स्कैल्प डायग्नोस्टिक सिस्टम: लेबल-मुक्त सेगमेंटेशन और प्रशिक्षण-मुक्त इमेज ट्रांसलेशन के साथ
इस पत्र में संबोधित समस्या विश्व स्तर पर स्कैल्प विकारों के व्यापक प्रसार से उत्पन्न होती है, जो वयस्क आबादी के एक महत्वपूर्ण हिस्से को प्रभावित करती है, जिसमें अमेरिका में लगभग 90% वयस्क किसी न किसी रूप की स्थिति का...
पृष्ठभूमि और अकादमिक वंश
उत्पत्ति और अकादमिक वंश
इस पत्र में संबोधित समस्या विश्व स्तर पर स्कैल्प विकारों के व्यापक प्रसार से उत्पन्न होती है, जो वयस्क आबादी के एक महत्वपूर्ण हिस्से को प्रभावित करती है, जिसमें अमेरिका में लगभग 90% वयस्क किसी न किसी रूप की स्थिति का अनुभव करते हैं [6]। इस उच्च प्रसार के बावजूद, कई मामले कम निदान किए जाते हैं। यह मुख्य रूप से दो महत्वपूर्ण कारकों के कारण है: विशेषज्ञ त्वचा मूल्यांकन तक सीमित पहुंच और नैदानिक उद्देश्यों के लिए मैनुअल एनोटेशन से जुड़ी उच्च लागत।
मेडिकल इमेजिंग और आर्टिफिशियल इंटेलिजेंस के अकादमिक क्षेत्र में, स्कैल्प की स्थितियों के लिए एआई-आधारित नैदानिक प्रणालियों का वादा कुछ समय से पहचाना गया है [4,11,19]। एलोपेसिया जैसी स्कैल्प-संबंधित बीमारियों की प्रगति को अधिक गंभीर परिणामों में रोकने के लिए प्रारंभिक पहचान महत्वपूर्ण है [16,17]। हालांकि, इन विकारों का प्रभावी निदान सूक्ष्म स्कैल्प इमेजरी से बाल गणना और मोटाई जैसी महत्वपूर्ण विशेषताओं को सटीक रूप से मापने पर बहुत अधिक निर्भर करता है। सटीक बाल सेगमेंटेशन की यह आवश्यकता वह जगह है जहाँ मुख्य समस्या उत्पन्न होती है। ऐतिहासिक संदर्भ कुशल और सुलभ दोनों तरह के उन्नत नैदानिक दृष्टिकोणों की स्पष्ट आवश्यकता को दर्शाता है, जो शोधकर्ताओं को स्वचालित प्रणालियों को विकसित करने के लिए प्रेरित करता है।
पिछले दृष्टिकोणों की मौलिक सीमा, या "दर्द बिंदु," जिसने लेखकों को यह पत्र लिखने के लिए मजबूर किया, उसे कई प्रमुख क्षेत्रों में तोड़ा जा सकता है:
- पिक्सेल-स्तरीय सेगमेंटेशन लेबल की कमी: पिक्सेल-स्तरीय बाल एनोटेशन उत्पन्न करना एक अत्यंत महंगा और समय लेने वाला प्रयास है। महत्वपूर्ण रूप से, ऐसे विस्तृत सेगमेंटेशन लेबल प्रदान करने वाले कोई सार्वजनिक रूप से उपलब्ध डेटासेट नहीं हैं। उदाहरण के लिए, प्रमुख संसाधन, AI-Hub [1], स्कैल्प की स्थितियों के लिए केवल वर्गीकरण लेबल प्रदान करता है, न कि मजबूत AI प्रशिक्षण के लिए आवश्यक दानेदार सेगमेंटेशन एनोटेशन। ग्राउंड-ट्रुथ सेगमेंटेशन डेटा की यह अनुपस्थिति पर्यवेक्षित शिक्षण विधियों को अव्यावहारिक बनाती है, जो आम तौर पर बहुत प्रभावी होती हैं।
- गंभीर डेटा असंतुलन: कई मौजूदा स्कैल्प छवि डेटासेट महत्वपूर्ण डेटा असंतुलन से पीड़ित हैं, विशेष रूप से गंभीर स्कैल्प स्थितियों के लिए (जैसा कि चित्र 2 में दर्शाया गया है)। महत्वपूर्ण, गंभीर मामलों के लिए नमूनों की यह कमी ऐसे AI मॉडल विकसित करना अत्यंत चुनौतीपूर्ण बनाती है जो रोग की गंभीरता के पूर्ण स्पेक्ट्रम में मजबूत और सटीक हों। पिछले गैर-उत्पादक संवर्द्धन विधियों ने दुर्लभ वर्गों, जैसे गंभीर सीबम [तालिका 3] के साथ काफी संघर्ष किया।
- पूर्व सेगमेंटेशन तकनीकों की सीमाएं: बालों के सेगमेंटेशन के लिए पहले के अनसुपरवाइज्ड तरीके, जो अक्सर पारंपरिक कंप्यूटर विजन तकनीकों [20,21,10] पर निर्भर करते थे, संकीर्ण बालों को सटीक रूप से सेगमेंट करने और जटिल बाल पैटर्न को कैप्चर करने में संघर्ष करते थे। SAM [12] जैसे आधुनिक फाउंडेशन मॉडल भी, शक्तिशाली होने के बावजूद, विशिष्ट मार्गदर्शन के बिना स्वचालित सेगमेंटेशन के लिए कम प्रभावी थे, और यादृच्छिक बिंदु चयन अक्सर उप-इष्टतम या भ्रमित करने वाले मास्क का कारण बनता था।
- इमेज ट्रांसलेशन के दौरान बाल विवरण संरक्षित करने में असमर्थता: विभिन्न स्कैल्प स्थितियों का अनुकरण करने के लिए छवियों का विस्तार करके डेटासेट को बढ़ाने का प्रयास करते समय, DiffuseIT [13] और AGG [14] जैसे मौजूदा डिफ्यूजन-आधारित इमेज ट्रांसलेशन मॉडल स्रोत छवि से आवश्यक बाल सामग्री की जानकारी को संरक्षित करने में विफल रहे। इसका मतलब था कि जबकि वे स्कैल्प शैलियों को बदल सकते थे, उन्होंने अक्सर निदान के लिए महत्वपूर्ण बाल विशेषताओं से समझौता किया, जिससे डेटा संवर्द्धन के लिए उनकी उपयोगिता बाधित हुई।
सहज डोमेन शब्द
यहां पेपर से कुछ विशेष डोमेन शब्द दिए गए हैं, जिन्हें सहज, रोजमर्रा की उपमाओं में अनुवादित किया गया है:
- हेयर सेगमेंटेशन मास्क: कल्पना कीजिए कि आपके पास किसी व्यक्ति के सिर की तस्वीर है, और आप केवल बालों को हाइलाइट करना चाहते हैं, शायद इसे रंग कर। एक हेयर सेगमेंटेशन मास्क एक डिजिटल स्टेंसिल की तरह है जो हर एक बाल को सटीक रूप से रेखांकित करता है, इसे स्कैल्प और पृष्ठभूमि से अलग करता है। यह एक बाइनरी छवि है जहां बाल पिक्सेल "चालू" (जैसे, सफेद) और गैर-बाल पिक्सेल "बंद" (जैसे, काले) होते हैं।
- स्यूडो-लेबलिंग: इसे एक शिक्षक की तरह सोचें जिसके पास परीक्षा के लिए उत्तर कुंजी नहीं है, इसलिए वह अपने सर्वोत्तम अनुमान या कुछ सरल नियमों के आधार पर एक "नकली" उत्तर कुंजी बनाता है। फिर वह इस नकली कुंजी का उपयोग एक नए छात्र को प्रशिक्षित करने के लिए करता है। इस पत्र में, चूंकि वास्तविक, पिक्सेल-सही बाल लेबल प्राप्त करना बहुत महंगा है, शोधकर्ता अपने सेगमेंटेशन मॉडल को शुरू में प्रशिक्षित करने के लिए सरल नियमों और पूर्व ज्ञान का उपयोग करके "स्यूडो-लेबल" (लगभग बाल मास्क) उत्पन्न करते हैं।
- डेटा असंतुलन: एक ऐसे कक्षा की कल्पना करें जहाँ 90% छात्र गणित में अच्छे हैं, लेकिन केवल 1% कविता में अच्छे हैं। यदि आप केवल इस कक्षा पर एक शिक्षक को प्रशिक्षित करते हैं, तो वे गणित पढ़ाने में उत्कृष्ट हो जाएंगे लेकिन कविता के साथ बहुत संघर्ष कर सकते हैं क्योंकि उन्होंने पर्याप्त उदाहरण नहीं देखे हैं। इस संदर्भ में डेटा असंतुलन का मतलब है कि हल्के स्कैल्प स्थितियों की कई छवियां हैं लेकिन गंभीर स्थितियों की बहुत कम, जिससे AI के लिए गंभीर मामलों का मज़बूती से निदान करना सीखना मुश्किल हो जाता है।
- डिफ्यूजन-आधारित इमेज ट्रांसलेशन: यह एक कलाकार की तरह है जो किसी व्यक्ति की तस्वीर ले सकता है और उसे बड़ा दिखाने के लिए फिर से पेंट कर सकता है, या उसके बालों का रंग बदल सकता है, जबकि उसके मूल चेहरे की विशेषताओं को बरकरार रखता है। एक डिफ्यूजन-आधारित इमेज ट्रांसलेशन मॉडल एक स्रोत छवि (जैसे, एक स्वस्थ स्कैल्प) लेता है और इसे एक अलग स्थिति (जैसे, रूसी से भरा स्कैल्प) दिखाने के लिए "फिर से पेंट" करता है, लेकिन यह विशेष रूप से मूल बाल विवरण, जैसे बालों की गणना और मोटाई को संरक्षित करने के लिए डिज़ाइन किया गया है।
- फाउंडेशन सेगमेंटेशन मॉडल (SAM): एक सुपर-स्मार्ट, सामान्य-उद्देश्य वाले डिजिटल सहायक की कल्पना करें जो किसी भी तस्वीर में किसी भी वस्तु को रेखांकित कर सकता है यदि आप उसे केवल एक संकेत देते हैं, जैसे वस्तु पर क्लिक करना। SAM एक शक्तिशाली AI मॉडल है जो लगभग कुछ भी सेगमेंट कर सकता है, लेकिन बालों के सेगमेंटेशन जैसे विशिष्ट कार्यों के लिए, इसे इष्टतम प्रदर्शन करने और बालों को स्कैल्प से अलग करने के लिए अभी भी थोड़ी मार्गदर्शन (जैसे "पॉइंट प्रॉम्प्ट") की आवश्यकता होती है।
