INST-IT: 명시적 시각 프롬프트 지시 튜닝을 통한 인스턴스 이해 강화
The problem addressed in this paper precisely originates from the recent advancements and, paradoxically, the limitations of Large Multimodal Models (LMMs) in the field of artificial intelligence, specifically within...
배경 및 학문적 계보
연구의 기원 및 학문적 계보
본 논문에서 다루는 문제는 인공지능 분야, 특히 컴퓨터 비전 및 자연어 처리 영역에서 최근의 발전과 역설적으로 그 한계로부터 정확히 기원한다. Large Multimodal Models (LMMs)는 "instruction tuning"에 힘입어 이미지와 비디오를 총체적, 즉 일반적인 수준에서 이해하고 다양한 사용자 지시를 따르는 데 상당한 돌파구를 마련했지만, "instance-level understanding"이라는 보다 세분화된 작업에서는 일관되게 어려움을 겪는다.
역사적으로 시각 데이터 내 개별 객체를 이해하려는 추구는 컴퓨터 비전 분야에서 오랜 목표였으며, 객체 탐지, 인스턴스 분할, 객체 추적과 같은 분야에서 광범위한 연구로 이어졌다. 그러나 LMMs의 등장과 함께 도전 과제는 변화했다. 이전 접근 방식, 특히 기존 LMMs의 "고충점(pain point)"은 사용자가 특정 질문을 할 때, 이미지나 비디오 내의 특정 요소 또는 "인스턴스"를 미세한 디테일과 정렬로 이해하는 능력의 부재이다. 예를 들어, LMM은 "사람들의 군중"을 묘사할 수는 있지만, "빨간 모자를 쓴 사람이 무엇을 하고 있는가?" 또는 "1번 사람과 2번 사람 간의 상호작용이 시간이 지남에 따라 어떻게 변했는가?"와 같은 질문에 답하지 못할 수 있다. 이러한 한계는 비디오에서 더욱 두드러지는데, 단순히 공간 정보뿐만 아니라 개별 인스턴스의 시간적 역학을 이해하는 것이 중요해진다. 기존의 멀티모달 데이터셋과 벤치마크는 주로 거친 수준의 지식을 제공하며, 이러한 미묘한 인스턴스 수준의 이해를 위해 LMMs를 훈련하고 평가하는 데 필요한 세밀한 주석이 부족하다. 이러한 근본적인 격차는 저자들이 명시적인 시각적 프롬프트 instruction tuning을 통해 LMMs의 개별 인스턴스 이해 능력을 향상시키기 위한 솔루션인 INST-IT를 개발하도록 강제했다.
직관적인 도메인 용어
- Large Multimodal Models (LMMs): 텍스트를 읽고 쓰는 것뿐만 아니라 이미지와 비디오를 "보고" "이해할" 수 있는 초지능 디지털 비서라고 상상해 보라. 사진을 보거나 클립을 시청한 후 자연어로 토론할 수 있는 개인 전문가를 갖는 것과 같다.
- Instruction Tuning: 이는 특정 작업의 많은 예시를 제공하고 정확히 무엇을 해야 하는지 알려줌으로써 그 초지능 비서를 가르치는 것과 같다. 예를 들어, 사진을 보여주고 "이 이미지를 설명하라" 또는 "이미지에 대한 이 질문에 답하라"고 "지시"한다. 비서는 수많은 예시를 보면서 이러한 지시를 따르는 법을 배운다.
- Instance-level Understanding: 전체 장면("많은 사람들이 있는 공원")을 설명하는 것 이상으로, 이는 비서가 장면 내의 개별 사물(인스턴스)에 초점을 맞출 수 있음을 의미한다. 공원에 있는 특정 사람을 가리키며 "그 사람은 무엇을 입고 있는가?" 또는 "그 개가 그 공과 놀고 있는가?"라고 질문할 수 있는 것과 같다. 각 특정 항목의 세부 사항과 그 관계를 이해하는 것이다.
- Set-of-Marks (SoMs) Visual Prompting: 이미지나 비디오에서 특정 객체 주위에 번호가 매겨진 스티커를 붙이거나 원을 그리는 것으로 생각하라. 스마트 비서가 주의를 기울이기를 원하는 인스턴스를 문자 그대로 "표시"하는 것이다. 예를 들어 "객체 #1을 보고, 그 다음 객체 #2를 보라." 이는 보다 정확한 이해를 위해 개별 항목에 대한 초점을 안내하는 데 도움이 된다.
표기법 테이블
| 표기법 | 설명 |
|---|---|
| LMMs | 여러 모달리티(예: 텍스트, 이미지, 비디오)에 걸쳐 콘텐츠를 이해하고 생성할 수 있는 Large Multimodal Models. |
| SoMs | Set-of-Marks 시각적 프롬프트로, 모델의 초점을 안내하기 위해 시각적 입력의 인스턴스에 숫자 ID를 오버레이하는 기법. |
| INST-IT | LMMs의 인스턴스 이해를 향상시키기 위한 제안된 프레임워크, 데이터셋 및 벤치마크. |
| $X_t$ | 타임스탬프 $t$에서의 시각 데이터(이미지 또는 비디오 프레임). |
| $X_{t-1}$ | 시간적 비교를 위해 사용되는 타임스탬프 $t-1$에서의 시각 데이터(이미지 또는 비디오 프레임). |
| $P^f$ | 프레임 수준 주석 생성을 위해 특별히 설계된 작업 프롬프트. |
| $Y_t^f$ | 인스턴스 설명, 이미지 캡션 및 시간적 차이를 포함하여 프레임 $t$에 대한 프레임 수준 주석 출력. |
| $P^{vid}$ | 비디오 수준 요약 생성을 위해 특별히 설계된 작업 프롬프트. |
| $Y^{vid}$ | 모든 프레임 수준 주석의 정보를 집계한 비디오 수준 요약 출력. |
| $P^{qa}$ | 개방형 질문-답변 쌍 생성을 위해 특별히 설계된 작업 프롬프트. |
| $Y^{qa}$ | 인스턴스 수준 이해에 초점을 맞춘 개방형 질문-답변 쌍 출력. |
| $\text{GPT}(\cdot)$ | 데이터 생성 파이프라인에서 지능형 주석가로 사용되는 GPT-4o 대규모 언어 모델을 나타낸다. |
| $N$ | 비디오의 총 프레임 수. |
| $M$ | 비디오에 대해 생성된 총 개방형 질문-답변 쌍 수. |
| SFT | INST-IT 데이터셋으로 LMMs를 향상시키는 데 사용되는 훈련 패러다임인 Supervised Fine-Tuning. |
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
대규모 멀티모달 모델(LMM)의 현재 상태는 상당한 이분법을 제시한다: 이미지를 전체적, 장면 수준에서 이해하는 데 놀라운 진전을 이루었지만, 개별 인스턴스 수준 이해를 요구하는 작업에 직면했을 때 일관되게 실패한다. 이는 LMM이 비디오의 일반적인 내용을 설명할 수는 있지만, 특히 속성, 관계 및 시간적 상호작용과 같은 특정 객체나 개체를 정확하게 식별, 추적 및 추론하는 데 어려움을 겪는다는 것을 의미한다.
바람직한 최종 목표는 LMM에 이미지와 비디오 모두에서 강력한 인스턴스 수준 이해 능력을 부여하는 것이다. 이는 모델이 특정 요소를 참조하는 사용자 지침을 정확하게 따르고, 미세한 세부 정보를 이해하며, 시간에 따른 동적 변화를 추적하도록 하는 것을 포함한다.
이러한 상태 사이의 정확한 누락된 연결 고리 또는 수학적 격차는 충분히 풍부하고, 인스턴스 기반이며, 다단계 지침 튜닝 데이터의 부재이다. 기존 데이터셋은 주로 LMM이 미세한 인스턴스 이해를 수행하도록 훈련하는 데 부적합한 거친 수준의 주석을 제공한다. 본 논문은 이러한 데이터를 생성하기 위한 새로운 파이프라인과 연속적인 지침 튜닝 패러다임을 도입하여 이 격차를 해소하고자 한다.
