Radar-Based Imaging for Sign Language Recognition in Medical Communication
This paper introduces a privacy preserving radar system for recognizing Italian Sign Language in medical settings, achieving high accuracy.
Background & Academic Lineage
Imagine being in a hospital emergency room enviornment. Communication needs to be fast, accurate, and deeply personal. For deaf and hard-of-hearing patients who rely on sign language, this situation often creates a severe communication barrier. While human interpreters are the gold standard, they are not always available at a moment's notice. This critical gap birthed the field of automatic Sign Language Recognition (SLR) in healthcare. Researchers realized that to provide equitable medical care, we needed machines capable of translating sign language into text or speech in real time. However, doing this in a hospital setting introduced a massive, unique set of constraints that the tech world had not fully anticipated.
The fundamental "pain point" of previous approaches is a severe clash between accuracy and privacy. Historically, SLR relied on two main methods. The first was wearable technology, like sensor-equipped gloves. While highly accurate, these are clunky, disrupt the natural flow of signing, and completely miss non-manual cues like facial expressions, which are crucial in sign language. The second, more modern approach relied on high-definition RGB and depth cameras. However, deploying continuous video recording in a clinical setting is a massive privacy violation. Hospitals are bound by strict ethical and legal regulations regarding patient anonymity. Furthermore, camera-based models struggle in low-light conditions or cluttered hospital rooms. While some early radar-based systems attempted to solve this privacy issue, they were fundamentally limited by tiny vocabularies—often just recognizing generic hand waves rather than the complex, specific medical lexicon required for actual patient-doctor communication. The authors of this paper were forced to innovate because previous models either compromised patient identity or simply lacked the vocabulary to be medically useful.
To understand how the authors solved this, let's break down some of the highly specialized domain terms used in their radar technology into intuitive, everyday analogies:
- Range Doppler Maps (RDM): Imagine a standard weather radar on the news, but instead of tracking massive storm clouds across a state, it tracks the exact distance and speed of a human hand. An RDM is essentially a visual heat map that tells the computer, "An object is exactly 0.5 meters away, and it is moving toward us at 2 meters per second."
- Moving Target Indication (MTI): Think of this as a pair of ultra-smart noise-canceling headphones, but for vision. In a hospital room, there is a lot of "static noise"—the bed, the walls, the medical monitors. The MTI filter completely mutes anything that isn't moving, allowing the radar to focus exclusively on the dynamic movements of the patient's hands and body.
- Micro-Doppler Signatures: Imagine being able to recognize a friend walking toward you from far away just by their unique gait or "swagger." Micro-Doppler signatures are the radar equivalent of that swagger. They capture the tiny, subtle flutters of fingers and wrists, creating a unique kinematic fingerprint for every specific sign language gesture.
- Latent Representations (Embeddings): Imagine taking a massive, 1,000-page textbook and summarizing it into a single, highly condensed cheat sheet that contains only the most critical facts. The neural network in this paper takes massive amounts of raw radar data and squishes it into a tiny, dense mathematical represntation so the system can process it at lightning speed to achive real-time translation.
Here is a breakdown of the key mathematical notations and parameters the authors used to configure their radar and train their artificial intelligence models:
| Notation / Parameter | Description |
|---|---|
| $60$ GHz | The center frequency of the millimeter-wave radar sensor used to capture fine-grained motion. |
| $1$ MHz | The sampling rate of the radar system. |
| $31$ | The transmit power level configured for the radar. |
| $40$ dB | The Intermediate Frequency (IF) gain applied to the radar signal. |
| $0.0312$ m | The spatial range resolution, meaning the radar can distinguish objects about 3 centimeters apart. |
| $1.60$ m | The maximum effective range of the radar setup, ideal for a patient sitting across from a doctor. |
| $4.11$ m/s | The maximum speed the radar can accurately track without distortion. |
| $0.0321$ m/s | The speed resolution, allowing the detection of very slow, subtle hand movements. |
| $0.077$ s | The repetition time for acquiring each radar frame. |
| $-90$ dB | The spectral threshold used to filter out background noise during data preprocessing. |
| $\beta_1 = 0.9, \beta_2 = 0.999$ | The decay rates for the AdamW optimizer used during the neural network's training phase. |
| $5 \cdot 10^{-5}$ | The learning rate used to train the autoencoder network. |
| $10^{-4}$ | The learning rate used to train the Transformer classifier network. |
| $5 \cdot 10^{-6}$ | The weight decay parameter applied to prevent the neural network from overfitting to the training data. |
Problem Definition & Constraints
Mapping Invisible Waves to Meaning: The Fundamental Gap
To understand the magnitude of what this paper accomplishes, we first need to define exactly where the system starts and where it needs to end up.
