FluoroSAM: A Language-promptable Foundation Model for Flexible X-ray Image Segmentation
Language promptable X-ray image segmentation would enable greater flexibility for human-in-the-loop workflows in diagnostic and interventional precision medicine.
Background & Academic Lineage
The Origin & Academic Lineage
The problem addressed by FluoroSAM originates from the critical need for more flexible and efficient X-ray image segmentation in diagnostic and interventional precision medicine. X-ray imaging is a foundational modality in healthcare, but its analysis has historically relied on task-specific machine learning models. These early models, while effective within narrow applications, suffered from significant limitations: they required extensive additional data, annotations, and training time to adapt to new tasks or expand their scope. This made them rigid and difficult to scale for broader clinical use.
The academic field saw the emergence of "foundation models" (FMs) and, more specifically, "language-aligned foundation models" (LFMs) as a promising direction to overcome these constraints. LFMs, trained on vast and diverse image and text data, offered the potential for broad applicability by allowing tasks to be specified using natural language. However, existing medical LFMs primarily focused on modalities like CT or MRI, where large, richly annotated datasets are readily available. X-ray imaging, by contrast, presents unique challenges: highly variable image appearance, diverse applications (from diagnostic chest X-rays to interventional fluoroscopy), and a scarcity of large, well-annotated datasets, especially for interventional procedures.
A significant "pain point" of previous approaches, including general-purpose foundation models like the Segment-Anything Model (SAM) and its successor SAM 2, was their inability to effectively handle the unique characteristics of X-ray images, particularly with text prompts. While SAM models excel at segmenting objects in natural images based on various prompts (mask, bounding box, point), their text-prompting capabilities often rely on models like CLIP, which were trained on natural images. Transferring this directly to X-ray images is problematic because X-rays are transmissive, leading to many overlapping projections of different anatomical and non-anatomical objects. This inherent ambiguity means that a single image patch might contain visual features from multiple objects, making it difficult for models trained on natural images to distinguish them. Furthermore, the limited availability of diverse, high-quality X-ray datasets, especially for complex interventional scenarios, severely hampered the development of flexible, language-promptable segmentation tools for this modality. Previous medical SAM variants, like MedSAM, often mitigated this ambiguity by restricting prompts to bounding boxes, which is undesirable for X-ray imaging as it still leaves significant ambiguity, makes automatic or non-expert prompting impractical, and reduces flexibility for human-in-the-loop systems. This paper aims to address these limitations by developing a language-promptable foundation model specifically tailored for the X-ray domain, leveraging synthetic data generation to overcome data scarcity.
Intuitive Domain Terms
- Language-aligned foundation models (LFMs): Imagine a super-smart assistant that can understand your spoken or typed instructions (like "segment the left lung") and then perform a complex task, such as identifying and outlining that specific part in an X-ray image. LFMs are like these assistants, trained on a huge amount of both images and text, so they learn to connect words with visual concepts, making them very versatile.
- Segmentation: Think of it like using a digital highlighter to precisely outline a specific object in an image. In medical imaging, this means drawing an exact boundary around an organ, a bone, or a medical tool. It's not just saying "there's a lung"; it's showing exactly where the lung is.
- Vector Quantization (VQ): This is like having a dictionary of visual concepts. When the model "sees" a new description or image feature, it tries to match it to the closest entry in its dictionary. This helps to standardize and simplify complex information, making it easier for the model to learn consistent relationships between language and images, even if the descriptions are slightly different. It's a way to make the model's understanding of concepts more robust and less sensitive to minor variations.
- Sim-to-real transfer: This is akin to a pilot training in a flight simulator before flying a real plane. In this context, it means training an AI model using highly realistic computer-generated (simulated) X-ray images and then applying that trained model to actual, real-world X-ray images. The goal is for the model to perform well in the real world despite learning primarily from simulated data, which is often easier and cheaper to produce in large quantities.
Notation Table
| Notation | Description |
|---|---|
Problem Definition & Constraints
Core Problem Formulation & The Dilemma
The core problem this paper addresses is the lack of a flexible, generalizable, and language-promptable foundation model for X-ray image segmentation, particularly for diverse and challenging medical X-ray scenarios.
Input/Current State:
Currently, X-ray image analysis relies on task-specific machine learning models. These models perform well within a narrow scope, but their fixed design and limited training data severely restrict their applicability across the broad X-ray domain. Expanding these models to support new classes or more complex queries demands significant additional data, annotations, and extensive retraining efforts. Existing foundation models (FMs) for medical imaging, while promising, have primarily focused on modalities where large, richly annotated datasets are readily available. However, X-ray imaging, especially interventional fluoroscopy, presents a unique challenge due to its highly variable image appearance, diverse applications, and a critical scarcity of richly annotated training data. Furthermore, X-ray images are transmissive by nature, meaning multiple anatomical and non-anatomical objects often overlap in projections, making it inherently difficult to distinguish them. Previous language-aligned FMs, like the Segment-Anything Model (SAM) and its successor SAM 2, rely on models like CLIP for text prompts, which were trained on natural images. It's not immediately clear how to effectively transfer this approach to X-ray images, where object boundaries are often indistinct and structures are superimposed.
Desired Endpoint (Output/Goal State):
The ultimate goal is to develop a language-promptable foundation model, named FluoroSAM, capable of comprehensive and language-aligned analysis of arbitrary medical X-ray images. This model should enable greater flexibility for human-in-the-loop workflows in diagnostic and interventional precision medicine. Specifically, FluoroSAM aims to segment a myriad of anatomical structures and tools based on natural language prompts, providing semantically meaningful masks for any object specified in an X-ray image. This would allow for more intuitive and efficient interaction in clinical settings, from interactive diagnostic systems to intelligent human-machine interfaces in image-guided interventions.