नोटेशन तालिका
| नोटेशन | विवरण |
|---|---|
समस्या परिभाषा और बाधाएँ
मुख्य समस्या सूत्रीकरण और दुविधा
इस पत्र का केंद्रीय समस्या सूक्ष्म छवियों से स्कैल्प रोगों के व्यापक निदान के लिए एक AI-संचालित प्रणाली, SCALPVISION का विकास है। यह स्पष्ट रूप से सीधा लक्ष्य दो महत्वपूर्ण, परस्पर जुड़े चुनौतियों से जटिल है।
इनपुट/वर्तमान स्थिति: प्रारंभिक बिंदु सूक्ष्म स्कैल्प छवियों का एक संग्रह है। जबकि मौजूदा डेटासेट, जैसे कि उल्लेखित AI-Hub डेटासेट, विभिन्न स्कैल्प स्थितियों (जैसे रूसी, अतिरिक्त सीबम, और एरिथेमा) और उनकी गंभीरता (अच्छा, हल्का, मध्यम, गंभीर) के लिए उच्च-स्तरीय वर्गीकरण लेबल प्रदान करते हैं, वे महत्वपूर्ण रूप से बालों के लिए पिक्सेल-स्तरीय सेगमेंटेशन लेबल का अभाव करते हैं। इसके अलावा, ये डेटासेट गंभीर डेटा असंतुलन से पीड़ित हैं, जिसमें गंभीर स्थितियों के लिए नमूनों की असमान रूप से कम संख्या है, जैसा कि चित्र 2 में दर्शाया गया है।
वांछित अंतिम बिंदु/लक्ष्य स्थिति: अंतिम लक्ष्य एक मजबूत प्रणाली है जो निम्न में सक्षम है:
1. महंगे और समय लेने वाले मैनुअल पिक्सेल-स्तरीय एनोटेशन पर भरोसा किए बिना इन सूक्ष्म छवियों के भीतर बालों को सटीक रूप से सेगमेंट करना। यह बाल सेगमेंटेशन बालों की गणना और मोटाई जैसी विशेषताओं को मापने के लिए महत्वपूर्ण है, जो निदान के लिए आवश्यक हैं।
2. प्रशिक्षण डेटा को प्रभावी ढंग से बढ़ाकर, विशेष रूप से कम प्रतिनिधित्व वाली गंभीर स्थितियों के लिए, स्कैल्प रोग की गंभीरता की भविष्यवाणियों की सटीकता में सुधार करना।
लुप्त कड़ी और दुविधा: सटीक लुप्त कड़ी सटीक, पिक्सेल-स्तरीय बाल मास्क की अनुपस्थिति है, जो पर्यवेक्षित सेगमेंटेशन मॉडल को प्रशिक्षित करने के लिए मौलिक हैं। यह अंतर सीधे बालों की मात्रात्मक विशेषताओं को निकालने की क्षमता को प्रभावित करता है, जो निदान के लिए आवश्यक हैं। दुविधा एक क्लासिक ट्रेड-ऑफ है: सटीक निदान के लिए उच्च-गुणवत्ता, सटीक बाल सेगमेंटेशन प्राप्त करना सर्वोपरि है, लेकिन पिक्सेल-स्तरीय लेबल प्राप्त करने की पारंपरिक विधि निषेधात्मक रूप से महंगी और समय लेने वाली है। इसे हल करने के पिछले प्रयासों में अक्सर या तो मैनुअल एनोटेशन (बड़े पैमाने पर अव्यावहारिक) या कम सटीक अनसुपरवाइज्ड तरीके शामिल होते थे। इसी तरह, जबकि डेटा संवर्द्धन डेटा असंतुलन को संबोधित करने की एक ज्ञात रणनीति है, चुनौती ऐसे सिंथेटिक चित्र उत्पन्न करने में है जो बालों के महत्वपूर्ण, बारीक विवरणों को विकृत या खोए बिना विभिन्न स्कैल्प स्थितियों को सटीक रूप से दर्शाते हैं। एक पहलू में सुधार (जैसे, विविध स्कैल्प स्थितियों को उत्पन्न करना) अक्सर दूसरे (जैसे, बाल विवरणों को संरक्षित करना) से समझौता करता है, जिससे पिछले शोधकर्ताओं को एक दर्दनाक दुविधा में फंसाया जाता है।
बाधाएँ और विफलता मोड
इस समस्या को हल करना कई कठोर, यथार्थवादी दीवारों के कारण अविश्वसनीय रूप से कठिन है जिनसे लेखक टकराए:
- डेटा-संचालित बाधा: पिक्सेल-स्तरीय सेगमेंटेशन लेबल की अनुपस्थिति: सबसे महत्वपूर्ण बाधा स्कैल्प छवियों के लिए पिक्सेल-स्तरीय बाल एनोटेशन वाले सार्वजनिक रूप से उपलब्ध डेटासेट की पूर्ण अनुपस्थिति है। इसका मतलब है कि सेगमेंटेशन के लिए पारंपरिक पर्यवेक्षित शिक्षण दृष्टिकोण अव्यावहारिक हैं, जिससे लेबल-मुक्त या स्यूडो-लेबलिंग रणनीतियों के विकास को मजबूर होना पड़ता है। AI-Hub डेटासेट, हालांकि वर्गीकरण के लिए व्यापक है, यह दानेदार जानकारी प्रदान नहीं करता है।
- डेटा-संचालित बाधा: गंभीर डेटा असंतुलन: उपलब्ध स्कैल्प छवि डेटासेट भारी रूप से तिरछे हैं। जैसा कि पृष्ठ 5 पर चित्र 2 स्पष्ट रूप से दिखाता है, "अच्छे" और "हल्के" मामले प्रचुर मात्रा में हैं, जबकि "मध्यम" और विशेष रूप से "गंभीर" स्थितियां दुर्लभ हैं। गंभीर मामलों के लिए डेटा की यह चरम विरलता मजबूत वर्गीकरण मॉडल को प्रशिक्षित करना अविश्वसनीय रूप से चुनौतीपूर्ण बनाती है जो सभी गंभीरता स्तरों पर अच्छी तरह से सामान्यीकृत हो सकते हैं। गैर-उत्पादक संवर्द्धन विधियां अक्सर गंभीर वर्गों के लिए इसे पर्याप्त रूप से संबोधित करने में विफल रहती हैं, जैसा कि अनुभाग 3.4 में उल्लेख किया गया है।
- भौतिक बाधा: जटिल बाल पैटर्न और शोर: सूक्ष्म स्कैल्प छवियां जटिल दृश्य जानकारी प्रस्तुत करती हैं। बाल पैटर्न विभिन्न कार्यों (रैखिक या शक्ति) का पालन कर सकते हैं, और संकीर्ण बालों को सटीक रूप से सेगमेंट करना स्वाभाविक रूप से कठिन होता है। इसके अलावा, रूसी जैसे शोर की उपस्थिति सेगमेंटेशन मॉडल को भ्रमित कर सकती है यदि ठीक से संभाला न जाए, जिससे गलत वर्गीकरण या गलत मास्क हो सकते हैं। मॉडल को स्पष्ट सीमा बनाए रखते हुए शोर से बालों को अलग करने की आवश्यकता है।
- कम्प्यूटेशनल बाधा: विशिष्ट कार्यों के लिए फाउंडेशन मॉडल की सीमाएं: शक्तिशाली होने के बावजूद, सेगमेंट एनीथिंग मॉडल (SAM) जैसे फाउंडेशन मॉडल एक चांदी की गोली नहीं हैं। जब बालों के सेगमेंटेशन पर लागू किया जाता है, तो सकारात्मक प्रॉम्प्ट के लिए एक मोटे मास्क से यादृच्छिक बिंदुओं का चयन अक्सर उप-इष्टतम परिणाम देता है। मास्क के किनारों के पास के बिंदु SAM को भ्रमित कर सकते हैं, और आंतरिक यादृच्छिकता नमूना बिंदुओं को समेकित कर सकती है, जिसके परिणामस्वरूप पूर्ण, सटीक मास्क के बजाय बालों के केवल एक सीमित सबसेट का सेगमेंटेशन होता है। इसके लिए एक परिष्कृत प्रॉम्प्टिंग तंत्र की आवश्यकता होती है।
- कम्प्यूटेशनल बाधा: इमेज ट्रांसलेशन के दौरान बाल विवरण संरक्षित करना: डेटा संवर्द्धन के लिए एक महत्वपूर्ण विफलता मोड इमेज ट्रांसलेशन प्रक्रिया के दौरान आवश्यक बाल विवरण या सिमेंटिक जानकारी का नुकसान है। बालों के जटिल संरचना और विशेषताओं को एक साथ संरक्षित करते हुए विभिन्न स्कैल्प स्थितियों (जैसे, गंभीरता बदलना) को उत्पन्न करना एक जटिल कार्य है। DiffuseIT और AGG जैसे पिछले जनरेटिव मॉडल इसमें संघर्ष करते थे, अक्सर समग्र जानकारी से समझौता करते थे या प्रभावी ढंग से सिमेंटिक जानकारी स्थानांतरित करने में विफल रहते थे, जैसा कि अनुभाग 3.3 में गुणात्मक परिणामों में उजागर किया गया है। इसके लिए निष्ठा सुनिश्चित करने के लिए एक सावधानीपूर्वक डिज़ाइन किए गए हानि फ़ंक्शन और मास्क मार्गदर्शन की आवश्यकता होती है।
यह दृष्टिकोण क्यों
चुनाव की अनिवार्यता
SCALPVISION के बहु-घटक दृष्टिकोण को अपनाना केवल एक प्राथमिकता नहीं बल्कि एक आवश्यकता थी, जो स्कैल्प विकार निदान की अनूठी चुनौतियों का सामना करने पर मौजूदा तरीकों की मौलिक सीमाओं से प्रेरित थी। मुख्य समस्या दोहरी थी: सूक्ष्म स्कैल्प छवियों में बालों के लिए पिक्सेल-स्तरीय सेगमेंटेशन लेबल की अनुपस्थिति और गंभीर डेटा असंतुलन, विशेष रूप से दुर्लभ, गंभीर स्थितियों के लिए।
