레이블 없는 분할 및 학습 없는 이미지 변환을 이용한 두피 진단 시스템
ScalpVision tackles data challenges for better, cheaper, and more accessible skin care.
배경 및 학술적 계보
기원 및 학술적 계보
본 논문에서 다루는 문제는 전 세계적으로 광범위하게 퍼져 있는 두피 질환에서 비롯된다. 성인 인구의 상당수가 영향을 받으며, 미국 성인의 거의 90%가 어떤 형태의 질환을 경험하는 것으로 알려져 있다 [6]. 이러한 높은 유병률에도 불구하고, 많은 사례가 진단되지 않은 채 남아 있다. 이는 주로 두 가지 결정적인 요인, 즉 전문가의 피부과적 평가에 대한 접근성 제한과 진단 목적의 수동 주석(annotation)과 관련된 높은 비용 때문이다.
의료 영상 및 인공지능의 학술 분야에서 두피 질환을 위한 AI 기반 진단 시스템의 가능성은 이미 오래전부터 인식되어 왔다 [4,11,19]. 탈모와 같은 두피 관련 질병의 진행을 더 심각한 결과로 막기 위해서는 조기 발견이 매우 중요하다 [16,17]. 그러나 이러한 질환의 효과적인 진단은 현미경적 두피 영상에서 모발 수 및 두께와 같은 중요 특징을 정확하게 측정하는 데 크게 의존한다. 이러한 정밀한 모발 분할의 필요성이 핵심적인 문제로 부상한다. 역사적 맥락은 효율적이고 접근 가능한 고급 진단 접근 방식에 대한 명확한 필요성을 보여주며, 연구자들로 하여금 자동화된 시스템을 개발하도록 추진한다.
본 논문의 저자들이 이 논문을 작성하게 된 근본적인 한계점, 즉 "고충점(pain point)"은 여러 핵심 영역으로 나눌 수 있다.
- 픽셀 수준 분할 레이블의 부재: 픽셀 수준의 모발 주석을 생성하는 것은 매우 비용이 많이 들고 시간이 많이 소요되는 작업이다. 결정적으로, 이러한 상세한 분할 레이블을 제공하는 공개적으로 사용 가능한 데이터셋은 없다. 예를 들어, 주요 자료원인 AI-Hub [1]는 두피 질환에 대한 분류 레이블만 제공할 뿐, 강력한 AI 학습에 필요한 세분화된 분할 주석은 제공하지 않는다. 이러한 정답(ground-truth) 분할 데이터의 부재는 일반적으로 매우 효과적인 지도 학습 방법의 적용을 불가능하게 만든다.
- 심각한 데이터 불균형: 많은 기존 두피 영상 데이터셋은 특히 심각한 두피 질환의 경우 상당한 데이터 불균형을 겪고 있다(그림 2 참조). 이러한 중요한, 심각한 사례에 대한 샘플 부족은 질병 심각도의 전체 스펙트럼에 걸쳐 강력하고 정확한 AI 모델을 개발하는 것을 극도로 어렵게 만든다. 이전의 비생성적 증강 방법은 심각한 피지(sebum)와 같은 희귀 클래스에 대해 상당한 어려움을 겪었다[표 3].
- 이전 분할 기법의 한계: 종종 전통적인 컴퓨터 비전 기법 [20,21,10]에 의존하는 모발 분할을 위한 이전의 비지도 방법들은 좁은 모발을 정확하게 분할하고 복잡한 모발 패턴을 포착하는 데 어려움을 겪었다. SAM [12]과 같은 최신 기반 모델조차도 강력하지만, 특정 안내 없이는 자동 분할에 덜 효과적이었으며, 임의의 점 선택은 종종 최적이 아니거나 혼란스러운 마스크를 초래했다.
- 이미지 변환 중 모발 세부 정보 보존 능력 부족: 이미지 변환을 통해 다른 두피 상태를 시뮬레이션하여 데이터셋을 증강하려고 할 때, DiffuseIT [13] 및 AGG [14]와 같은 기존 확산 기반 이미지 변환 모델은 원본 이미지의 필수 모발 내용 정보를 보존하는 데 실패했다. 이는 두피 스타일을 변경할 수는 있었지만, 진단에 중요한 모발 특징 자체를 자주 손상시켜 데이터 증강에 대한 유용성을 저해했다.
직관적인 도메인 용어
다음은 논문에서 사용된 몇 가지 전문 도메인 용어를 직관적이고 일상적인 비유로 번역한 것이다.
- 모발 분할 마스크(Hair Segmentation Mask): 누군가의 머리 사진이 있고, 머리카락 만 강조하고 싶다고 상상해 보자. 모발 분할 마스크는 모든 머리카락 가닥을 정확하게 윤곽을 그리고 두피와 배경에서 분리하는 디지털 스텐실과 같다. 모발 픽셀은 "켜짐"(예: 흰색)이고 비모발 픽셀은 "꺼짐"(예: 검은색)인 이진 이미지이다.
- 의사 레이블링(Pseudo-labeling): 답안지가 없는 선생님이 추측이나 간단한 규칙에 기반하여 "가짜" 답안지를 만드는 것과 같다. 그런 다음 이 가짜 답안지를 사용하여 새로운 학생을 가르친다. 이 논문에서는 픽셀 단위로 완벽한 실제 모발 레이블을 얻는 것이 너무 비싸기 때문에, 연구자들은 간단한 규칙과 사전 지식을 사용하여 "의사 레이블"(근사적인 모발 마스크)을 생성하여 분할 모델을 초기 학습시킨다.
- 데이터 불균형(Data Imbalance): 수학을 잘하는 학생이 90%이고 시를 잘하는 학생이 1%인 교실을 상상해 보자. 이 반 학생들만 가지고 선생님을 훈련시키면, 수학을 가르치는 데는 탁월해지겠지만, 충분한 예시를 보지 못했기 때문에 시에는 심각한 어려움을 겪을 수 있다. 이 맥락에서의 데이터 불균형은 경미한 두피 질환의 이미지는 많지만 심각한 질환의 이미지는 매우 적어 AI가 심각한 사례를 안정적으로 진단하는 방법을 배우기 어렵다는 것을 의미한다.
- 확산 기반 이미지 변환(Diffusion-based Image Translation): 사진 속 사람을 더 늙거나 젊게 보이게 하거나 심지어 머리 색깔까지 바꾸면서도 원래의 얼굴 특징을 그대로 유지하도록 사진을 다시 그릴 수 있는 예술가와 같다. 확산 기반 이미지 변환 모델은 원본 이미지(예: 건강한 두피)를 받아 다른 상태(예: 비듬이 있는 두피)를 보여주도록 "다시 그린다" 하지만, 모발 수와 두께와 같은 원래 모발 세부 정보를 보존하도록 특별히 설계되었다.
- 기반 분할 모델(Foundation Segmentation Model, SAM): 그림 속 어떤 물체든, 그 물체를 클릭하는 것과 같은 힌트만 주면 윤곽을 그릴 수 있는 매우 똑똑하고 범용적인 디지털 비서와 같다고 상상해 보자. SAM은 거의 모든 것을 분할할 수 있는 강력한 AI 모델이지만, 모발 분할과 같은 특정 작업의 경우 최적으로 수행하고 모발과 두피를 구별하기 위해 여전히 약간의 안내(예: "포인트 프롬프트")가 필요하다.
표기법 표
| 표기법 | 설명 |
|---|---|
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
본 논문이 다루는 핵심 문제는 현미경 이미지에서 두피 질환을 포괄적으로 진단하기 위한 AI 기반 시스템인 SCALPVISION을 개발하는 것이다. 이처럼 간단해 보이는 목표는 두 가지 중요하고 상호 연결된 과제로 인해 복잡해진다.
