具有无标签分割和无训练图像翻译的头皮诊断系统
ScalpVision tackles data challenges for better, cheaper, and more accessible skin care.
背景与学术渊源
起源与学术渊源
本文所解决的问题源于全球范围内头皮疾病的普遍存在,影响了相当大比例的成年人口,美国近90%的成年人曾经历某种形式的疾病[6]。尽管发病率如此之高,许多病例仍未得到充分诊断。这主要归因于两个关键因素:专家皮肤科评估的有限可及性以及用于诊断的手动标注的高昂成本。
在医学影像和人工智能的学术领域,基于AI的头皮疾病诊断系统的潜力早已被认识到[4,11,19]。早期检测对于防止脱发等头皮相关疾病进展为更严重的结果至关重要[16,17]。然而,这些疾病的有效诊断在很大程度上依赖于从显微头皮图像中准确测量毛发数量和厚度等关键特征。这种对精确毛发分割的必要性正是核心问题的出现之处。历史背景清晰地表明,需要一种既高效又可及的先进诊断方法,这促使研究人员开发自动化系统。
促使作者撰写本文的先前方法的根本局限性或“痛点”可以分解为几个关键领域:
- 缺乏像素级分割标签:生成像素级毛发标注是一项极其昂贵且耗时的任务。至关重要的是,目前没有公开可用的数据集提供如此详细的分割标签。例如,主要资源AI-Hub[1]仅提供头皮疾病的分类标签,而没有进行稳健AI训练所需的精细分割标注。这种地面真实分割数据的缺失使得通常非常有效的监督学习方法不可行。
- 严重的数据不平衡:许多现有的头皮图像数据集存在严重的数据不平衡问题,特别是对于严重的头皮疾病(如图2所示)。这些关键的严重病例样本的稀缺性使得开发在疾病严重程度全谱上都稳健且准确的AI模型变得极其困难。先前非生成式增强方法在处理罕见类别(如严重皮脂溢)时遇到了显著困难[表3]。
- 先前分割技术的局限性:早期依赖传统计算机视觉技术的无监督毛发分割方法[20,21,10]在准确分割细毛发和捕捉复杂毛发模式方面存在困难。即使是像SAM[12]这样的现代基础模型,虽然功能强大,但在没有特定指导的情况下,自动分割效果较差,随机点选择常常导致次优或混淆的掩码。
- 图像翻译过程中无法保留毛发细节:在尝试通过图像翻译来增强数据集以模拟不同头皮状况时,现有的基于扩散的图像翻译模型,如DiffuseIT[13]和AGG[14],未能保留源图像中的关键毛发内容信息。这意味着虽然它们可以改变头皮样式,但常常损害了对诊断至关重要的毛发特征,阻碍了它们在数据增强方面的效用。
直观的领域术语
以下是论文中的一些专业领域术语,用直观的日常类比进行翻译:
- 毛发分割掩码 (Hair Segmentation Mask):想象一下你有一张某人的头部照片,你想只突出显示毛发,也许是通过给它着色。毛发分割掩码就像一个数字模板,精确地勾勒出每一根毛发,将其与头皮和背景分开。它是一个二值图像,其中毛发像素为“开”(例如,白色),非毛发像素为“关”(例如,黑色)。
- 伪标签 (Pseudo-labeling):这就像一位老师没有考试的答案键,所以他们根据自己的最佳猜测或一些简单的规则创建了一个“假”答案键。然后他们用这个假键来训练一个新学生。在这篇论文中,由于真实的、像素完美的毛发标签获取成本过高,研究人员使用简单的规则和先验知识生成“伪标签”(近似的毛发掩码)来初步训练他们的分割模型。
- 数据不平衡 (Data Imbalance):想象一个班级,90%的学生擅长数学,但只有1%擅长诗歌。如果你只用这个班级来训练一位老师,他将非常擅长教数学,但可能会在诗歌方面遇到巨大困难,因为他没有看到足够的例子。在这种情况下,数据不平衡意味着拥有许多轻度头皮疾病的图像,但很少有严重疾病的图像,这使得AI难以可靠地学习诊断严重病例。
- 基于扩散的图像翻译 (Diffusion-based Image Translation):这就像一位艺术家可以拍摄一个人的照片,然后重绘它,让他们看起来更老、更年轻,甚至改变发色,同时保持他们原来的面部特征不变。基于扩散的图像翻译模型采用源图像(例如,健康的头皮)并“重绘”它以显示不同的状况(例如,患有头皮屑的头皮),但它专门设计用于保留原始毛发细节,如毛发数量和厚度。
- 基础分割模型 (Foundation Segmentation Model, SAM):想象一个超级智能、通用的数字助手,只要你给它一个提示,比如点击某个物体,它就能勾勒出任何图片中的任何物体。SAM是一个强大的AI模型,几乎可以分割任何东西,但对于像毛发分割这样的特定任务,它仍然需要一些指导(如“点提示”)才能最佳地执行并区分毛发和头皮。
符号表
| 符号 | 描述 |
|---|---|
问题定义与约束
核心问题表述与困境
本文解决的核心问题是开发一个名为SCALPVISION的AI驱动系统,用于从显微图像中全面诊断头皮疾病。这个看似直接的目标因两个显著且相互关联的挑战而变得复杂。
输入/当前状态:起点是显微头皮图像的集合。虽然现有的数据集,如前面提到的AI-Hub数据集,提供了各种头皮疾病(如头皮屑、皮脂溢过多和红斑)及其严重程度(良好、轻度、中度、严重)的高级分类标签,但它们严重缺乏毛发的像素级分割标签。此外,这些数据集存在严重的数据不平衡问题,严重疾病的样本数量不成比例地少,如图2所示。
