощны, их существующие реализации для редактирования видео оказались недостаточными.
- Многие были ограничены изменением внешнего вида, а не внесением существенных изменений в формы объектов или точной обработкой сложных фоновых редактирований.
- Некоторые требовали пошаговой настройки для каждого случая (например, LoRA движения I2VEdit), что увеличивало вычислительную сложность и замедляло процесс.
- Подходы, такие как ReVideo [31], использовали черные квадратные маски, которые удаляли важную информацию и сильно ограничивали их способность обрабатывать сложные фоновые редактирования и большие изменения формы, часто приводя к размытым границам и накопленным ошибкам в движении объектов.
- Структуры, не требующие обучения, такие как AnyV2V [27], страдали от ограниченной обобщающей способности и испытывали трудности со значительными изменениями формы или вставкой объектов. Pika [2] аналогично плохо работал при существенных изменениях формы или фоновых редактированиях.
- Методы, основанные на текстовых подсказках (например, InsV2V), часто были ограничены их обучающими данными и испытывали трудности со сложными, не связанными с внешним видом редактированиями.
- Традиционные конвейеры инпейнтинга (например, SAM-V2 + Propainter): Для таких задач, как удаление объектов, эти каскадные методы были отклонены в первую очередь потому, что они требуют плотных масочных аннотаций для всех кадров, трудоемкого и подверженного ошибкам процесса, которого GenProp полностью избегает. Кроме того, Propainter показал трудности с точным удалением таких эффектов объектов, как тени и отражения, которые GenProp надежно обрабатывает благодаря своему генеративному пониманию физических правил.
- SAM-V2 для отслеживания: Хотя SAM-V2 [39] отлично подходит для отслеживания масок, было отмечено, что он испытывает трудности с объектами-эффектами (отражениями, тенями) из-за смещений в его обучающих данных. GenProp, благодаря предварительному обучению на генерации видео, демонстрирует превосходное понимание физических правил, позволяя ему последовательно отслеживать эти связанные эффекты, что часто упускает SAM-V2.
По сути, авторы пришли к выводу, что, хотя компоненты этих альтернатив были полезны, ни один из них не предлагал всеобъемлющего, надежного и универсального решения, необходимого для бесшовного, разнообразного редактирования видео без существенных компромиссов в качестве, эффективности или универсальности. Новаторская интеграция GenProp селективного кодировщика контента, декодера предсказания маски, регионально-ориентированной потери и генерации синтетических данных поверх мощной модели I2V была единственным способом преодолеть эти коллективные ограничения.
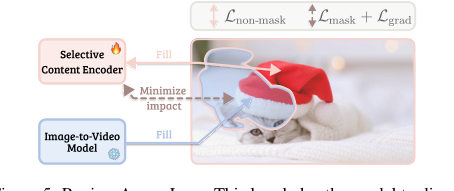 Figure 5. Region-Aware Loss. This loss helps the model to disen- tangle the edited region from the original content
Figure 5. Region-Aware Loss. This loss helps the model to disen- tangle the edited region from the original content
Математический и логический механизм
Мастер-уравнение
Основной механизм обучения GenProp инкапсулирован в его Регионально-ориентированной потере, которая направляет модель на одновременное распространение редактирований и сохранение оригинального контента. Хотя общая цель обучения заключается в минимизации суммы потерь по кадрам, фундаментальная функция потерь для одного кадра, которая объединяет все критические компоненты, выглядит следующим образом:
$$ \mathcal{L} = \mathcal{L}_{\text{non-mask}} + \lambda \cdot \mathcal{L}_{\text{mask}} + \beta \cdot \mathcal{L}_{\text{grad}} + \gamma \cdot \mathcal{L}_{\text{MPD}} $$
Это мастер-уравнение, наряду с общей целью обучения, которая суммирует эту потерю во времени, определяет, как модель учится выполнять генеративное распространение видео. Общая цель формально сформулирована как:
$$ \min_{\mathcal{E}} \sum_{i=2}^{T} \mathcal{L}(G(E(V), v'_1, v_i), V_i) $$
где $\mathcal{E}$ представляет обучаемые параметры модели.
Потерьменная аутопсия
Давайте разберем каждый компонент мастер-уравнения и общей цели:
-
$\mathcal{L}$ (Общая регионально-ориентированная потеря):
- Математическое определение: Это суммарное значение потерь для одного видеокадра, представляющее общую штрафную санкцию за отклонения от желаемого вывода и поведения.
- Физическая/логическая роль: Она служит основным сигналом для оптимизатора, указывая, насколько «плох» текущий вывод и внутренние состояния модели. Минимизация $\mathcal{L}$ означает улучшение производительности модели по всем ее целям.
- Почему сложение? Авторы используют сложение, потому что каждый член представляет собой отдельную цель или ограничение, которому должна соответствовать модель. Суммируя их, модель побуждается к одновременной оптимизации всех этих целей. Если один член высок, общая потеря высока, сигнализируя о необходимости корректировки в этом конкретном аспекте.
