INST-IT: 明示的な視覚的プロンプト指示チューニングによるインスタンス理解の向上
The problem addressed in this paper precisely originates from the recent advancements and, paradoxically, the limitations of Large Multimodal Models (LMMs) in the field of artificial intelligence, specifically within...
背景と学術的系譜
起源と学術的系譜
本稿で取り組む問題は、人工知能分野、特にコンピュータビジョンおよび自然言語処理における、大規模マルチモーダルモデル(LMMs)の近年の進歩と、逆説的ではあるがその限界に正確に由来する。LMMsは「インストラクションチューニング」により、画像や動画を全体的、あるいは一般的なレベルで理解し、多様なユーザーの指示に従うことができるようになり、大きな進歩を遂げたが、より粒度の細かいタスクである「インスタンスレベルの理解」には一貫して苦労している。
歴史的に、視覚データ内の個々のオブジェクトを理解する追求は、コンピュータビジョンにおける長年の目標であり、オブジェクト検出、インスタンスセグメンテーション、オブジェクト追跡などの分野で広範な研究につながってきた。しかし、LMMsの出現とともに、課題は変化した。以前のアプローチ、特に既存のLMMsの「ペインポイント」は、ユーザーがそれらについて特定の質問をした場合に、画像や動画内の特定の要素、あるいは「インスタンス」を、微細な詳細とアライメントをもって理解できないことである。例えば、LMMは「人々の群衆」を記述できるかもしれないが、「赤い帽子をかぶっている人は何をしているか?」や「人物1と人物2の間の相互作用は時間とともにどのように変化したか?」といった質問に答えることができないかもしれない。この限界は、空間情報だけでなく、個々のインスタンスの時間的ダイナミクスを理解することが重要になる動画において、さらに顕著になる。既存のマルチモーダルデータセットやベンチマークは、主に粗粒度の知識を提供しており、この微妙なインスタンスレベルの理解のためにLMMsを訓練および評価するために必要な微細なアノテーションを欠いている。この根本的なギャップにより、著者は、明示的な視覚プロンプトインストラクションチューニングを通じて、LMMsの個々のインスタンスを理解する能力を向上させるためのソリューションであるINST-ITを開発せざるを得なくなった。
直感的なドメイン用語
- 大規模マルチモーダルモデル(LMMs): テキストを読み書きできるだけでなく、画像や動画を「見て」「理解」できる超知能的なデジタルアシスタントを想像してほしい。写真を見たり、クリップを見たりして、自然言語でそれについて議論できるパーソナルエキスパートがいるようなものである。
- インストラクションチューニング: これは、その超知能アシスタントに、多くの具体的なタスクの例を与え、何をすべきかを正確に指示することによって教えるようなものである。例えば、画像を見せて、「この画像を説明して」とか、「この画像に関するこの質問に答えて」と「指示」する。アシスタントは、無数の例を見ることで、これらの指示に従うことを学ぶ。
- インスタンスレベルの理解: 単にシーン全体を記述する(例:「たくさんの人がいる公園」)のではなく、これはアシスタントがそのシーン内の個々のもの(インスタンス)に焦点を当てることができることを意味する。それは、公園の特定の人物を指差して、「あの人は何を着ているか?」とか、「あの犬はあのボールで遊んでいるか?」と尋ねることができるようなものである。それは、各特定のアイテムの詳細とその関係を理解することである。
- セット・オブ・マークス(SoMs)視覚プロンプティング: これは、画像や動画内の特定のオブジェクトに番号付きのステッカーを貼ったり、円を描いたりすることを想像してほしい。あなたは、スマートアシスタントに注意を払ってほしいインスタンスを文字通り「マーク」しており、「オブジェクト#1を見て、次にオブジェクト#2を見て」といった具合である。これは、より正確な理解のために個々のアイテムに焦点を誘導するのに役立つ。
表記表
| 表記 | 説明 |
|---|---|
| LMMs | 大規模マルチモーダルモデル。複数のモダリティ(例:テキスト、画像、動画)を理解し、生成する能力を持つ。 |
| SoMs | セット・オブ・マークス視覚プロンプト。モデルの焦点を誘導するために、視覚入力内のインスタンスに数値IDを重ねて表示する技術。 |
| INST-IT | LMMsにおけるインスタンス理解を向上させるための提案されたフレームワーク、データセット、およびベンチマーク。 |
| $X_t$ | タイムスタンプ $t$ における視覚データ(画像またはビデオフレーム)。 |
| $X_{t-1}$ | タイムスタンプ $t-1$ における視覚データ(画像またはビデオフレーム)。時間的比較に使用される。 |
| $P^f$ | フレームレベルのアノテーション生成のために特別に設計されたタスクプロンプト。 |
| $Y_t^f$ | フレーム $t$ に対するフレームレベルのアノテーション出力。インスタンスの説明、画像キャプション、および時間的差分を含む。 |
| $P^{vid}$ | ビデオレベルの要約生成のために特別に設計されたタスクプロンプト。 |
| $Y^{vid}$ | 全てのフレームレベルのアノテーションからの情報を集約したビデオレベルの要約出力。 |
| $P^{qa}$ | オープンエンドな質問応答ペアの生成のために特別に設計されたタスクプロンプト。 |
| $Y^{qa}$ | インスタンスレベルの理解に焦点を当てた、オープンエンドな質問応答ペアの出力。 |
| $\text{GPT}(\cdot)$ | データ生成パイプラインにおいてインテリジェントアノテーターとして使用されるGPT-4o大規模言語モデルを示す。 |
| $N$ | ビデオ内のフレームの総数。 |
| $M$ | ビデオに対して生成されたオープンエンドな質問応答ペアの総数。 |
| SFT | 教師ありファインチューニング。INST-ITデータセットを用いてLMMsを強化するために使用されるトレーニングパラダイム。 |
問題定義と制約
コア問題の定式化とジレンマ
現在の大規模マルチモーダルモデル(LMM)は、著しい進歩を遂げている一方で、ホリスティックなシーンレベルでの画像や動画の理解においては目覚ましい成果を上げているものの、インスタンスレベルの理解を必要とするタスクに直面すると一貫して失敗する、という重大な二律背反を呈している。これは、LMMが動画の一般的な内容を記述することはできるが、特にその属性、関係性、時間的相互作用において、動画内の特定のオブジェクトや個人を正確に識別、追跡、推論することに苦労することを意味する。
望ましい終着点は、LMMに画像と動画の両方にわたる堅牢なインスタンスレベルの理解能力を装備することである。これには、モデルが特定の要素を参照するユーザーの指示を正確に追跡し、それらの詳細な詳細を理解し、時間とともにそれらの動的な変化を追跡できるようにすることが含まれる。
