FluoroSAM: Модель-основа с языковым управлением для гибкой сегментации рентгеновских изображений
Проблема, решаемая FluoroSAM, проистекает из критической потребности в более гибкой и эффективной сегментации рентгеновских изображений в диагностической и интервенционной прецизионной медицине.
Предыстория и академическая родословная
Происхождение и академическая родословная
Проблема, решаемая FluoroSAM, проистекает из критической потребности в более гибкой и эффективной сегментации рентгеновских изображений в диагностической и интервенционной прецизионной медицине. Рентгенография является основополагающим методом в здравоохранении, однако ее анализ исторически опирался на специализированные модели машинного обучения. Эти ранние модели, будучи эффективными в узких областях применения, имели существенные ограничения: для адаптации к новым задачам или расширения их области действия требовалось значительное количество дополнительных данных, аннотаций и времени на обучение. Это делало их жесткими и трудными для масштабирования в клинической практике.
В академической среде появление "моделей-основ" (foundation models, FMs) и, в частности, "языковых моделей-основ" (language-aligned foundation models, LFMs) стало перспективным направлением для преодоления этих ограничений. LFMs, обученные на огромных и разнообразных наборах изображений и текстов, предлагали потенциал широкого применения, позволяя задавать задачи с использованием естественного языка. Однако существующие медицинские LFMs в основном фокусировались на таких модальностях, как КТ или МРТ, где доступны большие, богато аннотированные наборы данных. Рентгенография, напротив, представляет уникальные проблемы: высокая вариативность внешнего вида изображений, разнообразные применения (от диагностических рентгенограмм грудной клетки до интервенционной флюороскопии) и дефицит больших, хорошо аннотированных наборов данных, особенно для интервенционных процедур.
Существенной "болевой точкой" предыдущих подходов, включая универсальные модели-основы, такие как Segment-Anything Model (SAM) и ее преемник SAM 2, была их неспособность эффективно обрабатывать уникальные характеристики рентгеновских изображений, особенно с текстовыми подсказками. В то время как модели SAM превосходно сегментируют объекты на естественных изображениях на основе различных подсказок (маска, ограничивающая рамка, точка), их возможности текстового управления часто опираются на модели, такие как CLIP, которые были обучены на естественных изображениях. Прямое перенесение этого на рентгеновские изображения проблематично, поскольку рентгеновские лучи являются проникающими, что приводит к множеству накладывающихся проекций различных анатомических и неанатомических объектов. Эта присущая неоднозначность означает, что один и тот же фрагмент изображения может содержать визуальные признаки нескольких объектов, что затрудняет их различение для моделей, обученных на естественных изображениях. Кроме того, ограниченная доступность разнообразных, высококачественных наборов данных рентгеновских изображений, особенно для сложных интервенционных сценариев, серьезно препятствовала разработке гибких, управляемых языком инструментов сегментации для этой модальности. Предыдущие медицинские варианты SAM, такие как MedSAM, часто смягчали эту неоднозначность, ограничивая подсказки ограничивающими рамками, что нежелательно для рентгенографии, поскольку это все еще оставляет значительную неоднозначность, делает автоматическое или неэкспертное управление непрактичным и снижает гибкость для систем с участием человека. Данная статья направлена на устранение этих ограничений путем разработки языковой модели-основы, специально адаптированной для рентгеновского домена, с использованием генерации синтетических данных для преодоления дефицита данных.
Интуитивно понятные термины домена
- Языковые модели-основы (LFMs): Представьте себе суперумного помощника, который может понимать ваши устные или письменные инструкции (например, "сегментировать левое легкое") и затем выполнять сложную задачу, такую как идентификация и очерчивание этой конкретной части на рентгеновском изображении. LFMs подобны этим помощникам, обученным на огромном количестве как изображений, так и текстов, поэтому они учатся связывать слова с визуальными концепциями, что делает их очень универсальными.
- Сегментация: Представьте, что вы используете цифровой маркер для точного очерчивания конкретного объекта на изображении. В медицинской визуализации это означает нанесение точной границы вокруг органа, кости или медицинского инструмента. Это не просто сказать "здесь легкое"; это показать точно, где находится легкое.
- Векторная квантизация (VQ): Это похоже на наличие словаря визуальных концепций. Когда модель "видит" новое описание или визуальный признак, она пытается сопоставить его с ближайшей записью в своем словаре. Это помогает стандартизировать и упростить сложную информацию, облегчая модели изучение последовательных связей между языком и изображениями, даже если описания немного отличаются. Это способ сделать понимание концепций моделью более надежным и менее чувствительным к незначительным вариациям.
- Перенос из симуляции в реальность (Sim-to-real transfer): Это похоже на то, как пилот тренируется в авиационном симуляторе перед полетом на реальном самолете. В данном контексте это означает обучение ИИ-модели с использованием высокореалистичных компьютерно-генерированных (симулированных) рентгеновских изображений, а затем применение этой обученной модели к реальным рентгеновским изображениям. Цель состоит в том, чтобы модель хорошо работала в реальном мире, несмотря на обучение в основном на симулированных данных, которые часто легче и дешевле производить в больших количествах.
Таблица обозначений
| Обозначение | Описание |
|---|---|
Определение проблемы и ограничения
Формулировка основной проблемы и дилемма
Основная проблема, рассматриваемая в данной статье, заключается в отсутствии гибкой, обобщающей и управляемой языком модели-основы для сегментации рентгеновских изображений, особенно для разнообразных и сложных медицинских сценариев.
Вход/Текущее состояние:
В настоящее время анализ рентгеновских изображений опирается на специализированные модели машинного обучения. Эти модели хорошо работают в узкой области, но их фиксированная конструкция и ограниченные обучающие данные серьезно ограничивают их применимость в широком рентгеновском домене. Расширение этих моделей для поддержки новых классов или более сложных запросов требует значительного количества дополнительных данных, аннотаций и обширных усилий по переобучению. Существующие модели-основы (FM) для медицинской визуализации, хотя и перспективны, в основном фокусировались на модальностях, где доступны большие, богато аннотированные наборы данных. Однако рентгенография, особенно интервенционная флюороскопия, представляет собой уникальную проблему из-за высокой вариативности внешнего вида изображений, разнообразных применений и критического дефицита богато аннотированных обучающих данных. Кроме того, рентгеновские изображения по своей природе являются проникающими, что означает, что множество анатомических и неанатомических объектов часто накладываются друг на друга, что затрудняет их различение. Предыдущие языковые модели-основы, такие как Segment-Anything Model (SAM) и ее преемник SAM 2, полагаются на модели, такие как CLIP, для текстовых подсказок, которые были обучены на естественных изображениях. Не сразу ясно, как эффективно перенести этот подход на рентгеновские изображения, где границы объектов часто нечеткие, а структуры накладываются друг на друга.