-
$\mathcal{L}_{\text{non-mask}}$ (Потеря для неизмененной области):
- Математическое определение: $\mathcal{L}_{\text{non-mask}} = \mathbb{E}_{t \sim \mathcal{U}(1,T)} [\mathcal{L}_d((1 - m_t) \cdot v^{\text{out}}_t, (1 - m_t) \cdot v_t)]$. Это диффузионная среднеквадратичная ошибка (MSE), $\mathcal{L}_d$, вычисленная между сгенерированным выводом $v^{\text{out}}_t$ и истинным значением $v_t$, но только для областей, не покрытых маской $m_t$.
- Физическая/логическая роль: Этот член гарантирует, что части видео, которые не были отредактированы в первом кадре, остаются согласованными с оригинальным видеоконтентом на протяжении всей последовательности. Он действует как ограничение точности, предотвращая непреднамеренные изменения в неизмененном фоне или объектах.
- Почему $(1 - m_t) \cdot \text{frame}$? Поэлементное умножение на $(1 - m_t)$ эффективно «обнуляет» замаскированные (отредактированные) области, выделяя только неизмененные части кадров для расчета потерь. Это точный способ сосредоточить цель согласованности на конкретных областях.
-
$\mathcal{L}_{\text{mask}}$ (Потеря для измененной области):
- Математическое определение: $\mathcal{L}_{\text{mask}} = \mathbb{E}_{t \sim \mathcal{U}(1,T)} [\mathcal{L}_d(m_t \cdot v^{\text{out}}_t, m_t \cdot v_t)]$. Это диффузионная среднеквадратичная ошибка (MSE), $\mathcal{L}_d$, вычисленная между сгенерированным выводом $v^{\text{out}}_t$ и истинным значением $v_t$, но только для областей, покрытых маской $m_t$.
- Физическая/логическая роль: Этот член побуждает модель точно генерировать отредактированный контент и распространять изменения, внесенные в первый кадр. Он гарантирует, что изменения реалистично отображаются и согласованы в измененной области с течением времени.
- Почему $m_t \cdot \text{frame}$? Подобно $\mathcal{L}_{\text{non-mask}}$, поэлементное умножение на $m_t$ выделяет замаскированные (отредактированные) области, фокусируя цель генерации конкретно на этих областях.
-
$\lambda$ (Вес для $\mathcal{L}_{\text{mask}}$):
- Математическое определение: Положительный скалярный коэффициент (установлен в 2.0 в статье).
- Физическая/логическая роль: Этот гиперпараметр контролирует относительную важность точной генерации замаскированных (отредактированных) областей по сравнению с другими компонентами потерь. Более высокое значение $\lambda$ уделяет большее внимание правильному распространению редактирований.
- Почему умножение? Оно масштабирует вклад $\mathcal{L}_{\text{mask}}$ в общую потерю, позволяя точно настраивать баланс между различными целями.
-
$\mathcal{L}_{\text{grad}}$ (Потеря градиента):
- Математическое определение: $\mathcal{L}_{\text{grad}} = \mathbb{E}_{t \sim \mathcal{U}(1,T)} [m_t \cdot ||\Delta f||^2]$, где $\Delta f = \frac{f(E(V + \delta)) - f(E(V))}{\delta}$ является конечной разностью, аппроксимирующей градиент признаков селективного кодировщика контента (SCE) $f(E(V))$ по отношению к небольшой пертурбации $\delta$ во входном видео $V$.
- Физическая/логическая роль: Это критически важный член для разделения. Он наказывает SCE, если его выходные признаки значительно изменяются при небольшой пертурбации входного видео в пределах замаскированной области. Цель состоит в том, чтобы заставить SCE игнорировать отредактированные части и сосредоточиться исключительно на кодировании неизмененного контента. Это предотвращает непреднамеренное «восстановление» SCE удаленных объектов или вмешательство в задачу генерации модели I2V в измененных областях.
- Почему $||\Delta f||^2$? Квадрат нормы L2 измеряет величину изменения признаков. Минимизация этой величины побуждает признаки SCE быть стабильными и нечувствительными к пертурбациям в замаскированной области.
- Почему $m_t \cdot ||\Delta f||^2$? Маска $m_t$ гарантирует, что этот штраф за градиент применяется только к измененным областям, где SCE в идеале должен быть «слепым».
-
$\beta$ (Вес для $\mathcal{L}_{\text{grad}}$):
- Математическое определение: Положительный скалярный коэффициент (установлен в 1.0 в статье).
- Физическая/логическая роль: Этот гиперпараметр контролирует силу штрафа за градиент, влияя на то, насколько сильно SCE вынужден разделять свое кодирование от измененных областей.
- Почему умножение? Оно масштабирует вклад $\mathcal{L}_{\text{grad}}$ в общую потерю.
