TAPNext: 추적할 모든 점(TAP)을 다음 토큰 예측으로
The problem of "correspondence" has been a foundational challenge in computer vision for decades.
배경 및 학술적 계보
기원 및 학술적 계보
"대응(correspondence)" 문제는 수십 년간 컴퓨터 비전 분야의 근본적인 도전 과제였습니다. 이 분야의 저명한 인물인 타케오 카나데(Takeo Kanade)는 "대응, 대응, 그리고 대응!"을 세 가지 가장 근본적인 문제 중 하나로 유명하게 강조했습니다. 역사적으로 이는 이미지 간의 일치하는 점이나 영역을 찾는 것을 포함했으며, 이는 움직임 이해, 깊이 추정, 사진 모음에서 3D 장면 재구성 등과 같은 작업에 매우 중요했습니다.
최근 이 근본적인 문제는 부활을 경험했으며 비디오에서 "추적할 모든 점(Tracking Any Point, TAP)"으로 발전했습니다. 이 특정 문제는 광학 흐름(optical flow)과 같은 이전 접근 방식의 한계를 해결하기 위해 처음 등장했습니다. 광학 흐름 방법은 프레임 간 움직임을 추적할 수 있었지만, 긴 시간 범위에 걸쳐 상당한 드리프트(drift)가 발생하는 경우가 많았고 가려짐(occlusion)에 어려움을 겪었습니다. TAP는 비디오 전체에 걸쳐 고체 물체의 특정 점에 대한 밀집되고 장거리의 대응을 제공하는 데 중점을 둠으로써 이 격차를 해소하기 위해 도입되었습니다. 이 기능은 로보틱스, 비디오 편집, 3D 재구성, 액션 인식, 동물학, 심지어 의학을 포함한 광범위한 다운스트림 컴퓨터 비전 애플리케이션에 매우 가치가 있습니다.
저자들이 TAPNext를 개발하도록 강요한 이전 TAP 접근 방식의 근본적인 한계 또는 "고통점(pain point)"은 복잡하고 추적에 특화된 귀납적 편향(inductive biases)과 휴리스틱(heuristics)에 의존한다는 점에서 비롯됩니다. 많은 이전 모델은 프레임별 인코딩, 매칭을 위한 비용 볼륨(cost-volume) 계산, 후속 추적 개선을 포함하는 2단계 프로세스로 추적을 공식화했습니다. 이는 종종 추적이 해결되는 방식에 대한 제한적인 가정을 도입했으며, 예를 들어 이를 특징 공간에서의 외형 매칭 문제로 간주했습니다. 이러한 방법은 미분 가능한 argmax 연산, 쌍선형 특징 보간, 제한된 검색 창, 창 기반 추론을 포함한 수많은 휴리스틱 설계 요소를 자주 통합했습니다.
더욱이, 많은 기존 추적기는 현재 프레임 출력을 생성하기 위해 미래 프레임의 정보가 필요했으며, 이는 실시간 애플리케이션에 부적합했습니다. 로컬 창 기반 추론을 사용하는 온라인 방법조차도 연속 창 간에만 점을 전송하는 데 의존하기 때문에 장기 가려짐 중에 실패하는 경우가 많았습니다. 이러한 복잡한 아키텍처 및 알고리즘 선택은 이전 모델의 일반성, 확장성 및 전반적인 성능, 특히 장기 추적 벤치마크에서 제한했습니다. 저자들의 동기는 강력하고 명시적인 귀납적 편향을 부과하지 않고 이러한 한계를 극복할 수 있는 더 간단하고 확장 가능하며 성능이 뛰어난 모델을 구축하는 것이었습니다.
직관적인 도메인 용어
- 추적할 모든 점 (TAP, Tracking Any Point): 번잡한 거리의 비디오를 보고 있다고 상상해 보세요. 움직이는 자동차의 아주 작은 특정 페인트 조각이나 누군가의 재킷에 있는 특정 단추를 전체 클립 동안 따라가고 싶습니다. TAP는 정확히 이 작업을 수행하는 컴퓨터 비전 작업입니다. 비디오에서 움직이고 변화함에 따라 객체의 선택된 점의 정확한 위치를 식별하고 추적하는 것입니다.
- 귀납적 편향 (Inductive Biases): 모델이 학습하는 데 사용하는 내장된 가정 또는 "지름길"로 생각하십시오. 예를 들어, 아이에게 고양이를 식별하도록 가르치고 "고양이는 항상 뾰족한 귀를 가지고 있다"고 말한다면, 그것은 귀납적 편향입니다. 더 빨리 학습하는 데 도움이 되지만 접힌 귀를 가진 고양이를 잘못 식별하게 할 수도 있습니다. 컴퓨터 비전에서 이러한 편향은 모델 아키텍처의 설계 선택으로, 특정 방식으로 문제를 해결하도록 안내하지만 유연성이나 일반화 능력을 제한할 수도 있습니다.
- 비용 볼륨 계산 (Cost-Volume Computation): 형사가 "수배" 포스터의 용의자 얼굴을 대규모 군중의 모든 얼굴과 일치시키려고 노력하는 것을 상상해 보세요. 비용 볼륨은 군중의 각 얼굴이 용의자 얼굴과 얼마나 유사한지를 형사에게 정확히 알려주는 상세한 픽셀별 맵과 같습니다. 각 잠재적 위치를 일치시키는 "비용" 또는 불일치를 정량화합니다.
- 상태 공간 모델 (SSM, State-Space Model): 길고 펼쳐지는 이야기를 설명하는 이야기꾼을 고려하십시오. 이야기꾼은 처음부터 모든 세부 사항을 기억하는 대신 이야기의 현재 상황("상태")에 대한 간결하고 진화하는 요약을 유지합니다. 새로운 이벤트(비디오 프레임)가 발생하면 이 요약을 업데이트하여 매번 전체 이야기를 처음부터 다시 읽을 필요 없이 내러티브를 일관되게 유지하고 다음에 무슨 일이 일어날지 예측할 수 있습니다.
표기법 표
| 변수 | 설명 |
|---|---|
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
이 논문에서 다루는 핵심 문제는 비디오에서의 추적할 모든 점 (TAP, Tracking Any Point)입니다. 정확히 말하면, 모델의 시작점(입력/현재 상태)은 다음과 같이 구성됩니다.
- 각 프레임이 $H \times W$ 픽셀 크기의 RGB 이미지인 $T$ 프레임으로 구성된 비디오.
- 각각 시간 $t$와 비디오 내 공간 좌표 $(x, y)$로 정의되는 $Q$개의 쿼리 점 집합.
원하는 최종점(출력/목표 상태)은 비디오의 모든 프레임에 대해 각 쿼리 점의 좌표 $(x, y) \in [0, H] \times [0, W]$와 이진 가시성 플래그를 예측하는 것입니다.
이 논문이 해결하고자 하는 정확한 누락된 연결 또는 수학적 격차는 TAP 문제를 순차적 마스크 토큰 디코딩 작업으로 변환하는 것입니다. 복잡하고 추적에 특화된 귀납적 편향과 휴리스틱에 의존하는 대신, TAPNext는 점 추적을 보간(imputation) 문제로 프레임화합니다. 초기 쿼리 점 좌표가 주어지면, 모델의 작업은 모든 다른 프레임에 걸쳐 이러한 점의 알 수 없는 좌표를 나타내는 마스크된 토큰을 "채우거나" 보간하는 것입니다. 이는 쿼리 점 정보가 위치 인코딩을 통해 주입되는 비디오 토큰(이미지 패치에서 파생됨)과 점 좌표 토큰을 연결함으로써 달성됩니다. 그런 다음 모델은 마스크된 토큰을 예측하여 전체 궤적을 디코딩하는 방법을 학습합니다.
이 특정 문제를 해결하려는 이전 연구자들은 여러 고통스러운 절충안과 딜레마에 갇혀 있었습니다.
- 일반성 대 특수성: 기존 TAP 방법은 복잡하고 추적에 특화된 귀납적 편향과 휴리스틱에 크게 의존합니다. 이는 특정 시나리오에서 성능 향상을 제공할 수 있지만 모델의 일반성과 확장 가능성을 심각하게 제한합니다. 한 측면(예: 특수 아키텍처를 사용한 정확도)을 개선하는 것은 종종 다른 측면(예: 확장성 및 광범위한 적용 가능성)을 손상시킵니다.