이 문제는 이전 연구자들이 고통스러운 절충안에 갇히게 했다:
- 전체적 이해 vs. 미세한 이해: LMM의 전체 장면 이해 능력을 향상시키는 것은 종종 미세한 인스턴스 세부 정보에 대한 능력 희생을 동반하거나 그 반대이다. 이 둘을 동시에 달성하는 것은 상당한 도전이다.
- 이미지 vs. 비디오 인스턴스 이해: 정적 이미지에 대한 인스턴스 이해에서 일부 진전이 있었지만, 이를 동적 비디오로 확장하는 것은 상당한 복잡성을 야기한다. 비디오는 공간적 이해뿐만 아니라 시간적 역학을 추적하고 추론하는 능력, 즉 인스턴스가 시간에 따라 어떻게 변화하고, 이동하며, 상호작용하는지를 요구한다. 이 추가적인 차원은 비디오 인스턴스 이해를 "상당히 더 어렵게" 만든다.
- 주석 규모 vs. 품질: 개별 인스턴스에 대한 고품질의 미세한 주석을 생성하는 것은 노동 집약적이고 비용이 많이 든다. 이전의 노력은 대규모로 거친 수준의 데이터를 제공하거나 제한된 규모로 미세한 데이터를 제공했다. 딜레마는 복잡한 멀티모달 데이터(이미지 및 비디오)에 대해 대규모 및 고품질의 미세한 주석 모두를 효율적으로 생성하는 방법이다.
- 일반화 vs. 특수화: 특정 인스턴스 이해 작업에 대해 미세 조정된 모델은 훈련 데이터에 과적합될 위험이 있으며, 이는 일반적인 이해 능력을 저하시킬 수 있다. 과제는 다양한 이미지 및 비디오 작업에 걸쳐 일반적인 이해를 동시에 강화하면서 인스턴스 이해를 향상시키는 것이다.
제약 조건 및 실패 모드
LMM에서 강력한 인스턴스 수준 이해를 달성하는 문제는 저자들이 직면한 몇 가지 혹독하고 현실적인 벽 때문에 믿을 수 없을 정도로 어렵다:
- GPT-4o의 계산 오버헤드: 자동화된 데이터 주석 파이프라인은 효율적이지만 "GPT-4o의 오버헤드에 의해 제약된다." 이는 특히 비디오에 대한 대량의 고품질, 다단계 주석을 생성하는 것이 여전히 시간이 많이 걸리고 비용이 많이 드는 과정이며, 이러한 데이터를 생산할 수 있는 규모를 제한한다는 것을 의미한다.
- 하드웨어 메모리 한계: LMM의 훈련 과정, 특히 비디오 입력을 사용하는 경우 "GPU 메모리 한계에 의해 제약된다." 저자들은 명시적으로 "GPU 메모리 제약으로 인해 최대 프레임 수를 32개로, LLM의 컨텍스트 길이를 6K로 제한한다"고 명시하며, 더 길거나 고해상도 비디오 시퀀스를 처리하는 데 실질적인 장벽이 있음을 나타낸다.
- 환각 및 원시 시각적 입력으로부터의 산만함: LMM은 원시 시각적 입력을 직접 처리할 때 "환각과 산만함으로 고통받는다." 이러한 내재된 한계는 모델이 명시적인 지침 없이 특정 인스턴스에 대한 정보를 안정적으로 집중하고 추출하는 데 어려움을 겪는다는 것을 의미하며, 시각적 프롬프트의 사용을 필요로 한다.
- 인스턴스 기반 데이터의 부족: 근본적인 제약은 특히 비디오에 대한 지침 튜닝을 위한 "인스턴스 기반 데이터의 부족"이다. 이 데이터 격차는 LMM이 인스턴스 이해에 어려움을 겪는 주된 이유이며, 이러한 능력을 학습할 만큼 충분한 미세한 감독이 없기 때문이다.
- 시간적 역학의 복잡성: 비디오에서 인스턴스를 이해하려면 공간 정보뿐만 아니라 복잡한 "시간적 역학"을 포착해야 한다. 이는 객체 위치, 행동 및 관계의 연속 프레임 간 변화를 추적하는 것을 포함하며, 이는 정적 이미지 분석보다 훨씬 더 복잡한 작업이다.
- 데이터 품질 보증의 어려움: GPT-4o를 활용하는 자동화된 파이프라인이 있더라도 다단계, 미세한 주석의 고품질 및 일관성을 보장하는 것은 어렵다. 본 논문은 데이터 품질을 보장하기 위해 "엄격한 수동 검증 및 개선"이 필요하다고 언급하며, 신뢰할 수 있는 주석을 완전히 자동화하는 것의 어려움을 강조한다.
저자들은 이 맥락에서 LMM의 특정 실패 모드를 식별한다:
- 가려짐, 흐릿한 이미지, 작거나 붐비는 인스턴스: "인스턴스가 심하게 가려지거나, 이미지가 흐릿하거나, 인스턴스가 지나치게 작거나 붐비는" 시나리오에서 모델의 성능이 저하된다. 이는 시각 인식 시스템에 상당한 어려움을 제기하는 일반적인 실제 조건이다.
- 시각적 프롬프트로부터의 분포 이동: "시각적으로 프롬프트된 이미지를 사용하면 자연스러운 이미지로부터 분포 이동이 발생할 수 있다." 이는 모델이 이 이동을 완화하도록 신중하게 훈련되지 않은 경우 일반적인 이미지 이해 작업에 대한 성능 저하로 이어질 수 있다.
- 비디오 데이터에 의한 이미지 이해의 억제: 일반 지침 튜닝 데이터와 높은 비율의 비디오 데이터를 직접 혼합하면 "이미지 이해가 억제될 수 있다"는 점은 서로 다른 모달리티를 결합할 때 학습의 잠재적 불균형을 나타낸다.
- 훈련 데이터에 대한 과적합: 일부 모델은 시각적 프롬프트를 사용하더라도 "기본 모델인 LLaVA-1.5에 비해 약간의 개선만 보이며, 이는 훈련 데이터에 과적합되었기 때문일 수 있다." 이는 신중한 설계 없이는 모델이 일반화 가능한 인스턴스 이해를 학습하는 대신 훈련 예제를 암기할 수 있음을 시사한다.
- 모델 크기 또는 거친 수준 데이터의 불충분한 확장: 본 논문은 "단순히 모델 크기를 확장하는 것만으로는 인스턴스 이해의 문제를 해결할 수 없다"고 명시하며, "대규모 거친 수준의 주석은 필수적인 개선으로 이어지지 않는다"고 말한다. 이는 문제가 양적 확장이 아닌 데이터 및 훈련 방법론의 질적 변화를 요구한다는 점을 강조한다.
이 접근 방식은 왜
선택의 필연성
저자들이 명시적인 시각적 프롬프트 지시 튜닝을 추구하고 INST-IT 데이터셋 및 벤치마크를 구축하기로 결정한 것은 단순한 선호가 아니라 기존 대규모 멀티모달 모델(LMM)의 내재적 한계에서 비롯된 필연성이었다. 핵심적인 깨달음은 LMM이 이미지와 비디오를 전체적 또는 일반적인 수준에서 이해하는 데 상당한 발전을 이루었음에도 불구하고, "더 세밀한 이해와 정렬을 요구하는 인스턴스 수준의 이해에 지속적으로 어려움을 겪는다"는 점이었다(초록, 섹션 1). 이는 표준 CNN, 기본 Diffusion 모델 또는 Transformer와 같은 기존의 "SOTA" 방법들이 LMM에 통합되더라도, 정밀하고 객체 중심적인 추론을 요구하는 작업에는 근본적으로 불충분하다는 것을 의미한다.
