Система диагностики кожи головы с сегментацией без меток и трансляцией изображений без обучения
Проблема, рассматриваемая в данной статье, проистекает из повсеместного распространения заболеваний кожи головы во всем мире, затрагивающих значительную часть взрослого населения: около 90% взрослых в США страдают от...
Предыстория и академическая родословная
Происхождение и академическая родословная
Проблема, рассматриваемая в данной статье, проистекает из повсеместного распространения заболеваний кожи головы во всем мире, затрагивающих значительную часть взрослого населения: около 90% взрослых в США страдают от той или иной формы заболевания [6]. Несмотря на такую высокую распространенность, многие случаи остаются недиагностированными. Это в первую очередь связано с двумя критическими факторами: ограниченным доступом к экспертной дерматологической оценке и высокой стоимостью ручной аннотации для диагностических целей.
В академической области медицинской визуализации и искусственного интеллекта обещания диагностических систем на основе ИИ для заболеваний кожи головы признаются уже некоторое время [4, 11, 19]. Раннее выявление имеет решающее значение для предотвращения прогрессирования заболеваний, связанных с кожей головы, таких как алопеция, до более серьезных последствий [16, 17]. Однако эффективная диагностика этих расстройств в значительной степени зависит от точного измерения критических признаков, таких как количество и толщина волос, по микроскопическим изображениям кожи головы. Эта необходимость точной сегментации волос является источником основной проблемы. Исторический контекст показывает явную потребность в передовых диагностических подходах, которые были бы одновременно эффективными и доступными, побуждая исследователей к разработке автоматизированных систем.
Фундаментальное ограничение, или "болевая точка", предыдущих подходов, которое побудило авторов написать эту статью, можно разбить на несколько ключевых областей:
- Отсутствие меток сегментации на уровне пикселей: Создание аннотаций волос на уровне пикселей является чрезвычайно дорогостоящим и трудоемким занятием. Важно отметить, что общедоступных наборов данных, предоставляющих такие детальные метки сегментации, не существует. Например, основной ресурс, AI-Hub [1], предлагает только метки классификации для состояний кожи головы, а не детальные аннотации сегментации, необходимые для надежного обучения ИИ. Отсутствие данных сегментации с истинным положением дел делает методы обучения с учителем, которые обычно очень эффективны, невозможными.
- Сильный дисбаланс данных: Многие существующие наборы данных изображений кожи головы страдают от значительного дисбаланса данных, особенно в отношении тяжелых состояний кожи головы (как показано на рис. 2). Эта нехватка образцов для критических, тяжелых случаев делает чрезвычайно сложной разработку моделей ИИ, которые были бы надежными и точными во всем спектре тяжести заболевания. Предыдущие негенеративные методы аугментации значительно страдали от редких классов, таких как тяжелый себум [Таблица 3].
- Ограничения предыдущих методов сегментации: Более ранние методы сегментации волос без учителя, часто опирающиеся на традиционные методы компьютерного зрения [20, 21, 10], испытывали трудности с точной сегментацией тонких волос и улавливанием сложных узоров волос. Даже современные фундаментальные модели, такие как SAM [12], хотя и мощные, были менее эффективны для автоматической сегментации без специального руководства, а случайный выбор точек часто приводил к субоптимальным или запутанным маскам.
- Неспособность сохранить детали волос при трансляции изображений: При попытке аугментировать наборы данных путем трансляции изображений для имитации различных состояний кожи головы, существующие диффузионные модели трансляции изображений, такие как DiffuseIT [13] и AGG [14], не смогли сохранить существенную информацию о содержании волос из исходного изображения. Это означало, что, хотя они могли изменять стили кожи головы, они часто компрометировали сами волосяные признаки, критически важные для диагностики, что снижало их полезность для аугментации данных.
Интуитивные термины предметной области
Вот несколько специализированных терминов предметной области из статьи, переведенных в интуитивные, повседневные аналогии:
- Маска сегментации волос: Представьте, что у вас есть фотография головы человека, и вы хотите выделить только волосы, возможно, раскрасив их. Маска сегментации волос — это как цифровая трафарет, который точно очерчивает каждую прядь волос, отделяя ее от кожи головы и фона. Это бинарное изображение, где пиксели волос "включены" (например, белые), а пиксели не волос — "выключены" (например, черные).
- Псевдо-маркировка (Pseudo-labeling): Представьте себе учителя, у которого нет ключа с ответами к тесту, поэтому он создает "фальшивый" ключ с ответами, основываясь на своих лучших предположениях или некоторых простых правилах. Затем он использует этот фальшивый ключ для обучения нового ученика. В этой статье, поскольку получение реальных, идеально пиксельных меток волос слишком дорого, исследователи генерируют "псевдо-метки" (приблизительные маски волос), используя простые правила и предварительные знания для первоначального обучения своей модели сегментации.
- Дисбаланс данных: Представьте класс, где 90% учеников хорошо разбираются в математике, но только 1% — в поэзии. Если вы будете обучать учителя только на этом классе, он станет отличным преподавателем математики, но может ужасно справляться с поэзией, потому что не видел достаточно примеров. Дисбаланс данных в этом контексте означает наличие множества изображений легких состояний кожи головы, но очень мало — тяжелых, что затрудняет надежную диагностику тяжелых случаев для ИИ.
- Диффузионная трансляция изображений: Это похоже на художника, который может взять фотографию человека и перерисовать ее, чтобы он выглядел старше, моложе или даже изменил цвет волос, сохраняя при этом его оригинальные черты лица. Диффузионная модель трансляции изображений берет исходное изображение (например, здоровую кожу головы) и "перерисовывает" его, чтобы показать другое состояние (например, кожу головы, пораженную перхотью), но она специально разработана для сохранения оригинальных деталей волос, таких как количество и толщина волос.
- Фундаментальная модель сегментации (SAM): Представьте себе супер-умного, универсального цифрового помощника, который может очертить любой объект на любой картинке, если вы просто дадите ему подсказку, например, щелкнув по объекту. SAM — это мощная модель ИИ, которая может сегментировать почти все, но для конкретных задач, таких как сегментация волос, ей все еще требуется некоторое руководство (например, "точечные подсказки"), чтобы работать оптимально и отличать волосы от кожи головы.
Таблица обозначений
| Обозначение | Описание |
|---|---|
Определение проблемы и ограничения
Формулировка основной проблемы и дилемма
Основная проблема, которую решает данная статья, заключается в разработке системы на основе ИИ, SCALPVISION, для комплексной диагностики заболеваний кожи головы по микроскопическим изображениям. Эта, казалось бы, простая цель осложняется двумя значительными, взаимосвязанными проблемами.