입력/현재 상태: 시작점은 현미경 두피 이미지 모음이다. AI-Hub 데이터셋과 같은 기존 데이터셋은 다양한 두피 질환(예: 비듬, 과도한 피지, 홍반)과 그 심각도(양호, 경미, 보통, 심각)에 대한 높은 수준의 분류 레이블을 제공하지만, 결정적으로 모발에 대한 픽셀 수준 분할 레이블이 부족하다. 또한, 이러한 데이터셋은 그림 2에 설명된 바와 같이 심각한 질환에 대한 불균형적으로 적은 샘플 수를 가진 심각한 데이터 불균형을 겪고 있다.
원하는 최종 상태/목표 상태: 궁극적인 목표는 다음을 수행할 수 있는 강력한 시스템이다.
1. 비용이 많이 들고 시간이 많이 소요되는 수동 픽셀 수준 주석에 의존하지 않고 이러한 현미경 이미지 내에서 모발을 정확하게 분할한다. 이 모발 분할은 진단에 필수적인 모발 수 및 두께와 같은 특징을 측정하는 데 중요하다.
2. 훈련 데이터를 효과적으로 증강하여 두피 질환 심각도 예측의 정확도를 개선한다. 특히 과소 표현된 심각한 질환에 대해.
누락된 연결고리 및 딜레마: 정확한 누락된 연결고리는 지도 분할 모델을 훈련하는 데 필수적인 정확한 픽셀 수준 모발 마스크의 부재이다. 이 격차는 진단에 필수적인 모발의 정량적 특징을 추출하는 능력에 직접적인 영향을 미친다. 딜레마는 고전적인 절충안이다. 고품질의 정확한 모발 분할을 달성하는 것은 정확한 진단에 매우 중요하지만, 픽셀 수준 레이블을 얻는 전통적인 방법은 비용이 너무 많이 들고 시간이 너무 많이 소요된다. 이를 해결하려는 이전 시도는 종종 수동 주석(대규모로 비실용적) 또는 덜 정확한 비지도 방법을 포함했다. 마찬가지로, 데이터 증강은 데이터 불균형을 해결하기 위한 알려진 전략이지만, 과제는 중요한 미세한 모발 세부 정보를 왜곡하거나 손상시키지 않으면서 다양한 두피 상태를 정확하게 반영하는 합성 이미지를 생성하는 데 있다. 한 측면(예: 다양한 두피 상태 생성)을 개선하는 것은 종종 다른 측면(예: 모발 세부 정보 보존)을 손상시켜 이전 연구자들을 고통스러운 딜레마에 빠뜨린다.
제약 조건 및 실패 모드
이 문제를 해결하는 것은 저자들이 직면한 몇 가지 가혹하고 현실적인 벽 때문에 엄청나게 어렵다.
- 데이터 기반 제약 조건: 픽셀 수준 분할 레이블의 부재: 가장 큰 장애물은 두피 이미지에 대한 픽셀 수준 모발 주석이 포함된 공개적으로 사용 가능한 데이터셋이 완전히 없다는 것이다. 이는 분할을 위한 전통적인 지도 학습 접근 방식이 실현 불가능함을 의미하며, 레이블 없는 또는 의사 레이블링 전략의 개발을 강요한다. AI-Hub 데이터셋은 분류에는 광범위하지만, 이 세분화된 정보는 제공하지 않는다.
- 데이터 기반 제약 조건: 심각한 데이터 불균형: 사용 가능한 두피 이미지 데이터셋은 심하게 왜곡되어 있다. 5페이지의 그림 2에서 명확히 볼 수 있듯이, "양호" 및 "경미" 사례는 풍부하지만 "보통" 및 특히 "심각" 사례는 드물다. 중요한 심각한 사례에 대한 데이터의 극심한 희소성은 모든 심각도 수준에 걸쳐 잘 일반화될 수 있는 강력한 분류 모델을 훈련하는 것을 매우 어렵게 만든다. 비생성적 증강 방법은 섹션 3.4에서 언급했듯이 심각한 클래스에 대해 이를 적절하게 해결하는 데 종종 실패한다.
- 물리적 제약 조건: 복잡한 모발 패턴 및 노이즈: 현미경 두피 이미지는 복잡한 시각적 정보를 제시한다. 모발 패턴은 다양한 함수(선형 또는 거듭제곱)를 따를 수 있으며, 좁은 모발은 정확하게 분할하기가 본질적으로 어렵다. 또한, 비듬과 같은 노이즈의 존재는 적절하게 처리되지 않으면 분할 모델을 쉽게 혼란시켜 잘못된 분류나 부정확한 마스크를 초래할 수 있다. 모델은 명확한 경계를 유지하면서 노이즈로부터 모발을 구별해야 한다.
- 계산 제약 조건: 특정 작업에 대한 기반 모델의 한계: 강력하지만, Segment Anything Model (SAM)과 같은 기반 모델은 만능이 아니다. 모발 분할에 적용될 때, 긍정적인 프롬프트에 대해 거친 마스크에서 임의의 점을 선택하는 것만으로는 최적이 아닌 결과를 초래하는 경우가 많다. 마스크 가장자리 근처의 점은 SAM을 혼란시킬 수 있으며, 본질적인 무작위성은 샘플링된 점이 합쳐져 전체적이고 정확한 마스크가 아닌 제한된 모발 하위 집합의 분할을 초래할 수 있다. 이는 정교한 프롬프팅 메커니즘을 필요로 한다.
- 계산 제약 조건: 이미지 변환 중 모발 세부 정보 보존: 데이터 증강의 중요한 실패 모드는 이미지 변환 과정에서 필수적인 모발 세부 정보 또는 의미론적 정보의 손실이다. 모발의 복잡한 구조와 특징을 보존하면서 다양한 두피 상태(예: 심각도 변경)를 생성하는 것은 복잡한 작업이다. DiffuseIT 및 AGG와 같은 이전 생성 모델은 이 작업에 어려움을 겪었으며, 종종 섹션 3.3의 질적 결과에서 강조된 바와 같이 전체 정보를 손상시키거나 의미론적 정보를 효과적으로 전송하지 못했다. 이는 충실도를 보장하기 위해 신중하게 설계된 손실 함수와 마스크 안내를 필요로 한다.
왜 이 접근 방식인가
선택의 불가피성
SCALPVISION의 다중 구성 요소 접근 방식 채택은 단순히 선호가 아니라, 두피 질환 진단의 고유한 과제에 직면했을 때 기존 방법의 근본적인 한계에 의해 주도된 필수 사항이었다. 핵심 문제는 두 가지였다. 현미경 두피 이미지에서 모발에 대한 픽셀 수준 분할 레이블의 부재와 심각한 데이터 불균형, 특히 희귀하고 심각한 질환의 경우이다.
표준 CNN 또는 U-Net과 같은 전통적인 지도 분할 방법은 방대한 픽셀 단위의 정답 레이블을 요구하기 때문에 모발 분할에 즉시 적용할 수 없었다. 논문에서는 "대부분의 두피 질환 데이터셋에 분할 레이블이 부족하기 때문에 지도 학습 방법은 실현 불가능하다"(섹션 2.1)고 명시적으로 언급한다. 이러한 레이블을 생성하는 것은 비용이 너무 많이 들고 시간이 너무 많이 소요된다. 이 제약 조건으로 인해 저자들은 "레이블 없는" 분할 전략을 고안해야 했다.