- 정확성 대 실시간 지연: 많은 이전 추적기는 현재 프레임 출력을 예측하기 위해 미래 프레임을 사용하거나 창 기반 추론을 사용하여 높은 정확도를 달성합니다. 이 접근 방식은 본질적으로 지연을 도입하여 로보틱스와 같은 실시간 애플리케이션에 부적합합니다. 딜레마는 실시간 기능을 희생하지 않고 높은 추적 성능을 달성하는 방법입니다.
- 강건성 대 단순성: 전통적인 방법은 종종 프레임별 인코딩, 비용 볼륨 계산, 반복 개선과 같은 다단계 프로세스를 포함합니다. 이러한 복잡한 파이프라인은 강건성을 목표로 하지만, 미분 가능한 argmax, 쌍선형 보간, 제한된 검색 창과 같은 많은 휴리스틱 설계 요소를 도입하여 모델을 복잡하고 확장성이 떨어지게 만듭니다.
- 장기 추적 대 가려짐 처리: 광학 흐름 기반 방법은 장시간 범위에 걸쳐 상당한 드리프트를 겪고 가려짐에 어려움을 겪습니다. 장기 점 추적이 이를 해결하기 위해 도입되었지만, 많은 온라인 방법의 창 기반 추론은 연속 창 간에만 점을 전송하는 데 의존하기 때문에 특히 장기 가려짐 중에 추적 실패로 이어집니다.
제약 조건 및 실패 모드
추적할 모든 점 (TAP) 문제는 저자들이 직면한 몇 가지 가혹하고 현실적인 벽 때문에 해결하기가 매우 어렵습니다.
- 데이터 부족: TAP에 대한 실제 훈련 데이터는 부족합니다. 이는 이전 연구들이 합성 데이터에 크게 의존하게 만들며, 이는 "합성-실제" 격차를 해소하기 위해 복잡한 귀납적 편향과 사용자 정의 아키텍처에 의존해야 하므로 모델의 확장성과 일반성이 제한됩니다.
- 계산 복잡성 및 메모리 제한:
- 전통적인 방법은 종종 각 쿼리 점에 대해 비용 볼륨을 독립적으로 계산하는데, 이는 계산 비용이 많이 들 수 있습니다.
- 반복 개선 단계와 창 기반 추론 체계는 상당한 계산 오버헤드를 추가합니다.
- 하드웨어 메모리 제한은 일부 기준 모델(예: LocoTrack-B가 30GB 이상의 메모리 사용, 표 2 참조)의 높은 메모리 사용량에서 알 수 있듯이 실질적인 문제입니다. 메모리 효율적인 모델을 개발하는 것은 배포에 중요합니다.
- 실시간 지연 요구 사항: 로보틱스와 같은 애플리케이션의 경우 엄격한 실시간 지연이 중요한 제약 조건입니다. 현재 프레임 출력을 위해 미래 프레임 또는 대규모 시간 창을 처리해야 하는 방법은 본질적으로 적용 가능성이 제한됩니다.
- 시간적 일관성 및 드리프트: 긴 비디오 시퀀스에 걸쳐 시간적 일관성을 유지하는 것은 어렵습니다. 과거의 상태를 기반으로 미래 상태를 예측하는 자기 회귀 모델은 오류 누적에 취약하여 시간이 지남에 따라 상당한 드리프트가 발생합니다. 이는 많은 추적기의 주요 실패 모드입니다.
- 긴 비디오로의 일반화: 짧은 비디오 클립(예: 48 프레임)으로 훈련된 모델은 훨씬 더 긴 비디오(예: 150 프레임 이상)로 일반화하는 경우가 드뭅니다. 시간적 일반화의 이러한 제한은 특히 상태 공간 모델(SSM)의 경우 적절하게 완화되지 않으면 상당한 장애물입니다. 논문은 SSM을 시간적 주의(temporal attention)로 교체하면 시간적 일반화가 좋지 않으며, SSM을 사용하더라도 "150 프레임보다 긴 비디오의 전체 길이에서 장기 점 추적에 상당한 실패"가 발생한다고 언급합니다.
- 비미분 가능 연산: 미분 가능한 argmax 연산 또는 특징의 쌍선형 보간과 같은 이전 아키텍처의 많은 휴리스틱 설계 요소는 TAPNext가 더 간단하고 통합된 접근 방식을 위해 피하고자 하는 복잡성을 도입합니다.
- 가려짐 처리: 점은 비디오 내에서 장기간 가려질 수 있습니다. 이러한 가려짐을 통해 점을 강건하게 추적하고 가시성을 올바르게 예측하는 것은 지속적인 과제입니다. 창 기반 추론 방법은 장기 가려짐 중에 자주 실패합니다.
- 외형 변화: 추적된 점의 외형은 조명 변화, 시점 이동 또는 변형으로 인해 변경될 수 있어 외형 기반 매칭이 어렵습니다.
- 좌표 예측 정밀도: 좌표 예측 공간은 이미지 차원으로 제한되며, 불확실성(예: 다중 모드 예측)을 표현하는 동시에 높은 정밀도를 달성하는 것은 복잡한 작업입니다. 좌표 헤드는 연속 좌표를 예측하고 이미지 픽셀의 이산적 특성을 처리할 수 있어야 합니다.
- 합성-실제 간극: 주로 합성 데이터로 훈련된 모델은 시각적 특성의 차이로 인해 실제 비디오에서 잘 수행되지 않는 경우가 많으므로 이 도메인 격차를 해소하기 위한 강건한 메커니즘이 필요합니다. 논문은 의사 레이블이 지정된 실제 데이터로 훈련하는 것이 이에 유익하다고 언급합니다.
- 귀납적 편향 부족: TAPNext는 일반성을 위해 추적에 특화된 귀납적 편향을 제거하는 것을 목표로 하지만, 이는 모델이 데이터에서 이러한 필요한 휴리스틱을 유기적으로 학습해야 함을 의미하며, 이는 더 어려운 학습 문제가 될 수 있습니다. 논문은 일부 휴리스틱이 자연스럽게 나타나지만 모든 문제에 대해 보장되는 것은 아니라고 보여줍니다.
- 시각 정보 전파: 모델은 점이 가려진 후에도 추적된 점으로 덮인 영역에 대해 과거 프레임에서 미래 프레임으로 시각 정보를 정확하게 전파하는 방법을 학습해야 합니다. 모델에 특정 시각적 영역에 대한 이전 정보가 없으면 평균값으로 채울 수 있으며, 이는 실패 모드입니다. 이는 초기 점 그리드가 벗어난 후 나타나는 영역이 잘 재구성되지 않는 경우에 특히 관련이 있습니다. 모델이 추적된 점의 정확한 시각적 표현을 유지해야 하므로 이는 모델의 핵심 과제입니다. 이는 생성 모델로 간주되어서는 안 되며, 선형 프로빙 실험으로 간주되어야 합니다.
왜 이 접근 방식인가
선택의 불가피성
TAPNext의 저자들은 전통적인 최첨단(SOTA) 추적할 모든 점(TAP) 방법이 근본적으로 불충분하다는 결정적인 기로에 직면했습니다. 핵심적인 깨달음은 기존 TAP 접근 방식이 "복잡한 추적에 특화된 귀납적 편향과 휴리스틱"에 지나치게 의존한다는 것이었습니다(초록). 여기에는 비용 볼륨 계산, 반복 개선, 창 기반 추론, 명시적인 프레임별 외형 매칭과 같은 기술이 포함되었습니다. 이러한 방법은 합리적인 성능을 달성했지만, 합성 데이터에서 실제 데이터로의 "합성-실제" 격차를 해소하려고 할 때 모델의 일반성과 확장성을 본질적으로 제한했습니다.
이러한 깨달음이 발생한 정확한 순간은 이러한 복잡하고 수작업으로 설계된 구성 요소가 다음과 같다는 관찰에서 비롯된 것으로 보입니다.
1. 너무 제한적: 강력한 귀납적 편향으로 설계된 아키텍처는 다양한 시나리오로 확장하고 일반화하는 능력을 제한했습니다.
2. 진정한 온라인이 아님: 온라인 기능을 주장하는 많은 방법조차도 여전히 미래 프레임이나 대규모 시간 창에 의존하여 로보틱스와 같은 실시간 애플리케이션에 부적합했습니다. 이러한 의존성은 종종 장기 가려짐 중에 추적 실패로 이어졌습니다.
3. 휴리스틱 주도: 미분 가능한 argmax, 쌍선형 보간, 제한된 검색 창 및 기타 특정 설계 요소의 필요성은 전체 시스템을 복잡하고 취약하게 만들었습니다.
