医療コミュニケーションにおける手話認識のためのレーダーベースイメージング
This paper introduces a privacy-preserving radar system for recognizing Italian Sign Language in medical settings, achieving high accuracy.
背景と学術的系譜
病院の救急外来を想像してほしい。そこでは、迅速かつ正確で、かつ極めて個人的なコミュニケーションが求められる。手話に頼る聴覚障害者や難聴者にとって、この状況はしばしば深刻なコミュニケーションの障壁を生み出す。人間の通訳がゴールドスタンダードではあるが、常に即座に利用できるとは限らない。この重大なギャップが、医療分野における自動手話認識(SLR)という分野を生み出した。研究者たちは、公平な医療を提供するためには、手話をリアルタイムでテキストや音声に翻訳できる機械が必要だと認識した。しかし、病院という環境でこれを実現することは、テクノロジーの世界が完全には予期していなかった、巨大でユニークな制約をもたらした。
従来の「ペインポイント」は、精度とプライバシーの深刻な対立にあった。歴史的に、SLRは主に2つの方法に依存してきた。1つ目は、センサー付きグローブのようなウェアラブル技術である。これは非常に精度が高いが、かさばり、手話の自然な流れを妨げ、手話において極めて重要な表情などの非手話的キューを完全に捉えられない。2つ目の、より現代的なアプローチは、高解像度のRGBカメラと深度カメラに依存していた。しかし、臨床現場での連続的なビデオ録画の導入は、重大なプライバシー侵害となる。病院は、患者の匿名性に関する厳格な倫理的および法的規制に縛られている。さらに、カメラベースのモデルは、低照度環境や雑然とした病室では苦戦する。一部の初期のレーダーベースのシステムはこのプライバシー問題の解決を試みたが、それらは根本的に語彙が非常に限られており、しばしば実際の患者と医師のコミュニケーションに必要な複雑で具体的な医療用語ではなく、一般的な手の動きを認識する程度であった。本論文の著者たちは、従来のモデルが患者の身元を侵害するか、あるいは単に医学的に有用であるための語彙を欠いていたため、革新を余儀なくされた。
著者たちがこれをどのように解決したかを理解するために、彼らのレーダー技術で使用されている高度に専門化されたドメイン用語を、直感的で日常的なアナロジーに分解してみよう。
- Range Doppler Maps (RDM): テレビで見る標準的な気象レーダーを想像してほしい。ただし、州を横断する巨大な積乱雲を追跡するのではなく、人間の手の正確な距離と速度を追跡する。RDMは本質的に、コンピュータに「物体は正確に0.5メートル離れており、秒速2メートルでこちらに向かっている」と伝えるビジュアルヒートマップである。
- Moving Target Indication (MTI): これは、視覚のための超スマートなノイズキャンセリングヘッドホンのペアだと考えてほしい。病室には、ベッド、壁、医療モニターなど、多くの「静的ノイズ」がある。MTIフィルターは、動いていないものを完全にミュートし、レーダーが患者の手や体の動的な動きにのみ焦点を当てられるようにする。
- Micro-Doppler Signatures: 遠くから歩いてくる友人を、その独特の歩き方や「 swagger 」だけで認識できる能力を想像してほしい。Micro-Doppler signaturesは、その swagger のレーダー版である。これらは、指や手首の微細な、微妙な動きを捉え、あらゆる特定の手話ジェスチャーのユニークな運動学的フィンガープリントを作成する。
- Latent Representations (Embeddings): 1000ページの大著を、最も重要な事実だけを含む、非常に凝縮された単一のチートシートに要約することを想像してほしい。本論文のニューラルネットワークは、大量の生のレーダーデータを取得し、それを小さく密度の高い数学的表現に圧縮することで、システムがそれを超高速で処理し、リアルタイム翻訳を達成できるようにする。
