FluoroSAM: 柔軟なX線画像セグメンテーションのための言語プロンプト可能な基盤モデル
Language promptable X-ray image segmentation would enable greater flexibility for human-in-the-loop workflows in diagnostic and interventional precision medicine.
背景と学術的系譜
起源と学術的系譜
FluoroSAMが取り組む問題は、診断および介入型精密医療における、より柔軟で効率的なX線画像セグメンテーションのクリティカルなニーズに端を発する。X線イメージングはヘルスケアにおける基盤的なモダリティであるが、その分析は歴史的にタスク固有の機械学習モデルに依存してきた。これらの初期モデルは、狭い応用範囲内では効果的であったものの、新たなタスクへの適応やスコープの拡大のために、追加のデータ、アノテーション、およびトレーニング時間を大幅に必要とするという重大な制限を抱えていた。これにより、それらは硬直的で、より広範な臨床使用へのスケーリングが困難であった。
学術分野では、「基盤モデル」(FM)、特に「言語アラインメントされた基盤モデル」(LFM)が、これらの制約を克服するための有望な方向性として出現した。膨大かつ多様な画像とテキストデータでトレーニングされたLFMは、自然言語を使用してタスクを指定できることで、広範な適用可能性を提供する可能性があった。しかし、既存の医療用LFMは、主にCTやMRIなどのモダリティに焦点を当てていた。これらのモダリティでは、大規模で豊富にアノテーションされたデータセットが容易に入手可能である。対照的に、X線イメージングは、画像の外観の高度な変動性、多様な応用(診断用胸部X線から介入型透視まで)、そして大規模で適切にアノテーションされたデータセットの希少性、特に介入処置においては、独自の課題を提示する。
以前のアプローチ、一般目的の基盤モデルであるSegment-Anything Model(SAM)とその後継モデルSAM 2を含む、の「ペインポイント」は、X線画像のユニークな特性、特にテキストプロンプトでの効果的な処理能力の欠如であった。SAMモデルは、様々なプロンプト(マスク、バウンディングボックス、ポイント)に基づいて自然画像内のオブジェクトをセグメンテーションするのに優れているが、そのテキストプロンプト機能は、自然画像でトレーニングされたCLIPのようなモデルに依存することが多い。これをX線画像に直接転送することは問題がある。なぜなら、X線は透過性であり、異なる解剖学的および非解剖学的オブジェクトの多くの重なり合った投影をもたらすからである。この固有の曖昧さにより、単一の画像パッチが複数のオブジェクトの視覚的特徴を含む可能性があり、自然画像でトレーニングされたモデルがそれらを区別することを困難にする。さらに、多様で高品質なX線データセット、特に複雑な介入シナリオにおける限られた入手可能性は、このモダリティのための柔軟な、言語プロンプト可能なセグメンテーションツールの開発を著しく妨げてきた。MedSAMのような以前の医療用SAMバリアントは、プロンプトをバウンディングボックスに制限することでこの曖昧さを軽減することが多かったが、これはX線イメージングにとって望ましくない。なぜなら、依然としてかなりの曖昧さを残し、自動または非専門家によるプロンプトを非現実的にし、人間参加型システムのための柔軟性を低下させるからである。本稿は、合成データ生成を活用してデータ希少性を克服し、X線ドメインに特化された言語プロンプト可能な基盤モデルを開発することにより、これらの制限に対処することを目的とする。
直感的なドメイン用語
- 言語アラインメントされた基盤モデル(LFM): 「左肺をセグメント化して」のような話し言葉またはタイプされた指示を理解し、その後、X線画像内のその特定の部位を特定して輪郭を描くような複雑なタスクを実行できる、超知能アシスタントを想像してください。LFMはこれらのアシスタントのようなもので、膨大な量の画像とテキストでトレーニングされているため、単語と視覚的概念を結びつけることを学び、非常に汎用性が高くなります。
- セグメンテーション: 画像内の特定のオブジェクトを正確に輪郭を描くためにデジタルハイライターを使用するようなものです。医療画像では、これは臓器、骨、または医療器具の正確な境界を描くことを意味します。「肺がある」と言うだけでなく、肺が正確にどこにあるかを示します。
- ベクトル量子化(VQ): これは視覚的概念の辞書を持っているようなものです。モデルが新しい説明や画像特徴を「見た」とき、それは辞書内の最も近いエントリに一致させようとします。これにより、複雑な情報を標準化および単純化し、説明がわずかに異なる場合でも、モデルが言語と画像の間の整合性のある関係を学習しやすくなります。これは、モデルの概念理解をより堅牢にし、わずかな変動に対する感度を低くする方法です。
- Sim-to-real transfer: これは、実際の飛行機を操縦する前にフライトシミュレーターでトレーニングするパイロットに似ています。この文脈では、高度にリアルなコンピューター生成(シミュレートされた)X線画像を使用してAIモデルをトレーニングし、その後、そのトレーニング済みモデルを実際の、現実世界のX線画像に適用することを意味します。目標は、シミュレートされたデータから主に学習したにもかかわらず、モデルが現実世界でうまく機能することです。シミュレートされたデータは、多くの場合、大量に生成するのが容易で安価です。
記法表
| 記法 | 説明 |
|---|---|
問題定義と制約
コア問題定式化とジレンマ
本稿が取り組むコア問題は、特に多様で困難な医療用X線シナリオにおいて、X線画像セグメンテーションのための柔軟で汎用性があり、言語プロンプト可能な基盤モデルの欠如である。
入力/現在の状態:
現在、X線画像分析はタスク固有の機械学習モデルに依存している。これらのモデルは狭い範囲内では良好に機能するが、その固定された設計と限られたトレーニングデータは、広範なX線ドメイン全体での適用性を著しく制限する。これらのモデルを新しいクラスやより複雑なクエリをサポートするように拡張するには、大幅な追加データ、アノテーション、および広範な再トレーニングの努力が必要となる。医療画像のための既存の基盤モデル(FM)は有望であるが、主に大規模で豊富にアノテーションされたデータセットが容易に入手可能なモダリティに焦点を当ててきた。しかし、X線イメージング、特に介入型透視は、その高度に変動する画像外観、多様な応用、そして豊富にアノテーションされたトレーニングデータのクリティカルな希少性により、独自の課題を提示する。さらに、X線画像は本質的に透過性であり、複数の解剖学的および非解剖学的オブジェクトがしばしば投影で重なり合うため、それらを区別することが固有に困難である。SAMやSAM 2のような以前の言語アラインメントされたFMは、自然画像でトレーニングされたCLIPのようなモデルに依存してテキストプロンプトを処理する。これをX線画像に効果的に転送する方法はすぐには明らかではない。なぜなら、X線ではオブジェクトの境界がしばしば不明瞭で構造が重ね合わされているからである。
望ましい終点(出力/目標状態):