これらの状態間の正確な欠落リンクまたは数学的なギャップは、十分に豊かで、インスタンスに根ざした、マルチレベルの指示チューニングデータの欠如である。既存のデータセットは主に粗粒度の注釈を提供しており、これはLMMにファイングレインのインスタンス理解を実行させるための訓練には不十分である。本稿では、このようなデータを生成するための新しいパイプラインと連続的な指示チューニングパラダイムを導入することで、このギャップを埋めることを試みる。
この問題は、過去の研究者を痛みを伴うトレードオフに閉じ込めてきた。
- ホリスティック vs. ファイングレイン理解: LMMの全体的なシーンを理解する能力を向上させることが、しばしばファイングレインのインスタンス詳細を理解する能力を犠牲にするか、その逆となる。両方を同時に達成することは、重大な課題である。
- 画像 vs. 動画インスタンス理解: 静止画像におけるインスタンス理解についてはある程度の進歩が見られるが、これを動的な動画に拡張することは、かなりの複雑さを伴う。動画は空間的な理解だけでなく、時間的ダイナミクス—インスタンスが時間とともにどのように変化し、移動し、相互作用するか—を追跡し、推論する能力を必要とする。この追加次元は、動画インスタンス理解を「かなりの程度、より困難」なものにしている。
- アノテーションの規模 vs. 品質: 個々のインスタンスに対する高品質でファイングレインのアノテーションを作成することは、労働集約的で高価である。過去の取り組みは、大規模に粗粒度のデータを提供するか、限定的な規模でファイングレインのデータを提供したかのいずれかであった。ジレンマは、複雑なマルチモーダルデータ(画像と動画)に対して大規模かつ高品質なファイングレインのアノテーションの両方を効率的に生成する方法である。
- 汎化 vs. 特化: 特定のインスタンス理解タスクのためにファインチューニングされたモデルは、訓練データに過学習するリスクがあり、その一般的な理解能力を低下させる可能性がある。課題は、インスタンス理解を強化することと同時に、多様な画像および動画タスクにわたる一般的な理解を強化することである。
制約と失敗モード
LMMにおける堅牢なインスタンスレベルの理解を達成するという問題は、著者らが直面したいくつかの厳しい現実的な壁のために、信じられないほど困難である。
- GPT-4oの計算オーバーヘッド: 自動化されたデータアノテーションパイプラインは効率的ではあるものの、「GPT-4oのオーバーヘッドによって制約されている」。これは、特に動画の場合、高品質でマルチレベルのアノテーションを大量に生成することは、依然として時間のかかる高価なプロセスであり、そのようなデータを生成できる規模を制限することを示唆している。
- ハードウェアメモリの制限: LMMのトレーニングプロセス、特に動画入力を伴うものは、「GPUメモリの制限によって制約されている」。著者は、「GPUメモリの制約により、フレームの最大数を32に、LLMのコンテキスト長を6Kに制限している」と明示的に述べており、より長い、または高解像度の動画シーケンスを処理する上での実用的な障壁を示している。
- 生の視覚入力からの幻覚と注意散漫: LMMは、生の視覚入力を直接処理する際に、「幻覚と注意散漫に苦しむ」。この固有の制限は、モデルが明示的なガイダンスなしに特定のインスタンスに関する情報を確実に焦点を当てて抽出することに苦労することを意味し、視覚プロンプトの使用を必要とする。
- インスタンスに根ざしたデータの希少性: 指示チューニングのためのインスタンスに根ざしたデータの「希少性」、特に動画に関しては、根本的な制約である。このデータギャップは、LMMがインスタンス理解に苦労する主な理由であり、これらの能力を学習するための十分なファイングレインの監視が存在しない。
- 時間的ダイナミクスの複雑さ: 動画内のインスタンスを理解するには、空間情報だけでなく、複雑な「時間的ダイナミクス」を捉える必要がある。これには、連続するフレーム間でのオブジェクトの位置、アクション、および関係性の変化を追跡することが含まれ、これは静止画像分析よりも大幅に複雑なタスクである。
- データ品質保証の課題: GPT-4oを活用した自動化パイプラインを使用しても、マルチレベルでファイングレインのアノテーションの高品質と一貫性を確保することは困難である。本稿では、「データ品質を確保するために厳格な手動検証と洗練」が必要であると述べており、信頼性の高いアノテーションの完全な自動化の難しさを強調している。
著者は、この文脈におけるLMMの特定の失敗モードを特定している。
- オクルージョン、ぼやけた画像、小さすぎる/混雑したインスタンス: 「インスタンスが著しくオクルージョンされている、画像がぼやけている、またはインスタンスが過度に小さいか混雑している」シナリオでは、モデルのパフォーマンスが低下する。これらは、視覚認識システムにとって重大な課題を突きつける一般的な現実世界の条件である。
- 視覚プロンプトからの分布シフト: 「視覚的にプロンプトされた画像の使用は、自然画像からの分布シフトを導入する可能性がある」。モデルがこのシフトを軽減するように注意深く訓練されていない場合、これは一般的な画像理解タスクでのパフォーマンスの低下につながる可能性がある。
- 動画データによる画像理解の抑制: 一般的な指示チューニングデータに動画データを高い比率で直接混合すると、「画像理解が抑制される」可能性があり、異なるモダリティを組み合わせる際の学習の潜在的な不均衡を示唆している。
- 訓練データへの過学習: 一部のモデルは、視覚プロンプトを使用しても、「ベースラインであるLLaVA-1.5をわずかに上回る改善しか示さない」場合があり、これは訓練データへの過学習によるものである可能性がある。これは、注意深い設計なしには、モデルが汎化可能なインスタンス理解を学習するのではなく、訓練例を記憶してしまうことを示唆している。
- モデルサイズまたは粗粒度データのスケーリング不足: 本稿では、「モデルサイズの単純なスケーリングだけではインスタンス理解の課題に対処できない」こと、および「大規模な粗粒度アノテーションも本質的な改善につながらない」ことを明確に述べている。これは、この問題が単なる定量的スケーリングではなく、データとトレーニング方法論における質的なシフトを必要とすることを強調している。
このアプローチの理由
選択の必然性
著者らが明示的な視覚プロンプトによる指示チューニングを追求し、INST-ITデータセットとベンチマークを作成するという決定は、単なる好みではなく、既存の大規模マルチモーダルモデル(LMM)の固有の限界から生まれた必然であった。中心的な認識は、LMMが画像や動画を全体的、すなわち一般的なレベルで理解する上で著しい進歩を遂げた一方で、よりきめ細やかな理解とアライメントを必要とするインスタンスレベルの理解には一貫して「苦労している」という点であった(Abstract, Section 1)。これは、標準的なCNN、基本的なDiffusionモデル、あるいはTransformerのような従来の「SOTA」手法が、LMMに統合されたとしても、正確でオブジェクト固有の推論を要求するタスクには根本的に不十分であることを意味する。
