TAPNext: ट्रैकिंग एनी पॉइंट (TAP) को नेक्स्ट टोकन प्रेडिक्शन के रूप में
The problem of "correspondence" has been a foundational challenge in computer vision for decades.
पृष्ठभूमि और अकादमिक वंश
उत्पत्ति और अकादमिक वंश
"संगति" (correspondence) की समस्या दशकों से कंप्यूटर विज़न के क्षेत्र में एक मूलभूत चुनौती रही है। इस क्षेत्र के एक प्रमुख व्यक्ति, टेको कनाडे (Takeo Kanade) ने प्रसिद्ध रूप से "संगति, संगति, और संगति!" को तीन सबसे मौलिक समस्याओं में से एक के रूप में उजागर किया था। ऐतिहासिक रूप से, इसमें छवियों के बीच मिलान वाले बिंदुओं या क्षेत्रों को खोजना शामिल था, जो गति को समझने, गहराई का अनुमान लगाने और फोटो संग्रह से 3D दृश्यों के पुनर्निर्माण जैसे कार्यों के लिए महत्वपूर्ण था।
हाल ही में, इस मौलिक समस्या को एक पुनरुत्थान मिला है और यह वीडियो में "ट्रैकिंग एनी पॉइंट (TAP)" के रूप में विकसित हुई है। यह विशिष्ट समस्या पहले ऑप्टिकल फ्लो जैसे पुराने दृष्टिकोणों की सीमाओं को संबोधित करने के लिए उभरी। जबकि ऑप्टिकल फ्लो विधियाँ फ्रेम-दर-फ्रेम गति को ट्रैक कर सकती थीं, वे अक्सर लंबी समय-सीमा में महत्वपूर्ण बहाव (drift) से पीड़ित होती थीं और अवरोधों (occlusions) से जूझती थीं। TAP को इस अंतर को पाटने के लिए पेश किया गया था, जो पूरे वीडियो में ठोस वस्तुओं पर विशिष्ट बिंदुओं की घनी, लंबी-श्रेणी की संगति प्रदान करने पर केंद्रित था। यह क्षमता रोबोटिक्स, वीडियो संपादन, 3D पुनर्निर्माण, क्रिया पहचान, जूलॉजी और यहां तक कि चिकित्सा सहित विभिन्न प्रकार के डाउनस्ट्रीम कंप्यूटर विज़न अनुप्रयोगों के लिए अत्यधिक मूल्यवान है।
पिछले TAP दृष्टिकोणों की मूलभूत सीमा, या "दर्द बिंदु," जिसने लेखकों को TAPNext विकसित करने के लिए प्रेरित किया, वह जटिल, ट्रैकिंग-विशिष्ट आगमनात्मक पूर्वाग्रहों (inductive biases) और अनुमानों (heuristics) पर उनकी निर्भरता से उत्पन्न होती है। कई पूर्व मॉडलों ने प्रति-फ्रेम एन्कोडिंग, मिलान के लिए लागत-आयतन गणना (cost-volume computation), और बाद में ट्रैक शोधन (track refinement) को शामिल करने वाली दो-चरणीय प्रक्रिया के रूप में ट्रैकिंग को तैयार किया। इसने अक्सर ट्रैकिंग को कैसे हल किया जाना चाहिए, इसके बारे में प्रतिबंधात्मक धारणाएं पेश कीं, जैसे कि इसे फीचर स्पेस में एक उपस्थिति मिलान समस्या के रूप में देखना। इन विधियों में अक्सर कई अनुमानित डिजाइन तत्व शामिल होते थे, जिनमें डिफरेंशिएबल आर्गमैक्स ऑपरेशन (differentiable argmax operations), द्वि-रैखिक फीचर इंटरपोलेशन (bi-linear feature interpolation), प्रतिबंधित खोज विंडो (restricted search windows), और विंडो वाली अनुमान (windowed inference) शामिल हैं।
इसके अलावा, कई मौजूदा ट्रैकर्स को वर्तमान फ्रेम आउटपुट का उत्पादन करने के लिए भविष्य के फ्रेम से जानकारी की आवश्यकता होती है, जिससे वे वास्तविक समय अनुप्रयोगों के लिए अनुपयुक्त हो जाते हैं। यहां तक कि स्थानीय विंडो-आधारित अनुमान का उपयोग करने वाली ऑनलाइन विधियाँ भी लगातार विंडो के बीच बिंदुओं को स्थानांतरित करने पर उनकी निर्भरता के कारण लंबी अवधि के अवरोधों के दौरान अक्सर विफल हो जाती थीं। इन जटिल आर्किटेक्चर और एल्गोरिथम विकल्पों ने पिछले मॉडलों की सामान्यता, मापनीयता और समग्र प्रदर्शन को सीमित कर दिया, विशेष रूप से लंबी अवधि के ट्रैकिंग बेंचमार्क पर। लेखकों की प्रेरणा एक सरल, अधिक मापनीय और प्रदर्शनकारी मॉडल बनाना था जो मजबूत, स्पष्ट आगमनात्मक पूर्वाग्रहों को लागू किए बिना इन सीमाओं को दूर कर सके।
सहज डोमेन शब्द
- ट्रैकिंग एनी पॉइंट (TAP): कल्पना कीजिए कि आप एक व्यस्त सड़क का वीडियो देख रहे हैं, और आप एक चलती कार पर पेंट के एक छोटे, विशिष्ट धब्बे, या किसी व्यक्ति की जैकेट पर एक विशेष बटन को पूरी क्लिप के दौरान ट्रैक करना चाहते हैं। TAP कंप्यूटर विज़न का कार्य ठीक यही करना है: वीडियो में चलते और बदलते हुए किसी वस्तु पर किसी भी चुने हुए बिंदु के सटीक स्थान की पहचान करना और उसका अनुसरण करना।
- आगमनात्मक पूर्वाग्रह (Inductive Biases): इन्हें अंतर्निहित धारणाओं या "शॉर्टकट" के रूप में सोचें जिनका उपयोग मॉडल सीखने के लिए करता है। उदाहरण के लिए, यदि आप किसी बच्चे को बिल्लियों की पहचान करना सिखा रहे हैं, और आप उन्हें बताते हैं कि "बिल्लियों के कान हमेशा नुकीले होते हैं," तो यह एक आगमनात्मक पूर्वाग्रह है। यह उन्हें तेज़ी से सीखने में मदद करता है लेकिन मुड़े हुए कानों वाली बिल्ली की पहचान करने में उन्हें गलत कर सकता है। कंप्यूटर विज़न में, ये पूर्वाग्रह मॉडल के आर्किटेक्चर में डिजाइन विकल्प होते हैं जो इसे किसी समस्या को एक विशेष तरीके से हल करने के लिए निर्देशित करते हैं, लेकिन वे इसकी लचीलापन या सामान्यीकरण की क्षमता को भी सीमित कर सकते हैं।
- लागत-आयतन गणना (Cost-Volume Computation): एक जासूस की कल्पना करें जो एक "वांछित" पोस्टर से एक संदिग्ध के चेहरे को एक बड़ी भीड़ में हर एक चेहरे से मिलाने की कोशिश कर रहा है। एक लागत-आयतन एक विस्तृत, पिक्सेल-दर-पिक्सेल मानचित्र की तरह है जो जासूस को ठीक-ठीक बताता है कि भीड़ में प्रत्येक चेहरा संदिग्ध के चेहरे से कितना समान है। यह प्रत्येक संभावित स्थान का मिलान करने की "लागत" या असमानता को मापता है।
- स्टेट-स्पेस मॉडल (SSM): एक कहानीकार के बारे में सोचें जो एक लंबी, खुलती हुई कहानी सुना रहा है। शुरुआत से हर एक विवरण को याद रखने के बजाय, कहानीकार कहानी की वर्तमान स्थिति ( "स्थिति") का एक संक्षिप्त, विकसित सारांश बनाए रखता है। जैसे ही नई घटनाएँ (वीडियो फ्रेम) होती हैं, वे इस सारांश को अपडेट करते हैं, जिससे उन्हें हर बार पूरी कहानी को पृष्ठ एक से फिर से पढ़े बिना कथा को सुसंगत रखने और आगे क्या हो सकता है, इसका अनुमान लगाने की अनुमति मिलती है।
संकेतन तालिका
| चर | विवरण |
|---|---|
समस्या परिभाषा और बाधाएँ
मुख्य समस्या सूत्रीकरण और दुविधा
इस पत्र द्वारा संबोधित मुख्य समस्या वीडियो में ट्रैकिंग एनी पॉइंट (TAP) है। सटीक रूप से, मॉडल के लिए प्रारंभिक बिंदु (इनपुट/वर्तमान स्थिति) में शामिल हैं:
- $T$ फ्रेमों से युक्त एक वीडियो, जहाँ प्रत्येक फ्रेम $H \times W$ पिक्सेल का एक RGB छवि है।
- $Q$ क्वेरी बिंदुओं का एक सेट, प्रत्येक को उसके समय $t$ और वीडियो के भीतर स्थानिक निर्देशांक $(x, y)$ द्वारा परिभाषित किया गया है।
वांछित अंतिम बिंदु (आउटपुट/लक्ष्य स्थिति) वीडियो में प्रत्येक फ्रेम के लिए, प्रत्येक क्वेरी बिंदु के लिए उसके निर्देशांक $(x, y) \in [0, H] \times [0, W]$ और एक बाइनरी दृश्यता ध्वज (binary visibility flag) की भविष्यवाणी करना है।
सटीक लुप्त कड़ी या गणितीय अंतर जिसे यह पत्र पाटने का प्रयास करता है, वह TAP समस्या को अनुक्रमिक मास्क्ड टोकन डिकोडिंग कार्य (sequential masked token decoding task) में परिवर्तन है। जटिल, ट्रैकिंग-विशिष्ट आगमनात्मक पूर्वाग्रहों और अनुमानों पर निर्भर रहने के बजाय, TAPNext बिंदु ट्रैकिंग को एक आरोपण समस्या (imputation problem) के रूप में तैयार करता है। प्रारंभिक क्वेरी बिंदु निर्देशांकों को देखते हुए, मॉडल का कार्य सभी अन्य फ्रेमों में इन बिंदुओं के अज्ञात निर्देशांकों का प्रतिनिधित्व करने वाले मास्क्ड टोकन को "भरना" या आरोपण करना है। यह छवि पैच से प्राप्त वीडियो टोकन को बिंदु निर्देशांक टोकन के साथ जोड़कर प्राप्त किया जाता है, जहाँ क्वेरी बिंदु जानकारी को स्थिति एन्कोडिंग (positional encoding) के माध्यम से इंजेक्ट किया जाता है। फिर मॉडल मास्क्ड टोकन की भविष्यवाणी करके पूर्ण प्रक्षेपवक्र (trajectories) को डिकोड करना सीखता है।
इस विशिष्ट समस्या को हल करने का प्रयास करने वाले पिछले शोधकर्ताओं को कई दर्दनाक ट्रेड-ऑफ और दुविधाओं में फँसाया गया है:
- सामान्यता बनाम विशिष्टता: मौजूदा TAP विधियाँ जटिल, ट्रैकिंग-विशिष्ट आगमनात्मक पूर्वाग्रहों और अनुमानों पर बहुत अधिक निर्भर करती हैं। जबकि ये विशिष्ट परिदृश्यों में प्रदर्शन लाभ प्रदान कर सकते हैं, वे मॉडलों की सामान्यता और मापनीयता की क्षमता को गंभीर रूप से सीमित करते हैं। एक पहलू में सुधार (जैसे, विशेष आर्किटेक्चर के साथ सटीकता) अक्सर दूसरे को तोड़ता है (जैसे, मापनीयता और व्यापक प्रयोज्यता)।
