FluoroSAM: 유연한 X-ray 영상 분할을 위한 언어 프롬프트 기반 파운데이션 모델
Language promptable X-ray image segmentation would enable greater flexibility for human-in-the-loop workflows in diagnostic and interventional precision medicine.
배경 및 학술적 계보
기원 및 학술적 계보
FluoroSAM이 해결하고자 하는 문제는 진단 및 중재 정밀 의학 분야에서 보다 유연하고 효율적인 X-ray 영상 분할에 대한 중요하고도 절실한 필요성에서 비롯된다. X-ray 영상은 의료 분야의 근간을 이루는 영상 기법이지만, 그 분석은 역사적으로 특정 작업에 특화된 머신러닝 모델에 의존해 왔다. 이러한 초기 모델들은 좁은 응용 범위 내에서는 효과적이었으나, 새로운 작업에 적응하거나 범위를 확장하기 위해 상당한 추가 데이터, 주석, 그리고 훈련 시간이 필요하다는 중대한 한계를 가지고 있었다. 이는 모델을 경직되게 만들고 광범위한 임상적 사용을 위해 확장하기 어렵게 만들었다.
학계에서는 이러한 제약을 극복할 수 있는 유망한 방향으로 "파운데이션 모델(Foundation Models, FMs)"의 출현, 특히 "언어 정렬 파운데이션 모델(Language-aligned Foundation Models, LFMs)"을 주목하게 되었다. 방대하고 다양한 영상 및 텍스트 데이터로 훈련된 LFMs는 자연어를 사용하여 작업을 지정할 수 있게 함으로써 광범위한 적용 가능성을 제공했다. 그러나 기존의 의료용 LFMs는 주로 대규모의 풍부하게 주석이 달린 데이터셋이 쉽게 이용 가능한 CT 또는 MRI와 같은 영상 기법에 초점을 맞추었다. 대조적으로 X-ray 영상은 매우 가변적인 영상 외형, 다양한 응용 분야(진단용 흉부 X-ray부터 중재적 투시 촬영까지), 그리고 특히 중재 시술에 대한 대규모의 잘 주석이 달린 데이터셋의 부족이라는 독특한 어려움을 제시한다.
기존의 접근 방식, 특히 Segment-Anything Model (SAM) 및 그 후속 모델인 SAM 2와 같은 범용 파운데이션 모델의 중요한 "고충점(pain point)"은 X-ray 영상의 고유한 특성, 특히 텍스트 프롬프트와 함께 처리하는 데 있어 효과적으로 대처하지 못한다는 점이었다. SAM 모델들은 마스크, 경계 상자, 점과 같은 다양한 프롬프트를 기반으로 자연 영상에서 객체를 분할하는 데 탁월하지만, 텍스트 프롬프트 기능은 종종 CLIP과 같은 모델에 의존하는데, 이 모델들은 자연 영상으로 훈련되었다. 이를 X-ray 영상에 직접 적용하는 것은 문제가 있는데, X-ray는 투과성이기 때문에 다양한 해부학적 및 비해부학적 객체의 여러 중첩된 투영을 생성한다. 이러한 고유한 모호성 때문에 단일 영상 패치가 여러 객체의 시각적 특징을 포함할 수 있으며, 이는 자연 영상으로 훈련된 모델이 이를 구별하기 어렵게 만든다. 더욱이, 특히 복잡한 중재 시나리오에 대한 다양하고 고품질의 X-ray 데이터셋의 제한된 가용성은 이 영상 기법을 위한 유연하고 언어 프롬프트 기반의 분할 도구 개발을 심각하게 방해했다. MedSAM과 같은 이전의 의료용 SAM 변형 모델들은 종종 경계 상자로 프롬프트를 제한함으로써 이러한 모호성을 완화했지만, 이는 X-ray 영상에 바람직하지 않다. 왜냐하면 여전히 상당한 모호성을 남기고, 자동 또는 비전문가 프롬프팅을 비실용적으로 만들며, 인간-루프 시스템의 유연성을 감소시키기 때문이다. 본 논문은 합성 데이터 생성을 활용하여 데이터 부족 문제를 극복함으로써 X-ray 도메인에 특화된 언어 프롬프트 기반 파운데이션 모델을 개발하여 이러한 한계를 해결하는 것을 목표로 한다.
직관적인 도메인 용어
- 언어 정렬 파운데이션 모델 (Language-aligned foundation models, LFMs): "왼쪽 폐를 분할해 줘"와 같이 말하거나 입력한 지시를 이해하고, X-ray 영상에서 해당 특정 부분을 식별하고 윤곽을 그리는 것과 같은 복잡한 작업을 수행할 수 있는 초지능 보조원을 상상해 보라. LFMs는 이러한 보조원과 같으며, 방대한 양의 영상과 텍스트 데이터로 훈련되어 단어와 시각적 개념을 연결하는 방법을 학습하므로 매우 다재다능하다.
- 분할 (Segmentation): 영상에서 특정 객체의 정확한 윤곽을 그리기 위해 디지털 형광펜을 사용하는 것과 같다고 생각하라. 의료 영상에서는 이것이 장기, 뼈 또는 의료 기구의 정확한 경계를 그리는 것을 의미한다. 단순히 "폐가 있다"고 말하는 것이 아니라, 폐가 정확히 어디에 있는지 보여주는 것이다.
- 벡터 양자화 (Vector Quantization, VQ): 이것은 시각적 개념의 사전을 가지고 있는 것과 같다. 모델이 새로운 설명이나 영상 특징을 "볼" 때, 사전에서 가장 가까운 항목과 일치시키려고 시도한다. 이는 복잡한 정보를 표준화하고 단순화하는 데 도움이 되며, 설명이 약간 다르더라도 모델이 언어와 영상 간의 일관된 관계를 학습하기 쉽게 만든다. 이는 모델의 개념 이해를 더욱 견고하고 사소한 변화에 덜 민감하게 만드는 방법이다.
- 시뮬레이션-실제 전이 (Sim-to-real transfer): 실제 비행기를 조종하기 전에 비행 시뮬레이터에서 훈련하는 조종사와 유사하다. 이 맥락에서, 이는 매우 사실적인 컴퓨터 생성(시뮬레이션) X-ray 영상으로 AI 모델을 훈련한 다음, 훈련된 모델을 실제, 현실 세계의 X-ray 영상에 적용하는 것을 의미한다. 목표는 시뮬레이션된 데이터로부터 주로 학습했음에도 불구하고 모델이 실제 세계에서 잘 작동하도록 하는 것이며, 이는 종종 대량으로 생산하기가 더 쉽고 저렴하다.
표기법 표
| 표기법 | 설명 |
|---|---|
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
본 논문에서 다루는 핵심 문제는 X-ray 영상 분할, 특히 다양하고 어려운 의료 X-ray 시나리오에 대한 유연하고 일반화 가능하며 언어 프롬프트 기반의 파운데이션 모델이 부족하다는 것이다.
입력/현재 상태:
현재 X-ray 영상 분석은 특정 작업에 특화된 머신러닝 모델에 의존한다. 이러한 모델들은 좁은 범위 내에서 잘 작동하지만, 고정된 설계와 제한된 훈련 데이터로 인해 광범위한 X-ray 도메인에 걸쳐 적용 가능성이 심각하게 제한된다. 이러한 모델을 새로운 클래스나 더 복잡한 쿼리를 지원하도록 확장하려면 상당한 추가 데이터, 주석 및 광범위한 재훈련 노력이 필요하다. 의료 영상에 대한 기존 파운데이션 모델(FM)은 유망하지만, 주로 대규모의 풍부하게 주석이 달린 데이터셋이 쉽게 이용 가능한 영상 기법에 초점을 맞추었다. 그러나 X-ray 영상, 특히 중재적 투시 촬영은 매우 가변적인 영상 외형, 다양한 응용 분야, 그리고 풍부하게 주석이 달린 훈련 데이터의 심각한 부족이라는 독특한 어려움을 제시한다. 더욱이, X-ray 영상은 본질적으로 투과성이므로, 여러 해부학적 및 비해부학적 객체가 종종 투영에서 중첩되어 구별하기가 본질적으로 어렵다. Segment-Anything Model (SAM) 및 그 후속 모델인 SAM 2와 같은 이전의 언어 정렬 FM은 텍스트 프롬프트에 대해 CLIP과 같은 모델에 의존하는데, 이는 자연 영상으로 훈련되었다. X-ray 영상에 이 접근 방식을 효과적으로 전이하는 방법은 객체 경계가 종종 불분명하고 구조가 중첩되어 있기 때문에 즉시 명확하지 않다.
