FluoroSAM: लचीले एक्स-रे छवि विभाजन के लिए एक भाषा-प्रॉम्प्टेबल फाउंडेशन मॉडल
FluoroSAM द्वारा संबोधित समस्या नैदानिक और इंटरवेंशनल प्रिसिजन मेडिसिन में अधिक लचीले और कुशल एक्स रे छवि विभाजन की महत्वपूर्ण आवश्यकता से उत्पन्न होती है। एक्स रे इमेजिंग स्वास्थ्य सेवा में एक मूलभूत विधा है, लेकिन...
पृष्ठभूमि और अकादमिक वंश
उत्पत्ति और अकादमिक वंश
FluoroSAM द्वारा संबोधित समस्या नैदानिक और इंटरवेंशनल प्रिसिजन मेडिसिन में अधिक लचीले और कुशल एक्स-रे छवि विभाजन की महत्वपूर्ण आवश्यकता से उत्पन्न होती है। एक्स-रे इमेजिंग स्वास्थ्य सेवा में एक मूलभूत विधा है, लेकिन इसके विश्लेषण को ऐतिहासिक रूप से कार्य-विशिष्ट मशीन लर्निंग मॉडल पर निर्भर किया गया है। ये प्रारंभिक मॉडल, संकीर्ण अनुप्रयोगों में प्रभावी होने के बावजूद, महत्वपूर्ण सीमाओं से ग्रस्त थे: उन्हें नए कार्यों के अनुकूलन या उनके दायरे का विस्तार करने के लिए व्यापक अतिरिक्त डेटा, एनोटेशन और प्रशिक्षण समय की आवश्यकता होती थी। इसने उन्हें कठोर और व्यापक नैदानिक उपयोग के लिए स्केल करने में कठिन बना दिया।
अकादमिक क्षेत्र ने इन बाधाओं को दूर करने के लिए एक आशाजनक दिशा के रूप में "फाउंडेशन मॉडल" (FMs) और विशेष रूप से "भाषा-संरेखित फाउंडेशन मॉडल" (LFMs) के उद्भव को देखा। विशाल और विविध छवि और पाठ डेटा पर प्रशिक्षित LFMs, प्राकृतिक भाषा का उपयोग करके कार्यों को निर्दिष्ट करने की अनुमति देकर व्यापक प्रयोज्यता की क्षमता प्रदान करते हैं। हालांकि, मौजूदा मेडिकल LFMs ने मुख्य रूप से सीटी या एमआरआई जैसी विधाओं पर ध्यान केंद्रित किया है, जहां बड़े, समृद्ध रूप से एनोटेट किए गए डेटासेट आसानी से उपलब्ध हैं। इसके विपरीत, एक्स-रे इमेजिंग अद्वितीय चुनौतियां प्रस्तुत करती है: अत्यधिक परिवर्तनशील छवि उपस्थिति, विविध अनुप्रयोग (नैदानिक छाती एक्स-रे से इंटरवेंशनल फ्लोरोस्कोपी तक), और बड़े, अच्छी तरह से एनोटेट किए गए डेटासेट की कमी, विशेष रूप से इंटरवेंशनल प्रक्रियाओं के लिए।
पिछले दृष्टिकोणों का एक महत्वपूर्ण "दर्द बिंदु", जिसमें सेगमेंट-एनीथिंग मॉडल (SAM) और इसके उत्तराधिकारी SAM 2 जैसे सामान्य-उद्देश्य वाले फाउंडेशन मॉडल शामिल हैं, विशेष रूप से पाठ संकेतों के साथ एक्स-रे छवियों की अनूठी विशेषताओं को प्रभावी ढंग से संभालने में उनकी असमर्थता थी। जबकि SAM मॉडल विभिन्न संकेतों (मास्क, बाउंडिंग बॉक्स, पॉइंट) के आधार पर प्राकृतिक छवियों में वस्तुओं को विभाजित करने में उत्कृष्ट हैं, उनकी पाठ-संकेत क्षमताएं अक्सर CLIP जैसे मॉडल पर निर्भर करती हैं, जिन्हें प्राकृतिक छवियों पर प्रशिक्षित किया गया था। इसे सीधे एक्स-रे छवियों में स्थानांतरित करना समस्याग्रस्त है क्योंकि एक्स-रे ट्रांसमिसिव होते हैं, जिससे विभिन्न शारीरिक और गैर-शारीरिक वस्तुओं के कई ओवरलैपिंग अनुमान होते हैं। इस अंतर्निहित अस्पष्टता का मतलब है कि एक एकल छवि पैच में कई वस्तुओं की दृश्य विशेषताएं हो सकती हैं, जिससे प्राकृतिक छवियों पर प्रशिक्षित मॉडल के लिए उन्हें अलग करना मुश्किल हो जाता है। इसके अलावा, विविध, उच्च-गुणवत्ता वाले एक्स-रे डेटासेट की सीमित उपलब्धता, विशेष रूप से जटिल इंटरवेंशनल परिदृश्यों के लिए, इस विधा के लिए लचीले, भाषा-प्रॉम्प्टेबल विभाजन उपकरणों के विकास को गंभीर रूप से बाधित करती है। पिछले मेडिकल SAM वेरिएंट, जैसे MedSAM, अक्सर बाउंडिंग बॉक्स तक संकेतों को सीमित करके इस अस्पष्टता को कम करते थे, जो एक्स-रे इमेजिंग के लिए अवांछनीय है क्योंकि यह अभी भी महत्वपूर्ण अस्पष्टता छोड़ देता है, स्वचालित या गैर-विशेषज्ञ संकेत को अव्यावहारिक बनाता है, और मानव-इन-द-लूप सिस्टम के लिए लचीलेपन को कम करता है। यह पेपर सिंथेटिक डेटा पीढ़ी का लाभ उठाकर डेटा की कमी को दूर करने के लिए विशेष रूप से एक्स-रे डोमेन के लिए तैयार किए गए भाषा-प्रॉम्प्टेबल फाउंडेशन मॉडल विकसित करके इन सीमाओं को संबोधित करने का लक्ष्य रखता है।
सहज डोमेन शब्द
- भाषा-संरेखित फाउंडेशन मॉडल (LFMs): एक सुपर-स्मार्ट सहायक की कल्पना करें जो आपके बोले गए या टाइप किए गए निर्देशों को समझ सकता है (जैसे "बाएं फेफड़े को विभाजित करें") और फिर एक जटिल कार्य कर सकता है, जैसे कि एक्स-रे छवि में उस विशिष्ट भाग की पहचान करना और उसे रेखांकित करना। LFMs इन सहायकों की तरह हैं, जिन्हें छवियों और पाठ दोनों की एक बड़ी मात्रा पर प्रशिक्षित किया जाता है, इसलिए वे शब्दों को दृश्य अवधारणाओं से जोड़ना सीखते हैं, जिससे वे बहुत बहुमुखी बन जाते हैं।
- विभाजन (Segmentation): इसे एक छवि में एक विशिष्ट वस्तु को सटीक रूप से रेखांकित करने के लिए एक डिजिटल हाइलाइटर का उपयोग करने जैसा समझें। मेडिकल इमेजिंग में, इसका मतलब एक अंग, हड्डी या चिकित्सा उपकरण के चारों ओर एक सटीक सीमा बनाना है। यह सिर्फ यह कहना नहीं है कि "एक फेफड़ा है"; यह दिखा रहा है कि फेफड़ा ठीक कहाँ है।
- वेक्टर क्वांटाइजेशन (VQ): यह दृश्य अवधारणाओं की एक शब्दकोश रखने जैसा है। जब मॉडल एक नई विवरण या छवि सुविधा "देखता है", तो यह अपने शब्दकोश में निकटतम प्रविष्टि से मिलान करने का प्रयास करता है। यह जटिल जानकारी को मानकीकृत और सरल बनाने में मदद करता है, जिससे मॉडल के लिए भाषा और छवियों के बीच सुसंगत संबंध सीखना आसान हो जाता है, भले ही विवरण थोड़े भिन्न हों। यह मॉडल की अवधारणाओं की समझ को अधिक मजबूत और मामूली विविधताओं के प्रति कम संवेदनशील बनाने का एक तरीका है।
- सिम-टू-रियल ट्रांसफर (Sim-to-real transfer): यह एक पायलट के वास्तविक विमान उड़ाने से पहले उड़ान सिम्युलेटर में प्रशिक्षण जैसा है। इस संदर्भ में, इसका मतलब है कि अत्यधिक यथार्थवादी कंप्यूटर-जनित (सिम्युलेटेड) एक्स-रे छवियों का उपयोग करके एक एआई मॉडल को प्रशिक्षित करना और फिर उस प्रशिक्षित मॉडल को वास्तविक, वास्तविक दुनिया की एक्स-रे छवियों पर लागू करना। लक्ष्य यह है कि मॉडल बड़ी मात्रा में उत्पादन करने में आसान और सस्ता होने के कारण सिम्युलेटेड डेटा से मुख्य रूप से सीखने के बावजूद वास्तविक दुनिया में अच्छा प्रदर्शन करे।
संकेतन तालिका
| संकेतन | विवरण |
|---|---|
समस्या परिभाषा और बाधाएँ
मुख्य समस्या सूत्रीकरण और दुविधा
इस पेपर द्वारा संबोधित मुख्य समस्या एक्स-रे छवि विभाजन के लिए एक लचीले, सामान्यीकरण योग्य और भाषा-प्रॉम्प्टेबल फाउंडेशन मॉडल की कमी है, विशेष रूप से विविध और चुनौतीपूर्ण चिकित्सा एक्स-रे परिदृश्यों के लिए।
इनपुट/वर्तमान स्थिति:
वर्तमान में, एक्स-रे छवि विश्लेषण कार्य-विशिष्ट मशीन लर्निंग मॉडल पर निर्भर करता है। ये मॉडल एक संकीर्ण दायरे में अच्छा प्रदर्शन करते हैं, लेकिन उनका निश्चित डिजाइन और सीमित प्रशिक्षण डेटा व्यापक एक्स-रे डोमेन में उनकी प्रयोज्यता को गंभीर रूप से प्रतिबंधित करता है। इन मॉडलों को नई कक्षाओं या अधिक जटिल प्रश्नों का समर्थन करने के लिए विस्तारित करने के लिए महत्वपूर्ण अतिरिक्त डेटा, एनोटेशन और व्यापक पुन: प्रशिक्षण प्रयासों की आवश्यकता होती है। मेडिकल इमेजिंग के लिए मौजूदा फाउंडेशन मॉडल (FMs), आशाजनक होने के बावजूद, मुख्य रूप से उन विधाओं पर केंद्रित रहे हैं जहां बड़े, समृद्ध रूप से एनोटेट किए गए डेटासेट आसानी से उपलब्ध हैं। हालांकि, एक्स-रे इमेजिंग, विशेष रूप से इंटरवेंशनल फ्लोरोस्कोपी, अपनी अत्यधिक परिवर्तनशील छवि उपस्थिति, विविध अनुप्रयोगों और समृद्ध रूप से एनोटेट किए गए प्रशिक्षण डेटा की महत्वपूर्ण कमी के कारण एक अनूठी चुनौती प्रस्तुत करती है। इसके अलावा, एक्स-रे छवियां प्रकृति में ट्रांसमिसिव होती हैं, जिसका अर्थ है कि कई शारीरिक और गैर-शारीरिक वस्तुएं अक्सर अनुमानों में ओवरलैप होती हैं, जिससे उन्हें अलग करना स्वाभाविक रूप से मुश्किल हो जाता है। पिछले भाषा-संरेखित FMs, जैसे कि सेगमेंट-एनीथिंग मॉडल (SAM) और इसके उत्तराधिकारी SAM 2, पाठ संकेतों के लिए CLIP जैसे मॉडल पर निर्भर करते हैं, जिन्हें प्राकृतिक छवियों पर प्रशिक्षित किया गया था। यह तुरंत स्पष्ट नहीं है कि इस दृष्टिकोण को एक्स-रे छवियों में प्रभावी ढंग से कैसे स्थानांतरित किया जाए, जहां वस्तु सीमाएं अक्सर अस्पष्ट होती हैं और संरचनाएं सुपरिम्पोज्ड होती हैं।
