FluoroSAM:一种可语言提示的、用于灵活X射线图像分割的基础模型
Language promptable X-ray image segmentation would enable greater flexibility for human-in-the-loop workflows in diagnostic and interventional precision medicine.
背景与学术渊源
起源与学术渊源
FluoroSAM所解决的问题源于诊断和介入精准医疗领域对更灵活、更高效的X射线图像分割的迫切需求。X射线成像在医疗保健领域是一项基础性技术,但其分析历来依赖于特定任务的机器学习模型。这些早期模型虽然在狭窄的应用范围内有效,但存在显著局限性:它们需要大量额外的、标注好的数据和训练时间来适应新任务或扩展其范围。这使得它们在扩展到更广泛的临床应用时显得僵化且难以规模化。
学术界已将“基础模型”(Foundation Models, FMs)特别是“语言对齐基础模型”(Language-aligned Foundation Models, LFMs)视为克服这些限制的有前景的方向。LFMs通过海量且多样化的图像和文本数据进行训练,有潜力通过自然语言指定任务来实现广泛的应用。然而,现有的医学LFMs主要集中在CT或MRI等模态,这些模态通常拥有大量、标注丰富的可用数据集。相比之下,X射线成像面临着独特的挑战:图像外观高度可变,应用多样(从诊断性胸部X光片到介入性透视),并且缺乏大型、标注良好的数据集,尤其是在介入性手术方面。
先前方法的一个关键“痛点”,包括像Segment-Anything Model (SAM)及其后续版本SAM 2这样的通用基础模型,是它们无法有效处理X射线图像的独特特性,尤其是在文本提示方面。虽然SAM模型擅长基于各种提示(掩码、边界框、点)分割自然图像中的物体,但其文本提示能力通常依赖于CLIP等模型,而CLIP是在自然图像上训练的。将此直接应用于X射线图像存在问题,因为X射线是穿透性的,导致不同解剖结构和非解剖结构物体的多种重叠投影。这种固有的歧义意味着单个图像块可能包含来自多个物体的视觉特征,使得在自然图像上训练的模型难以区分它们。此外,多样化、高质量X射线数据集的有限可用性,尤其是在复杂的介入场景下,严重阻碍了开发用于此模态的灵活、可语言提示的分割工具。先前的医学SAM变体,如MedSAM,通常通过将提示限制在边界框内来缓解这种歧义,但这对于X射线成像来说是不可取的,因为它仍然存在显著的歧义,使得自动或非专家提示不切实际,并降低了人机协同系统的灵活性。本文旨在通过开发一种专门针对X射线领域量身定制的、可语言提示的基础模型来解决这些局限性,并利用合成数据生成来克服数据稀缺问题。
直观的领域术语
- 语言对齐基础模型 (LFMs):想象一个超级智能的助手,它能理解你的口头或书面指令(如“分割左肺”),然后执行一项复杂任务,例如在X射线图像中识别并勾勒出该特定部分。LFMs就像这些助手,它们接受了大量的图像和文本训练,因此学会了将词语与视觉概念联系起来,使其非常通用。
- 分割 (Segmentation):这就像使用数字荧光笔精确地勾勒出图像中的特定对象。在医学成像中,这意味着绘制出器官、骨骼或医疗器械的确切边界。它不仅仅是说“这里有肺”;而是要显示出肺的确切位置。
- 向量量化 (VQ):这就像拥有一个视觉概念词典。当模型“看到”新的描述或图像特征时,它会尝试将其匹配到词典中最接近的条目。这有助于标准化和简化复杂信息,使模型更容易学习语言和图像之间的一致关系,即使描述略有不同。这是一种使模型对概念的理解更加鲁棒且不易受微小变化影响的方法。
- 仿真到现实迁移 (Sim-to-real transfer):这类似于飞行员在驾驶真实飞机之前在飞行模拟器中进行训练。在此背景下,它意味着使用高度逼真的计算机生成(模拟)的X射线图像来训练AI模型,然后将该训练好的模型应用于实际的、真实世界的X射线图像。目标是使模型在现实世界中表现良好,尽管它主要从模拟数据中学习,而模拟数据通常更容易且更便宜地大量生产。
符号表
| 符号 | 描述 |
|---|---|
问题定义与约束
核心问题表述与困境
本文解决的核心问题是缺乏一种灵活、可泛化且可语言提示的基础模型,用于X射线图像分割,尤其是在多样化且具有挑战性的医学X射线场景中。
输入/当前状态:
目前,X射线图像分析依赖于特定任务的机器学习模型。这些模型在狭窄范围内表现良好,但其固定的设计和有限的训练数据严重限制了它们在广泛X射线领域内的适用性。将这些模型扩展到支持新类别或更复杂的查询,需要大量的额外数据、标注和广泛的重新训练工作。现有的医学成像基础模型虽然有前景,但主要集中在拥有大量、标注丰富数据集的模态上。然而,X射线成像,特别是介入性透视,由于其高度可变的图像外观、多样化的应用和关键的、标注丰富训练数据的稀缺性,带来了独特的挑战。此外,X射线图像本质上是穿透性的,这意味着多个解剖和非解剖物体经常在投影中重叠,使得区分它们变得固有地困难。先前的语言对齐基础模型,如Segment-Anything Model (SAM)及其后续版本SAM 2,依赖于CLIP等模型进行文本提示,而CLIP是在自然图像上训练的。如何有效地将这种方法迁移到X射线图像上并不明确,因为X射线图像的物体边界通常不清晰,结构是叠加的。
期望终点(输出/目标状态):