最終的な目標は、任意の医療用X線画像を包括的かつ言語アラインメントされた分析が可能な、FluoroSAMと名付けられた言語プロンプト可能な基盤モデルを開発することである。このモデルは、診断および介入型精密医療における人間参加型ワークフローのためのより大きな柔軟性を可能にするべきである。具体的には、FluoroSAMは、自然言語プロンプトに基づいて無数の解剖学的構造とツールをセグメンテーションし、X線画像内の指定された任意のオブジェクトに対して意味論的に意味のあるマスクを提供することを目指す。これにより、インタラクティブな診断システムから画像誘導介入におけるインテリジェントな人間機械インターフェースまで、臨床設定でのより直感的で効率的な相互作用が可能になる。
欠けているリンクまたは数学的ギャップ:
正確に欠けているリンクは、セグメンテーションのためのX線画像のユニークな視覚的特徴と自然言語プロンプトを効果的にアラインメントするための、堅牢で汎用性のあるメカニズムである。課題は、高レベルの言語的説明と、X線における低レベルでしばしば曖昧なピクセル情報との間のギャップを埋めることにある。本稿は、FluoroSAM内に新しいテキストエンコーダーアーキテクチャを導入することにより、この課題に対処する。このアーキテクチャは、凍結されたCLIPエンコーダーの上にベクトル量子化(VQ)モジュールを組み込んでいる。このVQレイヤーはクリティカルである。なぜなら、それはマスクデコーダーに一貫した信号を提供し、モダリティの固有の困難にもかかわらず、特にX線画像のためのトレーニング中に効果的な言語アラインメントを可能にするからである。このアーキテクチャ上の革新により、モデルは、テキストプロンプトがX線画像でのセグメンテーションを正確にガイドできる共有表現空間を学習できる。
痛みを伴うトレードオフまたはジレンマ:
以前の研究者を閉じ込めてきた中心的なジレンマは、モデルの汎用性/柔軟性と、高品質でアノテーションされたX線データの入手可能性との間のトレードオフである。広範な適用可能性と言語プロンプト可能性(LFMのような)を達成するには、通常、膨大な、豊富にアノテーションされたデータセットが必要である。しかし、X線イメージング、特に介入処置では、そのようなデータの深刻な不足に悩まされている。これにより、選択を強制される:狭い、タスク固有のモデルを開発して良好に機能させるか、データ希少性とX線画像解釈のユニークな課題のために苦労する汎用モデルを構築しようとするか。X線の透過性という性質もこれを悪化させる。なぜなら、一方の側面(例:重なり合う構造のセグメンテーション)を改善すると、曖昧さが導入されたり、より複雑でデータ集約的なソリューションが必要になったりすることがよくあるからである。例えば、バウンディングボックスプロンプト(他の医療モダリティのためにMedSAMによって使用される)は曖昧さを軽減できるが、人間と機械の相互作用の柔軟性と自然さを著しく制限する。これは言語プロンプト可能なシステムのコアメリットである。
制約と失敗モード
言語プロンプト可能なX線画像セグメンテーションの問題は、いくつかの厳しい、現実的な制約により、非常に困難である:
-
物理的制約:
- 透過性と重なり合った投影: X線画像は、体を通るX線の透過によって形成され、多くの解剖学的および非解剖学的オブジェクト(ツールなど)がしばしば重なり合う2D投影をもたらす。この固有の特性は、人間の専門家にとっても個々の構造を区別することを極めて困難にし、自動セグメンテーションにとって重大な障害となる。多くの臓器は明確に見えず、タスクをさらに複雑にする。
- 画像外観と応用の高い変動性: X線イメージングは、診断用胸部X線から介入型透視まで、幅広い応用を網羅している。これにより、人間の解剖学的構造、イメージングジオメトリ、視野角、および画像強度値に膨大な変動が生じる。モデルは、限られたデータでは達成が困難な、この広範な多様性に対して堅牢でなければならない。
-
計算的制約:
- データ生成とトレーニングのための高い計算コスト: データ希少性を克服するために、著者は大規模な合成データセット(FluoroSeg)を300万枚のX線画像で生成した。このシミュレーションプロセス自体が計算集約的であり、NVIDIA A6000 GPUで約6 GPU日を必要とする。このデータセットでのFluoroSAMのトレーニングも、2つのNVIDIA H100 GPUで6日間かかり、かなりのリソースを必要とする。これは、このようなモデルの開発に伴う実質的な計算負荷を強調している。
- VQコードブックサイズの制限: ベクトル量子化(VQ)モジュールは、変動するテキストプロンプトに対する堅牢性を向上させるが、そのコードブックサイズは、テキスト埋め込みの表現力を本質的に制限する。この設計上の選択は、一貫性のために有益であるが、理論的には、無限に広い範囲の新しいセグメンテーションクラスまたは高度に新規な言語プロンプトに対するフレームワークの汎用性を制限する。
-
データ駆動型制約:
- アノテーション付き実X線データの極端な希少性: これはおそらく最もクリティカルな制約である。X線イメージング、特に介入型X線用の、大規模で豊富にアノテーションされたデータセットの深刻な不足がある。この希少性により、現実世界のデータでの堅牢な言語アラインメントされた基盤モデルの直接トレーニングが不可能になり、合成データへの依存が必要となる。
- ドメインギャップ(Sim-to-real transfer): 合成データでのトレーニングは必要であるが、シミュレートされた画像と実際のX線画像との間にドメインギャップを導入する。トレーニング中に適用される強力なドメインランダム化技術(例:粗いドロップアウト、反転、ぼかし、ガウスコントラスト調整、ランダムウィンドウイング、CLAHEヒストグラム均等化)にもかかわらず、合成データは現実の手動アノテーションされたマスクと体系的に異なる可能性があり、現実世界のシナリオでのパフォーマンスに影響を与える可能性がある。
- 合成データにおける多様性の制限: FluoroSegのような大規模な合成データセットがあっても、使用されたベースCTスキャン数と表現された解剖学的構造の多様性には依然として制限がある。この多様性を拡張することは、スケーラブルではあるが、計算集約的である。
- 自然言語プロンプトの曖昧さ: 自然言語プロンプト自体が曖昧になる可能性があり、特にX線画像における重なり合う構造を参照する場合にそうなる。モデルは、「悪いプロンプト」を無視するように設計され、プロンプトごとに複数のマスクを予測して、最も正確なセグメンテーションを選択できるようにする必要がある。これは、モデルの出力と推論プロセスに複雑さを加える。
なぜこのアプローチなのか
選択の必然性
X線画像セグメンテーションに特化されたSegment-Anything Model(SAM)の言語プロンプト可能なバリアントであるFluoroSAMの採用は、既存の最先端(SOTA)手法の固有の制限を考慮すると、単なる選択ではなく必然的な必要性であった。著者は、狭い範囲内では効果的であった従来のタスク固有の機械学習モデルが、より広範な応用への有用性を拡大するために、法外な量の追加データ、アノテーション、およびトレーニング時間を要求することを認識した。これは、高度に変動する画像外観、多様な応用(診断用胸部X線から介入型透視まで)、そしてクリティカルなことに、大規模で豊富にアノテーションされたデータセットの希少性によって特徴付けられるX線イメージングモダリティにとって、特に問題であった。
