INST-IT:通过显式视觉提示指令调优提升实例理解能力
The problem addressed in this paper precisely originates from the recent advancements and, paradoxically, the limitations of Large Multimodal Models (LMMs) in the field of artificial intelligence, specifically within...
背景与学术渊源
起源与学术渊源
本文所解决的问题精确地源于人工智能领域,特别是在计算机视觉和自然语言处理方面,大型多模态模型(LMMs)的最新进展及其固有的局限性。尽管LMMs取得了重大突破,这在很大程度上归功于“指令调优”(instruction tuning),使其能够以整体或通用的方式理解图像和视频,并遵循各种用户指令,但它们在更细粒度的任务——“实例级理解”(instance-level understanding)方面却持续挣扎。
历史上,理解视觉数据中单个对象一直是计算机视觉领域一个长期存在的目标,催生了在目标检测、实例分割和目标跟踪等领域的大量研究。然而,随着LMMs的出现,挑战发生了转变。先前方法(特别是现有的LMMs)的“痛点”在于它们无法以细粒度的细节和对齐方式理解图像或视频中的特定元素或“实例”,尤其是在用户对其提出具体问题时。例如,一个LMM可能能够描述“一群人”,但却无法回答“戴红帽子的人在做什么?”或“第1个人和第2个人的互动是如何随时间变化的?”这样的问题。在视频中,这种局限性更为明显,因为不仅需要理解空间信息,还需要理解个体实例的时间动态。现有的多模态数据集和基准主要提供粗粒度知识,缺乏训练和评估LMMs进行这种细微实例级理解所必需的细粒度标注。这种根本性的差距促使作者开发了INST-IT,一个通过显式视觉提示指令调优来增强LMMs理解个体实例能力 的解决方案。
直观领域术语
- 大型多模态模型(LMMs): 想象一个超级智能的数字助手,它不仅能读写文本,还能“看见”并“理解”图像和视频。这就像拥有一个个人专家,可以查看一张照片或一段视频,然后用自然语言与你讨论它。
- 指令调优(Instruction Tuning): 这就像通过提供许多具体的任务示例来教导那个超级智能助手,并明确告诉它该做什么。例如,你给它看一张图片,并“指示”它:“描述这张图片”或“回答关于这张图片的这个问题”。助手通过看到无数的例子来学习遵循这些指令。
- 实例级理解(Instance-level Understanding): 与仅仅描述整个场景(例如,“一个有很多人的公园”)不同,这意味着助手可以专注于场景中的个体事物(实例)。这就像能够指向公园里的特定人物并提问:“那个人穿的是什么?”或“那只狗在玩那个球吗?”这是关于理解每个特定物品的细节及其关系。
- 标记集(Set-of-Marks, SoMs)视觉提示: 想象一下在图像或视频中的特定对象周围贴上编号的贴纸或画上圆圈。你实际上是在“标记”你希望智能助手关注的实例,例如“看对象#1,然后看对象#2”。这有助于引导其焦点到个体物品上,以获得更精确的理解。
符号表
| 符号 | 描述 |
|---|---|
| $X_{t-1}$ | 时间戳 $t-1$ 对应的视觉数据(图像或视频帧)。 |
| $P^f$ | 专门用于生成帧级标注的任务提示(prompt)。 |
| $Y_t^f$ | 帧 $t$ 的帧级标注输出,包括实例描述、图像标题和时间差异。 |
| $P^{vid}$ | 专门用于生成视频级摘要的任务提示。 |
| $Y^{vid}$ | 视频级摘要输出,聚合所有帧级标注的信息。 |
| $P^{qa}$ | 专门用于生成开放式问答对的任务提示。 |
| $Y^{qa}$ | 开放式问答对输出,侧重于实例级理解。 |
| $\text{GPT}(\cdot)$ | 表示 GPT-4o 大型语言模型,在数据生成流程中用作智能标注器。 |
| $N$ | 视频中的总帧数。 |
| $M$ | 为视频生成的开放式问答对总数。 |
| SFT | 监督微调(Supervised Fine-Tuning),用于使用 INST-IT 数据集增强 LMMs 的训练范式。 |
问题定义与约束
核心问题表述与困境
大型多模态模型(LMMs)的当前状态呈现出显著的两极分化:尽管它们在整体、场景级的图像和视频理解方面取得了卓越的进展,但在处理需要实例级理解的任务时却持续 falter。这意味着 LMMs 可以描述视频的总体内容,但难以精确识别、跟踪和推理其中的特定对象或个体,特别是它们的属性、关系和时间交互。
期望的最终目标是为 LMMs 提供跨越图像和视频的强大实例级理解能力。这包括使模型能够准确地遵循用户对特定元素发出的指令,理解它们的细粒度细节,并跟踪它们随时间的变化。
这些状态之间的确切缺失环节或数学鸿沟是缺乏足够丰富、实例为基础、多层次的指令调优数据。现有的数据集主要提供粗粒度标注,这不足以训练 LMMs 执行细粒度的实例理解。本文试图通过引入一种新颖的数据生成流程和一种连续的指令调优范式来弥合这一差距。
这个问题将先前的研究人员困在了一个痛苦的权衡之中:
