TAPNext: トラッキング・エニ・ポイント(TAP)を次トークン予測として
The problem of "correspondence" has been a foundational challenge in computer vision for decades.
背景と学術的系譜
起源と学術的系譜
「対応付け」の問題は、コンピュータビジョンの分野で数十年にわたり基礎的な課題であり続けている。この分野の著名な人物である竹尾加奈氏は、「対応付け、対応付け、そして対応付け!」を3つの最も基本的な問題の1つとして有名に強調した。歴史的には、これは画像間の点や領域の一致を見つけることを含み、運動の理解、深度推定、写真コレクションからの3Dシーン再構築などのタスクに不可欠であった。
より最近では、この基本的な問題は復活を遂げ、「ビデオにおけるトラッキング・エニ・ポイント(TAP)」へと進化している。この特定の課題は、まず、オプティカルフローのような以前のアプローチの限界に対処するために登場した。オプティカルフロー手法はフレーム間移動を追跡できたが、長期間にわたる大きなドリフトに苦しみ、オクルージョン(隠蔽)に対処するのが困難であった。TAPは、固体オブジェクト上の特定の点の、ビデオ全体にわたる高密度で長距離の対応付けを提供することに焦点を当てることで、このギャップを埋めるために導入された。この能力は、ロボティクス、ビデオ編集、3D再構築、アクション認識、動物学、さらには医学を含む、幅広い下流のコンピュータビジョンアプリケーションにとって非常に価値がある。
TAPNextを開発するに至った、以前のTAPアプローチの根本的な限界、すなわち「ペインポイント」は、複雑でトラッキング固有の帰納的バイアスとヒューリスティックに依存していることに起因する。多くの先行モデルは、フレームごとのエンコーディング、マッチングのためのコストボリューム計算、およびその後のトラック洗練を含む2段階のプロセスとしてトラッキングを定式化した。これはしばしば、トラッキングがどのように解決されるべきかについての制約的な仮定を導入した。例えば、それを特徴空間における外観マッチング問題として捉えるなどである。これらの手法は、微分可能なargmax操作、双線形特徴補間、制限された検索ウィンドウ、およびウィンドウ推論を含む、多数のヒューリスティック設計要素を頻繁に組み込んでいた。
さらに、多くの既存のトラッカーは、現在のフレーム出力を生成するために将来のフレームからの情報が必要であり、リアルタイムアプリケーションには不向きであった。ローカルウィンドウベースの推論を使用したオンライン手法でさえ、連続するウィンドウ間でのみ点を転送することに依存していたため、長期間のオクルージョン中に失敗することが多かった。これらの複雑なアーキテクチャとアルゴリズムの選択は、以前のモデルの一般性、スケーラビリティ、および全体的なパフォーマンス、特に長期トラッキングベンチマークにおいて制限していた。著者らの動機は、強力で明示的な帰納的バイアスを課すことなく、これらの限界を克服できる、よりシンプルでスケーラブルかつ高性能なモデルを構築することであった。
直感的なドメイン用語
- トラッキング・エニ・ポイント(TAP): 賑やかな通りのビデオを見ていると想像し、動いている車上の小さな特定のペンキの斑点、または誰かのジャケットの特定のボタンを、クリップ全体にわたって追跡したいとします。TAPは、まさにそれを行うコンピュータビジョンタスクです。ビデオ内で移動および変化するオブジェクト上の任意の選択された点の正確な位置を特定し、追跡することです。
- 帰納的バイアス: これらは、モデルが学習に使用する組み込みの仮定または「ショートカット」と考えてください。たとえば、子供に猫を識別するように教えていて、「猫は常に尖った耳を持っている」と伝えたとします。これは帰納的バイアスです。学習を速くするのに役立ちますが、耳が折りたたまれた猫を誤って識別する原因となる可能性があります。コンピュータビジョンでは、これらのバイアスはモデルのアーキテクチャにおける設計上の選択であり、特定の方法で問題を解決するように導きますが、その柔軟性や一般化能力を制限することもできます。
- コストボリューム計算: 容疑者の顔を「指名手配」ポスターから大規模な群衆のすべての顔と照合しようとしている探偵を想像してください。コストボリュームは、群衆の各顔が容疑者の顔とどれだけ似ているかを正確に探偵に伝える詳細なピクセルごとのマップのようなものです。各潜在的な位置の一致の「コスト」または非類似性を定量化します。
- 状態空間モデル(SSM): 長く展開される物語を語る語り手を考えてみてください。最初からすべての詳細を記憶するのではなく、語り手は物語の現在の状況(「状態」)の簡潔で進化する要約を維持します。新しいイベント(ビデオフレーム)が発生すると、この要約を更新し、毎回物語全体を最初から読み直すことなく、物語を首尾一貫させ、次に何が起こるかを予測できるようにします。
表記表
| 変数 | 説明 |
|---|---|
問題定義と制約
コア問題の定式化とジレンマ
この論文で扱われるコア問題は、ビデオにおけるトラッキング・エニ・ポイント(TAP)です。正確には、モデルの開始点(入力/現在の状態)は以下で構成されます。
- 各フレームが $H \times W$ ピクセルのRGB画像である $T$ フレームで構成されるビデオ。
- ビデオ内の時間 $t$ と空間座標 $(x, y)$ によって定義される $Q$ 個のクエリ点のセット。
望ましい終点(出力/目標状態)は、クエリされた各点について、ビデオ内のすべてのフレームに対する座標 $(x, y) \in [0, H] \times [0, W]$ とバイナリ可視性フラグを予測することです。
この論文が橋渡ししようとしている正確な欠落リンクまたは数学的ギャップは、TAP問題を逐次マスクドトークンデコーディングタスクに変換することです。複雑でトラッキング固有の帰納的バイアスとヒューリスティックに依存する代わりに、TAPNextはポイントトラッキングを補完問題として捉えます。初期クエリ点の座標が与えられた場合、モデルのタスクは、すべての他のフレームにわたるこれらの点の未知の座標を表すマスクされたトークンを「埋める」または補完することです。これは、クエリ点の情報が位置エンコーディングを介して注入される、画像パッチから派生したビデオトークンと座標トークンを連結することによって達成されます。その後、モデルはマスクされたトークンを予測することによって完全な軌跡をデコードすることを学習します。
この特定の問題を解決しようとした以前の研究者は、いくつかの苦痛なトレードオフとジレンマに陥っていました。
- 一般性と特異性: 既存のTAP手法は、複雑でトラッキング固有の帰納的バイアスとヒューリスティックに大きく依存しています。これらは特定のシナリオでパフォーマンスを向上させる可能性がありますが、モデルの一般性とスケーリングの可能性を著しく制限します。一方の側面(例:特殊なアーキテクチャでの精度)を改善すると、もう一方(例:スケーラビリティと広範な適用性)が壊れることがよくあります。
- 精度とリアルタイム遅延: 多くの先行トラッカーは、将来のフレームを使用して現在のフレーム出力を生成したり、ウィンドウ推論を使用したりすることで高い精度を達成しています。このアプローチは本質的に遅延を導入するため、ロボティクスのようなリアルタイムアプリケーションには不向きです。ジレンマは、リアルタイム機能を犠牲にすることなく、高いトラッキングパフォーマンスをどのように達成するかということです。
- 堅牢性とシンプルさ: 従来のメソッドは、フレームごとのエンコーディング、コストボリューム計算、および反復洗練などの多段階プロセスを伴うことがよくあります。これらの複雑なパイプラインは、ドリフトやオクルージョンに対する堅牢性を目指していますが、微分可能なargmax、双線形補間、制限された検索ウィンドウなどの多くのヒューリスティック設計要素を導入しており、モデルを複雑でスケーラビリティの低いものにしています。