원하는 최종 상태 (출력/목표 상태):
궁극적인 목표는 임의의 의료 X-ray 영상에 대한 포괄적이고 언어 정렬된 분석이 가능한 언어 프롬프트 기반 파운데이션 모델인 FluoroSAM을 개발하는 것이다. 이 모델은 진단 및 중재 정밀 의학에서 인간-루프 워크플로우에 대한 더 큰 유연성을 가능하게 해야 한다. 구체적으로, FluoroSAM은 자연어 프롬프트를 기반으로 수많은 해부학적 구조와 도구를 분할하여 X-ray 영상의 모든 객체에 대해 의미론적으로 의미 있는 마스크를 제공하는 것을 목표로 한다. 이를 통해 대화형 진단 시스템부터 영상 유도 중재의 지능형 인간-기계 인터페이스에 이르기까지 임상 환경에서 보다 직관적이고 효율적인 상호 작용이 가능해진다.
누락된 연결 또는 수학적 격차:
정확한 누락된 연결은 분할을 위해 X-ray 영상의 고유한 시각적 특징과 자연어 프롬프트를 효과적으로 정렬하는 강력하고 일반화 가능한 메커니즘이다. 과제는 고수준의 언어적 설명과 X-ray의 저수준, 종종 모호한 픽셀 정보 간의 격차를 해소하는 데 있다. 본 논문은 FluoroSAM 내에 새로운 텍스트 인코더 아키텍처를 도입하여 이러한 문제를 해결한다. 이 아키텍처는 고정된 CLIP 인코더 위에 벡터 양자화(VQ) 모듈을 통합한다. 이 VQ 계층은 매우 중요하며, 마스크 디코더에 보다 일관된 신호를 제공하여, 해당 영상 기법의 고유한 어려움에도 불구하고 특히 X-ray 영상에 대한 훈련 중에 효과적인 언어 정렬을 가능하게 한다. 이러한 아키텍처 혁신을 통해 모델은 텍스트 프롬프트가 X-ray 영상에서 분할을 정확하게 안내할 수 있는 공유 표현 공간을 학습할 수 있다.
고통스러운 절충 또는 딜레마:
이전 연구자들이 갇혀 있던 중심 딜레마는 모델의 일반화/유연성과 고품질, 주석이 달린 X-ray 데이터의 가용성 간의 절충이다. 광범위한 적용 가능성과 언어 프롬프트 기능(LFMs와 같은)을 달성하려면 일반적으로 방대한 양의 주석이 달린 데이터셋이 필요하다. 그러나 X-ray 영상, 특히 중재 시술의 경우 이러한 데이터가 심각하게 부족하다. 이는 유연성이 부족하지만 잘 작동하는 좁은 작업별 모델을 개발하거나, 데이터 부족과 X-ray 영상 해석의 고유한 어려움으로 인해 어려움을 겪는 일반화 가능한 모델을 구축하려는 시도 중 하나를 선택하도록 강요한다. X-ray의 투과성 특성은 이러한 문제를 더욱 악화시키는데, 한 측면(예: 중첩된 구조 분할)을 개선하면 종종 모호성이 도입되거나 더 복잡하고 데이터 집약적인 솔루션이 필요하다. 예를 들어, MedSAM이 다른 의료 영상 기법에 대해 경계 상자 프롬프트를 사용하지만, 이는 인간-기계 상호 작용의 유연성과 자연스러움을 심각하게 제한하는데, 이는 언어 프롬프트 시스템의 핵심 이점이다.
제약 조건 및 실패 모드
언어 프롬프트 기반 X-ray 영상 분할 문제는 다음과 같은 여러 가지 가혹하고 현실적인 제약 조건으로 인해 매우 어렵다.
-
물리적 제약 조건:
- 투과성 및 중첩 투영: X-ray 영상은 신체를 통과하는 X-선의 투과에 의해 형성되며, 많은 해부학적 및 비해부학적 객체(예: 도구)가 종종 중첩되는 2D 투영을 생성한다. 이러한 고유한 특성은 인간 전문가에게도 개별 구조를 구별하기 매우 어렵게 만들며, 자동 분할에 심각한 장애물을 제시한다. 많은 장기가 명확하게 보이지 않아 작업이 더욱 복잡해진다.
- 영상 외형 및 응용 분야의 높은 가변성: X-ray 영상은 진단용 흉부 X-ray부터 중재적 투시 촬영에 이르기까지 광범위한 응용 분야를 포함한다. 이는 인간 해부학, 영상 기하학, 시야각 및 영상 강도 값의 엄청난 가변성을 초래한다. 모델은 제한된 데이터로는 달성하기 어려운 이러한 광범위한 다양성에 대해 견고해야 한다.
-
계산적 제약 조건:
- 데이터 생성 및 훈련을 위한 높은 계산 비용: 데이터 부족을 극복하기 위해 저자들은 3백만 개의 X-ray 영상으로 구성된 대규모 합성 데이터셋(FluoroSeg)을 생성했다. 이 시뮬레이션 프로세스 자체는 계산 집약적이며, NVIDIA A6000 GPU에서 약 6 GPU 일의 시간이 소요된다. 이 데이터셋에서 FluoroSAM을 훈련하는 데도 상당한 리소스가 필요하며, 2개의 NVIDIA H100 GPU에서 6일이 소요된다. 이는 이러한 모델 개발과 관련된 상당한 계산 부담을 강조한다.
- VQ 코드북 크기 제한: 벡터 양자화(VQ) 모듈이 가변적인 텍스트 프롬프트에 대한 견고성을 향상시키지만, 코드북 크기는 본질적으로 텍스트 임베딩의 표현력을 제한한다. 이 설계 선택은 일관성에 유익하지만, 이론적으로는 프레임워크의 일반화 가능성을 무한히 넓은 범위의 새로운 분할 클래스나 매우 새로운 언어 프롬프트로 제한한다.
-
데이터 기반 제약 조건:
- 주석이 달린 실제 X-ray 데이터의 극심한 희소성: 이것은 아마도 가장 중요한 제약 조건일 것이다. X-ray 영상, 특히 중재적 X-ray 영상에 대한 대규모의 풍부하게 주석이 달린 데이터셋이 심각하게 부족하다. 이러한 희소성은 실제 데이터에 대한 강력한 언어 정렬 파운데이션 모델의 직접적인 훈련을 방지하여 합성 데이터에 의존하게 만든다.
- 도메인 격차 (시뮬레이션-실제 전이): 합성 데이터를 사용하여 훈련하는 것은 필요하지만, 시뮬레이션된 영상과 실제 X-ray 영상 간의 도메인 격차를 도입한다. 훈련 중에 적용된 강력한 도메인 무작위화 기법(예: 거친 드롭아웃, 반전, 블러링, 가우시안 대비 조정, 무작위 윈도잉, CLAHE 히스토그램 평활화)에도 불구하고, 합성 데이터는 실제 손으로 주석이 달린 마스크와 체계적으로 다를 수 있으며, 실제 시나리오에서의 성능에 영향을 미칠 수 있다.
- 합성 데이터의 제한된 다양성: FluoroSeg와 같은 대규모 합성 데이터셋에도 불구하고, 사용된 기본 CT 스캔 수와 표현된 해부학적 구조의 다양성에는 여전히 한계가 있다. 이러한 다양성을 확장하는 것은 계산 집약적이지만 확장 가능하다.
- 자연어 프롬프트의 모호성: 자연어 프롬프트 자체는 X-ray 영상의 중첩된 구조를 참조할 때 특히 모호할 수 있다. 모델은 "나쁜 프롬프트"를 무시하도록 설계되어야 하며, 주어진 프롬프트에 대해 여러 마스크를 예측하여 가장 정확한 분할을 선택할 수 있도록 해야 한다. 이는 모델의 출력 및 추론 프로세스에 복잡성을 더한다.
