Embedding Trajectory for Out-of-Distribution Detection in Mathematical Reasoning
Real-world data deviating from the independent and identically distributed (\textit{i.i.d.}) assumption of in-distribution training data poses security threats to deep networks, thus advancing out-of-distribution...
Background & Academic Lineage
The Origin & Academic Lineage
The problem of Out-of-Distribution (OOD) detection in mathematical reasoning for Generative Language Models (GLMs) is a relatively new and critical challenge. Historically, OOD detection algorithms primarily emerged to safeguard deep networks from real-world data that deviates from the independent and identically distributed (i.i.d.) assumption of training data. Early research in this field largely concentrated on vision and traditional text classification tasks.
As GLMs advanced, OOD detection methods were adapted for text generation scenarios like summarization and translation. These methods typically relied on either uncertainty estimation or embedding distance measurements. However, the academic field faced a significant "pain point" when these existing approaches were applied to mathematical reasoning tasks. Mathematical reasoning, a challenging generative task, presented unique characteristics in its output space that rendered traditional embedding-based methods ineffective. The authors explicitly state that, to their knowledge, they are the first to systematically study OOD detection in mathematical reasoning and identify the failure of conventional algorithms in this specific domain. This paper thus addresses a novel problem at the intersection of OOD detection and mathematical reasoning within the context of GLMs.
The fundamental limitation of previous approaches stems from a phenomenon the authors term "Pattern Collapse" in the output space of mathematical reasoning. Traditional embedding-based methods, which measure distances in a static embedding space (e.g., Mahalanobis Distance), assume that distinct semantic inputs will map to distinct regions in the embedding space. However, in mathematical reasoning, outputs are often symbolic (e.g., numbers, simple expressions) and are constructed from a limited vocabulary of tokens (like digits 0-9 and basic mathematical symbols). This causes semantically diverse mathematical problems to produce output embeddings that converge to a high-density, overlapping region in the latent space. Consequently, the static embedding distances between in-distribution (ID) and OOD samples become indistinguishable, making it impossible for previous methods to reliably detect OOD data. This "pattern collapse" effectively blurs the lines between what the model has seen and what it hasn't, forcing the authors to seek a new, dynamic approach.
Intuitive Domain Terms
- Out-of-Distribution (OOD) Data: Imagine you've trained a smart robot to sort red apples and green apples. If someone suddenly gives it a blue berry, that's OOD data. It's something the robot has never encountered during its training, and it might get confused or make a bad guess because it doesn't fit its learned categories.
- Generative Language Models (GLMs): Think of a GLM as a highly creative chef who can invent new recipes. You give the chef a theme (e.g., "a dessert for summer"), and they don't just pick from a cookbook; they combine ingredients and techniques to create a brand-new, unique dish. Similarly, GLMs generate new text, rather than just retrieving existing phrases.
- Pattern Collapse: Picture a large art gallery where each painting is unique. Now, imagine all those paintings are digitally compressed into tiny, low-resolution thumbnails. Many distinct paintings might end up looking very similar or even identical in their thumbnail form, making it hard to tell them apart. This "squishing" of unique patterns into a common, indistinguishable form is what happens in mathematical reasoning outputs, making them hard to differentiate.
- Embedding Trajectory: Consider a complex maze with many levels. When a mouse enters the maze, it leaves a trail as it navigates through each level. The "embedding trajectory" is like tracing that trail for a piece of information as it passes through each processing layer of a neural network. It shows not just where the information ends up, but the entire sequence of transformations it undergoes.
- Trajectory Volatility: Following the maze analogy, "trajectory volatility" is a measure of how erratic or smooth the mouse's path is between levels. If the mouse makes sudden, large changes in direction between levels, its path is highly volatile. If it moves predictably and smoothly, its volatility is low. This "bumpiness" or "smoothness" of the data's journey through the network can signal whether it's familiar or an unexpected, out-of-distribution input.
Notation Table
| Notation | Description | Type |
|---|---|---|
| $s$ | A given sample, typically an input-output pair. | Variable |
| $L$ | The total number of hidden layers in the generative language model. | Parameter |
| $d$ | The dimensionality of an embedding vector. | Parameter |
| $Y_l$ | The average embedding of the output sequence at layer $l$. | Variable |
| $V_I(s)$ | Dimension-independent volatility for sample $s$, capturing local trajectory changes across dimensions. | Variable |
| $V_J(s)$ | Dimension-joint volatility for sample $s$, capturing global changes in the trajectory using L2-norm. | Variable |
| $\mu_l$ | The mean vector of the Gaussian distribution fitted to in-distribution (ID) embeddings at layer $l$. | Parameter |
| $\Sigma_l$ | The covariance matrix of the Gaussian distribution fitted to ID embeddings at layer $l$. | Parameter |
| $f(Y_l)$ | The Mahalanobis Distance of the average embedding $Y_l$ from the ID Gaussian distribution $G_l$. | Variable |
| $S$ | The Trajectory Volatility (TV) Score for a sample, calculated as the average of Mahalanobis Distance differences between adjacent layers. | Variable |
| $k$ | The order of differential smoothing applied to the trajectory volatility. | Parameter |
| $\nabla^k S$ | The Trajectory Volatility (TV) Score with $k$-order differential smoothing. | Variable |
Problem Definition & Constraints
Core Problem Formulation & The Dilemma
The core problem addressed by this paper is the accurate detection of Out-of-Distribution (OOD) data in Generative Language Models (GLMs) when performing mathematical reasoning tasks.
