Scalp Diagnostic System With Label-Free Segmentation and Training-Free Image Translation
ScalpVision tackles data challenges for better, cheaper, and more accessible skin care.
Background & Academic Lineage
The Origin & Academic Lineage
The problem addressed in this paper originates from the widespread prevalence of scalp disorders globally, affecting a significant portion of the adult population, with nearly 90% of adults in the U.S. experiencing some form of condition [6]. Despite this high prevalence, many cases remain underdiagnosed. This is primarily due to two critical factors: limited access to expert dermatological evaluation and the high cost associated with manual annotation for diagnostic purposes.
In the academic field of medical imaging and artificial intelligence, the promise of AI-based diagnostic systems for scalp conditions has been recognized for some time [4,11,19]. Early detection is crucial to prevent the progression of scalp-related diseases, such as alopecia, into more serious outcomes [16,17]. However, the effective diagnosis of these disorders heavily relies on accurately measuring critical features like hair count and thickness from microscopic scalp imagery. This necessity for precise hair segmentation is where the core problem emerges. The historical context shows a clear need for advanced diagnostic approaches that are both efficient and accessible, pushing researchers to develop automated systems.
The fundamental limitation, or "pain point," of previous approaches that compelled the authors to write this paper can be broken down into several key areas:
- Lack of Pixel-Level Segmentation Labels: Generating pixel-level hair annotations is an incredibly costly and time-consuming endeavor. Crucially, there are no publicly available datasets that provide such detailed segmentation labels. For instance, the major resource, AI-Hub [1], only offers classification labels for scalp conditions, not the granular segmentation annotations needed for robust AI training. This absence of ground-truth segmentation data makes supervised learning methods, which are typically very effective, infeasible.
- Severe Data Imbalance: Many existing scalp image datasets suffer from significant data imbalance, particularly for severe scalp conditions (as illustrated in Fig. 2). This scarcity of samples for critical, severe cases makes it exceedingly challenging to develop AI models that are robust and accurate across the full spectrum of disease severity. Previous non-generative augmentation methods struggled significantly with rare classes, like severe sebum [Table 3].
 Figure 2. Data distribution of different severity within each scalp condition
Figure 2. Data distribution of different severity within each scalp condition
- Limitations of Prior Segmentation Techniques: Earlier unsupervised methods for hair segmentation, often relying on traditional computer vision techniques [20,21,10], struggled to accurately segment narrow hairs and capture intricate hair patterns. Even modern foundation models like SAM [12], while powerful, were less effective for automatic segmentation without specific guidance, and random point selection often led to suboptimal or confusing masks.
- Inability to Preserve Hair Details During Image Translation: When attempting to augment datasets by translating images to simulate different scalp conditions, existing diffusion-based image translation models like DiffuseIT [13] and AGG [14] failed to preserve essential hair content information from the source image. This meant that while they could alter scalp styles, they often compromised the very hair features critical for diagnosis, hindering their utility for data augmentation.
Intuitive Domain Terms
Here are a few specialized domain terms from the paper, translated into intuitive, everyday analogies:
- Hair Segmentation Mask: Imagine you have a picture of someone's head, and you want to highlight only the hair, perhaps by coloring it in. A hair segmentation mask is like a digital stencil that precisely outlines every single strand of hair, separating it from the scalp and background. It's a binary image where hair pixels are "on" (e.g., white) and non-hair pixels are "off" (e.g., black).
- Pseudo-labeling: Think of it like a teacher who doesn't have an answer key for a test, so they create a "fake" answer key based on their best guess or some simple rules. They then use this fake key to train a new student. In this paper, since real, pixel-perfect hair labels are too expensive to get, the researchers generate "pseudo-labels" (approximate hair masks) using simple rules and prior knowledge to initially train their segmentation model.
- Data Imbalance: Picture a classroom where 90% of students are good at math, but only 1% are good at poetry. If you train a teacher only on this class, they'll become excellent at teaching math but might struggle terribly with poetry because they haven't seen enough examples. Data imbalance in this context means having many images of mild scalp conditions but very few of severe ones, making it hard for an AI to learn to diagnose severe cases reliably.
- Diffusion-based Image Translation: This is like an artist who can take a photo of a person and repaint it to make them look older, younger, or even change their hair color, all while keeping their original facial features intact. A diffusion-based image translation model takes a source image (e.g., a healthy scalp) and "repaints" it to show a different condition (e.g., a dandruff-ridden scalp), but it's specifically designed to preserve the original hair details, like hair count and thickness.
- Foundation Segmentation Model (SAM): Imagine a super-smart, general-purpose digital assistant that can outline any object in any picture if you just give it a hint, like clicking on the object. SAM is a powerful AI model that can segment almost anything, but for specific tasks like hair segmentation, it still needs a little guidance (like "point prompts") to perform optimally and differentiate hair from scalp.
Notation Table
| Notation | Description
Problem Definition & Constraints
Core Problem Formulation & The Dilemma
The central problem this paper tackles is the development of an AI-driven system, SCALPVISION, for the comprehensive diagnosis of scalp diseases from microscopic images. This seemingly straightforward goal is complicated by two significant, interconnected challenges.
Input/Current State: The starting point is a collection of microscopic scalp images. While existing datasets, such as the AI-Hub dataset mentioned, provide high-level classification labels for various scalp conditions (like dandruff, excess sebum, and erythema) and their severity (good, mild, moderate, severe), they critically lack pixel-level segmentation labels for hair. Furthermore, these datasets suffer from severe data imbalance, with a disproportionately low number of samples for severe conditions, as illustrated in Figure 2.
