चिकित्सा संचार में सांकेतिक भाषा पहचान के लिए रडार-आधारित इमेजिंग
कल्पना कीजिए कि आप एक अस्पताल के आपातकालीन कक्ष के वातावरण में हैं। संचार तीव्र, सटीक और अत्यंत व्यक्तिगत होना चाहिए। बधिर और अल्पश्रवण रोगियों के लिए जो सांकेतिक भाषा पर निर्भर करते हैं, यह स्थिति अक्सर एक गंभीर...
पृष्ठभूमि और अकादमिक वंश
कल्पना कीजिए कि आप एक अस्पताल के आपातकालीन कक्ष के वातावरण में हैं। संचार तीव्र, सटीक और अत्यंत व्यक्तिगत होना चाहिए। बधिर और अल्पश्रवण रोगियों के लिए जो सांकेतिक भाषा पर निर्भर करते हैं, यह स्थिति अक्सर एक गंभीर संचार बाधा उत्पन्न करती है। जबकि मानव दुभाषिए स्वर्ण मानक हैं, वे हमेशा तुरंत उपलब्ध नहीं होते हैं। इस महत्वपूर्ण अंतर ने स्वास्थ्य सेवा में स्वचालित सांकेतिक भाषा पहचान (SLR) के क्षेत्र को जन्म दिया। शोधकर्ताओं ने महसूस किया कि समान चिकित्सा देखभाल प्रदान करने के लिए, हमें मशीनों की आवश्यकता है जो वास्तविक समय में सांकेतिक भाषा को पाठ या भाषण में अनुवाद करने में सक्षम हों। हालांकि, एक अस्पताल सेटिंग में ऐसा करने से बाधाओं का एक विशाल, अनूठा सेट पेश हुआ, जिसकी तकनीकी दुनिया ने पूरी तरह से भविष्यवाणी नहीं की थी।
पिछले दृष्टिकोणों का मौलिक "दर्द बिंदु" सटीकता और गोपनीयता के बीच एक गंभीर टकराव है। ऐतिहासिक रूप से, SLR दो मुख्य विधियों पर निर्भर था। पहला पहनने योग्य तकनीक थी, जैसे सेंसर-युक्त दस्ताने। जबकि अत्यधिक सटीक, ये अनाड़ी होते हैं, सांकेतिक भाषा के प्राकृतिक प्रवाह को बाधित करते हैं, और चेहरे की अभिव्यक्ति जैसी गैर-मैनुअल संकेतों को पूरी तरह से चूक जाते हैं, जो सांकेतिक भाषा में महत्वपूर्ण हैं। दूसरा, अधिक आधुनिक दृष्टिकोण उच्च-परिभाषा RGB और डेप्थ कैमरों पर निर्भर करता था। हालांकि, एक नैदानिक सेटिंग में निरंतर वीडियो रिकॉर्डिंग की तैनाती रोगी की गुमनामी के संबंध में सख्त नैतिक और कानूनी नियमों से बंधी अस्पतालों के लिए एक विशाल गोपनीयता उल्लंघन है। इसके अलावा, कैमरा-आधारित मॉडल कम रोशनी की स्थिति या अव्यवस्थित अस्पताल के कमरों में संघर्ष करते हैं। जबकि कुछ शुरुआती रडार-आधारित प्रणालियों ने इस गोपनीयता मुद्दे को हल करने का प्रयास किया, वे मौलिक रूप से छोटे शब्दावली द्वारा सीमित थे - अक्सर केवल सामान्य हाथ हिलाने को पहचानते थे, न कि वास्तविक रोगी-डॉक्टर संचार के लिए आवश्यक जटिल, विशिष्ट चिकित्सा शब्दावली को। इस पत्र के लेखकों को नवाचार करने के लिए मजबूर किया गया क्योंकि पिछले मॉडल या तो रोगी की पहचान से समझौता करते थे या चिकित्सकीय रूप से उपयोगी होने के लिए शब्दावली की कमी रखते थे।
यह समझने के लिए कि लेखकों ने इसे कैसे हल किया, आइए उनके रडार प्रौद्योगिकी में उपयोग किए जाने वाले कुछ अत्यधिक विशिष्ट डोमेन शब्दों को सहज, रोजमर्रा की उपमाओं में तोड़ें:
- रेंज डॉपलर मैप्स (RDM): समाचारों पर एक मानक मौसम रडार की कल्पना करें, लेकिन एक राज्य में विशाल तूफान के बादलों को ट्रैक करने के बजाय, यह एक मानव हाथ की सटीक दूरी और गति को ट्रैक करता है। एक RDM अनिवार्य रूप से एक दृश्य हीट मैप है जो कंप्यूटर को बताता है, "एक वस्तु ठीक 0.5 मीटर दूर है, और यह 2 मीटर प्रति सेकंड की गति से हमारी ओर बढ़ रही है।"
- मूविंग टारगेट इंडिकेशन (MTI): इसे दृष्टि के लिए, लेकिन अल्ट्रा-स्मार्ट नॉइज़-कैंसलिंग हेडफ़ोन की एक जोड़ी के रूप में सोचें। एक अस्पताल के कमरे में, बहुत अधिक "स्थिर शोर" होता है - बिस्तर, दीवारें, चिकित्सा मॉनिटर। MTI फ़िल्टर उन सभी को पूरी तरह से म्यूट कर देता है जो हिल नहीं रहे हैं, जिससे रडार विशेष रूप से रोगी के हाथों और शरीर की गतिशील गतिविधियों पर ध्यान केंद्रित कर सके।
- माइक्रो-डॉपलर सिग्नेचर: दूर से किसी मित्र को केवल उनके अनूठे चाल या "स्वैगर" से चलते हुए पहचानने में सक्षम होने की कल्पना करें। माइक्रो-डॉपलर सिग्नेचर उस स्वैगर के रडार समकक्ष हैं। वे उंगलियों और कलाई की छोटी, सूक्ष्म फड़फड़ाहट को पकड़ते हैं, जिससे हर विशिष्ट सांकेतिक भाषा इशारे के लिए एक अनूठा काइनेमेटिक फिंगरप्रिंट बनता है।
