TAPNext: Tracking Any Point (TAP) as Next Token Prediction
The problem of "correspondence" has been a foundational challenge in computer vision for decades.
Background & Academic Lineage
The Origin & Academic Lineage
The problem of "correspondence" has been a foundational challenge in computer vision for decades. Takeo Kanade, a prominent figure in the field, famously highlighted "correspondence, correspondence, and correspondence!" as one of the three most fundamental problems. Historically, this involved finding matching points or regions between images, which was crucial for tasks like understanding motion, estimating depth, and reconstructing 3D scenes from photo collections.
More recently, this fundamental problem has experienced a resurgence and evolved into "Tracking Any Point (TAP)" in video. This specific problem first emerged to address the limitations of earlier approaches like optical flow. While optical flow methods could track frame-to-frame motion, they often suffered from significant drift over longer time horizons and struggled with occlusions. TAP was introduced to bridge this gap by focusing on providing dense, long-range correspondence of specific points on solid objects throughout an entire video. This capability is highly valuable for a wide array of downstream computer vision applications, including robotics, video editing, 3D reconstruction, action recognition, zoology, and even medicine.
The fundamental limitation, or "pain point," of previous TAP approaches that compelled the authors to develop TAPNext stems from their reliance on complex, tracking-specific inductive biases and heuristics. Many prior models formulated tracking as a two-step process involving per-frame encoding, cost-volume computation for matching, and subsequent track refinement. This often introduced restrictive assumptions about how tracking should be solved, such as casting it as an appearance matching problem in feature space. These methods frequently incorporated numerous heuristic design elements, including differentiable argmax operations, bi-linear feature interpolation, restricted search windows, and windowed inference.
Furthermore, many existing trackers required information from future frames to produce current frame outputs, making them unsuitable for real-time applications. Even online methods that used local window-based inference often failed during long-term occlusions due to their reliance on transferring points only between consecutive windows. These complex architectures and algorithmic choices limited the generality, scalability, and overall performance of previous models, particularly on long-term tracking benchmarks. The authors' motivation was to build a simpler, more scalable, and performant model that could overcome these limitations without imposing strong, explicit inductive biases.
Intuitive Domain Terms
- Tracking Any Point (TAP): Imagine you're watching a video of a busy street, and you want to follow a tiny, specific speck of paint on a moving car, or a particular button on someone's jacket, throughout the entire clip. TAP is the computer vision task of doing exactly that: identifying and following the precise location of any chosen point on an object as it moves and changes in a video.
- Inductive Biases: Think of these as built-in assumptions or "shortcuts" that a model uses to learn. For example, if you're teaching a child to identify cats, and you tell them "cats always have pointy ears," that's an inductive bias. It helps them learn faster but might cause them to misidentify a cat with folded ears. In computer vision, these biases are design choices in the model's architecture that guide it to solve a problem in a particular way, but they can also limit its flexibility or ability to generalize.
- Cost-Volume Computation: Picture a detective trying to match a suspect's face from a "wanted" poster to every single face in a large crowd. A cost volume is like a detailed, pixel-by-pixel map that tells the detective exactly how similar each face in the crowd is to the suspect's face. It quantifies the "cost" or dissimilarity of matching each potential location.
- State-Space Model (SSM): Consider a storyteller who is narrating a long, unfolding tale. Instead of remembering every single detail from the very beginning, the storyteller maintains a concise, evolving summary of the story's current situation (the "state"). As new events (video frames) occur, they update this summary, allowing them to keep the narrative coherent and predict what might happen next without having to re-read the entire story from page one each time.
Notation Table
| Variable | Description |
|---|---|
Problem Definition & Constraints
Core Problem Formulation & The Dilemma
The core problem addressed by this paper is Tracking Any Point (TAP) in videos. Precisely, the starting point (input/current state) for the model consists of:
- A video comprising $T$ frames, where each frame is an RGB image of size $H \times W$ pixels.
- A set of $Q$ query points, each defined by its time $t$ and spatial coordinates $(x, y)$ within the video.
The desired endpoint (output/goal state) is to predict, for each queried point, its coordinate $(x, y) \in [0, H] \times [0, W]$ and a binary visibility flag for every frame in the video.
The exact missing link or mathematical gap that this paper attempts to bridge is the transformation of the TAP problem into a sequential masked token decoding task. Instead of relying on complex, tracking-specific inductive biases and heuristics, TAPNext frames point tracking as an imputation problem. Given the initial query point coordinates, the model's task is to "fill in" or impute the masked tokens representing the unknown coordinates of these points across all other frames. This is achieved by concatenating video tokens (derived from image patches) with point coordinate tokens, where the query point information is injected via positional encoding. The model then learns to decode the full trajectories by predicting the masked tokens.
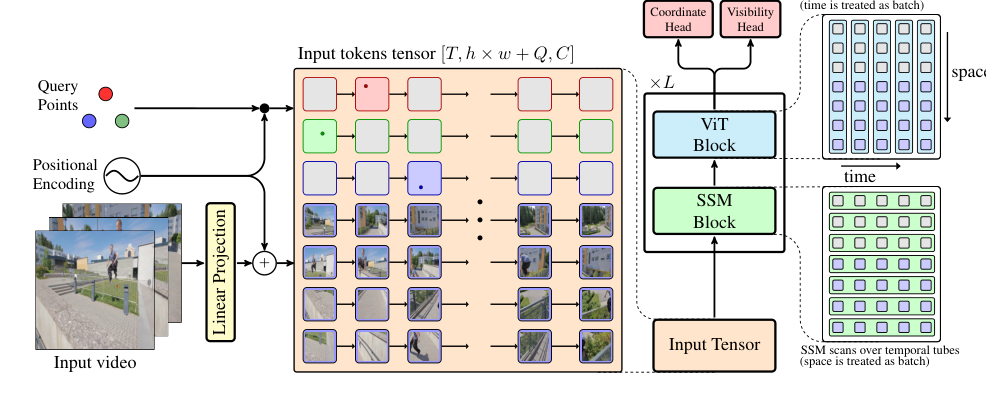 Figure 2. TAPNext performs tracking via imputation of unknown point coordinates given known ones (query points and the video). This imputation happens via temporal masked decoding of tokens: video tokens are concatenated with point coordinate tokens and the latter inject point query information via positional encoding
Figure 2. TAPNext performs tracking via imputation of unknown point coordinates given known ones (query points and the video). This imputation happens via temporal masked decoding of tokens: video tokens are concatenated with point coordinate tokens and the latter inject point query information via positional encoding
Previous researchers attempting to solve this specific problem have been trapped by several painful trade-offs and dilemmas:
- Generality vs. Specificity: Existing TAP methods heavily rely on complex, tracking-specific inductive biases and heuristics. While these might offer performance gains in specific scenarios, they severely limit the generallity and potential for scaling of the models. Improving one aspect (e.g., accuracy with specialized architectures) often breaks another (e.g., scalability and broad applicability).