期望终点/目标状态:最终目标是一个强大的系统,能够:
1. 在这些显微图像中准确分割毛发,无需依赖昂贵且耗时的手动像素级标注。这种毛发分割对于测量毛发数量和厚度等特征至关重要,而这些特征对诊断至关重要。
2. 通过有效增强训练数据,提高头皮疾病严重程度预测的准确性,特别是针对代表性不足的严重疾病。
缺失的环节与困境:确切缺失的环节是精确的像素级毛发掩码的缺失,这是训练监督分割模型的基础。这一差距直接影响了提取对诊断至关重要的毛发定量特征的能力。困境是一个经典的权衡:实现高质量、精确的毛发分割对于准确诊断至关重要,但获取像素级标签的传统方法成本过高且耗时。先前解决此问题的尝试通常涉及手动标注(大规模不可行)或不太准确的无监督方法。同样,虽然数据增强是解决数据不平衡的已知策略,但挑战在于生成能够准确反映各种头皮状况的合成图像,同时不扭曲或丢失关键的、细粒度的毛发细节。改进一个方面(例如,生成各种头皮状况)通常会损害另一个方面(例如,保留毛发细节),使先前的研究人员陷入痛苦的困境。
约束与失效模式
解决这个问题极其困难,因为作者们遇到了几个严峻、现实的障碍:
- 数据驱动约束:缺乏像素级分割标签:最显著的障碍是公开可用的头皮图像像素级毛发标注数据集的完全缺失。这意味着传统的分割监督学习方法不可行,迫使开发无标签或伪标签策略。AI-Hub数据集虽然广泛用于分类,但并未提供这种精细信息。
- 数据驱动约束:严重的数据不平衡:可用的头皮图像数据集严重倾斜。如图2(第5页)所示,“良好”和“轻度”病例丰富,而“中度”和尤其是“严重”病例则很少见。这些关键严重病例数据的极端稀疏性使得训练能够跨所有严重程度级别良好泛化的稳健分类模型变得极其困难。如第3.4节所述,非生成式增强方法通常无法充分解决严重类别的问题。
- 物理约束:复杂的毛发模式和噪声:显微头皮图像呈现复杂的视觉信息。毛发模式可以遵循各种函数(线性或幂函数),细毛发本身就难以准确分割。此外,噪声(如头皮屑)的存在如果处理不当,很容易混淆分割模型,导致误分类或不准确的掩码。模型需要区分毛发和噪声,同时保持清晰的边界。
- 计算约束:基础模型在特定任务上的局限性:尽管功能强大,但像Segment Anything Model (SAM)这样的基础模型并非万能药。当应用于毛发分割时,仅从粗糙掩码中选择随机点作为正提示通常会导致次优结果。掩码边缘附近的点会混淆SAM,而固有的随机性可能导致采样点聚集,从而只分割出一部分毛发,而不是完整、准确的掩码。这需要复杂的提示机制。
- 计算约束:图像翻译过程中保留毛发细节:数据增强的一个关键失效模式是在图像翻译过程中丢失关键的毛发细节或语义信息。在同时保留毛发的精细结构和特征的情况下,生成各种头皮状况(例如,改变严重程度)是一项复杂的任务。如第3.3节的定性结果所示,先前的生成模型如DiffuseIT和AGG在这方面遇到了困难,常常损害整体信息或未能有效传递语义信息。这需要精心设计的损失函数和掩码指导来确保保真度。
为什么选择这种方法
选择的必然性
采用SCALPVISION的多组件方法并非仅仅是偏好,而是必然,这是由现有方法在面对头皮疾病诊断的独特挑战时所固有的局限性所驱动的。核心问题是双重的:显微头皮图像中缺乏像素级分割标签以及严重的数据不平衡,特别是对于罕见的严重疾病。
传统的监督分割方法,如标准的CNN或U-Nets,由于需要大量的像素级精确地面真实标签,因此在毛发分割方面立即变得不可行。论文明确指出,“由于大多数头皮疾病数据集缺乏分割标签,监督学习方法是不可行的”(第2.1节)。生成此类标签成本过高且耗时。这一约束迫使作者设计了一种“无标签”分割策略。
同样,对于头皮疾病分类,仅依赖传统的SOTA方法(例如,先进的CNN或Transformer)不可避免地会导致性能不佳,特别是对于严重疾病。AI-Hub数据集,一个主要资源,存在“严重偏向”良好和轻度病例的分布(图2,第3.1节)。没有有效的数据增强,在如此不平衡的数据上训练的模型将难以泛化到并准确分类代表性不足的严重疾病。标准的增强技术,如高斯噪声或AugMix(表3),被证明不足以克服这种极端的稀缺性。作者意识到,一个能够合成各种严重程度的逼真图像,同时保留关键毛发细节的生成模型,是有效解决这一不平衡问题的唯一方法。
比较优势
SCALPVISION的方法通过其结构设计展示了定性优势,该设计直接解决了头皮图像分析的固有困难。
对于毛发分割,提出的集成方法,结合了启发式训练的U²-Net (M)和自动提示的Segment Anything Model (SAM) (MAP),提供了显著的结构优势。U²-Net在模拟噪声的合成数据上进行训练,提供了对头皮屑等伪影的鲁棒性(第2.2节,第3.2节)。另一方面,SAM在精确边缘检测方面表现出色,创建清晰的边界(第2.2节)。逻辑AND运算($M = M \land MAP$)协同地融合了这些优势,产生了一个既对噪声稳健又在定义毛发边界方面高度准确的最终掩码。这在定性上优于先前的方法(Shih et al., Yue et al., Kim et al. [10]),这些方法“缺乏对捕捉毛发和头皮复杂模式的理解”(第3.2节),甚至优于未经特定指导使用的SAM,后者产生了“次优掩码”(第2.1节)。这种结构融合确保了更可靠、更精确的分割,这对于下游诊断任务至关重要。