The starting point (Input/Current State) is a GLM that has been trained on in-distribution (ID) data, typically assuming an independent and identically distributed (i.i.d.) data distribution. When this GLM is presented with real-world inputs that deviate from this i.i.d. assumption (i.e., OOD data), its performance can degrade unexpectedly, leading to potentially harmful outcomes. Existing OOD detection methods for GLMs primarily rely on two approaches: uncertainty estimation and embedding distance measurement. While embedding-based methods have proven effective for traditional linguistic tasks like summarization and translation, they are found to be inapplicable for mathematical reasoning. This inapplicability stems from two unique phenomena observed in mathematical reasoning:
1. Vague Clustering in Input Space: The input embeddings for mathematical reasoning problems across various domains exhibit "vague clustering features" (Figure 1a, page 2), making it difficult for static embeddings to capture the inherent complexity and distinctions between different mathematical questions.
2. Pattern Collapse in Output Space: The output embeddings for mathematical reasoning exhibit "high-density characteristics with significant overlap between different domains" (Figure 1a, page 2). This phenomenon, termed "Pattern Collapse," occurs because mathematical outputs are often symbolic (e.g., digits 0-9, special symbols), compressing the search space and leading to substantial token sharing among mathematically distinct expressions. This causes the embeddings of diverse mathematical problems to converge to a high-density region, making them indistinguishable using traditional static embedding distance measures.
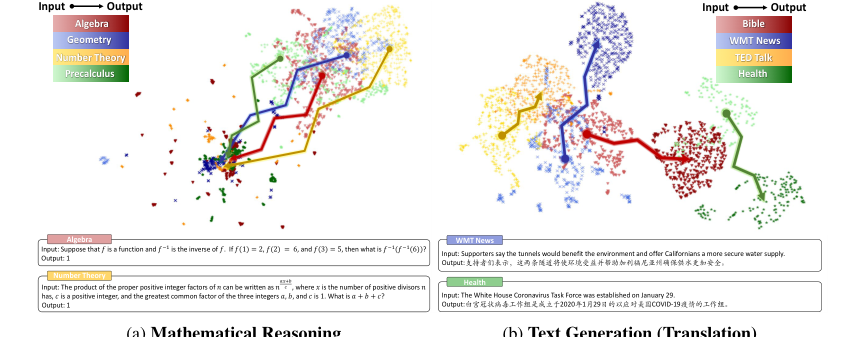 Figure 1. Embedding projection and cases of input and output spaces under mathematical reasoning and text generation scenarios. We select MATH [6] dataset for mathematical reasoning and OPUS [49] for text generation, each with four diverse domains. Different colors represent different domains, with lighter and darker shades indicating input and output. We use SimCSE [9] for sentence embeddings and UMAP [34] for dimensionality reduction. Appendix B shows detailed settings and examples
Figure 1. Embedding projection and cases of input and output spaces under mathematical reasoning and text generation scenarios. We select MATH [6] dataset for mathematical reasoning and OPUS [49] for text generation, each with four diverse domains. Different colors represent different domains, with lighter and darker shades indicating input and output. We use SimCSE [9] for sentence embeddings and UMAP [34] for dimensionality reduction. Appendix B shows detailed settings and examples
The desired endpoint (Output/Goal State) is a robust, lightweight OOD detection algorithm, named TV Score, specifically tailored for mathematical reasoning scenarios. This algorithm should effectively distinguish between ID and OOD samples, even in the presence of "pattern collapse." The ultimate goal is to achieve high discrimination accuracy, formalized as finding a score function $f(x, y, \theta)$ and a threshold $\epsilon$ that maximizes:
$$ \max_{f} P_{(x,y)\sim P_{X,Y}}[f(x,y,\theta) < \epsilon] + P_{(x,\tilde{y})\sim P_{\tilde{X},\tilde{Y}}}[f(x,\tilde{y},\theta) > \epsilon] $$
where $P_{X,Y}$ is the in-distribution joint data distribution and $P_{\tilde{X},\tilde{Y}}$ is the out-of-distribution joint data distribution (Equation 1, page 3). Furthermore, the method should be generalizable to other tasks with high-density output features, such as multiple-choice questions.
The exact missing link or mathematical gap that this paper attempts to bridge is the failure of static embedding-based OOD detection methods in mathematical reasoning due to the "pattern collapse" phenomenon. Previous methods calculate the Mahalanobis Distance between a new sample's embedding and the ID embedding distribution in a static input or output space (page 1). However, "pattern collapse" causes the endpoints of embedding trajectories for different mathematical reasoning samples to converge, rendering these static distance measures ineffective. The paper hypothesizes that while endpoints may collapse, the dynamic embedding trajectories leading to these endpoints will exhibit significant differences between ID and OOD samples. The missing link is therefore a mechanism to quantify these trajectory differences rather than static endpoint distances.
The painful trade-off or dilemma that has trapped previous researchers is the inherent conflict between the symbolic, high-density nature of mathematical reasoning outputs and the requirements of effective embedding-based OOD detection. In traditional text generation, distinct semantic meanings lead to well-separated embedding clusters, allowing embedding distance to work well. However, in mathematical reasoning, the conciseness and shared token vocabulary (e.g., digits) of answers cause diverse problems to map to very similar output embeddings. This "pattern collapse" means that improving the model's ability to generate correct mathematical answers (which are often scalar or simple expressions) inadvertently destroys the distinctiveness in the latent space that OOD detection methods rely on. Researchers were caught in a bind: either accept poor OOD detection for mathematical reasoning or fundamentally rethink how OOD is defined and measured in such a unique output space.