- सटीकता बनाम वास्तविक समय विलंबता: कई पूर्व ट्रैकर्स वर्तमान फ्रेम आउटपुट की भविष्यवाणी करने के लिए भविष्य के फ्रेम का उपयोग करके या विंडो वाली अनुमान का उपयोग करके उच्च सटीकता प्राप्त करते हैं। यह दृष्टिकोण स्वाभाविक रूप से विलंबता का परिचय देता है, जिससे वे रोबोटिक्स जैसे वास्तविक समय अनुप्रयोगों के लिए अनुपयुक्त हो जाते हैं। दुविधा यह है कि वास्तविक समय क्षमता का त्याग किए बिना उच्च ट्रैकिंग प्रदर्शन कैसे प्राप्त किया जाए।
- मजबूती बनाम सरलता: पारंपरिक विधियों में अक्सर प्रति-फ्रेम एन्कोडिंग, मिलान के लिए लागत-आयतन गणना, और पुनरावृत्त शोधन जैसी बहु-चरणीय प्रक्रियाएं शामिल होती हैं। ये जटिल पाइपलाइन, जबकि बहाव और अवरोधों के खिलाफ मजबूती का लक्ष्य रखती हैं, कई अनुमानित डिजाइन तत्वों (जैसे, डिफरेंशिएबल आर्गमैक्स, द्वि-रैखिक इंटरपोलेशन, प्रतिबंधित खोज विंडो) का परिचय देती हैं, जिससे मॉडल जटिल और कम मापनीय हो जाते हैं।
- लंबी अवधि की ट्रैकिंग बनाम अवरोधन हैंडलिंग: ऑप्टिकल फ्लो-आधारित विधियाँ लंबी समय-सीमा में महत्वपूर्ण बहाव से पीड़ित होती हैं और अवरोधों से जूझती हैं। जबकि लंबी अवधि के बिंदु ट्रैकिंग को संबोधित करने के लिए पेश किया गया था, कई ऑनलाइन विधियों में विंडो वाली अनुमान अभी भी ट्रैकिंग विफलताओं का कारण बनती है, खासकर लंबी अवधि के अवरोधों के दौरान, क्योंकि बिंदु लगातार विंडो के बीच स्थानांतरित होने पर खो सकते हैं।
बाधाएँ और विफलता मोड
TAP (ट्रैकिंग एनी पॉइंट) की समस्या को हल करना बेहद मुश्किल है क्योंकि लेखकों को कई कठोर, यथार्थवादी दीवारों का सामना करना पड़ा:
- डेटा की कमी: TAP के लिए वास्तविक दुनिया का प्रशिक्षण डेटा दुर्लभ है। यह पूर्व कार्यों को सिंथेटिक डेटा पर बहुत अधिक निर्भर रहने के लिए मजबूर करता है, जिसके लिए "सिम-टू-रियल" गैप को पाटने के लिए जटिल आगमनात्मक पूर्वाग्रहों और कस्टम आर्किटेक्चर की आवश्यकता होती है, जिससे मॉडलों की मापनीयता और सामान्यता सीमित हो जाती है।
- कम्प्यूटेशनल जटिलता और मेमोरी सीमाएँ:
- पारंपरिक विधियाँ अक्सर प्रत्येक क्वेरी बिंदु के लिए स्वतंत्र रूप से लागत-आयतन की गणना करती हैं, जो कम्प्यूटेशनल रूप से महंगी हो सकती है।
- पुनरावृत्त शोधन चरण और विंडो वाली अनुमान योजनाएं महत्वपूर्ण कम्प्यूटेशनल ओवरहेड जोड़ती हैं।
- हार्डवेयर मेमोरी सीमाएँ एक व्यावहारिक चिंता का विषय हैं, जैसा कि कुछ बेसलाइन मॉडलों (जैसे, लोकोट्रैक-बी जो 30 जीबी से अधिक मेमोरी का उपयोग करता है, जैसा कि तालिका 2 में दिखाया गया है) के उच्च मेमोरी उपयोग से स्पष्ट है। तैनाती के लिए मेमोरी-कुशल मॉडल विकसित करना महत्वपूर्ण है।
- वास्तविक समय विलंबता आवश्यकताएँ: रोबोटिक्स जैसे अनुप्रयोगों के लिए, सख्त वास्तविक समय विलंबता एक महत्वपूर्ण बाधा है। भविष्य के फ्रेम या वर्तमान फ्रेम भविष्यवाणियों को आउटपुट करने से पहले बड़े अस्थायी विंडो को संसाधित करने की आवश्यकता वाली विधियाँ स्वाभाविक रूप से अपनी प्रयोज्यता में सीमित हैं।
- टेम्पोरल कोहेरेंस और बहाव: लंबी वीडियो अनुक्रमों में टेम्पोरल कोहेरेंस बनाए रखना चुनौतीपूर्ण है। ऑटो-रेग्रेसिव मॉडल, जो पिछले वाले के आधार पर भविष्य की स्थितियों की भविष्यवाणी करते हैं, त्रुटियों के संचय से ग्रस्त होते हैं, जिससे समय के साथ महत्वपूर्ण बहाव होता है। यह कई ट्रैकर्स के लिए एक प्रमुख विफलता मोड है।
- लंबी वीडियो के लिए सामान्यीकरण: छोटी वीडियो क्लिप (जैसे, 48 फ्रेम) पर प्रशिक्षित मॉडल अक्सर काफी लंबी वीडियो (जैसे, 150 फ्रेम से अधिक) पर खराब सामान्यीकरण करते हैं। टेम्पोरल सामान्यीकरण में यह सीमा एक महत्वपूर्ण बाधा है, विशेष रूप से स्टेट-स्पेस मॉडल (SSMs) के लिए यदि ठीक से कम न किया जाए। पत्र नोट करता है कि मॉडल खराब टेम्पोरल सामान्यीकरण प्रदर्शित करता है जब SSM को टेम्पोरल अटेंशन के लिए स्वैप किया जाता है, और SSM के साथ भी, यदि पर्याप्त लंबी अनुक्रमों पर प्रशिक्षित न किया जाए तो "150 फ्रेम से अधिक वीडियो की पूरी लंबाई में लंबी अवधि के बिंदु ट्रैकिंग में महत्वपूर्ण विफलता" होती है।
- गैर-डिफरेंशिएबल ऑपरेशन: पूर्व आर्किटेक्चर में कई अनुमानित डिजाइन तत्व, जैसे डिफरेंशिएबल आर्गमैक्स ऑपरेशन या सुविधाओं का द्वि-रैखिक इंटरपोलेशन, जटिलताएँ पेश करते हैं जिन्हें TAPNext एक सरल, अधिक एकीकृत दृष्टिकोण के लिए टालना चाहता है।
- अवरोधन हैंडलिंग: वीडियो के भीतर विस्तारित अवधि के लिए बिंदु अवरुद्ध हो सकते हैं। इन अवरोधों के माध्यम से बिंदुओं को मजबूती से ट्रैक करना, और उनकी दृश्यता की सही भविष्यवाणी करना, एक लगातार चुनौती है। विंडो वाली अनुमान विधियाँ अक्सर लंबी अवधि के अवरोधों के दौरान विफल हो जाती हैं।
- उपस्थिति परिवर्तन: ट्रैक किए गए बिंदुओं की उपस्थिति प्रकाश भिन्नता, दृष्टिकोण शिफ्ट, या विरूपण के कारण बदल सकती है, जिससे उपस्थिति-आधारित मिलान मुश्किल हो जाता है।
- निर्देशांक भविष्यवाणी परिशुद्धता: निर्देशांक भविष्यवाणी स्थान छवि आयामों द्वारा सीमित है, और अनिश्चितता का प्रतिनिधित्व करते हुए (जैसे, मल्टीमॉडल भविष्यवाणियां) उच्च परिशुद्धता प्राप्त करना एक जटिल कार्य है। निर्देशांक हेड को निरंतर निर्देशांक की भविष्यवाणी करने और छवि पिक्सेल की असतत प्रकृति को संभालने में सक्षम होना चाहिए।
- सिम-टू-रियल गैप: मुख्य रूप से सिंथेटिक डेटा पर प्रशिक्षित मॉडल अक्सर दृश्य विशेषताओं में अंतर के कारण वास्तविक दुनिया के वीडियो पर अच्छा प्रदर्शन करने में संघर्ष करते हैं, जिसके लिए इस डोमेन गैप को पाटने के लिए मजबूत तंत्र की आवश्यकता होती है। पत्र में उल्लेख है कि छद्म-लेबल वाले वास्तविक डेटा पर प्रशिक्षण इसके लिए फायदेमंद है।
- आगमनात्मक पूर्वाग्रहों की कमी: जबकि TAPNext सामान्यता के लिए ट्रैकिंग-विशिष्ट आगमनात्मक पूर्वाग्रहों को हटाने का लक्ष्य रखता है, इसका मतलब यह भी है कि मॉडल को डेटा से स्वाभाविक रूप से इन आवश्यक अनुमानों को सीखना चाहिए, जो एक कठिन सीखने की समस्या हो सकती है। पत्र दिखाता है कि कुछ अनुमान स्वाभाविक रूप से उभरते हैं, लेकिन यह सभी समस्याओं के लिए गारंटीकृत नहीं है।
- दृश्य सूचना प्रसार: मॉडल को अतीत के फ्रेम से भविष्य के फ्रेम तक दृश्य सूचना को सटीक रूप से प्रसारित करना सीखना चाहिए, विशेष रूप से ट्रैक किए गए बिंदुओं द्वारा कवर किए गए क्षेत्रों के लिए, भले ही वे अवरुद्ध हो गए हों। यदि मॉडल में कुछ दृश्य क्षेत्रों के बारे में पिछली जानकारी नहीं है, तो यह उन्हें औसत मानों से भर सकता है, जो एक विफलता मोड है। यह विशेष रूप से उन क्षेत्रों के लिए प्रासंगिक है जो प्रारंभिक बिंदु ग्रिड के दूर जाने के बाद दिखाई देते हैं, जिनका अच्छी तरह से पुनर्निर्माण नहीं किया गया है। यह मॉडल के लिए एक प्रमुख चुनौती है, क्योंकि इसे ट्रैक किए गए बिंदुओं के दृश्य प्रतिनिधित्व को बनाए रखना चाहिए। इसे एक जनरेटिव मॉडल के रूप में नहीं देखा जाना चाहिए, बल्कि एक रैखिक जांच प्रयोग के रूप में देखा जाना चाहिए।
यह दृष्टिकोण क्यों
चुनाव की अनिवार्यता
TAPNext के लेखकों को एक महत्वपूर्ण मोड़ का सामना करना पड़ा जहाँ ट्रैकिंग एनी पॉइंट (TAP) के लिए पारंपरिक अत्याधुनिक (SOTA) विधियाँ मौलिक रूप से अपर्याप्त साबित हुईं। मुख्य अहसास यह था कि मौजूदा TAP दृष्टिकोण "जटिल ट्रैकिंग-विशिष्ट आगमनात्मक पूर्वाग्रहों और अनुमानों" (सार) पर अत्यधिक निर्भर थे। इनमें लागत-आयतन गणना, पुनरावृत्त शोधन, विंडो वाली अनुमान, और स्पष्ट प्रति-फ्रेम उपस्थिति मिलान जैसी तकनीकें शामिल थीं। जबकि इन विधियों ने उचित प्रदर्शन प्राप्त किया, उन्होंने स्वाभाविक रूप से मॉडलों की सामान्यता और मापनीयता को सीमित कर दिया, विशेष रूप से सिंथेटिक से वास्तविक दुनिया के डेटा तक "सिम-टू-रियल गैप" को पाटने का प्रयास करते समय।
इस अहसास का सटीक क्षण इस अवलोकन से उत्पन्न होता है कि ये जटिल, हाथ से तैयार किए गए घटक थे:
1. बहुत प्रतिबंधात्मक: मजबूत आगमनात्मक पूर्वाग्रहों के साथ डिज़ाइन किए गए आर्किटेक्चर ने उन्हें विविध परिदृश्यों में स्केल करने और सामान्य बनाने की उनकी क्षमता को सीमित कर दिया।