- लेटेंट रिप्रेजेंटेशन (एम्बेडिंग): एक विशाल, 1,000-पृष्ठ की पाठ्यपुस्तक लेने और इसे केवल सबसे महत्वपूर्ण तथ्यों वाले एक एकल, अत्यधिक संघनित चीट शीट में सारांशित करने की कल्पना करें। इस पत्र में तंत्रिका नेटवर्क भारी मात्रा में कच्चे रडार डेटा लेता है और इसे एक छोटी, सघन गणितीय प्रतिनिधित्व में निचोड़ता है ताकि सिस्टम वास्तविक समय अनुवाद प्राप्त करने के लिए बिजली की गति से इसे संसाधित कर सके।
यहां गणितीय संकेतन और मापदंडों का एक ब्रेकडाउन दिया गया है जिसका उपयोग लेखकों ने अपने रडार को कॉन्फ़िगर करने और अपने कृत्रिम बुद्धिमत्ता मॉडल को प्रशिक्षित करने के लिए किया है:
| संकेतन / पैरामीटर | विवरण |
|---|---|
| $60$ GHz | मिलीमीटर-वेव रडार सेंसर की केंद्र आवृत्ति का उपयोग महीन-दाने वाली गति को कैप्चर करने के लिए किया जाता है। |
| $1$ MHz | रडार प्रणाली की नमूना दर। |
| $31$ | रडार के लिए कॉन्फ़िगर किया गया ट्रांसमिट पावर स्तर। |
| $40$ dB | रडार सिग्नल पर लागू इंटरमीडिएट फ्रीक्वेंसी (IF) गेन। |
| $0.0312$ m | स्थानिक रेंज रिज़ॉल्यूशन, जिसका अर्थ है कि रडार लगभग 3 सेंटीमीटर अलग वस्तुओं को अलग कर सकता है। |
| $1.60$ m | रडार सेटअप की अधिकतम प्रभावी सीमा, जो डॉक्टर के सामने बैठे रोगी के लिए आदर्श है। |
| $4.11$ m/s | अधिकतम गति जिसे रडार विरूपण के बिना सटीक रूप से ट्रैक कर सकता है। |
| $0.0321$ m/s | गति रिज़ॉल्यूशन, बहुत धीमी, सूक्ष्म हाथ की गतिविधियों का पता लगाने की अनुमति देता है। |
| $0.077$ s | प्रत्येक रडार फ्रेम को प्राप्त करने के लिए पुनरावृत्ति समय। |
| $-90$ dB | डेटा प्रीप्रोसेसिंग के दौरान पृष्ठभूमि शोर को फ़िल्टर करने के लिए उपयोग किया जाने वाला स्पेक्ट्रल थ्रेशोल्ड। |
| $\beta_1 = 0.9, \beta_2 = 0.999$ | तंत्रिका नेटवर्क के प्रशिक्षण चरण के दौरान उपयोग किए जाने वाले AdamW ऑप्टिमाइज़र के लिए क्षय दरें। |
| $5 \cdot 10^{-5}$ | ऑटोएन्कोडर नेटवर्क को प्रशिक्षित करने के लिए उपयोग की जाने वाली सीखने की दर। |
| $10^{-4}$ | ट्रांसफार्मर क्लासिफायर नेटवर्क को प्रशिक्षित करने के लिए उपयोग की जाने वाली सीखने की दर। |
| $5 \cdot 10^{-6}$ | तंत्रिका नेटवर्क को प्रशिक्षण डेटा पर ओवरफिटिंग को रोकने के लिए लागू वजन क्षय पैरामीटर। |
समस्या परिभाषा और बाधाएँ
अदृश्य तरंगों को अर्थ में मैप करना: मूलभूत अंतर
इस पत्र की उपलब्धि के परिमाण को समझने के लिए, हमें पहले ठीक से परिभाषित करना होगा कि सिस्टम कहाँ से शुरू होता है और उसे कहाँ समाप्त करना है।
प्रारंभ बिंदु (इनपुट): सिस्टम दुनिया को कैमरे के लेंस से नहीं देखता है। इसके बजाय, यह 60 GHz मिलीमीटर-वेव रेडियो सिग्नल उत्सर्जित करता है और मानव शरीर से टकराकर वापस आने वाली प्रतिध्वनियों को सुनता है। इन प्रतिध्वनियों को गणितीय रूप से रेंज डॉपलर मैप्स (RDM) और मूविंग टारगेट इंडिकेशन्स (MTI) में रूपांतरित किया जाता है। एक आधारभूत पाठक के लिए, एक हीट मैप की कल्पना करें जो रंग या आकार नहीं दिखाता है, बल्कि केवल आपको बताता है कि एक गतिशील वस्तु कितनी दूर है (रेंज) और कितनी तेज़ी से चल रही है (डॉपलर वेग)। गणितीय रूप से, इनपुट उच्च-आयामी मैट्रिसेस का एक क्रम है $X = \{x_1, x_2, \dots, x_T\}$, जहाँ प्रत्येक फ्रेम $x_t \in \mathbb{R}^{128 \times 1024}$ है, और अनुक्रम की लंबाई $T$ व्यक्ति द्वारा संकेत बनाने में लगने वाले समय के आधार पर 13 से 66 फ्रेम के बीच भिन्न होती है।
लक्ष्य अवस्था (आउटपुट): वांछित आउटपुट एक एकल, अत्यधिक विशिष्ट अर्थपूर्ण लेबल है। सिस्टम को रडार मैप्स के इस अनुक्रम को $C = 126$ विशिष्ट इतालवी सांकेतिक भाषा (LIS) वर्गों (100 चिकित्सा शब्द और 26 वर्णमाला अक्षर) पर एक संभाव्यता वितरण में मैप करना होगा। हम एक गणितीय मैपिंग फ़ंक्शन $f: X \rightarrow Y$ की तलाश कर रहे हैं, जहाँ $Y \in \{1, 2, \dots, 126\}$।
लुप्त कड़ी: यहाँ गणितीय अंतर बहुत बड़ा है। मॉडल को अमूर्त, गैर-दृश्य भौतिकी डेटा (टकरा रही रेडियो तरंगें) को सटीक भाषाई अर्थ में अनुवाद करना होगा। इसे वेग और दूरी के उतार-चढ़ाव के एक अनुक्रम को देखना होगा और आत्मविश्वास से कहना होगा, "गतिशील द्रव्यमान का वह विशिष्ट पैटर्न 'डॉक्टर' का अर्थ है, न कि 'फेफड़ा'।"
क्रूर दुविधा: गोपनीयता बनाम सटीकता
