INST-IT: Улучшение понимания экземпляров посредством явной настройки инструкций с визуальными подсказками
Проблема, рассматриваемая в данной статье, непосредственно вытекает из последних достижений и, парадоксальным образом, ограничений больших мультимодальных моделей (LMM) в области искусственного интеллекта, в...
Предпосылки и академическая родословная
Истоки и академическая родословная
Проблема, рассматриваемая в данной статье, непосредственно вытекает из последних достижений и, парадоксальным образом, ограничений больших мультимодальных моделей (LMM) в области искусственного интеллекта, в частности, в компьютерном зрении и обработке естественного языка. В то время как LMM добились значительных прорывов, во многом благодаря "настройке инструкций" (instruction tuning), позволяющей им понимать изображения и видео на целостном, или общем, уровне и следовать разнообразным инструкциям пользователя, они постоянно испытывают трудности с более детальной задачей: "пониманием на уровне экземпляров" (instance-level understanding).
Исторически, стремление к пониманию отдельных объектов в визуальных данных было давней целью в компьютерном зрении, что привело к обширным исследованиям в таких областях, как обнаружение объектов, сегментация экземпляров и отслеживание объектов. Однако с появлением LMM задача сместилась. "Болевой точкой" предыдущих подходов, особенно существующих LMM, является их неспособность понимать конкретные элементы или "экземпляры" в изображении или видео с детальной точностью и выравниванием, особенно когда пользователи задают о них конкретные вопросы. Например, LMM может описать "толпу людей", но не сможет ответить на вопрос "Что делает человек в красной шляпе?" или "Как изменилось взаимодействие между человеком 1 и человеком 2 со временем?". Это ограничение еще более выражено в видео, где понимание не только пространственной информации, но и временной динамики отдельных экземпляров становится критически важным. Существующие мультимодальные наборы данных и бенчмарки в основном предлагают знания грубой зернистости, не имея детальных аннотаций, необходимых для обучения и оценки LMM для этого тонкого понимания на уровне экземпляров. Этот фундаментальный пробел вынудил авторов разработать INST-IT, решение для улучшения способности LMM понимать отдельные экземпляры посредством явной настройки инструкций с визуальными подсказками.
Интуитивные термины предметной области
- Большие мультимодальные модели (LMM): Представьте себе сверхразумного цифрового помощника, который может не только читать и писать текст, но и "видеть" и "понимать" изображения и видео. Это похоже на личного эксперта, который может посмотреть на фотографию или видеоклип, а затем обсудить его с вами на естественном языке.
- Настройка инструкций (Instruction Tuning): Это похоже на обучение этого сверхразумного помощника путем предоставления ему множества конкретных примеров задач и точного указания, что делать. Например, вы показываете ему изображение и "даете инструкцию": "Опиши это изображение" или "Ответь на этот вопрос об изображении". Помощник учится следовать этим инструкциям, видя бесчисленные примеры.
- Понимание на уровне экземпляров (Instance-level Understanding): Вместо простого описания всей сцены (например, "парк со множеством людей") это означает, что помощник может сосредоточиться на отдельных объектах (экземплярах) в этой сцене. Это похоже на то, как можно указать на конкретного человека в парке и спросить: "Что этот человек носит?" или "Играет ли эта собака с этим мячом?". Речь идет о понимании деталей каждого конкретного объекта и их взаимоотношений.
- Визуальные подсказки "Набор отметок" (Set-of-Marks (SoMs) Visual Prompting): Представьте, что вы ставите пронумерованные наклейки или рисуете круги вокруг определенных объектов на изображении или видео. Вы буквально "отмечаете" экземпляры, на которые хотите, чтобы умный помощник обратил внимание, например: "Посмотри на объект №1, затем на объект №2". Это помогает направить его внимание на отдельные объекты для более точного понимания.
Таблица обозначений
| Обозначение | Описание |
|---|---|
| LMMs | Большие мультимодальные модели, способные понимать и генерировать контент в различных модальностях (например, текст, изображения, видео). |
| SoMs | Визуальные подсказки "Набор отметок", техника, при которой числовые идентификаторы накладываются на экземпляры в визуальных входных данных для фокусировки модели. |
| INST-IT | Предлагаемая структура, набор данных и бенчмарк для улучшения понимания экземпляров в LMM. |
| $X_t$ | Визуальные данные (изображение или кадр видео) во временной точке $t$. |
| $X_{t-1}$ | Визуальные данные (изображение или кадр видео) во временной точке $t-1$, используемые для временного сравнения. |
| $P^f$ | Подсказка задачи, специально разработанная для генерации аннотаций на уровне кадров. |
| $Y_t^f$ | Аннотация на уровне кадров для кадра $t$, включающая описания экземпляров, подписи к изображениям и временные различия. |
| $P^{vid}$ | Подсказка задачи, специально разработанная для генерации сводок видео. |
| $Y^{vid}$ | Сводка на уровне видео, агрегирующая информацию из всех аннотаций на уровне кадров. |
| $P^{qa}$ | Подсказка задачи, специально разработанная для генерации пар вопросов и ответов с открытым концом. |
| $Y^{qa}$ | Выходные данные пар вопросов и ответов с открытым концом, ориентированные на понимание на уровне экземпляров. |
| $\text{GPT}(\cdot)$ | Обозначает большую языковую модель GPT-4o, используемую в качестве интеллектуального аннотатора в конвейере генерации данных. |
| $N$ | Общее количество кадров в видео. |
| $M$ | Общее количество пар вопросов и ответов с открытым концом, сгенерированных для видео. |
| SFT | Supervised Fine-Tuning (Супервизорная дообучение), парадигма обучения, используемая для улучшения LMM с помощью набора данных INST-IT. |
Определение проблемы и ограничения
Основная постановка проблемы и дилемма
Текущее состояние больших мультимодальных моделей (LMM) представляет собой значительную дихотомию: в то время как они достигли замечательного прогресса в понимании изображений и видео на целостном, сценарном уровне, они постоянно терпят неудачу при выполнении задач, требующих понимания на уровне экземпляров. Это означает, что LMM могут описывать общее содержание видео, но испытывают трудности с точным определением, отслеживанием и рассуждением о конкретных объектах или лицах в нем, особенно об их атрибутах, взаимоотношениях и временных взаимодействиях.
Желаемая конечная цель — наделить LMM надежными возможностями понимания на уровне экземпляров как для изображений, так и для видео. Это включает в себя предоставление моделям возможности точно следовать инструкциям пользователя, относящимся к конкретным элементам, понимать их детальные характеристики и отслеживать их динамические изменения во времени.