The Starting Point (Input): The system does not see the world through a camera lens. Instead, it emits 60 GHz millimeter-wave radio signals and listens to the echoes bouncing off a human body. These echoes are mathematically transformed into Range Doppler Maps (RDM) and Moving Target Indications (MTI). For a zero-base reader, imagine a heat map that doesn't show colors or shapes, but only tells you how far away a moving object is (Range) and how fast it is moving (Doppler velocity). Mathematically, the input is a sequence of high-dimensonal matrices $X = \{x_1, x_2, \dots, x_T\}$, where each frame $x_t \in \mathbb{R}^{128 \times 1024}$, and the sequence length $T$ varies between 13 and 66 frames depending on how long the person takes to make the sign.
The Goal State (Output): The desired output is a single, highly specific semantic label. The system must map this sequence of radar maps to a probability distribution over $C = 126$ distinct Italian Sign Language (LIS) classes (100 medical terms and 26 alphabet letters). We are looking for a mathematical mapping function $f: X \rightarrow Y$, where $Y \in \{1, 2, \dots, 126\}$.
The Missing Link: The mathematical gap here is massive. The model must translate abstract, non-visual physics data (bouncing radio waves) into precise linguistic meaning. It has to look at a sequence of velocity and distance fluctuations and confidently say, "That specific pattern of moving mass means 'doctor' and not 'lung'."
The Cruel Dilemma: Privacy vs. Accuracy
In science, whenever you optimize one parameter, you almost always break another. For automatic Sign Language Recognition (SLR), researchers have been trapped in a painful tug-of-war between Accuracy and Privacy.
Sign language is incredibly complex. It relies not just on broad arm movements, but on fine-grained manual cues (exact finger positioning) and non-manual cues (facial expressions, lip movements, torso shifts). Traditional RGB and depth cameras capture all of this perfectly, yielding high accuracy. However, in a clinical enviornment like a hospital room, installing high-resolution cameras violates strict patient privacy laws and ethical boundaries.
To achive privacy, you can use RADAR. Radar inherently obscures patient identity because it doesn't capture visual details—it just sees moving blobs of energy. But here is the dilemma: by switching to radar to protect privacy, you instantly blind your system to the fine-grained visual details (like facial expressions and finger shapes) that are absolutely critical for distinguishing between similar signs. Previous researchers were stuck: use cameras and violate privacy, or use radar and suffer terrible accuracy because the data is too abstract.
The Harsh Walls and Constraints
To solve this problem, the authors had to smash through several realistic, unforgiving constraints:
- The Hardware Memory Wall (Computational Constraints):
Radar data is incredibly dense. A single sign gesture produces a sequence of matrices of size $128 \times 1024$. If you try to feed this raw, high-dimensional video-like sequence directly into a single deep neural network to learn the temporal dynamics end-to-end, the mathematical operations explode. The authors explicitly note that doing this leads to excessive model complexity and immediately maxes out GPU memory limits. They were forced to decouple the problem into two stages (spatial compression first, then temporal sequence modeling) just to make the math computable on modern hardware. - The "Invisible" Non-Manual Cues (Physical Constraints):
Because radar operates at a wavelength that captures macro-motion (arms and hands), it completely misses micro-motions like a raised eyebrow or a specific lip shape. Since many sign language words share the exact same hand movements and only differ by facial expression, the mathematical model is forced to find hidden, subtle kinematic patterns in the arm's velocity to tell them apart, operating with a severe information deficit. - Variable Temporal Dynamics (Data-Driven Constraints):
Humans are not robots; they do not sign at a constant speed. One patient might sign a word in 1 second (13 frames), while an elderly patient might take 4 seconds (66 frames) for the exact same word. The model must be temporally invariant. It cannot rely on fixed-length inputs; it must dynamically align and interpret sequences of varying lengths, requiring advanced sequence modeling like Transformers to track long-range dependencies over time. - Extreme Data Scarcity:
Deep learning models are data-hungry. To map complex radar signals to 126 distinct medical signs, you need tens of thousands of examples. Prior to this paper, radar datasets for sign language were tiny, often limited to 5 or 10 generic gestures (like swiping left or right). The authors hit a wall where the data required to solve the problem simply did not exist, forcing them to build a massive, synchronized dataset of 25,830 sign instances from scratch before they could even begin to train their algorithms.