Constraints & Failure Modes
The problem of OOD detection in mathematical reasoning is insanely difficult due to several harsh, realistic constraints:
- Data-Driven Constraint: High-Density Output Space ("Pattern Collapse"): This is the most significant constraint. Mathematical reasoning outputs are "mathematically symbolic" (page 2), leading to a compressed search space. This increases the likelihood of overlap between questions from disparate domains. Crucially, GLMs tokenize mathematical expressions using a limited vocabulary (digits 0-9 and finite special symbols), resulting in "substantial token sharing" among mathematically distinct expressions (page 2, Section 6.2). This causes output embeddings to converge into a high-density, indistinguishable region, making traditional static embedding distance methods ineffective.
- Data-Driven Constraint: Vague Input Space Clustering: The input space for mathematical reasoning also exhibits "vague clustering features across various domains" (page 2, Figure 1a). This indicates that embeddings struggle to capture the full complexity of mathematical questions, further complicating OOD detection from the input side.
- Physical Constraint: Limited Data Availability: Mathematical reasoning datasets are "relatively small" (hundreds or thousands of samples), especially compared to the millions of samples available for traditional NLP tasks like translation or summarization (page 1, page 11, "Limitations"). This scarcity of data makes it challenging to train robust models and evaluate OOD detection methods reliably, increasing the randomness of results. The authors mitigate this by employing test sampling.
- Algorithmic Constraint: Difficulty in Quantifying Trajectory Differences: While static embedding differences can be measured with Mahalanobis Distance, "quantifying the difference between a trajectory and a trajectory cluster is less intuitive" (page 5). This requires a novel mathematical formulation to capture the dynamic changes in embedding space across layers, which the paper addresses by defining trajectory volatility.
- Algorithmic Constraint: Trajectory Outliers: Outliers in the embedding trajectory can "significantly impact feature extraction" (page 5). This noise can obscure the true underlying differences between ID and OOD trajectories, necessitating smoothing techniques to enhance robustness.
- Computational Constraint: Model Size and Training Resources: The method relies on large GLMs like Llama2-7B and GPT2-XL (page 6). Training these models requires significant computational resources (e.g., 4-card RTX 3090 for Llama2-7B, single RTX 3090 for GPT2-XL, page 23). While the proposed TV Score itself is "lightweight" in terms of its own computation (milliseconds, $O(Ldn)$ or $O(Ldk)$ complexity, page 22), it operates on top of these computationally intensive backbones.
- Data-Driven Constraint: Uncertainty of Data Leakage: For closed-source GLMs like Llama2-7B, there is uncertainty about whether specific OOD datasets might have been included in their pre-training data (page 23). This makes it difficult to definitively claim a dataset is OOD purely from a distributional perspective. The authors address this by defining OOD based on whether the dataset "exceeds the capabilities of the base model" (page 23).
Why This Approach
The Inevitability of the Choice
The adoption of the trajectory-based TV Score was not merely a preference but a necessity, driven by the unique and challenging characteristics of out-of-distribution (OOD) detection in mathematical reasoning tasks for generative language models (GLMs). The authors identified a critical failure point in traditional "SOTA" methods, such as standard embedding-based approaches, when confronted with this specific problem.
The exact moment the authors realized traditional methods were insufficient is clearly articulated in Section 1. While embedding-based methods had proven highly effective for conventional linguistic tasks like summarization and translation (as demonstrated by [43] using Mahalanobis Distance [22]), they encountered significant challenges in mathematical reasoning. This was due to the "high-density feature of output spaces" in this domain, a phenomenon the authors term "pattern collapse." This "pattern collapse" causes embedding-based methods to become inapplicable, as illustrated in Figure 1. The core issue is that outputs from disparate mathematical domains, despite being semantically distinct, converge to a high-density region in the embedding space, rendering them indistinguishable by static embedding distance measures. This realization forced a shift in focus from static embedding spaces to the dynamic "embedding trajectory" (Section 2), as it was the only viable path to capture the subtle differences between in-distribution (ID) and OOD samples.
Comparative Superiority
Beyond simple performance metrics, the TV Score method exhibits profound qualitiative superiority due to its structural advantages in handling the unique challenges of mathematical reasoning. The key lies in its ability to leverage the dynamic changes in embeddings across layers, rather than relying on static, final-layer embeddings.
The "pattern collapse" phenomenon, while making static embeddings indistinguishable, paradoxically creates "significant trajectory differences across samples" (Section 2, Figure 2). The TV Score capitalizes on this by measuring "trajectory volatility," which quantifies these dynamic shifts. This approach is inherently more robust to the high-density output space problem becuase it focuses on the process of embedding transformation rather than just the end state.