왜 이 접근 방식인가
선택의 불가피성
Segment-Anything Model (SAM)의 언어 프롬프트 기반 변형으로, 특히 X-ray 영상 분할에 특화된 FluoroSAM의 채택은 기존의 최첨단(SOTA) 방법의 고유한 한계를 고려할 때 단순한 선택이 아니라 불가피한 필요성이었다. 저자들은 전통적인 특정 작업 머신러닝 모델이 좁은 범위 내에서는 효과적이지만, 더 넓은 응용 분야로 유용성을 확장하기 위해 막대한 양의 추가 데이터, 주석 및 훈련 시간을 요구한다는 것을 깨달았다. 이는 특히 X-ray 영상 기법에 문제가 되었는데, 이는 매우 가변적인 영상 외형, 다양한 응용 분야(진단용 흉부 X-ray부터 중재적 투시 촬영까지), 그리고 결정적으로 대규모의 풍부하게 주석이 달린 데이터셋의 부족으로 특징지어진다.
결정적인 깨달음의 순간은 아마도 원래 SAM 또는 그 후속 모델인 SAM 2와 같은 저명한 언어 정렬 파운데이션 모델(LFM)의 직접적인 적용을 고려할 때 발생했을 것이다. 이러한 모델은 텍스트 프롬프트를 지원하지만, 근본적으로 이미지 패치를 언어 정렬 임베딩으로 변환하기 위해 CLIP [21]과 같은 사전 훈련된 LFM에 의존한다. 결정적인 통찰력은 CLIP이 주로 자연 영상으로 훈련되었기 때문에 X-ray 도메인으로 효과적으로 전이되지 않을 것이라는 점이었다. X-ray 영상은 투과성이며, 이는 명확한 경계와 중첩된 구조를 가진 자연 영상과 대조적으로, 수많은 중첩된 마스크를 포함한다. X-ray에 특화된 CLIP과 유사한 모델이 존재하더라도, 단일 이미지 패치는 여전히 여러 중첩된 객체의 시각적 특징을 포함하게 되어 명확한 구별이 극도로 어려워질 것이다. X-ray의 시각적 특성과 자연 영상으로 훈련된 모델의 가정 간의 이러한 근본적인 불일치는 기존 SOTA LFM의 직접적인 적용을 불충분하게 만들어 FluoroSAM과 같은 맞춤형 솔루션을 필요로 했다.
비교 우위
FluoroSAM의 질적 우수성은 X-ray 영상의 고유한 어려움을 극복하도록 설계된 구조적 혁신에서 비롯되며, 이 특정 도메인에서 이전의 황금 표준보다 압도적으로 우수하다. X-ray의 투과성 및 중첩된 해부학적 구조와 어려움을 겪는 모델과 달리, 고정된 CLIP 인코더 위에 벡터 양자화(VQ) 모듈을 통합한 FluoroSAM의 새로운 텍스트 인코더는 마스크 디코더에 보다 일관된 신호를 제공한다. 이 VQ 계층은 매우 중요하며, 이론적으로 완전히 새로운 분할 클래스에 대한 일반화 가능성을 제한하지만, 동일한 객체에 대한 다양한 설명에서 발생하는 변동성을 줄임으로써 새로운 언어 프롬프트에 대한 일반화 가능성을 크게 확장한다. 이는 FluoroSAM이 인간-루프 워크플로우에 대한 핵심 이점인 다양한 자연어 입력에 대해 더 견고하다는 것을 의미한다.
더욱이, 방대한 합성 FluoroSeg 데이터셋(3백만 개의 X-ray 영상)에서 처음부터 훈련할 수 있는 FluoroSAM의 능력은 구조적 이점을 제공한다. 이는 실제 X-ray 영상에 대한 결정적인 데이터 부족 문제를 우회하여, 실제 세계 데이터만으로는 불가능했을 광범위한 인간 해부학, 영상 기하학 및 시야각에 걸쳐 강력한 특징을 학습할 수 있게 한다. 정량적으로, FluoroSAM은 특히 텍스트 전용 프롬프팅에서 SAM 및 MedSAM을 능가하며, 실제 중재적 X-ray 영상에서 평균 IoU 0.47 및 Dice 점수 0.60을 달성한다. 2개의 점을 사용하더라도 FluoroSAM은 0.56 IoU 및 0.69 Dice를 달성하여 SAM 및 MedSAM을 능가한다. 예를 들어, MedSAM은 종종 "기저 해부학을 반영하지 못하고 단순히 제공된 상자를 채운다"고 언급하는데, 이는 경계 상자 제약을 넘어서는 질적 실패를 나타낸다. FluoroSAM의 다중 출력 기능은 각 프롬프트에 대해 여러 마스크를 예측하고 최적의 마스크를 선택함으로써 견고성과 유연성을 더욱 향상시켜 모호한 프롬프트를 더 잘 처리할 수 있게 한다. 이러한 구조적 설계는 메모리 복잡성을 $O(N^2)$에서 $O(N)$으로 줄이는 것이 아니라 질적 이해와 프롬프트 견고성을 개선함으로써, 다른 모델이 실패하는 도메인에서 유연하고 언어 정렬된 분할을 제공할 수 있도록 한다.
제약 조건과의 정렬
선택된 FluoroSAM 접근 방식은 X-ray 영상 분할의 가혹한 요구 사항과 완벽하게 정렬되어 "문제와 해결책의 결합"을 형성한다. 문제 정의에서 추론한 주요 제약 조건은 다음과 같다.
- 광범위한 적용 가능성 및 유연성 필요성: 전통적인 모델은 너무 협소하다. 언어 프롬프트 기반 파운데이션 모델로서 FluoroSAM은 본질적으로 광범위한 적용 가능성을 위해 설계되었으며, "자연어 프롬프트를 기반으로 수많은 해부학적 구조와 도구를 분할"할 수 있다 (1페이지). 이러한 유연성은 다양한 진단 및 중재 시나리오에 매우 중요하다.
- 풍부하게 주석이 달린 X-ray 데이터셋의 희소성: 이것은 아마도 가장 중요한 제약 조건일 것이다. X-ray 영상, 특히 중재 시술에 대한 풍부하게 주석이 달린 데이터셋이 심각하게 부족하다. FluoroSAM은 "다양한 인간 해부학, 영상 기하학 및 시야각의 광범위한 합성 X-ray 영상 3백만 개에서 처음부터 훈련"함으로써 이를 해결한다 (1페이지). FluoroSeg 데이터셋 생성은 이러한 데이터 병목 현상에 대한 직접적인 대응으로, 희소한 실제 데이터 주석에 의존하지 않고도 강력한 훈련을 가능하게 한다.
- X-ray 영상의 고유한 시각적 특성: X-ray는 투과성이며 중첩된 객체를 포함하여 명확한 경계 감지가 자연 영상으로 훈련된 모델에게 어렵다. FluoroSAM의 VQ를 포함한 새로운 텍스트 인코더는 이를 처리하기 위해 특별히 설계되었다. VQ 모듈은 동일한 객체에 대한 다양한 텍스트 설명에서 발생하는 변동성을 줄이는 데 도움이 되어, 마스크 디코더에 보다 일관된 신호를 제공하며, 이는 X-ray에서 중첩된 구조를 구별하는 데 필수적이다.
- 자연어 상호 작용 요구 사항: 직관적인 인간-루프 워크플로우를 가능하게 하고 모호성을 줄이기 위해. FluoroSAM의 핵심 설계는 "SAM의 언어 프롬프트 기반 변형"으로서 이를 직접적으로 충족시키며, 사용자가 복잡한 X-ray 장면에서 점 또는 경계 상자 프롬프트만 사용하는 것보다 훨씬 더 유연하고 모호하지 않은 자연어를 사용하여 분할 대상을 지정할 수 있게 한다.
- X-ray 유형 전반의 일반화 가능성: 다양한 시뮬레이션된 해부학, 기하학 및 시야각을 갖춘 FluoroSeg 데이터셋은 FluoroSAM이 진단용 흉부 X-ray부터 중재적 투시 촬영에 이르기까지 다양한 X-ray 응용 분야에 걸쳐 일반화되도록 훈련되었음을 보장한다. 이는 훈련 데이터에 대한 제로샷 평가에서 성공적으로 입증되었다.