- Accuracy vs. Real-time Latency: Many prior trackers achieve high accuracy by using future frames to predict current frame outputs, or by employing windowed inference. This approach inherently introduces latency, making them unsuitable for real-time applications like robotics. The dilemma is how to achieve high tracking performance without sacrificing real-time capability.
- Robustness vs. Simplicity: Traditional methods often involve multi-step processes like per-frame encoding, cost-volume computation for matching, and iterative refinement. These complex pipelines, while aiming for robustness against drift and occlusions, introduce many heuristic design elements (e.g., differentiable argmax, bi-linear interpolation, restricted search windows), making the models intricate and less scalable.
- Long-term Tracking vs. Occlusion Handling: Optical flow-based methods suffer from significant drift over long time horizons and struggle with occlusions. While long-term point tracking was introduced to address this, windowed inference in many online methods still leads to tracking failures, especially during long-term occlusions, as points can be lost when transferred between consecutive windows.
Constraints & Failure Modes
The problem of Tracking Any Point (TAP) is insanely difficult to solve due to several harsh, realistic walls the authors hit:
- Data Scarcity: Real-world training data for TAP is scarce. This forces prior works to rely heavily on synthetic data, which then necessitates complex inductive biases and custom architectures to bridge the "sim-to-real" gap, limiting the scalability and generallity of the models.
- Computational Complexity & Memory Limits:
- Traditional methods often compute cost volumes independently for every query point, which can be computationally expensive.
- Iterative refinement steps and windowed inference schemes add significant computational overhead.
- Hardware memory limits are a practical concern, as evidenced by the high memory usage of some baseline models (e.g., LocoTrack-B using over 30 GB of memory, as shown in Table 2). Developing models that are memory-efficient is crucial for deployment.
- Real-time Latency Requirements: For applications like robotics, strict real-time latency is a critical constraint. Methods that require processing future frames or large temporal windows before outputting current frame predictions are inherently limited in their applicability.
- Temporal Coherence & Drift: Maintaining temporal coherence across long video sequences is challenging. Auto-regressive models, which predict future states based on past ones, are prone to accumulation of errors, leading to significant drift over time. This is a major failure mode for many trackers.
- Generalization to Long Videos: Models trained on shorter video clips (e.g., 48 frames) often generalize poorly to significantly longer videos (e.g., greater than 150 frames). This limitation in temporal generalization is a significant hurdle, particularly for State-Space Models (SSMs) if not properly mitigated. The paper notes that the model exhibits poor temporal generalization when SSM is swapped for temporal attention, and even with SSMs, there is "significant failure in long term point tracking the full length of a video greater than 150 frames" if not trained on sufficiently long sequences.
- Non-differentiable Operations: Many heuristic design elements in prior architectures, such as the differentiable argmax operation or bi-linear interpolation of features, introduce complexities that TAPNext aims to avoid for a simpler, more unified approach.
- Occlusion Handling: Points can become occluded for extended periods within a video. Robustly tracking points through these occlusions, and correctly predicting their visibility, is a persistent challenge. Windowed inference methods often fail during long-term occlusions.
- Appearance Changes: The appearance of tracked points can change due to lighting variations, viewpoint shifts, or deformations, making appearance-based matching difficult.
- Coordinate Prediction Precision: The coordinate prediction space is bounded by image dimensions, and achieving high precision while also representing uncertainty (e.g., multimodal predictions) is a complex task. The coordinate head needs to be able to predict both continuous coordinates and handle the discrete nature of image pixels.
- Sim-to-Real Gap: Models trained predominantly on synthetic data often struggle to perform well on real-world videos due to differences in visual characteristics, requiring robust mechanisms to bridge this domain gap. The paper mentions that training on pseudo-labeled real data is beneficial for this.
- Lack of Inductive Biases: While TAPNext aims to remove tracking-specific inductive biases for generallity, this also means the model must learn these necessary heuristics organically from data, which can be a harder learning problem. The paper shows that some heuristics naturally emerge, but this is not guaranteed for all problems.
- Visual Information Propagation: The model must learn to propagate visual information accurately to future frames from past frames, especially for regions covered by tracked points, even after they were occluded. If the model does not have previous information about certain visual regions, it may simply fill them with average values, which is a failure mode. This is particularly relevant for areas that appear after the initial points grid moves away, which are not reconstructed well. This is a key challenge for the model, as it must maintain an accurate visual representation of the tracked points. This is not to be veiwed as a generative model, but rather a linear probing experiment.
Why This Approach
The Inevitability of the Choice
The authors of TAPNext faced a critical juncture where traditional state-of-the-art (SOTA) methods for Tracking Any Point (TAP) proved fundamentally insufficient. The core realization was that existing TAP approaches were overly reliant on "complex tracking-specific inductive biases and heuristics" (Abstract). These included techniques like cost-volume computation, iterative refinement, windowed inference, and explicit per-frame appearance matching. While these methods achieved reasonable performance, they inherently limited the generality and scalability of the models, particularly when trying to bridge the "sim-to-real gap" from synthetic to real-world data.
The exact moment of this realization appears to stem from the observation that these complex, hand-engineered components were:
1. Too restrictive: Architectures designed with strong inductive biases limited their ability to scale and generalize to diverse scenarios.
2. Not truly online: Many methods, even those claiming online capabilities, still relied on future frames or large temporal windows, making them unsuitable for real-time applications like robotics. This reliance often led to tracking failures during long-term occlusions.
3. Heuristic-driven: The need for differentiable argmax, bi-linear interpolation, restricted search windows, and other specific design elements made the overall system complex and brittle.