この認識が生まれた正確な瞬間は、指示チューニングにおけるブレークスルーにもかかわらず、現在のLMMが「ユーザーが最も関心を持っているインスタンス固有のコンテンツを理解するのに依然として苦労している」という観察によって暗黙のうちに強調されている(Fig. 1 (a)を参照、Section 1)。これは、基盤となるアーキテクチャが視覚データを処理できないという失敗ではなく、特に画像と動画の両方において、複雑なシーン内の特定のインスタンスに指示を「グラウンディング」する能力の欠如である。問題は強力なベースモデルの不足ではなく、モデルにきめ細やかなインスタンス理解を教えるために必要な「データと方法論」における重大なギャップであった。既存のマルチモーダルベンチマークやデータセットは、主に「画像と動画に対する粗い知識を提供し、個々のインスタンスに対するきめ細やかなアノテーションを欠いていた」(Page 2)。したがって、視覚プロンプトを通じて明示的にインスタンスレベルのガイダンスを提供し、専用の、豊富にアノテーションされたデータセットを作成するという新しいアプローチが、このギャップを埋めるための「唯一実行可能な解決策」であった。
比較優位性
INST-ITアプローチは、単純なパフォーマンス指標を超えて、いくつかの重要な側面で以前のゴールドスタンダードに対する質的な優位性を示している。
第一に、高次元のノイズや注意散漫に対処する能力に優れている。論文では、「生の視覚入力を直接処理することは、ハルシネーションや注意散漫に悩まされる」と指摘している(Section 2.1)。これを軽減するために、この手法はSet-of-Marks(SoMs)視覚プロンプトを採用しており、各インスタンスに数値IDをオーバーレイする。このシンプルでありながら効果的な拡張は、基盤となるGPT-4oモデルを「関心のあるインスタンスにより効果的に焦点を当てる」ように明示的にガイドし(Section 2.1)、それによって無関係な視覚情報の「ノイズ」を低減し、よりきめ細かく、より正確なアノテーションを可能にする。この構造的な利点により、モデルは視覚的な混乱を切り抜け、ユーザー指定のインスタンスに集中することができる。
第二に、この手法は動画入力のメモリ複雑性に対処する。明示的に $O(N^2)$ から $O(N)$ への削減を述べているわけではないが、著者らは「動画入力の視覚トークンの数を減らすために2×2空間プーリングを適用した」と述べている(Section 2.4)。この視覚トークンのダウンサンプリングは、計算量とメモリフットプリントの削減に直接貢献しており、長い動画シーケンスの処理や、実用的なGPUメモリ制約(Section 3.1)との整合性において重要である。
圧倒的な構造的利点は、画像と動画の両方、そして時間的ダイナミクスを含めて、真のインスタンスレベルの理解を促進する能力にある。全体的な理解に焦点を当てた以前の手法とは異なり、INST-ITのデータセットは、インスタンスレベルの説明、画像レベルのキャプション、時間的ダイナミクス、動画レベルの要約、および自由形式の質問応答ペアを含む、マルチレベルできめ細やかなアノテーションを提供する(Page 2, Section 2.1)。この豊富で構造化されたデータと、継続的な指示チューニングレシピを組み合わせることで、LMMはインスタンスを識別するだけでなく、その属性、関係、および時空間的進化を理解できるようになる。結果は、このアプローチが「他のインスタンス理解ベンチマークで一貫した改善」をもたらし、汎用ベンチマークでは「ベースラインに対して大幅な改善」をもたらしたことを示しており(Abstract, Section 3.2)、単なる過学習ではなく、汎用的な強化を示唆している。さらに、論文では、この手法が「大幅に少ない計算コストとデータコストで」、より大きく、より計算負荷の高いSFT LMMと同等のパフォーマンスを達成していることを強調している(Section 3.2)。これはその効率性の利点を浮き彫りにしている。
制約との整合性
選択された手法であるINST-ITは、問題定義で概説された暗黙的な制約と課題に完全に合致している。問題の厳しい要件と解決策の独自の特性とのこの「結婚」は、いくつかの方法で明らかである。
- インスタンスレベル理解ギャップへの対処: 主要な制約は、既存のLMMがファイングレインなインスタンス理解を達成できないことであった。INST-ITは、「インスタンスガイダンスのための明示的な視覚プロンプト指示チューニング」を提供することで、これを直接的に解決する(Abstract)。視覚プロンプトで拡張された指示チューニングパラダイムは、モデルに指示を特定の視覚エンティティにグラウンドすることを学習させることを強制する。
- データ不足の克服: 主要なボトルネックは「インスタンスレベルのデータセットの欠如」であった(Section 2.2)。INST-ITデータセットは、「画像と動画の両方を含み、明示的なインスタンスレベルの視覚プロンプトと個々のインスタンスにグラウンドされたファイングレインなアノテーションを備えた、最初のインスタンスグラウンド指示チューニングデータセット」として細心の注意を払って構築された(Contribution 1, Page 2)。これは、包括的でファイングレインなデータへのニーズを直接満たすものである。
- 動画における時空間的ダイナミクスの処理: 問題は、空間的および時間的理解の両方を必要とする動画におけるインスタンスの理解の困難さを強調した。INST-ITデータセットのマルチレベルアノテーションには、「時間的ダイナミクスの説明」と「動画レベルの要約」が含まれており(Page 2, Section 2.1)、モデルが時間の経過に伴う変化や相互作用を捉えるように明示的にトレーニングする。継続的な指示チューニングレシピは、この時空間的理解をさらに統合する。
- ハルシネーションと注意散漫の軽減: 生の視覚入力が「ハルシネーションと注意散漫」を引き起こすという制約(Section 2.1)は、「Set-of-Marks(SoMs)視覚プロンプト [88]」技術によって対処される。インスタンスに数値IDをオーバーレイすることで、モデルは特定のオブジェクトに焦点を当てるように明示的にガイドされ、それによって曖昧さが減少し、アノテーションの精度が向上する。
- 計算効率: 実用的な制約には、しばしば計算リソースが含まれる。「GPUメモリ制約のため、フレーム数を最大32に、LLMのコンテキスト長を6Kに制限する」ことや、「視覚トークン数を減らすために2×2空間プーリングを適用する」ことに言及している(Section 3.1)。INST-ITがより大きなSFT LMMと比較して「大幅に少ない計算コストとデータコスト」で強力なパフォーマンスを達成しているという事実は(Section 3.2)、リソース効率的な展開との整合性を示している。
代替案の却下
本論文は、マルチモーダルデータにおけるインスタンスレベル理解という中心的な問題に対処する上での欠点を強調することによって、いくつかの代替アプローチを暗黙的かつ明確に却下している。
第一に、特別な指示チューニングとデータなしで既存の「SOTA」LMMを単純に使用することの有効性を却下している。著者らは、これらのモデルが「画像や動画を全体的なレベルで理解できる一方で、インスタンス固有のコンテンツを理解するのに依然として苦労している」と述べている(Section 1)。これは、汎用LMMでさえ、このタスクに必要なファイングレインなグラウンディング能力を欠いていることを示唆している。問題は一般的な知性の欠如ではなく、インスタンス中心の指示追従の欠如である。