- 整体 vs. 细粒度理解: 提升 LMM 对整体场景的理解能力,往往会以牺牲其对细粒度实例细节的能力为代价,反之亦然。同时实现两者是一个重大挑战。
- 图像 vs. 视频实例理解: 尽管在静态图像的实例理解方面取得了一些进展,但将其扩展到动态视频则引入了相当大的复杂性。视频不仅需要空间理解,还需要跟踪和推理时间动态的能力——实例如何随时间变化、移动和交互。这一附加维度使得视频实例理解“相当更具挑战性”。
- 标注规模 vs. 质量: 为个体实例创建高质量、细粒度的标注是劳动密集型且昂贵的。先前的工作要么大规模提供粗粒度数据,要么有限规模提供细粒度数据。困境在于如何高效地为复杂的模态数据(图像和视频)生成大规模和高质量的细粒度标注。
- 泛化 vs. 专业化: 为特定实例理解任务微调的模型,存在过拟合到其训练数据的风险,可能损害其通用理解能力。挑战在于同时增强跨各种图像和视频任务的通用理解能力,并提升实例理解能力。
约束与失效模式
实现 LMMs 中稳健实例级理解的问题极其困难,原因在于作者们遇到的几个严峻、现实的障碍:
- GPT-4o 的计算开销: 自动数据标注流程虽然高效,但“受限于 GPT-4o 的开销”。这意味着生成大量高质量、多层次的标注,特别是对于视频,仍然是一个耗时且昂贵的过程,限制了此类数据的生产规模。
- 硬件内存限制: LMMs 的训练过程,特别是处理视频输入时,受到“GPU 内存限制”的制约。作者明确表示,“由于 GPU 内存限制,我们将最大帧数限制为 32,并将 LLMs 的上下文长度限制为 6K”,这表明处理更长或更高分辨率的视频序列存在实际障碍。
- 幻觉和原始视觉输入的干扰: LMMs 在直接处理原始视觉输入时,“会受到幻觉和干扰的影响”。这种固有的局限性意味着模型在没有明确指导的情况下难以可靠地聚焦于特定实例并提取信息,因此需要使用视觉提示。
- 实例基础数据的稀缺性: 一个根本性的约束是“实例基础数据的稀缺性”,特别是对于视频。这种数据差距是 LMMs 难以进行实例理解的主要原因,因为缺乏足够的细粒度监督来学习这些能力。
- 时间动态的复杂性: 理解视频中的实例不仅需要捕捉空间信息,还需要捕捉复杂的“时间动态”。这包括跟踪连续帧中对象位置、动作和关系的变化,这是一项比静态图像分析更复杂的任务。
- 数据质量保证挑战: 即使利用 GPT-4o 进行自动化流程,确保多层次、细粒度标注的高质量和一致性也是具有挑战性的。论文提到需要“严格的手动验证和完善”来确保数据质量,这凸显了完全自动化可靠标注的难度。
作者们确定了 LMMs 在此背景下的具体失效模式:
- 遮挡、模糊图像以及小型/拥挤的实例: 在“实例严重遮挡、图像模糊,或实例过多小型或拥挤”的情况下,模型的性能会下降。这些是视觉感知系统面临重大挑战的常见现实世界条件。
- 来自视觉提示的分布偏移: “视觉提示图像的使用可能会引入与自然图像的分布偏移”。如果模型没有经过仔细训练来减轻这种偏移,这可能导致在通用图像理解任务上的性能下降。
- 视频数据对图像理解的抑制: 将高比例的视频数据直接与通用指令调优数据混合,可能会“抑制图像理解”,这表明在组合不同模态时可能存在学习不平衡。
- 对训练数据的过拟合: 一些模型,即使使用了视觉提示,也只显示出“比其基线 LLaVA-1.5 有微小的改进,可能是由于对其训练数据的过拟合”。这表明,如果没有仔细的设计,模型可能会记住训练样本而不是学习可泛化的实例理解。
- 模型尺寸或粗粒度数据规模不足: 论文明确指出,“简单地扩大模型尺寸无法解决实例理解中的挑战”,并且“大规模粗粒度标注也无法带来本质性的改进”。这凸显了问题需要方法论和数据的定性转变,而不仅仅是定量扩展。
为什么选择这种方法
选择的必然性
作者选择进行显式视觉提示指令调优,并结合创建 INST-IT 数据集和基准,这不仅仅是一种偏好,而是源于现有大型多模态模型(LMMs)固有局限性的必然选择。核心认识是,尽管 LMMs 在整体或通用层面上理解图像和视频方面取得了重大进展,但它们持续“在需要更细粒度理解和对齐的实例级理解方面挣扎”(摘要,第 1 节)。这意味着传统的“SOTA”方法,如标准 CNN、基本 Diffusion 模型或 Transformer,即使集成到 LMMs 中,对于需要精确、对象特定推理的任务也根本不足。
这种认识的确切时刻隐含地体现在以下观察中:尽管在指令调优方面取得了突破,但当前的 LMMs“仍然难以理解用户最感兴趣的实例特定内容,如图 1 (a) 所示”(第 1 节)。这不是底层架构处理视觉数据的失败,而是它们将指令与复杂场景中的特定实例联系起来的能力不足,尤其是在图像和视频中。问题不在于缺乏强大的基础模型,而在于教授这些模型细粒度实例理解所需的数据和方法论存在关键差距。现有的多模态基准和数据集主要提供“图像和视频的粗粒度知识,缺乏个体实例的细粒度标注”(第 2 页)。因此,一种通过视觉提示明确提供实例级指导的新方法以及一个专用、丰富标注的数据集是弥合这一差距的唯一可行解决方案。
比较优势
INST-IT 方法在几个关键方面展示了超越先前黄金标准的定性优势,这些优势超出了简单的性能指标。