저자들은 모션 및 외형 단서를 사용하는 방법을 명시적으로 지시받지 않고도 점을 추적할 수 있는, 개념적으로 더 간단하고 더 일반적인 아키텍처가 필요하다고 결론지었습니다. 이는 그들이 TAP를 "순차적 마스크 토큰 디코딩" 문제로 간주하게 만들었고, 이전에 TRecViT [40]에서 탐구되었던 상태 공간 모델(SSM)을 시간 처리용, 비전 트랜스포머(ViT)를 공간 처리용으로 사용하는 일반 목적 구성 요소를 활용했습니다. 이 접근 방식은 이전 SOTA 방법의 복잡성, 일반성 부족 및 낮은 확장성이라는 한계를 극복할 수 있는 유일한 실행 가능한 해결책으로 간주되었습니다.
비교 우위
TAPNext는 단순한 성능 지표를 넘어 여러 핵심 측면에서 이전의 황금 표준에 비해 질적인 우수성을 보여줍니다.
- 창발적 휴리스틱: 가장 놀라운 장점 중 하나는 널리 사용되는 많은 추적 휴리스틱(예: 모션 클러스터 기반 주의, 좌표 기반 판독, 비용 볼륨 유사 주의)이 "TAPNext에서 종단 간 훈련을 통해 자연스럽게 나타난다"는 것입니다(초록, 그림 3). 이는 복잡한 수작업 설계 구성 요소의 필요성을 제거하여 모델을 훨씬 더 간단하고 강건하게 만듭니다.
- 향상된 시간적 일관성 및 가려짐 처리: 순환 상태 아키텍처, 특히 SSM을 사용함으로써 TAPNext는 시간적 일관성을 유지하고 시간 경과에 따른 추적 점의 역학을 효과적으로 포착할 수 있습니다. 이 구조적 이점은 점이 장기간 가려져 있을 때 자주 실패하는 창 기반 추론 방법보다 장기 가려짐을 훨씬 더 정확하게 처리할 수 있게 합니다.
- 메모리 및 지연 시간 감소: 이 논문은 TAPNext의 효율성에 대한 설득력력 있는 증거를 제공합니다. 예를 들어, TAPNext-B(프레임)는 LocoTrack-B(256x256)의 약 30.5GB에 비해 훨씬 낮은 메모리 사용량(예: 2.1-2.4GB)을 보여줍니다(표 2). 또한 지연 시간이 크게 단축되어 5.29-5.47ms 범위에서 작동하며, 이는 CoTracker3(80-177ms) 또는 LocoTrack-B(2210-8000ms)보다 수천 배 빠릅니다. 이는 실시간 애플리케이션에 압도적으로 우수합니다.
- 확장성 및 일반화: TAPNext는 최소한의 추적에 특화된 귀납적 편향으로 설계되어 더 잘 일반화할 수 있습니다. 훈련 중에 본 비디오보다 훨씬 긴(최대 5배) 비디오에서 점을 추적할 수 있으며, 이는 실제 시나리오에 중요한 기능입니다. SSM의 선형 순환은 오프라인 설정에서 시간 처리를 병렬화할 수 있게 하여 효율성을 더욱 높입니다.
- 다중 모드 예측: 종종 단일 궤적 가설에 의존하는 이전 방법과 달리 TAPNext의 좌표 분류 헤드는 다중 모드 예측을 나타낼 수 있어 불확실성을 표현할 수 있습니다. 이는 모호한 추적 상황을 처리하는 데 있어 질적인 도약입니다.
- 단순성 및 편향되지 않은 해결책: 적은 하이퍼파라미터와 추적에 특화된 귀납적 편향이 없는 모델의 개념적 단순성은 모델이 모션 및 외형에 대한 사전 정의된 개념에 의해 제약되지 않고 TAP 문제에 대한 편향되지 않은 해결책을 발견할 수 있게 합니다. 이는 더 적응 가능하고 잠재적으로 더 강력하게 만듭니다.
제약 조건과의 정렬
TAP를 순차적 마스크 토큰 디코딩으로 간주하고 TRecViT의 교차된 SSM 및 ViT 블록을 기반으로 하는 선택된 접근 방식은 문제의 가혹한 요구 사항과 완벽하게 일치하여 문제와 해결책 간의 강력한 "결합"을 형성합니다.
- 온라인 및 인과적 추적: 주요 제약 조건은 로보틱스 및 실시간 애플리케이션에 필수적인 순전히 온라인 및 인과적 추적의 필요성이었습니다. TAPNext는 프레임을 순차적으로 처리하고 SSM을 통해 순환 상태를 유지함으로써 이를 달성하여 현재 프레임에 대한 예측이 과거 정보에만 의존하도록 보장합니다. 이는 미래 프레임에 의존하는 많은 이전 방법의 한계를 직접적으로 해결합니다.
- 최소 지연: 특히 선형 순환 SSM의 사용을 포함하는 아키텍처 설계는 최소 지연을 가능하게 합니다. 각 프레임을 소비한 직후 점 예측을 출력하여 다른 SOTA 추적기에서 지연을 도입하는 시간 창 또는 반복 개선 단계를 피합니다.
- 확장성 및 일반성: 복잡한 귀납적 편향이 없는 확장 가능하고 일반적인 모델에 대한 요구는 TAPNext의 기성 아키텍처 구성 요소(SSM 및 ViT) 사용과 마스크 디코딩 작업으로의 공식화를 통해 충족됩니다. 이를 통해 모델은 명시적인 수작업 휴리스틱 없이 추적을 학습할 수 있어 다양한 시나리오와 더 긴 비디오에 더 잘 적응할 수 있습니다.
- 장기 가려짐 처리: SSM 계층이 유지하는 순환 상태는 시간적 일관성을 유지하고 장기 가려짐 중에도 점을 추적하는 데 중요합니다. 이는 점이 사라지고 다시 나타날 때 어려움을 겪는 창 기반 방법의 주요 약점을 직접적으로 해결합니다.
- 계산 효율성: SSM의 선형 순환은 시간 경과에 따른 병렬 추론을 가능하게 하여 계산 복잡성이 엄청나게 증가하지 않고 긴 비디오를 처리하는 데 중요합니다. 이는 시간 창 추론 또는 반복 개선에 의존하는 방법보다 중요한 이점이며, 이는 긴 시퀀스에 대해 계산 비용이 많이 들 수 있습니다.
- 불확실성 표현: 분류 작업으로서의 좌표 예측은 다중 모드 예측을 허용하여 불확실성을 표현할 필요성과 일치하며, 이는 종종 이전 점 추정 기반 방법에서 부족한 기능입니다.
대안의 거부
이 논문은 TAP의 맥락에서 다양한 인기 또는 전통적인 접근 방식의 고유한 한계를 강조함으로써 암묵적으로 그리고 명시적으로 거부합니다.
- 전통적인 SOTA 방법 (비용 볼륨, 반복 개선, 창 기반 추론): 저자들은 "TAP에 대한 기존 방법은 복잡한 추적에 특화된 귀납적 편향과 휴리스틱에 크게 의존한다"고 명시적으로 언급합니다(초록). 그들은 이를 "비용 볼륨 계산, 이어서 추적 개선 [11, 12, 21, 26]"으로 설명하며, "미분 가능한 argmax 연산 [12], 특징의 쌍선형 보간 [21], 제한된 검색 창 [9], 창 기반 추론 [26]을 포함한 많은 휴리스틱 설계 요소"를 포함합니다. 이들은 일반성, 확장성을 제한하고 종종 비인과적 처리를 요구하거나 장기 가려짐 중에 추적 실패로 이어지기 때문에 거부되었습니다. TAPNext의 목표는 이러한 "강력한 귀납적 편향"을 피하고 "개념적으로 더 간단한 아키텍처"를 개발하는 것이었습니다.
- 오프라인/비인과적 추적기: 많은 추적기는 "현재 프레임에 대한 출력을 생성하기 위해 미래 프레임을 사용하므로 실시간 시나리오에서의 적용 가능성이 제한됩니다." 이러한 비인과적 특성은 온라인 추적 요구 사항과 직접적으로 모순되어 대상 애플리케이션에 대한 거부를 초래했습니다.