विज्ञान में, जब भी आप एक पैरामीटर को अनुकूलित करते हैं, तो आप लगभग हमेशा दूसरे को तोड़ देते हैं। स्वचालित सांकेतिक भाषा पहचान (SLR) के लिए, शोधकर्ता सटीकता और गोपनीयता के बीच एक दर्दनाक खींचतान में फंसे हुए हैं।
सांकेतिक भाषा अविश्वसनीय रूप से जटिल है। यह न केवल व्यापक हाथ की हरकतों पर निर्भर करती है, बल्कि सूक्ष्म मैनुअल संकेतों (उंगली की सटीक स्थिति) और गैर-मैनुअल संकेतों (चेहरे के भाव, होंठों की हरकतें, धड़ का झुकाव) पर भी निर्भर करती है। पारंपरिक RGB और डेप्थ कैमरे इन सभी को पूरी तरह से कैप्चर करते हैं, जिससे उच्च सटीकता प्राप्त होती है। हालांकि, एक क्लिनिकल वातावरण जैसे अस्पताल के कमरे में, उच्च-रिज़ॉल्यूशन कैमरों को स्थापित करना सख्त रोगी गोपनीयता कानूनों और नैतिक सीमाओं का उल्लंघन करता है।
गोपनीयता प्राप्त करने के लिए, आप RADAR का उपयोग कर सकते हैं। रडार स्वाभाविक रूप से रोगी की पहचान को अस्पष्ट करता है क्योंकि यह दृश्य विवरण कैप्चर नहीं करता है - यह केवल गतिशील ऊर्जा के धब्बों को देखता है। लेकिन यहाँ दुविधा है: गोपनीयता की रक्षा के लिए रडार पर स्विच करके, आप तुरंत अपने सिस्टम को सूक्ष्म दृश्य विवरणों (जैसे चेहरे के भाव और उंगली के आकार) से अंधा कर देते हैं जो समान संकेतों के बीच अंतर करने के लिए बिल्कुल महत्वपूर्ण हैं। पिछले शोधकर्ता फंसे हुए थे: कैमरे का उपयोग करें और गोपनीयता का उल्लंघन करें, या रडार का उपयोग करें और भयानक सटीकता से पीड़ित हों क्योंकि डेटा बहुत अमूर्त है।
कठोर दीवारें और बाधाएँ
इस समस्या को हल करने के लिए, लेखकों को कई यथार्थवादी, क्षमा न करने वाली बाधाओं को पार करना पड़ा:
- हार्डवेयर मेमोरी वॉल (कम्प्यूटेशनल बाधाएँ):
रडार डेटा अविश्वसनीय रूप से सघन होता है। एक एकल संकेत हावभाव $128 \times 1024$ के आकार के मैट्रिसेस का एक अनुक्रम उत्पन्न करता है। यदि आप इस कच्चे, उच्च-आयामी वीडियो-जैसे अनुक्रम को सीधे एक एकल डीप न्यूरल नेटवर्क में फीड करने का प्रयास करते हैं ताकि टेम्पोरल डायनामिक्स को एंड-टू-एंड सीखा जा सके, तो गणितीय संचालन विस्फोट हो जाता है। लेखकों ने स्पष्ट रूप से उल्लेख किया है कि ऐसा करने से अत्यधिक मॉडल जटिलता होती है और तुरंत GPU मेमोरी की सीमाएं अधिकतम हो जाती हैं। उन्हें गणित को आधुनिक हार्डवेयर पर कम्प्यूटेबल बनाने के लिए समस्या को दो चरणों (पहले स्थानिक संपीड़न, फिर टेम्पोरल अनुक्रम मॉडलिंग) में अलग करने के लिए मजबूर होना पड़ा। - "अदृश्य" गैर-मैनुअल संकेत (भौतिक बाधाएँ):
चूंकि रडार मैक्रो-मोशन (हाथ और उंगलियां) को कैप्चर करने वाले तरंग दैर्ध्य पर संचालित होता है, यह भौंहें चढ़ाना या होंठों का विशिष्ट आकार जैसी सूक्ष्म गतियों को पूरी तरह से चूक जाता है। चूंकि कई सांकेतिक भाषा के शब्दों में बिल्कुल समान हाथ की हरकतें होती हैं और केवल चेहरे के भाव से भिन्न होती हैं, इसलिए गणितीय मॉडल को उन्हें अलग करने के लिए हाथ के वेग में छिपे हुए, सूक्ष्म गतिज पैटर्न खोजने के लिए मजबूर किया जाता है, जो एक गंभीर सूचना की कमी के साथ काम करता है। - परिवर्तनीय टेम्पोरल डायनामिक्स (डेटा-संचालित बाधाएँ):
मनुष्य रोबोट नहीं हैं; वे लगातार गति से संकेत नहीं करते हैं। एक रोगी एक शब्द को 1 सेकंड (13 फ्रेम) में संकेत कर सकता है, जबकि एक बुजुर्ग रोगी को उसी शब्द के लिए 4 सेकंड (66 फ्रेम) लग सकते हैं। मॉडल को टेम्पोरली इनवेरिएंट होना चाहिए। यह निश्चित-लंबाई वाले इनपुट पर भरोसा नहीं कर सकता है; इसे गतिशील रूप से विभिन्न लंबाई के अनुक्रमों को संरेखित और व्याख्या करना होगा, जिसके लिए समय के साथ लंबी दूरी की निर्भरताओं को ट्रैक करने के लिए ट्रांसफॉर्मर जैसे उन्नत अनुक्रम मॉडलिंग की आवश्यकता होती है। - चरम डेटा की कमी:
डीप लर्निंग मॉडल डेटा-भूखे होते हैं। जटिल रडार संकेतों को 126 विशिष्ट चिकित्सा संकेतों में मैप करने के लिए, आपको हजारों उदाहरणों की आवश्यकता होती है। इस पत्र से पहले, सांकेतिक भाषा के लिए रडार डेटासेट छोटे थे, अक्सर 5 या 10 सामान्य हावभाव (जैसे बाएं या दाएं स्वाइप करना) तक सीमित थे। लेखकों को एक दीवार का सामना करना पड़ा जहाँ समस्या को हल करने के लिए आवश्यक डेटा मौजूद नहीं था, जिससे उन्हें अपने एल्गोरिदम को प्रशिक्षित करना शुरू करने से पहले ही खरोंच से 25,830 संकेत उदाहरणों का एक विशाल, सिंक्रनाइज़्ड डेटासेट बनाने के लिए मजबूर होना पड़ा।