-
$\mathcal{L}_{\text{MPD}}$ (Потеря декодера предсказания маски):
- Математическое определение: Это потеря MSE между маской, предсказанной декодером предсказания маски (MPD), и истинной маской $m_t$.
- Физическая/логическая роль: Эта вспомогательная потеря явно обучает MPD точно идентифицировать измененные области. Делая это, она предоставляет четкий сигнал для общей модели о том, где находятся редактирования, что, в свою очередь, помогает направлять внимание и процесс генерации модели I2V в правильные области. Это улучшает точность карт внимания.
- Почему MSE? MSE является стандартной и эффективной функцией потерь для задач регрессии, включая предсказание попиксельных значений маски.
-
$\gamma$ (Вес для $\mathcal{L}_{\text{MPD}}$):
- Математическое определение: Положительный скалярный коэффициент (установлен в 1.0 в статье).
- Физическая/логическая роль: Этот гиперпараметр контролирует важность явной задачи предсказания маски.
- Почему умножение? Оно масштабирует вклад $\mathcal{L}_{\text{MPD}}$ в общую потерю.
-
$\mathbb{E}_{t \sim \mathcal{U}(1,T)}$ (Ожидание по временным шагам):
- Математическое определение: Среднее значение потерь по временным шагам $t$, выбранным равномерно от 1 до $T$.
- Физическая/логическая роль: Это гарантирует, что потери вычисляются и учитываются в различных кадрах видеопоследовательности, способствуя временной согласованности и обобщению по всему видео.
- Почему ожидание/равномерная выборка? Это обеспечивает надежную оценку потерь по всему видео, предотвращая переобучение модели на конкретных кадрах или временных позициях.
-
$\sum_{i=2}^{T}$ (Суммирование по кадрам):
- Математическое определение: Сумма регионально-ориентированной потери $\mathcal{L}$ для каждого кадра $i$ от 2 до $T$.
- Физическая/логическая роль: Это агрегирует пошаговые потери в единую цель для всей видеопоследовательности во время обучения. Первый кадр ($i=1$) является входным отредактированным кадром, поэтому задача распространения начинается со второго кадра.
- Почему суммирование? Потери каждого кадра вносят равный вклад в общий сигнал обучения, гарантируя, что модель учится последовательно распространять редактирования по всему видео.
-
$G(E(V), v'_1, v_i)$ (Сгенерированный выходной кадр):
- Математическое определение: Вывод модели генерации «изображение-в-видео» (I2V) $G$, обусловленный признаками из селективного кодировщика контента $E(V)$, измененным первым кадром $v'_1$ и оригинальным $i$-м кадром $v_i$ (используемым в качестве эталона для внутренней обработки модели I2V, хотя истинное значение $V_i$ используется для расчета потерь).
- Физическая/логическая роль: Это предсказание модели для $i$-го кадра измененного видео. Оно представляет собой результат распространения редактирования первого кадра при сохранении согласованности с неизмененными частями оригинального видео.
-
$E(V)$ (Признаки селективного кодировщика контента):
- Математическое определение: Скрытые признаки, извлеченные селективным кодировщиком контента $E$ из оригинального входного видео $V$.
- Физическая/логическая роль: Этот компонент предназначен для кодирования информации о неизмененных частях оригинального видео. Он предоставляет контекст модели I2V, направляя ее на сохранение оригинального контента там, где не было внесено никаких редактирований.
-
$v'_1$ (Измененный первый кадр):
- Математическое определение: Первый кадр видео, который был вручную или синтетически отредактирован.
- Физическая/логическая роль: Он служит якорем для распространения. Модель I2V использует его как отправную точку для понимания того, какие изменения необходимо распространить.
-
$v_i$ (Оригинальный $i$-й кадр):
- Математическое определение: $i$-й кадр оригинальной, неизмененной видеопоследовательности $V$.
- Физическая/логическая роль: Используется как часть входных данных для модели I2V во время обучения и как истинное значение для неизмененных областей при расчете потерь.
-
$V_i$ (Истинный синтетический видеокадр):
- Математическое определение: $i$-й кадр синтетической видеопоследовательности $V = \{V_1, V_2, ..., V_T\}$, которая генерируется путем применения оператора генерации данных $D$ к оригинальному видео.
- Физическая/логическая роль: Это целевой вывод для модели во время обучения, представляющий желаемый измененный видеокадр после распространения.
Пошаговый поток
Представьте GenProp как сложную фабрику по редактированию видео. Вот как единая абстрактная точка данных (видеокадр) проходит через ее сборочную линию во время обучения:
- Прием оригинального видео: На фабрику поступает оригинальная видеопоследовательность, назовем ее $V$. Это серия кадров, $V_1, V_2, ..., V_T$.