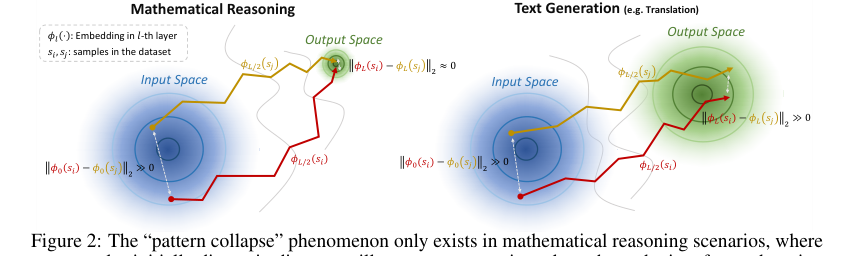 Figure 2. The “pattern collapse” phenomenon only exists in mathematical reasoning scenarios, where two samples initially distant in distance will converge approximately at the endpoint after undergoing embedding shifts, and does not occur in text generation scenarios. This produces a greater likelihood of trajectory variation under different samples in mathematical reasoning
Figure 2. The “pattern collapse” phenomenon only exists in mathematical reasoning scenarios, where two samples initially distant in distance will converge approximately at the endpoint after undergoing embedding shifts, and does not occur in text generation scenarios. This produces a greater likelihood of trajectory variation under different samples in mathematical reasoning
A crucial structural advantage is revealed by the "Early Stabilization" phenomenon (Section 2.2, Section 3). For ID data, GLMs tend to complete their reasoning in mid-to-late layers, leading to a suppression of embedding change magnitude in subsequent layers. In stark contrast, for OOD data, this magnitude remains persistently high, indicating a failure to complete coherent reasoning. This distinct dynamic behavior provides a powerful and reliable signal for OOD detection that static methods simply cannot capture.
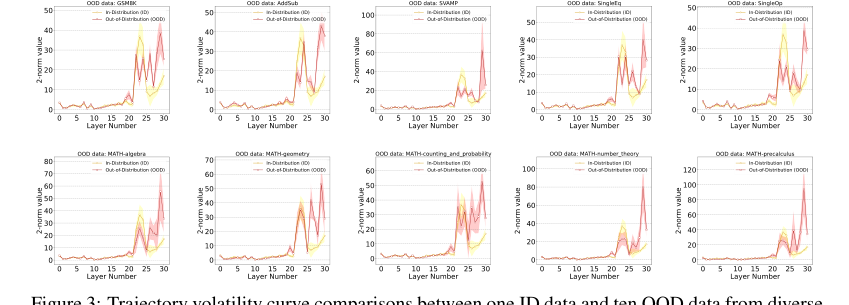 Figure 3. Trajectory volatility curve comparisons between one ID data and ten OOD data from diverse mathematical domains. Each trajectory represents the average of all samples from the corresponding datasets, with color shading being the sample standard deviation. Llama2-7B is used for the backbone
Figure 3. Trajectory volatility curve comparisons between one ID data and ten OOD data from diverse mathematical domains. Each trajectory represents the average of all samples from the corresponding datasets, with color shading being the sample standard deviation. Llama2-7B is used for the backbone
Furthermore, the method is described as "lightweight" (Section 3), implying computational efficiency. The optional differential smoothing technique (TV Score w/ DiSmo) further enhances robustness by mitigating the impact of outliers in trajectories, ensuring a smoother and more reliable signal (Section 3). The experimental results (Table 1, Table 2) quantitatively confirm this qualitative superiority, showing average AUROC improvements of over 10 points and a remarkable 80%+ reduction in FPR95 compared to baselines, even in challenging near-shift OOD scenarios where other methods suffer significant perfomance degradation.
Alignment with Constraints
The chosen trajectory-based approach, embodied by the TV Score, perfectly aligns with the stringent constraints inherent in OOD detection for mathematical reasoning.
- Constraint: OOD detection in GLMs for mathematical reasoning. The TV Score is purpose-built for this domain, directly addressing the "pattern collapse" and "high-density features" that make traditional methods fail (Abstract, Section 1). It specifically models and measures phenomena unique to mathematical reasoning, such as "Early Stabilization" (Section 2.2).
- Constraint: Overcoming the inapplicability of traditional embedding-based methods. The core motivation for TV Score is the demonstrated failure of static embedding methods in mathematical reasoning (Section 1, Section 6). By shifting to dynamic embedding trajectories, the method directly circumvents the limitations imposed by the output space's high density, where static embeddings lose their discriminative power (Section 2, Figure 2).
- Constraint: Need for a lightweight solution. The paper explicitly states that TV Score is a "lightweight OOD detection solution" (Section 3). Its computational complexity is efficient, with $O(Ldn)$ for ID distribution fitting and $O(Ldk)$ for score computation, making it practical for real-world GLM applications (Appendix D).
- Constraint: Scalability and generalizability to other high-density output tasks. The method is designed to be scalable and demonstrates "greater advantages in fine-grained detection scenarios" (Section 5.2). Crucially, the authors show its extensibility to other tasks exhibiting the "pattern collapse" property, such as multiple-choice questions, where it also outperforms traditional algorithms (Abstract, Section 5.2). This confirms its broad applicability beyond the initial mathematical reasoning focus.
Rejection of Alternatives
The paper provides clear reasoning for rejecting popular alternative OOD detection approaches, primarily focusing on why existing methods fail in the specific context of mathematical reasoning.
-
Traditional Static Embedding-Based Methods (e.g., Mahalanobis Distance on input/output embeddings): These methods, while effective for general text generation, are explicitly deemed "inapplicable" for mathematical reasoning (Section 1). The paper dedicates Section 6 to "Rethink Inapplicability of Static Embedding Methods," detailing two main reasons for their failure:
- Input Space Representation Dilemma: Mathematical expressions in the input space exhibit "vague clustering features" (Section 6.1, Figure 1a). Semantic embeddings, as shown in Table 4, do not accurately reflect mathematical relationships. For instance, a mathematically "in-distribution" expression might have a lower cosine similarity than a mathematically "out-of-distribution" one, making static input embeddings unreliable for OOD detection.