पारंपरिक पर्यवेक्षित सेगमेंटेशन विधियां, जैसे कि मानक CNNs या U-Nets, बालों के सेगमेंटेशन के लिए तुरंत अव्यावहारिक हो गईं क्योंकि उन्हें व्यापक, पिक्सेल-सटीक ग्राउंड ट्रुथ लेबल की आवश्यकता होती है। पत्र स्पष्ट रूप से बताता है कि "चूंकि अधिकांश स्कैल्प स्थिति डेटासेट में सेगमेंटेशन लेबल की कमी है, पर्यवेक्षित शिक्षण विधियां अव्यावहारिक हैं" (अनुभाग 2.1)। ऐसे लेबल उत्पन्न करना निषेधात्मक रूप से महंगा और समय लेने वाला है। इस बाधा ने लेखकों को एक "लेबल-मुक्त" सेगमेंटेशन रणनीति तैयार करने के लिए मजबूर किया।
इसी तरह, स्कैल्प स्थिति वर्गीकरण के लिए, केवल पारंपरिक SOTA विधियों (जैसे, उन्नत CNNs या ट्रांसफॉर्मर) पर निर्भर रहने से अनिवार्य रूप से खराब प्रदर्शन होगा, खासकर गंभीर स्थितियों के लिए। AI-Hub डेटासेट, एक प्राथमिक संसाधन, अच्छे और हल्के मामलों की ओर "भारी तिरछे" वितरण से पीड़ित है (चित्र 2, अनुभाग 3.1)। प्रभावी डेटा संवर्द्धन के बिना, ऐसे असंतुलित डेटा पर प्रशिक्षित मॉडल कम प्रतिनिधित्व वाली गंभीर स्थितियों को सामान्यीकृत करने और सटीक रूप से वर्गीकृत करने के लिए संघर्ष करेंगे। गॉसियन शोर या AugMix (तालिका 3) जैसे मानक संवर्द्धन तरीके इस चरम कमी को दूर करने के लिए अपर्याप्त साबित हुए। लेखकों ने महसूस किया कि विभिन्न स्कैल्प स्थितियों को सटीक रूप से दर्शाने वाली यथार्थवादी छवियों को संश्लेषित करने में सक्षम एक जनरेटिव मॉडल, जबकि महत्वपूर्ण बाल विवरणों को संरक्षित करना, इस असंतुलन को प्रभावी ढंग से संबोधित करने का एकमात्र तरीका था।
तुलनात्मक श्रेष्ठता
SCALPVISION का दृष्टिकोण अपनी संरचनात्मक डिजाइन के माध्यम से गुणात्मक श्रेष्ठता प्रदर्शित करता है, जो सीधे स्कैल्प छवि विश्लेषण की अंतर्निहित कठिनाइयों को संबोधित करता है।
बालों के सेगमेंटेशन के लिए, प्रस्तावित एनसेंबल विधि, जो एक ह्यूरिस्टिक-संचालित U²-Net (M) को स्वचालित रूप से प्रॉम्प्ट किए गए सेगमेंट एनीथिंग मॉडल (SAM) (MAP) के साथ जोड़ती है, एक महत्वपूर्ण संरचनात्मक लाभ प्रदान करती है। U²-Net, सिंथेटिक डेटा पर प्रशिक्षित, नकली शोर के साथ, रूसी जैसे कलाकृतियों के खिलाफ मजबूती प्रदान करता है (अनुभाग 2.2, अनुभाग 3.2)। दूसरी ओर, SAM सटीक किनारा पहचान में उत्कृष्टता प्राप्त करता है, स्पष्ट सीमाएं बनाता है (अनुभाग 2.2)। तार्किक AND ऑपरेशन ($M = M \land MAP$) सहक्रियात्मक रूप से इन शक्तियों को मर्ज करता है, जिससे एक अंतिम मास्क प्राप्त होता है जो शोर के प्रति मजबूत और बाल सीमाओं को परिभाषित करने में अत्यधिक सटीक दोनों है। यह पिछले तरीकों (शिह एट अल।, यू एट अल।, किम एट अल। [10]) की तुलना में गुणात्मक रूप से बेहतर है जो "बालों और स्कैल्प के जटिल पैटर्न को पकड़ने में समझ की कमी" (अनुभाग 3.2) रखते थे, और यहां तक कि बिना विशिष्ट मार्गदर्शन के उपयोग किए जाने वाले SAM की तुलना में भी, जिसने "उप-इष्टतम मास्क" (अनुभाग 2.1) उत्पन्न किए। यह संरचनात्मक संलयन अधिक विश्वसनीय और सटीक सेगमेंटेशन सुनिश्चित करता है, जो डाउनस्ट्रीम नैदानिक कार्यों के लिए महत्वपूर्ण है।
इमेज ट्रांसलेशन और डेटा संवर्द्धन के लिए, DiffuseIT-M अपने अद्वितीय मास्क मार्गदर्शन तंत्र के कारण बाहर खड़ा है। अन्य जनरेटिव मॉडल जैसे DiffuseIT [13] या AGG [14] के विपरीत, DiffuseIT-M विशेष रूप से "स्कैल्प स्थितियों को बदलते हुए बाल विवरणों को संरक्षित करने" (सार, अनुभाग 2.2) के लिए डिज़ाइन किया गया है। यह एक व्यापक हानि फ़ंक्शन, $l_{total}$, के माध्यम से प्राप्त किया जाता है, जिसमें एक मास्क संरक्षण हानि ($l_{mask}$) और रिवर्स डिफ्यूजन प्रक्रिया के दौरान एक मास्किंग दृष्टिकोण (समीकरण 5) शामिल है। यह संरचनात्मक डिजाइन अलग नियंत्रण की अनुमति देता है, यह सुनिश्चित करता है कि स्कैल्प सुविधाओं को संशोधित किया जा सके (जैसे, विभिन्न गंभीरता का अनुकरण करने के लिए) बालों की अखंडता से समझौता किए बिना, जो एक महत्वपूर्ण नैदानिक विशेषता है। मात्रात्मक रूप से, DiffuseIT-M बेहतर FID और LPIPS स्कोर (तालिका 2) प्राप्त करता है, जो बेसलाइन (अनुभाग 3.3) की तुलना में उच्च छवि निष्ठा और स्रोत सामग्री के बेहतर संरक्षण का संकेत देता है। गुणात्मक रूप से, चित्र 4 स्पष्ट रूप से दर्शाता है कि DiffuseIT और AGG "बाल सामग्री की जानकारी को संरक्षित करने में विफल" रहते हैं, एक महत्वपूर्ण दोष जिसे DiffuseIT-M दूर करता है। विशिष्ट छवि क्षेत्रों को बनाए रखते हुए दूसरों को बदलने की यह क्षमता चिकित्सा छवि संवर्द्धन के लिए एक गहरा संरचनात्मक लाभ है।
बाधाओं के साथ संरेखण
चुनी गई कार्यप्रणाली समस्या की कठोर आवश्यकताओं के साथ पूरी तरह से संरेखित होती है, जो चुनौतियों और समाधान के अद्वितीय गुणों के बीच एक "विवाह" बनाती है।
-
बाधा: पिक्सेल-स्तरीय सेगमेंटेशन लेबल की अनुपस्थिति।
- संरेखण: SCALPVISION का हेयर सेगमेंटेशन मॉड्यूल इसे "लेबल-मुक्त" बनाकर सीधे संबोधित करता है। यह ह्यूरिस्टिक-संचालित स्यूडो-लेबलिंग का लाभ उठाता है, जो बालों के पैटर्न (रैखिक या शक्ति कार्यों) के पूर्व ज्ञान के आधार पर सिंथेटिक चित्र उत्पन्न करता है, और SAM के लिए स्वचालित प्रॉम्प्टिंग। यह अभिनव प्रॉम्प्टिंग विधि व्यवस्थित रूप से मोटे सेगमेंटेशन मास्क से सकारात्मक और नकारात्मक बिंदु प्रॉम्प्ट उत्पन्न करती है, जो SAM को किसी भी मैनुअल पिक्सेल-स्तरीय एनोटेशन के बिना सटीक बाल मास्क उत्पन्न करने के लिए निर्देशित करती है (अनुभाग 2.1)। यह लेबल की कमी का एक सीधा और सुरुचिपूर्ण समाधान है।
-
बाधा: गंभीर डेटा असंतुलन, विशेष रूप से गंभीर स्थितियों के लिए।
- संरेखण: DiffuseIT-M जनरेटिव मॉडल इस पर काबू पाने के लिए आधारशिला है। यह विशेष रूप से डेटासेट संवर्द्धन (सार) के लिए डिज़ाइन किया गया है। मॉडल भारित नमूनाकरण का उपयोग करके यादृच्छिक रूप से चयनित छवियों को उच्च गंभीरता स्तरों में अनुवादित करता है, जहां चयन की संभावना वर्ग के आकार के व्युत्क्रमानुपाती होती है (अनुभाग 2.2)। यह तंत्र सीधे कम प्रतिनिधित्व वाले वर्गों को लक्षित करता है, संतुलित करने के लिए विविध और यथार्थवादी प्रशिक्षण नमूने उत्पन्न करता है। यह सुनिश्चित करता है कि वर्गीकरण मॉडल को गंभीर स्थितियों के पर्याप्त उदाहरणों के संपर्क में लाया जाए, जो मजबूत निदान के लिए महत्वपूर्ण है।
-
बाधा: मजबूत और सटीक निदान की आवश्यकता।
- संरेखण: मजबूत बाल सेगमेंटेशन (M और MAP को मिलाकर) सटीक बाल सुविधाएँ प्रदान करता है, जो निदान (अनुभाग 1) के लिए आवश्यक हैं। उच्च-निष्ठा संवर्धित चित्र उत्पन्न करने की DiffuseIT-M की क्षमता जो बाल विवरणों को संरक्षित करती है, यह सुनिश्चित करती है कि प्रशिक्षण डेटा यथार्थवादी और प्रासंगिक है, जिससे अधिक मजबूत वर्गीकरण मॉडल बनते हैं (अनुभाग 3.4)। सिस्टम के समग्र डिजाइन, लेबल-मुक्त सेगमेंटेशन से लेकर लक्षित डेटा संवर्द्धन तक, एक व्यापक और विश्वसनीय नैदानिक उपकरण बनाने के लिए तैयार है।
विकल्पों का अस्वीकरण
पत्र अंतर्निहित रूप से और स्पष्ट रूप से कई वैकल्पिक दृष्टिकोणों को उनकी विशिष्ट स्कैल्प विकार निदान बाधाओं को पूरा करने में असमर्थता के आधार पर अस्वीकार करता है।
-
पारंपरिक पर्यवेक्षित सेगमेंटेशन विधियां: इन्हें "पिक्सेल-स्तरीय सेगमेंटेशन लेबल की अनुपस्थिति" (अनुभाग 2.1) के कारण सीधे अस्वीकार कर दिया गया था। मानक U-Nets या Mask R-CNNs जैसी विधियों के लिए व्यापक मैनुअल एनोटेशन की आवश्यकता होती है, जो स्कैल्प डेटासेट के लिए उपलब्ध नहीं है। अन्य स्कैल्प सेगमेंटेशन दृष्टिकोणों [20,21,10] के मुकाबले तुलनात्मक परिणाम जटिल बाल पैटर्न को प्रभावी ढंग से पकड़ने में उनकी सीमाओं को और रेखांकित करते हैं (अनुभाग 3.2)।