第二に、本論文は他の一般的な指示チューニングデータセットを不十分として明確に却下している。表1とセクション2.2では、INST-ITをShareGPT4Video、LLaVA-Video、ViP-LLaVA-Dataなどのデータセットと比較している。以前の動画データセットは「インスタンスレベルのアノテーションなしで全体的な理解に焦点を当てている」と指摘しており、ViP-LLaVAは「画像に対するインスタンスアノテーションを提供しているが、動画データは一切含まれていない」と述べている。これは、INST-ITが提供する、画像と動画の両方にわたるマルチレベルでファイングレインな、インスタンスグラウンドアノテーションを必要とするという点で、これらの代替案の直接的な却下である。著者らは、「インスタンスレベルのデータセットの欠如がインスタンス理解の進歩を妨げている」(Section 2.2)と結論付けており、既存のデータセットは不十分である。
最後に、本論文は、モデルサイズを単純にスケーリングしたり、より粗いデータを使用したりしても問題が解決するという考えを却下している。「Qwen2VL-72Bは、そのより小さな7Bモデルと比較して大幅な改善を示しておらず、モデルサイズの単純なスケーリングではインスタンス理解の課題に対処できないことを示唆している」(Section 3.2)と観察している。同様に、「大規模な粗いアノテーションも本質的な改善につながらない」(Section 3.2)と指摘している。この推論は、解決策は既存の手法やデータのブルートフォーススケーリングにあるのではなく、特殊なデータと指示チューニングを通じた明示的なインスタンスレベルのガイダンスに焦点を当てたターゲットアプローチにあることを強調している。
 Figure 8. A data example from INST-IT Bench. Each test sample includes both open-ended QA and multiple-choice QA, focusing on specific instances or the relationships and interactions between instances
Figure 8. A data example from INST-IT Bench. Each test sample includes both open-ended QA and multiple-choice QA, focusing on specific instances or the relationships and interactions between instances
数学的・論理的メカニズム
マスター方程式
INST-IT の中核となる数学的および論理的なメカニズムは、モデルが最適化するための単一の目的関数ではなく、強力な大規模言語モデル(LLM)、特に GPT-4o を活用して、リッチでマルチグレインのアノテーションを作成する洗練されたデータ生成パイプラインである。これらのアノテーションは INST-IT データセットを形成し、他の LMM のインストラクションチューニングに使用される。このパイプライン内の基本的な操作は、それぞれアノテーション生成の異なる段階を表す 3 つの主要な方程式によって定義される。
1. フレームレベルアノテーション:
$$Y_t^f = \text{GPT}(P^f, X_t, X_{t-1})$$
2. ビデオレベル要約:
$$Y^{vid} = \text{GPT}(P^{vid}, [Y_1^f, Y_2^f, \ldots, Y_N^f])$$
3. オープンエンド質問応答ペア:
$$Y^{qa} = \text{GPT}(P^{qa}, [Y_1^f, Y_2^f, \ldots, Y_N^f])$$
項別解剖
これらの各方程式の構成要素を分解し、INST-IT フレームワークにおけるそれらの正確な役割を理解しよう。
方程式 (1): フレームレベルアノテーション
$$Y_t^f = \text{GPT}(P^f, X_t, X_{t-1})$$
* $Y_t^f$:
* 数学的定義: これは、特定のビデオフレーム(時刻 $t$)に対する GPT-4o モデルの出力である。構造化されたテキストアノテーションである。
* 物理的/論理的役割: 単一フレームに対する包括的で詳細なテキスト記述を表し、個々のインスタンス、全体的な画像の内容、および前のフレームとの時間的変化に関する詳細を含む。これは、後続の、より高レベルのアノテーションのすべてにおける基礎となる構成要素である。
* $\text{GPT}(\cdot)$:
* 数学的定義: これは、プロンプトと視覚的入力を受け取り、テキスト出力を生成する関数として扱われる GPT-4o 大規模言語モデルを示す。
* 物理的/論理的役割: GPT-4o はインテリジェントなアノテーターとして機能する。その高度なマルチモーダル理解能力は、視覚情報を解釈し、提供された指示に従って人間のような詳細な記述を生成するために活用される。著者は、複雑な視覚的推論を処理し、高品質なテキストを生成する優れた能力を持つ GPT-4o を選択した。これは、インスタンス理解の細かい性質にとって重要である。
* $P^f$:
* 数学的定義: フレームレベルアノテーションのために設計された「カスタマイズされたタスクプロンプト」である自然言語文字列。
* 物理的/論理的役割: このプロンプトは、GPT-4o に対する正確な指示セットとして機能する。フレームの特定の側面(例: 個々のインスタンス、全体的なシーン、時間的差異)に焦点を当てるようにモデルをガイドし、出力 $Y_t^f$ の望ましい構造と内容を指示する。このプロンプトの慎重な設計は、正確で関連性の高いアノテーションを引き出す鍵となる。
* $X_t$:
* 数学的定義: タイムスタンプ $t$ における現在のビデオフレームに対応する視覚データ。
* 物理的/論理的役割: これは GPT-4o の主要な視覚入力であり、記述される必要がある生のピクセル情報と視覚的コンテキストを提供する。
* $X_{t-1}$:
* 数学的定義: タイムスタンプ $t-1$ における前のビデオフレームに対応する視覚データ。
* 物理的/論理的役割: 前のフレームを含めることは、時間的ダイナミクスを捉えるために重要である。$X_t$ と $X_{t-1}$ を比較することにより、GPT-4o は時間の経過に伴うインスタンス間の動き、状態の変化、または相互作用を特定し記述できる。これはビデオ理解に不可欠である。
* 数学的演算子(関数適用): この操作は GPT-4o への関数呼び出しである。著者は、GPT-4o が単純な算術演算子ではなく複雑な生成モデルであるため、この関数表記を使用している。これは、入力(プロンプト、現在のフレーム、前のフレーム)を内部ニューラルネットワークアーキテクチャを通じて処理し、一貫したテキスト出力を生成する。
方程式 (2): ビデオレベル要約
$$Y^{vid} = \text{GPT}(P^{vid}, [Y_1^f, Y_2^f, \ldots, Y_N^f])$$
* $Y^{vid}$:
* 数学的定義: GPT-4o によって生成された、ビデオ全体のテキスト要約。
* 物理的/論理的役割: これは、すべての個々のフレームレベルアノテーションの詳細情報を一貫したストーリーに集約し、ビデオコンテンツの全体的で時系列的な物語を提供する。全体的な時空間の流れと主要なイベントを捉える。
* $\text{GPT}(\cdot)$: 方程式 (1) と同じ。
* $P^{vid}$:
