TAPNext: Отслеживание любой точки (TAP) как предсказание следующего токена
Проблема "соответствия" на протяжении десятилетий является фундаментальной проблемой в компьютерном зрении.
Предыстория и академическая родословная
Происхождение и академическая родословная
Проблема "соответствия" на протяжении десятилетий является фундаментальной проблемой в компьютерном зрении. Такео Канаде, выдающийся деятель в этой области, знаменито подчеркивал "соответствие, соответствие и еще раз соответствие!" как одну из трех наиболее фундаментальных проблем. Исторически это включало поиск совпадающих точек или областей между изображениями, что было критически важно для таких задач, как понимание движения, оценка глубины и реконструкция 3D-сцен из коллекций фотографий.
В последнее время эта фундаментальная проблема пережила возрождение и эволюционировала в "отслеживание любой точки (TAP)" в видео. Эта конкретная проблема впервые возникла для решения ограничений более ранних подходов, таких как оптический поток. В то время как методы оптического потока могли отслеживать движение от кадра к кадру, они часто страдали от значительного дрейфа на более длительных временных интервалах и испытывали трудности с окклюзиями. TAP был введен для преодоления этого разрыва, фокусируясь на обеспечении плотного, дальнего соответствия конкретных точек на твердых объектах на протяжении всего видео. Эта возможность высоко ценится для широкого спектра последующих приложений компьютерного зрения, включая робототехнику, редактирование видео, 3D-реконструкцию, распознавание действий, зоологию и даже медицину.
Фундаментальное ограничение, или "болевая точка", предыдущих подходов TAP, которое побудило авторов разработать TAPNext, проистекает из их зависимости от сложных, специфичных для отслеживания индуктивных смещений и эвристик. Многие предыдущие модели формулировали отслеживание как двухэтапный процесс, включающий кодирование каждого кадра, вычисление объемной стоимости для сопоставления и последующее уточнение траектории. Это часто вводило ограничительные предположения о том, как должно решаться отслеживание, например, рассматривая его как проблему сопоставления внешнего вида в пространстве признаков. Эти методы часто включали многочисленные эвристические элементы проектирования, включая дифференцируемые операции argmax, билинейную интерполяцию признаков, ограниченные окна поиска и оконный вывод.
Более того, многие существующие трекеры требовали информации из будущих кадров для получения выходных данных текущего кадра, что делало их непригодными для приложений реального времени. Даже онлайн-методы, которые использовали оконный вывод локальных окон, часто терпели неудачу при длительных окклюзиях из-за их зависимости от передачи точек только между последовательными окнами. Эти сложные архитектуры и алгоритмические решения ограничивали общность, масштабируемость и общую производительность предыдущих моделей, особенно на бенчмарках длительного отслеживания. Мотивацией авторов было создание более простой, более масштабируемой и производительной модели, которая могла бы преодолеть эти ограничения без наложения сильных, явных индуктивных смещений.
Интуитивные термины предметной области
- Отслеживание любой точки (TAP): Представьте, что вы смотрите видео оживленной улицы и хотите проследить крошечную, специфическую точку краски на движущемся автомобиле или конкретную пуговицу на чьей-то куртке на протяжении всего клипа. TAP — это задача компьютерного зрения, заключающаяся именно в этом: идентификация и отслеживание точного местоположения любой выбранной точки на объекте по мере его движения и изменения в видео.
- Индуктивные смещения: Думайте об этом как о встроенных предположениях или "ярлыках", которые модель использует для обучения. Например, если вы учите ребенка определять кошек и говорите ему: "у кошек всегда острые уши", это индуктивное смещение. Это помогает ему учиться быстрее, но может привести к тому, что он неправильно идентифицирует кошку со сложенными ушами. В компьютерном зрении эти смещения — это проектные решения в архитектуре модели, которые направляют ее к решению проблемы определенным образом, но они также могут ограничивать ее гибкость или способность к обобщению.
- Вычисление объемной стоимости: Представьте себе детектива, пытающегося сопоставить лицо подозреваемого с плаката "разыскивается" с каждым лицом в большой толпе. Объем стоимости — это как подробная, пиксельная карта, которая точно показывает детективу, насколько похоже каждое лицо в толпе на лицо подозреваемого. Он количественно определяет "стоимость" или несоответствие при сопоставлении каждого потенциального местоположения.
- Модель пространства состояний (SSM): Рассмотрите рассказчика, который повествует долгую, разворачивающуюся историю. Вместо того чтобы запоминать каждую деталь с самого начала, рассказчик поддерживает краткое, развивающееся резюме текущей ситуации в истории ("состояние"). По мере возникновения новых событий (видеокадров) он обновляет это резюме, позволяя ему сохранять связность повествования и предсказывать, что может произойти дальше, без необходимости каждый раз перечитывать всю историю с первой страницы.
Таблица обозначений
| Переменная | Описание |
|---|---|
Определение проблемы и ограничения
Основная формулировка проблемы и дилемма
Основная проблема, рассматриваемая в данной статье, — отслеживание любой точки (TAP) в видео. Точнее, исходная точка (входное/текущее состояние) для модели состоит из:
- Видео, состоящее из $T$ кадров, где каждый кадр представляет собой RGB-изображение размером $H \times W$ пикселей.
- Набор из $Q$ запросов точек, каждая из которых определяется своим временем $t$ и пространственными координатами $(x, y)$ в видео.
Желаемая конечная точка (выходное/целевое состояние) — предсказать для каждой запрошенной точки ее координаты $(x, y) \in [0, H] \times [0, W]$ и бинарный флаг видимости для каждого кадра в видео.
Точное недостающее звено или математический пробел, который данная статья пытается преодолеть, — это трансформация проблемы TAP в задачу последовательного декодирования маскированных токенов. Вместо того чтобы полагаться на сложные, специфичные для отслеживания индуктивные смещения и эвристики, TAPNext формулирует отслеживание точек как задачу импутации. Учитывая начальные координаты запрошенных точек, задача модели состоит в том, чтобы "заполнить" или импутировать маскированные токены, представляющие неизвестные координаты этих точек во всех остальных кадрах. Это достигается путем конкатенации токенов видео (полученных из патчей изображений) с токенами координат точек, где информация о запрошенных точках вводится через позиционное кодирование. Затем модель учится декодировать полные траектории, предсказывая маскированные токены.
Предыдущие исследователи, пытавшиеся решить эту конкретную проблему, оказались в ловушке нескольких болезненных компромиссов и дилемм:
- Общность против специфичности: Существующие методы TAP в значительной степени полагаются на сложные, специфичные для отслеживания индуктивные смещения и эвристики. Хотя они могут обеспечить прирост производительности в конкретных сценариях, они серьезно ограничивают общность и потенциал масштабирования моделей. Улучшение одного аспекта (например, точности с помощью специализированных архитектур) часто нарушает другой (например, масштабируемость и широкую применимость).
- Точность против задержки в реальном времени: Многие предыдущие трекеры достигают высокой точности, используя будущие кадры для получения выходных данных текущего кадра или применяя оконный вывод. Этот подход по своей сути вводит задержку, делая их непригодными для приложений реального времени, таких как робототехника. Дилемма заключается в том, как достичь высокой производительности отслеживания без ущерба для возможностей реального времени.