Why This Approach
To understand why the authors chose their specific two-stage pipeline—a custom convolutional autoencoder followed by a Transformer—we first have to look at the harsh reality of radar data. The 60 GHz mm-wave radar generates Range Doppler Maps (RDMs) and Moving Target Indication (MTI) maps. These are essentially video-like sequences of high-dimensional matrices, specifically $128 \times 1024$ per frame.
The exact moment the authors realized traditional state-of-the-art (SOTA) methods were insufficient was when they considered the sheer computational weight of the problem. As they explicitly state, trying to solve this directly with a single, massive end-to-end deep network would lead to "excessive model complexity and computational costs." Radar data is highly dimensional and sequential. If you feed raw $128 \times 1024$ frames across $T$ time steps directly into a standard 3D CNN or a pure Transformer, the memory requirements explode.
To solve this, they decoupled the problem into two distinct stages. First, they built a custom CNN autoencoder to compress the spatial data. Why a custom model instead of a famous pretrained SOTA model like ResNet or AlexNet? The authors realized that radar maps are fundamentally different from natural RGB images. They lack the complex visual textures of standard photos. Using a heavy, pretrained architecure would actually hurt performance. Instead, their custom 9-layer CNN with residual connections distills the massive radar frame into a highly compact 256-dimensional latent represntation.
This brings us to the comparative superiority of their method. By freezing the autoencoder and only feeding the 256-dimensional embeddings into the Transformer, they drastically reduce the memory bottleneck. The paper notes that this two-stage process "alleviates GPU memory constraints by avoiding full end-to-end training on raw data for every epoch." While they don't explicitly frame this as a reduction from $O(N^2)$ to $O(N)$ complexity in the text, the structural advantage is clear: the spatial processing is completely decoupled from the temporal processing.
Furthermore, the Transformer classifier is qualitatively superior for the second stage because it naturally handles variable-length sequences. Human sign language is dynamic; in their dataset, a sign can last anywhere from $T=13$ to $T=66$ frames. The Transformer's self-attention mechanism excels at modeling these long-range temporal dependencies without forcing the data into rigid, fixed-length windows. By fusing data from three separate radar antennas and combining standard RDMs with MTI maps (which zero out static background noise), the model becomes incredibly robust to environmental interference.
This approach represents a perfect "marriage" between the problem's constraints and the solution's properties. The medical setting demands absolute privacy, which the radar physically guarantees by capturing only motion and velocity, not identifiable faces. However, this creates the constraint of highly abstract, noisy, and computationaly heavy data. The autoencoder acts as the perfect filter, stripping away the noise and compressing the spatial dimensions, while the Transformer acts as the perfect temporal engine, decoding the actual meaning of the gesture over time.
If you are wondering why the authors didn't use other popular modern approaches like GANs or Diffusion models, to be honest, I'm not completely sure about this part either, as the paper does not explicitly mention or reject them. However, given that this is strictly a classification problem (mapping a sequence of radar frames to one of 126 specific sign classes) rather than a generative task, models designed to synthesize new data would likely introduce unnecessary overhead without solving the core classification constraint. The authors focused entirely on discriminative efficiency, which their autoencoder-Transformer pairing handles beautifully.
Mathematical & Logical Mechanism
Imagine a deaf patient in a hospital emergency room trying to communicate their symptoms to a doctor. An interpreter isn't immediately available, and using standard camera-based AI to translate their sign language introduces massive privacy risks—nobody wants high-definition video of their face and body recorded during a vulnerable medical moment.