Желаемый конечный результат (выход/целевое состояние):
Конечная цель — разработка управляемой языком модели-основы, названной FluoroSAM, способной к всестороннему и языковому анализу произвольных медицинских рентгеновских изображений. Эта модель должна обеспечивать большую гибкость для рабочих процессов с участием человека в диагностической и интервенционной прецизионной медицине. В частности, FluoroSAM стремится сегментировать множество анатомических структур и инструментов на основе подсказок естественного языка, предоставляя семантически значимые маски для любого объекта, указанного на рентгеновском изображении. Это позволит более интуитивно и эффективно взаимодействовать в клинических условиях, от интерактивных диагностических систем до интеллектуальных человеко-машинных интерфейсов в визуально-управляемых вмешательствах.
Отсутствующее звено или математический пробел:
Точным отсутствующим звеном является надежный и обобщающий механизм для эффективного согласования подсказок естественного языка с уникальными визуальными признаками рентгеновских изображений для сегментации. Задача заключается в преодолении разрыва между высокоуровневыми лингвистическими описаниями и низкоуровневой, часто неоднозначной, пиксельной информацией на рентгеновских снимках. Статья решает эту проблему, представляя новую архитектуру текстового кодировщика в рамках FluoroSAM. Эта архитектура включает модуль векторной квантизации (VQ) поверх замороженного кодировщика CLIP. Этот VQ-слой имеет решающее значение; он обеспечивает более последовательный сигнал для декодера маски, позволяя эффективно согласовывать язык во время обучения специально для рентгеновских изображений, несмотря на присущие сложности модальности. Это архитектурное новшество позволяет модели изучать общее пространство представлений, где текстовые подсказки могут точно направлять сегментацию на рентгеновских изображениях.
Болезненный компромисс или дилемма:
Центральная дилемма, которая поставила в тупик предыдущих исследователей, — это компромисс между обобщаемостью/гибкостью модели и доступностью высококачественных, аннотированных рентгеновских данных. Достижение широкой применимости и языковой управляемости (как у LFMs) обычно требует огромных, богато аннотированных наборов данных. Однако рентгенография, особенно для интервенционных процедур, страдает от острого недостатка таких данных. Это заставляет выбирать: либо разрабатывать узкие, специализированные модели, которые хорошо работают, но лишены гибкости, либо пытаться создавать обобщающие модели, которые испытывают трудности из-за дефицита данных и уникальных проблем интерпретации рентгеновских изображений. Проникающий характер рентгеновских лучей усугубляет эту проблему, поскольку улучшение одного аспекта (например, сегментация накладывающихся структур) часто вносит неоднозначность или требует более сложных, ресурсоемких решений. Например, хотя подсказки в виде ограничивающих рамок (используемые MedSAM для других медицинских модальностей) могут уменьшить неоднозначность, они серьезно ограничивают гибкость и естественность взаимодействия человека и машины, что является основным преимуществом управляемых языком систем.
Ограничения и режимы сбоя
Проблема управляемой языком сегментации рентгеновских изображений чрезвычайно сложна из-за нескольких жестких, реалистичных ограничений:
-
Физические ограничения:
- Проникающий характер и наложение проекций: Рентгеновские изображения формируются прохождением рентгеновских лучей через тело, что приводит к 2D-проекциям, где множество анатомических и неанатомических объектов (например, инструментов) часто накладываются друг на друга. Эта присущая характеристика затрудняет различение отдельных структур даже для экспертов-людей и представляет собой серьезное препятствие для автоматической сегментации. Многие органы не видны явно, что еще больше усложняет задачу.
- Высокая вариативность внешнего вида изображений и применений: Рентгенография охватывает широкий спектр применений, от диагностических рентгенограмм грудной клетки до интервенционной флюороскопии. Это приводит к огромной вариативности анатомии человека, геометрии съемки, углов обзора и значений интенсивности изображений. Модель должна быть устойчива к этому широкому разнообразию, чего трудно достичь при ограниченных данных.
-
Вычислительные ограничения:
- Высокая вычислительная стоимость генерации данных и обучения: Для преодоления дефицита данных авторы сгенерировали большой синтетический набор данных (FluoroSeg) из 3 миллионов рентгеновских изображений. Сам процесс симуляции является вычислительно затратным, требуя примерно 6 GPU-дней на NVIDIA A6000 GPU. Обучение FluoroSAM на этом наборе данных также требует значительных ресурсов, занимая 6 дней на 2 NVIDIA H100 GPU. Это подчеркивает существенную вычислительную нагрузку, связанную с разработкой такой модели.
- Ограничение размера кодовой книги VQ: Хотя модуль векторной квантизации (VQ) повышает устойчивость к переменным текстовым подсказкам, размер его кодовой книги внутренне ограничивает репрезентативную мощность текстовых вложений. Этот выбор дизайна, хотя и полезен для последовательности, теоретически ограничивает обобщаемость фреймворка до бесконечно широкого диапазона новых классов сегментации или крайне новых языковых подсказок.
-
Ограничения, связанные с данными:
- Крайняя разреженность аннотированных реальных рентгеновских данных: Это, пожалуй, самое критическое ограничение. Существует глубокий недостаток больших, богато аннотированных наборов данных для рентгенографии, особенно для интервенционных рентгеновских снимков. Этот дефицит препятствует прямому обучению надежных языковых моделей-основ на реальных данных, что требует опоры на синтетические данные.
- Разрыв домена (перенос из симуляции в реальность): Обучение на синтетических данных, хотя и необходимо, вносит разрыв домена между симулированными и реальными рентгеновскими изображениями. Несмотря на сильные методы рандомизации домена, применяемые во время обучения (например, грубое отбрасывание, инверсия, размытие, регулировка контрастности Гаусса, случайное оконное преобразование, эквализация гистограммы CLAHE), синтетические данные могут систематически отличаться от реальных масок, аннотированных вручную, что потенциально влияет на производительность в реальных сценариях.
- Ограниченное разнообразие в синтетических данных: Даже при наличии большого синтетического набора данных, такого как FluoroSeg, все еще существуют ограничения в количестве базовых КТ-сканов и разнообразии представленных анатомических структур. Расширение этого разнообразия, хотя и масштабируемо, вычислительно затратно.
- Неоднозначность подсказок естественного языка: Сами подсказки естественного языка могут быть неоднозначными, особенно когда они относятся к накладывающимся структурам на рентгеновских изображениях. Модель должна быть разработана для обработки "плохих подсказок", игнорируя их, и для предсказания нескольких масок для данной подсказки, позволяя выбрать наиболее точную сегментацию. Это добавляет сложности к выводу и процессу вывода модели.
Почему такой подход
Неизбежность выбора
Принятие FluoroSAM, управляемого языком варианта Segment-Anything Model (SAM), специально адаптированного для сегментации рентгеновских изображений, было не просто выбором, а неизбежной необходимостью, учитывая присущие ограничения существующих передовых (SOTA) методов. Авторы осознали, что традиционные специализированные модели машинного обучения, будучи эффективными в узких областях, требовали непомерно большого количества дополнительных данных, аннотаций и времени на обучение для расширения их полезности на более широкие области применения. Это было особенно проблематично для рентгенографической модальности, которая характеризуется высокой вариативностью внешнего вида изображений, разнообразными применениями (от диагностических рентгенограмм грудной клетки до интервенционной флюороскопии) и, критически, дефицитом больших, богато аннотированных наборов данных.