- 長期トラッキングとオクルージョン処理: オプティカルフローベースの手法は、長期間にわたる大きなドリフトに苦しみ、オクルージョンに対処するのが困難です。長期ポイントトラッキングがこれを解決するために導入されましたが、多くのオンライン手法におけるウィンドウ推論は、連続するウィンドウ間でのみ点を転送することに依存しているため、特に長期オクルージョン中にトラッキングの失敗につながります。
制約と失敗モード
Tracking Any Point(TAP)の問題は、著者らが直面したいくつかの厳しい現実的な壁のために解決するのが非常に困難です。
- データ不足: TAPの実際のトレーニングデータは不足しています。これにより、先行研究は合成データに大きく依存せざるを得なくなり、その結果、「シム・トゥ・リアル」ギャップを埋めるために複雑な帰納的バイアスとカスタムアーキテクチャが必要になり、モデルのスケーラビリティと一般性が制限されます。
- 計算複雑性とメモリ制限:
- 従来のメソッドは、しばしば各クエリポイントに対してコストボリュームを独立して計算しますが、これは計算コストが高くなる可能性があります。
- 反復洗練ステップとウィンドウ推論スキームは、かなりの計算オーバーヘッドを追加します。
- ハードウェアメモリの制限は実用的な懸念事項であり、一部のベースラインモデル(例:Table 2に示すように、30 GBを超えるメモリを使用するLocoTrack-B)の高いメモリ使用量によって証明されています。メモリ効率の高いモデルを開発することは、展開にとって重要です。
- リアルタイム遅延要件: ロボティクスなどのアプリケーションでは、厳密なリアルタイム遅延が重要な制約となります。現在のフレーム出力を生成するために将来のフレームまたは大きな時間ウィンドウを処理する必要がある手法は、その適用性において本質的に制限されています。
- 時間的整合性とドリフト: 長いビデオシーケンス全体で時間的整合性を維持することは困難です。過去の状態に基づいて将来の状態を予測する自己回帰モデルは、エラーの蓄積を起こしやすく、時間の経過とともに大きなドリフトにつながります。これは多くのトラッカーにとって主要な失敗モードです。
- 長尺ビデオへの一般化: 短いビデオクリップ(例:48フレーム)でトレーニングされたモデルは、大幅に長いビデオ(例:150フレーム以上)への一般化がしばしば不十分です。時間的一般化におけるこの制限は、特に状態空間モデル(SSM)が適切に軽減されない場合、重大な障害となります。論文では、SSMを時間的アテンションに置き換えるとモデルが時間的一般化において「劣る」ことが示されており、SSMを使用しても、十分に長いシーケンスでトレーニングされていない場合、「150フレームを超えるビデオの全長の長期ポイントトラッキングにおいて重大な失敗」が見られると指摘しています。
- 非微分可能な操作: 微分可能なargmax操作や特徴の双線形補間などの先行アーキテクチャにおける多くのヒューリスティック設計要素は、TAPNextがよりシンプルで統一されたアプローチのために回避しようとする複雑さを導入します。
- オクルージョン処理: 点はビデオ内で長期間オクルージョンされる可能性があります。これらのオクルージョンを通じて点を堅牢に追跡し、それらの可視性を正確に予測することは、持続的な課題です。ウィンドウ推論手法は、長期間のオクルージョン中にしばしば失敗します。
- 外観の変化: トラッキングされた点の外観は、照明の変化、視点シフト、または変形により変化する可能性があり、外観ベースのマッチングを困難にします。
- 座標予測精度: 座標予測空間は画像次元によって制限されており、不確実性(例:多峰性予測)を表現しながら高精度を達成することは複雑なタスクです。座標ヘッドは、連続座標を予測し、画像ピクセルの離散的な性質を処理できる必要があります。
- シム・トゥ・リアルギャップ: 主に合成データでトレーニングされたモデルは、視覚的特性の違いにより、実際のビデオでのパフォーマンスが低下することが多く、このドメインギャップを埋めるための堅牢なメカニズムが必要です。論文では、疑似ラベル付きの実際のデータでのトレーニングがこれに有益であると述べています。
- 帰納的バイアスの欠如: TAPNextは一般性のためにトラッキング固有の帰納的バイアスを削除することを目指していますが、これはモデルがこれらの必要なヒューリスティックを有機的にデータから学習する必要があることも意味し、これはより困難な学習問題となる可能性があります。論文では、いくつかのヒューリスティックが自然に現れることを示していますが、これはすべての問題で保証されるわけではありません。
- 視覚情報の伝播: モデルは、特にオクルージョンされた後でも、トラッキングされた点に覆われた領域から将来のフレームへの視覚情報の正確な伝播を学習する必要があります。モデルが特定の視覚領域に関する以前の情報を持っていない場合、平均値で埋められるだけであり、これは失敗モードです。これは、初期の点のグリッドが移動した後に現れる領域がうまく再構築されない場合に特に重要です。モデルはトラッキングされた点の正確な視覚表現を維持する必要があるため、これはモデルにとって重要な課題です。これは生成モデルとしてではなく、線形プローブ実験として見なされるべきではありません。
なぜこのアプローチなのか
選択の必然性
TAPNextの著者は、トラッキング・エニ・ポイント(TAP)のための従来の最先端(SOTA)手法が根本的に不十分であることが証明された重要な岐路に直面しました。コアの認識は、既存のTAPアプローチが「複雑なトラッキング固有の帰納的バイアスとヒューリスティック」に過度に依存しているということでした(要旨)。これらには、コストボリューム計算、反復洗練、ウィンドウ推論、および明示的なフレームごとの外観マッチングなどの技術が含まれていました。これらの手法は合理的なパフォーマンスを達成しましたが、本質的にモデルの一般性とスケーラビリティを制限しており、特に合成データから実際のデータへの「シム・トゥ・リアルギャップ」を埋めようとする場合にそうでした。
この認識の正確な瞬間は、これらの複雑で手作業で設計されたコンポーネントが次のようであったという観察から生じたようです。
1. 過度に制限的: 強力な帰納的バイアスで設計されたアーキテクチャは、多様なシナリオへのスケーリングと一般化の能力を制限しました。
2. 真にオンラインではない: オンライン機能を主張する多くの手法でさえ、将来のフレームまたは大きな時間ウィンドウに依存しており、ロボティクスのようなリアルタイムアプリケーションには不向きでした。この依存関係は、長期間のオクルージョン中にトラッキングの失敗につながることがよくありました。
3. ヒューリスティック駆動: 微分可能なargmax、双線形補間、制限された検索ウィンドウ、およびその他の特定の設計要素の必要性は、全体的なシステムを複雑で壊れやすくしました。
著者は、運動と外観の手がかりをどのように使用するかを明示的に指示されることなく、ポイントを追跡できる、概念的にシンプルで、より一般的で、アーキテクチャが必要であると結論付けました。これにより、TAPを「逐次マスクドトークンデコーディング」問題として捉え、時間処理のために状態空間モデル(SSM)や空間処理のためにビジョントランスフォーマー(ViT)などの汎用コンポーネントを活用するようになりました。これは、TRecViT [40]で以前に探求された組み合わせです。このアプローチは、以前のSOTA手法に固有の複雑さ、一般性の欠如、およびスケーラビリティの悪さの限界を克服するための唯一の実行可能な解決策であると見なされました。
比較優位性
TAPNextは、いくつかの重要な側面で、単なるパフォーマンス指標を超えて、以前のゴールドスタンダードに対して定性的な優位性を示しています。