Точным недостающим звеном или математическим пробелом между этими состояниями является отсутствие достаточно богатых, основанных на экземплярах, многоуровневых данных для настройки инструкций. Существующие наборы данных в основном предлагают аннотации грубой зернистости, которые не подходят для обучения LMM выполнению детального понимания экземпляров. Данная статья пытается устранить этот пробел, представляя новый конвейер для генерации таких данных и парадигму непрерывной настройки инструкций.
Эта проблема заставила предыдущих исследователей попасть в болезненный компромисс:
* Целостное против детального понимания: Улучшение способности LMM понимать общую сцену часто происходит за счет ее способности к детальному пониманию экземпляров, или наоборот. Достижение обоих одновременно является серьезной проблемой.
* Понимание экземпляров изображений против видео: Хотя некоторый прогресс был достигнут в понимании экземпляров для статических изображений, распространение этого на динамические видео создает значительную сложность. Видео требуют не только пространственного понимания, но и способности отслеживать и рассуждать о временной динамике — как экземпляры меняются, перемещаются и взаимодействуют во времени. Это дополнительное измерение делает понимание экземпляров видео "значительно более сложным".
* Масштаб аннотаций против качества: Создание высококачественных, детальных аннотаций для отдельных экземпляров является трудоемким и дорогостоящим процессом. Предыдущие усилия либо предоставляли данные грубой зернистости в большом масштабе, либо данные детальной зернистости в ограниченном масштабе. Дилемма заключается в том, как эффективно генерировать как крупномасштабные, так и высококачественные детальные аннотации для сложных мультимодальных данных (изображений и видео).
* Обобщение против специализации: Модели, дообученные для конкретных задач понимания экземпляров, рискуют переобучиться на своих тренировочных данных, потенциально ухудшая их общие способности к пониманию. Задача состоит в том, чтобы улучшить понимание экземпляров, одновременно укрепляя общее понимание в различных задачах с изображениями и видео.
Ограничения и режимы сбоя
Проблема достижения надежного понимания на уровне экземпляров в LMM чрезвычайно сложна из-за нескольких суровых, реалистичных стен, с которыми столкнулись авторы:
- Вычислительные накладные расходы GPT-4o: Автоматизированный конвейер аннотирования данных, хотя и эффективен, "ограничен накладными расходами GPT-4o". Это подразумевает, что генерация больших объемов высококачественных, многоуровневых аннотаций, особенно для видео, по-прежнему является трудоемким и дорогостоящим процессом, ограничивающим масштаб, в котором такие данные могут быть произведены.
- Пределы памяти оборудования: Процесс обучения LMM, особенно с видеовходами, ограничен "пределами памяти GPU". Авторы явно заявляют, что они "ограничивают максимальное количество кадров до 32, а длину контекста LLM до 6K из-за ограничений памяти GPU", что указывает на практический барьер для обработки более длинных или более высокоразрешающих видеопоследовательностей.
- Галлюцинации и отвлечение от необработанных визуальных входных данных: LMM при прямой обработке необработанных визуальных входных данных "страдают от галлюцинаций и отвлечения". Это присущее ограничение означает, что модели с трудом надежно фокусируются на конкретных экземплярах и извлекают информацию о них без явного руководства, что требует использования визуальных подсказок.
- Дефицит данных, основанных на экземплярах: Фундаментальное ограничение заключается в "дефиците данных, основанных на экземплярах", для настройки инструкций, особенно для видео. Этот пробел в данных является основной причиной того, что LMM испытывают трудности с пониманием экземпляров, поскольку недостаточно детального надзора для изучения этих возможностей.
- Сложность временной динамики: Понимание экземпляров в видео требует захвата не только пространственной информации, но и сложной "временной динамики". Это включает отслеживание изменений в положении объектов, действиях и взаимоотношениях между последовательными кадрами, что является значительно более сложной задачей, чем анализ статических изображений.
- Проблемы обеспечения качества данных: Даже при автоматизированном конвейере, использующем GPT-4o, обеспечение высокого качества и согласованности многоуровневых, детальных аннотаций является сложной задачей. В статье упоминается, что для обеспечения качества данных необходима "строгая ручная проверка и доработка", что подчеркивает трудность полной автоматизации надежного аннотирования.
Авторы выделяют конкретные режимы сбоя для LMM в этом контексте:
- Перекрытие, размытые изображения и мелкие/переполненные экземпляры: Производительность модели снижается в сценариях, где "экземпляры сильно перекрыты, изображение размыто, или экземпляры чрезмерно малы или переполнены". Это распространенные реальные условия, которые представляют значительные трудности для систем визуального восприятия.
- Сдвиг распределения от визуальных подсказок: Использование "изображений с визуальными подсказками может привести к сдвигу распределения от естественных изображений". Это может привести к снижению производительности на общих задачах понимания изображений, если модель не обучена тщательно для смягчения этого сдвига.
- Подавление понимания изображений видеоданными: Прямое смешивание высокого соотношения видеоданных с общими данными для настройки инструкций может "подавить понимание изображений", указывая на потенциальный дисбаланс в обучении при объединении различных модальностей.
- Переобучение на тренировочных данных: Некоторые модели, даже при использовании визуальных подсказок, показывают лишь "незначительное улучшение по сравнению с их базовым уровнем, т.е. LLaVA-1.5, возможно, из-за переобучения на их тренировочных данных". Это предполагает, что без тщательного проектирования модели могут запоминать тренировочные примеры, а не изучать обобщаемые способности к пониманию экземпляров.
- Недостаточное масштабирование размера модели или данных грубой зернистости: В статье прямо указано, что "простое масштабирование размера модели не может решить проблемы понимания экземпляров" и что "крупномасштабные аннотации грубой зернистости также не приводят к существенным улучшениям". Это подчеркивает, что проблема требует качественного сдвига в данных и методологии обучения, а не просто количественного масштабирования.
Почему такой подход
Неизбежность выбора
Решение авторов использовать явную настройку инструкций с визуальными подсказками в сочетании с созданием набора данных и бенчмарка INST-IT было не просто предпочтением, а необходимостью, обусловленной присущими ограничениями существующих больших мультимодальных моделей (LMM). Основное осознание заключалось в том, что, хотя LMM добились значительных успехов в понимании изображений и видео на целостном, или общем, уровне, они постоянно "испытывают трудности с пониманием на уровне экземпляров, которое требует более детального понимания и выравнивания" (Аннотация, Раздел 1). Это означает, что традиционные методы "SOTA", такие как стандартные CNN, базовые модели Diffusion или Трансформеры, даже будучи интегрированными в LMM, были принципиально недостаточны для задач, требующих точного, специфичного для объекта рассуждения.