- Надежность против простоты: Традиционные методы часто включают многоэтапные процессы, такие как кодирование каждого кадра, вычисление объемной стоимости для сопоставления и итеративное уточнение. Эти сложные конвейеры, хотя и направлены на надежность против дрейфа и окклюзий, вводят множество эвристических элементов проектирования (например, дифференцируемый argmax, билинейную интерполяцию, ограниченные окна поиска), что делает модели сложными и менее масштабируемыми.
- Длительное отслеживание против обработки окклюзий: Методы на основе оптического потока страдают от значительного дрейфа на длительных временных интервалах и испытывают трудности с окклюзиями. Хотя длительное отслеживание точек было введено для решения этой проблемы, оконный вывод во многих онлайн-методах по-прежнему приводит к сбоям отслеживания, особенно при длительных окклюзиях, поскольку точки могут быть потеряны при передаче между последовательными окнами.
Ограничения и режимы сбоя
Проблема отслеживания любой точки (TAP) чрезвычайно сложна для решения из-за нескольких суровых, реалистичных стен, с которыми столкнулись авторы:
- Нехватка данных: Реальных обучающих данных для TAP мало. Это вынуждает предыдущие работы в значительной степени полагаться на синтетические данные, что затем требует сложных индуктивных смещений и пользовательских архитектур для преодоления разрыва "сим-то-реал", ограничивая масштабируемость и общность моделей.
- Вычислительная сложность и ограничения памяти:
- Традиционные методы часто вычисляют объемы стоимости независимо для каждой запрошенной точки, что может быть вычислительно затратным.
- Этапы итеративного уточнения и схемы оконного вывода добавляют значительные вычислительные накладные расходы.
- Ограничения памяти оборудования являются практической проблемой, о чем свидетельствует высокое использование памяти некоторыми базовыми моделями (например, LocoTrack-B, использующий более 30 ГБ памяти, как показано в Таблице 2). Разработка энергоэффективных моделей имеет решающее значение для развертывания.
- Требования к задержке в реальном времени: Для таких приложений, как робототехника, строгая задержка в реальном времени является критическим ограничением. Методы, требующие обработки будущих кадров или больших временных окон перед выводом данных текущего кадра, по своей сути ограничены в применимости.
- Временная когерентность и дрейф: Поддержание временной когерентности на длинных видеопоследовательностях является сложной задачей. Авторегрессионные модели, которые предсказывают будущие состояния на основе прошлых, склонны к накоплению ошибок, что приводит к значительному дрейфу со временем. Это основной режим сбоя для многих трекеров.
- Обобщение на длинные видео: Модели, обученные на более коротких видеоклипах (например, 48 кадров), часто плохо обобщаются на значительно более длинные видео (например, более 150 кадров). Это ограничение временного обобщения является серьезным препятствием, особенно для моделей пространства состояний (SSM), если оно не смягчено должным образом. В статье отмечается, что модель демонстрирует плохую временную обобщаемость при замене SSM на временное внимание, и даже с SSM существует "значительный сбой в длительном отслеживании точек на протяжении всей длины видео более 150 кадров", если оно не обучено на достаточно длинных последовательностях.
- Недифференцируемые операции: Многие эвристические элементы проектирования в предыдущих архитектурах, такие как дифференцируемая операция argmax или билинейная интерполяция признаков, вводят сложности, которых TAPNext стремится избежать для более простого, унифицированного подхода.
- Обработка окклюзий: Точки могут быть окклюдированы в течение длительных периодов времени в видео. Надежное отслеживание точек через эти окклюзии и правильное предсказание их видимости является постоянной проблемой. Методы оконного вывода часто терпят неудачу при длительных окклюзиях.
- Изменения внешнего вида: Внешний вид отслеживаемых точек может изменяться из-за изменений освещения, сдвигов точки обзора или деформаций, что затрудняет сопоставление по внешнему виду.
- Точность предсказания координат: Пространство предсказания координат ограничено размерами изображения, и достижение высокой точности при одновременном представлении неопределенности (например, мультимодальных предсказаний) является сложной задачей. Координатная головка должна уметь предсказывать как непрерывные координаты, так и обрабатывать дискретную природу пикселей изображения.
- Разрыв сим-то-реал: Модели, обученные преимущественно на синтетических данных, часто плохо работают с реальными видео из-за различий в визуальных характеристиках, что требует надежных механизмов для преодоления этого разрыва домена. В статье упоминается, что обучение на псевдо-маркированных реальных данных полезно для этого.
- Отсутствие индуктивных смещений: Хотя TAPNext стремится устранить специфичные для отслеживания индуктивные смещения для общности, это также означает, что модель должна органично изучать эти необходимые эвристики из данных, что может быть более сложной проблемой обучения. В статье показано, что некоторые эвристики естественно возникают, но это не гарантировано для всех проблем.
- Распространение визуальной информации: Модель должна научиться точно распространять визуальную информацию в будущие кадры из прошлых кадров, особенно для областей, покрытых отслеживаемыми точками, даже после их окклюзии. Если у модели нет предыдущей информации о некоторых визуальных областях, она может просто заполнить их средними значениями, что является режимом сбоя. Это особенно актуально для областей, которые появляются после того, как сетка точек отодвигается, и которые плохо реконструируются. Это ключевая проблема для модели, поскольку она должна поддерживать точное визуальное представление отслеживаемых точек. Это не следует рассматривать как генеративную модель, а скорее как эксперимент с линейным зондированием.
Почему такой подход
Неизбежность выбора
Авторы TAPNext столкнулись с критическим моментом, когда традиционные передовые (SOTA) методы отслеживания любой точки (TAP) оказались принципиально недостаточными. Основное осознание заключалось в том, что существующие подходы TAP чрезмерно полагались на "сложные, специфичные для отслеживания индуктивные смещения и эвристики" (Abstract). К ним относились такие методы, как вычисление объемной стоимости, итеративное уточнение, оконный вывод и явное сопоставление внешнего вида каждого кадра. Хотя эти методы обеспечивали разумную производительность, они по своей сути ограничивали общность и масштабируемость моделей, особенно при попытке преодолеть разрыв "сим-то-реал" от синтетических к реальным данным.
Точный момент этого осознания, по-видимому, проистекает из наблюдения, что эти сложные, разработанные вручную компоненты были:
1. Слишком ограничительными: Архитектуры, разработанные с сильными индуктивными смещениями, ограничивали их способность масштабироваться и обобщаться на разнообразные сценарии.
2. Не по-настоящему онлайн: Многие методы, даже те, которые претендовали на онлайн-возможности, по-прежнему полагались на будущие кадры или большие временные окна, что делало их непригодными для приложений реального времени, таких как робототехника. Эта зависимость часто приводила к сбоям отслеживания при длительных окклюзиях.
3. Эвристически управляемыми: Необходимость дифференцируемого argmax, билинейной интерполяции, ограниченных окон поиска и других специфических проектных решений делала общую систему сложной и хрупкой.