- 創発的ヒューリスティック: 最も顕著な利点の1つは、広く使用されている多くのトラッキングヒューリスティック(例:モーションクラスターベースのアテンション、座標ベースの読み出し、およびコストボリュームのようなアテンション)が「TAPNextでエンドツーエンドトレーニングを通じて自然に創発する」(要旨、図3)ことです。これにより、複雑な手作業で設計されたコンポーネントの必要がなくなり、モデルが大幅にシンプルで堅牢になります。
- 強化された時間的整合性とオクルージョン処理: 再帰的な状態アーキテクチャ、特にSSMを採用することにより、TAPNextは時間的整合性を維持し、時間の経過とともにトラッキングされた点のダイナミクスを効果的に捉えることができます。この構造的な利点により、点が長期間オクルージョンされる場合にしばしば失敗するウィンドウベースの推論手法よりも、長期間のオクルージョンをはるかに正確に処理できます。
- メモリと遅延の削減: この論文は、TAPNextの効率性に関する説得力のある証拠を提供しています。たとえば、TAPNext-B(フレーム)は、LocoTrack-B(256x256)の約30.5 GBと比較して、大幅に低いメモリ使用量(例:2.1-2.4 GB)を示しています(Table 2)。さらに、その遅延は劇的に削減され、5.29-5.47 msの範囲で動作し、CoTracker3(80-177 ms)またはLocoTrack-B(2210-8000 ms)よりも桁違いに高速です。これにより、リアルタイムアプリケーションにとって圧倒的に優れています。
- スケーラビリティと一般化: TAPNextは、最小限のトラッキング固有の帰納的バイアスで設計されており、より良く一般化できます。トレーニング中に見たビデオよりも大幅に長い(最大5倍)ビデオで点を追跡でき、これは実際のシナリオで重要な機能です。SSMの線形再帰により、オフライン設定で時間処理を並列化することもでき、効率をさらに向上させます。
- 多峰性予測: 単一の軌跡仮説に依存することが多い以前の手法とは異なり、TAPNextの座標分類ヘッドは多峰性予測を表すことができ、不確実性を表現できます。これは、曖昧なトラッキング状況を処理する上での定性的な飛躍です。
- シンプルさとバイアスのない解決策: ハイパーパラメータが少なく、トラッキング固有の帰納的バイアスがないモデルの概念的なシンプルさにより、定義済みの運動と外観の概念に制約されるのではなく、TAP問題のバイアスのない解決策を発見できます。これにより、より適応性が高く、潜在的により強力になります。
制約との整合性
TAPを逐次マスクドトークンデコーディングとして捉え、TRecViTのインターリーブされたSSMとViTブロック上に構築された選択されたアプローチは、問題の厳しい要件と完全に一致し、問題と解決策の強力な「結婚」を形成します。
- オンラインおよび因果的トラッキング: 主要な制約は、ロボティクスやリアルタイムアプリケーションに不可欠な、純粋にオンラインで因果的なトラッキングの必要性でした。TAPNextは、フレームを逐次的に処理し、SSMを介して再帰的な状態を維持することによりこれを達成し、現在のフレームの予測が過去の情報のみに依存することを保証します。これは、将来のフレームに依存する多くの以前の手法の制限に直接対処します。
- 最小遅延: アーキテクチャの設計、特に線形再帰SSMの使用により、最小遅延が可能になります。各フレームを消費した直後にポイント予測を出力し、他のSOTAトラッカーで遅延を導入する時間ウィンドウまたは反復洗練ステップを回避します。
- スケーラビリティと一般性: 複雑な帰納的バイアスがなく、スケーラブルで一般的なモデルの需要は、TAPNextの市販のアーキテクチャコンポーネント(SSMとViT)の使用と、マスクデコーディングタスクとしての定式化によって満たされます。これにより、モデルは明示的な手作業で設計されたヒューリスティックなしでトラッキングを学習でき、多様なシナリオや長尺ビデオへの適応性が向上します。
- 長期オクルージョンの処理: SSMレイヤーによって維持される再帰的な状態は、時間的整合性を維持し、長期間のオクルージョン中でも点を追跡するために重要です。これは、点が消えて再表示されるときに苦労するウィンドウベースの手法の重大な弱点に直接対処します。
- 計算効率: SSMの線形再帰により、時間全体での並列推論が可能になり、計算複雑性の許容できない増加なしに長尺ビデオを処理するために不可欠です。これは、ウィンドウ推論または反復洗練に依存する手法と比較して重要な利点であり、拡張シーケンスでは計算コストが高くなる可能性があります。
- 不確実性の表現: 分類タスクとしての座標予測は、多峰性予測を表すことができ、不確実性を表現できるため、単一のポイント推定ベースの手法ではしばしば欠けている機能である不確実性を表現する必要性と一致します。
代替案の却下
この論文は、TAPの文脈におけるそれらの固有の限界を強調することによって、暗黙的および明示的にいくつかの人気のあるまたは従来ののアプローチを却下しています。
- 従来のSOTA手法(コストボリューム、反復洗練、ウィンドウ推論): 著者らは、「TAPの既存の手法は、複雑なトラッキング固有の帰納的バイアスとヒューリスティックに大きく依存している」(要旨)と明示的に述べています。彼らはこれらを「コストボリューム計算、それに続くトラック洗練[11, 12, 21, 26]」として詳細に説明しており、「微分可能なargmax操作[12]、特徴の双線形補間[21]、制限された検索ウィンドウ[9]、およびウィンドウ推論[26]を含む多くのヒューリスティック設計要素」を伴います。これらは、一般性、スケーラビリティを制限し、多くの場合、非因果的処理を必要とするか、長期オクルージョン中のトラッキングの失敗につながるため、却下されました。TAPNextの目標は、これらの「強力な帰納的バイアス」を回避し、「概念的にシンプルなアーキテクチャ」を開発することでした。
- オフライン/非因果的トラッカー: 多くのトラッカーは、「現在のフレームの出力を生成するために将来のフレームを使用することに依存しており、リアルタイムシナリオでの適用性を制限しています。」この非因果的な性質は、オンライントラッキングの要件と直接矛盾しており、ターゲットアプリケーションでの却下につながりました。
- ウィンドウベースのオンライントラッカー: いくつかの手法はローカルウィンドウを使用したオンライン機能を主張していましたが、論文では「大きな時間ウィンドウの使用と、連続するウィンドウ間でのみ点を転送することへの依存が、特にビデオの中間での長期オクルージョン中のトラッキングの失敗につながることが多い」と指摘しています[21, 26]。長期トラッキングベンチマークでのこのパフォーマンスの低下は、そのようなアプローチを真の再帰的、フレームごとのソリューションに優先して却下する原因となりました。
- 時間的アテンションを備えた標準トランスフォーマー: 系統的レビュー(Table 5)は、時間処理コンポーネントに標準的な時間的アテンションメカニズム(基本的なトランスフォーマーのものなど)を使用することの却下を明確に示しています。SSMを時間的アテンションに置き換えると、モデルは「RoPE [45]時間的位置エンコーディングを使用しているにもかかわらず、時間的一般化において劣る」ことが示されています。これは、トラッキングにおける長距離時間的整合性の特定のタスクでは、SSMが一般的な時間的アテンションよりも優れた構造的利点を提供することを示唆しており、これは長いシーケンスと一般化に苦労します。これは、単純な再帰がこの特定のタスクの複雑なアテンションよりも効果的であることを示唆する重要な発見です。
- 単一仮説ポイント推定: TAPIRやCo-Trackerのような以前の手法は、「各クエリに対して単一の軌跡仮説に対して複数の洗練ステップを実行し、その単一仮説の周りでローカル特徴サンプリングを実行します。」多峰性予測と不確実性を表すことができる座標分類ヘッドを備えたTAPNextは、暗黙的にこの単純で情報量の少ないアプローチを却下します。不確実性を表現する能力は、定性的な利点です。