最终目标是开发一个名为FluoroSAM的可语言提示的基础模型,能够对任意医学X射线图像进行全面且语言对齐的分析。该模型应为诊断和介入精准医疗中的人机协同工作流程提供更大的灵活性。具体而言,FluoroSAM旨在根据自然语言提示分割无数解剖结构和器械,为X射线图像中指定的任何物体提供语义上有意义的掩码。这将允许在临床环境中进行更直观、更高效的交互,从交互式诊断系统到图像引导介入中的智能人机界面。
缺失环节或数学鸿沟:
确切的缺失环节是,需要一种鲁棒且可泛化的机制,能够有效地将自然语言提示与X射线图像的独特视觉特征对齐,以进行分割。挑战在于弥合高层语言描述与X射线图像的低层、通常是模糊的像素信息之间的差距。本文通过在FluoroSAM中引入一种新颖的文本编码器架构来解决这一问题。该架构在冻结的CLIP编码器之上集成了一个向量量化(VQ)模块。这个VQ层至关重要;它为掩码解码器提供了更一致的信号,从而在X射线图像上进行训练时能够实现有效的语言对齐,尽管该模态存在固有的困难。这种架构创新允许模型学习一个共享的表示空间,其中文本提示可以准确地指导X射线图像中的分割。
痛苦的权衡或困境:
困扰先前研究人员的核心困境是模型泛化性/灵活性与高质量、标注X射线数据可用性之间的权衡。实现广泛适用性和语言提示性(如LFMs)通常需要海量、标注丰富的 数据集。然而,X射线成像,特别是介入性手术,严重缺乏此类数据。这迫使人们做出选择:要么开发在狭窄范围内表现良好但缺乏灵活性的特定任务模型,要么尝试构建泛化模型,但由于数据稀缺和X射线图像解释的独特挑战而举步维艰。X射线的穿透性性质进一步加剧了这种情况,因为改进一个方面(例如,分割重叠结构)通常会引入歧义或需要更复杂、数据密集型的解决方案。例如,虽然边界框提示(MedSAM在其他医学模态中使用)可以减少歧义,但它们严重限制了语言提示系统的核心优势——人机交互的灵活性和自然性。
约束与失效模式
由于存在一些严苛的、现实的约束,语言提示的X射线图像分割问题变得异常困难:
-
物理约束:
- 穿透性性质和重叠投影:X射线图像是通过X射线穿透身体形成的,导致2D投影,其中许多解剖结构和非解剖结构(如器械)经常重叠。这种固有的特性使得区分单个结构变得极其困难,即使对人类专家也是如此,并给自动分割带来了重大障碍。许多器官并不明显可见,这进一步使任务复杂化。
- 图像外观和应用的极高变异性:X射线成像涵盖了广泛的应用范围,从诊断性胸部X光片到介入性透视。这导致了人体解剖结构、成像几何形状、视角和图像强度值的巨大变异性。模型必须对这种广泛的多样性具有鲁棒性,这很难用有限的数据来实现。
-
计算约束:
- 数据生成和训练的高计算成本:为了克服数据稀缺性,作者生成了一个包含300万张X射线图像的大型合成数据集(FluoroSeg)。该模拟过程本身计算量巨大,在NVIDIA A6000 GPU上大约需要6个GPU天。在此数据集上训练FluoroSAM也需要大量资源,在2个NVIDIA H100 GPU上需要6天。这凸显了开发此类模型所带来的巨大计算负担。
- VQ码本大小限制:虽然向量量化(VQ)模块提高了对可变文本提示的鲁棒性,但其码本大小本质上限制了文本嵌入的表示能力。这种设计选择虽然有利于一致性,但理论上限制了该框架对无限范围的新分割类别或高度新颖语言提示的泛化能力。
-
数据驱动约束:
- 标注真实X射线数据的极度稀疏性:这也许是最关键的约束。对于X射线成像,特别是介入性X射线,缺乏大型、标注丰富的 数据集。这种稀缺性阻止了对真实世界数据进行鲁棒的语言对齐基础模型的直接训练,使得必须依赖合成数据。
- 领域差距(仿真到现实迁移):虽然有必要,但在合成数据上训练会引入模拟图像与真实X射线图像之间的领域差距。尽管在训练过程中应用了强大的领域随机化技术(例如,粗粒度dropout、反转、模糊、高斯对比度调整、随机窗宽、CLAHE直方图均衡化),但合成数据与真实手工标注掩码之间仍可能存在系统性差异,可能影响在真实世界场景中的性能。
- 合成数据多样性有限:即使拥有像FluoroSeg这样的大型合成数据集,所使用的基础CT扫描数量和代表的解剖结构多样性仍然存在局限性。虽然可以扩展这种多样性,但计算量很大。
- 自然语言提示的歧义性:自然语言提示本身可能存在歧义,尤其是在指代X射线图像中的重叠结构时。模型必须设计成能够通过忽略它们来处理“不良提示”,并为给定提示预测多个掩码,从而允许选择最准确的分割。这增加了模型输出和推理过程的复杂性。
为什么选择这种方法
选择的必然性
采用FluoroSAM,一种专门针对X射线图像分割的、可语言提示的Segment-Anything Model (SAM)变体,并非仅仅是一个选择,而是鉴于现有最先进(SOTA)方法固有局限性的必然需求。研究人员意识到,传统的特定任务机器学习模型虽然在狭窄范围内有效,但需要大量的额外数据、标注和训练时间才能将其效用扩展到更广泛的应用。这对于X射线成像模态尤其成问题,该模态的特点是图像外观高度可变、应用多样(从诊断性胸部X光片到介入性透视),并且关键在于缺乏大型、标注丰富的 数据集。
