基于雷达的医学交流手语识别成像
This paper introduces a privacy-preserving radar system for recognizing Italian Sign Language in medical settings, achieving high accuracy.
背景与学术传承
设想一下在医院急诊室的环境中。沟通需要快速、准确且高度个性化。对于依赖手语的聋哑和听障患者来说,这种情况常常会造成严重的沟通障碍。虽然人工翻译是黄金标准,但他们并非总能随时待命。这一关键的缺口催生了医疗领域自动手语识别(SLR)的研究。研究人员意识到,为了提供公平的医疗服务,我们需要能够实时将手语翻译成文本或语音的机器。然而,在医院环境中实现这一点引入了一系列技术界未曾完全预料到的巨大且独特的限制。
以往方法的根本“痛点”在于准确性和隐私之间的严重冲突。历史上,SLR 主要依赖两种方法。第一种是可穿戴技术,例如配备传感器的手套。虽然精度很高,但它们笨重,会干扰手语的自然流畅性,并且完全忽略了非手动线索,如面部表情,而这些在手语中至关重要。第二种,也是更现代的方法,依赖于高清 RGB 和深度摄像头。然而,在临床环境中部署连续视频录制是对隐私的严重侵犯。医院受到关于患者匿名的严格伦理和法律法规的约束。此外,基于摄像头的模型在低光照条件或杂乱的病房中表现不佳。虽然一些早期的雷达系统试图解决这一隐私问题,但它们在词汇量方面受到根本性限制——通常只能识别通用的挥手动作,而无法识别实际医患沟通所需的复杂、特定的医学词汇。本文的作者之所以被迫创新,是因为以往的模型要么损害了患者的身份信息,要么根本缺乏医学上可用的词汇量。
为了理解作者是如何解决这个问题的,让我们将他们雷达技术中使用的一些高度专业化的领域术语分解成直观的日常类比:
- Range Doppler Maps (RDM)(距离-多普勒图): 想象一下新闻中标准的が天气雷达,但它追踪的不是横跨一个州的巨大风暴云,而是人手的精确距离和速度。RDM 本质上是一个视觉热力图,告诉计算机:“一个物体距离我们 0.5 米,正以 2 米/秒的速度向我们移动。”
- Moving Target Indication (MTI)(动目标显示): 将其视为一副超智能降噪耳机,但用于视觉。在病房里,有很多“静态噪声”——床、墙壁、医疗监视器。MTI 滤波器会完全屏蔽任何不移动的物体,使雷达能够完全专注于患者手部和身体的动态运动。
- Micro-Doppler Signatures(微多普勒特征): 想象一下能够仅凭朋友独特的步态或“摇摆”方式,就能从远处认出他走过来。微多普勒特征就是雷达版的“摇摆”。它们捕捉手指和手腕微小、微妙的颤动,为每一种特定的手语手势创造独特的运动学指纹。
- Latent Representations (Embeddings)(潜在表示/嵌入): 想象一下将一本 1000 页的巨著浓缩成一张高度精炼的备忘单,其中只包含最关键的事实。本文中的神经网络将大量的原始雷达数据压缩成一个微小、密集 的数学表示,以便系统能够以闪电般的速度处理它,从而实现实时翻译。
以下是作者用于配置其雷达和训练其人工智能模型的关键数学符号和参数的细分:
| 符号/参数 | 描述 |
|---|---|
| $60$ GHz | 用于捕捉精细运动的毫米波雷达传感器的中心频率。 |
| $1$ MHz | 雷达系统的采样率。 |
| $31$ | 为雷达配置的发射功率等级。 |
| $40$ dB | 应用于雷达信号的中频(IF)增益。 |
| $0.0312$ m | 空间距离分辨率,意味着雷达可以区分约 3 厘米的物体。 |
| $1.60$ m | 雷达设置的最大有效范围,非常适合患者坐在医生对面。 |
| $4.11$ m/s | 雷达能够准确跟踪而不失真的最大速度。 |
| $0.0321$ m/s | 速度分辨率,能够检测非常缓慢、细微的手部运动。 |
| $0.077$ s | 获取每个雷达帧的重复时间。 |