Missing Link or Mathematical Gap:
The exact missing link is a robust and generalizable mechanism to effectively align natural language prompts with the unique visual features of X-ray images for segmentation. The challenge lies in bridging the gap between high-level linguistic descriptions and the low-level, often ambiguous, pixel information in X-rays. The paper addresses this by introducing a novel text encoder architecture within FluoroSAM. This architecture incorporates a Vector Quantization (VQ) module on top of a frozen CLIP encoder. This VQ layer is crucial; it provides a more consistent signal to the mask decoder, enabling effective language alignment during training specifically for X-ray images, despite the inherent difficulties of the modality. This architectural innovation allows the model to learn a shared representation space where text prompts can accurately guide segmentation in X-ray images.
Painful Trade-off or Dilemma:
The central dilemma that has trapped previous researchers is the trade-off between model generalizability/flexibility and the availability of high-quality, annotated X-ray data. Achieving broad applicability and language-promptability (like LFMs) typically requires vast, richly annotated datasets. However, X-ray imaging, particularly for interventional procedures, suffers from a severe lack of such data. This forces a choice: either develop narrow, task-specific models that perform well but lack flexibility, or attempt to build generalizable models that struggle due to data scarcity and the unique challenges of X-ray image interpretation. The transmissive nature of X-rays further exacerbates this, as improving one aspect (e.g., segmenting overlapping structures) often introduces ambiguity or requires more complex, data-intensive solutions. For instance, while bounding box prompts (used by MedSAM for other medical modalities) can reduce ambiguity, they severely limit the flexibility and naturalness of human-machine interaction, which is a core benefit of language-promptable systems.
Constraints & Failure Modes
The problem of language-promptable X-ray image segmentation is insanely difficult due to several harsh, realistic constraints:
-
Physical Constraints:
- Transmissive Nature and Overlapping Projections: X-ray images are formed by the transmission of X-rays through the body, resulting in 2D projections where many anatomical and non-anatomical objects (like tools) often overlap. This inherent characteristic makes it extremely challenging to distinguish individual structures, even for human experts, and poses a significant hurdle for automated segmentation. Many organs are not plainly visible, further complicating the task.
- High Variability in Image Appearance and Applications: X-ray imaging encompasses a wide spectrum of applications, from diagnostic chest X-rays to interventional fluoroscopy. This leads to immense variability in human anatomies, imaging geometries, viewing angles, and image intensity values. A model must be robust to this broad diversity, which is difficult to achieve with limited data.
-
Computational Constraints:
- High Computational Cost for Data Generation and Training: To overcome the data scarcity, the authors generated a large synthetic dataset (FluoroSeg) of 3 million X-ray images. This simulation process itself is computationally intensive, requiring approximately 6 GPU days on an NVIDIA A6000 GPU. Training FluoroSAM on this dataset also demands significant resources, taking 6 days on 2 NVIDIA H100 GPUs. This highlights the substantial computational burden associated with developing such a model.
- VQ Codebook Size Limitation: While the Vector Quantization (VQ) module improves robustness to variable text prompts, its codebook size intrinsically constrains the representational power of text embeddings. This design choice, while beneficial for consistency, theoretically limits the generalizability of the framework to an infinitely wide range of new segmentation classes or highly novel language prompts.
-
Data-driven Constraints:
- Extreme Sparsity of Annotated Real X-ray Data: This is perhaps the most critical constraint. There is a profound lack of large, richly annotated datasets for X-ray imaging, especially for interventional X-rays. This scarcity prevents direct training of robust language-aligned foundation models on real-world data, necessitating reliance on synthetic data.
- Domain Gap (Sim-to-Real Transfer): Training on synthetic data, while necessary, introduces a domain gap between the simulated images and real X-ray images. Despite strong domain randomization techniques applied during training (e.g., coarse dropout, inversion, blurring, Gaussian contrast adjustment, random windowing, CLAHE histogram equalization), the synthetic data may still differ systematically from real hand-annotated masks, potentially impacting performance on real-world scenarios.
- Limited Variety in Synthetic Data: Even with a large synthetic dataset like FluoroSeg, there are still limitations in the number of base CT scans used and the variety of anatomical structures represented. Expanding this variety, though scalable, is computationally intensive.
- Ambiguity of Natural Language Prompts: Natural language prompts themselves can be ambiguous, particularly when referring to overlapping structures in X-ray images. The model must be designed to handle "bad prompts" by ignoring them and to predict multiple masks for a given prompt, allowing for selection of the most accurate segmentation. This adds complexity to the model's output and inference process.
Why This Approach
The Inevitability of the Choice
The adoption of FluoroSAM, a language-promptable variant of the Segment-Anything Model (SAM) specifically tailored for X-ray image segmentation, was not merely a choice but an inevitable necessity given the inherent limitations of existing state-of-the-art (SOTA) methods. The authors realized that traditional task-specific machine learning models, while effective within narrow scopes, demanded prohibitive amounts of additional data, annotations, and training time to expand their utility to broader applications. This was particularly problematic for the X-ray imaging modality, which is characterized by highly variable image appearance, diverse applications (from diagnostic chest X-rays to interventional fluoroscopy), and critically, a scarcity of large, richly annotated datasets.
The "exact moment" of realization likely occurred when considering the direct application of prominent language-aligned foundation models (LFMs) like the original SAM or its successor, SAM 2. While these models support text prompts, they fundamentally rely on pre-trained LFMs such as CLIP [21] to convert image patches into language-aligned embeddings. The critical insight was that CLIP, trained predominantly on natural images, would not transfer effectively to the X-ray domain. X-ray images are transmissive, leading to numerous overlapping masks belonging to distinct objects, a stark contrast to natural images where objects typically have clear boundaries and nested structures. Even if an X-ray-specific CLIP-like model existed, a single image patch would still contain visual features from multiple, overlapping objects, making unambiguous distinction exceedingly difficult. This fundamental mismatch between the visual characteristics of X-rays and the assumptions of natural-image-trained models rendered direct application of existing SOTA LFMs insufficient, necessitating a bespoke solution like FluoroSAM.