当考虑直接应用像原始SAM或其后续版本SAM 2这样的著名语言对齐基础模型(LFMs)时,很可能发生了“顿悟时刻”。虽然这些模型支持文本提示,但它们根本上依赖于像CLIP [21]这样的预训练LFMs,将图像块转换为语言对齐的嵌入。关键的见解是,CLIP主要在自然图像上训练,无法有效地迁移到X射线领域。X射线图像是穿透性的,导致许多属于不同物体的重叠掩码,这与物体通常具有清晰边界和嵌套结构的自然图像形成鲜明对比。即使存在X射线特定的CLIP类模型,单个图像块仍然会包含多个重叠物体的视觉特征,使得明确区分变得极其困难。X射线视觉特征与自然图像训练模型的假设之间的这种根本性不匹配,使得直接应用现有的SOTA LFM不足以满足需求,从而催生了像FluoroSAM这样的定制化解决方案。
相对优越性
FluoroSAM的定性优势源于其旨在克服X射线成像独特挑战的结构创新,使其在该特定领域内明显优于先前的黄金标准。与那些在处理X射线的穿透性性质和重叠解剖结构方面存在困难的模型不同,FluoroSAM新颖的文本编码器集成了冻结CLIP编码器之上的向量量化(VQ)模块,为掩码解码器提供了更一致的信号。这个VQ层至关重要;虽然它理论上限制了对全新分割类别的泛化能力,但它通过减少由同一物体不同描述引起的变异性,显著扩展了对新语言提示的泛化能力。这意味着FluoroSAM对多样化的自然语言输入更加鲁棒,这是人机协同工作流程的关键优势。
此外,FluoroSAM能够在大规模合成数据集FluoroSeg(300万张X射线图像)上从头开始训练,提供了结构上的优势。这规避了真实X射线图像的关键数据稀缺问题,使模型能够学习跨越广泛人体解剖结构、成像几何形状和视角的大量鲁棒特征,而这仅凭真实世界数据是不可能实现的。在定量上,FluoroSAM在真实介入性X射线图像上,尤其是在仅文本提示方面,优于SAM和MedSAM,实现了0.47的平均IoU和0.60的Dice分数。即使使用2个点,FluoroSAM也能达到0.56的IoU和0.69的Dice,优于SAM和MedSAM。例如,MedSAM通常“未能反映底层解剖结构,而只是填充了提供的框”,这表明在边界框约束之外,在理解底层图像内容方面存在定性失败。FluoroSAM的多输出能力,为给定提示预测多个掩码并选择最佳掩码,进一步增强了其鲁棒性和灵活性,使其能够更优雅地处理歧义提示。这种结构设计使FluoroSAM能够在其他模型 falter 的领域提供灵活的、语言对齐的分割,而无需将内存复杂度从 $O(N^2)$ 降低到 $O(N)$,而是通过提高定性理解和提示鲁棒性来实现。
与约束的对齐
所选择的FluoroSAM方法完美地符合X射线图像分割的严苛要求,形成了“问题与解决方案的结合”。如问题定义中所推断,主要约束包括:
- 需要广泛的适用性和灵活性:传统模型过于狭窄。FluoroSAM作为一种可语言提示的基础模型,其设计本质上是为了广泛适用,能够“根据自然语言提示分割无数解剖结构和器械”(第1页)。这种灵活性对于多样化的诊断和介入场景至关重要。
- 标注丰富的X射线数据集的稀缺性:这也许是最显著的约束。FluoroSAM通过“在300万张合成X射线图像上从头开始训练,这些图像涵盖了广泛的人体解剖结构、成像几何形状和视角”(第1页)来解决这个问题。FluoroSeg数据集的创建是对这一数据瓶颈的直接回应,使得在不依赖稀缺的真实世界标注的情况下进行鲁棒训练成为可能。
- X射线图像独特的视觉特征:X射线是穿透性的,具有重叠物体,使得清晰的边界检测对于在自然图像上训练的模型来说具有挑战性。FluoroSAM新颖的带VQ的文本编码器正是为了处理这种情况而设计的。VQ模块有助于减少同一物体不同文本描述引起的变异性,为掩码解码器提供更一致的信号,这对于区分X射线中的重叠结构至关重要。
- 自然语言交互的需求:以实现直观的人机协同工作流程并减少歧义。FluoroSAM的核心设计是作为“SAM的可语言提示变体”,直接满足了这一需求,允许用户使用自然语言指定分割目标,这比仅使用点或边界框提示对于复杂的X射线场景来说更加灵活且歧义更少。
- 跨X射线类型的泛化性:FluoroSeg数据集具有广泛的模拟解剖结构、几何形状和视角,确保FluoroSAM经过训练,能够跨越不同的X射线应用实现泛化,从诊断性胸部X光片到介入性透视。这一点通过其在仅接受CXR的零样本评估中取得成功(尽管是在合成数据上训练的)得到了证明。
替代方案的拒绝
本文明确详细说明了为什么几种流行的替代方法未能成功或不足以解决X射线图像分割的可语言提示这一特定问题。
首先,传统的、特定任务的机器学习模型被拒绝,因为它们在狭窄范围内运行,并且需要大量的额外数据、标注和重新训练才能实现更广泛的使用或新类别(第1页)。这与开发灵活、广泛适用的基础模型的目标相悖。
其次,直接应用现有的基础模型,如SAM和SAM 2,特别是它们对CLIP进行文本提示的依赖,被认为不合适。研究人员强调,CLIP在自然图像上训练,难以处理X射线图像的独特特征,例如其穿透性以及重叠物体且边界不清晰的普遍性(第2-3页)。即使是CLIP类模型被改编用于X射线,在单个图像块中区分多个物体仍然会存在问题。这种根本性的不兼容导致了FluoroSAM新颖的带VQ的文本编码器的开发。
第三,MedSAM [18],另一个医学成像基础模型,尽管在其他领域取得了成功,但对于X射线应用也被拒绝。MedSAM主要依赖边界框提示来缓解歧义(第5页)。对于X射线成像,这种方法是不可取的,因为它:(a) 由于重叠结构仍然存在显著歧义,(b) 使得自动或非专家提示不切实际,并且 (c) 缺乏高级人机协同系统所需的灵活性(第5页)。本文进一步指出,MedSAM“通常未能反映底层解剖结构,而只是填充了提供的框”(第7页),这表明在边界框约束下,在理解图像内容方面存在定性失败。