2. वास्तव में ऑनलाइन नहीं: कई विधियाँ, यहाँ तक कि ऑनलाइन क्षमताओं का दावा करने वाली भी, अभी भी भविष्य के फ्रेम या बड़े अस्थायी विंडो पर निर्भर करती थीं, जिससे वे रोबोटिक्स जैसे वास्तविक समय अनुप्रयोगों के लिए अनुपयुक्त हो जाती थीं। यह निर्भरता अक्सर लंबी अवधि के अवरोधों के दौरान ट्रैकिंग विफलताओं का कारण बनती थी।
3. अनुमान-संचालित: डिफरेंशिएबल आर्गमैक्स, द्वि-रैखिक इंटरपोलेशन, प्रतिबंधित खोज विंडो, और अन्य विशिष्ट डिजाइन तत्वों की आवश्यकता ने समग्र प्रणाली को जटिल और भंगुर बना दिया।
लेखकों ने निष्कर्ष निकाला कि एक वैचारिक रूप से सरल, अधिक सामान्य आर्किटेक्चर की आवश्यकता थी - एक जो बिंदुओं को ट्रैक करना सीख सके बिना स्पष्ट रूप से यह निर्धारित किए कि गति और उपस्थिति संकेतों का उपयोग कैसे किया जाए। इसने उन्हें TAP को एक "अनुक्रमिक मास्क्ड टोकन डिकोडिंग" समस्या के रूप में तैयार करने के लिए प्रेरित किया, जो अस्थायी प्रसंस्करण के लिए स्टेट-स्पेस मॉडल (SSMs) और स्थानिक प्रसंस्करण के लिए विज़न ट्रांसफॉर्मर (ViTs) जैसे सामान्य-उद्देश्य वाले घटकों का लाभ उठाता है, एक संयोजन जिसे पहले TRecViT [40] में खोजा गया था। इस दृष्टिकोण को पिछले SOTA विधियों में निहित जटिलता, सामान्यता की कमी और खराब मापनीयता की सीमाओं को दूर करने के लिए एकमात्र व्यवहार्य समाधान माना गया।
तुलनात्मक श्रेष्ठता
TAPNext कई प्रमुख पहलुओं में पिछले स्वर्ण मानकों पर गुणात्मक श्रेष्ठता प्रदर्शित करता है, जो केवल प्रदर्शन मेट्रिक्स से परे है:
- उभरते अनुमान: सबसे आश्चर्यजनक लाभों में से एक यह है कि कई व्यापक रूप से उपयोग किए जाने वाले ट्रैकिंग अनुमान (जैसे, गति-क्लस्टर-आधारित ध्यान, निर्देशांक-आधारित रीडआउट, और लागत-आयतन-जैसे ध्यान) "TAPNext में एंड-टू-एंड प्रशिक्षण के माध्यम से स्वाभाविक रूप से उभरते हैं" (सार, चित्र 3)। यह जटिल, हाथ से तैयार किए गए घटकों की आवश्यकता को समाप्त करता है, जिससे मॉडल काफी सरल और अधिक मजबूत हो जाता है।
- उन्नत टेम्पोरल कोहेरेंस और अवरोधन हैंडलिंग: आवर्ती स्थिति आर्किटेक्चर, विशेष रूप से SSMs का उपयोग करके, TAPNext टेम्पोरल कोहेरेंस बनाए रख सकता है और समय के साथ ट्रैक किए गए बिंदुओं की गतिशीलता को प्रभावी ढंग से कैप्चर कर सकता है। यह संरचनात्मक लाभ इसे विंडो-आधारित अनुमान विधियों की तुलना में लंबी अवधि के अवरोधों को बहुत अधिक सटीकता से संभालने की अनुमति देता है, जो बिंदुओं के लंबे समय तक अवरुद्ध होने पर अक्सर विफल हो जाती हैं।
- कम मेमोरी और विलंबता: पत्र TAPNext की दक्षता का सम्मोहक प्रमाण प्रदान करता है। उदाहरण के लिए, TAPNext-B (फ्रेम) लोकोट्रैक-बी (256x256) की तुलना में काफी कम मेमोरी उपयोग (जैसे, 2.1-2.4 जीबी) प्रदर्शित करता है, जो लगभग 30.5 जीबी है (तालिका 2)। इसके अलावा, इसकी विलंबता काफी कम हो जाती है, जो 5.29-5.47 एमएस की सीमा में संचालित होती है, जो कोट्रैकर3 (80-177 एमएस) या लोकोट्रैक-बी (2210-8000 एमएस) से कई गुना तेज है। यह इसे वास्तविक समय अनुप्रयोगों के लिए अत्यधिक श्रेष्ठ बनाता है।
- मापनीयता और सामान्यीकरण: TAPNext को न्यूनतम ट्रैकिंग-विशिष्ट आगमनात्मक पूर्वाग्रहों के साथ डिज़ाइन किया गया है, जिससे यह बेहतर सामान्यीकरण कर सकता है। यह प्रशिक्षण के दौरान देखे गए वीडियो की तुलना में काफी लंबे (5 गुना तक) वीडियो में बिंदुओं को ट्रैक कर सकता है, जो वास्तविक दुनिया के परिदृश्यों के लिए एक महत्वपूर्ण क्षमता है। SSMs की रैखिक पुनरावृत्ति अस्थायी प्रसंस्करण को ऑफ़लाइन सेटिंग में समानांतर करने की अनुमति देती है, जिससे दक्षता और बढ़ जाती है।
- मल्टीमॉडल भविष्यवाणी: पूर्व विधियों के विपरीत जो अक्सर एकल प्रक्षेपवक्र परिकल्पना पर निर्भर करती हैं, TAPNext का निर्देशांक वर्गीकरण हेड मल्टीमॉडल भविष्यवाणियों का प्रतिनिधित्व कर सकता है, जिससे यह अनिश्चितता व्यक्त कर सकता है। यह अस्पष्ट ट्रैकिंग स्थितियों को संभालने में एक गुणात्मक छलांग है।
- सरलता और निष्पक्ष समाधान: मॉडल की वैचारिक सरलता, कुछ हाइपरपैरामीटर और कोई ट्रैकिंग-विशिष्ट आगमनात्मक पूर्वाग्रह नहीं होने के कारण, यह TAP समस्या का एक निष्पक्ष समाधान खोजने की अनुमति देता है, बजाय पूर्व-निर्धारित गति और उपस्थिति की धारणाओं द्वारा बाधित होने के। यह इसे अधिक अनुकूलनीय और संभावित रूप से अधिक शक्तिशाली बनाता है।
बाधाओं के साथ संरेखण
TAP को अनुक्रमिक मास्क्ड टोकन डिकोडिंग के रूप में कास्ट करने का चुना गया दृष्टिकोण, TRecViT के इंटरलीव्ड SSM और ViT ब्लॉक पर निर्मित, समस्या की कठोर आवश्यकताओं के साथ पूरी तरह से संरेखित होता है, जो समस्या और समाधान के बीच एक मजबूत "विवाह" बनाता है।
- ऑनलाइन और कारण ट्रैकिंग: एक प्राथमिक बाधा पूरी तरह से ऑनलाइन और कारण ट्रैकिंग की आवश्यकता थी, जो रोबोटिक्स और वास्तविक समय अनुप्रयोगों के लिए आवश्यक है। TAPNext इसे फ्रेम को क्रमिक रूप से संसाधित करके और SSMs के माध्यम से एक आवर्ती स्थिति बनाए रखकर प्राप्त करता है, यह सुनिश्चित करता है कि वर्तमान फ्रेम के लिए भविष्यवाणियां केवल पिछली जानकारी पर निर्भर करती हैं। यह सीधे कई पूर्व विधियों की सीमा को संबोधित करता है जो भविष्य के फ्रेम पर निर्भर करती हैं।
- न्यूनतम विलंबता: आर्किटेक्चर का डिज़ाइन, विशेष रूप से रैखिक आवर्ती SSMs का उपयोग, न्यूनतम विलंबता को सक्षम बनाता है। यह प्रत्येक फ्रेम का उपभोग करने के तुरंत बाद बिंदु भविष्यवाणियों को आउटपुट करता है, अन्य SOTA ट्रैकर्स में देरी का परिचय देने वाले अस्थायी विंडोइंग या पुनरावृत्त शोधन चरणों से बचता है।
- मापनीयता और सामान्यता: जटिल आगमनात्मक पूर्वाग्रहों से मुक्त, एक मापनीय और सामान्य मॉडल की मांग को TAPNext के ऑफ-द-शेल्फ आर्किटेक्चरल घटकों (SSMs और ViTs) के उपयोग और मास्क्ड डिकोडिंग कार्य के रूप में इसके सूत्रीकरण द्वारा पूरा किया जाता है। यह मॉडल को स्पष्ट, हाथ से तैयार किए गए अनुमानों के बिना ट्रैकिंग सीखने की अनुमति देता है, जिससे यह विविध परिदृश्यों और लंबी वीडियो के लिए अधिक अनुकूलनीय हो जाता है।
- लंबी अवधि के अवरोधों को संभालना: SSM परतों द्वारा बनाए रखी गई आवर्ती स्थिति लंबी अवधि के अवरोधों के दौरान भी टेम्पोरल कोहेरेंस बनाए रखने और बिंदुओं को ट्रैक करने के लिए महत्वपूर्ण है। यह सीधे विंडो-आधारित विधियों की एक महत्वपूर्ण कमजोरी को संबोधित करता है जो बिंदुओं के गायब होने और फिर से दिखाई देने पर संघर्ष करते हैं।
- कम्प्यूटेशनल दक्षता: SSMs की रैखिक पुनरावृत्ति समय के साथ समानांतर अनुमान की अनुमति देती है, जो कम्प्यूटेशनल जटिलता में निषेधात्मक वृद्धि के बिना लंबी वीडियो को संसाधित करने के लिए महत्वपूर्ण है। यह उन विधियों पर एक प्रमुख लाभ है जो विंडो वाली अनुमान या पुनरावृत्त शोधन पर निर्भर करती हैं, जो विस्तारित अनुक्रमों के लिए कम्प्यूटेशनल रूप से महंगी हो सकती हैं।
- अनिश्चितता प्रतिनिधित्व: वर्गीकरण कार्य के रूप में निर्देशांक भविष्यवाणी, मल्टीमॉडल भविष्यवाणियों का प्रतिनिधित्व करने की अनुमति देती है, अनिश्चितता का प्रतिनिधित्व करने की आवश्यकता के साथ संरेखित होती है, एक क्षमता जो अक्सर पूर्व बिंदु-अनुमान-आधारित विधियों में गायब होती है।
विकल्पों का अस्वीकरण
यह पत्र स्पष्ट रूप से और अप्रत्यक्ष रूप से कई लोकप्रिय या पारंपरिक दृष्टिकोणों को अस्वीकार करता है, TAP के संदर्भ में उनकी अंतर्निहित सीमाओं को उजागर करके।
- पारंपरिक SOTA विधियाँ (लागत-आयतन, पुनरावृत्त शोधन, विंडो वाली अनुमान): लेखकों ने स्पष्ट रूप से कहा है कि "TAP के लिए मौजूदा विधियाँ जटिल ट्रैकिंग-विशिष्ट आगमनात्मक पूर्वाग्रहों और अनुमानों पर बहुत अधिक निर्भर करती हैं" (सार)। उन्होंने इन्हें "लागत-आयतन गणना, उसके बाद ट्रैक शोधन [11, 12, 21, 26]," के रूप में विस्तृत किया है, जिसमें "कई अनुमानित डिजाइन तत्व शामिल हैं, जिनमें डिफरेंशिएबल आर्गमैक्स ऑपरेशन [12], सुविधाओं का द्वि-रैखिक इंटरपोलेशन [21], प्रतिबंधित खोज विंडो [9], और विंडो वाली अनुमान [26] शामिल हैं।" इन्हें इसलिए अस्वीकार कर दिया गया क्योंकि वे सामान्यता, मापनीयता को सीमित करते हैं और अक्सर गैर-कारण प्रसंस्करण की आवश्यकता होती है या लंबी अवधि के अवरोधों के दौरान ट्रैकिंग विफलताओं का कारण बनती हैं। TAPNext का लक्ष्य इन "मजबूत आगमनात्मक पूर्वाग्रहों" से बचना और एक "वैचारिक रूप से सरल आर्किटेक्चर" विकसित करना था।
