INST-IT: स्पष्ट विज़ुअल प्रॉम्प्ट इंस्ट्रक्शन ट्यूनिंग के माध्यम से इंस्टेंस समझ को बढ़ावा देना
इस पत्र में संबोधित समस्या कृत्रिम बुद्धिमत्ता के क्षेत्र में, विशेष रूप से कंप्यूटर विजन और प्राकृतिक भाषा प्रसंस्करण के भीतर, बड़े मल्टीमॉडल मॉडल (LMMs) की हालिया प्रगति और विरोधाभासी रूप से, उनकी सीमाओं से उत्पन्न...
पृष्ठभूमि और अकादमिक वंश
उत्पत्ति और अकादमिक वंश
इस पत्र में संबोधित समस्या कृत्रिम बुद्धिमत्ता के क्षेत्र में, विशेष रूप से कंप्यूटर विजन और प्राकृतिक भाषा प्रसंस्करण के भीतर, बड़े मल्टीमॉडल मॉडल (LMMs) की हालिया प्रगति और विरोधाभासी रूप से, उनकी सीमाओं से उत्पन्न होती है। जबकि LMMs ने "इंस्ट्रक्शन ट्यूनिंग" के कारण महत्वपूर्ण सफलताएँ हासिल की हैं, जिससे वे छवियों और वीडियो को समग्र, या सामान्य, स्तर पर समझने और विविध उपयोगकर्ता निर्देशों का पालन करने में सक्षम हुए हैं, वे लगातार एक अधिक दानेदार कार्य के साथ संघर्ष करते हैं: "इंस्टेंस-लेवल अंडरस्टैंडिंग"।
ऐतिहासिक रूप से, विज़ुअल डेटा के भीतर व्यक्तिगत वस्तुओं को समझने की खोज कंप्यूटर विजन में एक लंबे समय से चली आ रही लक्ष्य रही है, जिससे ऑब्जेक्ट डिटेक्शन, इंस्टेंस सेगमेंटेशन और ऑब्जेक्ट ट्रैकिंग जैसे क्षेत्रों में व्यापक शोध हुआ है। हालांकि, LMMs के उद्भव के साथ, चुनौती बदल गई। पिछले दृष्टिकोणों, विशेष रूप से मौजूदा LMMs, का "दर्द बिंदु" विशिष्ट तत्वों या "इंस्टेंस" को एक छवि या वीडियो के भीतर महीन-दानेदार विवरण और संरेखण के साथ समझने में उनकी असमर्थता है, खासकर जब उपयोगकर्ता उनके बारे में विशिष्ट प्रश्न पूछते हैं। उदाहरण के लिए, एक LMM "लोगों की भीड़" का वर्णन कर सकता है, लेकिन "लाल टोपी पहने व्यक्ति क्या कर रहा है?" या "व्यक्ति 1 और व्यक्ति 2 के बीच की बातचीत समय के साथ कैसे बदली है?" जैसे प्रश्न का उत्तर देने में विफल हो सकता है। यह सीमा वीडियो में और भी अधिक स्पष्ट है, जहां न केवल स्थानिक जानकारी बल्कि व्यक्तिगत इंस्टेंस की अस्थायी गतिशीलता को समझना भी महत्वपूर्ण हो जाता है। मौजूदा मल्टीमॉडल डेटासेट और बेंचमार्क मुख्य रूप से मोटे-दानेदार ज्ञान प्रदान करते हैं, जिसमें इस सूक्ष्म इंस्टेंस-स्तरीय समझ के लिए LMMs को प्रशिक्षित और मूल्यांकन करने के लिए आवश्यक महीन-दानेदार एनोटेशन की कमी होती है। इस मौलिक अंतर ने लेखकों को INST-IT विकसित करने के लिए मजबूर किया, जो स्पष्ट विज़ुअल प्रॉम्प्ट इंस्ट्रक्शन ट्यूनिंग के माध्यम से व्यक्तिगत इंस्टेंस को समझने की LMMs की क्षमता को बढ़ाने का एक समाधान है।
सहज डोमेन शब्द
- बड़े मल्टीमॉडल मॉडल (LMMs): एक सुपर-स्मार्ट डिजिटल सहायक की कल्पना करें जो न केवल पढ़ और लिख सकता है, बल्कि छवियों और वीडियो को "देख" और "समझ" भी सकता है। यह एक व्यक्तिगत विशेषज्ञ होने जैसा है जो एक तस्वीर देख सकता है या एक क्लिप देख सकता है और फिर आपके साथ प्राकृतिक भाषा में उस पर चर्चा कर सकता है।
- इंस्ट्रक्शन ट्यूनिंग: यह उस सुपर-स्मार्ट सहायक को कई विशिष्ट कार्यों के उदाहरण देकर और उसे ठीक-ठीक बताकर सिखाने जैसा है कि क्या करना है। उदाहरण के लिए, आप उसे एक तस्वीर दिखाते हैं और उसे "निर्देश" देते हैं: "इस छवि का वर्णन करें," या "छवि के बारे में इस प्रश्न का उत्तर दें।" सहायक अनगिनत उदाहरण देखकर इन निर्देशों का पालन करना सीखता है।
- इंस्टेंस-लेवल अंडरस्टैंडिंग: पूरे दृश्य का वर्णन करने के बजाय (जैसे, "कई लोगों के साथ एक पार्क"), इसका मतलब है कि सहायक उस दृश्य के भीतर व्यक्तिगत चीजों (इंस्टेंस) पर ध्यान केंद्रित कर सकता है। यह पार्क में एक विशिष्ट व्यक्ति की ओर इशारा करने और पूछने में सक्षम होने जैसा है, "वह व्यक्ति क्या पहने हुए है?" या "क्या वह कुत्ता उस गेंद से खेल रहा है?" यह प्रत्येक विशिष्ट वस्तु के विवरण और उनके संबंधों को समझने के बारे में है।
- सेट-ऑफ-मार्क्स (SoMs) विज़ुअल प्रॉम्प्टिंग: इसे एक छवि या वीडियो में विशिष्ट वस्तुओं के चारों ओर क्रमांकित स्टिकर लगाने या वृत्त बनाने के रूप में सोचें। आप उस स्मार्ट सहायक का ध्यान आकर्षित करने के लिए इंस्टेंस को सचमुच "चिह्नित" कर रहे हैं, जैसे "वस्तु #1 को देखें, फिर वस्तु #2 को।" यह अधिक सटीक समझ के लिए व्यक्तिगत वस्तुओं पर इसके फोकस को निर्देशित करने में मदद करता है।
संकेतन तालिका
| संकेतन | विवरण |
|---|---|
| LMMs | बड़े मल्टीमॉडल मॉडल, जो कई तौर-तरीकों (जैसे, पाठ, चित्र, वीडियो) में सामग्री को समझने और उत्पन्न करने में सक्षम हैं। |
| SoMs | सेट-ऑफ-मार्क्स विज़ुअल प्रॉम्प्ट, एक ऐसी तकनीक जहां मॉडल फोकस को निर्देशित करने के लिए विज़ुअल इनपुट में इंस्टेंस पर संख्यात्मक आईडी ओवरले की जाती हैं। |
| INST-IT | LMMs में इंस्टेंस समझ को बढ़ावा देने के लिए प्रस्तावित फ्रेमवर्क, डेटासेट और बेंचमार्क। |
| $X_t$ | टाइमस्टैम्प $t$ पर विज़ुअल डेटा (छवि या वीडियो फ्रेम)। |
| $X_{t-1}$ | टाइमस्टैम्प $t-1$ पर विज़ुअल डेटा (छवि या वीडियो फ्रेम), अस्थायी तुलना के लिए उपयोग किया जाता है। |
| $P^f$ | फ्रेम-स्तरीय एनोटेशन उत्पन्न करने के लिए विशेष रूप से डिज़ाइन किया गया कार्य प्रॉम्प्ट। |
| $Y_t^f$ | फ्रेम $t$ के लिए फ्रेम-स्तरीय एनोटेशन आउटपुट, जिसमें इंस्टेंस विवरण, छवि कैप्शन और अस्थायी अंतर शामिल हैं। |
| $P^{vid}$ | वीडियो-स्तरीय सारांश उत्पन्न करने के लिए विशेष रूप से डिज़ाइन किया गया कार्य प्रॉम्प्ट। |
| $Y^{vid}$ | वीडियो-स्तरीय सारांश आउटपुट, सभी फ्रेम-स्तरीय एनोटेशन से जानकारी को एकत्रित करता है। |
| $P^{qa}$ | खुले-छोर वाले प्रश्न-उत्तर जोड़े उत्पन्न करने के लिए विशेष रूप से डिज़ाइन किया गया कार्य प्रॉम्प्ट। |
| $Y^{qa}$ | खुले-छोर वाले प्रश्न-उत्तर जोड़े आउटपुट, इंस्टेंस-स्तरीय समझ पर ध्यान केंद्रित करते हुए। |
| $\text{GPT}(\cdot)$ | GPT-4o बड़े भाषा मॉडल को दर्शाता है, जिसका उपयोग डेटा जनरेशन पाइपलाइन में बुद्धिमान एनोटेटर के रूप में किया जाता है। |
| $N$ | एक वीडियो में फ्रेम की कुल संख्या। |
| $M$ | एक वीडियो के लिए उत्पन्न खुले-छोर वाले प्रश्न-उत्तर जोड़ों की कुल संख्या। |
| SFT | सुपरवाइज्ड फाइन-ट्यूनिंग, INST-IT डेटासेट के साथ LMMs को बढ़ाने के लिए उपयोग की जाने वाली प्रशिक्षण पद्धति। |
समस्या परिभाषा और बाधाएँ
मुख्य समस्या सूत्रीकरण और दुविधा
बड़े मल्टीमॉडल मॉडल (LMMs) की वर्तमान स्थिति एक महत्वपूर्ण द्वंद्व प्रस्तुत करती है: जबकि उन्होंने समग्र, दृश्य-स्तरीय पर छवियों और वीडियो को समझने में उल्लेखनीय प्रगति हासिल की है, वे लगातार इंस्टेंस-स्तरीय समझ की आवश्यकता वाले कार्यों का सामना करने पर विफल रहते हैं। इसका मतलब है कि LMMs एक वीडियो की सामान्य सामग्री का वर्णन कर सकते हैं, लेकिन उनमें विशिष्ट वस्तुओं या व्यक्तियों की पहचान करने, ट्रैक करने और तर्क करने में संघर्ष करते हैं, विशेष रूप से उनके गुणों, संबंधों और अस्थायी इंटरैक्शन।