"Точный момент" осознания, вероятно, наступил при рассмотрении прямого применения видных языковых моделей-основ (LFMs), таких как оригинальная SAM или ее преемник SAM 2. Хотя эти модели поддерживают текстовые подсказки, они фундаментально полагаются на предварительно обученные LFMs, такие как CLIP [21], для преобразования фрагментов изображений в языково-согласованные вложения. Критическим пониманием было то, что CLIP, обученный преимущественно на естественных изображениях, не будет эффективно переноситься в рентгеновский домен. Рентгеновские изображения являются проникающими, что приводит к многочисленным накладывающимся маскам, принадлежащим различным объектам, что резко контрастирует с естественными изображениями, где объекты обычно имеют четкие границы и вложенные структуры. Даже если бы существовала CLIP-подобная модель, специфичная для рентгеновских изображений, один фрагмент изображения все равно содержал бы визуальные признаки нескольких накладывающихся объектов, что делало бы однозначное различение чрезвычайно трудным. Это фундаментальное несоответствие между визуальными характеристиками рентгеновских снимков и предположениями моделей, обученных на естественных изображениях, сделало прямое применение существующих SOTA LFMs недостаточным, что потребовало специального решения, такого как FluoroSAM.
Сравнительное превосходство
Качественное превосходство FluoroSAM обусловлено его структурными инновациями, разработанными для преодоления уникальных проблем рентгенографии, что делает его подавляюще превосходящим предыдущие золотые стандарты в этой конкретной области. В отличие от моделей, которые испытывают трудности с проникающим характером рентгеновских снимков и наложением анатомий, новый текстовый кодировщик FluoroSAM, включающий модуль векторной квантизации (VQ) поверх замороженного кодировщика CLIP, обеспечивает более последовательный сигнал для декодера маски. Этот VQ-слой имеет решающее значение; хотя он теоретически ограничивает обобщаемость до совершенно новых классов сегментации, он значительно расширяет обобщаемость до новых языковых подсказок, уменьшая вариативность, возникающую из-за различных описаний одного и того же объекта. Это означает, что FluoroSAM более устойчив к разнообразным входным данным на естественном языке, что является ключевым преимуществом для рабочих процессов с участием человека.
Кроме того, способность FluoroSAM обучаться с нуля на огромном синтетическом наборе данных FluoroSeg (3 млн рентгеновских изображений) обеспечивает структурное преимущество. Это позволяет обойти критический дефицит данных для реальных рентгеновских изображений, позволяя модели изучать надежные признаки в широком спектре анатомии человека, геометрии съемки и углов обзора, что было бы невозможно только с реальными данными. Количественно FluoroSAM превосходит SAM и MedSAM, особенно при сегментации только текстом, достигая среднего IoU 0.47 и коэффициента Dice 0.60 на реальных интервенционных рентгеновских изображениях. Даже с 2 точками FluoroSAM достигает 0.56 IoU и 0.69 Dice, превосходя SAM и MedSAM. MedSAM, например, часто "не отражает лежащую в основе анатомию и просто заполняет предоставленную рамку", что указывает на качественный сбой в понимании лежащего в основе содержания изображения за пределами простых ограничений ограничивающей рамки. Многовыходная способность FluoroSAM, предсказывающая несколько масок для данной подсказки и выбирающая лучшую, дополнительно повышает его надежность и гибкость, позволяя ему более грациозно обрабатывать неоднозначные подсказки. Эта структурная конструкция позволяет FluoroSAM обеспечивать гибкую, языково-согласованную сегментацию в домене, где другие терпят неудачу, без необходимости уменьшать сложность памяти с $O(N^2)$ до $O(N)$, а скорее за счет улучшения качественного понимания и надежности подсказок.
Соответствие ограничениям
Выбранный подход FluoroSAM идеально соответствует жестким требованиям сегментации рентгеновских изображений, образуя "брак" между проблемой и решением. Основные ограничения, как следует из определения проблемы, включают:
- Необходимость широкой применимости и гибкости: Традиционные модели слишком узкие. FluoroSAM, как управляемая языком модель-основа, изначально разработана для широкой применимости, способная сегментировать "множество анатомических структур и инструментов на основе подсказок естественного языка" (стр. 1). Эта гибкость имеет решающее значение для разнообразных диагностических и интервенционных сценариев.
- Дефицит богато аннотированных рентгеновских наборов данных: Это, пожалуй, самое значительное ограничение. FluoroSAM решает эту проблему, обучаясь "с нуля на 3 млн синтетических рентгеновских изображений из широкого спектра анатомии человека, геометрии съемки и углов обзора" (стр. 1). Создание набора данных FluoroSeg является прямым ответом на этот дефицит данных, позволяя проводить надежное обучение без опоры на дефицитные реальные аннотации.
- Уникальные визуальные характеристики рентгеновских изображений: Рентгеновские снимки являются проникающими с накладывающимися объектами, что затрудняет четкое определение границ для моделей, обученных на естественных изображениях. Новый текстовый кодировщик FluoroSAM с VQ специально разработан для решения этой проблемы. VQ-модуль помогает уменьшить вариативность от различных текстовых описаний одного и того же объекта, обеспечивая более последовательный сигнал для декодера маски, что жизненно важно для различения накладывающихся структур на рентгеновских снимках.
- Требование естественного языкового взаимодействия: Для обеспечения интуитивно понятных рабочих процессов с участием человека и уменьшения неоднозначности. Основная конструкция FluoroSAM как "управляемого языком варианта SAM" напрямую удовлетворяет этому, позволяя пользователям указывать цели сегментации с использованием естественного языка, что гораздо более гибко и менее неоднозначно, чем только подсказки точек или ограничивающих рамок для сложных рентгеновских сцен.
- Обобщаемость для различных типов рентгеновских снимков: Набор данных FluoroSeg с его широким спектром симулированной анатомии, геометрии и углов обзора гарантирует, что FluoroSAM обучается обобщаться для различных рентгеновских применений, от диагностических рентгенограмм грудной клетки до интервенционной флюороскопии. Это демонстрируется его успешной оценкой в режиме zero-shot на CXR, несмотря на обучение на синтетических данных.
Отклонение альтернатив
В статье явно подробно описано, почему несколько популярных альтернативных подходов потерпели бы неудачу или были бы недостаточными для конкретной проблемы управляемой языком сегментации рентгеновских изображений.
Во-первых, традиционные, специализированные модели машинного обучения были отклонены, поскольку они работают в узкой области и требуют обширных дополнительных данных, аннотаций и переобучения для более широкого использования или новых классов (стр. 1). Это противоречит цели разработки гибкой, широко применимой модели-основы.
Во-вторых, прямое применение существующих моделей-основ, таких как SAM и SAM 2, особенно их опора на CLIP для текстовых подсказок, было признано непригодным. Авторы подчеркивают, что CLIP, будучи обученным на естественных изображениях, испытывает трудности с уникальными характеристиками рентгеновских изображений, такими как их проникающий характер и распространенность накладывающихся объектов без четких границ (стр. 2-3). Даже если бы CLIP-подобная модель была адаптирована для рентгеновских снимков, различение нескольких объектов в одном фрагменте изображения осталось бы проблематичным. Это фундаментальное несоответствие привело к разработке нового текстового кодировщика FluoroSAM с VQ.