- ऑफ़लाइन/गैर-कारण ट्रैकर्स: कई ट्रैकर्स "वर्तमान फ्रेम के लिए आउटपुट का उत्पादन करने के लिए भविष्य के फ्रेम का उपयोग करने पर निर्भर करते हैं, जिससे वास्तविक समय परिदृश्यों में उनकी प्रयोज्यता सीमित हो जाती है।" यह गैर-कारण प्रकृति लक्षित अनुप्रयोगों के लिए ऑनलाइन ट्रैकिंग की आवश्यकता के विपरीत थी, जिससे उनके अस्वीकरण का कारण बना।
- विंडो-आधारित ऑनलाइन ट्रैकर्स: जबकि कुछ विधियों ने स्थानीय विंडो का उपयोग करके ऑनलाइन क्षमताओं का दावा किया, पत्र नोट करता है कि "बड़े अस्थायी विंडोइंग और केवल लगातार विंडो के बीच बिंदुओं के हस्तांतरण पर उनकी निर्भरता अक्सर ट्रैकिंग विफलताओं का कारण बनती है, खासकर वीडियो के बीच में लंबी अवधि के अवरोधों के दौरान [21, 26]।" लंबी अवधि के ट्रैकिंग बेंचमार्क पर यह खराब प्रदर्शन ऐसे दृष्टिकोणों को एक सच्चे आवर्ती, प्रति-फ्रेम समाधान के पक्ष में अस्वीकार करने के कारण बना।
- टेम्पोरल अटेंशन के साथ मानक ट्रांसफॉर्मर: एक एब्लेशन अध्ययन (तालिका 5) अस्थायी प्रसंस्करण घटक के लिए मानक टेम्पोरल अटेंशन तंत्र (जैसे, मूल ट्रांसफॉर्मर में) का उपयोग करने के स्पष्ट अस्वीकरण प्रदान करता है। जब SSM को टेम्पोरल अटेंशन के लिए स्वैप किया जाता है, तो मॉडल "RoPE [45] टेम्पोरल पोजिशनल एम्बेडिंग का उपयोग करने के बावजूद खराब टेम्पोरल सामान्यीकरण प्रदर्शित करता है, जो समय के साथ सामान्यीकरण के लिए जाना जाता है।" यह इंगित करता है कि ट्रैकिंग में लंबी-श्रेणी की टेम्पोरल कोहेरेंस के विशिष्ट कार्य के लिए, SSMs सामान्य टेम्पोरल अटेंशन की तुलना में एक बेहतर संरचनात्मक लाभ प्रदान करते हैं, जो लंबी अनुक्रमों और सामान्यीकरण के साथ संघर्ष करता है। यह एक महत्वपूर्ण खोज है, जो बताती है कि इस विशेष समस्या के लिए जटिल ध्यान की तुलना में एक सरल पुनरावृत्ति अधिक प्रभावी है।
- एकल-परिकल्पना बिंदु अनुमान: TAPIR और Co-Tracker जैसी पूर्व विधियाँ "प्रति क्वेरी एकल प्रक्षेपवक्र परिकल्पना पर कई शोधन चरण करती हैं, और उस एकल परिकल्पना के आसपास स्थानीय फीचर नमूनाकरण करती हैं।" TAPNext का निर्देशांक वर्गीकरण हेड, जो मल्टीमॉडल भविष्यवाणियों और अनिश्चितता का प्रतिनिधित्व कर सकता है, इस सरल, कम जानकारीपूर्ण दृष्टिकोण को स्पष्ट रूप से अस्वीकार करता है। अनिश्चितता का प्रतिनिधित्व करने की क्षमता एक गुणात्मक लाभ है।
- पुनर्निर्माण के लिए जनरेटिव मॉडल: जबकि पत्र एक पुनर्निर्माण प्रयोग करता है, यह स्पष्ट रूप से कहा गया है कि इसे एक जनरेटिव मॉडल के रूप में नहीं देखा जाना चाहिए, बल्कि एक "रैखिक जांच प्रयोग" के रूप में देखा जाना चाहिए। प्राथमिक लक्ष्य ट्रैकिंग है, न कि छवि निर्माण, और लेखकों ने यह नहीं पाया कि एक छवि पुनर्निर्माण उद्देश्य "ट्रैकिंग प्रदर्शन में सुधार की ओर ले जाता है।" इसका तात्पर्य है कि जबकि टोकन आरोपण के लिए मास्क्ड ऑटोएन्कोडिंग का उपयोग किया जाता है, वीडियो फ्रेम के लिए एक पूर्ण जनरेटिव मॉडल मुख्य ट्रैकिंग कार्य के लिए आवश्यक या फायदेमंद नहीं माना गया था।
 Figure 1. Dense grid tracking with TAPNext. We show (a) the query points on the first frame of the video, (b) the resulting tracks on the final frame of the video for CoTracker3 [27], and (c) our proposed TAPNext method
Figure 1. Dense grid tracking with TAPNext. We show (a) the query points on the first frame of the video, (b) the resulting tracks on the final frame of the video for CoTracker3 [27], and (c) our proposed TAPNext method
गणितीय और तार्किक तंत्र
मास्टर समीकरण
TAPNext का मुख्य तंत्र निर्देशांक भविष्यवाणी (वर्गीकरण और प्रतिगमन दोनों) और दृश्यता भविष्यवाणी को संयोजित करने वाले एक बहु-कार्य हानि फ़ंक्शन द्वारा संचालित होता है। यह हानि TRecViT आर्किटेक्चर की प्रत्येक परत पर लागू होती है, जो मॉडल की गहराई में मजबूत सीखने को सुनिश्चित करती है। समग्र उद्देश्य समय के साथ बिंदु निर्देशांक और उनकी दृश्यता के लिए मॉडल की भविष्यवाणियों और ग्राउंड ट्रुथ के बीच विसंगति को कम करना है।
मास्टर समीकरण, कुल हानि $L_{total}$ का प्रतिनिधित्व करता है जिसे प्रशिक्षण के दौरान कम किया जाता है, इसे इस प्रकार व्यक्त किया जा सकता है:
$$ L_{total} = \frac{1}{L \cdot Q \cdot T} \sum_{l=1}^{L} \sum_{q=1}^{Q} \sum_{t=1}^{T} \left( L_{coord}^{(l)}(t,q) + L_{vis}^{(l)}(t,q) \right) $$
जहाँ $L_{coord}^{(l)}(t,q)$ समय $t$ पर क्वेरी बिंदु $q$ के लिए परत $l$ से निर्देशांक हानि है, और $L_{vis}^{(l)}(t,q)$ उसी बिंदु के लिए दृश्यता हानि है। इन व्यक्तिगत हानियों को आगे इस प्रकार परिभाषित किया गया है:
$$ L_{coord}^{(l)}(t,q) = L_{CE}(p_x^{(l)}(t,q), \text{target_bin}_x) + L_{CE}(p_y^{(l)}(t,q), \text{target_bin}_y) + L_{Huber}((\hat{x}^{(l)}_{t,q}, \hat{y}^{(l)}_{t,q}), (x_{t,q}, y_{t,q})) $$
$$ L_{vis}^{(l)}(t,q) = L_{BCE}(\hat{V}^{(l)}_{t,q}, V_{t,q}) $$
पद-दर-पद विच्छेदन
आइए इन समीकरणों के प्रत्येक घटक को उसके गणितीय परिभाषा और TAPNext ढांचे में उसकी भूमिका को समझने के लिए विच्छेदित करें।
-
$L_{total}$:
- गणितीय परिभाषा: कुल हानि फ़ंक्शन, जो TAPNext के प्रशिक्षण के दौरान कम किए जाने वाले समग्र उद्देश्य का प्रतिनिधित्व करता है। यह सभी परतों, क्वेरी बिंदुओं और समय चरणों में व्यक्तिगत हानियों का औसत योग है।
- भौतिक/तार्किक भूमिका: यह पद पूरे वीडियो अनुक्रम और सभी ट्रैक किए गए बिंदुओं पर मॉडल की भविष्यवाणियों की "गलती" को मापता है। $L_{total}$ को कम करके, मॉडल समय के साथ बिंदुओं की सटीक भविष्यवाणी करना सीखता है। सभी परतों में समान भार (जैसा कि पत्र में कहा गया है) के साथ योग एक रणनीतिक विकल्प है ताकि यह सुनिश्चित किया जा सके कि मध्यवर्ती प्रतिनिधित्व भी सार्थक हों, गहरी परतों में लुप्तप्राय ग्रेडिएंट्स के मुद्दों को रोका जा सके और पूरे नेटवर्क में मजबूत फीचर सीखने को बढ़ावा दिया जा सके। यह डीप सुपरविजन प्रशिक्षण को स्थिर करने और अंतिम प्रदर्शन में सुधार करने में मदद करता है।
- अन्य संक्रियाओं के बजाय योग क्यों? विभिन्न घटकों (निर्देशांक, दृश्यता) और विभिन्न परतों से हानियों को संयोजित करने के लिए योग का उपयोग किया जाता है। यह इंगित करता है कि ये सभी पहलू समग्र कार्य के लिए समान रूप से महत्वपूर्ण हैं, और किसी भी भाग में त्रुटियाँ सीधे कुल त्रुटि में योगदान करती हैं। $L \cdot Q \cdot T$ द्वारा औसत सामान्यीकरण हानि, इसे परतों, क्वेरी या फ्रेम की संख्या से स्वतंत्र बनाता है, जो विभिन्न इनपुट आकारों में स्थिर प्रशिक्षण के लिए महत्वपूर्ण है।
-
$L$:
- गणितीय परिभाषा: TRecViT बैकबोन में इंटरलीव्ड SSM और ViT परतों की कुल संख्या।
- भौतिक/तार्किक भूमिका: मॉडल की प्रसंस्करण पाइपलाइन की गहराई का प्रतिनिधित्व करता है। प्रत्येक परत छवि और बिंदु टोकन के स्थानिक-अस्थायी प्रतिनिधित्व को परिष्कृत करने में योगदान करती है। हानि को प्रत्येक परत पर लागू किया जाता है ताकि यह सुनिश्चित किया जा सके कि विभिन्न अमूर्तता स्तरों पर सुविधाएँ सार्थक हों और अंतिम भविष्यवाणी में योगदान करें, डीप सुपरविजन का एक रूप।
-
$Q$:
- गणितीय परिभाषा: वीडियो में ट्रैक किए जा रहे क्वेरी बिंदुओं की संख्या।
- भौतिक/तार्किक भूमिका: यह उन व्यक्तिगत बिंदुओं की संख्या है जिनकी प्रक्षेपवक्र की भविष्यवाणी करने का मॉडल को कार्य सौंपा गया है। मॉडल को एक साथ और सटीक रूप से कई बिंदुओं को ट्रैक करना सीखने के लिए सभी क्वेरी बिंदुओं पर हानि का योग किया जाता है।
-
$T$:
- गणितीय परिभाषा: वीडियो अनुक्रम में फ्रेमों की कुल संख्या।
- भौतिक/तार्किक भूमिका: वीडियो की अस्थायी सीमा का प्रतिनिधित्व करता है। मॉडल को पूरे वीडियो में बिंदुओं को लगातार ट्रैक करना सुनिश्चित करने के लिए सभी समय चरणों पर हानि का योग किया जाता है, उनकी अस्थायी गतिशीलता को कैप्चर करता है और अवरोधों को संभालता है।