Desired Endpoint/Goal State: The ultimate goal is a robust system capable of:
1. Accurately segmenting hair within these microscopic images without relying on costly and time-consuming manual pixel-level annotations. This hair segmentation is crucial for measuring features like hair count and thickness, which are vital for diagnosis.
2. Improving the accuracy of scalp disease severity predictions, particularly for the underrepresented severe conditions, by effectively augmenting the training data.
The Missing Link & The Dilemma: The exact missing link is the absence of precise, pixel-level hair masks, which are fundamental for training supervised segmentation models. This gap directly impacts the ability to extract quantitative features of hair, which are essential for diagnosis. The dilemma is a classic trade-off: achieving high-quality, precise hair segmentation is paramount for accurate diagnosis, but the traditional method of obtaining pixel-level labels is prohibitively expensive and time-consuming. Previous attempts to solve this often involved either manual annotation (impractical at scale) or less accurate unsupervised methods. Similarly, while data augmentation is a known strategy for addressing data imbalance, the challenge lies in generating synthetic images that accurately reflect diverse scalp conditions without distorting or losing the critical, fine-grained details of the hair. Improving one aspect (e.g., generating diverse scalp conditions) often compromises the other (e.g., preserving hair details), trapping previous researchers in a painful dilema.
Constraints & Failure Modes
Solving this problem is insanely difficult due to several harsh, realistic walls the authors hit:
- Data-Driven Constraint: Absence of Pixel-Level Segmentation Labels: The most significant hurdle is the complete lack of publicly available datasets with pixel-level hair annotations for scalp images. This means traditional supervised learning approaches for segmentation are not feasible, forcing the development of label-free or pseudo-labeling strategies. The AI-Hub dataset, while extensive for classification, does not provide this granular information.
- Data-Driven Constraint: Severe Data Imbalance: The available scalp image datasets are heavily skewed. As Figure 2 on page 5 clearly shows, "good" and "mild" cases are abundant, while "moderate" and especially "severe" conditions are rare. This extreme sparsity of data for critical severe cases makes it incredibly challenging to train robust classification models that can generalize well across all severity levels. Non-generative augmentation methods often fail to adequately address this for severe classes, as noted in Section 3.4.
- Physical Constraint: Intricat Hair Patterns and Noise: Microscopic scalp images present complex visual information. Hair patterns can follow various functions (linear or power), and narrow hairs are inherently difficult to segment accurately. Furthermore, the presence of noise, such as dandruff, can easily confuse segmentation models if not properly handled, leading to misclassifications or inaccurate masks. The model needs to differentiate hair from noise while maintaining clear boundaries.
- Computational Constraint: Foundation Model Limitations for Specific Tasks: While powerful, foundation models like Segment Anything Model (SAM) are not a silver bullet. When applied to hair segmentation, simply selecting random points from a coarse mask for positive prompts often leads to suboptimal results. Points near the edges of the mask can confuse SAM, and the intrinsic randomness can cause sampled points to coalesce, resulting in the segmentation of only a limited subset of hairs rather than a complete, accurate mask. This necessitates a sophisticated prompting mechanism.
- Computational Constraint: Preserving Hair Details During Image Translation: A critical failure mode for data augmentation is the loss of essential hair details or semantic information during the image translation process. Generating diverse scalp conditions (e.g., changing severity) while simultaneously preserving the intricate structure and features of the hair is a complex task. Previous generative models like DiffuseIT and AGG struggled with this, often compromising overall information or failing to transfer semantic information effectively, as highlighted in the qualitative results in Section 3.3. This requires a carefully designed loss function and mask guidance to ensure fidelity.
Why This Approach
The Inevitability of the Choice
The adoption of SCALPVISION's multi-component approach was not merely a preference but a necessity, driven by fundamental limitations of existing methods when confronted with the unique challenges of scalp disorder diagnosis. The core problem was two-fold: the absence of pixel-level segmentation labels for hair in microscopic scalp images and the severe data imbalance, particularly for rare, severe conditions.
Traditional supervised segmentation methods, such as standard CNNs or U-Nets, were immediately rendered unviable for hair segmentation because they demand extensive, pixel-accurate ground truth labels. The paper explicitly states that "since most scalp condition datasets lack segmentation labels, supervised learning methods are not feasible" (Section 2.1). Generating such labels is prohibitively costly and time-consuming. This constraint forced the authors to devise a "label-free" segmentation strategy.
Similarly, for scalp condition classification, relying solely on traditional SOTA methods (e.g., advanced CNNs or Transformers) would inevitably lead to poor performance, especially for severe conditions. The AI-Hub dataset, a primary resource, suffers from a "heavily skewed" distribution towards good and mild cases (Figure 2, Section 3.1). Without effective data augmentation, models trained on such imbalanced data would struggle to generalize to and accurately classify underrepresented severe conditions. Standard augmentation techniques like Gaussian noise or AugMix (Table 3) proved insufficient to overcome this extreme scarcity. The authors realized that a generative model capable of synthesizing realistic images of varying severity, while preserving crucial hair details, was the only way to address this imbalance effectively.
Comparative Superiority
SCALPVISION's approach demonstrates qualitative superiority through its structural design, which directly addresses the inherent difficulties of scalp image analysis.
