Радиолокационная визуализация для распознавания языка жестов в медицинской коммуникации
Представьте себе обстановку в больничной приемной.
Предпосылки и академическая преемственность
Представьте себе обстановку в больничной приемной. Коммуникация должна быть быстрой, точной и глубоко личной. Для глухих и слабослышащих пациентов, которые полагаются на язык жестов, эта ситуация часто создает серьезный коммуникационный барьер. Хотя переводчики-люди являются золотым стандартом, они не всегда доступны по первому требованию. Этот критический пробел породил область автоматического распознавания языка жестов (SLR) в здравоохранении. Исследователи осознали, что для обеспечения справедливого медицинского обслуживания нам нужны машины, способные в реальном времени переводить язык жестов в текст или речь. Однако применение этого в условиях больницы породило огромный, уникальный набор ограничений, которые технологический мир не мог полностью предвидеть.
Фундаментальная "болевая точка" предыдущих подходов — серьезное противоречие между точностью и конфиденциальностью. Исторически SLR полагался на два основных метода. Первый — носимые технологии, такие как перчатки с датчиками. Хотя они очень точны, они громоздки, нарушают естественный поток жестикуляции и полностью упускают невербальные сигналы, такие как выражение лица, которые имеют решающее значение в языке жестов. Второй, более современный подход, полагался на камеры высокого разрешения RGB и глубины. Однако развертывание непрерывной видеозаписи в клинических условиях является серьезным нарушением конфиденциальности. Больницы связаны строгими этическими и юридическими нормами, касающимися анонимности пациентов. Кроме того, модели на основе камер испытывают трудности в условиях низкой освещенности или загроможденных больничных палат. Хотя некоторые ранние радиолокационные системы пытались решить эту проблему конфиденциальности, они были принципиально ограничены крошечными словарями — часто распознавали лишь общие взмахи руками, а не сложный, специфический медицинский лексикон, необходимый для реального общения пациента с врачом. Авторы этой статьи были вынуждены внедрять инновации, поскольку предыдущие модели либо компрометировали личность пациента, либо просто не имели достаточного словарного запаса, чтобы быть медицински полезными.
Чтобы понять, как авторы решили эту проблему, давайте разберем некоторые узкоспециализированные термины предметной области, используемые в их радиолокационной технологии, на интуитивно понятные, повседневные аналогии:
- Карты диапазона-Доплера (RDM): Представьте себе стандартный метеорологический радар в новостях, но вместо отслеживания огромных грозовых облаков по штату он отслеживает точное расстояние и скорость человеческой руки. RDM — это, по сути, визуальная тепловая карта, которая говорит компьютеру: "Объект находится на расстоянии ровно 0,5 метра и движется к нам со скоростью 2 метра в секунду".
- Индикация движущихся целей (MTI): Думайте об этом как о паре ультра-умных наушников с шумоподавлением, но для зрения. В больничной палате много "статического шума" — кровати, стены, медицинские мониторы. Фильтр MTI полностью заглушает все, что не движется, позволяя радару сосредоточиться исключительно на динамических движениях рук и тела пациента.
- Микро-доплеровские сигнатуры: Представьте, что вы можете узнать друга, идущего к вам издалека, просто по его уникальной походке или "походке". Микро-доплеровские сигнатуры — это радиолокационный эквивалент этой походки. Они улавливают крошечные, тонкие трепетания пальцев и запястий, создавая уникальный кинематический отпечаток для каждого конкретного жеста языка жестов.
- Скрытые представления (вложения): Представьте, что вы взяли массивный учебник объемом 1000 страниц и сжали его до одной, очень плотной шпаргалки, содержащей только самые важные факты. Нейронная сеть в этой статье берет огромные объемы необработанных радиолокационных данных и сжимает их в крошечное, плотное математическое представление, чтобы система могла обрабатывать их со скоростью молнии для достижения перевода в реальном времени.