यह तरीका क्यों
यह समझने के लिए कि लेखकों ने अपने विशिष्ट दो-चरणीय पाइपलाइन—एक कस्टम कनवल्शनल ऑटोएनकोडर के बाद एक ट्रांसफार्मर—को क्यों चुना, हमें पहले रडार डेटा की कठोर वास्तविकता को देखना होगा। 60 GHz mm-वेव रडार रेंज डॉपलर मैप्स (RDMs) और मूविंग टारगेट इंडिकेशन (MTI) मैप्स उत्पन्न करता है। ये अनिवार्य रूप से उच्च-आयामी मैट्रिक्स के वीडियो-जैसे अनुक्रम हैं, विशेष रूप से प्रति फ्रेम $128 \times 1024$ ।
जिस क्षण लेखकों को एहसास हुआ कि पारंपरिक अत्याधुनिक (SOTA) विधियाँ अपर्याप्त थीं, वह तब था जब उन्होंने समस्या के भारी कम्प्यूटेशनल भार पर विचार किया। जैसा कि वे स्पष्ट रूप से बताते हैं, एक एकल, विशाल एंड-टू-एंड डीप नेटवर्क के साथ सीधे इसे हल करने का प्रयास करने से "अत्यधिक मॉडल जटिलता और कम्प्यूटेशनल लागत" होगी। रडार डेटा अत्यधिक आयामी और अनुक्रमिक होता है। यदि आप $T$ समय चरणों में कच्चे $128 \times 1024$ फ्रेम को सीधे एक मानक 3D CNN या एक शुद्ध ट्रांसफार्मर में फीड करते हैं, तो मेमोरी आवश्यकताएं बढ़ जाती हैं।
इसे हल करने के लिए, उन्होंने समस्या को दो अलग-अलग चरणों में विभाजित किया। सबसे पहले, उन्होंने स्थानिक डेटा को संपीड़ित करने के लिए एक कस्टम CNN ऑटोएनकोडर बनाया। प्रसिद्ध पूर्व-प्रशिक्षित SOTA मॉडल जैसे ResNet या AlexNet के बजाय एक कस्टम मॉडल क्यों? लेखकों ने महसूस किया कि रडार मैप्स प्राकृतिक RGB छवियों से मौलिक रूप से भिन्न होते हैं। उनमें मानक तस्वीरों की जटिल दृश्य बनावट का अभाव है। एक भारी, पूर्व-प्रशिक्षित आर्किटेक्चर का उपयोग वास्तव में प्रदर्शन को नुकसान पहुंचाएगा। इसके बजाय, अवशिष्ट कनेक्शन के साथ उनका कस्टम 9-परत CNN विशाल रडार फ्रेम को 256-आयामी अत्यधिक कॉम्पैक्ट अव्यक्त प्रतिनिधित्व में आसवित करता है।
यह हमें उनकी विधि की तुलनात्मक श्रेष्ठता तक ले जाता है। ऑटोएनकोडर को फ्रीज करके और केवल 256-आयामी एम्बेडिंग को ट्रांसफार्मर में फीड करके, वे मेमोरी बाधा को नाटकीय रूप से कम करते हैं। पेपर नोट करता है कि यह दो-चरणीय प्रक्रिया "प्रत्येक युग के लिए कच्चे डेटा पर पूर्ण एंड-टू-एंड प्रशिक्षण से बचकर GPU मेमोरी बाधाओं को कम करती है।" यद्यपि वे स्पष्ट रूप से इसे पाठ में $O(N^2)$ से $O(N)$ जटिलता में कमी के रूप में नहीं बताते हैं, संरचनात्मक लाभ स्पष्ट है: स्थानिक प्रसंस्करण पूरी तरह से अस्थायी प्रसंस्करण से अलग है।
इसके अलावा, ट्रांसफार्मर क्लासिफायर दूसरे चरण के लिए गुणात्मक रूप से बेहतर है क्योंकि यह स्वाभाविक रूप से चर-लंबाई अनुक्रमों को संभालता है। मानव सांकेतिक भाषा गतिशील है; उनके डेटासेट में, एक संकेत $T=13$ से $T=66$ फ्रेम तक कहीं भी रह सकता है। ट्रांसफार्मर का स्व-ध्यान तंत्र डेटा को कठोर, निश्चित-लंबाई वाली खिड़कियों में मजबूर किए बिना इन लंबी दूरी की अस्थायी निर्भरताओं को मॉडल करने में उत्कृष्ट है। तीन अलग-अलग रडार एंटेना से डेटा को फ्यूज करके और मानक RDMs को MTI मैप्स (जो स्थिर पृष्ठभूमि शोर को शून्य करते हैं) के साथ जोड़कर, मॉडल पर्यावरणीय हस्तक्षेप के प्रति अविश्वसनीय रूप से मजबूत हो जाता है।
यह दृष्टिकोण समस्या की बाधाओं और समाधान के गुणों के बीच एक आदर्श "विवाह" का प्रतिनिधित्व करता है। चिकित्सा सेटिंग पूर्ण गोपनीयता की मांग करती है, जिसे रडार भौतिक रूप से केवल गति और वेग को कैप्चर करके गारंटी देता है, न कि पहचान योग्य चेहरों को। हालांकि, यह अत्यधिक अमूर्त, शोरगुल वाले और कम्प्यूटेशनल रूप से भारी डेटा की बाधा पैदा करता है। ऑटोएनकोडर एक आदर्श फिल्टर के रूप में कार्य करता है, शोर को हटाता है और स्थानिक आयामों को संपीड़ित करता है, जबकि ट्रांसफार्मर एक आदर्श अस्थायी इंजन के रूप में कार्य करता है, जो समय के साथ हावभाव के वास्तविक अर्थ को डीकोड करता है।
यदि आप सोच रहे हैं कि लेखकों ने GANs या डिफ्यूजन मॉडल जैसे अन्य लोकप्रिय आधुनिक दृष्टिकोणों का उपयोग क्यों नहीं किया, तो सच कहूं तो, मुझे भी इस हिस्से के बारे में पूरी तरह से यकीन नहीं है, क्योंकि पेपर स्पष्ट रूप से उनका उल्लेख या अस्वीकार नहीं करता है। हालांकि, यह देखते हुए कि यह सख्ती से एक वर्गीकरण समस्या है (रडार फ्रेम के अनुक्रम को 126 विशिष्ट संकेत वर्गों में से एक पर मैप करना) न कि एक जनरेटिव कार्य, नए डेटा को संश्लेषित करने के लिए डिज़ाइन किए गए मॉडल संभवतः मुख्य वर्गीकरण बाधा को हल किए बिना अनावश्यक ओवरहेड पेश करेंगे। लेखकों ने पूरी तरह से विभेदक दक्षता पर ध्यान केंद्रित किया, जिसे उनके ऑटोएनकोडर-ट्रांसफार्मर युग्मन खूबसूरती से संभालता है।