वांछित अंतिम बिंदु (आउटपुट/लक्ष्य स्थिति):
अंतिम लक्ष्य एक भाषा-प्रॉम्प्टेबल फाउंडेशन मॉडल, जिसे FluoroSAM नाम दिया गया है, विकसित करना है जो मनमाने चिकित्सा एक्स-रे छवियों के व्यापक और भाषा-संरेखित विश्लेषण में सक्षम हो। इस मॉडल को नैदानिक और इंटरवेंशनल प्रिसिजन मेडिसिन में मानव-इन-द-लूप वर्कफ़्लो के लिए अधिक लचीलापन सक्षम करना चाहिए। विशेष रूप से, FluoroSAM का लक्ष्य प्राकृतिक भाषा संकेतों के आधार पर अनगिनत शारीरिक संरचनाओं और उपकरणों को विभाजित करना है, जो एक्स-रे छवि में निर्दिष्ट किसी भी वस्तु के लिए अर्थपूर्ण मास्क प्रदान करता है। यह नैदानिक सेटिंग्स में अधिक सहज और कुशल इंटरैक्शन की अनुमति देगा, इंटरैक्टिव नैदानिक प्रणालियों से लेकर छवि-निर्देशित हस्तक्षेपों में बुद्धिमान मानव-मशीन इंटरफेस तक।
लुप्त कड़ी या गणितीय अंतर:
सटीक लुप्त कड़ी विभाजन के लिए एक्स-रे छवियों की अनूठी दृश्य विशेषताओं के साथ प्राकृतिक भाषा संकेतों को प्रभावी ढंग से संरेखित करने के लिए एक मजबूत और सामान्यीकरण योग्य तंत्र है। चुनौती उच्च-स्तरीय भाषाई विवरणों और एक्स-रे में निम्न-स्तरीय, अक्सर अस्पष्ट, पिक्सेल जानकारी के बीच की खाई को पाटने में निहित है। पेपर FluoroSAM के भीतर एक उपन्यास पाठ एन्कोडर वास्तुकला पेश करके इस समस्या का समाधान करता है। यह वास्तुकला एक जमे हुए CLIP एन्कोडर के शीर्ष पर एक वेक्टर क्वांटाइजेशन (VQ) मॉड्यूल को शामिल करती है। यह VQ परत महत्वपूर्ण है; यह मास्क डिकोडर को एक अधिक सुसंगत संकेत प्रदान करता है, जिससे अस्पष्टता की अंतर्निहित कठिनाइयों के बावजूद, विशेष रूप से एक्स-रे छवियों के लिए प्रशिक्षण के दौरान प्रभावी भाषा संरेखण सक्षम होता है। यह वास्तुकला नवाचार मॉडल को एक साझा प्रतिनिधित्व स्थान सीखने की अनुमति देता है जहां पाठ संकेत एक्स-रे छवियों में विभाजन को सटीक रूप से निर्देशित कर सकते हैं।
दर्दनाक समझौता या दुविधा:
केंद्रीय दुविधा जिसने पिछले शोधकर्ताओं को फंसाया है, वह है मॉडल सामान्यीकरण/लचीलेपन और उच्च-गुणवत्ता वाले, एनोटेट किए गए एक्स-रे डेटा की उपलब्धता के बीच समझौता। व्यापक प्रयोज्यता और भाषा-प्रॉम्प्टेबिलिटी (जैसे LFMs) प्राप्त करने के लिए आम तौर पर विशाल, समृद्ध रूप से एनोटेट किए गए डेटासेट की आवश्यकता होती है। हालांकि, एक्स-रे इमेजिंग, विशेष रूप से इंटरवेंशनल प्रक्रियाओं के लिए, ऐसे डेटा की गंभीर कमी से ग्रस्त है। यह एक विकल्प को मजबूर करता है: या तो संकीर्ण, कार्य-विशिष्ट मॉडल विकसित करें जो अच्छा प्रदर्शन करते हैं लेकिन लचीलेपन की कमी रखते हैं, या सामान्यीकरण योग्य मॉडल बनाने का प्रयास करें जो डेटा की कमी और एक्स-रे छवि व्याख्या की अनूठी चुनौतियों के कारण संघर्ष करते हैं। एक्स-रे की ट्रांसमिसिव प्रकृति इसे और बढ़ाती है, क्योंकि एक पहलू में सुधार (जैसे, ओवरलैपिंग संरचनाओं को विभाजित करना) अक्सर अस्पष्टता पेश करता है या अधिक जटिल, डेटा-गहन समाधानों की आवश्यकता होती है। उदाहरण के लिए, जबकि बाउंडिंग बॉक्स संकेत (अन्य चिकित्सा विधाओं के लिए MedSAM द्वारा उपयोग किए जाते हैं) अस्पष्टता को कम कर सकते हैं, वे मानव-मशीन इंटरैक्शन की लचीलेपन और स्वाभाविकता को गंभीर रूप से सीमित करते हैं, जो भाषा-प्रॉम्प्टेबल सिस्टम का एक मुख्य लाभ है।
बाधाएँ और विफलता मोड
एक्स-रे छवि विभाजन की भाषा-प्रॉम्प्टेबल समस्या कई कठोर, यथार्थवादी बाधाओं के कारण अविश्वसनीय रूप से कठिन है:
-
भौतिक बाधाएँ:
- ट्रांसमिसिव प्रकृति और ओवरलैपिंग अनुमान: एक्स-रे छवियां शरीर के माध्यम से एक्स-रे के संचरण द्वारा बनती हैं, जिसके परिणामस्वरूप 2डी अनुमान होते हैं जहां कई शारीरिक और गैर-शारीरिक वस्तुएं (जैसे उपकरण) अक्सर ओवरलैप होती हैं। यह अंतर्निहित विशेषता व्यक्तिगत संरचनाओं को अलग करना बेहद चुनौतीपूर्ण बनाती है, यहां तक कि मानव विशेषज्ञों के लिए भी, और स्वचालित विभाजन के लिए एक महत्वपूर्ण बाधा प्रस्तुत करती है। कई अंग स्पष्ट रूप से दिखाई नहीं देते हैं, जिससे कार्य और जटिल हो जाता है।
- छवि उपस्थिति और अनुप्रयोगों में उच्च परिवर्तनशीलता: एक्स-रे इमेजिंग में अनुप्रयोगों की एक विस्तृत श्रृंखला शामिल है, नैदानिक छाती एक्स-रे से लेकर इंटरवेंशनल फ्लोरोस्कोपी तक। इससे मानव शरीर रचना, इमेजिंग ज्यामिति, देखने के कोण और छवि तीव्रता मानों में अत्यधिक परिवर्तनशीलता होती है। एक मॉडल को इस व्यापक विविधता के लिए मजबूत होना चाहिए, जिसे सीमित डेटा के साथ प्राप्त करना मुश्किल है।
-
कम्प्यूटेशनल बाधाएँ:
- डेटा जनरेशन और प्रशिक्षण के लिए उच्च कम्प्यूटेशनल लागत: डेटा की कमी को दूर करने के लिए, लेखकों ने 3 मिलियन एक्स-रे छवियों का एक बड़ा सिंथेटिक डेटासेट (FluoroSeg) उत्पन्न किया। यह सिमुलेशन प्रक्रिया स्वयं कम्प्यूटेशनल रूप से गहन है, जिसके लिए NVIDIA A6000 GPU पर लगभग 6 GPU दिन की आवश्यकता होती है। इस डेटासेट पर FluoroSAM को प्रशिक्षित करने के लिए भी महत्वपूर्ण संसाधनों की आवश्यकता होती है, जिसमें 2 NVIDIA H100 GPUs पर 6 दिन लगते हैं। यह ऐसे मॉडल को विकसित करने से जुड़े पर्याप्त कम्प्यूटेशनल बोझ को उजागर करता है।
- VQ कोडबुक आकार सीमा: जबकि वेक्टर क्वांटाइजेशन (VQ) मॉड्यूल परिवर्तनशील पाठ संकेतों के प्रति मजबूती में सुधार करता है, इसका कोडबुक आकार स्वाभाविक रूप से पाठ एम्बेडिंग की प्रतिनिधित्व शक्ति को सीमित करता है। यह डिजाइन विकल्प, हालांकि स्थिरता के लिए फायदेमंद है, सैद्धांतिक रूप से फ्रेमवर्क की सामान्यीकरण क्षमता को नए विभाजन वर्गों की अनंत चौड़ी सीमा या अत्यधिक उपन्यास भाषा संकेतों तक सीमित करता है।
-
डेटा-संचालित बाधाएँ:
- एनोटेट किए गए वास्तविक एक्स-रे डेटा की अत्यधिक विरलता: यह शायद सबसे महत्वपूर्ण बाधा है। एक्स-रे इमेजिंग, विशेष रूप से इंटरवेंशनल एक्स-रे के लिए, बड़े, समृद्ध रूप से एनोटेट किए गए डेटासेट की एक गहरी कमी है। यह कमी वास्तविक दुनिया के डेटा पर मजबूत भाषा-संरेखित फाउंडेशन मॉडल के प्रत्यक्ष प्रशिक्षण को रोकती है, जिससे सिंथेटिक डेटा पर निर्भरता की आवश्यकता होती है।
- डोमेन गैप (सिम-टू-रियल ट्रांसफर): सिंथेटिक डेटा पर प्रशिक्षण, हालांकि आवश्यक है, सिम्युलेटेड छवियों और वास्तविक एक्स-रे छवियों के बीच एक डोमेन गैप पेश करता है। प्रशिक्षण के दौरान लागू की गई मजबूत डोमेन रैंडमाइजेशन तकनीकों (जैसे, मोटे ड्रॉपआउट, उलटाव, धुंधलापन, गॉसियन कंट्रास्ट समायोजन, यादृच्छिक विंडोिंग, CLAHE हिस्टोग्राम इक्वलाइजेशन) के बावजूद, सिंथेटिक डेटा अभी भी वास्तविक हाथ-एनोटेट किए गए मास्क से व्यवस्थित रूप से भिन्न हो सकता है, संभावित रूप से वास्तविक दुनिया के परिदृश्यों पर प्रदर्शन को प्रभावित कर सकता है।
- सिंथेटिक डेटा में सीमित विविधता: यहां तक कि FluoroSeg जैसे बड़े सिंथेटिक डेटासेट के साथ, उपयोग किए गए आधार सीटी स्कैन की संख्या और प्रतिनिधित्व किए गए शारीरिक संरचनाओं की विविधता में अभी भी सीमाएं हैं। इस विविधता का विस्तार करना, हालांकि स्केलेबल है, कम्प्यूटेशनल रूप से गहन है।