以下は、著者たちがレーダーを設定し、人工知能モデルをトレーニングするために使用した主要な数学的表記法とパラメータの内訳である。
| Notation / Parameter | Description |
|---|---|
| $60$ GHz | 微細な動きを捉えるために使用されるミリ波レーダーセンサーの中心周波数。 |
| $1$ MHz | レーダーシステムのサンプリングレート。 |
| $31$ | レーダーに設定された送信電力レベル。 |
| $40$ dB | レーダー信号に適用される中間周波数(IF)ゲイン。 |
| $0.0312$ m | 空間的なレンジ分解能。これは、レーダーが約3センチメートル離れた物体を区別できることを意味する。 |
| $1.60$ m | レーダーセットアップの最大有効範囲。患者が医師の向かいに座っている状況に理想的である。 |
| $4.11$ m/s | 歪みなしに正確に追跡できるレーダーの最大速度。 |
| $0.0321$ m/s | 速度分解能。非常に遅く、微妙な手の動きの検出を可能にする。 |
| $0.077$ s | 各レーダーフレームを取得するための繰り返し時間。 |
| $-90$ dB | データ前処理中にバックグラウンドノイズを除去するために使用されるスペクトルしきい値。 |
| $\beta_1 = 0.9, \beta_2 = 0.999$ | ニューラルネットワークのトレーニング段階で使用されるAdamWオプティマイザーの減衰率。 |
| $5 \cdot 10^{-5}$ | オートエンコーダーネットワークをトレーニングするために使用される学習率。 |
| $10^{-4}$ | Transformer分類器ネットワークをトレーニングするために使用される学習率。 |
| $5 \cdot 10^{-6}$ | トレーニングデータへのニューラルネットワークの過学習を防ぐために適用される重み減衰パラメータ。 |
問題定義と制約
見えない波を意味にマッピングする:根本的なギャップ
本稿が達成したことの大きさを理解するためには、まずシステムがどこから始まり、どこへ到達する必要があるのかを正確に定義する必要がある。
出発点(入力): システムはカメラレンズを通して世界を見るわけではない。代わりに、60 GHzのミリ波無線信号を発信し、人体に反射して跳ね返ってきたエコーを聞き取る。これらのエコーは、数学的にレンジ・ドップラー・マップ(RDM)および移動ターゲット表示(MTI)に変換される。ゼロベースの読者のために、色や形を示さず、移動する物体が「どれだけ遠くにいるか」(レンジ)と「どれだけ速く動いているか」(ドップラー速度)だけを伝えるヒートマップを想像してほしい。数学的には、入力は高次元行列のシーケンス $X = \{x_1, x_2, \dots, x_T\}$ であり、各フレーム $x_t \in \mathbb{R}^{128 \times 1024}$ であり、シーケンス長 $T$ は、人がサインを行うのにかかる時間に応じて13から66フレームの間で変動する。
目標状態(出力): 望ましい出力は、単一の、非常に具体的な意味ラベルである。システムは、このレーダーマップのシーケンスを、$C = 126$ 個の異なるイタリア手話(LIS)クラス(100の医学用語と26のアルファベット文字)に対する確率分布にマッピングする必要がある。我々が求めているのは、数学的なマッピング関数 $f: X \rightarrow Y$ であり、$Y \in \{1, 2, \dots, 126\}$ である。
失われたリンク: ここでの数学的なギャップは非常に大きい。モデルは、抽象的で非視覚的な物理データ(跳ね返る電波)を、正確な言語的意味に翻訳しなければならない。速度と距離の変動のシーケンスを見て、「その特定の質量の移動パターンは、『医者』を意味し、『肺』ではない」と自信を持って言えなければならない。