Вот разбивка ключевых математических обозначений и параметров, которые авторы использовали для настройки своего радара и обучения моделей искусственного интеллекта:
| Обозначение / Параметр | Описание |
|---|---|
| $60$ ГГц | Центральная частота миллиметрового волнового радиолокационного датчика, используемого для захвата мелкозернистого движения. |
| $1$ МГц | Частота дискретизации радиолокационной системы. |
| $31$ | Уровень мощности передачи, настроенный для радара. |
| $40$ дБ | Усиление промежуточной частоты (ПЧ), применяемое к радиолокационному сигналу. |
| $0.0312$ м | Пространственное разрешение по дальности, означающее, что радар может различать объекты на расстоянии около 3 сантиметров. |
| $1.60$ м | Максимальная эффективная дальность радиолокационной установки, идеально подходящая для пациента, сидящего напротив врача. |
| $4.11$ м/с | Максимальная скорость, которую радар может точно отслеживать без искажений. |
| $0.0321$ м/с | Разрешение по скорости, позволяющее обнаруживать очень медленные, тонкие движения рук. |
| $0.077$ с | Время повторения для получения каждого радиолокационного кадра. |
| $-90$ дБ | Спектральный порог, используемый для фильтрации фонового шума во время предварительной обработки данных. |
| $\beta_1 = 0.9, \beta_2 = 0.999$ | Коэффициенты затухания для оптимизатора AdamW, используемого во время фазы обучения нейронной сети. |
| $5 \cdot 10^{-5}$ | Скорость обучения, используемая для обучения сети автокодировщика. |
| $10^{-4}$ | Скорость обучения, используемая для обучения сети классификатора Transformer. |
| $5 \cdot 10^{-6}$ | Параметр затухания весов, применяемый для предотвращения переобучения нейронной сети на обучающих данных. |
Определение проблемы и ограничения
Отображение невидимых волн на смысл: фундаментальный разрыв
Чтобы понять масштаб того, чего добилась эта статья, мы сначала должны определить, где именно начинается система и где ей нужно оказаться.
Отправная точка (вход): Система не видит мир через объектив камеры. Вместо этого она излучает миллиметровые радиоволны частотой 60 ГГц и слушает эхо, отражающееся от человеческого тела. Эти эхо-сигналы математически преобразуются в карты диапазона-Доплера (RDM) и индикаторы движущихся целей (MTI). Для читателя с нулевым уровнем знаний представьте тепловую карту, которая не показывает цвета или формы, а только сообщает вам, насколько далеко находится движущийся объект (дальность) и как быстро он движется (доплеровская скорость). Математически вход представляет собой последовательность матриц высокой размерности $X = \{x_1, x_2, \dots, x_T\}$, где каждый кадр $x_t \in \mathbb{R}^{128 \times 1024}$, а длина последовательности $T$ варьируется от 13 до 66 кадров в зависимости от того, сколько времени требуется человеку для выполнения жеста.
Целевое состояние (выход): Желаемый выход — это одна, высокоспецифичная семантическая метка. Система должна отобразить эту последовательность радиолокационных карт в распределение вероятностей по $C = 126$ различным классам итальянского языка жестов (LIS) (100 медицинских терминов и 26 букв алфавита). Мы ищем функцию математического отображения $f: X \rightarrow Y$, где $Y \in \{1, 2, \dots, 126\}$.
Отсутствующее звено: Математический разрыв здесь огромен. Модель должна преобразовывать абстрактные, невизуальные физические данные (отраженные радиоволны) в точный лингвистический смысл. Она должна взглянуть на последовательность флуктуаций скорости и расстояния и уверенно сказать: "Эта конкретная модель движущейся массы означает 'врач', а не 'легкое'".
Жестокая дилемма: конфиденциальность против точности
В науке, когда вы оптимизируете один параметр, вы почти всегда нарушаете другой. Для автоматического распознавания языка жестов (SLR) исследователи оказались в болезненной борьбе между точностью и конфиденциальностью.