Точный момент этого осознания неявно подчеркивается наблюдением, что текущие LMM, несмотря на прорывы в настройке инструкций, "все еще испытывают трудности с пониманием специфического для экземпляра контента, который наиболее интересует пользователей, как показано на рис. 1 (а)" (Раздел 1). Это не сбой базовых архитектур в обработке визуальных данных, а скорее их неспособность связывать инструкции с конкретными экземплярами в сложных сценах, особенно как в изображениях, так и в видео. Проблема заключалась не в отсутствии мощных базовых моделей, а в критическом пробеле в данных и методологии, необходимых для обучения этих моделей детальному пониманию экземпляров. Существующие мультимодальные бенчмарки и наборы данных в основном предлагали "знания грубой зернистости для изображений и видео, не имея детальных аннотаций для отдельных экземпляров" (стр. 2). Следовательно, новый подход, который явно предоставлял бы руководство на уровне экземпляров посредством визуальных подсказок и выделенного, богато аннотированного набора данных, был единственным жизнеспособным решением для устранения этого пробела.
Сравнительное превосходство
Подход INST-IT демонстрирует качественное превосходство над предыдущими золотыми стандартами по нескольким ключевым аспектам, выходящим за рамки простых метрик производительности.
Во-первых, он превосходно справляется с высокоразмерным шумом и отвлечениями. В статье отмечается, что "прямая обработка необработанных визуальных входных данных страдает от галлюцинаций и отвлечения" (Раздел 2.1). Для смягчения этого метод использует визуальные подсказки "Набор отметок" (SoMs), которые накладывают числовые идентификаторы на каждый экземпляр. Это простое, но эффективное дополнение явно направляет базовую модель GPT-4o на "более эффективную фокусировку на интересующих экземплярах" (Раздел 2.1), тем самым уменьшая "шум" нерелевантной визуальной информации и обеспечивая более детальные и точные аннотации. Это структурное преимущество позволяет модели проникать сквозь визуальный беспорядок и концентрироваться на указанных пользователем экземплярах.
Во-вторых, метод решает проблему сложности памяти для видеовходов. Хотя прямо не указывается сокращение с $O(N^2)$ до $O(N)$, авторы упоминают применение "пространственного пулинга 2 × 2 для уменьшения количества визуальных токенов во входных данных видео" (Раздел 2.4). Это понижающее дискретизацию визуальных токенов напрямую способствует снижению вычислительной нагрузки и требований к памяти, что критически важно для обработки длинных видеопоследовательностей и соответствует практическим ограничениям памяти GPU (Раздел 3.1).
Подавляющее структурное преимущество заключается в его способности способствовать истинному пониманию на уровне экземпляров как для изображений, так и для видео, включая временную динамику. В отличие от предыдущих методов, которые фокусировались на целостном понимании, набор данных INST-IT предоставляет многоуровневые, детальные аннотации, охватывающие описания на уровне экземпляров, подписи на уровне изображений, временную динамику, сводки на уровне видео и пары вопросов и ответов с открытым концом (стр. 2, Раздел 2.1). Эти богатые, структурированные данные в сочетании с рецептом непрерывной настройки инструкций позволяют LMM не только идентифицировать экземпляры, но и понимать их атрибуты, взаимоотношения и пространственно-временную эволюцию. Результаты показывают, что этот подход приводит к "последовательным улучшениям на других бенчмарках понимания экземпляров" и "существенным улучшениям по сравнению с базовым уровнем" на общих бенчмарках (Аннотация, Раздел 3.2), указывая на обобщаемое улучшение, а не просто на переобучение. Кроме того, в статье подчеркивается, что их метод достигает сопоставимой производительности с более крупными и более дорогостоящими вычислительно SFT LMM, "требуя при этом значительно меньших вычислительных затрат и затрат на данные" (Раздел 3.2), что подчеркивает его преимущество в эффективности.
Соответствие ограничениям
Выбранный метод, INST-IT, идеально соответствует неявным ограничениям и проблемам, изложенным в определении проблемы. Этот "брак" между суровыми требованиями проблемы и уникальными свойствами решения проявляется несколькими способами:
- Устранение пробела в понимании на уровне экземпляров: Основным ограничением была неспособность существующих LMM достичь детального понимания экземпляров. INST-IT напрямую решает эту проблему, предоставляя "явную настройку инструкций с визуальными подсказками для руководства по экземплярам" (Аннотация). Парадигма настройки инструкций, дополненная визуальными подсказками, заставляет модель учиться связывать инструкции с конкретными визуальными сущностями.
- Преодоление дефицита данных: Основным узким местом был "отсутствие наборов данных на уровне экземпляров" (Раздел 2.2). Набор данных INST-IT был тщательно создан как "первый набор данных для настройки инструкций, основанный на экземплярах, который включает как изображения, так и видео, содержащие явные визуальные подсказки на уровне экземпляров и детальные аннотации, основанные на отдельных экземплярах" (Вклад 1, стр. 2). Это напрямую удовлетворяет потребность в комплексных, детальных данных.
- Обработка пространственно-временной динамики в видео: Проблема подчеркивала сложность понимания экземпляров в видео, требующую как пространственного, так и временного понимания. Многоуровневые аннотации набора данных INST-IT включают "описания временной динамики" и "сводки на уровне видео" (стр. 2, Раздел 2.1), явно обучая модель захватывать изменения и взаимодействия во времени. Рецепт непрерывной настройки инструкций далее интегрирует это пространственно-временное понимание.
- Смягчение галлюцинаций и отвлечений: Ограничение необработанных визуальных входных данных, приводящее к "галлюцинациям и отвлечению" (Раздел 2.1), решается с помощью техники "визуальных подсказок 'Набор отметок' (SoMs) [88]". Накладывая числовые идентификаторы на экземпляры, модель явно направляется на фокусировку на конкретных объектах, тем самым уменьшая неоднозначность и повышая точность аннотирования.
- Вычислительная эффективность: Практические ограничения часто связаны с вычислительными ресурсами. В статье упоминается "ограничение максимального количества кадров до 32 и длины контекста LLM до 6K из-за ограничений памяти GPU" и применение "пространственного пулинга 2 × 2 для уменьшения количества визуальных токенов" (Раздел 3.1). Тот факт, что INST-IT достигает высокой производительности при "значительно меньших вычислительных затратах и затратах на данные" по сравнению с более крупными SFT LMM (Раздел 3.2), демонстрирует его соответствие ресурсоэффективному развертыванию.
Отклонение альтернатив
Статья неявно, но четко отвергает несколько альтернативных подходов, подчеркивая их недостатки в решении основной проблемы понимания на уровне экземпляров в мультимодальных данных.
Во-первых, она отвергает эффективность простого использования существующих LMM "SOTA" без специализированной настройки инструкций и данных. Авторы заявляют, что, хотя эти модели "могут понимать изображения и видео на целостном уровне, они все еще испытывают трудности с пониманием специфического для экземпляра контента" (Раздел 1). Это подразумевает, что общие LMM, даже мощные, не обладают детальными возможностями привязки, необходимыми для этой задачи. Проблема не в отсутствии общего интеллекта, а в отсутствии ориентированного на экземпляры следования инструкциям.