गणितीय और तार्किक तंत्र
कल्पना कीजिए कि एक बधिर रोगी अस्पताल के आपातकालीन कक्ष में डॉक्टर को अपने लक्षणों के बारे में बताने की कोशिश कर रहा है। दुभाषिया तुरंत उपलब्ध नहीं है, और उनके संकेत भाषा का अनुवाद करने के लिए मानक कैमरा-आधारित AI का उपयोग करने से गोपनीयता का भारी जोखिम होता है—कोई भी किसी कमजोर चिकित्सा क्षण के दौरान अपने चेहरे और शरीर की उच्च-परिभाषा वीडियो रिकॉर्डिंग नहीं चाहता है।
यह पत्र इसी सटीक बाधा को हल करता है, कैमरों को 60 GHz मिलीमीटर-तरंग RADAR से बदलकर। दृश्य पिक्सेल कैप्चर करने के बजाय, रडार रोगी से रेडियो तरंगों को उछालता है ताकि उनके हिलते हुए हाथों और शरीर की दूरी (रेंज) और वेग (डॉपलर) को मापा जा सके। परिणाम एक गोपनीयता-संरक्षण, चेहरा-रहित गति का नक्शा है। हालांकि, रडार डेटा अविश्वसनीय रूप से शोरगुल वाला, उच्च-आयामी और अनुक्रमिक होता है। लेखकों को इस विशाल रडार गूँज की धारा को एक कॉम्पैक्ट प्रारूप में संपीड़ित करने का तरीका खोजना पड़ा और फिर मशीन को उन गूँजों के अस्थायी अनुक्रम को "पढ़ना" सिखाना पड़ा ताकि 126 विभिन्न इतालवी संकेत भाषा (LIS) चिकित्सा शब्दों और अक्षरों को पहचाना जा सके।
वीडियो-जैसी रडार अनुक्रमों को संसाधित करने की कम्प्यूटेशनल बाधा को दूर करने के लिए, उन्होंने समस्या को दो चरणों में विभाजित किया: प्रत्येक व्यक्तिगत रडार फ्रेम को संपीड़ित करने के लिए एक Convolutional Neural Network (CNN) Autoencoder, और समय के साथ संपीड़ित फ्रेम के अनुक्रम का विश्लेषण करने के लिए एक Transformer नेटवर्क।
ईमानदारी से कहूं तो, मुझे पूरी तरह से यकीन नहीं है कि लेखकों ने अपने सटीक गणितीय सूत्रों को पाठ में प्रिंट न करने का विकल्प क्यों चुना—उन्होंने संभवतः यह मान लिया था कि दर्शक पहले से ही मानक डीप लर्निंग उद्देश्यों से परिचित थे। हालांकि, उन्होंने स्पष्ट रूप से कहा है कि उनके Transformer क्लासिफायर को "एक मानक क्रॉस-एंट्रॉपी लॉस को कम करके" अनुकूलित किया गया है। इसलिए, इस पूरे सिस्टम की शिक्षा को चलाने वाला पूर्ण मुख्य गणितीय इंजन Cross-Entropy Objective Function है।
$$ \mathcal{L}_{CE} = - \sum_{i=1}^{C} y_i \log(\hat{y}_i) $$
आइए इस समीकरण को तोड़कर समझें कि मॉडल रडार तरंगों को चिकित्सा शब्दावली में अनुवाद करना कैसे सीखता है:
- $\mathcal{L}_{CE}$: यह कुल Cross-Entropy Loss है।
- तार्किक भूमिका: यह मॉडल के लिए अंतिम "स्कोरकार्ड" या कंपास के रूप में कार्य करता है। एक उच्च मान का मतलब है कि मॉडल बुरी तरह भ्रमित है; शून्य के करीब का मान का मतलब है कि मॉडल संकेत भाषा के हावभाव को पूरी तरह से समझता है।
- $\sum_{i=1}^{C}$: सभी $C$ वर्गों (इस पत्र में, $C = 126$ LIS संकेत) पर योग ऑपरेटर।
- एक इंटीग्रल के बजाय योग क्यों? क्योंकि शब्दावली अलग-अलग श्रेणियों का एक असतत सेट है (जैसे, "डॉक्टर", "फेफड़ा", "गर्दन"), न कि मानों का एक सतत स्पेक्ट्रम। हमें हर एक संभावित शब्द पर दंड की गणना करनी होगी।
- $y_i$: Ground-truth लेबल।
- तार्किक भूमिका: यह पूर्ण सत्य है। यह रोगी द्वारा वास्तव में किए गए सही संकेत के लिए $1$ के बराबर है, और अन्य 125 गलत संकेतों के लिए $0$ है। यह एक सख्त फिल्टर के रूप में कार्य करता है, यह सुनिश्चित करता है कि गणित केवल सही उत्तर को सौंपी गई संभावना की परवाह करता है।
- $\hat{y}_i$: Transformer की लीनियर क्लासिफिकेशन लेयर द्वारा आउटपुट की गई अनुमानित संभावना।
- तार्किक भूमिका: यह मॉडल का सबसे अच्छा अनुमान है, 0 और 1 के बीच की एक संख्या, जो यह दर्शाती है कि यह कितना आश्वस्त है कि रडार गति शब्द $i$ के अनुरूप है।
- $\log$: मॉडल की भविष्यवाणी पर लागू प्राकृतिक लघुगणक।