- प्राकृतिक भाषा संकेतों की अस्पष्टता: प्राकृतिक भाषा संकेत स्वयं अस्पष्ट हो सकते हैं, विशेष रूप से एक्स-रे छवियों में ओवरलैपिंग संरचनाओं का उल्लेख करते समय। मॉडल को "खराब संकेतों" को अनदेखा करके संभालने के लिए डिज़ाइन किया जाना चाहिए और किसी दिए गए संकेत के लिए कई मास्क की भविष्यवाणी करनी चाहिए, जिससे सबसे सटीक विभाजन के चयन की अनुमति मिल सके। यह मॉडल के आउटपुट और अनुमान प्रक्रिया में जटिलता जोड़ता है।
यह दृष्टिकोण क्यों
विकल्प की अनिवार्यता
FluoroSAM का अपनाना, जो सेगमेंट-एनीथिंग मॉडल (SAM) का एक भाषा-प्रॉम्प्टेबल संस्करण है, जिसे विशेष रूप से एक्स-रे छवि विभाजन के लिए तैयार किया गया है, मौजूदा अत्याधुनिक (SOTA) विधियों की अंतर्निहित सीमाओं को देखते हुए केवल एक विकल्प नहीं बल्कि एक अनिवार्य आवश्यकता थी। लेखकों ने महसूस किया कि पारंपरिक कार्य-विशिष्ट मशीन लर्निंग मॉडल, संकीर्ण दायरे में प्रभावी होने के बावजूद, व्यापक अनुप्रयोगों के लिए अपनी उपयोगिता का विस्तार करने के लिए निषेधात्मक मात्रा में अतिरिक्त डेटा, एनोटेशन और प्रशिक्षण समय की मांग करते थे। यह विशेष रूप से एक्स-रे इमेजिंग विधा के लिए समस्याग्रस्त था, जो अत्यधिक परिवर्तनशील छवि उपस्थिति, विविध अनुप्रयोगों (नैदानिक छाती एक्स-रे से इंटरवेंशनल फ्लोरोस्कोपी तक), और महत्वपूर्ण रूप से, बड़े, समृद्ध रूप से एनोटेट किए गए डेटासेट की कमी की विशेषता है।
वास्तविक अहसास का "सही क्षण" तब हुआ जब मूल SAM या इसके उत्तराधिकारी SAM 2 जैसे प्रमुख भाषा-संरेखित फाउंडेशन मॉडल (LFMs) के प्रत्यक्ष अनुप्रयोग पर विचार किया गया। जबकि ये मॉडल पाठ संकेतों का समर्थन करते हैं, वे मौलिक रूप से पाठ को छवि-संरेखित एम्बेडिंग में परिवर्तित करने के लिए CLIP [21] जैसे पूर्व-प्रशिक्षित LFMs पर निर्भर करते हैं। महत्वपूर्ण अंतर्दृष्टि यह थी कि CLIP, मुख्य रूप से प्राकृतिक छवियों पर प्रशिक्षित, एक्स-रे डोमेन में प्रभावी ढंग से स्थानांतरित नहीं होगा। एक्स-रे छवियां ट्रांसमिसिव होती हैं, जिससे कई ओवरलैपिंग मास्क विभिन्न वस्तुओं से संबंधित होते हैं, जो प्राकृतिक छवियों के विपरीत होते हैं जहां वस्तुएं आम तौर पर स्पष्ट सीमाएं और नेस्टेड संरचनाएं होती हैं। भले ही एक एक्स-रे-विशिष्ट CLIP-जैसा मॉडल मौजूद हो, एक एकल छवि पैच में अभी भी कई, ओवरलैपिंग वस्तुओं की दृश्य विशेषताएं होंगी, जिससे स्पष्ट भेद करना अत्यंत कठिन हो जाएगा। एक्स-रे की दृश्य विशेषताओं और प्राकृतिक-छवि-प्रशिक्षित मॉडल की मान्यताओं के बीच यह मौलिक बेमेल मौजूदा SOTA LFMs के प्रत्यक्ष अनुप्रयोग को अपर्याप्त बनाता है, जिससे FluoroSAM जैसे एक विशेष समाधान की आवश्यकता होती है।
तुलनात्मक श्रेष्ठता
FluoroSAM की गुणात्मक श्रेष्ठता एक्स-रे इमेजिंग की अनूठी चुनौतियों को दूर करने के लिए डिज़ाइन की गई अपनी संरचनात्मक नवाचारों से उत्पन्न होती है, जिससे यह इस विशिष्ट डोमेन में पिछले स्वर्ण मानकों की तुलना में अत्यधिक श्रेष्ठ हो जाता है। उन मॉडलों के विपरीत जो एक्स-रे की ट्रांसमिसिव प्रकृति और ओवरलैपिंग शरीर रचनाओं से जूझते हैं, FluoroSAM का उपन्यास पाठ एन्कोडर, एक जमे हुए CLIP एन्कोडर के शीर्ष पर एक वेक्टर क्वांटाइजेशन (VQ) मॉड्यूल को शामिल करता है, मास्क डिकोडर को एक अधिक सुसंगत संकेत प्रदान करता है। यह VQ परत महत्वपूर्ण है; जबकि यह सैद्धांतिक रूप से पूरी तरह से नए विभाजन वर्गों के लिए सामान्यीकरण को सीमित करता है, यह विभिन्न विवरणों से उत्पन्न परिवर्तनशीलता को कम करके नए पाठ संकेतों के लिए सामान्यीकरण को महत्वपूर्ण रूप से विस्तारित करता है। इसका मतलब है कि FluoroSAM विविध प्राकृतिक भाषा इनपुट के प्रति अधिक मजबूत है, जो मानव-इन-द-लूप वर्कफ़्लो के लिए एक प्रमुख लाभ है।
इसके अलावा, FluoroSAM की विशाल, सिंथेटिक FluoroSeg डेटासेट (3M एक्स-रे छवियों) पर खरोंच से प्रशिक्षित होने की क्षमता एक संरचनात्मक लाभ प्रदान करती है। यह वास्तविक एक्स-रे छवियों के लिए महत्वपूर्ण डेटा कमी के मुद्दे को दरकिनार करता है, जिससे मॉडल को मानव शरीर रचना, इमेजिंग ज्यामिति और देखने के कोणों की एक विस्तृत विविधता में मजबूत सुविधाएँ सीखने की अनुमति मिलती है जो केवल वास्तविक दुनिया के डेटा के साथ असंभव होगी। मात्रात्मक रूप से, FluoroSAM SAM और MedSAM से बेहतर प्रदर्शन करता है, विशेष रूप से केवल पाठ संकेत के साथ, वास्तविक इंटरवेंशनल एक्स-रे छवियों पर 0.47 का औसत IoU और 0.60 का डाइस स्कोर प्राप्त करता है। 2 बिंदुओं के साथ भी, FluoroSAM 0.56 IoU और 0.69 डाइस प्राप्त करता है, जो SAM और MedSAM से बेहतर प्रदर्शन करता है। उदाहरण के लिए, MedSAM अक्सर "अंतर्निहित शरीर रचना को प्रतिबिंबित करने में विफल रहता है और बस प्रदान किए गए बॉक्स को भर देता है," जो साधारण बाउंडिंग बॉक्स बाधाओं से परे अंतर्निहित छवि सामग्री की समझ की गुणात्मक विफलता का संकेत देता है। FluoroSAM की मल्टी-आउटपुट क्षमता, प्रत्येक संकेत के लिए कई मास्क की भविष्यवाणी करना और सबसे सटीक का चयन करना, इसकी मजबूती और लचीलेपन को और बढ़ाता है, जिससे यह अस्पष्ट संकेतों को अधिक शालीनता से संभाल सकता है। यह संरचनात्मक डिजाइन FluoroSAM को एक ऐसे डोमेन में लचीला, भाषा-संरेखित विभाजन प्रदान करने में सक्षम बनाता है जहां अन्य विफल हो जाते हैं, जरूरी नहीं कि मेमोरी जटिलता को $O(N^2)$ से $O(N)$ तक कम करके बल्कि गुणात्मक समझ और संकेत मजबूती में सुधार करके।
बाधाओं के साथ संरेखण
चुना गया FluoroSAM दृष्टिकोण एक्स-रे छवि विभाजन की कठोर आवश्यकताओं के साथ पूरी तरह से संरेखित होता है, जो "समस्या और समाधान के बीच एक विवाह" बनाता है। प्राथमिक बाधाएं, जैसा कि समस्या परिभाषा से अनुमान लगाया गया है, में शामिल हैं:
- व्यापक प्रयोज्यता और लचीलेपन की आवश्यकता: पारंपरिक मॉडल बहुत संकीर्ण हैं। FluoroSAM, एक भाषा-प्रॉम्प्टेबल फाउंडेशन मॉडल के रूप में, स्वाभाविक रूप से व्यापक प्रयोज्यता के लिए डिज़ाइन किया गया है, जो "प्राकृतिक भाषा संकेतों के आधार पर अनगिनत शारीरिक संरचनाओं और उपकरणों को विभाजित करने में सक्षम है" (पृष्ठ 1)। यह लचीलापन विविध नैदानिक और इंटरवेंशनल परिदृश्यों के लिए महत्वपूर्ण है।
- समृद्ध रूप से एनोटेट किए गए एक्स-रे डेटासेट की कमी: यह शायद सबसे महत्वपूर्ण बाधा है। FluoroSAM इस समस्या का समाधान "3M सिंथेटिक एक्स-रे छवियों से खरोंच से प्रशिक्षित होकर, मानव शरीर रचना, इमेजिंग ज्यामिति और देखने के कोणों की एक विस्तृत विविधता से" (पृष्ठ 1) किया गया है। FluoroSeg डेटासेट का निर्माण इस डेटा बाधा के जवाब में एक सीधा कदम है, जो दुर्लभ वास्तविक दुनिया के एनोटेशन पर भरोसा किए बिना मजबूत प्रशिक्षण को सक्षम करता है।
- एक्स-रे छवियों की अनूठी दृश्य विशेषताएं: एक्स-रे ट्रांसमिसिव होते हैं जिनमें ओवरलैपिंग वस्तुएं होती हैं, जिससे स्पष्ट सीमा का पता लगाना प्राकृतिक छवियों पर प्रशिक्षित मॉडल के लिए चुनौतीपूर्ण हो जाता है। FluoroSAM का उपन्यास पाठ एन्कोडर VQ के साथ विशेष रूप से इसे संभालने के लिए इंजीनियर किया गया है। VQ मॉड्यूल एक ही वस्तु के लिए विभिन्न पाठ विवरणों से परिवर्तनशीलता को कम करने में मदद करता है, जिससे मास्क डिकोडर को एक अधिक सुसंगत संकेत मिलता है, जो एक्स-रे में ओवरलैपिंग संरचनाओं को अलग करने के लिए महत्वपूर्ण है।
- प्राकृतिक भाषा इंटरैक्शन की आवश्यकता: सहज मानव-इन-द-लूप वर्कफ़्लो को सक्षम करने और अस्पष्टता को कम करने के लिए। FluoroSAM का एक "भाषा-प्रॉम्प्टेबल SAM का संस्करण" के रूप में मूल डिजाइन सीधे इस आवश्यकता को पूरा करता है, जिससे उपयोगकर्ताओं को प्राकृतिक भाषा का उपयोग करके विभाजन लक्ष्यों को निर्दिष्ट करने की अनुमति मिलती है, जो जटिल एक्स-रे दृश्यों के लिए केवल बिंदु या बाउंडिंग बॉक्स संकेतों की तुलना में कहीं अधिक लचीला और कम अस्पष्ट है।