Авторы пришли к выводу, что необходима концептуально более простая, более общая архитектура — такая, которая могла бы научиться отслеживать точки, не будучи явно предписанной, как использовать подсказки движения и внешнего вида. Это привело их к формулировке TAP как задачи "последовательного декодирования маскированных токенов", используя общецелевые компоненты, такие как модели пространства состояний (SSM) для временной обработки и Vision Transformers (ViT) для пространственной обработки, комбинацию, ранее исследованную в TRecViT [40]. Этот подход был признан единственным жизнеспособным решением для преодоления ограничений сложности, отсутствия общности и плохой масштабируемости, присущих предыдущим SOTA методам.
Сравнительное превосходство
TAPNext демонстрирует качественное превосходство над предыдущими золотыми стандартами в нескольких ключевых аспектах, выходящих за рамки простых метрик производительности:
- Эмерджентные эвристики: Одним из наиболее поразительных преимуществ является то, что многие широко используемые эвристики отслеживания (например, внимание на основе кластеров движения, считывание на основе координат и внимание, похожее на объем стоимости) "естественно возникают в TAPNext посредством сквозного обучения" (Abstract, Figure 3). Это устраняет необходимость в сложных, разработанных вручную компонентах, делая модель значительно проще и надежнее.
- Улучшенная временная когерентность и обработка окклюзий: Используя рекуррентные архитектуры состояний, в частности SSM, TAPNext может поддерживать временную когерентность и эффективно улавливать динамику отслеживаемых точек во времени. Это структурное преимущество позволяет ему гораздо точнее обрабатывать длительные окклюзии, чем методы оконного вывода, которые часто терпят неудачу при длительных окклюзиях.
- Снижение потребления памяти и задержки: В статье представлены убедительные доказательства эффективности TAPNext. Например, TAPNext-B (кадр) потребляет значительно меньше памяти (например, 2,1-2,4 ГБ) по сравнению с LocoTrack-B (256x256) около 30,5 ГБ (Таблица 2). Кроме того, его задержка значительно снижена, находясь в диапазоне 5,29-5,47 мс, что на порядки быстрее, чем у CoTracker3 (80-177 мс) или LocoTrack-B (2210-8000 мс). Это делает его подавляюще превосходящим для приложений реального времени.
- Масштабируемость и обобщение: TAPNext разработан с минимальными специфичными для отслеживания индуктивными смещениями, что позволяет ему лучше обобщаться. Он может отслеживать точки в видео значительно дольше (до 5 раз), чем те, на которых он был обучен, что является критически важной возможностью для сценариев реального мира. Линейная рекуррентность SSM также позволяет распараллеливать временную обработку в автономном режиме, что еще больше повышает эффективность.
- Мультимодальное предсказание: В отличие от предыдущих методов, которые часто полагаются на одну гипотезу траектории, головка классификации координат TAPNext может представлять мультимодальные предсказания, позволяя ей выражать неопределенность. Это качественный скачок в обработке неоднозначных ситуаций отслеживания.
- Простота и непредвзятое решение: Концептуальная простота модели, с небольшим количеством гиперпараметров и без специфичных для отслеживания индуктивных смещений, позволяет ей находить непредвзятое решение проблемы TAP, а не быть ограниченной предопределенными представлениями о движении и внешнем виде. Это делает ее более адаптируемой и потенциально более мощной.
Соответствие ограничениям
Выбранный подход, заключающийся в формулировке TAP как задачи последовательного декодирования маскированных токенов, основанный на чередующихся блоках SSM и ViT TRecViT, идеально соответствует суровым требованиям проблемы, образуя прочный "брак" между проблемой и решением.
- Онлайн и причинно-следственное отслеживание: Основным ограничением была необходимость чисто онлайн и причинно-следственного отслеживания, что важно для робототехники и приложений реального времени. TAPNext достигает этого путем последовательной обработки кадров и поддержания рекуррентного состояния через SSM, гарантируя, что предсказания для текущего кадра зависят только от прошлой информации. Это напрямую решает проблему многих предыдущих методов, которые полагаются на будущие кадры.
- Минимальная задержка: Дизайн архитектуры, в частности использование линейных рекуррентных SSM, обеспечивает минимальную задержку. Он выдает предсказания точек сразу после обработки каждого кадра, избегая временного оконного или итеративного уточнения, которые вводят задержки в других SOTA трекерах.
- Масштабируемость и общность: Требование масштабируемой и общей модели, свободной от сложных индуктивных смещений, удовлетворяется использованием TAPNext стандартных архитектурных компонентов (SSM и ViT) и его формулировкой как задачи маскированного декодирования. Это позволяет модели изучать отслеживание без явных, разработанных вручную эвристик, делая ее более адаптируемой к разнообразным сценариям и более длинным видео.
- Обработка длительных окклюзий: Рекуррентное состояние, поддерживаемое слоями SSM, имеет решающее значение для поддержания временной когерентности и отслеживания точек даже во время длительных окклюзий. Это напрямую решает значительную слабость методов, основанных на окнах, которые испытывают трудности, когда точки исчезают и появляются снова.
- Вычислительная эффективность: Линейная рекуррентность SSM позволяет распараллеливать вывод во времени, что важно для обработки длинных видео без непомерного увеличения вычислительной сложности. Это ключевое преимущество перед методами, которые полагаются на оконный вывод или итеративное уточнение, которые могут стать вычислительно затратными для расширенных последовательностей.
- Представление неопределенности: Предсказание координат как задачи классификации, допускающей мультимодальные предсказания, соответствует необходимости представления неопределенности в отслеживании, возможности, часто отсутствующей в предыдущих методах предсказания точек.
Отклонение альтернатив
Статья неявно и явно отклоняет несколько популярных или традиционных подходов, подчеркивая их присущие ограничения в контексте TAP.
- Традиционные SOTA методы (объем стоимости, итеративное уточнение, оконный вывод): Авторы прямо заявляют, что "существующие методы для TAP в значительной степени полагаются на сложные, специфичные для отслеживания индуктивные смещения и эвристики" (Abstract). Они детализируют их как "вычисление объемной стоимости с последующим уточнением траектории [11, 12, 21, 26]", включающее "многие эвристические элементы проектирования, включая дифференцируемую операцию argmax [12], билинейную интерполяцию признаков [21], ограниченные окна поиска [9] и оконный вывод [26]". Они были отклонены, поскольку ограничивают общность, масштабируемость и часто требуют некаузальной обработки или приводят к сбоям отслеживания при длительных окклюзиях. Целью TAPNext было избежать этих "сильных индуктивных смещений" и разработать "концептуально более простую архитектуру".
- Автономные/некаузальные трекеры: Многие трекеры "полагаются на использование будущих кадров для получения выходных данных для текущего кадра, что ограничивает их применимость в сценариях реального времени". Эта некаузальная природа противоречила требованию онлайн-отслеживания, что привело к их отклонению для целевых приложений.
- Онлайн-трекеры на основе окон: Хотя некоторые методы претендовали на онлайн-возможности с использованием локальных окон, в статье отмечается, что их "зависимость от большого временного оконного и передачи точек только между последовательными окнами часто приводит к сбоям отслеживания, особенно при длительных окклюзиях в середине видео [21, 26]". Эта плохая производительность на бенчмарках длительного отслеживания привела к отклонению таких подходов в пользу истинно рекуррентного решения для каждого кадра.