마찬가지로, 두피 질환 분류의 경우, 전통적인 SOTA 방법(예: 고급 CNN 또는 Transformer)에만 의존하면 특히 심각한 질환의 경우 성능이 필연적으로 저하될 것이다. AI-Hub 데이터셋은 주요 자료원으로, "양호" 및 "경미" 사례에 대해 "심하게 왜곡된" 분포를 겪고 있다(그림 2, 섹션 3.1). 효과적인 데이터 증강 없이는 이러한 불균형 데이터로 훈련된 모델은 과소 표현된 심각한 질환을 일반화하고 정확하게 분류하는 데 어려움을 겪을 것이다. 가우시안 노이즈 또는 AugMix(표 3)와 같은 표준 증강 기법은 이 극심한 희소성을 극복하는 데 불충분했다. 저자들은 다양한 두피 상태를 정확하게 반영하면서도 필수적인 모발 세부 정보를 왜곡하거나 손상시키지 않는 현실적인 이미지 합성 능력을 갖춘 생성 모델이 이 불균형을 효과적으로 해결하는 유일한 방법이라는 것을 깨달았다.
비교 우위
SCALPVISION의 접근 방식은 두피 영상 분석의 고유한 어려움을 직접적으로 해결하는 구조적 설계를 통해 질적으로 우수함을 보여준다.
모발 분할의 경우, 제안된 앙상블 방법은 휴리스틱하게 훈련된 U²-Net (M)과 자동 프롬프트 기반 Segment Anything Model (SAM) (MAP)을 결합하여 상당한 구조적 이점을 제공한다. 합성 데이터와 시뮬레이션된 노이즈로 훈련된 U²-Net은 비듬과 같은 인공물에 대한 견고성을 제공한다(섹션 2.2, 섹션 3.2). 반면에 SAM은 정밀한 가장자리 감지에 뛰어나 명확한 경계를 생성한다(섹션 2.2). 논리적 AND 연산($M = M \land MAP$)은 이러한 강점을 시너지적으로 병합하여 노이즈에 강하고 모발 경계를 정의하는 데 매우 정확한 최종 마스크를 생성한다. 이는 "모발과 두피의 복잡한 패턴을 포착하는 데 대한 이해가 부족하다"(섹션 3.2)는 이전 방법들(Shih et al., Yue et al., Kim et al. [10])보다, 그리고 특정 안내 없이 사용된 SAM조차도 "최적이 아닌 마스크"를 생성한 것보다 질적으로 우수하다(섹션 2.1). 이러한 구조적 융합은 후속 진단 작업에 중요한 보다 안정적이고 정확한 분할을 보장한다.
이미지 변환 및 데이터 증강의 경우, DiffuseIT-M은 고유한 마스크 안내 메커니즘으로 인해 두드러진다. DiffuseIT [13] 또는 AGG [14]와 같은 다른 생성 모델과 달리 DiffuseIT-M은 "두피 상태를 변경하면서 모발 세부 정보를 보존하도록"(초록, 섹션 2.2) 특별히 설계되었다. 이는 마스크 보존 손실($l_{mask}$)과 역확산 과정 중 마스킹 접근 방식(방정식 5)을 포함하는 포괄적인 손실 함수를 통해 달성된다. 이러한 구조적 설계는 분리된 제어를 가능하게 하여, 모발의 무결성을 손상시키지 않으면서 두피 특징을 수정할 수 있도록(예: 다른 심각도를 시뮬레이션하기 위해) 보장하며, 이는 중요한 진단 특징이다. 정량적으로 DiffuseIT-M은 기준선(섹션 3.3)에 비해 더 높은 이미지 충실도와 원본 콘텐츠 보존을 나타내는 우수한 FID 및 LPIPS 점수(표 2)를 달성한다. 질적으로, 그림 4는 DiffuseIT와 AGG가 "모발 콘텐츠 정보를 보존하는 데 실패했다"는 것을 명확하게 보여주며, 이는 DiffuseIT-M이 극복하는 중요한 결함이다. 특정 이미지 영역을 유지하면서 다른 영역을 변환하는 이 능력은 의료 영상 증강에 있어 심오한 구조적 이점이다.
제약 조건과의 정렬
선택된 방법론은 문제의 가혹한 요구 사항과 완벽하게 일치하며, 과제와 솔루션의 고유한 속성 간의 "결합"을 형성한다.
-
제약 조건: 픽셀 수준 분할 레이블의 부재.
- 정렬: SCALPVISION의 모발 분할 모듈은 "레이블이 없는" 방식으로 이를 직접적으로 해결한다. 이는 모발 패턴(선형 또는 거듭제곱 함수)에 대한 사전 지식을 기반으로 합성 이미지를 생성하는 휴리스틱 기반 의사 레이블링과 SAM에 대한 자동 프롬프팅을 활용한다. 이 혁신적인 프롬프팅 방법은 거친 분할 마스크에서 긍정적 및 부정적 포인트 프롬프트를 체계적으로 생성하여, 수동 픽셀 수준 주석 없이도 SAM이 정확한 모발 마스크를 생성하도록 안내한다(섹션 2.1). 이는 레이블 부족에 대한 직접적이고 우아한 해결책이다.
-
제약 조건: 심각한 데이터 불균형, 특히 심각한 질환의 경우.
- 정렬: DiffuseIT-M 생성 모델은 이를 극복하는 초석이다. 이는 데이터셋 증강을 위해 특별히 설계되었다(초록). 이 모델은 가중치 샘플링을 사용하여 무작위로 선택된 이미지를 더 높은 심각도 수준으로 변환하며, 여기서 선택 확률은 클래스 크기에 반비례한다(섹션 2.2). 이 메커니즘은 과소 표현된 클래스를 직접적으로 대상으로 하여, 데이터셋의 균형을 맞추기 위한 다양하고 현실적인 훈련 샘플을 생성한다. 이는 분류 모델이 심각한 질환의 충분한 예시에 노출되도록 보장하며, 이는 강력한 진단에 매우 중요하다.
-
제약 조건: 강력하고 정확한 진단 필요성.
- 정렬: 강력한 모발 분할(M과 MAP의 결합)은 진단에 필수적인 정확한 모발 특징을 제공한다(섹션 1). 모발 세부 정보를 보존하는 고충실도 증강 이미지를 생성하는 DiffuseIT-M의 능력은 훈련 데이터가 현실적이고 관련성이 높도록 보장하여 보다 강력한 분류 모델로 이어진다(섹션 3.4). 레이블 없는 분할부터 대상 데이터 증강까지 전체 시스템의 설계는 포괄적이고 신뢰할 수 있는 진단 도구를 구축하는 데 중점을 둔다.
대안의 거부
본 논문은 특정 두피 질환 진단의 제약 조건을 충족하지 못하는 여러 대안 접근 방식을 암묵적으로 그리고 명시적으로 거부한다.
-
전통적인 지도 분할 방법: "픽셀 수준 분할 레이블의 부재"(섹션 2.1)로 인해 즉시 거부되었다. 표준 U-Net 또는 Mask R-CNN과 같은 방법은 방대한 수동 주석을 필요로 하며, 이는 두피 데이터셋에 대해 사용할 수 없다. 이전 두피 분할 접근 방식 [20,21,10]과의 비교 결과는 복잡한 모발 패턴을 효과적으로 포착하는 데 있어 이러한 방법의 한계를 더욱 강조한다(섹션 3.2).
-
기반 모델(예: SAM) 특정 안내 없이: SAM은 강력하지만, 저자들은 "긍정적 프롬프트에 대해 M에서 임의의 점을 선택하는 것이 종종 최적이 아닌 마스크를 초래했다"고 발견했으며, SAM은 "특정 안내 없이 사용될 때 자동 분할에 덜 효과적이었다"(섹션 2.1, 섹션 3.2). 이는 강력한 모델만으로는 충분하지 않으며, 이 도메인에서 효과적이려면 맞춤형 지능형 프롬프팅 메커니즘이 필요함을 강조한다.