Язык жестов невероятно сложен. Он опирается не только на широкие движения рук, но и на тонкие ручные сигналы (точное положение пальцев) и невербальные сигналы (выражение лица, движения губ, сдвиги корпуса). Традиционные камеры RGB и глубины идеально захватывают все это, обеспечивая высокую точность. Однако в клинических условиях, таких как больничная палата, установка камер высокого разрешения нарушает строгие законы о конфиденциальности пациентов и этические границы.
Для обеспечения конфиденциальности можно использовать РАДАР. Радар по своей сути скрывает личность пациента, поскольку не захватывает визуальные детали — он просто видит движущиеся пятна энергии. Но вот дилемма: переходя на радар для защиты конфиденциальности, вы мгновенно лишаете свою систему тонких визуальных деталей (таких как выражение лица и форма пальцев), которые абсолютно критичны для различения похожих жестов. Предыдущие исследователи оказались в тупике: использовать камеры и нарушать конфиденциальность, или использовать радар и страдать от ужасной точности, потому что данные слишком абстрактны.
Жесткие стены и ограничения
Чтобы решить эту проблему, авторам пришлось пробить несколько реалистичных, неумолимых ограничений:
- Стена памяти оборудования (вычислительные ограничения):
Радиолокационные данные невероятно плотные. Один жест языка жестов производит последовательность матриц размером $128 \times 1024$. Если попытаться подать эту необработанную, высокоразмерную видеоподобную последовательность непосредственно в одну глубокую нейронную сеть для изучения временной динамики сквозным образом, математические операции взорвутся. Авторы явно отмечают, что это приводит к чрезмерной сложности модели и немедленно исчерпывает пределы памяти GPU. Они были вынуждены разделить проблему на два этапа (сначала пространственное сжатие, затем моделирование временной последовательности), чтобы сделать математику вычислимой на современном оборудовании. - "Невидимые" невербальные сигналы (физические ограничения):
Поскольку радар работает на длине волны, которая улавливает макроскопическое движение (руки и кисти), он полностью упускает микроскопические движения, такие как поднятая бровь или определенная форма губ. Поскольку многие слова языка жестов имеют одинаковые движения рук и отличаются только выражением лица, математическая модель вынуждена находить скрытые, тонкие кинематические закономерности в скорости движения руки, чтобы различать их, работая с серьезным дефицитом информации. - Переменная временная динамика (ограничения, основанные на данных):
Люди — не роботы; они не жестикулируют с постоянной скоростью. Один пациент может выполнить слово за 1 секунду (13 кадров), в то время как пожилой пациент может потратить 4 секунды (66 кадров) на то же самое слово. Модель должна быть временно инвариантной. Она не может полагаться на входные данные фиксированной длины; она должна динамически выравнивать и интерпретировать последовательности переменной длины, требуя продвинутого моделирования последовательностей, такого как Трансформеры, для отслеживания долгосрочных зависимостей во времени. - Крайняя нехватка данных:
Модели глубокого обучения "голодны" до данных. Чтобы отобразить сложные радиолокационные сигналы на 126 различных медицинских жестов, вам нужны десятки тысяч примеров. До этой статьи радиолокационные наборы данных для языка жестов были крошечными, часто ограниченными 5 или 10 общими жестами (например, свайп влево или вправо). Авторы столкнулись со стеной, где данных, необходимых для решения проблемы, просто не существовало, что вынудило их создать массивный, синхронизированный набор данных из 25 830 примеров жестов с нуля, прежде чем они смогли приступить к обучению своих алгоритмов.
Почему такой подход
Чтобы понять, почему авторы выбрали свой конкретный двухэтапный конвейер — пользовательский сверточный автокодировщик, за которым следует Трансформер, — мы сначала должны взглянуть на суровую реальность радиолокационных данных. Миллиметровый радар 60 ГГц генерирует карты диапазона-Доплера (RDM) и карты индикации движущихся целей (MTI). Это, по сути, видеоподобные последовательности матриц высокой размерности, в частности $128 \times 1024$ на кадр.