대안의 거부
이 논문은 언어 프롬프트 기반 X-ray 영상 분할이라는 특정 문제에 대해 여러 인기 있는 대안적 접근 방식이 왜 실패했거나 불충분했는지 명시적으로 설명한다.
첫째, 전통적인 특정 작업 머신러닝 모델은 좁은 범위 내에서 작동하고 더 넓은 사용 또는 새로운 클래스에 대한 광범위한 추가 데이터, 주석 및 재훈련을 요구하기 때문에 거부되었다 (1페이지). 이는 유연하고 광범위하게 적용 가능한 파운데이션 모델을 개발하려는 목표와 모순된다.
둘째, SAM 및 SAM 2와 같은 기존 파운데이션 모델의 직접적인 적용, 특히 텍스트 프롬프트에 대한 CLIP 의존성은 부적합한 것으로 간주되었다. 저자들은 CLIP이 자연 영상으로 훈련되었기 때문에 X-ray 영상의 투과성 및 명확한 경계가 없는 중첩 객체의 빈도와 같은 고유한 특성과 어려움을 겪는다고 강조한다 (2-3페이지). CLIP과 유사한 모델이 X-ray에 맞게 조정되더라도, 단일 이미지 패치 내에서 여러 객체를 구별하는 것은 여전히 문제가 될 것이다. 이러한 근본적인 비호환성은 VQ를 포함한 FluoroSAM의 새로운 텍스트 인코더 개발로 이어졌다.
셋째, MedSAM [18]은 다른 도메인에서 성공했음에도 불구하고 X-ray 응용 분야에 대해 거부되었다. MedSAM은 주로 모호성을 완화하기 위해 경계 상자 프롬프트에 의존한다 (5페이지). X-ray 영상의 경우, 이 접근 방식은 다음과 같은 이유로 바람직하지 않다. (a) 중첩된 구조로 인해 여전히 상당한 모호성을 특징으로 하며, (b) 자동 또는 비전문가 프롬프팅을 비실용적으로 만들고, (c) 고급 인간-루프 시스템에 필요한 유연성이 부족하다 (5페이지). 본 논문은 또한 MedSAM이 "일반적으로 기저 해부학을 반영하지 못하고 단순히 제공된 상자를 채운다"고 언급하며 (7페이지), 경계 상자에 의해 제한될 때 영상 내용을 이해하는 질적 실패를 나타낸다.
마지막으로, 점 프롬프트와 함께 사용된 원래 SAM의 성능조차도 열등한 것으로 밝혀졌으며, FluoroSAM의 성능에 비해 "점점 더 잘못된 마스크"를 예측했다 (7페이지). 이는 SAM이 프롬프트 기능을 제공하지만, FluoroSAM에 도입된 특정 조정 없이는 X-ray 분할의 복잡성에 대해 근본적인 아키텍처와 훈련 데이터가 충분히 강력하지 않음을 시사한다.
이 논문은 분할 작업 자체에 대해 GAN 또는 확산 모델과 같은 다른 생성 모델의 거부를 명시적으로 논의하지 않는데, 이는 프롬프트 기반 분할과 X-ray 도메인에서 기존 파운데이션 모델의 한계에 초점을 맞추기 때문이다. 대안을 거부하는 핵심 이유는 일관되게 X-ray의 고유한 시각적 속성, 데이터 부족 및 유연한 언어 정렬 상호 작용의 결정적인 필요성을 처리하지 못한다는 점에 있다.
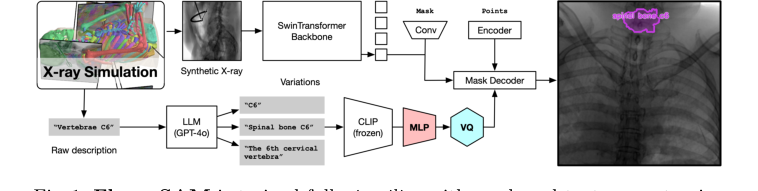 Figure 1. FluoroSAM is trained fully in silico with mask and text prompt pairs. It features a VQ layer that enables training language-aligned training on X-ray images
Figure 1. FluoroSAM is trained fully in silico with mask and text prompt pairs. It features a VQ layer that enables training language-aligned training on X-ray images
수학적 및 논리적 메커니즘
마스터 방정식
다른 많은 분할 모델과 마찬가지로 FluoroSAM의 학습 메커니즘의 핵심은 모델이 정확한 마스크를 생성하도록 안내하는 손실 함수에 있다. 논문은 여러 프롬프트와 선택 기준을 포함하는 복잡한 훈련 규정을 설명하지만, 단일 예측 마스크를 해당 실제 마스크와 비교하여 평가하는 근본적인 목표는 Dice Loss와 Focal Loss의 조합이다. 논문은 "우리는 마스크에 대해 Dice 및 focal loss를 사용한다"고 명시한다. 따라서 단일 마스크 예측에 대한 목표를 나타내는 마스터 방정식은 다음과 같이 표현될 수 있다.
$$ L_{mask}(P, G) = \lambda_{Dice} L_{Dice}(P, G) + \lambda_{Focal} L_{Focal}(P, G) $$
여기서 $P$는 예측된 분할 마스크(확률 행렬)를 나타내고 $G$는 이진 실제 마스크를 나타낸다. 개별 손실 구성 요소는 다음과 같이 정의된다.
$$ L_{Dice}(P, G) = 1 - \frac{2 \sum_{i=1}^N p_i g_i}{\sum_{i=1}^N p_i^2 + \sum_{i=1}^N g_i^2} $$
$$ L_{Focal}(P, G) = - \sum_{i=1}^N \left( g_i \alpha (1-p_i)^\gamma \log(p_i) + (1-g_i) (1-\alpha) p_i^\gamma \log(1-p_i) \right) $$
항별 분석
이러한 방정식을 해부하여 각 구성 요소의 역할을 이해해 보자.
-
$L_{mask}(P, G)$: 이것은 실제 $G$에 대한 단일 예측 마스크 $P$의 전체 손실 값이다.
- 수학적 정의: 일반적으로 0에서 1 사이(또는 Focal Loss의 경우 더 높음)의 스칼라 값으로, 예측된 분할과 실제 분할 간의 불일치를 정량화한다.
- 물리적/논리적 역할: 이것은 FluoroSAM 모델이 훈련 중에 최소화하려고 노력하는 주요 목적 함수이다. $L_{mask}$가 낮을수록 분할이 더 정확하다는 것을 나타낸다.
- 덧셈을 사용하는 이유: $L_{Dice}$와 $L_{Focal}$을 결합하기 위한 덧셈의 사용은 전체 분할 목표에 대한 주석 신호에 대한 기여을 모두 동시에 허용하여, 두 손실 중 하나만 단독으로 사용하는 것보다 더 포괄적이고 균형 잡힌 최적화 대상이 된다.
-
$\lambda_{Dice}$: Dice Loss 구성 요소의 가중치 계수이다.
- 수학적 정의: 양의 스칼라 상수이다. 논문은 명시적으로 값을 명시하지 않지만, 일반적으로 하이퍼파라미터 튜닝을 통해 설정된다.
- 물리적/논리적 역할: 이 계수는 전체 분할 목표에서 (Dice Loss로 측정된) 높은 중첩 달성의 중요성과 (Focal Loss로 측정된) 어려운 예시 픽셀에 집중하는 것의 상대적 중요성을 제어한다.
- 곱셈을 사용하는 이유: 곱셈은 복합 손실 함수 내에서 특정 손실 항의 기여를 확장하는 표준 방법이다.
-
$L_{Dice}(P, G)$: Dice Loss 구성 요소이다.
- 수학적 정의: $1 - \frac{2 \sum_{i=1}^N p_i g_i}{\sum_{i=1}^N p_i^2 + \sum_{i=1}^N g_i^2}$. 여기서 $p_i$는 픽셀 $i$에 대한 예측 확률이고, $g_i$는 픽셀 $i$에 대한 실제 레이블(0 또는 1)이다. 합계 $\sum_{i=1}^N$은 영상의 모든 $N$ 픽셀에 걸쳐 있다.
- 물리적/논리적 역할: 이 항은 주로 예측된 마스크와 실제 마스크 간의 공간적 중첩을 측정한다. 이는 예측된 마스크가 실제 객체의 모양과 범위를 밀접하게 일치하도록 하여 모델이 마스크를 생성하도록 장려한다.