В-третьих, MedSAM [18], другая модель-основа для медицинской визуализации, была отклонена для рентгенографических применений, несмотря на ее успех в других областях. MedSAM в основном полагается на подсказки в виде ограничивающих рамок для смягчения неоднозначности (стр. 5). Для рентгенографии этот подход нежелателен, поскольку он: (а) все еще характеризуется значительной неоднозначностью из-за накладывающихся структур, (б) делает автоматическое или неэкспертное управление непрактичным, и (в) не обладает гибкостью, необходимой для продвинутых систем с участием человека (стр. 5). В статье далее отмечается, что MedSAM "в целом не отражает лежащую в основе анатомию и просто заполняет предоставленную рамку" (стр. 7), что указывает на качественный сбой в понимании содержания изображения при ограничении ограничивающими рамками.
Наконец, даже производительность оригинальной SAM с подсказками точек оказалась ниже, предсказывая "все более ошибочные маски" по сравнению с производительностью FluoroSAM (стр. 7). Это предполагает, что, хотя SAM обеспечивает возможность подсказок, ее базовая архитектура и обучающие данные недостаточно надежны для сложностей сегментации рентгеновских изображений без специфических адаптаций, представленных в FluoroSAM.
В статье явно не обсуждается отклонение других генеративных моделей, таких как GAN или диффузионные модели, для самой задачи сегментации, поскольку основное внимание уделяется управляемой сегментации и ограничениям существующих моделей-основ в рентгеновском домене. Основная причина отклонения альтернатив последовательно вращается вокруг их неспособности обрабатывать уникальные визуальные свойства рентгеновских снимков, дефицит данных и критическую потребность в гибком, языково-согласованном взаимодействии.
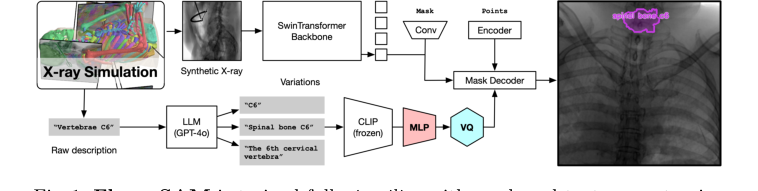 Figure 1. FluoroSAM is trained fully in silico with mask and text prompt pairs. It features a VQ layer that enables training language-aligned training on X-ray images
Figure 1. FluoroSAM is trained fully in silico with mask and text prompt pairs. It features a VQ layer that enables training language-aligned training on X-ray images
Математический и логический механизм
Основное уравнение
Основной механизм обучения FluoroSAM, как и многих моделей сегментации, заключается в его функции потерь, которая направляет модель на создание точных масок. Хотя в статье описан сложный режим обучения, включающий несколько подсказок и критериев выбора, фундаментальная цель оценки одной предсказанной маски по сравнению с ее истинным значением представляет собой комбинацию Dice Loss и Focal Loss. В статье говорится: "Мы используем Dice и focal loss для масок". Следовательно, основное уравнение, представляющее цель для предсказания одной маски, может быть выражено как:
$$ L_{mask}(P, G) = \lambda_{Dice} L_{Dice}(P, G) + \lambda_{Focal} L_{Focal}(P, G) $$
где $P$ представляет предсказанную маску сегментации (матрицу вероятностей), а $G$ представляет бинарную истинную маску. Отдельные компоненты потерь определяются как:
$$ L_{Dice}(P, G) = 1 - \frac{2 \sum_{i=1}^N p_i g_i}{\sum_{i=1}^N p_i^2 + \sum_{i=1}^N g_i^2} $$
$$ L_{Focal}(P, G) = - \sum_{i=1}^N \left( g_i \alpha (1-p_i)^\gamma \log(p_i) + (1-g_i) (1-\alpha) p_i^\gamma \log(1-p_i) \right) $$
Попиксельный разбор
Давайте разберем эти уравнения, чтобы понять роль каждого компонента:
-
$L_{mask}(P, G)$: Это общее значение потерь для одной предсказанной маски $P$ при заданном истинном значении $G$.
- Математическое определение: Скалярное значение, обычно от 0 до 1 (или выше для Focal Loss), количественно определяющее несоответствие между предсказанной и истинной сегментацией.
- Физическая/логическая роль: Это основная целевая функция, которую модель FluoroSAM стремится минимизировать во время обучения. Более низкое значение $L_{mask}$ указывает на более точную сегментацию.
- Почему сложение: Использование сложения для объединения $L_{Dice}$ и $L_{Focal}$ позволяет обоим аспектам качества сегментации — перекрытие (Dice) и правильная классификация сложных примеров (Focal) — одновременно вносить вклад в сигнал градиента. Это обеспечивает более полную и сбалансированную цель оптимизации, чем использование любой из потерь по отдельности.
-
$\lambda_{Dice}$: Коэффициент взвешивания для компонента Dice Loss.
- Математическое определение: Положительная скалярная константа. В статье ее значение явно не указано, но обычно она устанавливается путем настройки гиперпараметров.
- Физическая/логическая роль: Этот коэффициент контролирует относительную важность достижения высокого перекрытия (измеряемого Dice Loss) по сравнению с фокусировкой на пикселях, которые трудно классифицировать (измеряемого Focal Loss), в общей цели сегментации.
- Почему умножение: Умножение является стандартным способом масштабирования вклада конкретного члена потерь в составной функции потерь.
-
$L_{Dice}(P, G)$: Компонент Dice Loss.
- Математическое определение: $1 - \frac{2 \sum_{i=1}^N p_i g_i}{\sum_{i=1}^N p_i^2 + \sum_{i=1}^N g_i^2}$. Здесь $p_i$ — предсказанная вероятность для пикселя $i$, а $g_i$ — истинная метка (0 или 1) для пикселя $i$. Суммирование $\sum_{i=1}^N$ выполняется по всем $N$ пикселям изображения.
- Физическая/логическая роль: Этот член в основном измеряет пространственное перекрытие между предсказанной маской и истинным значением. Он особенно эффективен для задач со значительным дисбалансом классов, таких как сегментация небольших органов или инструментов на большом рентгеновском изображении, поскольку он изначально фокусируется на положительном (переднем) классе. Минимизация этого члена побуждает модель создавать маски, которые точно соответствуют форме и протяженности истинного объекта.
- Почему вычитание из 1: Сам коэффициент Dice является метрикой сходства, варьирующейся от 0 (нет перекрытия) до 1 (идеальное перекрытие). Вычитание его из 1 преобразует его в функцию потерь, где 0 представляет идеальную сегментацию, а 1 — полное несоответствие.
