INST-IT: Boosting Instance Understanding via Explicit Visual Prompt Instruction Tuning
The problem addressed in this paper precisely originates from the recent advancements and, paradoxically, the limitations of Large Multimodal Models (LMMs) in the field of artificial intelligence, specifically within...
Background & Academic Lineage
The Origin & Academic Lineage
The problem addressed in this paper precisely originates from the recent advancements and, paradoxically, the limitations of Large Multimodal Models (LMMs) in the field of artificial intelligence, specifically within computer vision and natural language processing. While LMMs have made significant breakthroughs, largely due to "instruction tuning," enabling them to understand images and videos at a holistic, or general, level and follow diverse user instructions, they consistently struggle with a more granular task: "instance-level understanding."
Historically, the pursuit of understanding individual objects within visual data has been a long-standing goal in computer vision, leading to extensive research in areas like object detection, instance segmentation, and object tracking. However, with the emergence of LMMs, the challenge shifted. The "pain point" of previuos approaches, particularly existing LMMs, is their inability to comprehend specific elements or "instances" within an image or video with fine-grained detail and alignment, especially when users pose specific questions about them. For example, an LMM might describe a "crowd of people," but fail to answer a question like "What is the person wearing a red hat doing?" or "How has the interaction between person 1 and person 2 changed over time?" This limitation is even more pronounced in videos, where understanding not just spatial information but also the temporal dynamics of individual instances becomes cruical. Existing multimodal datasets and benchmarks primarily offer coarse-grained knowledge, lacking the fine-grained annotations necessary to train and evaluate LMMs for this nuanced instance-level comprehenion. This fundamental gap forced the authors to develop INST-IT, a solution to enhance LMMs' ability to understand individual instances through explicit visual prompt instruction tuning.
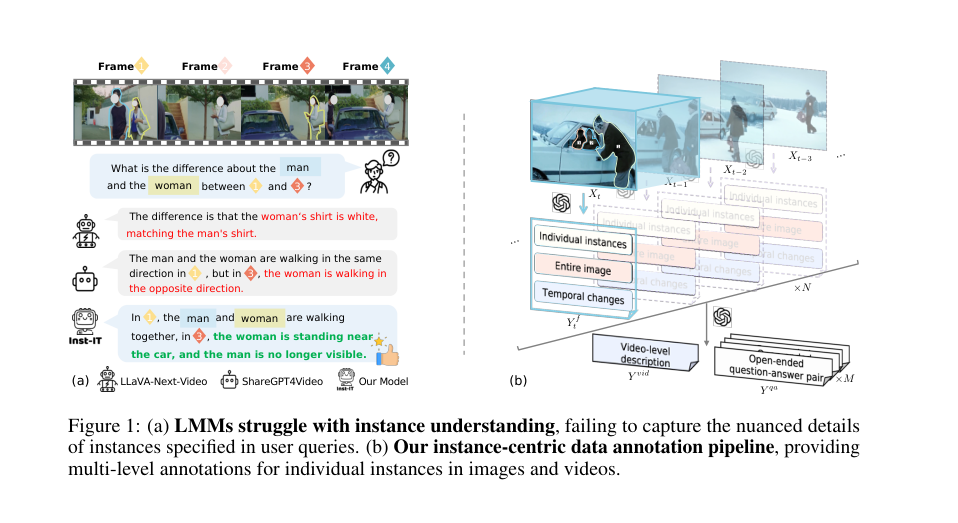 Figure 1. (a) LMMs struggle with instance understanding, failing to capture the nuanced details of instances specified in user queries. (b) Our instance-centric data annotation pipeline, providing multi-level annotations for individual instances in images and videos
Figure 1. (a) LMMs struggle with instance understanding, failing to capture the nuanced details of instances specified in user queries. (b) Our instance-centric data annotation pipeline, providing multi-level annotations for individual instances in images and videos
Intuitive Domain Terms
- Large Multimodal Models (LMMs): Imagine a super-smart digital assistant that can not only read and write text but also "see" and "understand" images and videos. It's like having a personal expert who can look at a photo or watch a clip and then discuss it with you in natural language.
- Instruction Tuning: This is like teaching that super-smart assistant by giving it many specific examples of tasks and telling it exactly what to do. For instance, you show it a picture and "instruct" it: "Describe this image," or "Answer this question about the image." The assistant learns to follow these instructions by seeing countless examples.
- Instance-level Understanding: Instead of just describing a whole scene (e.g., "a park with many people"), this means the assistant can focus on individual things (instances) within that scene. It's like being able to point at a specific person in the park and ask, "What is that person wearing?" or "Is that dog playing with that ball?" It's about understanding the details of each specific item and their relationships.
- Set-of-Marks (SoMs) Visual Prompting: Think of this as putting numbered stickers or drawing circles around specific objects in an image or video. You're literally "marking" the instances you want the smart assistant to pay attention to, like "Look at object #1, then object #2." This helps guide its focus to individual items for more precise understanding.
