ラベルフリーセグメンテーションとトレーニングフリー画像変換による頭皮診断システム
ScalpVision tackles data challenges for better, cheaper, and more accessible skin care.
背景と学術的系譜
起源と学術的系譜
本稿で取り組む問題は、世界的に蔓延している頭皮疾患に端を発しており、成人人口の相当な割合に影響を与え、米国では成人の約90%が何らかの疾患を経験している[6]。この高い有病率にもかかわらず、多くの症例は診断が不十分なままである。これは主に、専門的な皮膚科医による評価へのアクセスが限られていることと、診断目的での手動アノテーションに伴う高コストという2つの重要な要因によるものである。
医療画像および人工知能の学術分野では、頭皮疾患に対するAIベースの診断システムの可能性は、以前から認識されている[4,11,19]。脱毛症のような頭皮関連疾患の進行をより深刻な結果に防ぐためには、早期発見が不可欠である[16,17]。しかし、これらの疾患の効果的な診断は、微細な頭皮画像から毛髪数や太さといった重要な特徴を正確に測定することに大きく依存している。この精密な毛髪セグメンテーションの必要性が、根本的な問題を生じさせる。歴史的な文脈は、効率的かつアクセス可能な高度な診断アプローチの明確な必要性を示しており、研究者は自動化システムの開発を推進している。
著者らが本稿を執筆するに至った、以前のアプローチの根本的な限界、すなわち「ペインポイント」は、いくつかの主要な領域に分解できる。
- ピクセルレベルのセグメンテーションラベルの欠如: ピクセルレベルの毛髪アノテーションを生成することは、信じられないほどコストがかかり、時間のかかる作業である。決定的に、このような詳細なセグメンテーションラベルを提供する公開データセットは存在しない。例えば、主要なリソースであるAI-Hub[1]は、頭皮疾患の分類ラベルのみを提供しており、堅牢なAIトレーニングに必要な詳細なセグメンテーションアノテーションは提供していない。このグラウンドトゥルースのセグメンテーションデータの不在は、通常非常に効果的な教師あり学習手法の実行を不可能にする。
- 深刻なデータ不均衡: 多くの既存の頭皮画像データセットは、特に重度の頭皮疾患において、深刻なデータ不均衡に苦しんでいる(図2に示す通り)。このような重要な重症例のサンプルの希少性は、疾患の重症度の全スペクトルにわたってロバストかつ正確なAIモデルを開発することを極めて困難にする。以前の非生成的拡張手法は、重度の皮脂[表3]のような稀なクラスに苦労していた。
- 先行セグメンテーション技術の限界: 従来のコンピュータビジョン技術[20,21,10]に依存することが多かった毛髪セグメンテーションのための以前の教師なし手法は、細い毛髪を正確にセグメンテーションし、複雑な毛髪パターンを捉えるのに苦労した。SAM[12]のような最新の基盤モデルでさえ、強力ではあるが、特定のガイダンスなしでの自動セグメンテーションには効果が低く、ランダムな点の選択はしばしば最適でない、あるいは混乱を招くマスクにつながった。
- 画像変換中の毛髪詳細の維持能力の欠如: 画像を変換して異なる頭皮状態をシミュレートすることによりデータセットを拡張しようとする際、DiffuseIT[13]やAGG[14]のような既存の拡散ベースの画像変換モデルは、ソース画像からの重要な毛髪コンテンツ情報の維持に失敗した。これは、頭皮スタイルを変更することはできたものの、診断に不可欠な毛髪の特徴をしばしば損ない、データ拡張における有用性を妨げたことを意味する。
直感的なドメイン用語
以下に、本稿の専門的なドメイン用語を、直感的で日常的なアナロジーに翻訳したものをいくつか示す。
- 毛髪セグメンテーションマスク: 写真に写った人の頭があり、毛髪だけをハイライトしたいと想像してください。例えば、毛髪に色を塗るようなものです。毛髪セグメンテーションマスクは、一本一本の毛髪を正確に輪郭で囲み、頭皮や背景から分離するデジタルステンシルのようなものです。これは、毛髪ピクセルが「オン」(例:白)で、非毛髪ピクセルが「オフ」(例:黒)であるバイナリ画像です。
- 疑似ラベリング: 試験の解答集を持っていない先生が、自分の最良の推測や簡単なルールに基づいて「偽の」解答集を作成するようなものです。そして、その偽の解答集を使って新しい生徒を訓練します。本稿では、ピクセル単位で完璧な実際の毛髪ラベルを取得するのは高すぎるため、研究者は「疑似ラベル」(近似的な毛髪マスク)を簡単なルールと事前知識を使用して生成し、最初にセグメンテーションモデルを訓練します。
- データ不均衡: クラスルームで、生徒の90%が数学が得意だが、詩が得意なのは1%だけだと想像してください。このクラスだけで教師を訓練すると、その教師は数学を教えるのが非常に上手になりますが、十分な例を見ていないため、詩にはひどく苦労するかもしれません。この文脈でのデータ不均衡とは、軽度の頭皮疾患の画像はたくさんあるが、重度の疾患の画像は非常に少ないことを意味し、AIが重度の症例を確実に診断するように学習することを困難にします。
- 拡散ベース画像変換: これは、人の写真を撮って、元の顔の特徴を維持したまま、年を取らせたり、若返らせたり、髪の色を変えたりできるアーティストのようなものです。拡散ベース画像変換モデルは、ソース画像(例:健康な頭皮)を取り込み、それを「塗り直し」て別の状態(例:フケのある頭皮)を示しますが、毛髪数や太さといった元の毛髪の詳細を維持するように特別に設計されています。
- 基盤セグメンテーションモデル(SAM): どんな写真でも、オブジェクトをクリックするだけで、あらゆるオブジェクトを輪郭で囲むことができる、非常に賢く汎用的なデジタルアシスタントを想像してください。SAMはほとんどのものをセグメンテーションできる強力なAIモデルですが、毛髪セグメンテーションのような特定のタスクでは、最適なパフォーマンスを発揮し、毛髪と頭皮を区別するために、まだ少しガイダンス(「ポイントプロンプト」のようなもの)が必要です。
記法表
| 記法 | 説明 |
|---|---|
問題定義と制約
コア問題定式化とジレンマ
本稿が取り組む中心的な問題は、微細な画像から頭皮疾患を包括的に診断するためのAI駆動システム、SCALPVISIONの開発である。この一見単純な目標は、2つの重大で相互に関連する課題によって複雑化されている。
入力/現在の状態: 出発点は、微細な頭皮画像のコレクションである。AI-Hubデータセットのような既存のデータセットは、様々な頭皮疾患(フケ、過剰な皮脂、紅斑など)とその重症度(良好、軽度、中等度、重度)に対する高レベルの分類ラベルを提供しているが、決定的に毛髪のピクセルレベルのセグメンテーションラベルを欠いている。さらに、これらのデータセットは深刻なデータ不均衡に苦しんでおり、重症例のサンプル数が不均衡に少ない(図2に示す)。