| $-90$ dB | 在数据预处理期间用于过滤背景噪声的频谱阈值。 |
| $\beta_1 = 0.9, \beta_2 = 0.999$ | 在神经网络训练阶段使用的 AdamW 优化器的衰减率。 |
| $5 \cdot 10^{-5}$ | 用于训练自编码器网络的学习率。 |
| $10^{-4}$ | 用于训练 Transformer 分类器网络的学习率。 |
| $5 \cdot 10^{-6}$ | 应用的权重衰减参数,用于防止神经网络对训练数据过拟合。 |
问题定义与约束
将无形波映射至意义:根本性的鸿沟
为了理解本文所取得成就的宏大规模,我们首先需要精确定义系统的起点和终点。
起点(输入): 该系统并非通过摄像头镜头观察世界。相反,它发射 60 GHz 的毫米波无线电信号,并接收从人体反射回来的回波。这些回波经过数学变换,生成距离-多普勒图(Range Doppler Maps, RDM)和运动目标指示(Moving Target Indications, MTI)。对于零基础的读者来说,可以想象一张热力图,它不显示颜色或形状,只告诉你移动物体有多远(距离,Range)以及移动速度有多快(多普勒速度,Doppler velocity)。在数学上,输入是一个高维矩阵序列 $X = \{x_1, x_2, \dots, x_T\}$,其中每个帧 $x_t \in \mathbb{R}^{128 \times 1024}$,序列长度 $T$ 根据 người 做出手语所需的时间,在 13 到 66 帧之间变化。
目标状态(输出): 所期望的输出是单个、高度特定的语义标签。系统必须将此雷达图序列映射到 $C = 126$ 个不同的意大利手语(LIS)类别(100 个医学术语和 26 个字母)的概率分布。我们寻求一个数学映射函数 $f: X \rightarrow Y$,其中 $Y \in \{1, 2, \dots, 126\}$。
缺失的环节: 数学上的鸿沟在此处是巨大的。模型必须将抽象的、非视觉的物理数据(反射的无线电波)翻译成精确的语言意义。它必须观察一系列速度和距离的波动,并自信地说:“这种特定的移动质量模式意味着‘医生’而不是‘肺’。”
隐私与准确性的残酷困境
在科学研究中,当你优化一个参数时,几乎总是会破坏另一个。对于自动手语识别(SLR),研究人员一直被困在准确性与隐私的痛苦拉锯战中。
手语极其复杂。它不仅依赖于大幅度的手臂动作,还依赖于精细的手部线索(精确的手指位置)和非手部线索(面部表情、唇部运动、躯干移动)。传统的 RGB 和深度摄像头能够完美捕捉所有这些信息,从而获得高准确性。然而,在医院病房等临床环境中,安装高分辨率摄像头会违反严格的患者隐私法和伦理界限。
为了实现隐私保护,可以使用雷达。雷达本质上会模糊患者身份,因为它不捕捉视觉细节——它只看到移动的能量团块。但困境在于:通过切换到雷达来保护隐私,你立即使系统对区分相似手语至关重要的精细视觉细节(如面部表情和手指形状)变得盲目。先前的研究人员陷入僵局:使用摄像头则侵犯隐私,使用雷达则因数据过于抽象而导致准确性极差。
严酷的壁垒与约束
为了解决这个问题,作者们必须突破几个现实且严苛的约束:
- 硬件内存壁垒(计算约束):
雷达数据极其密集。一个手语手势会产生一个大小为 $128 \times 1024$ 的矩阵序列。如果你试图将这个原始的、高维的视频式序列直接输入到一个单一的深度神经网络中以端到端地学习时间动态,数学运算将呈指数级增长。作者们明确指出,这样做会导致模型复杂度过高,并立即耗尽 GPU 内存限制。他们被迫将问题分解为两个阶段(先进行空间压缩,然后进行时间序列建模),才能在现代硬件上进行可计算的数学处理。 - “隐形”的非手部线索(物理约束):
由于雷达的工作波长能够捕捉宏观运动(手臂和手),它完全错过了微观运动,如扬眉或特定的唇部形状。由于许多手语词汇具有完全相同的 the hand movements,仅通过面部表情来区分,因此数学模型被迫在手臂的速度中寻找隐藏的、微妙的运动学模式来区分它们,这面临着严重的信息赤字。 - 可变的时间动态(数据驱动约束):