-
$L_{coord}^{(l)}(t,q)$:
- गणितीय परिभाषा: परत $l$ से समय $t$ पर क्वेरी बिंदु $q$ के लिए संयुक्त निर्देशांक हानि। इसमें वर्गीकरण के लिए दो क्रॉस-एन्ट्रॉपी पद और प्रतिगमन के लिए एक हबर हानि पद शामिल है।
- भौतिक/तार्किक भूमिका: यह पद मॉडल को ट्रैक किए गए बिंदु के सटीक $(x,y)$ निर्देशांक की भविष्यवाणी करने के लिए प्रेरित करता है। वर्गीकरण और निरंतर प्रतिगमन दोनों के दोहरे दृष्टिकोण मॉडल को असतत स्थानिक स्थानों और महीन-दानेदार निरंतर पदों दोनों को कैप्चर करने की अनुमति देते हैं। वर्गीकरण पहलू मॉडल को मल्टीमॉडल भविष्यवाणियों और अनिश्चितता का प्रतिनिधित्व करने में मदद करता है, जो उन विधियों पर एक महत्वपूर्ण लाभ है जो केवल एक एकल निरंतर मान आउटपुट करती हैं। पत्र में उल्लेख है कि यह वर्गीकरण निर्देशांक हेड सबसे महत्वपूर्ण घटकों में से एक है।
-
$L_{CE}(p_x^{(l)}(t,q), \text{target_bin}_x)$ और $L_{CE}(p_y^{(l)}(t,q), \text{target_bin}_y)$:
- गणितीय परिभाषा: सॉफ्टमैक्स क्रॉस-एन्ट्रॉपी हानि। किसी दिए गए निर्देशांक (जैसे, x-निर्देशांक) के लिए, $p_x^{(l)}(t,q)$ $n$ असतत डिब्बे के लिए अनुमानित संभावनाओं का वेक्टर है, और $\text{target_bin}_x$ वन-हॉट एन्कोडेड ग्राउंड ट्रुथ बिन है।
$$ L_{CE}(p, \text{target}) = - \sum_{i=1}^{n} \text{target}_i \log(p_i) $$ - भौतिक/तार्किक भूमिका: ये पद निर्देशांक हेड को $x$ और $y$ निर्देशांकों को पूर्वनिर्धारित असतत डिब्बे में वर्गीकृत करने के लिए प्रशिक्षित करते हैं। यह वर्गीकरण दृष्टिकोण, [16] से प्रेरित होकर, महत्वपूर्ण है क्योंकि यह मॉडल को अनिश्चितता व्यक्त करने (जैसे, एक बिंदु कुछ संभावनाओं के साथ कई डिब्बे में हो सकता है) और मल्टीमॉडल भविष्यवाणियों को संभालने की अनुमति देता है, जो उन विधियों पर एक महत्वपूर्ण लाभ है जो केवल एक एकल निरंतर मान की भविष्यवाणी करती हैं।
- गणितीय परिभाषा: सॉफ्टमैक्स क्रॉस-एन्ट्रॉपी हानि। किसी दिए गए निर्देशांक (जैसे, x-निर्देशांक) के लिए, $p_x^{(l)}(t,q)$ $n$ असतत डिब्बे के लिए अनुमानित संभावनाओं का वेक्टर है, और $\text{target_bin}_x$ वन-हॉट एन्कोडेड ग्राउंड ट्रुथ बिन है।
-
$L_{Huber}((\hat{x}^{(l)}_{t,q}, \hat{y}^{(l)}_{t,q}), (x_{t,q}, y_{t,q}))$:
- गणितीय परिभाषा: हबर हानि, निरंतर अनुमानित निर्देशांक $(\hat{x}^{(l)}_{t,q}, \hat{y}^{(l)}_{t,q})$ पर ग्राउंड ट्रुथ निर्देशांक $(x_{t,q}, y_{t,q})$ के विरुद्ध लागू की जाती है। निरंतर निर्देशांक को क्लासिफायर संभावनाओं के अपेक्षित मान से प्राप्त किया जाता है: $\hat{x}^{(l)}_{t,q} = \sum_{i=1}^{n} b_{x,i} \cdot p_x^{(l)}(t,q,i)$ जहाँ $b_{x,i}$ बिन $i$ का केंद्र है।
$$ L_{Huber}(e) = \begin{cases} 0.5 e^2 & \text{यदि } |e| \le \delta \\ \delta (|e| - 0.5 \delta) & \text{यदि } |e| > \delta \end{cases} $$
जहाँ $e$ त्रुटि है (जैसे, $\hat{x} - x$) और $\delta$ एक हाइपरपैरामीटर है। - भौतिक/तार्किक भूमिका: यह पद एक प्रतिगमन हानि के रूप में कार्य करता है, निरंतर निर्देशांक भविष्यवाणियों को ठीक करता है। हबर हानि को एक साधारण L2 (माध्य वर्ग त्रुटि) हानि से अधिक चुना जाता है क्योंकि यह आउटलेर्स के प्रति कम संवेदनशील होता है। बिंदु ट्रैकिंग में, ग्राउंड ट्रुथ एनोटेशन में कभी-कभी मामूली अशुद्धियाँ हो सकती हैं या अवरोधों या तेज गति के कारण बिंदु क्षण भर में अप्रत्याशित स्थानों पर दिखाई दे सकते हैं। हबर हानि छोटे त्रुटियों (जैसे L2) के लिए एक चिकनी ग्रेडिएंट प्रदान करती है लेकिन बड़ी त्रुटियों (जैसे L1) के लिए एक रैखिक ग्रेडिएंट प्रदान करती है, जिससे यह ऐसे शोर के प्रति अधिक मजबूत हो जाता है और बड़ी त्रुटियों को हानि परिदृश्य पर हावी होने से रोकता है।
- गणितीय परिभाषा: हबर हानि, निरंतर अनुमानित निर्देशांक $(\hat{x}^{(l)}_{t,q}, \hat{y}^{(l)}_{t,q})$ पर ग्राउंड ट्रुथ निर्देशांक $(x_{t,q}, y_{t,q})$ के विरुद्ध लागू की जाती है। निरंतर निर्देशांक को क्लासिफायर संभावनाओं के अपेक्षित मान से प्राप्त किया जाता है: $\hat{x}^{(l)}_{t,q} = \sum_{i=1}^{n} b_{x,i} \cdot p_x^{(l)}(t,q,i)$ जहाँ $b_{x,i}$ बिन $i$ का केंद्र है।
-
$L_{vis}^{(l)}(t,q)$:
- गणितीय परिभाषा: परत $l$ से समय $t$ पर क्वेरी बिंदु $q$ के लिए दृश्यता हानि।
- भौतिक/तार्किक भूमिका: यह पद मॉडल को यह भविष्यवाणी करने के लिए प्रेरित करता है कि किसी दिए गए फ्रेम में ट्रैक किया गया बिंदु दिखाई दे रहा है या अवरुद्ध है। वास्तविक दुनिया के परिदृश्यों में जहाँ वस्तुएँ अक्सर दृष्टि से बाहर हो जाती हैं या अस्थायी रूप से छिपी रहती हैं, मजबूत ट्रैकिंग के लिए सटीक दृश्यता भविष्यवाणी महत्वपूर्ण है।
-
$L_{BCE}(\hat{V}^{(l)}_{t,q}, V_{t,q})$:
- गणितीय परिभाषा: सिग्मॉइड बाइनरी क्रॉस-एन्ट्रॉपी हानि। $\hat{V}^{(l)}_{t,q}$ दृश्यता की अनुमानित संभावना है (0 और 1 के बीच एक स्केलर), और $V_{t,q}$ बाइनरी ग्राउंड ट्रुथ है (0 अवरुद्ध के लिए, 1 दृश्यमान के लिए)।
$$ L_{BCE}(\hat{v}, v) = - (v \log(\hat{v}) + (1-v) \log(1-\hat{v})) $$ - भौतिक/तार्किक भूमिका: यह पद दृश्यता हेड को बाइनरी वर्गीकरण करने के लिए प्रशिक्षित करता है। यह मॉडल को दंडित करता है जब यह किसी बिंदु की दृश्यता स्थिति की गलत भविष्यवाणी करता है। सिग्मॉइड सक्रियण आउटपुट को एक संभावना सुनिश्चित करता है, और बाइनरी क्रॉस-एन्ट्रॉपी ऐसे दो-वर्ग समस्याओं के लिए मानक हानि है। मॉडल अनिश्चितता अनुमान का भी उपयोग करता है: यदि निर्देशांक के लिए 50% से अधिक संभाव्यता द्रव्यमान 8-पिक्सेल त्रिज्या के बाहर स्थित है, तो बिंदु को अवरुद्ध के रूप में चिह्नित किया जाता है, जो निर्देशांक अनिश्चितता और दृश्यता के बीच एक प्राकृतिक संबंध प्रदान करता है।
- गणितीय परिभाषा: सिग्मॉइड बाइनरी क्रॉस-एन्ट्रॉपी हानि। $\hat{V}^{(l)}_{t,q}$ दृश्यता की अनुमानित संभावना है (0 और 1 के बीच एक स्केलर), और $V_{t,q}$ बाइनरी ग्राउंड ट्रुथ है (0 अवरुद्ध के लिए, 1 दृश्यमान के लिए)।
चरण-दर-चरण प्रवाह
एक एकल अमूर्त डेटा बिंदु की कल्पना करें, जैसे कि एक चलती कार पर एक विशिष्ट पिक्सेल, जिसे हम एक वीडियो के माध्यम से ट्रैक करना चाहते हैं। यहाँ गणितीय इंजन TAPNext के माध्यम से इसकी यात्रा है:
-
इनपुट और टोकनाइजेशन:
- यात्रा एक वीडियो के साथ शुरू होती है, जो $T$ RGB फ्रेमों का एक अनुक्रम है, और $Q$ प्रारंभिक क्वेरी बिंदुओं का एक सेट है, प्रत्येक को उसके प्रारंभिक समय और $(x,y)$ निर्देशांकों द्वारा परिभाषित किया गया है।
- प्रत्येक वीडियो फ्रेम को पहले $h \times w$ गैर-ओवरलैपिंग छवि पैच के ग्रिड में विभाजित किया जाता है। इन पैच को फिर एक $C$-आयामी फीचर स्पेस में रैखिक रूप से प्रोजेक्ट किया जाता है, और स्थानिक स्थितिगत एम्बेडिंग जोड़े जाते हैं। यह कच्चे छवि डेटा को स्थितिगत एम्बेडिंग के साथ "छवि टोकन" के अनुक्रम में बदल देता है जिसका आकार $[T, h \times w, C]$ होता है।
- साथ ही, हमारे विशिष्ट क्वेरी बिंदु (और अन्य सभी के लिए), $T$ "पॉइंट ट्रैक टोकन" का एक अनुक्रम बनाया जाता है। जिस फ्रेम में हमारा बिंदु शुरू में क्वेरी किया गया है, उसके टोकन को उसके $(x,y)$ निर्देशांकों के अनुरूप स्थितिगत एम्बेडिंग के साथ इनिशियलाइज़ किया जाता है। सभी अन्य फ्रेमों के लिए, इसके टोकन को एक विशेष "मास्क टोकन" मान के साथ इनिशियलाइज़ किया जाता है, जो दर्शाता है कि इसकी स्थिति अज्ञात है और भविष्यवाणी की जानी है। इन बिंदु टोकन का आकार भी $[T, Q, C]$ होता है।
-
इनपुट टेंसर असेंबली:
- छवि टोकन और पॉइंट ट्रैक टोकन को फिर स्थानिक आयाम के साथ जोड़ा जाता है। यह $[T, h \times w + Q, C]$ आकार का एक एकीकृत "इनपुट टोकन टेंसर" बनाता है। इस टेंसर में अब सभी जानकारी होती है: वीडियो की दृश्य सामग्री और क्वेरी बिंदु जानकारी, ट्रैक किए जाने वाले फ्रेम के लिए मास्क्ड स्थितियों के साथ।
-
स्तरित स्थानिक-अस्थायी प्रसंस्करण (TRecViT):