वांछित अंतिम बिंदु LMMs को छवियों और वीडियो दोनों में मजबूत इंस्टेंस-स्तरीय समझ क्षमताओं से लैस करना है। इसमें मॉडल को विशिष्ट तत्वों का उल्लेख करने वाले उपयोगकर्ता निर्देशों का सटीक रूप से पालन करने, उनके महीन-दानेदार विवरणों को समझने और समय के साथ उनके गतिशील परिवर्तनों को ट्रैक करने में सक्षम बनाना शामिल है।
इस अवस्थाओं के बीच सटीक लापता कड़ी या गणितीय अंतर पर्याप्त रूप से समृद्ध, इंस्टेंस-ग्राउंडेड, बहु-स्तरीय इंस्ट्रक्शन-ट्यूनिंग डेटा की अनुपस्थिति है। मौजूदा डेटासेट मुख्य रूप से मोटे-दानेदार एनोटेशन प्रदान करते हैं, जो LMMs को महीन-दानेदार इंस्टेंस समझ करने के लिए प्रशिक्षित करने के लिए अपर्याप्त हैं। यह पत्र ऐसे डेटा उत्पन्न करने के लिए एक उपन्यास पाइपलाइन और एक निरंतर इंस्ट्रक्शन-ट्यूनिंग प्रतिमान का परिचय देकर इस अंतर को पाटने का प्रयास करता है।
इस समस्या ने पिछले शोधकर्ताओं को एक दर्दनाक ट्रेड-ऑफ में फंसा दिया है:
- समग्र बनाम महीन-दानेदार समझ: एक LMM की समग्र दृश्य को समझने की क्षमता में सुधार अक्सर महीन-दानेदार इंस्टेंस विवरणों के लिए इसकी क्षमता की कीमत पर आता है, या इसके विपरीत। एक साथ दोनों को प्राप्त करना एक महत्वपूर्ण चुनौती है।
- छवि बनाम वीडियो इंस्टेंस समझ: जबकि स्थिर छवियों के लिए इंस्टेंस समझ में कुछ प्रगति हुई है, इसे गतिशील वीडियो में विस्तारित करने में काफी जटिलताएँ आती हैं। वीडियो को न केवल स्थानिक समझ की आवश्यकता होती है, बल्कि अस्थायी गतिशीलता को ट्रैक करने और तर्क करने की क्षमता भी होती है - कैसे इंस्टेंस समय के साथ बदलते हैं, चलते हैं और बातचीत करते हैं। यह अतिरिक्त आयाम वीडियो इंस्टेंस समझ को "काफी अधिक चुनौतीपूर्ण" बनाता है।
- एनोटेशन स्केल बनाम गुणवत्ता: व्यक्तिगत इंस्टेंस के लिए उच्च-गुणवत्ता, महीन-दानेदार एनोटेशन बनाना श्रम-गहन और महंगा है। पिछले प्रयासों ने या तो बड़े पैमाने पर मोटे-दानेदार डेटा प्रदान किया या सीमित पैमाने पर महीन-दानेदार डेटा। दुविधा यह है कि जटिल मल्टीमॉडल डेटा (छवियों और वीडियो) के लिए कुशलतापूर्वक बड़े पैमाने पर और उच्च-गुणवत्ता वाले महीन-दानेदार एनोटेशन दोनों कैसे उत्पन्न करें।
- सामान्यीकरण बनाम विशेषज्ञता: विशिष्ट इंस्टेंस समझ कार्यों के लिए फाइन-ट्यून किए गए मॉडल अपने प्रशिक्षण डेटा के लिए ओवरफिट होने का जोखिम उठाते हैं, संभावित रूप से उनकी सामान्य समझ क्षमताओं को खराब करते हैं। चुनौती विविध छवि और वीडियो कार्यों में सामान्य समझ को मजबूत करते हुए इंस्टेंस समझ को बढ़ावा देना है।
बाधाएँ और विफलता मोड
LMMs में मजबूत इंस्टेंस-स्तरीय समझ प्राप्त करने की समस्या कई कठोर, यथार्थवादी दीवारों के कारण अविश्वसनीय रूप से कठिन है जिनसे लेखक टकराए:
- GPT-4o का कम्प्यूटेशनल ओवरहेड: स्वचालित डेटा एनोटेशन पाइपलाइन, कुशल होने के बावजूद, "GPT-4o के ओवरहेड द्वारा बाधित" है। इसका तात्पर्य है कि उच्च-गुणवत्ता, बहु-स्तरीय एनोटेशन की बड़ी मात्रा उत्पन्न करना, विशेष रूप से वीडियो के लिए, अभी भी एक समय लेने वाली और महंगी प्रक्रिया है, जो ऐसे डेटा का उत्पादन करने के पैमाने को सीमित करती है।
- हार्डवेयर मेमोरी सीमाएँ: LMMs के लिए प्रशिक्षण प्रक्रिया, विशेष रूप से वीडियो इनपुट के साथ, "GPU मेमोरी सीमाओं" द्वारा बाधित होती है। लेखकों ने स्पष्ट रूप से कहा है कि वे "GPU मेमोरी बाधाओं के कारण फ्रेम की अधिकतम संख्या को 32 और LLMs के संदर्भ लंबाई को 6K तक सीमित करते हैं," जो लंबे या उच्च-रिज़ॉल्यूशन वीडियो अनुक्रमों को संसाधित करने में एक व्यावहारिक बाधा का संकेत देता है।
- कच्चे विज़ुअल इनपुट से मतिभ्रम और व्याकुलता: LMMs, कच्चे विज़ुअल इनपुट को सीधे संसाधित करते समय, "मतिभ्रम और व्याकुलता से पीड़ित होते हैं।" यह अंतर्निहित सीमा मॉडल को स्पष्ट मार्गदर्शन के बिना विशिष्ट इंस्टेंस के बारे में जानकारी पर मज़बूती से ध्यान केंद्रित करने और निकालने के लिए संघर्ष करती है, जिससे विज़ुअल प्रॉम्प्ट के उपयोग की आवश्यकता होती है।
- इंस्टेंस-ग्राउंडेड डेटा की कमी: एक मौलिक बाधा इंस्ट्रक्शन ट्यूनिंग के लिए "इंस्टेंस-ग्राउंडेड डेटा की कमी" है, विशेष रूप से वीडियो के लिए। यह डेटा अंतर LMMs के इंस्टेंस समझ के साथ संघर्ष करने का प्राथमिक कारण है, क्योंकि इन क्षमताओं को सीखने के लिए पर्याप्त महीन-दानेदार पर्यवेक्षण नहीं है।
- अस्थायी गतिशीलता की जटिलता: वीडियो में इंस्टेंस को समझने के लिए न केवल स्थानिक जानकारी को कैप्चर करने की आवश्यकता होती है, बल्कि जटिल "अस्थायी गतिशीलता" को भी कैप्चर करने की आवश्यकता होती है। इसमें ऑब्जेक्ट की स्थिति, क्रियाओं और लगातार फ्रेम में संबंधों में परिवर्तन को ट्रैक करना शामिल है, जो स्थिर छवि विश्लेषण की तुलना में काफी अधिक जटिल कार्य है।
- डेटा गुणवत्ता आश्वासन चुनौतियाँ: GPT-4o का लाभ उठाने वाली एक स्वचालित पाइपलाइन के साथ भी, बहु-स्तरीय, महीन-दानेदार एनोटेशन की उच्च गुणवत्ता और स्थिरता सुनिश्चित करना चुनौतीपूर्ण है। पत्र में कहा गया है कि डेटा गुणवत्ता सुनिश्चित करने के लिए "कठोर मैनुअल सत्यापन और शोधन" आवश्यक है, जो विश्वसनीय एनोटेशन को पूरी तरह से स्वचालित करने में कठिनाई को उजागर करता है।
लेखक इस संदर्भ में LMMs के लिए विशिष्ट विफलता मोड की पहचान करते हैं:
- ऑक्लूजन, धुंधली छवियां, और छोटे/भीड़भाड़ वाले इंस्टेंस: मॉडल का प्रदर्शन उन परिदृश्यों में खराब हो जाता है जहां "इंस्टेंस गंभीर रूप से ऑक्लूडेड होते हैं, छवि धुंधली होती है, या इंस्टेंस अत्यधिक छोटे या भीड़भाड़ वाले होते हैं।" ये सामान्य वास्तविक दुनिया की स्थितियां हैं जो विज़ुअल धारणा प्रणालियों के लिए महत्वपूर्ण चुनौतियां पेश करती हैं।
- विज़ुअल प्रॉम्प्ट से वितरण शिफ्ट: "विज़ुअल रूप से प्रॉम्प्ट की गई छवियों का उपयोग प्राकृतिक छवियों से एक वितरण शिफ्ट पेश कर सकता है।" यदि मॉडल को इस शिफ्ट को कम करने के लिए सावधानीपूर्वक प्रशिक्षित नहीं किया जाता है, तो यह सामान्य छवि समझ कार्यों पर प्रदर्शन में गिरावट का कारण बन सकता है।
- कच्चे विज़ुअल इनपुट द्वारा छवि समझ का दमन: सामान्य इंस्ट्रक्शन-ट्यूनिंग डेटा के साथ उच्च अनुपात वाले वीडियो डेटा को सीधे मिश्रित करने से "छवि समझ का दमन हो सकता है," जो विभिन्न तौर-तरीकों को संयोजित करते समय सीखने में एक संभावित असंतुलन का संकेत देता है।
- प्रशिक्षण डेटा के लिए ओवरफिटिंग: कुछ मॉडल, विज़ुअल प्रॉम्प्ट का उपयोग करने के बावजूद, केवल "अपने बेसलाइन, यानी LLaVA-1.5, की तुलना में मामूली सुधार दिखाते हैं, संभवतः इसके प्रशिक्षण डेटा के लिए ओवरफिटिंग के कारण।" यह बताता है कि सावधानीपूर्वक डिजाइन के बिना, मॉडल सामान्य इंस्टेंस समझ सीखने के बजाय प्रशिक्षण उदाहरणों को याद कर सकते हैं।