最后,即使是原始SAM的点提示性能也被发现较差,与FluoroSAM的性能相比,预测的“掩码越来越错误”(第7页)。这表明,虽然SAM提供了提示能力,但其底层架构和训练数据不足以应对X射线分割的复杂性,而没有FluoroSAM中引入的特定适应性。
本文没有明确讨论拒绝其他生成模型(如GAN或Diffusion模型)用于分割任务本身,因为重点在于可提示分割以及现有基础模型在X射线领域的局限性。拒绝替代方案的核心理由始终围绕着它们无法处理X射线的独特视觉特性、数据稀缺性以及对灵活、语言对齐交互的关键需求。
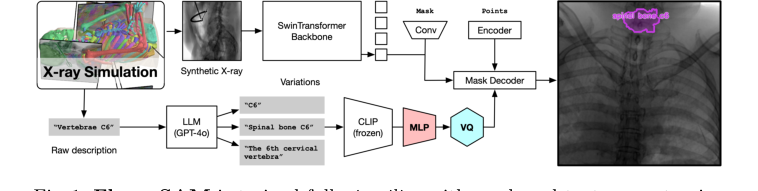 Figure 1. FluoroSAM is trained fully in silico with mask and text prompt pairs. It features a VQ layer that enables training language-aligned training on X-ray images
Figure 1. FluoroSAM is trained fully in silico with mask and text prompt pairs. It features a VQ layer that enables training language-aligned training on X-ray images
数学与逻辑机制
主方程
FluoroSAM的核心学习机制,与其他许多分割模型一样,在于其损失函数,该函数指导模型生成准确的掩码。虽然本文描述了一个涉及多个提示和选择标准的复杂训练方案,但评估单个预测掩码与其真实标签之间关系的根本目标是Dice Loss和Focal Loss的组合。本文指出,“我们使用Dice和focal loss来处理掩码。”因此,代表单个掩码预测目标的主方程可以表示为:
$$ L_{mask}(P, G) = \lambda_{Dice} L_{Dice}(P, G) + \lambda_{Focal} L_{Focal}(P, G) $$
其中 $P$ 代表预测的分割掩码(概率矩阵),$G$ 代表二值化的真实掩码。单个损失分量定义为:
$$ L_{Dice}(P, G) = 1 - \frac{2 \sum_{i=1}^N p_i g_i}{\sum_{i=1}^N p_i^2 + \sum_{i=1}^N g_i^2} $$
$$ L_{Focal}(P, G) = - \sum_{i=1}^N \left( g_i \alpha (1-p_i)^\gamma \log(p_i) + (1-g_i) (1-\alpha) p_i^\gamma \log(1-p_i) \right) $$
逐项解剖
让我们剖析这些方程,以理解每个组件的作用:
-
$L_{mask}(P, G)$:这是给定真实掩码 $G$ 的单个预测掩码 $P$ 的整体损失值。
- 数学定义:一个标量值,通常在0到1之间(对于Focal Loss可能更高),量化了预测掩码与真实分割之间的不相似性。
- 物理/逻辑作用:这是FluoroSAM模型在训练过程中力求最小化的主要目标函数。较低的 $L_{mask}$ 表示更准确的分割。
- 为什么是加法:通过加法组合 $L_{Dice}$ 和 $L_{Focal}$ 使用,允许两个分割质量方面——重叠(Dice)和正确分类难例(Focal)——同时为梯度信号做出贡献。这比单独使用任一损失提供了更全面、更平衡的优化目标。
-
$\lambda_{Dice}$:Dice Loss分量的权重系数。
- 数学定义:一个正标量常数。本文未明确说明其值,但通常通过超参数调整来设定。
- 物理/逻辑作用:该系数控制着在整体分割目标中,实现高重叠度(由Dice Loss衡量)与关注难分类像素(由Focal Loss衡量)的相对重要性。
- 为什么是乘法:乘法是复合损失函数中特定损失项贡献的标度化的标准方法。
-
$L_{Dice}(P, G)$:Dice Loss分量。
- 数学定义:$1 - \frac{2 \sum_{i=1}^N p_i g_i}{\sum_{i=1}^N p_i^2 + \sum_{i=1}^N g_i^2}$。其中,$p_i$ 是像素 $i$ 的预测概率,$g_i$ 是像素 $i$ 的二值化真实标签(0或1)。求和 $\sum_{i=1}^N$ 是对图像中所有 $N$ 个像素进行的。
- 物理/逻辑作用:该项主要衡量预测掩码与真实掩码之间的空间重叠。它对于类别不平衡显著的任务特别有效,例如在大型X射线图像中分割小型器官或器械,因为它本质上关注正类(前景)。最小化此项可以促使模型生成与真实物体形状和范围相匹配的掩码。
- 为什么是从1减去:Dice系数本身是一个相似性度量,范围从0(无重叠)到1(完美重叠)。从1中减去它将其转换为损失函数,其中0表示完美分割,1表示完全不相似。
- 为什么分母中使用平方和:对于概率预测($p_i \in [0,1]$),在分母中使用 $p_i^2$ 和 $g_i^2$ 将集合基数(元素数量)的概念推广到连续概率,使得损失函数可微分且适用于基于梯度的优化。
-
$\lambda_{Focal}$:Focal Loss分量的权重系数。
- 数学定义:一个正标量常数,通常通过超参数调整确定。