이러한 깨달음이 명시적으로 강조되는 순간은 현재 LMM들이 지시 튜닝에서 획기적인 발전을 이루었음에도 불구하고, "그림 1(a)에서 보여지듯이 사용자가 가장 관심을 갖는 인스턴스별 콘텐츠를 이해하는 데 여전히 어려움을 겪는다"는 관찰을 통해 암시적으로 드러난다(섹션 1). 이는 시각 데이터를 처리하는 기본 아키텍처의 실패가 아니라, 특히 이미지와 비디오 전반에 걸쳐 복잡한 장면 내의 특정 인스턴스에 지시를 정렬하는 능력의 부족 때문이다. 문제는 강력한 기본 모델의 부족이 아니라, 미세한 인스턴스 이해를 가르치는 데 필요한 데이터와 방법론의 결정적인 격차였다. 기존 멀티모달 벤치마크와 데이터셋은 주로 "이미지와 비디오에 대한 거친 수준의 지식을 제공했으며, 개별 인스턴스에 대한 미세한 주석이 부족했다"(2페이지). 따라서 시각적 프롬프트를 통한 명시적인 인스턴스 수준의 지침과 전용의 풍부하게 주석이 달린 데이터셋을 제공하는 새로운 접근 방식만이 이 격차를 해소할 수 있는 유일하게 실행 가능한 해결책이었다.
비교 우위
INST-IT 접근 방식은 단순한 성능 지표를 넘어 여러 핵심 측면에서 이전의 골드 스탠더드에 비해 질적인 우수성을 보여준다.
첫째, 고차원 노이즈와 방해 요소를 처리하는 데 탁월하다. 논문에서는 "원시 시각적 입력을 직접 처리하는 것은 환각과 방해에 취약하다"(섹션 2.1)고 언급한다. 이를 완화하기 위해, 이 방법은 각 인스턴스에 숫자 ID를 오버레이하는 Set-of-Marks (SoMs) 시각적 프롬프트를 사용한다. 이 간단하지만 효과적인 증강은 기본 GPT-4o 모델이 "관심 있는 인스턴스에 더 효과적으로 집중하도록"(섹션 2.1) 명시적으로 안내하여, 관련 없는 시각 정보의 "노이즈"를 줄이고 더 세밀하고 정확한 주석을 가능하게 한다. 이러한 구조적 이점은 모델이 시각적 혼란을 헤치고 사용자가 지정한 인스턴스에 집중할 수 있도록 한다.
둘째, 이 방법은 비디오 입력에 대한 메모리 복잡성을 다룬다. $O(N^2)$에서 $O(N)$으로의 명시적인 감소를 언급하지는 않지만, 저자들은 "비디오 입력의 시각적 토큰 수를 줄이기 위해 2 × 2 공간 풀링을 적용한다"(섹션 2.4)고 언급한다. 시각적 토큰의 이러한 다운샘플링은 계산 및 메모리 사용량을 줄이는 데 직접적으로 기여하며, 이는 긴 비디오 시퀀스를 처리하는 데 중요하고 실제 GPU 메모리 제약 조건과 일치한다(섹션 3.1).
압도적인 구조적 이점은 이미지와 비디오 전반에 걸쳐, 시간적 역학을 포함한 진정한 인스턴스 수준의 이해를 촉진하는 능력에 있다. 전체적인 이해에 초점을 맞춘 이전 방법들과 달리, INST-IT의 데이터셋은 인스턴스 수준 설명, 이미지 수준 캡션, 시간적 역학, 비디오 수준 요약 및 개방형 질문-답변 쌍을 포함하는 다단계의 미세한 주석을 제공한다(2페이지, 섹션 2.1). 이러한 풍부하고 구조화된 데이터는 지속적인 지시 튜닝 레시피와 결합되어 LMM이 인스턴스를 식별할 뿐만 아니라 그 속성, 관계 및 시공간적 진화를 이해할 수 있도록 한다. 결과는 이 접근 방식이 "다른 인스턴스 이해 벤치마크에서 일관된 개선"과 일반적인 벤치마크에서 "기본 모델에 비해 상당한 개선"을 가져온다(초록, 섹션 3.2)고 보여주며, 이는 단순한 과적합이 아닌 일반화 가능한 향상을 나타낸다. 또한, 이 논문은 해당 방법이 "상당히 적은 계산 및 데이터 비용을 요구하면서" 더 크고 계산 집약적인 SFT LMM과 "비교 가능한 성능"을 달성한다고 강조한다(섹션 3.2). 이는 효율성 이점을 강조한다.
제약 조건과의 정렬
선택된 방법인 INST-IT는 문제 정의에 명시된 암묵적인 제약 조건과 과제에 완벽하게 부합한다. 문제의 엄격한 요구 사항과 해결책의 고유한 속성 간의 이러한 "결합"은 여러 방식으로 분명하게 드러난다.
- 인스턴스 수준 이해 격차 해소: 주요 제약 조건은 기존 LMM의 미세한 인스턴스 이해 달성 능력 부족이었다. INST-IT는 "인스턴스 지침을 위한 명시적인 시각적 프롬프트 지시 튜닝"(초록)을 제공함으로써 이를 직접적으로 해결한다. 시각적 프롬프트로 증강된 지시 튜닝 패러다임은 모델이 지침을 특정 시각적 개체에 정렬하도록 학습하도록 강제한다.
- 데이터 부족 극복: 주요 병목 현상은 "인스턴스 수준 데이터셋의 부족"(섹션 2.2)이었다. INST-IT 데이터셋은 "이미지와 비디오를 모두 포함하고, 명시적인 인스턴스 수준 시각적 프롬프트와 개별 인스턴스에 기반한 미세한 주석을 특징으로 하는 최초의 인스턴스 기반 지시 튜닝 데이터셋"(기여 1, 2페이지)으로 세심하게 구축되었다. 이는 포괄적이고 미세한 데이터의 필요성을 직접적으로 충족시킨다.
- 비디오의 시공간적 역학 처리: 문제는 공간 및 시간적 이해를 모두 요구하는 비디오 내 인스턴스 이해의 어려움을 강조했다. INST-IT 데이터셋의 다단계 주석에는 "시간적 역학 설명" 및 "비디오 수준 요약"(2페이지, 섹션 2.1)이 포함되어 모델이 시간 경과에 따른 변화와 상호 작용을 포착하도록 명시적으로 훈련시킨다. 지속적인 지시 튜닝 레시피는 이러한 시공간적 이해를 더욱 통합한다.
- 환각 및 방해 완화: 원시 시각적 입력이 "환각과 방해"(섹션 2.1)를 유발하는 제약 조건은 "Set-of-Marks (SoMs) 시각적 프롬프트 [88]" 기술로 해결된다. 인스턴스에 숫자 ID를 오버레이함으로써 모델은 특정 객체에 집중하도록 명시적으로 안내되어 모호성을 줄이고 주석 정확도를 향상시킨다.
- 계산 효율성: 실제 제약 조건에는 종종 계산 리소스가 포함된다. 논문에서는 "GPU 메모리 제약으로 인해 최대 프레임 수를 32개로, LLM의 컨텍스트 길이를 6K로 제한"하고 "2 × 2 공간 풀링을 적용하여 시각적 토큰 수를 줄인다"(섹션 3.1)고 언급한다. INST-IT가 더 큰 SFT LMM에 비해 "상당히 적은 계산 및 데이터 비용"으로 강력한 성능을 달성한다는 사실(섹션 3.2)은 리소스 효율적인 배포와의 정렬을 보여준다.
대안의 거부
이 논문은 멀티모달 데이터 전반에 걸친 인스턴스 수준 이해의 핵심 문제를 해결하는 데 있어 단점을 강조함으로써, 여러 대안적 접근 방식을 암묵적으로 그러나 명확하게 거부한다.