Comparative Superiority
FluoroSAM's qualitative superiority stems from its structural innovations designed to overcome the unique challenges of X-ray imaging, making it overwhelmingly superior to previous gold standards in this specific domain. Unlike models that struggle with X-ray's transmissive nature and overlapping anatomies, FluoroSAM's novel text encoder, incorporating a vector quantization (VQ) module on top of a frozen CLIP encoder, provides a more consistent signal to the mask decoder. This VQ layer is crucial; while it theoretically limits generalizability to entirely new segmentation classes, it significantly expands generalizability to new language prompts by reducing the variability arising from disparate descriptions for the same object. This means FluoroSAM is more robust to diverse natural language inputs, a key advantage for human-in-the-loop workflows.
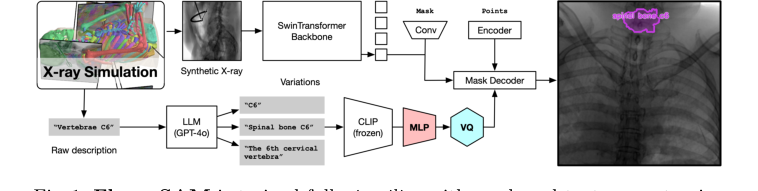 Figure 1. FluoroSAM is trained fully in silico with mask and text prompt pairs. It features a VQ layer that enables training language-aligned training on X-ray images
Figure 1. FluoroSAM is trained fully in silico with mask and text prompt pairs. It features a VQ layer that enables training language-aligned training on X-ray images
Furthermore, FluoroSAM's ability to be trained from scratch on the massive, synthetic FluoroSeg dataset (3M X-ray images) provides a structural advantage. This circumvents the critical data scarcity issue for real X-ray images, allowing the model to learn robust features across a wide variety of human anatomies, imaging geometries, and viewing angles that would be impossible with real-world data alone. Quantitatively, FluoroSAM outperforms SAM and MedSAM, especially with text-only prompting, achieving a mean IoU of 0.47 and a Dice score of 0.60 on real interventional X-ray images. Even with 2 points, FluoroSAM achieves 0.56 IoU and 0.69 Dice, outperforming SAM and MedSAM.
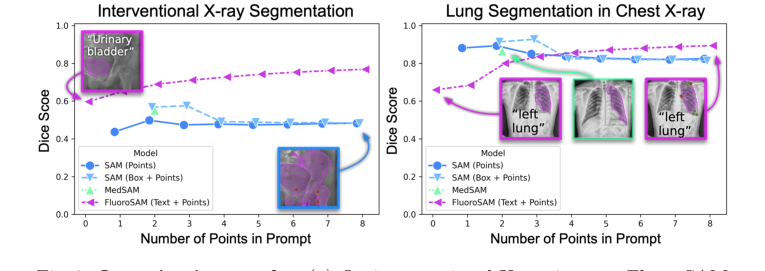 Figure 3. Quantitative results. (a) On interventional X-ray images, FluoroSAM outperforms its peers even with text-only prompting. (b) On CXRs, FluoroSAM adapts to hand-annotated lung segmentations despite being trained on synthetic data. MedSAM [18] includes this task in its training data
Figure 3. Quantitative results. (a) On interventional X-ray images, FluoroSAM outperforms its peers even with text-only prompting. (b) On CXRs, FluoroSAM adapts to hand-annotated lung segmentations despite being trained on synthetic data. MedSAM [18] includes this task in its training data
MedSAM, for instance, often "fails to reflect the underlying anatomy and simply fills the provided box," indicating a qualitative failure to understand the underlying image content beyond simple bounding box constraints. FluoroSAM's multi-output capability, predicting multiple masks for each prompt and selecting the best, further enhances its robustness and flexibility, allowing it to handle ambiguous prompts more gracefully. This structural design enables FluoroSAM to deliver flexible, language-aligned segmentation in a domain where others falter, without necessarily reducing memory complexity from $O(N^2)$ to $O(N)$ but rather by improving qualitative understanding and prompt robustness.
Alignment with Constraints
The chosen FluoroSAM approach perfectly aligns with the harsh requirements of X-ray image segmentation, forming a "marriage" between problem and solution. The primary constraints, as inferred from the problem definition, include:
- Need for broad applicability and flexibility: Traditional models are too narrow. FluoroSAM, as a language-promptable foundation model, is inherently designed for broad applicability, capable of segmenting "myriad anatomical structures and tools based on natural language prompts" (Page 1). This flexibility is crucial for diverse diagnostic and interventional scenarios.
- Scarcity of richly annotated X-ray datasets: This is perhaps the most significant constraint. FluoroSAM addresses this by being trained "from scratch on 3M synthetic X-ray images from a wide variety of human anatomies, imaging geometries, and viewing angles" (Page 1). The creation of the FluoroSeg dataset is a direct response to this data bottleneck, enabling robust training without relying on scarce real-world annotations.
- Unique visual characteristics of X-ray images: X-rays are transmissive with overlapping objects, making clear boundary detection challenging for models trained on natural images. FluoroSAM's novel text encoder with VQ is specifically engineered to handle this. The VQ module helps reduce the variability from disparate text descriptions for the same object, providing a more consistent signal to the mask decoder, which is vital for distinguishing overlapping structures in X-rays.
- Requirement for natural language interaction: To enable intuitive human-in-the-loop workflows and reduce ambiguity. FluoroSAM's core design as a "language-promptable variant of SAM" directly fulfills this, allowing users to specify segmentation targets using natural language, which is far more flexible and less ambiguous than point or bounding box prompts alone for complex X-ray scenes.