著名な言語アラインメントされた基盤モデル(LFM)であるオリジナルのSAMやその後継モデルSAM 2を直接適用することを検討した際に、実現の「正確な瞬間」が訪れた可能性が高い。これらのモデルはテキストプロンプトをサポートするが、基本的にテキストを画像アラインメントされた埋め込みに変換するためにCLIP [21]のような事前トレーニング済みLFMに依存している。クリティカルな洞察は、主に自然画像でトレーニングされたCLIPが、X線ドメインに効果的に転送されないであろうということだった。X線画像は透過性であり、多数の重なり合ったマスクが異なるオブジェクトに属する。これは、オブジェクトが通常明確な境界とネストされた構造を持つ自然画像とは対照的である。X線用に適応されたCLIPライクなモデルが存在したとしても、単一の画像パッチは依然として複数の重なり合ったオブジェクトの視覚的特徴を含むため、曖昧な区別は極めて困難なままであった。X線の視覚的特性と自然画像でトレーニングされたモデルの仮定との間のこの根本的な不一致は、既存のSOTA LFMの直接的な適用を不十分にし、FluoroSAMのようなカスタムソリューションを必要とした。
比較優位性
FluoroSAMの質的な優位性は、X線イメージングのユニークな課題を克服するために設計された構造的革新に由来しており、この特定のドメインにおける以前のゴールドスタンダードよりも圧倒的に優れている。X線の透過性と重なり合う解剖学的構造に苦労するモデルとは異なり、FluoroSAMの新しいテキストエンコーダーは、凍結されたCLIPエンコーダーの上にベクトル量子化(VQ)モジュールを組み込んでおり、マスクデコーダーに一貫した信号を提供する。このVQレイヤーはクリティカルである。それは理論的には完全に新しいセグメンテーションクラスへの汎用性を制限するが、同じオブジェクトに対する異なる説明から生じる変動を低減することにより、新しい言語プロンプトへの汎用性を大幅に拡大する。これは、FluoroSAMが人間参加型ワークフローの重要な利点である多様な自然言語入力に対してより堅牢であることを意味する。
さらに、FluoroSAMが大規模な合成FluoroSegデータセット(300万枚のX線画像)でゼロからトレーニングできる能力は、構造的な利点を提供する。これは、実際のX線画像におけるクリティカルなデータ希少性の問題を回避し、モデルが人間の解剖学的構造、イメージングジオメトリ、および視野角の広範な多様性にわたって堅牢な特徴を学習できるようにする。定量的には、FluoroSAMは、特にテキストのみのプロンプトで、SAMおよびMedSAMを上回り、実際の介入型X線画像で平均IoU 0.47、Diceスコア0.60を達成した。2つのポイントを使用しても、FluoroSAMはIoU 0.56、Dice 0.69を達成し、SAMおよびMedSAMを上回った。例えば、MedSAMはしばしば「基盤となる解剖学的構造を反映せず、単に提供されたボックスを埋めるだけ」であり、バウンディングボックス制約を超えた基盤となる画像コンテンツの理解の質的な失敗を示している。FluoroSAMのマルチ出力機能は、プロンプトごとに複数のマスクを予測し、最良のものを選択することで、堅牢性と柔軟性をさらに向上させ、曖昧なプロンプトをより優雅に処理できるようにする。この構造設計により、FluoroSAMは、メモリ複雑性を $O(N^2)$ から $O(N)$ に削減するのではなく、質的な理解とプロンプトの堅牢性を向上させることにより、他のモデルが失敗するドメインで、柔軟で言語アラインメントされたセグメンテーションを提供できる。
制約への整合性
選択されたFluoroSAMアプローチは、X線画像セグメンテーションの厳しい要件に完全に整合しており、問題と解決策の「結婚」を形成している。問題定義から推測される主な制約は次のとおりである。
- 広範な適用可能性と柔軟性の必要性: 従来のモデルは狭すぎる。言語プロンプト可能な基盤モデルとしてのFluoroSAMは、本質的に広範な適用性のために設計されており、「自然言語プロンプトに基づいて無数の解剖学的構造とツールをセグメンテーションする」能力がある(p.1)。この柔軟性は、多様な診断および介入シナリオにとってクリティカルである。
- 豊富にアノテーションされたX線データセットの希少性: これはおそらく最も重要な制約である。X線イメージング、特に介入型X線では、豊富にアノテーションされたデータセットの深刻な不足がある。FluoroSAMは、「広範な人間の解剖学的構造、イメージングジオメトリ、および視野角の多様性を持つ300万の合成X線画像」でゼロからトレーニングされることにより、これを解決する(p.1)。FluoroSegデータセットの作成は、このデータボトルネックへの直接的な対応であり、希少な現実世界の注釈に依存せずに堅牢なトレーニングを可能にする。
- X線画像のユニークな視覚的特性: X線は透過性であり、重なり合うオブジェクトがあり、自然画像でトレーニングされたモデルにとって明確な境界検出を困難にする。FluoroSAMのVQを備えた新しいテキストエンコーダーは、これを処理するために特別に設計されている。VQモジュールは、同じオブジェクトに対する異なるテキスト説明からの変動を低減するのに役立ち、マスクデコーダーに一貫した信号を提供し、X線における重なり合う構造の区別に不可欠である。
- 自然言語インタラクションの必要性: 直感的な人間参加型ワークフローを可能にし、曖昧さを低減するため。FluoroSAMの「SAMの言語プロンプト可能なバリアント」としてのコア設計は、これを直接満たし、ユーザーが自然言語を使用してセグメンテーションターゲットを指定できるようにする。これは、複雑なX線シーンでは、ポイントまたはバウンディングボックスプロンプトのみよりもはるかに柔軟で曖昧さが少ない。
- X線タイプの間の汎用性: 多様なシミュレートされた解剖学的構造、ジオメトリ、および視野角を持つFluoroSegデータセットは、FluoroSAMが診断用胸部X線から介入型透視まで、さまざまなX線応用全体で汎用性があるようにトレーニングされていることを保証する。これは、合成データでトレーニングされたにもかかわらず、CXRでのゼロショット評価に成功したことで実証されている。
代替案の却下
本稿は、言語プロンプト可能なX線画像セグメンテーションという特定の問題に対して、いくつかの人気のある代替アプローチがなぜ失敗したか、または不十分であったかを明確に詳述している。
第一に、従来のタスク固有の機械学習モデルは、狭い範囲内で動作し、より広範な応用や新しいクラスのために広範な追加データ、アノテーション、および再トレーニングを必要とするため、却下された(p.1)。これは、柔軟で広範に適用可能な基盤モデルを開発するという目標とは矛盾する。
第二に、SAMやSAM 2のような既存の基盤モデルの直接適用、特にテキストプロンプトのためのCLIPへの依存は不適切と見なされた。著者は、自然画像でトレーニングされたCLIPが、X線画像の透過性や明確な境界のない重なり合うオブジェクトの普及といったユニークな特性に苦労することを強調している(p.2-3)。X線用に適応されたCLIPライクなモデルが存在したとしても、単一の画像パッチ内の複数のオブジェクトを区別することは依然として問題のままであった。この根本的な不適合が、VQを備えたFluoroSAMの新しいテキストエンコーダーの開発につながった。