- Применение синтетического редактирования (генерация данных): Специальная «машина редактирования» (оператор генерации данных $D$) берет $V$ и применяет синтетическое редактирование к ее первому кадру, создавая измененный первый кадр $v'_1$. Она также генерирует соответствующие истинные измененные кадры $V_2, ..., V_T$ и бинарные маски $m_1, ..., m_T$, которые точно определяют измененные области в каждом кадре. Это дает нам целевое видео $V' = \{v'_1, V_2, ..., V_T\}$.
- Кодирование контента (селективный кодировщик контента, SCE): Все оригинальное видео $V$ подается в «селективный кодировщик контента» ($E$). Этот кодировщик действует как умный фильтр; его задача — извлечь признаки, представляющие неизмененный контент видео, намеренно пытаясь игнорировать любую информацию об областях, которые будут отредактированы. Он учится быть «слепым» к модификациям.
- Движок распространения (модель «изображение-в-видео»): Теперь для каждого последующего кадра $i$ (от 2 до $T$):
- Подается измененный первый кадр $v'_1$ (чертеж редактирования).
- Вводятся селективно закодированные признаки из $E(V)$ (контекст оригинальной, неизмененной сцены).
- Также предоставляется текущий временной шаг $i$.
- «Модель генерации «изображение-в-видео» ($G$) действует как основной движок распространения. Она принимает эти входные данные и генерирует свое лучшее предположение для $i$-го кадра измененного видео, которое мы называем $v^{\text{out}}_i$. Здесь происходит волшебство: редактирование из $v'_1$ распространяется, руководствуясь признаками оригинального контента.
- Предсказание маски (декодер предсказания маски, MPD): Одновременно «декодер предсказания маски» (MPD) берет внутренние скрытые представления из модели I2V и пытается предсказать маску $m_i$ для текущего кадра. Это похоже на датчик контроля качества, проверяющий, понимает ли модель, где находятся редактирования.
- Расчет потерь и обратная связь (регионально-ориентированная потеря): Для каждого сгенерированного кадра $v^{\text{out}}_i$:
- Проверка согласованности (потеря для неизмененной области): Неизмененные части $v^{\text{out}}_i$ (выбранные с помощью $(1-m_i)$) сравниваются с неизмененными частями истинного значения $V_i$. Любое расхождение здесь вносит вклад в $\mathcal{L}_{\text{non-mask}}$, побуждая модель сохранять оригинальный контент нетронутым.
- Проверка точности редактирования (потеря для измененной области): Отредактированные части $v^{\text{out}}_i$ (выбранные с помощью $m_i$) сравниваются с отредактированными частями истинного значения $V_i$. Любая ошибка здесь вносит вклад в $\mathcal{L}_{\text{mask}}$, побуждая модель точно распространять изменения.
- Проверка «слепоты» кодировщика (потеря градиента): Специальный «датчик градиента» проверяет, изменятся ли признаки SCE, если входные данные в пределах замаскированной области будут немного изменены. Если они изменятся, это добавляется к $\mathcal{L}_{\text{grad}}$, сообщая SCE быть еще более невосприимчивым к редактированиям.
- Проверка точности предсказания маски (потеря MPD): Предсказанная маска MPD сравнивается с истинной маской $m_i$, внося вклад в $\mathcal{L}_{\text{MPD}}$.
- Агрегирование общей потери: Все эти отдельные компоненты потерь ($\mathcal{L}_{\text{non-mask}}$, $\mathcal{L}_{\text{mask}}$, $\mathcal{L}_{\text{grad}}$, $\mathcal{L}_{\text{MPD}}$) взвешиваются ($\lambda, \beta, \gamma$) и суммируются, образуя общую регионально-ориентированную потерю $\mathcal{L}$ для этого кадра. Этот процесс повторяется для всех кадров от $i=2$ до $T$, и все эти пошаговые потери суммируются для получения общей цели.
- Корректировка параметров: Это общее значение цели затем передается «оптимизатору», который действует как менеджер фабрики. Он вычисляет, как каждый регулятор и циферблат (параметр модели) должны быть скорректированы, чтобы уменьшить эту общую потерю. Эти корректировки выполняются итеративно, уточняя SCE, модель I2V и MPD с каждым шагом обучения.
Этот полный цикл повторяется миллионы раз, постепенно обучая GenProp беспрепятственно распространять редактирования, сохраняя при этом остальную часть видео.
Динамика оптимизации
GenProp учится и сходится благодаря сложной взаимосвязи градиентного спуска и тщательно сформированного ландшафта потерь. Процесс оптимизации управляется минимизацией общей целевой функции, которая представляет собой сумму регионально-ориентированной потери $\mathcal{L}$ по всем кадрам от $i=2$ до $T$.