- यह संयुक्त इनपुट टेंसर फिर TRecViT बैकबोन में प्रवेश करता है, जो $L$ इंटरलीव्ड परतों से बना होता है। प्रत्येक परत एक दो-चरणीय प्रक्रिया है:
- SSM ब्लॉक (अस्थायी प्रसंस्करण): पहले, डेटा स्टेट-स्पेस मॉडल (SSM) ब्लॉक से गुजरता है। यह ब्लॉक अस्थायी आयाम ($T$) पर रैखिक पुनरावृत्ति करता है। यह संयुक्त स्थानिक आयाम ($h \times w + Q$) को एक बैच के रूप में मानता है। वैचारिक रूप से, यह समय के माध्यम से चलने वाली एक कन्वेयर बेल्ट की तरह है। SSM ब्लॉक पिछले फ्रेम से वर्तमान और भविष्य के फ्रेम तक कुशलतापूर्वक जानकारी प्रसारित करता है, जिससे मॉडल को बिंदु के प्रक्षेपवक्र और उपस्थिति की "स्मृति" बनाए रखने की अनुमति मिलती है। यह अवरोधों के माध्यम से और लंबी अवधि में ट्रैक करने के लिए महत्वपूर्ण है।
- ViT ब्लॉक (स्थानिक प्रसंस्करण): इसके बाद, SSM ब्लॉक का आउटपुट विज़न ट्रांसफॉर्मर (ViT) ब्लॉक में प्रवेश करता है। यह ब्लॉक प्रत्येक फ्रेम के भीतर सभी $h \times w + Q$ टोकन पर पूर्ण स्व-ध्यान (self-attention) करता है, समय आयाम ($T$) को एक बैच के रूप में मानता है। यहीं पर मॉडल एक एकल फ्रेम के भीतर "चारों ओर देखता है", जिससे छवि टोकन बिंदु टोकन पर ध्यान केंद्रित कर सकते हैं, और बिंदु टोकन एक-दूसरे पर और छवि टोकन पर ध्यान केंद्रित कर सकते हैं। यह स्थानिक मिश्रण मॉडल को बिंदु की स्थिति को उसके आसपास के सापेक्ष पहचानने और दृश्य संकेतों को एकीकृत करने में मदद करता है।
- यह दो-चरणीय प्रक्रिया (SSM फिर ViT) सभी $L$ परतों के लिए दोहराई जाती है, जो हमारे अमूर्त डेटा बिंदु के स्थानिक-अस्थायी प्रतिनिधित्व को लगातार परिष्कृत करती है।
- यह संयुक्त इनपुट टेंसर फिर TRecViT बैकबोन में प्रवेश करता है, जो $L$ इंटरलीव्ड परतों से बना होता है। प्रत्येक परत एक दो-चरणीय प्रक्रिया है:
-
भविष्यवाणी हेड:
- प्रत्येक परत $l$ से गुजरने के बाद, मॉडल $T \times Q$ ट्रैक टोकन का एक सेट आउटपुट करता है। इन टोकन को फिर दो अलग-अलग भविष्यवाणी हेड में फीड किया जाता है:
- निर्देशांक हेड (MLP): एक MLP (मल्टी-लेयर परसेप्ट्रॉन) प्रत्येक समय चरण में हमारे बिंदु के लिए ट्रैक टोकन लेता है। यह पहले $x$ और $y$ निर्देशांकों दोनों के लिए $n$ असतत डिब्बे के लिए संभावनाओं की भविष्यवाणी करता है। फिर, यह इन संभावनाओं से भारित करके अपेक्षित निरंतर $(x,y)$ निर्देशांक की गणना करता है।
- दृश्यता हेड (MLP): एक अन्य MLP उसी ट्रैक टोकन को लेता है और उस फ्रेम में हमारे बिंदु दिखाई दे रहा है या अवरुद्ध है, यह इंगित करने वाली एक बाइनरी संभावना की भविष्यवाणी करता है।
- प्रत्येक परत $l$ से गुजरने के बाद, मॉडल $T \times Q$ ट्रैक टोकन का एक सेट आउटपुट करता है। इन टोकन को फिर दो अलग-अलग भविष्यवाणी हेड में फीड किया जाता है:
-
हानि गणना और बैकप्रॉपैगेशन:
- प्रत्येक परत $l$, और प्रत्येक समय चरण $t$ और क्वेरी बिंदु $q$ के लिए, अनुमानित निर्देशांक $(\hat{x}^{(l)}_{t,q}, \hat{y}^{(l)}_{t,q})$ और दृश्यता $\hat{V}^{(l)}_{t,q}$ की तुलना ग्राउंड ट्रुथ $(x_{t,q}, y_{t,q})$ और $V_{t,q}$ से की जाती है।
- निर्देशांक हानि $L_{coord}^{(l)}(t,q)$ की गणना असतत बिन वर्गीकरण के लिए सॉफ्टमैक्स क्रॉस-एन्ट्रॉपी और निरंतर प्रतिगमन के लिए हबर हानि दोनों का उपयोग करके की जाती है।
- दृश्यता हानि $L_{vis}^{(l)}(t,q)$ की गणना सिग्मॉइड बाइनरी क्रॉस-एन्ट्रॉपी का उपयोग करके की जाती है।
- इन व्यक्तिगत हानियों को $L_{total}$ बनाने के लिए जोड़ा जाता है। इस कुल हानि का उपयोग फिर ग्रेडिएंट की गणना करने के लिए किया जाता है, जो पूरे नेटवर्क में मॉडल के मापदंडों को अपडेट करने के लिए वापस प्रचारित (backpropagated) किया जाता है। फॉरवर्ड पास, हानि गणना और बैकप्रॉपैगेशन की यह पुनरावृत्त प्रक्रिया मॉडल को अपनी ट्रैकिंग क्षमताओं को सीखने और सुधारने की अनुमति देती है।
अनुकूलन गतिकी
TAPNext तंत्र एक परिष्कृत एंड-टू-एंड पर्यवेक्षित प्रशिक्षण प्रक्रिया के माध्यम से सीखता है, अपडेट करता है और अभिसरण करता है, जो मुख्य रूप से बहु-घटक हानि फ़ंक्शन और आर्किटेक्चरल डिजाइन विकल्पों द्वारा संचालित होता है।
-
ग्रेडिएंट प्रवाह और डीप सुपरविजन: कुल हानि $L_{total}$ प्रत्येक परत $l$, प्रत्येक क्वेरी बिंदु $q$, और प्रत्येक समय चरण $t$ से हानियों का योग है। यह "डीप सुपरविजन" रणनीति सुनिश्चित करती है कि ग्रेडिएंट्स पूरे नेटवर्क में प्रभावी ढंग से प्रवाहित हों, अंतिम भविष्यवाणी हेड से लेकर प्रारंभिक परतों तक। प्रत्येक परत पर समान भार के साथ हानियों को लागू करके, मॉडल को अमूर्तता के कई स्तरों पर सार्थक और सटीक प्रतिनिधित्व सीखने के लिए प्रोत्साहित किया जाता है। यह बहुत गहरे नेटवर्क में आम लुप्तप्राय या विस्फोट करने वाले ग्रेडिएंट्स जैसी समस्याओं को कम करने में मदद करता है, और यह सुनिश्चित करता है कि मध्यवर्ती सुविधाएँ भी भविष्य कहनेवाला हों, जिससे एक अधिक मजबूत और स्थिर सीखने की प्रक्रिया होती है।
-
हानि परिदृश्य आकारण (निर्देशांक भविष्यवाणी): निर्देशांक भविष्यवाणी हेड एक महत्वपूर्ण नवाचार है, जो वर्गीकरण और प्रतिगमन दोनों को जोड़ता है।
- वर्गीकरण (सॉफ्टमैक्स क्रॉस-एन्ट्रॉपी): निर्देशांकों को $n$ डिब्बे में विभाजित करना और सॉफ्टमैक्स क्रॉस-एन्ट्रॉपी हानि का उपयोग करना हानि परिदृश्य को मल्टीमॉडल भविष्यवाणियों की अनुमति देने के लिए आकार देता है। यदि किसी बिंदु का वास्तविक स्थान अस्पष्ट है (जैसे, अवरोधन या गति धुंधलापन के कारण), तो मॉडल कई डिब्बे में संभावनाएँ निर्दिष्ट कर सकता है, बजाय इसके कि वह एकल, संभावित रूप से गलत, निरंतर मान के लिए प्रतिबद्ध हो। यह अनिश्चित परिदृश्यों में हानि परिदृश्य को चिकना और अधिक क्षमाशील बनाता है, क्योंकि मॉडल को थोड़ा सा गलत होने के लिए भारी दंडित नहीं किया जाता है यदि वह अभी भी बिंदु के सामान्य क्षेत्र को कैप्चर करता है।
- प्रतिगमन (हबर हानि): निरंतर निर्देशांकों पर हबर हानि एक मजबूत प्रतिगमन संकेत प्रदान करती है। छोटी त्रुटियों के लिए, यह L2 हानि की तरह व्यवहार करती है, निर्देशांकों को सटीक रूप से इंगित करने के लिए एक मजबूत ग्रेडिएंट प्रदान करती है। बड़ी त्रुटियों के लिए, यह L1-जैसी व्यवहार में परिवर्तित हो जाती है, जिससे यह आउटलेर्स या चरम भविष्यवाणी त्रुटियों के प्रति कम संवेदनशील हो जाती है। यह कुछ कठिन-से-ट्रैक बिंदुओं को हानि पर हावी होने और मॉडल के सीखने को उनके प्रति झुकाने से रोकता है, इस प्रकार एक अधिक स्थिर हानि परिदृश्य को आकार देता है।
-
टेम्पोरल कोहेरेंस और पुनरावृत्ति (SSM): आवर्ती SSM ब्लॉक मॉडल द्वारा समय के साथ अपनी आंतरिक स्थिति को अपडेट करने के तरीके के लिए मौलिक हैं। प्रशिक्षण के दौरान, SSM पिछले फ्रेम से वर्तमान फ्रेम तक प्रासंगिक जानकारी प्रसारित करना सीखता है। यह मॉडल को टेम्पोरल कोहेरेंस बनाए रखने और बिंदुओं को ट्रैक करने की अनुमति देता है, भले ही वे विस्तारित अवधि के लिए अवरुद्ध हों। SSM परतों के माध्यम से प्रवाहित होने वाले ग्रेडिएंट्स मॉडल को सिखाते हैं कि कौन सी जानकारी याद रखनी है और भविष्य की स्थितियों की भविष्यवाणी करने के लिए इसे कैसे रूपांतरित करना है। पत्र में लंबी वीडियो क्षरण के लिए आंशिक शमन का उल्लेख किया गया है "एसएसएम में फॉरगेट गेट को 0.0 और 0.1 के बीच क्लिप करके, और क्वेरी फीचर्स को वीडियो टोकन की लंबाई में प्रसारित करके"। यह बहुत लंबी अनुक्रमों पर जानकारी को बनाए रखने और प्रसारित करने की SSM की क्षमता को बेहतर बनाने के लिए SSM की आंतरिक गतिशीलता में एक विशिष्ट समायोजन है, जिससे स्थिति का क्षय या अप्रासंगिक होना रोका जा सके।
-
स्थानिक इंटरैक्शन (ViT अटेंशन): ViT ब्लॉक, अपने पूर्ण स्व-ध्यान तंत्र के साथ, मॉडल को जटिल स्थानिक संबंधों को सीखने में सक्षम बनाते हैं। ध्यान तंत्र के माध्यम से प्रवाहित होने वाले ग्रेडिएंट्स मॉडल को सिखाते हैं कि किसी विशेष बिंदु के प्रतिनिधित्व को अपडेट करते समय विभिन्न छवि पैच और अन्य बिंदु टोकन के महत्व को कैसे भारित किया जाए। यह मॉडल को विभिन्न ट्रैकिंग अनुमानों को स्वाभाविक रूप से सीखने की अनुमति देता है, जैसे "लागत-आयतन-जैसे ध्यान" (उपस्थिति मिलान), "निर्देशांक-आधारित रीडआउट" (स्थानिक संदर्भ का उपयोग करना), और "गति-क्लस्टर-आधारित रीडआउट" (चलती वस्तुओं को समूहित करना), बिना इन्हें स्पष्ट रूप से इसके आर्किटेक्चर में इंजीनियर किए। ये उभरते व्यवहार एंड-टू-एंड सीखने की शक्ति को प्रदर्शित करते हैं जो मॉडल के आंतरिक तर्क को आकार देते हैं।