- मॉडल आकार या मोटे-दानेदार डेटा का अपर्याप्त स्केलिंग: पत्र स्पष्ट रूप से कहता है कि "केवल मॉडल आकार को बढ़ाने से इंस्टेंस समझ में चुनौतियों का समाधान नहीं हो सकता है" और "बड़े पैमाने पर मोटे-दानेदार एनोटेशन भी आवश्यक सुधार नहीं करते हैं।" यह इस बात पर प्रकाश डालता है कि समस्या के लिए केवल मात्रात्मक स्केलिंग के बजाय डेटा और प्रशिक्षण पद्धति में गुणात्मक बदलाव की आवश्यकता है।
यह दृष्टिकोण क्यों
पसंद की अनिवार्यता
लेखकों का स्पष्ट विज़ुअल प्रॉम्प्ट इंस्ट्रक्शन ट्यूनिंग का पीछा करने का निर्णय, INST-IT डेटासेट और बेंचमार्क के निर्माण के साथ मिलकर, केवल एक प्राथमिकता नहीं थी, बल्कि मौजूदा बड़े मल्टीमॉडल मॉडल (LMMs) की अंतर्निहित सीमाओं से उत्पन्न एक आवश्यकता थी। मुख्य अहसास यह था कि जबकि LMMs ने समग्र, या सामान्य, स्तर पर छवियों और वीडियो को समझने में महत्वपूर्ण प्रगति की थी, वे लगातार "इंस्टेंस-लेवल अंडरस्टैंडिंग के साथ संघर्ष करते हैं जिसके लिए अधिक महीन-दानेदार समझ और संरेखण की आवश्यकता होती है" (सार, अनुभाग 1)। इसका मतलब है कि पारंपरिक "SOTA" विधियां, जैसे कि मानक CNNs, बुनियादी डिफ्यूजन मॉडल, या ट्रांसफॉर्मर, LMMs में एकीकृत होने पर भी, सटीक, वस्तु-विशिष्ट तर्क की मांग वाले कार्यों के लिए मौलिक रूप से अपर्याप्त थे।
इस अहसास का सटीक क्षण निहित रूप से इस अवलोकन से उजागर होता है कि वर्तमान LMMs, इंस्ट्रक्शन ट्यूनिंग में सफलताओं के बावजूद, "अभी भी इंस्टेंस-विशिष्ट सामग्री को समझने के लिए संघर्ष करते हैं जिसमें उपयोगकर्ता सबसे अधिक रुचि रखते हैं, जैसा कि चित्र 1 (ए) में दर्शाया गया है" (अनुभाग 1)। यह अंतर्निहित आर्किटेक्चर की विज़ुअल डेटा को संसाधित करने की क्षमता की विफलता नहीं है, बल्कि जटिल दृश्यों के भीतर विशिष्ट इंस्टेंस को निर्देशों को ग्राउंड करने की उनकी अक्षमता है, खासकर छवियों और वीडियो दोनों में। समस्या शक्तिशाली आधार मॉडल की कमी नहीं थी, बल्कि इन मॉडलों को महीन-दानेदार इंस्टेंस समझ सिखाने के लिए आवश्यक डेटा और पद्धति में एक महत्वपूर्ण अंतर था। मौजूदा मल्टीमॉडल बेंचमार्क और डेटासेट मुख्य रूप से "छवियों और वीडियो के लिए मोटे-दानेदार ज्ञान प्रदान करते थे, जिसमें व्यक्तिगत इंस्टेंस के लिए महीन-दानेदार एनोटेशन की कमी थी" (पृष्ठ 2)। इसलिए, विज़ुअल प्रॉम्प्ट और एक समर्पित, समृद्ध रूप से एनोटेट किए गए डेटासेट के माध्यम से स्पष्ट रूप से इंस्टेंस-स्तरीय मार्गदर्शन प्रदान करने वाला एक नया दृष्टिकोण इस अंतर को पाटने का एकमात्र व्यवहार्य समाधान था।
तुलनात्मक श्रेष्ठता
INST-IT दृष्टिकोण कई प्रमुख पहलुओं में पिछले स्वर्ण मानकों पर गुणात्मक श्रेष्ठता प्रदर्शित करता है, जो साधारण प्रदर्शन मेट्रिक्स से परे है।
सबसे पहले, यह उच्च-आयामी शोर और व्याकुलता को संभालने में उत्कृष्ट है। पत्र में कहा गया है कि "कच्चे विज़ुअल इनपुट को सीधे संसाधित करने से मतिभ्रम और व्याकुलता होती है" (अनुभाग 2.1)। इसे कम करने के लिए, विधि सेट-ऑफ-मार्क्स (SoMs) विज़ुअल प्रॉम्प्ट का उपयोग करती है, जो प्रत्येक इंस्टेंस पर संख्यात्मक आईडी ओवरले करती है। यह सरल लेकिन प्रभावी वृद्धि स्पष्ट रूप से अंतर्निहित GPT-4o मॉडल को "रुचि के इंस्टेंस पर अधिक प्रभावी ढंग से ध्यान केंद्रित करने" (अनुभाग 2.1) के लिए निर्देशित करती है, जिससे अप्रासंगिक विज़ुअल जानकारी के "शोर" को कम किया जाता है और महीन-दानेदार, अधिक सटीक एनोटेशन सक्षम होते हैं। यह संरचनात्मक लाभ मॉडल को विज़ुअल अव्यवस्था से निपटने और उपयोगकर्ता-निर्दिष्ट इंस्टेंस पर ध्यान केंद्रित करने की अनुमति देता है।
दूसरे, विधि वीडियो इनपुट के लिए मेमोरी जटिलता को संबोधित करती है। $O(N^2)$ से $O(N)$ तक कमी को स्पष्ट रूप से बताए बिना, लेखकों ने "वीडियो इनपुट में विज़ुअल टोकन की संख्या को कम करने के लिए 2 × 2 स्थानिक पूलिंग लागू करने" (अनुभाग 2.4) का उल्लेख किया है। विज़ुअल टोकन की यह डाउनसैंपलिंग कम्प्यूटेशनल और मेमोरी फुटप्रिंट को कम करने में सीधे योगदान करती है, जो लंबे वीडियो अनुक्रमों को संसाधित करने के लिए महत्वपूर्ण है और व्यावहारिक GPU मेमोरी बाधाओं (अनुभाग 3.1) के अनुरूप है।
अत्यधिक संरचनात्मक लाभ छवियों और वीडियो दोनों में, अस्थायी गतिशीलता सहित, वास्तविक इंस्टेंस-स्तरीय समझ को बढ़ावा देने की इसकी क्षमता में निहित है। पूर्व विधियों के विपरीत जो समग्र समझ पर केंद्रित थीं, INST-IT का डेटासेट बहु-स्तरीय, महीन-दानेदार एनोटेशन प्रदान करता है जिसमें इंस्टेंस-स्तरीय विवरण, छवि-स्तरीय कैप्शन, अस्थायी गतिशीलता, वीडियो-स्तरीय सारांश और खुले-छोर वाले प्रश्न-उत्तर जोड़े (पृष्ठ 2, अनुभाग 2.1) शामिल हैं। यह समृद्ध, संरचित डेटा, निरंतर इंस्ट्रक्शन-ट्यूनिंग रेसिपी के साथ मिलकर, LMMs को न केवल इंस्टेंस की पहचान करने में सक्षम बनाता है, बल्कि उनके गुणों, संबंधों और स्पेटियोटेम्पोरल विकास को भी समझने में सक्षम बनाता है। परिणाम बताते हैं कि यह दृष्टिकोण "अन्य इंस्टेंस समझ बेंचमार्क पर लगातार सुधार" और सामान्य बेंचमार्क पर "बेसलाइन पर महत्वपूर्ण सुधार" की ओर ले जाता है (सार, अनुभाग 3.2), जो ओवरफिटिंग के बजाय एक सामान्यीकृत वृद्धि का संकेत देता है। इसके अलावा, पत्र इस बात पर प्रकाश डालता है कि इसकी विधि बड़े, अधिक कम्प्यूटेशनल रूप से महंगे SFT LMMs के बराबर प्रदर्शन प्राप्त करती है "काफी कम कम्प्यूटेशनल और डेटा लागत की आवश्यकता के साथ" (अनुभाग 3.2), इसके दक्षता लाभ को रेखांकित करता है।
बाधाओं के साथ संरेखण
चुनी गई विधि, INST-IT, समस्या परिभाषा में उल्लिखित निहित बाधाओं और चुनौतियों के साथ पूरी तरह से संरेखित होती है। समस्या की कठोर आवश्यकताओं और समाधान के अद्वितीय गुणों के बीच यह "विवाह" कई तरीकों से स्पष्ट है:
- इंस्टेंस-लेवल अंडरस्टैंडिंग गैप को संबोधित करना: प्राथमिक बाधा मौजूदा LMMs की महीन-दानेदार इंस्टेंस समझ प्राप्त करने में असमर्थता थी। INST-IT "इंस्टेंस मार्गदर्शन के लिए स्पष्ट विज़ुअल प्रॉम्प्ट इंस्ट्रक्शन ट्यूनिंग" (सार) प्रदान करके सीधे इसे संबोधित करता है। विज़ुअल प्रॉम्प्ट द्वारा संवर्धित इंस्ट्रक्शन-ट्यूनिंग प्रतिमान मॉडल को विशिष्ट विज़ुअल संस्थाओं को निर्देशों को ग्राउंड करना सीखने के लिए मजबूर करता है।
- डेटा की कमी को दूर करना: एक बड़ी बाधा "इंस्टेंस-स्तरीय डेटासेट की कमी" (अनुभाग 2.2) थी। INST-IT डेटासेट को सावधानीपूर्वक "पहला इंस्टेंस-ग्राउंडेड इंस्ट्रक्शन-ट्यूनिंग डेटासेट के रूप में निर्मित किया गया था जिसमें चित्र और वीडियो दोनों शामिल हैं, जिसमें स्पष्ट इंस्टेंस-स्तरीय विज़ुअल प्रॉम्प्ट और व्यक्तिगत इंस्टेंस पर ग्राउंडेड महीन-दानेदार एनोटेशन शामिल हैं" (योगदान 1, पृष्ठ 2)। यह व्यापक, महीन-दानेदार डेटा की आवश्यकता को सीधे पूरा करता है।
- वीडियो में स्पेटियोटेम्पोरल डायनेमिक्स को संभालना: समस्या ने वीडियो में इंस्टेंस को समझने की कठिनाई पर जोर दिया, जिसके लिए स्थानिक और अस्थायी दोनों समझ की आवश्यकता होती है। INST-IT डेटासेट के बहु-स्तरीय एनोटेशन में "अस्थायी गतिशीलता विवरण" और "वीडियो-स्तरीय सारांश" (पृष्ठ 2, अनुभाग 2.1) शामिल हैं, जो मॉडल को समय के साथ परिवर्तनों और इंटरैक्शन को कैप्चर करने के लिए स्पष्ट रूप से प्रशिक्षित करते हैं। निरंतर इंस्ट्रक्शन ट्यूनिंग रेसिपी इस स्पेटियोटेम्पोरल समझ को और एकीकृत करती है।