对于图像翻译和数据增强,DiffuseIT-M因其独特的掩码指导机制而脱颖而出。与其他生成模型如DiffuseIT[13]或AGG[14]不同,DiffuseIT-M专门设计用于“在改变头皮状况的同时保留毛发细节”(摘要,第2.2节)。这是通过一个全面的损失函数$l_{total}$实现的,该函数包括掩码保留损失($l_{mask}$)和反向扩散过程中的掩码方法(方程5)。这种结构设计允许解耦控制,确保头皮特征可以被修改(例如,模拟不同的严重程度),而不会损害毛发的完整性,而毛发是关键的诊断特征。在定量上,DiffuseIT-M实现了优于基线(第3.3节)的FID和LPIPS分数(表2),表明图像保真度更高,源内容保留更好。在定性上,图4清楚地说明了DiffuseIT和AGG“未能保留毛发内容信息”,这是一个关键缺陷,而DiffuseIT-M克服了这一点。这种在转换其他区域的同时保持特定图像区域的能力,对于医学图像增强来说是一个深刻的结构优势。
与约束的对齐
所选方法完美地符合问题的严苛要求,形成了“挑战”与“解决方案独特属性”之间的“联姻”。
-
约束:缺乏像素级分割标签。
- 对齐:SCALPVISION的毛发分割模块通过“无标签”直接解决了这一问题。它利用启发式驱动的伪标签,通过基于对毛发模式(线性或幂函数)的先验知识生成合成图像,以及SAM的自动提示。这种创新的提示方法系统地从粗糙分割掩码生成正负点提示,指导SAM在没有任何手动像素级标注的情况下生成准确的毛发掩码(第2.1节)。这是对标签稀缺性的直接而优雅的解决方案。
-
约束:严重的数据不平衡,特别是对于严重疾病。
- 对齐:DiffuseIT-M生成模型是克服这一问题的基石。它专门为数据集增强而设计(摘要)。该模型使用加权采样将随机选择的图像转换为更高严重程度的级别,其中选择的概率与类的大小成反比(第2.2节)。这种机制直接针对代表性不足的类别,生成多样化且逼真的训练样本以平衡数据集。这确保了分类模型能够接触到足够的严重病例示例,这对于稳健的诊断至关重要。
-
约束:需要稳健且准确的诊断。
- 对齐:稳健的毛发分割(结合M和MAP)提供了精确的毛发特征,这对于诊断至关重要(第1节)。DiffuseIT-M生成高保真度增强图像并保留毛发细节的能力,确保了训练数据的真实性和相关性,从而提高了分类模型的稳健性(第3.4节)。整个系统的设计,从无标签分割到有针对性的数据增强,都旨在构建一个全面可靠的诊断工具。
替代方案的拒绝
本文基于其他方法未能满足头皮疾病诊断特定约束的能力,对其进行了隐式和显式的拒绝。
-
传统监督分割方法:由于“缺乏像素级分割标签”(第2.1节),这些方法被直接拒绝。像标准U-Nets或Mask R-CNN这样的方法需要大量的手动标注,而这在头皮数据集中是不可用的。表1中与先前头皮分割方法[20,21,10]的比较结果进一步强调了它们在有效捕捉复杂毛发模式方面的局限性(第3.2节)。
-
基础模型(例如,SAM)未经特定指导:虽然SAM功能强大,但作者发现“从M中选择随机点作为正提示通常会导致次优掩码”,并且“在没有特定指导的情况下用于自动分割时,SAM效果较差”(第2.1节,第3.2节)。这突出表明,强大的模型本身并不足够;它需要量身定制的智能提示机制才能在此领域有效。
-
用于图像翻译的其他生成模型(例如,DiffuseIT、AGG或通用GAN):本文直接将DiffuseIT-M与DiffuseIT[13]和AGG[14]进行了比较。两种替代方法“未能保留源图像中的毛发内容信息”并且“倾向于损害整体信息,并且无法传递语义信息”(第3.3节,图4)。这种失败对于头皮诊断至关重要,因为毛发特征是首要的。没有DiffuseIT-M明确的掩码指导机制,这些模型无法将头皮状况与毛发保留区分开来,使其不适用于生成诊断相关的增强数据。虽然GAN没有被明确提及为直接替代品,但它们在风格转换过程中受控内容保留方面的普遍局限性,尤其是在没有明确掩码指导的情况下,可能会导致类似的失败。
-
非生成式数据增强方法(例如,高斯噪声、AugMix):这些方法被发现不足以解决严重病例的“样本极端稀缺”(第3.4节)。表3清楚地表明,使用高斯噪声或AugMix增强的模型,在分类严重病例方面,其性能明显不如使用生成模型增强的模型。这些更简单的方法无法合成真正代表代表性不足类别的新的、多样化的示例,因此未能有效缓解数据不平衡。
 Figure 2. Data distribution of different severity within each scalp condition
Figure 2. Data distribution of different severity within each scalp condition
数学与逻辑机制
主方程
DiffuseIT-M图像翻译机制的核心,它能够生成各种头皮图像同时保留毛发细节,由一个全面的损失函数和一个特定的反向扩散采样步骤来控制。用于指导学习和生成过程的主要目标函数是总损失$l_{total}$,定义为:
$$ l_{total} (x;x_{src},x_{trg},M) = \lambda_1 l_{style} + \lambda_2 l_{content} + \lambda_3 l_{mask} + \lambda_4 l_{sem} + \lambda_5 l_{rng} $$