This paper solves this exact constraint by replacing cameras with a 60 GHz millimeter-wave RADAR. Instead of capturing visual pixels, the radar bounces radio waves off the patient to measure the distance (range) and velocity (Doppler) of their moving hands and body. The result is a privacy-preserving, faceless map of motion. However, radar data is incredibly noisy, high-dimensional, and sequential. The authors had to figure out how to compress this massive stream of radar echoes into a compact format and then teach a machine to "read" the temporal sequence of those echoes to recognize 126 different Italian Sign Language (LIS) medical terms and letters.
To overcome the computational bottleneck of processing video-like radar sequences, they split the problem into two stages: a Convolutional Neural Network (CNN) Autoencoder to compress each individual radar frame, and a Transformer network to analyze the sequence of compressed frames over time.
To be honest, I'm not completely sure why the authors chose not to print their exact mathematical formulas in the text—they likely assumed the audience was already familiar with standard deep learning objectives. However, they explicitly state that their Transformer classifier is optimized by "minimizing a standard cross-entropy loss." Therefore, the absolute core mathematical engine driving the learning of this entire system is the Cross-Entropy Objective Function.
$$ \mathcal{L}_{CE} = - \sum_{i=1}^{C} y_i \log(\hat{y}_i) $$
Let's tear this equation apart to understand exactly how the model learns to translate radar waves into medical vocabulary:
- $\mathcal{L}_{CE}$: This is the total Cross-Entropy Loss.
- Logical role: It acts as the ultimate "scorecard" or compass for the model. A high value means the model is terribly confused; a value close to zero means the model perfectly understands the sign language gesture.
- $\sum_{i=1}^{C}$: The summation operator over all $C$ classes (in this paper, $C = 126$ LIS signs).
- Why a sum instead of an integral? Because the vocabulary is a discrete set of distinct categories (e.g., "doctor", "lung", "neck"), not a continuous spectrum of values. We must tally up the penalty across every single possible word.
- $y_i$: The ground-truth label.
- Logical role: This is the absolute truth. It equals $1$ for the correct sign the patient actually performed, and $0$ for the other 125 incorrect signs. It acts as a strict filter, ensuring the math only cares about the probability assigned to the correct answer.
- $\hat{y}_i$: The predicted probability output by the Transformer's linear classification layer.
- Logical role: This is the model's best guess, a number between 0 and 1, representing how confident it is that the radar motion corresponds to word $i$.
- $\log$: The natural logarithm applied to the model's prediction.
- Why use a log here? The logarithm heavily pentalizes the model when it is confidently wrong. If the correct answer is "doctor" ($y_i = 1$) but the model predicts a probability of $0.01$, $\log(0.01)$ yields a massive negative number. It acts like an exponential rubber band, violently snapping the model's weights back into place when it makes a severe mistake.
- $-$ (Negative sign): Because probabilities ($\hat{y}_i$) are always between 0 and 1, their logarithm is always negative. We add a negative sign to flip the result into a positive "cost" that the optimizer can minimize.
Let's trace the exact lifecycle of a single abstract data point passing through this mechanical assembly line.
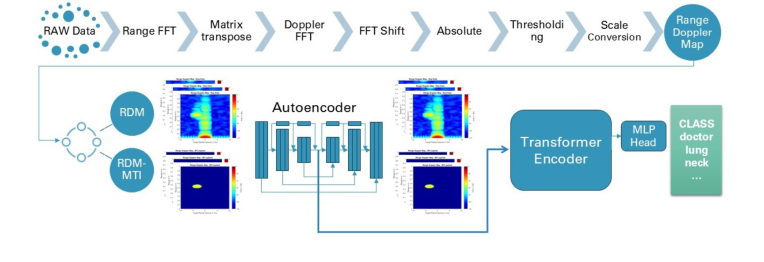 Figure 1. Overview of the end-to-end architecture of the proposed method
Figure 1. Overview of the end-to-end architecture of the proposed method
First, a raw 60 GHz radar wave bounces off the patient's moving hands and returns to the sensor. Through Fast Fourier Transforms (FFTs), this raw signal is converted into a Range Doppler Map (RDM)—a 2D grid showing where the motion is and how fast it's moving. This $128 \times 1024$ grid enters the CNN Autoencoder. The autoencoder acts like a trash compactor, squeezing the massive grid through 9 convolutional layers until it becomes a dense, 256-dimensional latent represntation vector.