- Почему сумма квадратов в знаменателе: Для вероятностных предсказаний ($p_i \in [0,1]$) использование $p_i^2$ и $g_i^2$ в знаменателе обобщает концепцию мощности множества (количества элементов) до непрерывных вероятностей, делая функцию потерь дифференцируемой и пригодной для оптимизации на основе градиента.
-
$\lambda_{Focal}$: Коэффициент взвешивания для компонента Focal Loss.
- Математическое определение: Положительная скалярная константа, обычно определяемая путем настройки гиперпараметров.
- Физическая/логическая роль: Подобно $\lambda_{Dice}$, этот коэффициент регулирует влияние Focal Loss в общей потере, балансируя его фокус на сложных примерах с акцентом Dice Loss на общем перекрытии.
- Почему умножение: Стандартный механизм масштабирования для членов потерь.
-
$L_{Focal}(P, G)$: Компонент Focal Loss.
- Математическое определение: $- \sum_{i=1}^N \left( g_i \alpha (1-p_i)^\gamma \log(p_i) + (1-g_i) (1-\alpha) p_i^\gamma \log(1-p_i) \right)$.
- Физическая/логическая роль: Эта потеря решает проблему дисбаланса классов, уменьшая вклад хорошо классифицированных примеров (легких отрицательных) и фокусируя обучение модели на сложных, неправильно классифицированных примерах. На рентгеновских изображениях пиксели фона часто значительно преобладают над пикселями переднего плана, и Focal Loss предотвращает перегрузку модели легкими предсказаниями фона.
- Почему $\alpha$: Это фактор взвешивания для положительного класса. Он балансирует важность положительных и отрицательных примеров, что может быть полезно, если один класс изначально более важен или реже встречается.
- Почему $(1-p_i)^\gamma$ или $p_i^\gamma$: Это модулирующие факторы. Если пиксель хорошо классифицирован (например, $p_i$ высок, когда $g_i=1$), то $(1-p_i)$ мал, а $(1-p_i)^\gamma$ становится еще меньше (для $\gamma > 0$), эффективно уменьшая его вклад в потери. И наоборот, для неправильно классифицированных пикселей фактор близок к 1, а потери остаются значительными. Этот механизм "фокусирует" обучение на сложных примерах.
- Почему $\log(p_i)$: Это фундаментальный компонент перекрестной энтропии, который измеряет "сюрприз" или ошибку предсказания. Затем модулирующий фактор масштабирует эту ошибку.
-
$P$: Предсказанная маска.
- Математическое определение: 2D-матрица (или 3D для объемных данных) с плавающей запятой, где каждый элемент $p_{ij} \in [0, 1]$ представляет предсказанную вероятность того, что пиксель $(i,j)$ принадлежит переднему объекту.
- Физическая/логическая роль: Это вывод декодера маски FluoroSAM, представляющий наилучшее предположение модели для сегментации.
-
$G$: Истинная маска.
- Математическое определение: 2D-бинарная матрица, где каждый элемент $g_{ij} \in \{0, 1\}$ указывает, принадлежит ли пиксель $(i,j)$ истинно переднему плану (1) или фону (0).
- Физическая/логическая роль: Это "правильный ответ", предоставленный набором данных FluoroSeg, по сравнению с которым сравниваются предсказания модели для расчета потерь.
-
$p_i, g_i$: Индивидуальные вероятности и метки пикселей.
- Математическое определение: $p_i \in [0, 1]$ — предсказанная вероятность для одного пикселя, а $g_i \in \{0, 1\}$ — соответствующая истинная метка.
- Физическая/логическая роль: Это наименьшие единицы предсказания и истины, чьи агрегированные вклады формируют общие потери маски.
-
$\sum$: Оператор суммирования.
- Математическое определение: Суммирует значения по определенному множеству, в данном случае, по всем пикселям $i=1, \dots, N$ в изображении.
- Физическая/логическая роль: Агрегирует индивидуальные попиксельные вклады для вычисления общих потерь Dice и Focal для всей маски сегментации.
Пошаговый поток
Представьте, что одиночное рентгеновское изображение и подсказка на естественном языке поступают в систему FluoroSAM, подобно тому, как элементы движутся по сложной сборочной линии:
- Прием изображения (Визуальный путь): Рентгеновское изображение, скажем, грудной клетки пациента, сначала поступает в Кодировщик изображений. Этот кодировщик, построенный на основе SwinTransformer, действует как специализированный блок обработки изображений. Он тщательно сканирует изображение, извлекая иерархические визуальные признаки на различных масштабах. Представьте, что он разбивает изображение на все более абстрактные представления, от простых краев и текстур до сложных анатомических паттернов.
- Интерпретация подсказки (Языковой путь): Одновременно подсказка на естественном языке, например, "сегментировать левое легкое", подается в Текстовый кодировщик. Этот кодировщик является многоступенчатым блоком:
- Сначала замороженный кодировщик CLIP берет текст и преобразует его в числовое вложение высокой размерности, улавливая его семантическое значение.
- Затем многослойный перцептрон (MLP) дополнительно обрабатывает это вложение, уточняя его представление.
- Наконец, узкое место векторной квантизации (VQ) квантует это уточненное вложение в дискретный "токен подсказки". Этот VQ-слой действует как лингвистический фильтр, стандартизируя значение подсказки в последовательный, дискретный код, который остальная часть модели может легко понять, независимо от незначительных вариаций в формулировке.
- Слияние признаков и генерация маски: Богатые визуальные признаки из Кодировщика изображений и дискретный токен подсказки из Текстового кодировщика затем объединяются. Это слияние направляет Декодер маски, который является творческим движком модели. Основываясь на комбинированной визуальной и лингвистической информации, Декодер маски не просто создает одну маску; он генерирует несколько кандидатских масок сегментации для запрошенного объекта. Это похоже на то, как несколько опытных мастеров предлагают немного разные контуры для "левого легкого".
- Оценка потерь и выбор: Для каждой из этих кандидатских масок система вычисляет ее $L_{mask}$, используя Dice Loss и Focal Loss по сравнению с истинной маской (которая доступна во время обучения). Затем модель выбирает кандидатскую маску, которая дает наименьшее значение $L_{mask}$. Этот процесс выбора гарантирует, что модель всегда стремится к максимально точной сегментации, учитывая подсказку.
- Обратное распространение и обучение: Потери от выбранной маски, в частности от текстовой подсказки, точки 1, точки 8 и дополнительной случайной точечной подсказки, затем используются для вычисления градиентов. Эти градиенты подобны точным инструкциям, которые проходят обратно через Декодер маски и Кодировщик изображений (часть CLIP Текстового кодировщика заморожена, но MLP и компоненты VQ обновляются). Эти инструкции сообщают каждому параметру в обучаемых частях сети, как он должен корректироваться, чтобы уменьшить потери и улучшить будущие сегментации. Этот итеративный процесс предсказания, оценки, выбора и корректировки — это то, как FluoroSAM учится точно сегментировать рентгеновские изображения на основе естественного языка.
Динамика оптимизации
Процесс обучения FluoroSAM представляет собой динамическое взаимодействие минимизации потерь, обновлений на основе градиента и стратегической аугментации данных, все разработано для навигации по сложному ландшафту потерь и достижения надежной производительности.