- मतिभ्रम और व्याकुलता को कम करना: कच्चे विज़ुअल इनपुट से "मतिभ्रम और व्याकुलता" (अनुभाग 2.1) की बाधा को "सेट-ऑफ-मार्क्स (SoMs) विज़ुअल प्रॉम्प्ट [88]" तकनीक द्वारा संबोधित किया जाता है। इंस्टेंस पर संख्यात्मक आईडी ओवरले करके, मॉडल को स्पष्ट रूप से विशिष्ट वस्तुओं पर ध्यान केंद्रित करने के लिए निर्देशित किया जाता है, जिससे अस्पष्टता कम होती है और एनोटेशन सटीकता में सुधार होता है।
- कम्प्यूटेशनल दक्षता: व्यावहारिक बाधाओं में अक्सर कम्प्यूटेशनल संसाधन शामिल होते हैं। पत्र में "GPU मेमोरी बाधाओं के कारण फ्रेम की अधिकतम संख्या को 32 और LLMs के संदर्भ लंबाई को 6K तक सीमित करना" और "विज़ुअल टोकन को कम करने के लिए 2 × 2 स्थानिक पूलिंग लागू करना" (अनुभाग 3.1) का उल्लेख है। तथ्य यह है कि INST-IT बड़े SFT LMMs (अनुभाग 3.2) की तुलना में "काफी कम कम्प्यूटेशनल और डेटा लागत" के साथ मजबूत प्रदर्शन प्राप्त करता है, संसाधन-कुशल परिनियोजन के साथ इसके संरेखण को प्रदर्शित करता है।
विकल्पों का अस्वीकरण
यह पत्र स्पष्ट रूप से, फिर भी स्पष्ट रूप से, कई वैकल्पिक दृष्टिकोणों को अस्वीकार करता है, जो मल्टीमॉडल डेटा में इंस्टेंस-स्तरीय समझ की मुख्य समस्या को संबोधित करने में उनकी कमियों को उजागर करके।
सबसे पहले, यह विशेष इंस्ट्रक्शन ट्यूनिंग और डेटा के बिना मौजूदा "SOTA" LMMs के उपयोग की प्रभावकारिता को खारिज करता है। लेखकों का कहना है कि जबकि ये मॉडल "समग्र स्तर पर छवियों और वीडियो को समझ सकते हैं, वे अभी भी इंस्टेंस-विशिष्ट सामग्री को समझने के लिए संघर्ष करते हैं" (अनुभाग 1)। इसका तात्पर्य है कि सामान्य LMMs, शक्तिशाली होने पर भी, इस कार्य के लिए आवश्यक महीन-दानेदार ग्राउंडिंग क्षमताओं की कमी रखते हैं। समस्या सामान्य बुद्धि की कमी नहीं है, बल्कि इंस्टेंस-केंद्रित निर्देश-अनुसरण की कमी है।
दूसरे, यह पत्र स्पष्ट रूप से अन्य लोकप्रिय इंस्ट्रक्शन-ट्यूनिंग डेटासेट को अपर्याप्त के रूप में खारिज करता है। तालिका 1 और अनुभाग 2.2 में, यह INST-IT की तुलना ShareGPT4Video, LLaVA-Video, और ViP-LLaVA-Data जैसे डेटासेट से करता है। यह नोट करता है कि पूर्व वीडियो डेटासेट "इंस्टेंस-स्तरीय एनोटेशन के बिना, समग्र समझ पर ध्यान केंद्रित करते हैं," और जबकि ViP-LLaVA "छवियों के लिए इंस्टेंस एनोटेशन प्रदान करता है, इसमें कोई वीडियो डेटा शामिल नहीं है।" यह इन विकल्पों का एक सीधा अस्वीकरण है क्योंकि वे INST-IT द्वारा पेश किए जाने वाले आवश्यक बहु-स्तरीय, महीन-दानेदार, इंस्टेंस-ग्राउंडेड एनोटेशन छवियों और वीडियो दोनों में प्रदान करने में विफल रहते हैं। लेखक निष्कर्ष निकालते हैं कि "इंस्टेंस-स्तरीय डेटासेट की कमी इंस्टेंस समझ की उन्नति में बाधा डालती है" (अनुभाग 2.2), जिससे मौजूदा डेटासेट अपर्याप्त हो जाते हैं।
अंत में, यह पत्र इस विचार को खारिज करता है कि केवल मॉडल आकार को बढ़ाने या अधिक मोटे-दानेदार डेटा का उपयोग करने से समस्या हल हो जाएगी। यह देखता है कि "Qwen2VL-72B अपने छोटे 7B मॉडल पर महत्वपूर्ण सुधार नहीं दिखाता है, यह दर्शाता है कि केवल मॉडल आकार को बढ़ाने से इंस्टेंस समझ में चुनौतियों का समाधान नहीं हो सकता है" (अनुभाग 3.2)। इसी तरह, यह नोट करता है कि "बड़े पैमाने पर मोटे-दानेदार एनोटेशन भी आवश्यक सुधार नहीं करते हैं" (अनुभाग 3.2)। यह तर्क इस बात पर प्रकाश डालता है कि समाधान मौजूदा विधियों या डेटा के क्रूर-बल स्केलिंग में नहीं है, बल्कि विशेष डेटा और इंस्ट्रक्शन ट्यूनिंग के माध्यम से स्पष्ट इंस्टेंस-स्तरीय मार्गदर्शन पर ध्यान केंद्रित करने वाले एक लक्षित दृष्टिकोण में है।
 Figure 8. A data example from INST-IT Bench. Each test sample includes both open-ended QA and multiple-choice QA, focusing on specific instances or the relationships and interactions between instances
Figure 8. A data example from INST-IT Bench. Each test sample includes both open-ended QA and multiple-choice QA, focusing on specific instances or the relationships and interactions between instances
गणितीय और तार्किक तंत्र
मास्टर समीकरण
INST-IT का मुख्य गणितीय और तार्किक तंत्र एक मॉडल के लिए अनुकूलन फ़ंक्शन नहीं है, बल्कि एक शक्तिशाली बड़े भाषा मॉडल (LLM), विशेष रूप से GPT-4o का लाभ उठाने वाला एक परिष्कृत डेटा जनरेशन पाइपलाइन है, ताकि समृद्ध, बहु-ग्रैन्युलैरिटी एनोटेशन बनाए जा सकें। ये एनोटेशन तब INST-IT डेटासेट बनाते हैं, जिसका उपयोग अन्य LMMs को इंस्ट्रक्शन-ट्यून करने के लिए किया जाता है। इस पाइपलाइन के भीतर मौलिक संचालन तीन प्रमुख समीकरणों द्वारा परिभाषित किए गए हैं, प्रत्येक एनोटेशन पीढ़ी के एक अलग चरण का प्रतिनिधित्व करता है:
1. फ्रेम-स्तरीय एनोटेशन:
$$Y_t^f = \text{GPT}(P^f, X_t, X_{t-1})$$
2. वीडियो-स्तरीय सारांश:
$$Y^{vid} = \text{GPT}(P^{vid}, [Y_1^f, Y_2^f, \ldots, Y_N^f])$$
3. खुले-छोर वाले प्रश्न-उत्तर जोड़े:
$$Y^{qa} = \text{GPT}(P^{qa}, [Y_1^f, Y_2^f, \ldots, Y_N^f])$$
पद-दर-पद विच्छेदन
आइए इन समीकरणों के प्रत्येक घटक का विश्लेषण करें ताकि INST-IT ढांचे में उनकी सटीक भूमिका को समझा जा सके।
समीकरण (1): फ्रेम-स्तरीय एनोटेशन
$$Y_t^f = \text{GPT}(P^f, X_t, X_{t-1})$$
* $Y_t^f$:
* गणितीय परिभाषा: यह समय $t$ पर एक विशिष्ट वीडियो फ्रेम के लिए GPT-4o मॉडल का आउटपुट है। यह एक संरचित पाठ्य एनोटेशन है।
* भौतिक/तार्किक भूमिका: यह व्यक्तिगत इंस्टेंस, समग्र छवि सामग्री और पिछले फ्रेम के सापेक्ष अस्थायी परिवर्तनों को शामिल करते हुए, एक एकल फ्रेम के लिए व्यापक, महीन-दानेदार पाठ्य विवरण का प्रतिनिधित्व करता है। यह सभी बाद के, उच्च-स्तरीय एनोटेशन के लिए मूलभूत निर्माण खंड है।
* $\text{GPT}(\cdot)$:
* गणितीय परिभाषा: यह GPT-4o बड़े भाषा मॉडल को दर्शाता है, जिसे पाठ्य आउटपुट उत्पन्न करने के लिए एक प्रॉम्प्ट और विज़ुअल इनपुट लेने वाले फ़ंक्शन के रूप में माना जाता है।
* भौतिक/तार्किक भूमिका: GPT-4o बुद्धिमान एनोटेटर के रूप में कार्य करता है। इसके उन्नत मल्टीमॉडल समझ क्षमताओं का उपयोग विज़ुअल जानकारी की व्याख्या करने और प्रदान किए गए निर्देशों के अनुसार मानव-जैसी, विस्तृत विवरण उत्पन्न करने के लिए किया जाता है। लेखकों ने GPT-4o को जटिल विज़ुअल तर्क को संभालने और उच्च-गुणवत्ता वाले पाठ उत्पन्न करने की अपनी बेहतर क्षमता के लिए चुना, जो इंस्टेंस समझ की महीन-दानेदार प्रकृति के लिए महत्वपूर्ण है।
* $P^f$:
* गणितीय परिभाषा: एक प्राकृतिक भाषा स्ट्रिंग, विशेष रूप से फ्रेम-स्तरीय एनोटेशन के लिए डिज़ाइन किया गया "अनुकूलित कार्य प्रॉम्प्ट"।