- Стандартные трансформеры с временным вниманием: Абляционное исследование (Таблица 5) предоставляет явное отклонение от использования стандартных механизмов временного внимания (таких как в базовых трансформерах) для компонента временной обработки. Когда SSM заменяется временным вниманием, модель "демонстрирует плохую временную обобщаемость, несмотря на использование временного позиционного вложения RoPE [45], которое известно своей обобщаемостью во времени". Это указывает на то, что для конкретной задачи дальнего временного когерентности при отслеживании SSM предлагают превосходящее структурное преимущество перед общим временным вниманием, которое испытывает трудности с более длинными последовательностями и обобщением. Это важное открытие, предполагающее, что более простая рекуррентность более эффективна, чем сложное внимание, для данной конкретной проблемы.
- Оценка точек с одной гипотезой: Предыдущие методы, такие как TAPIR и Co-Tracker, выполняют "несколько этапов уточнения на одной гипотезе траектории на запрос и выполняют локальную выборку признаков вокруг этой единственной гипотезы". Головка классификации координат TAPNext, которая может представлять мультимодальные предсказания и неопределенность, неявно отклоняет этот более простой, менее информативный подход. Способность представлять неопределенность является качественным преимуществом.
- Генеративные модели для реконструкции: Хотя статья и проводит эксперимент по реконструкции, явно указано, что это не следует рассматривать как генеративную модель, а скорее как "эксперимент с линейным зондированием". Основная цель — отслеживание, а не генерация изображений, и авторы не обнаружили, что цель реконструкции изображений "приводит к улучшению производительности отслеживания". Это подразумевает, что, хотя маскированное автокодирование используется для импутации токенов, полная генеративная модель видеокадров не считалась необходимой или полезной для основной задачи отслеживания.
 Figure 1. Dense grid tracking with TAPNext. We show (a) the query points on the first frame of the video, (b) the resulting tracks on the final frame of the video for CoTracker3 [27], and (c) our proposed TAPNext method
Figure 1. Dense grid tracking with TAPNext. We show (a) the query points on the first frame of the video, (b) the resulting tracks on the final frame of the video for CoTracker3 [27], and (c) our proposed TAPNext method
Математический и логический механизм
Главное уравнение
Основной механизм TAPNext управляется многозадачной функцией потерь, которая объединяет предсказание координат (как классификацию, так и регрессию) и предсказание видимости. Эта функция потерь применяется на каждом слое архитектуры TRecViT, обеспечивая надежное обучение на глубине модели. Общая цель состоит в минимизации расхождения между предсказаниями модели и истинными значениями для координат точек и их видимости во времени.
Главное уравнение, представляющее общие потери $L_{total}$, минимизируемые во время обучения, может быть выражено следующим образом:
$$ L_{total} = \frac{1}{L \cdot Q \cdot T} \sum_{l=1}^{L} \sum_{q=1}^{Q} \sum_{t=1}^{T} \left( L_{coord}^{(l)}(t,q) + L_{vis}^{(l)}(t,q) \right) $$
где $L_{coord}^{(l)}(t,q)$ — потери координат для запрошенной точки $q$ во времени $t$ из слоя $l$, а $L_{vis}^{(l)}(t,q)$ — потери видимости для той же точки. Эти индивидуальные потери далее определяются как:
$$ L_{coord}^{(l)}(t,q) = L_{CE}(p_x^{(l)}(t,q), \text{target_bin}_x) + L_{CE}(p_y^{(l)}(t,q), \text{target_bin}_y) + L_{Huber}((\hat{x}^{(l)}_{t,q}, \hat{y}^{(l)}_{t,q}), (x_{t,q}, y_{t,q})) $$
$$ L_{vis}^{(l)}(t,q) = L_{BCE}(\hat{V}^{(l)}_{t,q}, V_{t,q}) $$
Поэлементный разбор
Давайте разберем каждый компонент этих уравнений, чтобы понять его математическое определение и роль в рамках TAPNext.
-
$L_{total}$:
- Математическое определение: Общая функция потерь, представляющая общую цель, которая должна быть минимизирована во время обучения TAPNext. Это средняя сумма индивидуальных потерь по всем слоям, запросам точек и временным шагам.
- Физическая/логическая роль: Этот термин количественно определяет, насколько "неправильны" предсказания модели по всей видеопоследовательности и для всех отслеживаемых точек. Минимизируя $L_{total}$, модель учится точно предсказывать как местоположение, так и видимость точек во времени. Суммирование по слоям с равными весами (как указано в статье) является стратегическим выбором для обеспечения того, чтобы промежуточные представления также были осмысленными, предотвращая проблемы, такие как исчезающие градиенты в более глубоких слоях, и способствуя надежному обучению признаков на протяжении всей сети. Это глубокое наблюдение помогает стабилизировать обучение и улучшить конечную производительность.
- Почему сумма вместо других операций? Суммирование используется для объединения потерь от различных компонентов (координаты, видимость) и различных слоев. Это подразумевает, что все эти аспекты одинаково важны для общей задачи, и ошибки в любой части напрямую способствуют общим потерям. Усреднение по $L \cdot Q \cdot T$ нормализует потери, делая их независимыми от количества слоев, запросов или кадров, что имеет решающее значение для стабильного обучения при различных размерах входных данных.
-
$L$:
- Математическое определение: Общее количество чередующихся слоев SSM и ViT в основе TRecViT.
- Физическая/логическая роль: Представляет глубину конвейера обработки модели. Каждый слой способствует уточнению пространственно-временных представлений токенов изображений и точек. Потери применяются на каждом слое, чтобы гарантировать, что признаки на разных уровнях абстракции имеют смысл и способствуют конечному предсказанию, что является формой глубокого наблюдения.
-
$Q$:
- Математическое определение: Количество запрошенных точек, отслеживаемых в видео.
- Физическая/логическая роль: Это количество отдельных точек, траектории которых модель должна предсказать. Потери суммируются по всем запрошенным точкам, чтобы гарантировать, что модель учится отслеживать несколько точек одновременно и точно.
-
$T$:
- Математическое определение: Общее количество кадров в видеопоследовательности.
- Физическая/логическая роль: Представляет временной диапазон видео. Потери суммируются по всем временным шагам, чтобы гарантировать, что модель последовательно отслеживает точки на протяжении всего видео, улавливая их временную динамику и обрабатывая окклюзии.
-
$L_{coord}^{(l)}(t,q)$:
- Математическое определение: Комбинированные потери координат для запрошенной точки $q$ во времени $t$ из слоя $l$. Они состоят из двух членов перекрестной энтропии для классификации и одного члена потерь Хьюбера для регрессии.
- Физическая/логическая роль: Этот член заставляет модель предсказывать точные координаты $(x,y)$ отслеживаемой точки. Двойной подход классификации по бинам и непрерывной регрессии позволяет модели улавливать как дискретные пространственные местоположения, так и точные непрерывные положения. Аспект классификации помогает модели представлять мультимодальные предсказания и неопределенность, что является значительным преимуществом по сравнению с методами, которые предсказывают только одно непрерывное значение. В статье отмечается, что эта классификационная координатная головка является одним из важнейших компонентов.