- 창 기반 온라인 추적기: 일부 방법은 로컬 창을 사용하여 온라인 기능을 주장했지만, 논문은 "대규모 시간 창에 대한 의존성과 연속 창 간에만 점을 전송하는 것이 종종 추적 실패로 이어진다"고 언급합니다. 특히 비디오 중간의 장기 가려짐에서 [21, 26]. 장기 추적 벤치마크에서의 이러한 낮은 성능은 진정한 순환, 프레임별 솔루션을 선호하여 이러한 접근 방식을 거부하게 만들었습니다.
- 시간적 주의를 갖춘 표준 트랜스포머: 무효화 연구(표 5)는 시간 처리 구성 요소에 대한 표준 시간적 주의 메커니즘(기본 트랜스포머의 것과 같은)을 사용하는 것을 명확하게 거부합니다. SSM이 시간적 주의로 교체되면 모델은 "RoPE [45] 시간적 위치 임베딩을 사용함에도 불구하고 시간적 일반화가 좋지 않다"고 언급합니다. 이는 장거리 시간적 일관성이라는 특정 작업에 대해 SSM이 일반 시간적 주의보다 우수한 구조적 이점을 제공하며, 이는 긴 시퀀스와 일반화에 어려움을 겪는다는 것을 시사합니다. 이는 단순한 순환이 이 특정 문제에 대한 복잡한 주의보다 더 효과적임을 시사하는 중요한 발견입니다.
- 단일 가설 점 추정: TAPIR 및 Co-Tracker와 같은 이전 방법은 "쿼리당 단일 궤적 가설에 대한 여러 개선 단계, 그리고 해당 단일 가설 주위의 로컬 특징 샘플링을 수행합니다." 다중 모드 예측 및 불확실성을 나타낼 수 있는 좌표 분류 헤드를 갖춘 TAPNext는 암묵적으로 이 더 간단하고 덜 유익한 접근 방식을 거부합니다. 불확실성을 표현하는 능력은 질적인 이점입니다.
- 재구성을 위한 생성 모델: 논문은 재구성 실험을 수행하지만, 이는 생성 모델로 간주되어서는 안 되며, "선형 프로빙 실험"으로 명시적으로 언급됩니다. 주요 목표는 추적이며 이미지 생성이 아닙니다. 저자들은 이미지 재구성 목표가 "추적 성능 향상으로 이어지지 않는다"고 밝혔습니다. 이는 마스크 자동 인코딩이 토큰 보간에 사용되지만, 비디오 프레임에 대한 완전한 생성 모델은 핵심 추적 작업에 필요하거나 유익하지 않은 것으로 간주되었음을 시사합니다.
 Figure 1. Dense grid tracking with TAPNext. We show (a) the query points on the first frame of the video, (b) the resulting tracks on the final frame of the video for CoTracker3 [27], and (c) our proposed TAPNext method
Figure 1. Dense grid tracking with TAPNext. We show (a) the query points on the first frame of the video, (b) the resulting tracks on the final frame of the video for CoTracker3 [27], and (c) our proposed TAPNext method
수학적 및 논리적 메커니즘
마스터 방정식
TAPNext의 핵심 메커니즘은 좌표 예측(분류 및 회귀 모두)과 가시성 예측을 결합한 다중 작업 손실 함수에 의해 구동됩니다. 이 손실은 TRecViT 아키텍처의 모든 계층에 적용되어 모델 깊이 전반에 걸쳐 강력한 학습을 보장합니다. 전반적인 목표는 시간 경과에 따른 점 좌표 및 가시성에 대한 모델의 예측과 실제 값 간의 불일치를 최소화하는 것입니다.
훈련 중에 최소화되는 총 손실 $L_{total}$을 나타내는 마스터 방정식은 다음과 같이 표현될 수 있습니다.
$$ L_{total} = \frac{1}{L \cdot Q \cdot T} \sum_{l=1}^{L} \sum_{q=1}^{Q} \sum_{t=1}^{T} \left( L_{coord}^{(l)}(t,q) + L_{vis}^{(l)}(t,q) \right) $$
여기서 $L_{coord}^{(l)}(t,q)$는 계층 $l$의 시간 $t$, 쿼리 점 $q$에 대한 좌표 손실이고, $L_{vis}^{(l)}(t,q)$는 동일한 점에 대한 가시성 손실입니다. 이러한 개별 손실은 다음과 같이 추가로 정의됩니다.
$$ L_{coord}^{(l)}(t,q) = L_{CE}(p_x^{(l)}(t,q), \text{target_bin}_x) + L_{CE}(p_y^{(l)}(t,q), \text{target_bin}_y) + L_{Huber}((\hat{x}^{(l)}_{t,q}, \hat{y}^{(l)}_{t,q}), (x_{t,q}, y_{t,q})) $$
$$ L_{vis}^{(l)}(t,q) = L_{BCE}(\hat{V}^{(l)}_{t,q}, V_{t,q}) $$
항별 분석
이러한 방정식의 각 구성 요소를 분해하여 수학적 정의와 TAPNext 프레임워크에서의 역할을 이해해 보겠습니다.
-
$L_{total}$:
- 수학적 정의: 총 손실 함수로, TAPNext 훈련 중에 최소화되는 전반적인 목표를 나타냅니다. 모든 계층, 쿼리 점 및 시간 단계에 걸친 개별 손실의 평균 합계입니다.
- 물리적/논리적 역할: 이 항은 비디오 시퀀스 전체와 추적된 모든 점에 대해 모델 예측이 얼마나 "잘못되었는지"를 정량화합니다. $L_{total}$을 최소화함으로써 모델은 시간이 지남에 따라 점의 위치와 가시성을 정확하게 예측하는 방법을 학습합니다. 모든 가중치가 동일한 계층에 대한 합계(논문에서 언급된 대로)는 중간 표현도 의미가 있도록 보장하고 더 깊은 계층의 기울기 소실 문제를 방지하며 강력한 특징 학습을 촉진하는 전략적 선택입니다. 이 깊은 감독은 훈련을 안정화하고 최종 성능을 향상시키는 데 도움이 됩니다.
- 다른 연산 대신 합계를 사용하는 이유?: 합계는 다른 구성 요소(좌표, 가시성) 및 다른 계층의 손실을 결합하는 데 사용됩니다. 이는 이러한 모든 측면이 전체 작업에 동일하게 중요하며 어느 부분의 오류도 총 오류에 직접적으로 기여한다는 것을 의미합니다. $L \cdot Q \cdot T$로 평균을 내면 손실이 정규화되어 계층, 쿼리 또는 프레임 수에 독립적이 되므로 다양한 입력 크기에 걸쳐 안정적인 훈련에 중요합니다.
-
$L$:
- 수학적 정의: TRecViT 백본에 있는 교차된 SSM 및 ViT 계층의 총 수입니다.
- 물리적/논리적 역할: 모델의 처리 파이프라인 깊이를 나타냅니다. 각 계층은 이미지 및 점 토큰의 시공간 표현을 개선하는 데 기여합니다. 손실은 각 계층에 적용되어 다양한 추상화 수준의 특징이 의미가 있고 최종 예측에 기여하도록 보장합니다. 이는 깊은 감독의 한 형태입니다.
-
$Q$:
- 수학적 정의: 비디오에서 추적되는 쿼리 점의 수입니다.
- 물리적/논리적 역할: 이는 모델이 궤적을 예측하도록 의뢰된 개별 점의 수입니다. 모델이 여러 점을 동시에 정확하게 추적하도록 보장하기 위해 모든 쿼리 점에 대해 손실이 합산됩니다.
-
$T$:
- 수학적 정의: 비디오 시퀀스의 총 프레임 수입니다.
- 물리적/논리적 역할: 비디오의 시간적 범위를 나타냅니다. 모델이 비디오 전체에 걸쳐 점을 일관되게 추적하고 시간적 역학과 가려짐을 처리하도록 보장하기 위해 모든 시간 단계에 대해 손실이 합산됩니다.
-
$L_{coord}^{(l)}(t,q)$:
- 수학적 정의: 계층 $l$의 시간 $t$, 쿼리 점 $q$에 대한 결합된 좌표 손실입니다. 이는 분류용 교차 엔트로피 두 개와 회귀용 허버 손실 한 개로 구성됩니다.
- 물리적/논리적 역할: 이 항은 모델이 추적된 점의 정확한 $(x,y)$ 좌표를 예측하도록 유도합니다. 분류와 연속 회귀의 이중 접근 방식은 모델이 이산 공간 위치와 미세한 연속 위치를 모두 포착할 수 있도록 합니다. 분류 측면은 모델이 다중 모드 예측과 불확실성을 표현할 수 있도록 도와주며, 이는 단일 점 추정치만 출력하는 방법보다 중요한 이점입니다. 논문은 이 분류 좌표 헤드가 가장 중요한 구성 요소 중 하나라고 언급합니다.