Notation Table
| Notation | Description |
|---|---|
| LMMs | Large Multimodal Models, capable of understanding and generating content across multiple modalities (e.g., text, images, videos). |
| SoMs | Set-of-Marks visual prompts, a technique where numerical IDs are overlaid on instances in visual inputs to guide model focus. |
| INST-IT | The proposed framework, dataset, and benchmark for boosting instance understanding in LMMs. |
| $X_t$ | Visual data (image or video frame) at timestamp $t$. |
| $X_{t-1}$ | Visual data (image or video frame) at timestamp $t-1$, used for temporal comparison. |
| $P^f$ | Task prompt specifically designed for generating frame-level annotations. |
| $Y_t^f$ | Frame-level annotation output for frame $t$, including instance descriptions, image captions, and temporal differences. |
| $P^{vid}$ | Task prompt specifically designed for generating video-level summaries. |
| $Y^{vid}$ | Video-level summary output, aggregating information from all frame-level annotations. |
| $P^{qa}$ | Task prompt specifically designed for generating open-ended question-answer pairs. |
| $Y^{qa}$ | Open-ended question-answer pairs output, focusing on instance-level understanding. |
| $\text{GPT}(\cdot)$ | Denotes the GPT-4o large language model, used as the intelligent annotator in the data generation pipeline. |
| $N$ | Total number of frames in a video. |
| $M$ | Total number of open-ended question-answer pairs generated for a video. |
| SFT | Supervised Fine-Tuning, the training paradigm used to enhance LMMs with the INST-IT dataset. |
Problem Definition & Constraints
Core Problem Formulation & The Dilemma
The current state of Large Multimodal Models (LMMs) presents a significant dichotomy: while they have achieved remarkable progress in understanding images and videos at a holistic, scene-level, they consistently falter when confronted with tasks requiring instance-level understanding. This means LMMs can describe the general content of a video, but struggle to precisely identify, track, and reason about specific objects or individuals within it, especially their attributes, relationships, and temporal interactions.
The desired endpoint is to equip LMMs with robust instance-level comprehension capabilities across both images and videos. This involves enabling models to accurately follow user instructions that refer to specific elements, understand their fine-grained details, and track their dynamic changes over time.
The exact missing link or mathematical gap between these states is the absence of sufficiently rich, instance-grounded, multi-level instruction-tuning data. Existing datasets primarily offer coarse-grained annotations, which are inadequate for training LMMs to perform fine-grained instance understanding. This paper attempts to bridge this gap by introducing a novel pipeline for generating such data and a continuous instruction-tuning paradigm.
This problem has trapped previous researchers in a painful trade-off:
- Holistic vs. Fine-grained Comprehension: Improving an LMM's ability to understand the overall scene often comes at the expense of its capacity for fine-grained instance details, or vice versa. Achieving both simultaneously is a significant challenge.
- Image vs. Video Instance Understanding: While some progress has been made in instance understanding for static images, extending this to dynamic videos introduces considerable complexity. Videos demand not only spatial comprehension but also the ability to track and reason about temporal dynamics—how instances change, move, and interact over time. This added dimension makes video instance understanding "considerably more challenging."
- Annotation Scale vs. Quality: Creating high-quality, fine-grained annotations for individual instances is labor-intensive and expensive. Previous efforts either provided coarse-grained data at scale or fine-grained data at limited scale. The dilemma is how to generate both large-scale and high-quality fine-grained annotations for complex multimodal data (images and videos) efficiently.
- Generalization vs. Specialization: Models fine-tuned for specific instance understanding tasks risk overfitting to their training data, potentially degrading their general comprehension abilities. The challenge is to boost instance understanding while simultaneously strengthening general comprehension across diverse image and video tasks.
Constraints & Failure Modes
The problem of achieving robust instance-level understanding in LMMs is insanely difficult due to several harsh, realistic walls the authors hit:
- Computational Overhead of GPT-4o: The automated data annotation pipeline, while efficient, is "constrained by the overhead of GPT-4o." This implies that generating large volumes of high-quality, multi-level annotations, especially for videos, is still a time-consuming and costly process, limiting the scale at which such data can be produced.
- Hardware Memory Limits: The training process for LMMs, particularly with video inputs, is constrained by "GPU memory limits." The authors explicitly state they "limit the maximum number of frames to 32 and the context length of LLMs to 6K due to GPU memory constraints," indicating a practical barrier to processing longer or higher-resolution video sequences.
- Hallucinations and Distraction from Raw Visual Inputs: LMMs, when directly processing raw visual inputs, "suffer from hallucinations and distraction." This inherent limitation means models struggle to reliably focus on and extract information about specific instances without explicit guidance, necessitating the use of visual prompts.
- Scarcity of Instance-Grounded Data: A fundamental constraint is the "scarcity of instance-grounded data" for instruction tuning, particularly for videos. This data gap is the primary reason LMMs struggle with instance understanding, as there isn't enough fine-grained supervision to learn these capabilities.
- Complexity of Temporal Dynamics: Understanding instances in videos requires capturing not just spatial information but also intricate "temporal dynamics." This involves tracking changes in object position, actions, and relationships across consecutive frames, which is a significantly more complex task than static image analysis.
- Data Quality Assurance Challenges: Even with an automated pipeline leveraging GPT-4o, ensuring the high quality and consistency of multi-level, fine-grained annotations is challenging. The paper mentions "rigorous manual verification and refinement" is necessary to ensure data quality, highlighting the difficulty in fully automating reliable annotation.
The authors identify specific failure modes for LMMs in this context:
- Occlusion, Blurry Images, and Small/Crowded Instances: The model's performance degrades in scenarios where "instances are severely occluded, the image is blurry, or instances are excessively small or crowded." These are common real-world conditions that pose significant challenges for visual perception systems.
- Distribution Shift from Visual Prompts: The use of "visually prompted images may introduce a distribution shift from natural images." This can lead to a decline in performance on generic image understanding tasks if the model is not carefully trained to mitigate this shift.
- Suppression of Image Understanding by Video Data: Directly mixing a high ratio of video data with general instruction-tuning data can "suppress image understanding," indicating a potential imbalance in learning when combining different modalities.