- यहां लॉग का उपयोग क्यों करें? लघुगणक मॉडल को तब भारी दंडित करता है जब वह आत्मविश्वास से गलत होता है। यदि सही उत्तर "डॉक्टर" ($y_i = 1$) है लेकिन मॉडल $0.01$ की संभावना की भविष्यवाणी करता है, तो $\log(0.01)$ एक विशाल नकारात्मक संख्या देता है। यह एक घातीय रबर बैंड की तरह काम करता है, जब मॉडल एक गंभीर गलती करता है तो मॉडल के भार को हिंसक रूप से वापस जगह पर खींचता है।
- $-$ (ऋणात्मक चिह्न): क्योंकि संभावनाएं ($\hat{y}_i$) हमेशा 0 और 1 के बीच होती हैं, उनका लघुगणक हमेशा ऋणात्मक होता है। हम परिणाम को एक सकारात्मक "लागत" में पलटने के लिए एक ऋणात्मक चिह्न जोड़ते हैं जिसे ऑप्टिमाइज़र कम कर सकता है।
आइए इस यांत्रिक असेंबली लाइन से गुजरने वाले एक एकल अमूर्त डेटा बिंदु के सटीक जीवनचक्र का पता लगाएं।
सबसे पहले, एक कच्ची 60 GHz रडार तरंग रोगी के हिलते हुए हाथों से टकराकर सेंसर पर लौट आती है। फास्ट फूरियर ट्रांसफॉर्म (FFTs) के माध्यम से, इस कच्चे सिग्नल को एक रेंज डॉपलर मैप (RDM) में परिवर्तित किया जाता है—एक 2D ग्रिड जो दिखाता है कि गति कहां है और यह कितनी तेजी से चल रही है। यह $128 \times 1024$ ग्रिड CNN Autoencoder में प्रवेश करता है। ऑटोएनकोडर एक कचरा कंपैक्टर की तरह काम करता है, विशाल ग्रिड को 9 कनवल्शनल परतों के माध्यम से निचोड़ता है जब तक कि यह एक सघन, 256-आयामी लेटेंट प्रतिनिधित्व वेक्टर नहीं बन जाता।
इसके बाद, क्योंकि एक संकेत भाषा हावभाव में समय लगता है (1 से 4 सेकंड तक फैला हुआ), इन 256-आयामी वैक्टरों का एक अनुक्रम पंक्तिबद्ध किया जाता है। एक सीखने योग्य "क्लास टोकन" सामने जोड़ा जाता है, और स्थितिगत एम्बेडिंग जोड़े जाते हैं ताकि मॉडल को फ्रेम के कालानुक्रमिक क्रम का पता चल सके। यह अनुक्रम Transformer में प्रवाहित होता है। Transformer का मल्टी-हेड सेल्फ-अटेंशन मैकेनिज्म हर फ्रेम की हर दूसरी फ्रेम से तुलना करता है, यह पता लगाता है कि समय के साथ हाथ की गति कैसे बदलती है। अंत में, क्लास टोकन—जो अब पूरे अस्थायी संदर्भ से समृद्ध है—को 126 संभावनाओं ($\hat{y}_i$) को बाहर निकालने के लिए एक लीनियर लेयर से गुजारा जाता है। उच्चतम संभावना अंतिम अनुवादित शब्द है।
यह तंत्र वास्तव में कैसे सीखता है और अभिसरण करता है? यहां अनुकूलन गतिशीलता को इसके उच्च आयामों के भार के तहत मॉडल को ढहने से रोकने के लिए सावधानीपूर्वक व्यवस्थित किया गया है।
यदि लेखकों ने Autoencoder और Transformer को एक साथ (एंड-टू-एंड) प्रशिक्षित करने का प्रयास किया होता, तो GPU मेमोरी फट जाती और लॉस लैंडस्केप अराजक, स्थानीय न्यूनतम से भरा होता। इसके बजाय, वे 15 युगों के बाद Autoencoder को फ्रीज कर देते हैं। Autoencoder के भार को लॉक करके, वे एक स्थिर, अपरिवर्तनीय नींव बनाते हैं।
फिर Transformer को AdamW ऑप्टिमाइज़र का उपयोग करके 700 युगों तक प्रशिक्षित किया जाता है। लेखकों ने स्पष्ट रूप से ग्रेडिएंट क्लिपिंग को 5 के अधिकतम नॉर्म पर सेट किया है। लॉस लैंडस्केप में, रडार डेटा कभी-कभी अचानक, बड़े पैमाने पर त्रुटियां (लॉस में स्पाइक्स) उत्पन्न कर सकता है, जो सामान्य रूप से ग्रेडिएंट को विस्फोट करने और मॉडल के सीखे हुए भार को तोड़ने का कारण बनेगा। ग्रेडिएंट क्लिपिंग एक गति सीमा के रूप में कार्य करता है, यह सुनिश्चित करता है कि चाहे लॉस लैंडस्केप कितना भी खड़ी हो जाए, मॉडल केवल नीचे की ओर एक सुरक्षित आकार का कदम उठाता है। $5 \cdot 10^{-6}$ के वेट डीके (जो न्यूरल भार को बहुत बड़ा होने और प्रशिक्षण डेटा को याद रखने से रोकने के लिए एक कोमल गुरुत्वाकर्षण खिंचाव के रूप में कार्य करता है) के साथ मिलकर, मॉडल 93.6% सटीकता तक सुचारू रूप से अभिसरण करता है, यह साबित करता है कि हम वास्तव में अदृश्य रेडियो तरंगों के माध्यम से जटिल मानव भाषा को समझ सकते हैं।
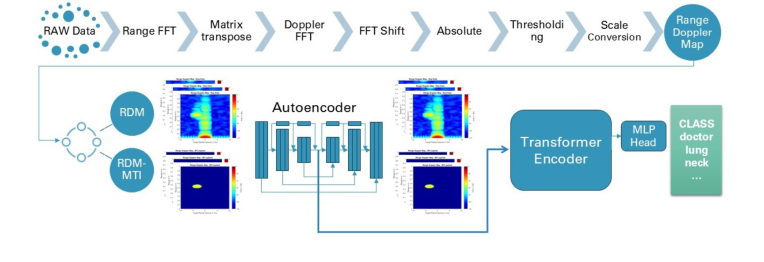 Figure 1. Overview of the end-to-end architecture of the proposed method
Figure 1. Overview of the end-to-end architecture of the proposed method
परिणाम, सीमाएँ और निष्कर्ष
कल्पना कीजिए कि आप किसी विदेशी देश के अस्पताल में हैं, और डॉक्टर को यह समझाने की कोशिश कर रहे हैं कि आपको सीने में तेज दर्द हो रहा है, लेकिन आप उनकी भाषा नहीं बोलते हैं। अब, कल्पना कीजिए कि आप बहरे हैं, और आपकी प्राथमिक भाषा इतालवी सांकेतिक भाषा (LIS) जैसी दृश्य-हावभाव प्रणाली है। यदि तुरंत कोई दुभाषिया उपलब्ध न हो, तो संचार बाधा जीवन के लिए खतरा बन सकती है।