首先,它在处理高维噪声和干扰方面表现出色。论文指出,“直接处理原始视觉输入会受到幻觉和干扰的影响”(第 2.1 节)。为了缓解这一问题,该方法采用了标记集(SoMs)视觉提示,在每个实例上叠加了数字 ID。这种简单而有效的数据增强明确指导底层的 GPT-4o 模型“更有效地关注感兴趣的实例”(第 2.1 节),从而减少了无关视觉信息的“噪声”,并实现了更细粒度、更准确的标注。这种结构优势使得模型能够穿透视觉混乱,专注于用户指定的实例。
其次,该方法解决了视频输入的内存复杂性问题。尽管没有明确说明从 $O(N^2)$ 降低到 $O(N)$,但作者提到应用了“2 × 2 空间池化以减少视频输入中的视觉 token 数量”(第 2.4 节)。这种视觉 token 的下采样直接有助于减少计算和内存占用,这对于处理长视频序列至关重要,并符合实际的 GPU 内存限制(第 3.1 节)。
压倒性的结构优势在于其能够促进跨图像和视频的真正的实例级理解,包括时间动态。与专注于整体理解的先前方法不同,INST-IT 的数据集提供了多层次、细粒度的标注,涵盖了实例级描述、图像级标题、时间动态、视频级摘要和开放式问答对(第 2 页,第 2.1 节)。这种丰富、结构化的数据,结合连续指令调优的配方,使得 LMMs 不仅能够识别实例,还能理解它们的属性、关系和时空演变。结果表明,这种方法能够“在其他实例理解基准上持续改进”,并在通用基准上“显著优于基线”(摘要,第 3.2 节),表明是一种可泛化的增强而非简单的过拟合。此外,论文强调,其方法在实现与更大、计算成本更高的 SFT LMMs 相当的性能的同时,“所需的计算和数据成本显著降低”(第 3.2 节),这凸显了其效率优势。
与约束的一致性
所选方法 INST-IT 与问题定义中隐含的约束和挑战完美契合。这种“婚姻”——问题严苛的要求与解决方案的独特属性——在多个方面都显而易见:
- 解决实例级理解差距: 主要约束是现有 LMMs 无法实现细粒度实例理解。INST-IT 通过提供“用于实例指导的显式视觉提示指令调优”(摘要)直接解决了这一问题。指令调优范式,通过视觉提示增强,迫使模型学习将指令与特定的视觉实体联系起来。
- 克服数据稀缺性: 主要瓶颈是“缺乏实例级数据集”(第 2.2 节)。INST-IT 数据集经过精心构建,是“第一个实例基础的指令调优数据集,包含图像和视频,具有显式的实例级视觉提示和基于个体实例的细粒度标注”(贡献 1,第 2 页)。这直接满足了对全面、细粒度数据的需求。
- 处理视频中的时空动态: 问题强调了理解视频中实例的难度,需要空间和时间理解。INST-IT 数据集的多层次标注包括“时间动态描述”和“视频级摘要”(第 2 页,第 2.1 节),明确训练模型捕捉随时间的变化和交互。连续指令调优配方进一步整合了这种时空理解。
- 减轻幻觉和干扰: 原始视觉输入导致“幻觉和干扰”(第 2.1 节)的约束通过“标记集(SoMs)视觉提示 [88]”技术得到解决。通过在实例上叠加数字 ID,模型被明确引导关注特定对象,从而减少歧义并提高标注准确性。
- 计算效率: 实际约束通常涉及计算资源。论文提到“由于 GPU 内存限制,将最大帧数限制为 32,并将 LLMs 的上下文长度限制为 6K”,并应用了“2 × 2 空间池化以减少视觉 token 数量”(第 3.1 节)。INST-IT 与更大的 SFT LMMs 相比,以“显著降低的计算和数据成本”取得了强大的性能(第 3.2 节),这表明其符合资源高效部署的要求。
替代方案的拒绝
本文通过强调现有 LMMs 在解决跨模态数据的实例级理解核心问题方面的不足,隐含但清晰地拒绝了几种替代方法。
首先,它排除了仅使用现有“SOTA”LMMs 而不进行专门指令调优和数据的情况。作者指出,尽管这些模型“可以以整体水平理解图像和视频,但它们仍然难以理解实例特定的内容”(第 1 节)。这意味着通用的 LMMs,即使是强大的模型,也缺乏这项任务所需的细粒度基础能力。问题不在于缺乏通用智能,而在于缺乏以实例为中心的指令遵循能力。
其次,本文明确拒绝了其他流行的指令调优数据集作为不足。在表 1 和第 2.2 节中,它将 INST-IT 与 ShareGPT4Video、LLaVA-Video 和 ViP-LLaVA-Data 等数据集进行了比较。它指出,现有的视频数据集“侧重于整体理解,而没有实例级标注”,并且尽管 ViP-LLaVA“为图像提供了实例标注,但它不包含任何视频数据”。这是对这些替代方案的直接拒绝,因为它们未能提供 INST-IT 所提供的跨图像和视频的多层次、细粒度、实例基础标注。作者总结道,“缺乏实例级数据集阻碍了实例理解的进步”(第 2.2 节),使得现有数据集不足。
最后,本文拒绝了简单地扩大模型规模或使用更多粗粒度数据就能解决问题的观点。它观察到“Qwen2VL-72B 相对于其较小的 7B 模型并未显示出实质性改进,这表明简单地扩大模型尺寸无法解决实例理解中的挑战”(第 3.2 节)。同样,它指出“大规模粗粒度标注也无法带来本质性的改进”(第 3.2 节)。这一推理强调,解决方案不在于现有方法或数据的粗暴扩展,而在于通过专门的数据和指令调优,采取一种明确的实例级指导的针对性方法。