- Overfitting to Training Data: Some models, even when using visual prompts, show only "minor improvement over its baseline, i.e. LLaVA-1.5, possibly due to overfitting to its training data." This suggests that without careful design, models can memorize training examples rather than learning generalizable instance understanding.
- Insufficient Scaling of Model Size or Coarse-grained Data: The paper explicitly states that "simply scaling up the model size cannot address the challenges in instance understanding" and that "large-scale coarse-grained annotations do not lead to essential improvements either." This highlights that the problem requires a qualitative shift in data and training methodology, not just quantitative scaling.
Why This Approach
The Inevitability of the Choice
The authors' decision to pursue explicit visual prompt instruction tuning, coupled with the creation of the INST-IT dataset and benchmark, wasn't merely a preference but a necessity born from the inherent limitations of existing Large Multimodal Models (LMMs). The core realization was that while LMMs had made significant strides in understanding images and videos at a holistic, or general, level, they consistently "struggle with instance-level understanding that requires a more fine-grained comprehension and alignment" (Abstract, Section 1). This means that traditional "SOTA" methods, such as standard CNNs, basic Diffusion models, or Transformers, even when integrated into LMMs, were fundamentally insufficient for tasks demanding precise, object-specific reasoning.
The exact moment of this realization is implicitly highlighted by the observation that current LMMs, despite breakthroughs in instruction tuning, "still struggle to comprehend instance-specific content that the users are most interested in, as illustrated in Fig. 1 (a)" (Section 1). This isn't a failure of the underlying architectures to process visual data, but rather their inability to ground instructions to specific instances within complex scenes, especially across both images and videos. The problem wasn't a lack of powerful base models, but a critical gap in the data and methodology required to teach these models fine-grained instance understanding. Existing multimodal benchmarks and datasets primarily offered "coarse-grained knowledge for images and videos, lacking fine-grained annotations for individual instances" (Page 2). Therefore, a new approach that explicitly provided instance-level guidance through visual prompts and a dedicated, richly annotated dataset was the only viable solution to bridge this gap.
Figure 1. (a) LMMs struggle with instance understanding, failing to capture the nuanced details of instances specified in user queries. (b) Our instance-centric data annotation pipeline, providing multi-level annotations for individual instances in images and videos
Comparative Superiority
The INST-IT approach demonstrates qualitative superiority over previous gold standards in several key aspects, extending beyond simple performance metrics.
Firstly, it excels in handling high-dimensional noise and distractions. The paper notes that "Directly processing the raw visual inputs suffers from hallucinations and distraction" (Section 2.1). To mitigate this, the method employs Set-of-Marks (SoMs) visual prompts, which overlay numerical IDs on each instance. This simple yet effective augmentation explicitly guides the underlying GPT-4o model to "focus more effectively on the instances of interest" (Section 2.1), thereby reducing the "noise" of irrelevant visual information and enabling finer-grained, more accurate annotations. This structural advantage allows the model to cut through visual clutter and concentrate on the user-specified instances.
 Figure 3. Set-of-Marks visual prompting on the original videos. Each instance is assigned a unique numeric ID, which remains consistent across all frames
Figure 3. Set-of-Marks visual prompting on the original videos. Each instance is assigned a unique numeric ID, which remains consistent across all frames
Secondly, the method addresses memory complexity for video inputs. While not explicitly stating a reduction from $O(N^2)$ to $O(N)$, the authors mention applying "2 × 2 spatial pooling to reduce the number of visual tokens in the video inputs" (Section 2.4). This downsampling of visual tokens directly contributes to reducing the computational and memory footprint, which is crucial for processing long video sequences and aligns with practical GPU memory constraints (Section 3.1).
The overwhelming structural advantage lies in its ability to foster true instance-level comprehension across both images and videos, including temporal dynamics. Unlike prior methods that focused on holistic understanding, INST-IT's dataset provides multi-level, fine-grained annotations encompassing instance-level descriptions, image-level captions, temporal dynamics, video-level summaries, and open-ended question-answer pairs (Page 2, Section 2.1). This rich, structured data, combined with the continuous instruction-tuning recipe, enables LMMs to not only identify instances but also understand their attributes, relationships, and spatiotemporal evolution. The results show that this approach leads to "consistent improvements on other instance understanding benchmarks" and "significant improvements over the baseline" on generic benchmarks (Abstract, Section 3.2), indicating a generalizable enhancement rather than mere overfitting. Furthermore, the paper highlights that its method achieves comparable performance to larger, more computationally expensive SFT LMMs "while requiring significantly less computational and data cost" (Section 3.2), underscoring its efficiency advantage.
 Figure 2. Visualization of data structure in INST-IT Dataset. For each video, we provide (a) N frame-level annotations, (b) a video-level description, and (c) M open-ended question-answer pairs. A complete example data can be found in Sec. C.3
Figure 2. Visualization of data structure in INST-IT Dataset. For each video, we provide (a) N frame-level annotations, (b) a video-level description, and (c) M open-ended question-answer pairs. A complete example data can be found in Sec. C.3
Alignment with Constraints
The chosen method, INST-IT, perfectly aligns with the implicit constraints and challenges outlined in the problem definition. This "marriage" between the problem's harsh requirements and the solution's unique properties is evident in several ways:
- Addressing the Instance-Level Understanding Gap: The primary constraint was the inability of existing LMMs to achieve fine-grained instance understanding. INST-IT directly tackles this by providing "explicit visual prompt Instruction Tuning for instance guidance" (Abstract). The instruction-tuning paradigm, augmented with visual prompts, forces the model to learn to ground instructions to specific visual entities.