ऐतिहासिक रूप से, प्रौद्योगिकीविदों ने अस्पताल के कमरों में RGB (मानक वीडियो) कैमरे लगाकर सांकेतिक भाषा को स्वचालित रूप से टेक्स्ट में अनुवाद करने का प्रयास किया है। लेकिन इससे एक बड़ी समस्या उत्पन्न होती है: गोपनीयता। अस्पताल अत्यधिक संवेदनशील स्थान होते हैं। मरीज़ कमजोर अवस्थाओं में उन्हें रिकॉर्ड करने वाले हाई-डेफिनिशन कैमरों को नहीं चाहते हैं। इसके अलावा, कैमरे कुख्यात रूप से नाजुक होते हैं; यदि प्रकाश व्यवस्था खराब हो या पृष्ठभूमि अव्यवस्थित हो, तो वे विफल हो जाते हैं।
यह पत्र एक शानदार, विज्ञान-फाई-ध्वनि वाला समाधान प्रस्तुत करता है: सांकेतिक भाषा को "पढ़ने" के लिए 60 GHz मिलीमीटर-वेव (mm-wave) रडार का उपयोग करना। किसी व्यक्ति के चेहरे या शरीर की पहचान करने वाले दृश्य पिक्सेल को कैप्चर करने के बजाय, रडार रोगी पर रेडियो तरंगें उछालता है और उनके हाथों और बाहों की सूक्ष्म गतियों और वेगों को मापता है। रडार व्यक्ति को देखे बिना भाषा की गतिविज्ञान को देखता है।
आइए विस्तार से देखें कि लेखकों ने इस गोपनीयता-संरक्षण अनुवाद मशीन को कैसे इंजीनियर किया।
बाधाएँ और गणितीय समस्या
रडार डेटा मानक तस्वीर जैसा नहीं होता है। जब 60 GHz रडार पल्स साइनर से टकराते हैं, तो लौटने वाले संकेतों को रेंज डॉपलर मैप्स (RDMs) और मूविंग टारगेट इंडिकेशन (MTI) मैप्स में संसाधित किया जाता है। आप इन्हें हीटमैप के रूप में सोच सकते हैं जो दिखाते हैं कि कोई वस्तु कहाँ है (रेंज) और वह कितनी तेज़ी से चल रही है (डॉपलर वेग)।
यहां बाधा डेटा आयाम और कम्प्यूटेशनल अधिभार है। एक एकल संकेत हावभाव में 1 से 4 सेकंड लगते हैं, जिससे 66 रडार फ्रेम तक का अनुक्रम उत्पन्न होता है। यदि आप इस विशाल, उच्च-आयामी वीडियो-जैसी अनुक्रम को सीधे एक गहरे शिक्षण नेटवर्क में फीड करने का प्रयास करते हैं, तो कंप्यूटर की मेमोरी जाम हो जाएगी, और मॉडल ओवरफिट हो जाएगा (अंतर्निहित पैटर्न सीखने के बजाय प्रशिक्षण डेटा को याद कर लेगा)।
गणितीय रूप से, समस्या एक अनुक्रम वर्गीकरण कार्य है। हमें रडार फ्रेम का एक अनुक्रम $X = \{x_1, x_2, \dots, x_T\}$ दिया गया है, जहाँ $T$ फ्रेम की चर संख्या है, और हमें इस अनुक्रम को एक विशिष्ट सांकेतिक भाषा वर्ग लेबल $y \in \{1, 2, \dots, 126\}$ पर मैप करने की आवश्यकता है।
मेमोरी बाधाओं को दूर करने के लिए, लेखकों ने समस्या को दो-चरणीय पाइपलाइन में निर्दयतापूर्वक अलग कर दिया:
चरण 1: स्थानिक संपीड़न (ऑटोएनकोडर)
पूरे अनुक्रम को एक साथ संसाधित करने के बजाय, उन्होंने प्रत्येक फ्रेम को व्यक्तिगत रूप से संसाधित करने के लिए एक कस्टम कन्वेन्शनल न्यूरल नेटवर्क (CNN) ऑटोएनकोडर बनाया। एनकोडर फ़ंक्शन $E$ एक विशाल रडार फ्रेम $x_t$ लेता है और इसे एक सघन, निम्न-आयामी वेक्टर $z_t \in \mathbb{R}^{256}$ में निचोड़ता है। यह सुनिश्चित करने के लिए कि इस संपीड़ित वेक्टर में वास्तव में महत्वपूर्ण गति डेटा शामिल है, एक डिकोडर फ़ंक्शन $D$ मूल फ्रेम को पुनर्निर्मित करने का प्रयास करता है: $\hat{x}_t = D(z_t)$। नेटवर्क को $x_t$ और $\hat{x}_t$ के बीच के अंतर को कम करने के लिए प्रशिक्षित किया जाता है। एक बार प्रशिक्षित होने के बाद, डिकोडर को फेंक दिया जाता है, और हम रडार डेटा के कॉम्पैक्ट प्रतिनिधित्व उत्पन्न करने के लिए एनकोडर को रखते हैं।
चरण 2: लौकिक वर्गीकरण (ट्रांसफार्मर)
अब, मॉडल के पास वैक्टर का एक हल्का अनुक्रम $Z = \{z_1, z_2, \dots, z_T\}$ है। चूंकि सांकेतिक भाषा गतिशील है (गतियों का क्रम मायने रखता है), वे इस अनुक्रम को एक ट्रांसफार्मर नेटवर्क में फीड करते हैं। ट्रांसफार्मर पूरे अनुक्रम को देखने और यह पता लगाने के लिए मल्टी-हेड सेल्फ-अटेंशन का उपयोग करता है कि कौन सी गतियाँ किन संकेतों से संबंधित हैं। यह 126 संभावित चिकित्सा संकेतों में एक संभाव्यता वितरण $\hat{y}$ आउटपुट करता है। मॉडल को मानक क्रॉस-एंट्रॉपी लॉस का उपयोग करके अनुकूलित किया जाता है:
$$ \mathcal{L} = -\sum_{c=1}^{C} y_c \log(\hat{y}_c) $$
जहाँ $C = 126$ वर्गों की कुल संख्या है।
प्रयोगात्मक वास्तुकला और "पीड़ित"