첫째, 특별한 지시 튜닝과 데이터 없이 기존 "SOTA" LMM을 단순히 사용하는 것의 효과를 일축한다. 저자들은 이러한 모델들이 "전체적인 수준에서 이미지와 비디오를 이해할 수 있지만, 인스턴스별 콘텐츠를 이해하는 데 여전히 어려움을 겪는다"(섹션 1)고 말한다. 이는 일반적인 LMM, 심지어 강력한 모델조차도 이 작업을 위해 필요한 미세한 정렬 능력이 부족하다는 것을 시사한다. 문제는 일반 지능의 부족이 아니라 인스턴스 중심의 지시 따르기의 부족이다.
둘째, 이 논문은 다른 인기 있는 지시 튜닝 데이터셋을 불충분한 것으로 명시적으로 거부한다. 표 1과 섹션 2.2에서 INST-IT를 ShareGPT4Video, LLaVA-Video, ViP-LLaVA-Data와 같은 데이터셋과 비교한다. 이전 비디오 데이터셋이 "인스턴스 수준 주석 없이 전체적인 이해에 초점을 맞춘다"고 언급하며, ViP-LLaVA는 "이미지에 대한 인스턴스 주석을 제공하지만 비디오 데이터는 포함하지 않는다"고 지적한다. 이는 INST-IT가 제공하는 필요한 다단계, 미세한, 인스턴스 기반 주석을 이미지와 비디오 모두에 대해 제공하지 못하기 때문에 이러한 대안을 직접적으로 거부하는 것이다. 저자들은 "인스턴스 수준 데이터셋의 부족이 인스턴스 이해의 발전을 저해한다"(섹션 2.2)고 결론지으며, 기존 데이터셋이 부적절함을 시사한다.
마지막으로, 이 논문은 단순히 모델 크기를 확장하거나 더 거친 수준의 데이터를 사용하는 것이 문제를 해결할 것이라는 개념을 거부한다. "Qwen2VL-72B가 더 작은 7B 모델에 비해 상당한 개선을 보이지 않아, 단순히 모델 크기를 확장하는 것만으로는 인스턴스 이해의 어려움을 해결할 수 없음을 나타낸다"(섹션 3.2)고 관찰한다. 마찬가지로, "대규모의 거친 수준 주석도 필수적인 개선으로 이어지지 않는다"(섹션 3.2)고 언급한다. 이러한 추론은 해결책이 기존 방법이나 데이터의 무차별적인 확장에 있는 것이 아니라, 전문화된 데이터와 지시 튜닝을 통한 명시적인 인스턴스 수준 지침에 초점을 맞춘 표적 접근 방식에 있음을 강조한다.
 Figure 8. A data example from INST-IT Bench. Each test sample includes both open-ended QA and multiple-choice QA, focusing on specific instances or the relationships and interactions between instances
Figure 8. A data example from INST-IT Bench. Each test sample includes both open-ended QA and multiple-choice QA, focusing on specific instances or the relationships and interactions between instances
수학 및 논리 메커니즘
마스터 방정식
INST-IT의 핵심 수학적 및 논리적 메커니즘은 모델이 최적화해야 할 단일 목적 함수가 아니라, 강력한 대규모 언어 모델(LLM), 특히 GPT-4o를 활용하여 풍부하고 다중 세분화된 주석을 생성하는 정교한 데이터 생성 파이프라인이다. 이러한 주석은 INST-IT 데이터셋을 형성하며, 이는 다른 LMM을 instruction-tune하는 데 사용된다. 이 파이프라인 내의 기본 연산은 세 가지 주요 방정식으로 정의되며, 각 방정식은 주석 생성의 고유한 단계를 나타낸다.
1. 프레임 수준 주석:
$$Y_t^f = \text{GPT}(P^f, X_t, X_{t-1})$$
2. 비디오 수준 요약:
$$Y^{vid} = \text{GPT}(P^{vid}, [Y_1^f, Y_2^f, \ldots, Y_N^f])$$
3. 개방형 질문-답변 쌍:
$$Y^{qa} = \text{GPT}(P^{qa}, [Y_1^f, Y_2^f, \ldots, Y_N^f])$$
용어별 분석
INST-IT 프레임워크에서 각 방정식의 구성 요소가 정확히 어떤 역할을 하는지 이해하기 위해 각 요소를 분석해 보자.
방정식 (1): 프레임 수준 주석
$$Y_t^f = \text{GPT}(P^f, X_t, X_{t-1})$$
* $Y_t^f$:
* 수학적 정의: 시간 $t$에서의 특정 비디오 프레임에 대한 GPT-4o 모델의 출력이다. 구조화된 텍스트 주석이다.
* 물리적/논리적 역할: 개별 인스턴스, 전체 이미지 내용, 이전 프레임과의 시간적 변화를 포함하여 단일 프레임에 대한 포괄적이고 세분화된 텍스트 설명을 나타낸다. 이는 모든 후속의 상위 수준 주석에 대한 기초 빌딩 블록이다.
* $\text{GPT}(\cdot)$:
* 수학적 정의: 프롬프트와 시각적 입력을 받아 텍스트 출력을 생성하는 함수로 취급되는 GPT-4o 대규모 언어 모델을 나타낸다.
* 물리적/논리적 역할: GPT-4o는 지능형 주석가 역할을 한다. 고급 멀티모달 이해 능력을 활용하여 시각적 정보를 해석하고 제공된 지침에 따라 인간과 유사한 상세한 설명을 생성한다. 저자들은 복잡한 시각적 추론을 처리하고 고품질 텍스트를 생성하는 데 있어 GPT-4o의 우수한 능력을 선택했으며, 이는 인스턴스 이해의 세분화된 특성에 매우 중요하다.
* $P^f$:
* 수학적 정의: 프레임 수준 주석을 위해 설계된 "맞춤형 작업 프롬프트"인 자연어 문자열이다.
* 물리적/논리적 역할: 이 프롬프트는 GPT-4o에 대한 정확한 지침 세트 역할을 한다. 프레임의 특정 측면(예: 개별 인스턴스, 전체 장면, 시간적 차이)에 집중하도록 모델을 안내하고 출력 $Y_t^f$의 원하는 구조와 내용을 결정한다. 이 프롬프트의 신중한 설계는 정확하고 관련성 있는 주석을 이끌어내는 데 핵심이다.
* $X_t$:
* 수학적 정의: 타임스탬프 $t$에서의 현재 비디오 프레임에 해당하는 시각적 데이터이다.
* 물리적/논리적 역할: 이는 GPT-4o의 주요 시각적 입력으로, 설명해야 할 원시 픽셀 정보와 시각적 컨텍스트를 제공한다.
* $X_{t-1}$:
* 수학적 정의: 타임스탬프 $t-1$에서의 이전 비디오 프레임에 해당하는 시각적 데이터이다.
* 물리적/논리적 역할: 이전 프레임을 포함하는 것은 시간적 역학을 캡처하는 데 중요하다. $X_t$와 $X_{t-1}$을 비교함으로써 GPT-4o는 시간 경과에 따른 인스턴스 간의 움직임, 상태 변화 또는 상호 작용을 식별하고 설명할 수 있으며, 이는 비디오 이해에 필수적이다.
* 수학적 연산자 (함수 적용): 이 연산은 GPT-4o에 대한 함수 호출이다. 저자들은 GPT-4o가 단순한 산술 연산자가 아니라 복잡한 생성 모델이기 때문에 이 함수 표기법을 사용한다. 이는 내부 신경망 아키텍처를 통해 입력(프롬프트, 현재 프레임, 이전 프레임)을 처리하여 일관된 텍스트 출력을 생성한다.
방정식 (2): 비디오 수준 요약
$$Y^{vid} = \text{GPT}(P^{vid}, [Y_1^f, Y_2^f, \ldots, Y_N^f])$$
* $Y^{vid}$:
* 수학적 정의: GPT-4o에 의해 생성된 전체 비디오의 텍스트 요약이다.