プライバシー対精度:残酷なジレンマ
科学において、一つのパラメータを最適化すると、ほぼ必ず別のパラメータが損なわれる。自動手話認識(SLR)において、研究者たちは「精度」と「プライバシー」という痛みを伴う綱引きに囚われてきた。
手話は信じられないほど複雑である。それは、広範な腕の動きだけでなく、微細な手先の動き(正確な指の位置)や非手先の動き(表情、唇の動き、胴体の傾き)にも依存する。従来のRGBおよび深度カメラはこれらすべてを完璧に捉え、高い精度をもたらす。しかし、病院の部屋のような臨床環境では、高解像度カメラの設置は厳格な患者プライバシー法および倫理的境界に違反する。
プライバシーを達成するためには、レーダーを使用できる。レーダーは、視覚的な詳細を捉えないため、本質的に患者の身元を曖昧にする――それは単に移動するエネルギーの塊を見るだけである。しかし、ここにジレンマがある:プライバシーを保護するためにレーダーに切り替えることで、システムは、類似のサインを区別するために絶対に不可欠な微細な視覚的詳細(表情や指の形など)を見えなくしてしまう。以前の研究者たちは行き詰まっていた:カメラを使用するとプライバシーを侵害し、レーダーを使用するとデータが抽象的すぎるために精度が著しく低下するという状況であった。
厳しい壁と制約
この問題を解決するために、著者たちは現実的で容赦のないいくつかの制約を打ち破る必要があった:
- ハードウェアメモリの壁(計算上の制約):
レーダーデータは信じられないほど高密度である。単一のサインジェスチャーは、$128 \times 1024$ のサイズの行列のシーケンスを生成する。この生の、高次元のビデオのようなシーケンスを、時間的ダイナミクスをエンドツーエンドで学習するために単一のディープニューラルネットワークに直接フィードしようとすると、数学的な演算が爆発する。著者たちは、これを行うと過剰なモデル複雑性につながり、GPUメモリの制限を即座に最大化すると明記している。彼らは、現代のハードウェアで数学を計算可能にするために、問題を2段階(まず空間圧縮、次に時間シーケンスモデリング)に分離することを余儀なくされた。 - 「見えない」非手先の合図(物理的な制約):
レーダーは、マクロモーション(腕や手)を捉える波長で動作するため、眉を上げる、特定の唇の形などのマイクロモーションを完全に無視する。多くの手話単語は全く同じ手の動きを共有し、表情によってのみ区別されるため、数学モデルは、腕の速度における隠れた微妙な運動学的パターンを見つけて区別することを余儀なくされ、深刻な情報不足の中で動作する。 - 可変時間ダイナミクス(データ駆動型の制約):
人間はロボットではない。一定の速度でサインするわけではない。ある患者は1秒(13フレーム)で単語をサインするかもしれないが、高齢の患者は全く同じ単語に4秒(66フレーム)かかるかもしれない。モデルは時間的に不変でなければならない。固定長の入力に依存することはできず、可変長のシーケンスを動的にアラインメントし解釈する必要がある。これは、時間とともに長期的な依存関係を追跡するために、Transformerのような高度なシーケンスモデリングを必要とする。 - 極端なデータ不足:
ディープラーニングモデルはデータ飢餓である。複雑なレーダー信号を126個の異なる医学的サインにマッピングするには、数万の例が必要である。本稿以前は、手話のためのレーダーデータセットは非常に小さく、しばしば5つか10の一般的なジェスチャー(左右のスワイプなど)に限定されていた。著者たちは、問題を解決するために必要なデータが存在しないという壁にぶつかり、アルゴリズムのトレーニングを開始する前に、25,830のサインインスタンスからなる大規模で同期されたデータセットをゼロから構築することを余儀なくされた。
このアプローチの理由