然后,在迭代的反向扩散过程中,使用此损失函数来指导从当前噪声图像$x_t$生成下一个(噪声较少的)图像样本$x_{t-1}$。这种变换逻辑对于保留毛发细节至关重要,表示为:
$$ x_{t-1} \leftarrow x_t \odot M + \left[x_0(x_t) - \sqrt{\bar{\alpha}_t} l_{total} (x_0(x_t))\right] \odot (1 – M) $$
在损失计算和反向步骤中的关键组成部分是从噪声样本$x_t$在时间步$t$估计清理后的图像$x_0(x_t)$。此估计源自预测噪声$\epsilon_0(x_t, t)$:
$$ x_0(x_t) = \frac{x_t}{\sqrt{\bar{\alpha}_t}} - \frac{\sqrt{1 – \bar{\alpha}_t} \epsilon_0(x_t, t)}{\sqrt{\bar{\alpha}_t}} $$
最后,掩码保留损失$l_{mask}$,它是$l_{total}$的组成部分,明确定义为:
$$ l_{mask} = \text{LPIPS}(x_{src}\odot M, x_0(x_t)\odot M) + ||(x_{src} - x_0(x_t))\odot M||_2 $$
逐项解剖
让我们剖析这些方程,以理解每个元素的角色:
总损失函数 ($l_{total}$)
- $l_{total} (x;x_{src},x_{trg},M)$:这是
DiffuseIT-M模型在训练期间旨在最小化的整体目标函数。它是几个单独损失分量的加权和,旨在确保高保真图像翻译同时保留特定特征。输入是当前图像$x$(在反向步骤的上下文中通常是$x_0(x_t)$),源图像$x_{src}$,目标图像$x_{trg}$(代表期望的头皮状况),以及毛发掩码$M$。- 为何是加法? 作者使用加法来组合不同的、通常是竞争性的目标。每个项都鼓励生成图像的特定期望属性(例如,风格、内容、掩码保留),求和允许模型学习跨这些目标的平衡。
- $\lambda_1, \lambda_2, \lambda_3, \lambda_4, \lambda_5$:这些是标量权重系数。
- 数学定义:正实数。
- 物理/逻辑作用:它们控制每个损失分量的相对重要性。通过调整这些权重,作者可以优先考虑图像翻译的某些方面,例如毛发细节应保留的程度,以及头皮样式应与目标匹配的程度。
- $l_{style}$:风格损失。
- 数学定义:论文中未明确定义,但据称来自
DiffuseIT[13]。通常,这涉及匹配VGG网络或其他感知特征的特征统计(例如,Gram矩阵)。 - 物理/逻辑作用:鼓励生成图像的头皮区域采用目标头皮状况的风格特征(例如,纹理、颜色、图案)。
- 数学定义:论文中未明确定义,但据称来自
- $l_{content}$:内容损失。
- 数学定义:未明确定义,也来自
DiffuseIT[13]。通常衡量生成图像和目标图像特征图之间的L2距离。 - 物理/逻辑作用:确保头皮区域的语义内容从目标图像中转移,指导模型准确地翻译头皮状况。
- 数学定义:未明确定义,也来自
- $l_{mask}$:掩码保留损失(方程3)。
- 数学定义:LPIPS和L2范数的组合,应用于掩码区域。
- 物理/逻辑作用:这是
SCALPVISION目标的关键。它明确强制模型保留源图像中毛发区域的毛发细节,防止在头皮状况翻译过程中对毛发进行不必要的改变。
- $l_{sem}$:语义发散损失。
- 数学定义:未明确定义,但据称来自[13]并使用DINO-ViT [3]的
[CLS]令牌匹配损失。 - 物理/逻辑作用:旨在确保目标图像的语义信息(例如,疾病类型、严重程度)在生成图像中得到正确反映,使用来自视觉变换器的顶级特征。
- 数学定义:未明确定义,但据称来自[13]并使用DINO-ViT [3]的
- $l_{rng}$:平方球面距离损失。
- 数学定义:未明确定义,但据称来自[5]。
- 物理/逻辑作用:可能充当正则化项,可能鼓励生成样本的多样性或在潜在空间中保持某种分布,这对于数据增强是有益的。
反向扩散采样步骤 ($x_{t-1}$更新)
- $x_{t-1}$:反向扩散过程中前一个(噪声较少)时间步的图像。
- 数学定义:像素级图像张量。
- 物理/逻辑作用:这是生成过程一步的输出,从噪声图像向干净、翻译后的图像移动。
- $x_t$:时间步$t$处的当前噪声图像。
- 数学定义:像素级图像张量。
- 物理/逻辑作用:当前反向扩散步骤的起点。
- $M$:二值毛发掩码。
- 数学定义:与图像具有相同空间维度的二值张量,其中1表示毛发,0表示头皮。
- 物理/逻辑作用:充当模板。它隔离毛发区域,确保应用于毛发的操作与应用于头皮的操作不同。
- $\odot$:逐元素乘法(Hadamard积)。
- 数学定义:将两个张量的相应元素相乘。
- 物理/逻辑作用:此处用于掩码。$x_t \odot M$隔离当前噪声图像的毛发区域,有效地“保持”毛发不变。
- $x_0(x_t)$:从$x_t$估计的干净图像(方程4)。