-
$L_{CE}(p_x^{(l)}(t,q), \text{target_bin}_x)$ 및 $L_{CE}(p_y^{(l)}(t,q), \text{target_bin}_y)$:
- 수학적 정의: 소프트맥스 교차 엔트로피 손실입니다. 주어진 좌표(예: x 좌표)에 대해 $p_x^{(l)}(t,q)$는 $n$개의 이산 빈에 대한 예측 확률 벡터이고, $\text{target_bin}_x$는 원-핫 인코딩된 실제 빈입니다.
$$ L_{CE}(p, \text{target}) = - \sum_{i=1}^{n} \text{target}_i \log(p_i) $$ - 물리적/논리적 역할: 이러한 항은 좌표 헤드가 x 및 y 좌표를 미리 정의된 이산 빈으로 분류하도록 훈련합니다. [16]에서 영감을 받은 이 분류 접근 방식은 모델이 불확실성을 표현할 수 있고(예: 점이 특정 확률로 여러 빈 중 하나에 있을 수 있음) 다중 모드 예측을 처리할 수 있기 때문에 중요합니다. 이는 단일 연속 값만 예측하는 방법과 비교할 때 상당한 이점입니다.
- 수학적 정의: 소프트맥스 교차 엔트로피 손실입니다. 주어진 좌표(예: x 좌표)에 대해 $p_x^{(l)}(t,q)$는 $n$개의 이산 빈에 대한 예측 확률 벡터이고, $\text{target_bin}_x$는 원-핫 인코딩된 실제 빈입니다.
-
$L_{Huber}((\hat{x}^{(l)}_{t,q}, \hat{y}^{(l)}_{t,q}), (x_{t,q}, y_{t,q}))$:
- 수학적 정의: 연속 예측 좌표 $(\hat{x}^{(l)}_{t,q}, \hat{y}^{(l)}_{t,q})$와 실제 좌표 $(x_{t,q}, y_{t,q})$에 적용되는 허버 손실입니다. 연속 좌표는 분류 확률의 기대값에서 파생됩니다: $\hat{x}^{(l)}_{t,q} = \sum_{i=1}^{n} b_{x,i} \cdot p_x^{(l)}(t,q,i)$ 여기서 $b_{x,i}$는 빈 $i$의 중심입니다.
$$ L_{Huber}(e) = \begin{cases} 0.5 e^2 & \text{if } |e| \le \delta \\ \delta (|e| - 0.5 \delta) & \text{if } |e| > \delta \end{cases} $$
여기서 $e$는 오류(예: $\hat{x} - x$)이고 $\delta$는 하이퍼파라미터입니다. - 물리적/논리적 역할: 이 항은 연속 좌표 예측을 미세 조정하는 회귀 손실 역할을 합니다. 허버 손실은 이상값에 덜 민감하기 때문에 단순한 L2(평균 제곱 오차) 손실보다 선택됩니다. 점 추적에서 실제 레이블에는 약간의 부정확성이 있을 수 있거나 점이 가려짐 또는 빠른 움직임으로 인해 일시적으로 예상치 못한 위치에 나타날 수 있습니다. 허버 손실은 작은 오류에 대해 더 부드러운 기울기(L2와 같음)를 제공하지만 큰 오류에 대해 선형 기울기(L1과 같음)를 제공하여 이러한 노이즈에 더 강건하고 큰 오류가 손실 영역을 지배하는 것을 방지합니다.
- 수학적 정의: 연속 예측 좌표 $(\hat{x}^{(l)}_{t,q}, \hat{y}^{(l)}_{t,q})$와 실제 좌표 $(x_{t,q}, y_{t,q})$에 적용되는 허버 손실입니다. 연속 좌표는 분류 확률의 기대값에서 파생됩니다: $\hat{x}^{(l)}_{t,q} = \sum_{i=1}^{n} b_{x,i} \cdot p_x^{(l)}(t,q,i)$ 여기서 $b_{x,i}$는 빈 $i$의 중심입니다.
-
$L_{vis}^{(l)}(t,q)$:
- 수학적 정의: 계층 $l$의 시간 $t$, 쿼리 점 $q$에 대한 가시성 손실입니다.
- 물리적/논리적 역할: 이 항은 모델이 주어진 프레임에서 추적된 점이 보이는지 또는 가려졌는지 예측하도록 유도합니다. 객체가 자주 시야에서 벗어나거나 일시적으로 숨겨지는 실제 시나리오에서 정확한 가시성 예측은 강건한 추적에 매우 중요합니다.
-
$L_{BCE}(\hat{V}^{(l)}_{t,q}, V_{t,q})$:
- 수학적 정의: 시그모이드 이진 교차 엔트로피 손실입니다. $\hat{V}^{(l)}_{t,q}$는 가시성 예측 확률(0과 1 사이의 스칼라)이고, $V_{t,q}$는 이진 실제 값(가려짐 0, 보임 1)입니다.
$$ L_{BCE}(\hat{v}, v) = - (v \log(\hat{v}) + (1-v) \log(1-\hat{v})) $$ - 물리적/논리적 역할: 이 항은 가시성 헤드가 이진 분류를 수행하도록 훈련합니다. 점의 가시성 상태를 잘못 예측할 때 모델을 페널티합니다. 시그모이드 활성화는 출력이 확률이 되도록 보장하고, 이진 교차 엔트로피는 이러한 두 가지 클래스 문제에 대한 표준 손실입니다. 모델은 불확실성 추정도 사용합니다. 좌표에 대한 확률 질량의 50% 이상이 8픽셀 반경 밖에 있으면 점이 가려진 것으로 표시되어 좌표 불확실성과 가시성 간의 자연스러운 연결을 제공합니다.
- 수학적 정의: 시그모이드 이진 교차 엔트로피 손실입니다. $\hat{V}^{(l)}_{t,q}$는 가시성 예측 확률(0과 1 사이의 스칼라)이고, $V_{t,q}$는 이진 실제 값(가려짐 0, 보임 1)입니다.
단계별 흐름
움직이는 자동차의 특정 픽셀과 같이 비디오를 통해 추적해야 하는 단일 추상 데이터 포인트를 상상해 보세요. 다음은 TAPNext 수학 엔진을 통한 여정입니다.
-
입력 및 토큰화:
- 여정은 $T$개의 RGB 프레임으로 구성된 비디오와 각 프레임의 시작 시간 및 $(x,y)$ 좌표로 정의되는 $Q$개의 초기 쿼리 점 집합으로 시작됩니다.
- 각 비디오 프레임은 먼저 $h \times w$ 그리드의 비겹치는 이미지 패치로 분할됩니다. 그런 다음 이러한 패치는 $C$ 차원 특징 공간으로 선형 투영되고 공간 위치 임베딩이 추가됩니다. 이를 통해 원시 이미지 데이터가 $[T, h \times w, C]$ 형태의 이미지 토큰 시퀀스로 변환됩니다.
- 동시에, 특정 쿼리 점(및 다른 모든 점)에 대해 $T$개의 점 추적 토큰 시퀀스가 생성됩니다. 점이 처음 쿼리되는 프레임의 경우 해당 토큰은 $(x,y)$ 좌표에 해당하는 위치 임베딩으로 초기화됩니다. 다른 모든 프레임의 경우 해당 토큰은 특수 "마스크 토큰" 값으로 초기화되어 위치가 알려지지 않았으며 예측해야 함을 나타냅니다. 이러한 점 토큰도 $[T, Q, C]$ 형태를 갖습니다.
-
입력 텐서 조립:
- 그런 다음 이미지 토큰과 점 추적 토큰이 공간 차원을 따라 연결됩니다. 이를 통해 $[T, h \times w + Q, C]$ 형태의 통합된 "입력 토큰 텐서"가 생성됩니다. 이 텐서에는 이제 비디오의 시각적 내용과 쿼리 점 정보가 포함되며, 추적해야 하는 프레임에 대한 마스크된 위치가 있습니다.
-
계층화된 시공간 처리 (TRecViT):
- 이 결합된 입력 텐서는 $L$개의 교차된 계층으로 구성된 TRecViT 백본에 들어갑니다. 각 계층은 2단계 프로세스입니다.