- Generalizability across X-ray types: The FluoroSeg dataset, with its wide range of simulated anatomies, geometries, and viewing angles, ensures that FluoroSAM is trained to be generalizable across different X-ray applications, from diagnostic chest X-rays to interventional fluoroscopy. This is demonstrated by its sucessfully zero-shot evaluation on CXRs despite being trained on synthetic data.
Rejection of Alternatives
The paper explicitly details why several popular alternative approaches would have failed or were insufficient for the specific problem of language-promptable X-ray image segmentation.
Firstly, traditional, task-specific machine learning models were rejected becuase they operate within a narrow scope and require extensive additional data, annotations, and retraining for broader use or new classes (Page 1). This contradicts the goal of developing a flexible, broadly applicable foundation model.
Secondly, the direct application of existing foundation models like SAM and SAM 2, particularly their reliance on CLIP for text prompts, was deemed unsuitable. The authors highlight that CLIP, being trained on natural images, struggles with the unqiue characteristics of X-ray images, such as their transmissive nature and the prevalence of overlapping objects without clear boundaries (Page 2-3). Even if a CLIP-like model were adapted for X-rays, distinguishing multiple objects within a single image patch would remain problematic. This fundamental incompatibility led to the development of FluoroSAM's novel text encoder with VQ.
Thirdly, MedSAM [18], another medical imaging foundation model, was rejected for X-ray applications despite its success in other domains. MedSAM primarily relies on bounding box prompts to mitigate ambiguity (Page 5). For X-ray imaging, this approach is undesirable because it: (a) still features significant ambiguity due to overlapping structures, (b) makes automatic or non-expert prompting impractical, and (c) lacks the flexibility required for advanced human-in-the-loop systems (Page 5). The paper further notes that MedSAM "generally fails to reflect the underlying anatomy and simply fills the provided box" (Page 7), indicating a qualitative failure to understand the image content when constrained by bounding boxes.
Finally, even the original SAM's performance with point prompting was found to be inferior, predicting "increasingly erroneous masks" compared to FluoroSAM's performance (Page 7). This suggests that while SAM offers promptability, its underlying architecture and training data are not robust enough for the complexities of X-ray segmentation without the specific adaptations introduced in FluoroSAM.
The paper does not explicitly discuss the rejection of other generative models like GANs or Diffusion models for the segmentation task itself, as the focus is on promptable segmentation and the limitations of existing foundation models in the X-ray domain. The core reasoning for rejecting alternatives consistently revolves around their inability to handle X-ray's unique visual properties, data scarcity, and the critical need for flexible, language-aligned interaction.
Mathematical & Logical Mechanism
The Master Equation
The core of FluoroSAM's learning mechanism, like many segmentation models, lies in its loss function, which guides the model to produce accurate masks. While the paper describes a complex training regimen involving multiple prompts and selection criteria, the fundamental objective for evaluating a single predicted mask against its ground truth is a combination of Dice Loss and Focal Loss. The paper states, "We use Dice and focal loss for masks." Therefore, the master equation representing the objective for a single mask prediction can be expressed as:
$$ L_{mask}(P, G) = \lambda_{Dice} L_{Dice}(P, G) + \lambda_{Focal} L_{Focal}(P, G) $$
where $P$ represents the predicted segmentation mask (a matrix of probabilities) and $G$ represents the binary ground truth mask. The individual loss components are defined as:
$$ L_{Dice}(P, G) = 1 - \frac{2 \sum_{i=1}^N p_i g_i}{\sum_{i=1}^N p_i^2 + \sum_{i=1}^N g_i^2} $$
$$ L_{Focal}(P, G) = - \sum_{i=1}^N \left( g_i \alpha (1-p_i)^\gamma \log(p_i) + (1-g_i) (1-\alpha) p_i^\gamma \log(1-p_i) \right) $$
Term-by-Term Autopsy
Let's dissect these equations to understand the role of each component:
-
$L_{mask}(P, G)$: This is the overall loss value for a single predicted mask $P$ given the ground truth $G$.
- Mathematical Definition: A scalar value, typically between 0 and 1 (or higher for Focal Loss), quantifying the dissimilarity between the predicted and true segmentation.
- Physical/Logical Role: This is the primary objective function that the FluoroSAM model strives to minimize during training. A lower $L_{mask}$ indicates a more accurate segmentation.
- Why addition: The use of addition to combine $L_{Dice}$ and $L_{Focal}$ allows both aspects of segmentation quality—overlap (Dice) and correct classification of hard examples (Focal)—to contribute simultaneously to the gradient signal. This provides a more comprehensive and balanced optimization target than using either loss in isolation.
-
$\lambda_{Dice}$: The weighting coefficient for the Dice Loss component.
- Mathematical Definition: A positive scalar constant. The paper does not explicitly state its value, but it's typically set through hyperparameter tuning.
- Physical/Logical Role: This coefficient controls the relative importance of achieving high overlap (as measured by Dice Loss) compared to focusing on hard-to-classify pixels (as measured by Focal Loss) in the overall segmentation objective.
- Why multiplication: Multiplication is the standard way to scale the contribution of a specific loss term within a composite loss function.
-
$L_{Dice}(P, G)$: The Dice Loss component.
- Mathematical Definition: $1 - \frac{2 \sum_{i=1}^N p_i g_i}{\sum_{i=1}^N p_i^2 + \sum_{i=1}^N g_i^2}$. Here, $p_i$ is the predicted probability for pixel $i$, and $g_i$ is the ground truth label (0 or 1) for pixel $i$. The summation $\sum_{i=1}^N$ is over all $N$ pixels in the image.