Входные данные/Текущее состояние: Отправной точкой является коллекция микроскопических изображений кожи головы. Хотя существующие наборы данных, такие как упомянутый AI-Hub, предоставляют высокоуровневые метки классификации для различных состояний кожи головы (например, перхоть, избыток себума и эритема) и их тяжести (хорошее, легкое, умеренное, тяжелое), они критически не имеют меток сегментации волос на уровне пикселей. Кроме того, эти наборы данных страдают от сильного дисбаланса данных, с непропорционально малым количеством образцов для тяжелых состояний, как показано на рисунке 2.
Желаемый конечный пункт/Целевое состояние: Конечная цель — надежная система, способная:
1. Точно сегментировать волосы на этих микроскопических изображениях без использования дорогостоящих и трудоемких ручных аннотаций на уровне пикселей. Эта сегментация волос имеет решающее значение для измерения таких признаков, как количество и толщина волос, которые жизненно важны для диагностики.
2. Повысить точность прогнозирования тяжести заболеваний кожи головы, особенно для недостаточно представленных тяжелых состояний, путем эффективной аугментации обучающих данных.
Утраченное звено и дилемма: Точным недостающим звеном является отсутствие точных масок волос на уровне пикселей, которые являются фундаментальными для обучения моделей сегментации с учителем. Этот пробел напрямую влияет на способность извлекать количественные признаки волос, которые необходимы для диагностики. Дилемма заключается в классическом компромиссе: достижение высококачественной, точной сегментации волос имеет первостепенное значение для точной диагностики, но традиционный метод получения меток на уровне пикселей является непомерно дорогим и трудоемким. Предыдущие попытки решить эту проблему часто включали либо ручную аннотацию (непрактичную в больших масштабах), либо менее точные методы без учителя. Аналогично, хотя аугментация данных является известной стратегией для решения проблемы дисбаланса данных, задача заключается в создании синтетических изображений, которые точно отражают различные состояния кожи головы без искажения или потери критически важных, детальных признаков волос. Улучшение одного аспекта (например, создание разнообразных состояний кожи головы) часто компрометирует другой (например, сохранение деталей волос), заставляя предыдущих исследователей попасть в болезненную дилемму.
Ограничения и режимы отказа
Решение этой проблемы чрезвычайно сложно из-за нескольких суровых, реалистичных стен, с которыми столкнулись авторы:
- Ограничение, обусловленное данными: Отсутствие меток сегментации на уровне пикселей: Самым значительным препятствием является полное отсутствие общедоступных наборов данных с аннотациями волос на уровне пикселей для изображений кожи головы. Это означает, что традиционные подходы к обучению с учителем для сегментации невозможны, что вынуждает к разработке стратегий без меток или псевдо-маркировки. Набор данных AI-Hub, хотя и обширен для классификации, не предоставляет этой детальной информации.
- Ограничение, обусловленное данными: Сильный дисбаланс данных: Доступные наборы данных изображений кожи головы сильно смещены. Как четко показано на рисунке 2 на странице 5, случаи "хорошего" и "легкого" состояния изобилуют, тогда как "умеренные" и особенно "тяжелые" состояния редки. Эта крайняя разреженность данных для критических тяжелых случаев делает чрезвычайно сложным обучение надежных моделей классификации, которые могут хорошо обобщаться на всех уровнях тяжести. Негенеративные методы аугментации часто не могут адекватно решить эту проблему для тяжелых классов, как отмечено в разделе 3.4.
- Физическое ограничение: Сложные узоры волос и шум: Микроскопические изображения кожи головы представляют собой сложную визуальную информацию. Узоры волос могут следовать различным функциям (линейным или степенным), и тонкие волосы inherently трудно сегментировать точно. Кроме того, наличие шума, такого как перхоть, может легко сбить с толку модели сегментации, если с ним не обращаться должным образом, что приведет к ошибочным классификациям или неточным маскам. Модель должна отличать волосы от шума, сохраняя при этом четкие границы.
- Вычислительное ограничение: Ограничения фундаментальных моделей для конкретных задач: Хотя мощные, фундаментальные модели, такие как Segment Anything Model (SAM), не являются панацеей. При применении к сегментации волос простое выбор случайных точек из грубой маски для положительных подсказок часто приводит к субоптимальным результатам. Точки на краях маски могут сбить с толку SAM, а присущая случайность может привести к тому, что выбранные точки сольются, что приведет к сегментации только ограниченного подмножества волос, а не полной, точной маски. Это требует сложного механизма подсказок.
- Вычислительное ограничение: Сохранение деталей волос при трансляции изображений: Критическим режимом отказа для аугментации данных является потеря существенных деталей волос или семантической информации в процессе трансляции изображений. Создание разнообразных состояний кожи головы (например, изменение тяжести) при одновременном сохранении сложной структуры и признаков волос является сложной задачей. Предыдущие генеративные модели, такие как DiffuseIT и AGG, испытывали трудности с этим, часто компрометируя общую информацию или не передавая семантическую информацию эффективно, как подчеркнуто в качественных результатах в разделе 3.3. Это требует тщательно разработанной функции потерь и масочного руководства для обеспечения точности.
Почему такой подход
Неизбежность выбора
Принятие многокомпонентного подхода SCALPVISION было не просто предпочтением, а необходимостью, обусловленной фундаментальными ограничениями существующих методов при столкновении с уникальными проблемами диагностики заболеваний кожи головы. Основная проблема была двоякой: отсутствие меток сегментации на уровне пикселей для волос на микроскопических изображениях кожи головы и сильный дисбаланс данных, особенно для редких, тяжелых состояний.
Традиционные методы сегментации с учителем, такие как стандартные CNN или U-Net, были немедленно признаны нежизнеспособными для сегментации волос, поскольку они требуют обширных, точных на уровне пикселей меток истинного положения дел. В статье прямо указано, что "поскольку большинство наборов данных о состояниях кожи головы не имеют меток сегментации, методы обучения с учителем невозможны" (Раздел 2.1). Создание таких меток является непомерно дорогим и трудоемким. Это ограничение вынудило авторов разработать стратегию сегментации "без меток".
Аналогично, для классификации состояний кожи головы, полагаясь исключительно на традиционные SOTA методы (например, передовые CNN или Трансформеры), неизбежно привело бы к плохой производительности, особенно для тяжелых состояний. Набор данных AI-Hub, основной ресурс, страдает от "сильно смещенного" распределения в сторону хороших и легких случаев (Рисунок 2, Раздел 3.1). Без эффективной аугментации данных модели, обученные на таких несбалансированных данных, испытывали бы трудности с обобщением и точной классификацией недостаточно представленных тяжелых состояний. Стандартные методы аугментации, такие как гауссовский шум или AugMix (Таблица 3), оказались недостаточными для преодоления этой крайней нехватки. Авторы осознали, что генеративная модель, способная синтезировать реалистичные изображения различной степени тяжести при сохранении критически важных деталей волос, была единственным способом эффективно устранить этот дисбаланс.