-
फाउंडेशन मॉडल (जैसे, SAM) बिना विशिष्ट मार्गदर्शन के: जबकि SAM शक्तिशाली है, लेखकों ने पाया कि "M से यादृच्छिक बिंदुओं का चयन सकारात्मक प्रॉम्प्ट के लिए अक्सर उप-इष्टतम मास्क का कारण बनता है" और SAM "बिना विशिष्ट मार्गदर्शन के उपयोग किए जाने पर स्वचालित सेगमेंटेशन के लिए कम प्रभावी था" (अनुभाग 2.1, अनुभाग 3.2)। यह इस बात पर प्रकाश डालता है कि एक शक्तिशाली मॉडल अकेले पर्याप्त नहीं है; इसे इस डोमेन में प्रभावी होने के लिए एक अनुरूप, बुद्धिमान प्रॉम्प्टिंग तंत्र की आवश्यकता है।
-
इमेज ट्रांसलेशन के लिए अन्य जनरेटिव मॉडल (जैसे, DiffuseIT, AGG, या सामान्य GANs): पत्र सीधे DiffuseIT-M की तुलना DiffuseIT [13] और AGG [14] से करता है। दोनों विकल्प "स्रोत छवि से बाल सामग्री की जानकारी को संरक्षित करने में विफल" रहे और "समग्र जानकारी से समझौता करने और सिमेंटिक जानकारी स्थानांतरित करने में असमर्थ थे" (अनुभाग 3.3, चित्र 4)। यह विफलता स्कैल्प निदान के लिए महत्वपूर्ण है, जहां बाल विशेषताएं सर्वोपरि हैं। DiffuseIT-M के स्पष्ट मास्क मार्गदर्शन तंत्र के बिना, ये मॉडल नैदानिक रूप से प्रासंगिक संवर्धित डेटा उत्पन्न करने के लिए अनुपयुक्त, स्कैल्प स्थिति को बाल संरक्षण से अलग नहीं कर सकते। जबकि GANs को सीधे विकल्प के रूप में उल्लेख नहीं किया गया है, स्पष्ट मास्क मार्गदर्शन के बिना, विशेष रूप से शैली हस्तांतरण के दौरान नियंत्रित सामग्री संरक्षण में उनकी सामान्य सीमाएं, संभवतः समान विफलताओं का कारण बनेंगी।
-
गैर-उत्पादक डेटा संवर्द्धन विधियां (जैसे, गॉसियन शोर, AugMix): ये विधियां गंभीर स्थितियों के लिए "नमूनों की चरम कमी" (अनुभाग 3.4) को संबोधित करने के लिए अपर्याप्त पाई गईं। तालिका 3 स्पष्ट रूप से दिखाती है कि गॉसियन शोर या AugMix के साथ संवर्धित मॉडल जनरेटिव मॉडल के साथ संवर्धित लोगों की तुलना में काफी खराब प्रदर्शन करते हैं, विशेष रूप से गंभीर मामलों के वर्गीकरण के लिए। ये सरल विधियां नए, विविध उदाहरणों को संश्लेषित नहीं कर सकती हैं जो वास्तव में कम प्रतिनिधित्व वाले वर्गों का प्रतिनिधित्व करते हैं, इस प्रकार डेटा असंतुलन को प्रभावी ढंग से कम करने में विफल रहते हैं।
 Figure 2. Data distribution of different severity within each scalp condition
Figure 2. Data distribution of different severity within each scalp condition
गणितीय और तार्किक तंत्र
मास्टर समीकरण
DiffuseIT-M इमेज ट्रांसलेशन तंत्र का मूल, जो बालों के विवरणों को संरक्षित करते हुए विविध स्कैल्प छवियों के निर्माण को सक्षम बनाता है, एक व्यापक हानि फ़ंक्शन और एक विशिष्ट रिवर्स डिफ्यूजन नमूनाकरण चरण द्वारा शासित होता है। प्राथमिक उद्देश्य फ़ंक्शन जो सीखने और पीढ़ी प्रक्रिया का मार्गदर्शन करता है, कुल हानि, $l_{total}$ है, जिसे इस प्रकार परिभाषित किया गया है:
$$ l_{total} (x;x_{src},x_{trg},M) = \lambda_1 l_{style} + \lambda_2 l_{content} + \lambda_3 l_{mask} + \lambda_4 l_{sem} + \lambda_5 l_{rng} $$
इस हानि फ़ंक्शन का उपयोग तब पुनरावृत्त रिवर्स डिफ्यूजन प्रक्रिया के भीतर अगले, कम शोर वाले छवि नमूने, $x_{t-1}$, को वर्तमान शोर वाले छवि $x_t$ से उत्पन्न करने के लिए किया जाता है। यह परिवर्तन तर्क, बालों के विवरणों को संरक्षित करने के लिए महत्वपूर्ण है, इस प्रकार दिया गया है:
$$ x_{t-1} \leftarrow x_t \odot M + \left[x_0(x_t) - \sqrt{\bar{\alpha}_t} l_{total} (x_0(x_t))\right] \odot (1 – M) $$
कुल हानि गणना और रिवर्स चरण दोनों में एक महत्वपूर्ण घटक अनुमानित साफ छवि, $x_0(x_t)$ है, जो एक शोर वाले नमूने $x_t$ से समय चरण $t$ पर है। यह अनुमान अनुमानित शोर $\epsilon_0(x_t, t)$ से प्राप्त होता है:
$$ x_0(x_t) = \frac{x_t}{\sqrt{\bar{\alpha}_t}} - \frac{\sqrt{1 – \bar{\alpha}_t} \epsilon_0(x_t, t)}{\sqrt{\bar{\alpha}_t}} $$
अंत में, मास्क संरक्षण हानि, $l_{mask}$, जो $l_{total}$ का एक घटक है, स्पष्ट रूप से परिभाषित है:
$$ l_{mask} = \text{LPIPS}(x_{src}\odot M, x_0(x_t)\odot M) + ||(x_{src} - x_0(x_t))\odot M||_2 $$
पद-दर-पद विच्छेदन
आइए प्रत्येक तत्व की भूमिका को समझने के लिए इन समीकरणों का विश्लेषण करें:
कुल हानि फ़ंक्शन ($l_{total}$)
- $l_{total} (x;x_{src},x_{trg},M)$: यह समग्र उद्देश्य फ़ंक्शन है जिसे
DiffuseIT-Mमॉडल प्रशिक्षण के दौरान कम करने का लक्ष्य रखता है। यह कई व्यक्तिगत हानि घटकों का एक भारित योग है, जिसे उच्च-निष्ठा छवि अनुवाद सुनिश्चित करने के लिए डिज़ाइन किया गया है, जबकि विशिष्ट सुविधाओं को संरक्षित किया गया है। इनपुट वर्तमान छवि $x$ (जो रिवर्स चरण के संदर्भ में आमतौर पर $x_0(x_t)$ है), स्रोत छवि $x_{src}$, लक्ष्य छवि $x_{trg}$ (वांछित स्कैल्प स्थिति का प्रतिनिधित्व करती है), और बाल मास्क $M$ हैं।- जोड़ क्यों? लेखक विभिन्न, अक्सर प्रतिस्पर्धी, उद्देश्यों को संयोजित करने के लिए जोड़ का उपयोग करते हैं। प्रत्येक पद उत्पन्न छवि में एक विशिष्ट वांछित गुण को प्रोत्साहित करता है (जैसे, शैली, सामग्री, मास्क संरक्षण), और उन्हें जोड़ना मॉडल को इन लक्ष्यों में संतुलन सीखने की अनुमति देता है।
- $\lambda_1, \lambda_2, \lambda_3, \lambda_4, \lambda_5$: ये स्केलर भार गुणांक हैं।
- गणितीय परिभाषा: सकारात्मक वास्तविक संख्याएँ।
- भौतिक/तार्किक भूमिका: वे प्रत्येक हानि घटक के सापेक्ष महत्व को नियंत्रित करते हैं। इन भारों को समायोजित करके, लेखक छवि अनुवाद के कुछ पहलुओं को प्राथमिकता दे सकते हैं, जैसे कि बालों के विवरणों को कितनी मजबूती से संरक्षित किया जाना चाहिए, इसकी तुलना में स्कैल्प शैली को लक्ष्य से कितनी बारीकी से मेल खाना चाहिए।
- $l_{style}$: शैली हानि।
- गणितीय परिभाषा: पत्र में स्पष्ट रूप से परिभाषित नहीं है, लेकिन
DiffuseIT[13] से कहा गया है। आम तौर पर, इसमें VGG नेटवर्क या इसी तरह के वैचारिक सुविधाओं से फीचर आँकड़ों (जैसे, ग्राम मैट्रिक्स) का मिलान करना शामिल होता है। - भौतिक/तार्किक भूमिका: उत्पन्न छवि के स्कैल्प क्षेत्र को लक्ष्य स्कैल्प स्थिति की शैलीगत विशेषताओं (जैसे, बनावट, रंग, पैटर्न) को अपनाने के लिए प्रोत्साहित करता है।
- गणितीय परिभाषा: पत्र में स्पष्ट रूप से परिभाषित नहीं है, लेकिन
- $l_{content}$: सामग्री हानि।
- गणितीय परिभाषा: स्पष्ट रूप से परिभाषित नहीं है,
DiffuseIT[13] से भी। अक्सर उत्पन्न और लक्ष्य छवियों की फीचर मैप्स के बीच L2 दूरी को मापता है। - भौतिक/तार्किक भूमिका: यह सुनिश्चित करता है कि स्कैल्प क्षेत्र की उच्च-स्तरीय सिमेंटिक सामग्री लक्ष्य छवि से स्थानांतरित हो, जिससे मॉडल को स्कैल्प स्थिति को सटीक रूप से अनुवादित करने के लिए निर्देशित किया जा सके।
- गणितीय परिभाषा: स्पष्ट रूप से परिभाषित नहीं है,
- $l_{mask}$: मास्क संरक्षण हानि (समीकरण 3)।