Во-вторых, статья явно отвергает другие популярные наборы данных для настройки инструкций как недостаточные. В Таблице 1 и Разделе 2.2 она сравнивает INST-IT с такими наборами данных, как ShareGPT4Video, LLaVA-Video и ViP-LLaVA-Data. Отмечается, что предыдущие видео наборы данных "ориентированы на целостное понимание без аннотаций на уровне экземпляров", и хотя ViP-LLaVA "предлагает аннотации экземпляров для изображений, он не включает никаких видеоданных". Это прямое отклонение этих альтернатив, поскольку они не предоставляют необходимых многоуровневых, детальных, основанных на экземплярах аннотаций как для изображений, так и для видео, которые предлагает INST-IT. Авторы приходят к выводу, что "отсутствие наборов данных на уровне экземпляров препятствует развитию понимания экземпляров" (Раздел 2.2), делая существующие наборы данных неадекватными.
Наконец, статья отвергает идею о том, что простое масштабирование размера модели или использование большего количества данных грубой зернистости решит проблему. Отмечается, что "Qwen2VL-72B не показывает существенных улучшений по сравнению с его меньшей моделью 7B, что указывает на то, что простое масштабирование размера модели не может решить проблемы понимания экземпляров" (Раздел 3.2). Аналогично, отмечается, что "крупномасштабные аннотации грубой зернистости также не приводят к существенным улучшениям" (Раздел 3.2). Эти рассуждения подчеркивают, что решение заключается не в грубом масштабировании существующих методов или данных, а в целенаправленном подходе, который фокусируется на явном руководстве на уровне экземпляров посредством специализированных данных и настройки инструкций.
 Figure 8. A data example from INST-IT Bench. Each test sample includes both open-ended QA and multiple-choice QA, focusing on specific instances or the relationships and interactions between instances
Figure 8. A data example from INST-IT Bench. Each test sample includes both open-ended QA and multiple-choice QA, focusing on specific instances or the relationships and interactions between instances
Математический и логический механизм
Мастер-уравнение
Основной математический и логический механизм INST-IT — это не единая целевая функция для оптимизации моделью, а скорее сложный конвейер генерации данных, который использует мощную большую языковую модель (LLM), в частности GPT-4o, для создания богатых, многогранных аннотаций. Эти аннотации затем формируют набор данных INST-IT, который используется для настройки инструкций других LMM. Основные операции в этом конвейере определяются тремя ключевыми уравнениями, каждое из которых представляет собой отдельный этап генерации аннотаций:
1. Аннотация на уровне кадров:
$$Y_t^f = \text{GPT}(P^f, X_t, X_{t-1})$$
2. Сводка на уровне видео:
$$Y^{vid} = \text{GPT}(P^{vid}, [Y_1^f, Y_2^f, \ldots, Y_N^f])$$
3. Пары вопросов и ответов с открытым концом:
$$Y^{qa} = \text{GPT}(P^{qa}, [Y_1^f, Y_2^f, \ldots, Y_N^f])$$
Пословный разбор
Давайте разберем каждый компонент этих уравнений, чтобы понять их точную роль в рамках INST-IT.
Уравнение (1): Аннотация на уровне кадров
$$Y_t^f = \text{GPT}(P^f, X_t, X_{t-1})$$
* $Y_t^f$:
* Математическое определение: Это выход модели GPT-4o для конкретного кадра видео во временной точке $t$. Это структурированная текстовая аннотация.
* Физическая/логическая роль: Она представляет собой всестороннее, детальное текстовое описание для одного кадра, охватывающее детали об отдельных экземплярах, общем содержании изображения и временных изменениях по сравнению с предыдущим кадром. Это фундаментальный строительный блок для всех последующих, более высокоуровневых аннотаций.
* $\text{GPT}(\cdot)$:
* Математическое определение: Обозначает большую языковую модель GPT-4o, рассматриваемую как функцию, которая принимает подсказку и визуальные входные данные для генерации текстового вывода.
* Физическая/логическая роль: GPT-4o действует как интеллектуальный аннотатор. Его расширенные возможности мультимодального понимания используются для интерпретации визуальной информации и генерации подробных описаний, похожих на человеческие, в соответствии с предоставленными инструкциями. Авторы выбрали GPT-4o за его превосходную способность обрабатывать сложные визуальные рассуждения и генерировать высококачественный текст, что имеет решающее значение для детального характера понимания экземпляров.
* $P^f$:
* Математическое определение: Строка естественного языка, в частности "специализированная подсказка задачи", разработанная для аннотирования на уровне кадров.
* Физическая/логическая роль: Эта подсказка служит точным набором инструкций для GPT-4o. Она направляет модель на фокусировку на конкретных аспектах кадра (например, отдельных экземплярах, общей сцене, временных различиях) и определяет желаемую структуру и содержание вывода $Y_t^f$. Тщательная разработка этой подсказки является ключом к получению точных и релевантных аннотаций.
* $X_t$:
* Математическое определение: Визуальные данные, соответствующие текущему кадру видео во временной точке $t$.
* Физическая/логическая роль: Это основной визуальный вход для GPT-4o, предоставляющий необработанную пиксельную информацию и визуальный контекст, который необходимо описать.
* $X_{t-1}$:
* Математическое определение: Визуальные данные, соответствующие предыдущему кадру видео во временной точке $t-1$.
* Физическая/логическая роль: Включение предыдущего кадра критически важно для захвата временной динамики. Сравнивая $X_t$ и $X_{t-1}$, GPT-4o может идентифицировать и описывать движения, изменения состояния или взаимодействия между экземплярами во времени, что необходимо для понимания видео.
* Математический оператор (применение функции): Операция представляет собой вызов функции к GPT-4o. Авторы используют это функциональное обозначение, поскольку GPT-4o является сложной генеративной моделью, а не простым арифметическим оператором. Он обрабатывает входные данные (подсказку, текущий кадр, предыдущий кадр) через свою внутреннюю архитектуру нейронной сети для получения связного текстового вывода.
Уравнение (2): Сводка на уровне видео
$$Y^{vid} = \text{GPT}(P^{vid}, [Y_1^f, Y_2^f, \ldots, Y_N^f])$$
* $Y^{vid}$:
* Математическое определение: Текстовая сводка всего видео, сгенерированная GPT-4o.
* Физическая/логическая роль: Она обеспечивает целостное, хронологическое повествование о содержании видео, агрегируя детальную информацию из всех отдельных аннотаций на уровне кадров в связную историю. Она захватывает общую пространственно-временную динамику и ключевые события.