-
이미지 변환을 위한 다른 생성 모델(예: DiffuseIT, AGG 또는 일반 GAN): 본 논문은 DiffuseIT-M을 DiffuseIT [13] 및 AGG [14]와 직접 비교한다. 두 대안 모두 "원본 이미지에서 모발 콘텐츠 정보를 보존하는 데 실패했으며"(섹션 3.3, 그림 4) "전반적인 정보를 손상시키는 경향이 있었고 의미론적 정보를 효과적으로 전송하지 못했다". 이 실패는 모발 특징이 가장 중요한 두피 진단에 치명적이다. DiffuseIT-M의 명시적인 마스크 안내 메커니즘 없이는 이러한 모델은 두피 상태와 모발 보존을 분리할 수 없어 진단적으로 관련성 있는 증강 데이터를 생성하는 데 부적합하다. GAN은 명시적으로 직접적인 대안으로 언급되지 않았지만, 마스크 안내 없이 제어된 콘텐츠 보존에서의 일반적인 한계는 유사한 실패로 이어질 가능성이 높다.
-
비생성적 데이터 증강 방법(예: 가우시안 노이즈, AugMix): 이러한 방법은 심각한 질환에 대한 "샘플의 극심한 희소성"(섹션 3.4)을 해결하는 데 불충분한 것으로 밝혀졌다. 표 3은 가우시안 노이즈 또는 AugMix로 증강된 모델이 생성 모델로 증강된 모델보다, 특히 심각한 사례를 분류하는 데 있어 훨씬 더 나쁜 성능을 보인다는 것을 명확히 보여준다. 이러한 더 간단한 방법은 과소 표현된 클래스를 진정으로 나타내는 새롭고 다양한 예시를 합성할 수 없어 데이터 불균형을 효과적으로 완화하는 데 실패한다.
 Figure 2. Data distribution of different severity within each scalp condition
Figure 2. Data distribution of different severity within each scalp condition
수학적 및 논리적 메커니즘
마스터 방정식
모발 세부 정보를 보존하면서 다양한 두피 이미지를 생성할 수 있게 하는 DiffuseIT-M 이미지 변환 메커니즘의 핵심은 포괄적인 손실 함수와 특정 역확산 샘플링 단계에 의해 지배된다. 학습 및 생성 프로세스를 안내하는 주요 목표 함수는 다음과 같이 정의된 총 손실, $l_{total}$이다.
$$ l_{total} (x;x_{src},x_{trg},M) = \lambda_1 l_{style} + \lambda_2 l_{content} + \lambda_3 l_{mask} + \lambda_4 l_{sem} + \lambda_5 l_{rng} $$
이 손실 함수는 다음으로 주어진, 더 노이즈가 적은 이미지 샘플, $x_{t-1}$을 생성하기 위해 반복적인 역확산 프로세스 내에서 사용된다.
$$ x_{t-1} \leftarrow x_t \odot M + \left[x_0(x_t) - \sqrt{\bar{\alpha}_t} l_{total} (x_0(x_t))\right] \odot (1 – M) $$
손실 계산과 역단계 모두에서 중요한 구성 요소는 시간 단계 $t$에서 노이즈가 있는 샘플 $x_t$로부터 정제된 이미지, $x_0(x_t)$의 추정이다. 이 추정은 예측된 노이즈 $\epsilon_0(x_t, t)$로부터 파생된다.
$$ x_0(x_t) = \frac{x_t}{\sqrt{\bar{\alpha}_t}} - \frac{\sqrt{1 – \bar{\alpha}_t} \epsilon_0(x_t, t)}{\sqrt{\bar{\alpha}_t}} $$
마지막으로, $l_{total}$의 구성 요소인 마스크 보존 손실, $l_{mask}$는 명시적으로 다음과 같이 정의된다.
$$ l_{mask} = \text{LPIPS}(x_{src}\odot M, x_0(x_t)\odot M) + ||(x_{src} - x_0(x_t))\odot M||_2 $$
항별 분석
이 방정식들을 해부하여 각 요소의 역할을 이해해 보자.
총 손실 함수 ($l_{total}$)
- $l_{total} (x;x_{src},x_{trg},M)$:
DiffuseIT-M모델이 훈련 중에 최소화하려고 하는 전체 목표 함수이다. 이는 여러 개별 손실 구성 요소의 가중 합으로, 고충실도 이미지 변환을 보장하면서 모발 세부 정보를 보존하도록 설계되었다. 입력은 현재 이미지 $x$(역단계의 맥락에서 일반적으로 $x_0(x_t)$), 원본 이미지 $x_{src}$, 대상 이미지 $x_{trg}$(원하는 두피 상태를 나타냄), 그리고 모발 마스크 $M$이다.- 덧셈을 사용하는 이유? 저자들은 다양한, 종종 상충되는 목표를 결합하기 위해 덧셈을 사용한다. 각 항은 생성된 이미지의 특정 바람직한 속성(예: 스타일, 내용, 마스크 보존)을 장려하며, 이를 합산함으로써 모델은 이러한 목표 전반에 걸쳐 균형을 학습할 수 있다.
- $\lambda_1, \lambda_2, \lambda_3, \lambda_4, \lambda_5$: 이들은 스칼라 가중 계수이다.
- 수학적 정의: 양의 실수.
- 물리적/논리적 역할: 각 손실 구성 요소의 상대적 중요도를 제어한다. 이러한 가중치를 조정함으로써 저자들은 모발 세부 정보를 얼마나 강하게 보존해야 하는지 또는 두피 스타일이 대상과 얼마나 가깝게 일치해야 하는지와 같은 이미지 변환의 특정 측면을 우선시할 수 있다.
- $l_{style}$: 스타일 손실.
- 수학적 정의: 논문에서 명시적으로 정의되지 않았지만
DiffuseIT[13]에서 가져온 것으로 명시되어 있다. 일반적으로 VGG 네트워크 또는 유사한 인식 특징의 특징 통계(예: 그램 행렬)를 일치시키는 것을 포함한다. - 물리적/논리적 역할: 생성된 이미지의 두피 영역이 대상 두피 상태의 스타일 특성(예: 질감, 색상, 패턴)을 채택하도록 장려한다.
- 수학적 정의: 논문에서 명시적으로 정의되지 않았지만
- $l_{content}$: 내용 손실.
- 수학적 정의: 명시적으로 정의되지 않았으며,
DiffuseIT[13]에서도 가져왔다. 종종 생성된 이미지와 대상 이미지의 특징 맵 간의 L2 거리를 측정한다. - 물리적/논리적 역할: 두피 영역의 고수준 의미론적 내용이 대상 이미지에서 전송되도록 보장하여, 모델이 두피 상태를 정확하게 변환하도록 안내한다.
- 수학적 정의: 명시적으로 정의되지 않았으며,
- $l_{mask}$: 마스크 보존 손실 (방정식 3).
- 수학적 정의: 마스크 영역에 적용된 LPIPS와 L2 노름의 조합.
- 물리적/논리적 역할: 이는
SCALPVISION의 목표에 매우 중요하다. 이는 원본 이미지의 모발 세부 정보를 마스크된 모발 영역 내에 보존하도록 명시적으로 강제하여, 두피 상태 변환 중에 모발에 대한 원치 않는 변경을 방지한다.
- $l_{sem}$: 의미론적 발산 손실.
- 수학적 정의: 명시적으로 정의되지 않았지만 [13]에서 가져왔으며 DINO-ViT [3]의
[CLS]토큰 일치 손실을 사용한다고 명시되어 있다. - 물리적/논리적 역할: 비전 트랜스포머의 고수준 특징을 사용하여 생성된 이미지에 대상 이미지의 의미론적 정보(예: 질병 유형, 심각도)가 올바르게 반영되도록 한다.