Сравнительное превосходство
SCALPVISION демонстрирует качественное превосходство благодаря своей структурной конструкции, которая напрямую решает присущие трудности анализа изображений кожи головы.
Для сегментации волос предлагаемый ансамблевый метод, сочетающий эвристически обученный U²-Net (M) с автоматически подсказываемым Segment Anything Model (SAM) (MAP), предлагает значительное структурное преимущество. U²-Net, обученный на синтетических данных с имитированным шумом, обеспечивает устойчивость к артефактам, таким как перхоть (Раздел 2.2, Раздел 3.2). SAM, с другой стороны, преуспевает в точной детекции краев, создавая четкие границы (Раздел 2.2). Логическая операция И ($M = M \land MAP$) синергетически объединяет эти сильные стороны, давая окончательную маску, которая является одновременно устойчивой к шуму и высокоточной в определении границ волос. Это качественно превосходит предыдущие методы (Shih et al., Yue et al., Kim et al. [10]), которые "не понимают, как улавливать сложные узоры волос и кожи головы" (Раздел 3.2), и даже SAM, используемый без специального руководства, который давал "субоптимальные маски" (Раздел 2.1). Это структурное слияние обеспечивает более надежную и точную сегментацию, критически важную для последующих диагностических задач.
Для трансляции изображений и аугментации данных DiffuseIT-M выделяется благодаря своему уникальному механизму масочного руководства. В отличие от других генеративных моделей, таких как DiffuseIT [13] или AGG [14], DiffuseIT-M специально разработан для "сохранения деталей волос при изменении состояний кожи головы" (Аннотация, Раздел 2.2). Это достигается с помощью комплексной функции потерь, $l_{total}$, которая включает потери на сохранение маски ($l_{mask}$) и масочный подход во время обратного диффузионного процесса (Уравнение 5). Эта структурная конструкция позволяет осуществлять раздельное управление, гарантируя, что признаки кожи головы могут быть изменены (например, для имитации различных степеней тяжести) без ущерба для целостности волос, что является критическим диагностическим признаком. Количественно DiffuseIT-M достигает превосходных показателей FID и LPIPS (Таблица 2), что указывает на более высокое качество изображения и лучшее сохранение исходного содержимого по сравнению с базовыми моделями (Раздел 3.3). Качественно, Рисунок 4 ясно иллюстрирует, что DiffuseIT и AGG "не смогли сохранить информацию о содержании волос", что является критическим недостатком, который преодолевает DiffuseIT-M. Эта способность сохранять определенные области изображения при преобразовании других является глубоким структурным преимуществом для аугментации медицинских изображений.
Соответствие ограничениям
Выбранная методология идеально соответствует суровым требованиям проблемы, образуя "брак" между вызовами и уникальными свойствами решения.
-
Ограничение: Отсутствие меток сегментации на уровне пикселей.
- Соответствие: Модуль сегментации волос SCALPVISION напрямую решает эту проблему, будучи "без меток". Он использует эвристически управляемую псевдо-маркировку, генерируя синтетические изображения на основе предварительных знаний о паттернах волос (линейные или степенные функции) и автоматическое подсказывание для SAM. Этот инновационный метод подсказок систематически генерирует положительные и отрицательные точечные подсказки из грубой маски сегментации, направляя SAM на получение точных масок волос без какой-либо ручной аннотации на уровне пикселей (Раздел 2.1). Это прямое и элегантное решение проблемы нехватки меток.
-
Ограничение: Сильный дисбаланс данных, особенно для тяжелых состояний.
- Соответствие: Генеративная модель DiffuseIT-M является краеугольным камнем для преодоления этого. Она специально разработана для аугментации набора данных (Аннотация). Модель транслирует случайно выбранные изображения в более высокие уровни тяжести, используя взвешенную выборку, где вероятность выбора обратно пропорциональна размеру класса (Раздел 2.2). Этот механизм напрямую нацелен на недостаточно представленные классы, генерируя разнообразные и реалистичные обучающие образцы для балансировки набора данных. Это гарантирует, что модель классификации будет иметь достаточно примеров тяжелых состояний, что критически важно для надежной диагностики.
-
Ограничение: Необходимость надежной и точной диагностики.
- Соответствие: Надежная сегментация волос (сочетание M и MAP) обеспечивает точные признаки волос, которые необходимы для диагностики (Раздел 1). Способность DiffuseIT-M генерировать аугментированные изображения высокой точности, сохраняющие детали волос, гарантирует, что обучающие данные являются реалистичными и релевантными, что приводит к более надежным моделям классификации (Раздел 3.4). Общая конструкция системы, от сегментации без меток до целевой аугментации данных, направлена на создание комплексного и надежного диагностического инструмента.
Отклонение альтернатив
Статья неявно и явно отклоняет несколько альтернативных подходов на основе их неспособности соответствовать конкретным ограничениям диагностики заболеваний кожи головы.
-
Традиционные методы сегментации с учителем: Они были отклонены outright из-за "отсутствия меток сегментации на уровне пикселей" (Раздел 2.1). Методы, такие как стандартные U-Net или Mask R-CNN, требуют обширной ручной аннотации, которая недоступна для наборов данных кожи головы. Сравнительные результаты в Таблице 1 по сравнению с предыдущими подходами к сегментации кожи головы [20, 21, 10] далее подчеркивают их ограничения в эффективном улавливании сложных узоров волос (Раздел 3.2).
-
Фундаментальные модели (например, SAM) без специального руководства: Хотя SAM мощный, авторы обнаружили, что "выбор случайных точек из M для положительных подсказок часто приводил к субоптимальным маскам", и что SAM был "менее эффективен для автоматической сегментации при использовании без специального руководства" (Раздел 2.1, Раздел 3.2). Это подчеркивает, что одной мощной модели недостаточно; ей требуется индивидуальный, интеллектуальный механизм подсказок, чтобы быть эффективной в этой области.
-
Другие генеративные модели для трансляции изображений (например, DiffuseIT, AGG или общие GAN): Статья напрямую сравнивает DiffuseIT-M с DiffuseIT [13] и AGG [14]. Обе альтернативы "не смогли сохранить информацию о содержании волос из исходного изображения" и "имели тенденцию компрометировать общую информацию и не могли передать семантическую информацию" (Раздел 3.3, Рисунок 4). Этот отказ критически важен для диагностики кожи головы, где признаки волос имеют первостепенное значение. Без явного механизма масочного руководства DiffuseIT-M эти модели не могут отделить состояние кожи головы от сохранения волос, что делает их непригодными для создания диагностически релевантных аугментированных данных. Хотя GAN явно не упоминаются как прямая альтернатива, их общие ограничения в контролируемом сохранении содержимого при передаче стиля, особенно без явного масочного руководства, вероятно, приведут к аналогичным отказам.