- Physical/Logical Role: This term primarily measures the spatial overlap between the predicted mask and the ground truth. It is particularly effective for tasks with significant class imbalance, such as segmenting small organs or tools in a large X-ray image, because it inherently focuses on the positive (foreground) class. Minimizing this term encourages the model to produce masks that closely match the shape and extent of the true object.
- Why subtraction from 1: The Dice coefficient itself is a similarity metric, ranging from 0 (no overlap) to 1 (perfect overlap). Subtracting it from 1 transforms it into a loss function, where 0 represents perfect segmentation and 1 represents complete dissimilarity.
- Why sum of squares in denominator: For probabilistic predictions ($p_i \in [0,1]$), using $p_i^2$ and $g_i^2$ in the denominator generalizes the concept of set cardinality (number of elements) to continuous probabilities, making the loss function differentiable and suitable for gradient-based optimization.
-
$\lambda_{Focal}$: The weighting coefficient for the Focal Loss component.
- Mathematical Definition: A positive scalar constant, typically determined via hyperparameter tuning.
- Physical/Logical Role: Similar to $\lambda_{Dice}$, this coefficient adjusts the influence of the Focal Loss in the total loss, balancing its focus on hard examples against the Dice Loss's emphasis on overall overlap.
- Why multiplication: Standard scaling mechanism for loss terms.
-
$L_{Focal}(P, G)$: The Focal Loss component.
- Mathematical Definition: $- \sum_{i=1}^N \left( g_i \alpha (1-p_i)^\gamma \log(p_i) + (1-g_i) (1-\alpha) p_i^\gamma \log(1-p_i) \right)$.
- Physical/Logical Role: This loss addresses the problem of class imbalance by down-weighting the contribution of well-classified examples (easy negatives) and focusing the model's training on hard, misclassified examples. In X-ray images, background pixels often far outnumber foreground pixels, and Focal Loss prevents the model from being overwhelmed by easy background predictions.
- Why $\alpha$: This is a weighting factor for the positive class. It balances the importance of positive and negative examples, which can be useful if one class is inherently more important or rarer.
- Why $(1-p_i)^\gamma$ or $p_i^\gamma$: These are modulating factors. If a pixel is well-classified (e.g., $p_i$ is high when $g_i=1$), then $(1-p_i)$ is small, and $(1-p_i)^\gamma$ becomes even smaller (for $\gamma > 0$), effectively reducing its loss contribution. Conversely, for misclassified pixels, the factor is close to 1, and the loss remains significant. This mechanism "focuses" the learning on the hard examples.
- Why $\log(p_i)$: This is the fundamental cross-entropy component, which measures the "surprise" or error of the prediction. The modulating factor then scales this error.
-
$P$: The predicted mask.
- Mathematical Definition: A 2D matrix (or 3D for volumetric data) of floating-point values, where each element $p_{ij} \in [0, 1]$ represents the predicted probability that pixel $(i,j)$ belongs to the foreground object.
- Physical/Logical Role: This is the output of the FluoroSAM's mask decoder, representing the model's best guess for the segmentation.
-
$G$: The ground truth mask.
- Mathematical Definition: A 2D binary matrix, where each element $g_{ij} \in \{0, 1\}$ indicates whether pixel $(i,j)$ truly belongs to the foreground (1) or background (0).
- Physical/Logical Role: This is the "correct answer" provided by the FluoroSeg dataset, against which the model's predictions are compared to calculate the loss.
-
$p_i, g_i$: Individual pixel probabilities and labels.
- Mathematical Definition: $p_i \in [0, 1]$ is the predicted probability for a single pixel, and $g_i \in \{0, 1\}$ is its corresponding ground truth label.
- Physical/Logical Role: These represent the smallest units of prediction and truth, whose aggregated contributions form the overall mask loss.
-
$\sum$: The summation operator.
- Mathematical Definition: Sums values over a defined set, in this case, all pixels $i=1, \dots, N$ in the image.
- Physical/Logical Role: Aggregates the individual pixel-wise contributions to compute the total Dice and Focal Loss for the entire segmentation mask.
Step-by-Step Flow
Imagine a single X-ray image and a natural language prompt entering the FluoroSAM system, much like items moving along a sophisticated assembly line:
- Image Ingestion (Visual Pathway): An X-ray image, say of a patient's chest, first enters the Image Encoder. This encoder, built on a SwinTransformer backbone, acts like a specialized visual processing unit. It meticulously scans the image, extracting hierarchical visual features at various scales. Think of it as breaking down the image into increasingly abstract representations, from simple edges and textures to complex anatomical patterns.
- Prompt Interpretation (Language Pathway): Simultaneously, a natural language prompt, such as "segment the left lung," is fed into the Text Encoder. This encoder is a multi-stage unit:
- First, a frozen CLIP encoder takes the text and converts it into a high-dimensional numerical embedding, capturing its semantic meaning.
- Next, a Multi-Layer Perceptron (MLP) further processes this embedding, refining its representation.
- Finally, a Vector Quantization (VQ) bottleneck quantizes this refined embedding into a discrete "prompt token." This VQ layer is like a linguistic filter, standardizing the prompt's meaning into a consistent, discrete code that the rest of the model can easily understand, regardless of minor variations in phrasing.
Figure 1. FluoroSAM is trained fully in silico with mask and text prompt pairs. It features a VQ layer that enables training language-aligned training on X-ray images
- Feature Fusion & Mask Generation: The rich visual features from the Image Encoder and the discrete prompt token from the Text Encoder are then brought together. This fusion guides the Mask Decoder, which is the creative engine of the model. Based on the combined visual and linguistic information, the Mask Decoder doesn't just produce one mask; it generates multiple candidate segmentation masks for the requested object. This is like having several skilled artisans each proposing a slightly different outline for the "left lung."