- 1에서 빼는 이유: Dice 계수 자체는 0(중첩 없음)에서 1(완벽한 중첩)까지의 유사성 측정값이다. 이를 1에서 빼면 손실 함수로 변환되며, 여기서 0은 완벽한 분할을 나타내고 1은 완전한 불일치를 나타낸다.
- 분모에 제곱의 합을 사용하는 이유: 확률적 예측($p_i \in [0,1]$)의 경우, 분모에 $p_i^2$ 및 $g_i^2$를 사용하면 집합 크기(요소 수)의 개념을 연속 확률로 일반화하여 손실 함수를 미분 가능하게 만들고 기울기 기반 최적화에 적합하게 만든다.
-
$\lambda_{Focal}$: Focal Loss 구성 요소의 가중치 계수이다.
- 수학적 정의: 일반적으로 하이퍼파라미터 튜닝을 통해 결정되는 양의 스칼라 상수이다.
- 물리적/논리적 역할: $\lambda_{Dice}$와 유사하게, 이 계수는 전체 손실에서 Focal Loss의 영향을 조정하여, 어려운 예시에 대한 집중을 Dice Loss의 전체 중첩 강조와 균형을 맞춘다.
- 곱셈을 사용하는 이유: 손실 항의 표준 확장 메커니즘이다.
-
$L_{Focal}(P, G)$: Focal Loss 구성 요소이다.
- 수학적 정의: $- \sum_{i=1}^N \left( g_i \alpha (1-p_i)^\gamma \log(p_i) + (1-g_i) (1-\alpha) p_i^\gamma \log(1-p_i) \right)$.
- 물리적/논리적 역할: 이 손실은 잘 분류된 예시(쉬운 음성)의 기여를 줄이고 어려운, 잘못 분류된 예시에 대한 모델의 훈련을 집중시킴으로써 클래스 불균형 문제를 해결한다. X-ray 영상에서 배경 픽셀은 종종 전경 픽셀보다 훨씬 많으며, Focal Loss는 모델이 쉬운 배경 예측에 압도되지 않도록 한다.
- $\alpha$를 사용하는 이유: 이것은 양성 클래스의 가중치 요소이다. 이는 양성 및 음성 예시의 중요성을 균형 있게 조절하는데, 한 클래스가 본질적으로 더 중요하거나 드문 경우 유용할 수 있다.
- $(1-p_i)^\gamma$ 또는 $p_i^\gamma$를 사용하는 이유: 이것들은 변조 요소이다. 픽셀이 잘 분류되면(예: $g_i=1$일 때 $p_i$가 높음), $(1-p_i)$는 작고, $(1-p_i)^\gamma$는 더 작아지며($\gamma > 0$인 경우), 손실 기여를 효과적으로 줄인다. 반대로, 잘못 분류된 픽셀의 경우, 요소는 1에 가깝고 손실은 상당하게 유지된다. 이 메커니즘은 어려운 예시에 학습을 "집중"시킨다.
- $\log(p_i)$를 사용하는 이유: 이것은 예측의 "놀라움" 또는 오류를 측정하는 기본적인 교차 엔트로피 구성 요소이다. 변조 요소는 이 오류를 확장한다.
-
$P$: 예측된 마스크이다.
- 수학적 정의: 각 요소 $p_{ij} \in [0, 1]$가 픽셀 $(i,j)$가 전경 객체에 속할 예측 확률을 나타내는 2D 행렬(또는 볼륨 데이터의 경우 3D)이다.
- 물리적/논리적 역할: 이것은 FluoroSAM의 마스크 디코더의 출력으로, 모델이 요청된 객체에 대한 최선의 분할 추측을 나타낸다.
-
$G$: 실제 마스크이다.
- 수학적 정의: 각 요소 $g_{ij} \in \{0, 1\}$가 픽셀 $(i,j)$가 실제로 전경(1) 또는 배경(0)에 속하는지 여부를 나타내는 2D 이진 행렬이다.
- 물리적/논리적 역할: 이것은 FluoroSeg 데이터셋에서 제공하는 "정답"으로, 모델의 예측이 손실을 계산하기 위해 비교된다.
-
$p_i, g_i$: 개별 픽셀 확률 및 레이블이다.
- 수학적 정의: $p_i \in [0, 1]$는 단일 픽셀에 대한 예측 확률이고, $g_i \in \{0, 1\}$는 해당 실제 레이블이다.
- 물리적/논리적 역할: 이것들은 예측 및 실제의 가장 작은 단위로, 이들의 집계된 기여가 전체 마스크 손실을 형성한다.
-
$\sum$: 합계 연산자이다.
- 수학적 정의: 정의된 집합, 이 경우 영상의 모든 픽셀 $i=1, \dots, N$에 걸쳐 값을 합산한다.
- 물리적/논리적 역할: 전체 분할 마스크에 대한 총 Dice 및 Focal Loss를 계산하기 위해 개별 픽셀별 기여를 집계한다.
단계별 흐름
단일 X-ray 영상과 자연어 프롬프트가 정교한 조립 라인을 따라 항목이 이동하는 것처럼 FluoroSAM 시스템으로 들어가는 것을 상상해 보라.
- 영상 입력 (시각 경로): 흉부 환자의 X-ray 영상이 먼저 영상 인코더로 들어간다. 특화된 시각 처리 장치와 같은 이 인코더는 SwinTransformer 백본을 기반으로 한다. 이 인코더는 영상을 세심하게 스캔하여 다양한 스케일에서 계층적 시각 특징을 추출한다. 이는 영상을 단순한 에지 및 질감에서 복잡한 해부학적 패턴으로 점진적으로 추상화된 표현으로 분해하는 것과 같다.
- 프롬프트 해석 (언어 경로): 동시에 "왼쪽 폐를 분할해 줘"와 같은 자연어 프롬프트가 텍스트 인코더로 공급된다. 이 인코더는 다단계 장치이다.
- 먼저, 고정된 CLIP 인코더가 텍스트를 받아 의미론적 의미를 포착하는 고차원 숫자 임베딩으로 변환한다.
- 다음으로, 다층 퍼셉트론(MLP)이 이 임베딩을 추가로 처리하여 표현을 정제한다.
- 마지막으로, 벡터 양자화(VQ) 병목 현상이 이 정제된 임베딩을 이산적인 "프롬프트 토큰"으로 양자화한다. 이 VQ 계층은 언어 필터와 같아서, 나머지 모델이 쉽게 이해할 수 있도록 프롬프트의 의미를 일관되고 이산적인 코드로 표준화하며, 구문의 사소한 변형에 관계없이 작동한다.
- 특징 융합 및 마스크 생성: 영상 인코더의 풍부한 시각 특징과 텍스트 인코더의 이산 프롬프트 토큰이 함께 가져와진다. 이 융합은 모델의 창의적인 엔진인 마스크 디코더를 안내한다. 결합된 시각 및 언어 정보를 기반으로, 마스크 디코더는 단 하나의 마스크를 생성하는 것이 아니라 요청된 객체에 대해 여러 개의 후보 분할 마스크를 생성한다. 이는 마치 숙련된 장인 여러 명이 "왼쪽 폐"에 대해 약간 다른 윤곽을 각각 제안하는 것과 같다.
- 손실 평가 및 선택: 이러한 각 후보 마스크에 대해 시스템은 실제 실제 마스크(훈련 중에 사용 가능)에 대해 Dice 및 Focal Loss를 사용하여 $L_{mask}$를 계산한다. 그런 다음 시스템은 가장 낮은 $L_{mask}$를 생성하는 후보 마스크를 선택한다. 이 선택 프로세스는 모델이 프롬프트에 따라 가능한 가장 정확한 분할을 항상 추구하도록 보장한다.
- 역전파 및 학습: 선택된 마스크(특히 텍스트 프롬프트, 점 1, 점 8 및 추가 무작위 점 프롬프트)의 손실은 기울기를 계산하는 데 사용된다. 이러한 기울기는 마스크 디코더와 영상 인코더(텍스트 인코더의 CLIP 부분은 고정되어 있지만 MLP 및 VQ 구성 요소는 업데이트됨)를 통해 역방향으로 흐르는 정확한 지침과 같다. 이러한 지침은 각 매개변수가 손실을 줄이고 향후 분할을 개선하기 위해 어떻게 조정되어야 하는지를 네트워크의 훈련 가능한 부분에 알려준다. 이러한 반복적인 예측, 평가, 선택 및 조정 프로세스를 통해 FluoroSAM은 자연어 기반으로 X-ray 영상을 정확하게 분할하는 방법을 학습한다.