-
$L_{CE}(p_x^{(l)}(t,q), \text{target_bin}_x)$ и $L_{CE}(p_y^{(l)}(t,q), \text{target_bin}_y)$:
- Математическое определение: Потери перекрестной энтропии Softmax. Для данной координаты (например, x-координаты) $p_x^{(l)}(t,q)$ — это вектор предсказанных вероятностей для $n$ дискретных бинов, а $\text{target_bin}_x$ — это one-hot закодированный истинный бин.
$$ L_{CE}(p, \text{target}) = - \sum_{i=1}^{n} \text{target}_i \log(p_i) $$ - Физическая/логическая роль: Эти члены обучают координатную головку классифицировать x и y координаты по предопределенным дискретным бинам. Этот подход к классификации, вдохновленный [16], имеет решающее значение, поскольку он позволяет модели выражать неопределенность (например, точка может находиться в одном из нескольких бинов с определенными вероятностями) и обрабатывать мультимодальные предсказания, что является значительным преимуществом по сравнению с методами, которые предсказывают только одно непрерывное значение.
- Математическое определение: Потери перекрестной энтропии Softmax. Для данной координаты (например, x-координаты) $p_x^{(l)}(t,q)$ — это вектор предсказанных вероятностей для $n$ дискретных бинов, а $\text{target_bin}_x$ — это one-hot закодированный истинный бин.
-
$L_{Huber}((\hat{x}^{(l)}_{t,q}, \hat{y}^{(l)}_{t,q}), (x_{t,q}, y_{t,q}))$:
- Математическое определение: Потери Хьюбера, применяемые к непрерывным предсказанным координатам $(\hat{x}^{(l)}_{t,q}, \hat{y}^{(l)}_{t,q})$ против истинных координат $(x_{t,q}, y_{t,q})$. Непрерывные координаты получаются из математического ожидания вероятностей классификатора: $\hat{x}^{(l)}_{t,q} = \sum_{i=1}^{n} b_{x,i} \cdot p_x^{(l)}(t,q,i)$, где $b_{x,i}$ — центр бина $i$.
$$ L_{Huber}(e) = \begin{cases} 0.5 e^2 & \text{if } |e| \le \delta \\ \delta (|e| - 0.5 \delta) & \text{if } |e| > \delta \end{cases} $$
где $e$ — ошибка (например, $\hat{x} - x$), а $\delta$ — гиперпараметр. - Физическая/логическая роль: Этот член действует как регрессионные потери, точно настраивая предсказания непрерывных координат. Потери Хьюбера выбираются вместо простых потерь L2 (среднеквадратичной ошибки), поскольку они менее чувствительны к выбросам. В отслеживании точек аннотации истинных значений могут иногда содержать незначительные неточности, или точки могут временно появляться в неожиданных местах из-за окклюзий или быстрого движения. Потери Хьюбера обеспечивают более плавный градиент для малых ошибок (как L2), но линейный градиент для больших ошибок (как L1), что делает их более устойчивыми к такому шуму и предотвращает доминирование больших ошибок над ландшафтом потерь.
- Математическое определение: Потери Хьюбера, применяемые к непрерывным предсказанным координатам $(\hat{x}^{(l)}_{t,q}, \hat{y}^{(l)}_{t,q})$ против истинных координат $(x_{t,q}, y_{t,q})$. Непрерывные координаты получаются из математического ожидания вероятностей классификатора: $\hat{x}^{(l)}_{t,q} = \sum_{i=1}^{n} b_{x,i} \cdot p_x^{(l)}(t,q,i)$, где $b_{x,i}$ — центр бина $i$.
-
$L_{vis}^{(l)}(t,q)$:
- Математическое определение: Потери видимости для запрошенной точки $q$ во времени $t$ из слоя $l$.
- Физическая/логическая роль: Этот член заставляет модель предсказывать, видна ли отслеживаемая точка или окклюдирована в данном кадре. Точное предсказание видимости имеет решающее значение для надежного отслеживания, особенно в сценариях реального мира, где объекты часто исчезают из поля зрения или временно скрыты.
-
$L_{BCE}(\hat{V}^{(l)}_{t,q}, V_{t,q})$:
- Математическое определение: Потери бинарной перекрестной энтропии Сигмоиды. $\hat{V}^{(l)}_{t,q}$ — предсказанная вероятность видимости (скаляр от 0 до 1), а $V_{t,q}$ — бинарное истинное значение (0 для окклюдированного, 1 для видимого).
$$ L_{BCE}(\hat{v}, v) = - (v \log(\hat{v}) + (1-v) \log(1-\hat{v})) $$ - Физическая/логическая роль: Этот член обучает головку видимости выполнять бинарную классификацию. Он наказывает модель, когда она неправильно предсказывает статус видимости точки. Сигмоидная активация гарантирует, что выход является вероятностью, а бинарная перекрестная энтропия является стандартной функцией потерь для таких двухклассовых задач. Модель также использует оценку неопределенности: если более 50% массы вероятности для координат приходится за пределы радиуса в 8 пикселей, точка помечается как окклюдированная, что обеспечивает естественную связь между неопределенностью координат и видимостью.
- Математическое определение: Потери бинарной перекрестной энтропии Сигмоиды. $\hat{V}^{(l)}_{t,q}$ — предсказанная вероятность видимости (скаляр от 0 до 1), а $V_{t,q}$ — бинарное истинное значение (0 для окклюдированного, 1 для видимого).
Пошаговый поток
Представьте себе одну абстрактную точку данных, скажем, конкретный пиксель на движущемся автомобиле, который мы хотим отслеживать в видео. Вот его путь через математический движок TAPNext:
-
Входные данные и токенизация:
- Путешествие начинается с видео, последовательности $T$ RGB-кадров и набора из $Q$ начальных запрошенных точек, каждая из которых определяется своим начальным временем и координатами $(x,y)$.
- Каждый видеокадр сначала разбивается на сетку $h \times w$ неперекрывающихся патчей изображения. Затем эти патчи линейно проецируются в $C$-мерное пространство признаков и добавляются позиционные вложения. Это преобразует необработанные данные изображения в последовательность "токенов изображения" формы $[T, h \times w, C]$.
- Одновременно для нашей конкретной запрошенной точки (и всех остальных) создается последовательность из $T$ "токенов траектории точки". Для кадра, где наша точка изначально запрашивается, ее токен инициализируется позиционным вложением, соответствующим ее координатам $(x,y)$. Для всех остальных кадров ее токен инициализируется специальным значением "маскированного токена", указывающим, что ее положение неизвестно и требует предсказания. Эти токены точек также имеют форму $[T, Q, C]$.
-
Сборка входного тензора:
- Затем токены изображения и токены траектории точки конкатенируются вдоль пространственного измерения. Это создает унифицированный "тензор входных токенов" формы $[T, h \times w + Q, C]$. Этот тензор теперь содержит всю информацию: визуальное содержимое видео и информацию о запрошенных точках, с маскированными положениями для отслеживаемых кадров.