著者らがカスタム畳み込みオートエンコーダーとそれに続くTransformerという特定の2段階パイプラインを選択した理由を理解するには、まずレーダーデータの厳しい現実を概観する必要がある。60 GHz mm波レーダーは、Range Doppler Maps (RDMs) および Moving Target Indication (MTI) マップを生成する。これらは本質的に、高次元行列のビデオライクなシーケンスであり、具体的にはフレームあたり $128 \times 1024$ である。
著者が従来のstate-of-the-art (SOTA) 手法では不十分であると認識した正確な瞬間は、問題の純粋な計算上の重さを考慮したときであった。彼らが明示的に述べているように、この問題を単一の巨大なエンドツーエンドのディープネットワークで直接解決しようとすると、「過剰なモデル複雑性と計算コスト」につながる。レーダーデータは次元が高く、シーケンシャルである。生の $128 \times 1024$ フレームを $T$ 時間ステップにわたって標準的な3D CNNまたは純粋なTransformerに直接入力すると、メモリ要件が爆発する。
これを解決するために、彼らは問題を2つの明確な段階に分離した。まず、カスタムCNNオートエンコーダーを構築して空間データを圧縮した。なぜ有名な事前学習済みSOTAモデルであるResNetやAlexNetではなくカスタムモデルなのか?著者は、レーダーマップは自然なRGB画像とは根本的に異なると認識した。それらは標準的な写真のような複雑な視覚的テクスチャを欠いている。重い事前学習済みアーキテクチャを使用すると、実際にはパフォーマンスが低下する。代わりに、残差接続を備えたカスタム9層CNNは、巨大なレーダーフレームを非常にコンパクトな256次元の潜在表現に蒸留する。
これにより、彼らの手法の比較優位性が明らかになる。オートエンコーダーを固定し、256次元の埋め込みのみをTransformerに入力することで、メモリのボトルネックを劇的に削減する。論文では、この2段階プロセスが「エポックごとに生のデータに対する完全なエンドツーエンドトレーニングを回避することにより、GPUメモリの制約を緩和する」と指摘している。彼らはこれを明示的にテキスト内で $O(N^2)$ から $O(N)$ の複雑さへの削減として表現していないが、構造的な利点は明らかである。空間処理は時間処理から完全に分離されている。
さらに、Transformer分類器は、可変長のシーケンスを自然に処理できるため、第2段階において質的に優れている。人間の手話は動的であり、彼らのデータセットでは、ある手話は $T=13$ から $T=66$ フレームまで持続する可能性がある。Transformerの自己注意メカニズムは、データを厳格で固定長のウィンドウに強制することなく、これらの長距離の時間的依存関係をモデル化するのに優れている。3つの別々のレーダーアンテナからのデータを融合し、標準的なRDMと静的な背景ノイズをゼロにするMTIマップを組み合わせることで、モデルは環境干渉に対して信じられないほど堅牢になる。
このアプローチは、問題の制約と解決策の特性との完璧な「結婚」を表している。医療現場では絶対的なプライバシーが要求されるが、レーダーは顔を識別できるものではなく、動きと速度のみをキャプチャすることで物理的にこれを保証する。しかし、これは高度に抽象的でノイズが多く、計算負荷の高いデータという制約を生み出す。オートエンコーダーは完璧なフィルターとして機能し、ノイズを除去して空間次元を圧縮する一方、Transformerは完璧な時間エンジンとして機能し、時間の経過とともにジェスチャーの実際の意味をデコードする。
著者がGANやDiffusionモデルのような他の人気のある現代的なアプローチを使用しなかった理由について疑問に思っているなら、正直なところ、私もこの部分については完全には確信が持てない。なぜなら、論文ではそれらを明示的に言及したり拒否したりしていないからである。しかし、これが生成タスクではなく、厳密に分類問題(レーダーフレームのシーケンスを126の特定のサインクラスのいずれかにマッピングする)であると考えると、新しいデータを合成するように設計されたモデルは、コアの分類制約を解決することなく、不必要なオーバーヘッドをもたらす可能性が高い。著者は、オートエンコーダーとTransformerのペアリングが美しく処理する識別効率に完全に焦点を当てた。