* भौतिक/तार्किक भूमिका: यह प्रॉम्प्ट GPT-4o के लिए एक सटीक निर्देश सेट के रूप में कार्य करता है। यह मॉडल को फ्रेम के विशिष्ट पहलुओं (जैसे, व्यक्तिगत इंस्टेंस, समग्र दृश्य, अस्थायी अंतर) पर ध्यान केंद्रित करने के लिए निर्देशित करता है और $Y_t^f$ आउटपुट की वांछित संरचना और सामग्री को निर्धारित करता है। इस प्रॉम्प्ट के सावधानीपूर्वक डिजाइन सटीक और प्रासंगिक एनोटेशन प्राप्त करने की कुंजी है।
* $X_t$:
* गणितीय परिभाषा: टाइमस्टैम्प $t$ पर वर्तमान वीडियो फ्रेम के अनुरूप विज़ुअल डेटा।
* भौतिक/तार्किक भूमिका: यह GPT-4o के लिए प्राथमिक विज़ुअल इनपुट है, जो कच्चे पिक्सेल जानकारी और विज़ुअल संदर्भ प्रदान करता है जिसका वर्णन करने की आवश्यकता है।
* $X_{t-1}$:
* गणितीय परिभाषा: टाइमस्टैम्प $t-1$ पर पिछले वीडियो फ्रेम के अनुरूप विज़ुअल डेटा।
* भौतिक/तार्किक भूमिका: पिछले फ्रेम को शामिल करना अस्थायी गतिशीलता को पकड़ने के लिए महत्वपूर्ण है। $X_t$ और $X_{t-1}$ की तुलना करके, GPT-4o समय के साथ इंस्टेंस के बीच आंदोलनों, स्थिति में परिवर्तन या इंटरैक्शन की पहचान और वर्णन कर सकता है, जो वीडियो समझ के लिए आवश्यक है।
* गणितीय ऑपरेटर (फ़ंक्शन अनुप्रयोग): ऑपरेशन GPT-4o को एक फ़ंक्शन कॉल है। लेखक इस कार्यात्मक संकेतन का उपयोग करते हैं क्योंकि GPT-4o एक जटिल जनरेटिव मॉडल है, न कि एक साधारण अंकगणितीय ऑपरेटर। यह इनपुट (प्रॉम्प्ट, वर्तमान फ्रेम, पिछला फ्रेम) को एक सुसंगत पाठ्य आउटपुट उत्पन्न करने के लिए अपने आंतरिक तंत्रिका नेटवर्क आर्किटेक्चर के माध्यम से संसाधित करता है।
समीकरण (2): वीडियो-स्तरीय सारांश
$$Y^{vid} = \text{GPT}(P^{vid}, [Y_1^f, Y_2^f, \ldots, Y_N^f])$$
* $Y^{vid}$:
* गणितीय परिभाषा: GPT-4o द्वारा उत्पन्न पूरे वीडियो का पाठ्य सारांश।
* भौतिक/तार्किक भूमिका: यह सभी व्यक्तिगत फ्रेम-स्तरीय एनोटेशन से विस्तृत जानकारी को एक सुसंगत कहानी में एकत्रित करते हुए, वीडियो सामग्री का एक समग्र, कालानुक्रमिक कथा प्रदान करता है। यह समग्र स्पेटियोटेम्पोरल प्रवाह और मुख्य घटनाओं को कैप्चर करता है।
* $\text{GPT}(\cdot)$: समीकरण (1) के समान।
* $P^{vid}$:
* गणितीय परिभाषा: एक प्राकृतिक भाषा स्ट्रिंग, विशेष रूप से वीडियो-स्तरीय सारांश के लिए डिज़ाइन किया गया "कार्य प्रॉम्प्ट"।
* भौतिक/तार्किक भूमिका: यह प्रॉम्प्ट GPT-4o को फ्रेम-स्तरीय विवरणों के अनुक्रम से एक व्यापक सारांश को संश्लेषित करने का निर्देश देता है, कालानुक्रमिक क्रम और मुख्य वस्तुओं और घटनाओं पर ध्यान केंद्रित करना सुनिश्चित करता है।
* $[Y_1^f, Y_2^f, \ldots, Y_N^f]$:
* गणितीय परिभाषा: वीडियो के लिए उत्पन्न सभी फ्रेम-स्तरीय एनोटेशन ($Y_t^f$) की एक क्रमबद्ध सूची या अनुक्रम, पहले फ्रेम ($t=1$) से अंतिम फ्रेम ($t=N$) तक।
* भौतिक/तार्किक भूमिका: यह अनुक्रम वीडियो की घटनाओं की पाठ्य "मेमोरी" या "ट्रांसक्रिप्ट" के रूप में कार्य करता है, GPT-4o को सभी महीन-दानेदार विवरण प्रदान करता है जिसकी उसे एक उच्च-स्तरीय सारांश बनाने की आवश्यकता होती है। एकल समेकित मान के बजाय सूची (निहित रूप से जानकारी का योग) का उपयोग GPT-4o को अस्थायी प्रगति और घटनाओं के बीच संबंधों को संसाधित करने की अनुमति देता है।
* $N$:
* गणितीय परिभाषा: वीडियो में फ्रेम की कुल संख्या।
* भौतिक/तार्किक भूमिका: यह स्केलर वीडियो की लंबाई और इस प्रकार वीडियो सारांश के लिए विचार किए जाने वाले फ्रेम-स्तरीय एनोटेशन की संख्या को इंगित करता है।
समीकरण (3): खुले-छोर वाले प्रश्न-उत्तर जोड़े
$$Y^{qa} = \text{GPT}(P^{qa}, [Y_1^f, Y_2^f, \ldots, Y_N^f])$$
* $Y^{qa}$:
* गणितीय परिभाषा: GPT-4o द्वारा उत्पन्न $M$ खुले-छोर वाले प्रश्न-उत्तर जोड़ों का एक सेट, $\{(q_i, a_i)\}_{i=1}^M$ ।
* भौतिक/तार्किक भूमिका: ये जोड़े LMMs को इंस्टेंस-स्तरीय समझ और तर्क पर परीक्षण और प्रशिक्षित करने के लिए डिज़ाइन किए गए हैं। वे विशिष्ट इंस्टेंस, उनके गुणों, संबंधों और अस्थायी परिवर्तनों पर ध्यान केंद्रित करते हैं, जो इंस्ट्रक्शन-ट्यूनिंग डेटा का एक समृद्ध स्रोत प्रदान करते हैं।
* $\text{GPT}(\cdot)$: समीकरण (1) के समान।
* $P^{qa}$:
* गणितीय परिभाषा: एक प्राकृतिक भाषा स्ट्रिंग, विशेष रूप से खुले-छोर वाले QA जोड़े उत्पन्न करने के लिए डिज़ाइन किया गया "कार्य प्रॉम्प्ट"।
* भौतिक/तार्किक भूमिका: यह प्रॉम्प्ट GPT-4o को प्रदान किए गए फ्रेम-स्तरीय एनोटेशन के आधार पर विविध और प्रासंगिक प्रश्न और सटीक उत्तर तैयार करने के लिए निर्देशित करता है। यह सुनिश्चित करता है कि QA जोड़े इंस्टेंस-स्तरीय समझ को लक्षित करते हैं।
* $[Y_1^f, Y_2^f, \ldots, Y_N^f]$: समीकरण (2) के समान।
* भौतिक/तार्किक भूमिका: वीडियो सारांश के समान, यह अनुक्रम उस व्यापक पाठ्य संदर्भ को प्रदान करता है जिससे GPT-4o प्रश्न और उत्तर प्राप्त कर सकता है, जिसके लिए इसे विस्तृत घटनाओं और संस्थाओं पर तर्क करने की आवश्यकता होती है।
चरण-दर-चरण प्रवाह
एक परिष्कृत डेटा एनोटेशन फैक्ट्री में प्रवेश करने वाले एक वीडियो की कल्पना करें। यहाँ बताया गया है कि एक एकल वीडियो की जानकारी INST-IT पाइपलाइन के माध्यम से कैसे संसाधित होती है:
- विज़ुअल इनपुट रिसेप्शन: फ्रेम $X_1, X_2, \ldots, X_N$ के अनुक्रम से बना एक कच्चा वीडियो, पहले स्टेशन पर आता है।
- इंस्टेंस हाइलाइटिंग (विज़ुअल प्रॉम्प्टिंग): इस स्टेशन पर, एक पूर्व-प्रसंस्करण चरण प्रत्येक फ्रेम के भीतर व्यक्तिगत इंस्टेंस (वस्तुओं) की पहचान करता है। प्रत्येक पहचाने गए इंस्टेंस के लिए, एक अद्वितीय संख्यात्मक आईडी सीधे उस पर ओवरले की जाती है, जिससे "सेट-ऑफ-मार्क्स" (SoM) विज़ुअल प्रॉम्प्ट बनता है। यह सुनिश्चित करता है कि बाद के एनोटेशन चरण इन पहचाने गए इंस्टेंस पर स्पष्ट रूप से ध्यान केंद्रित करें।
- फ्रेम-स्तरीय एनोटेशन असेंबली लाइन:
- वीडियो फ्रेम GPT-4o "एनोटेशन इंजन" में क्रमिक रूप से फीड किए जाते हैं।
- पहले फ्रेम $X_1$ के लिए, इसे एक विशिष्ट "फ्रेम-स्तरीय प्रॉम्प्ट" $P^f$ (और $X_0$ के लिए एक प्लेसहोल्डर के रूप में क्योंकि कोई पिछला फ्रेम नहीं है) के साथ जोड़ा जाता है। GPT-4o इसे संसाधित करता है और $Y_1^f$ आउटपुट करता है, जो इंस्टेंस, समग्र छवि और किसी भी अस्थायी परिवर्तन (या उनकी कमी) का एक विस्तृत पाठ्य विवरण है।
- प्रत्येक बाद के फ्रेम $X_t$ (जहां $t > 1$) के लिए, इसे इसके तत्काल पूर्ववर्ती $X_{t-1}$ और उसी $P^f$ के साथ जोड़ा जाता है। यह जोड़ी, प्रॉम्प्ट के साथ, GPT-4o में प्रवेश करती है।
- GPT-4o तब $X_t$ और $X_{t-1}$ का सावधानीपूर्वक विश्लेषण करता है, $Y_t^f$ उत्पन्न करता है, जिसमें $X_t$ में इंस्टेंस का विवरण, समग्र दृश्य, और महत्वपूर्ण रूप से, $X_{t-1}$ और $X_t$ के बीच देखे गए अंतर और गतिशीलता शामिल हैं।