-
Формирование ландшафта потерь: Комбинация Dice Loss и Focal Loss имеет решающее значение для формирования ландшафта оптимизации. Dice Loss, хотя и эффективен для дисбаланса классов, иногда может страдать от невыпуклости и плато, особенно когда предсказанная маска имеет небольшое перекрытие с истинным значением. Focal Loss дополняет это, агрессивно уменьшая вклад легких примеров, тем самым увеличивая относительную важность пикселей, которые трудно классифицировать. Это эффективно увеличивает градиенты вокруг сложных областей, предотвращая застревание модели в локальных минимумах или доминирование легко предсказуемых фоновых пикселей. Цель состоит в том, чтобы создать ландшафт, где путь к лучшей сегментации более ясен и прямолинеен.
-
Поведение градиента и обновления: Во время обучения градиенты $L_{mask}$ (от выбранных подсказок) вычисляются по отношению ко всем обучаемым параметрам в Кодировщике изображений и Декодере маски, а также к компонентам MLP и VQ Текстового кодировщика. Эти градиенты указывают направление и величину корректировок параметров, необходимых для уменьшения потерь. Параметры модели затем итеративно обновляются с использованием оптимизатора (обычно Adam или его варианта, хотя в статье явно не указано). Этот итеративный процесс перемещает "позицию" модели в многомерном пространстве параметров к областям с более низкими потерями, постепенно улучшая точность сегментации.
-
Расписание скорости обучения: В статье указано тщательно разработанное расписание скорости обучения: линейный разогрев от $8 \times 10^{-6}$ до базовой скорости $8 \times 10^{-4}$ в течение 20 тыс. итераций, за которым следуют уменьшения в 10 раз на шагах 200 тыс. и 400 тыс.
- Разогрев: Начальная низкая скорость обучения предотвращает большие, дестабилизирующие обновления, когда параметры модели случайно инициализированы и далеки от оптимального состояния. Это позволяет модели "найти свою опору" в ландшафте потерь.
- Затухание: Уменьшение скорости обучения на более поздних этапах обучения помогает модели точно настраивать свои параметры, позволяя ей более точно сходиться к минимуму, не перескакивая и не колеблясь. Это похоже на переход от больших, исследовательских шагов к меньшим, более точным корректировкам по мере приближения к цели.
-
Динамика векторной квантизации (VQ): Узкое место VQ в текстовом кодировщике вводит дискретный элемент в иначе непрерывную нейронную сеть. Обучение с VQ обычно включает такие методы, как прямой проход (straight-through estimator), чтобы позволить градиентам проходить через дискретный шаг квантизации. Этот механизм заставляет текстовые вложения в конечный набор "кодовых" векторов, что помогает в изучении надежных, языково-согласованных представлений. Хотя он теоретически ограничивает обобщаемость до новых классов, он повышает надежность к переменным языковым подсказкам для известных классов, отображая различные формулировки в последовательные дискретные токены. Это делает модель менее чувствительной к точному формулированию подсказки.
-
Надежность за счет аугментации и рандомизации:
- Текстовая аугментация: Использование gpt-40 для генерации до 30 разнообразных подсказок для каждой маски значительно расширяет лингвистическую вариативность обучающих данных. Это делает FluoroSAM надежным к различным способам, которыми пользователи могут формулировать свои запросы на сегментацию, предотвращая переобучение на конкретные формулировки подсказок.
- Рандомизация домена: Применение "сильной рандомизации домена" к синтетическим рентгеновским изображениям (например, грубое отбрасывание, инверсия, размытие, регулировка контрастности Гаусса [10]) является критической стратегией для переноса из симуляции в реальность. Это заставляет модель изучать признаки, инвариантные к различным внешним видам изображений, что делает ее более надежной при столкновении с реальными рентгеновскими изображениями, отличающимися от синтетических обучающих данных. Это эффективно сглаживает ландшафт потерь, делая модель менее чувствительной к незначительным вариациям входных данных.
-
Многовыходность и выбор: Способность FluoroSAM предсказывать несколько масок для одной подсказки и затем выбирать ту, которая имеет наименьшие потери во время обучения, действует как внутренний механизм самокоррекции. Это похоже на ансамбль предсказаний, где выбирается лучшее, что приводит к более надежному и точному окончательному результату. Во время вывода головка предсказания IOU берет на себя этот выбор, оценивая, какая маска наиболее вероятно правильна. Этот динамический процесс выбора способствует общей стабильности и производительности модели.
Результаты, ограничения и заключение
Экспериментальный дизайн и базовые модели
Для строгого подтверждения возможностей FluoroSAM авторы разработали комплексную экспериментальную установку, включающую как синтетические, так и реальные рентгеновские данные, противопоставляя свою модель установленным базовым моделям.
Основой обучения FluoroSAM является набор данных FluoroSeg, массивное собрание из 3 миллионов синтетических рентгеновских изображений. Этот набор данных был тщательно сгенерирован in silico для симуляции огромного спектра анатомии человека, геометрии съемки и углов обзора, что имеет решающее значение для захвата вариативности реальной рентгенографии. Конвейер симуляции начинался с 1621 КТ-скана высокого разрешения из базы данных изображений умерших людей Нью-Мексико [5], которые затем были сегментированы на 128 классов органов с использованием TotalSegmentator [27] для получения поверхностных сеток. Для имитации разнообразных радиологических исследований среда выбирала как стандартные виды (например, грудная клетка, брюшная полость), так и полностью случайные виды C-дуги, фокусируясь на основном органе с различными углами. Критически важно, что 464 смоделированных компьютерных хирургических инструмента, каждый с исчерпывающими текстовыми описаниями, были случайным образом размещены в поле зрения. Изображения были отрисованы с разрешением $512^2$ пикселей, с псевдо-истинными масками и соответствующими текстовыми описаниями. Этот процесс был высокоэффективным, генерируя от 6,5 до 15,7 изображений в секунду на NVIDIA A6000 GPU, в общей сложности 2,95 миллиона изображений примерно за 6 GPU-дней. Набор данных был разделен в соотношении 90/10% для обучения и валидации на основе исходных КТ-сканов.
Сам FluoroSAM, управляемый языком вариант SAM [15], был обучен с нуля на FluoroSeg. Его новый текстовый кодировщик, состоящий из замороженного кодировщика CLIP [21], многослойного перцептрона (MLP) с двумя скрытыми слоями и узкого места векторной квантизации (VQ) [20], был центральным для обеспечения языкового согласования. Для повышения обобщаемости текстовая аугментация выполнялась с использованием gpt-40 [1] для генерации до 30 разнообразных подсказок на маску. Связанные маски органов были процедурно объединены в 38 групп (например, "левые ребра"), и иногда выбирались "плохие подсказки" (отсутствующие на изображении), чтобы научить модель игнорировать нерелевантные запросы. Кодировщик изображений использовал основу SwinTransformer (Swin-L для финальной модели), предварительно обученную на ImageNet-22k и далее на сокращенном наборе классов FluoroSeg для сегментации экземпляров. Для облегчения переноса из симуляции в реальность во время обучения применялись сильные методы рандомизации домена, включая грубое отбрасывание, инверсию, размытие, регулировку контрастности Гаусса [10], случайное оконное преобразование и эквализацию гистограммы CLAHE. Обучение включало 9 подсказок на маску (1 текстовая, 8 точек), используя Dice и focal loss, с обратным распространением конкретных компонентов потерь. Модель обучалась в течение 10 эпох в течение 6 дней на 2 NVIDIA H100 GPU.