* $\text{GPT}(\cdot)$: То же, что и в Уравнении (1).
* $P^{vid}$:
* Математическое определение: Строка естественного языка, в частности "подсказка задачи", разработанная для суммирования на уровне видео.
* Физическая/логическая роль: Эта подсказка инструктирует GPT-4o синтезировать всестороннюю сводку из последовательности описаний на уровне кадров, обеспечивая хронологический порядок и фокусировку на основных объектах и событиях.
* $[Y_1^f, Y_2^f, \ldots, Y_N^f]$:
* Математическое определение: Упорядоченный список или последовательность всех аннотаций на уровне кадров ($Y_t^f$), сгенерированных для видео, от первого кадра ($t=1$) до последнего кадра ($t=N$).
* Физическая/логическая роль: Эта последовательность служит текстовой "памятью" или "транскриптом" событий видео, предоставляя GPT-4o все необходимые детальные сведения для построения высокоуровневой сводки. Использование списка (неявно сумма информации), а не единого агрегированного значения, позволяет GPT-4o обрабатывать временную прогрессию и взаимосвязи между событиями.
* $N$:
* Математическое определение: Общее количество кадров в видео.
* Физическая/логическая роль: Это скаляр указывает на длину видео и, следовательно, на количество аннотаций на уровне кадров, которые необходимо учитывать для сводки видео.
Уравнение (3): Пары вопросов и ответов с открытым концом
$$Y^{qa} = \text{GPT}(P^{qa}, [Y_1^f, Y_2^f, \ldots, Y_N^f])$$
* $Y^{qa}$:
* Математическое определение: Набор из $M$ пар вопросов и ответов с открытым концом, $\{(q_i, a_i)\}_{i=1}^M$, сгенерированных GPT-4o.
* Физическая/логическая роль: Эти пары предназначены для тестирования и обучения LMM пониманию и рассуждению на уровне экземпляров. Они фокусируются на конкретных экземплярах, их атрибутах, взаимоотношениях и временных изменениях, предоставляя богатый источник данных для настройки инструкций.
* $\text{GPT}(\cdot)$: То же, что и в Уравнении (1).
* $P^{qa}$:
* Математическое определение: Строка естественного языка, в частности "подсказка задачи", разработанная для генерации пар вопросов и ответов с открытым концом.
* Физическая/логическая роль: Эта подсказка направляет GPT-4o на формулирование разнообразных и контекстуально релевантных вопросов и точных ответов на основе предоставленных аннотаций на уровне кадров. Она гарантирует, что пары вопросов и ответов нацелены на понимание на уровне экземпляров.
* $[Y_1^f, Y_2^f, \ldots, Y_N^f]$: То же, что и в Уравнении (2).
* Физическая/логическая роль: Подобно суммированию видео, эта последовательность предоставляет всесторонний текстовый контекст, из которого GPT-4o может извлекать вопросы и ответы, требуя от него рассуждения над детальными событиями и сущностями.
Пошаговый поток
Представьте, что видео поступает на сложный завод по аннотированию данных. Вот как информация одного видео обрабатывается через конвейер INST-IT:
- Прием визуального ввода: На первую станцию поступает необработанное видео, состоящее из последовательности кадров $X_1, X_2, \ldots, X_N$.
- Выделение экземпляров (визуальное подсказывание): На этой станции предварительный этап идентифицирует отдельные экземпляры (объекты) в каждом кадре. Для каждого обнаруженного экземпляра на него накладывается уникальный числовой идентификатор, создавая визуальную подсказку "Набор отметок" (SoM). Это гарантирует, что последующие этапы аннотирования будут явно фокусироваться на этих идентифицированных экземплярах.
- Сборочная линия аннотирования на уровне кадров:
- Кадры видео последовательно подаются в "движок аннотирования" GPT-4o.
- Для первого кадра $X_1$ он объединяется со специальной "подсказкой на уровне кадров" $P^f$ (и плейсхолдером для $X_0$, поскольку предыдущего кадра нет). GPT-4o обрабатывает это и выводит $Y_1^f$, подробное текстовое описание экземпляров, общего изображения и любых временных изменений (или их отсутствия).
- Для каждого последующего кадра $X_t$ (где $t > 1$) он сопоставляется с его непосредственным предшественником $X_{t-1}$ и той же $P^f$. Эта пара вместе с подсказкой поступает в GPT-4o.
- Затем GPT-4o тщательно анализирует $X_t$ и $X_{t-1}$, генерируя $Y_t^f$, который включает описания экземпляров в $X_t$, общую сцену и, что критически важно, различия и динамику, наблюдаемые между $X_{t-1}$ и $X_t$.
- Этот процесс повторяется до тех пор, пока все $N$ кадров не будут аннотированы, в результате чего получится полная последовательность аннотаций на уровне кадров: $[Y_1^f, Y_2^f, \ldots, Y_N^f]$. Эта последовательность похожа на подробный журнал всего, что происходит покадрово.
- Синтез сводки на уровне видео: Полный журнал аннотаций на уровне кадров $[Y_1^f, \ldots, Y_N^f]$ теперь собран. Вся эта текстовая последовательность вместе с "подсказкой для сводки на уровне видео" $P^{vid}$ подается в другой экземпляр движка GPT-4o. Задача этого движка — действовать как опытный составитель сводок, синтезируя все детальные сведения в связное, хронологическое повествование $Y^{vid}$, описывающее события и пространственно-временную информацию всего видео.
- Генерация вопросов и ответов: Параллельно с суммированием, тот же журнал $[Y_1^f, \ldots, Y_N^f]$ также подается в третий движок GPT-4o, на этот раз с "подсказкой для вопросов и ответов с открытым концом" $P^{qa}$. Задача этого движка — действовать как творческий генератор вопросов и ответов, производя набор разнообразных и ориентированных на экземпляры пар вопросов и ответов $Y^{qa}$. Эти пары вопросов и ответов предназначены для проверки понимания моделью отдельных экземпляров и их взаимоотношений на протяжении всего видео.
- Интеграция набора данных: Все эти сгенерированные аннотации ($Y_t^f$, $Y^{vid}$, $Y^{qa}$) для видео затем упаковываются вместе, образуя богатую, многоуровневую, основанную на экземплярах запись в наборе данных INST-IT. Эти данные теперь готовы к использованию для настройки инструкций. Как показано на рис. 2, эти аннотации включают следующие аспекты:
Динамика оптимизации
Сам по себе фреймворк INST-IT — это в первую очередь механизм генерации и подготовки данных, а не модель, которая подвергается прямой оптимизации в традиционном смысле (т.е. у нее нет параметров, которые обновляются с помощью градиентов). Вместо этого его "динамика оптимизации" наблюдается в том, как он позволяет другим большим мультимодальным моделям (LMM) учиться, обновляться и сходиться более эффективно.