* 数学的定義: ビデオレベル要約のために設計された「タスクプロンプト」である自然言語文字列。
* 物理的/論理的役割: このプロンプトは、GPT-4o にフレームレベル記述のシーケンスから包括的な要約を合成するように指示し、時系列順序と主要なオブジェクトおよびイベントへの焦点を保証する。
* $[Y_1^f, Y_2^f, \ldots, Y_N^f]$:
* 数学的定義: ビデオに対して生成されたすべてのフレームレベルアノテーション ($Y_t^f$) の順序付けられたリストまたはシーケンス。最初のフレーム ($t=1$) から最後のフレーム ($t=N$) まで。
* 物理的/論理的役割: このシーケンスは、ビデオイベントのテキストベースの「メモリ」または「トランスクリプト」として機能し、GPT-4o に高レベルの要約を構築するために必要なすべての詳細情報を提供する。単一の集約値ではなくリスト(暗黙的に情報の合計)を使用することで、GPT-4o はイベント間の時間的進行と関係を処理できる。
* $N$:
* 数学的定義: ビデオ内のフレームの総数。
* 物理的/論理的役割: このスカラーは、ビデオの長さを、したがってビデオ要約を考慮するために必要なフレームレベルアノテーションの数を指定する。
方程式 (3): オープンエンド質問応答ペア
$$Y^{qa} = \text{GPT}(P^{qa}, [Y_1^f, Y_2^f, \ldots, Y_N^f])$$
* $Y^{qa}$:
* 数学的定義: GPT-4o によって生成された $M$ 個のオープンエンド質問応答ペアのセット、$\{(q_i, a_i)\}_{i=1}^M$。
* 物理的/論理的役割: これらのペアは、インスタンスレベルの理解と推論に関する LMM のテストとトレーニングを目的としている。特定のインスタンス、それらの属性、関係、および時間的変化に焦点を当て、インストラクションチューニングデータの豊富なソースを提供する。
* $\text{GPT}(\cdot)$: 方程式 (1) と同じ。
* $P^{qa}$:
* 数学的定義: オープンエンド QA ペアの生成のために設計された「タスクプロンプト」である自然言語文字列。
* 物理的/論理的役割: このプロンプトは、GPT-4o に、提供されたフレームレベルアノテーションに基づいて、多様で文脈的に関連性の高い質問と正確な回答を定式化するように指示する。QA ペアがインスタンスレベルの理解を対象としていることを保証する。
* $[Y_1^f, Y_2^f, \ldots, Y_N^f]$: 方程式 (2) と同じ。
* 物理的/論理的役割: ビデオ要約と同様に、このシーケンスは GPT-4o が質問と回答を導き出すための包括的なテキストコンテキストを提供し、イベントとエンティティの詳細にわたって推論することを要求する。
ステップバイステップフロー
洗練されたデータアノテーション工場にビデオが入ってくる様子を想像してほしい。INST-IT パイプラインを通じて 1 つのビデオの情報がどのように処理されるかを以下に示す。
- 視覚入力受信: フレームのシーケンス $X_1, X_2, \ldots, X_N$ からなる生のビデオが最初のステーションに到着する。
- インスタンスハイライト(視覚プロンプト): このステーションでは、プリプロセスステップにより、各フレーム内の個々のインスタンス(オブジェクト)が特定される。検出された各インスタンスに対して、一意の数値 ID が直接オーバーレイされ、「Set-of-Marks」(SoM)視覚プロンプトが作成される。これにより、後続のアノテーションステップがこれらの特定されたインスタンスに明示的に焦点を当てるようになる。
- フレームレベルアノテーション組立ライン:
- ビデオフレームは、GPT-4o の「アノテーションエンジン」に順次供給される。
- 最初のフレーム $X_1$ については、特定の「フレームレベルプロンプト」$P^f$(および前のフレームがないため $X_0$ のプレースホルダー)と組み合わされる。GPT-4o はこれを処理し、$Y_1^f$ を出力する。これは、インスタンス、全体的な画像、および時間的変化(またはその欠如)の詳細なテキスト記述である。
- 各後続フレーム $X_t$ ($t > 1$) については、その直前のフレーム $X_{t-1}$ と同じ $P^f$ とペアにされる。このペアはプロンプトとともに GPT-4o に入力される。
- GPT-4o は $X_t$ と $X_{t-1}$ を綿密に分析し、$Y_t^f$ を生成する。これには、$X_t$ のインスタンス、全体的なシーン、そして最も重要なことに、$X_{t-1}$ と $X_t$ の間で観察された差異とダイナミクスの記述が含まれる。
- このプロセスは、$N$ 個すべてのフレームがアノテーションされるまで繰り返され、フレームレベルアノテーションの完全なシーケンス $[Y_1^f, Y_2^f, \ldots, Y_N^f]$ が生成される。このシーケンスは、フレームごとに発生しているすべてのことの詳細なログブックのようなものである。
- ビデオレベル要約合成: フレームレベルアノテーション $[Y_1^f, \ldots, Y_N^f]$ の完全なログブックが収集される。このテキストシーケンス全体は、「ビデオレベル要約プロンプト」$P^{vid}$ とともに、GPT-4o エンジンの別のインスタンスに供給される。このエンジンのタスクは、熟練した要約者として機能し、すべての詳細な情報を、ビデオ全体のイベントと時空間情報を記述する、まとまりのある時系列的な物語 $Y^{vid}$ に合成することである。
- 質問応答生成: 要約と並行して、同じログブック $[Y_1^f, \ldots, Y_N^f]$ が 3 番目の GPT-4o エンジンにも供給される。今回は「オープンエンド QA プロンプト」$P^{qa}$ が使用される。このエンジンの役割は、創造的な質問生成者および回答者として機能し、多様でインスタンスに焦点を当てた質問応答ペアのセット $Y^{qa}$ を生成することである。これらの QA ペアは、ビデオ全体にわたる個々のインスタンスとその関係の理解をモデルに問いかけるように設計されている。
- データセット統合: ビデオのこれらの生成されたアノテーション ($Y_t^f$, $Y^{vid}$, $Y^{qa}$) はすべてパッケージ化され、INST-IT データセットの豊かでマルチレベルのインスタンスグラウンデッドエントリを形成する。このデータは、インストラクションチューニングに使用できる状態になる。図 2 に示すように、これらのアノテーションには以下の側面が含まれる。
最適化ダイナミクス
INST-IT フレームワーク自体は、主にデータ生成および準備メカニズムであり、従来の意味での直接的な最適化を受けるモデルではない(つまり、勾配によって更新されるパラメータを持たない)。むしろ、その「最適化ダイナミクス」は、他の大規模マルチモーダルモデル(LMM)がより効果的に学習、更新、および収束できるように可能にする方法で観察される。
LMM(LLaVA-NeXT のような)が INST-IT データセットを使用してトレーニングされる場合、学習プロセスは次のように展開される。
-