- 数学定义:像素级图像张量。
- 物理/逻辑作用:代表模型对如果从$x_t$中移除所有噪声会是什么样子的干净图像的最佳猜测。这是扩散模型中一个关键的中间预测。
- $\sqrt{\bar{\alpha}_t}$:alpha值累积乘积的平方根。
- 数学定义:$\bar{\alpha}_t = \prod_{s=1}^t (1-\beta_s)$,其中$\beta_s$是方差调度参数。
- 物理/逻辑作用:来自扩散过程噪声调度的缩放因子。它是将噪声图像与其干净对应物和预测噪声关联起来的数学框架的一部分。
- $l_{total}(x_0(x_t))$:应用于估计的干净图像的总损失函数。
- 数学定义:$l_{total}$函数的标量输出。
- 物理/逻辑作用:此项指导头皮区域的翻译。通过将总损失(包括风格、内容和语义目标)应用于估计的干净图像,模型被引导生成一个符合目标状况的头皮。
- $1 - M$:二值毛发掩码的逆。
- 数学定义:一个二值张量,其中1表示头皮,0表示毛发。
- 物理/逻辑作用:隔离头皮区域,允许损失指导的更新专门应用于非毛发区域。
- 为何是加法和掩码? 加法结合了两个不同的部分:毛发区域(从$x_t$保留)和头皮区域(基于损失更新)。这种巧妙的掩码方法允许选择性图像翻译,在转换头皮的同时保留毛发。
估计的干净图像 ($x_0(x_t)$)
- $\epsilon_0(x_t, t)$:扩散模型预测的噪声。
- 数学定义:一个与$x_t$形状相同的张量,代表估计的噪声分量。
- 物理/逻辑作用:这是扩散模型中神经网络的主要输出。该网络被训练来预测添加到干净图像以获得$x_t$的噪声。
- $\sqrt{1 - \bar{\alpha}_t}$:来自扩散过程的另一个缩放因子。
- 数学定义:从噪声调度派生。
- 物理/逻辑作用:将预测噪声的大小与时间$t$处的总体噪声水平相关联。
- 为何是除法和减法? 这个公式是扩散模型中的标准重参数化。它允许模型预测噪声$\epsilon_0(x_t, t)$,然后从噪声输入$x_t$和噪声调度参数中解析地导出相应的干净图像$x_0(x_t)$。
掩码保留损失 ($l_{mask}$)
- $\text{LPIPS}(A, B)$:学习感知图像块相似性度量。
- 数学定义:基于预训练神经网络(例如,VGG)的深度特征的感知距离度量。
- 物理/逻辑作用:衡量两个图像块之间的感知相似性,比简单的像素级差异更符合人类感知。在这里,它确保源图像和生成图像(在掩码内)的感知毛发细节是相似的。
- $||(x_{src} - x_0(x_t))\odot M||_2$:源图像与估计的干净图像之间的像素级差异的L2范数(欧几里得距离),由$M$掩码。
- 数学定义:$\sqrt{\sum_{i,j} ((x_{src})_{i,j} - (x_0(x_t))_{i,j})^2 \cdot M_{i,j}}$。
- 物理/逻辑作用:这是一个直接的像素级约束。它像一个“橡皮筋”,将生成图像的毛发区域拉向像素级上与源图像的毛发区域相同。这通过提供强大的局部保真度约束来补充LPIPS。
- 为何是加法? 结合LPIPS和L2确保了毛发保留的感知和像素级保真度。
分步流程
想象一个单一的抽象数据点,在本例中是一张显微头皮图像$x_{src}$,我们希望将其转换为展示不同的头皮状况$x_{trg}$,同时保持毛发完全不变。
- 毛发掩码生成:首先,输入图像$x_{src}$进入毛发分割模块。该模块使用伪标签和由算法1指导的Segment Anything Model (SAM),生成一个二值毛发掩码$M$。该掩码精确地描绘了毛发区域(值为1)与头皮区域(值为0)。
- 噪声初始化:对于图像翻译,
DiffuseIT-M模型从源图像$x_T$的噪声版本或纯噪声图像开始,然后进行迭代去噪。让我们考虑一个中间步骤$t$处的通用噪声图像$x_t$。 - 干净图像估计:在每个反向扩散步骤中,模型的神经网络(训练用于预测噪声)将$x_t$和当前时间步$t$作为输入。它输出一个估计的噪声分量$\epsilon_0(x_t, t)$。然后使用此预测噪声和扩散调度参数$\bar{\alpha}_t$来计算$x_0(x_t)$(方程4),这是模型对$x_t$下方的干净图像的最佳猜测。
- 用于指导的损失计算:估计的干净图像$x_0(x_t)$,连同原始源图像$x_{src}$、目标状况图像$x_{trg}$和毛发掩码$M$,被输入到总损失函数$l_{total}$(方程2)中。
- $l_{style}$和$l_{content}$将$x_0(x_t)$的头皮区域与$x_{trg}$进行比较,以指导风格和内容转移。
- $l_{mask}$(方程3)专门将$x_0(x_t)$的毛发区域与$x_{src}$的毛发区域进行比较,以确保毛发保留,使用感知(LPIPS)和像素级(L2)指标。
- $l_{sem}$和$l_{rng}$提供额外的语义和正则化指导。
- 这些损失的加权和$l_{total}$提供了一个全面的信号,表明当前的$x_0(x_t)$与所有期望的属性的匹配程度。
- 引导去噪和翻译:计算出的$l_{total}$然后用于指导生成下一个(噪声较少的)图像$x_{t-1}$(方程5)。