The authors concluded that a conceptually simpler, more general architecture was needed—one that could learn to track points without being explicitly prescribed how to use motion and appearance cues. This led them to cast TAP as a "sequential masked token decoding" problem, leveraging general-purpose components like State-Space Models (SSMs) for temporal processing and Vision Transformers (ViTs) for spatial processing, a combination previously explored in TRecViT [40]. This approach was deemed the only viable solution to overcome the limitations of complexity, lack of generality, and poor scalability inherent in prior SOTA methods.
Comparative Superiority
TAPNext demonstrates qualitative superiority over previous gold standards in several key aspects, extending beyond mere performance metrics:
- Emergent Heuristics: One of the most striking advantages is that many widely used tracking heuristics (e.g., motion-cluster-based attention, coordinate-based readout, and cost-volume-like attention) "emerge naturally in TAPNext through end-to-end training" (Abstract, Figure 3). This eliminates the need for complex, hand-engineered components, making the model significantly simpler and more robust.
- Enhanced Temporal Coherence and Occlusion Handling: By employing recurrent state architectures, specifically SSMs, TAPNext can maintain temporal coherence and effectively capture the dynamics of tracked points across time. This structural advantage allows it to handle long-term occlusions much more accurately than window-based inference methods, which often fail when points are occluded for extended periods.
- Reduced Memory and Latency: The paper provides compelling evidence of TAPNext's efficiency. For instance, TAPNext-B (frame) exhibits significantly lower memory usage (e.g., 2.1-2.4 GB) compared to LocoTrack-B (256x256) at around 30.5 GB (Table 2). Furthermore, its latency is drastically reduced, operating in the range of 5.29-5.47 ms, which is orders of magnitude faster than CoTracker3 (80-177 ms) or LocoTrack-B (2210-8000 ms). This makes it overwhelmingly superior for real-time applications.
- Scalability and Generalization: TAPNext is designed with minimal tracking-specific inductive biases, allowing it to generalize better. It can track points in videos significantly longer (up to 5x) than those seen during training, a crucial capability for real-world scenarios. The linear recurrence of SSMs also enables temporal processing to be parallelized in an offline setting, further boosting efficiency.
- Multimodal Prediction: Unlike prior methods that often rely on a single trajectory hypothesis, TAPNext's coordinate classification head can represent multimodal predictions, allowing it to express uncertainty. This is a qualitative leap in handling ambiguous tracking situations.
- Simplicity and Unbiased Solution: The model's conceptual simplicity, with few hyperparameters and no tracking-specific inductive biases, allows it to discover an unbiased solution to the TAP problem, rather than being constrained by predefined notions of motion and appearance. This makes it more adaptable and potentially more powerful.
Alignment with Constraints
The chosen approach of casting TAP as sequential masked token decoding, built upon TRecViT's interleaved SSM and ViT blocks, perfectly aligns with the problem's harsh requirements, forming a strong "marriage" between problem and solution.
- Online and Causal Tracking: A primary constraint was the need for purely online and causal tracking, essential for robotics and real-time applications. TAPNext achieves this by processing frames sequentially and maintaining a recurrent state via SSMs, ensuring that predictions for the current frame only depend on past information. This directly addresses the limitation of many prior methods that rely on future frames.
- Minimal Latency: The architecture's design, particularly the use of linear recurrent SSMs, enables minimal latency. It outputs point predictions immediately after consuming each frame, avoiding the temporal windowing or iterative refinement steps that introduce delays in other SOTA trackers.
- Scalability and Generality: The demand for a scalable and general model, free from complex inductive biases, is met by TAPNext's use of off-the-shelf architectural components (SSMs and ViTs) and its formulation as a masked decoding task. This allows the model to learn tracking without explicit, hand-engineered heuristics, making it more adaptable to diverse scenarios and longer videos.
- Handling Long-Term Occlusions: The recurrent state maintained by the SSM layers is crucial for preserving temporal coherence and tracking points even during long-term occlusions. This directly tackles a significant weakness of window-based methods that struggle when points disappear and reappear.
- Computational Efficiency: The linear recurrence of SSMs allows for parallel inference over time, which is vital for processing long videos without a prohibitive increase in computational complexity. This is a key advantage over methods that rely on windowed inference or iterative refinement, which can become computationally expensive for extended sequences.
- Uncertainty Representation: The coordinate prediction as a classification task, allowing for multimodal predictions, aligns with the need to represent uncertainty in tracking, a capability often lacking in prior point-estimate-based methods.
Rejection of Alternatives
The paper implicitly and explicitly rejects several popular or traditional approaches by highlighting their inherent limitations in the context of TAP.
- Traditional SOTA Methods (Cost-Volume, Iterative Refinement, Windowed Inference): The authors explicitly state that "existing methods for TAP rely heavily on complex tracking-specific inductive biases and heuristics" (Abstract). They detail these as "cost-volume computation, followed by track refinement [11, 12, 21, 26]," involving "many heuristic design elements, including the differentiable argmax operation [12], bi-linear interpolation of features [21], restricted search windows [9], and windowed inference [26]." These were rejected becuase they limit generality, scalability, and often require non-causal processing or lead to tracking failures during long-term occlusions. TAPNext's goal was to avoid these "strong inductive biases" and develop a "conceptually simpler architecture."
- Offline/Non-Causal Trackers: Many trackers "rely on using future frames to produce outputs for the current frame, limiting their applicability in real-time scenarios." This non-causal nature was a direct contradiction to the requirement for online tracking, leading to their rejection for the target applications.
- Window-Based Online Trackers: While some methods claimed online capabilities using local windows, the paper notes their "reliance on large temporal windowing and the transfer of points only between consecutive windows often leads to tracking failures, especially during long-term occlusions in the middle of a video [21, 26]." This poor performance on long-term tracking benchmarks led to the rejection of such approaches in favor of a truly recurrent, per-frame solution.
- Standard Transformers with Temporal Attention: An ablation study (Table 5) provides a clear rejection of using standard temporal attention mechanisms (like those in basic Transformers) for the temporal processing component. When the SSM is swapped for temporal attention, the model "exhibits poor temporal generalization despite using the RoPE [45] temporal positional embedding which is known to generalize over time." This indicates that for the specific task of long-range temporal coherence in tracking, SSMs offer a superior structural advantage over general temporal attention, which struggles with longer sequences and generalization. This is a crucial finding, suggesting that a simpler recurrence is more effective than complex attention for this particular problem.