Next, because a sign language gesture takes time (spanning 1 to 4 seconds), a sequence of these 256-dimensional vectors is lined up. A learnable "class token" is attached to the front, and positional embeddings are added so the model knows the chronological order of the frames. This sequence flows into the Transformer. The Transformer's multi-head self-attention mechanism compares every frame to every other frame, figuring out how the trajectory of the hand changes over time. Finally, the class token—now enriched with the entire temporal context—is pushed through a linear layer to spit out 126 probabilities ($\hat{y}_i$). The highest probability is the final translated word.
How does this mechanism actually learn and converge? The optimization dynamics here are carefully orchestrated to prevent the model from collapsing under the weight of its own high dimensons.
If the authors tried to train the Autoencoder and the Transformer simultaneously (end-to-end), the GPU memory would explode and the loss landscape would be chaotic, filled with local minima. Instead, they freeze the Autoencoder after 15 epochs. By locking the Autoencoder's weights, they create a stable, unchanging foundation.
The Transformer is then trained for 700 epochs using the AdamW optimizer. The authors explicitly set gradient clipping at a maximum norm of 5. In the loss landscape, radar data can sometimes produce sudden, massive errors (spikes in the loss), which would normally cause the gradients to explode and shatter the model's learned weights. Gradient clipping acts as a speed limit, ensuring that no matter how steep the loss landscape gets, the model only takes a safely sized step downhill. Combined with a weight decay of $5 \cdot 10^{-6}$ (which acts as a gentle gravitational pull keeping the neural weights from growing too large and memorizing the training data), the model smoothly converges to an impressive 93.6% accuracy, proving that we can indeed understand complex human language through invisible radio waves.
Results, Limitations & Conclusion
Imagine you are in a hospital in a foreign country, trying to explain to a doctor that you are experiencing severe chest pain, but you don't speak their language. Now, imagine you are deaf, and your primary language is a visual-gestural system like Italian Sign Language (LIS). If an interpreter isn't immediately available, the communication barrier could be life-threatening.
Historically, technologists have tried to solve this by placing RGB (standard video) cameras in hospital rooms to automatically translate sign language into text. But this introduces a massive problem: privacy. Hospitals are highly sensitive spaces. Patients do not want high-definition cameras recording them in vulnerable states. Furthermore, cameras are notoriously finicky; if the lighting is poor or the background is cluttered, they fail.
This paper introduces a brilliant, sci-fi-sounding solution: using 60 GHz millimeter-wave (mm-wave) radar to "read" sign language. Instead of capturing visual pixels that identify a person's face or body, radar bounces radio waves off the patient and measures the micro-motions and velocities of their hands and arms. The radar sees the kinematics of the language without seeing the person.
Let's break down exactly how the authors engineered this privacy-preserving translation machine.
The Constraints and the Mathematical Problem
Radar data is not like a standard photograph. When the 60 GHz radar pulses hit the signer, the returning signals are processed into Range Doppler Maps (RDMs) and Moving Target Indication (MTI) maps. You can think of these as heatmaps that show where an object is (range) and how fast it is moving (Doppler velocity).
The constraint here is data dimensionality and computational overload. A single sign gesture takes 1 to 4 seconds, generating a sequence of up to 66 radar frames. If you try to feed this massive, high-dimensional video-like sequence directly into a single deep learning network, the computer's memory will choke, and the model will overfit (memorize the training data rather than learning the underlying patterns).
Mathematically, the problem is a sequence classification task. We are given a sequence of radar frames $X = \{x_1, x_2, \dots, x_T\}$, where $T$ is the variable number of frames, and we need to map this sequence to a specific sign language class label $y \in \{1, 2, \dots, 126\}$.