- Output Space "Pattern Collapse": This is the most critical issue (Section 6.2, Figure 1a). The output space of mathematical reasoning is characterized by high density and significant overlap across domains. This "pattern collapse" occurs at two levels:
- Expression Level: Mathematical outputs are often scalar (e.g., "4"), compressing the search space and increasing the likelihood of overlap between vastly different mathematical questions (e.g., "1+3=" and "$\int x dx=$" both yielding "4") (Section 6.2).
- Token Level: GLMs tokenize mathematical expressions using a limited set of digits (0-9) and special symbols. This leads to substantial token sharing even for mathematically distinct expressions, causing the collapse at the token level during autoregressive prediction (Section 6.2, Table 6).
Table 5 empirically confirms this rejection, showing that Mahalanobis Distance on static embeddings yields near-random AUROC scores (around 50) in many settings.
-
Uncertainty Estimation Methods (e.g., Maximum Softmax Probability, Monte-Carlo Dropout, Sequence Perplexity): These methods are included as baselines in the experiments (Section 4.1, Table 1, Table 2, Table 3). While the paper doesn't provide a detailed theoretical breakdown of why they fail for mathematical reasoning, their consistent and significant underperformance compared to TV Score (often by 10+ AUROC points and 80%+ FPR95 reduction) implies their inadequacy. The unique phenomena of "pattern collapse" and "Early Stabilization" are not directly addressed by these uncertainty-based approaches, which typically focus on predictive confidence rather than the dynamic evolution of embeddings.
-
Chain-of-Thought (CoT) Techniques: The paper considers CoT as a potential alternative to "expand the output space size" and mitigate "pattern collapse" (Section 6.3). However, the authors conclude that "despite that CoT expands the output space size, the output answer is still essentially related to the difficulty and digit of mathematical reasoning, and the semantic embedding representation cannot reflect these features accurately." Empirical results in Table 5(b) show that even with CoT, the detection accuracy using Mahalanobis Distance remains poor and highly variable, indicating that CoT alone is insufficient to resolve the fundamental issues for OOD detection in this domain.
Mathematical & Logical Mechanism
The Master Equation
The core of this paper's mechanism for Out-of-Distribution (OOD) detection in mathematical reasoning is the Trajectory Volatility (TV) Score, $S$. This score quantifies the dynamic changes in a sample's embedding as it propagates through the layers of a generative language model (GLM). The master equation for the TV Score is defined as:
$$ S = \frac{1}{L} \sum_{l=1}^{L} |f(y_l) - f(y_{l-1})| $$
This equation relies on an intermediate function, $f(y_l)$, which calculates the Mahalanobis Distance of an embedding at a specific layer $l$. This function is given by:
$$ f(y_l) = (y_l - \mu_l)^T (\Sigma_l)^{-1} (y_l - \mu_l) $$
Term-by-Term Autopsy
Let's dissect these equations to understand each component's role:
For the TV Score ($S$) equation:
- $S$:
- Mathematical Definition: The Trajectory Volatility Score for a given input sample.
- Physical/Logical Role: This is the final scalar value that serves as the OOD detection score. A higher $S$ indicates greater volatility in the sample's embedding trajectory across the GLM's layers, which is hypothesized to be a distinguishing characteristic of OOD samples in mathematical reasoning tasks.
- Why addition instead of multiplication, or an integral instead of a summation: The authors use summation because the GLM has a discrete number of layers ($L$). Summation aggregates the individual changes in Mahalanobis distance between adjacent layers. Addition is chosen to accumulate the magnitudes of these changes, providing a total measure of "path length" or fluctuation. Multiplication would drastically scale the score, making it less interpretable as a direct measure of volatility and potentially leading to numerical instability.
- $\frac{1}{L}$:
- Mathematical Definition: The reciprocal of $L$, where $L$ is the total number of hidden layers in the GLM.
- Physical/Logical Role: This term acts as a normalization factor. It converts the sum of layer-wise volatilities into an average volatility per layer. This ensures that the TV Score is comparable across models with different numbers of layers or when analyzing trajectories of varying lengths.
- $\sum_{l=1}^{L}$:
- Mathematical Definition: The summation operator, iterating from the first layer ($l=1$) up to the last layer ($L$).
- Physical/Logical Role: This operator aggregates the individual volatility contributions from each transition between adjacent layers. It sums up how much the Mahalanobis distance "jumps" or "shifts" as the sample's representation progresses through the model's depth.
- $| \cdot |$:
- Mathematical Definition: The absolute value function.
- Physical/Logical Role: This ensures that only the magnitude of the difference in Mahalanobis distance between adjacent layers is considered, not its direction (i.e., whether the distance increased or decreased). The focus is purely on the extent of change, which is central to measuring volatility.
- $f(y_l)$:
- Mathematical Definition: The Mahalanobis Distance of the average embedding $y_l$ at layer $l$.
- Physical/Logical Role: This term quantifies how "far" the sample's embedding at layer $l$ is from the typical distribution of in-distribution (ID) samples at that same layer. It transforms a high-dimensional embedding into a single scalar value representing its "ID-ness" at that specific layer.
- $f(y_{l-1})$:
- Mathematical Definition: The Mahalanobis Distance of the average embedding $y_{l-1}$ at the layer immediately preceding layer $l$.
- Physical/Logical Role: Similar to $f(y_l)$, but for the previous layer. The difference $|f(y_l) - f(y_{l-1})|$ specifically measures the change in "ID-ness" as the sample's representation evolves from layer $l-1$ to layer $l$.