インストラクションチューニング目的: LMM は、生成されたテキスト応答と INST-IT データセットによって提供されるグラウンドトゥルースアノテーションとの差を最小限に抑えることにより、指示に従うようにトレーニングされる。これは通常、クロスエントロピー損失(または負の対数尤度損失)のような標準的な言語モデリング目的を使用して達成される。視覚特徴 $V$(画像/ビデオフレームから派生したもの、SoM を含む場合がある)とテキスト指示 $I$ からなる入力が与えられた場合、モデルはトークンのシーケンス $T = (t_1, t_2, \ldots, t_L)$ を生成する。目的は、入力が与えられた正しいトークンシーケンスを生成する確率を最大化することであり、これは通常 $\prod_{k=1}^L P(t_k | V, I, t_1, \ldots, t_{k-1})$ として分解される。単一のトレーニングサンプル $(V, I, T_{target})$ の損失は次のようになる。
$$ \mathcal{L} = - \sum_{k=1}^L \log P(t_{target,k} | V, I, t_1, \ldots, t_{k-1}) $$
ここで、$t_{target,k}$ は INST-IT データセットからのグラウンドトゥルースアノテーションのトークンである。 -
共同トレーニングパラダイム: この論文では、最適化ダイナミクスの中心となる「連続インストラクションチューニングレシピ」(セクション 2.4、3.4)を提案している。このレシピは以下を含む。
- データの混合: 豊富なインスタンスレベルのマルチグレインアノテーションと明示的な視覚プロンプトを持つ INST-IT データセットは、既存の一般的なインストラクションチューニングデータ(例: LLaVA-NeXT-DATA)と組み合わされる。この共同トレーニングにより、LMM は詳細なインスタンス理解を学習し、多様なタスク全体での広範な一般的な理解能力を維持することが保証される。
- 分布シフトの軽減: 主要な課題は、「視覚的にプロンプトされた画像は自然画像から分布シフトを導入する可能性がある」(セクション 3.4)ことであり、一般的なタスクのパフォーマンスを低下させる可能性がある。これを相殺するために、連続教師ありファインチューニング(SFT)パラダイムが適用される。この段階では、ビジョンエンコーダーの初期レイヤー(特に最初の 12 層)は「凍結」される(セクション 3.1)。この凍結は、自然画像から学習された低レベルの視覚特徴を保持するのに役立ち、モデルが視覚的にプロンプトされたデータに過学習するのを防ぎ、画像とビデオの両方のタスクでバランスの取れたパフォーマンスを達成する。
-
最適化プロセス:
- フォワードパス: トレーニング中、LMM は視覚入力(画像/ビデオフレーム、SoM で拡張)をビジョンエンコーダーを通して処理し、視覚特徴を抽出する。これらの特徴は、言語モデルの埋め込み空間に投影される。次に、言語モデルはテキスト指示と視覚特徴を処理して、テキスト応答を生成する。
- バックワードパス: 生成された応答は、クロスエントロピー損失を使用して INST-IT データセットからのグラウンドトゥルースアノテーションと比較される。勾配が計算され、言語モデルと投影層を通してバックプロパゲーションされる。凍結戦略により、勾配はビジョンエンコーダーの後部レイヤー(凍結されていない場合)、投影層、および言語モデルのみを更新する。
- 収束: モデルパラメータは、学習率スケジュール(例: コサイン学習率スケジュール)とともに、オプティマイザー(例: セクション 3.1 で言及されている AdamW)を使用して反復的に更新される。目標は、LMM が詳細なインスタンスレベルの記述を正確に生成し、視覚プロンプトに基づいて質問に回答できるようになり、同時に強力な一般的なマルチモーダル理解を維持する状態に収束することである。
この連続インストラクションチューニングパラダイムは、データの種類とモデルコンポーネントの選択的な凍結の慎重なバランスにより、LMM が広範な能力を犠牲にすることなく望ましいインスタンスレベルの理解を学習できるようにする「最適化ダイナミクス」である。
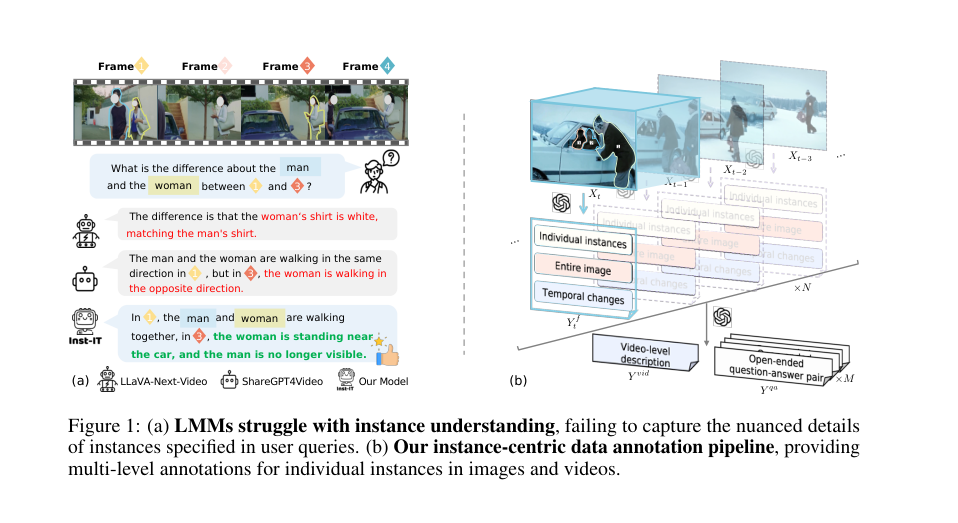 Figure 1. (a) LMMs struggle with instance understanding, failing to capture the nuanced details of instances specified in user queries. (b) Our instance-centric data annotation pipeline, providing multi-level annotations for individual instances in images and videos
Figure 1. (a) LMMs struggle with instance understanding, failing to capture the nuanced details of instances specified in user queries. (b) Our instance-centric data annotation pipeline, providing multi-level annotations for individual instances in images and videos
結果、限界および結論
実験設計とベースライン
主張を厳密に検証するため、著者らは包括的な実験セットアップを構築した。彼らの中核的なアプローチは、明示的な視覚プロンプト指示チューニングによる大規模マルチモーダルモデル(LMM)の強化であり、INST-ITと名付けられた。強化の主要な「対象」またはベースラインアーキテクチャとして、広く採用されているLLaVA-NeXT [44]が選択された。このベースラインは通常、言語モデルとしてVicuna-1.5-7B [16]、ビジョンエンコーダーとしてCLIP-ViT-336 [67]を使用していた。より高度な実験のために、SigLIP-SO400M-384 [97]を搭載したQwen2-7B [87]も採用した。
実験設計は、新しい画像・動画の共同トレーニングパイプラインを中心に展開された。このパイプラインは、新たに作成されたINST-ITデータセットと既存のオープンソースLLaVA-NeXT-DATA [48]を綿密に組み合わせた。彼らのアーキテクチャの重要な要素は、Set-of-Marks (SoM) 視覚プロンプト [88]による全ての画像および動画フレームの拡張であった。この技術は、LMMに個々のインスタンスに焦点を当てるよう明示的に指示するものであり、先行研究との重要な差別化要因である。
INST-ITデータセット自体は、51kの画像と21kの動画から構成される重要な貢献である。個々のインスタンスに基づいたマルチレベルのファイングレインアノテーションを備え、207kの画像レベルキャプション、135kの時系列ダイナミクス記述、21kの動画レベルキャプション、および335kのオープンエンド質問応答ペアが含まれる。