数学的・論理的メカニズム
病院の救急外来で、聴覚障がいのある患者が医師に症状を伝えようとしている状況を想像してほしい。通訳がすぐに利用できない場合、標準的なカメラベースのAIを使用して手話を翻訳すると、プライバシーに関する重大なリスクが生じる。誰もが、脆弱な医療の瞬間に顔や体の高解像度ビデオを記録されることを望まないだろう。
本論文は、カメラを60 GHzミリ波レーダーに置き換えることで、この正確な制約を解決する。レーダーは視覚的なピクセルをキャプチャする代わりに、電波を患者に跳ね返らせ、動く手や体の距離(レンジ)と速度(ドップラー)を測定する。その結果、プライバシーが保護された、顔のない動きのマッピングが得られる。しかし、レーダーデータは信じられないほどノイズが多く、高次元で、シーケンシャルである。著者らは、この膨大なレーダーエコーのストリームをコンパクトな形式に圧縮し、次に機械にそれらのエコーの時間的シーケンスを「読み取る」ことを教え、126種類のイタリア手話(LIS)の医療用語と文字を認識させる方法を見つけ出す必要があった。
ビデオのようなレーダーシーケンスを処理する計算上のボトルネックを克服するために、問題は2段階に分割された。個々のレーダーフレームを圧縮するための畳み込みニューラルネットワーク(CNN)オートエンコーダーと、時間とともに圧縮されたフレームのシーケンスを分析するためのTransformerネットワークである。
正直に言うと、著者がテキストに正確な数式を印刷しなかった理由は完全にはわからない。おそらく、読者が標準的な深層学習の目的をすでに理解していると仮定したのだろう。しかし、彼らはTransformer分類器が「標準的なクロスエントロピー損失を最小化することによって」最適化されると明示的に述べている。したがって、このシステム全体の学習を駆動する絶対的な中心的な数学的エンジンは、クロスエントロピー目的関数である。
$$ \mathcal{L}_{CE} = - \sum_{i=1}^{C} y_i \log(\hat{y}_i) $$
この方程式を分解して、モデルがレーダー波を医療語彙に翻訳する方法を正確に理解しよう。
- $\mathcal{L}_{CE}$: これは総クロスエントロピー損失である。
- 論理的役割: モデルの究極の「スコアカード」またはコンパスとして機能する。値が高いほど、モデルはひどく混乱していることを意味し、ゼロに近い値は、モデルが手話ジェスチャーを完全に理解していることを意味する。
- $\sum_{i=1}^{C}$: $C$個のすべてのクラス(本論文では $C = 126$ LISサイン)にわたる総和演算子。
- なぜ積分ではなく総和なのか? 語彙は、連続的な値のスペクトルではなく、離散的なカテゴリのセット(例:「医師」、「肺」、「首」)であるため。すべての単語にわたるペナルティを合計する必要がある。
- $y_i$: グラウンドトゥルースラベル。
- 論理的役割: これは絶対的な真実である。患者が実際に実行した正しいサインの場合は $1$、他の125個の誤ったサインの場合は $0$ に等しい。これは厳格なフィルターとして機能し、数学が正しい答えに割り当てられた確率のみを考慮するようにする。
- $\hat{y}_i$: Transformerの線形分類層から出力される予測確率。
- 論理的役割: これはモデルの最良の推測であり、0から1の間の数値で、レーダーの動きが単語 $i$ に対応する自信を表す。
- $\log$: モデルの予測に適用される自然対数。
- なぜここで対数を使用するのか? 対数は、モデルが自信を持って間違っている場合に、モデルを大きくペナルティする。正しい答えが「医師」($y_i = 1$) で、モデルが確率 $0.01$ を予測した場合、$\log(0.01)$ は巨大な負の数になる。これは指数的なゴムバンドのように機能し、モデルが深刻な間違いを犯したときに、モデルの重みを激しく元の位置に戻す。