최적화 역학
FluoroSAM의 학습 과정은 손실 최소화, 기울기 기반 업데이트 및 전략적 데이터 증강의 역동적인 상호 작용으로, 복잡한 손실 지형을 탐색하고 강력한 성능을 달성하도록 설계되었다.
-
손실 지형 형성: Dice Loss와 Focal Loss의 조합은 최적화 지형을 형성하는 데 중요하다. Dice Loss는 클래스 불균형에 효과적이지만, 예측된 마스크가 실제 마스크와 거의 중첩되지 않을 때 비볼록성과 평탄화 현상이 발생할 수 있다. Focal Loss는 쉬운 예시의 중요성을 적극적으로 줄임으로써 이를 보완하여, 잘못 분류된 예시에 대한 상대적 중요성을 높인다. 이는 어려운 영역 주변의 기울기를 효과적으로 가파르게 만들어 모델이 지역 최소값에 갇히거나 쉽게 예측되는 배경 픽셀에 압도되는 것을 방지한다. 목표는 더 명확하고 직접적인 분할 개선 경로를 제공하는 지형을 만드는 것이다.
-
기울기 동작 및 업데이트: 훈련 중에 $L_{mask}$의 기울기(선택된 프롬프트에서)는 영상 인코더 및 마스크 디코더의 모든 훈련 가능한 매개변수와 텍스트 인코더의 MLP 및 VQ 구성 요소에 대해 계산된다. 이러한 기울기는 손실을 감소시키기 위해 필요한 매개변수 조정의 방향과 크기를 나타낸다. 그런 다음 모델 매개변수는 반복적으로 최적화 프로그램(일반적으로 Adam 또는 그 변형, 논문에서 명시적으로 언급되지 않음)을 사용하여 업데이트된다. 이 반복적인 프로세스는 모델의 "위치"를 고차원 매개변수 공간에서 낮은 손실 영역으로 이동시켜 분할 정확도를 점진적으로 향상시킨다.
-
학습률 스케줄: 논문은 신중하게 설계된 학습률 스케줄을 명시한다. 20k 반복에 걸쳐 $8 \times 10^{-6}$에서 기본 속도 $8 \times 10^{-4}$까지 선형 워밍업한 후, 200k 및 400k 단계에서 10배씩 감소한다.
- 워밍업: 초기 낮은 학습률은 모델 매개변수가 무작위로 초기화되고 최적 상태에서 멀리 떨어져 있을 때 크고 불안정한 업데이트를 방지한다. 이는 모델이 손실 지형에서 "발판을 찾도록" 한다.
- 감쇠: 훈련 후반에 학습률을 줄이면 모델이 매개변수를 미세 조정하여 과도하게 넘어서거나 진동하지 않고 더 정확하게 최소값으로 수렴할 수 있다. 이는 목표에 접근할 때 큰 탐색적 단계에서 더 작고 정밀한 조정으로 전환하는 것과 같다.
-
벡터 양자화 (VQ) 역학: 텍스트 인코더의 VQ 병목 현상은 연속적인 신경망에 이산적인 요소를 도입한다. VQ를 사용한 훈련은 일반적으로 이산 양자화 단계를 통해 기울기가 통과하도록 허용하는 스트레이트-쓰루 추정기와 같은 기술을 포함한다. 이 메커니즘은 텍스트 임베딩을 "코드북" 벡터의 유한 집합으로 강제하여, 강력하고 언어 정렬된 표현을 학습하는 데 도움이 된다. 이는 새로운 클래스에 대한 일반화 가능성을 이론적으로 제한하지만, 다양한 구문에서 일관된 이산 토큰으로 매핑함으로써 알려진 클래스에 대한 가변적인 언어 프롬프트에 대한 견고성을 향상시킨다. 이는 모델이 프롬프트의 정확한 문구에 덜 민감하게 만든다.
-
증강 및 무작위화를 통한 견고성:
- 텍스트 증강: gpt-40을 사용하여 각 마스크에 대해 최대 30개의 다양한 프롬프트를 생성하는 것은 훈련 데이터의 언어적 다양성을 크게 확장한다. 이는 FluoroSAM을 사용자가 분할 요청을 표현하는 다양한 방식에 대해 견고하게 만들어 특정 프롬프트 구문에 대한 과적합을 방지한다.
- 도메인 무작위화: 합성 X-ray 영상에 "강력한 도메인 무작위화"(예: 거친 드롭아웃, 반전, 블러링, 가우시안 대비 조정 [10], 무작위 윈도잉, CLAHE 히스토그램 평활화)를 적용하는 것은 시뮬레이션-실제 전이를 위한 중요한 전략이다. 이는 모델이 다양한 영상 외형에 불변하는 특징을 학습하도록 강제하여, 합성 훈련 데이터와 다른 실제 X-ray 영상을 접할 때 더 견고하게 만든다. 이는 모델이 사소한 입력 변형에 덜 민감하게 만들어 손실 지형을 효과적으로 평활화한다.
-
다중 출력 및 선택: 단일 프롬프트에 대해 여러 마스크를 예측하고 훈련 중에 손실이 가장 낮은 마스크를 선택하는 FluoroSAM의 능력은 내부 자체 수정 메커니즘으로 작용한다. 이는 예측 앙상블과 유사하며, 최상의 예측이 선택되어 보다 안정적이고 정확한 최종 출력을 제공한다. 추론 중에 IoU 예측 헤드가 이 선택을 담당하여 가장 정확할 가능성이 높은 마스크를 추정한다. 이러한 동적 선택 프로세스는 모델의 전반적인 안정성과 성능에 기여한다.
결과, 한계 및 결론
실험 설계 및 기준선
FluoroSAM의 능력을 엄격하게 검증하기 위해 저자들은 합성 및 실제 X-ray 데이터를 모두 포함하는 포괄적인 실험 설계를 구성하여, 모델을 기존 기준선과 비교했다.
FluoroSAM 훈련의 기초는 FluoroSeg 데이터셋으로, 3백만 개의 합성 X-ray 영상으로 구성된 방대한 컬렉션이다. 이 데이터셋은 실제 X-ray 영상의 가변성을 포착하는 데 중요한 다양한 인간 해부학, 영상 기하학 및 시야각을 시뮬레이션하기 위해 인 실리코로 세심하게 생성되었다. 시뮬레이션 파이프라인은 New Mexico Decedent Image Database [5]의 1,621개의 고해상도 CT 스캔으로 시작되었으며, 이는 TotalSegmentator [27]를 사용하여 128개의 장기 클래스로 분할되어 표면 메쉬를 파생시켰다. 다양한 방사선 검사를 모방하기 위해 환경은 표준 뷰(예: 흉부, 복부)와 완전히 무작위 C-arm 뷰를 샘플링했으며, 다양한 각도에서 주요 장기에 초점을 맞췄다. 결정적으로, 각각 포괄적인 텍스트 설명이 포함된 464개의 컴퓨터 모델링된 수술 도구가 시야 내에 무작위로 배치되었다. 영상은 $512^2$ 픽셀로 렌더링되었으며, 의사 실제(pseudo-ground truth) 마스크 및 관련 텍스트 설명이 포함되었다. 이 프로세스는 NVIDIA A6000 GPU에서 초당 6.5~15.7개의 영상으로 매우 효율적이었으며, 약 6 GPU 일 동안 총 295만 개의 영상을 생성했다. 데이터셋은 원래 CT 스캔을 기반으로 훈련 및 검증을 위해 90/10%로 분할되었다.