-
BootsTAP (शिक्षक-छात्र सीखना): वास्तविक डेटा पर फाइन-ट्यूनिंग के लिए, TAPNext एक शिक्षक-छात्र सेटअप का उपयोग करता है जिसे BootsTAP कहा जाता है। 'शिक्षक' मॉडल, 'छात्र' के भार का एक घातीय मूविंग एवरेज, अदूषित, पूर्ण-रिज़ॉल्यूशन वास्तविक वीडियो पर स्थिर छद्म-लेबल प्रदान करता है। 'छात्र' TAPNext मॉडल तब इन छद्म-लेबल से सीखता है, लेकिन वीडियो के एफाइन-रूपांतरित और दूषित संस्करणों पर। हानि केवल छात्र को वापस प्रचारित की जाती है। यह तंत्र मॉडल को सामान्य वास्तविक दुनिया के भ्रष्टाचारों और एफाइन परिवर्तनों के प्रति अपरिवर्तनीय एक मजबूत समाधान में अभिसरण करने में मदद करता है, प्रभावी ढंग से सिम-टू-रियल गैप को पालता है और जटिल आगमनात्मक पूर्वाग्रहों पर निर्भर किए बिना सामान्यीकरण में सुधार करता है। शिक्षक की स्थिरता छात्र को छद्म-लेबल पर ढहने या ओवरफिट होने से रोकती है।
संक्षेप में, TAPNext एक सावधानीपूर्वक डिज़ाइन किए गए हानि फ़ंक्शन के माध्यम से अपने स्थानिक-अस्थायी प्रतिनिधित्व और भविष्यवाणी हेड को पुनरावृत्त रूप से परिष्कृत करके अभिसरण करता है जो सटीक स्थानीयकरण और मजबूत दृश्यता अनुमान दोनों को प्रोत्साहित करता है, जबकि इसके आवर्ती और ध्यान तंत्र समय और स्थान में जानकारी को अनुकूल रूप से प्रसारित और एकीकृत करना सीखते हैं। दोहरी निर्देशांक हानि और BootsTAP रणनीति एक लचीला और सटीक मॉडल को आकार देने के लिए महत्वपूर्ण हैं।
परिणाम, सीमाएँ और निष्कर्ष
प्रयोगात्मक डिजाइन और बेसलाइन
TAPNext के गणितीय दावों को कठोरता से मान्य करने और इसकी श्रेष्ठता प्रदर्शित करने के लिए, लेखकों ने एक व्यापक प्रयोगात्मक सेटअप तैयार किया। प्रशिक्षण और मूल्यांकन दोनों के लिए प्राथमिक बेंचमार्क TAP-Vid [11] का उपयोग किया गया था, जिसमें Kubric द्वारा उत्पन्न सिंथेटिक डेटा और दो मानव-लेबल वाले मूल्यांकन डेटासेट शामिल थे: DAVIS (30 वीडियो, 24 से 105 फ्रेम) और Kinetics (1150 वीडियो, 250 फ्रेम)।
उनकी प्रशिक्षण रणनीति का एक प्रमुख पहलू पिछले कार्यों की तुलना में काफी बड़े सिंथेटिक डेटासेट का उपयोग था, जिसमें 500,000 वीडियो शामिल थे, प्रत्येक 48 फ्रेम लंबा, और कैमरा पैनिंग और गति धुंधलापन जैसे चुनौतीपूर्ण तत्वों को शामिल किया गया था। वास्तविक दुनिया के फाइन-ट्यूनिंग के लिए, BootsTAPNext मॉडल ने इंटरनेट से 15 मिलियन वीडियो क्लिप का लाभ उठाया, जो 48 फ्रेम लंबा भी था, BootsTAP [13] स्व-पर्यवेक्षित प्रशिक्षण योजना का पालन करते हुए। इसमें सिंथेटिक डेटा पर 300,000 चरणों का प्रारंभिक प्रशिक्षण, उसके बाद वास्तविक वीडियो पर 1,500 चरणों का स्व-पर्यवेक्षित प्रशिक्षण शामिल था। मॉडल को 256 x 256 के रिज़ॉल्यूशन पर प्रशिक्षित किया गया था, जिसमें 256 वीडियो के बैच का उपयोग किया गया था, जिसमें 256 पॉइंट क्वेरी थे। दो मॉडल वेरिएंट विकसित किए गए: TAPNext-S (56M पैरामीटर) और TAPNext-B (194M पैरामीटर), क्रमशः $10^{-3}$ और $5 \times 10^{-4}$ की अलग-अलग पीक लर्निंग रेट के साथ, एक कोसाइन क्षय अनुसूची के तहत।
अनुमान के लिए, TAPNext मॉडल का मूल्यांकन 256 x 256 रिज़ॉल्यूशन पर किया गया था। लेखकों ने एक क्वेरी-स्ट्राइडेड मूल्यांकन का उपयोग किया, वीडियो को प्रत्येक क्वेरी बिंदु से आगे और पीछे दोनों तरफ चलाया, और एक समय में एक क्वेरी बिंदु को ट्रैक किया, बेहतर प्रदर्शन के लिए CoTracker [26] के समान स्थानीय और वैश्विक समर्थन बिंदुओं को शामिल किया।
जिसके विरुद्ध TAPNext की कठोरता से तुलना की गई, वह बेसलाइन मॉडल थे, जिन्हें उनकी विलंबता विशेषताओं के अनुसार वर्गीकृत किया गया था:
- फ्रेम-विलंबता विधियाँ: TAPNet [11], ऑनलाइन TAPIR [53], ऑनलाइन BootsTAP [13], Track-On [1]। ये मॉडल प्रत्येक फ्रेम का उपभोग करने के तुरंत बाद भविष्यवाणियां आउटपुट करते हैं।
- विंडो वाली-अनुमान विधियाँ: TAPIR [12], BootsTAP [13], TAPTR [34], TAPTRv2 [33], TAPTRv3 [41], PIPs [21], CoTracker2 [26], CoTracker3 [27]। इन्हें ट्रैक आउटपुट करने से पहले फ्रेम के एक टुकड़े (आमतौर पर $T=8$) की आवश्यकता होती है।
- वीडियो-विलंबता विधियाँ: OmniMotion [55], Dino-Tracker [51], LocoTrack-B [9]। इन मॉडलों को पॉइंट ट्रैक उत्पन्न करने से पहले पूरे वीडियो को इनपुट के रूप में आवश्यक होता है।
TAPNext के मुख्य तंत्र के लिए निश्चित प्रमाण तीन मानक मेट्रिक्स का उपयोग करके मापा गया था:
1. अवरोधन सटीकता (OA): एक बिंदु दिखाई दे रहा है या नहीं, इसका वर्गीकरण करने की सटीकता।
2. निर्देशांक सटीकता (davg): ग्राउंड ट्रुथ से 1, 2, 4, 8, और 16 पिक्सेल की सीमाओं के भीतर अनुमानित निर्देशांक वाले बिंदुओं का औसत अंश।
3. औसत जकार्ड: अवरोधन और निर्देशांक सटीकता का एक संयुक्त माप।
साक्ष्य क्या साबित करते हैं
प्रायोगिक परिणाम निर्विवाद प्रमाण प्रदान करते हैं कि TAPNext का मुख्य तंत्र—ट्रैकिंग एनी पॉइंट (TAP) को अनुक्रमिक मास्क्ड टोकन डिकोडिंग के रूप में स्टेट-स्पेस मॉडल (SSMs) के साथ एक सरल आवर्ती आर्किटेक्चर के रूप में तैयार करना—अत्यधिक प्रभावी है। जैसा कि तालिका 1 में दिखाया गया है, TAPNext TAP-Vid बेंचमार्क पर आठ में से बारह रिपोर्ट किए गए मेट्रिक्स में एक नया अत्याधुनिक ट्रैकिंग प्रदर्शन प्राप्त करता है, अक्सर अन्य ऑनलाइन (1-फ्रेम-विलंबता) विधियों पर महत्वपूर्ण मार्जिन के साथ। यह विशेष रूप से प्रभावशाली है, यह देखते हुए कि TAPNext न्यूनतम विलंबता के साथ संचालित होता है, जिससे यह रोबोटिक्स जैसे वास्तविक समय अनुप्रयोगों के लिए उपयुक्त हो जाता है।
एक महत्वपूर्ण खोज यह है कि TAPNext यह जटिल, ट्रैकिंग-विशिष्ट आगमनात्मक पूर्वाग्रहों या अनुमानों पर निर्भर किए बिना प्राप्त करता है जो पहले के अत्याधुनिक तरीकों में आम थे। यह पुनरावृत्त या विंडो वाली अनुमान, परीक्षण-समय अनुकूलन, लागत मात्रा, फीचर इंटरपोलेशन, टोकन फीचर इंजीनियरिंग, और स्थानीय खोज विंडो को छोड़ देता है। इसके बजाय, मॉडल की सरलता, स्टेट-स्पेस मॉडल (SSMs) और विज़न ट्रांसफॉर्मर (ViTs) जैसे ओपन-सोर्स आर्किटेक्चरल घटकों पर निर्मित, इसे एक बड़े सिंथेटिक डेटासेट पर एंड-टू-एंड प्रशिक्षण के माध्यम से स्वाभाविक रूप से इन अनुमानों को सीखने की अनुमति देती है। ध्यान मानचित्रों के विज़ुअलाइज़ेशन (चित्र 3 और 4) पुष्टि करते हैं कि TAPNext स्वाभाविक रूप से लागत-आयतन-जैसे उपस्थिति मिलान, निर्देशांक-आधारित रीडआउट, और गति-क्लस्टर-आधारित रीडआउट हेड के समान ध्यान पैटर्न विकसित करता है - ऐसे तंत्र जिन्हें इसके आर्किटेक्चर में स्पष्ट रूप से प्रोग्राम नहीं किया गया था।
इसके अलावा, TAPNext उल्लेखनीय सामान्यीकरण क्षमताएं प्रदर्शित करता है। 48-फ्रेम वीडियो पर प्रशिक्षित होने के बावजूद, यह पांच गुना लंबे वीडियो (जैसे, किनेटिक्स डेटासेट में 250-फ्रेम वीडियो) में बिंदुओं को सफलतापूर्वक ट्रैक करता है। यह मजबूत टेम्पोरल सामान्यीकरण इसके SSM परतों की आवर्ती प्रकृति के लिए जिम्मेदार है, जो बिंदुओं को कारण रूप से ऑनलाइन संसाधित करते हैं और लंबी अवधि के अवरोधों के दौरान भी टेम्पोरल कोहेरेंस बनाए रखते हैं। एब्लेशन अध्ययन (तालिका 4) वर्गीकरण निर्देशांक हेड की महत्वपूर्ण भूमिका को उजागर करते हैं, जो वर्गीकरण और प्रतिगमन दोनों हानि का उपयोग करता है, और 8x8 पिक्सेल छवि पैच आकार का चुनाव। अस्थायी प्रसंस्करण के लिए SSMs की श्रेष्ठता को तालिका 5 द्वारा और रेखांकित किया गया है, जो दिखाता है कि SSMs को टेम्पोरल अटेंशन से बदलने से खराब टेम्पोरल सामान्यीकरण होता है, भले ही उन्नत पोजिशनल एम्बेडिंग का उपयोग किया गया हो।