Когда LMM (например, LLaVA-NeXT) обучается с использованием набора данных INST-IT, процесс обучения разворачивается следующим образом:
-
Цель настройки инструкций: LMM обучается следовать инструкциям, минимизируя разницу между сгенерированными текстовыми ответами и эталонными аннотациями, предоставленными набором данных INST-IT. Это обычно достигается с использованием стандартной цели языкового моделирования, такой как перекрестная энтропия (или потеря отрицательного логарифма правдоподобия). Учитывая вход, состоящий из визуальных признаков $V$ (полученных из изображений/видеокадров, потенциально с SoMs) и текстовой инструкции $I$, модель генерирует последовательность токенов $T = (t_1, t_2, \ldots, t_L)$. Цель состоит в том, чтобы максимизировать вероятность генерации правильной последовательности токенов при заданном входе, что обычно разлагается как $\prod_{k=1}^L P(t_k | V, I, t_1, \ldots, t_{k-1})$. Потеря для одного тренировочного примера $(V, I, T_{target})$ будет:
$$ \mathcal{L} = - \sum_{k=1}^L \log P(t_{target,k} | V, I, t_1, \ldots, t_{k-1}) $$
где $t_{target,k}$ — это токены эталонной аннотации из набора данных INST-IT. -
Парадигма совместного обучения: В статье предлагается "рецепт непрерывной настройки инструкций" (Раздел 2.4, 3.4), который является центральным для динамики оптимизации. Этот рецепт включает:
- Смешивание данных: Набор данных INST-IT с его богатыми аннотациями на уровне экземпляров, многогранной гранулярностью и явными визуальными подсказками смешивается с существующими общими данными для настройки инструкций (например, LLaVA-NeXT-DATA). Это совместное обучение гарантирует, что LMM изучает как детальное понимание экземпляров, так и сохраняет свои более широкие общие способности к пониманию в различных задачах.
- Смягчение сдвига распределения: Ключевая проблема заключается в том, что "изображения с визуальными подсказками могут привести к сдвигу распределения от естественных изображений" (Раздел 3.4), что может ухудшить производительность на общих задачах. Для противодействия этому на этапе непрерывной супервизорной дообучения (SFT) применяются. Во время этого этапа начальные слои визуального энкодера (в частности, первые 12 слоев) "замораживаются" (Раздел 3.1). Это замораживание помогает сохранить низкоуровневые визуальные признаки, изученные на естественных изображениях, и предотвращает переобучение модели на данных с визуальными подсказками, тем самым достигая сбалансированной производительности как на задачах с изображениями, так и на задачах с видео.
-
Процесс оптимизации:
- Прямой проход: Во время обучения LMM обрабатывает визуальный вход (изображения/видеокадры, дополненные SoMs) через свой визуальный энкодер для извлечения визуальных признаков. Затем эти признаки проецируются в пространство вложений языковой модели. Затем языковая модель обрабатывает текстовую инструкцию и визуальные признаки для генерации текстового ответа.
- Обратный проход: Сгенерированный ответ сравнивается с эталонной аннотацией из набора данных INST-IT с использованием перекрестной энтропии. Градиенты вычисляются и обратно распространяются через языковую модель и проекционный слой. Из-за стратегии замораживания градиенты обновляют только более поздние слои визуального энкодера (если они не заморожены), проекционный слой и языковую модель.
- Сходимость: Параметры модели итеративно обновляются с использованием оптимизатора (например, AdamW, как упомянуто в Разделе 3.1) с расписанием скорости обучения (например, расписание косинусной скорости обучения). Цель состоит в том, чтобы LMM сошлась к состоянию, в котором она может точно генерировать детальные описания на уровне экземпляров и отвечать на вопросы на основе визуальных подсказок, сохраняя при этом сильное общее мультимодальное понимание.
Эта парадигма непрерывной настройки инструкций с ее тщательным балансом типов данных и выборочным замораживанием компонентов модели является "динамикой оптимизации", которая позволяет LMM изучать желаемое понимание на уровне экземпляров, не жертвуя их более широкими возможностями.
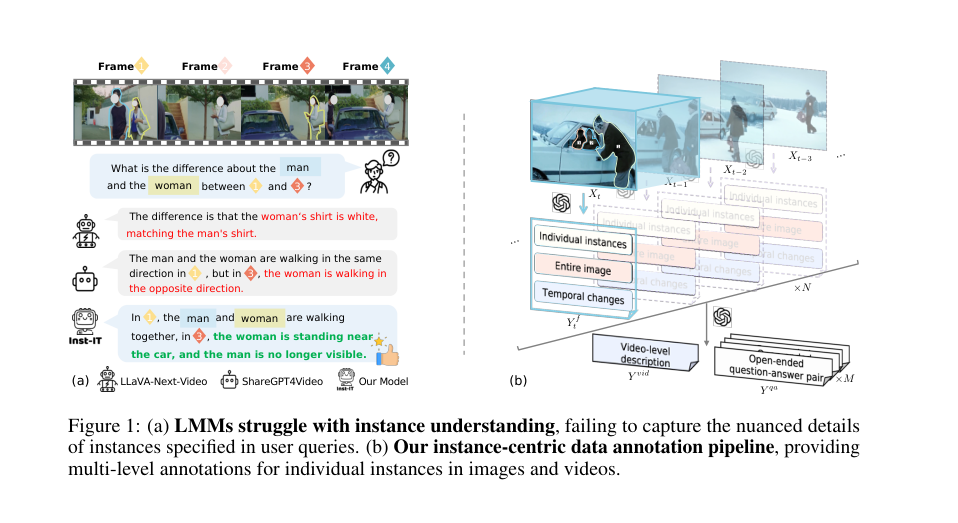 Figure 1. (a) LMMs struggle with instance understanding, failing to capture the nuanced details of instances specified in user queries. (b) Our instance-centric data annotation pipeline, providing multi-level annotations for individual instances in images and videos
Figure 1. (a) LMMs struggle with instance understanding, failing to capture the nuanced details of instances specified in user queries. (b) Our instance-centric data annotation pipeline, providing multi-level annotations for individual instances in images and videos
Результаты, ограничения и заключение
Экспериментальный дизайн и базовые модели
Чтобы строго подтвердить свои утверждения, авторы разработали комплексную экспериментальную установку. Их основной подход заключался в улучшении больших мультимодальных моделей (LMM) посредством явной настройки инструкций с визуальными подсказками, названной INST-IT. Основной "жертвой" или базовой архитектурой, выбранной для улучшения, была LLaVA-NeXT [44], широко используемая модель. Эта базовая модель обычно использовала Vicuna-1.5-7B [16] в качестве своей языковой модели и CLIP-ViT-336 [67] в качестве своего визуального энкодера. Для более продвинутых экспериментов они также использовали Qwen2-7B [87] с SigLIP-SO400M-384 [97].