- $-$(負号): 確率 ($\hat{y}_i$) は常に0から1の間にあるため、その対数は常に負である。負号を追加して結果を反転させ、オプティマイザーが最小化できる正の「コスト」にする。
この機械的な組み立てラインを通過する単一の抽象的なデータポイントの正確なライフサイクルを追ってみよう。
まず、生の60 GHzレーダー波が患者の動く手に跳ね返り、センサーに戻る。高速フーリエ変換(FFT)を通じて、この生の信号はレンジ・ドップラーマップ(RDM)に変換される。これは、動きがどこにあり、どれくらいの速さで動いているかを示す2Dグリッドである。この $128 \times 1024$ のグリッドがCNNオートエンコーダーに入力される。オートエンコーダーはゴミ圧縮機のように機能し、巨大なグリッドを9つの畳み込み層を通して絞り込み、256次元の密な潜在表現ベクトルにする。
次に、手話ジェスチャーには時間がかかる(1〜4秒間)ため、これらの256次元ベクトルのシーケンスが並べられる。学習可能な「クラス・トークン」が先頭に取り付けられ、位置エンベディングが追加されるため、モデルはフレームの時間的順序を認識する。このシーケンスがTransformerに流れる。Transformerのマルチヘッド自己注意メカニズムは、各フレームを他のすべてのフレームと比較し、手の軌跡が時間とともにどのように変化するかを把握する。最後に、クラス・トークンは、完全な時間的コンテキストで強化された後、線形層を通過して126個の確率 ($\hat{y}_i$) を出力する。最も高い確率は最終的な翻訳された単語である。
このメカニズムは実際にどのように学習し、収束するのだろうか?ここでは、モデルが高次元の重みに押しつぶされるのを防ぐために、最適化ダイナミクスが慎重に調整されている。
著者らがオートエンコーダーとTransformerを同時に(エンドツーエンドで)トレーニングしようとした場合、GPUメモリは爆発し、損失ランドスケープは局所的最小値で満たされた混沌としたものになっただろう。代わりに、15エポック後にオートエンコーダーをフリーズする。オートエンコーダーの重みをロックすることで、安定した不変の基盤が作成される。
その後、TransformerはAdamWオプティマイザーを使用して700エポックの間トレーニングされる。著者らは、勾配クリッピングを最大ノルム5に明示的に設定した。損失ランドスケープでは、レーダーデータは時折、突然の、巨大なエラー(損失のスパイク)を生成することがあり、通常は勾配を爆発させ、モデルの学習済み重みを破壊する。勾配クリッピングは速度制限として機能し、損失ランドスケープがどれほど急峻になっても、モデルは安全なサイズのステップで下り坂を進むだけであることを保証する。重み減衰 $5 \cdot 10^{-6}$(ニューラル重みが大きくなりすぎてトレーニングデータを記憶するのを防ぐ、穏やかな重力のようなプルとして機能する)と組み合わせることで、モデルはスムーズに印象的な93.6%の精度に収束し、目に見えない電波を通じて複雑な人間の言語を理解できることを証明している。
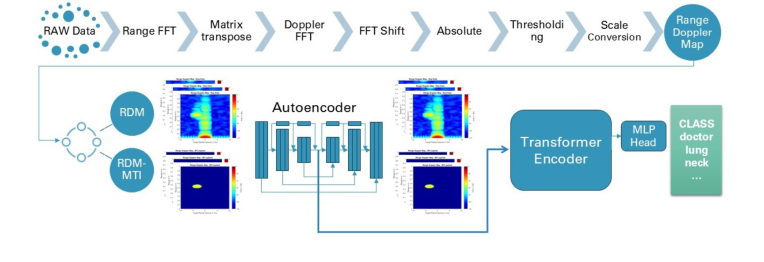 Figure 1. Overview of the end-to-end architecture of the proposed method
Figure 1. Overview of the end-to-end architecture of the proposed method
結果、限界および結論
外国の病院で、言葉が通じない医師に激しい胸痛を訴えなければならない状況を想像してほしい。さらに、あなたが聴覚障害者であり、主要言語がイタリア手話(LIS)のような視覚・身振り言語であると想像してほしい。通訳がすぐに利用できない場合、コミュニケーションの壁は生命を脅かす可能性がある。