For the Mahalanobis Distance ($f(y_l)$) equation:
- $y_l$:
- Mathematical Definition: The average embedding of the output sequence tokens at layer $l$. It is a $d$-dimensional vector, calculated as $y_l = \frac{1}{T} \sum_{t=1}^{T} h_t^l$, where $h_t^l$ is the output embedding of the $t$-th token at layer $l$ and $T$ is the number of tokens.
- Physical/Logical Role: This vector represents the aggregated semantic and mathematical information of the entire output sequence at a particular depth within the GLM. It's the "state" of the sample's output representation at layer $l$.
- $\mu_l$:
- Mathematical Definition: The mean vector of the Gaussian distribution $G_l = N(\mu_l, \Sigma_l)$ that has been fitted to all in-distribution (ID) sample embeddings at layer $l$. It is also a $d$-dimensional vector.
- Physical/Logical Role: This vector represents the "center" or "typical" embedding for an ID sample at layer $l$. It serves as the reference point for what is considered "normal" at that specific layer.
- $(y_l - \mu_l)$:
- Mathematical Definition: A vector representing the difference between the sample's embedding $y_l$ and the mean ID embedding $\mu_l$ at layer $l$.
- Physical/Logical Role: This is the deviation vector, indicating how much the current sample's embedding deviates from the average ID embedding at layer $l$.
- $(\cdot)^T$:
- Mathematical Definition: The transpose operator.
- Physical/Logical Role: In this context, it transforms the column vector $(y_l - \mu_l)$ into a row vector, which is necessary for the matrix multiplication in the quadratic form of the Mahalanobis distance.
- $(\Sigma_l)^{-1}$:
- Mathematical Definition: The inverse of the covariance matrix $\Sigma_l$. $\Sigma_l$ is the covariance matrix of the Gaussian distribution $G_l = N(\mu_l, \Sigma_l)$ fitted to all in-distribution (ID) sample embeddings at layer $l$. It is a $d \times d$ matrix.
- Physical/Logical Role: This is a cruical component of the Mahalanobis distance. It accounts for the correlations and variances among the dimensions of the ID embedding space at layer $l$. By inverting it, the distance metric effectively "whitens" the data, normalizing for different scales and rotations in the feature space. This makes the distance more robust to the actual geometry of the ID data distribution, providing a more meaningful measure of "distance" than simple Euclidean distance.
- $(\cdot)^T (\cdot)^{-1} (\cdot)$:
- Mathematical Definition: The quadratic form, specifically the squared Mahalanobis distance.
- Physical/Logical Role: This entire expression calculates the Mahalanobis distance squared. It measures the distance between $y_l$ and $\mu_l$ in units of standard deviations, effectively normalizing for the spread and orientation of the ID data cloud. This provides a robust measure of how "unlikely" an embedding is under the ID distribution at layer $l$.
Step-by-Step Flow
Imagine a single, abstract data point – let's call it a "query sample" $s$ – entering the OOD detection pipeline. Here's its journey through the mathematical engine:
- Initial Embedding Generation: The query sample $s$ (e.g., a mathematical problem) is fed into a pre-trianed Generative Language Model (GLM). The GLM processes the input and generates an output sequence (e.g., the mathematical solution).
- Layer-wise Output Embeddings: As the GLM generates the output sequence, its internal layers produce token embeddings. For each of the $T$ tokens in the output sequence, a $d$-dimensional embedding vector $h_t^l$ is extracted from each of the $L$ hidden layers ($l=1, \dots, L$).
- Sentence-level Aggregation: For each layer $l$, all $T$ token embeddings $h_t^l$ from the output sequence are averaged to form a single, representative $d$-dimensional vector $y_l$. This $y_l$ encapsulates the overall output representation at that specific layer. This step effectively traces an "embedding trajectory" for the sample through the GLM's layers: $y_1 \to y_2 \to \dots \to y_L$.
- ID Distribution Reference: Prior to processing the query sample, the system has already established a "normal" reference. This involves collecting a large set of known in-distribution (ID) samples, passing them through the same GLM, and computing their layer-wise average embeddings. For each layer $l$, a Gaussian distribution $G_l = N(\mu_l, \Sigma_l)$ is fitted to these ID embeddings. This means the mean vector $\mu_l$ and covariance matrix $\Sigma_l$ are statistically estimated, characterising the typical ID embedding space at each layer.
- Mahalanobis Distance Mapping: Now, for our query sample's trajectory, at each layer $l$, its average embedding $y_l$ is mapped to a scalar value $f(y_l)$ using the Mahalanobis distance formula. This calculation uses the pre-computed ID mean $\mu_l$ and covariance $\Sigma_l$ for that specific layer. This step transforms the complex $d$-dimensional embedding into a simpler scalar that indicates how "ID-like" it is at that layer, accounting for the shape of the ID data cloud.
- Volatility Measurement: The system then looks at the change in this "ID-likeness" between successive layers. For each adjacent pair of layers $(l-1, l)$, the absolute difference $|f(y_l) - f(y_{l-1})|$ is computed. This measures the magnitude of the shift in Mahalanobis distance as the sample's representation moves from one layer to the next.
- TV Score Aggregation: All these layer-wise volatility magnitudes are summed up and then divided by the total number of layers $L$ to obtain the final Trajectory Volatility Score $S$. This $S$ is a single, averaged measure of how much the sample's "ID-likeness" fluctuates throughout its journey in the GLM's latent space.