- Single-Hypothesis Point Estimation: Prior methods like TAPIR and Co-Tracker perform "multiple refinement steps on a single trajectory hypothesis per query, and perform local feature sampling around that single hypothesis." TAPNext's coordinate classification head, which can represent multimodal predictions and uncertainty, implicitly rejects this simpler, less informative approach. The ability to represent uncertainty is a qualitative advantage.
- Generative Models for Reconstruction: While the paper does perform a reconstruction experiment, it's explicitly stated that this should not be veiewed as a generative model, but rather a "linear probing experiment." The primary goal is tracking, not image generation, and the authors did not find that an image reconstruction objective "leads to improved tracking performance." This implies that while masked autoencoding is used for token imputation, a full generative model for video frames was not deemed necessary or beneficial for the core tracking task.
 Figure 4. Point-to-point attention map visualizations. Tracked points are nodes and (scaled) attention weights are edges, the thicker the edge the higher the weight between points. Two frames from a video are used to visualize two attention layers. Note that in all images we see strong attention between points on objects that are moving together. See higher resolution images in Appendix D
Figure 4. Point-to-point attention map visualizations. Tracked points are nodes and (scaled) attention weights are edges, the thicker the edge the higher the weight between points. Two frames from a video are used to visualize two attention layers. Note that in all images we see strong attention between points on objects that are moving together. See higher resolution images in Appendix D
Mathematical & Logical Mechanism
The Master Equation
The core mechanism of TAPNext is driven by a multi-task loss function that combines coordinate prediction (both classification and regression) and visibility prediction. This loss is applied at every layer of the TRecViT architecture, ensuring robust learning across the model's depth. The overall objective is to minimize the discrepancy between the model's predictions and the ground truth for point coordinates and their visibility over time.
The master equation, representing the total loss $L_{total}$ minimized during training, can be expressed as:
$$ L_{total} = \frac{1}{L \cdot Q \cdot T} \sum_{l=1}^{L} \sum_{q=1}^{Q} \sum_{t=1}^{T} \left( L_{coord}^{(l)}(t,q) + L_{vis}^{(l)}(t,q) \right) $$
where $L_{coord}^{(l)}(t,q)$ is the coordinate loss for query point $q$ at time $t$ from layer $l$, and $L_{vis}^{(l)}(t,q)$ is the visibility loss for the same point. These individual losses are further defined as:
$$ L_{coord}^{(l)}(t,q) = L_{CE}(p_x^{(l)}(t,q), \text{target_bin}_x) + L_{CE}(p_y^{(l)}(t,q), \text{target_bin}_y) + L_{Huber}((\hat{x}^{(l)}_{t,q}, \hat{y}^{(l)}_{t,q}), (x_{t,q}, y_{t,q})) $$
$$ L_{vis}^{(l)}(t,q) = L_{BCE}(\hat{V}^{(l)}_{t,q}, V_{t,q}) $$
Term-by-Term Autopsy
Let's dissect each component of these equations to understand its mathematical definition and its role in the TAPNext framework.
-
$L_{total}$:
- Mathematical Definition: The total loss function, representing the overall objective to be minimized during the training of TAPNext. It is an average sum of individual losses across all layers, query points, and time steps.
- Physical/Logical Role: This term quantifies how "wrong" the model's predictions are across the entire video sequence and for all tracked points. By minimizing $L_{total}$, the model learns to accurately predict both the location and visibility of points over time. The summation across layers with equal weights (as stated in the paper) is a strategic choice to ensure that intermediate representations are also well-formed, preventing issues like vanishing gradients in deeper layers and promoting robust feature learning throughout the network. This deep supervision helps stabilize training and improve final performance.
- Why sum instead of other operations? Summation is used to combine the losses from different components (coordinates, visibility) and different layers. This implies that all these aspects are equally important for the overall task, and errors in any part contribute directly to the total error. Averaging by $L \cdot Q \cdot T$ normalizes the loss, making it independent of the number of layers, queries, or frames, which is crucial for stable training across varying input sizes.
-
$L$:
- Mathematical Definition: The total number of interleaved SSM and ViT layers in the TRecViT backbone.
- Physical/Logical Role: Represents the depth of the model's processing pipeline. Each layer contributes to refining the spatio-temporal representations of image and point tokens. The loss is applied at every layer to ensure that features at different levels of abstraction are meaningful and contribute to the final prediction, a form of deep supervision.
-
$Q$:
- Mathematical Definition: The number of query points being tracked in the video.
- Physical/Logical Role: This is the count of individual points whose trajectories the model is tasked with predicting. The loss is summed over all query points to ensure that the model learns to track multiple points simultaneously and accurately.
-
$T$:
- Mathematical Definition: The total number of frames in the video sequence.
- Physical/Logical Role: Represents the temporal extent of the video. The loss is summed over all time steps to ensure that the model tracks points consistently throughout the entire video, capturing their temporal dynamics and handling occlusions.
-
$L_{coord}^{(l)}(t,q)$:
- Mathematical Definition: The combined coordinate loss for query point $q$ at time $t$ from layer $l$. It consists of two cross-entropy terms for classification and one Huber loss term for regression.
- Physical/Logical Role: This term drives the model to predict the precise $(x,y)$ coordinates of the tracked point. The dual approach of classification into bins and continuous regression allows the model to capture both discrete spatial locations and fine-grained continuous positions. The classification aspect helps the model represent multimodal predictions and uncertainty, which is vital for ambiguous situations or occlusions, unlike methods that only output a single point estimate.
-
$L_{CE}(p_x^{(l)}(t,q), \text{target_bin}_x)$ and $L_{CE}(p_y^{(l)}(t,q), \text{target_bin}_y)$:
- Mathematical Definition: Softmax Cross-Entropy loss. For a given coordinate (e.g., x-coordinate), $p_x^{(l)}(t,q)$ is the vector of predicted probabilities for $n$ discrete bins, and $\text{target_bin}_x$ is the one-hot encoded ground truth bin.
$$ L_{CE}(p, \text{target}) = - \sum_{i=1}^{n} \text{target}_i \log(p_i) $$ - Physical/Logical Role: These terms train the coordinate head to classify the $x$ and $y$ coordinates into predefined discrete bins. This classification approach, inspired by [16], is crucial because it allows the model to express uncertainty (e.g., a point could be in one of several bins with certain probabilities) and handle multimodal predictions, which is a significant advantage over methods that only predict a single continuous value. The paper notes that this classification coordinate head is one of the most important components.