-
Обучение на основе градиентов: Параметры модели ($\mathcal{E}$) селективного кодировщика контента (SCE), модели генерации «изображение-в-видео» (I2V) и декодера предсказания маски (MPD) обновляются итеративно с использованием оптимизатора (например, Adam, как это обычно бывает для диффузионных моделей). Это включает вычисление градиентов общей потери по отношению к каждому параметру. Эти градиенты указывают направление и величину, в которой параметры должны быть скорректированы для уменьшения потерь. Скорость обучения (например, 5e-5 с планировщиком косинусного затухания и линейным прогревом) контролирует размер шага этих корректировок. Также поддерживается экспоненциальное скользящее среднее (EMA) параметров модели, которое часто приводит к более стабильному обучению и лучшей конечной производительности за счет усреднения шумных обновлений. Пороговое значение нормы градиента (0.001) применяется для предотвращения взрывных градиентов и обеспечения стабильности обучения.
-
Формирование ландшафта потерь для разделения и согласованности: Уникальный дизайн регионально-ориентированной потери ($\mathcal{L}$) является ключом к формированию ландшафта потерь и направлению обучения модели:
- Сбалансированная оптимизация областей: Члены $\mathcal{L}_{\text{mask}}$ и $\mathcal{L}_{\text{non-mask}}$ создают ландшафт потерь с двумя основными «долинами». Одна долина поощряет точную генерацию в измененных областях, гарантируя реалистичность распространяемых изменений. Другая долина способствует высокой точности оригинального контента в неизмененных областях. Взвешивая эти члены с помощью $\lambda$, авторы могут сбалансировать фокус модели, предотвращая ее либо игнорирование редактирований, либо порчу оригинального фона. Эта двойная цель помогает модели ориентироваться в сложном ландшафте, где она должна как создавать новый контент, так и сохранять существующий.
- Принуждение к селективности SCE: Член $\mathcal{L}_{\text{grad}}$ особенно изобретателен. Наказывая SCE, если его признаки изменяются при возмущении входной замаскированной области, он создает «плоскую» область в ландшафте потерь для вывода SCE по отношению к измененным областям. Это заставляет SCE изучать представление, которое инвариантно к модификациям, фактически делая его «слепым» к редактированиям. Это разделяет роль SCE (кодирование оригинального контекста) от роли модели I2V (распространение редактирований), предотвращая такие проблемы, как призрачность или повторное появление удаленных объектов. Без этого SCE может попытаться восстановить оригинальный контент везде, препятствуя распространению изменений.
- Явное руководство вниманием: Член $\mathcal{L}_{\text{MPD}}$ предоставляет явный, контролируемый сигнал для модели, чтобы идентифицировать, где находятся редактирования. Это помогает внутренним механизмам внимания модели I2V фокусироваться на правильных областях для генерации и модификации. Явно изучая маску, модель получает более четкое понимание «границ» между измененным и неизмененным контентом, что приводит к более точному распространению и меньшему замешательству. Этот член потерь помогает создать более резкую, более определенную границу в ландшафте потерь для областей, требующих модификации.
-
Итеративное уточнение и сходимость: На протяжении многих итераций модель итеративно обновляет свои параметры. Модель I2V учится генерировать все более реалистичные и временно согласованные видеокадры на основе измененного первого кадра и контекста SCE. SCE учится извлекать надежные, инвариантные к редактированию признаки из оригинального видео. MPD учится точно предсказывать измененные области. Этот непрерывный цикл обратной связи, управляемый регионально-ориентированной потерей, побуждает модель к состоянию, в котором она может беспрепятственно распространять разнообразные редактирования первого кадра по всей видеопоследовательности, сохраняя при этом высокую точность неизмененного контента. Модель сходится, когда градиенты становятся очень малыми, указывая на то, что дальнейшие обновления параметров дают минимальное улучшение потерь.