- 物理/逻辑作用:与 $\lambda_{Dice}$ 类似,该系数调整Focal Loss在总损失中的影响,平衡其对难例的关注与Dice Loss对整体重叠的强调。
- 为什么是乘法:损失项的标准标度化机制。
-
$L_{Focal}(P, G)$:Focal Loss分量。
- 数学定义:$- \sum_{i=1}^N \left( g_i \alpha (1-p_i)^\gamma \log(p_i) + (1-g_i) (1-\alpha) p_i^\gamma \log(1-p_i) \right)$。
- 物理/逻辑作用:该损失通过降低易于分类的示例(易负例)的贡献来解决类别不平衡问题,并将模型的训练集中在难分类的示例上。在X射线图像中,背景像素通常远多于前景像素,Focal Loss可以防止模型被易于预测的背景所压倒。
- 为什么是 $\alpha$:这是正类的加权因子。它平衡了正例和负例的重要性,如果一个类别本身更重要或更稀有,这可能很有用。
- 为什么是 $(1-p_i)^\gamma$ 或 $p_i^\gamma$:这些是调制因子。如果一个像素被正确分类(例如,$g_i=1$ 时 $p_i$ 很高),那么 $(1-p_i)$ 很小,而 $(1-p_i)^\gamma$ 变得更小(对于 $\gamma > 0$),从而有效地降低了其损失贡献。相反,对于被错误分类的像素,该因子接近1,损失仍然显著。这种机制将学习“聚焦”于难例。
- 为什么是 $\log(p_i)$:这是交叉熵的基本组成部分,它衡量了预测的“惊喜”或错误。然后,调制因子对该错误进行标度。
-
$P$:预测掩码。
- 数学定义:一个二维矩阵(或三维用于体积数据),其中每个元素 $p_{ij} \in [0, 1]$ 表示像素 $(i,j)$ 属于前景对象的预测概率。
- 物理/逻辑作用:这是FluoroSAM掩码解码器的输出,代表模型对分割的最佳猜测。
-
$G$:真实掩码。
- 数学定义:一个二维二值化矩阵,其中每个元素 $g_{ij} \in \{0, 1\}$ 表示像素 $(i,j)$ 是否真正属于前景(1)或背景(0)。
- 物理/逻辑作用:这是FluoroSeg数据集提供的“正确答案”,模型的预测将与此进行比较以计算损失。
-
$p_i, g_i$:单个像素的概率和标签。
- 数学定义:$p_i \in [0, 1]$ 是单个像素的预测概率,$g_i \in \{0, 1\}$ 是其对应的真实标签。
- 物理/逻辑作用:这些代表了预测和真实的最基本单位,它们的聚合贡献构成了整体掩码损失。
-
$\sum$:求和运算符。
- 数学定义:对定义集合中的值求和,在此情况下是对图像中的所有像素 $i=1, \dots, N$ 求和。
- 物理/逻辑作用:聚合单个像素的贡献,以计算整个分割掩码的Dice和Focal Loss。
分步流程
想象一个X射线图像和一个自然语言提示进入FluoroSAM系统,就像物品沿着复杂的装配线移动一样:
- 图像摄入(视觉通路):一张X射线图像,例如患者的胸部X光片,首先进入图像编码器。该编码器基于SwinTransformer骨干构建,就像一个专业的视觉处理单元。它仔细扫描图像,提取不同尺度的分层视觉特征。可以将其视为将图像分解为越来越抽象的表示,从简单的边缘和纹理到复杂的解剖模式。
- 提示解释(语言通路):同时,一个自然语言提示,例如“分割左肺”,被输入到文本编码器。该编码器是一个多阶段单元:
- 首先,一个冻结的CLIP编码器接收文本并将其转换为高维数值嵌入,捕捉其语义含义。
- 接下来,一个多层感知机(MLP)进一步处理此嵌入,优化其表示。
- 最后,一个向量量化(VQ)瓶颈将此优化后的嵌入量化为一个离散的“提示令牌”。这个VQ层就像一个语言过滤器,将提示的含义标准化为模型可以轻松理解的一致、离散代码,无论措辞如何略有不同。
- 特征融合与掩码生成:然后,来自图像编码器的丰富视觉特征和来自文本编码器的离散提示令牌被整合在一起。这种融合指导着掩码解码器,它是模型的创意引擎。基于结合的视觉和语言信息,掩码解码器不仅仅生成一个掩码;它为请求的对象生成多个候选分割掩码。这就像有几位技艺精湛的工匠为“左肺”提出了略有不同的轮廓。
- 损失评估与选择:对于这些候选掩码中的每一个,系统使用Dice和Focal Loss与真实掩码(在训练期间可用)进行比较来计算其 $L_{mask}$。然后,模型选择产生最低 $L_{mask}$ 的候选掩码。此选择过程确保模型始终致力于在给定提示的情况下实现最准确的分割。
- 反向传播与学习:然后,从选定的掩码(特别是来自文本提示、点1、点8以及一个额外的随机点提示)的损失被用来计算梯度。这些梯度就像精确的指令,通过掩码解码器和图像编码器(文本编码器的CLIP部分被冻结,但MLP和VQ组件会更新)向后流动。这些指令告诉网络可训练部分中的每个参数如何调整以减少损失并改进未来的分割。这种预测、评估、选择和调整的迭代过程就是FluoroSAM学会根据自然语言准确分割X射线图像的方式。
优化动力学
FluoroSAM的学习过程是损失最小化、基于梯度的更新和战略性数据增强的动态交互,所有这些都旨在导航复杂的损失景观并实现鲁棒的性能。
-