- 再構築のための生成モデル: 論文は再構築実験を実行しますが、これは生成モデルとしてではなく、「線形プローブ実験」として見なされるべきであると明示的に述べられています。主な目標はトラッキングであり、ビデオフレームの画像生成ではありません。著者らは、マスクされたオートエンコーディングがトークン補完に使用される場合でも、ビデオフレームの完全な生成モデルは、コアトラッキングタスクに必要または有益であるとは見なされなかったと述べています。
 Figure 1. Dense grid tracking with TAPNext. We show (a) the query points on the first frame of the video, (b) the resulting tracks on the final frame of the video for CoTracker3 [27], and (c) our proposed TAPNext method
Figure 1. Dense grid tracking with TAPNext. We show (a) the query points on the first frame of the video, (b) the resulting tracks on the final frame of the video for CoTracker3 [27], and (c) our proposed TAPNext method
数学的・論理的メカニズム
マスター方程式
TAPNextのコアメカニズムは、座標予測(分類と回帰の両方)と可視性予測を組み合わせたマルチタスク損失関数によって駆動されます。この損失は、TRecViTアーキテクチャのすべてのレイヤーに適用され、モデルの深さ全体にわたる堅牢な学習を保証します。全体的な目的は、モデルの予測と、時間経過に伴うポイント座標とその可視性のグラウンドトゥルースとの間の乖離を最小限に抑えることです。
トレーニング中に最小化される総損失 $L_{total}$ を表すマスター方程式は、次のように表すことができます。
$$ L_{total} = \frac{1}{L \cdot Q \cdot T} \sum_{l=1}^{L} \sum_{q=1}^{Q} \sum_{t=1}^{T} \left( L_{coord}^{(l)}(t,q) + L_{vis}^{(l)}(t,q) \right) $$
ここで、$L_{coord}^{(l)}(t,q)$ はレイヤー $l$ の時間 $t$ におけるクエリポイント $q$ の座標損失であり、$L_{vis}^{(l)}(t,q)$ は同じ点の可視性損失です。これらの個々の損失はさらに次のように定義されます。
$$ L_{coord}^{(l)}(t,q) = L_{CE}(p_x^{(l)}(t,q), \text{target_bin}_x) + L_{CE}(p_y^{(l)}(t,q), \text{target_bin}_y) + L_{Huber}((\hat{x}^{(l)}_{t,q}, \hat{y}^{(l)}_{t,q}), (x_{t,q}, y_{t,q})) $$
$$ L_{vis}^{(l)}(t,q) = L_{BCE}(\hat{V}^{(l)}_{t,q}, V_{t,q}) $$
用語ごとの解剖
これらの各方程式のコンポーネントを分解して、その数学的定義とTAPNextフレームワークにおけるその役割を理解しましょう。
-
$L_{total}$:
- 数学的定義: 総損失関数であり、TAPNextのトレーニング中に最小化される全体的な目的を表します。すべてのレイヤー、クエリポイント、および時間ステップにわたる個々の損失の平均合計です。
- 物理的/論理的役割: この項は、ビデオシーケンス全体およびすべての追跡されたポイントに対して、モデルの予測がどれほど「間違っている」かを定量化します。$L_{total}$ を最小化することにより、モデルは時間経過に伴う点の位置と可視性の両方を正確に予測することを学習します。レイヤー全体での(論文で述べられているように)等しい重みでの合計は、深いレイヤーでの勾配消失の問題を防ぎ、ネットワーク全体での堅牢な特徴学習を促進するために、中間表現も適切に形成されることを保証するための戦略的な選択です。この深い監督は、トレーニングを安定させ、最終的なパフォーマンスを向上させます。
- なぜ合計なのか? 合計は、異なるコンポーネント(座標、可視性)と異なるレイヤーからの損失を組み合わせるために使用されます。これは、これらのすべての側面が全体的なタスクにとって等しく重要であり、いずれかの部分のエラーが総エラーに直接寄与することを意味します。$L \cdot Q \cdot T$ による平均化は損失を正規化し、レイヤー、クエリ、またはフレームの数に依存しないようにします。これは、さまざまな入力サイズにわたる安定したトレーニングに不可欠です。
-
$L$:
- 数学的定義: TRecViTバックボーンのインターリーブされたSSMおよびViTレイヤーの総数。
- 物理的/論理的役割: モデルの処理パイプラインの深さを表します。各レイヤーは、画像トークンとポイントトークンの時空間表現の洗練に貢献します。損失は、異なる抽象化レベルの特徴が意味があり、最終的な予測に貢献することを保証するために、各レイヤーに適用されます。これは深い監督の一形態です。
-
$Q$:
- 数学的定義: ビデオで追跡されているクエリポイントの数。
- 物理的/論理的役割: これは、モデルが軌跡を予測するタスクを実行している個々のポイントの数です。モデルが複数のポイントを同時に正確に追跡することを学習することを保証するために、すべてのクエリポイントにわたって損失が合計されます。
-
$T$:
- 数学的定義: ビデオシーケンスの総フレーム数。
- 物理的/論理的役割: ビデオの時間的範囲を表します。モデルがビデオ全体で一貫して点を追跡し、それらの時間的ダイナミクスを捉え、オクルージョンを処理することを保証するために、すべての時間ステップにわたって損失が合計されます。
-
$L_{coord}^{(l)}(t,q)$:
- 数学的定義: レイヤー $l$ の時間 $t$ におけるクエリポイント $q$ の結合座標損失。分類用のクロスエントロピー2つと回帰用のHuber損失1つで構成されます。
- 物理的/論理的役割: この項は、モデルが追跡された点の正確な $(x,y)$ 座標を予測するように駆動します。分類と連続回帰の二重アプローチにより、モデルは離散的な空間位置と細かい連続位置の両方を捉えることができます。分類の側面は、モデルが多峰性予測と不確実性を表現するのに役立ちます。これは、単一のポイント推定値のみを出力する手法とは対照的に、曖昧な状況やオクルージョンに不可欠です。
-
$L_{CE}(p_x^{(l)}(t,q), \text{target_bin}_x)$ および $L_{CE}(p_y^{(l)}(t,q), \text{target_bin}_y)$:
- 数学的定義: ソフトマックスクロスエントロピー損失。指定された座標(例:x座標)について、$p_x^{(l)}(t,q)$ は $n$ 個の離散ビンに対する予測確率のベクトルであり、$\text{target_bin}_x$ はワンホットエンコードされたグラウンドトゥルースビンです。
$$ L_{CE}(p, \text{target}) = - \sum_{i=1}^{n} \text{target}_i \log(p_i) $$ - 物理的/論理的役割: これらの項は、座標ヘッドがxおよびy座標を定義済みの離散ビンに分類するようにトレーニングします。この分類アプローチは、[16]に触発されており、モデルが不確実性を表現できる(例:点が複数のビンに特定の確率で入る可能性がある)ため、多峰性予測を可能にするため、非常に重要です。これは、単一の連続値を予測するだけの手法よりも大きな利点です。論文では、この分類座標ヘッドが最も重要なコンポーネントの1つであると述べています。