For hair segmentation, the proposed ensemble method, combining a heuristically-trained U²-Net (M) with an automatically prompted Segment Anything Model (SAM) (MAP), offers a significant structural advantage. The U²-Net, trained on synthetic data with simulated noise, provides robustness against artifacts like dandruff (Section 2.2, Section 3.2). SAM, on the other hand, excels in precise edge detection, creating clear boundaries (Section 2.2). The logical AND operation ($M = M \land MAP$) synergistically merges these strengths, yielding a final mask that is both robust to noise and highly accurate in defining hair boundaries. This is qualitatively superior to previous methods (Shih et al., Yue et al., Kim et al. [10]) which "lack an understanding in capturing the intricate patterns of hair and the scalp" (Section 3.2), and even to SAM used without specific guidance, which produced "suboptimal masks" (Section 2.1). This structural fusion ensures a more reliable and precise segmentation, crucial for downstream diagnostic tasks.
For image translation and data augmentation, DiffuseIT-M stands out due to its unique mask guidance mechanism. Unlike other generative models like DiffuseIT [13] or AGG [14], DiffuseIT-M is specifically designed to "preserve hair details while altering scalp conditions" (Abstract, Section 2.2). This is achieved through a comprehensive loss function, $l_{total}$, which includes a mask preservation loss ($l_{mask}$) and a masking approach during the reverse diffusion process (Equation 5). This structural design allows for disentangled control, ensuring that scalp features can be modified (e.g., to simulate different severities) without compromising the integrity of the hair, which is a critical diagnostic feature. Quantitatively, DiffuseIT-M achieves superior FID and LPIPS scores (Table 2), indicating higher image fidelity and better preservation of source content compared to baselines (Section 3.3). Qualitatively, Figure 4 clearly illustrates that DiffuseIT and AGG "fail to preserve the hair content information," a critical flaw that DiffuseIT-M overcomes. This ability to maintain specific image regions while transforming others is a profound structural advantage for medical image augmentation.
Alignment with Constraints
The chosen methodology perfectly aligns with the problem's harsh requirements, forming a "marriage" between the challenges and the solution's unique properties.
- Constraint: Absence of pixel-level segmentation labels.
- Alignment: SCALPVISION's hair segmentation module directly addresses this by being "label-free." It leverages heuristic-driven pseudo-labeling by generating synthetic images based on prior knowledge of hair patterns (linear or power functions) and automatic prompting for SAM. This innovative prompting method systematically generates positive and negative point prompts from a coarse segmentation mask, guiding SAM to produce accurate hair masks without any manual pixel-level annotation (Section 2.1). This is a direct and elegant solution to the label scarcity.
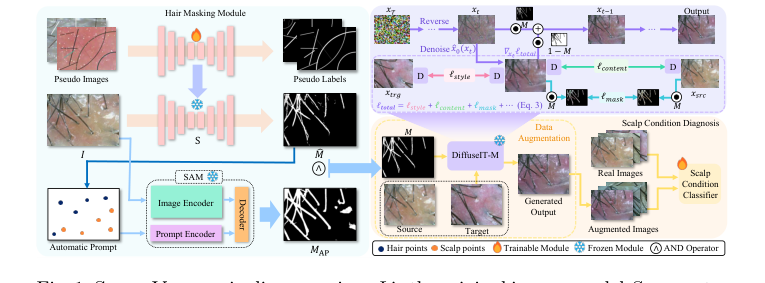 Figure 1. ScalpVision pipeline overview: I is the original image, model S generates the hair segmentation mask ˆ M using a pseudo-training set, MAP is the SAM- produced mask, and M is the combined hair segmentation mask. The “Automatic Prompt” for refining segmentation comes from ˆ M. xsrc and xtrg are the source and target images, with M as the mask image of xsrc. The weighted image sum is denoted by ⊙and D stands for DINO-ViT [3]
Figure 1. ScalpVision pipeline overview: I is the original image, model S generates the hair segmentation mask ˆ M using a pseudo-training set, MAP is the SAM- produced mask, and M is the combined hair segmentation mask. The “Automatic Prompt” for refining segmentation comes from ˆ M. xsrc and xtrg are the source and target images, with M as the mask image of xsrc. The weighted image sum is denoted by ⊙and D stands for DINO-ViT [3]
-
Constraint: Severe data imbalance, especially for severe conditions.
- Alignment: The DiffuseIT-M generative model is the cornerstone for overcoming this. It is specifically designed for dataset augmentation (Abstract). The model translates randomly chosen images into higher severity levels using weighted sampling, where the probability of selection is inversely proportional to the class's size (Section 2.2). This mechanism directly targets the underrepresented classes, generating diverse and realistic training samples to balance the dataset. This ensures that the classification model is exposed to sufficient examples of severe conditions, which is crucial for robust diagnosis.
-
Constraint: Need for robust and accurate diagnosis.
- Alignment: The robust hair segmentation (combining M and MAP) provides precise hair features, which are essential for diagnosis (Section 1). The DiffuseIT-M's ability to generate high-fidelity augmented images that preserve hair details ensures that the training data is realistic and relevant, leading to more robust classification models (Section 3.4). The overall system's design, from label-free segmentation to targeted data augmentation, is geared towards building a comprehensive and reliable diagnostic tool.
Rejection of Alternatives
The paper implicitly and explicitly rejects several alternative approaches based on their inability to meet the specific constraints of scalp disorder diagnosis.
-
Traditional Supervised Segmentation Methods: These were rejected outright due to the "absence of pixel-level segmentation labels" (Section 2.1). Methods like standard U-Nets or Mask R-CNNs require extensive manual annotation, which is not available for scalp datasets. The comparative results in Table 1 against prior scalp segmentation approaches [20,21,10] further underscore their limitations in capturing intricate hair patterns effectively (Section 3.2).