第三に、MedSAM [18]、別の医療画像基盤モデルは、他のドメインでの成功にもかかわらず、X線応用には却下された。MedSAMは主にバウンディングボックスプロンプトに依存して曖昧さを軽減する(p.5)。X線イメージングでは、このアプローチは望ましくない。なぜなら:(a)重なり合う構造によるかなりの曖昧さを依然として特徴とし、(b)自動または非専門家によるプロンプトを非現実的にし、(c)高度な人間参加型システムに必要な柔軟性を欠いているからである(p.5)。本稿はさらに、MedSAMが「一般的に基盤となる解剖学的構造を反映せず、単に提供されたボックスを埋めるだけ」であり(p.7)、バウンディングボックスによって制約された場合の画像コンテンツの理解の質的な失敗を示していると指摘している。
最後に、ポイントプロンプトを使用したオリジナルのSAMのパフォーマンスでさえ劣っていることが判明し、FluoroSAMのパフォーマンスと比較して「ますます誤ったマスク」を予測した(p.7)。これは、SAMがプロンプト可能性を提供するものの、その基盤となるアーキテクチャとトレーニングデータが、FluoroSAMで導入された特定の適応なしには、X線セグメンテーションの複雑さに対して十分に堅牢ではないことを示唆している。
本稿は、セグメンテーションタスク自体に対するGANや拡散モデルのような他の生成モデルの却下を明示的に議論していない。なぜなら、焦点はプロンプト可能なセグメンテーションと、X線ドメインにおける既存の基盤モデルの制限にあるからである。代替案を却下する主な理由は、一貫してX線のユニークな視覚的特性、データ希少性、および柔軟な言語アラインメントされた相互作用のクリティカルな必要性を処理できないことに起因する。
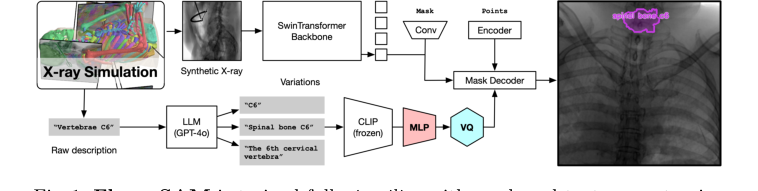 Figure 1. FluoroSAM is trained fully in silico with mask and text prompt pairs. It features a VQ layer that enables training language-aligned training on X-ray images
Figure 1. FluoroSAM is trained fully in silico with mask and text prompt pairs. It features a VQ layer that enables training language-aligned training on X-ray images
数学的および論理的メカニズム
マスター方程式
多くのセグメンテーションモデルと同様に、FluoroSAMの学習メカニズムの核心は、モデルが正確なマスクを生成するように導く損失関数にある。本稿では、複数のプロンプトと選択基準を含む複雑なトレーニングレジメンを説明しているが、単一の予測マスクをそのグラウンドトゥルースに対して評価する基本的な目的は、Dice LossとFocal Lossの組み合わせである。本稿では、「マスクにはDiceとFocal Lossを使用する」と述べている。したがって、単一マスク予測の目的を表すマスター方程式は次のように表すことができる。
$$ L_{mask}(P, G) = \lambda_{Dice} L_{Dice}(P, G) + \lambda_{Focal} L_{Focal}(P, G) $$
ここで、$P$は予測されたセグメンテーションマスク(確率の行列)を表し、$G$はバイナリグラウンドトゥルースマスクを表す。個々の損失成分は次のように定義される。
$$ L_{Dice}(P, G) = 1 - \frac{2 \sum_{i=1}^N p_i g_i}{\sum_{i=1}^N p_i^2 + \sum_{i=1}^N g_i^2} $$
$$ L_{Focal}(P, G) = - \sum_{i=1}^N \left( g_i \alpha (1-p_i)^\gamma \log(p_i) + (1-g_i) (1-\alpha) p_i^\gamma \log(1-p_i) \right) $$
用語ごとの解剖
これらの数式を分解して、各コンポーネントの役割を理解しよう。
-
$L_{mask}(P, G)$: これは、グラウンドトゥルース$G$が与えられた単一の予測マスク$P$の全体的な損失値である。
- 数学的定義: スカラー値であり、通常は0から1(またはFocal Lossの場合はそれ以上)の範囲で、予測されたセグメンテーションと真のセグメンテーションとの間の不一致を定量化する。
- 物理的/論理的役割: これは、FluoroSAMモデルがトレーニング中に最小化しようとする主要な目的関数である。より低い$L_{mask}$は、より正確なセグメンテーションを示す。
- 加算する理由: $L_{Dice}$と$L_{Focal}$を組み合わせるための加算の使用により、両方のセグメンテーション品質の側面(Diceによるオーバーラップ、Focalによるハード例の正しい分類)が同時に勾配信号に寄与できる。これにより、どちらかの損失を単独で使用するよりも、包括的でバランスの取れた最適化ターゲットが得られる。
-
$\lambda_{Dice}$: Dice Loss成分の重み付け係数。
- 数学的定義: 正のスカラー定数。本稿ではその値は明示されていないが、通常はハイパーパラメータチューニングを通じて設定される。
- 物理的/論理的役割: この係数は、全体的なセグメンテーション目的において、Dice Loss(Dice係数で測定)による高いオーバーラップの達成と、ハードに分類されるピクセルに焦点を当てること(Focal Lossで測定)の相対的な重要性を制御する。
- 乗算する理由: 乗算は、複合損失関数内の特定の損失項の寄与をスケーリングするための標準的な方法である。
-
$L_{Dice}(P, G)$: Dice Loss成分。
- 数学的定義: $1 - \frac{2 \sum_{i=1}^N p_i g_i}{\sum_{i=1}^N p_i^2 + \sum_{i=1}^N g_i^2}$。ここで、$p_i$はピクセル$i$の予測確率であり、$g_i$はピクセル$i$のグラウンドトゥルースラベル(0または1)である。総和 $\sum_{i=1}^N$ は、画像内のすべての$N$ピクセルにわたる。
- 物理的/論理的役割: この項は、主に予測マスクとグラウンドトゥルースとの間の空間的オーバーラップを測定する。これは、小さな臓器やツールを大きなX線画像でセグメンテーションする場合など、クラスの不均衡が著しいタスクに特に効果的である。なぜなら、それは本質的に正(前景)クラスに焦点を当てるからである。この項を最小化することは、モデルが真のオブジェクトの形状と範囲に密接に一致するマスクを生成することを奨励する。
- 1から減算する理由: Dice係数自体は類似性メトリックであり、0(オーバーラップなし)から1(完全なオーバーラップ)の範囲である。それを1から減算することにより、損失関数に変換され、0は完全なセグメンテーション、1は完全な不一致を表す。
- 分母に二乗和を使用する理由: 確率的予測($p_i \in [0,1]$)の場合、$p_i^2$と$g_i^2$を分母に使用すると、集合の要素数(要素の数)の概念が連続確率に一般化され、損失関数が微分可能になり、勾配ベースの最適化に適したものになる。
-
$\lambda_{Focal}$: Focal Loss成分の重み付け係数。
- 数学的定義: 正のスカラー定数であり、通常はハイパーパラメータチューニングを通じて決定される。
- 物理的/論理的役割: $\lambda_{Dice}$と同様に、この係数は総損失におけるFocal Lossの影響を調整し、ハード例への焦点をDice Lossの全体的なオーバーラップへの重点とバランスさせる。