-
Негенеративные методы аугментации данных (например, гауссовский шум, AugMix): Эти методы оказались недостаточными для решения "крайней нехватки образцов" для тяжелых состояний (Раздел 3.4). Таблица 3 четко показывает, что модели, аугментированные гауссовским шумом или AugMix, работают значительно хуже, чем модели, аугментированные генеративными моделями, особенно при классификации тяжелых случаев. Эти более простые методы не могут создавать новые, разнообразные примеры, которые действительно представляют недостаточно представленные классы, тем самым неэффективно смягчая дисбаланс данных.
 Figure 2. Data distribution of different severity within each scalp condition
Figure 2. Data distribution of different severity within each scalp condition
Математический и логический механизм
Мастер-уравнение
Ядром механизма трансляции изображений DiffuseIT-M, который позволяет генерировать разнообразные изображения кожи головы при сохранении деталей волос, является комплексная функция потерь и специфический шаг обратного диффузионного сэмплирования. Основная целевая функция, которая направляет процесс обучения и генерации, — это общие потери, $l_{total}$, определяемые как:
$$ l_{total} (x;x_{src},x_{trg},M) = \lambda_1 l_{style} + \lambda_2 l_{content} + \lambda_3 l_{mask} + \lambda_4 l_{sem} + \lambda_5 l_{rng} $$
Эта функция потерь затем используется в итеративном процессе обратной диффузии для управления генерацией следующего, менее зашумленного образца изображения, $x_{t-1}$, из текущего зашумленного изображения $x_t$. Эта логика преобразования, критически важная для сохранения деталей волос, задается как:
$$ x_{t-1} \leftarrow x_t \odot M + \left[x_0(x_t) - \sqrt{\bar{\alpha}_t} l_{total} (x_0(x_t))\right] \odot (1 – M) $$
Критическим компонентом как в расчете потерь, так и в обратном шаге является оценка очищенного изображения, $x_0(x_t)$, из зашумленного образца $x_t$ на временном шаге $t$. Эта оценка получается из предсказанного шума $\epsilon_0(x_t, t)$:
$$ x_0(x_t) = \frac{x_t}{\sqrt{\bar{\alpha}_t}} - \frac{\sqrt{1 – \bar{\alpha}_t} \epsilon_0(x_t, t)}{\sqrt{\bar{\alpha}_t}} $$
Наконец, потери на сохранение маски, $l_{mask}$, которая является компонентом $l_{total}$, явно определяются как:
$$ l_{mask} = \text{LPIPS}(x_{src}\odot M, x_0(x_t)\odot M) + ||(x_{src} - x_0(x_t))\odot M||_2 $$
Поэлементный разбор
Давайте разберем эти уравнения, чтобы понять роль каждого элемента:
Общая функция потерь ($l_{total}$)
- $l_{total} (x;x_{src},x_{trg},M)$: Это общая целевая функция, которую модель
DiffuseIT-Mстремится минимизировать во время обучения. Это взвешенная сумма нескольких отдельных компонентов потерь, разработанная для обеспечения высокоточного преобразования изображений при сохранении специфических признаков. Входными данными являются текущее изображение $x$ (которое обычно является $x_0(x_t)$ в контексте обратного шага), исходное изображение $x_{src}$, целевое изображение $x_{trg}$ (представляющее желаемое состояние кожи головы) и маска волос $M$.- Почему сложение? Авторы используют сложение для объединения различных, часто конкурирующих, целей. Каждый член поощряет определенное желаемое свойство в сгенерированном изображении (например, стиль, содержимое, сохранение маски), а их суммирование позволяет модели научиться балансу между этими целями.
- $\lambda_1, \lambda_2, \lambda_3, \lambda_4, \lambda_5$: Это скалярные коэффициенты взвешивания.
- Математическое определение: Положительные действительные числа.
- Физическая/логическая роль: Они контролируют относительную важность каждого компонента потерь. Регулируя эти веса, авторы могут отдавать приоритет определенным аспектам преобразования изображения, например, насколько сильно должны сохраняться детали волос по сравнению с тем, насколько точно стиль кожи головы должен соответствовать целевому.
- $l_{style}$: Потери на стиль.
- Математическое определение: Явно не определено в статье, но указано, что оно взято из
DiffuseIT[13]. Обычно это включает соответствие статистик признаков (например, матриц Грамма) из сетей VGG или аналогичных перцептивных признаков. - Физическая/логическая роль: Поощряет область кожи головы сгенерированного изображения принимать стилистические характеристики (например, текстуру, цвет, узоры) целевого состояния кожи головы.
- Математическое определение: Явно не определено в статье, но указано, что оно взято из
- $l_{content}$: Потери на содержимое.
- Математическое определение: Явно не определено, также из
DiffuseIT[13]. Часто измеряет L2-расстояние между картами признаков сгенерированного и целевого изображений. - Физическая/логическая роль: Гарантирует, что семантическое содержимое высокого уровня области кожи головы передается из целевого изображения, направляя модель на точное преобразование состояния кожи головы.
- Математическое определение: Явно не определено, также из
- $l_{mask}$: Потери на сохранение маски (Уравнение 3).
- Математическое определение: Комбинация LPIPS и L2-нормы, примененная к маскированным областям.
- Физическая/логическая роль: Это критически важно для цели
SCALPVISION. Он явно заставляет модель сохранять детали волос из исходного изображения в маскированных областях волос, предотвращая нежелательные изменения волос во время преобразования состояния кожи головы.
- $l_{sem}$: Потери на семантическое расхождение.
- Математическое определение: Явно не определено, но указано, что оно взято из [13] и использует потери на соответствие токена
[CLS]из DINO-ViT [3]. - Физическая/логическая роль: Направлено на обеспечение того, чтобы семантическая информация (например, тип заболевания, тяжесть) целевого изображения правильно отражалась в сгенерированном изображении, используя высокоуровневые признаки из vision transformer.
- Математическое определение: Явно не определено, но указано, что оно взято из [13] и использует потери на соответствие токена
- $l_{rng}$: Потери на квадратное сферическое расстояние.
- Математическое определение: Явно не определено, но указано, что оно взято из [5].
- Физическая/логическая роль: Вероятно, действует как регуляризационный член, возможно, поощряя разнообразие в сгенерированных образцах или поддерживая определенное распределение в латентном пространстве, что полезно для аугментации данных.
Шаг обратного диффузионного сэмплирования ($x_{t-1}$ обновление)
- $x_{t-1}$: Изображение на предыдущем (менее зашумленном) временном шаге в процессе обратной диффузии.