-
Foundation Models (e.g., SAM) without specific guidance: While SAM is powerful, the authors found that "selecting random points from M for positive prompts often led to suboptimal masks" and that SAM was "less effective for automatic segmentation when used without specific guidance" (Section 2.1, Section 3.2). This highlights that a powerful model alone is insufficient; it requires a tailored, intelligent prompting mechanism to be effective in this domain.
-
Other Generative Models for Image Translation (e.g., DiffuseIT, AGG, or general GANs): The paper directly compares DiffuseIT-M with DiffuseIT [13] and AGG [14]. Both alternatives "fail to preserve the hair content information from the source image" and "tended to compromise overall information and were unable to transfer the semantic information" (Section 3.3, Figure 4). This failure is critical for scalp diagnosis, where hair features are paramount. Without the explicit mask guidance mechanism of DiffuseIT-M, these models cannot disentangle the scalp condition from hair preservation, making them unsuitable for generating diagnostically relevant augmented data. While GANs are not explicitly mentioned as a direct alternative, their general limitations in controlled content preservation during style transfer, especially without explicit mask guidance, would likely lead to similar failures.
-
Non-Generative Data Augmentation Methods (e.g., Gaussian Noise, AugMix): These methods were found to be insufficient for addressing the "extreme scarcity of samples" for severe conditions (Section 3.4). Table 3 clearly shows that models augmented with Gaussian Noise or AugMix perform significantly worse than those augmented with generative models, particularly for classifying severe cases. These simpler methods cannot synthesize new, diverse examples that truly represent the underrepresented classes, thus failing to mitigate the data imbalance effectively.
Mathematical & Logical Mechanism
The Master Equation
The core of the DiffuseIT-M image translation mechanism, which enables the generation of diverse scalp images while preserving hair details, is governed by a comprehensive loss function and a specific reverse diffusion sampling step. The primary objective function that guides the learning and generation process is the total loss, $l_{total}$, defined as:
$$ l_{total} (x;x_{src},x_{trg},M) = \lambda_1 l_{style} + \lambda_2 l_{content} + \lambda_3 l_{mask} + \lambda_4 l_{sem} + \lambda_5 l_{rng} $$
This loss function is then used within the iterative reverse diffusion process to guide the generation of the next, less noisy image sample, $x_{t-1}$, from the current noisy image $x_t$. This transformation logic, crucial for preserving hair details, is given by:
$$ x_{t-1} \leftarrow x_t \odot M + \left[x_0(x_t) - \sqrt{\bar{\alpha}_t} l_{total} (x_0(x_t))\right] \odot (1 – M) $$
A critical component in both the loss calculation and the reverse step is the estimation of the cleaned image, $x_0(x_t)$, from a noisy sample $x_t$ at time step $t$. This estimation is derived from the predicted noise $\epsilon_0(x_t, t)$:
$$ x_0(x_t) = \frac{x_t}{\sqrt{\bar{\alpha}_t}} - \frac{\sqrt{1 – \bar{\alpha}_t} \epsilon_0(x_t, t)}{\sqrt{\bar{\alpha}_t}} $$
Finally, the mask preservation loss, $l_{mask}$, which is a component of $l_{total}$, is explicitly defined as:
$$ l_{mask} = \text{LPIPS}(x_{src}\odot M, x_0(x_t)\odot M) + ||(x_{src} - x_0(x_t))\odot M||_2 $$
Term-by-Term Autopsy
Let's dissect these equations to understand each element's role:
Total Loss Function ($l_{total}$)
- $l_{total} (x;x_{src},x_{trg},M)$: This is the overall objective function that the
DiffuseIT-Mmodel aims to minimize during training. It's a weighted sum of several individual loss components, designed to ensure high-fidelity image translation while preserving specific features. The inputs are the current image $x$ (which is typically $x_0(x_t)$ in the context of the reverse step), the source image $x_{src}$, the target image $x_{trg}$ (representing the desired scalp condition), and the hair mask $M$.- Why addition? The authors use addition to combine different, often competing, objectives. Each term encourages a specific desired property in the generated image (e.g., style, content, mask preservation), and summing them allows the model to learn a balance across these goals.
- $\lambda_1, \lambda_2, \lambda_3, \lambda_4, \lambda_5$: These are scalar weighting coefficients.
- Mathematical Definition: Positive real numbers.
- Physical/Logical Role: They control the relative importance of each loss component. By adjusting these weights, the authors can prioritize certain aspects of the image translation, such as how strongly hair details should be preserved versus how closely the scalp style should match the target.
- $l_{style}$: Style loss.
- Mathematical Definition: Not explicitly defined in the paper, but stated to be from
DiffuseIT[13]. Typically, this involves matching feature statistics (e.g., Gram matrices) from VGG networks or similar perceptual features. - Physical/Logical Role: Encourages the generated image's scalp region to adopt the stylistic characteristics (e.g., texture, color, patterns) of the target scalp condition.
- Mathematical Definition: Not explicitly defined in the paper, but stated to be from
- $l_{content}$: Content loss.
- Mathematical Definition: Not explicitly defined, also from
DiffuseIT[13]. Often measures the L2 distance between feature maps of the generated and target images. - Physical/Logical Role: Ensures that the high-level semantic content of the scalp region is transferred from the target image, guiding the model to translate the scalp condition accurately.
- Mathematical Definition: Not explicitly defined, also from
- $l_{mask}$: Mask preservation loss (Equation 3).
- Mathematical Definition: A combination of LPIPS and L2 norm, applied to masked regions.