- OOD Classification: Finally, the calculated TV Score $S$ for the query sample is compared against a predefind threshold $\epsilon$. If $S$ exceeds $\epsilon$, the sample is flagged as Out-of-Distribution; otherwise, it's considered In-Distribution. The underlying hypothesis is that OOD samples, especially in mathematical reasoning, will exhibit higher trajectory volatility due to phenomena like "pattern collapse."
Optimization Dynamics
It's important to clarify that the Trajectory Volatility (TV) Score mechanism itself, as proposed in this paper, is a post-hoc detection method rather than a model that undergoes traditional gradient-based optimization or learning. It does not have a loss function that is minimized, nor does it iteratively update its own parameters through backpropagation.
Instead, the mechanism's "learning" or "adaptation" occurs in two distinct stages:
- Pre-trained Generative Language Model (GLM): The core of the system relies on a pre-trained GLM (e.g., Llama2-7B or GPT2-XL). This GLM is trained separately on vast amounts of data, including in-distribution mathematical reasoning problems. During this pre-training phase, the GLM learns to generate coherent and mathematically sound outputs, and in doing so, it develops its internal embedding representations across its layers. The weights and parameters of this GLM are fixed when the TV Score method is applied. The embeddings $y_l$ are simply outputs of this static, pre-trained model.
- In-Distribution (ID) Reference Fitting: The only "fitting" or "learning" specific to the TV Score method is the one-time statistical estimation of the Gaussian distributions $G_l = N(\mu_l, \Sigma_l)$ for each layer $l$.
- Mean ($\mu_l$): For each layer, $\mu_l$ is computed as the empirical mean of all ID sample embeddings collected at that layer.
- Covariance ($\Sigma_l$): Similarly, $\Sigma_l$ is the empirical covariance matrix of these ID sample embeddings at layer $l$.
These parameters ($\mu_l, \Sigma_l$) are calculated once from a designated set of in-distribution training data. They are then fixed and serve as the static "reference" for what constitutes a "normal" embedding at each layer. There are no iterative updates or gradients involved in determining $\mu_l$ and $\Sigma_l$ beyond their initial calculation.
The final step of OOD detection involves comparing the calculated TV Score $S$ to a threshold $\epsilon$. This threshold is typically determined empirically on a validation set, for instance, by optimizing metrics like AUROC or FPR95 (as mentioned in Section 4.2). This threshold selection is a form of hyperparameter tuning, not an iterative learning process that shapes a loss landscape or updates model states.
In essence, the TV Score mechanism is a statistical scoring function that leverages the fixed, learned representations of a pre-trained GLM and a statistically defined reference for ID data. It does not learn, update, or converge through gradient descent or similar optimization dynamics itself.
Results, Limitations & Conclusion
Experimental Design & Baselines
To rigorously validate their mathematical claims, the authors architected a comprehensive experimental setup focusing on out-of-distribution (OOD) detection in generative language models (GLMs) for mathematical reasoning. The evaluation was split into two primary scenarios: Offline Detection and Online Detection.
For Offline Detection, the goal was to classify whether samples from a given list were OOD. The key metrics employed were AUROC (Area Under the Receiver Operating Characteristic curve) and FPR95 (False Positive Rate at 95% True Positive Rate). For Online Detection, the task involved calculating an optimal classification threshold to directly determine if new samples were OOD, using discrimination accuracy and robustness (measured as sampling variance).
The "victims" (baseline models) against which the proposed TV Score was ruthlessly compared were five training-free methods, chosen due to the scarcity of OOD detection methods on GLMs:
1. Maximum Softmax Probability (Prob.) [12]
2. Monte-Carlo Dropout [8]
3. Sequence Perplexity [3]
4. Input Embedding [43]
5. Output Embedding [43]
The experimental design utilized MultiArith [44] as the in-distribution (ID) dataset, comprising math word problems on arithmetic reasoning. For OOD data, two distinct scenarios were considered:
* Far-shift OOD: This involved the MATH dataset [11], encompassing five diverse mathematical domains (algebra, geometry, counting and probability, number theory, and precalculus). These problems are of college difficulty, contrasting with MultiArith's elementary school level, ensuring a significant distributional shift.
* Near-shift OOD: This included five arithmetic reasoning datasets (GSM8K [6], SVAMP [39], AddSub [13], SingleEq [18], and SingleOp [18]). While also math word problems, they require different reasoning steps and knowledge points compared to MultiArith, representing a more subtle distributional shift.
The ID data (MultiArith) was split into 360 samples for training and 240 for testing. To mitigate randomness from the small test set, a test sampling size of 1000 was used, ensuring a balanced number of positive (OOD) and negative (ID) samples. The backbone GLMs used were Llama2-7B [50] and GPT2-XL (1.5B) [5], trained on the MultiArith ID training set. The rationality of OOD dataset selection was rigorously checked by confirming that these datasets exceeded the capabilities of the base models, exhibiting very low accuracy on them, thus validating their OOD status from a model performance perspective. For the TV Score with Differential Smoothing (TV Score w/ DiSmo), the smoothing order $k$ was varied from 1 to 5, and the best performance was reported.
What the Evidence Proves
The experimental results provide definitive, undeniable evidence that the core mechanism of trajectory volatility effectively distinguishes ID and OOD samples in mathematical reasoning, substantially outperforming traditional algorithms.
In Offline Detection, the TV Score demonstrated remarkable superiority:
* Far-shift OOD: Our method achieved an average AUROC of 98.76 (Llama2-7B) and 93.47 (GPT2-XL), surpassing the optimal baseline by over 10 points. More strikingly, the FPR95 metric was 5.21 (Llama2-7B) and 9.89 (GPT2-XL), representing an 80%+ reduction compared to the best baseline. This clearly indicates that by analyzing the dynamic embedding trajectory, the model can robustly identify samples from significantly different mathematical domains.