人不是机器人,他们不会以恒定的速度打手语。一位患者可能在 1 秒内(13 帧)完成一个词的手语,而一位老年患者可能需要 4 秒(66 帧)才能完成完全相同的词。模型必须是时间不变的。它不能依赖于固定长度的输入;它必须动态地对齐和解释不同长度的序列,这需要像 Transformers 这样的高级序列建模技术来跟踪随时间推移的长距离依赖关系。 - 极端的数据稀缺性:
深度学习模型是数据饥渴的。要将复杂的雷达信号映射到 126 个不同的医学手语,你需要数万个样本。在本论文之前,用于手语的雷达数据集非常小,通常仅限于 5 或 10 个通用手势(如向左或向右滑动)。作者们遇到了一个瓶颈,即解决问题所需的数据根本不存在,这迫使他们在能够开始训练算法之前,从零开始构建了一个包含 25,830 个手语实例的大规模同步数据集。
为何采用此方法
为了理解作者为何选择其特定的两阶段流水线——一个定制的卷积自编码器后接一个Transformer,我们首先需要审视雷达数据的严峻现实。60 GHz毫米波雷达生成距离多普勒图(Range Doppler Maps, RDMs)和动目标显示图(Moving Target Indication, MTI maps)。这些本质上是类似视频的高维矩阵序列,每帧具体尺寸为$128 \times 1024$。
作者意识到传统的最先进(SOTA)方法不足的精确时刻,是当他们考虑该问题的巨大计算量时。正如他们明确指出的那样,尝试用一个单一的、庞大的端到端深度网络直接解决这个问题将导致“过度的模型复杂性和计算成本”。雷达数据是高维且序列化的。如果将跨越$T$个时间步的原始$128 \times 1024$帧直接输入到标准的3D CNN或纯Transformer中,内存需求将呈指数级增长。
为了解决这个问题,他们将问题分解为两个独立的阶段。首先,他们构建了一个定制的CNN自编码器来压缩空间数据。为何选择定制模型而非像ResNet或AlexNet这样的著名预训练SOTA模型?作者意识到雷达图与自然RGB图像在根本上是不同的。它们缺乏标准照片中复杂的视觉纹理。使用一个沉重的、预训练的架构实际上会损害性能。相反,他们定制的、带有残差连接的9层CNN将庞大的雷达帧提炼成一个高度紧凑的256维潜在表示。
这引出了我们方法的相对优越性。通过冻结自编码器,仅将256维嵌入输入Transformer,他们极大地缓解了内存瓶颈。论文指出,这个两阶段过程“通过避免每个epoch对原始数据进行完全的端到端训练,从而缓解了GPU内存限制。”尽管他们在文本中没有明确将其表述为从$O(N^2)$复杂度降低到$O(N)$,但结构优势是显而易见的:空间处理与时间处理完全解耦。
此外,Transformer分类器在第二阶段具有定性优势,因为它自然地处理可变长度序列。人类手语是动态的;在他们的数据集中,一个手势可以持续$T=13$到$T=66$帧不等。Transformer的自注意力机制擅长建模这些长程时间依赖性,而无需将数据强制放入刚性的、固定长度的窗口中。通过融合来自三个独立雷达天的数据,并将标准的RDM与MTI图(后者会消除静态背景噪声)相结合,该模型对环境干扰变得异常鲁棒。
这种方法代表了问题约束与解决方案特性之间完美的“结合”。医疗环境要求绝对的隐私,雷达通过仅捕获运动和速度,而非可识别的面部,从而在物理上保证了这一点。然而,这也带来了高度抽象、嘈杂且计算量大的数据的约束。自编码器充当了完美的过滤器,剥离了噪声并压缩了空间维度,而Transformer则充当了完美的时序引擎,随着时间的推移解码手势的实际含义。
如果您想知道作者为何没有使用其他流行的现代方法,如GANs或Diffusion模型,老实说,我对此部分也不完全确定,因为论文没有明确提及或拒绝它们。然而,考虑到这是一个严格的分类问题(将一系列雷达帧映射到126个特定手语类别之一),而不是一个生成任务,设计用于合成新数据的模型很可能会引入不必要的开销,而无法解决核心的分类约束。作者完全专注于判别效率,而他们的自编码器-Transformer组合完美地处理了这一点。