To overcome the memory constraints, the authors ruthlessly decoupled the problem into a two-stage pipeline:
Stage 1: Spatial Compression (The Autoencoder)
Instead of processing the whole sequence at once, they built a custom Convolutional Neural Network (CNN) autoencoder to process each frame individually. The encoder function $E$ takes a massive radar frame $x_t$ and squishes it into a dense, low-dimensional vector $z_t \in \mathbb{R}^{256}$. To ensure this compressed vector actually contains the important motion data, a decoder function $D$ tries to reconstruct the original frame: $\hat{x}_t = D(z_t)$. The network is trained to minimize the difference between $x_t$ and $\hat{x}_t$. Once trained, the decoder is thrown away, and we keep the encoder to generate compact represntations of the radar data.
Stage 2: Temporal Classification (The Transformer)
Now, the model has a lightweight sequence of vectors $Z = \{z_1, z_2, \dots, z_T\}$. Because sign language is dynamic (the order of movements matters), they feed this sequence into a Transformer network. The Transformer uses multi-head self-attention to look at the entire sequence and figure out which movements correlate with which signs. It outputs a probability distribution $\hat{y}$ across the 126 possible medical signs. The model is optimized using standard cross-entropy loss:
$$ \mathcal{L} = -\sum_{c=1}^{C} y_c \log(\hat{y}_c) $$
where $C = 126$ is the total number of classes.
The Experimental Architecture and the "Victims"
The authors didn't just build this system and claim it worked; they architected a highly controlled, multimodal arena to prove their mathematical claims. They recorded a massive dataset of 25,830 sign instances using radar, standard RGB cameras, and depth sensors simultaneously. This allowed them to pit their radar model directly against vision-based models on the exact same gestures.
The "victims" (baseline models) in this experiment were state-of-the-art vision models, including De Coster et al.'s RGB Video Transformer Network and Vahdani's RGB-D 3D CNN, as well as prior radar-based gesture models (Jhaung, Debnath, Arab).
The definitive, undeniable evidence of their success lies in the final metrics. When utilizing three radar antennas and combining both RDM and MTI data streams, their radar model achieved a staggering 93.6% accuracy. It completely defeated the leading RGB-based model (which only managed 88.4%).
This is a profound result. It proves that the micro-Doppler signatures captured by radar contain more robust, distinguishable linguistic features for this specific task than actual visual pixels. Furthermore, they proved through ablation studies that freezing the autoencoder during the Transformer's training was the key to preventing overfitting, allowing the simpler model to achive superior generalization. It’s the equivalent of buying a highly effective security system for USD 150 that outperforms a \$1,000 camera setup, all while keeping your identity completely hidden.
Discussion Topics for Future Evolution
Based on the brilliant foundation laid by this paper, here are several avenues for future exploration and critical thinking:
1. The "Non-Manual" Cue Dilemma in Radar
Sign language is not just about hand waving; it relies heavily on non-manual cues like facial expressions, eyebrow raises, and subtle lip movements to convey grammar and tone. Radar is exceptional at tracking gross motor movements of the limbs, but can it capture the micro-muscular changes of a facial expression? If we increase the radar frequency to capture these micro-movements, do we risk inadvertently capturing enough biometric data to reconstruct a face, thereby destroying the very privacy the system was built to protect?
2. Transitioning from Isolated Signs to Continuous Co-articulation
This study focuses on 126 isolated signs. However, natural human communication is continuous. In fluent sign language, the end of one sign physically blends into the beginning of the next—a phenomenon known as co-articulation. How must the Transformer architecture evolve to segment a continuous stream of radar data into distinct words? Would a sliding-window approach suffice, or do we need a fundamentally different mathematical framework, such as Connectionist Temporal Classification (CTC), to handle unsegmented radar sequences in a chaotic hospital enviornment?
3. Cross-Linguistic and Cross-Subject Generalization
The dataset was built using Italian Sign Language (LIS) performed by a single subject. Every human has a unique kinematic signature—different arm lengths, different signing speeds, and different resting postures. If we train a radar model on Subject A, will the micro-Doppler signatures generalize to Subject B? Furthermore, could the latent embeddings learned by the autoencoder for LIS be transferrable to American Sign Language (ASL) or British Sign Language (BSL)? Exploring unsupervised domain adaptation techniques to calibrate the radar model to new patients in real-time will be a critical next step for global scalability.