- Loss Evaluation & Selection: For each of these candidate masks, the system calculates its $L_{mask}$ using the Dice and Focal Loss against the true ground truth mask (which is available during training). The model then selects the candidate mask that yields the lowest $L_{mask}$. This selection process ensures that the model is always striving for the most accurate possible segmentation given the prompt.
- Backpropagation & Learning: The loss from the selected mask, specifically from the text prompt, point 1, point 8, and an additional random point prompt, is then used to compute gradients. These gradients are like precise instructions that flow backward through the Mask Decoder and the Image Encoder (the Text Encoder's CLIP part is frozen, but the MLP and VQ components are updated). These instructions tell each parameter in the trainable parts of the network how it needs to adjust to reduce the loss and improve future segmentations. This iterative process of prediction, evaluation, selection, and adjustment is how FluoroSAM learns to accurately segment X-ray images based on natural language.
Optimization Dynamics
FluoroSAM's learning process is a dynamic interplay of loss minimization, gradient-based updates, and strategic data augmentation, all designed to navigate a complex loss landscape and achieve robust performance.
-
Loss Landscape Shaping: The combination of Dice Loss and Focal Loss is crucial for shaping the optimization landscape. Dice Loss, while effective for class imbalance, can sometimes suffer from non-convexity and plateaus, especially when the predicted mask has little overlap with the ground truth. Focal Loss complements this by aggressively down-weighting easy examples, thereby increasing the relative importance of hard-to-classify pixels. This effectively steepens the gradients around challenging regions, preventing the model from getting stuck in local minima or being dominated by easily predicted background pixels. The goal is to create a landscape where the path to better segmentation is clearer and more direct.
-
Gradient Behavior and Updates: During training, the gradients of the $L_{mask}$ (from the selected prompts) are computed with respect to all trainable parameters in the Image Encoder and Mask Decoder, as well as the MLP and VQ components of the Text Encoder. These gradients indicate the direction and magnitude of parameter adjustments needed to decrease the loss. The model parameters are then updated iteratively using an optimizer (typically Adam or a variant, though not explicitly stated in the paper). This iterative process moves the model's "position" in the high-dimensional parameter space towards regions of lower loss, gradually improving its segmentation accuracy.
-
Learning Rate Schedule: The paper specifies a carefully designed learning rate schedule: a linear warm-up from $8 \times 10^{-6}$ to a base rate of $8 \times 10^{-4}$ over 20k iterations, followed by reductions by a factor of 10 at steps 200k and 400k.
- Warm-up: The initial low learning rate prevents large, destabilizing updates when the model parameters are randomly initialized and far from an optimal state. It allows the model to "find its footing" in the loss landscape.
- Decay: Reducing the learning rate later in training helps the model fine-tune its parameters, allowing it to converge more precisely to a minimum without overshooting or oscillating. This is like switching from large, exploratory steps to smaller, more precise adjustments as you approach a target.
-
Vector Quantization (VQ) Dynamics: The VQ bottleneck in the text encoder introduces a discrete element into an otherwise continuous neural network. Training with VQ typically involves techniques like the straight-through estimator to allow gradients to pass through the discrete quantization step. This mechanism forces the text embeddings into a finite set of "codebook" vectors, which helps in learning robust, language-aligned representations. While it theoretically limits generalizability to new classes, it enhances robustness to variable language prompts for known classes by mapping diverse phrasings to consistent discrete tokens. This makes the model less sensitive to the exact wording of a prompt.
-
Robustness through Augmentation and Randomization:
- Text Augmentation: The use of gpt-40 to generate up to 30 diverse prompts for each mask significantly expands the training data's linguistic variability. This makes FluoroSAM robust to different ways users might phrase their segmentation requests, preventing overfitting to specific prompt phrasings.
- Domain Randomization: Applying "strong domain randomization" to the synthetic X-ray images (e.g., coarse dropout, inversion, blurring, contrast adjustment) is a critical strategy for sim-to-real transfer. It forces the model to learn features that are invariant to various image appearances, making it more robust when encountering real-world X-ray images that differ from the synthetic training data. This effectively smooths out the loss landscape by making the model less sensitive to minor input variations.
-
Multi-output and Selection: FluoroSAM's ability to predict multiple masks for a single prompt and then select the one with the lowest loss during training acts as an internal self-correction mechanism. This is akin to an ensemble of predictions, where the best one is chosen, leading to a more reliable and accurate final output. During inference, an IOU prediction head takes over this selection, estimating which mask is most likely correct. This dynamic selection process contributes to the model's overall stability and performance.
Results, Limitations & Conclusion
Experimental Design & Baselines
To rigorously validate FluoroSAM's capabilities, the authors architected a comprehensive experimental setup involving both synthetic and real-world X-ray data, pitting their model against established baselines.
The foundation of FluoroSAM's training is the FluoroSeg dataset, a massive collection of 3 million synthetic X-ray images. This dataset was meticulously generated in silico to simulate a vast array of human anatomies, imaging geometries, and viewing angles, crucial for capturing the variability of real X-ray imaging. The simulation pipeline began with 1,621 high-resolution CT scans from the New Mexico Decedent Image Database [5], which were then segmented into 128 organ classes using TotalSegmentator [27] to derive surface meshes. To mimic diverse radiological exams, the environment sampled both standard views (e.g., chest, abdominal) and fully random C-arm views, focusing on a primary organ with varied angles. Crucially, 464 computer-modeled surgical tools, each with comprehensive text descriptions, were randomly placed within the field of view. Images were rendered at $512^2$ pixels, complete with pseudo-ground truth masks and associated text descriptions. This process was highly efficient, generating 6.5 to 15.7 images per second on an NVIDIA A6000 GPU, totaling 2.95 million images in approximately 6 GPU days. The dataset was split 90/10% for training and validation based on the original CT scans.