- गणितीय परिभाषा: मास्क्ड क्षेत्रों पर लागू, LPIPS और L2 मानदंड का एक संयोजन।
- भौतिक/तार्किक भूमिका: यह
SCALPVISIONके लक्ष्य के लिए महत्वपूर्ण है। यह स्पष्ट रूप से मॉडल को स्रोत छवि से बालों के विवरणों को मास्क्ड बाल क्षेत्रों में संरक्षित करने के लिए मजबूर करता है, स्कैल्प स्थिति अनुवाद के दौरान अवांछित परिवर्तनों को रोकता है।
- $l_{sem}$: सिमेंटिक विचलन हानि।
- गणितीय परिभाषा: स्पष्ट रूप से परिभाषित नहीं है, लेकिन [13] से कहा गया है और DINO-ViT [3] से
[CLS]टोकन मिलान हानि का उपयोग करता है। - भौतिक/तार्किक भूमिका: यह सुनिश्चित करने का लक्ष्य रखता है कि लक्ष्य छवि की सिमेंटिक जानकारी (जैसे, रोग का प्रकार, गंभीरता) उत्पन्न छवि में सही ढंग से परिलक्षित हो, एक विजन ट्रांसफार्मर से उच्च-स्तरीय सुविधाओं का उपयोग करके।
- गणितीय परिभाषा: स्पष्ट रूप से परिभाषित नहीं है, लेकिन [13] से कहा गया है और DINO-ViT [3] से
- $l_{rng}$: वर्ग गोलाकार दूरी हानि।
- गणितीय परिभाषा: स्पष्ट रूप से परिभाषित नहीं है, लेकिन [5] से कहा गया है।
- भौतिक/तार्किक भूमिका: संभवतः एक नियमितीकरण पद के रूप में कार्य करता है, संभवतः उत्पन्न नमूनों में विविधता को प्रोत्साहित करता है या अव्यक्त स्थान में एक निश्चित वितरण बनाए रखता है, जो डेटा संवर्द्धन के लिए फायदेमंद है।
रिवर्स डिफ्यूजन सैंपलिंग स्टेप ($x_{t-1}$ अपडेट)
- $x_{t-1}$: रिवर्स डिफ्यूजन प्रक्रिया में पिछले (कम शोर वाले) समय चरण पर छवि।
- गणितीय परिभाषा: एक पिक्सेल-वार छवि टेंसर।
- भौतिक/तार्किक भूमिका: यह जनरेटिव प्रक्रिया के एक चरण का आउटपुट है, जो एक शोर वाली छवि से एक साफ, अनुवादित छवि की ओर बढ़ रहा है।
- $x_t$: समय चरण $t$ पर वर्तमान शोर वाली छवि।
- गणितीय परिभाषा: एक पिक्सेल-वार छवि टेंसर।
- भौतिक/तार्किक भूमिका: वर्तमान रिवर्स डिफ्यूजन चरण के लिए प्रारंभिक बिंदु।
- $M$: बाइनरी बाल मास्क।
- गणितीय परिभाषा: छवि के समान स्थानिक आयामों वाला एक बाइनरी टेंसर, जहां 1 बाल इंगित करता है और 0 स्कैल्प इंगित करता है।
- भौतिक/तार्किक भूमिका: एक स्टेंसिल के रूप में कार्य करता है। यह बाल क्षेत्रों को अलग करता है, यह सुनिश्चित करता है कि बालों पर लागू संचालन स्कैल्प पर लागू होने वाले लोगों से अलग हों।
- $\odot$: तत्व-वार गुणन (हैडमार्ड उत्पाद)।
- गणितीय परिभाषा: दो टेंसरों के संगत तत्वों को गुणा करता है।
- भौतिक/तार्किक भूमिका: यहां मास्किंग के लिए उपयोग किया जाता है। $x_t \odot M$ वर्तमान शोर वाली छवि के बाल क्षेत्र को अलग करता है, प्रभावी रूप से बालों को वैसे ही "रखता" है जैसा वे हैं।
- $x_0(x_t)$: $x_t$ से अनुमानित साफ छवि (समीकरण 4)।
- गणितीय परिभाषा: एक पिक्सेल-वार छवि टेंसर।
- भौतिक/तार्किक भूमिका: यह साफ छवि का प्रतिनिधित्व करता है जो मॉडल का सबसे अच्छा अनुमान है यदि $x_t$ से सभी शोर हटा दिए गए होते। यह डिफ्यूजन मॉडल में एक महत्वपूर्ण मध्यवर्ती भविष्यवाणी है।
- $\sqrt{\bar{\alpha}_t}$: अल्फा मानों के संचयी उत्पाद का वर्गमूल।
- गणितीय परिभाषा: $\bar{\alpha}_t = \prod_{s=1}^t (1-\beta_s)$, जहां $\beta_s$ विचरण अनुसूची पैरामीटर हैं।
- भौतिक/तार्किक भूमिका: डिफ्यूजन प्रक्रिया के शोर अनुसूची से प्राप्त एक स्केलिंग कारक। यह शोर वाली छवियों को उनके साफ समकक्षों और अनुमानित शोर से संबंधित गणितीय ढांचे का हिस्सा है।
- $l_{total}(x_0(x_t))$: अनुमानित साफ छवि पर लागू कुल हानि फ़ंक्शन।
- गणितीय परिभाषा: $l_{total}$ फ़ंक्शन का स्केलर आउटपुट।
- भौतिक/तार्किक भूमिका: यह पद स्कैल्प क्षेत्र के अनुवाद का मार्गदर्शन करता है। अनुमानित साफ छवि पर कुल हानि (जिसमें शैली, सामग्री और सिमेंटिक उद्देश्य शामिल हैं) लागू करके, मॉडल को लक्ष्य स्थिति से मेल खाने वाले स्कैल्प को उत्पन्न करने के लिए प्रेरित किया जाता है।
- $1 - M$: बाइनरी बाल मास्क का व्युत्क्रम।
- गणितीय परिभाषा: एक बाइनरी टेंसर जहां 1 स्कैल्प इंगित करता है और 0 बाल इंगित करता है।
- भौतिक/तार्किक भूमिका: स्कैल्प क्षेत्र को अलग करता है, जिससे हानि-निर्देशित अपडेट विशेष रूप से गैर-बाल क्षेत्रों पर लागू किया जा सके।
- जोड़ और मास्किंग क्यों? जोड़ दो अलग-अलग भागों को जोड़ता है: बाल क्षेत्र ( $x_t$ से संरक्षित) और स्कैल्प क्षेत्र (हानि के आधार पर अद्यतन)। यह चतुर मास्किंग दृष्टिकोण चयनात्मक छवि अनुवाद की अनुमति देता है, बालों को संरक्षित करते हुए स्कैल्प को रूपांतरित करता है।
अनुमानित साफ छवि ($x_0(x_t)$)
- $\epsilon_0(x_t, t)$: डिफ्यूजन मॉडल द्वारा अनुमानित शोर।
- गणितीय परिभाषा: $x_t$ के समान आकार का एक टेंसर, अनुमानित शोर घटक का प्रतिनिधित्व करता है।
- भौतिक/तार्किक भूमिका: यह डिफ्यूजन मॉडल के भीतर न्यूरल नेटवर्क का प्राथमिक आउटपुट है। नेटवर्क को उस शोर की भविष्यवाणी करने के लिए प्रशिक्षित किया जाता है जिसे एक साफ छवि को $x_t$ प्राप्त करने के लिए जोड़ा गया था।
- $\sqrt{1 - \bar{\alpha}_t}$: डिफ्यूजन प्रक्रिया से एक और स्केलिंग कारक।
- गणितीय परिभाषा: शोर अनुसूची से प्राप्त।
- भौतिक/तार्किक भूमिका: अनुमानित शोर के परिमाण को समय $t$ पर समग्र शोर स्तर से संबंधित करता है।
- विभाजन और घटाव क्यों? यह सूत्र डिफ्यूजन मॉडल में एक मानक पुन: पैरामीट्रिजेशन है। यह मॉडल को शोर $\epsilon_0(x_t, t)$ की भविष्यवाणी करने और फिर शोर अनुसूची मापदंडों और शोर वाले इनपुट $x_t$ से संबंधित साफ छवि $x_0(x_t)$ को विश्लेषणात्मक रूप से प्राप्त करने की अनुमति देता है।
मास्क संरक्षण हानि ($l_{mask}$)
- $\text{LPIPS}(A, B)$: लर्नड परसेप्चुअल इमेज पैच सिमिलैरिटी मीट्रिक।
- गणितीय परिभाषा: एक पूर्व-प्रशिक्षित न्यूरल नेटवर्क (जैसे, VGG) से गहरी सुविधाओं पर आधारित एक वैचारिक दूरी मीट्रिक।
- भौतिक/तार्किक भूमिका: दो छवि पैच के बीच वैचारिक समानता को मापता है, जो सरल पिक्सेल-वार अंतरों की तुलना में मानव धारणा के साथ बेहतर ढंग से संरेखित होता है। यहां, यह सुनिश्चित करता है कि स्रोत और उत्पन्न छवियों (मास्क के भीतर) में अनुभूति बाल विवरण समान हों।
- $||(x_{src} - x_0(x_t))\odot M||_2$: स्रोत छवि और अनुमानित साफ छवि के पिक्सेल-वार अंतर का L2 मानदंड (यूक्लिडियन दूरी), $M$ द्वारा मास्क्ड।
- गणितीय परिभाषा: $\sqrt{\sum_{i,j} ((x_{src})_{i,j} - (x_0(x_t))_{i,j})^2 \cdot M_{i,j}}$।
- भौतिक/तार्किक भूमिका: यह एक प्रत्यक्ष पिक्सेल-स्तरीय बाधा के रूप में कार्य करता है। यह एक "रबर बैंड" की तरह कार्य करता है, जो उत्पन्न छवि के बाल क्षेत्र को स्रोत छवि के बाल क्षेत्र के पिक्सेल-वार समान होने के लिए खींचता है। यह LPIPS को पिक्सेल-स्तरीय स्थानीय निष्ठा बाधा प्रदान करने के लिए पूरक है।
- जोड़ क्यों? LPIPS और L2 को संयोजित करने से बालों के संरक्षण के लिए वैचारिक और पिक्सेल-स्तरीय दोनों निष्ठा सुनिश्चित होती है।
चरण-दर-चरण प्रवाह
एक एकल अमूर्त डेटा बिंदु की कल्पना करें, जो इस मामले में एक सूक्ष्म स्कैल्प छवि, $x_{src}$ है, जिसे हम एक अलग स्कैल्प स्थिति, $x_{trg}$ प्रदर्शित करने के लिए बदलना चाहते हैं, जबकि बालों को ठीक वैसे ही रखते हैं जैसे वे हैं।