- Overcoming Data Scarcity: A major bottleneck was the "lack of instance-level datasets" (Section 2.2). The INST-IT Dataset was meticulously constructed as "the first instance-grounded instruction-tuning dataset that includes both images and videos, featuring explicit instance-level visual prompts and fine-grained annotations grounded on individual instances" (Contribution 1, Page 2). This directly fulfills the need for comprehensive, fine-grained data.
- Handling Spatiotemporal Dynamics in Videos: The problem emphasized the difficulty of understanding instances in videos, requiring both spatial and temporal comprehension. The INST-IT Dataset's multi-level annotations include "temporal dynamics descriptions" and "video-level summaries" (Page 2, Section 2.1), explicitly training the model to capture changes and interactions over time. The continuous instruction tuning recipe further integrates this spatiotemporal understanding.
- Mitigating Hallucinations and Distractions: The constraint of raw visual inputs leading to "hallucinations and distraction" (Section 2.1) is addressed by the "Set-of-Marks (SoMs) visual prompt [88]" technique. By overlaying numerical IDs on instances, the model is explicitly guided to focus on specific objects, thereby reducing ambiguity and improving annotation accuracy.
- Computational Efficiency: Practical constraints often involve computational resources. The paper mentions "limiting the maximum number of frames to 32 and the context length of LLMs to 6K due to GPU memory constraints" and applying "2 × 2 spatial pooling to reduce the number of visual tokens" (Section 3.1). The fact that INST-IT achieves strong performance with "significantly less computational and data cost" compared to larger SFT LMMs (Section 3.2) demonstrates its alignment with resource-efficient deployment.
Rejection of Alternatives
The paper implicitly, yet clearly, rejects several alternative approaches by highlighting their shortcomings in addressing the core problem of instance-level understanding across multimodal data.
Firstly, it dismisses the efficacy of simply using existing "SOTA" LMMs without specialized instruction tuning and data. The authors state that while these models "can understand images and videos at a holistic level, they still struggle to comprehend instance-specific content" (Section 1). This implies that generic LMMs, even powerful ones, lack the fine-grained grounding capabilities necessary for this task. The problem is not a lack of general intelligence, but a lack of instance-centric instruction-following.
Secondly, the paper explicitly rejects other popular instruction-tuning datasets as insufficient. In Table 1 and Section 2.2, it compares INST-IT with datasets like ShareGPT4Video, LLaVA-Video, and ViP-LLaVA-Data. It notes that prior video datasets "focus on holistic understanding without instance-level annotations," and while ViP-LLaVA "offers instance annotations for images, it does not include any video data." This is a direct rejection of these alternatives because they fail to provide the necessary multi-level, fine-grained, instance-grounded annotations across both images and videos that INST-IT offers. The authors conclude that "the lack of instance-level datasets hinders the advancement of instance understanding" (Section 2.2), making existing datasets inadequate.
Finally, the paper rejects the notion that simply scaling up model size or using more coarse-grained data would solve the problem. It observes that "Qwen2VL-72B does not show substantial improvements over its smaller 7B model, indicating that simply scaling up the model size cannot address the challenges in instance understanding" (Section 3.2). Similarly, it notes that "large-scale coarse-grained annotations do not lead to essential improvements either" (Section 3.2). This reasoning underscores that the solution lies not in brute-force scaling of existing methods or data, but in a targeted approach that focuses on explicit instance-level guidance through specialized data and instruction tuning.
Mathematical & Logical Mechanism
The Master Equation
The core mathematical and logical mechanism of INST-IT is not a single objective function for a model to optimize, but rather a sophisticated data generation pipeline that leverages a powerful Large Language Model (LLM), specifically GPT-4o, to create rich, multi-granularity annotations. These annotations then form the INST-IT Dataset, which is used to instruction-tune other LMMs. The fundamental operations within this pipeline are defined by three key equations, each representing a distinct stage of annotation generation:
1. Frame-level Annotation:
$$Y_t^f = \text{GPT}(P^f, X_t, X_{t-1})$$
2. Video-level Summary:
$$Y^{vid} = \text{GPT}(P^{vid}, [Y_1^f, Y_2^f, \ldots, Y_N^f])$$
3. Open-ended Question-Answer Pairs:
$$Y^{qa} = \text{GPT}(P^{qa}, [Y_1^f, Y_2^f, \ldots, Y_N^f])$$
Term-by-Term Autopsy
Let's dissect each component of these equations to understand their precise role in the INST-IT framework.
Equation (1): Frame-level Annotation
$$Y_t^f = \text{GPT}(P^f, X_t, X_{t-1})$$
* $Y_t^f$:
* Mathematical Definition: This is the output of the GPT-4o model for a specific video frame at time $t$. It's a structured textual annotation.
* Physical/Logical Role: It represents the comprehensive, fine-grained textual description for a single frame, encompassing details about individual instances, the overall image content, and temporal changes relative to the previous frame. This is the foundational building block for all subsequent, higher-level annotations.
* $\text{GPT}(\cdot)$:
* Mathematical Definition: This denotes the GPT-4o large language model, treated as a function that takes a prompt and visual inputs to generate textual output.
* Physical/Logical Role: GPT-4o acts as the intelligent annotator. Its advanced multimodal understanding capabilities are harnessed to interpret visual information and generate human-like, detailed descriptions according to the provided instructions. The authors chose GPT-4o for its superior ability to handle complex visual reasoning and generate high-quality text, which is crucial for the fine-grained nature of instance understanding.
* $P^f$:
* Mathematical Definition: A natural language string, specifically a "tailored task prompt" designed for frame-level annotation.