- 数学的定義: ソフトマックスクロスエントロピー損失。指定された座標(例:x座標)について、$p_x^{(l)}(t,q)$ は $n$ 個の離散ビンに対する予測確率のベクトルであり、$\text{target_bin}_x$ はワンホットエンコードされたグラウンドトゥルースビンです。
-
$L_{Huber}((\hat{x}^{(l)}_{t,q}, \hat{y}^{(l)}_{t,q}), (x_{t,q}, y_{t,q}))$:
- 数学的定義: Huber損失。連続予測座標 $(\hat{x}^{(l)}_{t,q}, \hat{y}^{(l)}_{t,q})$ とグラウンドトゥルース座標 $(x_{t,q}, y_{t,q})$ に適用されます。連続座標は、分類確率の期待値から導出されます:$\hat{x}^{(l)}_{t,q} = \sum_{i=1}^{n} b_{x,i} \cdot p_x^{(l)}(t,q,i)$ ここで、$b_{x,i}$ はビン $i$ の中心です。
$$ L_{Huber}(e) = \begin{cases} 0.5 e^2 & \text{if } |e| \le \delta \\ \delta (|e| - 0.5 \delta) & \text{if } |e| > \delta \end{cases} $$
ここで、$e$ は誤差(例:$\hat{x} - x$)であり、$\delta$ はハイパーパラメータです。 - 物理的/論理的役割: この項は回帰損失として機能し、連続座標予測を微調整します。Huber損失は、外れ値に対してそれほど敏感ではないため、単純なL2(平均二乗誤差)損失よりも選択されます。ポイントトラッキングでは、グラウンドトゥルースアノテーションはわずかに不正確である場合や、オクルージョンや急速な動きのために点が一時的に予期しない場所に現れる場合があります。Huber損失は、小さな誤差に対しては滑らかな勾配(L2のような)を提供しますが、大きな誤差に対しては線形勾配(L1のような)を提供するため、このようなノイズに対してより堅牢であり、大きな誤差が損失ランドスケープを支配するのを防ぎます。
- 数学的定義: Huber損失。連続予測座標 $(\hat{x}^{(l)}_{t,q}, \hat{y}^{(l)}_{t,q})$ とグラウンドトゥルース座標 $(x_{t,q}, y_{t,q})$ に適用されます。連続座標は、分類確率の期待値から導出されます:$\hat{x}^{(l)}_{t,q} = \sum_{i=1}^{n} b_{x,i} \cdot p_x^{(l)}(t,q,i)$ ここで、$b_{x,i}$ はビン $i$ の中心です。
-
$L_{vis}^{(l)}(t,q)$:
- 数学的定義: レイヤー $l$ の時間 $t$ におけるクエリポイント $q$ の可視性損失。
- 物理的/論理的役割: この項は、モデルが追跡された点が指定されたフレームで可視であるかオクルージョンされているかを予測するように駆動します。正確な可視性予測は、オブジェクトが頻繁に視野から外れたり一時的に隠されたりする実際のシナリオでは、堅牢なトラッキングに不可欠です。
-
$L_{BCE}(\hat{V}^{(l)}_{t,q}, V_{t,q})$:
- 数学的定義: シグモイド二項クロスエントロピー損失。$\hat{V}^{(l)}_{t,q}$ は可視性の予測確率(0から1の間のスカラー)であり、$V_{t,q}$ はバイナリグラウンドトゥルース(オクルージョンされている場合は0、可視の場合は1)です。
$$ L_{BCE}(\hat{v}, v) = - (v \log(\hat{v}) + (1-v) \log(1-\hat{v})) $$ - 物理的/論理的役割: この項は、可視性ヘッドが二項分類を実行するようにトレーニングします。モデルが点の可視性ステータスを誤って予測した場合にペナルティを課します。シグモイド活性化により出力が確率になり、二項クロスエントロピーはこのような2クラス問題の標準的な損失です。モデルは不確実性推定値も使用します。座標の確率質量が8ピクセル半径の外にある場合、点はオクルージョンされているとマークされ、座標の不確実性と可視性の間に自然なリンクが提供されます。
- 数学的定義: シグモイド二項クロスエントロピー損失。$\hat{V}^{(l)}_{t,q}$ は可視性の予測確率(0から1の間のスカラー)であり、$V_{t,q}$ はバイナリグラウンドトゥルース(オクルージョンされている場合は0、可視の場合は1)です。
ステップバイステップの流れ
移動する車上の特定のピクセルなど、ビデオを通して追跡したい単一の抽象的なデータポイントを想像してください。これは、TAPNextの数学エンジンを通過する旅です。
-
入力とトークン化:
- 旅は、$T$ 個のRGBフレームのシーケンスであるビデオと、各開始時間と $(x,y)$ 座標によって定義される $Q$ 個の初期クエリ点のセットから始まります。
- 各ビデオフレームは、まず $h \times w$ 個の非オーバーラップする画像パッチのグリッドに分割されます。これらのパッチは次に $C$ 次元の特徴空間に線形に投影され、空間位置エンコーディングが追加されます。これにより、生の画像データは $[T, h \times w, C]$ の形状を持つ「画像トークン」のシーケンスに変換されます。
- 同時に、私たちの特定のクエリポイント(および他のすべてのポイント)のために、$T$ 個の「ポイントトラックトークン」のシーケンスが作成されます。点が最初にクエリされたフレームについては、そのトークンは $(x,y)$ 座標に対応する位置エンコーディングで初期化されます。他のすべてのフレームについては、そのトークンは特別な「マスクトークン」値で初期化され、その位置が不明であり予測する必要があることを示します。これらのポイントトークンも $[T, Q, C]$ の形状を持ちます。
-
入力テンソル組み立て:
- 次に、画像トークンとポイントトラックトークンが空間次元に沿って連結されます。これにより、$[T, h \times w + Q, C]$ の形状を持つ統一された「入力トークンテンソル」が作成されます。このテンソルには、ビデオの視覚的内容とクエリポイント情報が含まれており、追跡する必要があるフレームの位置がマスクされています。
-
階層的時空間処理(TRecViT):
- この結合された入力テンソルは、TRecViTバックボーンに入り、これは $L$ 個のインターリーブされたレイヤーで構成されます。各レイヤーは2段階のプロセスです。
- SSMブロック(時間処理): まず、データは状態空間モデル(SSM)ブロックを通過します。このブロックは、時間次元($T$)に沿って線形再帰を実行します。空間次元($h \times w + Q$)全体をバッチとして扱います。概念的には、これは時間を通るコンベアベルトのようなものです。SSMブロックは、過去のフレームから現在のフレームおよび将来のフレームへの情報を効率的に伝播し、モデルがポイントの軌跡と外観の「メモリ」を維持できるようにします。これは、オクルージョンや長期間にわたる追跡に不可欠です。
- ViTブロック(空間処理): 次に、SSMブロックの出力はビジョントランスフォーマー(ViT)ブロックに入ります。このブロックは、各フレーム内のすべての $h \times w + Q$ トークンにわたって完全な自己アテンションを実行し、時間次元($T$)をバッチとして扱います。ここで、モデルは単一フレーム内の「周囲を見回し」、画像トークンがポイントトークンにアテンションを向け、ポイントトークンが互いに、および画像トークンにアテンションを向けることができます。この空間混合により、モデルはポイントの位置を周囲との関係で特定し、視覚的な手がかりを統合できます。