- बाल मास्क जनरेशन: सबसे पहले, इनपुट छवि $x_{src}$ हेयर सेगमेंटेशन मॉड्यूल में प्रवेश करती है। यह मॉड्यूल, स्यूडो-लेबलिंग और SAM (एल्गोरिथम 1 द्वारा निर्देशित) का उपयोग करके, एक बाइनरी हेयर मास्क, $M$ उत्पन्न करता है। यह मास्क स्कैल्प क्षेत्रों (मान 0) से बाल क्षेत्रों (मान 1) को सटीक रूप से सीमांकित करता है।
- शोर आरंभीकरण: इमेज ट्रांसलेशन के लिए,
DiffuseIT-Mमॉडल स्रोत छवि, $x_T$ के एक शोर वाले संस्करण, या एक शुद्ध शोर छवि से शुरू होता है, जिसे तब पुनरावृत्त रूप से डीनोइज़ किया जाता है। आइए एक मध्यवर्ती चरण $t$ पर एक सामान्य शोर वाली छवि $x_t$ पर विचार करें। - साफ छवि अनुमान: प्रत्येक रिवर्स डिफ्यूजन चरण में, मॉडल का न्यूरल नेटवर्क (शोर की भविष्यवाणी करने के लिए प्रशिक्षित) $x_t$ और वर्तमान समय चरण $t$ को इनपुट के रूप में लेता है। यह एक अनुमानित शोर घटक, $\epsilon_0(x_t, t)$ आउटपुट करता है। इस अनुमानित शोर का उपयोग तब डिफ्यूजन शेड्यूल पैरामीटर $\bar{\alpha}_t$ के साथ $x_0(x_t)$ (समीकरण 4) की गणना करने के लिए किया जाता है, जो $x_t$ के अंतर्निहित साफ छवि का मॉडल का सबसे अच्छा अनुमान है।
- मार्गदर्शन के लिए हानि गणना: अनुमानित साफ छवि $x_0(x_t)$, मूल स्रोत छवि $x_{src}$, लक्ष्य स्थिति छवि $x_{trg}$, और बाल मास्क $M$ के साथ, कुल हानि फ़ंक्शन, $l_{total}$ (समीकरण 2) में फीड की जाती है।
- $l_{style}$ और $l_{content}$ $x_{trg}$ के साथ $x_0(x_t)$ के स्कैल्प क्षेत्र की तुलना करते हैं ताकि शैली और सामग्री हस्तांतरण का मार्गदर्शन किया जा सके।
- $l_{mask}$ (समीकरण 3) विशेष रूप से $x_0(x_t)$ के बाल क्षेत्र की तुलना $x_{src}$ के बाल क्षेत्र से करता है ताकि बालों के संरक्षण को सुनिश्चित किया जा सके, दोनों वैचारिक (LPIPS) और पिक्सेल-वार (L2) मेट्रिक्स का उपयोग किया जा सके।
- $l_{sem}$ और $l_{rng}$ अतिरिक्त सिमेंटिक और नियमितीकरण मार्गदर्शन प्रदान करते हैं।
- इन हानियों का भारित योग, $l_{total}$, एक व्यापक संकेत प्रदान करता है कि वर्तमान $x_0(x_t)$ सभी वांछित गुणों के साथ कितनी अच्छी तरह संरेखित है।
- निर्देशित डीनोइजिंग और अनुवाद: इस गणना की गई $l_{total}$ का उपयोग तब अगली, कम शोर वाली छवि, $x_{t-1}$ (समीकरण 5) उत्पन्न करने के लिए किया जाता है।
- $x_t$ का बाल भाग $x_t \odot M$ द्वारा संरक्षित है। यह सुनिश्चित करता है कि स्रोत छवि से बाल संरचना सीधे आगे ले जाई जाए।
- स्कैल्प भाग को अनुमानित साफ छवि $x_0(x_t)$ के हानि-निर्देशित पद $[x_0(x_t) - \sqrt{\bar{\alpha}_t} l_{total} (x_0(x_t))]$ को स्कैल्प क्षेत्र, $(1-M)$ पर लागू करके अद्यतन किया जाता है। यह पद प्रभावी रूप से $x_0(x_t)$ के स्कैल्प पिक्सेल को लक्ष्य स्थिति की ओर धकेलता है, जो कुल हानि से प्रभावित होता है।
- इन दो मास्क्ड घटकों को तब $x_{t-1}$ बनाने के लिए जोड़ा जाता है, जिसमें अब संरक्षित बाल और एक स्कैल्प है जो लक्ष्य स्थिति के करीब एक कदम है।
- अभिसरण के लिए पुनरावृति: चरण 3 से 5 की यह प्रक्रिया कई समय चरणों, $t=T, T-1, \dots, 1$ के लिए पुनरावृत्त रूप से दोहराई जाती है। प्रत्येक चरण के साथ, छवि कम शोर वाली हो जाती है, और स्कैल्प क्षेत्र धीरे-धीरे लक्ष्य स्थिति से मेल खाने के लिए रूपांतरित होता है जबकि बाल बरकरार रहते हैं।
- अंतिम आउटपुट: सभी चरणों के बाद, अंतिम $x_0$ (या $t=1$ पर $x_{t-1}$) उत्पन्न छवि है, जो $x_{src}$ की स्कैल्प स्थिति में $x_{trg}$ का अनुवाद है जिसमें $x_{src}$ के बाल संरक्षित हैं।
अनुकूलन गतिशीलता
DiffuseIT-M तंत्र $l_{total}$ हानि फ़ंक्शन द्वारा निर्देशित, एक मानक डिफ्यूजन मॉडल प्रशिक्षण प्रक्रिया के माध्यम से अपने मापदंडों को सीखता और अद्यतन करता है।
- मॉडल प्रशिक्षण:
DiffuseIT-Mके भीतर अंतर्निहित न्यूरल नेटवर्क (जो $\epsilon_0(x_t, t)$ या $x_0(x_t)$ की भविष्यवाणी करता है) को छवियों के एक बड़े डेटासेट का उपयोग करके प्रशिक्षित किया जाता है। प्रशिक्षण के दौरान, शोर को साफ छवियों में जोड़ा जाता है ताकि शोर वाले नमूने $x_t$ बनाए जा सकें। मॉडल तब $x_t$ से शोर या साफ छवि की भविष्यवाणी करना सीखता है। $l_{total}$ फ़ंक्शन इस सीखने के उद्देश्य के रूप में कार्य करता है। - हानि परिदृश्य आकार देना: $l_{total}$ फ़ंक्शन बहु-आयामी तरीके से हानि परिदृश्य को आकार देता है:
- बाल संरक्षण घाटियाँ: $l_{mask}$ पद हानि परिदृश्य में गहरी घाटियाँ बनाता है जहाँ उत्पन्न बाल क्षेत्र स्रोत के बालों से निकटता से मेल खाते हैं। मास्क्ड क्षेत्र के भीतर बाल संरचना या उपस्थिति में कोई भी विचलन इस हानि में एक तेज वृद्धि का परिणाम देगा, प्रभावी रूप से बालों में परिवर्तन को दंडित करेगा।
- स्कैल्प परिवर्तन ग्रेडिएंट्स: $l_{style}$, $l_{content}$, और $l_{sem}$ पद स्कैल्प क्षेत्र को रूपांतरित करने के लिए मॉडल को निर्देशित करते हैं। इन हानियों से ग्रेडिएंट मॉडल मापदंडों को उन स्कैल्प सुविधाओं को उत्पन्न करने के लिए प्रेरित करते हैं जो लक्ष्य स्थिति के साथ संरेखित होती हैं। उदाहरण के लिए, यदि उत्पन्न स्कैल्प में $x_{trg}$ से वांछित बनावट की कमी है, तो $l_{style}$ ग्रेडिएंट मॉडल को उस बनावट को उत्पन्न करने के लिए निर्देशित करेगा।
- स्थिरता/विविधता के लिए नियमितीकरण: $l_{rng}$ पद प्रशिक्षण को नियमित करने में मदद करता है, संभावित रूप से हानि परिदृश्य को चिकना करता है या मॉडल को विविध समाधानों का पता लगाने के लिए प्रोत्साहित करता है, जो डेटा संवर्द्धन के लिए विविध नमूने उत्पन्न करने के लिए फायदेमंद है।
- ग्रेडिएंट डिसेंट: मॉडल के मापदंडों को एडम या एसजीडी जैसे अनुकूलन एल्गोरिथम का उपयोग करके पुनरावृत्त रूप से अद्यतन किया जाता है। प्रत्येक प्रशिक्षण चरण में, मॉडल मापदंडों के संबंध में $l_{total}$ के ग्रेडिएंट की गणना की जाती है। ये ग्रेडिएंट कुल हानि को कम करने के लिए प्रत्येक पैरामीटर में आवश्यक परिवर्तन की दिशा और परिमाण इंगित करते हैं। मापदंडों को तब ग्रेडिएंट के विपरीत दिशा में समायोजित किया जाता है।
- पुनरावृत्त शोधन: कई प्रशिक्षण पुनरावृत्तियों पर, मॉडल $\epsilon_0(x_t, t)$ (या $x_0(x_t)$) की भविष्यवाणी करना सीखता है ताकि जब इस भविष्यवाणी का उपयोग रिवर्स डिफ्यूजन प्रक्रिया में किया जाता है, तो परिणामी $x_0(x_t)$ $l_{total}$ को कम करता है। इसका मतलब है कि मॉडल ऐसी छवियां उत्पन्न करना सीखता है जहां बाल संरक्षित होते हैं और स्कैल्प स्थितियों का सटीक रूप से अनुवाद किया जाता है।
- अभिसरण: प्रशिक्षण तब तक जारी रहता है जब तक कि एक सत्यापन सेट पर मॉडल का प्रदर्शन बेहतर नहीं हो जाता है, यह दर्शाता है कि यह एक ऐसी स्थिति में अभिसरण कर गया है जहां यह वांछित छवि अनुवाद कार्यों को प्रभावी ढंग से कर सकता है। $\lambda_i$ भारों का संतुलन विभिन्न उद्देश्यों के बीच एक अच्छा ट्रेड-ऑफ प्राप्त करने और एक स्थिर अभिसरण सुनिश्चित करने के लिए महत्वपूर्ण है। पत्र "वर्गीकरण के लिए चार एमएलपी हेड्स के साथ एक पूर्व-प्रशिक्षित बैकबोन को फाइन-ट्यूनिंग" का भी उल्लेख करता है, जो डाउनस्ट्रीम कार्य के लिए एक अलग अनुकूलन कदम है, लेकिन जनरेटिव मॉडल की सीखने मुख्य रूप से $l_{total}$ को कम करने से प्रेरित होती है।