 Figure 8. A data example from INST-IT Bench. Each test sample includes both open-ended QA and multiple-choice QA, focusing on specific instances or the relationships and interactions between instances
Figure 8. A data example from INST-IT Bench. Each test sample includes both open-ended QA and multiple-choice QA, focusing on specific instances or the relationships and interactions between instances
数学与逻辑机制
主方程
INST-IT 的核心数学和逻辑机制不是一个模型优化的单一目标函数,而是一个复杂的、利用强大的大型语言模型(LLM),特别是 GPT-4o,来创建丰富、多粒度的标注的数据生成流程。这些标注随后构成了 INST-IT 数据集,用于指令调优其他 LMMs。该流程中的基本操作由三个关键方程定义,每个方程代表一个不同的标注生成阶段:
1. 帧级标注:
$$Y_t^f = \text{GPT}(P^f, X_t, X_{t-1})$$
2. 视频级摘要:
$$Y^{vid} = \text{GPT}(P^{vid}, [Y_1^f, Y_2^f, \ldots, Y_N^f])$$
3. 开放式问答对:
$$Y^{qa} = \text{GPT}(P^{qa}, [Y_1^f, Y_2^f, \ldots, Y_N^f])$$
逐项解剖
让我们剖析这些方程的每个组成部分,以理解它们在 INST-IT 框架中的精确作用。
方程 (1):帧级标注
$$Y_t^f = \text{GPT}(P^f, X_t, X_{t-1})$$
* $Y_t^f$:
* 数学定义: 这是 GPT-4o 模型在时间 $t$ 的特定视频帧的输出。它是一个结构化的文本标注。
* 物理/逻辑作用: 它代表了单帧的全面、细粒度文本描述,包括个体实例的细节、整体图像内容以及相对于前一帧的时间变化。这是所有后续、更高级别标注的基础构建块。
* $\text{GPT}(\cdot)$:
* 数学定义: 这表示 GPT-4o 大型语言模型,被视为一个接受提示和视觉输入以生成文本输出的函数。
* 物理/逻辑作用: GPT-4o 作为智能标注器。它先进的多模态理解能力被用来解释视觉信息,并根据提供的指令生成类似人类的、详细的描述。作者选择 GPT-4o 是因为它在处理复杂的视觉推理和生成高质量文本方面具有卓越的能力,这对于实例理解的细粒度性质至关重要。
* $P^f$:
* 数学定义: 一个自然语言字符串,特别是为帧级标注设计的“定制任务提示”。
* 物理/逻辑作用: 此提示充当 GPT-4o 的精确指令集。它指导模型关注帧的特定方面(例如,个体实例、整体场景、时间变化),并决定输出 $Y_t^f$ 的期望结构和内容。此提示的精心设计是引发准确且相关标注的关键。
* $X_t$:
* 数学定义: 与时间戳 $t$ 处的当前视频帧对应的视觉数据。
* 物理/逻辑作用: 这是 GPT-4o 的主要视觉输入,提供了需要描述的原始像素信息和视觉上下文。
* $X_{t-1}$:
* 数学定义: 与时间戳 $t-1$ 处的上一视频帧对应的视觉数据。
* 物理/逻辑作用: 包含上一帧对于捕捉时间动态至关重要。通过比较 $X_t$ 和 $X_{t-1}$,GPT-4o 可以识别和描述实例随时间的变化、状态变化或交互,这对于视频理解至关重要。
* 数学运算符(函数应用): 该操作是对 GPT-4o 的函数调用。作者使用这种函数式表示法是因为 GPT-4o 是一个复杂的生成模型,而不是一个简单的算术运算符。它通过其内部神经网络架构处理输入(提示、当前帧、上一帧)以产生连贯的文本输出。
方程 (2):视频级摘要
$$Y^{vid} = \text{GPT}(P^{vid}, [Y_1^f, Y_2^f, \ldots, Y_N^f])$$
* $Y^{vid}$:
* 数学定义: 由 GPT-4o 生成的整个视频的文本摘要。
* 物理/逻辑作用: 它提供了视频内容的整体、按时间顺序排列的叙述,将所有帧级标注的详细信息聚合到一个连贯的故事中。它捕捉了整体的时空流程和关键事件。
* $\text{GPT}(\cdot)$: 同方程 (1)。
* $P^{vid}$:
* 数学定义: 一个自然语言字符串,特别是为视频级摘要设计的“任务提示”。
* 物理/逻辑作用: 此提示指示 GPT-4o 从一系列帧级描述中综合一个全面的摘要,确保按时间顺序排列,并关注主要对象和事件。
* $[Y_1^f, Y_2^f, \ldots, Y_N^f]$:
* 数学定义: 为视频生成的从第一帧 ($t=1$) 到最后一帧 ($t=N$) 的所有帧级标注 ($Y_t^f$) 的有序列表或序列。
* 物理/逻辑作用: 此序列充当视频事件的文本“记忆”或“记录”,为 GPT-4o 提供了构建高级摘要所需的所有细粒度细节。使用列表(隐含信息求和)而不是单个聚合值,允许 GPT-4o 处理事件的时间进程和关系。
* $N$:
* 数学定义: 视频中的总帧数。
* 物理/逻辑作用: 这个标量表示视频的长度,因此是为视频摘要需要考虑的帧级标注的数量。