- 수학적 정의: 명시적으로 정의되지 않았지만 [13]에서 가져왔으며 DINO-ViT [3]의
- $l_{rng}$: 제곱 구면 거리 손실.
- 수학적 정의: 명시적으로 정의되지 않았지만 [5]에서 가져왔다고 명시되어 있다.
- 물리적/논리적 역할: 잠재 공간에서 특정 분포를 유지하거나 생성 샘플의 다양성을 촉진할 수 있는 정규화 항 역할을 할 가능성이 높으며, 이는 데이터 증강에 유익하다.
역확산 샘플링 단계 ($x_{t-1}$ 업데이트)
- $x_{t-1}$: 역확산 프로세스의 이전(더 적은 노이즈) 시간 단계에서의 이미지.
- 수학적 정의: 픽셀 단위 이미지 텐서.
- 물리적/논리적 역할: 노이즈가 있는 이미지에서 깨끗하고 변환된 이미지로 이동하는 생성 프로세스의 한 단계의 출력이다.
- $x_t$: 시간 단계 $t$에서의 현재 노이즈가 있는 이미지.
- 수학적 정의: 픽셀 단위 이미지 텐서.
- 물리적/논리적 역할: 현재 역확산 단계의 시작점이다.
- $M$: 이진 모발 마스크.
- 수학적 정의: 이미지와 동일한 공간 차원을 가진 이진 텐서로, 1은 모발을 나타내고 0은 두피를 나타낸다.
- 물리적/논리적 역할: 스텐실 역할을 한다. 모발 영역을 분리하여 모발에 적용되는 연산이 두피에 적용되는 연산과 구별되도록 한다.
- $\odot$: 요소별 곱셈(아다마르 곱).
- 수학적 정의: 두 텐서의 해당 요소를 곱한다.
- 물리적/논리적 역할: 여기서는 마스킹에 사용된다. $x_t \odot M$은 현재 노이즈가 있는 이미지의 모발 영역을 분리하여 모발을 그대로 "유지"한다.
- $x_0(x_t)$: $x_t$로부터 추정된 깨끗한 이미지 (방정식 4).
- 수학적 정의: 픽셀 단위 이미지 텐서.
- 물리적/논리적 역할: $x_t$에서 모든 노이즈가 제거되었다고 가정할 때 깨끗한 이미지의 모델의 최선의 추측을 나타낸다. 이는 확산 모델에서 중요한 중간 예측이다.
- $\sqrt{\bar{\alpha}_t}$: 알파 값의 누적 곱의 제곱근.
- 수학적 정의: $\bar{\alpha}_t = \prod_{s=1}^t (1-\beta_s)$, 여기서 $\beta_s$는 분산 스케줄 매개변수이다.
- 물리적/논리적 역할: 확산 프로세스의 노이즈 스케줄에서 파생된 스케일링 인수이다. 노이즈가 있는 이미지를 깨끗한 이미지 및 예측된 노이즈와 연결하는 수학적 프레임워크의 일부이다.
- $l_{total}(x_0(x_t))$: 추정된 깨끗한 이미지에 적용된 총 손실 함수.
- 수학적 정의: $l_{total}$ 함수의 스칼라 출력.
- 물리적/논리적 역할: 이 항은 두피 영역의 변환을 안내한다. 총 손실(스타일, 내용 및 의미론적 목표 포함)을 추정된 깨끗한 이미지에 적용함으로써, 모델은 대상 상태와 일치하는 두피를 생성하도록 유도된다.
- $1 - M$: 이진 모발 마스크의 역.
- 수학적 정의: 1은 두피를 나타내고 0은 모발을 나타내는 이진 텐서.
- 물리적/논리적 역할: 두피 영역을 분리하여 손실 기반 업데이트를 비모발 영역에만 적용할 수 있도록 한다.
- 덧셈과 마스킹을 사용하는 이유? 덧셈은 두 가지 별개의 부분을 결합한다. 모발 영역( $x_t$에서 보존됨)과 두피 영역(손실 기반 업데이트). 이 영리한 마스킹 접근 방식은 모발을 보존하면서 두피를 선택적으로 이미지 변환할 수 있도록 한다.
추정된 깨끗한 이미지 ($x_0(x_t)$)
- $\epsilon_0(x_t, t)$: 확산 모델에 의해 예측된 노이즈.
- 수학적 정의: $x_t$와 동일한 모양의 텐서로, 추정된 노이즈 구성 요소를 나타낸다.
- 물리적/논리적 역할: 이는 확산 모델 내 신경망의 주요 출력이다. 이 네트워크는 깨끗한 이미지에 추가되어 $x_t$가 된 노이즈를 예측하도록 훈련된다.
- $\sqrt{1 - \bar{\alpha}_t}$: 확산 프로세스의 또 다른 스케일링 인수.
- 수학적 정의: 노이즈 스케줄에서 파생됨.
- 물리적/논리적 역할: 시간 $t$에서의 전체 노이즈 수준과 예측된 노이즈의 크기를 연결한다.
- 나눗셈과 뺄셈을 사용하는 이유? 이 공식은 확산 모델의 표준 재매개변수화이다. 이를 통해 모델은 노이즈 $\epsilon_0(x_t, t)$를 예측하고, 노이즈가 있는 입력 $x_t$와 노이즈 스케줄 매개변수로부터 해당 깨끗한 이미지 $x_0(x_t)$를 분석적으로 도출할 수 있다.
마스크 보존 손실 ($l_{mask}$)
- $\text{LPIPS}(A, B)$: 학습된 인식 이미지 패치 유사도 메트릭.
- 수학적 정의: 사전 훈련된 신경망(예: VGG)의 딥 특징을 기반으로 하는 인식 거리 메트릭.
- 물리적/논리적 역할: 단순한 픽셀 단위 차이보다 인간 인식과 더 잘 일치하는 이미지 패치 간의 인식 유사성을 측정한다. 여기서는 소스 및 생성된 이미지(마스크 내)의 인식된 모발 세부 정보가 유사하도록 한다.
- $||(x_{src} - x_0(x_t))\odot M||_2$: 소스 이미지와 추정된 깨끗한 이미지 간의 픽셀 단위 차이를 $M$으로 마스킹한 L2 노름(유클리드 거리).
- 수학적 정의: $\sqrt{\sum_{i,j} ((x_{src})_{i,j} - (x_0(x_t))_{i,j})^2 \cdot M_{i,j}}$.
- 물리적/논리적 역할: 이는 직접적인 픽셀 단위 제약 조건이다. 생성된 이미지의 모발 영역을 소스 이미지의 모발 영역과 픽셀 단위로 동일하게 만들도록 모델 파라미터를 "당기는" "고무줄" 역할을 한다. 이는 픽셀 수준의 지역적 충실도 제약 조건을 제공함으로써 LPIPS를 보완한다.
- 덧셈을 사용하는 이유? LPIPS와 L2를 결합하면 모발 보존을 위한 인식 및 픽셀 수준 충실도가 모두 보장된다.
단계별 흐름
여기서는 두피 상태(스칼프 조건)를 변경하면서 모발을 그대로 유지하기 위해 변환하려는 현미경 두피 이미지, $x_{src}$인 단일 추상 데이터 포인트를 상상해 보자.
- 모발 마스크 생성: 먼저, 입력 이미지 $x_{src}$가 모발 분할 모듈로 들어간다. 이 모듈은 의사 레이블링과 알고리즘 1에 의해 안내되는 Segment Anything Model (SAM)을 사용하여 이진 모발 마스크, $M$을 생성한다. 이 마스크는 모발 영역(값 1)과 두피 영역(값 0)을 정확하게 구분한다.