これまで、技術者たちは病院の部屋にRGB(標準ビデオ)カメラを設置し、手話を自動的にテキストに翻訳しようと試みてきた。しかし、これにはプライバシーという大きな問題が生じる。病院は非常に機密性の高い空間である。患者は、脆弱な状態で高精細カメラに撮影されることを望まない。さらに、カメラは悪名高いほど気まぐれであり、照明が悪かったり、背景が散らかっていたりすると、機能しなくなる。
本稿では、SFのような響きを持つ素晴らしい解決策を紹介する:60 GHzミリ波(mm-wave)レーダーを使用して手話を「読み取る」ことである。顔や体の個人を特定する視覚的なピクセルをキャプチャする代わりに、レーダーは患者に電波を跳ね返し、手や腕の微細な動きと速度を測定する。レーダーは人を見ることなく、言語の運動学を見る。
著者らがこのプライバシーを保護する翻訳マシンをどのように設計したかを詳しく見ていこう。
制約と数学的問題
レーダーデータは標準的な写真とは異なる。60 GHzレーダーパルスが手話話者に当たると、返ってくる信号はRange Doppler Maps(RDMs)とMoving Target Indication(MTI)マップに処理される。これらは、物体がどこにあるか(レンジ)とどれくらいの速さで動いているか(ドップラー速度)を示すヒートマップと考えることができる。
ここでの制約は、データの次元性と計算負荷の過負荷である。単一の手話ジェスチャーは1〜4秒かかり、最大66個のレーダーフレームのシーケンスを生成する。この巨大で高次元なビデオのようなシーケンスを単一のディープラーニングネットワークに直接入力しようとすると、コンピュータのメモリが詰まり、モデルはoverfit(基盤となるパターンを学習するのではなく、訓練データを記憶してしまう)してしまう。
数学的には、この問題はシーケンス分類タスクである。我々はレーダーフレームのシーケンス $X = \{x_1, x_2, \dots, x_T\}$ を与えられ、ここで $T$ はフレームの可変数であり、このシーケンスを特定の手話クラスラベル $y \in \{1, 2, \dots, 126\}$ にマッピングする必要がある。
メモリの制約を克服するために、著者は問題を2段階のパイプラインに徹底的に分離した。
ステージ1:空間圧縮(オートエンコーダー)
シーケンス全体を一度に処理するのではなく、カスタム畳み込みニューラルネットワーク(CNN)オートエンコーダーを構築し、各フレームを個別に処理した。エンコーダー関数 $E$ は、巨大なレーダーフレーム $x_t$ を受け取り、それを密な低次元ベクトル $z_t \in \mathbb{R}^{256}$ に圧縮する。この圧縮されたベクトルが実際に重要な運動データを含んでいることを保証するために、デコーダー関数 $D$ が元のフレームを再構築しようとする:$\hat{x}_t = D(z_t)$。ネットワークは、$x_t$ と $\hat{x}_t$ の差を最小化するように訓練される。訓練が完了したら、デコーダーは破棄され、エンコーダーを使用してレーダーデータのコンパクトな表現を生成する。
ステージ2:時間的分類(トランスフォーマー)
これで、モデルは軽量なベクトルのシーケンス $Z = \{z_1, z_2, \dots, z_T\}$ を持つことになる。手話は動的(動きの順序が重要)であるため、このシーケンスをトランスフォーマーネットワークにフィードする。トランスフォーマーはマルチヘッド自己注意機構を使用してシーケンス全体を調べ、どの動きがどのサインと相関しているかを把握する。それは126個の可能な医療サインにわたる確率分布 $\hat{y}$ を出力する。モデルは標準的なクロスエントロピー損失を使用して最適化される:
$$ \mathcal{L} = -\sum_{c=1}^{C} y_c \log(\hat{y}_c) $$
ここで $C = 126$ はクラスの総数である。
実験アーキテクチャと「犠牲者」