- Mathematical Definition: Softmax Cross-Entropy loss. For a given coordinate (e.g., x-coordinate), $p_x^{(l)}(t,q)$ is the vector of predicted probabilities for $n$ discrete bins, and $\text{target_bin}_x$ is the one-hot encoded ground truth bin.
-
$L_{Huber}((\hat{x}^{(l)}_{t,q}, \hat{y}^{(l)}_{t,q}), (x_{t,q}, y_{t,q}))$:
- Mathematical Definition: Huber loss, applied to the continuous predicted coordinates $(\hat{x}^{(l)}_{t,q}, \hat{y}^{(l)}_{t,q})$ against the ground truth coordinates $(x_{t,q}, y_{t,q})$. The continuous coordinates are derived from the expected value of the classifier probabilities: $\hat{x}^{(l)}_{t,q} = \sum_{i=1}^{n} b_{x,i} \cdot p_x^{(l)}(t,q,i)$ where $b_{x,i}$ is the center of bin $i$.
$$ L_{Huber}(e) = \begin{cases} 0.5 e^2 & \text{if } |e| \le \delta \\ \delta (|e| - 0.5 \delta) & \text{if } |e| > \delta \end{cases} $$
where $e$ is the error (e.g., $\hat{x} - x$) and $\delta$ is a hyperparameter. - Physical/Logical Role: This term acts as a regression loss, fine-tuning the continuous coordinate predictions. Huber loss is chosen over a simple L2 (mean squared error) loss because it is less sensitive to outliers. In point tracking, ground truth annotations can sometimes have minor inaccuracies or points might briefly appear in unexpected locations due to occlusions or rapid motion. Huber loss provides a smoother gradient for small errors (like L2) but a linear gradient for large errors (like L1), making it more robust to such noise and preventing large errors from dominating the loss landscape.
- Mathematical Definition: Huber loss, applied to the continuous predicted coordinates $(\hat{x}^{(l)}_{t,q}, \hat{y}^{(l)}_{t,q})$ against the ground truth coordinates $(x_{t,q}, y_{t,q})$. The continuous coordinates are derived from the expected value of the classifier probabilities: $\hat{x}^{(l)}_{t,q} = \sum_{i=1}^{n} b_{x,i} \cdot p_x^{(l)}(t,q,i)$ where $b_{x,i}$ is the center of bin $i$.
-
$L_{vis}^{(l)}(t,q)$:
- Mathematical Definition: The visibility loss for query point $q$ at time $t$ from layer $l$.
- Physical/Logical Role: This term drives the model to predict whether a tracked point is visible or occluded in a given frame. Accurate visibility prediction is crucial for robust tracking, especially in real-world scenarios where objects frequently go out of view or are temporarily hidden.
-
$L_{BCE}(\hat{V}^{(l)}_{t,q}, V_{t,q})$:
- Mathematical Definition: Sigmoid Binary Cross-Entropy loss. $\hat{V}^{(l)}_{t,q}$ is the predicted probability of visibility (a scalar between 0 and 1), and $V_{t,q}$ is the binary ground truth (0 for occluded, 1 for visible).
$$ L_{BCE}(\hat{v}, v) = - (v \log(\hat{v}) + (1-v) \log(1-\hat{v})) $$ - Physical/Logical Role: This term trains the visibility head to perform binary classification. It penalizes the model when it incorrectly predicts a point's visibility status. Sigmoid activation ensures the output is a probability, and binary cross-entropy is the standard loss for such two-class problems. The model also uses an uncertainty estimate: if more than 50% of the probability mass for coordinates lies outside an 8-pixel radius, the point is marked as occluded, providing a natural link between coordinate uncertainty and visibility.
- Mathematical Definition: Sigmoid Binary Cross-Entropy loss. $\hat{V}^{(l)}_{t,q}$ is the predicted probability of visibility (a scalar between 0 and 1), and $V_{t,q}$ is the binary ground truth (0 for occluded, 1 for visible).
Step-by-Step Flow
Imagine a single abstract data point, say a specific pixel on a moving car, that we want to track through a video. Here's its journey through the TAPNext mathematical engine:
-
Input & Tokenization:
- The journey begins with a video, a sequence of $T$ RGB frames, and a set of $Q$ initial query points, each defined by its starting time and $(x,y)$ coordinates.
- Each video frame is first partitioned into a grid of $h \times w$ non-overlapping image patches. These patches are then linearly projected into a $C$-dimensional feature space, and spatial positional embeddings are added. This transforms the raw image data into a sequence of "image tokens" with shape $[T, h \times w, C]$.
- Simultaneously, for our specific query point (and all others), a sequence of $T$ "point track tokens" is created. For the frame where our point is initially queried, its token is initialized with a positional embedding corresponding to its $(x,y)$ coordinates. For all other frames, its token is initialized with a special "mask token" value, signifying that its position is unknown and needs to be predicted. These point tokens also have a shape of $[T, Q, C]$.
-
Input Tensor Assembly:
- The image tokens and point track tokens are then concatenated along the spatial dimension. This creates a unified "input tokens tensor" of shape $[T, h \times w + Q, C]$. This tensor now contains all the information: the visual content of the video and the query point information, with masked positions for the frames to be tracked.
-
Layered Spatio-Temporal Processing (TRecViT):
- This combined input tensor then enters the TRecViT backbone, which consists of $L$ interleaved layers. Each layer is a two-stage process:
- SSM Block (Temporal Processing): First, the data passes through a State-Space Model (SSM) block. This block performs linear recurrence over the temporal dimension ($T$). It treats the combined spatial dimension ($h \times w + Q$) as a batch. Conceptually, this is like a conveyor belt moving through time. The SSM block efficiently propagates information from past frames to the current and future frames, allowing the model to maintain a "memory" of the point's trajectory and appearance. This is crucial for tracking through occlusions and over long durations.