- यह प्रक्रिया तब तक दोहराई जाती है जब तक कि सभी $N$ फ्रेम एनोटेट नहीं हो जाते, जिससे फ्रेम-स्तरीय एनोटेशन का एक पूरा अनुक्रम बनता है: $[Y_1^f, Y_2^f, \ldots, Y_N^f]$। यह अनुक्रम फ्रेम-दर-फ्रेम होने वाली हर चीज का एक विस्तृत लॉगबुक जैसा है।
- वीडियो-स्तरीय सारांश संश्लेषण: फ्रेम-स्तरीय एनोटेशन $[Y_1^f, \ldots, Y_N^f]$ की पूरी लॉगबुक अब एकत्र की जाती है। यह संपूर्ण पाठ्य अनुक्रम, एक "वीडियो-स्तरीय सारांश प्रॉम्प्ट" $P^{vid}$ के साथ, GPT-4o इंजन के तीसरे उदाहरण में फीड किया जाता है। इस इंजन का कार्य एक कुशल सारांशकर्ता के रूप में कार्य करना है, जो सभी दानेदार विवरणों को एक सुसंगत, कालानुक्रमिक कथा $Y^{vid}$ में संश्लेषित करता है जो पूरे वीडियो की घटनाओं और स्पेटियोटेम्पोरल जानकारी का वर्णन करता है।
- प्रश्न-उत्तर निर्माण: सारांश के समानांतर, वही लॉगबुक $[Y_1^f, \ldots, Y_N^f]$ तीसरे GPT-4o इंजन में फीड की जाती है, इस बार एक "खुले-छोर वाले QA प्रॉम्प्ट" $P^{qa}$ के साथ। इस इंजन की भूमिका एक रचनात्मक प्रश्न जनरेटर और उत्तरदाता के रूप में कार्य करना है, जो विविध और इंस्टेंस-केंद्रित प्रश्न-उत्तर जोड़े $Y^{qa}$ का उत्पादन करता है। ये QA जोड़े मॉडल की वीडियो में व्यक्तिगत इंस्टेंस और उनके संबंधों की समझ को जांचने के लिए डिज़ाइन किए गए हैं।
- डेटासेट एकीकरण: वीडियो के लिए ये सभी उत्पन्न एनोटेशन ($Y_t^f$, $Y^{vid}$, $Y^{qa}$) फिर एक साथ पैक किए जाते हैं, INST-IT डेटासेट में एक समृद्ध, बहु-स्तरीय, इंस्टेंस-ग्राउंडेड प्रविष्टि बनाते हैं। यह डेटा अब इंस्ट्रक्शन ट्यूनिंग के लिए उपयोग के लिए तैयार है। जैसा कि चित्र 2 में दर्शाया गया है, इन एनोटेशन में निम्नलिखित पहलू शामिल हैं:
अनुकूलन गतिशीलता
INST-IT फ्रेमवर्क स्वयं मुख्य रूप से एक डेटा जनरेशन और तैयारी तंत्र है, न कि एक मॉडल जो पारंपरिक अर्थों में सीधे अनुकूलन से गुजरता है (यानी, इसके पैरामीटर नहीं होते हैं जिन्हें ग्रेडिएंट के माध्यम से अपडेट किया जाता है)। इसके बजाय, इसके "अनुकूलन गतिशीलता" इस बात में देखी जाती है कि यह अन्य बड़े मल्टीमॉडल मॉडल (LMMs) को अधिक प्रभावी ढंग से सीखने, अपडेट करने और अभिसरण करने में कैसे सक्षम बनाता है।
जब INST-IT डेटासेट का उपयोग करके एक LMM (जैसे LLaVA-NeXT) को प्रशिक्षित किया जाता है, तो सीखने की प्रक्रिया इस प्रकार सामने आती है:
-
इंस्ट्रक्शन ट्यूनिंग ऑब्जेक्टिव: LMM को INST-IT डेटासेट द्वारा प्रदान किए गए ग्राउंड-ट्रुथ एनोटेशन और इसके उत्पन्न पाठ्य प्रतिक्रियाओं के बीच अंतर को कम करके निर्देशों का पालन करने के लिए प्रशिक्षित किया जाता है। यह आमतौर पर एक मानक भाषा मॉडलिंग उद्देश्य का उपयोग करके प्राप्त किया जाता है, जैसे कि क्रॉस-एंट्रॉपी लॉस (या नकारात्मक लॉग-लाइकलीहुड लॉस)। इनपुट में विज़ुअल फीचर्स $V$ (छवियों/वीडियो फ्रेम से प्राप्त, संभावित रूप से SoMs के साथ) और एक पाठ्य निर्देश $I$ शामिल होने पर, मॉडल टोकन का एक अनुक्रम $T = (t_1, t_2, \ldots, t_L)$ उत्पन्न करता है। उद्देश्य इनपुट को देखते हुए सही टोकन अनुक्रम उत्पन्न करने की संभावना को अधिकतम करना है, जिसे आमतौर पर $\prod_{k=1}^L P(t_k | V, I, t_1, \ldots, t_{k-1})$ के रूप में विघटित किया जाता है। एक एकल प्रशिक्षण नमूना $(V, I, T_{target})$ के लिए हानि होगी:
$$ \mathcal{L} = - \sum_{k=1}^L \log P(t_{target,k} | V, I, t_1, \ldots, t_{k-1}) $$
जहां $t_{target,k}$ INST-IT डेटासेट से ग्राउंड-ट्रुथ एनोटेशन के टोकन हैं। -
संयुक्त प्रशिक्षण प्रतिमान: पत्र एक "निरंतर इंस्ट्रक्शन ट्यूनिंग रेसिपी" (अनुभाग 2.4, 3.4) का प्रस्ताव करता है जो अनुकूलन गतिशीलता के केंद्र में है। इस रेसिपी में शामिल हैं:
- डेटा मिश्रण: INST-IT डेटासेट, अपने समृद्ध इंस्टेंस-स्तरीय, बहु-ग्रैन्युलैरिटी एनोटेशन और स्पष्ट विज़ुअल प्रॉम्प्ट के साथ, मौजूदा सामान्य इंस्ट्रक्शन-ट्यूनिंग डेटा (जैसे, LLaVA-NeXT-DATA) के साथ जोड़ा जाता है। यह संयुक्त प्रशिक्षण सुनिश्चित करता है कि LMM दोनों महीन-दानेदार इंस्टेंस समझ सीखता है और विविध कार्यों में अपनी व्यापक सामान्य समझ क्षमताओं को बनाए रखता है।
- वितरण शिफ्ट को कम करना: एक प्रमुख चुनौती यह है कि "विज़ुअल रूप से प्रॉम्प्ट की गई छवियों से प्राकृतिक छवियों से एक वितरण शिफ्ट पेश कर सकता है" (अनुभाग 3.4), संभावित रूप से सामान्य कार्यों पर प्रदर्शन को खराब कर सकता है। इसका मुकाबला करने के लिए, निरंतर सुपरवाइज्ड फाइन-ट्यूनिंग (SFT) प्रतिमान लागू किया जाता है। इस चरण के दौरान, विजन एनकोडर की प्रारंभिक परतें (विशेष रूप से, पहली 12 परतें) "फ्रीज" की जाती हैं (अनुभाग 3.1)। यह फ्रीजिंग प्राकृतिक छवियों से सीखी गई निम्न-स्तरीय विज़ुअल विशेषताओं को संरक्षित करने में मदद करती है और मॉडल को विज़ुअल रूप से प्रॉम्प्ट किए गए डेटा के लिए ओवरफिट होने से रोकती है, जिससे छवि और वीडियो दोनों कार्यों में संतुलित प्रदर्शन प्राप्त होता है।
-
अनुकूलन प्रक्रिया:
- फॉरवर्ड पास: प्रशिक्षण के दौरान, एक LMM विज़ुअल इनपुट (छवि/वीडियो फ्रेम, SoMs के साथ संवर्धित) को विज़ुअल फीचर्स निकालने के लिए अपने विजन एनकोडर के माध्यम से संसाधित करता है। इन फीचर्स को फिर भाषा मॉडल के एम्बेडिंग स्पेस में प्रोजेक्ट किया जाता है। भाषा मॉडल तब पाठ्य निर्देश और विज़ुअल फीचर्स को संसाधित करके एक पाठ्य प्रतिक्रिया उत्पन्न करता है।
- बैकवर्ड पास: उत्पन्न प्रतिक्रिया की तुलना INST-IT डेटासेट से ग्राउंड-ट्रुथ एनोटेशन से क्रॉस-एंट्रॉपी लॉस का उपयोग करके की जाती है। ग्रेडिएंट की गणना की जाती है और भाषा मॉडल और प्रोजेक्शन परत के माध्यम से बैकप्रोपैगेट किया जाता है। फ्रीजिंग रणनीति के कारण, ग्रेडिएंट केवल विजन एनकोडर की बाद की परतों (यदि अनफ्रीज्ड), प्रोजेक्शन परत और भाषा मॉडल को अपडेट करते हैं।
- अभिसरण: मॉडल पैरामीटर को एक लर्निंग रेट शेड्यूल (जैसे, अनुभाग 3.1 में उल्लिखित कोसाइन लर्निंग रेट शेड्यूल) के साथ एक ऑप्टिमाइज़र (जैसे, AdamW) का उपयोग करके पुनरावृत्त रूप से अपडेट किया जाता है। लक्ष्य LMM को एक ऐसी स्थिति में अभिसरण करना है जहां यह विज़ुअल प्रॉम्प्ट के आधार पर सटीक महीन-दानेदार, इंस्टेंस-स्तरीय विवरण उत्पन्न कर सके और प्रश्नों का उत्तर दे सके, जबकि मजबूत सामान्य मल्टीमॉडल समझ को बनाए रख सके।
यह निरंतर इंस्ट्रक्शन-ट्यूनिंग प्रतिमान, डेटा प्रकारों के अपने सावधानीपूर्वक संतुलन और मॉडल घटकों के चयनात्मक फ्रीजिंग के साथ, "अनुकूलन गतिशीलता" है जो LMMs को उनकी व्यापक क्षमताओं का त्याग किए बिना वांछित इंस्टेंस-स्तरीय समझ सीखने की अनुमति देता है।
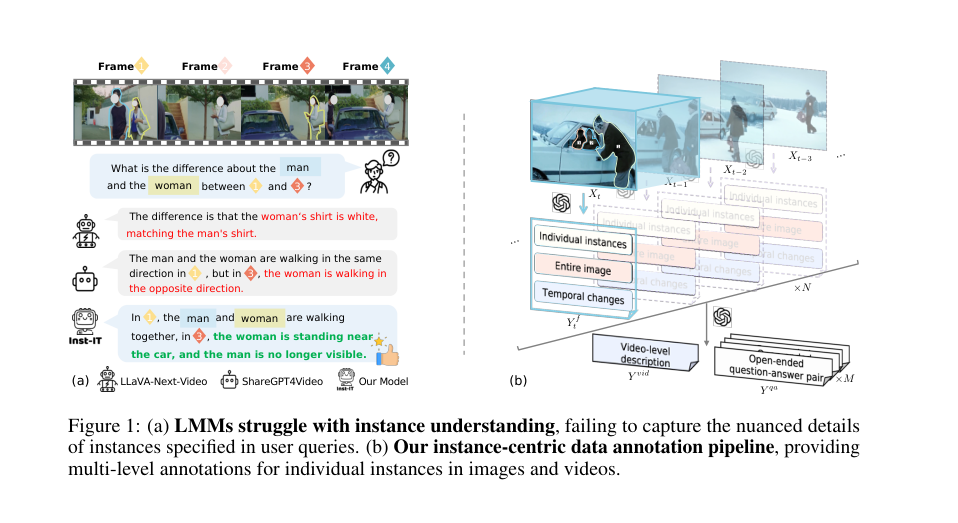 Figure 1. (a) LMMs struggle with instance understanding, failing to capture the nuanced details of instances specified in user queries. (b) Our instance-centric data annotation pipeline, providing multi-level annotations for individual instances in images and videos