- この2段階プロセス(SSM、次にViT)は、すべての $L$ レイヤーで繰り返され、抽象的なデータポイントの時空間表現が段階的に洗練されます。
- この結合された入力テンソルは、TRecViTバックボーンに入り、これは $L$ 個のインターリーブされたレイヤーで構成されます。各レイヤーは2段階のプロセスです。
-
予測ヘッド:
- 各レイヤー $l$ を通過した後、モデルは $T \times Q$ 個のトラックトークンのセットを出力します。これらのトークンは、2つの別々の予測ヘッドに入力されます。
- 座標ヘッド(MLP): MLP(多層パーセプトロン)は、各時間ステップのポイントのトラックトークンを受け取ります。まず、x座標とy座標の両方に対して $n$ 個の離散ビンに対する確率を予測します。次に、これらの確率で重み付けされたビン中心の合計によって、期待される連続 $(x,y)$ 座標を計算します。
- 可視性ヘッド(MLP): 別のMLPは同じトラックトークンを受け取り、そのフレームでポイントが可視であるかオクルージョンされているかを示すバイナリ確率を予測します。
- 各レイヤー $l$ を通過した後、モデルは $T \times Q$ 個のトラックトークンのセットを出力します。これらのトークンは、2つの別々の予測ヘッドに入力されます。
-
損失計算とバックプロパゲーション:
- 各レイヤー $l$、および各時間ステップ $t$ とクエリポイント $q$ について、予測された座標 $(\hat{x}^{(l)}_{t,q}, \hat{y}^{(l)}_{t,q})$ と可視性 $\hat{V}^{(l)}_{t,q}$ は、グラウンドトゥルース $(x_{t,q}, y_{t,q})$ と $V_{t,q}$ と比較されます。
- 座標損失 $L_{coord}^{(l)}(t,q)$ は、ビン分類用のソフトマックスクロスエントロピーと連続回帰用のHuber損失の両方を使用して計算されます。
- 可視性損失 $L_{vis}^{(l)}(t,q)$ は、シグモイド二項クロスエントロピーを使用して計算されます。
- これらの個々の損失は合計されて $L_{total}$ を形成します。この総損失は、勾配を計算するために使用され、ネットワーク全体にバックプロパゲートされてモデルのパラメータが更新されます。この順伝播、損失計算、およびバックプロパゲーションの反復プロセスにより、モデルは追跡能力を学習および改善できます。
最適化ダイナミクス
TAPNextメカニズムは、主にマルチコンポーネント損失関数とアーキテクチャ設計の選択によって駆動される、洗練されたエンドツーエンドの教師ありトレーニングプロセスを通じて学習、更新、および収束します。
-
勾配フローと深い監督: 総損失 $L_{total}$ は、すべてのレイヤー $l$、すべてのクエリポイント $q$、およびすべての時間ステップ $t$ からの損失の合計です。この「深い監督」戦略により、勾配がモデルの最終予測ヘッドから最初のレイヤーまで、ネットワーク全体に効果的に流れることが保証されます。各レイヤーに等しい重みで損失を適用することにより、モデルは複数の抽象化レベルで意味のある正確な表現を学習するように奨励されます。これは、非常に深いネットワークで一般的な勾配消失または爆発などの問題を軽減し、中間特徴も意味があることを保証し、より堅牢で安定した学習プロセスにつながります。
-
損失ランドスケープの形成(座標予測): 座標予測ヘッドは重要なイノベーションであり、分類と回帰の両方を組み合わせています。
- 分類(ソフトマックスクロスエントロピー): 座標を $n$ 個のビンに離散化し、ソフトマックスクロスエントロピー損失を使用することで、損失ランドスケープが多峰性予測を可能にするように形成されます。ポイントの真の位置が曖昧な場合(例:オクルージョンやモーションブラーのため)、モデルは単一の、潜在的に間違った連続値にコミットすることを強制されるのではなく、複数のビンに確率を割り当てることができます。これにより、モデルがまだポイントの一般的な領域を捉えている場合でも、わずかにずれていることに対して重く罰せられないため、損失ランドスケープがより滑らかで寛容になります。
- 回帰(Huber損失): 連続座標の期待値に対するHuber損失は、堅牢な回帰信号を提供します。小さな誤差に対してはL2損失のように動作し、正確に座標を特定するための強力な勾配を提供します。大きな誤差に対しては、L1のような動作に移行し、外れ値や極端な予測誤差に対する感度を低くします。これにより、追跡が難しい少数のポイントが損失を支配し、それらに向かってモデルの学習を歪めるのを防ぎ、したがって、より安定した損失ランドスケープを形成します。
-
時間的整合性と再帰(SSM): 再帰的なSSMブロックは、モデルが時間とともに内部状態を更新する方法の基本です。トレーニング中、SSMは過去のフレームから現在のフレームへの関連情報を伝播することを学習します。これにより、モデルは時間的整合性を維持し、長期間オクルージョンされている場合でも点を追跡できます。SSMレイヤーを流れる勾配は、モデルにどの情報を記憶し、どのようにそれを変換して将来の状態を予測するかを教えます。論文では、SSMの忘却ゲートを0.0から0.1の間にクリップし、クエリ特徴をビデオトークンの長さにブロードキャストすることによって、長尺ビデオの劣化に対する部分的な緩和について言及しています。これは、非常に長いシーケンスにわたって情報を保持および伝播する能力を向上させるためのSSMの内部ダイナミクスへの特定の調整であり、状態が減衰したり無関係になったりするのを防ぎます。
-
空間相互作用(ViTアテンション): 完全な自己アテンションメカニズムを備えたViTブロックにより、モデルは複雑な空間関係を学習できます。アテンションメカニズムを流れる勾配は、モデルが特定のポイントの表現を更新する際に、さまざまな画像パッチや他のポイントトークンの重要性をどのように重み付けするかをモデルに教えます。これにより、モデルは、アーキテクチャに明示的にプログラムされていなくても、コストボリュームのような外観マッチング、座標ベースの読み出し、およびモーションクラスターベースの読み出しなどのさまざまなトラッキングヒューリスティックを暗黙的に学習できます。これらの創発的な振る舞いは、モデルの内部ロジックを形成する上でのエンドツーエンド学習の力を示しています。
-
BootsTAP(教師あり学習): 実際のデータでのファインチューニングのために、TAPNextはBootsTAPと呼ばれる教師あり学習セットアップを採用します。 '教師'モデルは、 '学生'の重みの指数移動平均であり、破損していない、フル解像度の実際のビデオに安定した疑似ラベルを提供します。 '学生'TAPNextモデルは、これらの疑似ラベルから学習しますが、アフィン変換および破損したビデオのバージョンで学習します。損失は学生にのみバックプロパゲートされます。このメカニズムは、モデルが一般的な現実世界の破損やアフィン変換に対する不変の堅牢なソリューションに収束するのを助け、複雑な帰納的バイアスに依存することなく、シム・トゥ・リアルギャップを効果的に埋め、一般化を改善します。教師の安定性は、学生が疑似ラベルのノイズに崩壊したり過学習したりするのを防ぎます。
要するに、TAPNextは、厳密に設計された損失関数を通じて時空間表現と予測ヘッドを反復的に洗練することにより収束します。これは、正確な局在化と堅牢な可視性推定の両方を奨励し、再帰的およびアテンションメカニズムは時間と空間にわたる情報の適応的な伝播と統合を学習します。二重座標損失とBootsTAP戦略は、回復力があり正確なモデルを形成するための鍵です。
結果、限界、結論
実験設計とベースライン