FluoroSAM 자체는 SAM [15]의 언어 프롬프트 기반 변형으로, FluoroSeg에서 처음부터 훈련되었다. 고정된 CLIP 인코더 [21], 두 개의 은닉층 다층 퍼셉트론(MLP) 및 벡터 양자화(VQ) 병목 현상 [20]으로 구성된 새로운 텍스트 인코더는 언어 정렬을 가능하게 하는 핵심이었다. 일반화 가능성을 향상시키기 위해 gpt-40 [1]을 사용하여 각 마스크에 대해 최대 30개의 다양한 프롬프트를 생성하여 텍스트 증강을 수행했다. 관련 장기 마스크는 절차적으로 38개의 그룹(예: "왼쪽 갈비뼈")으로 결합되었으며, "나쁜 프롬프트"(영상에 존재하지 않음)는 때때로 모델이 관련 없는 쿼리를 무시하도록 가르치기 위해 샘플링되었다. 영상 인코더는 ImageNet-22k에서 사전 훈련된 후 FluoroSeg 클래스의 축소된 세트에서 인스턴스 분할을 위해 추가로 훈련된 SwinTransformer 백본(최종 모델의 경우 Swin-L)을 사용했다. 시뮬레이션-실제 전이를 촉진하기 위해 훈련 중에 거친 드롭아웃, 반전, 블러링, 가우시안 대비 조정 [10], 무작위 윈도잉 및 CLAHE 히스토그램 평활화를 포함한 강력한 도메인 무작위화 기법이 적용되었다. 훈련에는 9개의 프롬프트(텍스트 1개, 점 8개)가 포함되었으며, Dice 및 focal loss를 사용했으며, 특정 손실 구성 요소가 역전파되었다. 모델은 2개의 NVIDIA H100 GPU에서 6일 동안 10 에포크 동안 훈련되었다.
평가를 위해 FluoroSAM은 실제 X-ray 영상에서 여러 "희생자" 기준선 모델과 경쟁했다.
1. 실제 중재적 X-ray 영상: 전체 몸통 표본(대퇴골 중간에서 T2까지)에서 획득한 등록된 X-ray 영상 데이터셋으로, Brainlab Loop-X 장치를 사용했다. 실제 마스크는 4개의 탐색된 콘빔 CT 영상의 스티칭 및 장기 분할 투영 [27]을 통해 생성되었다. 평가는 영상 크기의 2.5%보다 큰 1,741개의 마스크로 제한되었다. 기준선에는 원래 SAM [15](점 또는 경계 상자 프롬프트 사용) 및 MedSAM [18](의료 영상에 일반적으로 경계 상자 프롬프트 사용)이 포함되었다. 측정 항목은 IoU, Dice 점수 및 Hausdorff 거리(HDD)였다.
2. 흉부 X-ray (CXR)에 대한 제로샷 평가: 폐 분할에 손으로 주석이 달린 1,131개의 CXR [2] 데이터셋. 이는 FluoroSAM이 다른 X-ray 영상 기법 및 실제 주석으로 일반화하는 능력을 테스트했다. 동일한 기준선인 SAM 및 MedSAM이 사용되었으며, IoU, Dice 및 HDD가 보고되었다.
증거가 증명하는 것
실험 증거는 FluoroSAM의 핵심 메커니즘, 즉 X-ray 영상에 대한 언어 프롬프트 기반 분할이 효과적이며, 완전히 합성 데이터로 훈련되었음에도 불구하고 기존 방법보다 종종 우수하다는 것을 명확하게 증명한다.
실제 중재적 X-ray 영상에서 FluoroSAM은 텍스트 전용 프롬프트로 그 능력을 보여주었다. 표 1 및 그림 3a에 표시된 바와 같이, FluoroSAM은 평균 IoU 0.47 및 Dice 점수 0.60을 달성했다. 이 성능은 FluoroSAM에 텍스트 프롬프트만 제공되었을 때 SAM(점 사용 시 IoU 0.36, Dice 0.50; 상자 사용 시 IoU 0.42, Dice 0.57) 및 MedSAM(IoU 0.41, Dice 0.55)을 능가했다. 이는 FluoroSAM의 새로운 텍스트 인코더와 VQ 계층이 자연어를 해석하고 어려운 실제 시나리오에서 정확한 분할을 생성하는 능력을 검증하는 중요한 증거이다. 점 프롬프트가 추가되었을 때, FluoroSAM의 성능은 더욱 향상되어 2개의 점으로 IoU 0.56 및 Dice 0.69, 8개의 점으로 IoU 0.64, Dice 0.77, HDD 60.8에 도달했으며, 이러한 모든 측정 항목에서 기준선을 일관되게 능가했다. 여기서 결정적인 증거는 FluoroSAM이 고유한 텍스트 프롬프트 기능을 사용하여 정량적으로 비교했을 때, 더 제한적인 점 또는 상자 프롬프트에 의존하는 모델보다 성능이 우수하거나 동등했다는 점이다.
CXR에 대한 제로샷 평가는 FluoroSAM의 일반화 가능성과 시뮬레이션-실제 전이 능력을 부인할 수 없는 증거를 제공했다. 합성 데이터로만 훈련되었음에도 불구하고, FluoroSAM은 실제 CXR의 손으로 주석이 달린 폐 분할에 놀랍도록 잘 적응했다. 텍스트 전용 프롬프트로, 평균 IoU 0.50 및 Dice 점수 0.66을 달성했다(표 1, 그림 3b). SAM이 여러 점 또는 상자 프롬프트를 제공했을 때 더 높은 점수(예: 2개의 점으로 IoU 0.83, Dice 0.89)를 달성할 수 있었지만, 8개의 점으로 FluoroSAM의 성능(IoU 0.81, Dice 0.89)은 매우 경쟁력이 있었으며, SAM의 8점 성능(IoU 0.73, Dice 0.82)을 능가했다. 이는 합성 데이터로 훈련된 FluoroSAM이 강력한 도메인 무작위화와 결합되어, 시뮬레이션된 투영과 손으로 주석이 달린 마스크 간의 체계적인 차이를 고려할 때, 보지 못한 실제 진단 X-ray 영상 및 작업으로 일반화될 수 있음을 보여준다.
또한, 그림 4의 질적 사용자 연구는 VQ 계층의 효능이 다양한 텍스트 프롬프트에 대한 분할 견고성을 향상시키는 데 결정적인 증거를 제공했다. "엉덩이 옆의 뼈는 무엇입니까?"라고 질문했을 때, VQ가 있는 FluoroSAM은 대퇴골을 올바르게 분할했지만, VQ가 없는 경우에는 실패했다. 이는 VQ가 동일한 객체에 대한 다양한 설명에서 발생하는 변동성을 줄임으로써 새로운 언어 프롬프트에 대한 일반화에 도움이 된다는 저자들의 주장을 직접적으로 뒷받침하며, 모델을 자연어의 뉘앙스에 더 탄력적으로 만든다.
마지막으로, 그림 5에 제시된 질적 결과 및 다운스트림 응용 프로그램은 FluoroSAM의 실제 유용성을 보여준다. 그 유연성은 효율적인 X-ray 주석, 환자 중심 건강 교육, 지능형 로봇 C-arm 위치 지정 및 자율 콜리메이션을 가능하게 하여, 핵심 메커니즘이 정량적으로뿐만 아니라 임상 워크플로우에서 풍부한 인간-기계 상호 작용을 가능하게 하는 데에도 작동함을 보여준다.
한계 및 향후 방향
FluoroSAM은 상당한 발전을 이루었지만, 저자들은 미래 연구 및 개발을 위한 비옥한 토양 역할을 하는 몇 가지 한계를 솔직하게 인정한다.
주요 한계 중 하나는 FluoroSeg 데이터셋의 범위에 있다. 3백만 개라는 방대한 양에도 불구하고, 기본 CT 스캔 수와 표현된 해부학적 구조의 다양성으로 여전히 제한된다. 더 많은 CT 영상을 포함하도록 이 데이터셋을 확장하는 것, 잠재적으로 최근에 공개된 TotalSegmentator 작업 또는 골절 조각 [23]과 같은 보다 전문화된 데이터셋에서 가져오는 것은 명확한 발전 방향이다. 그러나 이 확장은 자동화된 파이프라인에도 불구하고 계산 집약적이므로 시뮬레이션 환경의 지속적인 최적화가 필요함을 시사한다.
또 다른 고유한 과제는 X-ray 영상 자체의 특성에서 비롯된다. 투과성이므로 중첩된 투영을 생성하며, 여기서 많은 장기가 명확하게 보이지 않는다. 이러한 모호성은 분할을 어려운 작업으로 만들며, FluoroSAM은 잘 수행하지만, 이는 영상 기법의 근본적인 제약이다. 훈련을 위해 합성 데이터에만 의존하는 것은 시뮬레이션-실제 전이의 성공에도 불구하고, 일부 CXR 결과에서 관찰된 바와 같이, 실제 손으로 주석이 달린 데이터로 훈련된 모델과 미묘한 체계적인 차이를 도입할 수 있다.