- 乗算する理由: 損失項の標準的なスケーリングメカニズム。
-
$L_{Focal}(P, G)$: Focal Loss成分。
- 数学的定義: $- \sum_{i=1}^N \left( g_i \alpha (1-p_i)^\gamma \log(p_i) + (1-g_i) (1-\alpha) p_i^\gamma \log(1-p_i) \right)$。
- 物理的/論理的役割: この損失は、適切に分類された例(簡単なネガティブ)の寄与をダウンウェイトすることにより、クラスの不均衡の問題に対処し、モデルのトレーニングをハードで誤って分類された例に集中させる。X線画像では、背景ピクセルは前景ピクセルをはるかに上回ることが多く、Focal Lossは、モデルが簡単な背景予測に圧倒されるのを防ぐ。
- $\alpha$を使用する理由: これは正クラスの重み付け係数である。正例と負例の重要性をバランスさせ、一方のクラスが本質的により重要であるか、またはよりまれである場合に役立つ可能性がある。
- $(1-p_i)^\gamma$または$p_i^\gamma$を使用する理由: これらは変調因子である。ピクセルが適切に分類された場合(例:$g_i=1$のときに$p_i$が高い)、$(1-p_i)$は小さくなり、$(1-p_i)^\gamma$はさらに小さくなる($\gamma > 0$の場合)、その損失寄与を効果的に低減する。逆に、誤って分類されたピクセルの場合、因子は1に近く、損失は依然として大きい。このメカニズムは、ハード例にトレーニングを「集中」させる。
- $\log(p_i)$を使用する理由: これは基本的なクロスエントロピー成分であり、予測の「驚き」またはエラーを測定する。変調因子は次にこのエラーをスケーリングする。
-
$P$: 予測マスク。
- 数学的定義: 各要素$p_{ij} \in [0, 1]$がピクセル$(i,j)$が前景オブジェクトに属する予測確率を表す、浮動小数点値の2D行列(またはボリュームデータの場合は3D)。
- 物理的/論理的役割: これはFluoroSAMのマスクデコーダーの出力であり、モデルのセグメンテーションの最良の推測を表す。
-
$G$: グラウンドトゥルースマスク。
- 数学的定義: 各要素$g_{ij} \in \{0, 1\}$がピクセル$(i,j)$が真に前景(1)または背景(0)に属するかどうかを示す、バイナリ2D行列。
- 物理的/論理的役割: これはFluoroSegデータセットによって提供される「正解」であり、モデルの予測が損失を計算するために比較される。
-
$p_i, g_i$: 個々のピクセル確率とラベル。
- 数学的定義: $p_i \in [0, 1]$は単一ピクセルの予測確率であり、$g_i \in \{0, 1\}$は対応するグラウンドトゥルースラベルである。
- 物理的/論理的役割: これらは予測と真実の最小単位を表し、それらの集計された寄与が全体のマスク損失を形成する。
-
$\sum$: 総和演算子。
- 数学的定義: 定義された集合(この場合は画像内のすべてのピクセル$i=1, \dots, N$)にわたる値を合計する。
- 物理的/論理的役割: 個々のピクセルごとの寄与を集計して、画像全体のDiceおよびFocal Lossを計算する。
ステップバイステップフロー
単一のX線画像と自然言語プロンプトが、洗練された高度な組み立てラインを流れるアイテムのように、FluoroSAMシステムに入力されるのを想像してください。
- 画像取り込み(視覚経路): X線画像、例えば患者の胸部の画像が、まず画像エンコーダーに入力される。このエンコーダーは、SwinTransformerバックボーン上に構築されており、特殊な視覚処理ユニットのように機能する。画像全体をスキャンし、さまざまなスケールで階層的な視覚的特徴を抽出する。これは、単純なエッジやテクスチャから複雑な解剖学的パターンまで、画像をますます抽象的な表現に分解するようなものです。
- プロンプト解釈(言語経路): 同時に、「左肺をセグメント化して」のような自然言語プロンプトがテキストエンコーダーに入力される。このエンコーダーは多段階ユニットである。
- まず、凍結されたCLIPエンコーダーがテキストを受け取り、その意味論的意味を捉えた高次元数値埋め込みに変換する。
- 次に、多層パーセプトロン(MLP)がこの埋め込みをさらに処理し、その表現を洗練させる。
- 最後に、ベクトル量子化(VQ)ボトルネックがこの洗練された埋め込みを離散的な「プロンプトトークン」に量子化する。このVQレイヤーは、言語フィルターのようなもので、プロンプトの意味を、モデルの残りの部分が容易に理解できる一貫した離散コードに標準化する。これにより、フレーズのわずかな違いに関係なく、モデルはプロンプトを容易に理解できる。
- 特徴融合とマスク生成: 画像エンコーダーからの豊富な視覚的特徴と、テキストエンコーダーからの離散プロンプトトークンが、次に統合される。この融合はマスクデコーダーをガイドする。マスクデコーダーは、モデルの創造的なエンジンである。組み合わせられた視覚的および言語的情報に基づいて、マスクデコーダーは単一のマスクを生成するだけでなく、要求されたオブジェクトに対して複数の候補セグメンテーションマスクを生成する。これは、数人の熟練した職人が「左肺」のわずかに異なる輪郭をそれぞれ提案するようなものである。
- 損失評価と選択: これらの候補マスクのそれぞれについて、システムはグラウンドトゥルースマスク(トレーニング中に利用可能)に対して、Dice LossとFocal Lossを使用して$L_{mask}$を計算する。次に、システムは最も低い $L_{mask}$をもたらす候補マスクを選択する。この選択プロセスにより、モデルはプロンプトに基づいて可能な限り正確なセグメンテーションを常に目指すことが保証される。
- バックプロパゲーションと学習: 選択されたマスクからの損失、特にテキストプロンプト、ポイント1、ポイント8、および追加のランダムポイントプロンプトからの損失が、勾配を計算するために使用される。これらの勾配は、マスクデコーダーと画像エンコーダー(テキストエンコーダーのCLIP部分は凍結されているが、MLPとVQコンポーネントは更新される)を逆方向に流れる正確な指示のようなものである。これらの指示は、ネットワークのトレーニング可能な部分の各パラメータが、損失を削減し、将来のセグメンテーションを改善するためにどのように調整する必要があるかを伝える。この反復プロセスは、FluoroSAMが自然言語に基づいてX線画像を正確にセグメンテーションすることを学習する方法である。
最適化ダイナミクス
FluoroSAMの学習プロセスは、損失最小化、勾配ベースの更新、および戦略的なデータ拡張の動的な相互作用であり、すべて複雑な損失ランドスケープをナビゲートし、堅牢なパフォーマンスを達成するように設計されている。
-
損失ランドスケープの形成: Dice LossとFocal Lossの組み合わせは、最適化ランドスケープを形成する上でクリティカルである。Dice Lossは、クラスの不均衡に効果的であるが、予測マスクがグラウンドトゥルースとのオーバーラップがほとんどない場合、非凸性やプラトーに苦しむことがある。Focal Lossは、簡単な例を積極的にダウンウェイトすることにより、これを補完し、それによって誤って分類されたピクセルの相対的な重要性を高める。これにより、勾配が困難な領域の周りで急になり、モデルが局所的最小値に閉じ込められたり、簡単に予測される背景ピクセルに支配されたりするのを防ぐ。目標は、より良いセグメンテーションへのパスがより明確で直接的であるランドスケープを作成することである。