Figure 1. (a) LMMs struggle with instance understanding, failing to capture the nuanced details of instances specified in user queries. (b) Our instance-centric data annotation pipeline, providing multi-level annotations for individual instances in images and videos
परिणाम, सीमाएँ और निष्कर्ष
प्रायोगिक डिजाइन और बेसलाइन
अपने दावों को कठोरता से मान्य करने के लिए, लेखकों ने एक व्यापक प्रायोगिक सेटअप तैयार किया। उनके मुख्य दृष्टिकोण में स्पष्ट विज़ुअल प्रॉम्प्ट इंस्ट्रक्शन ट्यूनिंग के माध्यम से बड़े मल्टीमॉडल मॉडल (LMMs) को बढ़ाना शामिल था, जिसे INST-IT कहा जाता है। वृद्धि के लिए चुना गया प्राथमिक "पीड़ित" या बेसलाइन आर्किटेक्चर LLaVA-NeXT [44] था, जो एक व्यापक रूप से अपनाया गया मॉडल है। इस बेसलाइन ने आम तौर पर अपने भाषा मॉडल के रूप में Vicuna-1.5-7B [16] और अपने विजन एनकोडर के रूप में CLIP-ViT-336 [67] का उपयोग किया। अधिक उन्नत प्रयोगों के लिए, उन्होंने SigLIP-SO400M-384 [97] के साथ Qwen2-7B [87] का भी उपयोग किया।
प्रायोगिक डिजाइन एक उपन्यास छवि-वीडियो संयुक्त प्रशिक्षण पाइपलाइन पर केंद्रित था। इस पाइपलाइन ने नव निर्मित INST-IT डेटासेट को मौजूदा ओपन-सोर्स LLaVA-NeXT-DATA [48] के साथ सावधानीपूर्वक जोड़ा। उनके आर्किटेक्चर का एक महत्वपूर्ण तत्व सभी छवियों और वीडियो फ्रेम को सेट-ऑफ-मार्क्स (SoM) विज़ुअल प्रॉम्प्ट [88] के साथ संवर्धित करना था। इस तकनीक ने स्पष्ट रूप से LMMs को व्यक्तिगत इंस्टेंस पर ध्यान केंद्रित करने के लिए निर्देशित किया, जो पिछले काम से एक प्रमुख अंतर है।
INST-IT डेटासेट स्वयं एक महत्वपूर्ण योगदान है, जिसमें 51k चित्र और 21k वीडियो शामिल हैं। इसमें व्यक्तिगत इंस्टेंस पर ग्राउंडेड बहु-स्तरीय, महीन-दानेदार एनोटेशन शामिल हैं, जिसमें 207k छवि-स्तरीय कैप्शन, 135k अस्थायी गतिशीलता विवरण, 21k वीडियो-स्तरीय कैप्शन और 335k खुले-छोर वाले प्रश्न-उत्तर जोड़े शामिल हैं।
मूल्यांकन के लिए, लेखकों ने INST-IT बेंच पेश किया, जो छवियों और वीडियो दोनों में इंस्टेंस-स्तरीय समझ का निदान करने के लिए विशेष रूप से डिज़ाइन किया गया एक मानव-सत्यापित बेंचमार्क है। इस बेंचमार्क में 338 छवियों के लिए 1,000 खुले-छोर वाले और बहुविकल्पीय प्रश्न-उत्तर जोड़े और 206 वीडियो के लिए 1,000 प्रश्न-उत्तर जोड़े शामिल हैं। खुले-छोर वाले प्रश्न-उत्तर प्रतिक्रियाओं का मूल्यांकन सटीकता और इंस्टेंस आईडी संदर्भ शुद्धता के लिए GPT-4o [61] का उपयोग करके किया गया था। अपने कस्टम बेंचमार्क से परे, उन्होंने RefCOCOg [53] और ViP-Bench [5] जैसे स्थापित इंस्टेंस समझ बेंचमार्क के साथ-साथ AI2D [28], ChartQA [54], Egoschema [52], और NEXT-QA [85] जैसे सामान्य छवि और वीडियो समझ बेंचमार्क पर भी अपने मॉडल का परीक्षण किया।
बेसलाइन मॉडल जिन्हें उन्होंने हराने का लक्ष्य रखा था, उनमें अत्याधुनिक LMMs की एक विस्तृत श्रृंखला शामिल थी:
- मालिकाना मॉडल: GPT-4o [61] और Gemini-1.5-flash [72]।
- ओपन-सोर्स छवि मॉडल: LLaVA-1.5 [43], ViP-LLaVA [5], SOM-LLaVA [86], और प्रत्यक्ष बेसलाइन LLaVA-NeXT [44]।
- ओपन-सोर्स वीडियो मॉडल: LLaVA-NeXT-Video [103], ShareGPT4Video [10], LLaVA-OV [31], LLaVA-Video [104], InternVL2 [13], और Qwen2-VL-Instruct [82]।
इस व्यापक प्रायोगिक डिजाइन, इसके कस्टम डेटासेट, बेंचमार्क और बेसलाइन के विविध सेट के साथ, INST-IT की प्रभावशीलता का गहन मूल्यांकन करने की अनुमति दी।
जो सबूत साबित करते हैं
प्रायोगिक परिणाम निर्णायक, निर्विवाद सबूत प्रदान करते हैं कि INST-IT दृष्टिकोण LMMs में इंस्टेंस-स्तरीय समझ को महत्वपूर्ण रूप से बढ़ावा देता है, जबकि उनकी सामान्य समझ क्षमताओं को भी मजबूत करता है।
INST-IT बेंच (तालिका 2) पर, INST-IT द्वारा संवर्धित मॉडल ने उत्कृष्ट प्रदर्शन प्रदर्शित किया। उदाहरण के लिए, Vicuna-7B के साथ LLaVA-NeXT-INST-IT ने छवि ओपन-एंडेड (OE) प्रश्न-उत्तर में 68.6 और मल्टीपल-चॉइस (MC) प्रश्न-उत्तर में 63.0 हासिल किया, जो LLaVA-NeXT बेसलाइन (छवि के लिए तालिका 2 से 46.0 OE, 42.4 MC) की तुलना में एक महत्वपूर्ण छलांग है। वीडियो कार्यों में, INST-IT संवर्धित मॉडल ने 49.3 OE और 42.1 MC स्कोर किया, जो LLaVA-NeXT-Video बेसलाइन (25.8 OE, 24.8 MC) से काफी बेहतर प्रदर्शन करता है। पत्र स्पष्ट रूप से "औसत स्कोर पर लगभग 20% का सुधार" बताता है, जो INST-IT के मुख्य तंत्र का एक मजबूत सत्यापन है।
अपने स्वयं के बेंचमार्क से परे, INST-IT मॉडल ने अन्य स्थापित इंस्टेंस समझ बेंचमार्क पर लगातार सुधार दिखाया:
- RefCOCOg [53] पर, LLaVA-NeXT-INST-IT-Vicuna-7B मॉडल ने अपने LLaVA-NeXT-Vicuna-7B बेसलाइन (63.0% बनाम 52.2%) पर 10.8% का सुधार हासिल किया। यह कठिन सबूत है कि स्पष्ट विज़ुअल प्रॉम्प्ट इंस्ट्रक्शन ट्यूनिंग सीधे मॉडल की संदर्भित अभिव्यक्तियों को समझने और उन्हें विशिष्ट इंस्टेंस पर ग्राउंड करने की क्षमता को बढ़ाता है।
- ViP-Bench [5] (तालिका 5) के लिए, Vicuna-7B के साथ INST-IT ने मानव-शैली विज़ुअल प्रॉम्प्ट का उपयोग करते समय, ViP-LLaVA के बराबर प्रदर्शन प्राप्त किया, और कुछ मामलों में उससे बेहतर भी। यह विशेष रूप से सम्मोहक है क्योंकि ViP-LLaVA को ViP-Bench डेटासेट पर फाइन-ट्यून किया गया था, जबकि INST-IT का मूल्यांकन शून्य-शॉट तरीके से किया गया था, जो मजबूत सामान्यीकरण क्षमताओं को प्रदर्शित करता है।
इसके अलावा, सामान्य बेंचमार्क पर मॉडल की सामान्य समझ क्षमताओं में भी महत्वपूर्ण लाभ देखा गया:
- छवि बेंचमार्क (तालिका 3) के लिए, INST-IT ने लगातार LLaVA-NeXT बेसलाइन को बेहतर प्रदर्शन किया। विशेष रूप से, इसने Vicuna-7B वेरिएंट के साथ AI2D [28] पर 4.4% और ChartQA [54] पर 13.5% का लाभ हासिल किया। इन बेंचमार्क के लिए ग्राउंडिंग और तर्क की आवश्यकता होती है, यह दर्शाता है कि INST-IT की महीन-दानेदार समझ व्यापक विज़ुअल तर्क में तब्दील होती है।
- वीडियो बेंचमार्क (तालिका 4) पर, INST-IT मॉडल ने LLaVA-NeXT और LLaVA-NeXT-Video दोनों बेसलाइन को महत्वपूर्ण रूप से बेहतर प्रदर्शन किया। उदाहरण के लिए, इसने Vicuna-7B वेरिएंट के साथ Egoschema [52] पर 7.8% और NEXT-QA [85] पर 11.8% का सुधार दिखाया। ये परिणाम पुष्टि करते हैं कि स्पष्ट विज़ुअल प्रॉम्प्ट के माध्यम से इंस्टेंस-स्तरीय समझ को बढ़ाना सामान्य स्पेटियोटेम्पोरल समझ को बेहतर बनाने के लिए एक कुशल रणनीति है।
एब्लेशन अध्ययन ने योगदानों को और अलग किया:
- निरंतर इंस्ट्रक्शन-ट्यूनिंग प्रतिमान (तालिका 6) महत्वपूर्ण था। वीडियो डेटा को सामान्य इंस्ट्रक्शन डेटा के साथ सीधे मिश्रित करने से छवि समझ में गिरावट आई, लेकिन फ्रीज किए गए विजन एनकोडर के साथ प्रस्तावित निरंतर SFT ने छवि और वीडियो दोनों कार्यों में संतुलित प्रदर्शन प्राप्त किया, विज़ुअल रूप से प्रॉम्प्ट की गई छवियों से वितरण शिफ्ट को कम किया।