लेखकों ने केवल यह प्रणाली नहीं बनाई और दावा किया कि यह काम करती है; उन्होंने अपने गणितीय दावों को साबित करने के लिए एक अत्यधिक नियंत्रित, मल्टीमॉडल क्षेत्र को आर्किटेक्ट किया। उन्होंने रडार, मानक RGB कैमरों और गहराई सेंसर का एक साथ उपयोग करके 25,830 संकेत उदाहरणों का एक विशाल डेटासेट रिकॉर्ड किया। इसने उन्हें अपने रडार मॉडल को सीधे विज़न-आधारित मॉडल के खिलाफ ठीक उन्हीं हावभावों पर खड़ा करने की अनुमति दी।
इस प्रयोग में "पीड़ित" (बेसलाइन मॉडल) अत्याधुनिक विज़न मॉडल थे, जिनमें डी कोस्टर एट अल. का RGB वीडियो ट्रांसफार्मर नेटवर्क और वाहदानी का RGB-D 3D CNN, साथ ही पिछले रडार-आधारित हावभाव मॉडल (झाउंग, देबनाथ, अरब) शामिल थे।
उनकी सफलता का निर्णायक, निर्विवाद प्रमाण अंतिम मेट्रिक्स में निहित है। तीन रडार एंटेना का उपयोग करते हुए और RDM और MTI डेटा स्ट्रीम दोनों को मिलाकर, उनके रडार मॉडल ने एक आश्चर्यजनक 93.6% सटीकता हासिल की। इसने अग्रणी RGB-आधारित मॉडल (जिसने केवल 88.4% का प्रबंधन किया) को पूरी तरह से पछाड़ दिया।
यह एक गहरा परिणाम है। यह साबित करता है कि रडार द्वारा कैप्चर किए गए माइक्रो-डॉपलर हस्ताक्षर इस विशिष्ट कार्य के लिए वास्तविक दृश्य पिक्सेल की तुलना में अधिक मजबूत, विशिष्ट भाषाई विशेषताएं रखते हैं। इसके अलावा, उन्होंने एब्लेशन अध्ययनों के माध्यम से साबित किया कि ट्रांसफार्मर के प्रशिक्षण के दौरान ऑटोएनकोडर को फ्रीज करना ओवरफिटिंग को रोकने की कुंजी थी, जिससे सरल मॉडल को बेहतर सामान्यीकरण प्राप्त करने की अनुमति मिली। यह USD 150 के लिए एक अत्यधिक प्रभावी सुरक्षा प्रणाली खरीदने के बराबर है जो $1,000 के कैमरा सेटअप से बेहतर प्रदर्शन करती है, वह भी आपकी पहचान को पूरी तरह से छिपाए रखते हुए।
भविष्य के विकास के लिए चर्चा विषय
इस पत्र द्वारा रखी गई शानदार नींव के आधार पर, भविष्य के अन्वेषण और महत्वपूर्ण सोच के लिए यहां कई रास्ते दिए गए हैं:
1. रडार में "गैर-मैनुअल" संकेत दुविधा
सांकेतिक भाषा केवल हाथ हिलाने के बारे में नहीं है; यह व्याकरण और स्वर व्यक्त करने के लिए चेहरे के भाव, भौंहें उठाने और सूक्ष्म होंठों की हरकतों जैसे गैर-मैनुअल संकेतों पर बहुत अधिक निर्भर करती है। रडार अंगों की सकल मोटर गतियों को ट्रैक करने में असाधारण है, लेकिन क्या यह चेहरे के भावों के सूक्ष्म-मांसपेशीय परिवर्तनों को पकड़ सकता है? यदि हम इन सूक्ष्म गतियों को पकड़ने के लिए रडार आवृत्ति बढ़ाते हैं, तो क्या हम अनजाने में चेहरे को पुनर्निर्मित करने के लिए पर्याप्त बायोमेट्रिक डेटा कैप्चर करने का जोखिम उठाते हैं, जिससे उस गोपनीयता को नष्ट कर दिया जाता है जिसे सिस्टम बनाने के लिए बनाया गया था?
2. अलग-अलग संकेतों से निरंतर सह-कलाकारिता में संक्रमण
यह अध्ययन 126 अलग संकेतों पर केंद्रित है। हालांकि, प्राकृतिक मानव संचार निरंतर होता है। धाराप्रवाह सांकेतिक भाषा में, एक संकेत का अंत दूसरे की शुरुआत में शारीरिक रूप से मिश्रित हो जाता है - एक घटना जिसे सह-कलाकारिता के रूप में जाना जाता है। ट्रांसफार्मर वास्तुकला को रडार डेटा की एक निरंतर धारा को अलग-अलग शब्दों में खंडित करने के लिए कैसे विकसित होना चाहिए? क्या एक स्लाइडिंग-विंडो दृष्टिकोण पर्याप्त होगा, या हमें अराजक अस्पताल वातावरण में अनसेगमेंटेड रडार अनुक्रमों को संभालने के लिए कनेक्शनिस्ट टेम्पोरल क्लासिफिकेशन (CTC) जैसे मौलिक रूप से भिन्न गणितीय ढांचे की आवश्यकता होगी?
3. क्रॉस-भाषाई और क्रॉस-विषय सामान्यीकरण
डेटासेट इतालवी सांकेतिक भाषा (LIS) का उपयोग करके एक ही विषय द्वारा किया गया था। हर इंसान के पास एक अद्वितीय गतिज हस्ताक्षर होता है—विभिन्न बांह की लंबाई, विभिन्न हस्ताक्षर गति और विभिन्न आराम की मुद्राएँ। यदि हम विषय A पर एक रडार मॉडल को प्रशिक्षित करते हैं, तो क्या माइक्रो-डॉपलर हस्ताक्षर विषय B के लिए सामान्यीकृत होंगे? इसके अलावा, क्या LIS के लिए ऑटोएनकोडर द्वारा सीखे गए अव्यक्त एम्बेडिंग को अमेरिकी सांकेतिक भाषा (ASL) या ब्रिटिश सांकेतिक भाषा (BSL) में स्थानांतरित किया जा सकता है? नए रोगियों को वास्तविक समय में रडार मॉडल को कैलिब्रेट करने के लिए अनसुपरवाइज्ड डोमेन एडैप्टेशन तकनीकों की खोज वैश्विक स्केलेबिलिटी के लिए एक महत्वपूर्ण अगला कदम होगा।