* 물리적/논리적 역할: 이는 모든 개별 프레임 수준 주석의 상세한 정보를 일관된 이야기로 집계하여 비디오 내용의 총체적이고 연대기적인 서사를 제공한다. 전체 시공간 흐름과 주요 이벤트를 포착한다.
* $\text{GPT}(\cdot)$: 방정식 (1)과 동일하다.
* $P^{vid}$:
* 수학적 정의: 비디오 수준 요약을 위해 설계된 "작업 프롬프트"인 자연어 문자열이다.
* 물리적/논리적 역할: 이 프롬프트는 GPT-4o에게 프레임 수준 설명 시퀀스로부터 포괄적인 요약을 합성하도록 지시하며, 연대기적 순서와 주요 객체 및 이벤트에 대한 집중을 보장한다.
* $[Y_1^f, Y_2^f, \ldots, Y_N^f]$:
* 수학적 정의: 첫 번째 프레임($t=1$)부터 마지막 프레임($t=N$)까지 비디오에 대해 생성된 모든 프레임 수준 주석($Y_t^f$)의 순서가 지정된 목록 또는 시퀀스이다.
* 물리적/논리적 역할: 이 시퀀스는 비디오 이벤트의 텍스트 "메모리" 또는 "전사본" 역할을 하며, GPT-4o가 높은 수준의 요약을 구성하는 데 필요한 모든 세분화된 세부 정보를 제공한다. 단일 집계 값 대신 목록(암묵적으로 정보의 합계)을 사용하면 GPT-4o가 시간적 진행 및 이벤트 간의 관계를 처리할 수 있다.
* $N$:
* 수학적 정의: 비디오의 총 프레임 수이다.
* 물리적/논리적 역할: 이 스칼라는 비디오의 길이를 나타내므로 비디오 요약을 위해 고려해야 하는 프레임 수준 주석의 수를 나타낸다.
방정식 (3): 개방형 질문-답변 쌍
$$Y^{qa} = \text{GPT}(P^{qa}, [Y_1^f, Y_2^f, \ldots, Y_N^f])$$
* $Y^{qa}$:
* 수학적 정의: GPT-4o에 의해 생성된 $M$개의 개방형 질문-답변 쌍의 집합, $\{(q_i, a_i)\}_{i=1}^M$이다.
* 물리적/논리적 역할: 이러한 쌍은 LMM을 인스턴스 수준 이해 및 추론에 대해 테스트하고 훈련하도록 설계되었다. 특정 인스턴스, 해당 속성, 관계 및 시간적 변화에 초점을 맞춰 instruction-tuning 데이터의 풍부한 소스를 제공한다.
* $\text{GPT}(\cdot)$: 방정식 (1)과 동일하다.
* $P^{qa}$:
* 수학적 정의: 개방형 QA 쌍 생성을 위해 설계된 "작업 프롬프트"인 자연어 문자열이다.
* 물리적/논리적 역할: 이 프롬프트는 GPT-4o에게 제공된 프레임 수준 주석을 기반으로 다양하고 맥락적으로 관련성 있는 질문과 정확한 답변을 공식화하도록 안내한다. QA 쌍이 인스턴스 수준 이해를 대상으로 하도록 보장한다.
* $[Y_1^f, Y_2^f, \ldots, Y_N^f]$: 방정식 (2)와 동일하다.
* 물리적/논리적 역할: 비디오 요약과 유사하게, 이 시퀀스는 GPT-4o가 질문과 답변을 도출할 수 있는 포괄적인 텍스트 컨텍스트를 제공하며, 이를 통해 상세한 이벤트 및 엔티티에 대한 추론이 필요하다.
단계별 흐름
정교한 데이터 주석 공장에 들어가는 비디오를 상상해 보라. INST-IT 파이프라인을 통해 단일 비디오의 정보가 어떻게 처리되는지 살펴보자.
- 시각적 입력 수신: 프레임 시퀀스 $X_1, X_2, \ldots, X_N$으로 구성된 원시 비디오가 첫 번째 스테이션에 도착한다.
- 인스턴스 강조 표시 (시각적 프롬프팅): 이 스테이션에서는 사전 처리 단계에서 각 프레임 내의 개별 인스턴스(객체)를 식별한다. 감지된 각 인스턴스에 대해 고유한 숫자 ID가 직접 위에 오버레이되어 "Set-of-Marks" (SoM) 시각적 프롬프트를 생성한다. 이는 후속 주석 단계가 이러한 식별된 인스턴스에 명시적으로 초점을 맞추도록 보장한다.
- 프레임 수준 주석 조립 라인:
- 비디오 프레임이 순차적으로 GPT-4o "주석 엔진"에 공급된다.
- 첫 번째 프레임 $X_1$의 경우, 특정 "프레임 수준 프롬프트" $P^f$(이전 프레임이 없으므로 $X_0$에 대한 플레이스홀더 포함)와 결합된다. GPT-4o는 이를 처리하고 인스턴스, 전체 이미지 및 시간적 변화(또는 그 부재)에 대한 상세한 텍스트 설명인 $Y_1^f$를 출력한다.
- 각 후속 프레임 $X_t$($t > 1$)의 경우, 즉각적인 이전 프레임 $X_{t-1}$ 및 동일한 $P^f$와 쌍을 이룬다. 이 쌍은 프롬프트와 함께 GPT-4o에 입력된다.
- GPT-4o는 $X_t$와 $X_{t-1}$을 세심하게 분석하여 $X_t$의 인스턴스, 전체 장면, 그리고 가장 중요하게는 $X_{t-1}$과 $X_t$ 사이에서 관찰된 차이점 및 역학에 대한 설명을 포함하는 $Y_t^f$를 생성한다.
- 이 프로세스는 모든 $N$ 프레임이 주석될 때까지 반복되어 프레임 수준 주석의 완전한 시퀀스인 $[Y_1^f, Y_2^f, \ldots, Y_N^f]$를 생성한다. 이 시퀀스는 프레임별로 발생하는 모든 일에 대한 상세한 로그북과 같다.
- 비디오 수준 요약 합성: 프레임 수준 주석의 전체 로그북 $[Y_1^f, \ldots, Y_N^f]$이 이제 수집된다. 이 전체 텍스트 시퀀스는 "비디오 수준 요약 프롬프트" $P^{vid}$와 함께 GPT-4o 엔진의 또 다른 인스턴스에 공급된다. 이 엔진의 작업은 숙련된 요약가 역할을 하여, 모든 세분화된 세부 정보를 전체 비디오의 이벤트 및 시공간 정보를 설명하는 응집력 있고 연대기적인 서사 $Y^{vid}$로 합성하는 것이다.
- 질문-답변 생성: 요약과 병행하여, 동일한 로그북 $[Y_1^f, \ldots, Y_N^f]$은 "개방형 QA 프롬프트" $P^{qa}$와 함께 세 번째 GPT-4o 엔진에 공급된다. 이 엔진의 역할은 창의적인 질문 생성기 및 답변자 역할을 하여, 비디오 전체에서 개별 인스턴스와 그 관계에 대한 모델의 이해를 조사하도록 설계된 다양하고 인스턴스 중심적인 질문-답변 쌍 세트 $Y^{qa}$를 생성하는 것이다.
- 데이터셋 통합: 비디오에 대한 이러한 모든 생성된 주석($Y_t^f$, $Y^{vid}$, $Y^{qa}$)은 함께 패키징되어 INST-IT 데이터셋의 풍부하고 다중 수준의 인스턴스 기반 항목을 형성한다. 이 데이터는 이제 instruction tuning에 사용될 준비가 되었다. 그림 2에 설명된 대로 이러한 주석에는 다음 측면이 포함된다.