-
Многослойная пространственно-временная обработка (TRecViT):
- Этот объединенный входной тензор затем поступает в основу TRecViT, которая состоит из $L$ чередующихся слоев. Каждый слой представляет собой двухэтапный процесс:
- Блок SSM (Временная обработка): Сначала данные проходят через блок модели пространства состояний (SSM). Этот блок выполняет линейную рекуррентность по временному измерению ($T$). Он рассматривает объединенное пространственное измерение ($h \times w + Q$) как пакет. Концептуально это похоже на конвейерную ленту, движущуюся во времени. Блок SSM эффективно передает информацию из прошлых кадров в текущий и будущие кадры, позволяя модели поддерживать "память" о траектории и внешнем виде точки. Это критически важно для отслеживания через окклюзии и на длительных интервалах.
- Блок ViT (Пространственная обработка): Затем выход блока SSM поступает в блок Vision Transformer (ViT). Этот блок выполняет полное самовнимание по всем $h \times w + Q$ токенам в каждом кадре, рассматривая временное измерение ($T$) как пакет. Здесь модель "осматривается" в пределах одного кадра, позволяя токенам изображения обращать внимание на токены точек, а токенам точек — обращать внимание друг на друга и на токены изображений. Это пространственное смешивание помогает модели идентифицировать положение точки относительно ее окружения и интегрировать визуальные подсказки.
- Этот двухэтапный процесс (SSM затем ViT) повторяется для всех $L$ слоев, постепенно уточняя пространственно-временное представление нашей абстрактной точки данных.
- Этот объединенный входной тензор затем поступает в основу TRecViT, которая состоит из $L$ чередующихся слоев. Каждый слой представляет собой двухэтапный процесс:
-
Предсказательные головки:
- После прохождения через каждый слой $l$ модель выводит набор из $T \times Q$ токенов траектории. Эти токены затем подаются в две отдельные предсказательные головки:
- Координатная головка (MLP): MLP (многослойный перцептрон) принимает токен траектории для нашей точки в каждом временном шаге. Сначала он предсказывает вероятности для $n$ дискретных бинов как для x, так и для y координат. Затем он вычисляет ожидаемую непрерывную координату $(x,y)$ путем суммирования центров бинов, взвешенных этими вероятностями.
- Головка видимости (MLP): Другой MLP принимает тот же токен траектории и предсказывает бинарную вероятность, указывающую, видна ли наша точка или окклюдирована в этом кадре.
- После прохождения через каждый слой $l$ модель выводит набор из $T \times Q$ токенов траектории. Эти токены затем подаются в две отдельные предсказательные головки:
-
Вычисление потерь и обратное распространение:
- Для каждого слоя $l$ и каждого временного шага $t$ и запрошенной точки $q$ предсказанные координаты $(\hat{x}^{(l)}_{t,q}, \hat{y}^{(l)}_{t,q})$ и видимость $\hat{V}^{(l)}_{t,q}$ сравниваются с истинными значениями $(x_{t,q}, y_{t,q})$ и $V_{t,q}$.
- Потери координат $L_{coord}^{(l)}(t,q)$ вычисляются с использованием как перекрестной энтропии для классификации бинов, так и потерь Хьюбера для непрерывной регрессии.
- Потери видимости $L_{vis}^{(l)}(t,q)$ вычисляются с использованием бинарной перекрестной энтропии Сигмоиды.
- Эти индивидуальные потери суммируются для формирования $L_{total}$. Эта общая потеря затем используется для вычисления градиентов, которые обратным образом распространяются по всей сети для обновления параметров модели. Этот итеративный процесс прямого прохода, вычисления потерь и обратного распространения позволяет модели учиться и улучшать свои возможности отслеживания.
Динамика оптимизации
Механизм TAPNext обучается, обновляется и сходится посредством сложного процесса сквозного контролируемого обучения, в основном управляемого многокомпонентной функцией потерь и выбором архитектуры.
-
Поток градиентов и глубокое наблюдение: Общие потери $L_{total}$ являются суммой потерь из каждого слоя $l$, для каждой запрошенной точки $q$ и каждого временного шага $t$. Эта стратегия "глубокого наблюдения" гарантирует эффективный поток градиентов по всей сети, от конечных предсказательных головок до самых начальных слоев. Применяя потери на каждом слое с равными весами, модель побуждается к обучению осмысленных и точных представлений на нескольких уровнях абстракции. Это помогает смягчить проблемы, такие как исчезающие или взрывающиеся градиенты, распространенные в очень глубоких сетях, и гарантирует, что промежуточные признаки также являются предсказательными, что приводит к более надежному и стабильному процессу обучения.
-
Формирование ландшафта потерь (предсказание координат): Головка предсказания координат является критическим нововведением, сочетающим классификацию и регрессию.
- Классификация (перекрестная энтропия Softmax): Дискретизация координат на $n$ бинов и использование потерь перекрестной энтропии Softmax формирует ландшафт потерь, позволяющий мультимодальные предсказания. Если истинное положение точки неоднозначно (например, из-за окклюзии или размытия движения), модель может присвоить вероятности нескольким бинам, вместо того чтобы быть вынужденной придерживаться одного, потенциально неверного, непрерывного значения. Это делает ландшафт потерь более плавным и снисходительным в неопределенных сценариях, поскольку модель не сильно наказывается за небольшое отклонение, если она все еще улавливает общее расположение точки.
- Регрессия (потери Хьюбера): Потери Хьюбера на непрерывных ожидаемых координатах обеспечивают надежный регрессионный сигнал. Для малых ошибок они ведут себя как потери L2, обеспечивая сильный градиент для точного определения координат. Для больших ошибок они переходят к линейному поведению, подобному L1, что делает их менее чувствительными к выбросам или экстремальным ошибкам предсказания. Это предотвращает доминирование нескольких трудно отслеживаемых точек над потерями и искажение обучения модели в их сторону, тем самым формируя более стабильный ландшафт потерь.
-
Временная когерентность и рекуррентность (SSM): Рекуррентные блоки SSM являются основой того, как модель обновляет свое внутреннее состояние во времени. Во время обучения SSM учится передавать релевантную информацию из прошлых кадров в текущий кадр. Это позволяет модели поддерживать временную когерентность и отслеживать точки даже при длительных окклюзиях. Градиенты, протекающие через слои SSM, учат модель, какую информацию следует запоминать и как ее преобразовывать для предсказания будущих состояний. В статье упоминается частичное смягчение деградации длинных видео путем "ограничения вентиля забывания в SSM между 0,0 и 0,1 и трансляции признаков запросов по всей длине токенов видео". Это специфическая корректировка внутренней динамики SSM для улучшения его способности сохранять и передавать информацию на очень длинных последовательностях, предотвращая распад состояния или его неактуальность.
-
Пространственное взаимодействие (внимание ViT): Блоки ViT с их полным механизмом самовнимания позволяют модели изучать сложные пространственные отношения. Градиенты, протекающие через механизмы внимания, учат модель взвешивать важность различных патчей изображений и других токенов точек при обновлении представления конкретной точки. Это позволяет модели неявно изучать различные эвристики отслеживания, такие как "внимание, похожее на объем стоимости" (сопоставление внешнего вида), "считывание на основе координат" (использование пространственного контекста) и "считывание на основе кластеров движения" (группировка движущихся объектов), без явного программирования их в архитектуру. Эти эмерджентные поведения демонстрируют силу сквозного обучения в формировании внутренней логики модели.