- Physical/Logical Role: This is crucial for
SCALPVISION's goal. It explicitly forces the model to preserve the hair details from the source image within the masked hair regions, preventing unwanted alterations to hair during scalp condition translation.
- $l_{sem}$: Semantic divergence loss.
- Mathematical Definition: Not explicitly defined, but stated to be from [13] and uses
[CLS]token matching loss from DINO-ViT [3]. - Physical/Logical Role: Aims to ensure that the semantic information (e.g., disease type, severity) of the target image is correctly reflected in the generated image, using high-level features from a vision transformer.
- Mathematical Definition: Not explicitly defined, but stated to be from [13] and uses
- $l_{rng}$: Squared spherical distance loss.
- Mathematical Definition: Not explicitly defined, but stated to be from [5].
- Physical/Logical Role: Likely acts as a regularization term, possibly encouraging diversity in generated samples or maintaining a certain distribution in the latent space, which is beneficial for data augmentation.
Reverse Diffusion Sampling Step ($x_{t-1}$ update)
- $x_{t-1}$: The image at the previous (less noisy) time step in the reverse diffusion process.
- Mathematical Definition: A pixel-wise image tensor.
- Physical/Logical Role: This is the output of one step of the generative process, moving from a noisy image towards a clean, translated image.
- $x_t$: The current noisy image at time step $t$.
- Mathematical Definition: A pixel-wise image tensor.
- Physical/Logical Role: The starting point for the current reverse diffusion step.
- $M$: The binary hair mask.
- Mathematical Definition: A binary tensor of the same spatial dimensions as the image, where 1 indicates hair and 0 indicates scalp.
- Physical/Logical Role: Acts as a stencil. It isolates the hair regions, ensuring that operations applied to the hair are distinct from those applied to the scalp.
- $\odot$: Element-wise multiplication (Hadamard product).
- Mathematical Definition: Multiplies corresponding elements of two tensors.
- Physical/Logical Role: Used here for masking. $x_t \odot M$ isolates the hair region of the current noisy image, effectively "keeping" the hair as it is.
- $x_0(x_t)$: The estimated clean image from $x_t$ (Equation 4).
- Mathematical Definition: A pixel-wise image tensor.
- Physical/Logical Role: Represents the model's best guess of what the clean image would look like if all noise were removed from $x_t$. This is a crucial intermediate prediction in diffusion models.
- $\sqrt{\bar{\alpha}_t}$: Square root of the cumulative product of alpha values.
- Mathematical Definition: $\bar{\alpha}_t = \prod_{s=1}^t (1-\beta_s)$, where $\beta_s$ are variance schedule parameters.
- Physical/Logical Role: A scaling factor derived from the diffusion process's noise schedule. It's part of the mathematical framework that relates noisy images to their clean counterparts and the predicted noise.
- $l_{total}(x_0(x_t))$: The total loss function applied to the estimated clean image.
- Mathematical Definition: The scalar output of the $l_{total}$ function.
- Physical/Logical Role: This term guides the translation of the scalp region. By applying the total loss (which includes style, content, and semantic objectives) to the estimated clean image, the model is nudged to generate a scalp that matches the target condition.
- $1 - M$: The inverse of the binary hair mask.
- Mathematical Definition: A binary tensor where 1 indicates scalp and 0 indicates hair.
- Physical/Logical Role: Isolates the scalp region, allowing the loss-guided update to be applied specifically to the non-hair areas.
- Why addition and masking? The addition combines two distinct parts: the hair region (preserved from $x_t$) and the scalp region (updated based on the loss). This clever masking approach allows for selective image translation, preserving hair while transforming the scalp.
Estimated Clean Image ($x_0(x_t)$)
- $\epsilon_0(x_t, t)$: The noise predicted by the diffusion model.
- Mathematical Definition: A tensor of the same shape as $x_t$, representing the estimated noise component.
- Physical/Logical Role: This is the primary output of the neural network within the diffusion model. The network is trained to predict the noise that was added to a clean image to get $x_t$.
- $\sqrt{1 - \bar{\alpha}_t}$: Another scaling factor from the diffusion process.
- Mathematical Definition: Derived from the noise schedule.
- Physical/Logical Role: Relates the magnitude of the predicted noise to the overall noise level at time $t$.
- Why division and subtraction? This formula is a standard reparameterization in diffusion models. It allows the model to predict the noise $\epsilon_0(x_t, t)$ and then analytically derive the corresponding clean image $x_0(x_t)$ from the noisy input $x_t$ and the noise schedule parameters.
Mask Preservation Loss ($l_{mask}$)
- $\text{LPIPS}(A, B)$: Learned Perceptual Image Patch Similarity metric.
- Mathematical Definition: A perceptual distance metric based on deep features from a pre-trained neural network (e.g., VGG).
- Physical/Logical Role: Measures the perceptual similarity between two image patches, which aligns better with human perception than simple pixel-wise differences. Here, it ensures that the perceived hair details in the source and generated images (within the mask) are similar.
- $||(x_{src} - x_0(x_t))\odot M||_2$: The L2 norm (Euclidean distance) of the pixel-wise difference between the source image and the estimated clean image, masked by $M$.
- Mathematical Definition: $\sqrt{\sum_{i,j} ((x_{src})_{i,j} - (x_0(x_t))_{i,j})^2 \cdot M_{i,j}}$.
- Physical/Logical Role: This is a direct pixel-level constraint. It acts like a "rubber band," pulling the hair region of the generated image to be pixel-wise identical to the hair region of the source image. This complements LPIPS by providing a strong local fidelity constraint.