- ViT Block (Spatial Processing): Next, the output of the SSM block enters a Vision Transformer (ViT) block. This block performs full self-attention across all $h \times w + Q$ tokens within each frame, treating the time dimension ($T$) as a batch. This is where the model "looks around" within a single frame, allowing image tokens to attend to point tokens, and point tokens to attend to each other and to image tokens. This spatial mixing helps the model identify the point's location relative to its surroundings and integrate visual cues.
- This two-stage process (SSM then ViT) is repeated for all $L$ layers, progressively refining the spatio-temporal representation of our abstract data point.
- This combined input tensor then enters the TRecViT backbone, which consists of $L$ interleaved layers. Each layer is a two-stage process:
-
Prediction Heads:
- After passing through each layer $l$, the model outputs a set of $T \times Q$ track tokens. These tokens are then fed into two separate prediction heads:
- Coordinate Head (MLP): An MLP (Multi-Layer Perceptron) takes the track token for our point at each time step. It first predicts probabilities for $n$ discrete bins for both the $x$ and $y$ coordinates. Then, it computes the expected continuous $(x,y)$ coordinate by summing the bin centers weighted by these probabilities.
- Visibility Head (MLP): Another MLP takes the same track token and predicts a binary probability indicating whether our point is visible or occluded in that frame.
- After passing through each layer $l$, the model outputs a set of $T \times Q$ track tokens. These tokens are then fed into two separate prediction heads:
-
Loss Computation & Backpropagation:
- For every layer $l$, and for every time step $t$ and query point $q$, the predicted coordinates $(\hat{x}^{(l)}_{t,q}, \hat{y}^{(l)}_{t,q})$ and visibility $\hat{V}^{(l)}_{t,q}$ are compared against the ground truth $(x_{t,q}, y_{t,q})$ and $V_{t,q}$.
- The coordinate loss $L_{coord}^{(l)}(t,q)$ is calculated using both softmax cross-entropy for the bin classification and Huber loss for the continuous regression.
- The visibility loss $L_{vis}^{(l)}(t,q)$ is calculated using sigmoid binary cross-entropy.
- These individual losses are summed up to form the $L_{total}$. This total loss is then used to compute gradients, which are backpropagated through the entire network to update the model's parameters. This iterative process of forward pass, loss calculation, and backpropagation allows the model to learn and improve its tracking capabilities.
Optimization Dynamics
The TAPNext mechanism learns, updates, and converges through a sophisticated end-to-end supervised training process, primarily driven by the multi-component loss function and the architectural design choices.
-
Gradient Flow and Deep Supervision: The total loss $L_{total}$ is a sum of losses from every layer $l$, for every query point $q$, and every time step $t$. This "deep supervision" strategy ensures that gradients flow effectively throughout the entire network, from the final prediction heads all the way back to the initial layers. By applying losses at each layer with equal weights, the model is encouraged to learn meaningful and accurate representations at multiple levels of abstraction. This helps mitigate issues like vanishing or exploding gradients, common in very deep networks, and ensures that intermediate features are also predictive, leading to a more robust and stable learning process.
-
Loss Landscape Shaping (Coordinate Prediction): The coordinate prediction head is a critical innovation, combining both classification and regression.
- Classification (Softmax Cross-Entropy): Discretizing coordinates into $n$ bins and using softmax cross-entropy loss shapes the loss landscape to allow for multimodal predictions. If a point's true location is ambiguous (e.g., due to occlusion or motion blur), the model can assign probabilities to multiple bins, rather than being forced to commit to a single, potentially incorrect, continuous value. This makes the loss landscape smoother and more forgiving in uncertain scenarios, as the model isn't heavily penalized for being slightly off if it still captures the general region of the point.
- Regression (Huber Loss): The Huber loss on the continuous expected coordinates provides a robust regression signal. For small errors, it behaves like an L2 loss, providing a strong gradient to precisely pinpoint the coordinates. For larger errors, it transitions to an L1-like behavior, making it less sensitive to outliers or extreme prediction errors. This prevents a few difficult-to-track points from dominating the loss and skewing the model's learning towards them, thus shaping a more stable loss landscape.
-
Temporal Coherence and Recurrence (SSM): The recurrent SSM blocks are fundamental to how the model updates its internal state over time. During training, the SSM learns to propagate relevant information from past frames to the current frame. This allows the model to maintain temporal coherence and track points even when they are occluded for extended periods. The gradients flowing through the SSM layers teach the model which information to remember and how to transform it to predict future states. The paper mentions a partial mitigation for long video degradation by "clipping the forget gate in the SSM to between 0.0 and 0.1, and broadcasting the query features across the length of the video tokens". This is a specific adjustment to the SSM's internal dynamics to improve its ability to retain and propagate information over very long sequences, preventing the state from decaying or becoming irrelevant.
-
Spatial Interaction (ViT Attention): The ViT blocks, with their full self-attention mechanism, enable the model to learn complex spatial relationships. Gradients flowing through the attention mechanisms teach the model how to weigh the importance of different image patches and other point tokens when updating a specific point's representation. This allows the model to implicitly learn various tracking heuristics, such as "cost-volume-like attention" (matching appearance), "coordinate-based readout" (using spatial context), and "motion-cluster-based readout" (grouping moving objects), without these being explicitly engineered into the architecture. These emergent behaviors demonstrate the power of end-to-end learning in shaping the model's internal logic.
-
BootsTAP (Teacher-Student Learning): For fine-tuning on real data, TAPNext employs a teacher-student setup called BootsTAP. The 'teacher' model, an exponential moving average of the 'student's weights, provides stable pseudo-labels on uncorrupted, full-resolution real videos. The 'student' TAPNext model then learns from these pseudo-labels, but on affine-transformed and corrupted versions of the videos. The loss is backpropagated only to the student. This mechanism helps the model converge to a robust solution that is invariant to common real-world corruptions and affine transformations, effectively bridging the sim-to-real gap and improving generalization without relying on complex inductive biases. The teacher's stability prevents the student from collapsing or overfitting to noisy pseudo-labels.
In essence, TAPNext converges by iteratively refining its spatio-temporal representations and prediction heads through a carefully designed loss function that encourages both precise localization and robust visibility estimation, while its recurrent and attention mechanisms learn to adaptively propagate and integrate information across time and space. The dual coordinate loss and the BootsTAP strategy are key to shaping a resilient and accurate model.