-
BootsTAP (обучение учитель-ученик): Для дообучения на реальных данных TAPNext использует конфигурацию учитель-ученик под названием BootsTAP. "Учительская" модель, экспоненциальное скользящее среднее весов "ученика", предоставляет стабильные псевдо-маркировки на неповрежденных реальных видео полного разрешения. "Ученик" TAPNext затем учится на этих псевдо-маркировках, но на аффинно трансформированных и поврежденных версиях видео. Потери обратным образом распространяются только на ученика. Этот механизм помогает модели сходиться к надежному решению, инвариантному к распространенным искажениям реального мира и аффинным преобразованиям, эффективно преодолевая разрыв сим-то-реал и улучшая обобщение без опоры на сложные индуктивные смещения. Стабильность учителя предотвращает коллапс ученика или его переобучение на шумных псевдо-маркировках.
По сути, TAPNext сходится путем итеративного уточнения своих пространственно-временных представлений и предсказательных головок посредством тщательно разработанной функции потерь, которая способствует как точному локализации, так и надежной оценке видимости, в то время как его рекуррентные механизмы и механизмы внимания учатся адаптивно передавать и интегрировать информацию во времени и пространстве. Двойные потери координат и стратегия BootsTAP являются ключом к формированию устойчивой и точной модели.
Результаты, ограничения и заключение
Экспериментальный дизайн и базовые модели
Для строгой проверки математических утверждений TAPNext и демонстрации его превосходства авторы разработали комплексную экспериментальную установку. Основным бенчмарком, используемым как для обучения, так и для оценки, был TAP-Vid [11], который включает синтетические данные, сгенерированные Kubric, и два набора данных для оценки, размеченных человеком: DAVIS (30 видео, 24-105 кадров) и Kinetics (1150 видео, 250 кадров).
Ключевым аспектом их стратегии обучения было использование значительно большего синтетического набора данных, чем в предыдущих работах, состоящего из 500 000 видео, каждое длиной 48 кадров, и включающего сложные элементы, такие как панорамирование камеры и размытие движения. Для дообучения на реальных данных модель BootsTAPNext использовала 15 миллионов видеоклипов из Интернета, также длиной 48 кадров, следуя схеме самообучения BootsTAP [13]. Это включало первоначальные 300 000 шагов на синтетических данных, за которыми последовали дополнительные 1500 шагов самообучения на реальных видео. Модель обучалась с разрешением 256x256, используя пакеты из 256 видео, каждое с 256 запросами точек. Были разработаны два варианта модели: TAPNext-S (56M параметров) и TAPNext-B (194M параметров) с различными пиковыми скоростями обучения $10^{-3}$ и $5 \times 10^{-4}$ соответственно, в рамках графика косинусного затухания.
Для вывода модели TAPNext оценивались с разрешением 256x256. Авторы использовали оценку с шагом запроса, запуская видео как вперед, так и назад от каждой точки запроса, и отслеживали по одной точке запроса за раз, включая локальные и глобальные опорные точки, аналогично CoTracker [26], для улучшения производительности.
"Жертвы" (базовые модели), с которыми TAPNext беспощадно сравнивался, охватывали широкий спектр существующих методов TAP, классифицированных по их характеристикам задержки:
- Методы с задержкой на кадр: TAPNet [11], Online TAPIR [53], Online BootsTAP [13], Track-On [1]. Эти модели выдают предсказания сразу после обработки каждого кадра.
- Методы оконного вывода: TAPIR [12], BootsTAP [13], TAPTR [34], TAPTRv2 [33], TAPTRv3 [41], PIPs [21], CoTracker2 [26], CoTracker3 [27]. Они требуют фрагмента кадров (обычно $T=8$) перед выводом траекторий.
- Методы с задержкой на видео: OmniMotion [55], Dino-Tracker [51], LocoTrack-B [9]. Эти модели требуют всего видео в качестве входных данных перед выдачей траекторий точек.
Окончательные доказательства основного механизма TAPNext измерялись с использованием трех стандартных метрик:
1. Точность окклюзии (OA): Точность классификации, видна ли точка или нет.
2. Точность координат (davg): Средняя доля точек, предсказанные координаты которых находятся в пределах порогов 1, 2, 4, 8 и 16 пикселей от истинного значения.
3. Средний Жаккар: Комбинированная мера точности окклюзии и координат.
Что доказывают свидетельства
Экспериментальные результаты предоставляют неоспоримые доказательства того, что основной механизм TAPNext — формулировка отслеживания любой точки (TAP) как последовательного декодирования маскированных токенов с простой рекуррентной архитектурой — высокоэффективен. Как показано в Таблице 1, TAPNext достигает нового передового уровня производительности отслеживания по восьми из двенадцати представленных метрик на бенчмарке TAP-Vid, часто со значительным отрывом от других онлайн-методов (с задержкой 1 кадр). Это особенно впечатляет, учитывая, что TAPNext работает с минимальной задержкой, что делает его пригодным для приложений реального времени, таких как робототехника.
Ключевым выводом является то, что TAPNext достигает этого без использования сложных, специфичных для отслеживания индуктивных смещений или эвристик, распространенных в предыдущих передовых методах. Он отказывается от итеративного или оконного вывода, оптимизации времени тестирования, объемов стоимости, интерполяции признаков, инженерии признаков токенов и окон локального поиска. Вместо этого простота модели, построенная на основе общедоступных архитектурных компонентов, таких как модели пространства состояний (SSM) и Vision Transformers (ViT), позволяет ей естественным образом изучать эти эвристики посредством сквозного обучения на большом синтетическом наборе данных. Визуализации карт внимания (Рисунки 3 и 4) подтверждают, что TAPNext органично развивает паттерны внимания, напоминающие сопоставление внешнего вида, похожее на объем стоимости, считывание на основе координат и считывание на основе кластеров движения — механизмы, которые не были явно запрограммированы в его архитектуру.
Более того, TAPNext демонстрирует замечательные возможности обобщения. Несмотря на обучение на 48-кадровых видео, он успешно отслеживает точки в видео до пяти раз длиннее (например, 250-кадровые видео в наборе данных Kinetics). Это надежное временное обобщение приписывается рекуррентной природе его слоев SSM, которые обрабатывают точки причинно-следственно онлайн и поддерживают временную когерентность даже во время длительных окклюзий. Абляционные исследования (Таблица 4) подчеркивают критическую роль классификационной координатной головки, которая использует как классификацию, так и регрессионные потери, а также выбор размера патча изображения 8x8 пикселей. Превосходство SSM для временной обработки далее подчеркивается в Таблице 5, которая показывает, что замена SSM временным вниманием приводит к плохой временной обобщаемости, даже с продвинутыми позиционными вложениями.
С точки зрения эффективности, Таблица 2 однозначно доказывает преимущество TAPNext. Он достигает лучшей скорости отслеживания с оконным выводом и самой низкой задержки с по-кадровым выводом, потребляя при этом наименьшее количество памяти по сравнению с базовыми моделями, такими как CoTracker3 и LocoTrack-B. Качественные результаты, описанные авторами, далее подтверждают эти выводы, демонстрируя способность TAPNext обрабатывать окклюзии, быстрое движение и более точно отслеживать тонкие/маленькие объекты без текстуры, чем конкуренты. Способность модели точно распространять визуальную информацию для отслеживаемых областей, даже когда они окклюдированы, предполагает, что слои SSM эффективно кодируют и распространяют информацию о внешнем виде во времени.