著者らはこのシステムを構築して機能すると主張しただけでなく、数学的な主張を証明するために高度に制御されたマルチモーダルアリーナを設計した。彼らは、レーダー、標準RGBカメラ、および深度センサーを同時に使用して、25,830個のサインインスタンスの巨大なデータセットを記録した。これにより、彼らのレーダーモデルを、全く同じジェスチャーで視覚ベースのモデルと直接比較することができた。
この実験における「犠牲者」(ベースラインモデル)は、De CosterらによるRGB Video Transformer NetworkやVahdaniによるRGB-D 3D CNN、および以前のレーダーベースのジェスチャーモデル(Jhaung、Debnath、Arab)を含む、最先端の視覚モデルであった。
彼らの成功の決定的で否定できない証拠は、最終的なメトリクスにある。3つのレーダーアンテナを使用し、RDMとMTIの両方のデータストリームを組み合わせた場合、彼らのレーダーモデルは驚異的な93.6%の精度を達成した。これは、わずか88.4%しか達成できなかった主要なRGBベースモデルを完全に凌駕した。
これは画期的な結果である。レーダーによってキャプチャされたマイクロドップラー署名が、実際の視覚ピクセルよりも、この特定のタスクにおいてより堅牢で識別可能な言語的特徴を含んでいることを証明している。さらに、アブレーションスタディを通じて、トランスフォーマーの訓練中にオートエンコーダーを固定することがoverfittingを防ぐ鍵であり、より単純なモデルが優れた汎化を達成することを可能にしたことを証明した。これは、個人情報を完全に隠したまま、150米ドルの非常に効果的なセキュリティシステムが1,000米ドルのカメラセットアップを上回るようなものである。
将来の進化のための議論トピック
本稿で築かれた素晴らしい基盤に基づき、将来の探求と批判的思考のためのいくつかの方向性を以下に示す。
1. レーダーにおける「非マニュアル」キューのジレンマ
手話は単なる手の動きだけではない。文法やトーンを伝えるために、表情、眉の上げ下げ、微妙な唇の動きなどの非マニュアルキューに大きく依存している。レーダーは手足の粗大な運動の追跡に優れているが、顔の表情の微細な筋肉の変化を捉えることができるだろうか?顔の微細な動きを捉えるためにレーダー周波数を上げると、顔を再構築するのに十分な生体認証データを意図せず捉えてしまい、システムが保護するために構築されたプライバシーそのものを破壊するリスクはないだろうか?
2. 個々のサインから連続的な共連結への移行
本研究は126個の個々のサインに焦点を当てている。しかし、自然な人間のコミュニケーションは連続的である。流暢な手話では、あるサインの終わりが次のサインの始まりに物理的に融合する。これは共連結(co-articulation)として知られる現象である。連続的なレーダーデータのストリームを個別の単語にセグメント化するために、トランスフォーマーアーキテクチャはどのように進化する必要があるだろうか?スライディングウィンドウアプローチで十分だろうか、それとも、混沌とした病院環境でセグメント化されていないレーダーシーケンスを処理するために、Connectionist Temporal Classification(CTC)のような根本的に異なる数学的フレームワークが必要だろうか?
3. 言語間および被験者間の汎化
データセットは、単一の被験者によって行われたイタリア手話(LIS)を使用して構築された。すべての人間は独自の運動学的署名を持っている。異なる腕の長さ、異なる手話速度、異なる安静時の姿勢である。被験者Aでレーダーモデルを訓練した場合、マイクロドップラー署名は被験者Bに汎化するだろうか?さらに、LISのためにオートエンコーダーによって学習された潜在埋め込みは、アメリカ手話(ASL)やイギリス手話(BSL)に転移可能だろうか?新しい患者にリアルタイムでレーダーモデルを調整するための教師なしドメイン適応技術を探求することは、グローバルなスケーラビリティにとって重要な次のステップとなるだろう。