方程 (3):开放式问答对
$$Y^{qa} = \text{GPT}(P^{qa}, [Y_1^f, Y_2^f, \ldots, Y_N^f])$$
* $Y^{qa}$:
* 数学定义: 由 GPT-4o 生成的 $M$ 个开放式问答对的集合,$\{(q_i, a_i)\}_{i=1}^M$。
* 物理/逻辑作用: 这些对旨在测试和训练 LMMs 的实例级理解和推理能力。它们侧重于特定实例、它们的属性、关系和时间变化,提供了丰富的指令调优数据来源。
* $\text{GPT}(\cdot)$: 同方程 (1)。
* $P^{qa}$:
* 数学定义: 一个自然语言字符串,特别是为生成开放式 QA 对设计的“任务提示”。
* 物理/逻辑作用: 此提示指导 GPT-4o 根据提供的帧级标注,制定多样化且上下文相关的问答。它确保 QA 对针对实例级理解。
* $[Y_1^f, Y_2^f, \ldots, Y_N^f]$: 同方程 (2)。
* 物理/逻辑作用: 与视频摘要类似,此序列提供了 GPT-4o 可以从中推导出问答的全面文本上下文,要求它对详细事件和实体进行推理。
逐步流程
想象一个视频进入一个复杂的自动数据标注工厂。以下是单个视频的信息如何通过 INST-IT 流程处理:
- 接收视觉输入: 由一系列帧 $X_1, X_2, \ldots, X_N$ 组成的原始视频到达第一个工位。
- 实例高亮(视觉提示): 在此工位,预处理步骤识别每个帧中的个体实例(对象)。对于每个检测到的实例,都会在其上直接叠加一个唯一的数字 ID,创建一个“标记集”(SoM)视觉提示。这确保了后续的标注步骤明确关注这些已识别的实例。
- 帧级标注流水线:
- 视频帧按顺序输入 GPT-4o“标注引擎”。
- 对于第一帧 $X_1$,它与一个特定的“帧级提示”$P^f$(以及一个 $X_0$ 的占位符,因为没有前一帧)结合。GPT-4o 处理此输入并输出 $Y_1^f$,这是对实例、整体图像以及任何时间变化(或缺乏变化)的详细文本描述。
- 对于每个后续帧 $X_t$(其中 $t > 1$),它与其紧邻的前一帧 $X_{t-1}$ 和相同的 $P^f$ 配对。此对与提示一起进入 GPT-4o。
- GPT-4o 然后仔细分析 $X_t$ 和 $X_{t-1}$,生成 $Y_t^f$,其中包含 $X_t$ 中实例的描述、整体场景,以及至关重要的——在 $X_{t-1}$ 和 $X_t$ 之间观察到的差异和动态。
- 此过程一直重复,直到所有 $N$ 帧都被标注,从而得到一个完整的帧级标注序列:$[Y_1^f, Y_2^f, \ldots, Y_N^f]$。这个序列就像一个详细的日志本,记录着逐帧发生的一切。
- 视频级摘要合成: 帧级标注的完整日志本 $[Y_1^f, \ldots, Y_N^f]$ 现在被收集起来。整个文本序列,以及一个“视频级摘要提示”$P^{vid}$,被输入到另一个 GPT-4o 引擎实例中。这个引擎的任务是充当一个熟练的摘要员,将所有细粒度细节综合成一个连贯的、按时间顺序排列的叙述 $Y^{vid}$,描述整个视频的事件和时空信息。
- 问答生成: 与摘要同时,相同的日志本 $[Y_1^f, \ldots, Y_N^f]$ 也被输入到第三个 GPT-4o 引擎中,这次是带有“开放式 QA 提示”$P^{qa}$。这个引擎的角色是充当一个富有创意的问答生成器,生成一组多样化且以实例为中心的问答对 $Y^{qa}$。这些问答对旨在探测模型对视频中个体实例及其关系的理解。
- 数据集集成: 该视频的所有这些生成标注($Y_t^f$、$Y^{vid}$、$Y^{qa}$)随后被打包在一起,形成 INST-IT 数据集中的一个丰富、多层次、实例基础的条目。这些数据现在已准备好用于指令调优。如图 2 所示,这些标注包括以下方面:
优化动力学
INST-IT 框架本身主要是一个数据生成和准备机制,而不是一个传统意义上进行直接优化的模型(即,它没有通过梯度更新的参数)。相反,它的“优化动力学”体现在它如何使其他大型多模态模型(LMMs)能够更有效地学习、更新和收敛。
当使用 INST-IT 数据集训练 LMM(如 LLaVA-NeXT)时,学习过程如下展开:
-
指令调优目标: LMM 被训练来遵循指令,通过最小化其生成的文本响应与 INST-IT 数据集提供的真实标注之间的差异来实现。这通常使用标准的语言建模目标来完成,例如交叉熵损失(或负对数似然损失)。给定一个由视觉特征 $V$(来自图像/视频帧,可能带有 SoMs)和文本指令 $I$ 组成的输入,模型生成一个 token 序列 $T = (t_1, t_2, \ldots, t_L)$。目标是最大化生成正确 token 序列的概率,给定输入,这通常分解为 $\prod_{k=1}^L P(t_k | V, I, t_1, \ldots, t_{k-1})$。单个训练样本 $(V, I, T_{target})$ 的损失将是:
$$ \mathcal{L} = - \sum_{k=1}^L \log P(t_{target,k} | V, I, t_1, \ldots, t_{k-1}) $$