* Physical/Logical Role: This prompt serves as a precise instruction set for GPT-4o. It guides the model to focus on specific aspects of the frame (e.g., individual instances, overall scene, temporal differences) and dictates the desired structure and content of the output $Y_t^f$. The careful design of this prompt is key to eliciting accurate and relevant annotations.
* $X_t$:
* Mathematical Definition: The visual data corresponding to the current video frame at timestamp $t$.
* Physical/Logical Role: This is the primary visual input for GPT-4o, providing the raw pixel information and visual context that needs to be described.
* $X_{t-1}$:
* Mathematical Definition: The visual data corresponding to the previous video frame at timestamp $t-1$.
* Physical/Logical Role: Including the previous frame is critical for capturing temporal dynamics. By comparing $X_t$ and $X_{t-1}$, GPT-4o can identify and describe movements, changes in state, or interactions between instances over time, which is essential for video understanding.
* Mathematical Operator (Function Application): The operation is a function call to GPT-4o. The authors use this functional notation because GPT-4o is a complex generative model, not a simple arithmetic operator. It processes the inputs (prompt, current frame, previous frame) through its internal neural network architecture to produce a coherent textual output.
Equation (2): Video-level Summary
$$Y^{vid} = \text{GPT}(P^{vid}, [Y_1^f, Y_2^f, \ldots, Y_N^f])$$
* $Y^{vid}$:
* Mathematical Definition: The textual summary of the entire video, generated by GPT-4o.
* Physical/Logical Role: This provides a holistic, chronological narrative of the video content, aggregating the detailed information from all individual frame-level annotations into a coherent story. It captures the overall spatiotemporal flow and key events.
* $\text{GPT}(\cdot)$: Same as in Equation (1).
* $P^{vid}$:
* Mathematical Definition: A natural language string, specifically a "task prompt" designed for video-level summarization.
* Physical/Logical Role: This prompt instructs GPT-4o to synthesize a comprehensive summary from the sequence of frame-level descriptions, ensuring chronological order and focus on main objects and events.
* $[Y_1^f, Y_2^f, \ldots, Y_N^f]$:
* Mathematical Definition: An ordered list or sequence of all frame-level annotations ($Y_t^f$) generated for the video, from the first frame ($t=1$) to the last frame ($t=N$).
* Physical/Logical Role: This sequence serves as the textual "memory" or "transcript" of the video's events, providing GPT-4o with all the fine-grained details it needs to construct a high-level summary. The use of a list (implicitly a summation of information) rather than a single aggregated value allows GPT-4o to process the temporal progression and relationships between events.
* $N$:
* Mathematical Definition: The total number of frames in the video.
* Physical/Logical Role: This scalar indicates the length of the video and thus the number of frame-level annotations that need to be considered for the video summary.
Equation (3): Open-ended Question-Answer Pairs
$$Y^{qa} = \text{GPT}(P^{qa}, [Y_1^f, Y_2^f, \ldots, Y_N^f])$$
* $Y^{qa}$:
* Mathematical Definition: A set of $M$ open-ended question-answer pairs, $\{(q_i, a_i)\}_{i=1}^M$, generated by GPT-4o.
* Physical/Logical Role: These pairs are designed to test and train LMMs on instance-level understanding and reasoning. They focus on specific instances, their attributes, relationships, and temporal changes, providing a rich source of instruction-tuning data.
* $\text{GPT}(\cdot)$: Same as in Equation (1).
* $P^{qa}$:
* Mathematical Definition: A natural language string, specifically a "task prompt" designed for generating open-ended QA pairs.
* Physical/Logical Role: This prompt guides GPT-4o to formulate diverse and contextually relevant questions and accurate answers based on the provided frame-level annotations. It ensures the QA pairs target instance-level comprehension.
* $[Y_1^f, Y_2^f, \ldots, Y_N^f]$: Same as in Equation (2).
* Physical/Logical Role: Similar to video summarization, this sequence provides the comprehensive textual context from which GPT-4o can derive questions and answers, requiring it to reason over the detailed events and entities.
Step-by-Step Flow
Imagine a video entering a sophisticated data annotation factory. Here's how a single video's information is processed through the INST-IT pipeline:
- Visual Input Reception: A raw video, consisting of a sequence of frames $X_1, X_2, \ldots, X_N$, arrives at the first station.
- Instance Highlighting (Visual Prompting): At this station, a pre-processing step identifies individual instances (objects) within each frame. For every detected instance, a unique numerical ID is overlaid directly onto it, creating a "Set-of-Marks" (SoM) visual prompt. This ensures that the subsequent annotation steps explicitly focus on these identified instances.
Figure 3. Set-of-Marks visual prompting on the original videos. Each instance is assigned a unique numeric ID, which remains consistent across all frames
- Frame-Level Annotation Assembly Line:
- The video frames are fed sequentially into the GPT-4o "annotation engine."
- For the first frame $X_1$, it's combined with a specific "frame-level prompt" $P^f$ (and a placeholder for $X_0$ as there's no previous frame). GPT-4o processes this and outputs $Y_1^f$, a detailed textual description of instances, the overall image, and any temporal changes (or lack thereof).
- For each subsequent frame $X_t$ (where $t > 1$), it's paired with its immediate predecessor $X_{t-1}$ and the same $P^f$. This pair, along with the prompt, enters GPT-4o.
- GPT-4o then meticulously analyzes $X_t$ and $X_{t-1}$, generating $Y_t^f$, which includes descriptions of instances in $X_t$, the overall scene, and crucially, the differences and dynamics observed between $X_{t-1}$ and $X_t$.