Для оценки FluoroSAM соревновался с несколькими "жертвами" базовых моделей на реальных рентгеновских изображениях:
1. Реальные интервенционные рентгеновские изображения: Набор данных зарегистрированных рентгеновских изображений от полного торса (от середины бедра до T2), полученных с помощью устройства Brainlab Loop-X. Истинные маски были сгенерированы путем сшивания четырех навигированных конусно-лучевых КТ-изображений и проецирования сегментаций органов [27]. Оценка была ограничена 1741 маской размером более 2,5% изображения. Базовые модели включали оригинальную SAM [15] (с подсказками точек или ограничивающих рамок) и MedSAM [18] (который обычно использует подсказки ограничивающих рамок для медицинских изображений). Метриками были Intersection over Union (IoU), коэффициент Dice и расстояние Хаусдорфа (HDD).
2. Оценка в режиме zero-shot на рентгенограммах грудной клетки (CXR): Набор данных из 1131 CXR [2] с аннотированными вручную сегментациями легких. Это тестировало способность FluoroSAM обобщаться на другую рентгенографическую модальность и реальные аннотации без специального обучения. Использовались те же базовые модели, SAM и MedSAM, и сообщались IoU, Dice и HDD.
Что доказывают доказательства
Экспериментальные данные однозначно доказывают, что основной механизм FluoroSAM — управляемая языком сегментация рентгеновских изображений — эффективен и часто превосходит существующие методы, даже при обучении исключительно на синтетических данных.
На реальных интервенционных рентгеновских изображениях FluoroSAM продемонстрировал свое мастерство с помощью подсказок только текстом. Как показано в Таблице 1 и на Рис. 3а, FluoroSAM достиг среднего IoU 0.47 и коэффициента Dice 0.60. Эта производительность заметно превзошла его аналоги SAM (IoU 0.36, Dice 0.50 с точками; IoU 0.42, Dice 0.57 с рамками) и MedSAM (IoU 0.41, Dice 0.55), когда FluoroSAM получал только текстовые подсказки. Это критически важное доказательство, поскольку оно подтверждает способность нового текстового кодировщика FluoroSAM и VQ-слоя интерпретировать естественный язык и генерировать точные сегментации в сложном реальном сценарии. При добавлении точечных подсказок производительность FluoroSAM еще больше улучшилась, достигнув IoU 0.56 и Dice 0.69 с 2 точками, и IoU 0.64, Dice 0.77 и HDD 60.8 с 8 точками, последовательно превосходя базовые модели по этим метрикам. Окончательным доказательством здесь является прямое количественное сравнение, где FluoroSAM, с его уникальной возможностью текстового управления, превзошел или сравнялся с производительностью моделей, полагающихся на более ограниченные точечные или рамочные подсказки.
Оценка в режиме zero-shot на CXR предоставила неоспоримые доказательства обобщаемости FluoroSAM и возможностей переноса из симуляции в реальность. Несмотря на то, что FluoroSAM обучался исключительно на синтетических данных, он удивительно хорошо адаптировался к аннотированным вручную сегментациям легких на реальных CXR. С подсказками только текстом он достиг среднего IoU 0.50 и коэффициента Dice 0.66 (Таблица 1, Рис. 3б). Хотя SAM, при использовании нескольких точечных или рамочных подсказок, мог достичь более высоких показателей (например, IoU 0.83, Dice 0.89 для 2 точек), производительность FluoroSAM с 8 точками (IoU 0.81, Dice 0.89) была очень конкурентоспособной, даже превосходя производительность SAM с 8 точками (IoU 0.73, Dice 0.82). Это демонстрирует, что обучение FluoroSAM на синтетических данных в сочетании с надежной рандомизацией домена позволяет ему обобщаться на невиданные ранее реальные диагностические рентгеновские изображения и задачи, что является значительным достижением, учитывая систематические различия между синтетическими проекциями и масками, аннотированными вручную.
Кроме того, качественное исследование пользователей (Рис. 4) предоставило убедительные доказательства эффективности VQ-слоя в улучшении надежности сегментации к переменным текстовым подсказкам. Когда его спросили "Какая кость находится рядом с бедром?", FluoroSAM с VQ правильно сегментировал бедренную кость, в то время как без VQ он потерпел неудачу. Это напрямую подтверждает утверждение авторов о том, что VQ помогает обобщаться на новые языковые подсказки, уменьшая вариативность от различных описаний одного и того же объекта, делая модель более устойчивой к нюансам естественного языка.
Наконец, качественные результаты и последующие применения, показанные на Рис. 5, иллюстрируют практическую полезность FluoroSAM. Его гибкость обеспечивает эффективную аннотацию рентгеновских снимков, персонализированное обучение пациентов и интеллектуальное позиционирование роботизированной C-дуги и автономную коллимацию, демонстрируя, что основной механизм работает не только количественно, но и обеспечивает богатое взаимодействие человека и машины в клинических рабочих процессах.
Ограничения и будущие направления
Хотя FluoroSAM представляет собой значительный шаг вперед, авторы откровенно признают несколько ограничений, которые также служат плодотворной почвой для будущих исследований и разработок.
Одно из основных ограничений заключается в области применения набора данных FluoroSeg. Хотя он огромен и насчитывает 3 миллиона изображений, он все еще ограничен количеством базовых КТ-сканов и разнообразием представленных анатомических структур. Расширение этого набора данных путем включения большего количества КТ-изображений, возможно, из недавно выпущенных задач TotalSegmentator или более специализированных наборов данных, таких как фрагменты переломов [23], является явным путем вперед. Однако это расширение вычислительно затратно, даже с автоматизированным конвейером, что предполагает необходимость дальнейшей оптимизации среды симуляции.
Другая присущая проблема связана с природой самих рентгеновских изображений. Они являются проникающими, что приводит к накладывающимся проекциям, где многие органы не видны явно. Эта неоднозначность делает сегментацию трудной задачей, и хотя FluoroSAM работает хорошо, это фундаментальное ограничение модальности. Опора исключительно на синтетические данные для обучения, несмотря на успех переноса из симуляции в реальность, также может вносить тонкие систематические различия по сравнению с моделями, обученными на реальных, аннотированных вручную данных, как наблюдалось в некоторых результатах CXR.
Размер кодовой книги векторной квантизации (VQ) идентифицируется как конкретное архитектурное ограничение. Хотя VQ качественно улучшает надежность к переменным текстовым подсказкам, его фиксированный размер внутренне ограничивает репрезентативную мощность текстовых вложений. Это приемлемый компромисс в текущем контексте, но для поддержки еще более широкого спектра анатомических структур и более тонких подсказок могут потребоваться альтернативные стратегии или развитый VQ-механизм. Это может включать динамическое расширение кодовой книги или иерархические подходы VQ.