評価のため、著者らはINST-IT Benchを導入した。これは、画像と動画の両方におけるインスタンスレベルの理解を診断するために特別に設計された、人間によって検証されたベンチマークである。このベンチマークには、338の画像に対する1,000のオープンエンドおよび多肢選択式のQAペア、および206の動画に対する1,000のQAペアが含まれる。オープンエンドQA応答は、精度とインスタンスID参照の正確性についてGPT-4o [61]を使用して評価された。カスタムベンチマークを超えて、RefCOCOg [53]やViP-Bench [5]のような確立されたインスタンス理解ベンチマーク、およびAI2D [28]、ChartQA [54]、Egoschema [52]、NEXT-QA [85]のような一般的な画像・動画理解ベンチマークでもモデルをテストした。
彼らが打ち負かすことを目指したベースラインモデルには、幅広い最先端LMMが含まれていた。
- プロプライエタリモデル: GPT-4o [61] および Gemini-1.5-flash [72]。
- オープンソース画像モデル: LLaVA-1.5 [43]、ViP-LLaVA [5]、SOM-LLaVA [86]、および直接的なベースラインであるLLaVA-NeXT [44]。
- オープンソース動画モデル: LLaVA-NeXT-Video [103]、ShareGPT4Video [10]、LLaVA-OV [31]、LLaVA-Video [104]、InternVL2 [13]、およびQwen2-VL-Instruct [82]。
カスタムデータセット、ベンチマーク、および多様なベースラインセットを備えたこの包括的な実験設計により、INST-ITの効果を徹底的に評価することができた。
証拠が示すもの
実験結果は、INST-ITアプローチがLMMにおけるインスタンスレベルの理解を大幅に向上させると同時に、一般的な理解能力も強化するという、決定的で否定できない証拠を提供する。
INST-IT Bench(表2)では、INST-ITによって強化されたモデルは優れたパフォーマンスを示した。例えば、Vicuna-7Bを搭載したLLaVA-NeXT-INST-ITは、画像オープンエンド(OE)QAで68.6、多肢選択(MC)QAで63.0を達成し、LLaVA-NeXTベースライン(表2の画像OEで46.0、MCで42.4)と比較して大幅な飛躍を遂げた。動画タスクでは、INST-IT強化モデルはOEで49.3、MCで42.1を記録し、LLaVA-NeXT-Videoベースライン(OEで25.8、MCで24.8)を大幅に上回った。論文では明確に「平均スコアで約20%の改善」と述べられており、これはINST-ITのコアメカニズムの堅牢な検証である。
独自のベンチマークを超えて、INST-ITモデルは他の確立されたインスタンス理解ベンチマークでも一貫した改善を示した。
- RefCOCOg [53]では、LLaVA-NeXT-INST-IT-Vicuna-7Bモデルは、LLaVA-NeXT-Vicuna-7Bベースライン(63.0%対52.2%)を10.8%上回った。これは、明示的な視覚プロンプト指示チューニングが、参照表現を理解し、特定のインスタンスにグラウンドするモデルの能力を直接強化するという確固たる証拠である。
- ViP-Bench [5](表5)では、Vicuna-7Bを用いたINST-ITは、特に人間スタイルの視覚プロンプトを使用した際に、ViP-LLaVAに匹敵する、あるいは場合によってはそれを上回るパフォーマンスを達成した。これは、ViP-LLaVAがViP-Benchデータセットでファインチューニングされたのに対し、INST-ITはゼロショットで評価され、強力な汎化能力を示したという点で特に説得力がある。
さらに、モデルの一般的な理解能力も、広く使用されている汎用ベンチマークで大幅に向上した。
- 画像ベンチマーク(表3)では、INST-ITはLLaVA-NeXTベースラインを一貫して上回った。具体的には、Vicuna-7BバリアントでAI2D [28]で4.4%、ChartQA [54]で13.5%のゲインを達成した。これらのベンチマークはグラウンディングと推論を必要とし、INST-ITのファイングレイン理解がより広範な視覚推論に翻訳されることを示唆している。
- 動画ベンチマーク(表4)では、INST-ITモデルはLLaVA-NeXTおよびLLaVA-NeXT-Videoベースラインの両方を大幅に上回った。例えば、Vicuna-7BバリアントでEgoschema [52]で7.8%、NEXT-QA [85]で11.8%の改善を示した。これらの結果は、明示的な視覚プロンプトによるインスタンスレベルの理解の強化が、一般的な時空間理解を向上させるための効率的な戦略であることを確認している。
アブレーションスタディは、貢献をさらに詳細に分析した。
- 連続指示チューニングパラダイム(表6)は重要であった。動画データを一般的な指示データと直接混合すると画像理解が低下したが、凍結されたビジョンエンコーダーを用いた提案された連続SFTは、画像と動画の両方のタスクでバランスの取れたパフォーマンスを達成し、視覚的にプロンプトされた画像からの分布シフトを緩和した。
- 詳細なデータセットの組み合わせ(表7)は、インスタンスレベルおよび画像レベルのフレームキャプションが画像インスタンス理解に不可欠である一方、時間的差異、動画レベル記述、およびQAが動画インスタンス理解に不可欠であることを明らかにした。INST-ITデータセットの画像コンポーネントを組み込むことが、最終的に最もバランスの取れたパフォーマンスをもたらした。
要するに、証拠は、INST-ITのマルチレベル、インスタンスグラウンドアノテーションが、明示的な視覚プロンプトと連続指示チューニングパラダイムと組み合わさることで、LMMに優れたファイングレインインスタンス理解を効果的に装備し、それが全体的なマルチモーダル理解を強化することを、疑いの余地なく証明している。
限界と今後の方向性
INST-ITはLMMのインスタンスレベル理解における重要な進歩を示すが、著者らはいくつかの限界を率直に認め、将来の開発のためのエキサイティングな方向性を提案している。
現在の限界:
1. 計算コスト: 現在の実験は主に7Bおよび1.5Bパラメータモデルで実施されている。はるかに大きなモデル(例えば70B以上)へのスケーリングは、かなりの計算コストによって制約されており、現在の研究の範囲を制限している。
2. GPT-4oのオーバーヘッド: 効果的ではあるが、自動データアノテーションパイプラインはGPT-4oに依存している。これは固有のオーバーヘッドを導入し、さらに大規模で多様なデータセットを生成する際のボトルネックとなる可能性がある。
3. 失敗ケース: モデルは、重度にオクルージョンされたインスタンス、ぼやけた画像、または過度に小さいまたは混雑したインスタンスのような困難なシナリオで時折苦労する。これらはLMMにとって一般的な障害であり、堅牢性を改善できる領域を示している。
4. 公平性とバイアス: 多くの大規模マルチモーダルモデルと同様に、INST-ITは、トレーニングデータまたはモデルの学習済み表現に起因する可能性のある、公平性とバイアスに関連する潜在的なリスクに直面している。これは、継続的な注意を必要とする重要な倫理的考慮事項である。
今後の方向性と議論のトピック:
これらの発見に基づいて、さらなる開発と進化のためのいくつかの議論のトピックが現れる。
-
スケーリングと自己教師ありデータ生成:
- 法外なコストなしに、はるかに大きなLMMにスケーリングできる、インスタンスレベルの指示チューニングのための、より計算効率の高い方法をどのように開発できるか?