Экспериментальный дизайн был сосредоточен на новом конвейере совместного обучения изображений и видео. Этот конвейер тщательно объединил недавно созданный набор данных INST-IT с существующими общедоступными данными LLaVA-NeXT-DATA [48]. Важным элементом их архитектуры было дополнение всех изображений и видеокадров визуальными подсказками "Набор отметок" (SoM) [88]. Эта техника явно направляла LMM на фокусировку на отдельных экземплярах, что является ключевым отличием от предыдущих работ.
Сам набор данных INST-IT является значительным вкладом, состоящим из 51 тыс. изображений и 21 тыс. видео. Он содержит многоуровневые, детальные аннотации, основанные на отдельных экземплярах, включая 207 тыс. подписей к изображениям, 135 тыс. описаний временной динамики, 21 тыс. подписей к видео и 335 тыс. пар вопросов и ответов с открытым концом.
Для оценки авторы представили INST-IT Bench, проверенный человеком бенчмарк, специально разработанный для диагностики понимания на уровне экземпляров как в изображениях, так и в видео. Этот бенчмарк включает 1000 пар вопросов и ответов с открытым концом и с множественным выбором для 338 изображений и 1000 пар вопросов и ответов для 206 видео. Ответы на вопросы с открытым концом оценивались с помощью GPT-4o [61] на точность и правильность ссылок на идентификаторы экземпляров. Помимо собственного бенчмарка, они также протестировали свои модели на установленных бенчмарках понимания экземпляров, таких как RefCOCOg [53] и ViP-Bench [5], а также на общих бенчмарках понимания изображений и видео, таких как AI2D [28], ChartQA [54], Egoschema [52] и NEXT-QA [85].
Базовые модели, которые они стремились превзойти, включали широкий спектр передовых LMM:
* Проприетарные модели: GPT-4o [61] и Gemini-1.5-flash [72].
* Модели с открытым исходным кодом для изображений: LLaVA-1.5 [43], ViP-LLaVA [5], SOM-LLaVA [86] и прямая базовая модель LLaVA-NeXT [44].
* Модели с открытым исходным кодом для видео: LLaVA-NeXT-Video [103], ShareGPT4Video [10], LLaVA-OV [31], LLaVA-Video [104], InternVL2 [13] и Qwen2-VL-Instruct [82].
Этот комплексный экспериментальный дизайн с собственным набором данных, бенчмарком и разнообразным набором базовых моделей позволил провести тщательную оценку эффективности INST-IT.
Что доказывают доказательства
Экспериментальные результаты предоставляют окончательные, неоспоримые доказательства того, что подход INST-IT значительно улучшает понимание на уровне экземпляров в LMM, одновременно укрепляя их общие способности к пониманию.
На INST-IT Bench (Таблица 2) модели, улучшенные INST-IT, продемонстрировали выдающуюся производительность. Например, LLaVA-NeXT-INST-IT с Vicuna-7B достигла 68,6 в вопросах и ответах с открытым концом (OE) для изображений и 63,0 в вопросах и ответах с множественным выбором (MC), что является существенным скачком по сравнению с базовой моделью LLaVA-NeXT (46,0 OE, 42,4 MC для изображений из Таблицы 2). В задачах с видео модель, улучшенная INST-IT, показала 49,3 OE и 42,1 MC, значительно превзойдя базовую модель LLaVA-NeXT-Video (25,8 OE, 24,8 MC). В статье прямо указано "улучшение почти на 20% среднего балла", что является надежным подтверждением основного механизма INST-IT.
Помимо собственного бенчмарка, модели INST-IT показали последовательные улучшения на других установленных бенчмарках понимания экземпляров:
* На RefCOCOg [53] модель LLaVA-NeXT-INST-IT-Vicuna-7B показала улучшение на 10,8% по сравнению с ее базовой моделью LLaVA-NeXT-Vicuna-7B (63,0% против 52,2%). Это убедительное доказательство того, что явная настройка инструкций с визуальными подсказками напрямую улучшает способность модели понимать референциальные выражения и связывать их с конкретными экземплярами.
* Для ViP-Bench [5] (Таблица 5) INST-IT с Vicuna-7B показал производительность, сопоставимую с ViP-LLaVA, а в некоторых случаях даже превосходящую ее, особенно при использовании визуальных подсказок в стиле человека. Это особенно убедительно, поскольку ViP-LLaVA была дообучена на наборе данных ViP-Bench, в то время как INST-IT оценивался в режиме нулевого выстрела, демонстрируя сильные обобщающие способности.
Более того, общие способности моделей к пониманию также показали значительный рост на широко используемых общих бенчмарках:
* Для бенчмарков изображений (Таблица 3) INST-IT последовательно превосходил базовую модель LLaVA-NeXT. В частности, он показал прирост на 4,4% на AI2D [28] и на 13,5% на ChartQA [54] с вариантом Vicuna-7B. Эти бенчмарки требуют привязки и рассуждения, что указывает на то, что детальное понимание INST-IT переносится на более широкое визуальное рассуждение.
* На видео бенчмарках (Таблица 4) модели INST-IT значительно превзошли как базовые модели LLaVA-NeXT, так и LLaVA-NeXT-Video. Например, он показал улучшение на 7,8% на Egoschema [52] и на 11,8% на NEXT-QA [85] с вариантом Vicuna-7B. Эти результаты подтверждают, что улучшение понимания на уровне экземпляров посредством явных визуальных подсказок является эффективной стратегией для улучшения общего пространственно-временного понимания.
Анализ абляции далее детализировал вклад:
* Парадигма непрерывной настройки инструкций (Таблица 6) была решающей. Прямое смешивание видеоданных с общими инструкциями привело к снижению понимания изображений, но предложенная непрерывная SFT с замороженным визуальным энкодером достигла сбалансированной производительности как на задачах с изображениями, так и на задачах с видео, смягчая сдвиги распределения от изображений с визуальными подсказками.
* Детальная комбинация набора данных (Таблица 7) показала, что подписи к кадрам на уровне экземпляров и на уровне изображений необходимы для понимания экземпляров изображений, в то время как временные различия, описания на уровне видео и QA жизненно важны для понимания экземпляров видео. Включение компонента изображений набора данных INST-IT в конечном итоге привело к наиболее сбалансированной производительности.
По сути, доказательства недвусмысленно подтверждают, что многоуровневые, основанные на экземплярах аннотации INST-IT в сочетании с явным визуальным подсказыванием и парадигмой непрерывной настройки инструкций эффективно наделяют LMM превосходным детальным пониманием экземпляров, что, в свою очередь, укрепляет их общее мультимодальное понимание.