- एक्स-रे प्रकारों में सामान्यीकरण: FluoroSeg डेटासेट, अपने सिम्युलेटेड शरीर रचनाओं, ज्यामिति और देखने के कोणों की विस्तृत श्रृंखला के साथ, यह सुनिश्चित करता है कि FluoroSAM को विभिन्न एक्स-रे अनुप्रयोगों, नैदानिक छाती एक्स-रे से लेकर इंटरवेंशनल फ्लोरोस्कोपी तक सामान्यीकरण के लिए प्रशिक्षित किया गया है। यह प्रशिक्षण के दौरान सिंथेटिक डेटा के बावजूद CXRs पर इसके सफलतापूर्वक शून्य-शॉट मूल्यांकन द्वारा प्रदर्शित किया गया है।
विकल्पों का अस्वीकरण
पेपर स्पष्ट रूप से बताता है कि क्यों कई लोकप्रिय वैकल्पिक दृष्टिकोण एक्स-रे छवि विभाजन के भाषा-प्रॉम्प्टेबल समस्या के लिए विफल हो गए होंगे या अपर्याप्त थे।
सबसे पहले, पारंपरिक, कार्य-विशिष्ट मशीन लर्निंग मॉडल को अस्वीकार कर दिया गया था क्योंकि वे एक संकीर्ण दायरे में काम करते हैं और व्यापक उपयोग या नए वर्गों के लिए व्यापक अतिरिक्त डेटा, एनोटेशन और पुन: प्रशिक्षण की आवश्यकता होती है (पृष्ठ 1)। यह एक लचीले, व्यापक रूप से प्रयोज्य फाउंडेशन मॉडल विकसित करने के लक्ष्य का खंडन करता है।
दूसरे, मूल SAM या SAM 2 जैसे मौजूदा फाउंडेशन मॉडल का प्रत्यक्ष अनुप्रयोग, विशेष रूप से पाठ संकेतों के लिए CLIP पर उनकी निर्भरता, अनुपयुक्त माना गया। लेखकों ने इस बात पर प्रकाश डाला कि CLIP, प्राकृतिक छवियों पर प्रशिक्षित होने के कारण, एक्स-रे छवियों की अनूठी विशेषताओं, जैसे कि उनकी ट्रांसमिसिव प्रकृति और स्पष्ट सीमाओं के बिना ओवरलैपिंग वस्तुओं की व्यापकता से जूझता है (पृष्ठ 2-3)। भले ही एक्स-रे के लिए एक CLIP-जैसा मॉडल अनुकूलित किया गया हो, एक एकल छवि पैच के भीतर कई वस्तुओं को अलग करना समस्याग्रस्त बना रहेगा। यह मौलिक बेमेल FluoroSAM के उपन्यास पाठ एन्कोडर के साथ VQ के विकास की ओर ले गया।
तीसरे, MedSAM [18], एक अन्य मेडिकल इमेजिंग फाउंडेशन मॉडल, को अन्य डोमेन में इसकी सफलता के बावजूद एक्स-रे अनुप्रयोगों के लिए अस्वीकार कर दिया गया था। MedSAM मुख्य रूप से अस्पष्टता को कम करने के लिए बाउंडिंग बॉक्स संकेतों पर निर्भर करता है (पृष्ठ 5)। एक्स-रे इमेजिंग के लिए, यह दृष्टिकोण अवांछनीय है क्योंकि यह: (ए) ओवरलैपिंग संरचनाओं के कारण अभी भी महत्वपूर्ण अस्पष्टता दिखाता है, (बी) स्वचालित या गैर-विशेषज्ञ संकेत को अव्यावहारिक बनाता है, और (सी) उन्नत मानव-इन-द-लूप सिस्टम के लिए आवश्यक लचीलेपन का अभाव है (पृष्ठ 5)। पेपर आगे नोट करता है कि MedSAM "आम तौर पर अंतर्निहित शरीर रचना को प्रतिबिंबित करने में विफल रहता है और बस प्रदान किए गए बॉक्स को भर देता है" (पृष्ठ 7), जो बाउंडिंग बॉक्स द्वारा सीमित होने पर छवि सामग्री की समझ की गुणात्मक विफलता का संकेत देता है।
अंत में, बिंदु संकेत के साथ मूल SAM का प्रदर्शन भी अपर्याप्त पाया गया, जो FluoroSAM के प्रदर्शन की तुलना में "बढ़ती त्रुटिपूर्ण मास्क" की भविष्यवाणी करता है (पृष्ठ 7)। यह बताता है कि जबकि SAM संकेत क्षमता प्रदान करता है, इसकी अंतर्निहित वास्तुकला और प्रशिक्षण डेटा FluoroSAM में पेश किए गए विशिष्ट अनुकूलन के बिना एक्स-रे विभाजन की जटिलताओं के लिए पर्याप्त मजबूत नहीं हैं।
पेपर स्पष्ट रूप से अन्य जनरेटिव मॉडल जैसे GANs या डिफ्यूजन मॉडल को विभाजन कार्य के लिए अस्वीकार करने पर चर्चा नहीं करता है, क्योंकि ध्यान प्रॉम्प्टेबल विभाजन और एक्स-रे डोमेन में मौजूदा फाउंडेशन मॉडल की सीमाओं पर है। विकल्पों को अस्वीकार करने का मुख्य तर्क लगातार एक्स-रे की अनूठी दृश्य गुणों, डेटा की कमी और लचीले, भाषा-संरेखित इंटरैक्शन की महत्वपूर्ण आवश्यकता को संभालने में उनकी असमर्थता के इर्द-गिर्द घूमता है।
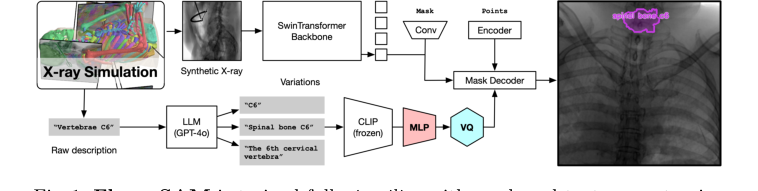 Figure 1. FluoroSAM is trained fully in silico with mask and text prompt pairs. It features a VQ layer that enables training language-aligned training on X-ray images
Figure 1. FluoroSAM is trained fully in silico with mask and text prompt pairs. It features a VQ layer that enables training language-aligned training on X-ray images
गणितीय और तार्किक तंत्र
मास्टर समीकरण
FluoroSAM के सीखने के तंत्र का मूल, कई विभाजन मॉडल की तरह, इसके हानि फ़ंक्शन में निहित है, जो मॉडल को सटीक मास्क उत्पन्न करने के लिए निर्देशित करता है। जबकि पेपर में कई संकेतों और चयन मानदंडों को शामिल करने वाले एक जटिल प्रशिक्षण व्यवस्था का वर्णन किया गया है, एक एकल अनुमानित मास्क का उसके ग्राउंड ट्रुथ के खिलाफ मूल्यांकन के लिए मौलिक उद्देश्य डाइस लॉस और फोकल लॉस का संयोजन है। पेपर कहता है, "हम मास्क के लिए डाइस और फोकल लॉस का उपयोग करते हैं।" इसलिए, एक एकल मास्क भविष्यवाणी के लिए उद्देश्य का प्रतिनिधित्व करने वाला मास्टर समीकरण इस प्रकार व्यक्त किया जा सकता है:
$$ L_{mask}(P, G) = \lambda_{Dice} L_{Dice}(P, G) + \lambda_{Focal} L_{Focal}(P, G) $$
जहां $P$ अनुमानित विभाजन मास्क (संभावनाओं का एक मैट्रिक्स) का प्रतिनिधित्व करता है और $G$ बाइनरी ग्राउंड ट्रुथ मास्क का प्रतिनिधित्व करता है। व्यक्तिगत हानि घटकों को इस प्रकार परिभाषित किया गया है:
$$ L_{Dice}(P, G) = 1 - \frac{2 \sum_{i=1}^N p_i g_i}{\sum_{i=1}^N p_i^2 + \sum_{i=1}^N g_i^2} $$
$$ L_{Focal}(P, G) = - \sum_{i=1}^N \left( g_i \alpha (1-p_i)^\gamma \log(p_i) + (1-g_i) (1-\alpha) p_i^\gamma \log(1-p_i) \right) $$
पद-दर-पद ऑटोप्सी
आइए इन समीकरणों को समझने के लिए कि प्रत्येक घटक की क्या भूमिका है, उनका विश्लेषण करें:
-
$L_{mask}(P, G)$: यह ग्राउंड ट्रुथ $G$ दिए जाने पर एक एकल अनुमानित मास्क $P$ के लिए समग्र हानि मान है।
- गणितीय परिभाषा: एक स्केलर मान, आमतौर पर 0 और 1 के बीच (या फोकल लॉस के लिए उच्च), अनुमानित और सत्य विभाजन के बीच असमानता को मापता है।
- भौतिक/तार्किक भूमिका: यह प्राथमिक उद्देश्य फ़ंक्शन है जिसे FluoroSAM मॉडल प्रशिक्षण के दौरान कम करने का प्रयास करता है। एक निम्न $L_{mask}$ अधिक सटीक विभाजन को इंगित करता है।
- जोड़ का उपयोग क्यों: $L_{Dice}$ और $L_{Focal}$ को संयोजित करने के लिए जोड़ का उपयोग दोनों पहलुओं (ओवरलैप और कठिन उदाहरणों का सही वर्गीकरण) को समग्र विभाजन उद्देश्य में एक साथ योगदान करने की अनुमति देता है। यह किसी भी हानि को अलग से उपयोग करने की तुलना में अधिक व्यापक और संतुलित अनुकूलन लक्ष्य प्रदान करता है।
-
$\lambda_{Dice}$: डाइस लॉस घटक के लिए भारण गुणांक।
- गणितीय परिभाषा: एक सकारात्मक स्केलर स्थिरांक। पेपर स्पष्ट रूप से इसका मान नहीं बताता है, लेकिन इसे आमतौर पर हाइपरपैरामीटर ट्यूनिंग के माध्यम से सेट किया जाता है।
- भौतिक/तार्किक भूमिका: यह गुणांक समग्र विभाजन उद्देश्य में उच्च ओवरलैप (डाइस लॉस द्वारा मापा गया) प्राप्त करने के महत्व को नियंत्रित करता है, इसकी तुलना में कठिन-से-वर्गीकृत पिक्सेल (फोकल लॉस द्वारा मापा गया) पर ध्यान केंद्रित करने के महत्व को नियंत्रित करता है।
- गुणा का उपयोग क्यों: गुणा एक समग्र हानि फ़ंक्शन के भीतर एक विशिष्ट हानि पद के योगदान को स्केल करने का मानक तरीका है।
-
$L_{Dice}(P, G)$: डाइस लॉस घटक।
- गणितीय परिभाषा: $1 - \frac{2 \sum_{i=1}^N p_i g_i}{\sum_{i=1}^N p_i^2 + \sum_{i=1}^N g_i^2}$। यहाँ, $p_i$ पिक्सेल $i$ के लिए अनुमानित संभावना है, और $g_i$ पिक्सेल $i$ के लिए ग्राउंड ट्रुथ लेबल (0 या 1) है। योग $\sum_{i=1}^N$ छवि में सभी $N$ पिक्सेल पर है।