望ましい終点/目標状態: 最終的な目標は、以下の能力を持つ堅牢なシステムである。
1. 高価で時間のかかる手動ピクセルレベルのアノテーションに依存することなく、これらの微細な画像内の毛髪を正確にセグメンテーションすること。この毛髪セグメンテーションは、診断に不可欠な毛髪数や太さといった特徴を測定するために重要である。
2. トレーニングデータを効果的に拡張することにより、特に過小評価されている重症例の頭皮疾患重症度予測の精度を向上させること。
失われたリンクとジレンマ: 正確なピクセルレベルの毛髪マスクの不在が、まさに失われたリンクである。これは、教師ありセグメンテーションモデルのトレーニングに不可欠である。このギャップは、毛髪の定量的な特徴を抽出する能力に直接影響を与え、診断に不可欠である。ジレンマは古典的なトレードオフである。高品質で正確な毛髪セグメンテーションの達成は、正確な診断に不可欠であるが、ピクセルレベルのラベルを取得する従来の方法は、費用がかかりすぎて現実的ではない。この問題を解決するための過去の試みは、しばしば手動アノテーション(大規模では非現実的)または精度が低い教師なし手法のいずれかを含んでいた。同様に、データ拡張はデータ不均衡に対処するための既知の戦略であるが、課題は、毛髪の重要で詳細な詳細を歪めたり失ったりすることなく、多様な頭皮状態を正確に反映する合成画像を生成することにある。一方の側面(例:多様な頭皮状態の生成)を改善すると、もう一方(例:毛髪詳細の維持)が損なわれることが多く、過去の研究者を苦痛なジレンマに閉じ込めていた。
制約と失敗モード
この問題を解決することは、著者らが直面したいくつかの厳しい現実的な壁により、非常に困難である。
- データ駆動型制約:ピクセルレベルのセグメンテーションラベルの不在: 最も重大な障害は、頭皮画像のピクセルレベルの毛髪アノテーションを持つ公開データセットが完全に欠如していることである。これは、セグメンテーションのための従来の教師あり学習アプローチが実行不可能であることを意味し、ラベルフリーまたは疑似ラベリング戦略の開発を強制する。AI-Hubデータセットは、分類には広範であるが、この詳細な情報を提供していない。
- データ駆動型制約:深刻なデータ不均衡: 利用可能な頭皮画像データセットは、大きく偏っている。図5のページ5に明確に示すように、「良好」および「軽度」の症例は豊富であるが、「中等度」、特に「重度」の症例は稀である。重要な重症例のデータが極端に少ないため、すべての重症度レベルにわたってうまく一般化できるロバストな分類モデルをトレーニングすることは、非常に困難である。非生成的拡張手法は、セクション3.4で述べたように、重症クラスに対してこれを適切に対処できないことが多い。
- 物理的制約:複雑な毛髪パターンとノイズ: 微細な頭皮画像は、複雑な視覚情報を提供する。毛髪パターンは様々な関数(線形またはべき乗)に従うことがあり、細い毛髪のセグメンテーションは本質的に困難である。さらに、フケのようなノイズの存在は、適切に処理されない場合、セグメンテーションモデルを容易に混乱させ、誤分類や不正確なマスクにつながる可能性がある。モデルは、明確な境界を維持しながら、ノイズから毛髪を区別する必要がある。
- 計算的制約:特定のタスクにおける基盤モデルの限界: 強力ではあるが、Segment Anything Model(SAM)のような基盤モデルは万能薬ではない。毛髪セグメンテーションに適用する場合、粗いマスクからランダムな点を選択してポジティブプロンプトとして使用するだけでは、最適でない結果につながることが多い。マスクの端の近くの点はSAMを混乱させる可能性があり、固有のランダム性はサンプリングされた点が収束し、完全な正確なマスクではなく、限られたサブセットの毛髪のセグメンテーションにつながる可能性がある。これには、洗練されたプロンプトメカニズムが必要である。
- 計算的制約:画像変換中の毛髪詳細の維持: データ拡張の重要な失敗モードは、画像変換プロセス中の重要な毛髪詳細または意味情報の損失である。毛髪の複雑な構造と特徴を維持しながら、多様な頭皮状態(例:重症度の変更)を生成することは、複雑なタスクである。DiffuseIT[13]やAGG[14]のような以前の生成モデルはこれに苦労し、セクション3.3の定性的な結果で強調されているように、しばしば全体的な情報を損なったり、意味情報を効果的に転送できなかったりした。これには、忠実性を確保するために慎重に設計された損失関数とマスクガイダンスが必要である。
なぜこのアプローチなのか
選択の必然性
SCALPVISIONのマルチコンポーネントアプローチの採用は、単なる好みではなく、頭皮疾患診断のユニークな課題に直面した際の既存手法の根本的な限界によって駆動された必然であった。中心的な問題は二重であった:微細な頭皮画像における毛髪のピクセルレベルのセグメンテーションラベルの不在と、特に稀で重症な疾患における深刻なデータ不均衡である。
標準的なCNNやU-Netのような従来の教師ありセグメンテーション手法は、広範でピクセル単位で正確なグラウンドトゥルースラベルを要求するため、毛髪セグメンテーションには即座に実行不可能となった。本稿では、「ほとんどの頭皮疾患データセットはセグメンテーションラベルを欠いているため、教師あり学習手法は実行不可能である」(セクション2.1)と明記している。このようなラベルの生成は、費用がかかりすぎて現実的ではない。この制約により、著者らは「ラベルフリー」セグメンテーション戦略を考案せざるを得なかった。
同様に、頭皮疾患分類に関しては、従来のSOTA手法(例:高度なCNNやTransformer)のみに依存すると、特に重症例において、必然的にパフォーマンスが悪化するだろう。AI-Hubデータセットは、主要なリソースであるが、「良好」および「軽度」の症例に偏った分布に苦しんでいる(図2、セクション3.1)。効果的なデータ拡張なしでは、このような不均衡なデータでトレーニングされたモデルは、過小評価されている重症例に一般化して正確に分類するのに苦労するだろう。ガウシアンノイズやAugMix[7]のような標準的な拡張手法は、この極端な希少性を克服するには不十分であることが判明した。著者らは、毛髪の詳細を維持しながら、様々な重症度をシミュレートする現実的な画像を合成できる生成モデルが、この不均衡を効果的に対処する唯一の方法であると認識した。
比較優位性
SCALPVISIONのアプローチは、頭皮画像分析の固有の困難に直接対処するその構造設計を通じて、定性的な優位性を示す。