 Figure 1. GenProp. We propose a generative video propagation framework (GenProp), which can seamlessly propagate any first frame edit through the video. GenProp supports a wide range of video applications, including (a) complete object removal with effects such as shadows and reflections, (b) background replacement with realistic effects, (c) object insertion where inserted objects have physically plausible motion (i.e., blueberries falling while spoon goes up), (d) tracking of objects and their associated effects, and (e) multiple edits (outpainting, insertion, removal) at a single inference run
Figure 1. GenProp. We propose a generative video propagation framework (GenProp), which can seamlessly propagate any first frame edit through the video. GenProp supports a wide range of video applications, including (a) complete object removal with effects such as shadows and reflections, (b) background replacement with realistic effects, (c) object insertion where inserted objects have physically plausible motion (i.e., blueberries falling while spoon goes up), (d) tracking of objects and their associated effects, and (e) multiple edits (outpainting, insertion, removal) at a single inference run
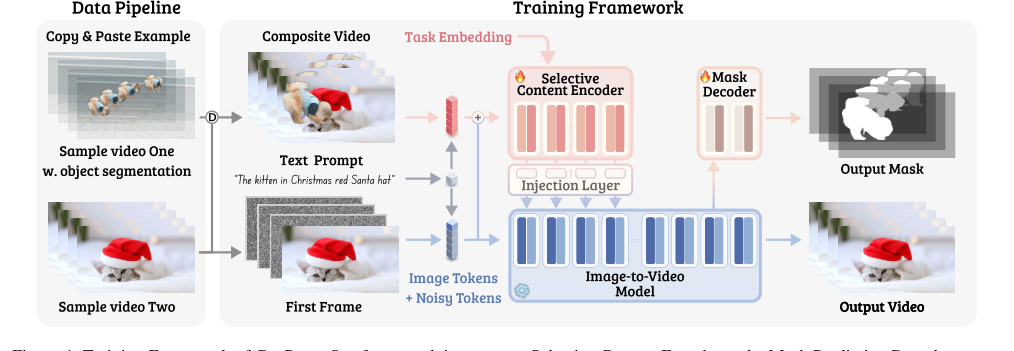 Figure 4. Training Framework of GenProp. Our framework integrates a Selective Content Encoder and a Mask Prediction Decoder on top of the I2V generation model, enforcing the model to propagate the edited region while preserving the content in the original video for all other regions. With synthetic data augmentations and task embeddings, our model is trained to propagate various changes in the first frame
Figure 4. Training Framework of GenProp. Our framework integrates a Selective Content Encoder and a Mask Prediction Decoder on top of the I2V generation model, enforcing the model to propagate the edited region while preserving the content in the original video for all other regions. With synthetic data augmentations and task embeddings, our model is trained to propagate various changes in the first frame
Результаты, ограничения и заключение
Экспериментальный дизайн и базовые модели
Для строгой проверки возможностей GenProp авторы разработали комплексную экспериментальную установку, используя две различные базовые модели генерации видео: вариант DiT, аналогичный Sora [32], и вариант U-Net, основанный на Stable Video Diffusion (SVD) [5]. Вариант DiT, который в конечном итоге дал превосходное качество генерации видео, был обучен для генерации «изображение-в-видео» (I2V) для 32, 64 и 128 кадров в секунду (FPS) при 12 и 24 кадрах в секунду, с базовым разрешением 360p. Компоненты селективного кодировщика контента (SCE) и декодера предсказания маски (MPD) были обучены при замороженной модели I2V, гарантируя, что основной механизм GenProp фокусируется на распространении редактирований, а не на повторном обучении генерации видео с нуля.
Обучение включало скорость обучения $5 \times 10^{-5}$ с планировщиком косинусного затухания и линейным прогревом, а также экспоненциальное скользящее среднее для стабильности. Порог нормы градиента 0.001 применялся для предотвращения нестабильности. Руководство без классификатора (CFG) было установлено на 20. Важным аспектом обучения была схема генерации синтетических данных, которая использовала различные коэффициенты аугментации (0.5, 0.375, 0.125) для задач копирования и вставки, маскирования и заполнения, а также цветового заполнения. Регионально-ориентированная (RA) потеря, жизненно важная для разделения измененных и неизмененных областей, использовала специфические параметры взвешивания: $\lambda = 2.0$, $\beta = 1.0$ и $\gamma = 1.0$. Все эксперименты проводились на 32 или 64 GPU NVIDIA A100, подчеркивая значительные вычислительные ресурсы.
«Жертвы» (базовые модели), с которыми сравнивался GenProp, варьировались в зависимости от задачи. Для общего редактирования видео он сравнивался с InsV2V [8], AnyV2V [27], Pika [2] и ReVideo [31]. Для удаления объектов в качестве базовой модели использовался каскадный конвейер SAM-V2 [39] (для отслеживания масок) и Propainter [64] (для инпейнтинга). Для отслеживания объектов прямым конкурентом был SAM-V2 [39].
Количественные оценки проводились на двух тестовых наборах:
1. Классический тестовый набор: Состоящий из набора данных DAVIS [36] из TGVE [51], с текстовыми подсказками «Описание изменения объекта», фокусирующимися на замене объектов и редактировании внешнего вида.
2. Сложный тестовый набор: Коллекция из 30 вручную отобранных видео из Pexels [1] и Adobe Stock [3], содержащих более сложные сценарии, такие как замена крупных объектов, вставка объектов и замена фона. Редактирование в этом наборе выполнялось с использованием коммерческих инструментов редактирования фотографий или специфических базовых методов (например, инструмента боксирования Pika онлайн, извлечения точек движения ReVideo).
Окончательным доказательством успеха GenProp были измерены с помощью нескольких метрик:
- PSNRm: Пиковое отношение сигнал/шум, рассчитанное специально вне измененной области для количественной оценки согласованности неизмененного контента.
- CLIP-T: Косинусное сходство между вложениями CLIP [38] измененного кадра и текстовой подсказки, оценивающее соответствие тексту.
- CLIP-I: Расстояние между признаками CLIP [38] между кадрами, измеряющее согласованность от кадра к кадру.
- Исследование пользователей: Оценка человеком, проведенная на Amazon MTurk [45] с участием 121 человека, которые сравнивали результаты GenProp с базовыми моделями и оригинальными видео, оценивая соответствие инструкциям и общее визуальное качество.