- भौतिक/तार्किक भूमिका: यह पद मुख्य रूप से अनुमानित मास्क और ग्राउंड ट्रुथ के बीच स्थानिक ओवरलैप को मापता है। यह महत्वपूर्ण वर्ग असंतुलन वाले कार्यों के लिए विशेष रूप से प्रभावी है, जैसे कि एक बड़े एक्स-रे छवि में छोटे अंगों या उपकरणों को विभाजित करना, क्योंकि यह स्वाभाविक रूप से सकारात्मक (अग्रभूमि) वर्ग पर ध्यान केंद्रित करता है। इस पद को कम करने से मॉडल को वास्तविक वस्तु के आकार और सीमा से निकटता से मेल खाने वाले मास्क उत्पन्न करने के लिए प्रोत्साहित किया जाता है।
- 1 से घटाव क्यों: डाइस गुणांक स्वयं एक समानता मीट्रिक है, जो 0 (कोई ओवरलैप नहीं) से 1 (पूर्ण ओवरलैप) तक होता है। इसे 1 से घटाने से यह एक हानि फ़ंक्शन में बदल जाता है, जहां 0 पूर्ण विभाजन का प्रतिनिधित्व करता है और 1 पूर्ण असमानता का प्रतिनिधित्व करता है।
- हर में वर्गों के योग का उपयोग क्यों: संभाव्य भविष्यवाणियों ($p_i \in [0,1]$) के लिए, $p_i^2$ और $g_i^2$ का उपयोग हर में सेट कार्डिनैलिटी (तत्वों की संख्या) की अवधारणा को निरंतर संभावनाओं तक सामान्यीकृत करता है, जिससे हानि फ़ंक्शन अवकलनीय हो जाता है और ग्रेडिएंट-आधारित अनुकूलन के लिए उपयुक्त हो जाता है।
-
$\lambda_{Focal}$: फोकल लॉस घटक के लिए भारण गुणांक।
- गणितीय परिभाषा: एक सकारात्मक स्केलर स्थिरांक, जिसे आमतौर पर हाइपरपैरामीटर ट्यूनिंग के माध्यम से निर्धारित किया जाता है।
- भौतिक/तार्किक भूमिका: $\lambda_{Dice}$ के समान, यह गुणांक कुल हानि में फोकल लॉस के प्रभाव को समायोजित करता है, कठिन उदाहरणों पर इसके ध्यान को डाइस लॉस के समग्र ओवरलैप पर जोर देने के साथ संतुलित करता है।
- गुणा का उपयोग क्यों: हानि पदों के लिए मानक स्केलिंग तंत्र।
-
$L_{Focal}(P, G)$: फोकल लॉस घटक।
- गणितीय परिभाषा: $- \sum_{i=1}^N \left( g_i \alpha (1-p_i)^\gamma \log(p_i) + (1-g_i) (1-\alpha) p_i^\gamma \log(1-p_i) \right)$।
- भौतिक/तार्किक भूमिका: यह हानि अच्छी तरह से वर्गीकृत उदाहरणों (आसान नकारात्मक) के योगदान को कम करके वर्ग असंतुलन की समस्या को संबोधित करती है और प्रशिक्षण को कठिन, गलत वर्गीकृत उदाहरणों पर केंद्रित करती है। एक्स-रे छवियों में, पृष्ठभूमि पिक्सेल अक्सर अग्रभूमि पिक्सेल की संख्या से कहीं अधिक होते हैं, और फोकल लॉस मॉडल को आसान पृष्ठभूमि भविष्यवाणियों से अभिभूत होने से रोकता है।
- $\alpha$ क्यों: यह सकारात्मक वर्ग के लिए एक भारण कारक है। यह सकारात्मक और नकारात्मक उदाहरणों के महत्व को संतुलित करता है, जो तब उपयोगी हो सकता है जब एक वर्ग स्वाभाविक रूप से अधिक महत्वपूर्ण या दुर्लभ हो।
- $(1-p_i)^\gamma$ या $p_i^\gamma$ क्यों: ये मॉड्यूलेटिंग कारक हैं। यदि एक पिक्सेल अच्छी तरह से वर्गीकृत है (जैसे, $p_i$ उच्च है जब $g_i=1$), तो $(1-p_i)$ छोटा है, और $(1-p_i)^\gamma$ और भी छोटा हो जाता है ($\gamma > 0$ के लिए), प्रभावी रूप से इसके हानि योगदान को कम करता है। इसके विपरीत, गलत वर्गीकृत उदाहरणों के लिए, कारक 1 के करीब होता है, और हानि महत्वपूर्ण बनी रहती है। यह तंत्र कठिन उदाहरणों पर सीखने को "केंद्रित" करता है।
- $\log(p_i)$ क्यों: यह मौलिक क्रॉस-एंट्रॉपी घटक है, जो भविष्यवाणी के "आश्चर्य" या त्रुटि को मापता है। मॉड्यूलेटिंग कारक फिर इस त्रुटि को स्केल करता है।
-
$P$: अनुमानित मास्क।
- गणितीय परिभाषा: फ्लोटिंग-पॉइंट मानों का एक 2डी मैट्रिक्स (या वॉल्यूमेट्रिक डेटा के लिए 3डी), जहां प्रत्येक तत्व $p_{ij} \in [0, 1]$ अग्रभूमि वस्तु से संबंधित होने वाले पिक्सेल $(i,j)$ की अनुमानित संभावना का प्रतिनिधित्व करता है।
- भौतिक/तार्किक भूमिका: यह FluoroSAM के मास्क डिकोडर का आउटपुट है, जो मॉडल के विभाजन के लिए सर्वोत्तम अनुमान का प्रतिनिधित्व करता है।
-
$G$: ग्राउंड ट्रुथ मास्क।
- गणितीय परिभाषा: एक 2डी बाइनरी मैट्रिक्स, जहां प्रत्येक तत्व $g_{ij} \in \{0, 1\}$ इंगित करता है कि पिक्सेल $(i,j)$ वास्तव में अग्रभूमि (1) या पृष्ठभूमि (0) से संबंधित है या नहीं।
- भौतिक/तार्किक भूमिका: यह FluoroSeg डेटासेट द्वारा प्रदान किया गया "सही उत्तर" है, जिसके विरुद्ध मॉडल की भविष्यवाणियों की तुलना हानि की गणना के लिए की जाती है।
-
$p_i, g_i$: व्यक्तिगत पिक्सेल संभावनाएँ और लेबल।
- गणितीय परिभाषा: $p_i \in [0, 1]$ एक एकल पिक्सेल के लिए अनुमानित संभावना है, और $g_i \in \{0, 1\}$ इसका संबंधित ग्राउंड ट्रुथ लेबल है।
- भौतिक/तार्किक भूमिका: ये भविष्यवाणी और सत्य की सबसे छोटी इकाइयां हैं, जिनके समेकित योगदान समग्र मास्क हानि बनाते हैं।
-
$\sum$: योग ऑपरेटर।
- गणितीय परिभाषा: एक परिभाषित सेट पर मानों का योग करता है, इस मामले में, छवि में सभी पिक्सेल $i=1, \dots, N$।
- भौतिक/तार्किक भूमिका: पूरे विभाजन मास्क के लिए कुल डाइस और फोकल हानि की गणना करने के लिए व्यक्तिगत पिक्सेल-वार योगदान को एकत्रित करता है।
चरण-दर-चरण प्रवाह
एक एकल एक्स-रे छवि और एक प्राकृतिक भाषा संकेत की कल्पना करें जो FluoroSAM सिस्टम में प्रवेश कर रहा है, जैसे कि परिष्कृत असेंबली लाइन के साथ आइटम चलते हैं:
- छवि अंतर्ग्रहण (दृश्य पथ): एक एक्स-रे छवि, मान लीजिए एक रोगी के सीने की, पहले छवि एन्कोडर में प्रवेश करती है। यह एन्कोडर, एक SwinTransformer बैकबोन पर निर्मित, एक विशेष दृश्य प्रसंस्करण इकाई की तरह कार्य करता है। यह विभिन्न पैमानों पर पदानुक्रमित दृश्य सुविधाओं को निकालते हुए, छवि को सावधानीपूर्वक स्कैन करता है। इसे सरल किनारों और बनावट से लेकर जटिल शारीरिक पैटर्न तक, छवि को तेजी से अमूर्त अभ्यावेदन में तोड़ने के रूप में सोचें।
- संकेत व्याख्या (भाषा पथ): साथ ही, एक प्राकृतिक भाषा संकेत, जैसे "बाएं फेफड़े को विभाजित करें," पाठ एन्कोडर में डाला जाता है। यह एन्कोडर एक बहु-चरणीय इकाई है:
- सबसे पहले, एक जमे हुए CLIP एन्कोडर पाठ लेता है और इसे एक उच्च-आयामी संख्यात्मक एम्बेडिंग में परिवर्तित करता है, जो इसके अर्थ को पकड़ता है।
- इसके बाद, एक मल्टी-लेयर परसेप्ट्रॉन (MLP) इस एम्बेडिंग को और संसाधित करता है, इसके प्रतिनिधित्व को परिष्कृत करता है।
- अंत में, एक वेक्टर क्वांटाइजेशन (VQ) बॉटलनेक इस परिष्कृत एम्बेडिंग को एक असतत "संकेत टोकन" में क्वांटाइज करता है। यह VQ परत एक भाषाई फिल्टर की तरह है, जो मॉडल के बाकी हिस्सों द्वारा आसानी से समझे जाने वाले सुसंगत, असतत कोड में संकेत के अर्थ को मानकीकृत करती है, भले ही वाक्यांशों में मामूली भिन्नता हो।
- फ़ीचर फ़्यूज़न और मास्क जनरेशन: छवि एन्कोडर से समृद्ध दृश्य सुविधाओं और पाठ एन्कोडर से असतत संकेत टोकन को फिर एक साथ लाया जाता है। यह फ़्यूज़न मास्क डिकोडर को निर्देशित करता है, जो मॉडल का रचनात्मक इंजन है। संयुक्त दृश्य और भाषाई जानकारी के आधार पर, मास्क डिकोडर सिर्फ एक मास्क नहीं बनाता है; यह अनुरोधित वस्तु के लिए कई उम्मीदवार विभाजन मास्क उत्पन्न करता है। यह कई कुशल कारीगरों की तरह है जो प्रत्येक "बाएं फेफड़े" के लिए थोड़ा अलग रूपरेखा प्रस्तावित करते हैं।
- हानि मूल्यांकन और चयन: इन उम्मीदवार मास्क में से प्रत्येक के लिए, सिस्टम सत्य ग्राउंड ट्रुथ मास्क (जो प्रशिक्षण के दौरान उपलब्ध है) के खिलाफ डाइस और फोकल लॉस का उपयोग करके अपने $L_{mask}$ की गणना करता है। फिर सिस्टम उस उम्मीदवार मास्क का चयन करता है जो सबसे कम $L_{mask}$ उत्पन्न करता है। यह चयन प्रक्रिया सुनिश्चित करती है कि मॉडल हमेशा संकेत के आधार पर सबसे सटीक संभव विभाजन के लिए प्रयास कर रहा है।