FluoroSAM itself, a language-promptable variant of SAM [15], was trained from scratch on FluoroSeg. Its novel text encoder, comprising a frozen CLIP encoder [21], a two-hidden-layer multi-layer perceptron (MLP), and a vector quantization (VQ) bottleneck [20], was central to enabling language alignment. To enhance generalizability, text augmentation was performed using gpt-40 [1] to generate up to 30 diverse prompts per mask. Related organ masks were procedurally combined into 38 groups (e.g., "left ribs"), and "bad prompts" (not present in the image) were occasionally sampled to teach the model to ignore irrelevant queries. The image encoder utilized a SwinTransformer backbone (Swin-L for the final model), pre-trained on ImageNet-22k and further on a reduced set of FluoroSeg classes for instance segmentation. To facilitate sim-to-real transfer, strong domain randomization techniques were applied during training, including coarse dropout, inversion, blurring, Gaussian contrast adjustment [10], random windowing, and CLAHE histogram equalization. Training involved 9 prompts per mask (1 text, 8 points), using Dice and focal loss, with specific loss components backpropagated. The model was trained for 10 epochs over 6 days on 2 NVIDIA H100 GPUs.
For evaluation, FluoroSAM faced off against several "victim" baseline models on real X-ray images:
1. Real Interventional X-ray images: A dataset of registered X-ray images from a full torso specimen (mid-femur to T2) acquired with a Brainlab Loop-X device. Ground truth masks were generated by stitching four navigated cone-beam CT images and projecting organ segmentations [27]. Evaluation was limited to 1,741 masks larger than 2.5% of the image size. Baselines included the original SAM [15] (prompted with points or bounding boxes) and MedSAM [18] (which typically uses bounding box prompts for medical images). Metrics were Intersection over Union (IoU), Dice score, and Hausdorff Distance (HDD).
2. Zero-shot evaluation on Chest X-rays (CXR): A dataset of 1,131 CXRs [2] with hand-annotated lung segmentations. This tested FluoroSAM's ability to generalize to a different X-ray modality and real-world annotations without specific training. The same baselines, SAM and MedSAM, were used, and IoU, Dice, and HDD were reported.
What the Evidence Proves
The experimental evidence definitively proves FluoroSAM's core mechanism—language-promptable segmentation for X-ray images—is effective and often superior to existing methods, even when trained exclusively on synthetic data.
On real interventional X-ray images, FluoroSAM demonstrated its prowess with text-only prompts. As shown in Table 1 and Fig. 3a, FluoroSAM achieved a mean IoU of 0.47 and a Dice score of 0.60. This performance notably outperformed its peers, SAM (IoU 0.36, Dice 0.50 with points; IoU 0.42, Dice 0.57 with boxes) and MedSAM (IoU 0.41, Dice 0.55), when FluoroSAM was given only text prompts. This is a critical piece of evidence, as it validates the ability of FluoroSAM's novel text encoder and VQ layer to interpret natural language and generate accurate segmentations in a challenging real-world scenario. When point prompts were added, FluoroSAM's performance further improved, reaching IoU 0.56 and Dice 0.69 with 2 points, and IoU 0.64, Dice 0.77, and HDD 60.8 with 8 points, consistently outperforming the baselines across these metrics. The definitive evidence here is the direct quantitative comparison where FluoroSAM, with its unique text-prompting capability, either surpassed or matched the performance of models relying on more constrained point or box prompts.
Figure 3. Quantitative results. (a) On interventional X-ray images, FluoroSAM outperforms its peers even with text-only prompting. (b) On CXRs, FluoroSAM adapts to hand-annotated lung segmentations despite being trained on synthetic data. MedSAM [18] includes this task in its training data
The zero-shot evaluation on CXRs provided undeniable proof of FluoroSAM's generalizability and sim-to-real transfer capabilities. Despite being trained solely on synthetic data, FluoroSAM adapted remarkably well to hand-annotated lung segmentations on real CXRs. With text-only prompts, it achieved a mean IoU of 0.50 and a Dice score of 0.66 (Table 1, Fig. 3b). While SAM, when provided with multiple point or box prompts, could achieve higher scores (e.g., IoU 0.83, Dice 0.89 for 2 points), FluoroSAM's performance with 8 points (IoU 0.81, Dice 0.89) was highly competitive, even surpassing SAM's 8-point performance (IoU 0.73, Dice 0.82). This demonstrates that FluoroSAM's training on synthetic data, coupled with robust domain randomization, enables it to generalize to unseen real-world diagnostic X-ray images and tasks, a significant achievement given the systematic differences between synthetic projections and hand-annotated masks.
Furthermore, the qualitative user study (Fig. 4) provided compelling evidence for the efficacy of the VQ layer in improving segmentation robustness to variable text prompts. When asked "What's the bone next to the hip?", FluoroSAM with VQ correctly segmented the femur, whereas without VQ, it failed. This directly supports the authors' claim that VQ helps generalize to new language prompts by reducing variability from disparate descriptions for the same object, making the model more resilient to natural language nuances.
Finally, the qualitative results and downstream applications showcased in Fig. 5 illustrate the practical utility of FluoroSAM. Its flexibility enables efficient X-ray annotation, patient-centered health education, and intelligent robotic C-arm positioning and autonomous collimation, demonstrating that the core mechanism works not just quantitatively but also in enabling rich human-machine interaction in clinical workflows.