- Математическое определение: Тензор изображения попиксельно.
- Физическая/логическая роль: Это выход одного шага генеративного процесса, переход от зашумленного изображения к чистому, преобразованному изображению.
- $x_t$: Текущее зашумленное изображение на временном шаге $t$.
- Математическое определение: Тензор изображения попиксельно.
- Физическая/логическая роль: Отправная точка для текущего шага обратной диффузии.
- $M$: Бинарная маска волос.
- Математическое определение: Бинарный тензор того же пространственного размера, что и изображение, где 1 указывает на волосы, а 0 — на кожу головы.
- Физическая/логическая роль: Действует как трафарет. Он изолирует области волос, гарантируя, что операции, применяемые к волосам, отличаются от операций, применяемых к коже головы.
- $\odot$: Поэлементное умножение (произведение Адамара).
- Математическое определение: Умножает соответствующие элементы двух тензоров.
- Физическая/логическая роль: Используется здесь для маскирования. $x_t \odot M$ изолирует область волос текущего зашумленного изображения, эффективно "сохраняя" волосы как есть.
- $x_0(x_t)$: Оцененное чистое изображение из $x_t$ (Уравнение 4).
- Математическое определение: Тензор изображения попиксельно.
- Физическая/логическая роль: Представляет собой наилучшее предположение модели о том, как будет выглядеть чистое изображение, если бы весь шум был удален из $x_t$. Это критически важное промежуточное предсказание в диффузионных моделях.
- $\sqrt{\bar{\alpha}_t}$: Квадратный корень из кумулятивного произведения альфа-значений.
- Математическое определение: $\bar{\alpha}_t = \prod_{s=1}^t (1-\beta_s)$, где $\beta_s$ — параметры графика дисперсии.
- Физическая/логическая роль: Масштабирующий коэффициент, полученный из графика шума диффузионного процесса. Это часть математической структуры, связывающей зашумленные изображения с их чистыми аналогами и предсказанным шумом.
- $l_{total}(x_0(x_t))$: Общие потери, примененные к оцененному чистому изображению.
- Математическое определение: Скалярный выход функции $l_{total}$.
- Физическая/логическая роль: Этот член направляет преобразование области кожи головы. Применяя общие потери (которые включают цели стиля, содержимого и семантики) к оцененному чистому изображению, модель подталкивается к генерации кожи головы, соответствующей целевому состоянию.
- $1 - M$: Инверсия бинарной маски волос.
- Математическое определение: Бинарный тензор, где 1 указывает на кожу головы, а 0 — на волосы.
- Физическая/логическая роль: Изолирует область кожи головы, позволяя применять обновление, управляемое потерями, специально к областям, не являющимся волосами.
- Почему сложение и маскирование? Сложение объединяет две отдельные части: область волос (сохраненную из $x_t$) и область кожи головы (обновленную на основе потерь). Этот умный подход маскирования позволяет выборочно преобразовывать изображения, сохраняя волосы при трансформации кожи головы.
Оцененное чистое изображение ($x_0(x_t)$)
- $\epsilon_0(x_t, t)$: Шум, предсказанный диффузионной моделью.
- Математическое определение: Тензор той же формы, что и $x_t$, представляющий оцененный компонент шума.
- Физическая/логическая роль: Это основной выход нейронной сети в диффузионной модели. Сеть обучена предсказывать шум, который был добавлен к чистому изображению, чтобы получить $x_t$.
- $\sqrt{1 - \bar{\alpha}_t}$: Еще один масштабирующий коэффициент из диффузионного процесса.
- Математическое определение: Получено из графика шума.
- Физическая/логическая роль: Связывает величину предсказанного шума с общим уровнем шума на временном шаге $t$.
- Почему деление и вычитание? Эта формула является стандартной репараметризацией в диффузионных моделях. Она позволяет модели предсказывать шум $\epsilon_0(x_t, t)$ и затем аналитически выводить соответствующее чистое изображение $x_0(x_t)$ из зашумленного входного сигнала $x_t$ и параметров графика шума.
Потери на сохранение маски ($l_{mask}$)
- $\text{LPIPS}(A, B)$: Метрика перцептивного сходства изображений на основе патчей (Learned Perceptual Image Patch Similarity).
- Математическое определение: Метрика перцептивного расстояния, основанная на глубоких признаках из предварительно обученной нейронной сети (например, VGG).
- Физическая/логическая роль: Измеряет перцептивное сходство между двумя патчами изображений, что лучше соответствует человеческому восприятию, чем простые попиксельные различия. Здесь он гарантирует, что воспринимаемые детали волос в исходном и сгенерированном изображениях (в пределах маски) схожи.
- $||(x_{src} - x_0(x_t))\odot M||_2$: L2-норма (евклидово расстояние) попиксельной разницы между исходным изображением и оцененным чистым изображением, маскированная $M$.
- Математическое определение: $\sqrt{\sum_{i,j} ((x_{src})_{i,j} - (x_0(x_t))_{i,j})^2 \cdot M_{i,j}}$.
- Физическая/логическая роль: Это прямое ограничение на уровне пикселей. Оно действует как "резиновая лента", притягивая область волос сгенерированного изображения к области волос исходного изображения попиксельно. Это дополняет LPIPS, предоставляя сильное ограничение локальной точности.
- Почему сложение? Объединение LPIPS и L2 гарантирует как перцептивную, так и попиксельную точность сохранения волос.
Пошаговый поток
Представьте себе один абстрактный набор данных, который в данном случае является микроскопическим изображением кожи головы, $x_{src}$, которое мы хотим преобразовать, чтобы оно демонстрировало другое состояние кожи головы, $x_{trg}$, сохраняя при этом волосы точно такими же, какими они были.
- Генерация маски волос: Сначала входное изображение $x_{src}$ поступает в модуль сегментации волос. Этот модуль, используя псевдо-маркировку и Segment Anything Model (SAM), управляемый Алгоритмом 1, генерирует бинарную маску волос, $M$. Эта маска точно очерчивает области волос (значение 1) от областей кожи головы (значение 0).
- Инициализация шумом: Для трансляции изображений модель
DiffuseIT-Mначинает с зашумленной версии исходного изображения, $x_T$, или изображения с чистым шумом, которое затем итеративно шумоподавляется. Рассмотрим общий зашумленный образ $x_t$ на промежуточном шаге $t$. - Оценка чистого изображения: На каждом шаге обратной диффузии нейронная сеть модели (обученная предсказывать шум) принимает $x_t$ и текущий временной шаг $t$ в качестве входных данных. Она выдает оцененный компонент шума, $\epsilon_0(x_t, t)$. Этот предсказанный шум затем используется с параметром графика диффузии $\bar{\alpha}_t$ для вычисления $x_0(x_t)$ (Уравнение 4), наилучшего предположения модели о чистом изображении, лежащем в основе $x_t$.