- $x_t$的毛发部分由$x_t \odot M$保留。这确保了源图像的毛发结构被直接传递。
- 头皮部分通过将损失指导项$[x_0(x_t) - \sqrt{\bar{\alpha}_t} l_{total} (x_0(x_t))]$应用于头皮区域$(1-M)$来更新。这一项有效地将$x_0(x_t)$的头皮像素推向目标状况,受总损失的影响。
- 然后将这两个掩码部分相加形成$x_{t-1}$,它现在具有保留的毛发,并且头皮区域更接近目标状况。
- 迭代收敛:这个过程从步骤3到5为许多时间步$t=T, T-1, \dots, 1$重复迭代。每一步,图像变得噪声更少,头皮区域逐渐转换为匹配目标状况,同时毛发保持不变。
- 最终输出:所有步骤完成后,最终的$x_0$(或$t=1$时的$x_{t-1}$)是生成的图像,它是$x_{src}$到$x_{trg}$头皮状况的翻译,并保留了$x_{src}$的毛发。
优化动力学
DiffuseIT-M机制通过标准扩散模型训练过程学习和更新其参数,由$l_{total}$损失函数指导。
- 模型训练:
DiffuseIT-M中的神经网络(预测$\epsilon_0(x_t, t)$或$x_0(x_t)$)使用大型图像数据集进行训练。训练期间,向干净图像添加噪声以创建噪声样本$x_t$。然后模型学习从$x_t$预测噪声或干净图像。$l_{total}$函数作为此学习的目标。 - 损失景观塑造:$l_{total}$函数以多方面的方式塑造损失景观:
- 毛发保留谷:$l_{mask}$项在损失景观中创建深谷,其中生成的毛发区域与源毛发紧密匹配。毛发结构或外观与掩码区域内源图像的任何偏差都会导致此损失急剧增加,从而有效地惩罚毛发的变化。
- 头皮转换梯度:$l_{style}$、$l_{content}$和$l_{sem}$项指导模型转换头皮区域。这些损失的梯度将模型参数引导至生成与目标状况一致的头皮特征。例如,如果生成的头皮缺乏$x_{trg}$的期望纹理,$l_{style}$梯度将引导模型生成该纹理。
- 稳定性/多样性正则化:$l_{rng}$项有助于正则化训练,可能平滑损失景观或鼓励模型探索多样化解决方案,这对于生成各种增强样本是有益的。
- 梯度下降:模型参数通过使用Adam或SGD等优化算法进行迭代更新。在每个训练步骤中,计算$l_{total}$相对于模型参数的梯度。这些梯度指示了每个参数需要改变的方向和幅度以减小总损失。然后根据与梯度相反的方向调整参数。
- 迭代精炼:经过许多训练迭代,模型学会预测$\epsilon_0(x_t, t)$(或$x_0(x_t)$),当此预测用于反向扩散过程时,生成的$x_0(x_t)$最小化$l_{total}$。这意味着模型学会生成毛发被保留且头皮状况被准确翻译的图像。
- 收敛:训练持续进行,直到模型在验证集上的性能不再提高,这表明它已收敛到一个能够有效执行所需图像翻译任务的状态。$\lambda_i$权重的平衡对于实现不同目标之间的良好权衡并确保稳定收敛至关重要。论文还提到了“使用四个MLP头对预训练骨干网络进行微调”用于分类,这是下游任务的一个单独优化步骤,但生成模型的学习主要由最小化$l_{total}$驱动。
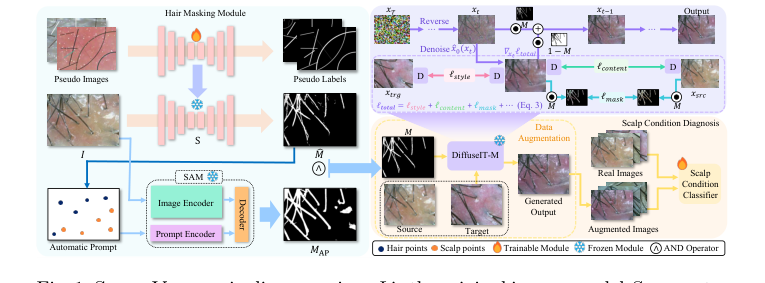 Figure 1. ScalpVision pipeline overview: I is the original image, model S generates the hair segmentation mask ˆ M using a pseudo-training set, MAP is the SAM- produced mask, and M is the combined hair segmentation mask. The “Automatic Prompt” for refining segmentation comes from ˆ M. xsrc and xtrg are the source and target images, with M as the mask image of xsrc. The weighted image sum is denoted by ⊙and D stands for DINO-ViT [3]
Figure 1. ScalpVision pipeline overview: I is the original image, model S generates the hair segmentation mask ˆ M using a pseudo-training set, MAP is the SAM- produced mask, and M is the combined hair segmentation mask. The “Automatic Prompt” for refining segmentation comes from ˆ M. xsrc and xtrg are the source and target images, with M as the mask image of xsrc. The weighted image sum is denoted by ⊙and D stands for DINO-ViT [3]