- Why addition? Combining LPIPS and L2 ensures both perceptual and pixel-level fidelity for hair preservation.
Step-by-Step Flow
Imagine a single abstract data point, which in this case is a microscopic scalp image, $x_{src}$, that we want to transform to exhibit a different scalp condition, $x_{trg}$, while keeping the hair exactly as it is.
- Hair Mask Generation: First, the input image $x_{src}$ enters the hair segmentation module. This module, using pseudo-labeling and the Segment Anything Model (SAM) guided by Algorithm 1, generates a binary hair mask, $M$. This mask precisely delineates hair regions (value 1) from scalp regions (value 0).
- Noisy Initialization: For the image translation, the
DiffuseIT-Mmodel starts with a noisy version of the source image, $x_T$, or a pure noise image, which is then iteratively denoised. Let's consider a general noisy image $x_t$ at an intermediate step $t$. - Clean Image Estimation: At each reverse diffusion step, the model's neural network (trained to predict noise) takes $x_t$ and the current time step $t$ as input. It outputs an estimated noise component, $\epsilon_0(x_t, t)$. This predicted noise is then used with the diffusion schedule parameter $\bar{\alpha}_t$ to compute $x_0(x_t)$ (Equation 4), the model's best guess of the clean image underlying $x_t$.
- Loss Calculation for Guidance: The estimated clean image $x_0(x_t)$, along with the original source image $x_{src}$, the target condition image $x_{trg}$, and the hair mask $M$, are fed into the total loss function, $l_{total}$ (Equation 2).
- $l_{style}$ and $l_{content}$ compare the scalp region of $x_0(x_t)$ with $x_{trg}$ to guide the style and content transfer.
- $l_{mask}$ (Equation 3) specifically compares the hair region of $x_0(x_t)$ with the hair region of $x_{src}$ to ensure hair preservation, using both perceptual (LPIPS) and pixel-wise (L2) metrics.
- $l_{sem}$ and $l_{rng}$ provide additional semantic and regularization guidance.
- The weighted sum of these losses, $l_{total}$, provides a comprehensive signal indicating how well the current $x_0(x_t)$ aligns with all the desired properties.
- Guided Denoising and Translation: This calculated $l_{total}$ is then used to guide the generation of the next, less noisy image, $x_{t-1}$ (Equation 5).
- The hair part of $x_t$ is preserved by $x_t \odot M$. This ensures that the hair structure from the source image is carried forward directly.
- The scalp part is updated by applying the loss-guided term $[x_0(x_t) - \sqrt{\bar{\alpha}_t} l_{total} (x_0(x_t))]$ to the scalp region, $(1-M)$. This term effectively pushes the scalp pixels of $x_0(x_t)$ towards the target condition, influenced by the overall loss.
- These two masked components are then added together to form $x_{t-1}$, which now has preserved hair and a scalp that is a step closer to the target condition.
- Iteration to Convergence: This process from step 3 to 5 repeats iteratively for many time steps, $t=T, T-1, \dots, 1$. With each step, the image becomes less noisy, and the scalp region progressively transforms to match the target condition while the hair remains intact.
- Final Output: After all steps, the final $x_0$ (or $x_{t-1}$ at $t=1$) is the generated image, which is a translation of $x_{src}$ to $x_{trg}$'s scalp condition with $x_{src}$'s hair preserved.
Optimization Dynamics
The DiffuseIT-M mechanism learns and updates its parameters through a standard training process for diffusion models, guided by the $l_{total}$ loss function.
- Model Training: The underlying neural network within
DiffuseIT-M(which predicts $\epsilon_0(x_t, t)$ or $x_0(x_t)$) is trained using a large dataset of images. During training, noise is added to clean images to create noisy samples $x_t$. The model then learns to predict the noise or the clean image from $x_t$. The $l_{total}$ function acts as the objective for this learning. - Loss Landscape Shaping: The $l_{total}$ function shapes the loss landscape in a multi-faceted way:
- Hair Preservation Valleys: The $l_{mask}$ term creates deep valleys in the loss landscape where the generated hair regions closely match the source hair. Any deviation in hair structure or appearance from the source image within the masked region will result in a steep increase in this loss, effectively penalizing changes to hair.
- Scalp Transformation Gradients: The $l_{style}$, $l_{content}$, and $l_{sem}$ terms guide the model to transform the scalp region. The gradients from these losses push the model parameters to generate scalp features that align with the target condition. For instance, if the generated scalp lacks the desired texture from $x_{trg}$, the $l_{style}$ gradient will steer the model towards generating that texture.
- Regularization for Stability/Diversity: The $l_{rng}$ term helps to regularize the training, potentially smoothing the loss landscape or encouraging the model to explore diverse solutions, which is beneficial for generating varied augmentation samples.
- Gradient Descent: The model's parameters are updated iteratively using an optimization algorithm like Adam or SGD. At each training step, the gradients of $l_{total}$ with respect to the model's parameters are computed. These gradients indicate the direction and magnitude of change needed for each parameter to reduce the total loss. The parameters are then adjusted in the direction opposite to the gradient.
- Iterative Refinement: Over many training iterations, the model learns to predict $\epsilon_0(x_t, t)$ (or $x_0(x_t)$) such that when this prediction is used in the reverse diffusion process, the resulting $x_0(x_t)$ minimizes $l_{total}$. This means the model learns to generate images where hair is preserved and scalp conditions are accurately translated.