दक्षता के मामले में, तालिका 2 निश्चित रूप से TAPNext के लाभ को साबित करती है। यह विंडो वाली अनुमान के साथ सर्वोत्तम ट्रैकिंग गति और प्रति-फ्रेम अनुमान के साथ सबसे कम विलंबता प्राप्त करता है, जबकि CoTracker3 और LocoTrack-B जैसे बेसलाइन की तुलना में सबसे कम मेमोरी की खपत भी करता है। गुणात्मक परिणाम, जैसा कि लेखकों द्वारा वर्णित है, इन निष्कर्षों को और मजबूत करते हैं, TAPNext की अवरोधों, तेज गति को संभालने और पतली/छोटी, बनावट-रहित वस्तुओं को प्रतिस्पर्धियों की तुलना में अधिक सटीकता से ट्रैक करने की क्षमता दिखाते हैं। ट्रैक किए गए क्षेत्रों के लिए दृश्य सूचना को सटीक रूप से प्रसारित करने की मॉडल की क्षमता, भले ही अवरुद्ध हो, यह बताती है कि SSM परतें समय के साथ उपस्थिति जानकारी को प्रभावी ढंग से एन्कोड और प्रसारित करती हैं।
सीमाएँ और भविष्य की दिशाएँ
जबकि TAPNext बिंदु ट्रैकिंग में एक महत्वपूर्ण छलांग का प्रतिनिधित्व करता है, पत्र स्पष्ट रूप से एक उल्लेखनीय सीमा को स्वीकार करता है: "150 फ्रेम से अधिक वीडियो की पूरी लंबाई में लंबी अवधि के बिंदु ट्रैकिंग में महत्वपूर्ण विफलता।" यह समस्या मुख्य रूप से स्टेट-स्पेस मॉडल की वर्तमान अक्षमता के कारण है जो उस 48 फ्रेम की तुलना में काफी लंबे वीडियो क्लिप के लिए प्रभावी ढंग से सामान्यीकरण नहीं कर पाता है जिस पर इसे प्रशिक्षित किया गया था। यद्यपि SSM में फॉरगेट गेट को क्लिप करके और क्वेरी फीचर्स को प्रसारित करके एक आंशिक शमन पाया गया था, यह सुधार के लिए एक प्रमुख क्षेत्र बना हुआ है। SSMs में इस सीमा को संबोधित करना TAPNext के पहले से ही मजबूत ट्रैकिंग प्रदर्शन को और बढ़ाने के लिए एक बड़ा अवसर प्रस्तुत करता है।
आगे देखते हुए, TAPNext से प्राप्त निष्कर्ष कई रोमांचक चर्चा विषयों और भविष्य के शोध के लिए रास्ते खोलते हैं:
-
चरम टेम्पोरल सामान्यीकरण के लिए SSMs को आगे बढ़ाना: 150 फ्रेम से अधिक वीडियो के साथ वर्तमान सीमा बताती है कि गिरावट के बिना मनमाने ढंग से लंबे अनुक्रमों को संभालने वाले उपन्यास SSM आर्किटेक्चर या प्रशिक्षण पद्धतियों की आवश्यकता है। क्या पदानुक्रमित SSMs या अनुकूली पुनरावृत्ति तंत्र विकसित किए जा सकते हैं जो लंबी दूरी की निर्भरताओं को बेहतर ढंग से प्रबंधित कर सकें? क्या होगा यदि हम वीडियो की लंबाई के साथ स्केल करने के लिए SSMs के भीतर गतिशील मेमोरी आवंटन का पता लगाएं?
-
"नेक्स्ट टोकन प्रेडिक्शन" प्रतिमान का विस्तार: पत्र प्रस्तावित करता है कि TAPNext ढांचा, जो TAP को नेक्स्ट टोकन प्रेडिक्शन के रूप में कास्ट करता है, "वीडियो में कई अन्य कंप्यूटर विज़न कार्यों के लिए विस्तारित किया जा सकता है।" यह एक गहरा बयान है। इस प्रतिमान को ऑब्जेक्ट डिटेक्शन, सेगमेंटेशन, या यहां तक कि वीडियो जनरेशन जैसे कार्यों के लिए कैसे अनुकूलित किया जा सकता है, जहां टेम्पोरल कोहेरेंस और बिंदु-स्तरीय समझ महत्वपूर्ण है? क्या इस दृष्टिकोण से एक एकीकृत वीडियो फाउंडेशन मॉडल उभर सकता है?
-
उभरते अनुमानों की समझ को गहरा करना: यह अवलोकन कि जटिल ट्रैकिंग अनुमान (गति, निर्देशांक, उपस्थिति मिलान) एंड-टू-एंड प्रशिक्षण से स्वाभाविक रूप से उभरते हैं, आकर्षक है। भविष्य का काम इस बात की गहरी जांच कर सकता है कि ये अनुमान क्यों और कैसे उभरते हैं। क्या हम ऐसे उभरते गुणों के परिणामस्वरूप होने वाले आंतरिक तंत्रों को बेहतर ढंग से समझने के लिए प्रयोग या व्याख्यात्मक उपकरण डिजाइन कर सकते हैं? यह और भी सामान्य-उद्देश्य वाले और कम पक्षपाती आर्किटेक्चर के डिजाइन को सूचित कर सकता है।
-
निर्देशांक हेड और अनिश्चितता अनुमान का अनुकूलन: वर्गीकरण निर्देशांक हेड को TAPNext के सबसे महत्वपूर्ण घटकों में से एक के रूप में पहचाना गया है। इसके मापदंडों में आगे का शोध, विशेष रूप से मल्टीमॉडल भविष्यवाणियों का प्रतिनिधित्व करने और असतत डिब्बे से निरंतर निर्देशांक आउटपुट को परिष्कृत करने के लिए, महत्वपूर्ण लाभ प्रदान कर सकता है। इसके अतिरिक्त, मॉडल की अंतर्निहित अनिश्चितता अनुमान को बढ़ाना, शायद अधिक परिष्कृत संभाव्य मॉडलिंग को एकीकृत करके, चुनौतीपूर्ण परिदृश्यों में मजबूती में सुधार कर सकता है।
-
ओपन-सोर्स योगदानों का लाभ उठाना: अनुमान कोड और मॉडल भार को तुरंत ओपन-सोर्स करने के लेखकों की प्रतिबद्धता, प्रशिक्षण कोड के लिए योजनाओं के साथ, एक महत्वपूर्ण कदम है। यह व्यापक शोध समुदाय को TAPNext को तेजी से प्रयोग करने, निर्माण करने और विकसित करने में सक्षम करेगा। भविष्य की चर्चाओं को इस सहयोगात्मक विकास को सर्वोत्तम रूप से बढ़ावा देने पर ध्यान केंद्रित करना चाहिए, शायद सामुदायिक-संचालित बेंचमार्क या साझा चुनौतियों के माध्यम से जो लंबी अवधि की ट्रैकिंग की सीमाओं को आगे बढ़ाते हैं।
-
BootsTAP के साथ सिम-टू-रियल गैप को पाटना: BootsTAP फाइन-ट्यूनिंग रणनीति सिम-टू-रियल गैप को पाटने के लिए फायदेमंद साबित हुई। भविष्य का काम अधिक उन्नत स्व-पर्यवेक्षित या अर्ध-पर्यवेक्षित सीखने की तकनीकों का पता लगा सकता है जो दुर्लभ वास्तविक दुनिया के एनोटेट किए गए डेटा पर निर्भरता को और कम करते हैं, जिससे TAP मॉडल और भी अधिक मापनीय और विविध वास्तविक दुनिया के परिदृश्यों पर लागू हो जाते हैं।
ये विविध दृष्टिकोण इस बात पर प्रकाश डालते हैं कि TAPNext सिर्फ एक नया अत्याधुनिक मॉडल नहीं है, बल्कि एक मूलभूत कार्य है जो सामान्य-उद्देश्य, सरल और मापनीय वीडियो समझ में अनुसंधान की एक नई लहर को प्रेरित कर सकता है।
 Table 1. Tracking performance for TAPNext and baseline models. TAPNext achieves a new state-of-the-art point tracking performance on eight of the twelve metrics, while also achieving the lowest possible latency. Methods are organized by their latency. Latency: video - these models require the entire video as input before outputting the point tracks. Latency: window - these models output tracks of length T after consuming a chunk of T frames (typically T = 8). After filling a buffer of T frames, these models can operate in a per-frame fashion. Latency: frame - these models have minimal latency by outputting point predictions immediately after consuming each frame. In each column, the best performing values are in bold, the second best are underlined
Table 1. Tracking performance for TAPNext and baseline models. TAPNext achieves a new state-of-the-art point tracking performance on eight of the twelve metrics, while also achieving the lowest possible latency. Methods are organized by their latency. Latency: video - these models require the entire video as input before outputting the point tracks. Latency: window - these models output tracks of length T after consuming a chunk of T frames (typically T = 8). After filling a buffer of T frames, these models can operate in a per-frame fashion. Latency: frame - these models have minimal latency by outputting point predictions immediately after consuming each frame. In each column, the best performing values are in bold, the second best are underlined
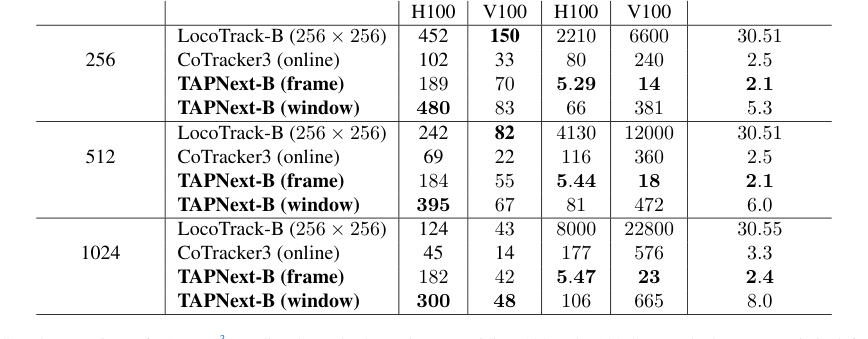 Table 2. Speed comparison of TAPNext3to online Cotracker3 running on Nvidia V100 and H100 GPUs. The latency metric is defined as the maximum (worst case) time between passing a frame to the model and receiving predicted points and it includes the time it takes to fill and process the initial frame buffer. All models are implemented in PyTorch. TAPNext (frame) is per frame inference of TAPNext. TAPNext (window) is when we track with non-overlapping chunks of 32 frames
Table 2. Speed comparison of TAPNext3to online Cotracker3 running on Nvidia V100 and H100 GPUs. The latency metric is defined as the maximum (worst case) time between passing a frame to the model and receiving predicted points and it includes the time it takes to fill and process the initial frame buffer. All models are implemented in PyTorch. TAPNext (frame) is per frame inference of TAPNext. TAPNext (window) is when we track with non-overlapping chunks of 32 frames