Точный момент, когда авторы поняли, что традиционные передовые (SOTA) методы недостаточны, наступил, когда они рассмотрели огромный вычислительный вес проблемы. Как они явно заявляют, попытка решить это напрямую с помощью одной, массивной сквозной глубокой сети привела бы к "чрезмерной сложности модели и вычислительным затратам". Радиолокационные данные являются высокоразмерными и последовательными. Если подать необработанные кадры $128 \times 1024$ в течение $T$ временных шагов непосредственно в стандартную 3D CNN или чистый Трансформер, требования к памяти взлетят.
Чтобы решить эту проблему, они разделили задачу на два отдельных этапа. Во-первых, они построили пользовательский сверточный автокодировщик для сжатия пространственных данных. Почему пользовательская модель вместо известной предварительно обученной SOTA модели, такой как ResNet или AlexNet? Авторы поняли, что радиолокационные карты принципиально отличаются от естественных RGB-изображений. Им не хватает сложных визуальных текстур стандартных фотографий. Использование тяжелой, предварительно обученной архитектуры фактически ухудшило бы производительность. Вместо этого их пользовательская 9-слойная CNN с остаточными соединениями дистиллирует массивный радиолокационный кадр в высококомпактное скрытое представление размерностью 256.
Это подводит нас к сравнительному превосходству их метода. Замораживая автокодировщик и подавая только вложения размерностью 256 в Трансформер, они значительно уменьшают узкое место памяти. В статье отмечается, что этот двухэтапный процесс "снижает ограничения памяти GPU, избегая полного сквозного обучения на необработанных данных для каждой эпохи". Хотя они явно не формулируют это как снижение сложности с $O(N^2)$ до $O(N)$ в тексте, структурное преимущество очевидно: пространственная обработка полностью отделена от временной обработки.
Кроме того, классификатор Трансформер качественно превосходит на втором этапе, поскольку он естественным образом обрабатывает последовательности переменной длины. Человеческий язык жестов динамичен; в их наборе данных жест может длиться от 13 до 66 кадров. Механизм самовнимания Трансформера отлично подходит для моделирования этих долгосрочных временных зависимостей без принудительного помещения данных в жесткие окна фиксированной длины. Объединяя данные из трех отдельных радиолокационных антенн и комбинируя стандартные RDM с картами MTI (которые обнуляют статический фоновый шум), модель становится невероятно устойчивой к помехам окружающей среды.
Этот подход представляет собой идеальное "слияние" ограничений проблемы и свойств решения. Медицинская обстановка требует абсолютной конфиденциальности, которую радар физически гарантирует, захватывая только движение и скорость, а не идентифицируемые лица. Однако это создает ограничение высокоабстрактных, шумных и вычислительно тяжелых данных. Автокодировщик действует как идеальный фильтр, отсеивая шум и сжимая пространственные измерения, в то время как Трансформер действует как идеальный временной движок, декодируя фактический смысл жеста во времени.
Если вы задаетесь вопросом, почему авторы не использовали другие популярные современные подходы, такие как GAN или диффузионные модели, честно говоря, я тоже не до конца уверен в этой части, поскольку в статье они явно не упоминаются и не отвергаются. Однако, учитывая, что это строго задача классификации (отображение последовательности радиолокационных кадров на один из 126 конкретных классов жестов), а не генеративная задача, модели, разработанные для синтеза новых данных, вероятно, ввели бы ненужные накладные расходы, не решая основное ограничение классификации. Авторы сосредоточились исключительно на дискриминативной эффективности, которую их пара автокодировщик-Трансформер прекрасно обрабатывает.