최적화 역학
INST-IT 프레임워크 자체는 주로 데이터 생성 및 준비 메커니즘이며, 전통적인 의미에서 직접적인 최적화를 거치는 모델이 아니다(즉, 그래디언트를 통해 업데이트되는 매개변수가 없다). 대신, 다른 대규모 멀티모달 모델(LMM)이 더 효과적으로 학습, 업데이트 및 수렴하도록 가능하게 하는 방식에서 "최적화 역학"이 관찰된다.
LMM(예: LLaVA-NeXT)이 INST-IT 데이터셋을 사용하여 훈련될 때, 학습 과정은 다음과 같이 진행된다.
-
Instruction Tuning 목표: LMM은 생성된 텍스트 응답과 INST-IT 데이터셋에서 제공된 Ground Truth 주석 간의 차이를 최소화하여 지침을 따르도록 훈련된다. 이는 일반적으로 교차 엔트로피 손실(또는 음의 로그 가능도 손실)과 같은 표준 언어 모델링 목표를 사용하여 달성된다. 시각적 특징 $V$(이미지/비디오 프레임에서 파생되며, 잠재적으로 SoM 포함)와 텍스트 지침 $I$로 구성된 입력이 주어졌을 때, 모델은 토큰 시퀀스 $T = (t_1, t_2, \ldots, t_L)$를 생성한다. 목표는 입력이 주어졌을 때 올바른 토큰 시퀀스를 생성할 확률을 최대화하는 것이며, 이는 일반적으로 $\prod_{k=1}^L P(t_k | V, I, t_1, \ldots, t_{k-1})$로 분해된다. 단일 훈련 샘플 $(V, I, T_{target})$에 대한 손실은 다음과 같다.
$$ \mathcal{L} = - \sum_{k=1}^L \log P(t_{target,k} | V, I, t_1, \ldots, t_{k-1}) $$
여기서 $t_{target,k}$는 INST-IT 데이터셋의 Ground Truth 주석 토큰이다. -
공동 훈련 패러다임: 이 논문은 최적화 역학의 중심인 "연속 instruction tuning 레시피"(섹션 2.4, 3.4)를 제안한다. 이 레시피는 다음을 포함한다.
- 데이터 혼합: 풍부한 인스턴스 수준, 다중 세분화된 주석 및 명시적인 시각적 프롬프트를 포함하는 INST-IT 데이터셋은 기존의 일반 instruction-tuning 데이터(예: LLaVA-NeXT-DATA)와 결합된다. 이 공동 훈련은 LMM이 세분화된 인스턴스 이해를 학습하고 다양한 작업에 걸쳐 광범위한 일반 이해 능력을 유지하도록 보장한다.
- 분포 이동 완화: 주요 과제는 "시각적으로 프롬프트된 이미지가 자연 이미지로부터 분포 이동을 유발할 수 있다"(섹션 3.4)는 것이며, 이는 일반 작업의 성능을 저하시킬 수 있다. 이를 상쇄하기 위해 연속 지도 미세 조정(SFT) 패러다임이 적용된다. 이 단계 동안, 비전 인코더의 초기 레이어(특히 첫 12개 레이어)는 "고정"(섹션 3.1)된다. 이 고정은 자연 이미지에서 학습된 저수준 시각적 특징을 보존하는 데 도움이 되며, 모델이 시각적으로 프롬프트된 데이터에 과적합되는 것을 방지하여 이미지 및 비디오 작업 모두에서 균형 잡힌 성능을 달성한다.
-
최적화 프로세스:
- 순방향 전달: 훈련 중 LMM은 비전 인코더를 통해 시각적 입력(SoM으로 보강된 이미지/비디오 프레임)을 처리하여 시각적 특징을 추출한다. 이러한 특징은 언어 모델의 임베딩 공간으로 투영된다. 그런 다음 언어 모델은 텍스트 지침과 시각적 특징을 처리하여 텍스트 응답을 생성한다.
- 역방향 전달: 생성된 응답은 교차 엔트로피 손실을 사용하여 INST-IT 데이터셋의 Ground Truth 주석과 비교된다. 그래디언트가 계산되고 언어 모델 및 투영 레이어를 통해 역전파된다. 고정 전략으로 인해 그래디언트는 비전 인코더의 후반 레이어(고정되지 않은 경우), 투영 레이어 및 언어 모델만 업데이트한다.
- 수렴: 모델 매개변수는 학습률 스케줄러(예: 코사인 학습률 스케줄러)와 함께 옵티마이저(예: 섹션 3.1에서 언급된 AdamW)를 사용하여 반복적으로 업데이트된다. 목표는 LMM이 광범위한 멀티모달 이해 능력을 유지하면서 세분화된 인스턴스 수준 설명을 정확하게 생성하고 시각적 프롬프트를 기반으로 질문에 답할 수 있는 상태로 수렴하는 것이다.
이러한 연속 instruction-tuning 패러다임은 데이터 유형의 신중한 균형과 모델 구성 요소의 선택적 고정을 통해, LMM이 광범위한 능력을 희생하지 않고 원하는 인스턴스 수준 이해를 학습할 수 있도록 하는 "최적화 역학"이다.
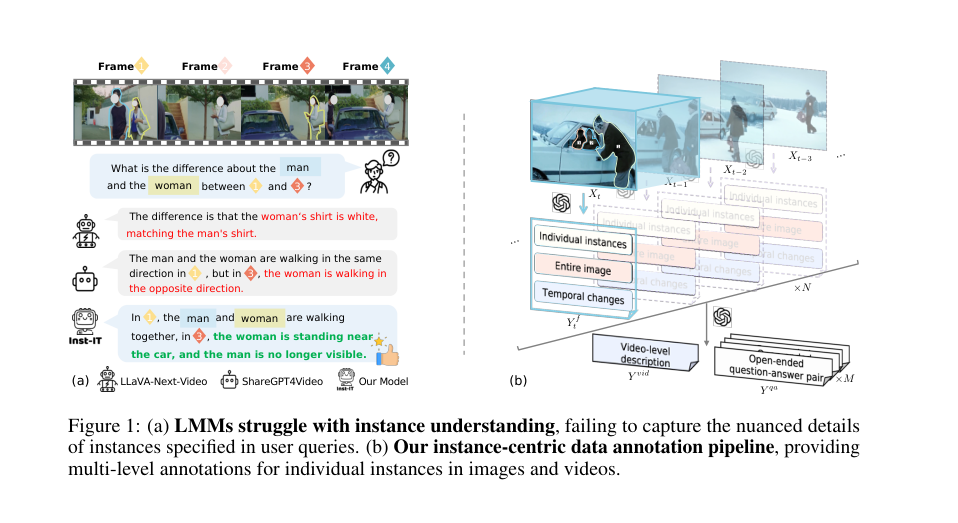 Figure 1. (a) LMMs struggle with instance understanding, failing to capture the nuanced details of instances specified in user queries. (b) Our instance-centric data annotation pipeline, providing multi-level annotations for individual instances in images and videos
Figure 1. (a) LMMs struggle with instance understanding, failing to capture the nuanced details of instances specified in user queries. (b) Our instance-centric data annotation pipeline, providing multi-level annotations for individual instances in images and videos
결과, 한계점 및 결론
실험 설계 및 베이스라인
주장들을 엄격하게 검증하기 위해, 저자들은 포괄적인 실험 설정을 설계하였다. 핵심 접근 방식은 명시적인 시각적 프롬프트 지시 튜닝을 통해 Large Multimodal Models (LMMs)를 향상시키는 것이었으며, 이를 INST-IT라고 명명하였다. 향상 대상이 된 주요 "희생양" 또는 베이스라인 아키텍처는 널리 채택된 모델인 LLaVA-NeXT [44]였다. 이 베이스라인은 일반적으로 언어 모델로 Vicuna-1.5-7B [16]를, 비전 인코더로 CLIP-ViT-336 [67]를 사용하였다. 더 발전된 실험을 위해, Qwen2-7B [87]와 SigLIP-SO400M-384 [97]를 사용하기도 하였다.