毛髪セグメンテーションに関して、ヒューリスティックにトレーニングされたU²-Net(M)と自動プロンプト付きSegment Anything Model(SAM)(MAP)を組み合わせた提案されたアンサンブル手法は、構造的な利点を提供する。合成データとシミュレートされたノイズでトレーニングされたU²-Netは、フケのようなアーティファクトに対するロバスト性を提供する(セクション2.2、セクション3.2)。一方、SAMは正確なエッジ検出に優れており、明確な境界を作成する(セクション2.2)。論理AND演算($M = M \land MAP$)は、これらの強みを相乗的にマージし、ノイズに対してロバストでありながら毛髪境界の定義において非常に正確な最終マスクをもたらす。これは、「毛髪と頭皮の複雑なパターンを捉える理解を欠いている」(セクション3.2)先行手法(Shih et al., Yue et al., Kim et al. [10])や、特定のガイダンスなしで使用された場合のSAMでさえ、「最適でないマスク」(セクション2.1)を生成したことよりも定性的に優れている。この構造的な融合は、下流の診断タスクに不可欠な、より信頼性が高く正確なセグメンテーションを保証する。
画像変換とデータ拡張に関しては、DiffuseIT-Mは、そのユニークなマスクガイダンスメカニズムにより際立っている。DiffuseIT[13]やAGG[14]のような他の生成モデルとは異なり、DiffuseIT-Mは「頭皮の状態を変更しながら毛髪の詳細を維持するように特別に設計されている」(要旨、セクション2.2)。これは、マスク維持損失($l_{mask}$)と逆拡散プロセス中のマスキングアプローチ(式5)を含む包括的な損失関数によって達成される。この構造設計により、分離制御が可能になり、診断に不可欠な毛髪の完全性を損なうことなく、頭皮の特徴を変更できる(例:重症度をシミュレートするために)。定量的には、DiffuseIT-Mはベースライン(セクション3.3)と比較して、より高い画像忠実度とソースコンテンツの維持の改善を示す、優れたFIDおよびLPIPSスコア(表2)を達成している。定性的には、図4はDiffuseITとAGGが「毛髪コンテンツ情報の維持に失敗した」ことを明確に示しており、これはDiffuseIT-Mが克服する重要な欠陥である。画像の一部を変換しながら特定の画像領域を維持するこの能力は、医療画像拡張にとって深刻な構造的利点である。
制約との整合性
選択された方法論は、問題の厳しい要件に完全に整合しており、課題とソリューションのユニークなプロパティとの「結婚」を形成している。
-
制約:ピクセルレベルのセグメンテーションラベルの不在。
- 整合性: SCALPVISIONの毛髪セグメンテーションモジュールは、「ラベルフリー」であることにより、これを直接解決する。これは、毛髪パターンの事前知識(線形またはべき乗関数)に基づいた合成画像を生成するヒューリスティック駆動の疑似ラベリングと、SAMの自動プロンプトを活用する。この革新的なプロンプト方法は、手動のピクセルレベルのアノテーションなしに正確な毛髪マスクを生成するために、粗いセグメンテーションマスクから体系的にポジティブおよびネガティブのポイントプロンプトを生成する(セクション2.1)。これは、ラベル不足に対する直接的かつエレガントな解決策である。
-
制約:深刻なデータ不均衡、特に重症例。
- 整合性: DiffuseIT-M生成モデルは、これを克服するための礎である。これは特にデータセット拡張(要旨)のために設計されている。モデルは、クラスのサイズに反比例する選択確率を持つ重み付きサンプリングを使用して、ランダムに選択された画像をより高い重症度レベルに変換する(セクション2.2)。このメカニズムは、過小評価されているクラスを直接ターゲットにし、データセットをバランスさせるための多様で現実的なトレーニングサンプルを生成する。これにより、分類モデルが重症例の十分な例にさらされることが保証され、これはロバストな診断に不可欠である。
-
制約:ロバストで正確な診断の必要性。
- 整合性: ロバストな毛髪セグメンテーション(MとMAPの組み合わせ)は、診断に不可欠な正確な毛髪特徴を提供する(セクション1)。毛髪詳細を維持する高品質な拡張画像を生成するDiffuseIT-Mの能力は、トレーニングデータが現実的で関連性があることを保証し、よりロバストな分類モデルにつながる(セクション3.4)。システム全体の設計は、ラベルフリーセグメンテーションからターゲットデータ拡張まで、包括的で信頼性の高い診断ツールの構築に向けられている。
代替案の却下
本稿は、頭皮疾患診断の特定の制約を満たせないという理由で、いくつかの代替アプローチを暗黙的および明示的に却下している。
-
従来の教師ありセグメンテーション手法: 「ピクセルレベルのセグメンテーションラベルの不在」(セクション2.1)により、これらは即座に却下された。標準的なU-NetやMask R-CNNのような手法は、広範な手動アノテーションを必要とするが、これは頭皮データセットでは利用できない。先行する頭皮セグメンテーションアプローチ[20,21,10]に対する比較結果は、複雑な毛髪パターンを効果的に捉える上でのそれらの限界をさらに強調している(セクション3.2)。
-
基盤モデル(例:SAM)の特定のガイダンスなし: SAMは強力であるが、著者らは「Mからランダムな点を選択してポジティブプロンプトとして使用すると、最適でないマスクにつながることが多い」と見出し、SAMは「特定のガイダンスなしで使用すると、自動セグメンテーションには効果が低い」(セクション2.1、セクション3.2)と見出した。これは、強力なモデルだけでは不十分であり、このドメインで効果を発揮するには、調整されたインテリジェントなプロンプトメカニズムが必要であることを強調している。
-
画像変換のための他の生成モデル(例:DiffuseIT、AGG、または一般的なGAN): 本稿は、DiffuseIT[13]およびAGG[14]とDiffuseIT-Mを直接比較している。両方の代替案は、「ソース画像からの毛髪コンテンツ情報の維持に失敗し」、「全体的な情報を損ない、意味情報を転送できなかった」(セクション3.3、図4)傾向があった。この失敗は、毛髪特徴が最重要である頭皮診断にとって致命的である。DiffuseIT-Mの明示的なマスクガイダンスメカニズムなしでは、これらのモデルは頭皮状態と毛髪維持を分離できず、診断的に関連性のある拡張データを生成するには不適切である。GANは明示的に直接の代替案として言及されていないが、マスクガイダンスなしでの制御されたコンテンツ維持におけるそれらの一般的な限界は、同様の失敗につながる可能性が高い。
-
非生成的データ拡張手法(例:ガウシアンノイズ、AugMix): これらの手法は、重症例の「サンプル数の極端な希少性」に対処するには不十分であることが判明した(セクション3.4)。表3は、ガウシアンノイズまたはAugMixで拡張されたモデルが、特に重症例の分類において、生成モデルで拡張されたモデルよりも大幅にパフォーマンスが低いことを明確に示している。これらの単純な手法は、過小評価されているクラスを真に表す新しい多様な例を合成できず、データ不均衡を効果的に軽減できない。