Что доказывают доказательства
Доказательства однозначно подтверждают, что основной механизм GenProp работает на практике, устанавливая его в качестве ведущей структуры для генеративного распространения видео. Как показано в Таблице 1, GenProp значительно превосходит другие методы по большинству метрик, особенно на более требовательном Сложном тестовом наборе. Это не просто инкрементальное улучшение; это демонстрация принципиально более надежного и универсального подхода.
Например, при замене объектов и замене фона (Рисунок 6a, 6b) GenProp продемонстрировал свою способность беспрепятственно изменять объекты с совершенно разными формами и независимым движением, а также выполнять сложные фоновые редактирования. Это напрямую устраняет основное ограничение базовых моделей, таких как InsV2V [8] и Pika [2], которые испытывают трудности со значительными изменениями формы или вставкой объектов из-за их зависимости от текстовых подсказок или ограниченных обучающих данных. AnyV2V [27] также страдал от ограниченной обобщающей способности, а ReVideo [31] часто давал размытые границы и накапливал ошибки от своего механизма отслеживания точек. Способность GenProp обрабатывать эти сложные сценарии без необходимости плотного маскирования для каждого кадра является свидетельством его подхода, основанного на распространении.
При удалении объектов и эффектов (Рисунок 6c, 6d) GenProp преуспел не только в удалении объектов, но и связанных с ними эффектов, таких как тени и отражения, а также в реалистичной реконструкции больших скрытых областей. Базовая модель SAM+Propainter, хотя и эффективна для инпейнтинга, испытывала трудности с удалением этих тонких эффектов, на что указывают ее более низкие показатели CLIP-I и предпочтения пользователей в Таблице 2. Единый подход GenProp, использующий генеративные модели, по своей сути понимает, как правдоподобно заполнять удаленные области, включая контекст сцены.
Для отслеживания объектов и эффектов (Рисунок 6e) GenProp продемонстрировал последовательное отслеживание объектов и связанных с ними эффектов, даже когда они были инициализированы заливкой сплошным цветом. Хотя SAM-V2 [39] быстрее для отслеживания в реальном времени и может давать точные маски, предварительное обучение GenProp на генерации видео дает ему сильное понимание физических правил, позволяя отслеживать эффекты, которые SAM-V2 часто упускает из-за своих ограниченных и смещенных обучающих данных. Это подчеркивает потенциал моделей, основанных на генерации, для решения классических задач зрения с более глубоким пониманием динамики сцены.
Исследования аберраций далее предоставили неоспоримые доказательства эффективности ключевых компонентов GenProp:
- Декодер предсказания маски (MPD) значительно улучшил как соответствие тексту, так и согласованность (Таблица 3). Без него выходные маски часто были ухудшены, что приводило к неполному удалению объектов и путанице относительно того, какие области следует распространять, а какие сохранять (Рисунок 7, строки 1-2). MPD явное обучение помогает модели разделять изменения и обеспечивает полное удаление объектов, даже при сильном скрытии.
- Регионально-ориентированная потеря (RA Loss) была критически важна для стабильного и последовательного распространения редактирований первого кадра. Без RA Loss оригинальный объект постепенно начинал появляться в последующих кадрах, препятствуя распространению (Рисунок 7, строки 3-5). Эта потеря гарантирует, что измененные области стабильно распространяются, а неизмененные области остаются согласованными.
- Аугментация цветовым заполнением оказалась решающим фактором для устранения сбоев распространения, особенно при больших изменениях формы. Она явно обучает модель отслеживанию, направляя ее на поддержание модификаций на протяжении всей последовательности, позволяя выполнять сложные редактирования, такие как превращение девочки в маленькую кошку (Рисунок 7, строки 6-8).
Таким образом, успех GenProp основан на его тщательном дизайне, использовании генеративной мощи моделей I2V, селективного кодировщика контента, декодера предсказания маски и регионально-ориентированной потери, все обученные с универсальной конвейером генерации синтетических данных. Эта комбинация позволяет ему безжалостно доказывать свои математические утверждения, последовательно превосходя базовые модели в разнообразных и сложных задачах редактирования видео.
Ограничения и будущие направления
Хотя GenProp представляет собой значительный шаг вперед в генеративном распространении видео, важно признать его присущие ограничения и рассмотреть направления для будущего развития. Одно из неявных ограничений — вычислительная стоимость; обучение на нескольких GPU NVIDIA A100 предполагает, что развертывание этой модели для редактирования видео в реальном времени высокого разрешения на оборудовании потребительского класса все еще может быть проблемой. Кроме того, зависимость от синтетических данных, хотя и обеспечивает универсальность, может вводить смещения или снижать обобщающую способность для чрезвычайно новых, некурируемых реальных сценариев, которые значительно отличаются от синтетического распределения. Статья также отмечает, что традиционные метрики качества иногда не улавливают реализм сгенерированных результатов, что требует исследований пользователей, что указывает на пробел в автоматизированной, всеобъемлющей оценке.