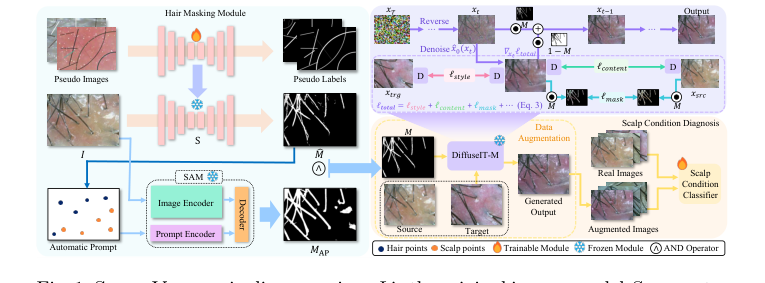 Figure 1. ScalpVision pipeline overview: I is the original image, model S generates the hair segmentation mask ˆ M using a pseudo-training set, MAP is the SAM- produced mask, and M is the combined hair segmentation mask. The “Automatic Prompt” for refining segmentation comes from ˆ M. xsrc and xtrg are the source and target images, with M as the mask image of xsrc. The weighted image sum is denoted by ⊙and D stands for DINO-ViT [3]
Figure 1. ScalpVision pipeline overview: I is the original image, model S generates the hair segmentation mask ˆ M using a pseudo-training set, MAP is the SAM- produced mask, and M is the combined hair segmentation mask. The “Automatic Prompt” for refining segmentation comes from ˆ M. xsrc and xtrg are the source and target images, with M as the mask image of xsrc. The weighted image sum is denoted by ⊙and D stands for DINO-ViT [3]
परिणाम, सीमाएँ और निष्कर्ष
प्रयोगात्मक डिजाइन और बेसलाइन
SCALPVISION के मुख्य तंत्रों को कठोरता से मान्य करने के लिए, लेखकों ने प्रत्येक घटक को लक्षित करने वाले प्रयोगों की एक श्रृंखला तैयार की: बाल सेगमेंटेशन, सिंथेटिक छवि जनरेशन, और स्कैल्प स्थिति वर्गीकरण।
बाल सेगमेंटेशन के लिए, प्राथमिक लक्ष्य लेबल-मुक्त दृष्टिकोण की प्रभावशीलता को साबित करना था। मुख्य AI-Hub डेटासेट में पिक्सेल-स्तरीय सेगमेंटेशन लेबल की अनुपस्थिति को देखते हुए, विशेषज्ञों द्वारा मैन्युअल रूप से एनोटेट किए गए 150 परीक्षण छवियों का एक विशेष उपसमूह ग्राउंड ट्रुथ के रूप में काम करने के लिए। इस क्षेत्र में "पीड़ित" (बेसलाइन मॉडल) में पारंपरिक कंप्यूटर विजन विधियां जैसे कि शिया एट अल। [20], यू एट अल। [21], और किम एट अल। [10], साथ ही शक्तिशाली फाउंडेशन मॉडल, SAM [12] शामिल थे। प्रदर्शन को मानक मेट्रिक्स का उपयोग करके मापा गया: पिक्सेल-एफ1, जैकार्ड, और डाइस स्कोर। प्रारंभिक भोला सेगमेंटेशन मास्क ($M$), SAM-उत्पादित मास्क ($M_{AP}$), और उनके अंतिम संयुक्त मास्क ($M$) के योगदान को अलग करने के लिए एक महत्वपूर्ण एब्लेशन अध्ययन भी आयोजित किया गया था।
सिंथेटिक छवि जनरेशन मॉड्यूल, DiffuseIT-M, को बालों के विवरणों को संरक्षित करते हुए विविध स्कैल्प छवियों को बनाने की अपनी क्षमता को प्रदर्शित करने के लिए अन्य जनरेटिव मॉडल के मुकाबले मूल्यांकन किया गया था। यहां बेसलाइन DiffuseIT [13] और AGG [14] थे। प्रयोगों ने फ्रेशेट इंसेप्शन डिस्टेंस (FID) [8] और लर्नड परसेप्चुअल इमेज पैच सिमिलैरिटी (LPIPS) [22] स्कोर का उपयोग करके छवि निष्ठा को क्रूरतापूर्वक साबित किया। इसके अलावा, मास्क मार्गदर्शन के प्रभाव का विशेष रूप से विभिन्न मास्क स्थितियों के तहत छवि अनुवाद के परिणामों की तुलना करके परीक्षण किया गया था: हमारा प्रस्तावित 1-M मार्गदर्शन, रिवर्स मास्क M, कोई मास्क नहीं (0), और एक पूर्ण मास्क (1)।
अंत में, स्कैल्प स्थिति वर्गीकरण के लिए, पूरे AI-Hub डेटासेट, जिसमें 95,910 छवियां शामिल थीं (प्रशिक्षण के लिए 72,342, परीक्षण के लिए 23,568, और सत्यापन के लिए 21,703 में विभाजित), का उपयोग किया गया था। त्वचा विशेषज्ञों ने इन छवियों को तीन स्थितियों - रूसी, अतिरिक्त सीबम, और एरिथेमा - के लिए लेबल किया था, प्रत्येक को चार गंभीरता स्तरों में वर्गीकृत किया गया था: अच्छा, हल्का, मध्यम, और गंभीर। डेटासेट के अंतर्निहित झुकाव को "अच्छे" और "हल्के" मामलों की ओर स्वीकार करते हुए (जैसा कि चित्र 2 में दिखाया गया है), प्रयोगों का उद्देश्य यह दिखाना था कि जनरेटिव संवर्द्धन इस असंतुलन को कैसे संबोधित कर सकता है। दो अलग-अलग वर्गीकरण बैकबोन का उपयोग किया गया था: DenseNet [9] (एक CNN) और EfficientFormerV2 [15] (एक ट्रांसफार्मर), विभिन्न आर्किटेक्चर में निष्कर्षों की मजबूती सुनिश्चित करने के लिए। विभिन्न संवर्द्धन रणनीतियों को एक-दूसरे के खिलाफ खड़ा किया गया था: गॉसियन शोर, AugMix [7], DiffuseIT [13], AGG [14], और "हमारा" (SCALPVISION का DiffuseIT-M)। निश्चित प्रमाण समग्र मैक्रो-एफ1 स्कोर और तीन बीमारियों में प्रत्येक गंभीरता स्तर के लिए व्यक्तिगत एफ1 स्कोर में मांगा गया था।
साक्ष्य क्या साबित करते हैं
प्रायोगिक साक्ष्य SCALPVISION के मुख्य तंत्रों का निर्विवाद प्रमाण प्रदान करते हैं।
बाल सेगमेंटेशन के लिए, तालिका 1 निश्चित रूप से दिखाती है कि हमारे संयुक्त मास्क $M$ ने सभी मेट्रिक्स (पिक्सेल-एफ1: 0.868, जैकार्ड: 0.649, डाइस: 0.786) में बेहतर प्रदर्शन हासिल किया। यह केवल एक मामूली सुधार नहीं था; इसने सभी पारंपरिक कंप्यूटर विजन बेसलाइन और यहां तक कि स्टैंडअलोन SAM मॉडल को भी काफी पार कर लिया। तार्किक AND ऑपरेशन के माध्यम से शोर के प्रति प्रारंभिक भोला सेगमेंटेशन मॉडल की मजबूती ($M$) को SAM की बेहतर किनारा पहचान ($M_{AP}$) के साथ संयोजित करने का वास्तुशिल्प विकल्प महत्वपूर्ण था। यह संलयन, जैसा कि चित्र 3 में नेत्रहीन पुष्टि की गई है, स्पष्ट, सटीक और शोर-प्रतिरोधी बाल मास्क उत्पन्न करता है, यह साबित करता है कि SAM के लिए ह्यूरिस्टिक-संचालित स्यूडो-लेबलिंग और स्वचालित प्रॉम्प्टिंग विधि ने लेबल की कमी और व्यक्तिगत मॉडल कमजोरियों की सीमाओं को प्रभावी ढंग से दूर किया। "पीड़ितों" को स्पष्ट रूप से हराया गया था, हमारे तरीके ने पूर्व कला की तुलना में जटिल बाल पैटर्न की अधिक व्यापक समझ का प्रदर्शन किया।
सिंथेटिक छवि जनरेशन में, DiffuseIT-M ("हमारा") ने अपने जनरेटिव मॉडल समकक्षों की तुलना में काफी बेहतर निष्ठा स्कोर प्राप्त करके अपनी क्षमता का प्रदर्शन किया। तालिका 2 FID 74.84 और LPIPS 0.353 की रिपोर्ट करती है, जो DiffuseIT (FID: 138.42, LPIPS: 0.463) और AGG (FID: 141.70, LPIPS: 0.492) की तुलना में काफी कम (उच्च गुणवत्ता का संकेत) हैं। चित्र 4 और चित्र 5 में नेत्रहीन साक्ष्य इसे और मजबूत करते हैं। जबकि बेसलाइन बालों की सामग्री को संरक्षित करने या सिमेंटिक जानकारी को सटीक रूप से स्थानांतरित करने के लिए संघर्ष करते थे, DiffuseIT-M ने स्कैल्प स्थितियों को प्रभावी ढंग से बदलते हुए स्रोत बालों के विवरणों को सफलतापूर्वक बनाए रखा। मास्क मार्गदर्शन पर प्रयोग विशेष रूप से बताने वाले थे: 1-M मास्क मार्गदर्शन का उपयोग अनुवाद के दौरान बालों की विशेषताओं को बनाए रखने के लिए महत्वपूर्ण था, जबकि अन्य मास्क स्थितियां (कोई मास्क नहीं, पूर्ण मास्क, या रिवर्स मास्क) या तो न्यूनतम परिवर्तन का कारण बनीं या बालों और स्कैल्प दोनों को अंधाधुंध रूप से बदल दिया। यह कठोर साक्ष्य साबित करता है कि DiffuseIT-M का मास्क-निर्देशित डिफ्यूजन तंत्र नियंत्रित छवि अनुवाद में अत्यधिक प्रभावी है, जो डेटा संवर्द्धन के लिए एक महत्वपूर्ण कदम है।