数学与逻辑机制
想象一位在医院急诊室的失聪患者正试图向医生表达自己的症状。此时,口译员可能无法立即到位,而使用基于摄像头的标准人工智能来翻译手语会带来巨大的隐私风险——没有人希望在脆弱的医疗时刻被高清录制面部和身体的视频。
本文正是解决了这一精确的限制,通过用 60 GHz 毫米波雷达取代摄像头。雷达不捕捉视觉像素,而是将无线电波反射到患者身上,以测量其移动手部和身体的距离(距离)和速度(多普勒)。其结果是一个保护隐私、无面部特征的运动图。然而,雷达数据极其嘈杂、高维且具有序列性。作者们必须弄清楚如何将海量的雷达回波流压缩成紧凑的格式,然后教会机器“阅读”这些回波的时间序列,以识别 126 种不同的意大利手语 (LIS) 医疗术语和字母。
为了克服处理类似视频的雷达序列所带来的计算瓶颈,他们将问题分解为两个阶段:一个卷积神经网络 (CNN) 自动编码器用于压缩每个单独的雷达帧,以及一个 Transformer 网络用于分析压缩帧随时间的序列。
坦白说,我并不完全确定作者们为何选择不在文中打印出精确的数学公式——他们很可能假设读者已经熟悉标准的深度学习目标。然而,他们明确表示,他们的 Transformer 分类器是通过“最小化标准交叉熵损失”来优化的。因此,驱动整个系统学习的绝对核心数学引擎是交叉熵目标函数。
$$ \mathcal{L}_{CE} = - \sum_{i=1}^{C} y_i \log(\hat{y}_i) $$
让我们来解析这个方程,以确切理解模型如何将雷达波转化为医疗词汇:
- $\mathcal{L}_{CE}$:这是总的交叉熵损失。
- 逻辑作用:它充当模型的最终“记分卡”或指南针。高值表示模型非常困惑;接近零的值表示模型完美理解了手语姿势。
- $\sum_{i=1}^{C}$:所有 $C$ 个类别(在本论文中,$C = 126$ 个 LIS 手语)的求和运算符。
- 为何是求和而非积分? 因为词汇是一个离散的、不同的类别集合(例如,“医生”、“肺”、“颈部”),而不是一个连续的值谱。我们必须计算每个单词的惩罚总和。
- $y_i$:真实标签。
- 逻辑作用:这是绝对的真理。对于患者实际执行的正确手语,它等于 $1$,对于其他 125 个不正确的信号,它等于 $0$。它充当一个严格的过滤器,确保数学只关注分配给正确答案的概率。
- $\hat{y}_i$:由 Transformer 的线性分类层预测的概率输出。
- 逻辑作用:这是模型的最佳猜测,一个介于 0 和 1 之间的数字,表示它对雷达运动对应于单词 $i$ 的置信度。
- $\log$:应用于模型预测的自然对数。
- 为何在此使用对数? 对数会严重惩罚模型在自信地出错时。如果正确答案是“医生”($y_i = 1$),但模型预测的概率为 $0.01$,则 $\log(0.01)$ 会产生一个巨大的负数。它就像一个指数橡皮筋,当模型犯下严重错误时,会剧烈地将模型的权重拉回原位。
- $-$(负号):因为概率 ($\hat{y}_i$) 始终在 0 和 1 之间,所以它们的对数始终为负数。我们添加一个负号来翻转结果,使其成为一个正的“成本”,优化器可以最小化该成本。
让我们追踪一个抽象数据点通过这个机械流水线的确切生命周期。
首先,原始的 60 GHz 雷达波从患者移动的手上反射回来,并返回到传感器。通过快速傅里叶变换 (FFT),该原始信号被转换为距离-多普勒图 (RDM)——一个二维网格,显示运动的位置和速度。这个 $128 \times 1024$ 的网格进入 CNN 自动编码器。自动编码器就像一个垃圾压缩机,通过 9 个卷积层将巨大的网格压缩,直到它变成一个密集、256 维的潜在表示向量。