- Расчет потерь для руководства: Оцененное чистое изображение $x_0(x_t)$, вместе с исходным изображением $x_{src}$, изображением целевого состояния $x_{trg}$ и маской волос $M$, подаются в общую функцию потерь, $l_{total}$ (Уравнение 2).
- $l_{style}$ и $l_{content}$ сравнивают область кожи головы $x_0(x_t)$ с $x_{trg}$ для управления передачей стиля и содержимого.
- $l_{mask}$ (Уравнение 3) специально сравнивает область волос $x_0(x_t)$ с областью волос $x_{src}$ для обеспечения сохранения волос, используя как перцептивные (LPIPS), так и попиксельные (L2) метрики.
- $l_{sem}$ и $l_{rng}$ предоставляют дополнительное семантическое руководство и регуляризацию.
- Взвешенная сумма этих потерь, $l_{total}$, предоставляет комплексный сигнал, указывающий, насколько текущий $x_0(x_t)$ соответствует всем желаемым свойствам.
- Управляемое шумоподавление и трансляция: Этот рассчитанный $l_{total}$ затем используется для управления генерацией следующего, менее зашумленного изображения, $x_{t-1}$ (Уравнение 5).
- Часть волос $x_t$ сохраняется с помощью $x_t \odot M$. Это гарантирует, что структура волос из исходного изображения переносится напрямую.
- Часть кожи головы обновляется путем применения члена, управляемого потерями, $[x_0(x_t) - \sqrt{\bar{\alpha}_t} l_{total} (x_0(x_t))]$ к области кожи головы, $(1-M)$. Этот член фактически подталкивает пиксели кожи головы $x_0(x_t)$ к целевому состоянию, под влиянием общих потерь.
- Эти две маскированные части затем складываются, образуя $x_{t-1}$, который теперь имеет сохраненные волосы и кожу головы, которая на шаг ближе к целевому состоянию.
- Итерация до сходимости: Этот процесс от шага 3 до 5 повторяется итеративно для многих временных шагов, $t=T, T-1, \dots, 1$. С каждым шагом изображение становится менее зашумленным, а область кожи головы постепенно трансформируется, чтобы соответствовать целевому состоянию, в то время как волосы остаются неизменными.
- Окончательный результат: После всех шагов окончательный $x_0$ (или $x_{t-1}$ при $t=1$) является сгенерированным изображением, которое является трансляцией $x_{src}$ в состояние кожи головы $x_{trg}$ с сохраненными волосами $x_{src}$.
Динамика оптимизации
Механизм DiffuseIT-M обучается и обновляет свои параметры посредством стандартного процесса обучения для диффузионных моделей, управляемого функцией потерь $l_{total}$.
- Обучение модели: Нейронная сеть, лежащая в основе
DiffuseIT-M(которая предсказывает $\epsilon_0(x_t, t)$ или $x_0(x_t)$), обучается с использованием большого набора данных изображений. Во время обучения к чистым изображениям добавляется шум для создания зашумленных образцов $x_t$. Затем модель учится предсказывать шум или чистое изображение из $x_t$. Функция $l_{total}$ действует как цель этого обучения. - Формирование ландшафта потерь: Функция $l_{total}$ формирует ландшафт потерь многогранно:
- Долины сохранения волос: Член $l_{mask}$ создает глубокие долины в ландшафте потерь, где сгенерированные области волос тесно соответствуют исходным волосам. Любое отклонение в структуре или внешнем виде волос от исходного изображения в маскированной области приведет к резкому увеличению этих потерь, эффективно наказывая изменения волос.
- Градиенты трансформации кожи головы: Члены $l_{style}$, $l_{content}$ и $l_{sem}$ направляют модель к преобразованию области кожи головы. Градиенты от этих потерь подталкивают параметры модели к генерации признаков кожи головы, которые соответствуют целевому состоянию. Например, если сгенерированная кожа головы не имеет желаемой текстуры из $x_{trg}$, градиент $l_{style}$ направит модель к генерации этой текстуры.
- Регуляризация для стабильности/разнообразия: Член $l_{rng}$ помогает регулировать обучение, потенциально сглаживая ландшафт потерь или поощряя модель исследовать разнообразные решения, что полезно для генерации разнообразных образцов аугментации.
- Градиентный спуск: Параметры модели итеративно обновляются с использованием алгоритма оптимизации, такого как Adam или SGD. На каждом шаге обучения вычисляются градиенты $l_{total}$ по отношению к параметрам модели. Эти градиенты указывают направление и величину изменения, необходимого для каждого параметра, чтобы уменьшить общие потери. Затем параметры корректируются в направлении, противоположном градиенту.
- Итеративное уточнение: В течение многих итераций обучения модель учится предсказывать $\epsilon_0(x_t, t)$ (или $x_0(x_t)$) таким образом, чтобы при использовании этого предсказания в процессе обратной диффузии полученный $x_0(x_t)$ минимизировал $l_{total}$. Это означает, что модель учится генерировать изображения, где волосы сохраняются, а состояния кожи головы точно преобразуются.
- Сходимость: Обучение продолжается до тех пор, пока производительность модели на наборе валидации больше не улучшается, что указывает на то, что она сошлась к состоянию, где она может эффективно выполнять желаемые задачи преобразования изображений. Баланс весов $\lambda_i$ имеет решающее значение для достижения хорошего компромисса между различными целями и обеспечения стабильной сходимости. В статье также упоминается "дообучение предварительно обученного бэкбона с четырьмя MLP-головами" для классификации, что является отдельным шагом оптимизации для последующей задачи, но обучение генеративной модели в основном управляется минимизацией $l_{total}$.