- This process repeats until all $N$ frames have been annotated, resulting in a complete sequence of frame-level annotations: $[Y_1^f, Y_2^f, \ldots, Y_N^f]$. This sequence is like a detailed logbook of everything happening frame-by-frame.
- Video-Level Summary Synthesis: The complete logbook of frame-level annotations $[Y_1^f, \ldots, Y_N^f]$ is now collected. This entire textual sequence, along with a "video-level summary prompt" $P^{vid}$, is fed into another instance of the GPT-4o engine. This engine's task is to act as a skilled summarizer, synthesizing all the granular details into a cohesive, chronological narrative $Y^{vid}$ that describes the entire video's events and spatiotemporal information.
- Question-Answer Generation: In parallel with the summarization, the same logbook $[Y_1^f, \ldots, Y_N^f]$ is also fed into a third GPT-4o engine, this time with an "open-ended QA prompt" $P^{qa}$. This engine's role is to act as a creative question generator and answerer, producing a set of diverse and instance-focused question-answer pairs $Y^{qa}$. These QA pairs are designed to probe the model's understanding of individual instances and their relationships throughout the video.
- Dataset Integration: All these generated annotations ($Y_t^f$, $Y^{vid}$, $Y^{qa}$) for the video are then packaged together, forming a rich, multi-level, instance-grounded entry in the INST-IT Dataset. This data is now ready to be used for instruction tuning. As illustrated in Fig. 2, these annotations include the following aspects:
Figure 2. Visualization of data structure in INST-IT Dataset. For each video, we provide (a) N frame-level annotations, (b) a video-level description, and (c) M open-ended question-answer pairs. A complete example data can be found in Sec. C.3
Optimization Dynamics
The INST-IT framework itself is primarily a data generation and preparation mechanism, not a model that undergoes direct optimization in the traditional sense (i.e., it doesn't have parameters that are updated via gradients). Instead, its "optimization dynamics" are observed in how it enables other Large Multimodal Models (LMMs) to learn, update, and converge more effectively.
When an LMM (like LLaVA-NeXT) is trained using the INST-IT Dataset, the learning process unfolds as follows:
-
Instruction Tuning Objective: The LMM is trained to follow instructions by minimizing the difference between its generated textual responses and the ground-truth annotations provided by the INST-IT Dataset. This is typically achieved using a standard language modeling objective, such as cross-entropy loss (or negative log-likelihood loss). Given an input consisting of visual features $V$ (derived from images/video frames, potentially with SoMs) and a textual instruction $I$, the model generates a sequence of tokens $T = (t_1, t_2, \ldots, t_L)$. The objective is to maximize the probability of generating the correct sequence of tokens given the input, which is usually decomposed as $\prod_{k=1}^L P(t_k | V, I, t_1, \ldots, t_{k-1})$. The loss for a single training sample $(V, I, T_{target})$ would be:
$$ \mathcal{L} = - \sum_{k=1}^L \log P(t_{target,k} | V, I, t_1, \ldots, t_{k-1}) $$
where $t_{target,k}$ are the tokens of the ground-truth annotation from the INST-IT dataset. -
Joint Training Paradigm: The paper proposes a "continuous instruction tuning recipe" (Section 2.4, 3.4) that is central to the optimization dynamics. This recipe involves:
- Mixing Data: The INST-IT Dataset, with its rich instance-level, multi-granularity annotations and explicit visual prompts, is combined with existing general instruction-tuning data (e.g., LLaVA-NeXT-DATA). This joint training ensures that the LMM learns both fine-grained instance understanding and maintains its broader general comprehension capabilities across diverse tasks.
- Mitigating Distribution Shift: A key challenge is that "visually prompted images may introduce a distribution shift from natural images" (Section 3.4), potentially degrading performance on generic tasks. To counteract this, the continuous supervised fine-tuning (SFT) paradigm is applied. During this stage, the initial layers of the vision encoder (specifically, the first 12 layers) are "frozen" (Section 3.1). This freezing helps preserve the low-level visual features learned from natural images and prevents the model from overfitting to the visually prompted data, thereby achieving a balanced performance across both image and video tasks.
-
Optimization Process:
- Forward Pass: During training, an LMM processes the visual input (image/video frames, augmented with SoMs) through its vision encoder to extract visual features. These features are then projected into the language model's embedding space. The language model then processes the textual instruction and the visual features to generate a textual response.
- Backward Pass: The generated response is compared to the ground-truth annotation from the INST-IT dataset using the cross-entropy loss. Gradients are computed and backpropagated through the language model and the projection layer. Due to the freezing strategy, gradients only update the later layers of the vision encoder (if unfrozen), the projection layer, and the language model.
- Convergence: The model parameters are iteratively updated using an optimizer (e.g., AdamW, as mentioned in Section 3.1) with a learning rate schedule (e.g., cosine learning rate schedule). The goal is for the LMM to converge to a state where it can accurately generate fine-grained, instance-level descriptions and answer questions based on visual prompts, while retaining strong general multimodal comprehension.
This continuous instruction-tuning paradigm, with its careful balance of data types and selective freezing of model components, is the "optimization dynamic" that allows LMMs to learn the desired instance-level understanding without sacrificing their broader capabilities.
Results, Limitations & Conclusion
Experimental Design & Baselines
To rigorously validate their claims, the authors architected a comprehensive experimental setup. Their core approach involved enhancing Large Multimodal Models (LMMs) through explicit visual prompt instruction tuning, dubbed INST-IT. The primary "victim" or baseline architecture chosen for enhancement was LLaVA-NeXT [44], a widely adopted model. This baseline typically used Vicuna-1.5-7B [16] as its language model and CLIP-ViT-336 [67] as its vision encoder. For more advanced experiments, they also employed Qwen2-7B [87] with SigLIP-SO400M-384 [97].