Заглядывая вперед, результаты FluoroSAM открывают несколько захватывающих тем для обсуждения в будущих разработках:
- Масштабируемость и разнообразие синтетических данных: Как мы можем дальше масштабировать генерацию синтетических данных, чтобы охватить еще более широкий спектр патологий, демографических групп пациентов и артефактов визуализации, выходя за рамки простого анатомического разнообразия? Могут ли генеративные ИИ-модели использоваться для синтеза новых КТ-сканов или дополнения существующих для создания еще более разнообразных обучающих данных для FluoroSeg, вместо того чтобы полагаться исключительно на существующие КТ-базы данных?
- Гибридные парадигмы обучения: Учитывая успех переноса из симуляции в реальность, каковы оптимальные стратегии для объединения синтетических и ограниченных реальных аннотированных данных? Может ли полуавтоматическое или самообучающееся обучение, использующее огромные объемы неразмеченных реальных рентгеновских данных, еще больше повысить производительность и надежность FluoroSAM без необходимости обширной ручной аннотации?
- Продвинутое понимание языка: Как FluoroSAM может развиваться для интерпретации более сложных, многоэтапных или неоднозначных подсказок естественного языка, двигаясь к анализу рентгеновских изображений на основе "цепочки рассуждений" [9]? Это потребует более глубокого семантического понимания и способностей к рассуждению, потенциально более тесно интегрируя с большими языковыми моделями, чем просто для текстовой аугментации.
- Персонализация и адаптивность: Может ли FluoroSAM быть адаптирован к конкретной анатомии пациента или клиническому контексту? Например, может ли он учиться на небольшом наборе аннотаций, специфичных для пациента, для повышения точности сегментации для этого человека, или адаптироваться к уникальным характеристикам различных рентгеновских аппаратов или протоколов? Это было бы критически важно для приложений прецизионной медицины.
- Этические соображения и доверие: По мере интеграции FluoroSAM в рабочие процессы с участием человека, каковы этические последствия опоры на ИИ для критически важных медицинских задач? Как мы можем обеспечить прозрачность, объяснимость и построить доверие к ИИ-системе, которая интерпретирует подсказки естественного языка для сегментации, особенно при работе с неоднозначными или новыми запросами? Надежность к "плохим подсказкам" — хорошее начало, но требуется большее для клинического развертывания.
- Мультимодальная интеграция за пределами текста: Хотя язык является мощной подсказкой, может ли FluoroSAM выиграть от интеграции других модальностей в качестве подсказок, таких как физиологические сигналы, история болезни пациента или даже тактильная обратная связь в интервенционных условиях? Это могло бы предоставить более богатую контекстную информацию, дополнительно уменьшая неоднозначность и улучшая взаимодействие.
В конечном счете, разработка FluoroSAM является важным шагом на пути к гибким, управляемым языком моделям-основам в рентгенографии, обещая открыть новые пути как в диагностической, так и в интервенционной медицине. Выявленные ограничения — это не препятствия, а скорее четкие указатели для исследований следующего поколения.
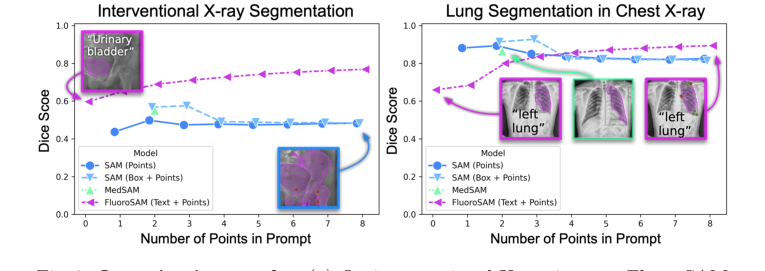 Figure 3. Quantitative results. (a) On interventional X-ray images, FluoroSAM outperforms its peers even with text-only prompting. (b) On CXRs, FluoroSAM adapts to hand-annotated lung segmentations despite being trained on synthetic data. MedSAM [18] includes this task in its training data
Figure 3. Quantitative results. (a) On interventional X-ray images, FluoroSAM outperforms its peers even with text-only prompting. (b) On CXRs, FluoroSAM adapts to hand-annotated lung segmentations despite being trained on synthetic data. MedSAM [18] includes this task in its training data
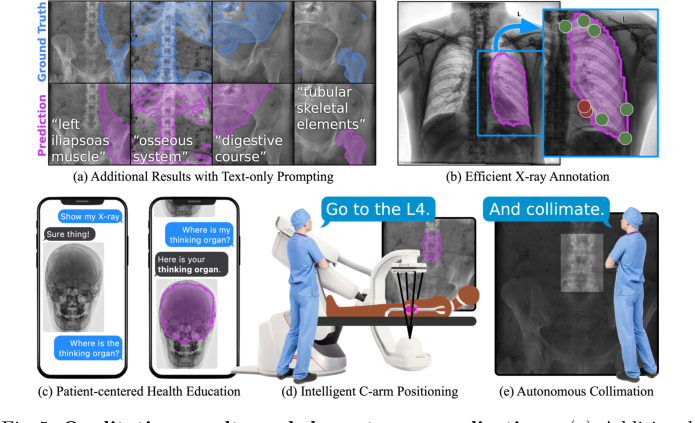 Figure 5. Qualitative results and downstream applications. (a) Additional results on real X-ray images, with text prompts not used during training. The flexibility of text prompting supports a wide variety of downstream applications. (b) Efficient annotation of X-rays can reduce clinical burden and accelerate real data annotation. (c) Flexible text-based prompting may lend itself to patient- facing education, empowering patients to better understand their own anatomy. In the OR, FluoroSAM can be integrated with robotic C-arms to deliver intel- ligent positioning (d) and autonomous collimation (e), reducing radiation [14]. These figures use real FluoroSAM predictions on real radiographs
Figure 5. Qualitative results and downstream applications. (a) Additional results on real X-ray images, with text prompts not used during training. The flexibility of text prompting supports a wide variety of downstream applications. (b) Efficient annotation of X-rays can reduce clinical burden and accelerate real data annotation. (c) Flexible text-based prompting may lend itself to patient- facing education, empowering patients to better understand their own anatomy. In the OR, FluoroSAM can be integrated with robotic C-arms to deliver intel- ligent positioning (d) and autonomous collimation (e), reducing radiation [14]. These figures use real FluoroSAM predictions on real radiographs
 Figure 4. In a limited user study, we observe qualitative results consistent with the hypothesis that VQ improves segmentation robustness to variable text prompts. For example, FluoroSAM with VQ was able to correctly segment the femur, answering the question “What’s the bone next to the hip?”
Figure 4. In a limited user study, we observe qualitative results consistent with the hypothesis that VQ improves segmentation robustness to variable text prompts. For example, FluoroSAM with VQ was able to correctly segment the femur, answering the question “What’s the bone next to the hip?”