Ограничения и будущие направления
Хотя TAPNext знаменует собой значительный скачок вперед в отслеживании точек, в статье честно признается заметное ограничение: "значительный сбой в длительном отслеживании точек на протяжении всей длины видео более 150 кадров". Эта проблема в основном связана с текущей неспособностью модели пространства состояний эффективно обобщаться на видеоклипы, значительно превышающие 48 кадров, на которых она была обучена. Хотя было найдено частичное смягчение путем ограничения вентиля забывания в SSM и трансляции признаков запросов, это остается ключевой областью для будущего улучшения. Решение этого ограничения в SSM представляет собой большую возможность для дальнейшего повышения уже сильной производительности отслеживания TAPNext.
Заглядывая вперед, выводы TAPNext открывают несколько захватывающих тем для обсуждения и направлений для будущих исследований:
-
Развитие SSM для экстремального временного обобщения: Текущее ограничение с видео, превышающими 150 кадров, указывает на потребность в новых архитектурах SSM или методологиях обучения, которые могут обрабатывать произвольно длинные последовательности без деградации. Могут ли быть разработаны иерархические SSM или адаптивные рекуррентные механизмы для лучшего управления дальними зависимостями? Что, если мы исследуем динамическое выделение памяти в SSM для масштабирования с длиной видео?
-
Расширение парадигмы "предсказания следующего токена": Статья предполагает, что фреймворк TAPNext, который формулирует TAP как предсказание следующего токена, может быть расширен до "многих других задач компьютерного зрения в видео". Это глубокое заявление. Как эта парадигма может быть адаптирована для таких задач, как обнаружение объектов, сегментация или даже генерация видео, где временная когерентность и понимание на уровне точек имеют решающее значение? Может ли из этого подхода возникнуть унифицированная модель видеоосновы?
-
Углубление понимания эмерджентных эвристик: Наблюдение, что сложные эвристики отслеживания (движение, координаты, сопоставление внешнего вида) возникают естественным образом из сквозного обучения, завораживает. Будущие работы могли бы глубже изучить, почему и как возникают эти эвристики. Можем ли мы разработать эксперименты или инструменты интерпретируемости, чтобы лучше понять внутренние механизмы, ведущие к таким эмерджентным свойствам? Это могло бы информировать дизайн еще более общих и менее предвзятых архитектур.
-
Оптимизация координатной головки и оценки неопределенности: Классификационная координатная головка идентифицирована как один из важнейших компонентов TAPNext. Дальнейшие исследования ее параметризации, особенно для представления мультимодальных предсказаний и уточнения непрерывного вывода координат из дискретных бинов, могут принести значительные выгоды. Кроме того, улучшение присущей модели оценки неопределенности, возможно, путем интеграции более сложных вероятностных моделей, могло бы повысить надежность в сложных сценариях.
-
Использование вклада с открытым исходным кодом: Приверженность авторов немедленному открытию кода вывода и весов модели, с планами по предоставлению кода обучения, является критически важным шагом. Это позволит более широкому исследовательскому сообществу быстро экспериментировать, развивать и совершенствовать TAPNext. Будущие обсуждения должны быть сосредоточены на том, как наилучшим образом способствовать этому совместному развитию, возможно, через бенчмарки, управляемые сообществом, или общие вызовы, которые раздвигают границы длительного отслеживания.
-
Преодоление разрыва сим-то-реал с помощью BootsTAP: Стратегия дообучения BootsTAP оказалась полезной для преодоления разрыва сим-то-реал. Будущие работы могли бы исследовать более продвинутые методы самообучения или полуобучения, которые еще больше снижают зависимость от редких аннотированных данных реального мира, делая модели TAP еще более масштабируемыми и применимыми к разнообразным реальным сценариям.
Эти разнообразные точки зрения подчеркивают, что TAPNext — это не просто новая передовая модель, а основополагающая работа, которая может вдохновить новую волну исследований в области универсального, простого и масштабируемого понимания видео.
 Table 1. Tracking performance for TAPNext and baseline models. TAPNext achieves a new state-of-the-art point tracking performance on eight of the twelve metrics, while also achieving the lowest possible latency. Methods are organized by their latency. Latency: video - these models require the entire video as input before outputting the point tracks. Latency: window - these models output tracks of length T after consuming a chunk of T frames (typically T = 8). After filling a buffer of T frames, these models can operate in a per-frame fashion. Latency: frame - these models have minimal latency by outputting point predictions immediately after consuming each frame. In each column, the best performing values are in bold, the second best are underlined
Table 1. Tracking performance for TAPNext and baseline models. TAPNext achieves a new state-of-the-art point tracking performance on eight of the twelve metrics, while also achieving the lowest possible latency. Methods are organized by their latency. Latency: video - these models require the entire video as input before outputting the point tracks. Latency: window - these models output tracks of length T after consuming a chunk of T frames (typically T = 8). After filling a buffer of T frames, these models can operate in a per-frame fashion. Latency: frame - these models have minimal latency by outputting point predictions immediately after consuming each frame. In each column, the best performing values are in bold, the second best are underlined
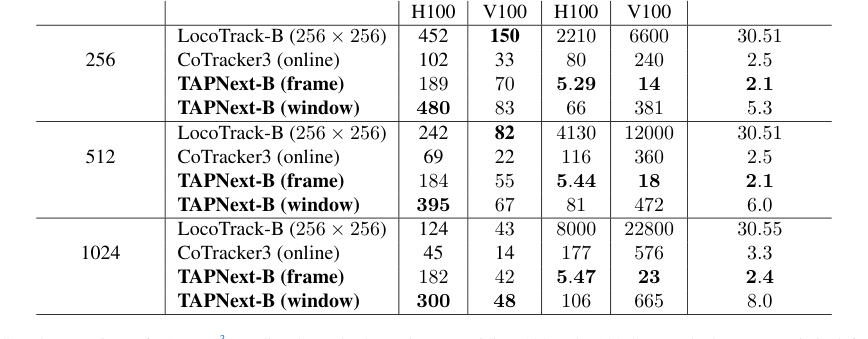 Table 2. Speed comparison of TAPNext3to online Cotracker3 running on Nvidia V100 and H100 GPUs. The latency metric is defined as the maximum (worst case) time between passing a frame to the model and receiving predicted points and it includes the time it takes to fill and process the initial frame buffer. All models are implemented in PyTorch. TAPNext (frame) is per frame inference of TAPNext. TAPNext (window) is when we track with non-overlapping chunks of 32 frames
Table 2. Speed comparison of TAPNext3to online Cotracker3 running on Nvidia V100 and H100 GPUs. The latency metric is defined as the maximum (worst case) time between passing a frame to the model and receiving predicted points and it includes the time it takes to fill and process the initial frame buffer. All models are implemented in PyTorch. TAPNext (frame) is per frame inference of TAPNext. TAPNext (window) is when we track with non-overlapping chunks of 32 frames