 Figure 2. Data distribution of different severity within each scalp condition
Figure 2. Data distribution of different severity within each scalp condition
数学的・論理的メカニズム
マスター方程式
毛髪詳細を維持しながら多様な頭皮画像を生成することを可能にするDiffuseIT-M画像変換メカニズムの核心は、包括的な損失関数と特定の逆拡散サンプリングステップによって支配されている。学習および生成プロセスをガイドする主要な目的関数は、合計損失、$l_{total}$であり、次のように定義される。
$$ l_{total} (x;x_{src},x_{trg},M) = \lambda_1 l_{style} + \lambda_2 l_{content} + \lambda_3 l_{mask} + \lambda_4 l_{sem} + \lambda_5 l_{rng} $$
この損失関数は、現在のノイズの多い画像サンプル、$x_t$から次の、よりノイズの少ない画像サンプル、$x_{t-1}$を生成するために、反復的な逆拡散プロセス内で使用される。毛髪詳細の維持に不可欠なこの変換ロジックは、次のように与えられる。
$$ x_{t-1} \leftarrow x_t \odot M + \left[x_0(x_t) - \sqrt{\bar{\alpha}_t} l_{total} (x_0(x_t))\right] \odot (1 – M) $$
損失計算と逆ステップの両方における重要なコンポーネントは、時間ステップ$t$におけるノイズの多いサンプル$x_t$からクリーニングされた画像、$x_0(x_t)$の推定である。この推定は、予測されたノイズ $\epsilon_0(x_t, t)$から導出される。
$$ x_0(x_t) = \frac{x_t}{\sqrt{\bar{\alpha}_t}} - \frac{\sqrt{1 – \bar{\alpha}_t} \epsilon_0(x_t, t)}{\sqrt{\bar{\alpha}_t}} $$
最後に、損失関数$l_{total}$のコンポーネントであるマスク維持損失、$l_{mask}$は、明示的に次のように定義される。
$$ l_{mask} = \text{LPIPS}(x_{src}\odot M, x_0(x_t)\odot M) + ||(x_{src} - x_0(x_t))\odot M||_2 $$
用語ごとの解剖
これらの数式を分解して、各要素の役割を理解しよう。
合計損失関数 ($l_{total}$)
- $l_{total} (x;x_{src},x_{trg},M)$: これは、
DiffuseIT-Mモデルがトレーニング中に最小化しようとする全体的な目的関数である。これは、高忠実度の画像変換を保証しつつ、特定の詳細を維持するように設計された、いくつかの個別の損失コンポーネントの重み付き合計である。入力は、現在の画像$x$(逆ステップの文脈では通常$x_0(x_t)$)、ソース画像$x_{src}$、ターゲット画像$x_{trg}$(望ましい頭皮状態を表す)、および毛髪マスク$M$である。- 加算の理由: 著者らは、異なる、しばしば競合する目的を組み合わせるために加算を使用している。各項は、生成された画像に特定の望ましい特性(例:スタイル、コンテンツ)を奨励し、それらを合計することで、モデルがこれらの目標間のバランスを学習できるようになる。
- $\lambda_1, \lambda_2, \lambda_3, \lambda_4, \lambda_5$: これらはスカラー重み係数である。
- 数学的定義: 正の実数。
- 物理的/論理的役割: 各損失コンポーネントの相対的な重要性を制御する。これらの重みを調整することにより、著者らは、毛髪の詳細をどれだけ強く維持するか、または頭皮スタイルをターゲットにどれだけ密接に一致させるかといった、画像変換の特定の側面を優先できる。
- $l_{style}$: スタイル損失。
- 数学的定義: 本稿では明示的に定義されていないが、
DiffuseIT[13]からのものであると述べられている。通常、これはVGGネットワークなどの知覚特徴からの特徴統計量(例:グラム行列)の一致を含む。 - 物理的/論理的役割: 生成された画像の頭皮領域が、ターゲット頭皮状態の様式的特徴(例:テクスチャ、色、パターン)を採用することを奨励する。
- 数学的定義: 本稿では明示的に定義されていないが、
- $l_{content}$: コンテンツ損失。
- 数学的定義: 明示的に定義されておらず、
DiffuseIT[13]からも同様である。しばしば、生成画像とターゲット画像の間の特徴マップのL2距離を測定する。 - 物理的/論理的役割: 頭皮領域のハイレベルな意味コンテンツがターゲット画像から転送されることを保証し、モデルが頭皮状態を正確に変換するようにガイドする。
- 数学的定義: 明示的に定義されておらず、
- $l_{mask}$: マスク維持損失(式3)。
- 数学的定義: マスクされた領域に適用されるLPIPSとL2ノルムの組み合わせ。
- 物理的/論理的役割: これは
SCALPVISIONの目標にとって重要である。ソース画像からの毛髪詳細をマスクされた毛髪領域内に維持することを明示的に強制し、毛髪への望ましくない変更を防ぐ。
- $l_{sem}$: 意味的ダイバージェンス損失。
- 数学的定義: 明示的に定義されていないが、[13]からのものであり、DINO-ViT[3]の
[CLS]トークンマッチング損失を使用すると述べられている。 - 物理的/論理的役割: ビジョン・トランスフォーマーからの高レベル特徴を使用して、ターゲット画像の意味情報(例:疾患の種類、重症度)が生成画像に正しく反映されることを目指す。
- 数学的定義: 明示的に定義されていないが、[13]からのものであり、DINO-ViT[3]の
- $l_{rng}$: 球状距離の二乗損失。
- 数学的定義: 明示的に定義されていないが、[5]からのものであると述べられている。
- 物理的/論理的役割: おそらく正則化項として機能し、生成サンプルにおける多様性を奨励したり、潜在空間における特定の分布を維持したりする可能性があり、データ拡張に有益である。
逆拡散サンプリングステップ ($x_{t-1}$更新)
- $x_{t-1}$: 逆拡散プロセスの前の(ノイズの少ない)時間ステップにおける画像。
- 数学的定義: ピクセルごとの画像テンソル。
- 物理的/論理的役割: これは、ノイズの多い画像からクリーンで変換された画像への生成プロセスの1ステップの出力である。
- $x_t$: 時間ステップ$t$における現在のノイズの多い画像。