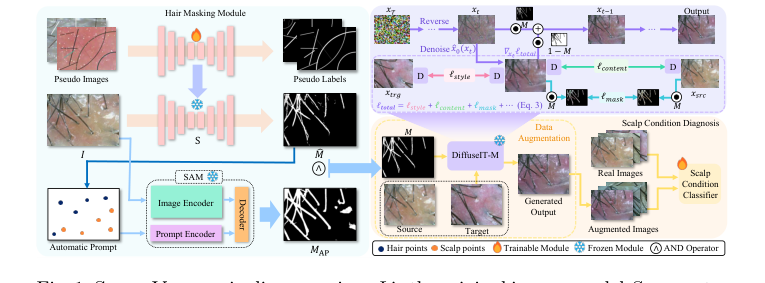 Figure 1. ScalpVision pipeline overview: I is the original image, model S generates the hair segmentation mask ˆ M using a pseudo-training set, MAP is the SAM- produced mask, and M is the combined hair segmentation mask. The “Automatic Prompt” for refining segmentation comes from ˆ M. xsrc and xtrg are the source and target images, with M as the mask image of xsrc. The weighted image sum is denoted by ⊙and D stands for DINO-ViT [3]
Figure 1. ScalpVision pipeline overview: I is the original image, model S generates the hair segmentation mask ˆ M using a pseudo-training set, MAP is the SAM- produced mask, and M is the combined hair segmentation mask. The “Automatic Prompt” for refining segmentation comes from ˆ M. xsrc and xtrg are the source and target images, with M as the mask image of xsrc. The weighted image sum is denoted by ⊙and D stands for DINO-ViT [3]
Результаты, ограничения и заключение
Экспериментальный дизайн и базовые модели
Для строгой проверки основных механизмов SCALPVISION авторы разработали серию экспериментов, нацеленных на каждый компонент: сегментация волос, генерация синтетических изображений и классификация состояний кожи головы.
Для сегментации волос основной целью было доказать эффективность их подхода без меток. Учитывая отсутствие меток сегментации на уровне пикселей в основном наборе данных AI-Hub, был вручную аннотирован специальный поднабор из 150 тестовых изображений экспертами для использования в качестве истинного положения дел. "Жертвами" (базовыми моделями) на этой арене были традиционные методы компьютерного зрения, такие как методы Shih et al. [20], Yue et al. [21] и Kim et al. [10], а также мощная фундаментальная модель SAM [12]. Производительность была количественно оценена с использованием стандартных метрик: Pixel-F1, Jaccard и Dice. Также было проведено важное исследование абляции, сравнивающее начальную наивную маску сегментации ($M$), маску, полученную SAM ($M_{AP}$), и их окончательную комбинированную маску ($M$), чтобы изолировать вклад каждой части.
Модуль генерации синтетических изображений, DiffuseIT-M, был оценен по сравнению с другими генеративными моделями, чтобы продемонстрировать его способность создавать разнообразные изображения кожи головы при сохранении деталей волос. Базовыми моделями здесь были DiffuseIT [13] и AGG [14]. Эксперименты безжалостно доказали точность изображений, используя метрики Fréchet Inception Distance (FID) [8] и Learned Perceptual Image Patch Similarity (LPIPS) [22]. Кроме того, влияние масочного руководства было специально протестировано путем сравнения результатов трансляции изображений при различных условиях маскирования: наше предлагаемое руководство 1-M, обратная маска M, отсутствие маски (0) и полная маска (1).
Наконец, для классификации состояний кожи головы использовался весь набор данных AI-Hub, состоящий из 95 910 изображений (разделенных на 72 342 для обучения, 23 568 для тестирования и 21 703 для валидации). Дерматологи маркировали эти изображения по трем состояниям — перхоть, избыток себума и эритема — каждое из которых было категоризировано по четырем уровням тяжести: хорошее, легкое, умеренное и тяжелое. Признавая присущий набору данных перекос в сторону "хороших" и "легких" случаев (как показано на рис. 2), эксперименты были направлены на демонстрацию того, как генеративная аугментация может решить эту проблему дисбаланса. Были противопоставлены две различные базовые модели классификации: DenseNet [9] (CNN) и EfficientFormerV2 [15] (Трансформер), чтобы обеспечить надежность выводов для различных архитектур. Различные стратегии аугментации были противопоставлены друг другу: гауссовский шум, AugMix [7], DiffuseIT [13], AGG [14] и "Наши" (DiffuseIT-M SCALPVISION). Окончательные доказательства искались в общем макро-F1-показателе и индивидуальных F1-показателях для каждого уровня тяжести по трем заболеваниям.
Что доказывают доказательства
Экспериментальные доказательства предоставляют неоспоримые доказательства основных механизмов SCALPVISION.
Для сегментации волос Таблица 1 однозначно показывает, что наша комбинированная маска $M$ достигла превосходной производительности по всем метрикам (Pixel-F1: 0.868, Jaccard: 0.649, Dice: 0.786). Это было не просто незначительное улучшение; оно значительно превзошло все традиционные базовые модели компьютерного зрения и даже автономную модель SAM. Архитектурный выбор объединения устойчивости начальной модели сегментации к шуму ($M$) с превосходным обнаружением краев SAM ($M_{AP}$) посредством операции логического И был ключом. Это слияние, как визуально подтверждено на Рисунке 3, дало четкие, точные и устойчивые к шуму маски волос, доказав, что эвристически управляемая псевдо-маркировка и метод автоматического подсказывания для SAM эффективно преодолели ограничения нехватки меток и слабостей отдельных моделей. "Жертвы" были явно побеждены, поскольку наш метод продемонстрировал более полное понимание сложных узоров волос, чем предыдущие работы.
В генерации синтетических изображений DiffuseIT-M ("Наши") продемонстрировал свое мастерство, достигнув значительно лучших показателей точности, чем его генеративные модели-аналоги. Таблица 2 сообщает FID 74.84 и LPIPS 0.353, что значительно ниже (указывает на более высокое качество), чем у DiffuseIT (FID: 138.42, LPIPS: 0.463) и AGG (FID: 141.70, LPIPS: 0.492). Визуальные доказательства на Рисунке 4 и Рисунке 5 еще больше укрепляют это. В то время как базовые модели испытывали трудности с сохранением содержания волос или точной передачей семантической информации, DiffuseIT-M успешно сохранял исходные детали волос, эффективно изменяя состояния кожи головы. Эксперименты по масочному руководству были особенно показательными: использование масочного руководства 1-M было критически важно для сохранения признаков волос во время трансляции, в то время как другие условия маскирования (отсутствие маски, полная маска или обратная маска) либо приводили к минимальным изменениям, либо изменяли волосы и кожу головы без разбора. Эти жесткие доказательства подтверждают, что диффузионный механизм DiffuseIT-M, управляемый маской, высокоэффективен в контролируемой трансляции изображений, что является критическим шагом для аугментации данных.
Наиболее убедительные доказательства общего влияния системы пришли из классификации состояний кожи головы. Таблица 3 недвусмысленно демонстрирует, что "Наши" (аугментация DiffuseIT-M SCALPVISION) последовательно достигали самых высоких макро-F1-показателей как для бэкбонов DenseNet (0.636), так и для EfficientFormerV2 (0.635). Это была не просто общая победа; она была особенно выражена в решении проблемы сильного дисбаланса данных. Например, при классификации "тяжелого" себума, негенеративные методы аугментации, такие как гауссовский шум и AugMix, дали F1-показатели 0.000, что указывает на полный провал в классификации этого редкого, но важного состояния. В резком контрасте, "Наши" достигли F1-показателей 0.430 (DenseNet) и 0.406 (EfficientFormerV2) для тяжелого себума. Это неоспоримое, неопровержимое доказательство того, что генеративная аугментация данных, в частности способность DiffuseIT-M создавать высококачественные, разнообразные образцы для недостаточно представленных классов, напрямую приводит к улучшению диагностической производительности, особенно для сложных, редких состояний. Это доказывает, что сохранение как стиля кожи головы, так и информации о содержании волос имеет первостепенное значение для точной классификации.