- 노이즈 초기화: 이미지 변환을 위해
DiffuseIT-M모델은 소스 이미지의 노이즈가 있는 버전, $x_T$ 또는 순수한 노이즈 이미지로 시작하며, 이는 반복적으로 노이즈가 제거된다. 중간 단계 $t$에서의 일반적인 노이즈가 있는 이미지 $x_t$를 고려해 보자. - 깨끗한 이미지 추정: 각 역확산 단계에서 모델의 신경망(노이즈를 예측하도록 훈련됨)은 $x_t$와 현재 시간 단계 $t$를 입력으로 받는다. 이는 추정된 노이즈 구성 요소, $\epsilon_0(x_t, t)$를 출력한다. 이 예측된 노이즈는 확산 스케줄 매개변수 $\bar{\alpha}_t$와 함께 $x_t$로부터 깨끗한 이미지의 모델의 최선의 추측인 $x_0(x_t)$를 계산하는 데 사용된다 (방정식 4).
- 안내를 위한 손실 계산: 추정된 깨끗한 이미지 $x_0(x_t)$, 원본 소스 이미지 $x_{src}$, 대상 조건 이미지 $x_{trg}$, 그리고 모발 마스크 $M$은 총 손실 함수, $l_{total}$ (방정식 2)에 입력된다.
- $l_{style}$ 및 $l_{content}$는 $x_0(x_t)$의 두피 영역을 $x_{trg}$와 비교하여 스타일 및 내용 전송을 안내한다.
- $l_{mask}$ (방정식 3)는 $x_0(x_t)$의 모발 영역을 $x_{src}$의 모발 영역과 구체적으로 비교하여 마스크를 사용한 인식(LPIPS) 및 픽셀 단위(L2) 메트릭 모두를 사용하여 모발 보존을 보장한다.
- $l_{sem}$ 및 $l_{rng}$는 추가적인 의미론적 및 정규화 안내를 제공한다.
- 이러한 손실의 가중 합인 $l_{total}$은 현재 $x_0(x_t)$가 모든 바람직한 속성과 일치하는 정도를 나타내는 포괄적인 신호를 제공한다.
- 안내된 노이즈 제거 및 변환: 이 계산된 $l_{total}$은 다음, 더 적은 노이즈가 있는 이미지, $x_{t-1}$ (방정식 5)을 생성하는 데 사용된다.
- $x_t$의 모발 부분은 $x_t \odot M$으로 보존된다. 이는 소스 이미지의 모발 구조가 직접 전달되도록 보장한다.
- 두피 부분은 두피 영역 $(1-M)$에 손실 기반 항 $[x_0(x_t) - \sqrt{\bar{\alpha}_t} l_{total} (x_0(x_t))]$을 적용하여 업데이트된다. 이 항은 $x_0(x_t)$의 두피 픽셀을 총 손실의 영향을 받아 대상 상태에 일치하도록 효과적으로 밀어낸다.
- 이 두 개의 마스크된 구성 요소가 합산되어 $x_{t-1}$을 형성하며, 이는 보존된 모발과 대상 상태에 가까워지는 단계인 두피를 갖는다.
- 수렴을 위한 반복: 이 프로세스(단계 3~5)는 여러 시간 단계, $t=T, T-1, \dots, 1$에 대해 반복적으로 반복된다. 각 단계마다 이미지는 노이즈가 줄어들고 두피 영역은 대상 상태에 일치하도록 점진적으로 변환되는 동시에 모발은 그대로 유지된다.
- 최종 출력: 모든 단계를 거친 후, 최종 $x_0$(또는 $t=1$에서의 $x_{t-1}$)는 생성된 이미지로, $x_{src}$의 모발이 보존된 상태로 $x_{src}$를 $x_{trg}$의 두피 상태로 변환한 것이다.
최적화 역학
DiffuseIT-M 메커니즘은 $l_{total}$ 손실 함수에 의해 안내되는 확산 모델의 표준 훈련 프로세스를 통해 매개변수를 학습하고 업데이트한다.
- 모델 훈련:
DiffuseIT-M내의 신경망( $\epsilon_0(x_t, t)$ 또는 $x_0(x_t)$를 예측하는)은 대규모 이미지 데이터셋을 사용하여 훈련된다. 훈련 중에 노이즈가 깨끗한 이미지에 추가되어 노이즈가 있는 샘플 $x_t$가 생성된다. 그런 다음 모델은 $x_t$로부터 노이즈 또는 깨끗한 이미지를 예측하는 방법을 학습한다. $l_{total}$ 함수는 이 학습의 목표 역할을 한다. - 손실 지형 형성: $l_{total}$ 함수는 다면적인 방식으로 손실 지형을 형성한다.
- 모발 보존 계곡: $l_{mask}$ 항은 생성된 모발 영역이 소스 모발과 밀접하게 일치하는 손실 지형에서 깊은 계곡을 생성한다. 마스크된 영역 내에서 소스 이미지의 모발 구조 또는 모양에서 벗어나는 것은 이 손실의 가파른 증가를 초래하여 모발 변경을 효과적으로 처벌한다.
- 두피 변환 기울기: $l_{style}$, $l_{content}$, $l_{sem}$ 항은 모델이 두피 영역을 변환하도록 안내한다. 이러한 손실의 기울기는 모델 매개변수를 대상 상태와 일치하는 두피 특징을 생성하도록 유도한다. 예를 들어, 생성된 두피에 $x_{trg}$의 원하는 질감이 부족하면 $l_{style}$ 기울기가 해당 질감을 생성하도록 모델을 유도한다.
- 안정성/다양성을 위한 정규화: $l_{rng}$ 항은 훈련을 정규화하는 역할을 하며, 잠재적으로 손실 지형을 부드럽게 하거나 모델이 다양한 솔루션을 탐색하도록 장려하여 데이터 증강에 유익하다.
- 기울기 하강: 모델의 매개변수는 Adam 또는 SGD와 같은 최적화 알고리즘을 사용하여 반복적으로 업데이트된다. 각 훈련 단계에서 모델 매개변수에 대한 $l_{total}$의 기울기가 계산된다. 이러한 기울기는 총 손실을 줄이기 위해 각 매개변수에 필요한 변경의 방향과 크기를 나타낸다. 그런 다음 매개변수는 기울기의 반대 방향으로 조정된다.
- 반복적 개선: 수많은 훈련 반복을 거치면서 모델은 $l_{total}$을 최소화하는 $x_0(x_t)$를 생성하도록 예측 $\epsilon_0(x_t, t)$(또는 $x_0(x_t)$)를 학습한다. 이는 모델이 모발이 보존되고 두피 상태가 정확하게 변환된 이미지를 생성하도록 학습한다는 것을 의미한다.
- 수렴: 모델의 검증 세트 성능이 더 이상 개선되지 않을 때까지 훈련이 계속되며, 이는 모델이 원하는 이미지 변환 작업을 효과적으로 수행할 수 있는 상태로 수렴했음을 나타낸다. $\lambda_i$ 가중치의 균형은 다양한 목표 간의 좋은 절충을 달성하고 안정적인 수렴을 보장하는 데 중요하다. 논문에서는 분류를 위해 "사전 훈련된 백본을 네 개의 MLP 헤드로 미세 조정"하는 것도 언급하지만, 이는 다운스트림 작업에 대한 별도의 최적화 단계이며, 생성 모델의 학습은 주로 $l_{total}$을 최소화함으로써 주도된다.