- 数学的定義: ピクセルごとの画像テンソル。
- 物理的/論理的役割: 現在の逆拡散ステップの開始点。
- $M$: バイナリ毛髪マスク。
- 数学的定義: 画像と同じ空間次元を持つバイナリテンソルで、1は毛髪、0は頭皮を示す。
- 物理的/論理的役割: ステンシルのように機能する。毛髪領域を分離し、毛髪に適用される操作が頭皮に適用される操作と異なることを保証する。
- $\odot$: 要素ごとの乗算(アダマール積)。
- 数学的定義: 2つのテンソルの対応する要素を乗算する。
- 物理的/論理的役割: ここではマスキングに使用される。$x_t \odot M$は、現在のノイズの多い画像の毛髪領域を分離し、実質的に毛髪をそのまま「保持」する。
- $x_0(x_t)$: $x_t$から推定されたクリーンな画像(式4)。
- 数学的定義: ピクセルごとの画像テンソル。
- 物理的/論理的役割: $x_t$からすべてのノイズが除去された場合のクリーンな画像がどのようなものになるかというモデルの最良の推測を表す。これは拡散モデルにおける重要な中間予測である。
- $\sqrt{\bar{\alpha}_t}$: アルファ値の累積積の平方根。
- 数学的定義: $\bar{\alpha}_t = \prod_{s=1}^t (1-\beta_s)$、ここで$\beta_s$は分散スケジュールパラメータである。
- 物理的/論理的役割: ノイズスケジュールの拡散プロセスから導出されたスケーリング係数。ノイズの多い画像とそれらのクリーンな対応物および予測されたノイズの関係を関連付ける数学的フレームワークの一部である。
- $l_{total}(x_0(x_t))$: 推定されたクリーンな画像に適用される合計損失関数。
- 数学的定義: $l_{total}$関数のスカラー出力。
- 物理的/論理的役割: この項は、頭皮領域の変換をガイドする。合計損失(スタイル、コンテンツ、意味目的を含む)を推定されたクリーンな画像に適用することにより、モデルはターゲット状態に一致する頭皮を生成するように誘導される。
- $1 - M$: バイナリ毛髪マスクの逆。
- 数学的定義: 1が頭皮、0が毛髪を示すバイナリテンソル。
- 物理的/論理的役割: 頭皮領域を分離し、損失ガイド付き更新を非毛髪領域にのみ適用できるようにする。
- 加算とマスキングの理由: 加算は2つの異なる部分を組み合わせる:毛髪領域($x_t$から維持)と頭皮領域(損失に基づいて更新)。この巧妙なマスキングアプローチにより、毛髪を維持しながら頭皮を選択的に画像変換できる。
クリーンな画像推定 ($x_0(x_t)$)
- $\epsilon_0(x_t, t)$: 拡散モデルによって予測されたノイズ。
- 数学的定義: $x_t$と同じ形状のテンソルで、推定されたノイズ成分を表す。
- 物理的/論理的役割: これは、拡散モデル内のニューラルネットワークの主な出力である。ネットワークは、クリーンな画像にノイズを加えて$x_t$を得るために追加されたノイズを予測するようにトレーニングされている。
- $\sqrt{1 - \bar{\alpha}_t}$: 拡散プロセスからの別のスケーリング係数。
- 数学的定義: ノイズスケジュールから導出される。
- 物理的/論理的役割: 予測されたノイズの大きさと時間$t$における全体的なノイズレベルの関係を関連付ける。
- 除算と減算の理由: この式は、拡散モデルにおける標準的な再パラメータ化である。これにより、モデルはノイズ $\epsilon_0(x_t, t)$を予測し、その後、ノイズの多い入力$x_t$とノイズスケジュールパラメータから対応するクリーンな画像 $x_0(x_t)$を解析的に導出できる。
マスク維持損失 ($l_{mask}$)
- $\text{LPIPS}(A, B)$: 学習された知覚画像パッチ類似性メトリック。
- 数学的定義: 事前トレーニングされたニューラルネットワーク(例:VGG)からの深層特徴に基づく知覚距離メトリック。
- 物理的/論理的役割: ピクセルごとの差よりも人間の知覚によりよく一致する画像パッチ間の知覚的類似性を測定する。ここでは、ソース画像と生成画像(マスク内)の知覚された毛髪詳細が類似していることを保証する。
- $||(x_{src} - x_0(x_t))\odot M||_2$: ソース画像と推定されたクリーンな画像とのピクセルごとの差のL2ノルム(ユークリッド距離)、$M$でマスクされたもの。
- 数学的定義: $\sqrt{\sum_{i,j} ((x_{src})_{i,j} - (x_0(x_t))_{i,j})^2 \cdot M_{i,j}}$。
- 物理的/論理的役割: これは直接的なピクセルレベルの制約である。これは「ゴムバンド」のように機能し、生成画像の毛髪領域をソース画像の毛髪領域とピクセル単位で同一になるように引き寄せる。これは、強力なローカル忠実度制約を提供するLPIPSを補完する。
- 加算の理由: LPIPSとL2を組み合わせることで、毛髪維持のための知覚的およびピクセルレベルの両方の忠実性が保証される。
ステップごとのフロー
ここでは、ソース画像$x_{src}$を、毛髪をそのままに保ちながら別の頭皮状態$x_{trg}$を示すように変換したい、という1つの抽象的なデータポイントを想像してみよう。
- 毛髪マスク生成: まず、入力画像$x_{src}$が毛髪セグメンテーションモジュールに入る。このモジュールは、疑似ラベリングとアルゴリズム1でガイドされたSegment Anything Model(SAM)を使用して、バイナリ毛髪マスク$M$を生成する。このマスクは、毛髪領域(値1)と頭皮領域(値0)を正確に区切る。
- ノイズ初期化: 画像変換のために、
DiffuseIT-Mモデルはソース画像のノイズバージョン、$x_T$、または純粋なノイズ画像から開始し、それを反復的にノイズ除去する。中間ステップ$t$における一般的なノイズ画像$x_t$を考える。 - クリーン画像推定: 各逆拡散ステップで、モデルのニューラルネットワーク(ノイズを予測するようにトレーニングされている)は、$x_t$と現在の時間ステップ$t$を入力として受け取る。それは、推定されたノイズ成分、$\epsilon_0(x_t, t)$を出力する。この予測されたノイズは、拡散スケジュールパラメータ$\bar{\alpha}_t$とともに使用され、$x_t$から得られるクリーンな画像のモデルの最良の推測である$x_0(x_t)$(式4)を計算する。
- ガイダンスのための損失計算: 推定されたクリーンな画像$x_0(x_t)$は、元のソース画像$x_{src}$、ターゲット状態画像$x_{trg}$、および毛髪マスク$M$とともに、合計損失関数、$l_{total}$(式2)に供給される。