- विस्तृत डेटासेट संयोजन (तालिका 7) से पता चला कि इंस्टेंस-स्तरीय और छवि-स्तरीय फ्रेम कैप्शन छवि इंस्टेंस समझ के लिए आवश्यक हैं, जबकि अस्थायी अंतर, वीडियो-स्तरीय विवरण और QA वीडियो इंस्टेंस समझ के लिए महत्वपूर्ण हैं। INST-IT डेटासेट के छवि घटक को शामिल करने से अंततः सबसे संतुलित प्रदर्शन प्राप्त हुआ।
संक्षेप में, सबूत स्पष्ट रूप से साबित करते हैं कि INST-IT के बहु-स्तरीय, इंस्टेंस-ग्राउंडेड एनोटेशन स्पष्ट विज़ुअल प्रॉम्प्टिंग और एक निरंतर इंस्ट्रक्शन-ट्यूनिंग प्रतिमान के साथ मिलकर LMMs को बेहतर महीन-दानेदार इंस्टेंस समझ से लैस करने में प्रभावी हैं, जो बदले में उनकी समग्र मल्टीमॉडल समझ को मजबूत करता है।
सीमाएँ और भविष्य की दिशाएँ
जबकि INST-IT LMMs के लिए इंस्टेंस-स्तरीय समझ में एक महत्वपूर्ण प्रगति प्रस्तुत करता है, लेखक ईमानदारी से कई सीमाओं को स्वीकार करते हैं और विकास के रोमांचक रास्ते प्रस्तावित करते हैं।
वर्तमान सीमाएँ:
1. कम्प्यूटेशनल लागत: वर्तमान प्रयोग मुख्य रूप से 7B और 1.5B पैरामीटर मॉडल पर किए जाते हैं। बहुत बड़े मॉडल (जैसे, 70B या उससे अधिक) तक स्केलिंग निषेधात्मक लागतों द्वारा बाधित होती है, जो वर्तमान शोध के दायरे को सीमित करती है।
2. GPT-4o ओवरहेड: स्वचालित डेटा एनोटेशन पाइपलाइन, प्रभावी होने के बावजूद, GPT-4o पर निर्भर करती है। यह एक अंतर्निहित ओवरहेड प्रस्तुत करता है, जो और भी बड़े और अधिक विविध डेटासेट उत्पन्न करने के लिए एक बाधा हो सकता है।
3. विफलता के मामले: मॉडल कभी-कभी चुनौतीपूर्ण परिदृश्यों में संघर्ष करते हैं जैसे कि गंभीर रूप से ऑक्लूडेड इंस्टेंस, धुंधली छवियां, या अत्यधिक छोटे या भीड़भाड़ वाले इंस्टेंस। ये LMMs के लिए सामान्य बाधाएं हैं और उन क्षेत्रों का संकेत देते हैं जहां मजबूती में सुधार किया जा सकता है।
4. निष्पक्षता और पूर्वाग्रह: कई बड़े मल्टीमॉडल मॉडल की तरह, INST-IT प्रशिक्षण डेटा या मॉडल के सीखे गए अभ्यावेदन से उत्पन्न होने वाले निष्पक्षता और पूर्वाग्रह से संबंधित संभावित जोखिमों का सामना करता है। यह एक महत्वपूर्ण नैतिक विचार है जिस पर निरंतर ध्यान देने की आवश्यकता है।
भविष्य की दिशाएँ और चर्चा विषय:
इन निष्कर्षों के आधार पर, आगे के विकास और विकास के लिए कई चर्चा विषय उभरते हैं:
-
स्केलिंग और स्व-पर्यवेक्षित डेटा जनरेशन:
- हम इंस्टेंस-स्तरीय इंस्ट्रक्शन ट्यूनिंग के लिए अधिक कम्प्यूटेशनल रूप से कुशल तरीके कैसे विकसित कर सकते हैं जो अत्यधिक लागतों के बिना बहुत बड़े LMMs तक स्केलिंग की अनुमति देते हैं?
- क्या हम "मॉडल-इन-द-लूप" दृष्टिकोण की ओर बढ़ सकते हैं जहां मॉडल स्वयं, एक बार आंशिक रूप से प्रशिक्षित होने के बाद, अधिक उच्च-गुणवत्ता, स्व-संश्लेषित इंस्टेंस-स्तरीय डेटा उत्पन्न करने में सहायता करता है, जिससे GPT-4o जैसे महंगे मालिकाना एपीआई पर निर्भरता कम हो जाती है? इसमें पुनरावृत्ति शोधन शामिल हो सकता है जहां मॉडल डेटा उत्पन्न करता है, एक छोटा मानव सत्यापन चरण होता है, और मॉडल को फिर से प्रशिक्षित किया जाता है।
-
चुनौतीपूर्ण विज़ुअल स्थितियों के प्रति बढ़ी हुई मजबूती:
- कौन से उपन्यास वास्तुशिल्प डिजाइन या प्रशिक्षण रणनीतियाँ विशेष रूप से पहचाने गए विफलता के मामलों (ऑक्लूजन, धुंधलापन, छोटे/भीड़भाड़ वाले इंस्टेंस) को संबोधित कर सकती हैं? क्या अनिश्चितता अनुमान या मल्टी-व्यू फ्यूजन तकनीकों को शामिल करने से इन कठिन परिदृश्यों में प्रदर्शन में सुधार हो सकता है?
- हम इन विफलता मोड को विशेष रूप से लक्षित करने वाले विविध और चुनौतीपूर्ण उदाहरण बनाने के लिए सिंथेटिक डेटा जनरेशन का अधिक प्रभावी ढंग से लाभ कैसे उठा सकते हैं, जिससे मॉडल की मजबूती में सुधार हो?
-
पूर्वाग्रह को कम करना और निष्पक्षता सुनिश्चित करना:
- निष्पक्षता और पूर्वाग्रह के मुद्दों की क्षमता को देखते हुए, INST-IT डेटासेट और भविष्य के डेटासेट को अधिक न्यायसंगत और प्रतिनिधि बनाने के लिए क्या व्यवस्थित डेटा फ़िल्टरिंग और सत्यापन दृष्टिकोण लागू किए जा सकते हैं?
- डेटा-केंद्रित समाधानों से परे, इंस्टेंस समझ में पूर्वाग्रहों का पता लगाने और कम करने के लिए क्या मॉडल-अज्ञेय या मॉडल-विशिष्ट तकनीकें (जैसे, डीबायसिंग एल्गोरिदम, इंस्टेंस-स्तरीय निर्णयों का ऑडिट करने के लिए व्याख्या योग्य एआई विधियां) विकसित की जा सकती हैं?
-
विस्तारित स्पेटियोटेम्पोरल तर्क और भविष्य कहनेवाला क्षमताएँ:
- जबकि INST-IT वर्तमान और अस्थायी परिवर्तनों का वर्णन करने में उत्कृष्ट है, हम LMMs को अधिक जटिल स्पेटियोटेम्पोरल तर्क करने के लिए कैसे आगे बढ़ा सकते हैं, जैसे कि भविष्य की क्रियाओं या इंस्टेंस के प्रक्षेपवक्र की भविष्यवाणी करना, या एक वीडियो में इंस्टेंस के बीच दीर्घकालिक कारण संबंधों को समझना?
- क्या भौतिकी-सूचित तंत्रिका नेटवर्क या सामान्य ज्ञान तर्क मॉड्यूल को शामिल करने से मॉडल की अवलोकन से परे इंस्टेंस इंटरैक्शन के बारे में तर्क करने की क्षमता और बढ़ सकती है?
-
वास्तविक दुनिया परिनियोजन और मानव-एआई सहयोग:
- उन अनुप्रयोगों में INST-IT फ्रेमवर्क को कैसे एकीकृत किया जा सकता है जहां उपयोगकर्ताओं को संख्यात्मक आईडी की तुलना में अधिक सहज इंटरफेस के माध्यम से, इंटरैक्टिव रूप से रुचि के इंस्टेंस को निर्दिष्ट करने की आवश्यकता होती है?
- महीन-दानेदार विज़ुअल समझ की आवश्यकता वाले कार्यों में मानव-एआई सहयोग के लिए क्या निहितार्थ हैं? क्या INST-IT-संवर्धित LMMs वीडियो संपादन, निगरानी विश्लेषण, या वैज्ञानिक अवलोकन जैसे कार्यों के लिए अधिक प्रभावी सहायक के रूप में काम कर सकते हैं, सटीक इंस्टेंस-स्तरीय अंतर्दृष्टि प्रदान करके? यह मानव उपयोगकर्ताओं के लिए मॉडल के इंस्टेंस-स्तरीय तर्क की व्याख्यात्मकता के बारे में भी प्रश्न उठाता है।
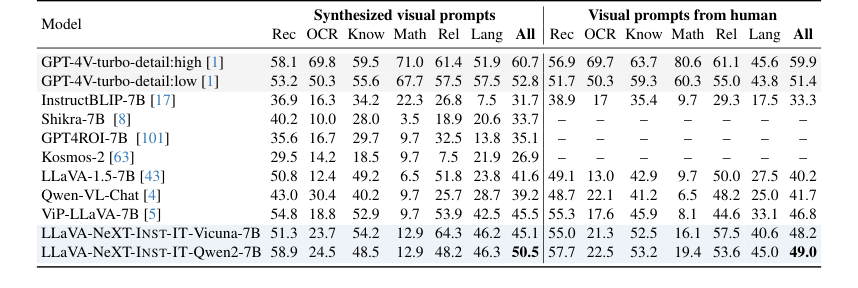 Table 5. Results on ViP-Bench. We perform evaluation with our INST-IT models without fine-tuning
Table 5. Results on ViP-Bench. We perform evaluation with our INST-IT models without fine-tuning
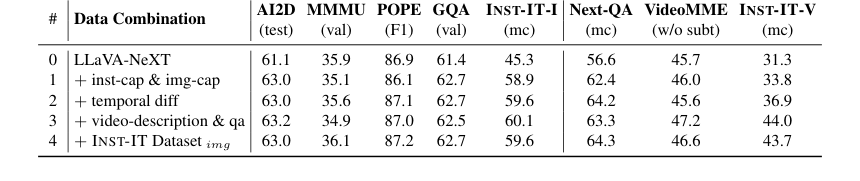 Table 7. Ablation on detailed data combination. The dataset combination in line #3 corresponds to the video part of INST-IT Dataset, while line #4 represents the complete INST-IT Dataset by incorporating the image part into line #3
Table 7. Ablation on detailed data combination. The dataset combination in line #3 corresponds to the video part of INST-IT Dataset, while line #4 represents the complete INST-IT Dataset by incorporating the image part into line #3
 Table 9. Statistical and lexical analysis of INST-IT Dataset. We present the results for each annotation level as well as the entire dataset
Table 9. Statistical and lexical analysis of INST-IT Dataset. We present the results for each annotation level as well as the entire dataset