Results, Limitations & Conclusion
Experimental Design & Baselines
To rigorously validate TAPNext's mathematical claims and demonstrate its superiority, the authors architected a comprehensive experimental setup. The primary benchmark used for both training and evaluation was TAP-Vid [11], which comprises synthetic data generated by Kubric and two human-labeled evaluation datasets: DAVIS (30 videos, 24 to 105 frames) and Kinetics (1150 videos, 250 frames).
A key aspect of their training strategy was the use of a significantly larger synthetic dataset than prior works, consisting of 500,000 videos, each 48 frames long, and incorporating challenging elements like camera panning and motion blur. For real-world fine-tuning, the BootsTAPNext model leveraged 15 million video clips from the internet, also 48 frames in length, following the BootsTAP [13] self-supervised training scheme. This involved an initial 300,000 steps on synthetic data, followed by an additional 1,500 steps of self-supervised training on real videos. The model was trained at a resolution of 256 x 256, using batches of 256 videos, each with 256 point queries. Two model variants were developed: TAPNext-S (56M parameters) and TAPNext-B (194M parameters), with distinct peak learning rates of $10^{-3}$ and $5 \times 10^{-4}$ respectively, under a cosine decay schedule.
For inference, TAPNext models were evaluated at 256 x 256 resolution. The authors employed a query-strided evaluation, running the video both forwards and backwards from each query point, and tracked one query point at a time, incorporating local and global support points similar to CoTracker [26] for improved performance.
The "victims" (baseline models) against which TAPNext was ruthlessly compared spanned a wide range of existing TAP methods, categorized by their latency characteristics:
- Frame-latency methods: TAPNet [11], Online TAPIR [53], Online BootsTAP [13], Track-On [1]. These models output predictions immediately after consuming each frame.
- Windowed-inference methods: TAPIR [12], BootsTAP [13], TAPTR [34], TAPTRv2 [33], TAPTRv3 [41], PIPs [21], CoTracker2 [26], CoTracker3 [27]. These require a chunk of frames (typically $T=8$) before outputting tracks.
- Video-latency methods: OmniMotion [55], Dino-Tracker [51], LocoTrack-B [9]. These models require the entire video as input before producing point tracks.
The definitive evidence for TAPNext's core mechanism was measured using three standard metrics:
1. Occlusion Accuracy (OA): The accuracy of classifying whether a point is visible or not.
2. Coordinate Accuracy (davg): The average fraction of points whose predicted coordinates fall within thresholds of 1, 2, 4, 8, and 16 pixels from the ground truth.
3. Average Jaccard: A combined measure of occlusion and coordinate accuracy.
What the Evidence Proves
The experimental results provide undeniable evidence that TAPNext's core mechanism—casting Tracking Any Point (TAP) as sequential masked token decoding with a simple recurrent architecture—is highly effective. As shown in Table 1, TAPNext achieves a new state-of-the-art tracking performance across eight of the twelve reported metrics on the TAP-Vid benchmark, often with substantial margins over other online (1-frame-latency) methods. This is particularly impressive given that TAPNext operates with minimal latency, making it suitable for real-time applications like robotics.
 Figure 1. Dense grid tracking with TAPNext. We show (a) the query points on the first frame of the video, (b) the resulting tracks on the final frame of the video for CoTracker3 [27], and (c) our proposed TAPNext method
Figure 1. Dense grid tracking with TAPNext. We show (a) the query points on the first frame of the video, (b) the resulting tracks on the final frame of the video for CoTracker3 [27], and (c) our proposed TAPNext method
A crucial finding is that TAPNext achieves this without relying on complex, tracking-specific inductive biases or heuristics common in prior state-of-the-art methods. It eschews iterative or windowed inference, test-time optimization, cost volumes, feature interpolation, token feature engineering, and local search windows. Instead, the model's simplicity, built upon open-source architectural components like State-Space Models (SSMs) and Vision Transformers (ViTs), allows it to learn these heuristics naturally through end-to-end training on a large synthetic dataset. Visualizations of attention maps (Figures 3 and 4) confirm that TAPNext organically develops attention patterns resembling cost-volume-like appearance matching, coordinate-based readout, and motion-cluster-based readout heads—mechanisms that were not explicitly programmed into its architecture.
 Figure 3. Three attention patterns learned by TAPNext. We vi- sualize attention maps where the attention queries are the point track tokens and the keys are image tokens, which correspond to 8 × 8 patches. Each row is a certain (layer, head) pair. We ob- serve patterns: (top) Cost-volume-like attention head; (middle) Coordinate-based readout head; (bottom) motion-cluster-based readout head. Note that these are just intermediate heads in the backbone. Higher resolution image and full attention maps in Appendix D
Figure 3. Three attention patterns learned by TAPNext. We vi- sualize attention maps where the attention queries are the point track tokens and the keys are image tokens, which correspond to 8 × 8 patches. Each row is a certain (layer, head) pair. We ob- serve patterns: (top) Cost-volume-like attention head; (middle) Coordinate-based readout head; (bottom) motion-cluster-based readout head. Note that these are just intermediate heads in the backbone. Higher resolution image and full attention maps in Appendix D
Furthermore, TAPNext demonstrates remarkable generalization capabilities. Despite being trained on 48-frame videos, it successfully tracks points in videos up to five times longer (e.g., 250-frame videos in the Kinetics dataset). This robust temporal generalization is attributed to the recurrent nature of its SSM layers, which process points causally online and maintain temporal coherence even during long-term occlusions. Ablation studies (Table 4) highlight the critical role of the classification coordinate head, which uses both classification and regression loss, and the choice of an 8x8 pixel image patch size. The superiority of SSMs for temporal processing is further underscored by Table 5, which shows that replacing SSMs with temporal attention leads to poor temporal generalization, even with advanced positional embeddings.
In terms of efficiency, Table 2 definitively proves TAPNext's advantage. It achieves the best tracking speed with windowed inference and the lowest latency with per-frame inference, while also consuming the least amount of memory compared to baselines like CoTracker3 and LocoTrack-B. Qualitative results, as described by the authors, further reinforce these findings, showing TAPNext's ability to handle occlusions, fast motion, and track thin/small, texture-less objects more accurately than competitors. The model's ability to propagate visual information accurately for tracked regions, even when occluded, suggests that the SSM layers effectively encode and propagate appearance information over time.