- $l_{style}$と$l_{content}$は、$x_0(x_t)$の頭皮領域と$x_{trg}$を比較して、スタイルとコンテンツの転送をガイドする。
- $l_{mask}$(式3)は、$x_0(x_t)$の毛髪領域と$x_{src}$の毛髪領域を具体的に比較して、毛髪維持を保証し、知覚的(LPIPS)およびピクセル単位(L2)の両方のメトリックを使用する。
- $l_{sem}$と$l_{rng}$は、追加の意味的および正則化ガイダンスを提供する。
- これらの損失の重み付き合計、$l_{total}$は、現在の$x_0(x_t)$がすべての望ましい特性にどれだけ整合しているかを示す包括的な信号を提供する。
- ガイド付きノイズ除去と変換: この計算された$l_{total}$は、次の、よりノイズの少ない画像、$x_{t-1}$(式5)の生成をガイドするために使用される。
- $x_t$の毛髪部分は、$x_t \odot M$によって維持される。これにより、ソース画像からの毛髪構造が直接引き継がれることが保証される。
- 頭皮部分は、損失ガイド付き項$[x_0(x_t) - \sqrt{\bar{\alpha}_t} l_{total} (x_0(x_t))]$を頭皮領域、$(1-M)$に適用することにより更新される。この項は、合計損失の影響を受けて、実質的に$x_0(x_t)$の頭皮ピクセルをターゲット状態に押し込む。
- これらの2つのマスクされたコンポーネントは、次に加算されて$x_{t-1}$を形成し、これは維持された毛髪とターゲット状態に近づいた頭皮を持つことになる。
- 収束までの反復: ステップ3から5までのこのプロセスは、多くの時間ステップ、$t=T, T-1, \dots, 1$に対して反復的に繰り返される。各ステップで、画像はノイズが少なくなり、頭皮領域はターゲット状態に一致するように徐々に変換され、毛髪はそのまま維持される。
- 最終出力: すべてのステップの後、最終的な$x_0$(または$t=1$での$x_{t-1}$)は生成された画像であり、$x_{src}$の毛髪を維持した$x_{src}$から$x_{trg}$への変換である。
最適化ダイナミクス
DiffuseIT-Mメカニズムは、$l_{total}$損失関数によってガイドされる拡散モデルの標準的なトレーニングプロセスを通じて、そのパラメータを学習および更新する。
- モデルトレーニング:
DiffuseIT-M内のニューラルネットワーク($\epsilon_0(x_t, t)$または$x_0(x_t)$を予測する)は、画像の大規模データセットを使用してトレーニングされる。トレーニング中、クリーンな画像にノイズが追加され、ノイズの多いサンプル$x_t$が作成される。次に、モデルは$x_t$からノイズまたはクリーンな画像を予測するように学習する。$l_{total}$関数は、この学習の目的として機能する。 - 損失ランドスケープの形成: $l_{total}$関数は、多面的な方法で損失ランドスケープを形成する。
- 毛髪維持の谷: $l_{mask}$項は、生成された毛髪領域がソース毛髪と密接に一致する損失ランドスケープに深い谷を作成する。マスクされた領域内のソース画像からの毛髪構造または外観の逸脱は、この損失の急激な増加につながり、毛髪への変更を実質的に罰する。
- 頭皮変換勾配: $l_{style}$、$l_{content}$、および$l_{sem}$項は、モデルが頭皮領域を変換するようにガイドする。これらの損失からの勾配は、生成された頭皮がターゲット状態に一致する頭皮特徴を生成するようにモデルパラメータを誘導する。例えば、生成された頭皮に$x_{trg}$からの望ましいテクスチャがない場合、$l_{style}$勾配はモデルをそのテクスチャを生成するように誘導する。
- 安定性/多様性のための正則化: $l_{rng}$項は、トレーニングを正則化するのに役立ち、潜在空間における多様なソリューションの探索を奨励する可能性があり、データ拡張の生成に有益である。
- 勾配降下: モデルのパラメータは、AdamやSGDのような最適化アルゴリズムを使用して反復的に更新される。各トレーニングステップで、$l_{total}$のモデルパラメータに対する勾配が計算される。これらの勾配は、合計損失を削減するために各パラメータに必要な変更の方向と大きさを示す。次に、パラメータは勾配とは反対の方向に調整される。
- 反復的改善: 多くのトレーニング反復を通じて、モデルは、その予測が逆拡散プロセスで使用されるときに、結果の$x_0(x_t)$が$l_{total}$を最小化するように、$\epsilon_0(x_t, t)$(または$x_0(x_t)$)を予測するように学習する。これは、モデルが毛髪が維持され、頭皮状態が正確に変換される画像を生成するように学習することを意味する。
- 収束: モデルの検証セットでのパフォーマンスが改善しなくなるまでトレーニングは継続され、これは、望ましい画像変換タスクを効果的に実行できる状態に収束したことを示す。$\lambda_i$重みのバランスは、異なる目的間の良いトレードオフを達成し、安定した収束を保証するために重要である。本稿では、「4つのMLPヘッドを持つ事前トレーニング済みバックボーンのファインチューニング」についても言及しており、これは分類のための別個の最適化ステップであるが、生成モデルの学習は主に$l_{total}$の最小化によって駆動される。
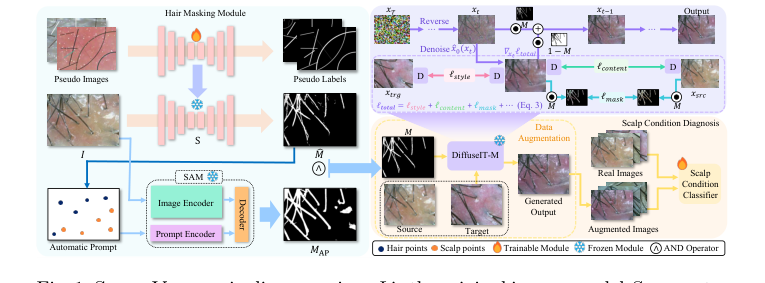 Figure 1. ScalpVision pipeline overview: I is the original image, model S generates the hair segmentation mask ˆ M using a pseudo-training set, MAP is the SAM- produced mask, and M is the combined hair segmentation mask. The “Automatic Prompt” for refining segmentation comes from ˆ M. xsrc and xtrg are the source and target images, with M as the mask image of xsrc. The weighted image sum is denoted by ⊙and D stands for DINO-ViT [3]