接下来,由于手语姿势需要时间(跨度为 1 到 4 秒),因此将这些 256 维向量的序列排列起来。在前面附加一个可学习的“类别标记”,并添加位置嵌入,以便模型了解帧的时间顺序。该序列流入 Transformer。Transformer 的多头自注意力机制将每一帧与其他所有帧进行比较,弄清楚手部轨迹随时间如何变化。最后,现在已包含完整时间上下文的类别标记被推过一个线性层,输出 126 个概率 ($\hat{y}_i$)。最高概率就是最终翻译的单词。
这个机制是如何实际学习和收敛的?这里的优化动态经过精心协调,以防止模型因自身高维度的权重而崩溃。
如果作者尝试同时(端到端)训练自动编码器和 Transformer,GPU 内存将会爆炸,损失景观也会混乱不堪,充满局部最小值。相反,他们在 15 个 epoch 后冻结了自动编码器。通过锁定自动编码器的权重,他们创建了一个稳定、不变的基础。
然后,使用 AdamW 优化器对 Transformer 进行 700 个 epoch 的训练。作者明确将梯度裁剪设置为最大范数 5。在损失景观中,雷达数据有时会产生突然的、巨大的错误(损失中的尖峰),这通常会导致梯度爆炸并破坏模型学到的权重。梯度裁剪充当限速器,确保无论损失景观有多陡峭,模型都只会安全地向下迈出一小步。结合权重衰减 $5 \cdot 10^{-6}$(它充当一种温和的引力,防止神经网络权重变得过大并记忆训练数据),模型平稳地收敛到令人印象深刻的 93.6% 的准确率,证明我们确实可以通过看不见的无线电波来理解复杂的人类语言。
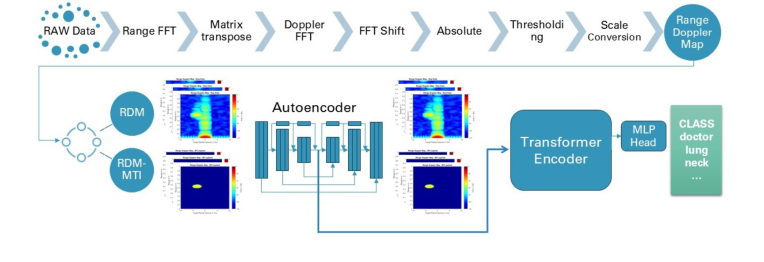 Figure 1. Overview of the end-to-end architecture of the proposed method
Figure 1. Overview of the end-to-end architecture of the proposed method
结果、局限性与结论
想象一下,您身处一家外国医院,正试图向一位医生解释您正遭受剧烈胸痛,但您不会说他们的语言。再想象一下,您是聋哑人,您的主要语言是意大利手语(LIS)这样的视觉-手势系统。如果无法立即获得翻译,沟通障碍可能会危及生命。
历史上,技术人员试图通过在病房中放置RGB(标准视频)摄像头来自动将手语翻译成文本来解决这个问题。但这引入了一个巨大的问题:隐私。医院是高度敏感的场所。患者不希望在脆弱的状态下被高清摄像头录制。此外,摄像头出了名的挑剔;如果光线不足或背景杂乱,它们就会失效。
本文介绍了一种绝妙的、听起来像科幻小说般的解决方案:利用60 GHz毫米波(mm-wave)雷达来“读取”手语。 雷达不是捕捉识别个人面部或身体的视觉像素,而是将无线电波从患者身上反射回来,并测量其手部和手臂的微小运动和速度。雷达看到的是语言的运动学,而不是人。
让我们详细分析一下作者是如何设计出这种保护隐私的翻译机的。
约束条件与数学问题
雷达数据不像标准照片。当60 GHz雷达脉冲击中手语使用者时,返回的信号会被处理成距离-多普勒图(Range Doppler Maps, RDMs)和移动目标指示(Moving Target Indication, MTI)图。您可以将它们视为热力图,显示物体的位置(距离)和移动速度(多普勒速度)。
这里的约束是数据维度和计算过载。一个手语手势需要1到4秒,生成多达66帧雷达图像。如果您试图将这种海量、高维的类视频序列直接输入到单个深度学习网络中,计算机的内存将不堪重负,模型将出现过拟合(即记住训练数据而不是学习底层模式)。
从数学上讲,这个问题是一个序列分类任务。我们给定一个雷达帧序列 $X = \{x_1, x_2, \dots, x_T\}$,其中 $T$ 是可变的帧数,我们需要将此序列映射到一个特定的手语类别标签 $y \in \{1, 2, \dots, 126\}$。
为了克服内存限制,作者将问题无情地解耦成一个两阶段流水线:
阶段1:空间压缩(自编码器)