Limitations & Future Directions
While TAPNext marks a significant leap forward in point tracking, the paper candidly acknowledges a notable limitation: a "significant failure in long term point tracking the full length of a video greater than 150 frames." This issue is primarily attributed to the state-space model's current inability to generalize effectively to video clips substantially longer than the 48 frames it was trained on. Although a partial mitigation was found by clipping the forget gate in the SSM and broadcasting query features, this remains a key area for future improvement. Addressing this limitation in SSMs presents a large opportunity to further enhance TAPNext's already strong tracking performance.
Looking ahead, the findings from TAPNext open up several exciting discussion topics and avenues for future research:
-
Advancing SSMs for Extreme Temporal Generalization: The current limitation with videos exceeding 150 frames suggests a need for novel SSM architectures or training methodologies that can handle arbitrarily long sequences without degradation. Could hierarchical SSMs or adaptive recurrence mechanisms be developed to better manage long-range dependencies? What if we explore dynamic memory allocation within SSMs to scale with video length?
-
Expanding the "Next Token Prediction" Paradigm: The paper proposes that the TAPNext framework, which casts TAP as next token prediction, can be extended to "many other computer vision tasks in video." This is a profound statement. How can this paradigm be adapted for tasks like object detection, segmentation, or even video generation, where temporal coherence and point-level understanding are crucial? Could a unified video foundation model emerge from this approach?
-
Deepening the Understanding of Emergent Heuristics: The observation that complex tracking heuristics (motion, coordinate, appearance matching) emerge naturally from end-to-end training is fascinating. Future work could delve deeper into why and how these heuristics emerge. Can we design experiments or interpretability tools to better understand the internal mechanisms that lead to such emergent properties? This could inform the design of even more general-purpose and less biased architectures.
-
Optimizing the Coordinate Head and Uncertainty Estimation: The classification coordinate head is identified as one of TAPNext's most important components. Further research into its parameterization, particularly for representing multimodal predictions and refining continuous coordinate output from discrete bins, could yield significant gains. Additionally, enhancing the model's inherent uncertainty estimation, perhaps by integrating more sophisticated probabilistic modeling, could improve robustness in challenging scenarios.
-
Leveraging Open-Source Contributions: The authors' commitment to immediately open-sourcing inference code and model weights, with plans for training code, is a critical step. This will enable the broader research community to experiment, build upon, and evolve TAPNext rapidly. Future discussions should focus on how to best foster this collaborative development, perhaps through community-driven benchmarks or shared challenges that push the boundaries of long-term tracking.
-
Bridging the Sim-to-Real Gap with BootsTAP: The BootsTAP fine-tuning strategy proved beneficial for bridging the sim-to-real gap. Future work could explore more advanced self-supervised or semi-supervised learning techniques that further reduce reliance on scarce real-world annotated data, making TAP models even more scalable and applicable to diverse real-world scenarios.
These diverse perspectives highlight that TAPNext is not just a new state-of-the-art model, but a foundational work that could inspire a new wave of research in general-purpose, simple, and scalable video understanding.
 Table 1. Tracking performance for TAPNext and baseline models. TAPNext achieves a new state-of-the-art point tracking performance on eight of the twelve metrics, while also achieving the lowest possible latency. Methods are organized by their latency. Latency: video - these models require the entire video as input before outputting the point tracks. Latency: window - these models output tracks of length T after consuming a chunk of T frames (typically T = 8). After filling a buffer of T frames, these models can operate in a per-frame fashion. Latency: frame - these models have minimal latency by outputting point predictions immediately after consuming each frame. In each column, the best performing values are in bold, the second best are underlined
Table 1. Tracking performance for TAPNext and baseline models. TAPNext achieves a new state-of-the-art point tracking performance on eight of the twelve metrics, while also achieving the lowest possible latency. Methods are organized by their latency. Latency: video - these models require the entire video as input before outputting the point tracks. Latency: window - these models output tracks of length T after consuming a chunk of T frames (typically T = 8). After filling a buffer of T frames, these models can operate in a per-frame fashion. Latency: frame - these models have minimal latency by outputting point predictions immediately after consuming each frame. In each column, the best performing values are in bold, the second best are underlined
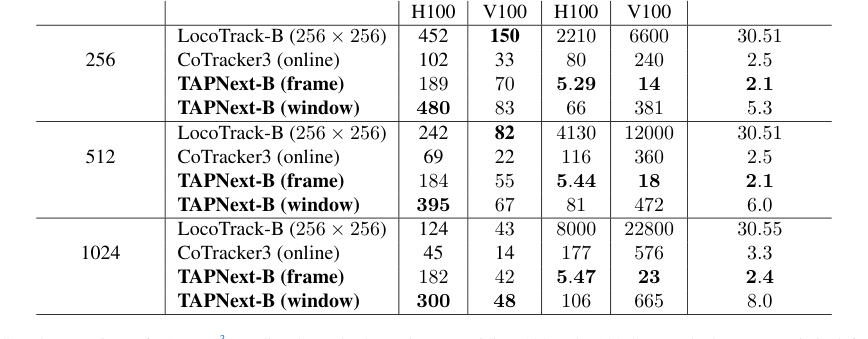 Table 2. Speed comparison of TAPNext3to online Cotracker3 running on Nvidia V100 and H100 GPUs. The latency metric is defined as the maximum (worst case) time between passing a frame to the model and receiving predicted points and it includes the time it takes to fill and process the initial frame buffer. All models are implemented in PyTorch. TAPNext (frame) is per frame inference of TAPNext. TAPNext (window) is when we track with non-overlapping chunks of 32 frames
Table 2. Speed comparison of TAPNext3to online Cotracker3 running on Nvidia V100 and H100 GPUs. The latency metric is defined as the maximum (worst case) time between passing a frame to the model and receiving predicted points and it includes the time it takes to fill and process the initial frame buffer. All models are implemented in PyTorch. TAPNext (frame) is per frame inference of TAPNext. TAPNext (window) is when we track with non-overlapping chunks of 32 frames