The experimental design centered on a novel image-video joint training pipeline. This pipeline meticulously combined the newly created INST-IT Dataset with existing open-source LLaVA-NeXT-DATA [48]. A crucial element of their architecture was the augmentation of all images and video frames with Set-of-Marks (SoM) visual prompts [88]. This technique explicitly guided the LMMs to focus on individual instances, a key differentiator from prior work.
The INST-IT Dataset itself is a significant contribution, comprising 51k images and 21k videos. It features multi-level, fine-grained annotations grounded on individual instances, including 207k image-level captions, 135k temporal dynamics descriptions, 21k video-level captions, and 335k open-ended question-answer pairs.
For evaluation, the authors introduced the INST-IT Bench, a human-verified benchmark specifically designed to diagnose instance-level understanding in both images and videos. This benchmark includes 1,000 open-ended and multiple-choice QA pairs for 338 images and 1,000 QA pairs for 206 videos. Open-ended QA responses were evaluated using GPT-4o [61] for accuracy and instance ID reference correctness. Beyond their custom benchmark, they also tested their models on established instance understanding benchmarks like RefCOCOg [53] and ViP-Bench [5], as well as generic image and video understanding benchmarks such as AI2D [28], ChartQA [54], Egoschema [52], and NEXT-QA [85].
The baseline models they aimed to defeat included a wide array of state-of-the-art LMMs:
- Proprietary Models: GPT-4o [61] and Gemini-1.5-flash [72].
- Open-source Image Models: LLaVA-1.5 [43], ViP-LLaVA [5], SOM-LLaVA [86], and the direct baseline LLaVA-NeXT [44].
- Open-source Video Models: LLaVA-NeXT-Video [103], ShareGPT4Video [10], LLaVA-OV [31], LLaVA-Video [104], InternVL2 [13], and Qwen2-VL-Instruct [82].
This comprehensive experimental design, with its custom dataset, benchmark, and a diverse set of baselines, allowed for a thorough assessment of INST-IT's effectiveness.
What the Evidence Proves
The experimental results provide definitive, undeniable evidence that the INST-IT approach significantly boosts instance-level understanding in LMMs, while also strengthening their generl comprehension capabilities.
On the INST-IT Bench (Table 2), the models enhanced by INST-IT demonstrated outstanding performance. For instance, LLaVA-NeXT-INST-IT with Vicuna-7B achieved 68.6 in image Open-Ended (OE) Q&A and 63.0 in Multiple-Choice (MC) Q&A, a substantial leap compared to the LLaVA-NeXT baseline (46.0 OE, 42.4 MC for image from Table 2). In video tasks, the INST-IT enhanced model scored 49.3 OE and 42.1 MC, significantly outperforming the LLaVA-NeXT-Video baseline (25.8 OE, 24.8 MC). The paper explicitly states an "improvement of nearly 20% on average score," which is a robust validation of INST-IT's core mechanism.
Beyond their own benchmark, INST-IT models showed consistent improvements on other established instance understanding benchmarks:
- On RefCOCOg [53], the LLaVA-NeXT-INST-IT-Vicuna-7B model achieved a 10.8% improvement over its LLaVA-NeXT-Vicuna-7B baseline (63.0% vs. 52.2%). This is hard evidence that the explicit visual prompt instruction tuning directly enhances the model's ability to comprehend referring expressions and ground them to specific instances.
- For ViP-Bench [5] (Table 5), INST-IT with Vicuna-7B achieved performance comparable to, and in some cases even surpassed, ViP-LLaVA, especially when using human-style visual prompts. This is particularly compelling because ViP-LLaVA was fine-tuned on the ViP-Bench dataset, whereas INST-IT was evaluated in a zero-shot manner, demonstrating strong generalization capabilities.
Furthermore, the models' general comprehension capabilities also saw significant gains on widely used generic benchmarks:
- For image benchmarks (Table 3), INST-IT consistently outperformed the LLaVA-NeXT baseline. Specifically, it achieved a 4.4% gain on AI2D [28] and a 13.5% gain on ChartQA [54] with the Vicuna-7B variant. These benchmarks require grounding and reasoning, indicating that INST-IT's fine-grained understanding translates to broader visual reasoning.
- On video benchmarks (Table 4), INST-IT models significantly outperformed both LLaVA-NeXT and LLaVA-NeXT-Video baselines. For instance, it showed a 7.8% improvement on Egoschema [52] and an 11.8% improvement on NEXT-QA [85] with the Vicuna-7B variant. These results confirm that enhancing instance-level understanding through explicit visual prompts is an efficent strategy for improving generic spatiotemporal comprehension.
Ablation studies further dissected the contributions:
- The continuous instruction-tuning paradigm (Table 6) was crucial. Directly mixing video data with general instruction data led to a decline in image understanding, but the proposed continuous SFT with a frozen vision encoder achieved balanced performance across both image and video tasks, mitigating distribution shifts from visually prompted images.
- The detailed dataset combination (Table 7) revealed that instance-level and image-level frame captions are essential for image instance understanding, while temporal differences, video-level descriptions, and QA are vital for video instance understanding. Incorporating the image component of the INST-IT Dataset ultimately yielded the most balanced performance.
In essence, the evidence unequivocally proves that INST-IT's multi-level, instance-grounded annotations combined with explicit visual prompting and a continuous instruction-tuning paradigm effectively equip LMMs with superior fine-grained instance understanding, which in turn bolsters their overall multimodal comprehension.