与其一次性处理整个序列,不如构建一个自定义的卷积神经网络(CNN)自编码器来单独处理每一帧。编码器函数 $E$ 接收一个海量的雷达帧 $x_t$,并将其压缩成一个密集、低维的向量 $z_t \in \mathbb{R}^{256}$。为了确保这个压缩向量确实包含重要的运动数据,解码器函数 $D$ 尝试重构原始帧:$\hat{x}_t = D(z_t)$。网络被训练来最小化 $x_t$ 和 $\hat{x}_t$ 之间的差异。训练完成后,解码器被丢弃,我们保留编码器来生成雷达数据的紧凑表示。
阶段2:时间分类(Transformer)
现在,模型拥有一个轻量级的向量序列 $Z = \{z_1, z_2, \dots, z_T\}$。由于手语是动态的(运动的顺序很重要),他们将这个序列输入到一个Transformer网络中。Transformer使用多头自注意力机制来查看整个序列,并确定哪些运动与哪些手语相关。它输出一个跨越126个可能医疗手语类别的概率分布 $\hat{y}$。模型使用标准的交叉熵损失进行优化:
$$ \mathcal{L} = -\sum_{c=1}^{C} y_c \log(\hat{y}_c) $$
其中 $C = 126$ 是总类别数。
实验架构与“受试者”
作者们不仅构建了这个系统并声称它有效,他们还设计了一个高度受控的多模态环境来证明他们的数学假设。他们同时使用雷达、标准RGB摄像头和深度传感器,记录了一个包含25,830个手语实例的海量数据集。这使得他们能够将他们的雷达模型直接与基于视觉的模型在完全相同的姿势上进行比较。
本次实验中的“受试者”(基线模型)是顶尖的视觉模型,包括De Coster等人提出的RGB视频Transformer网络和Vahdani提出的RGB-D 3D CNN,以及之前的基于雷达的手势模型(Jhaung、Debnath、Arab)。
他们成功的决定性、无可辩驳的证据在于最终的指标。当使用三个雷达天线并结合RDM和MTI数据流时,他们的雷达模型达到了惊人的93.6%的准确率。它完全击败了领先的RGB模型(该模型仅达到88.4%)。
这是一个深刻的结果。它证明了雷达捕获的微多普勒特征对于这项特定任务比实际视觉像素包含更鲁棒、更具辨别力的语言特征。此外,他们通过消融研究证明,在Transformer训练期间冻结自编码器是防止过拟合的关键,从而使更简单的模型能够实现卓越的泛化能力。这相当于花150美元购买了一个性能远超1000美元摄像头的安全系统,同时还能完全隐藏您的身份。
未来演进的讨论话题
基于本文奠定的杰出基础,以下是未来探索和批判性思考的几个方向:
1. 雷达中的“非手动”线索困境
手语不仅仅是手部动作;它严重依赖于面部表情、眉毛抬高等非手动线索,以及微妙的唇部运动来传达语法和语气。雷达在追踪肢体的大幅度运动方面表现出色,但它能否捕捉到面部表情的微肌肉变化?如果我们提高雷达频率来捕捉这些微动作,是否会冒着无意中捕获足够生物识别数据来重构人脸的风险,从而破坏了该系统旨在保护的隐私?
2. 从孤立手势到连续共articulation的过渡
本研究侧重于126个孤立的手势。然而,自然的人类交流是连续的。在流利的手语中,一个手势的结尾与下一个手势的开头在物理上融合在一起——这种现象被称为共articulation。Transformer架构必须如何演变才能将连续的雷达数据流分割成不同的词语?滑动窗口方法是否足够,还是我们需要一个根本不同的数学框架,例如连接主义时间分类(Connectionist Temporal Classification, CTC),来处理混乱的医院环境中未分割的雷达序列?
3. 跨语言和跨主体泛化能力
该数据集是使用一名受试者表演的意大利手语(LIS)构建的。每个人都有独特的运动学特征——不同的臂长、不同的手语速度和不同的静息姿势。如果我们用受试者A训练一个雷达模型,微多普勒特征能否泛化到受试者B?此外,自编码器为LIS学习到的潜在嵌入是否可以迁移到美国手语(ASL)或英国手语(BSL)?探索无监督域适应技术以实时校准雷达模型以适应新患者将是实现全球可扩展性的关键下一步。