- बैकप्रॉपैगेशन और सीखना: चयनित मास्क से हानि, विशेष रूप से पाठ संकेत, बिंदु 1, बिंदु 8, और एक अतिरिक्त यादृच्छिक बिंदु संकेत से, ग्रेडिएंट की गणना के लिए उपयोग की जाती है। ये ग्रेडिएंट सटीक निर्देशों की तरह हैं जो मास्क डिकोडर और छवि एन्कोडर (पाठ एन्कोडर का CLIP भाग जमे हुए है, लेकिन MLP और VQ घटक अपडेट किए गए हैं) के माध्यम से पीछे की ओर प्रवाहित होते हैं। ये निर्देश प्रत्येक पैरामीटर को बताते हैं कि हानि को कम करने और भविष्य के विभाजनों में सुधार करने के लिए इसे कैसे समायोजित करने की आवश्यकता है। भविष्यवाणी, मूल्यांकन, चयन और समायोजन की यह पुनरावृत्ति प्रक्रिया है जिससे FluoroSAM प्राकृतिक भाषा के आधार पर एक्स-रे छवियों को सटीक रूप से विभाजित करना सीखता है।
अनुकूलन गतिशीलता
FluoroSAM की सीखने की प्रक्रिया हानि न्यूनीकरण, ग्रेडिएंट-आधारित अपडेट और रणनीतिक डेटा वृद्धि का एक गतिशील अंतःक्रिया है, जो सभी एक जटिल हानि परिदृश्य को नेविगेट करने और मजबूत प्रदर्शन प्राप्त करने के लिए डिज़ाइन किए गए हैं।
-
हानि परिदृश्य आकारण: डाइस लॉस और फोकल लॉस का संयोजन अनुकूलन परिदृश्य को आकार देने के लिए महत्वपूर्ण है। डाइस लॉस, वर्ग असंतुलन के लिए प्रभावी होने के बावजूद, कभी-कभी गैर-उत्तलता और पठारों से पीड़ित हो सकता है, खासकर जब अनुमानित मास्क का ग्राउंड ट्रुथ के साथ बहुत कम ओवरलैप होता है। फोकल लॉस आसान उदाहरणों के योगदान को आक्रामक रूप से कम करके इसका पूरक है, जिससे कठिन-से-वर्गीकृत पिक्सेल का सापेक्ष महत्व बढ़ जाता है। यह प्रभावी रूप से चुनौतीपूर्ण क्षेत्रों के आसपास ग्रेडिएंट को तेज करता है, जिससे मॉडल स्थानीय न्यूनतम में फंसने या आसानी से अनुमानित पृष्ठभूमि पिक्सेल द्वारा हावी होने से बचता है। लक्ष्य एक ऐसा परिदृश्य बनाना है जहां बेहतर विभाजन का मार्ग स्पष्ट और अधिक सीधा हो।
-
ग्रेडिएंट व्यवहार और अपडेट: प्रशिक्षण के दौरान, $L_{mask}$ (चयनित संकेतों से) के ग्रेडिएंट सभी प्रशिक्षित पैरामीटर के लिए छवि एन्कोडर और मास्क डिकोडर, साथ ही पाठ एन्कोडर के MLP और VQ घटकों के संबंध में गणना की जाती है। ये ग्रेडिएंट पैरामीटर समायोजन की दिशा और परिमाण को इंगित करते हैं जिनकी हानि को कम करने के लिए आवश्यकता होती है। मॉडल पैरामीटर को पुनरावृत्त रूप से एक अनुकूलक (आमतौर पर एडम या एक प्रकार, हालांकि पेपर में स्पष्ट रूप से नहीं कहा गया है) का उपयोग करके अपडेट किया जाता है। यह पुनरावृत्ति प्रक्रिया मॉडल की "स्थिति" को उच्च-आयामी पैरामीटर स्थान में निम्न हानि वाले क्षेत्रों की ओर ले जाती है, धीरे-धीरे इसके विभाजन सटीकता में सुधार करती है।
-
लर्निंग रेट शेड्यूल: पेपर एक सावधानीपूर्वक डिज़ाइन किए गए लर्निंग रेट शेड्यूल को निर्दिष्ट करता है: 20k पुनरावृत्तियों पर $8 \times 10^{-6}$ से $8 \times 10^{-4}$ की आधार दर तक एक रैखिक वार्म-अप, जिसके बाद 200k और 400k चरणों में 10 के कारक से कमी आती है।
- वार्म-अप: प्रारंभिक कम लर्निंग रेट तब होती है जब मॉडल पैरामीटर यादृच्छिक रूप से इनिशियलाइज़ किए जाते हैं और एक इष्टतम स्थिति से दूर होते हैं, तब बड़े, अस्थिर करने वाले अपडेट को रोकता है। यह मॉडल को हानि परिदृश्य में "अपना पैर जमाने" की अनुमति देता है।
- क्षय: प्रशिक्षण के बाद में लर्निंग रेट को कम करने से मॉडल को अपने पैरामीटर को ठीक करने में मदद मिलती है, जिससे यह ओवरशूटिंग या दोलन के बिना अधिक सटीक रूप से एक न्यूनतम पर अभिसरण कर सकता है। यह लक्ष्य के करीब पहुंचने पर बड़े, खोजपूर्ण चरणों से छोटे, अधिक सटीक समायोजन में स्विच करने जैसा है।
-
वेक्टर क्वांटाइजेशन (VQ) गतिशीलता: पाठ एन्कोडर में VQ बॉटलनेक एक निरंतर तंत्रिका नेटवर्क में एक असतत तत्व पेश करता है। स्ट्रेट-थ्रू एस्टिमेटर जैसी तकनीकों का उपयोग करके प्रशिक्षण के साथ VQ आमतौर पर असतत क्वांटाइजेशन चरण के माध्यम से ग्रेडिएंट को पास करने की अनुमति देता है। यह तंत्र पाठ एम्बेडिंग को "कोडबुक" वैक्टर के एक परिमित सेट में मजबूर करता है, जो मजबूत, भाषा-संरेखित अभ्यावेदन सीखने में मदद करता है। जबकि यह सैद्धांतिक रूप से नए वर्गों के लिए सामान्यीकरण को सीमित करता है, यह ज्ञात वर्गों के लिए विभिन्न वाक्यांशों को सुसंगत असतत टोकन पर मैप करके परिवर्तनशील भाषा संकेतों के प्रति मजबूती को बढ़ाता है। यह मॉडल को संकेत के सटीक शब्दों के प्रति कम संवेदनशील बनाता है।
-
वृद्धि और यादृच्छिकीकरण के माध्यम से मजबूती:
- पाठ वृद्धि: प्रत्येक मास्क के लिए 30 विविध संकेतों तक उत्पन्न करने के लिए gpt-40 [1] का उपयोग प्रशिक्षण डेटा की भाषाई परिवर्तनशीलता का महत्वपूर्ण रूप से विस्तार करता है। यह FluoroSAM को विभिन्न तरीकों से उपयोगकर्ताओं द्वारा अपने विभाजन अनुरोधों को वाक्यांशित करने के प्रति मजबूत बनाता है, जिससे विशिष्ट संकेत वाक्यांशों के लिए ओवरफिटिंग को रोका जा सके।
- डोमेन रैंडमाइजेशन: सिंथेटिक एक्स-रे छवियों पर "मजबूत डोमेन रैंडमाइजेशन" लागू करना (जैसे, मोटे ड्रॉपआउट, उलटाव, धुंधलापन, गॉसियन कंट्रास्ट समायोजन [10]) सिम-टू-रियल ट्रांसफर के लिए एक महत्वपूर्ण रणनीति है। यह मॉडल को विभिन्न छवि उपस्थितियों के लिए अपरिवर्तनीय सुविधाओं को सीखने के लिए मजबूर करता है, जिससे यह सिंथेटिक प्रशिक्षण डेटा से भिन्न वास्तविक दुनिया की एक्स-रे छवियों का सामना करने पर अधिक मजबूत हो जाता है। यह प्रभावी रूप से मॉडल को इनपुट विविधताओं में मामूली भिन्नताओं के प्रति कम संवेदनशील बनाकर हानि परिदृश्य को चिकना करता है।
-
बहु-आउटपुट और चयन: FluoroSAM की एक संकेत के लिए कई मास्क उत्पन्न करने और फिर प्रशिक्षण के दौरान सबसे कम हानि वाले को चुनने की क्षमता एक आंतरिक स्व-सुधार तंत्र के रूप में कार्य करती है। यह भविष्यवाणियों के एक समूह की तरह है, जहां सर्वश्रेष्ठ को चुना जाता है, जिससे अधिक विश्वसनीय और सटीक अंतिम आउटपुट प्राप्त होता है। अनुमान के दौरान, एक IOU भविष्यवाणी हेड इस चयन का कार्यभार संभालता है, यह अनुमान लगाता है कि कौन सा मास्क सबसे अधिक संभावना सही है। यह गतिशील चयन प्रक्रिया मॉडल की समग्र स्थिरता और प्रदर्शन में योगदान करती है।
परिणाम, सीमाएँ और निष्कर्ष
प्रयोगात्मक डिजाइन और बेसलाइन
FluoroSAM की क्षमताओं को कठोरता से मान्य करने के लिए, लेखकों ने सिंथेटिक और वास्तविक दुनिया दोनों एक्स-रे डेटा को शामिल करते हुए एक व्यापक प्रयोगात्मक सेटअप तैयार किया, जिसने अपने मॉडल को स्थापित बेसलाइन के खिलाफ खड़ा किया।
FluoroSAM के प्रशिक्षण की नींव FluoroSeg डेटासेट है, जो 3 मिलियन सिंथेटिक एक्स-रे छवियों का एक विशाल संग्रह है। इस डेटासेट को वास्तविक एक्स-रे इमेजिंग की परिवर्तनशीलता को पकड़ने के लिए महत्वपूर्ण मानव शरीर रचना, इमेजिंग ज्यामिति और देखने के कोणों की एक विशाल सरणी का अनुकरण करने के लिए इन सिलिको में सावधानीपूर्वक उत्पन्न किया गया था। सिमुलेशन पाइपलाइन 1,621 उच्च-रिज़ॉल्यूशन सीटी स्कैन से शुरू हुई, जो न्यू मैक्सिको डेसेंट इमेज डेटाबेस [5] से थी, जिन्हें बाद में टोटलसेगमेंटेटर [27] का उपयोग करके 128 अंग वर्गों में विभाजित किया गया ताकि सतह मेश प्राप्त किया जा सके। विविध रेडियोलॉजिकल परीक्षाओं की नकल करने के लिए, वातावरण ने मानक दृश्यों (जैसे, छाती, पेट) और पूरी तरह से यादृच्छिक सी-आर्म दृश्यों दोनों का नमूना लिया, जिसमें विविध कोणों के साथ एक प्राथमिक अंग पर ध्यान केंद्रित किया गया। महत्वपूर्ण रूप से, 464 कंप्यूटर-मॉडल वाले सर्जिकल उपकरण, प्रत्येक व्यापक पाठ विवरण के साथ, यादृच्छिक रूप से दृश्य के क्षेत्र में रखे गए थे। छवियों को $512^2$ पिक्सेल पर प्रस्तुत किया गया था, जिसमें छद्म-ग्राउंड ट्रुथ मास्क और संबंधित पाठ विवरण शामिल थे। यह प्रक्रिया अत्यधिक कुशल थी, NVIDIA A6000 GPU पर 6.5 से 15.7 छवियों प्रति सेकंड उत्पन्न करती थी, लगभग 6 GPU दिनों में 2.95 मिलियन छवियों का कुल योग। डेटासेट को मूल सीटी स्कैन के आधार पर प्रशिक्षण और सत्यापन के लिए 90/10% विभाजित किया गया था।