Figure 1. ScalpVision pipeline overview: I is the original image, model S generates the hair segmentation mask ˆ M using a pseudo-training set, MAP is the SAM- produced mask, and M is the combined hair segmentation mask. The “Automatic Prompt” for refining segmentation comes from ˆ M. xsrc and xtrg are the source and target images, with M as the mask image of xsrc. The weighted image sum is denoted by ⊙and D stands for DINO-ViT [3]
結果、限界、および結論
実験設計とベースライン
SCALPVISIONのコアメカニズムを厳密に検証するために、著者らは毛髪セグメンテーション、合成画像生成、および頭皮状態分類の各コンポーネントをターゲットとした一連の実験を設計した。
毛髪セグメンテーションに関しては、主な目標は、ラベルフリーアプローチの有効性を証明することであった。主要なAI-Hubデータセットにピクセルレベルのセグメンテーションラベルが存在しないため、専門家によって手動でアノテーションされた150のテスト画像の特別なサブセットが、グラウンドトゥルースとして使用された。この分野の「犠牲者」(ベースラインモデル)には、Shih et al.[20]、Yue et al.[21]、Kim et al.[10]による従来のコンピュータビジョン手法や、強力な基盤モデルであるSAM[12]が含まれていた。パフォーマンスは、標準的なメトリック:ピクセルF1、ジャカード、およびダイススコアを使用して定量化された。また、初期の単純なセグメンテーションマスク($M$)、SAMによって生成されたマスク($M_{AP}$)、およびそれらの最終的な結合マスク($M$)を比較する重要なアブレーションスタディが実施され、各部分の寄与を分離した。
合成画像生成モジュールであるDiffuseIT-Mは、毛髪詳細を維持しながら多様な頭皮画像を作成する能力を実証するために、他の生成モデルと比較して評価された。ここでは、ベースラインはDiffuseIT[13]およびAGG[14]であった。実験は、Fréchet Inception Distance(FID)[8]およびLearned Perceptual Image Patch Similarity(LPIPS)[22]スコアを使用して、画像忠実度を厳しく証明した。さらに、マスクガイダンスの影響は、異なるマスク条件(提案された1-Mガイダンス、逆マスクM、マスクなし(0)、およびフルマスク(1))下での画像変換結果を比較することによって具体的にテストされた。
最後に、頭皮状態分類に関しては、AI-Hubデータセット全体(95,910枚の画像、トレーニング用72,342枚、テスト用23,568枚、検証用21,703枚に分割)が使用された。皮膚科医は、これらの画像を3つの状態—フケ、過剰な皮脂、および紅斑—についてラベル付けしており、それぞれが4つの重症度レベル:良好、軽度、中等度、および重度に分類されていた。データセットの「良好」および「軽度」の症例への固有の偏りを認識している(図2に示す通り)、実験は、生成拡張がこの不均衡にどのように対処できるかを示すことを目的とした。2つの異なる分類バックボーン:DenseNet[9](CNN)およびEfficientFormerV2[15](Transformer)が採用され、異なるアーキテクチャ全体での結果のロバスト性を保証した。さまざまな拡張戦略が互いに競合させられた:ガウシアンノイズ、AugMix[7]、DiffuseIT[13]、AGG[14]、および「Ours」(SCALPVISIONのDiffuseIT-M)。決定的な証拠は、3つの疾患の各重症度レベルに対する全体的なマクロF1スコアと個々のF1スコアで求められた。
証拠が証明すること
実験的証拠は、SCALPVISIONのコアメカニズムの否定できない証明を提供する。
毛髪セグメンテーションに関しては、表1は、結合マスク$M$がすべてのメトリック(ピクセルF1:0.868、ジャカード:0.649、ダイス:0.786)で優れたパフォーマンスを達成したことを決定的に示している。これは単なるわずかな改善ではなく、すべての従来のコンピュータビジョンベースライン、さらにはスタンドアロンのSAMモデルを大幅に上回った。単純なセグメンテーションモデルのノイズに対するロバスト性($M$)とSAMの優れたエッジ検出($M_{AP}$)を論理AND演算で組み合わせるというアーキテクチャの選択が鍵であった。この融合は、図3で視覚的に確認できるように、明確で正確でノイズに強い毛髪マスクをもたらし、ヒューリスティック駆動の疑似ラベリングとSAMの自動プロンプト法が、ラベル不足と個々のモデルの弱点の限界を効果的に克服したことを証明した。 「犠牲者」は明らかに敗北し、我々の手法は先行技術よりも複雑な毛髪パターンのより包括的な理解を示した。
合成画像生成において、DiffuseIT-M(「Ours」)は、その生成モデルの競合相手よりも大幅に優れた忠実度スコアを達成することで、その能力を示した。表2は、DiffuseIT(FID:138.42、LPIPS:0.463)およびAGG(FID:141.70、LPIPS:0.492)よりも大幅に低い(高品質を示す)FID 74.84およびLPIPS 0.353を報告している。図4および図5の視覚的証拠は、これをさらに強化している。ベースラインが毛髪コンテンツの維持や意味情報の正確な転送に苦労した一方で、DiffuseIT-Mはソース毛髪の詳細を維持しながら、頭皮状態を効果的に変更することに成功した。マスクガイダンスに関する実験は特に示唆的であった:1-Mマスクガイダンスを使用することは、変換中の毛髪特徴の維持に不可欠であったが、他のマスク条件(マスクなし、フルマスク、または逆マスク)は、最小限の変更をもたらすか、毛髪と頭皮の両方を無差別に変更した。このハードエビデンスは、DiffuseIT-Mのマスクガイド付き拡散メカニズムが、データ拡張に不可欠な制御された画像変換において非常に効果的であることを証明している。
システム全体のインパクトに対する最も説得力のある証拠は、頭皮状態分類から得られた。表3は、「Ours」(SCALPVISIONのDiffuseIT-M拡張)が、DenseNet(0.636)およびEfficientFormerV2(0.635)バックボーンの両方で一貫して最も高いマクロF1スコアを達成したことを否定できないほど示している。これは単なる全体的な勝利ではなく、特に重症データ不均衡に対処する上で顕著であった。例えば、「重度」の皮脂を分類する場合、ガウシアンノイズやAugMixのような非生成的拡張手法はF1スコア0.000を達成し、この稀ではあるが重要な状態の分類に完全な失敗を示した。対照的に、「Ours」は、重度の皮脂に対してF1スコア0.430(DenseNet)および0.406(EfficientFormerV2)を達成した。これは、生成データ拡張、特にDiffuseIT-Mが過小評価されているクラスのために高品質で多様なサンプルを作成する能力が、特に困難で稀な状態に対して、診断パフォーマンスの向上に直接つながるという、決定的で否定できない証拠である。これは、頭皮スタイルと毛髪コンテンツ情報の両方を維持することが、正確な分類にとって最重要であることを証明している。