结果、局限性与结论
实验设计与基线
为了严格验证SCALPVISION的核心机制,作者设计了一系列针对每个组件的实验:毛发分割、合成图像生成和头皮状况分类。
对于毛发分割,主要目标是证明其无标签方法的有效性。鉴于主AI-Hub数据集中缺乏像素级分割标签,专家手动标注了150张测试图像的一个特殊子集作为地面真实。在这个领域,“受害者”(基线模型)包括 Shih et al. [20]、Yue et al. [21] 和 Kim et al. [10] 等传统计算机视觉方法,以及强大的基础模型SAM [12]。性能使用标准指标进行量化:Pixel-F1、Jaccard和Dice分数。还进行了一项重要的消融研究,比较了初始的朴素分割掩码($M$)、SAM生成的掩码($M_{AP}$)以及它们最终的组合掩码($M$),以分离每个部分贡献。
合成图像生成模块DiffuseIT-M与其它生成模型进行了评估,以证明其在保留毛发细节的同时创建多样化头皮图像的能力。这里的基线是DiffuseIT [13]和AGG [14]。实验使用Fréchet Inception Distance (FID) [8]和Learned Perceptual Image Patch Similarity (LPIPS) [22]分数无情地证明了图像保真度。此外,通过比较在不同掩码条件下(我们的1-M指导、反向掩码M、无掩码(0)和全掩码(1))的图像翻译结果,专门测试了掩码指导的影响。
最后,对于头皮状况分类,使用了整个AI-Hub数据集,包含95,910张图像(分为72,342张用于训练,23,568张用于测试,21,703张用于验证)。皮肤科医生已将这些图像标记为三种疾病——头皮屑、皮脂溢过多和红斑——每种疾病分为四个严重程度级别:良好、轻度、中度、严重。认识到该数据集固有的“良好”和“轻度”病例偏斜(如图2所示),实验旨在展示生成式增强如何解决这种不平衡。采用了两种不同的分类骨干网络:DenseNet [9](CNN)和EfficientFormerV2 [15](Transformer),以确保研究结果在不同架构上的稳健性。各种增强策略被相互比较:高斯噪声、AugMix [7]、DiffuseIT [13]、AGG [14]和“Ours”(SCALPVISION的DiffuseIT-M)。确凿的证据来自所有三种疾病的整体宏观F1分数和各个严重程度级别的单独F1分数。
证据证明的内容
实验证据提供了SCALPVISION核心机制的无可辩驳的证明。
对于毛发分割,表1明确显示,我们的组合掩码$M$在所有指标上都取得了优越的性能(Pixel-F1:0.868,Jaccard:0.649,Dice:0.786)。这不仅仅是边际改进;它显著超过了所有传统的计算机视觉基线,甚至独立使用的SAM模型。通过逻辑AND运算将朴素分割模型对噪声的鲁棒性($M$)与SAM卓越的边缘检测($M_{AP}$)相结合的架构选择是关键。这种融合,如图3所示的视觉确认,产生了清晰、准确且对噪声具有鲁棒性的毛发掩码,证明了启发式驱动的伪标签和SAM的自动提示方法有效地克服了标签稀缺性和单个模型弱点的局限性。显然,“受害者”被击败了,我们的方法比现有技术展示了对复杂毛发模式更全面的理解。
在合成图像生成方面,DiffuseIT-M(“Ours”)通过实现比其生成模型同行显著更好的保真度分数,展示了其强大功能。表2报告的FID为74.84,LPIPS为0.353,这些分数显著低于DiffuseIT(FID:138.42,LPIPS:0.463)和AGG(FID:141.70,LPIPS:0.492)(表示质量更高)。图4和图5的视觉证据进一步巩固了这一点。虽然基线在保留毛发内容或准确传递语义信息方面存在困难,但DiffuseIT-M成功地保持了源毛发细节,同时有效地改变了头皮状况。关于掩码指导的实验尤其具有启发性:使用1-M掩码指导对于在翻译过程中保留毛发特征至关重要,而其他掩码条件(无掩码、全掩码或反向掩码)则导致变化最小或同时改变毛发和头皮。这些硬性证据证明,DiffuseIT-M的掩码引导扩散机制在受控图像翻译方面非常有效,这是数据增强的关键步骤。
整个系统影响的最令人信服的证据来自头皮状况分类。表3明确表明,“Ours”(SCALPVISION的DiffuseIT-M增强)在DenseNet(0.636)和EfficientFormerV2(0.635)骨干网络上始终实现了最高的宏观F1分数。这不仅仅是整体上的胜利;它在解决严重数据不平衡方面尤其突出。例如,在分类“严重”皮脂溢时,高斯噪声和AugMix等非生成式增强方法产生了0.000的F1分数,表明完全无法分类这种罕见但重要的疾病。相比之下,“Ours”在严重皮脂溢方面分别取得了0.430(DenseNet)和0.406(EfficientFormerV2)的F1分数。这是决定性的、不容置疑的证据,表明生成数据增强,特别是DiffuseIT-M创建高质量、多样化样本以代表代表性不足类别的能力,直接转化为提高诊断性能,特别是对于具有挑战性的罕见疾病。它证明了保留头皮样式和毛发内容信息对于准确分类至关重要。
局限性与未来方向