FluoroSAM स्वयं, SAM [15] का एक भाषा-प्रॉम्प्टेबल संस्करण, FluoroSeg पर खरोंच से प्रशिक्षित किया गया था। इसका उपन्यास पाठ एन्कोडर, जिसमें एक जमे हुए CLIP एन्कोडर [21], एक दो-छिपी-परत मल्टी-लेयर परसेप्ट्रॉन (MLP), और एक वेक्टर क्वांटाइजेशन (VQ) बॉटलनेक [20] शामिल है, भाषा संरेखण को सक्षम करने में केंद्रीय था। सामान्यीकरण को बढ़ाने के लिए, पाठ वृद्धि gpt-40 [1] का उपयोग करके प्रति मास्क 30 विविध संकेतों तक उत्पन्न की गई थी। संबंधित अंग मास्क को प्रक्रियात्मक रूप से 38 समूहों में संयोजित किया गया था (जैसे, "बाएं पसलियां"), और "खराब संकेत" (छवि में मौजूद नहीं) कभी-कभी मॉडल को अप्रासंगिक प्रश्नों को अनदेखा करने के लिए सिखाने के लिए नमूना लिए गए थे। छवि एन्कोडर ने एक SwinTransformer बैकबोन (अंतिम मॉडल के लिए Swin-L) का उपयोग किया, जिसे ImageNet-22k पर पूर्व-प्रशिक्षित किया गया और इंस्टेंस विभाजन के लिए FluoroSeg वर्गों के एक कम सेट पर आगे प्रशिक्षित किया गया। सिम-टू-रियल ट्रांसफर को सुविधाजनक बनाने के लिए, प्रशिक्षण के दौरान मजबूत डोमेन रैंडमाइजेशन तकनीकों को लागू किया गया था, जिसमें मोटे ड्रॉपआउट, उलटाव, धुंधलापन, गॉसियन कंट्रास्ट समायोजन [10], यादृच्छिक विंडोिंग और CLAHE हिस्टोग्राम इक्वलाइजेशन शामिल थे। प्रशिक्षण में 10 युग शामिल थे जो 2 NVIDIA H100 GPUs पर 6 दिनों तक चलते थे।
मूल्यांकन के लिए, FluoroSAM को कई "पीड़ित" बेसलाइन मॉडल के खिलाफ वास्तविक एक्स-रे छवियों पर सामना करना पड़ा:
1. वास्तविक इंटरवेंशनल एक्स-रे छवियां: एक पूर्ण धड़ नमूने (मध्य-फीमर से टी2) से पंजीकृत एक्स-रे छवियों का एक डेटासेट जिसे ब्रेनलैब लूप-एक्स डिवाइस के साथ अधिग्रहित किया गया था। ग्राउंड ट्रुथ मास्क को चार नेविगेटेड कोन-बीम सीटी छवियों को सिलाई करके और अंग विभाजनों [27] को प्रोजेक्ट करके उत्पन्न किया गया था। मूल्यांकन 1,741 मास्क तक सीमित था जो छवि आकार के 2.5% से बड़े थे। बेसलाइन में मूल SAM [15] (बिंदुओं या बाउंडिंग बॉक्स के साथ संकेतित) और MedSAM [18] (जो आमतौर पर चिकित्सा छवियों के लिए बाउंडिंग बॉक्स संकेतों का उपयोग करता है) शामिल थे। मेट्रिक्स इंटरसेक्शन ओवर यूनियन (IoU), डाइस स्कोर और हॉसडॉर्फ दूरी (HDD) थे।
2. चेस्ट एक्स-रे (CXR) पर शून्य-शॉट मूल्यांकन: फेफड़े के एनोटेशन के साथ 1,131 CXRs [2] का एक डेटासेट। इसने FluoroSAM की क्षमता का परीक्षण किया कि वह बिना किसी विशिष्ट प्रशिक्षण के विभिन्न एक्स-रे विधा और वास्तविक दुनिया के एनोटेशन के लिए सामान्यीकरण कर सके। वही बेसलाइन, SAM और MedSAM, का उपयोग किया गया था, और IoU, डाइस और HDD की रिपोर्ट की गई थी।
साक्ष्य क्या साबित करते हैं
प्रायोगिक साक्ष्य निश्चित रूप से साबित करते हैं कि FluoroSAM का मुख्य तंत्र - एक्स-रे छवियों के लिए भाषा-प्रॉम्प्टेबल विभाजन - प्रभावी है और अक्सर मौजूदा विधियों से बेहतर है, भले ही केवल सिंथेटिक डेटा पर प्रशिक्षित किया गया हो।
वास्तविक इंटरवेंशनल एक्स-रे छवियों पर, FluoroSAM ने केवल पाठ संकेतों के साथ अपनी क्षमता का प्रदर्शन किया। जैसा कि तालिका 1 और चित्र 3a में दिखाया गया है, FluoroSAM ने 0.47 का औसत IoU और 0.60 का डाइस स्कोर प्राप्त किया। यह प्रदर्शन उल्लेखनीय रूप से अपने साथियों, SAM (IoU 0.36, डाइस 0.50 बिंदुओं के साथ; IoU 0.42, बॉक्स के साथ डाइस 0.57) और MedSAM (IoU 0.41, डाइस 0.55) से बेहतर था, जब FluoroSAM को केवल पाठ संकेत दिए गए थे। यह एक महत्वपूर्ण साक्ष्य है, क्योंकि यह FluoroSAM के उपन्यास पाठ एन्कोडर और VQ परत की प्राकृतिक भाषा की व्याख्या करने और एक चुनौतीपूर्ण वास्तविक दुनिया के परिदृश्य में सटीक विभाजन उत्पन्न करने की क्षमता को मान्य करता है। जब बिंदु संकेत जोड़े गए, तो FluoroSAM का प्रदर्शन और भी बेहतर हुआ, 2 बिंदुओं के साथ IoU 0.56 और डाइस 0.69 तक पहुंच गया, और 8 बिंदुओं के साथ IoU 0.64, डाइस 0.77, और HDD 60.8 तक पहुंच गया, इन मेट्रिक्स में लगातार बेसलाइन से बेहतर प्रदर्शन किया। यहां निर्णायक साक्ष्य प्रत्यक्ष मात्रात्मक तुलना है जहां FluoroSAM, अपनी अनूठी पाठ-संकेत क्षमता के साथ, अधिक प्रतिबंधित बिंदु या बॉक्स संकेतों पर निर्भर मॉडलों के प्रदर्शन से बेहतर या मेल खाता है।
CXR पर शून्य-शॉट मूल्यांकन ने FluoroSAM के सामान्यीकरण और सिम-टू-रियल ट्रांसफर क्षमताओं का निर्विवाद प्रमाण प्रदान किया। केवल सिंथेटिक डेटा पर प्रशिक्षित होने के बावजूद, FluoroSAM वास्तविक CXRs पर हाथ-एनोटेट किए गए फेफड़े के विभाजनों के लिए उल्लेखनीय रूप से अनुकूलित हुआ। केवल पाठ संकेतों के साथ, इसने 0.50 का औसत IoU और 0.66 का डाइस स्कोर प्राप्त किया (तालिका 1, चित्र 3b)। जबकि SAM, जब कई बिंदु या बॉक्स संकेतों के साथ प्रदान किया जाता है, तो उच्च स्कोर प्राप्त कर सकता है (जैसे, 2 बिंदुओं के लिए IoU 0.83, डाइस 0.89), 8 बिंदुओं के साथ FluoroSAM का प्रदर्शन (IoU 0.81, डाइस 0.89) अत्यधिक प्रतिस्पर्धी था, यहां तक कि SAM के 8-बिंदु प्रदर्शन (IoU 0.73, डाइस 0.82) से भी बेहतर था। यह दर्शाता है कि सिंथेटिक डेटा पर FluoroSAM का प्रशिक्षण, मजबूत डोमेन रैंडमाइजेशन के साथ मिलकर, इसे अनदेखे वास्तविक दुनिया के नैदानिक एक्स-रे छवियों और कार्यों के लिए सामान्यीकरण करने में सक्षम बनाता है, जो सिंथेटिक अनुमानों और हाथ-एनोटेट किए गए मास्क के बीच व्यवस्थित अंतर को देखते हुए एक महत्वपूर्ण उपलब्धि है।
इसके अलावा, गुणात्मक उपयोगकर्ता अध्ययन (चित्र 4) ने परिवर्तनशील पाठ संकेतों के प्रति विभाजन मजबूती में सुधार करने में VQ परत की प्रभावकारिता के लिए सम्मोहक साक्ष्य प्रदान किए। जब पूछा गया "कूल्हे के बगल में हड्डी क्या है?", FluoroSAM ने VQ के साथ फीमर को सही ढंग से विभाजित किया, जबकि VQ के बिना, यह विफल रहा। यह लेखकों के दावे का सीधे समर्थन करता है कि VQ विभिन्न विवरणों से परिवर्तनशीलता को कम करके नए भाषा संकेतों के लिए सामान्यीकरण में मदद करता है, जिससे मॉडल प्राकृतिक भाषा की बारीकियों के प्रति अधिक लचीला हो जाता है।
अंत में, चित्र 5 में प्रदर्शित गुणात्मक परिणाम और डाउनस्ट्रीम अनुप्रयोग FluoroSAM की व्यावहारिक उपयोगिता को दर्शाते हैं। इसका लचीलापन कुशल एक्स-रे एनोटेशन, रोगी-केंद्रित स्वास्थ्य शिक्षा, और बुद्धिमान रोबोटिक सी-आर्म पोजिशनिंग और स्वायत्त कोलिमेशन को सक्षम बनाता है, यह दर्शाता है कि मुख्य तंत्र न केवल मात्रात्मक रूप से काम करता है बल्कि नैदानिक वर्कफ़्लो में समृद्ध मानव-मशीन इंटरैक्शन को सक्षम करने में भी काम करता है।
सीमाएँ और भविष्य की दिशाएँ
जबकि FluoroSAM एक महत्वपूर्ण छलांग प्रस्तुत करता है, लेखकों ने ईमानदारी से कई सीमाओं को स्वीकार किया है जो भविष्य के अनुसंधान और विकास के लिए उपजाऊ जमीन के रूप में भी काम करती हैं।
एक प्राथमिक सीमा FluoroSeg डेटासेट के दायरे में निहित है। हालांकि 3 मिलियन छवियों पर विशाल, यह अभी भी आधार सीटी स्कैन की संख्या और प्रतिनिधित्व किए गए शारीरिक संरचनाओं की विविधता से सीमित है। अधिक सीटी छवियों को शामिल करके इस डेटासेट का विस्तार करना, संभवतः हाल ही में जारी टोटलसेगमेंटेटर कार्यों या फ्रैक्चर टुकड़ों [23] जैसे अधिक विशिष्ट डेटासेट से, एक स्पष्ट आगे का मार्ग है। हालांकि, यह विस्तार कम्प्यूटेशनल रूप से गहन है, भले ही स्वचालित पाइपलाइन के साथ, सिमुलेशन वातावरण के निरंतर अनुकूलन की आवश्यकता का सुझाव देता है।