- モデル自体が、部分的にトレーニングされた後、より高品質で自己合成されたインスタンスレベルのデータを生成するのを支援する「モデルインザループ」アプローチに向かうことができるか?これにより、高価なプロプライエタリAPI(GPT-4oなど)への依存を減らすことができるか?これには、モデルがデータを生成し、小規模な人間による検証ステップが行われ、モデルが再トレーニングされるという反復的な洗練が含まれる可能性がある。
-
困難な視覚条件に対する堅牢性の向上:
- 特定された失敗ケース(オクルージョン、ぼやけ、小さい/混雑したインスタンス)に特に対処できる、新しいアーキテクチャ設計またはトレーニング戦略は何か?不確実性推定またはマルチビュー融合技術を組み込むことで、これらの困難なシナリオでのパフォーマンスを向上させることができるか?
- モデルの堅牢性を向上させるために、これらの失敗モードを具体的にターゲットとする多様で困難な例を作成するために、合成データ生成をより効果的に活用するにはどうすればよいか?
-
バイアスの軽減と公平性の確保:
- 公平性とバイアスの問題の可能性を考慮すると、INST-ITデータセットおよび将来のデータセットがより公平で代表的であることを保証するために、どのような体系的なデータフィルタリングおよび検証アプローチを実装できるか?
- データ中心のソリューションを超えて、インスタンス理解におけるバイアスを検出し軽減するために、どのようなモデルに依存しない、またはモデル固有の技術(例:デバイアスアルゴリズム、インスタンスレベルの決定を監査するための説明可能なAI手法)を開発できるか?
-
時空間推論と予測能力の拡大:
- INST-ITは現在の状態と時間的変化の記述に優れているが、LMMに、インスタンスの将来のアクションや軌跡を予測する、または動画内のインスタンス間の長期的な因果関係を理解するなど、より複雑な時空間推論を実行させるにはどうすればよいか?
- 物理学に基づいたニューラルネットワークまたは常識推論モジュールを統合することで、単なる観察を超えたインスタンス間の相互作用について推論するモデルの能力をさらに強化できるか?
-
実世界展開と人間-AI協調:
- ユーザーが数値IDよりも直感的なインターフェースを介して関心のあるインスタンスをインタラクティブに指定する必要がある実世界アプリケーションに、INST-ITフレームワークをどのように統合できるか?
- ファイングレインの視覚的理解を必要とするタスクにおける人間-AI協調への影響は何か?INST-IT強化LMMは、正確なインスタンスレベルの洞察を提供することにより、ビデオ編集、監視分析、あるいは科学的観察などのタスクのためのより効果的なアシスタントとして機能できるか?これはまた、人間ユーザーに対するモデルのインスタンスレベル推論の解釈可能性に関する疑問も提起する。
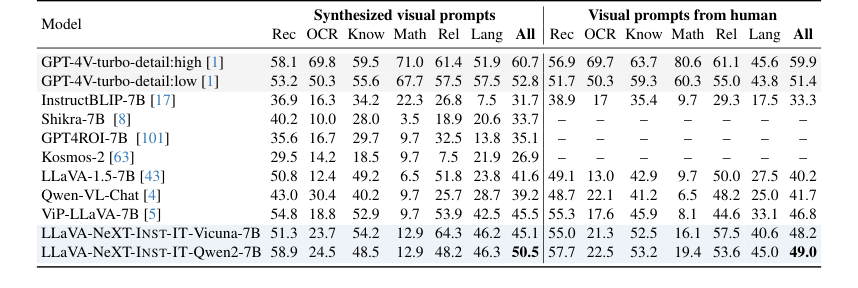 Table 5. Results on ViP-Bench. We perform evaluation with our INST-IT models without fine-tuning
Table 5. Results on ViP-Bench. We perform evaluation with our INST-IT models without fine-tuning
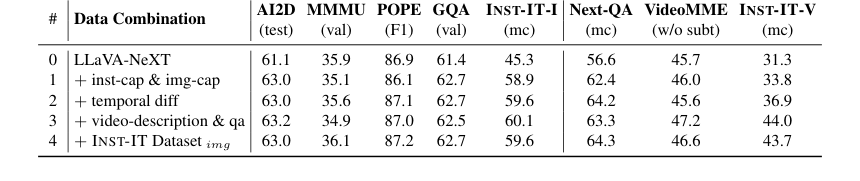 Table 7. Ablation on detailed data combination. The dataset combination in line #3 corresponds to the video part of INST-IT Dataset, while line #4 represents the complete INST-IT Dataset by incorporating the image part into line #3
Table 7. Ablation on detailed data combination. The dataset combination in line #3 corresponds to the video part of INST-IT Dataset, while line #4 represents the complete INST-IT Dataset by incorporating the image part into line #3
 Table 9. Statistical and lexical analysis of INST-IT Dataset. We present the results for each annotation level as well as the entire dataset
Table 9. Statistical and lexical analysis of INST-IT Dataset. We present the results for each annotation level as well as the entire dataset
他の分野との同型
構造的骨格
動的なビジュアルデータ全体にわたる個々のエンティティに対する、きめ細かくマルチレベルなアノテーションを生成するために、強力な生成モデルを誘導する明示的かつ構造化された視覚的キューを活用するメカニズム。その後、このリッチ化されたデータを使用して、他の大規模マルチモーダルモデルのインスタンスレベルの理解能力を強化する。