-
勾配の挙動と更新: トレーニング中、$L_{mask}$の勾配(選択されたプロンプトから)は、画像エンコーダーとマスクデコーダーのすべてのトレーニング可能なパラメータ、およびテキストエンコーダーのMLPとVQコンポーネントに対して計算される。これらの勾配は、損失を減少させるために必要なパラメータ調整の方向と大きさを示す。次に、モデルパラメータは、反復的にオプティマイザー(通常はAdamまたはそのバリアント、本稿では明示されていないが)を使用して更新される。この反復プロセスは、モデルの「位置」を高次元パラメータ空間で低損失領域に向かって移動させ、セグメンテーション精度を徐々に向上させる。
-
学習率スケジュール: 本稿では、慎重に設計された学習率スケジュールを指定している。すなわち、8x10^-6から8x10^-4のベースレートへの線形ウォームアップを20kイテレーションにわたって行い、その後、200kおよび400kのステップで10倍の削減を行う。
- ウォームアップ: 初期低学習率は、モデルパラメータがランダムに初期化され、最適状態から遠く離れている場合に、大きすぎる不安定な更新を防ぐ。これにより、モデルは損失ランドスケープで「足場を見つける」ことができる。
- 減衰: トレーニング後半で学習率を減らすことは、モデルがパラメータを微調整するのに役立ち、オーバーシュートや振動なしに、より正確に最小値に収束できるようにする。これは、ターゲットに近づくにつれて、大きくて探索的なステップから、より小さく、より正確な調整に切り替えるようなものである。
-
ベクトル量子化(VQ)ダイナミクス: テキストエンコーダーのVQボトルネックは、それ以外は連続的なニューラルネットワークに離散的な要素を導入する。VQを使用したトレーニングは、通常、勾配が離散量子化ステップを通過できるようにするストレートスルー推定器のような技術を伴う。このメカニズムは、テキスト埋め込みを有限の「コードブック」ベクトルセットに強制し、堅牢で言語アラインメントされた表現の学習に役立つ。それは理論的には新しいクラスへの汎用性を制限するが、同じオブジェクトに対する異なる説明からの変動を低減することにより、既知のクラスに対する変動する言語プロンプトへの堅牢性を向上させる。これにより、モデルはプロンプトの正確な言葉遣いに対する感度が低下する。
-
拡張とランダム化による堅牢性:
- テキスト拡張: gpt-40を使用して、マスクごとに最大30の多様なプロンプトを生成することは、トレーニングデータの言語的変動を大幅に拡大する。これにより、FluoroSAMは、ユーザーがセグメンテーション要求を表現するさまざまな方法に対して堅牢になり、特定のプロンプトフレーズへの過学習を防ぐ。
- ドメインランダム化: 合成X線画像に「強力なドメインランダム化」(例:粗いドロップアウト、反転、ぼかし、ガウスコントラスト調整 [10]、ランダムウィンドウイング、CLAHEヒストグラム均等化)を適用することは、sim-to-real転送のためのクリティカルな戦略である。これは、モデルがさまざまな画像外観に対して不変な特徴を学習することを強制し、合成トレーニングデータとは異なる現実世界のX線画像に遭遇したときに、より堅牢になる。これは、モデルがわずかな入力変動に対して感度が低くなるようにすることにより、損失ランドスケープを効果的に平滑化する。
-
マルチ出力と選択: FluoroSAMが単一プロンプトに対して複数のマスクを予測し、トレーニング中に最も低い損失を持つものを選択できる能力は、内部的な自己修正メカニズムとして機能する。これは、アンサンブル予測のようなもので、最良のものが選択され、より信頼性が高く正確な最終出力につながる。推論中、IOU予測ヘッドがこの選択を引き継ぎ、どのマスクが最も正確である可能性が高いかを推定する。この動的な選択プロセスは、モデルの全体的な安定性とパフォーマンスに貢献する。
結果、限界、および結論
実験設計とベースライン
FluoroSAMの能力を厳密に検証するために、著者は合成データと現実世界のX線データの両方を含む包括的な実験セットアップを設計し、そのモデルを確立されたベースラインと比較した。
FluoroSAMのトレーニングの基盤は、300万枚の合成X線画像の大規模なコレクションであるFluoroSegデータセットである。このデータセットは、現実のX線イメージングの変動性を捉えるために不可欠な、人間の解剖学的構造、イメージングジオメトリ、および視野角の広範な配列をシミュレートするために、in silicoで細心の注意を払って生成された。シミュレーションパイプラインは、New Mexico Decedent Image Database [5]からの1,621枚の高解像度CTスキャンから始まり、TotalSegmentator [27]を使用して128の臓器クラスにセグメンテーションされ、表面メッシュを導き出した。多様な放射線検査を模倣するために、環境は標準的なビュー(例:胸部、腹部)とランダムなCアームビューの両方をサンプリングし、さまざまな角度で主要な臓器に焦点を当てた。クリティカルに、464個のコンピューターモデリングされた外科用ツールが、それぞれ包括的なテキスト説明とともに、視野内にランダムに配置された。画像は$512^2$ピクセルでレンダリングされ、疑似グラウンドトゥルースマスクと関連するテキスト説明が完全であった。このプロセスは非常に効率的であり、NVIDIA A6000 GPUで毎秒6.5から15.7枚の画像を生成し、約6 GPU日で合計295万枚の画像を生成した。データセットは、元のCTスキャンに基づいて、トレーニングと検証のために90/10%に分割された。
FluoroSAM自体は、SAM [15]の言語プロンプト可能なバリアントであり、FluoroSegでゼロからトレーニングされた。凍結されたCLIPエンコーダー [21]、2つの隠れ層を持つマルチレイヤーパーセプトロン(MLP)、およびベクトル量子化(VQ)ボトルネック [20]で構成されるその新しいテキストエンコーダーは、言語アラインメントを可能にする中心であった。汎用性を向上させるために、テキスト拡張はgpt-40 [1]を使用して実行され、マスクごとに最大30の多様なプロンプトが生成された。関連する臓器マスクは手続き的に38グループ(例:「左肋骨」)に結合され、「悪いプロンプト」(画像に存在しない)は、モデルに無関係なクエリを無視するように教えるために時折サンプリングされた。画像エンコーダーは、ImageNet-22kで事前トレーニングされ、インスタンスセグメンテーションのためにFluoroSegクラスの削減セットでさらにトレーニングされたSwinTransformerバックボーン(最終モデルにはSwin-L)を使用した。sim-to-real転送を促進するために、トレーニング中に強力なドメインランダム化技術が適用された。これには、粗いドロップアウト、反転、ぼかし、ガウスコントラスト調整 [10]、ランダムウィンドウイング、およびCLAHEヒストグラム均等化が含まれる。トレーニングには、マスクあたり9つのプロンプト(テキスト1つ、ポイント8つ)が含まれ、DiceとFocal Lossが使用され、特定の損失成分がバックプロパゲーションされた。モデルは、2つのNVIDIA H100 GPUで6日間、10エポックトレーニングされた。
評価のために、FluoroSAMは、現実世界のX線画像でいくつかの「犠牲」ベースラインモデルと対峙した。