Математический и логический механизм
Представьте себе глухого пациента в больничной приемной, пытающегося объяснить врачу свои симптомы. Переводчик немедленно недоступен, а использование стандартного ИИ на основе камер для перевода их языка жестов создает огромные риски для конфиденциальности — никто не хочет, чтобы во время уязвимого медицинского момента записывалось видео высокого разрешения его лица и тела.
Эта статья решает именно это ограничение, заменяя камеры миллиметровым радиолокатором 60 ГГц. Вместо захвата визуальных пикселей радар отражает радиоволны от пациента, измеряя расстояние (дальность) и скорость (Доплер) его движущихся рук и тела. Результатом является сохраняющая конфиденциальность, безликая карта движения. Однако радиолокационные данные чрезвычайно шумные, высокоразмерные и последовательные. Авторам пришлось выяснить, как сжать этот массивный поток радиолокационных эхо-сигналов в компактный формат, а затем научить машину "читать" временную последовательность этих эхо-сигналов для распознавания 126 различных медицинских терминов и букв итальянского языка жестов (LIS).
Чтобы преодолеть вычислительное узкое место при обработке видеоподобных радиолокационных последовательностей, они разделили проблему на два этапа: сверточная нейронная сеть (CNN) автокодировщик для сжатия каждого отдельного радиолокационного кадра и сеть Трансформер для анализа последовательности сжатых кадров во времени.
Честно говоря, я не до конца уверен, почему авторы решили не печатать свои точные математические формулы в тексте — они, вероятно, предполагали, что аудитория уже знакома со стандартными целями глубокого обучения. Однако они явно заявляют, что их классификатор Трансформер оптимизируется путем "минимизации стандартной кросс-энтропийной потери". Следовательно, абсолютным основным математическим двигателем, управляющим обучением всей этой системы, является функция кросс-энтропийной потери.
$$ \mathcal{L}_{CE} = - \sum_{i=1}^{C} y_i \log(\hat{y}_i) $$
Давайте разберем это уравнение, чтобы понять, как именно модель учится преобразовывать радиолокационные волны в медицинский словарь:
- $\mathcal{L}_{CE}$: Это общая кросс-энтропийная потеря.
- Логическая роль: Она действует как окончательный "счет" или компас для модели. Высокое значение означает, что модель ужасно запутана; значение, близкое к нулю, означает, что модель идеально понимает жест языка жестов.
- $\sum_{i=1}^{C}$: Оператор суммирования по всем $C$ классам (в данной статье $C = 126$ жестов LIS).
- Почему сумма вместо интеграла? Потому что словарь представляет собой дискретный набор различных категорий (например, "врач", "легкое", "шея"), а не непрерывный спектр значений. Мы должны подсчитать штраф по каждому возможному слову.
- $y_i$: Метка истинной цели (ground truth).
- Логическая роль: Это абсолютная истина. Она равна $1$ для правильного жеста, который пациент фактически выполнил, и $0$ для остальных 125 неправильных жестов. Она действует как строгий фильтр, гарантируя, что математика заботится только о вероятности, присвоенной правильному ответу.
- $\hat{y}_i$: Прогнозируемая вероятность, выданная линейным классификационным слоем Трансформера.
- Логическая роль: Это наилучшая догадка модели, число от 0 до 1, представляющее, насколько она уверена, что радиолокационное движение соответствует слову $i$.
- $\log$: Натуральный логарифм, применяемый к прогнозу модели.
- Зачем здесь использовать логарифм? Логарифм сильно наказывает модель, когда она уверенно ошибается. Если правильный ответ — "врач" ($y_i = 1$), но модель предсказывает вероятность $0.01$, $\log(0.01)$ дает огромное отрицательное число. Он действует как экспоненциальная резинка, яростно возвращающая веса модели на место, когда она совершает серьезную ошибку.