- Convergence: The training continues until the model's performance on a validation set no longer improves, indicating that it has converged to a state where it can effectively perform the desired image translation tasks. The balance of the $\lambda_i$ weights is crucial for achieving a good trade-off between the different objectives and ensuring a stable convergence. The paper also mentions "fine-tuning a pretrained backbone with four MLP heads" for classification, which is a separate optimization step for the downstream task, but the generative model's learning is primarily driven by minimizing $l_{total}$.
Results, Limitations & Conclusion
Experimental Design & Baselines
To rigorously validate SCALPVISION's core mechanisms, the authors architected a series of experiments targeting each component: hair segmentation, synthetic image generation, and scalp condition classification.
For hair segmentation, the primary goal was to prove the efficacy of their label-free approach. Given the absence of pixel-level segmentation labels in the main AI-Hub dataset, a specialized subset of 150 test images was manually annotated by experts to serve as ground truth. The "victims" (baseline models) in this arena included traditional computer vision methods like those by Shih et al. [20], Yue et al. [21], and Kim et al. [10], alongside the powerful foundation model, SAM [12]. Performance was quantified using standard metrics: Pixel-F1, Jaccard, and Dice scores. An important ablation study was also conducted, comparing the initial naive segmentation mask ($M$), the SAM-produced mask ($M_{AP}$), and their final combined mask ($M$) to isolate the contribution of each part.
The synthetic image generation module, DiffuseIT-M, was evaluated against other generative models to demonstrate its ability to create diverse scalp images while preserving hair details. The baselines here were DiffuseIT [13] and AGG [14]. The experiments ruthlessly proved image fidelity using the Fréchet Inception Distance (FID) [8] and Learned Perceptual Image Patch Similarity (LPIPS) [22] scores. Furthermore, the impact of mask guidance was specifically tested by comparing image translation results under different mask conditions: our proposed 1-M guidance, the reverse mask M, no mask (0), and a full mask (1).
Finally, for scalp condition classification, the entire AI-Hub dataset, comprising 95,910 images (split into 72,342 for training, 23,568 for testing, and 21,703 for validation), was utilized. Dermatologists had labeled these images for three conditions—dandruff, excess sebum, and erythema—each categorized into four severity levels: good, mild, moderate, and severe. Acknowledging the dataset's inherent skew towards "good" and "mild" cases (as shown in Fig. 2), the experiments aimed to show how generative augmentation could address this imbalance. Two different classification backbones were employed: DenseNet [9] (a CNN) and EfficientFormerV2 [15] (a Transformer), to ensure robustness of findings across different architectures. Various augmentation strategies were pitted against each other: Gaussian Noise, AugMix [7], DiffuseIT [13], AGG [14], and "Ours" (SCALPVISION's DiffuseIT-M). The definitive evidence was sought in the overall macro-F1 score and individual F1 scores for each severity level across the three diseases.
What the Evidence Proves
The experimental evidence provides undeniable proof of SCALPVISION's core mechanisms.
For hair segmentation, Table 1 definitively shows that our combined mask $M$ achieved superior performance across all metrics (Pixel-F1: 0.868, Jaccard: 0.649, Dice: 0.786). This wasn't just a marginal improvement; it significantly surpassed all traditional computer vision baselines and even the standalone SAM model. The architectural choice of combining the naive segmentation model's robustness to noise ($M$) with SAM's superior edge detection ($M_{AP}$) via a logical AND operation was the key. This fusion, as visually confirmed in Figure 3, yielded clear, accurate, and noise-resilient hair masks, proving that the heuristic-driven pseudo-labeling and automatic prompting method for SAM effectively overcame the limitations of label scarcity and individual model weaknesses. The "victims" were clearly defeated, with our method demonstrating a more comprehensive understanding of intricate hair patterns than prior art.
In synthetic image generation, DiffuseIT-M ("Ours") showcased its prowess by achieving substantially better fidelity scores than its generative model counterparts. Table 2 reports an FID of 74.84 and an LPIPS of 0.353, which are significantly lower (indicating higher quality) than DiffuseIT (FID: 138.42, LPIPS: 0.463) and AGG (FID: 141.70, LPIPS: 0.492). The visual evidence in Figure 4 and Figure 5 further solidifies this. While baselines struggled to preserve hair content or transfer semantic information accurately, DiffuseIT-M succesfully maintained source hair details while effectively altering scalp conditions. The experiments on mask guidance were particularly telling: using the 1-M mask guidance was cruical for retaining hair features during translation, whereas other mask conditions (no mask, full mask, or reverse mask) either resulted in minimal changes or altered both hair and scalp indiscriminately. This hard evidence proves that DiffuseIT-M's mask-guided diffusion mechanism is highly effective in controlled image translation, a critical step for data augmentation.
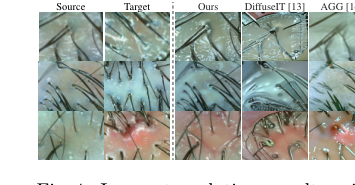 Figure 4. Image translation results with different generative models, where the goal is to preserve source hairlines while changing the scalp
Figure 4. Image translation results with different generative models, where the goal is to preserve source hairlines while changing the scalp
The most compelling evidence for the overall system's impact came from scalp condition classification. Table 3 unequivocally demonstrates that "Ours" (SCALPVISION's DiffuseIT-M augmentation) consistently achieved the highest macro-F1 scores for both DenseNet (0.636) and EfficientFormerV2 (0.635) backbones. This was not merely an overall win; it was particularly pronounced in addressing the severe data imbalance. For instance, in classifying "severe" sebum, non-generative augmentation methods like Gaussian Noise and AugMix yielded F1 scores of 0.000, indicating a complete failure to classify this rare but important condition. In stark contrast, "Ours" achieved F1 scores of 0.430 (DenseNet) and 0.406 (EfficientFormerV2) for severe sebum. This is definitive, undeniable evidence that the generative data augmentation, specifically DiffuseIT-M's ability to create high-quality, diverse samples for underrepresented classes, directly translates to enhanced diagnostic performance, especially for challenging, rare conditions. It proves that preserving both scalp style and hair content information is paramount for accurate classification.