एक और अंतर्निहित चुनौती एक्स-रे छवियों की प्रकृति से उत्पन्न होती है। वे ट्रांसमिसिव होते हैं, जिसके परिणामस्वरूप ओवरलैपिंग अनुमान होते हैं जहां कई अंग स्पष्ट रूप से दिखाई नहीं देते हैं। यह अस्पष्टता विभाजन को एक कठिन कार्य बनाती है, और जबकि FluoroSAM अच्छा प्रदर्शन करता है, यह विधा की एक मौलिक बाधा है। प्रशिक्षण के लिए केवल सिंथेटिक डेटा पर निर्भरता, सिम-टू-रियल ट्रांसफर में इसकी सफलता के बावजूद, मॉडल पर सूक्ष्म व्यवस्थित अंतर पेश कर सकती है जो वास्तविक, हाथ-एनोटेट किए गए डेटा पर प्रशिक्षित मॉडल की तुलना में है, जैसा कि कुछ CXR परिणामों में देखा गया है।
वेक्टर क्वांटाइजेशन (VQ) कोडबुक का आकार एक विशिष्ट वास्तुशिल्प सीमा के रूप में पहचाना जाता है। जबकि VQ गुणात्मक रूप से परिवर्तनशील पाठ संकेतों के प्रति मजबूती में सुधार करता है, इसका निश्चित आकार स्वाभाविक रूप से पाठ एम्बेडिंग की प्रतिनिधित्व शक्ति को सीमित करता है। यह वर्तमान संदर्भ में एक स्वीकार्य व्यापार-बंद है, लेकिन शारीरिक संरचनाओं और अधिक सूक्ष्म संकेतों की एक और भी व्यापक श्रेणी का समर्थन करने के लिए, वैकल्पिक रणनीतियों या एक विकसित VQ तंत्र आवश्यक हो सकता है। इसमें गतिशील कोडबुक विस्तार या पदानुक्रमित VQ दृष्टिकोण शामिल हो सकते हैं।
आगे देखते हुए, FluoroSAM से प्राप्त निष्कर्ष भविष्य के विकास के लिए कई रोमांचक चर्चा विषयों को खोलते हैं:
- सिंथेटिक डेटा की स्केलेबिलिटी और विविधता: हम केवल शारीरिक विविधता से परे, विकृति, रोगी जनसांख्यिकी और इमेजिंग कलाकृतियों की एक और भी व्यापक श्रृंखला को शामिल करने के लिए सिंथेटिक डेटा पीढ़ी को और कैसे स्केल कर सकते हैं? क्या जनरेटिव एआई मॉडल को FluoroSeg के लिए और भी विविध प्रशिक्षण डेटा बनाने के लिए नए सीटी स्कैन को संश्लेषित करने या मौजूदा लोगों को बढ़ाने के लिए उपयोग किया जा सकता है, बजाय केवल मौजूदा सीटी डेटाबेस पर निर्भर रहने के?
- हाइब्रिड प्रशिक्षण प्रतिमान: सिम-टू-रियल ट्रांसफर की सफलता को देखते हुए, सिंथेटिक और सीमित वास्तविक दुनिया के एनोटेट किए गए डेटा को संयोजित करने के लिए इष्टतम रणनीतियाँ क्या हैं? क्या बड़े पैमाने पर, बिना लेबल वाले वास्तविक एक्स-रे डेटा का लाभ उठाने वाला एक अर्ध-पर्यवेक्षित या स्व-पर्यवेक्षित सीखने का दृष्टिकोण, व्यापक मैनुअल एनोटेशन की आवश्यकता के बिना FluoroSAM के प्रदर्शन और मजबूती को और बढ़ावा दे सकता है?
- उन्नत भाषा समझ: FluoroSAM अधिक जटिल, बहु-चरणीय, या अस्पष्ट प्राकृतिक भाषा संकेतों की व्याख्या करने के लिए कैसे विकसित हो सकता है, जो "सोच-श्रृंखला" आधारित एक्स-रे छवि विश्लेषण [9] की ओर बढ़ रहा है? इसके लिए पाठ वृद्धि के लिए केवल पाठ वृद्धि के साथ कसकर एकीकृत करने की तुलना में गहरी अर्थ संबंधी समझ और तर्क क्षमताओं की आवश्यकता होगी।
- निजीकरण और अनुकूलनशीलता: क्या FluoroSAM को विशिष्ट रोगी शरीर रचना या नैदानिक संदर्भों के अनुकूल बनाया जा सकता है? उदाहरण के लिए, क्या यह उस व्यक्ति के लिए विभाजन सटीकता में सुधार करने के लिए रोगी-विशिष्ट एनोटेशन के एक छोटे सेट से सीख सकता है, या विभिन्न एक्स-रे मशीनों या प्रोटोकॉल की अनूठी विशेषताओं के अनुकूल हो सकता है? यह प्रिसिजन मेडिसिन अनुप्रयोगों के लिए महत्वपूर्ण होगा।
- नैतिक विचार और विश्वास: जैसे-जैसे FluoroSAM मानव-इन-द-लूप वर्कफ़्लो में एकीकृत होता है, महत्वपूर्ण चिकित्सा कार्यों के लिए एआई पर निर्भरता के नैतिक निहितार्थ क्या हैं? हम पारदर्शिता, व्याख्यात्मकता कैसे सुनिश्चित कर सकते हैं, और एक एआई प्रणाली में विश्वास कैसे बना सकते हैं जो विभाजन के लिए प्राकृतिक भाषा संकेतों की व्याख्या करती है, खासकर अस्पष्ट या उपन्यास प्रश्नों से निपटते समय? "खराब संकेतों" के प्रति मजबूती एक अच्छी शुरुआत है, लेकिन नैदानिक परिनियोजन के लिए और अधिक की आवश्यकता है।
- पाठ से परे बहुविध एकीकरण: जबकि भाषा एक शक्तिशाली संकेत है, क्या FluoroSAM अन्य विधाओं को संकेतों के रूप में एकीकृत करने से लाभान्वित हो सकता है, जैसे कि शारीरिक संकेत, रोगी इतिहास, या इंटरवेंशनल सेटिंग्स में हैप्टिक फीडबैक? यह समृद्ध प्रासंगिक जानकारी प्रदान कर सकता है, अस्पष्टता को और कम कर सकता है और इंटरैक्शन को बढ़ा सकता है।
अंततः, FluoroSAM का विकास एक्स-रे इमेजिंग में लचीले, भाषा-प्रॉम्प्टेबल फाउंडेशन मॉडल की ओर एक महत्वपूर्ण कदम है, जो नैदानिक और इंटरवेंशनल दोनों चिकित्सा में नए रास्ते खोलने का वादा करता है। पहचानी गई सीमाएं बाधाएं नहीं हैं बल्कि अगली पीढ़ी के अनुसंधान के लिए स्पष्ट संकेत हैं।
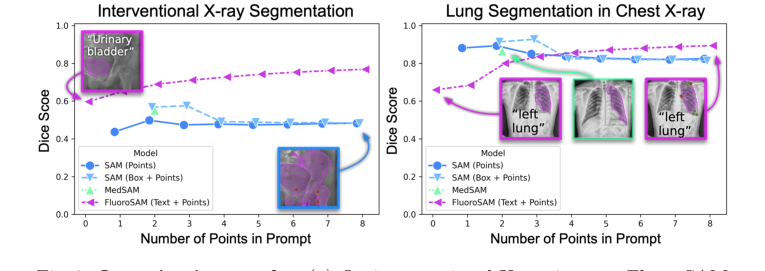 Figure 3. Quantitative results. (a) On interventional X-ray images, FluoroSAM outperforms its peers even with text-only prompting. (b) On CXRs, FluoroSAM adapts to hand-annotated lung segmentations despite being trained on synthetic data. MedSAM [18] includes this task in its training data
Figure 3. Quantitative results. (a) On interventional X-ray images, FluoroSAM outperforms its peers even with text-only prompting. (b) On CXRs, FluoroSAM adapts to hand-annotated lung segmentations despite being trained on synthetic data. MedSAM [18] includes this task in its training data
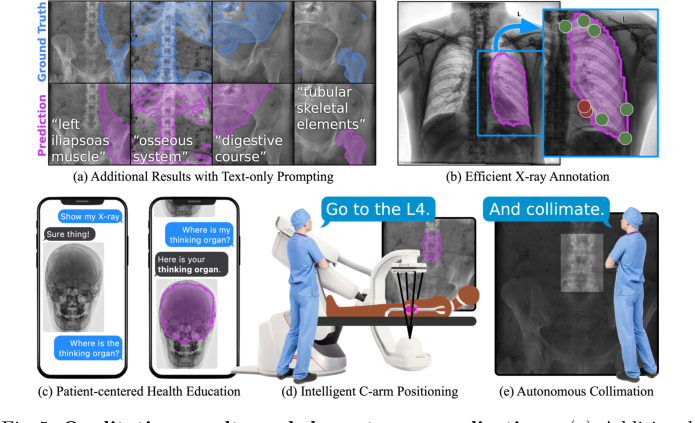 Figure 5. Qualitative results and downstream applications. (a) Additional results on real X-ray images, with text prompts not used during training. The flexibility of text prompting supports a wide variety of downstream applications. (b) Efficient annotation of X-rays can reduce clinical burden and accelerate real data annotation. (c) Flexible text-based prompting may lend itself to patient- facing education, empowering patients to better understand their own anatomy. In the OR, FluoroSAM can be integrated with robotic C-arms to deliver intel- ligent positioning (d) and autonomous collimation (e), reducing radiation [14]. These figures use real FluoroSAM predictions on real radiographs
Figure 5. Qualitative results and downstream applications. (a) Additional results on real X-ray images, with text prompts not used during training. The flexibility of text prompting supports a wide variety of downstream applications. (b) Efficient annotation of X-rays can reduce clinical burden and accelerate real data annotation. (c) Flexible text-based prompting may lend itself to patient- facing education, empowering patients to better understand their own anatomy. In the OR, FluoroSAM can be integrated with robotic C-arms to deliver intel- ligent positioning (d) and autonomous collimation (e), reducing radiation [14]. These figures use real FluoroSAM predictions on real radiographs
 Figure 4. In a limited user study, we observe qualitative results consistent with the hypothesis that VQ improves segmentation robustness to variable text prompts. For example, FluoroSAM with VQ was able to correctly segment the femur, answering the question “What’s the bone next to the hip?”
Figure 4. In a limited user study, we observe qualitative results consistent with the hypothesis that VQ improves segmentation robustness to variable text prompts. For example, FluoroSAM with VQ was able to correctly segment the femur, answering the question “What’s the bone next to the hip?”