其中 $t_{target,k}$ 是 INST-IT 数据集中真实标注的 token。 -
联合训练范式: 该论文提出了一种“连续指令调优配方”(第 2.4 节,3.4 节),这是优化动力学的核心。该配方包括:
- 混合数据: INST-IT 数据集,具有丰富的实例级、多粒度标注和显式视觉提示,与现有的通用指令调优数据(例如,LLaVA-NeXT-DATA)相结合。这种联合训练确保 LMM 同时学习细粒度实例理解并保持其在各种任务上的更广泛通用理解能力。
- 减轻分布偏移: 一个关键挑战是“视觉提示图像可能会引入与自然图像的分布偏移”(第 3.4 节),这可能导致在通用任务上的性能下降。为了抵消这一点,应用了连续监督微调(SFT)范式。在此阶段,视觉编码器的初始层(特别是前 12 层)被“冻结”(第 3.1 节)。这种冻结有助于保留从自然图像中学到的低级视觉特征,并防止模型过拟合到视觉提示数据,从而在图像和视频任务上实现平衡的性能。
-
优化过程:
- 前向传播: 在训练过程中,LMM 通过其视觉编码器处理视觉输入(图像/视频帧,用 SoMs 增强)以提取视觉特征。然后将这些特征投影到语言模型的嵌入空间。然后,语言模型处理文本指令和视觉特征以生成文本响应。
- 反向传播: 使用交叉熵损失将生成的响应与 INST-IT 数据集中的真实标注进行比较。计算梯度并反向传播通过语言模型和投影层。由于冻结策略,梯度仅更新视觉编码器的较后层(如果未冻结)、投影层和语言模型。
- 收敛: 使用优化器(例如,如第 3.1 节所述的 AdamW)和学习率调度器(例如,余弦学习率调度器)迭代更新模型参数。目标是使 LMM 收敛到一个状态,在该状态下,它能够根据视觉提示准确地生成细粒度的实例级描述和回答问题,同时保持强大的通用多模态理解能力。
这种连续指令调优范式,通过仔细平衡数据类型和选择性冻结模型组件,是使 LMMs 能够学习所需的实例级理解而不会牺牲其更广泛能力的“优化动力学”。
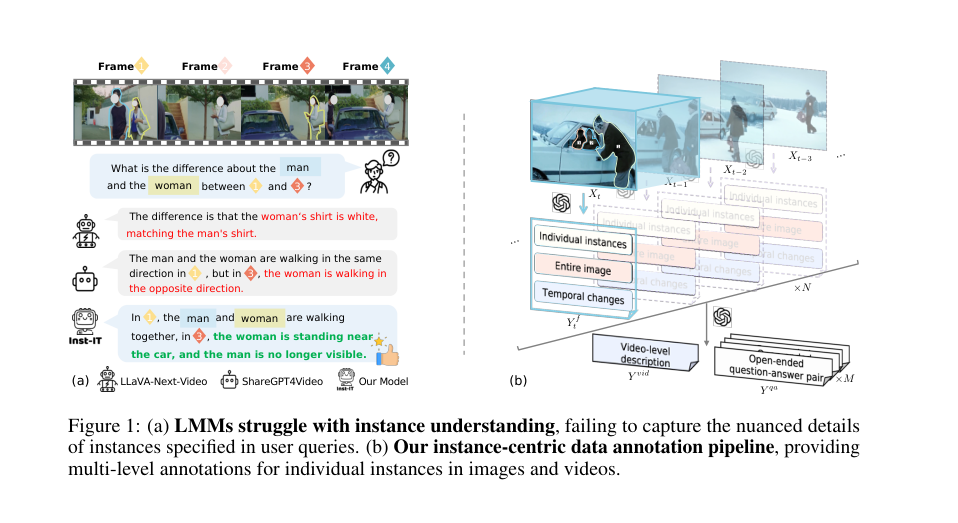 Figure 1. (a) LMMs struggle with instance understanding, failing to capture the nuanced details of instances specified in user queries. (b) Our instance-centric data annotation pipeline, providing multi-level annotations for individual instances in images and videos
Figure 1. (a) LMMs struggle with instance understanding, failing to capture the nuanced details of instances specified in user queries. (b) Our instance-centric data annotation pipeline, providing multi-level annotations for individual instances in images and videos
结果、局限性与结论
实验设计与基线
为了严格验证其主张,作者们设计了一个全面的实验设置。他们的核心方法是通过显式视觉提示指令调优来增强大型多模态模型(LMMs),称为 INST-IT。选择用于增强的主要“受害者”或基线架构是 LLaVA-NeXT [44],这是一个广泛采用的模型。该基线通常使用 Vicuna-1.5-7B [16] 作为其语言模型,使用 CLIP-ViT-336 [67] 作为其视觉编码器。对于更高级的实验,他们还使用了 Qwen2-7B [87] 和 SigLIP-SO400M-384 [97]。
实验设计围绕着一种新颖的图像-视频联合训练流程。该流程精心组合了新创建的 INST-IT 数据集和现有的开源 LLaVA-NeXT-DATA [48]。他们架构的一个关键要素是使用标记集(SoM)视觉提示 [88] 来增强所有图像和视频帧。这项技术明确指导 LMMs 关注个体实例,这是与先前工作的一个关键区别。
INST-IT 数据集本身是一项重大贡献,包含 51k 张图像和 21k 个视频。它具有基于个体实例的多层次、细粒度标注,包括 207k 个图像级标题、135k 个时间动态描述、21k 个视频级标题和 335k 个开放式问答对。
在评估方面,作者们引入了 INST-IT Bench,这是一个经过人类验证的基准,专门用于诊断图像和视频中的实例级理解能力。该基准包含 1,000 个用于 338 张图像的开放式和多项选择 QA 对,以及 206 个视频的 1,000 个 QA 对。开放式 QA 回答使用 GPT-4o [61] 进行准确性和实例 ID 引用正确性评估。除了自定义基准外,他们还在已有的实例理解基准(如 RefCOCOg [53] 和 ViP-Bench [5])以及通用图像和视频理解基准(如 AI2D [28]、ChartQA [54]、Egoschema [52] 和 NEXT-QA [85])上测试了他们的模型。