Ограничения и будущие направления
Хотя SCALPVISION представляет собой надежное и инновационное решение для диагностики заболеваний кожи головы, важно признать его текущие ограничения и рассмотреть направления для будущего развития.
Одно из присущих ограничений проистекает из самого набора данных. Несмотря на то, что AI-Hub является крупным ресурсом, он сильно смещен в сторону "хороших" и "легких" состояний кожи головы, при этом тяжелые случаи редки. Хотя метод генеративной аугментации SCALPVISION значительно смягчает этот дисбаланс, присущая нехватка реальных тяжелых случаев все еще может представлять проблемы для обобщения на чрезвычайно разнообразные или новые тяжелые проявления, которые не очень хорошо представлены даже в аугментированных данных. Кроме того, ручная аннотация для сегментации волос проводилась на относительно небольшом подмножестве из 150 тестовых изображений. Хотя этого достаточно для первоначальной проверки, более широкий, более разнообразный набор вручную аннотированных изображений мог бы еще больше укрепить надежность модели сегментации в различных типах волос и условиях съемки. Кроме того, текущая система фокусируется на трех конкретных заболеваниях кожи головы: перхоть, избыток себума и эритема. Эта сфера, хотя и ценна, означает, что она еще не охватывает весь спектр дерматологических заболеваний, поражающих кожу головы.
Заглядывая вперед, несколько захватывающих направлений могут способствовать дальнейшему развитию этих выводов:
- Расширение диагностического охвата: Авторы явно заявляют о своем намерении расширить исследования на такие состояния, как алопеция, используя информацию о волосах. Это естественное и необходимое развитие в направлении действительно обобщенной диагностической системы. Будущие работы могут изучить, как структура SCALPVISION адаптируется к состояниям, где паттерны выпадения волос, а не только поверхностные состояния кожи головы, являются основными диагностическими признаками.
- Интеграция мультимодальных данных: В настоящее время система полагается исключительно на микроскопические изображения кожи головы. Интеграция других диагностических данных, таких как история болезни пациента, генетические маркеры или даже макроскопические изображения, может привести к более целостной и точной диагностике, потенциально уменьшая ложноположительные или ложноотрицательные результаты, которые могут возникнуть при анализе только изображений.
- Клиническое внедрение и пользовательский опыт: Чтобы SCALPVISION стал действительно ценным инструментом, его интеграция в клинические рабочие процессы имеет первостепенное значение. Это потребует разработки удобных интерфейсов для дерматологов, обеспечения соответствия медицинским нормам и проведения обширных клинических испытаний в реальных условиях для проверки его производительности в различных группах пациентов и условиях. Как мы можем сделать эту технологию беспрепятственно помогающей клиницистам, не увеличивая их рабочую нагрузку?
- Объяснимость и доверие: Хотя модель демонстрирует высокую производительность, понимание почему она принимает определенные диагностические решения, имеет решающее значение для построения доверия среди медицинских работников. Будущие исследования могут сосредоточиться на повышении объяснимости ИИ, возможно, путем выделения конкретных областей изображения или признаков, которые вносят наибольший вклад в диагноз, тем самым предоставляя действенные идеи для клиницистов.
- Персонализированные рекомендации по лечению: Переходя от диагностики, SCALPVISION потенциально может развиваться, чтобы предлагать персонализированные планы лечения на основе выявленного состояния, тяжести и даже индивидуальных характеристик пациента. Это потребует интеграции баз медицинских знаний и, возможно, данных, специфичных для пациента.
- Решение проблем конфиденциальности данных и этики: Как и в случае любой системы ИИ, обрабатывающей конфиденциальные медицинские данные, необходимо уделять пристальное внимание конфиденциальности данных, безопасности и этичному развертыванию. Как мы можем обеспечить ответственное использование таких мощных диагностических инструментов, особенно при работе с генеративными моделями, которые потенциально могут создавать синтетические данные пациентов?
- Исследование передовых генеративных архитектур: Хотя DiffuseIT-M высокоэффективен, область генеративного ИИ быстро развивается. Исследование новых диффузионных моделей, GAN или других генеративных архитектур может привести к дальнейшим улучшениям в точности изображений, разнообразии и контроле, потенциально приводя к еще более надежным стратегиям аугментации данных.
Эти обсуждения подчеркивают, что SCALPVISION — это не просто диагностический инструмент, а основополагающая структура с огромным потенциалом для преобразования дерматологической помощи, при условии, что его ограничения будут устранены, а его возможности будут продуманно расширены.
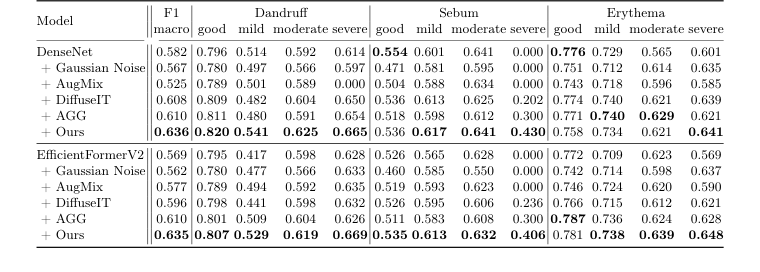 Table 3. Performance of scalp condition classification with various augmentation methods, denoted after “+” symbol, on the test set. The second column displays the overall macro-F1 score, while the columns from the third onward show the F1 scores for each severity level of the three diseases
Table 3. Performance of scalp condition classification with various augmentation methods, denoted after “+” symbol, on the test set. The second column displays the overall macro-F1 score, while the columns from the third onward show the F1 scores for each severity level of the three diseases
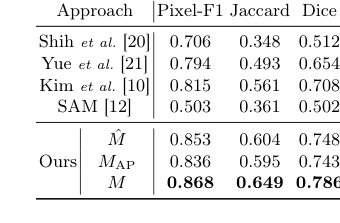 Table 1. Performance of hair segmenta- tion on the test set
Table 1. Performance of hair segmenta- tion on the test set
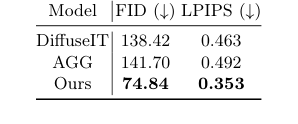 Table 2. Quantitative analysis of image- to-image translation
Table 2. Quantitative analysis of image- to-image translation