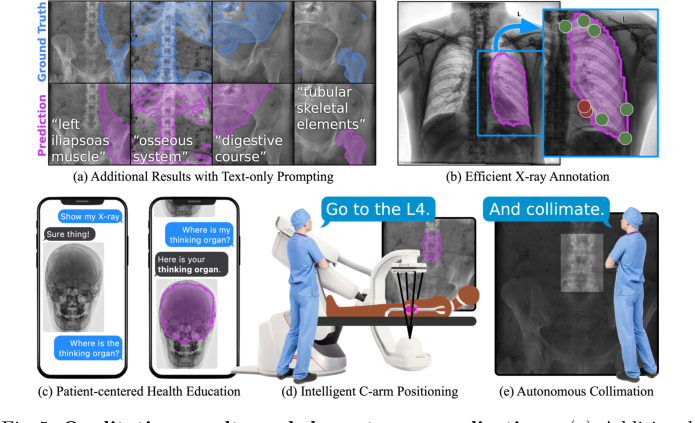 Figure 5. Qualitative results and downstream applications. (a) Additional results on real X-ray images, with text prompts not used during training. The flexibility of text prompting supports a wide variety of downstream applications. (b) Efficient annotation of X-rays can reduce clinical burden and accelerate real data annotation. (c) Flexible text-based prompting may lend itself to patient- facing education, empowering patients to better understand their own anatomy. In the OR, FluoroSAM can be integrated with robotic C-arms to deliver intel- ligent positioning (d) and autonomous collimation (e), reducing radiation [14]. These figures use real FluoroSAM predictions on real radiographs
Figure 5. Qualitative results and downstream applications. (a) Additional results on real X-ray images, with text prompts not used during training. The flexibility of text prompting supports a wide variety of downstream applications. (b) Efficient annotation of X-rays can reduce clinical burden and accelerate real data annotation. (c) Flexible text-based prompting may lend itself to patient- facing education, empowering patients to better understand their own anatomy. In the OR, FluoroSAM can be integrated with robotic C-arms to deliver intel- ligent positioning (d) and autonomous collimation (e), reducing radiation [14]. These figures use real FluoroSAM predictions on real radiographs
Limitations & Future Directions
While FluoroSAM presents a significant leap forward, the authors candidly acknowledge several limitations that also serve as fertile ground for future research and development.
One primary limitation lies in the scope of the FluoroSeg dataset. Although vast at 3 million images, it is still constrained by the number of base CT scans and the variety of anatomical structures represented. Expanding this dataset by incorporating more CT images, potentially from recently released TotalSegmentator tasks or more specialized datasets like fracture fragments [23], is a clear path forward. However, this expansion is computationally intensive, even with the automated pipeline, suggesting a need for continued optimization of the simulation environment.
Another inherent challenge stems from the nature of X-ray images themselves. They are transmissive, leading to overlapping projections where many organs are not plainly visible. This ambiguity makes segmentation a difficult task, and while FluoroSAM performs well, it's a fundamental constraint of the modality. The reliance solely on synthetic data for training, despite its success in sim-to-real transfer, might also introduce subtle systematic differences compared to models trained on real, hand-annotated data, as observed in some CXR results.
The Vector Quantization (VQ) codebook size is identified as a specific architectural limitation. While VQ qualitatively improves robustness to variable text prompts, its fixed size inherently constrains the representational power of text embeddings. This is an acceptable trade-off in the current context, but for supporting an even wider range of anatomical structures and more nuanced prompts, alternative strategies or an evolved VQ mechanism might be necessary. This could involve dynamic codebook expansion or hierarchical VQ approaches.
Looking ahead, the findings from FluoroSAM open up several exciting discussion topics for future development:
- Scalability and Diversity of Synthetic Data: How can we further scale synthetic data generation to encompass an even broader spectrum of pathologies, patient demographics, and imaging artifacts, moving beyond just anatomical variety? Could generative AI models be used to synthesize new CT scans or augment existing ones to create even more diverse training data for FluoroSeg, rather than relying solely on existing CT databases?
- Hybrid Training Paradigms: Given the success of sim-to-real transfer, what are the optimal strategies for combining synthetic and limited real-world annotated data? Could a semi-supervised or self-supervised learning approach, leveraging vast amounts of unlabeled real X-ray data, further boost FluoroSAM's performance and robustness without requiring extensive manual annotation?
- Advanced Language Understanding: How can FluoroSAM evolve to interpret more complex, multi-step, or ambiguous natural language prompts, moving towards "chain-of-thought" based X-ray image analysis [9]? This would require deeper semantic understanding and reasoning capabilities, potentially integrating with large language models more tightly than just for text augmentation.
- Personalization and Adaptability: Can FluoroSAM be adapted to specific patient anatomies or clinical contexts? For instance, could it learn from a small set of patient-specific annotations to improve segmentation accuracy for that individual, or adapt to the unique characteristics of different X-ray machines or protocols? This would be crucial for precision medicine applications.
- Ethical Considerations and Trust: As FluoroSAM integrates into human-in-the-loop workflows, what are the ethical implications of relying on AI for critical medical tasks? How can we ensure transparency, explainability, and build trust in an AI system that interprets natural language prompts for segmentation, especially when dealing with ambiguous or novel queries? The robustness to "bad prompts" is a good start, but more is needed for clinical deployment.
- Multimodal Integration Beyond Text: While language is a powerful prompt, could FluoroSAM benefit from integrating other modalities as prompts, such as physiological signals, patient history, or even haptic feedback in interventional settings? This could provide richer contextual information, further reducing ambiguity and enhancing interaction.
Ultimately, the development of FluoroSAM is a pivotal step towards flexible, language-promptable foundation models in X-ray imaging, promising to unlock new avenues in both diagnostic and interventional medicine. The identified limitations are not roadblocks but rather clear signposts for the next generation of research.
 Figure 4. In a limited user study, we observe qualitative results consistent with the hypothesis that VQ improves segmentation robustness to variable text prompts. For example, FluoroSAM with VQ was able to correctly segment the femur, answering the question “What’s the bone next to the hip?”
Figure 4. In a limited user study, we observe qualitative results consistent with the hypothesis that VQ improves segmentation robustness to variable text prompts. For example, FluoroSAM with VQ was able to correctly segment the femur, answering the question “What’s the bone next to the hip?”