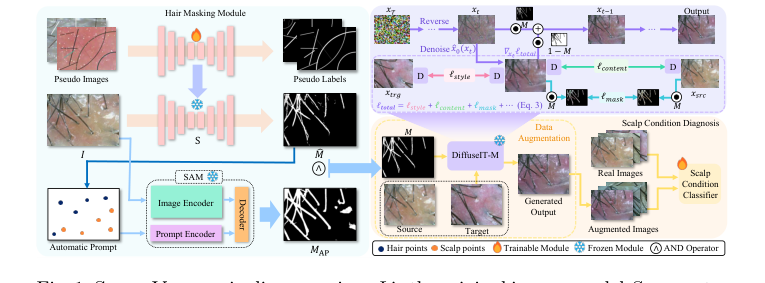 Figure 1. ScalpVision pipeline overview: I is the original image, model S generates the hair segmentation mask ˆ M using a pseudo-training set, MAP is the SAM- produced mask, and M is the combined hair segmentation mask. The “Automatic Prompt” for refining segmentation comes from ˆ M. xsrc and xtrg are the source and target images, with M as the mask image of xsrc. The weighted image sum is denoted by ⊙and D stands for DINO-ViT [3]
Figure 1. ScalpVision pipeline overview: I is the original image, model S generates the hair segmentation mask ˆ M using a pseudo-training set, MAP is the SAM- produced mask, and M is the combined hair segmentation mask. The “Automatic Prompt” for refining segmentation comes from ˆ M. xsrc and xtrg are the source and target images, with M as the mask image of xsrc. The weighted image sum is denoted by ⊙and D stands for DINO-ViT [3]
결과, 한계 및 결론
실험 설계 및 기준선
SCALPVISION의 핵심 메커니즘을 엄격하게 검증하기 위해 저자들은 모발 분할, 합성 이미지 생성, 두피 질환 분류 등 각 구성 요소를 대상으로 하는 일련의 실험을 설계했다.
모발 분할의 경우, 주요 목표는 레이블 없는 접근 방식의 효과를 입증하는 것이었다. 주요 AI-Hub 데이터셋에 픽셀 수준 분할 레이블이 없다는 점을 감안할 때, 전문가가 수동으로 주석을 단 150개의 테스트 이미지로 구성된 특수 하위 세트가 정답으로 사용되었다. 이 분야의 "희생자"(기준선 모델)에는 Shih et al. [20], Yue et al. [21], Kim et al. [10]의 전통적인 컴퓨터 비전 방법과 강력한 기반 모델인 SAM [12]이 포함되었다. 성능은 표준 메트릭인 Pixel-F1, Jaccard 및 Dice 점수로 정량화되었다. 또한 초기 단순 분할 마스크($M$), SAM 생성 마스크($M_{AP}$), 그리고 최종 결합 마스크($M$)를 비교하는 중요한 절제 연구가 수행되어 각 부분의 기여도를 분리했다.
합성 이미지 생성 모듈인 DiffuseIT-M은 모발 세부 정보를 보존하면서 다양한 두피 이미지를 생성하는 능력을 입증하기 위해 다른 생성 모델과 비교하여 평가되었다. 여기서 기준선은 DiffuseIT [13] 및 AGG [14]였다. 실험은 Fréchet Inception Distance (FID) [8] 및 Learned Perceptual Image Patch Similarity (LPIPS) [22] 점수를 사용하여 이미지 충실도를 철저히 입증했다. 또한, 마스크 안내의 영향은 다른 마스크 조건(제안된 1-M 안내, 역 마스크 M, 마스크 없음(0), 전체 마스크(1)) 하에서의 이미지 변환 결과를 비교함으로써 구체적으로 테스트되었다.
마지막으로, 두피 질환 분류를 위해 AI-Hub 데이터셋 전체(95,910개 이미지, 훈련용 72,342개, 테스트용 23,568개, 검증용 21,703개로 분할)가 사용되었다. 피부과 의사들은 이 이미지들에 대해 세 가지 질환(비듬, 과도한 피지, 홍반)을 레이블링했으며, 각 질환은 양호, 경미, 보통, 심각의 네 가지 심각도 수준으로 분류되었다. 그림 2에서 볼 수 있듯이 데이터셋이 "양호" 및 "경미" 사례에 편중되어 있다는 점을 인정하고, 실험은 생성적 증강이 이 불균형을 어떻게 해결할 수 있는지 보여주는 것을 목표로 했다. 두 가지 다른 분류 백본(CNN인 DenseNet [9] 및 Transformer인 EfficientFormerV2 [15])이 사용되어 다양한 아키텍처에 걸쳐 결과의 견고성을 보장했다. 다양한 증강 전략이 비교되었다. 가우시안 노이즈, AugMix [7], DiffuseIT [13], AGG [14], 그리고 "Ours"(SCALPVISION의 DiffuseIT-M)였다. 결정적인 증거는 세 가지 질병에 대한 각 심각도 수준별 개별 F1 점수와 전체 매크로 F1 점수에서 찾아졌다.
증거가 입증하는 것
실험 증거는 SCALPVISION의 핵심 메커니즘에 대한 부인할 수 없는 증거를 제공한다.
모발 분할의 경우, 표 1은 우리의 결합 마스크 $M$이 모든 메트릭(Pixel-F1: 0.868, Jaccard: 0.649, Dice: 0.786)에서 우수한 성능을 달성했음을 명확히 보여준다. 이는 단순한 점진적인 개선이 아니라, 모든 전통적인 컴퓨터 비전 기준선과 독립적인 SAM 모델을 훨씬 능가했다. 논리적 AND 연산을 통해 단순 분할 모델의 노이즈에 대한 견고성($M$)과 SAM의 우수한 가장자리 감지($M_{AP}$)를 결합한 구조적 선택이 핵심이었다. 그림 3에서 시각적으로 확인된 이 융합은 명확하고 정확하며 노이즈에 강한 모발 마스크를 생성하여, 휴리스틱 기반 의사 레이블링과 SAM에 대한 자동 프롬프팅 방법이 레이블 부족 및 개별 모델 약점의 한계를 효과적으로 극복했음을 증명했다. "희생자"는 명확하게 패배했으며, 우리의 방법은 이전 기술보다 복잡한 모발 패턴에 대한 보다 포괄적인 이해를 보여주었다.
합성 이미지 생성에서 DiffuseIT-M("Ours")은 생성 모델 동료보다 훨씬 더 나은 충실도 점수를 달성함으로써 그 능력을 보여주었다. 표 2는 FID 74.84 및 LPIPS 0.353을 보고하며, 이는 DiffuseIT(FID: 138.42, LPIPS: 0.463) 및 AGG(FID: 141.70, LPIPS: 0.492)보다 훨씬 낮다(더 높은 품질을 나타냄). 그림 4 및 그림 5의 시각적 증거는 이를 더욱 공고히 한다. 기준선이 모발 콘텐츠를 보존하거나 의미론적 정보를 정확하게 전송하는 데 어려움을 겪었던 반면, DiffuseIT-M은 두피 상태를 효과적으로 변경하면서 소스 모발 세부 정보를 성공적으로 유지했다. 마스크 안내에 대한 실험은 특히 중요했다. 1-M 마스크 안내를 사용하는 것이 변환 중에 모발 특징을 유지하는 데 결정적이었던 반면, 다른 마스크 조건(마스크 없음, 전체 마스크 또는 역 마스크)은 최소한의 변경을 초래하거나 모발과 두피를 무차별적으로 변경했다. 이 확실한 증거는 DiffuseIT-M의 마스크 안내 확산 메커니즘이 데이터 증강에 중요한 제어된 이미지 변환에 매우 효과적임을 증명한다.