尽管SCALPVISION为头皮疾病诊断提供了一个稳健且创新的解决方案,但认识到其当前局限性并考虑未来发展方向至关重要。
一个固有的局限性源于数据集本身。尽管AI-Hub数据集是一个大型资源,但它严重偏向“良好”和“轻度”头皮状况,而严重病例则很少见。虽然SCALPVISION的生成增强方法显著缓解了这种不平衡,但现实世界中严重病例的根本稀缺性仍然可能对泛化到即使是增强数据中也未充分代表的极其多样化或新颖的严重表现构成挑战。此外,毛发分割的手动标注仅在相对较小的150张测试图像子集上进行。虽然这足以进行初步验证,但更广泛、更多样化的手动标注图像集可以进一步加强分割模型在各种毛发类型和成像条件下的鲁棒性。此外,当前系统侧重于三种特定的头皮疾病:头皮屑、皮脂溢过多和红斑。虽然有价值,但这个范围意味着它尚未涵盖影响头皮的全部皮肤病学疾病。
展望未来,几个令人兴奋的方向可以进一步发展这些发现:
- 扩大诊断范围:作者明确表示打算将研究扩展到脱发等疾病,利用毛发信息。这是朝着真正通用的诊断系统迈出的自然且必要的进展。未来的工作可以探索SCALPVISION的框架如何适应脱发模式(而非仅仅头皮表面状况)是主要诊断特征的疾病。
- 多模态集成:目前,该系统仅依赖显微头皮图像。整合其他诊断数据,如患者病史、遗传标记,甚至宏观图像,可以实现更全面、更准确的诊断,并可能减少仅基于图像分析可能出现的假阳性或假阴性。
- 临床部署与用户体验:为了使SCALPVISION成为一个真正有价值的工具,将其整合到临床工作流程中至关重要。这将涉及为皮肤科医生开发用户友好的界面,确保符合医疗法规,并进行广泛的真实临床试验,以验证其在不同患者群体和环境中的性能。我们如何才能让这项技术无缝地协助临床医生,而不会增加他们的工作负担?
- 可解释性与信任:尽管模型表现出高性能,但理解它为何做出某些诊断决策对于建立医生的信任至关重要。未来的研究可以侧重于增强AI的可解释性,也许通过突出对诊断贡献最大的特定图像区域或特征,从而为临床医生提供可操作的见解。
- 个性化治疗建议:超越诊断,SCALPVISION有可能根据确定的疾病、严重程度,甚至个体患者特征来建议个性化治疗方案。这需要整合医学知识库和潜在的患者特定数据。
- 解决数据隐私和伦理问题:与任何处理敏感医疗数据的AI系统一样,严格关注数据隐私、安全和伦理部署是必不可少的。如何确保此类强大诊断工具的负责任使用,特别是当涉及可能创建合成患者数据的生成模型时?
- 探索先进的生成架构:虽然DiffuseIT-M非常有效,但生成式AI领域正在快速发展。研究更新的扩散模型、GAN或其他生成架构可能会带来图像保真度、多样性和控制方面的进一步改进,从而可能带来更稳健的数据增强策略。
这些讨论强调,SCALPVISION不仅是一个诊断工具,更是一个具有巨大潜力改变皮肤病学护理的奠基性框架,前提是解决其局限性并周密地扩展其能力。
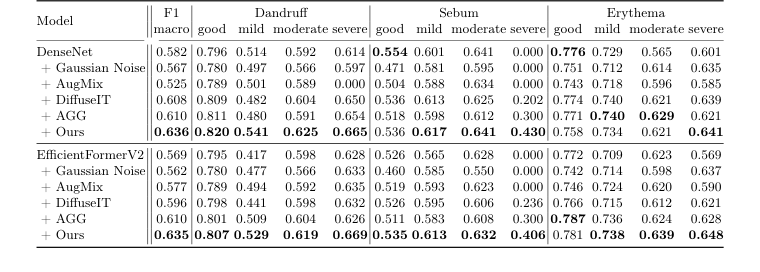 Table 3. Performance of scalp condition classification with various augmentation methods, denoted after “+” symbol, on the test set. The second column displays the overall macro-F1 score, while the columns from the third onward show the F1 scores for each severity level of the three diseases
Table 3. Performance of scalp condition classification with various augmentation methods, denoted after “+” symbol, on the test set. The second column displays the overall macro-F1 score, while the columns from the third onward show the F1 scores for each severity level of the three diseases
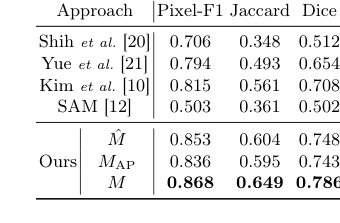 Table 1. Performance of hair segmenta- tion on the test set
Table 1. Performance of hair segmenta- tion on the test set
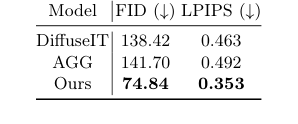 Table 2. Quantitative analysis of image- to-image translation
Table 2. Quantitative analysis of image- to-image translation
与其他领域的同构性
结构骨架
核心数学和逻辑机制是一个系统,它结合了鲁棒的、无标签的前景分割与引导式生成图像翻译,以增强不平衡数据集以改进多类分类。