- SSM 블록 (시간 처리): 먼저 데이터가 상태 공간 모델(SSM) 블록을 통과합니다. 이 블록은 시간 차원($T$)에 걸쳐 선형 순환을 수행합니다. 이는 공간 차원($h \times w + Q$)을 배치로 취급합니다. 개념적으로 이는 시간을 통해 움직이는 컨베이어 벨트와 같습니다. SSM 블록은 과거 프레임의 정보를 현재 및 미래 프레임으로 효율적으로 전파하여 모델이 점의 궤적과 외형에 대한 "기억"을 유지할 수 있도록 합니다. 이는 가려짐을 통해 그리고 장기간에 걸쳐 추적하는 데 중요합니다.
- ViT 블록 (공간 처리): 다음으로 SSM 블록의 출력이 비전 트랜스포머(ViT) 블록에 들어갑니다. 이 블록은 각 프레임 내에서 모든 $h \times w + Q$ 토큰에 걸쳐 완전한 자체 주의를 수행하며, 시간 차원($T$)을 배치로 취급합니다. 여기서 모델은 단일 프레임 내에서 "주변을 둘러보며" 이미지 토큰이 점 토큰에 주의를 기울이고 점 토큰이 서로 및 이미지 토큰에 주의를 기울일 수 있도록 합니다. 이러한 공간 혼합은 모델이 점의 위치를 주변과의 관계에서 식별하고 시각적 단서를 통합하는 데 도움이 됩니다.
- 이 2단계 프로세스(SSM 후 ViT)는 모든 $L$ 계층에 대해 반복되어 추상 데이터 포인트의 시공간 표현을 점진적으로 개선합니다.
- 이 결합된 입력 텐서는 $L$개의 교차된 계층으로 구성된 TRecViT 백본에 들어갑니다. 각 계층은 2단계 프로세스입니다.
-
예측 헤드:
- 각 계층 $l$을 통과한 후 모델은 $T \times Q$개의 추적 토큰 집합을 출력합니다. 이러한 토큰은 두 개의 별도 예측 헤드로 공급됩니다.
- 좌표 헤드 (MLP): MLP(다층 퍼셉트론)는 각 시간 단계의 점에 대한 추적 토큰을 가져옵니다. 먼저 x 및 y 좌표 모두에 대해 $n$개의 이산 빈에 대한 확률을 예측합니다. 그런 다음 이러한 확률로 가중치를 부여한 빈 중심의 합계를 계산하여 예상 연속 $(x,y)$ 좌표를 계산합니다.
- 가시성 헤드 (MLP): 또 다른 MLP는 동일한 추적 토큰을 가져와 해당 프레임에서 점이 보이는지 또는 가려졌는지 나타내는 이진 확률을 예측합니다.
- 각 계층 $l$을 통과한 후 모델은 $T \times Q$개의 추적 토큰 집합을 출력합니다. 이러한 토큰은 두 개의 별도 예측 헤드로 공급됩니다.
-
손실 계산 및 역전파:
- 각 계층 $l$, 각 시간 단계 $t$ 및 쿼리 점 $q$에 대해 예측된 좌표 $(\hat{x}^{(l)}_{t,q}, \hat{y}^{(l)}_{t,q})$와 가시성 $\hat{V}^{(l)}_{t,q}$가 실제 $(x_{t,q}, y_{t,q})$ 및 $V_{t,q}$와 비교됩니다.
- 좌표 손실 $L_{coord}^{(l)}(t,q)$는 빈 분류에 대한 소프트맥스 교차 엔트로피와 연속 회귀에 대한 허버 손실을 모두 사용하여 계산됩니다.
- 가시성 손실 $L_{vis}^{(l)}(t,q)$는 시그모이드 이진 교차 엔트로피를 사용하여 계산됩니다.
- 이러한 개별 손실은 합산되어 $L_{total}$을 형성합니다. 그런 다음 이 총 손실을 사용하여 기울기를 계산하고 전체 네트워크를 통해 역전파하여 모델 매개변수를 업데이트합니다. 이러한 순차적인 순방향 전달, 손실 계산 및 역전파 프로세스를 통해 모델은 추적 기능을 학습하고 개선할 수 있습니다.
최적화 역학
TAPNext 메커니즘은 주로 다중 구성 요소 손실 함수와 아키텍처 설계 선택에 의해 주도되는 정교한 종단 간 지도 학습 훈련 프로세스를 통해 학습, 업데이트 및 수렴합니다.
-
기울기 흐름 및 깊은 감독: 총 손실 $L_{total}$은 모든 계층 $l$, 모든 쿼리 점 $q$, 모든 시간 단계 $t$의 손실 합계입니다. 이 "깊은 감독" 전략은 최종 예측 헤드에서 초기 계층까지 전체 네트워크를 통해 기울기가 효과적으로 흐르도록 보장합니다. 각 계층에 동일한 가중치로 손실을 적용함으로써 모델은 여러 추상화 수준에서 의미 있고 정확한 표현을 학습하도록 장려됩니다. 이는 매우 깊은 네트워크에서 흔히 발생하는 기울기 소실 또는 폭발과 같은 문제를 완화하고 중간 특징도 예측 가능하도록 하여 더 강건하고 안정적인 학습 프로세스를 보장합니다.
-
손실 영역 형성 (좌표 예측): 좌표 예측 헤드는 중요한 혁신으로, 분류와 회귀를 모두 결합합니다.
- 분류 (소프트맥스 교차 엔트로피): 좌표를 $n$개의 빈으로 이산화하고 소프트맥스 교차 엔트로피 손실을 사용하면 손실 영역이 다중 모드 예측을 허용하도록 형성됩니다. 점의 실제 위치가 모호한 경우(예: 가려짐 또는 모션 블러로 인해), 모델은 단일, 잠재적으로 잘못된 연속 값으로 커밋하도록 강요되는 대신 여러 빈에 확률을 할당할 수 있습니다. 이는 모델이 점의 일반적인 영역을 여전히 포착하는 경우 약간 벗어나는 것에 대해 심하게 페널티를 받지 않기 때문에 불확실한 시나리오에서 손실 영역을 더 부드럽고 관대하게 만듭니다.
- 회귀 (허버 손실): 연속 예상 좌표에 대한 허버 손실은 강건한 회귀 신호를 제공합니다. 작은 오류의 경우 L2 손실처럼 작동하여 좌표를 정확하게 찾는 강력한 기울기를 제공합니다. 큰 오류의 경우 L1과 유사한 동작으로 전환되어 이상값이나 극단적인 예측 오류에 덜 민감합니다. 이는 몇 개의 추적하기 어려운 점이 손실을 지배하고 모델 학습을 해당 점으로 치우치게 하는 것을 방지하여 더 안정적인 손실 영역을 형성합니다.
-
시간적 일관성 및 순환 (SSM): 순환 SSM 블록은 모델이 시간이 지남에 따라 내부 상태를 업데이트하는 방식의 기초입니다. 훈련 중에 SSM은 과거 프레임의 관련 정보를 현재 프레임으로 전파하는 방법을 학습합니다. 이를 통해 모델은 시간적 일관성을 유지하고 장기간 가려짐 중에도 점을 추적할 수 있습니다. SSM 계층을 통해 흐르는 기울기는 모델이 어떤 정보를 기억하고 미래 상태를 예측하기 위해 어떻게 변환해야 하는지를 가르칩니다. 논문은 "SSM의 망각 게이트를 0.0과 0.1 사이로 클리핑하고 쿼리 특징을 비디오 토큰의 길이에 걸쳐 브로드캐스팅"함으로써 장기 비디오 저하에 대한 부분적인 완화를 언급합니다. 이는 SSM의 내부 역학에 대한 특정 조정으로, 매우 긴 시퀀스에 걸쳐 정보를 유지하고 전파하는 능력을 개선하여 상태가 쇠퇴하거나 관련성이 없어지는 것을 방지합니다.
-
공간 상호 작용 (ViT 주의): 완전한 자체 주의 메커니즘을 갖춘 ViT 블록은 모델이 복잡한 공간 관계를 학습할 수 있도록 합니다. 주의 메커니즘을 통해 흐르는 기울기는 모델이 특정 점의 표현을 업데이트할 때 다양한 이미지 패치와 다른 점 토큰의 중요도를 가중하는 방법을 가르칩니다. 이를 통해 모델은 명시적으로 설계되지 않고도 "비용 볼륨 유사 주의"(외형 매칭), "좌표 기반 판독"(공간 컨텍스트 사용), "모션 클러스터 기반 판독"(움직이는 객체 그룹화)과 같은 다양한 추적 휴리스틱을 암묵적으로 학습할 수 있습니다. 이러한 창발적 행동은 종단 간 학습이 모델의 내부 논리를 형성하는 데 얼마나 강력한지를 보여줍니다.