TAPNextの数学的主張を厳密に検証し、その優位性を示すために、著者らは包括的な実験セットアップを設計しました。トレーニングと評価の両方に使用された主なベンチマークはTAP-Vid [11]であり、Kubricによって生成された合成データと、DAVIS(30ビデオ、24〜105フレーム)およびKinetics(1150ビデオ、250フレーム)の2つの人間ラベル付き評価データセットで構成されています。
トレーニング戦略の重要な側面は、先行研究よりも大幅に大きな合成データセット(500,000本のビデオ、各48フレーム長)を使用し、カメラパンやモーションブラーなどの挑戦的な要素を組み込んだことです。実際のファインチューニングのために、BootsTAPNextモデルはインターネットから1500万本のビデオクリップ(長さも48フレーム)を使用し、BootsTAP [13]の自己教師ありトレーニングスキームに従いました。これには、合成データでの初期300,000ステップ、それに続く実際のビデオでの追加の1500ステップの自己教師ありトレーニングが含まれていました。モデルは256 x 256の解像度でトレーニングされ、256個のビデオのバッチ、各バッチに256個のポイントクエリが使用されました。TAPNext-S(56Mパラメータ)とTAPNext-B(194Mパラメータ)の2つのモデルバリアントが開発され、それぞれ異なるピーク学習率 $10^{-3}$ と $5 \times 10^{-4}$ を持ち、コサイン減衰スケジュールに従いました。
推論では、TAPNextモデルは256 x 256の解像度で評価されました。著者らは、クエリごとにビデオを順方向と逆方向の両方で実行し、一度に1つのクエリポイントを追跡し、CoTracker [26]と同様に、パフォーマンス向上のためにローカルおよびグローバルサポートポイントを組み込む、クエリストライド評価を採用しました。
TAPNextが徹底的に比較された「犠牲者」(ベースラインモデル)は、遅延特性によって分類される、さまざまなTAP手法にまたがっていました。
- フレーム遅延手法: TAPNet [11]、Online TAPIR [53]、Online BootsTAP [13]、Track-On [1]。これらのモデルは、各フレームを消費した直後に予測を出力します。
- ウィンドウ推論手法: TAPIR [12]、BootsTAP [13]、TAPTR [34]、TAPTRv2 [33]、TAPTRv3 [41]、PIPs [21]、CoTracker2 [26]、CoTracker3 [27]。これらは、トラックを出力する前にフレームのチャンク(通常 $T=8$)を必要とします。
- ビデオ遅延手法: OmniMotion [55]、Dino-Tracker [51]、LocoTrack-B [9]。これらのモデルは、ポイントトラックを生成する前にビデオ全体を入力として必要とします。
TAPNextのコアメカニズムの決定的な証拠は、3つの標準的な指標を使用して測定されました。
1. オクルージョン精度(OA): ポイントが可視であるかどうかを分類する精度。
2. 座標精度(davg): 予測された座標がグラウンドトゥルースから1、2、4、8、16ピクセルのしきい値内にあるポイントの平均割合。
3. 平均Jaccard: オクルージョンと座標精度の組み合わせ測定値。
証拠が証明すること
実験結果は、TAPNextのコアメカニズム、すなわちTracking Any Point(TAP)を、シンプルな再帰アーキテクチャを使用した逐次マスクドトークンデコーディングとして捉えることが非常に効果的であるという否定できない証拠を提供します。Table 1に示すように、TAPNextは、特にリアルタイムアプリケーションに適した最小遅延で動作することを考えると、TAP-Vidベンチマークで8つの報告された指標のうち8つで、他のオンライン(1フレーム遅延)手法を大幅に上回る新しい最先端のトラッキングパフォーマンスを達成しています。
重要な発見は、TAPNextが、以前の最先端手法に共通する複雑なトラッキング固有の帰納的バイアスやヒューリスティックに依存することなく、これを達成していることです。反復的またはウィンドウ推論、テスト時最適化、コストボリューム、特徴補間、トークン特徴エンジニアリング、およびローカル検索ウィンドウを回避しています。代わりに、状態空間モデル(SSM)やビジョントランスフォーマー(ViT)などのオープンソースアーキテクチャコンポーネントに基づいたモデルのシンプルさは、大規模な合成データセットでのエンドツーエンドトレーニングを通じて、これらのヒューリスティックを自然に学習することを可能にします。アテンションマップの視覚化(図3および4)は、TAPNextが、アーキテクチャに明示的にプログラムされていなかったコストボリュームのような外観マッチング、座標ベースの読み出し、およびモーションクラスターベースの読み出しに似たアテンションパターンを自律的に開発していることを確認しています。
さらに、TAPNextは驚異的な一般化能力を示しています。48フレームのビデオでトレーニングされたにもかかわらず、5倍長いビデオ(例:Kineticsデータセットの250フレームビデオ)でポイントを正常に追跡します。この堅牢な時間的一般化は、SSMレイヤーの再帰的な性質に起因しており、これらはポイントをオンラインで因果的に処理し、長期間のオクルージョン中でも時間的整合性を維持します。系統的レビュー(Table 4)は、分類と回帰の両方の損失を使用する分類座標ヘッドと、8x8ピクセルの画像パッチサイズの選択の重要な役割を強調しています。時間処理におけるSSMの優位性は、SSMを時間的アテンションに置き換えると、高度な位置エンコーディングを使用しても、時間的一般化が劣ることが示されているTable 5によってさらに強調されています。
効率の面では、Table 2はTAPNextの利点を明確に証明しています。ウィンドウ推論で最高のトラッキング速度とフレーム遅延で最小の遅延を達成しながら、CoTracker3やLocoTrack-Bなどのベースラインと比較して最も少ないメモリを消費します。定性的な結果は、著者によって説明されているように、これらの発見をさらに強化し、TAPNextがオクルージョン、高速モーションを処理し、競合他社よりも正確に細い/小さい、テクスチャのないオブジェクトを追跡する能力を示しています。モデルが、オクルージョンされた後でも、追跡された領域の視覚情報を正確に伝播する能力は、SSMレイヤーが時間とともに外観情報を効果的にエンコードおよび伝播することを示唆しています。
限界と将来の方向性
TAPNextはポイントトラッキングにおける大きな飛躍を示していますが、この論文は、「150フレームを超えるビデオの長期ポイントトラッキングにおける重大な失敗」という顕著な限界を率直に認めています。この問題は、主に、トレーニングされた48フレームよりも大幅に長いビデオクリップに効果的に一般化できない状態空間モデルの現在の能力に起因します。SSMの忘却ゲートをクリップし、クエリ特徴をブロードキャストすることによる部分的な緩和が見つかりましたが、これは将来の改善のための主要な領域です。SSMにおけるこの限界に対処することは、TAPNextのすでに強力なトラッキングパフォーマンスをさらに向上させるための大きな機会を提供します。
将来を見据えると、TAPNextからの発見は、いくつかのエキサイティングな議論のトピックと将来の研究の方向性を開きます。
-
極端な時間的一般化のためのSSMの進歩: 150フレームを超えるビデオでの現在の限界は、劣化なしに任意の長さのシーケンスを処理できる新しいSSMアーキテクチャまたはトレーニング方法論の必要性を示唆しています。階層SSMまたは適応的再帰メカニズムを開発して、長距離依存関係をより良く管理できますか?ビデオ長に合わせてスケーリングするSSM内の動的メモリ割り当てを検討しますか?