损失景观塑造:Dice Loss和Focal Loss的组合对于塑造优化景观至关重要。Dice Loss虽然在类别不平衡方面有效,但有时会遇到非凸性和平台问题,尤其是在预测掩码与真实掩码重叠很少的情况下。Focal Loss通过积极地降低易例的权重来补充这一点,从而增加难分类像素的相对重要性。这有效地加陡了挑战性区域附近的梯度,防止模型陷入局部最小值或被易于预测的背景像素所主导。目标是创建一个路径更清晰、更直接的景观,以实现更好的分割。
-
梯度行为与更新:在训练过程中,$L_{mask}$(来自选定的提示)的梯度是相对于图像编码器和掩码解码器中的所有可训练参数,以及文本编码器的MLP和VQ组件计算的。这些梯度指示了参数调整以降低损失的方向和幅度。然后,模型参数使用优化器(通常是Adam或其变体,尽管本文未明确说明)进行迭代更新。这个迭代过程将模型在多维参数空间中的“位置”移动到低损失区域,逐渐提高其分割精度。
-
学习率调度:本文指定了一个精心设计的学习率调度:在20k次迭代中从 $8 \times 10^{-6}$ 线性预热到 $8 \times 10^{-4}$ 的基准速率,然后在200k和400k步时分别按10的因子减小。
- 预热:初始的低学习率可以防止模型参数随机初始化且远离最优状态时发生大的、不稳定的更新。它允许模型在损失景观中“找到立足点”。
- 衰减:在训练后期降低学习率有助于模型微调其参数,使其能够更精确地收敛到最小值,而不会过冲或振荡。这就像在接近目标时,从大的探索性步骤切换到小的、精确的调整。
-
向量量化(VQ)动力学:文本编码器中的VQ瓶颈将离散元素引入了原本连续的神经网络。使用VQ进行训练通常涉及诸如直通估计器(straight-through estimator)之类的技术,以允许梯度穿过离散量化步骤。这种机制迫使文本嵌入进入有限的“码本”向量集,这有助于学习鲁棒的、语言对齐的表示。虽然它理论上限制了对新类别的泛化能力,但它通过将不同的措辞映射到一致的离散令牌,提高了对可变语言提示的鲁棒性。这使得模型对提示的确切措辞不那么敏感。
-
通过增强和随机化实现鲁棒性:
- 文本增强:使用gpt-40为每个掩码生成多达30个不同的提示,极大地扩展了训练数据的语言变异性。这使得FluoroSAM对用户可能提出的不同分割请求方式具有鲁棒性,防止了对特定提示措辞的过拟合。
- 领域随机化:在合成X射线图像上应用“强领域随机化”(例如,粗粒度dropout、反转、模糊、高斯对比度调整 [10]、随机窗宽、CLAHE直方图均衡化)是仿真到现实迁移的关键策略。它迫使模型学习对各种图像外观不变的特征,使其在遇到与合成训练数据系统性不同的真实X射线图像时更具鲁棒性。这有效地平滑了损失景观,使模型对微小的输入变化不那么敏感。
-
多输出与选择:FluoroSAM能够为单个提示生成多个掩码,然后在训练期间选择损失最低的掩码,这充当了内部的自我纠正机制。这类似于预测的集成,其中选择最佳预测,从而产生更可靠、更准确的最终输出。在推理过程中,IOU预测头接管了这一选择,估计哪个掩码最可能是正确的。这种动态选择过程有助于模型的整体稳定性和性能。
结果、局限性与结论
实验设计与基线
为了严格验证FluoroSAM的能力,作者设计了一个全面的实验设置,包括合成和真实X射线数据,并将他们的模型与已建立的基线进行比较。
FluoroSAM训练的基础是FluoroSeg数据集,这是一个包含300万张合成X射线图像的海量集合。该数据集是通过计算机模拟精心生成的,旨在模拟广泛的人体解剖结构、成像几何形状和视角,这对于捕捉真实X射线成像的多样性至关重要。模拟流程始于新墨西哥州遗体图像数据库 [5] 中的1621个高分辨率CT扫描,然后使用TotalSegmentator [27]将其分割成128个器官类别,以导出表面网格。为了模拟多样的放射学检查,环境采样了标准视图(例如,胸部、腹部)和完全随机的C臂视图,重点关注具有不同角度的主要器官。至关重要的是,464个计算机建模的手术器械,每个都带有全面的文本描述,被随机放置在视野中。图像以 $512^2$ 像素渲染,并附带伪真实掩码和相关的文本描述。该过程效率很高,在NVIDIA A6000 GPU上每秒生成6.5到15.7张图像,总计约295万张图像,耗时约6个GPU天。数据集根据原始CT扫描按90/10%的比例分为训练集和验证集。
FluoroSAM本身,作为SAM [15] 的一个可语言提示变体,在FluoroSeg上进行了从头训练。其新颖的文本编码器,包括一个冻结的CLIP编码器 [21]、一个两层隐藏层多层感知机(MLP)和一个向量量化(VQ)瓶颈 [20],是实现语言对齐的关键。为了增强泛化能力,使用gpt-40 [1] 进行文本增强,为每个掩码生成多达30个不同的提示。相关的器官掩码被程序化地组合成38个组(例如,“左肋骨”),并且偶尔采样“不良提示”(图像中不存在的提示),以教会模型忽略不相关的查询。图像编码器使用了SwinTransformer骨干(最终模型使用Swin-L),在ImageNet-22k上进行了预训练,并在缩减的FluoroSeg类别集上进一步进行了实例分割训练。为了促进仿真到现实迁移,在训练过程中应用了强领域随机化技术,包括粗粒度dropout、反转、模糊、高斯对比度调整 [10]、随机窗宽和CLAHE直方图均衡化。训练涉及每个掩码9个提示(1个文本,8个点),使用Dice和focal loss,并将特定的损失分量进行反向传播。模型在2个NVIDIA H100 GPU上训练了10个epoch,耗时6天。
为了进行评估,FluoroSAM在真实X射线图像上与几个“受害者”基线模型进行了较量:
1. 真实介入性X射线图像:一个来自全身标本(从股骨中部到T2)的注册X射线图像数据集,使用Brainlab Loop-X设备采集。真实掩码是通过拼接四个导航式锥束CT图像并投影器官分割 [27] 生成的。评估仅限于大于图像面积2.5%的1741个掩码。基线包括原始SAM [15](使用点或边界框提示)和MedSAM [18](通常使用边界框提示进行医学图像分割)。指标为交并比(IoU)、Dice分数和Hausdorff距离(HDD)。
2. 胸部X光片(CXR)的零样本评估:一个包含1131张CXR [2] 的数据集,带有手工标注的肺部分割。这测试了FluoroSAM在没有特定训练的情况下,泛化到不同X射线模态和真实世界标注的能力。使用了相同的基线SAM和MedSAM,并报告了IoU、Dice和HDD。
证据证明的内容
实验证据明确证明了FluoroSAM的核心机制——用于X射线图像分割的可语言提示分割——是有效的,并且通常优于现有方法,即使仅在合成数据上进行训练。
在真实介入性X射线图像上,FluoroSAM在仅使用文本提示的情况下展示了其强大能力。如表1和图3a所示,FluoroSAM实现了0.47的平均IoU和0.60的Dice分数。在FluoroSAM仅使用文本提示的情况下,这一性能显著优于其同类模型SAM(使用点提示时IoU为0.36,Dice为0.50;使用框提示时IoU为0.42,Dice为0.57)和MedSAM(IoU为0.41,Dice为0.55)。这是一个关键证据,因为它验证了FluoroSAM新颖的文本编码器和VQ层能够解释自然语言并在具有挑战性的真实世界场景中生成准确的分割。当添加点提示时,FluoroSAM的性能进一步提高,使用2个点时达到IoU 0.56和Dice 0.69,使用8个点时达到IoU 0.64、Dice 0.77和HDD 60.8,在这些指标上始终优于基线。这里的决定性证据是直接的定量比较,其中FluoroSAM凭借其独特的文本提示能力,要么超越了,要么匹配了依赖于更受限的点或框提示的模型。
CXR上的零样本评估提供了FluoroSAM泛化能力和仿真到现实迁移能力的无可辩驳的证据。尽管仅在合成数据上进行训练,FluoroSAM在真实CXR的手工标注肺部分割上表现出惊人的适应性。使用仅文本提示,它实现了0.50的平均IoU和0.66的Dice分数(表1,图3b)。虽然SAM在提供多个点或框提示时可以达到更高的分数(例如,2个点时IoU为0.83,Dice为0.89),但FluoroSAM使用8个点(IoU为0.81,Dice为0.89)的性能极具竞争力,甚至超过了SAM的8点性能(IoU为0.73,Dice为0.82)。这表明FluoroSAM在合成数据上的训练,加上强大的领域随机化,使其能够泛化到未见过的真实世界诊断X射线图像和任务,这是一个重大的成就,考虑到合成投影与手工标注掩码之间存在的系统性差异。
此外,定性用户研究(图4)为VQ层在提高分割对可变文本提示的鲁棒性方面提供了令人信服的证据。当被问及“髋部旁边的骨头是什么?”时,带VQ的FluoroSAM正确地分割了股骨,而没有VQ则失败了。这直接支持了作者的说法,即VQ通过减少同一物体不同描述引起的变异性,有助于泛化到新的语言提示,从而使模型对自然语言的细微差别更加健壮。
最后,图5中展示的定性结果和下游应用说明了FluoroSAM的实际效用。其灵活性使得高效的X射线标注、以患者为中心的健康教育以及智能机器人C臂定位和自主准直成为可能,这表明核心机制不仅在定量上有效,而且能够实现临床工作流程中丰富的人机交互。
局限性与未来方向
虽然FluoroSAM代表了X射线图像分割领域可语言提示基础模型的一个重大飞跃,但作者坦诚地承认了几个局限性,这些局限性也为未来的研究和开发提供了肥沃的土壤。
一个主要局限性在于FluoroSeg数据集的范围。尽管拥有300万张图像,但它仍然受到基础CT扫描数量和代表的解剖结构多样性的限制。通过纳入更多CT图像来扩展该数据集,可能来自最近发布的TotalSegmentator任务或更专业的数据库,如骨折片段 [23],是一个明确的前进方向。然而,即使有自动化流程,这种扩展在计算上仍然是密集的,这表明需要持续优化模拟环境。
另一个固有的挑战源于X射线图像本身的性质。它们是穿透性的,导致重叠投影,许多器官并不明显可见。这种歧义使得分割成为一项困难的任务,尽管FluoroSAM表现良好,但这是该模态的基本限制。尽管在仿真到现实迁移方面取得了成功,但仅依赖合成数据进行训练,也可能引入与在真实、手工标注数据上训练的模型相比的细微系统性差异,正如在一些CXR结果中所观察到的那样。
向量量化(VQ)码本的大小被确定为一个特定的架构限制。虽然VQ在定性上提高了对可变文本提示的鲁棒性,但其固定大小本质上限制了文本嵌入的表示能力。在当前情况下,这是一个可接受的权衡,但为了支持更广泛的解剖结构和更细致的提示,可能需要替代策略或演进的VQ机制。这可能包括动态码本扩展或分层VQ方法。
展望未来,FluoroSAM的发现为未来的发展开启了几个令人兴奋的讨论话题:
- 合成数据的可扩展性和多样性:我们如何进一步扩展合成数据生成,以涵盖更广泛的病理、患者人口统计学和成像伪影,而不仅仅是解剖结构的多样性?能否使用生成式AI模型来合成新的CT扫描或增强现有扫描,以创建比仅依赖现有CT数据库更丰富的FluoroSeg训练数据?