전체 시스템의 영향에 대한 가장 설득력 있는 증거는 두피 질환 분류에서 나왔다. 표 3은 "Ours"(SCALPVISION의 DiffuseIT-M 증강)가 DenseNet (0.636) 및 EfficientFormerV2 (0.635) 백본 모두에 대해 일관되게 가장 높은 매크로 F1 점수를 달성했음을 부인할 수 없이 보여준다. 이는 단순히 전반적인 승리가 아니라, 특히 심각한 데이터 불균형을 해결하는 데 있어 두드러졌다. 예를 들어, "심각한" 피지를 분류할 때, 가우시안 노이즈 및 AugMix와 같은 비생성적 증강 방법은 0.000의 F1 점수를 산출하여 이 드물지만 중요한 질환을 분류하는 데 완전한 실패를 나타냈다. 대조적으로, "Ours"는 심각한 피지에 대해 0.430(DenseNet) 및 0.406(EfficientFormerV2)의 F1 점수를 달성했다. 이는 생성적 데이터 증강, 특히 과소 표현된 클래스에 대한 고품질의 다양한 샘플을 생성하는 DiffuseIT-M의 능력이 진단 성능 향상으로 직접 이어진다는 결정적이고 부인할 수 없는 증거이며, 특히 어려운 희귀 질환의 경우 더욱 그렇다. 이는 두피 스타일과 모발 콘텐츠 정보 모두를 보존하는 것이 정확한 분류에 매우 중요하다는 것을 증명한다.
한계 및 향후 방향
SCALPVISION은 두피 질환 진단을 위한 강력하고 혁신적인 솔루션을 제시하지만, 현재의 한계를 인정하고 향후 개발을 고려하는 것이 중요하다.
내재된 한계 중 하나는 데이터셋 자체에서 비롯된다. AI-Hub 데이터셋은 "양호" 및 "경미" 두피 상태에 크게 편중되어 있으며 심각한 사례는 드물다. SCALPVISION의 생성적 증강 방법이 이 불균형을 크게 완화하지만, 실제 심각한 사례의 근본적인 희소성은 증강된 데이터에서도 잘 표현되지 않은 극도로 다양하거나 새로운 심각한 표현에 대한 일반화에 여전히 어려움을 초래할 수 있다. 또한, 모발 분할을 위한 수동 주석은 상대적으로 적은 150개의 테스트 이미지 하위 세트에 대해 수행되었다. 초기 검증에는 충분했지만, 더 광범위하고 다양한 수동 주석 이미지 세트는 다양한 모발 유형 및 영상 조건에 걸쳐 분할 모델의 견고성을 더욱 강화할 수 있다. 또한, 현재 시스템은 비듬, 과도한 피지, 홍반의 세 가지 특정 두피 질환에 초점을 맞춘다. 이 범위는 가치 있지만, 피부과 질환의 전체 스펙트럼을 아직 다루지 않는다는 것을 의미한다.
앞으로 몇 가지 흥미로운 방향은 이러한 결과를 더욱 발전시킬 수 있다.
- 진단 범위 확장: 저자들은 모발 정보를 활용하여 탈모와 같은 질환으로 연구를 확장할 의도를 명시적으로 밝힌다. 이는 진정한 일반화된 진단 시스템을 향한 자연스럽고 필요한 진행이다. 향후 연구는 모발 표면 상태보다는 탈모 패턴이 주요 진단 특징인 질환에 SCALPVISION의 프레임워크가 어떻게 적응하는지 탐색할 수 있다.
- 다중 모드 통합: 현재 시스템은 현미경 두피 영상에만 의존한다. 환자 병력, 유전적 표지자 또는 거시적 이미지와 같은 다른 진단 데이터를 통합하면 보다 전체적이고 정확한 진단으로 이어질 수 있으며, 영상만으로는 발생할 수 있는 위양성 또는 위음성을 줄일 수 있다.
- 임상 배포 및 사용자 경험: SCALPVISION이 진정으로 가치 있는 도구가 되려면 임상 워크플로우에 통합하는 것이 무엇보다 중요하다. 여기에는 피부과 의사를 위한 사용자 친화적인 인터페이스 개발, 의료 규정 준수 보장, 다양한 환자 집단 및 설정에서 성능을 검증하기 위한 광범위한 실제 임상 시험 수행이 포함될 것이다. 이 기술이 작업량을 늘리지 않고 임상의를 어떻게 원활하게 지원할 수 있을까?
- 설명 가능성 및 신뢰: 모델이 높은 성능을 보여주더라도, 의료 전문가들 사이에서 신뢰를 구축하기 위해서는 왜 특정 진단 결정을 내리는지 이해하는 것이 중요하다. 향후 연구는 AI의 설명 가능성을 향상시키는 데 초점을 맞출 수 있으며, 아마도 진단에 가장 많이 기여하는 특정 이미지 영역 또는 특징을 강조하여 임상의에게 실행 가능한 통찰력을 제공할 수 있다.
- 개인 맞춤형 치료 권장 사항: 진단을 넘어, SCALPVISION은 식별된 질환, 심각도 및 심지어 개별 환자 특성에 기반한 개인 맞춤형 치료 계획을 제안하도록 발전할 수 있다. 이를 위해서는 의료 지식 기반 및 잠재적으로 환자별 데이터 통합이 필요하다.
- 데이터 개인 정보 보호 및 윤리적 고려 사항: 민감한 의료 데이터를 처리하는 모든 AI 시스템과 마찬가지로, 데이터 개인 정보 보호, 보안 및 윤리적 배포에 대한 엄격한 주의가 필수적이다. 생성 모델이 잠재적으로 합성 환자 데이터를 생성할 수 있는 상황에서 이러한 강력한 진단 도구의 책임감 있는 사용을 어떻게 보장할 수 있을까?
- 고급 생성 아키텍처 탐색: DiffuseIT-M은 매우 효과적이지만, 생성 AI 분야는 빠르게 발전하고 있다. 최신 확산 모델, GAN 또는 기타 생성 아키텍처를 조사하면 이미지 충실도, 다양성 및 제어 기능이 더욱 향상되어 잠재적으로 더욱 강력한 데이터 증강 전략으로 이어질 수 있다.
이러한 논의는 SCALPVISION이 진단 도구일 뿐만 아니라, 한계가 해결되고 기능이 신중하게 확장된다면 피부과 치료를 변화시킬 엄청난 잠재력을 가진 기본 프레임워크임을 강조한다.
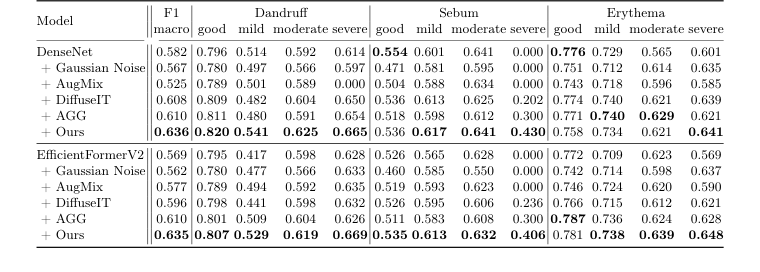 Table 3. Performance of scalp condition classification with various augmentation methods, denoted after “+” symbol, on the test set. The second column displays the overall macro-F1 score, while the columns from the third onward show the F1 scores for each severity level of the three diseases
Table 3. Performance of scalp condition classification with various augmentation methods, denoted after “+” symbol, on the test set. The second column displays the overall macro-F1 score, while the columns from the third onward show the F1 scores for each severity level of the three diseases
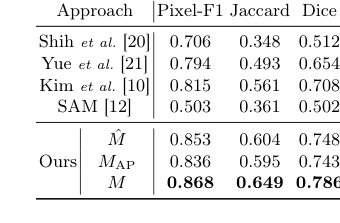 Table 1. Performance of hair segmenta- tion on the test set
Table 1. Performance of hair segmenta- tion on the test set
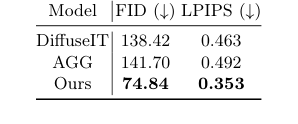 Table 2. Quantitative analysis of image- to-image translation
Table 2. Quantitative analysis of image- to-image translation