他们旨在超越的基线模型包括各种最先进的 LMMs:
- 专有模型: GPT-4o [61] 和 Gemini-1.5-flash [72]。
- 开源图像模型: LLaVA-1.5 [43]、ViP-LLaVA [5]、SOM-LLaVA [86] 和直接基线 LLaVA-NeXT [44]。
- 开源视频模型: LLaVA-NeXT-Video [103]、ShareGPT4Video [10]、LLaVA-OV [31]、LLaVA-Video [104]、InternVL2 [13] 和 Qwen2-VL-Instruct [82]。
这种全面的实验设计,包括自定义数据集、基准和多样化的基线,为彻底评估 INST-IT 的有效性提供了可能。
证据证明了什么
实验结果提供了确凿、不可否认的证据,表明 INST-IT 方法显著提升了 LMMs 的实例级理解能力,同时也增强了它们的通用理解能力。
在 INST-IT Bench(表 2)上,经过 INST-IT 增强的模型表现出色。例如,使用 Vicuna-7B 的 LLaVA-NeXT-INST-IT 在图像开放式(OE)问答和多项选择(MC)问答中分别取得了 68.6 和 63.0 的分数,与 LLaVA-NeXT 基线(图像来自表 2 的 46.0 OE,42.4 MC)相比有了显著飞跃。在视频任务中,INST-IT 增强模型得分分别为 49.3 OE 和 42.1 MC,显著优于 LLaVA-NeXT-Video 基线(25.8 OE,24.8 MC)。论文明确指出“平均得分提高了近 20%”,这是对 INST-IT 核心机制的有力验证。
除了他们自己的基准之外,INST-IT 模型在其他已建立的实例理解基准上也显示出持续的改进:
- 在 RefCOCOg [53] 上,LLaVA-NeXT-INST-IT-Vicuna-7B 模型比其 LLaVA-NeXT-Vicuna-7B 基线提高了 10.8%(63.0% vs. 52.2%)。这有力地证明了显式视觉提示指令调优直接增强了模型理解引用表达式并将其与特定实例关联的能力。
- 对于 ViP-Bench [5](表 5),使用 Vicuna-7B 的 INST-IT 在使用人类风格视觉提示时,取得了与 ViP-LLaVA 相当甚至在某些情况下超越的性能。这一点尤其引人注目,因为 ViP-LLaVA 是在 ViP-Bench 数据集上微调的,而 INST-IT 是在零样本情况下进行评估的,这表明了强大的泛化能力。
此外,模型在广泛使用的通用基准上的通用理解能力也得到了显著提升:
- 对于图像基准(表 3),INST-IT 模型持续优于 LLaVA-NeXT 基线。具体来说,使用 Vicuna-7B 变体在 AI2D [28] 上提高了 4.4%,在 ChartQA [54] 上提高了 13.5%。这些基准需要基础和推理能力,表明 INST-IT 的细粒度理解转化为更广泛的视觉推理能力。
- 在视频基准(表 4)上,INST-IT 模型显著优于 LLaVA-NeXT 和 LLaVA-NeXT-Video 基线。例如,使用 Vicuna-7B 变体在 Egoschema [52] 上提高了 7.8%,在 NEXT-QA [85] 上提高了 11.8%。这些结果证实,通过显式视觉提示增强实例级理解是提高通用时空理解效率的策略。
消融研究进一步剖析了各项贡献:
- 连续指令调优范式(表 6)至关重要。将视频数据与通用指令数据直接混合会导致图像理解能力下降,但提出的连续 SFT 和冻结视觉编码器在图像和视频任务上实现了平衡的性能,减轻了来自视觉提示图像的分布偏移。
- 详细的数据集组合(表 7)显示,实例级和图像级帧标题对于图像实例理解至关重要,而时间差异、视频级描述和 QA 对于视频实例理解至关重要。最终,整合 INST-IT 数据集的图像部分产生了最平衡的性能。
总之,证据明确证明 INST-IT 的多层次、实例基础标注与显式视觉提示和连续指令调优范式相结合,有效地为 LMMs 提供了卓越的细粒度实例理解能力,进而增强了它们的整体多模态理解能力。
局限性与未来方向
尽管 INST-IT 在 LMMs 的实例级理解方面取得了重大进展,但作者们坦诚地承认了几个局限性,并提出了激动人心的未来发展方向。
当前局限性:
1. 计算成本: 当前的实验主要在 7B 和 1.5B 参数模型上进行。扩展到更大的模型(例如,70B 或更高)受到高昂计算成本的限制,这限制了当前研究的范围。
2. GPT-4o 开销: 自动数据标注流程虽然有效,但依赖于 GPT-4o。这引入了固有的开销,可能成为生成更大、更多样化数据集的瓶颈。
3. 失效案例: 模型有时在具有挑战性的场景中会遇到困难,例如严重遮挡的实例、模糊的图像,或实例过于小型或拥挤。这些是 LMMs 的常见障碍,表明了可以改进鲁棒性的领域。
4. 公平性与偏见: 与许多大型多模态模型一样,INST-IT 面临潜在的公平性和偏见风险,这可能源于训练数据或模型学到的表示。这是一个关键的伦理考量,需要持续关注。
未来方向与讨论话题:
基于这些发现,出现了几个供进一步发展和演进的讨论话题:
-
规模化与自监督数据生成:
- 如何开发计算效率更高的实例级指令调优方法,使其能够在不产生过高成本的情况下扩展到更大的 LMMs?