Заглядывая вперед, авторы явно планируют расширить модель для поддержки редактирования более чем одного ключевого кадра, что значительно повысит ее гибкость для сложных, многоэтапных рабочих процессов редактирования. Они также стремятся раскрыть дополнительные видеозадачи, которые могут быть поддержаны структурой, предполагая, что присущая генеративная мощь GenProp имеет неиспользованный потенциал.
Помимо этих немедленных планов, возникает несколько тем для обсуждения для дальнейшего развития и эволюции этих результатов:
-
Улучшенный пользовательский контроль и интерпретируемость: Хотя GenProp упрощает процесс редактирования, устраняя необходимость в плотных масках, как можно интегрировать более интуитивный и гранулированный пользовательский контроль для точной настройки редактирований? Может ли система «человек в цикле», возможно, с интерактивными механизмами обратной связи, позволить пользователям более точно направлять процесс распространения, не возвращая сложность традиционных методов? Изучение методов, чтобы сделать внутреннее «рассуждение» модели (например, карты внимания) более интерпретируемым для пользователей, также может способствовать большему доверию и контролю.
-
Надежность в реальном мире и нехватка данных: Текущая структура в значительной степени выигрывает от синтетических данных. Однако реальные видеоданные часто содержат шум, скрытия и непредсказуемые паттерны движения, не полностью охваченные синтетическими наборами данных. Будущие работы могут исследовать методы адаптации домена или стратегии самообучения для повышения надежности GenProp на неконтролируемых видео «в дикой природе», потенциально снижая зависимость от тщательно разработанных синтетических данных.
-
Эффективность и масштабируемость для производства: Для более широкого внедрения оптимизация GenProp для более быстрого вывода и снижения потребления памяти имеет решающее значение. Исследование таких методов, как дистилляция знаний, обрезка моделей или более эффективные архитектурные решения, может позволить развертывание на периферийных устройствах или для обработки более длинных видео высокого разрешения в реальном времени. Каковы компромиссы между качеством генерации, скоростью и потреблением ресурсов, и как их можно сбалансировать для практических применений?
-
Мультимодальная интеграция и контекстуальное понимание: Видео по своей сути мультимодально. Как GenProp можно расширить для включения аудио, текстовых описаний, выходящих за рамки подсказок, или даже информации о 3D-сцене для создания более согласованных и иммерсивных редактирований? Например, редактирование движения объекта может автоматически вызывать соответствующие корректировки звуковых эффектов, или понимание 3D-геометрии сцены может привести к более физически точным взаимодействиям и световым эффектам для вставленных объектов.
-
Этические последствия и ответственный ИИ: По мере того как генеративное редактирование видео становится все более сложным, способность создавать высокореалистичный, но манипулированный контент вызывает серьезные этические проблемы. Будущие обсуждения должны проактивно рассматривать, как разрабатывать и развертывать такие мощные инструменты ответственно, включая механизмы обнаружения манипулированного контента, установление четких руководящих принципов использования и обеспечение прозрачности в ИИ-сгенерированных медиа. Это критически важный аспект для долгосрочного социального воздействия этой технологии.
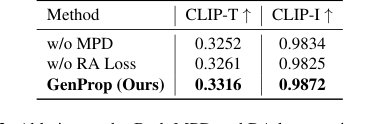 Table 3. Ablation study. Both MPD and RA loss can improve the success rate of editing and the quality of the output video
Table 3. Ablation study. Both MPD and RA loss can improve the success rate of editing and the quality of the output video
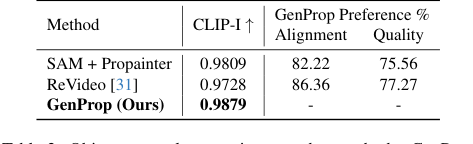 Table 2. Object removal comparison to other methods. GenProp outperforms baselines on consistency, alignment, and quality
Table 2. Object removal comparison to other methods. GenProp outperforms baselines on consistency, alignment, and quality
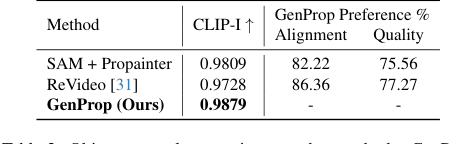 Table 1. Video editing benchmark compared to existing models. PSNRm measures the consistency outside the edited region. CLIP-T and CLIP-I measure text alignment and frame consistency. User study shows the percentage of users who preferred Ours over the compared method on alignment (left) and quality (right). GenProp significantly outperforms the other methods on the Challenging Set
Table 1. Video editing benchmark compared to existing models. PSNRm measures the consistency outside the edited region. CLIP-T and CLIP-I measure text alignment and frame consistency. User study shows the percentage of users who preferred Ours over the compared method on alignment (left) and quality (right). GenProp significantly outperforms the other methods on the Challenging Set