실험 설계는 새로운 이미지-비디오 공동 학습 파이프라인에 중점을 두었다. 이 파이프라인은 새로 생성된 INST-IT Dataset과 기존의 오픈소스 LLaVA-NeXT-DATA [48]를 세심하게 결합하였다. 아키텍처의 핵심 요소는 모든 이미지와 비디오 프레임에 Set-of-Marks (SoM) 시각적 프롬프트 [88]를 증강하는 것이었다. 이 기법은 LMMs가 개별 인스턴스에 집중하도록 명시적으로 유도했으며, 이는 이전 연구와의 중요한 차별점이다.
INST-IT Dataset 자체는 51k개의 이미지와 21k개의 비디오로 구성된 중요한 기여이다. 이는 207k개의 이미지 레벨 캡션, 135k개의 시간적 동적 설명, 21k개의 비디오 레벨 캡션, 그리고 335k개의 개방형 질문-답변 쌍을 포함하는 다단계의 세밀한 인스턴스 기반 주석을 특징으로 한다.
평가를 위해, 저자들은 이미지와 비디오 모두에서 인스턴스 레벨 이해를 진단하기 위해 특별히 설계된 인간 검증 벤치마크인 INST-IT Bench를 도입하였다. 이 벤치마크는 338개의 이미지에 대한 1,000개의 개방형 및 객관식 QA 쌍과 206개의 비디오에 대한 1,000개의 QA 쌍을 포함한다. 개방형 QA 응답은 정확성과 인스턴스 ID 참조 정확성을 위해 GPT-4o [61]를 사용하여 평가되었다. 자체 벤치마크 외에도, RefCOCOg [53] 및 ViP-Bench [5]와 같은 기존의 인스턴스 이해 벤치마크와 AI2D [28], ChartQA [54], Egoschema [52], 그리고 NEXT-QA [85]와 같은 일반적인 이미지 및 비디오 이해 벤치마크에서도 모델을 테스트하였다.
이들이 능가하고자 했던 베이스라인 모델들은 다음과 같은 광범위한 최신 LMMs를 포함하였다:
- 상용 모델: GPT-4o [61] 및 Gemini-1.5-flash [72].
- 오픈소스 이미지 모델: LLaVA-1.5 [43], ViP-LLaVA [5], SOM-LLaVA [86], 그리고 직접적인 베이스라인인 LLaVA-NeXT [44].
- 오픈소스 비디오 모델: LLaVA-NeXT-Video [103], ShareGPT4Video [10], LLaVA-OV [31], LLaVA-Video [104], InternVL2 [13], 그리고 Qwen2-VL-Instruct [82].
자체 데이터셋, 벤치마크, 그리고 다양한 베이스라인을 포함하는 이러한 포괄적인 실험 설계는 INST-IT의 효과를 철저하게 평가할 수 있게 하였다.
증거가 입증하는 바
실험 결과는 INST-IT 접근 방식이 LMMs의 인스턴스 레벨 이해를 크게 향상시키면서도 일반적인 이해 능력을 강화한다는 명확하고 부인할 수 없는 증거를 제공한다.
INST-IT Bench (Table 2)에서 INST-IT로 향상된 모델들은 뛰어난 성능을 보였다. 예를 들어, Vicuna-7B를 사용한 LLaVA-NeXT-INST-IT는 이미지 개방형 (OE) Q&A에서 68.6점, 객관식 (MC) Q&A에서 63.0점을 달성했으며, 이는 LLaVA-NeXT 베이스라인 (Table 2의 이미지 OE 46.0점, MC 42.4점)에 비해 상당한 도약이었다. 비디오 작업에서는 INST-IT 향상 모델이 49.3점의 OE와 42.1점의 MC를 기록하여 LLaVA-NeXT-Video 베이스라인 (25.8점 OE, 24.8점 MC)을 크게 능가하였다. 논문에서는 명시적으로 "평균 점수에서 거의 20%의 향상"을 언급하며, 이는 INST-IT의 핵심 메커니즘에 대한 강력한 검증이다.
자체 벤치마크를 넘어, INST-IT 모델들은 다른 기존 인스턴스 이해 벤치마크에서도 일관된 개선을 보였다:
- RefCOCOg [53]에서 LLaVA-NeXT-INST-IT-Vicuna-7B 모델은 LLaVA-NeXT-Vicuna-7B 베이스라인 (52.2% 대비 63.0%)에 비해 10.8%의 향상을 달성하였다. 이는 명시적인 시각적 프롬프트 지시 튜닝이 참조 표현을 이해하고 특정 인스턴스에 연결하는 모델의 능력을 직접적으로 향상시킨다는 강력한 증거이다.
- ViP-Bench [5] (Table 5)의 경우, Vicuna-7B를 사용한 INST-IT는 인간 스타일의 시각적 프롬프트를 사용할 때 ViP-LLaVA와 비교 가능한 성능을 보였으며, 일부 경우에는 이를 능가하기도 하였다. 이는 ViP-LLaVA가 ViP-Bench 데이터셋에 대해 fine-tuning된 반면, INST-IT는 zero-shot 방식으로 평가되었음에도 불구하고 강력한 일반화 능력을 보여주었다는 점에서 특히 설득력이 있다.
더 나아가, 모델의 일반적인 이해 능력 또한 널리 사용되는 일반 벤치마크에서 상당한 이득을 보았다:
- 이미지 벤치마크 (Table 3)에서 INST-IT는 LLaVA-NeXT 베이스라인을 일관되게 능가하였다. 특히, Vicuna-7B 변형을 사용하여 AI2D [28]에서 4.4%, ChartQA [54]에서 13.5%의 향상을 달성하였다. 이러한 벤치마크는 grounding과 추론을 요구하며, 이는 INST-IT의 세밀한 이해가 더 넓은 시각적 추론으로 이어진다는 것을 시사한다.
- 비디오 벤치마크 (Table 4)에서 INST-IT 모델은 LLaVA-NeXT와 LLaVA-NeXT-Video 베이스라인 모두를 크게 능가하였다. 예를 들어, Vicuna-7B 변형을 사용하여 Egoschema [52]에서 7.8%, NEXT-QA [85]에서 11.8%의 향상을 보였다. 이러한 결과는 명시적인 시각적 프롬프트를 통한 인스턴스 레벨 이해 향상이 일반적인 시공간 이해를 개선하는 효율적인 전략임을 확인시켜 준다.
Ablation studies는 기여도를 더욱 세분화하였다:
- 연속 지시 튜닝 패러다임 (Table 6)은 중요하였다. 비디오 데이터를 일반 지시 데이터와 직접 혼합하는 것은 이미지 이해도를 저하시켰지만, 제안된 연속 SFT와 고정된 비전 인코더는 시각적으로 프롬프트된 이미지로부터의 분포 변화를 완화하면서 이미지와 비디오 작업 모두에서 균형 잡힌 성능을 달성하였다.
- 상세한 데이터셋 조합 (Table 7)은 인스턴스 레벨 및 이미지 레벨 프레임 캡션이 이미지 인스턴스 이해에 필수적인 반면, 시간적 차이, 비디오 레벨 설명, 그리고 QA는 비디오 인스턴스 이해에 매우 중요하다는 것을 보여주었다. INST-IT Dataset의 이미지 구성 요소를 통합하는 것이 궁극적으로 가장 균형 잡힌 성능을 가져왔다.
본질적으로, 증거는 INST-IT의 다단계, 인스턴스 기반 주석이 명시적인 시각적 프롬프팅 및 연속 지시 튜닝 패러다임과 결합되어 LMMs에 우수한 세밀한 인스턴스 이해 능력을 효과적으로 부여하며, 이는 결과적으로 전반적인 멀티모달 이해를 강화한다는 것을 명백히 입증한다.