Limitations & Future Directions
While SCALPVISION presents a robust and innovative solution for scalp disorder diagnosis, it's important to acknowledge its current limitations and consider avenues for future development.
One inherent limitation stems from the dataset itself. Despite being a large resource, the AI-Hub dataset is heavily skewed towards "good" and "mild" scalp conditions, with severe cases being rare. While SCALPVISION's generative augmentation method significantly mitigates this imbalance, the underlying scarcity of real-world severe cases could still pose challenges for generalization to extremely diverse or novel severe presentations not well-represented even in augmented data. Additionally, the manual annotation for hair segmentation was performed on a relatively small subset of 150 test images. While sufficient for initial validation, a broader, more diverse set of manually annotated images could further strengthen the segmentation model's robustness across various hair types and imaging conditions. Furthermore, the current system focuses on three specific scalp diseases: dandruff, excess sebum, and erythema. This scope, while valuable, means it doesn't yet cover the full spectrum of dermatological conditions affecting the scalp.
Looking ahead, several exciting directions could further evolve these findings:
- Expanding Diagnostic Scope: The authors explicitly state their intention to extend research to conditions like alopecia, leveraging hair information. This is a natural and necessary progression towards a truly generalized diagnostic system. Future work could explore how SCALPVISION's framework adapts to conditions where hair loss patterns, rather than just scalp surface conditions, are the primary diagnostic features.
- Multi-modal Integration: Currently, the system relies solely on microscopic scalp imagery. Integrating other diagnostic data, such as patient history, genetic markers, or even macroscopic images, could lead to a more holistic and accurate diagnosis, potentially reducing false positives or negatives that might arise from image-only analysis.
- Clinical Deployment & User Experience: For SCALPVISION to become a truly valuable tool, its integration into clinical workflows is paramount. This would involve developing user-friendly interfaces for dermatologists, ensuring compliance with medical regulations, and conducting extensive real-world clinical trials to validate its performance in diverse patient populations and settings. How can we make this technology seamlessly assist clinicians without adding to their workload?
- Explainability and Trust: While the model shows high performance, understanding why it makes certain diagnostic decisions is crucial for building trust among medical professionals. Future research could focus on enhancing the explainability of the AI, perhaps by highlighting specific image regions or features that contribute most to a diagnosis, thereby providing actionable insights for clinicians.
- Personalized Treatment Recommendations: Moving beyond diagnosis, SCALPVISION could potentially evolve to suggest personalized treatment plans based on the identified condition, severity, and even individual patient characteristics. This would require integrating medical knowledge bases and potentially patient-specific data.
- Addressing Data Privacy and Ethical Concerns: As with any AI system handling sensitive medical data, rigorous attention to data privacy, security, and ethical deployment is essential. How can we ensure the responsible use of such powerful diagnostic tools, particularly when dealing with generative models that could potentially create synthetic patient data?
- Exploring Advanced Generative Architectures: While DiffuseIT-M is highly effective, the field of generative AI is rapidly advancing. Investigating newer diffusion models, GANs, or other generative architectures could yield further improvements in image fidelity, diversity, and control, potentially leading to even more robust data augmentation strategies.
These discussions highlight that SCALPVISION is not just a diagnostic tool but a foundational framework with immense potential to transform dermatological care, provided its limitations are addressed and its capabilities are thoughtfully expanded.
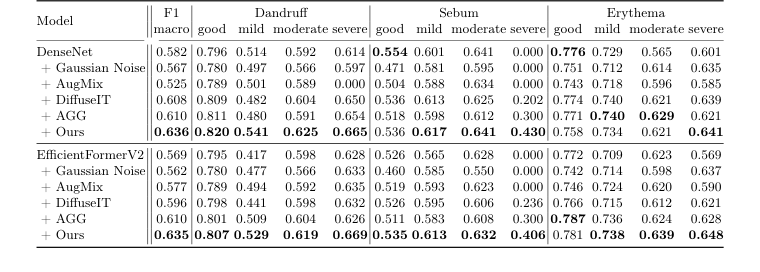 Table 3. Performance of scalp condition classification with various augmentation methods, denoted after “+” symbol, on the test set. The second column displays the overall macro-F1 score, while the columns from the third onward show the F1 scores for each severity level of the three diseases
Table 3. Performance of scalp condition classification with various augmentation methods, denoted after “+” symbol, on the test set. The second column displays the overall macro-F1 score, while the columns from the third onward show the F1 scores for each severity level of the three diseases
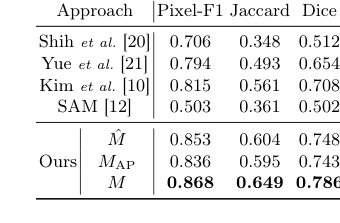 Table 1. Performance of hair segmenta- tion on the test set
Table 1. Performance of hair segmenta- tion on the test set
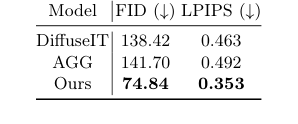 Table 2. Quantitative analysis of image- to-image translation
Table 2. Quantitative analysis of image- to-image translation