Limitations & Future Directions
While INST-IT presents a significant advancement in instance-level understanding for LMMs, the authors candidly acknowledge several limitations and propose exciting avenues for future development.
Current Limitations:
1. Computational Cost: The current experiments are primarily conducted on 7B and 1.5B parameter models. Scaling to much larger models (e.g., 70B or beyond) is constrained by the substantial computational cost, which limits the scope of current research.
2. GPT-4o Overhead: The automated data annotation pipeline, while effective, relies on GPT-4o. This introduces an inherent overhead, which can be a bottleneck for generating even larger and more diverse datasets.
3. Failure Cases: The models occasionally struggle in challenging scenarios such as severely occluded instances, blurry images, or instances that are excessively small or crowded. These are common hurdles for LMMs and indicate areas where robustness can be improved.
4. Fairness and Bias: Like many large multimodal models, INST-IT faces potential risks related to fairness and bias, which could stem from the training data or the model's learned representations. This is a critical ethical consideration that requires ongoing attention.
Future Directions & Discussion Topics:
Building upon these findings, several discussion topics emerge for further development and evolution:
-
Scaling and Self-Supervised Data Generation:
- How can we develop more computationally efficent methods for instance-level instruction tuning that allow for scaling to much larger LMMs without prohibitive costs?
- Can we move towards a "model-in-the-loop" approach where the model itself, once partially trained, assists in generating more high-quality, self-synthesized instance-level data, reducing reliance on expensive proprietary APIs like GPT-4o? This could involve iterative refinement where the model generates data, a smaller human verification step occurs, and the model is retrained.
-
Enhanced Robustness to Challenging Visual Conditions:
- What novel architectural designs or training strategies could specifically address the identified failure cases (occlusion, blur, small/crowded instances)? Could incorporating uncertainty estimation or multi-view fusion techniques improve performance in these difficult scenarios?
- How can we leverage synthetic data generation more effectively to create diverse and challenging examples that specifically target these failure modes, thereby improving model robustness?
-
Mitigating Bias and Ensuring Fairness:
- Given the potential for fairness and bias issues, what systematic data filtering and validation approaches can be implemented to ensure the INST-IT Dataset and future datasets are more equitable and representative?
- Beyond data-centric solutions, what model-agnostic or model-specific techniques (e.g., debiasing algorithms, explainable AI methods to audit instance-level decisions) can be developed to detect and mitigate biases in instance understanding?
-
Expanding Spatiotemporal Reasoning and Predictive Capabilities:
- While INST-IT excels at describing current and temporal changes, how can we push LMMs to perform more complex spatiotemporal reasoning, such as predicting future actions or trajectories of instances, or understanding long-term causal relationships between instances in a video?
- Could integrating physics-informed neural networks or common-sense reasoning modules further enhance the model's ability to reason about instance interactions beyond mere observation?
-
Real-world Deployment and Human-AI Collaboration:
- How can the INST-IT framework be integrated into real-world applications where users need to interactively specify instances of interest, perhaps through more intuitive interfaces than numerical IDs?
- What are the implications for human-AI collaboration in tasks requiring fine-grained visual understanding? Can INST-IT-enhanced LMMs serve as more effective assistants for tasks like video editing, surveillance analysis, or even scientific observation, by providing precise instance-level insights? This also raises questions about the interpretability of the model's instance-level reasoning to human users.
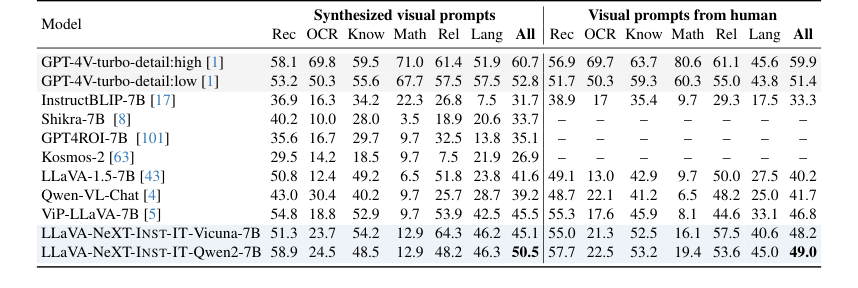 Table 5. Results on ViP-Bench. We perform evaluation with our INST-IT models without fine-tuning
Table 5. Results on ViP-Bench. We perform evaluation with our INST-IT models without fine-tuning
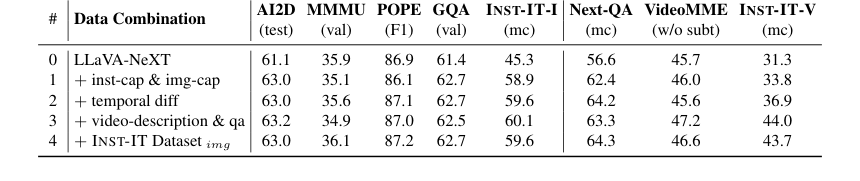 Table 7. Ablation on detailed data combination. The dataset combination in line #3 corresponds to the video part of INST-IT Dataset, while line #4 represents the complete INST-IT Dataset by incorporating the image part into line #3
Table 7. Ablation on detailed data combination. The dataset combination in line #3 corresponds to the video part of INST-IT Dataset, while line #4 represents the complete INST-IT Dataset by incorporating the image part into line #3
 Table 9. Statistical and lexical analysis of INST-IT Dataset. We present the results for each annotation level as well as the entire dataset
Table 9. Statistical and lexical analysis of INST-IT Dataset. We present the results for each annotation level as well as the entire dataset
 Table 13. INST-IT Dataset video-level caption
Table 13. INST-IT Dataset video-level caption