限界と将来の方向性
SCALPVISIONは頭皮疾患診断のための堅牢で革新的なソリューションを提示しているが、その現在の限界を認識し、将来の開発のための道筋を考慮することが重要である。
固有の限界の1つは、データセット自体に由来する。AI-Hubデータセットは、相当なリソースであるにもかかわらず、「良好」および「軽度」の頭皮状態に大きく偏っており、重症例は稀である。SCALPVISIONの生成拡張方法は、この不均衡を大幅に緩和するが、重症例の実際の希少性の根底にあることは、拡張データでも十分に表現されていない極端に多様なまたは新しい重症プレゼンテーションへの一般化に依然として課題を提起する可能性がある。さらに、毛髪セグメンテーションのための手動アノテーションは、150のテスト画像の比較的少数のサブセットに対して実行された。初期検証には十分であったが、より広範で多様な手動アノテーション画像のセットは、さまざまな毛髪タイプや画像条件にわたるセグメンテーションモデルのロバスト性をさらに強化できるだろう。さらに、現在のシステムは、フケ、過剰な皮脂、および紅斑という3つの特定の頭皮疾患に焦点を当てている。この範囲は価値があるが、頭皮に影響を与える皮膚科疾患の全スペクトルをまだカバーしていないことを意味する。
将来に向けて、いくつかのエキサイティングな方向性がこれらの発見をさらに進化させる可能性がある。
- 診断範囲の拡大: 著者らは、毛髪情報を活用して脱毛症のような状態に研究を拡大する意図を明示的に述べている。これは、真に汎用的な診断システムに向けた自然で必要な進歩である。将来の研究では、毛髪数や太さだけでなく、毛髪の喪失パターンが主要な診断特徴である状態に対して、SCALPVISIONのフレームワークがどのように適応するかを探求できる。
- マルチモーダル統合: 現在、システムは微細な頭皮画像のみに依存している。患者の病歴、遺伝子マーカー、または肉眼画像のような他の診断データを統合することは、画像のみの分析から生じる可能性のある偽陽性または偽陰性を減らす、より包括的で正確な診断につながる可能性がある。
- 臨床展開とユーザーエクスペリエンス: SCALPVISIONが真に価値のあるツールとなるためには、臨床ワークフローへの統合が不可欠である。これには、皮膚科医向けのユーザーフレンドリーなインターフェースの開発、医療規制への準拠の確保、および多様な患者集団と設定でそのパフォーマンスを検証するための広範な実臨床試験の実施が含まれるだろう。この技術を、作業負荷を増やすことなく臨床医をシームレスに支援するようにどのように構成できるだろうか?
- 説明可能性と信頼: モデルは高いパフォーマンスを示すが、なぜそれが特定の診断を下すのかを理解することは、医療専門家の間で信頼を築くために不可欠である。将来の研究は、AIの説明可能性を高めることに焦点を当てる可能性があり、おそらく診断に最も貢献する画像領域または特徴を強調することによって、臨床医に実行可能な洞察を提供する。
- パーソナライズされた治療推奨: 診断を超えて、SCALPVISIONは、特定された状態、重症度、さらには個々の患者の特徴に基づいて、パーソナライズされた治療計画を提案するように進化する可能性がある。これには、医療知識ベースおよび潜在的に患者固有のデータの統合が必要になるだろう。
- データプライバシーと倫理的懸念への対処: 機密性の高い医療データを扱うあらゆるAIシステムと同様に、データプライバシー、セキュリティ、および倫理的展開への厳格な注意が不可欠である。特に合成患者データを作成できる生成モデルを扱う場合、このような強力な診断ツールの責任ある使用をどのように保証できるだろうか?
- 高度な生成アーキテクチャの探求: DiffuseIT-Mは非常に効果的であるが、生成AIの分野は急速に進歩している。新しい拡散モデル、GAN、またはその他の生成アーキテクチャを調査することで、画像忠実度、多様性、および制御のさらなる改善が得られ、さらにロバストなデータ拡張戦略につながる可能性がある。
これらの議論は、SCALPVISIONが単なる診断ツールではなく、その限界が対処され、その能力が慎重に拡張されれば、皮膚科ケアを変革する計り知れない可能性を持つ基本的なフレームワークであることを強調している。
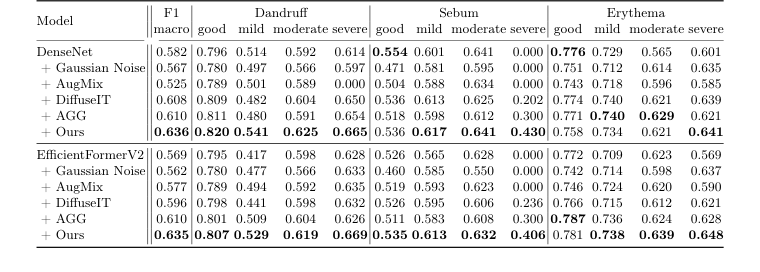 Table 3. Performance of scalp condition classification with various augmentation methods, denoted after “+” symbol, on the test set. The second column displays the overall macro-F1 score, while the columns from the third onward show the F1 scores for each severity level of the three diseases
Table 3. Performance of scalp condition classification with various augmentation methods, denoted after “+” symbol, on the test set. The second column displays the overall macro-F1 score, while the columns from the third onward show the F1 scores for each severity level of the three diseases
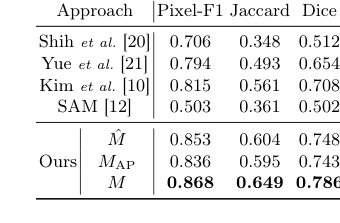 Table 1. Performance of hair segmenta- tion on the test set
Table 1. Performance of hair segmenta- tion on the test set
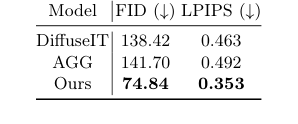 Table 2. Quantitative analysis of image- to-image translation
Table 2. Quantitative analysis of image- to-image translation