- $-$ (Знак минус): Поскольку вероятности ($\hat{y}_i$) всегда находятся в диапазоне от 0 до 1, их логарифм всегда отрицателен. Мы добавляем знак минус, чтобы преобразовать результат в положительную "стоимость", которую оптимизатор может минимизировать.
Давайте проследим точный жизненный цикл одного абстрактного набора данных, проходящего через этот механический сборочный конвейер.
Сначала сырая радиоволна 60 ГГц отражается от движущихся рук пациента и возвращается к датчику. С помощью быстрого преобразования Фурье (FFT) этот сырой сигнал преобразуется в карту диапазона-Доплера (RDM) — 2D-сетку, показывающую, где находится движение и с какой скоростью оно движется. Эта сетка $128 \times 1024$ поступает в CNN автокодировщик. Автокодировщик действует как пресс для мусора, сжимая огромную сетку через 9 сверточных слоев, пока она не станет плотным скрытым представлением размерностью 256.
Затем, поскольку жест языка жестов занимает время (охватывая от 1 до 4 секунд), последовательность этих векторов размерностью 256 выстраивается в ряд. К началу добавляется обучаемый "класс-токен", а также добавляются позиционные вложения, чтобы модель знала хронологический порядок кадров. Эта последовательность поступает в Трансформер. Механизм многоголовочного самовнимания Трансформера сравнивает каждый кадр с каждым другим кадром, выясняя, как траектория руки меняется со временем. Наконец, класс-токен — теперь обогащенный полным временным контекстом — пропускается через линейный слой, чтобы выдать 126 вероятностей ($\hat{y}_i$). Наивысшая вероятность — это окончательное переведенное слово.
Как этот механизм фактически учится и сходится? Динамика оптимизации здесь тщательно оркестрована, чтобы предотвратить коллапс модели под весом ее собственных высоких размерностей.
Если бы авторы попытались обучать автокодировщик и Трансформер одновременно (сквозным образом), память GPU взорвалась бы, а ландшафт потерь был бы хаотичным, заполненным локальными минимумами. Вместо этого они замораживают автокодировщик после 15 эпох. Заблокировав веса автокодировщика, они создают стабильный, неизменный фундамент.
Затем Трансформер обучается в течение 700 эпох с использованием оптимизатора AdamW. Авторы явно установили ограничение градиента на максимальную норму 5. В ландшафте потерь радиолокационные данные иногда могут вызывать внезапные, массивные ошибки (всплески потерь), которые обычно приводили бы к взрыву градиентов и разрушению выученных весов модели. Ограничение градиента действует как ограничение скорости, гарантируя, что независимо от того, насколько крутым становится ландшафт потерь, модель делает только безопасно большой шаг вниз. В сочетании с затуханием весов $5 \cdot 10^{-6}$ (которое действует как мягкая гравитационная сила, удерживающая веса нейронной сети от чрезмерного роста и запоминания обучающих данных), модель плавно сходится к впечатляющей точности 93,6%, доказывая, что мы действительно можем понимать сложный человеческий язык через невидимые радиоволны.
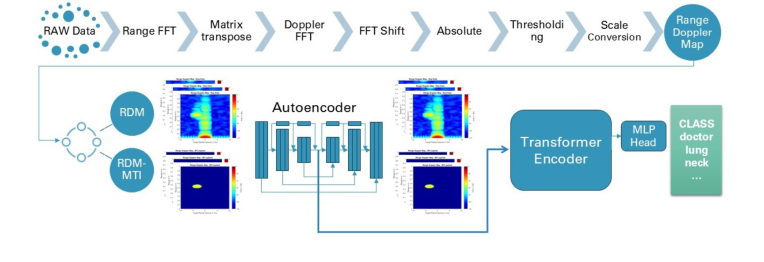 Figure 1. Overview of the end-to-end architecture of the proposed method
Figure 1. Overview of the end-to-end architecture of the proposed method
Результаты, ограничения и заключение
Представьте, что вы находитесь в больнице в чужой стране и пытаетесь объяснить врачу, что у вас сильная боль в груди, но вы не говорите на его языке. Теперь представьте, что вы глухой, и ваш основной язык — визуально-жестовая система, такая как итальянский язык жестов (LIS). Если переводчик немедленно недоступен, коммуникационный барьер может быть опасен для жизни.