समग्र प्रणाली के प्रभाव के लिए सबसे सम्मोहक साक्ष्य स्कैल्प स्थिति वर्गीकरण से आया। तालिका 3 स्पष्ट रूप से प्रदर्शित करती है कि "हमारा" (SCALPVISION का DiffuseIT-M संवर्द्धन) लगातार DenseNet (0.636) और EfficientFormerV2 (0.635) बैकबोन दोनों के लिए उच्चतम मैक्रो-एफ1 स्कोर प्राप्त करता है। यह केवल एक समग्र जीत नहीं थी; यह विशेष रूप से गंभीर डेटा असंतुलन को संबोधित करने में स्पष्ट था। उदाहरण के लिए, "गंभीर" सीबम के वर्गीकरण के लिए, गॉसियन शोर और AugMix जैसे गैर-उत्पादक संवर्द्धन विधियों ने 0.000 के एफ1 स्कोर उत्पन्न किए, जो इस दुर्लभ लेकिन महत्वपूर्ण स्थिति को वर्गीकृत करने में पूर्ण विफलता का संकेत देता है। इसके विपरीत, "हमारा" ने गंभीर सीबम के लिए एफ1 स्कोर 0.430 (DenseNet) और 0.406 (EfficientFormerV2) प्राप्त किया। यह निश्चित, निर्विवाद साक्ष्य है कि जनरेटिव डेटा संवर्द्धन, विशेष रूप से उच्च-गुणवत्ता, विविध नमूने बनाने की DiffuseIT-M की क्षमता कम प्रतिनिधित्व वाले वर्गों के लिए, सीधे नैदानिक प्रदर्शन में वृद्धि में तब्दील होती है, विशेष रूप से चुनौतीपूर्ण, दुर्लभ स्थितियों के लिए। यह साबित करता है कि सटीक वर्गीकरण के लिए स्कैल्प शैली और बाल सामग्री की जानकारी दोनों को संरक्षित करना सर्वोपरि है।
सीमाएँ और भविष्य की दिशाएँ
जबकि SCALPVISION स्कैल्प विकार निदान के लिए एक मजबूत और अभिनव समाधान प्रस्तुत करता है, इसकी वर्तमान सीमाओं को स्वीकार करना और भविष्य के विकास के लिए रास्ते पर विचार करना महत्वपूर्ण है।
एक अंतर्निहित सीमा स्वयं डेटासेट से उत्पन्न होती है। एक बड़े संसाधन के बावजूद, AI-Hub डेटासेट "अच्छे" और "हल्के" स्कैल्प स्थितियों की ओर भारी तिरछा है, जिसमें गंभीर मामले दुर्लभ हैं। जबकि SCALPVISION का जनरेटिव संवर्द्धन विधि इस असंतुलन को महत्वपूर्ण रूप से कम करती है, गंभीर मामलों की अंतर्निहित कमी अभी भी उन गंभीर प्रस्तुतियों के लिए सामान्यीकरण के लिए चुनौतियां पेश कर सकती है जो संवर्धित डेटा में भी अच्छी तरह से प्रतिनिधित्व नहीं करती हैं। इसके अतिरिक्त, बाल सेगमेंटेशन के लिए मैनुअल एनोटेशन अपेक्षाकृत छोटे 150 परीक्षण छवियों के सबसेट पर किया गया था। जबकि प्रारंभिक सत्यापन के लिए पर्याप्त है, मैन्युअल रूप से एनोटेट की गई छवियों का एक व्यापक, अधिक विविध सेट विभिन्न बाल प्रकारों और इमेजिंग स्थितियों में बाल सेगमेंटेशन मॉडल की मजबूती को और मजबूत कर सकता है। इसके अलावा, वर्तमान प्रणाली तीन विशिष्ट स्कैल्प रोगों पर केंद्रित है: रूसी, अतिरिक्त सीबम, और एरिथेमा। यह दायरा, हालांकि मूल्यवान है, इसका मतलब है कि यह अभी तक स्कैल्प को प्रभावित करने वाले त्वचा रोगों के पूर्ण स्पेक्ट्रम को कवर नहीं करता है।
आगे देखते हुए, कई रोमांचक दिशाएं इन निष्कर्षों को और विकसित कर सकती हैं:
- नैदानिक दायरे का विस्तार: लेखक स्पष्ट रूप से बालों की जानकारी का लाभ उठाते हुए, एलोपेसिया जैसी स्थितियों में अनुसंधान का विस्तार करने के अपने इरादे को बताते हैं। यह एक सामान्यीकृत नैदानिक प्रणाली की ओर एक स्वाभाविक और आवश्यक प्रगति है। भविष्य का काम यह पता लगा सकता है कि SCALPVISION का ढांचा उन स्थितियों के अनुकूल कैसे होता है जहां बालों के पैटर्न, न कि केवल स्कैल्प सतह की स्थिति, प्राथमिक नैदानिक विशेषताएं हैं।
- बहु-मोडल एकीकरण: वर्तमान में, प्रणाली केवल सूक्ष्म स्कैल्प इमेजरी पर निर्भर करती है। रोगी इतिहास, आनुवंशिक मार्कर, या यहां तक कि मैक्रोस्कोपिक छवियों जैसे अन्य नैदानिक डेटा को एकीकृत करने से अधिक समग्र और सटीक निदान हो सकता है, जिससे केवल छवि-आधारित विश्लेषण से उत्पन्न होने वाले झूठे सकारात्मक या नकारात्मक को कम किया जा सकता है।
- नैदानिक परिनियोजन और उपयोगकर्ता अनुभव: SCALPVISION को एक वास्तव में मूल्यवान उपकरण बनने के लिए, नैदानिक कार्यप्रवाहों में इसका एकीकरण सर्वोपरि है। इसमें त्वचा विशेषज्ञों के लिए उपयोगकर्ता-अनुकूल इंटरफेस विकसित करना, चिकित्सा नियमों का अनुपालन सुनिश्चित करना, और विभिन्न रोगी आबादी और सेटिंग्स में इसके प्रदर्शन को मान्य करने के लिए व्यापक वास्तविक दुनिया नैदानिक परीक्षण करना शामिल होगा। हम इस तकनीक को उनके कार्यभार को बढ़ाए बिना चिकित्सकों की सहायता कैसे कर सकते हैं?
- व्याख्यात्मकता और विश्वास: जबकि मॉडल उच्च प्रदर्शन दिखाता है, यह समझना कि यह कुछ नैदानिक निर्णय क्यों लेता है, चिकित्सा पेशेवरों के बीच विश्वास बनाने के लिए महत्वपूर्ण है। भविष्य के शोध AI की व्याख्यात्मकता को बढ़ाने पर ध्यान केंद्रित कर सकते हैं, शायद उन विशिष्ट छवि क्षेत्रों या सुविधाओं को हाइलाइट करके जो निदान में सबसे अधिक योगदान करते हैं, इस प्रकार चिकित्सकों के लिए कार्रवाई योग्य अंतर्दृष्टि प्रदान करते हैं।
- व्यक्तिगत उपचार सिफारिशें: निदान से परे, SCALPVISON संभावित रूप से पहचानी गई स्थिति, गंभीरता, और यहां तक कि व्यक्तिगत रोगी विशेषताओं के आधार पर व्यक्तिगत उपचार योजनाओं का सुझाव देने के लिए विकसित हो सकता है। इसके लिए चिकित्सा ज्ञान आधारों और संभावित रूप से रोगी-विशिष्ट डेटा को एकीकृत करने की आवश्यकता होगी।
- डेटा गोपनीयता और नैतिक चिंताओं को संबोधित करना: संवेदनशील चिकित्सा डेटा को संभालने वाली किसी भी AI प्रणाली के साथ, डेटा गोपनीयता, सुरक्षा और नैतिक परिनियोजन पर कठोर ध्यान आवश्यक है। हम ऐसे शक्तिशाली नैदानिक उपकरणों के जिम्मेदार उपयोग को कैसे सुनिश्चित कर सकते हैं, विशेष रूप से जनरेटिव मॉडल से निपटते समय जो संभावित रूप से सिंथेटिक रोगी डेटा बना सकते हैं?
- उन्नत जनरेटिव आर्किटेक्चर की खोज: जबकि DiffuseIT-M अत्यधिक प्रभावी है, जनरेटिव AI का क्षेत्र तेजी से आगे बढ़ रहा है। नए डिफ्यूजन मॉडल, GANs, या अन्य जनरेटिव आर्किटेक्चर की जांच छवि निष्ठा, विविधता और नियंत्रण में और सुधार कर सकती है, जिससे संभावित रूप से और भी मजबूत डेटा संवर्द्धन रणनीतियां बन सकती हैं।
ये चर्चाएं उजागर करती हैं कि SCALPVISION सिर्फ एक नैदानिक उपकरण नहीं है, बल्कि एक मूलभूत ढांचा है जिसमें त्वचाविज्ञान देखभाल को बदलने की अपार क्षमता है, बशर्ते इसकी सीमाओं को संबोधित किया जाए और इसकी क्षमताओं को विचारपूर्वक विस्तारित किया जाए।
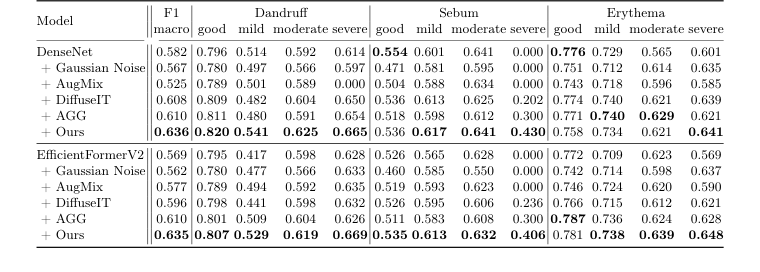 Table 3. Performance of scalp condition classification with various augmentation methods, denoted after “+” symbol, on the test set. The second column displays the overall macro-F1 score, while the columns from the third onward show the F1 scores for each severity level of the three diseases
Table 3. Performance of scalp condition classification with various augmentation methods, denoted after “+” symbol, on the test set. The second column displays the overall macro-F1 score, while the columns from the third onward show the F1 scores for each severity level of the three diseases
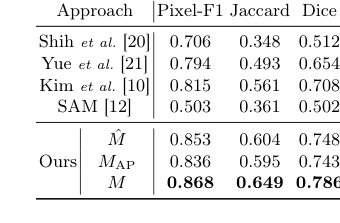 Table 1. Performance of hair segmenta- tion on the test set
Table 1. Performance of hair segmenta- tion on the test set
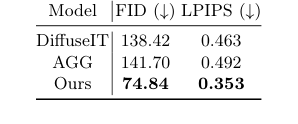 Table 2. Quantitative analysis of image- to-image translation
Table 2. Quantitative analysis of image- to-image translation