-
BootsTAP (교사-학생 학습): 실제 데이터에 대한 미세 조정을 위해 TAPNext는 BootsTAP라는 교사-학생 설정을 사용합니다. '교사' 모델은 '학생' 가중치의 지수 이동 평균으로, 손상되지 않은 전체 해상도 실제 비디오에 대한 안정적인 의사 레이블을 제공합니다. 그런 다음 '학생' TAPNext 모델은 이러한 의사 레이블로부터 학습하지만, 비디오의 아핀 변환 및 손상된 버전에 대해 학습합니다. 손실은 학생에게만 역전파됩니다. 이 메커니즘은 모델이 일반적인 실제 손상 및 아핀 변환에 불변하는 강건한 솔루션으로 수렴하도록 도와 합성-실제 간극을 효과적으로 해소하고 복잡한 귀납적 편향에 의존하지 않고 일반화를 개선합니다. 교사의 안정성은 학생이 노이즈가 많은 의사 레이블에 과적합되거나 붕괴되는 것을 방지합니다.
본질적으로 TAPNext는 정밀한 국소화와 강건한 가시성 추정을 모두 장려하는 신중하게 설계된 손실 함수를 통해 시공간 표현과 예측 헤드를 반복적으로 개선함으로써 수렴하며, 순환 및 주의 메커니즘은 시간과 공간에 걸쳐 정보를 적응적으로 전파하고 통합하는 방법을 학습합니다. 이중 좌표 손실과 BootsTAP 전략은 탄력 있고 정확한 모델을 형성하는 데 중요합니다.
결과, 한계 및 결론
실험 설계 및 기준선
TAPNext의 수학적 주장을 엄격하게 검증하고 우수성을 입증하기 위해 저자들은 포괄적인 실험 설계를 구성했습니다. 훈련 및 평가에 사용된 주요 벤치마크는 Kubric에서 생성된 합성 데이터와 두 개의 인간 레이블이 지정된 평가 데이터셋(DAVIS, 30개 비디오, 24~105 프레임 및 Kinetics, 1150개 비디오, 250 프레임)으로 구성된 TAP-Vid [11]입니다.
훈련 전략의 핵심 측면은 이전 연구보다 훨씬 큰 합성 데이터셋을 사용하는 것이었습니다. 이 데이터셋은 500,000개의 비디오로 구성되었으며, 각 비디오는 48 프레임 길이이고 카메라 팬 및 모션 블러와 같은 어려운 요소를 포함했습니다. 실제 미세 조정을 위해 BootsTAPNext 모델은 BootsTAP [13] 자체 지도 학습 체계를 따라 인터넷에서 1500만 개의 비디오 클립(48 프레임 길이)을 활용했습니다. 여기에는 합성 데이터에서 초기 300,000단계, 이어서 실제 비디오에서 추가 1,500단계의 자체 지도 학습이 포함되었습니다. 모델은 256 x 256 해상도에서 훈련되었으며, 256개의 점 쿼리가 있는 256개의 비디오 배치로 훈련되었습니다. TAPNext-S(5.6천만 개 매개변수) 및 TAPNext-B(1억 9,400만 개 매개변수)의 두 가지 모델 변형이 개발되었으며, 각각 코사인 감쇠 일정 하에서 $10^{-3}$ 및 $5 \times 10^{-4}$의 다른 최고 학습 속도를 가집니다.
추론의 경우 TAPNext 모델은 256 x 256 해상도에서 평가되었습니다. 저자들은 쿼리 스트라이드 평가를 사용하여 비디오를 각 쿼리 점에서 순방향 및 역방향으로 실행하고, CoTracker [26]와 유사하게 성능 향상을 위해 로컬 및 전역 지원 점을 통합하여 한 번에 하나의 쿼리 점을 추적했습니다.
TAPNext의 핵심 메커니즘과 비교하여 엄격하게 비교된 "희생자"(기준선 모델)는 지연 시간 특성에 따라 분류된 다양한 기존 TAP 방법으로 구성되었습니다.
- 프레임 지연 시간 방법: TAPNet [11], Online TAPIR [53], Online BootsTAP [13], Track-On [1]. 이러한 모델은 각 프레임을 소비한 직후 예측을 출력합니다.
- 창 기반 추론 방법: TAPIR [12], BootsTAP [13], TAPTR [34], TAPTRv2 [33], TAPTRv3 [41], PIPs [21], CoTracker2 [26], CoTracker3 [27]. 이러한 방법은 트랙을 출력하기 전에 프레임 청크(일반적으로 $T=8$)가 필요합니다.
- 비디오 지연 시간 방법: OmniMotion [55], Dino-Tracker [51], LocoTrack-B [9]. 이러한 모델은 점 트랙을 생성하기 전에 전체 비디오를 입력으로 필요로 합니다.
TAPNext의 핵심 메커니즘에 대한 결정적인 증거는 세 가지 표준 지표를 사용하여 측정되었습니다.
1. 가려짐 정확도 (OA): 점이 보이는지 여부를 분류하는 정확도입니다.
2. 좌표 정확도 (davg): 실제 값에서 1, 2, 4, 8, 16 픽셀 임계값 내에 예측된 좌표가 있는 점의 평균 비율입니다.
3. 평균 자카드: 가려짐 및 좌표 정확도의 결합된 측정값입니다.
증거가 증명하는 것
실험 결과는 TAPNext의 핵심 메커니즘, 즉 추적할 모든 점(TAP)을 간단한 순환 아키텍처를 기반으로 한 순차적 마스크 토큰 디코딩으로 간주하는 것이 매우 효과적이라는 부인할 수 없는 증거를 제공합니다. 표 1에서 볼 수 있듯이 TAPNext는 TAP-Vid 벤치마크에서 보고된 12개 지표 중 8개에서 새로운 최첨단 추적 성능을 달성했으며, 종종 다른 온라인(1 프레임 지연 시간) 방법보다 상당한 차이를 보였습니다. 이는 TAPNext가 로보틱스와 같은 실시간 애플리케이션에 적합한 최소 지연 시간으로 작동한다는 점을 고려할 때 특히 인상적입니다.
중요한 발견은 TAPNext가 복잡한 추적에 특화된 귀납적 편향이나 이전 최첨단 방법에서 흔히 사용되는 휴리스틱에 의존하지 않고 이를 달성한다는 것입니다. 반복 또는 창 기반 추론, 테스트 시간 최적화, 비용 볼륨, 특징 보간, 토큰 특징 엔지니어링 및 로컬 검색 창을 사용하지 않습니다. 대신, 상태 공간 모델(SSM) 및 비전 트랜스포머(ViT)와 같은 오픈 소스 아키텍처 구성 요소를 기반으로 구축된 모델의 단순성은 대규모 합성 데이터셋에서 종단 간 훈련을 통해 이러한 휴리스틱을 자연스럽게 학습할 수 있게 합니다. 주의 맵(그림 3 및 4)의 시각화는 TAPNext가 비용 볼륨 유사 외형 매칭, 좌표 기반 판독 및 모션 클러스터 기반 판독 헤드와 유사한 주의 패턴을 유기적으로 개발했음을 확인합니다. 이러한 메커니즘은 아키텍처에 명시적으로 프로그래밍되지 않았습니다.
또한 TAPNext는 놀라운 일반화 기능을 보여줍니다. 48 프레임 비디오로 훈련되었음에도 불구하고 최대 5배 더 긴 비디오(예: Kinetics 데이터셋의 250 프레임 비디오)에서 점을 성공적으로 추적합니다. 이러한 강건한 시간적 일반화는 SSM 계층의 순환 특성 덕분이며, 이는 점을 인과적으로 온라인으로 처리하고 장기 가려짐 중에도 시간적 일관성을 유지합니다. 무효화 연구(표 4)는 분류 및 회귀 손실을 모두 사용하는 분류 좌표 헤드와 8x8 픽셀 이미지 패치 크기 선택의 중요한 역할을 강조합니다. 시간 처리를 위한 SSM의 우수성은 표 5에서 더욱 강조되며, SSM을 시간적 주의로 교체하면 고급 위치 임베딩을 사용하더라도 시간적 일반화가 좋지 않다는 것을 보여줍니다.