1. 現実の介入型X線画像: フル胴体標本(T2から大腿骨中部まで)の登録X線画像データセットで、Brainlab Loop-Xデバイスで取得された。グラウンドトゥルースマスクは、4つのナビゲートされたコーンビームCT画像をステッチし、臓器セグメンテーションを投影することによって生成された [27]。評価は、画像サイズの2.5%を超える1,741マスクに限定された。ベースラインには、オリジナルのSAM [15](ポイントまたはバウンディングボックスでプロンプトされた)とMedSAM [18](医療画像には通常バウンディングボックスプロンプトを使用する)が含まれた。メトリックは、Intersection over Union(IoU)、Diceスコア、およびHausdorff Distance(HDD)であった。
2. 胸部X線(CXR)でのゼロショット評価: 肺のセグメンテーションを手動で注釈付けした1,131枚のCXR [2]のデータセット。これは、FluoroSAMが異なるX線モダリティと現実世界の注釈に、特定のトレーニングなしで一般化する能力をテストした。同じベースラインであるSAMとMedSAMが使用され、IoU、Dice、およびHDDが報告された。
証拠が証明すること
実験的証拠は、合成データのみでトレーニングされた場合でも、FluoroSAMのコアメカニズム—言語プロンプト可能なX線画像セグメンテーション—が効果的であり、しばしば既存の方法よりも優れていることを断定的に証明している。
現実の介入型X線画像では、FluoroSAMはテキストのみのプロンプトでその能力を示した。表1と図3aに示すように、FluoroSAMは平均IoU 0.47、Diceスコア0.60を達成した。このパフォーマンスは、FluoroSAMにテキストプロンプトのみが与えられた場合、その仲間であるSAM(ポイントでIoU 0.36、Dice 0.50;ボックスでIoU 0.42、Dice 0.57)およびMedSAM(IoU 0.41、Dice 0.55)を著しく上回った。これはクリティカルな証拠である。なぜなら、それはFluoroSAMの新しいテキストエンコーダーとVQレイヤーが自然言語を解釈し、困難な現実世界のシナリオで正確なセグメンテーションを生成する能力を検証するからである。ポイントプロンプトが追加された場合、FluoroSAMのパフォーマンスはさらに向上し、2つのポイントでIoU 0.56、Dice 0.69、8つのポイントでIoU 0.64、Dice 0.77、HDD 60.8に達し、これらのメトリック全体でベースラインを一貫して上回った。ここでの決定的な証拠は、そのユニークなテキストプロンプト機能を持つFluoroSAMが、より制約されたポイントまたはボックスプロンプトに依存するモデルのパフォーマンスを上回るか、それに匹敵する直接的な定量的比較である。
CXRでのゼロショット評価は、FluoroSAMの汎用性とsim-to-real転送能力の否定できない証拠を提供した。合成データのみでトレーニングされたにもかかわらず、FluoroSAMは現実のCXRでの手動アノテーションされた肺セグメンテーションに驚くほど適応した。テキストのみのプロンプトでは、平均IoU 0.50、Diceスコア0.66を達成した(表1、図3b)。SAMが複数のポイントまたはボックスプロンプトを与えられた場合に高いスコア(例:2ポイントでIoU 0.83、Dice 0.89)を達成できた一方で、8ポイントでのFluoroSAMのパフォーマンス(IoU 0.81、Dice 0.89)は非常に競争力があり、SAMの8ポイントパフォーマンス(IoU 0.73、Dice 0.82)を上回った。これは、合成データでのトレーニングと堅牢なドメインランダム化の組み合わせにより、FluoroSAMが、合成投影と手動アノテーションされたマスクとの間の体系的な違いにもかかわらず、未知の現実世界の診断X線画像とタスクに一般化できることを示している。
さらに、質的なユーザー調査(図4)は、VQレイヤーの有効性が、変動するテキストプロンプトに対するセグメンテーションの堅牢性を向上させるという説得力のある証拠を提供した。「腰の隣の骨は何ですか?」と尋ねられたとき、VQを備えたFluoroSAMは正確に大腿骨をセグメンテーションしたが、VQなしでは失敗した。これは、VQが同じオブジェクトに対する異なる説明からの変動を低減することにより、新しい言語プロンプトへの汎用性を向上させるという著者の主張を直接支持し、モデルを自然言語のニュアンスに対してより回復力のあるものにする。
最後に、図5で示された質的な結果と下流の応用は、FluoroSAMの実用的な有用性を示している。その柔軟性は、効率的なX線アノテーション、患者中心の健康教育、およびインテリジェントなロボットCアームポジショニングと自律コリメーションを可能にし、コアメカニズムが定量的だけでなく、臨床ワークフローにおける豊かな人間と機械の相互作用を可能にすることを示している。
限界と将来の方向性
FluoroSAMは大きな飛躍を表しているが、著者は、将来の研究開発の肥沃な土壌としても機能するいくつかの限界を率直に認めている。
主な限界の1つは、FluoroSegデータセットのスコープにある。300万枚の画像で膨大であるにもかかわらず、ベースCTスキャン数と表現された解剖学的構造の多様性によって依然として制約されている。最近リリースされたTotalSegmentatorタスクや、骨折断片 [23]のようなより専門的なデータセットからのCT画像をさらに組み込むことにより、このデータセットを拡張することは、明確な前進の道である。しかし、この拡張は、自動化されたパイプラインがあっても、シミュレーション環境の継続的な最適化の必要性を示唆しており、計算集約的である。
もう1つの固有の課題は、X線画像自体の性質に起因する。それらは透過性であり、多くの臓器が明確に見えない重なり合った投影をもたらす。この曖昧さはセグメンテーションを困難なタスクにし、FluoroSAMは良好に機能するが、モダリティの根本的な制約である。トレーニングのための合成データへの単独の依存は、そのsim-to-real転送における成功にもかかわらず、一部のCXR結果で観察されたように、現実の手動アノテーションされたデータでトレーニングされたモデルと比較して、微妙な体系的な違いを導入する可能性がある。
ベクトル量子化(VQ)コードブックサイズは、特定のアーキテクチャ上の限界として特定されている。VQは質的に変動するテキストプロンプトに対する堅牢性を向上させるが、その固定サイズは、テキスト埋め込みの表現力を本質的に制限する。これは現在の文脈では許容できるトレードオフであるが、さらに広範な解剖学的構造とより微妙なプロンプトをサポートするためには、代替戦略または進化したVQメカニズムが必要になる可能性がある。これには、動的なコードブック拡張または階層的VQアプローチが含まれる可能性がある。
将来を見据えると、FluoroSAMの開発は、いくつかのエキサイティングな議論のトピックを次の開発のために開いている。
- 合成データのスケーラビリティと多様性: 病状、患者人口統計、およびイメージングアーティファクトのさらに広範なスペクトルを網羅するために、合成データ生成をさらにスケーリングするにはどうすればよいか?既存のCTデータベースに依存するのではなく、さらに多様なトレーニングデータを作成するために、生成AIモデルを使用して新しいCTスキャンを合成したり、既存のものを拡張したりできるか?