한계점 및 향후 방향
INST-IT는 LMMs의 인스턴스 레벨 이해에서 상당한 발전을 제시하지만, 저자들은 몇 가지 한계점을 솔직하게 인정하고 흥미로운 개발 방향을 제안한다.
현재의 한계점:
1. 계산 비용: 현재 실험은 주로 7B 및 1.5B 파라미터 모델에서 수행되었다. 훨씬 더 큰 모델 (예: 70B 이상)로 확장하는 것은 상당한 계산 비용에 의해 제약되며, 이는 현재 연구의 범위를 제한한다.
2. GPT-4o 오버헤드: 자동화된 데이터 주석 파이프라인은 효과적이지만 GPT-4o에 의존한다. 이는 내재된 오버헤드를 도입하며, 더 크고 다양한 데이터셋을 생성하는 데 병목 현상이 될 수 있다.
3. 실패 사례: 모델은 때때로 심하게 가려진 인스턴스, 흐릿한 이미지, 또는 과도하게 작거나 붐비는 인스턴스와 같은 어려운 시나리오에서 어려움을 겪는다. 이는 LMMs의 일반적인 장애물이며, 견고성을 개선할 수 있는 영역을 나타낸다.
4. 공정성 및 편향: 많은 대규모 멀티모달 모델과 마찬가지로, INST-IT는 학습 데이터 또는 모델의 학습된 표현에서 비롯될 수 있는 공정성 및 편향과 관련된 잠재적 위험에 직면한다. 이는 지속적인 주의가 필요한 중요한 윤리적 고려 사항이다.
향후 방향 및 논의 주제:
이러한 발견을 바탕으로, 추가 개발 및 발전을 위한 몇 가지 논의 주제가 등장한다:
-
확장 및 자기 지도 데이터 생성:
- 엄청난 비용 없이 훨씬 더 큰 LMMs로 확장할 수 있는, 인스턴스 레벨 지시 튜닝을 위한 계산적으로 더 효율적인 방법을 어떻게 개발할 수 있는가?
- 모델 자체가 부분적으로 학습된 후, 비싼 상용 API (예: GPT-4o)에 대한 의존도를 줄이면서 더 높은 품질의 자체 합성 인스턴스 레벨 데이터를 생성하는 데 도움을 주는 "모델 인 루프" 접근 방식으로 나아갈 수 있는가? 이는 모델이 데이터를 생성하고, 소규모 인간 검증 단계가 발생하며, 모델이 재학습되는 반복적인 개선을 포함할 수 있다.
-
어려운 시각적 조건에 대한 향상된 견고성:
- 식별된 실패 사례 (가려짐, 흐릿함, 작거나 붐비는 인스턴스)를 특별히 해결할 수 있는 새로운 아키텍처 설계 또는 학습 전략은 무엇인가? 불확실성 추정 또는 다중 뷰 융합 기법을 통합하면 이러한 어려운 시나리오에서 성능을 향상시킬 수 있는가?
- 모델 견고성을 개선하기 위해, 이러한 실패 모드를 구체적으로 목표로 하는 다양하고 어려운 예제를 생성하기 위해 합성 데이터 생성을 어떻게 더 효과적으로 활용할 수 있는가?
-
편향 완화 및 공정성 보장:
- 공정성 및 편향 문제의 잠재력을 고려할 때, INST-IT Dataset 및 향후 데이터셋이 더 공정하고 대표성을 갖도록 보장하기 위해 어떤 체계적인 데이터 필터링 및 검증 접근 방식을 구현할 수 있는가?
- 데이터 중심 솔루션을 넘어, 인스턴스 이해에서 편향을 감지하고 완화하기 위해 어떤 모델 불문 또는 모델별 기법 (예: 편향 완화 알고리즘, 인스턴스 레벨 결정을 감사하기 위한 설명 가능한 AI 방법)을 개발할 수 있는가?
-
시공간 추론 및 예측 능력 확장:
- INST-IT는 현재 및 시간적 변화를 설명하는 데 뛰어나지만, LMMs를 인스턴스의 미래 행동 또는 궤적을 예측하거나 비디오에서 인스턴스 간의 장기적인 인과 관계를 이해하는 것과 같은 더 복잡한 시공간 추론을 수행하도록 어떻게 발전시킬 수 있는가?
- 물리 기반 신경망 또는 상식 추론 모듈을 통합하면 단순한 관찰을 넘어선 인스턴스 상호 작용에 대한 모델의 추론 능력을 더욱 향상시킬 수 있는가?
-
실제 배포 및 인간-AI 협업:
- 사용자가 숫자 ID보다 더 직관적인 인터페이스를 통해 관심 있는 인스턴스를 대화식으로 지정해야 하는 실제 응용 프로그램에 INST-IT 프레임워크를 어떻게 통합할 수 있는가?
- 세밀한 시각적 이해를 요구하는 작업에서 인간-AI 협업에 대한 시사점은 무엇인가? INST-IT 향상 LMMs는 비디오 편집, 감시 분석, 또는 과학적 관찰과 같은 작업에서 보다 효과적인 조력자 역할을 하여 정밀한 인스턴스 레벨 통찰력을 제공할 수 있는가? 이는 또한 인간 사용자에게 모델의 인스턴스 레벨 추론의 해석 가능성에 대한 질문을 제기한다.
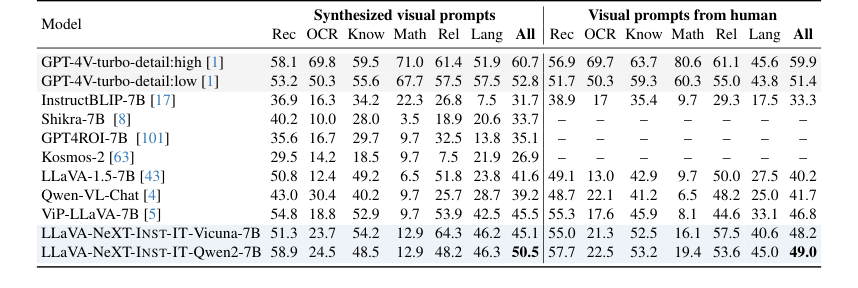 Table 5. Results on ViP-Bench. We perform evaluation with our INST-IT models without fine-tuning
Table 5. Results on ViP-Bench. We perform evaluation with our INST-IT models without fine-tuning
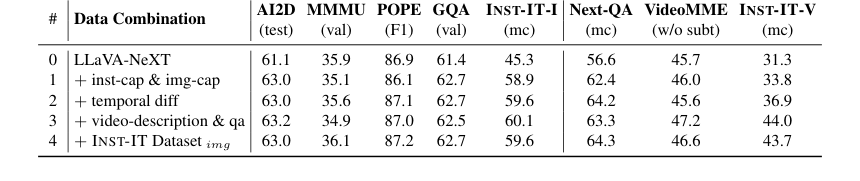 Table 7. Ablation on detailed data combination. The dataset combination in line #3 corresponds to the video part of INST-IT Dataset, while line #4 represents the complete INST-IT Dataset by incorporating the image part into line #3
Table 7. Ablation on detailed data combination. The dataset combination in line #3 corresponds to the video part of INST-IT Dataset, while line #4 represents the complete INST-IT Dataset by incorporating the image part into line #3
 Table 9. Statistical and lexical analysis of INST-IT Dataset. We present the results for each annotation level as well as the entire dataset
Table 9. Statistical and lexical analysis of INST-IT Dataset. We present the results for each annotation level as well as the entire dataset
다른 분야와의 동형 사상
구조적 골격
동적 시각 데이터 전반에 걸쳐 개별 개체에 대한 세밀하고 다층적인 주석을 생성하도록 강력한 생성 모델을 안내하기 위해 명시적이고 구조화된 시각적 단서를 활용하는 메커니즘이며, 이후 이 풍부한 데이터를 사용하여 다른 대규모 멀티모달 모델의 인스턴스 수준 이해 능력을 향상시킵니다.