Исторически сложилось так, что технологи пытались решить эту проблему, размещая в больничных палатах камеры RGB (стандартное видео) для автоматического перевода языка жестов в текст. Но это создает огромную проблему: конфиденциальность. Больницы — это высокочувствительные пространства. Пациенты не хотят, чтобы камеры высокого разрешения записывали их в уязвимых состояниях. Кроме того, камеры печально известны своей капризностью; если освещение плохое или фон загроможден, они выходят из строя.
Эта статья представляет блестящее, похожее на научную фантастику решение: использование миллиметрового (мм-волнового) радара 60 ГГц для "чтения" языка жестов. Вместо захвата визуальных пикселей, идентифицирующих лицо или тело человека, радар отражает радиоволны от пациента и измеряет микродвижения и скорости его рук и предплечий. Радар видит кинематику языка, не видя человека.
Давайте разберем, как именно авторы разработали эту машину перевода, сохраняющую конфиденциальность.
Ограничения и математическая задача
Радиолокационные данные не похожи на обычную фотографию. Когда импульсы радара 60 ГГц попадают на говорящего, возвращающиеся сигналы обрабатываются в карты диапазона-Доплера (RDM) и карты индикации движущихся целей (MTI). Вы можете думать о них как о тепловых картах, показывающих, где находится объект (дальность) и как быстро он движется (доплеровская скорость).
Ограничением здесь является размерность данных и вычислительная перегрузка. Один жест языка жестов занимает от 1 до 4 секунд, генерируя последовательность до 66 радиолокационных кадров. Если попытаться подать эту массивную, высокоразмерную видеоподобную последовательность непосредственно в одну сеть глубокого обучения, память компьютера будет перегружена, и модель переобучится (запомнит обучающие данные, а не выучит основные закономерности).
Математически задача представляет собой классификацию последовательностей. Нам дана последовательность радиолокационных кадров $X = \{x_1, x_2, \dots, x_T\}$, где $T$ — переменное количество кадров, и нам нужно отобразить эту последовательность на конкретную метку класса языка жестов $y \in \{1, 2, \dots, 126\}$.
Чтобы преодолеть ограничения памяти, авторы безжалостно разделили проблему на двухэтапный конвейер:
Этап 1: Пространственное сжатие (Автокодировщик)
Вместо одновременной обработки всей последовательности они построили пользовательский сверточный автокодировщик (CNN) для индивидуальной обработки каждого кадра. Функция кодировщика $E$ принимает массивный радиолокационный кадр $x_t$ и сжимает его в плотный вектор низкой размерности $z_t \in \mathbb{R}^{256}$. Чтобы гарантировать, что этот сжатый вектор действительно содержит важные данные о движении, функция декодера $D$ пытается восстановить исходный кадр: $\hat{x}_t = D(z_t)$. Сеть обучается минимизировать разницу между $x_t$ и $\hat{x}_t$. После обучения декодер отбрасывается, а кодировщик сохраняется для генерации компактных представлений радиолокационных данных.
Этап 2: Временная классификация (Трансформер)
Теперь у модели есть легкая последовательность векторов $Z = \{z_1, z_2, \dots, z_T\}$. Поскольку язык жестов динамичен (порядок движений имеет значение), они подают эту последовательность в сеть Трансформер. Трансформер использует многоголовочное самовнимание для просмотра всей последовательности и определения того, какие движения коррелируют с какими жестами. Он выдает распределение вероятностей $\hat{y}$ по 126 возможным медицинским жестам. Модель оптимизируется с использованием стандартной кросс-энтропийной потери:
$$ \mathcal{L} = -\sum_{c=1}^{C} y_c \log(\hat{y}_c) $$
где $C = 126$ — общее количество классов.