Ограничения и будущие направления
Хотя INST-IT представляет собой значительный прогресс в понимании на уровне экземпляров для LMM, авторы откровенно признают несколько ограничений и предлагают захватывающие направления для дальнейшего развития.
Текущие ограничения:
1. Вычислительная стоимость: Текущие эксперименты в основном проводятся на моделях с 7B и 1.5B параметрами. Масштабирование до гораздо более крупных моделей (например, 70B или выше) ограничено существенными вычислительными затратами, что ограничивает сферу текущих исследований.
2. Накладные расходы GPT-4o: Автоматизированный конвейер аннотирования данных, хотя и эффективен, полагается на GPT-4o. Это вносит присущие накладные расходы, которые могут стать узким местом для генерации еще более крупных и разнообразных наборов данных.
3. Случаи сбоя: Модели иногда испытывают трудности в сложных сценариях, таких как сильно перекрытые экземпляры, размытые изображения или экземпляры, которые чрезмерно малы или переполнены. Это распространенные препятствия для LMM и указывают на области, где можно улучшить надежность.
4. Справедливость и предвзятость: Как и многие большие мультимодальные модели, INST-IT сталкивается с потенциальными рисками, связанными со справедливостью и предвзятостью, которые могут исходить из тренировочных данных или изученных моделью представлений. Это критический этический аспект, требующий постоянного внимания.
Будущие направления и темы для обсуждения:
Основываясь на этих выводах, возникает несколько тем для дальнейшего развития и эволюции:
-
Масштабирование и самообучающаяся генерация данных:
- Как мы можем разработать более вычислительно эффективные методы для настройки инструкций на уровне экземпляров, которые позволят масштабировать до гораздо более крупных LMM без непомерных затрат?
- Можем ли мы перейти к подходу "модель в цикле", где сама модель, после частичного обучения, помогает генерировать более высококачественные, самосинтезированные данные на уровне экземпляров, уменьшая зависимость от дорогих проприетарных API, таких как GPT-4o? Это может включать итеративное уточнение, где модель генерирует данные, происходит небольшой шаг ручной проверки, и модель переобучается.
-
Улучшенная устойчивость к сложным визуальным условиям:
- Какие новые архитектурные конструкции или стратегии обучения могут специально решать выявленные случаи сбоя (перекрытие, размытие, мелкие/переполненные экземпляры)? Могут ли методы оценки неопределенности или слияния нескольких видов улучшить производительность в этих сложных сценариях?
- Как мы можем более эффективно использовать генерацию синтетических данных для создания разнообразных и сложных примеров, которые специально нацелены на эти случаи сбоя, тем самым улучшая надежность модели?
-
Смягчение предвзятости и обеспечение справедливости:
- Учитывая потенциальные проблемы справедливости и предвзятости, какие систематические подходы к фильтрации и валидации данных могут быть реализованы для обеспечения большей справедливости и репрезентативности набора данных INST-IT и будущих наборов данных?
- Помимо решений, ориентированных на данные, какие методы, независимые от модели или специфичные для модели (например, алгоритмы устранения предвзятости, методы объяснимого ИИ для аудита решений на уровне экземпляров), могут быть разработаны для обнаружения и смягчения предвзятости в понимании экземпляров?
-
Расширение пространственно-временных рассуждений и предиктивных возможностей:
- В то время как INST-IT превосходно описывает текущие и временные изменения, как мы можем продвинуть LMM к выполнению более сложных пространственно-временных рассуждений, таких как прогнозирование будущих действий или траекторий экземпляров, или понимание долгосрочных причинно-следственных связей между экземплярами в видео?
- Может ли интеграция физически обоснованных нейронных сетей или модулей здравого смысла далее улучшить способность модели рассуждать о взаимодействиях экземпляров за пределами простого наблюдения?
-
Реальное развертывание и сотрудничество человека и ИИ:
- Как фреймворк INST-IT может быть интегрирован в реальные приложения, где пользователи должны интерактивно указывать интересующие экземпляры, возможно, через более интуитивные интерфейсы, чем числовые идентификаторы?
- Каковы последствия для сотрудничества человека и ИИ в задачах, требующих детального визуального понимания? Могут ли LMM, улучшенные INST-IT, служить более эффективными помощниками для таких задач, как редактирование видео, анализ видеонаблюдения или даже научные наблюдения, предоставляя точные сведения на уровне экземпляров? Это также поднимает вопросы об интерпретируемости рассуждений модели на уровне экземпляров для пользователей-людей.
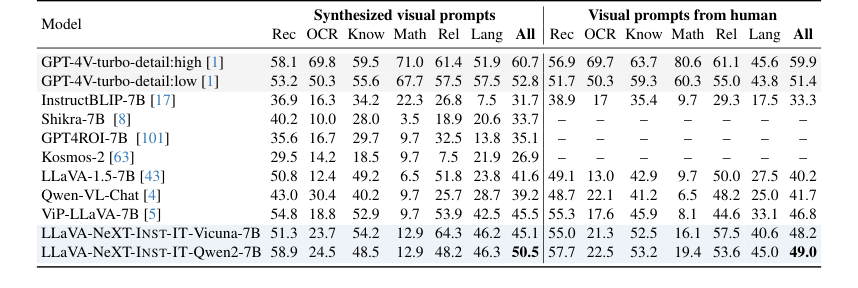 Table 5. Results on ViP-Bench. We perform evaluation with our INST-IT models without fine-tuning
Table 5. Results on ViP-Bench. We perform evaluation with our INST-IT models without fine-tuning
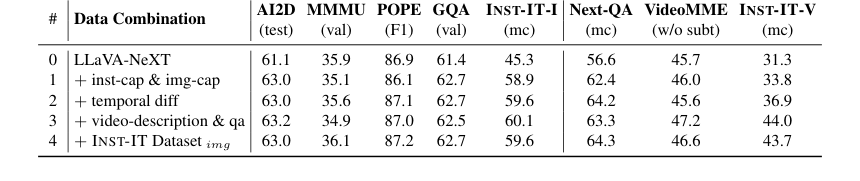 Table 7. Ablation on detailed data combination. The dataset combination in line #3 corresponds to the video part of INST-IT Dataset, while line #4 represents the complete INST-IT Dataset by incorporating the image part into line #3
Table 7. Ablation on detailed data combination. The dataset combination in line #3 corresponds to the video part of INST-IT Dataset, while line #4 represents the complete INST-IT Dataset by incorporating the image part into line #3
 Table 9. Statistical and lexical analysis of INST-IT Dataset. We present the results for each annotation level as well as the entire dataset
Table 9. Statistical and lexical analysis of INST-IT Dataset. We present the results for each annotation level as well as the entire dataset