-
「次トークン予測」パラダイムの拡張: この論文は、TAPを次トークン予測として捉えるTAPNextフレームワークが、「ビデオにおける他の多くのコンピュータビジョンタスクに拡張できる」と提案しています。これは深遠な声明です。時間的整合性とポイントレベルの理解が重要なオブジェクト検出、セグメンテーション、またはビデオ生成などのタスクに、このパラダイムをどのように適応させることができますか?このアプローチから統一されたビデオ基盤モデルが出現する可能性がありますか?
-
創発的ヒューリスティックの理解の深化: 複雑なトラッキングヒューリスティック(モーション、座標、外観マッチング)がエンドツーエンドトレーニングから自然に創発するという観察は魅力的です。将来の研究では、これらのヒューリスティックが創発する理由と方法をさらに深く掘り下げることができます。これらの創発的な特性につながる内部メカニズムをよりよく理解するために、実験や解釈ツールを設計できますか?これは、さらに汎用性が高く、バイアスの少ないアーキテクチャの設計に情報を提供する可能性があります。
-
座標ヘッドと不確実性推定の最適化: 分類座標ヘッドは、TAPNextの最も重要なコンポーネントの1つとして特定されています。特に多峰性予測を表し、離散ビンから連続座標出力を洗練する上でのパラメータ化に関するさらなる研究は、大幅な改善をもたらす可能性があります。さらに、より洗練された確率的モデリングを統合することによって、モデルの固有の不確実性推定を強化することは、困難なシナリオでの堅牢性を向上させる可能性があります。
-
オープンソース貢献の活用: トレーニングコードとモデルウェイトの推論コードをすぐにオープンソース化するという著者らのコミットメントは、重要なステップです。これにより、より広範な研究コミュニティがTAPNextを迅速に実験、構築、進化させることができます。将来の議論は、コミュニティ主導のベンチマークや、長期トラッキングの境界を押し広げる挑戦を通じて、この共同開発をどのように最もよく促進するかを中心に展開する必要があります。
-
BootsTAPによるシム・トゥ・リアルギャップの橋渡し: BootsTAPファインチューニング戦略は、シム・トゥ・リアルギャップを橋渡しするのに有益であることが証明されました。将来の研究では、希少な実際の注釈付きデータへの依存をさらに減らす、より高度な自己教師ありまたは半教師あり学習技術を探索して、TAPモデルをさらにスケーラブルにし、多様な実際のシナリオに適用できるようにすることができます。
これらの多様な視点は、TAPNextが単なる新しい最先端モデルではなく、汎用、シンプル、スケーラブルなビデオ理解の新しい波を刺激する可能性のある基盤的な作品であることを強調しています。
 Table 1. Tracking performance for TAPNext and baseline models. TAPNext achieves a new state-of-the-art point tracking performance on eight of the twelve metrics, while also achieving the lowest possible latency. Methods are organized by their latency. Latency: video - these models require the entire video as input before outputting the point tracks. Latency: window - these models output tracks of length T after consuming a chunk of T frames (typically T = 8). After filling a buffer of T frames, these models can operate in a per-frame fashion. Latency: frame - these models have minimal latency by outputting point predictions immediately after consuming each frame. In each column, the best performing values are in bold, the second best are underlined
Table 1. Tracking performance for TAPNext and baseline models. TAPNext achieves a new state-of-the-art point tracking performance on eight of the twelve metrics, while also achieving the lowest possible latency. Methods are organized by their latency. Latency: video - these models require the entire video as input before outputting the point tracks. Latency: window - these models output tracks of length T after consuming a chunk of T frames (typically T = 8). After filling a buffer of T frames, these models can operate in a per-frame fashion. Latency: frame - these models have minimal latency by outputting point predictions immediately after consuming each frame. In each column, the best performing values are in bold, the second best are underlined
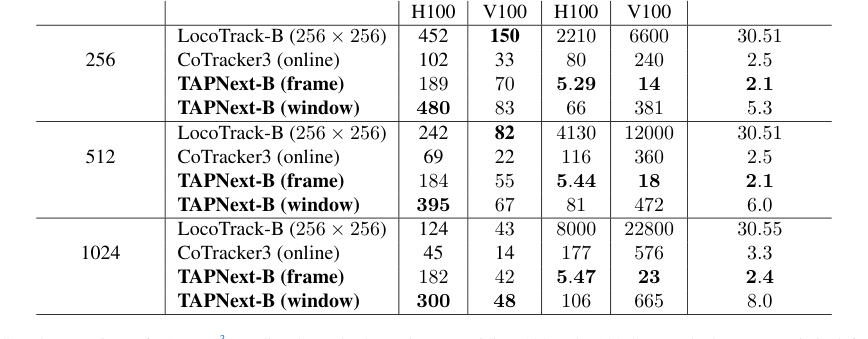 Table 2. Speed comparison of TAPNext3to online Cotracker3 running on Nvidia V100 and H100 GPUs. The latency metric is defined as the maximum (worst case) time between passing a frame to the model and receiving predicted points and it includes the time it takes to fill and process the initial frame buffer. All models are implemented in PyTorch. TAPNext (frame) is per frame inference of TAPNext. TAPNext (window) is when we track with non-overlapping chunks of 32 frames
Table 2. Speed comparison of TAPNext3to online Cotracker3 running on Nvidia V100 and H100 GPUs. The latency metric is defined as the maximum (worst case) time between passing a frame to the model and receiving predicted points and it includes the time it takes to fill and process the initial frame buffer. All models are implemented in PyTorch. TAPNext (frame) is per frame inference of TAPNext. TAPNext (window) is when we track with non-overlapping chunks of 32 frames
他の分野との同型性
構造的骨格
既知のトークンと学習された時間的・空間的関係を活用して、時空間データストリームの欠落トークンを補完する、再帰的なシーケンス・トゥ・シーケンスモデル。