- ハイブリッドトレーニングパラダイム: sim-to-real転送の成功を考慮すると、合成データと限られた現実世界の注釈付きデータを組み合わせる最適な戦略は何であるか?膨大な量のラベルなしX線データを活用した半教師ありまたは自己教師あり学習アプローチは、広範な手動アノテーションを必要とせずに、FluoroSAMのパフォーマンスと堅牢性をさらに向上させることができるか?
- 高度な言語理解: FluoroSAMは、より複雑で、多段階で、または曖昧な自然言語プロンプトを解釈し、「思考連鎖」ベースのX線画像分析 [9]に向かって進むことができるか?これには、テキスト拡張のためだけでなく、大規模言語モデルとのより緊密な統合を必要とする、より深い意味論的理解と推論能力が必要となるだろう。
- パーソナライゼーションと適応性: FluoroSAMは、特定の患者の解剖学的構造または臨床コンテキストに適応できるか?例えば、その個人に対するセグメンテーション精度を向上させるために、少数の患者固有のアノテーションから学習できるか、または異なるX線装置またはプロトコルのユニークな特性に適応できるか?これは精密医療応用にとってクリティカルだろう。
- 倫理的考慮事項と信頼: FluoroSAMが人間参加型ワークフローに統合されるにつれて、クリティカルな医療タスクのためのAIへの依存の倫理的影響は何であるか?曖昧または新規なクエリを扱う場合、特に、自然言語プロンプトをセグメンテーションのために解釈するAIシステムへの透明性、説明可能性、および信頼をどのように確保できるか?「悪いプロンプト」に対する堅牢性は良いスタートであるが、臨床展開にはさらに多くのものが必要である。
- テキスト以外のマルチモーダル統合: 言語は強力なプロンプトであるが、FluoroSAMは、生理学的信号、患者履歴、または介入設定での触覚フィードバックのような他のモダリティをプロンプトとして統合することから利益を得ることができるか?これは、より豊かなコンテキスト情報を提供し、曖昧さをさらに低減し、相互作用を強化する可能性がある。
最終的に、FluoroSAMの開発は、X線イメージングにおける柔軟な、言語プロンプト可能な基盤モデルに向けた重要なステップであり、診断および介入型医療の両方で新しい道を開くことを約束する。特定された限界は障害ではなく、むしろ次世代の研究のための明確な標識である。
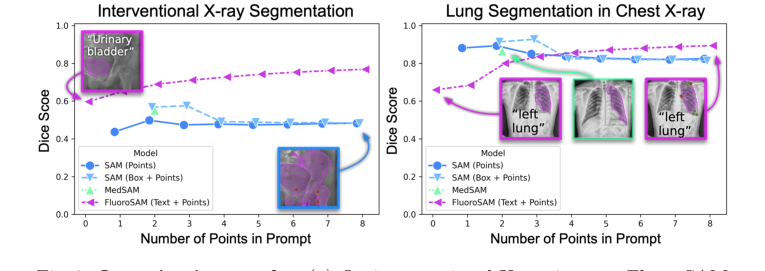 Figure 3. Quantitative results. (a) On interventional X-ray images, FluoroSAM outperforms its peers even with text-only prompting. (b) On CXRs, FluoroSAM adapts to hand-annotated lung segmentations despite being trained on synthetic data. MedSAM [18] includes this task in its training data
Figure 3. Quantitative results. (a) On interventional X-ray images, FluoroSAM outperforms its peers even with text-only prompting. (b) On CXRs, FluoroSAM adapts to hand-annotated lung segmentations despite being trained on synthetic data. MedSAM [18] includes this task in its training data
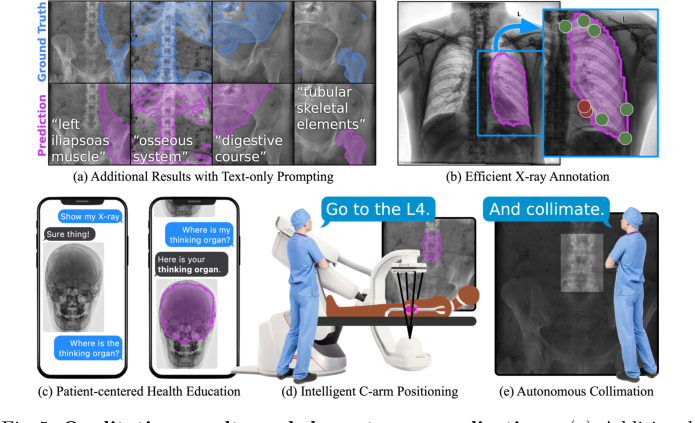 Figure 5. Qualitative results and downstream applications. (a) Additional results on real X-ray images, with text prompts not used during training. The flexibility of text prompting supports a wide variety of downstream applications. (b) Efficient annotation of X-rays can reduce clinical burden and accelerate real data annotation. (c) Flexible text-based prompting may lend itself to patient- facing education, empowering patients to better understand their own anatomy. In the OR, FluoroSAM can be integrated with robotic C-arms to deliver intel- ligent positioning (d) and autonomous collimation (e), reducing radiation [14]. These figures use real FluoroSAM predictions on real radiographs
Figure 5. Qualitative results and downstream applications. (a) Additional results on real X-ray images, with text prompts not used during training. The flexibility of text prompting supports a wide variety of downstream applications. (b) Efficient annotation of X-rays can reduce clinical burden and accelerate real data annotation. (c) Flexible text-based prompting may lend itself to patient- facing education, empowering patients to better understand their own anatomy. In the OR, FluoroSAM can be integrated with robotic C-arms to deliver intel- ligent positioning (d) and autonomous collimation (e), reducing radiation [14]. These figures use real FluoroSAM predictions on real radiographs
 Figure 4. In a limited user study, we observe qualitative results consistent with the hypothesis that VQ improves segmentation robustness to variable text prompts. For example, FluoroSAM with VQ was able to correctly segment the femur, answering the question “What’s the bone next to the hip?”
Figure 4. In a limited user study, we observe qualitative results consistent with the hypothesis that VQ improves segmentation robustness to variable text prompts. For example, FluoroSAM with VQ was able to correctly segment the femur, answering the question “What’s the bone next to the hip?”