Экспериментальная архитектура и "жертвы"
Авторы не просто построили эту систему и заявили, что она работает; они спроектировали высококонтролируемую, мультимодальную арену, чтобы доказать свои математические утверждения. Они записали массивный набор данных из 25 830 примеров жестов, используя одновременно радар, стандартные камеры RGB и датчики глубины. Это позволило им напрямую сравнить свою радиолокационную модель с моделями на основе зрения на тех же жестах.
"Жертвами" (базовыми моделями) в этом эксперименте были передовые модели на основе зрения, включая RGB Video Transformer Network Де Костера и др. и 3D CNN на основе RGB-D Вахдани, а также предыдущие радиолокационные модели жестов (Jhaung, Debnath, Arab).
Окончательным, неоспоримым доказательством их успеха являются финальные метрики. При использовании трех радиолокационных антенн и объединении потоков данных RDM и MTI их радиолокационная модель достигла ошеломляющей точности 93,6%. Она полностью превзошла ведущую модель на основе RGB (которая показала только 88,4%).
Это глубокий результат. Он доказывает, что микро-доплеровские сигнатуры, захваченные радаром, содержат больше надежных, различимых лингвистических признаков для этой конкретной задачи, чем фактические визуальные пиксели. Кроме того, они доказали с помощью абляционных исследований, что замораживание автокодировщика во время обучения Трансформера было ключом к предотвращению переобучения, позволяя более простой модели достичь превосходной обобщающей способности. Это эквивалентно покупке высокоэффективной системы безопасности за 150 долларов США, которая превосходит камерную установку за 1000 долларов, при этом полностью скрывая вашу личность.
Темы для обсуждения для будущей эволюции
Основываясь на блестящем фундаменте, заложенном этой статьей, вот несколько направлений для будущих исследований и критического мышления:
1. Дилемма "невербальных" сигналов в радаре
Язык жестов — это не просто взмахи руками; он сильно опирается на невербальные сигналы, такие как выражение лица, поднятие бровей и тонкие движения губ, для передачи грамматики и тона. Радар исключительно хорошо отслеживает грубые движения конечностей, но может ли он уловить микромышечные изменения выражения лица? Если мы увеличим частоту радара для захвата этих микродвижений, не рискуем ли мы непреднамеренно захватить достаточно биометрических данных для реконструкции лица, тем самым уничтожив ту самую конфиденциальность, которую система была создана для защиты?
2. Переход от изолированных жестов к непрерывной коартикуляции
Данное исследование фокусируется на 126 изолированных жестах. Однако естественное человеческое общение непрерывно. В беглом языке жестов конец одного жеста физически сливается с началом следующего — явление, известное как коартикуляция. Как архитектура Трансформера должна эволюционировать, чтобы сегментировать непрерывный поток радиолокационных данных на отдельные слова? Достаточно ли будет подхода с скользящим окном, или нам нужна принципиально иная математическая структура, такая как Connectionist Temporal Classification (CTC), для обработки несегментированных радиолокационных последовательностей в хаотичной больничной обстановке?
3. Межъязыковая и межсубъектная обобщаемость
Набор данных был создан с использованием итальянского языка жестов (LIS), исполняемого одним субъектом. Каждый человек имеет уникальную кинематическую подпись — разную длину рук, разную скорость жестикуляции и разную позу покоя. Если мы обучим радиолокационную модель на Субъекте А, обобщатся ли микро-доплеровские сигнатуры на Субъекта Б? Кроме того, могут ли скрытые вложения, выученные автокодировщиком для LIS, быть переносимы на американский язык жестов (ASL) или британский язык жестов (BSL)? Исследование методов адаптации домена без учителя для калибровки радиолокационной модели на новых пациентах в реальном времени будет критически важным следующим шагом для глобальной масштабируемости.