- 混合训练范式:鉴于仿真到现实迁移的成功,结合合成和有限的真实世界标注数据的最佳策略是什么?能否利用大量的未标注真实X射线数据,通过半监督或自监督学习方法,在无需大量手动标注的情况下进一步提高FluoroSAM的性能和鲁棒性?
- 高级语言理解:FluoroSAM如何演进以解释更复杂、多步骤或模糊的自然语言提示,朝着基于“思维链”的X射线图像分析 [9] 发展?这可能需要比仅用于文本增强更紧密的与大型语言模型集成,以实现更深层次的语义理解和推理能力。
- 个性化与适应性:FluoroSAM能否适应特定的患者解剖结构或临床背景?例如,它能否从一组少量的患者特定标注中学习,以提高该个体的分割精度,或者适应不同X射线设备或协议的独特特性?这对于精准医疗应用至关重要。
- 伦理考量与信任:随着FluoroSAM集成到人机协同工作流程中,依赖AI进行关键医疗任务的伦理影响是什么?我们如何确保透明度、可解释性,并建立对解释自然语言提示进行分割的AI系统的信任,尤其是在处理模糊或新颖的查询时?对“不良提示”的鲁棒性是一个好的开始,但对于临床部署来说,还需要更多。
- 超越文本的多模态集成:虽然语言是一种强大的提示,但FluoroSAM能否通过集成其他模态作为提示来受益,例如生理信号、患者病史,甚至介入环境中的触觉反馈?这可以提供更丰富的上下文信息,进一步减少歧义并增强交互。
最终,FluoroSAM的开发是朝着X射线成像领域灵活、可语言提示的基础模型迈出的关键一步,有望在诊断和介入医学领域开辟新途径。已确定的局限性并非障碍,而是下一代研究的明确路标。
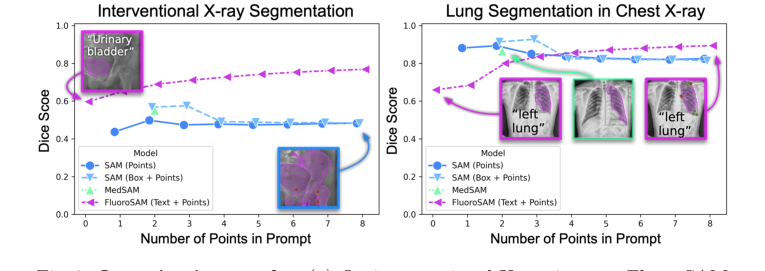 Figure 3. Quantitative results. (a) On interventional X-ray images, FluoroSAM outperforms its peers even with text-only prompting. (b) On CXRs, FluoroSAM adapts to hand-annotated lung segmentations despite being trained on synthetic data. MedSAM [18] includes this task in its training data
Figure 3. Quantitative results. (a) On interventional X-ray images, FluoroSAM outperforms its peers even with text-only prompting. (b) On CXRs, FluoroSAM adapts to hand-annotated lung segmentations despite being trained on synthetic data. MedSAM [18] includes this task in its training data
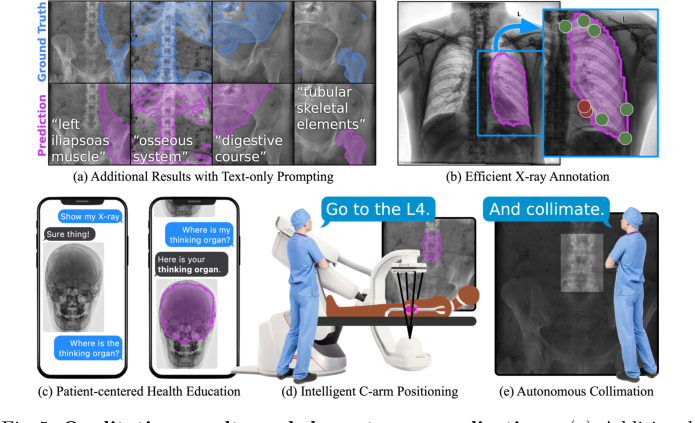 Figure 5. Qualitative results and downstream applications. (a) Additional results on real X-ray images, with text prompts not used during training. The flexibility of text prompting supports a wide variety of downstream applications. (b) Efficient annotation of X-rays can reduce clinical burden and accelerate real data annotation. (c) Flexible text-based prompting may lend itself to patient- facing education, empowering patients to better understand their own anatomy. In the OR, FluoroSAM can be integrated with robotic C-arms to deliver intel- ligent positioning (d) and autonomous collimation (e), reducing radiation [14]. These figures use real FluoroSAM predictions on real radiographs
Figure 5. Qualitative results and downstream applications. (a) Additional results on real X-ray images, with text prompts not used during training. The flexibility of text prompting supports a wide variety of downstream applications. (b) Efficient annotation of X-rays can reduce clinical burden and accelerate real data annotation. (c) Flexible text-based prompting may lend itself to patient- facing education, empowering patients to better understand their own anatomy. In the OR, FluoroSAM can be integrated with robotic C-arms to deliver intel- ligent positioning (d) and autonomous collimation (e), reducing radiation [14]. These figures use real FluoroSAM predictions on real radiographs
 Figure 4. In a limited user study, we observe qualitative results consistent with the hypothesis that VQ improves segmentation robustness to variable text prompts. For example, FluoroSAM with VQ was able to correctly segment the femur, answering the question “What’s the bone next to the hip?”
Figure 4. In a limited user study, we observe qualitative results consistent with the hypothesis that VQ improves segmentation robustness to variable text prompts. For example, FluoroSAM with VQ was able to correctly segment the femur, answering the question “What’s the bone next to the hip?”
与其他领域的同构性
结构骨架
一个系统,它能够鲁棒地将多样化、高维的文本描述映射到复杂视觉数据中的相应空间区域,从而实现灵活的、由提示驱动的分割。