- 我们能否转向“模型在循环中”的方法,即一旦部分训练好的模型,它本身就可以协助生成更高质量、自合成的实例级数据,从而减少对 GPT-4o 等昂贵专有 API 的依赖?这可能涉及迭代改进,模型生成数据,进行少量人工验证,然后重新训练模型。
-
增强对挑战性视觉条件的鲁棒性:
- 哪些新颖的架构设计或训练策略可以专门解决已识别的失效案例(遮挡、模糊、小型/拥挤实例)?在这些困难场景中整合不确定性估计或多视图融合技术是否可以提高性能?
- 如何更有效地利用合成数据生成来创建多样化且具有挑战性的示例,这些示例专门针对这些失效模式,从而提高模型鲁棒性?
-
减轻偏见并确保公平性:
- 鉴于潜在的公平性和偏见问题,可以实施哪些系统的数据过滤和验证方法来确保 INST-IT 数据集和未来的数据集更加公平和具有代表性?
- 除了数据中心解决方案之外,可以开发哪些模型无关或模型特定的技术(例如,去偏算法、用于审计实例级决策的可解释 AI 方法)来检测和减轻实例理解中的偏见?
-
扩展时空推理和预测能力:
- 虽然 INST-IT 在描述当前和时间变化方面表现出色,但我们如何推动 LMMs 进行更复杂时空推理,例如预测实例的未来动作或轨迹,或理解视频中实例之间的长期因果关系?
- 整合受物理启发的神经网络或常识推理模块是否能进一步增强模型对实例交互的推理能力,而不仅仅是观察?
-
实际部署与人机协作:
- INST-IT 框架如何集成到需要用户交互式指定感兴趣实例的实际应用中,也许通过比数字 ID 更直观的界面?
- 在需要细粒度视觉理解的任务中,INST-IT 增强的 LMMs 能否作为更有效的助手,通过提供精确的实例级见解来完成视频编辑、监控分析甚至科学观察等任务?这还引发了模型实例级推理的可解释性对人类用户的影响问题。
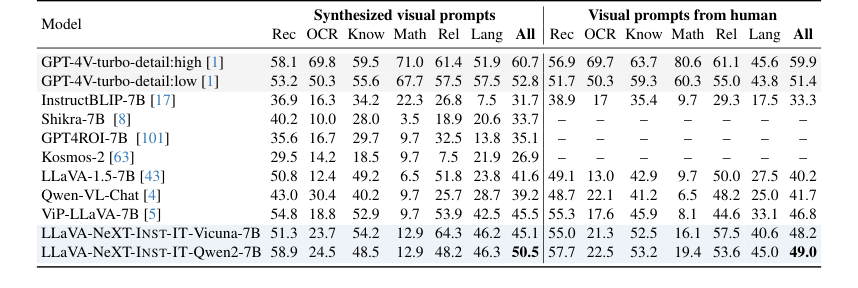 Table 5. Results on ViP-Bench. We perform evaluation with our INST-IT models without fine-tuning
Table 5. Results on ViP-Bench. We perform evaluation with our INST-IT models without fine-tuning
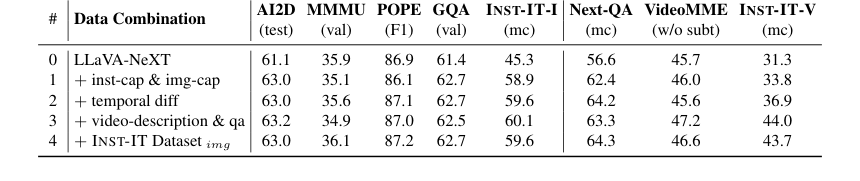 Table 7. Ablation on detailed data combination. The dataset combination in line #3 corresponds to the video part of INST-IT Dataset, while line #4 represents the complete INST-IT Dataset by incorporating the image part into line #3
Table 7. Ablation on detailed data combination. The dataset combination in line #3 corresponds to the video part of INST-IT Dataset, while line #4 represents the complete INST-IT Dataset by incorporating the image part into line #3
 Table 9. Statistical and lexical analysis of INST-IT Dataset. We present the results for each annotation level as well as the entire dataset
Table 9. Statistical and lexical analysis of INST-IT Dataset. We present the results for each annotation level as well as the entire dataset
与其他领域的同构性
结构骨架
一种机制,它利用显式的、结构化的视觉线索来指导强大的生成模型,为动态视觉数据中的个体实体生成细粒度的、多层次的标注,随后利用这些丰富的数据来增强其他大型多模态模型的实例级理解能力。