벡터 양자화(VQ) 코드북 크기는 특정 아키텍처 한계로 식별된다. VQ는 질적으로 다양한 텍스트 프롬프트에 대한 견고성을 향상시키지만, 고정된 크기는 본질적으로 텍스트 임베딩의 표현력을 제한한다. 이것은 현재 맥락에서 받아들여지는 절충이지만, 훨씬 더 넓은 범위의 해부학적 구조와 더 미묘한 프롬프트를 지원하려면 대안적인 전략이나 진화된 VQ 메커니즘이 필요할 수 있다. 이는 동적 코드북 확장 또는 계층적 VQ 접근 방식을 포함할 수 있다.
미래를 내다볼 때, FluoroSAM의 개발은 몇 가지 흥미로운 논의 주제를 열어준다.
- 합성 데이터의 확장성 및 다양성: 해부학적 다양성을 넘어 병리, 환자 인구 통계 및 영상 아티팩트의 훨씬 더 넓은 스펙트럼을 포괄하기 위해 합성 데이터 생성을 어떻게 더 확장할 수 있는가? 생성 AI 모델을 사용하여 기존 CT 스캔을 증강하거나 새로운 CT 스캔을 합성하여 기존 CT 데이터베이스에만 의존하는 것보다 더 다양한 훈련 데이터를 FluoroSeg에 생성할 수 있는가?
- 하이브리드 훈련 패러다임: 시뮬레이션-실제 전이의 성공을 고려할 때, 합성 데이터와 제한된 실제 주석 데이터를 결합하는 최적의 전략은 무엇인가? 방대한 양의 레이블이 없는 실제 X-ray 데이터를 활용하는 준지도 또는 자기 지도 학습 접근 방식은 광범위한 수동 주석 없이 FluoroSAM의 성능과 견고성을 더욱 향상시킬 수 있는가?
- 고급 언어 이해: FluoroSAM은 "사고 연쇄" 기반 X-ray 영상 분석 [9]과 더 긴밀하게 통합하여 더 복잡하거나 다단계적이거나 모호한 자연어 프롬프트를 해석하도록 어떻게 발전할 수 있는가? 이는 텍스트 증강보다 더 깊은 의미론적 이해 및 추론 능력을 요구할 것이다.
- 개인화 및 적응성: FluoroSAM은 특정 환자 해부학 또는 임상 맥락에 맞게 조정될 수 있는가? 예를 들어, 해당 개인에 대한 분할 정확도를 개선하기 위해 소수의 환자별 주석 세트에서 학습할 수 있는가, 또는 다른 X-ray 기계 또는 프로토콜의 고유한 특성에 적응할 수 있는가? 이는 정밀 의학 응용 분야에 중요할 것이다.
- 윤리적 고려 사항 및 신뢰: FluoroSAM이 인간-루프 워크플로우에 통합됨에 따라, 중요한 의료 작업에 대한 AI 의존의 윤리적 함의는 무엇인가? 모호하거나 새로운 쿼리를 처리할 때, 특히 자연어 프롬프트를 해석하는 AI 시스템에 대한 투명성, 설명 가능성 및 신뢰를 어떻게 보장할 수 있는가? "나쁜 프롬프트"에 대한 견고성은 좋은 시작이지만, 임상 배포를 위해서는 더 많은 것이 필요하다.
- 텍스트를 넘어선 다중 모달 통합: 언어는 강력한 프롬프트이지만, FluoroSAM은 생리 신호, 환자 이력 또는 중재 설정에서의 햅틱 피드백과 같은 다른 모달리티를 프롬프트로 통합함으로써 이익을 얻을 수 있는가? 이는 더 풍부한 맥락 정보를 제공하여 모호성을 더욱 줄이고 상호 작용을 향상시킬 수 있다.
궁극적으로 FluoroSAM의 개발은 X-ray 영상에서 유연하고 언어 프롬프트 기반 파운데이션 모델을 향한 중요한 단계이며, 진단 및 중재 의학 모두에서 새로운 길을 열어줄 것을 약속한다. 식별된 한계는 장애물이 아니라 차세대 연구를 위한 명확한 표지판이다.
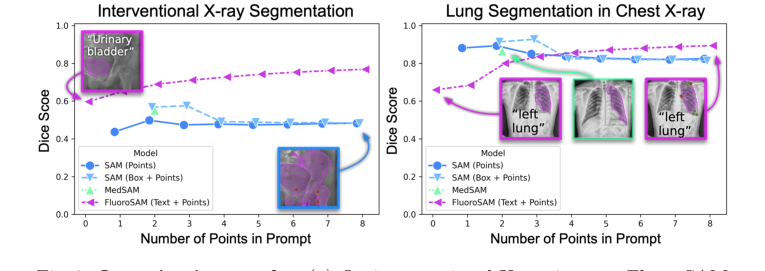 Figure 3. Quantitative results. (a) On interventional X-ray images, FluoroSAM outperforms its peers even with text-only prompting. (b) On CXRs, FluoroSAM adapts to hand-annotated lung segmentations despite being trained on synthetic data. MedSAM [18] includes this task in its training data
Figure 3. Quantitative results. (a) On interventional X-ray images, FluoroSAM outperforms its peers even with text-only prompting. (b) On CXRs, FluoroSAM adapts to hand-annotated lung segmentations despite being trained on synthetic data. MedSAM [18] includes this task in its training data
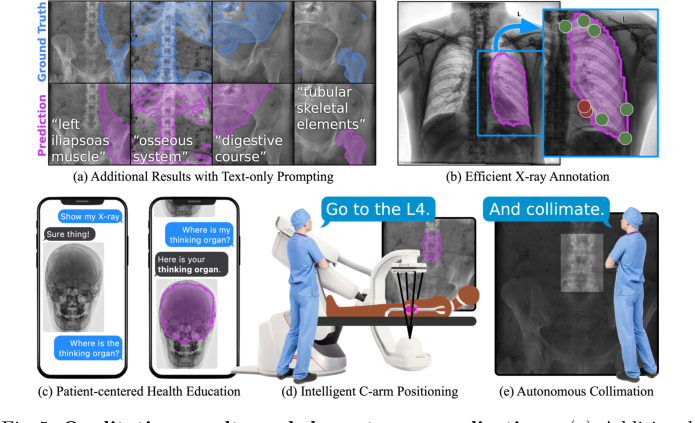 Figure 5. Qualitative results and downstream applications. (a) Additional results on real X-ray images, with text prompts not used during training. The flexibility of text prompting supports a wide variety of downstream applications. (b) Efficient annotation of X-rays can reduce clinical burden and accelerate real data annotation. (c) Flexible text-based prompting may lend itself to patient- facing education, empowering patients to better understand their own anatomy. In the OR, FluoroSAM can be integrated with robotic C-arms to deliver intel- ligent positioning (d) and autonomous collimation (e), reducing radiation [14]. These figures use real FluoroSAM predictions on real radiographs
Figure 5. Qualitative results and downstream applications. (a) Additional results on real X-ray images, with text prompts not used during training. The flexibility of text prompting supports a wide variety of downstream applications. (b) Efficient annotation of X-rays can reduce clinical burden and accelerate real data annotation. (c) Flexible text-based prompting may lend itself to patient- facing education, empowering patients to better understand their own anatomy. In the OR, FluoroSAM can be integrated with robotic C-arms to deliver intel- ligent positioning (d) and autonomous collimation (e), reducing radiation [14]. These figures use real FluoroSAM predictions on real radiographs
 Figure 4. In a limited user study, we observe qualitative results consistent with the hypothesis that VQ improves segmentation robustness to variable text prompts. For example, FluoroSAM with VQ was able to correctly segment the femur, answering the question “What’s the bone next to the hip?”
Figure 4. In a limited user study, we observe qualitative results consistent with the hypothesis that VQ improves segmentation robustness to variable text prompts. For example, FluoroSAM with VQ was able to correctly segment the femur, answering the question “What’s the bone next to the hip?”