효율성 측면에서 표 2는 TAPNext의 이점을 명확하게 입증합니다. 창 기반 추론으로 최고의 추적 속도를 달성하고 프레임별 추론으로 가장 낮은 지연 시간을 달성하는 동시에 CoTracker3 및 LocoTrack-B와 같은 기준선에 비해 가장 적은 메모리를 소비합니다. 저자들이 설명한 질적 결과는 이러한 발견을 더욱 강화하며, TAPNext가 경쟁사보다 가려짐, 빠른 움직임 및 텍스처가 없는 얇은/작은 객체를 더 정확하게 추적하는 능력을 보여줍니다. 모델이 추적된 영역에 대해 가려진 경우에도 시각 정보를 정확하게 전파하는 능력은 SSM 계층이 외형 정보를 시간 경과에 따라 효과적으로 인코딩하고 전파함을 시사합니다.
한계 및 향후 방향
TAPNext는 점 추적 분야에서 상당한 도약을 이루었지만, 이 논문은 "150 프레임보다 긴 비디오의 전체 길이에서 장기 점 추적에 상당한 실패"라는 주목할 만한 한계를 솔직하게 인정합니다. 이 문제는 주로 상태 공간 모델이 훈련된 것보다 훨씬 긴 비디오 클립에 효과적으로 일반화할 수 없다는 현재의 능력 부족 때문입니다. SSM의 망각 게이트를 클리핑하고 쿼리 특징을 브로드캐스팅하여 부분적인 완화가 발견되었지만, 이는 향후 개선을 위한 핵심 영역으로 남아 있습니다. SSM의 이러한 한계를 해결하는 것은 이미 강력한 TAPNext 추적 성능을 더욱 향상시킬 수 있는 큰 기회를 제공합니다.
앞으로 TAPNext의 결과는 몇 가지 흥미로운 토론 주제와 향후 연구 방향을 열어줍니다.
-
극단적인 시간적 일반화를 위한 SSM 발전: 150 프레임 이상 비디오의 현재 한계는 성능 저하 없이 임의로 긴 시퀀스를 처리할 수 있는 새로운 SSM 아키텍처 또는 훈련 방법론의 필요성을 시사합니다. 장거리 종속성을 더 잘 관리하기 위해 계층적 SSM 또는 적응형 순환 메커니즘을 개발할 수 있을까요? 비디오 길이에 따라 확장하기 위해 SSM 내에서 동적 메모리 할당을 탐색해 볼까요?
-
"다음 토큰 예측" 패러다임 확장: 이 논문은 TAP를 다음 토큰 예측으로 간주하는 TAPNext 프레임워크가 "비디오의 다른 많은 컴퓨터 비전 작업에 확장될 수 있다"고 제안합니다. 이것은 심오한 진술입니다. 시간적 일관성과 점 수준 이해가 중요한 객체 감지, 분할 또는 비디오 생성과 같은 작업에 이 패러다임을 어떻게 적용할 수 있을까요? 이러한 접근 방식에서 통합된 비디오 기반 모델이 나올 수 있을까요?
-
창발적 휴리스틱에 대한 이해 심화: 복잡한 추적 휴리스틱(모션, 좌표, 외형 매칭)이 종단 간 훈련에서 자연스럽게 나타난다는 관찰은 매우 흥미롭습니다. 향후 연구는 이러한 휴리스틱이 왜 그리고 어떻게 나타나는지에 대해 더 깊이 파고들 수 있습니다. 이러한 창발적 속성으로 이어지는 내부 메커니즘을 더 잘 이해하기 위해 실험이나 해석 도구를 설계할 수 있을까요? 이는 더 일반적이고 덜 편향된 아키텍처 설계를 알릴 수 있습니다.
-
좌표 헤드 및 불확실성 추정 최적화: 분류 좌표 헤드는 TAPNext의 가장 중요한 구성 요소 중 하나로 식별됩니다. 특히 다중 모드 예측을 나타내고 이산 빈에서 연속 좌표 출력을 개선하는 데 있어 매개변수화에 대한 추가 연구는 상당한 이득을 가져올 수 있습니다. 또한, 더 정교한 확률적 모델링을 통합하여 모델의 내재된 불확실성 추정을 향상시키면 어려운 시나리오에서 강건성이 향상될 수 있습니다.
-
오픈 소스 기여 활용: 저자들이 추론 코드와 모델 가중치를 즉시 오픈 소싱하고 훈련 코드도 계획하는 것은 중요한 단계입니다. 이는 더 넓은 연구 커뮤니티가 TAPNext를 신속하게 실험하고 구축하며 발전시킬 수 있도록 할 것입니다. 향후 논의는 커뮤니티 주도 벤치마크 또는 비디오 이해의 경계를 넓히는 공유 과제를 통해 이러한 협력 개발을 가장 잘 육성하는 방법에 초점을 맞춰야 합니다.
-
BootsTAP를 이용한 합성-실제 간극 해소: BootsTAP 미세 조정 전략은 합성-실제 간극을 해소하는 데 유익한 것으로 입증되었습니다. 향후 연구는 희소한 실제 주석 데이터에 대한 의존성을 더욱 줄여 TAP 모델을 더욱 확장 가능하고 다양한 실제 시나리오에 적용할 수 있게 하는 고급 자체 지도 또는 반지도 학습 기술을 탐색할 수 있습니다.
이러한 다양한 관점은 TAPNext가 단순한 새로운 최첨단 모델이 아니라 다양한 과학 분야에 적용 가능한 강력하고 일반화 가능한 솔루션을 '보편적 구조 라이브러리'에 추가하는 보편적인 수학적 패턴, 즉 순차적 마스크 보간의 사례임을 강력하게 보여줍니다.
 Table 1. Tracking performance for TAPNext and baseline models. TAPNext achieves a new state-of-the-art point tracking performance on eight of the twelve metrics, while also achieving the lowest possible latency. Methods are organized by their latency. Latency: video - these models require the entire video as input before outputting the point tracks. Latency: window - these models output tracks of length T after consuming a chunk of T frames (typically T = 8). After filling a buffer of T frames, these models can operate in a per-frame fashion. Latency: frame - these models have minimal latency by outputting point predictions immediately after consuming each frame. In each column, the best performing values are in bold, the second best are underlined
Table 1. Tracking performance for TAPNext and baseline models. TAPNext achieves a new state-of-the-art point tracking performance on eight of the twelve metrics, while also achieving the lowest possible latency. Methods are organized by their latency. Latency: video - these models require the entire video as input before outputting the point tracks. Latency: window - these models output tracks of length T after consuming a chunk of T frames (typically T = 8). After filling a buffer of T frames, these models can operate in a per-frame fashion. Latency: frame - these models have minimal latency by outputting point predictions immediately after consuming each frame. In each column, the best performing values are in bold, the second best are underlined
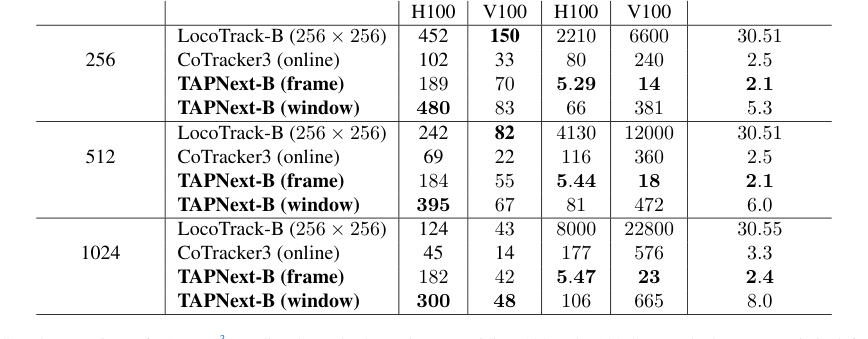 Table 2. Speed comparison of TAPNext3to online Cotracker3 running on Nvidia V100 and H100 GPUs. The latency metric is defined as the maximum (worst case) time between passing a frame to the model and receiving predicted points and it includes the time it takes to fill and process the initial frame buffer. All models are implemented in PyTorch. TAPNext (frame) is per frame inference of TAPNext. TAPNext (window) is when we track with non-overlapping chunks of 32 frames
Table 2. Speed comparison of TAPNext3to online Cotracker3 running on Nvidia V100 and H100 GPUs. The latency metric is defined as the maximum (worst case) time between passing a frame to the model and receiving predicted points and it includes the time it takes to fill and process the initial frame buffer. All models are implemented in PyTorch. TAPNext (frame) is per frame inference of TAPNext. TAPNext (window) is when we track with non-overlapping chunks of 32 frames