* Near-shift OOD: Even in this more challenging scenario, where baselines suffered significant performance degradation (AUROC below 60, FPR95 above 80), our method maintained excellent performance, with AUROC scores above 90 and FPR95 below 30. This proves the greater adaptability and robustness of the TV Score to subtle distributional shifts.
Model Analysis further revealed interesting phenomena: GPT2-XL exhibited more stable performance across far- and near-shift settings, while Llama2-7B showed a more pronounced degradation for baselines in the near-shift setting. The differential smoothing technique (DiSmo) was particularly effective on GPT2-XL, suggesting it helps mitigate anomalous learning tendencies in the latent spaces of smaller models. Crucially, our method almost passed all significance tests, unlike embedding-based baselines which showed higher susceptibility to sampling error.
For Online Detection, the TV Score achieved an average of 20-point accuracy improvement over embedding-based methods in both far-shift and near-shift OOD settings, with some datasets showing over 40 points improvement. This stronger robustness, reflected in lower sampling variance, means the optimal OOD classification threshold can be found more consistently in real-world scenarios, reducing risks from uncontrollable data acquisition.
Beyond detection, the TV Score also proved effective for OOD Quality Estimation. When measuring correlation with a binary matching quality metric, our method showed up to 100% improvement in Kendall correlation and up to 100% (far-shift) / 30% (near-shift) improvement in Spearman correlation for Llama2-7B over SOTA baselines. This hard evidence indicates that TV scores not only discriminate ID/OOD but also accurately reflect the quality and precision of generated mathematical reasoning.
Finally, the method's Generalizability was demonstrated on the MMLU multiple-choice question dataset, a task also characterized by "pattern collapse." Our TV Score outperformed all traditional algorithms in this setting, showing scalability and advantages in fine-grained detection scenarios, particularly where traditional embedding-based methods struggled.
Limitations & Future Directions
While the TV Score demonstrates significant advancements in OOD detection for mathematical reasoning, it's important to acknowledge the inherent limitations and consider avenues for future development.
The primary limitation highlighted by the authors is the relatively small size of datasets available for mathematical reasoning. Unlike traditional linguistic tasks that boast millions of samples, mathematical reasoning datasets are typically in the hundreds or thousands. This scarcity makes it challenging to train and evaluate models robustly. The authors addressed this by employing test sampling to reduce randomness and mitigate data imbalance in small-scale testing, but the fundamental issue of data availability remains. Another observation was that the performance of differential smoothing (DiSmo) fluctuated across different settings, and excessive smoothing (e.g., $k > 2$) could lead to a loss of useful feature information, decreasing detection accuracy.
Looking ahead, several future directions emerge from this work, offering diverse perspectives for evolution:
- Addressing Data Scarcity in Mathematical Reasoning: Given the difficulty in collecting and labeling large-scale mathematical reasoning data, future research could explore more advanced data augmentation techniques specifically tailored for mathematical expressions. Could synthetic data generation, perhaps guided by formal mathematical properties or theorem provers, provide a scalable solution? Investigating few-shot or zero-shot OOD detection methods that are less reliant on extensive ID datasets would also be valuable.
- Deepening the Understanding of "Pattern Collapse": The paper identifies "pattern collapse" as a critical phenomenon. A deeper theoretical and empirical investigation into its root causes, beyond the current token and expression level analysis, could lead to novel mitigation strategies. Can we design GLM architectures or training objectives that are inherently more resistant to pattern collapse in symbolic domains?
- Expanding Generalizability to Other Symbolic AI Tasks: The successful extension to multiple-choice questions is promising. This suggests the TV Score could be applicable to a broader range of symbolic AI tasks where output spaces are constrained and exhibit "pattern collapse," such as code generation, logical inference, or structured prediction. Future work could systematically identify and validate other such domains, potentially leading to a unified OOD detection framework for symbolic AI.
- Refining Trajectory Volatility Measures: The current TV Score uses dimension-independent and dimension-joint volatility. Exploring more sophisticated measures of embedding trajectory dynamics, such as curvature, torsion, or even adaptive smoothing techniques that dynamically adjust $k$ based on sample characteristics, could potentially yield even finer-grained and more robust OOD detection.
- Hybrid OOD Detection Approaches: While embedding-based methods, particularly trajectory volatility, have proven superior in this context, integrating them with uncertainty estimation techniques (e.g., Bayesian neural networks, ensemble methods) could lead to more robust hybrid OOD detectors. Such an approach might leverage the strengths of both paradigms, providing a more comprehensive assessment of OODness.
- Computational Efficiency for Large Models: As GLMs continue to grow in size and layer count, the computational complexity of fitting ID distributions ($O(Ldn)$) and score computation ($O(Ldk)$) could become a bottleneck. Future work could focus on optimizing these operations, perhaps through approximation techniques, hardware acceleration, or more efficient statistical modeling of embedding distributions.
- Theoretical Guarantees for Pattern Collapse and Trajectory Volatility: The paper provides empirical evidence and theoretical intuition. Developing more rigorous theoretical guarantees for why "pattern collapse" occurs in mathematical reasoning and why trajectory volatility is a reliable signal for OOD samples would strengthen the foundation of this approach. This could involve formalizing the conditions under which these phenomena hold and proving bounds on the effectiveness of the TV Score.
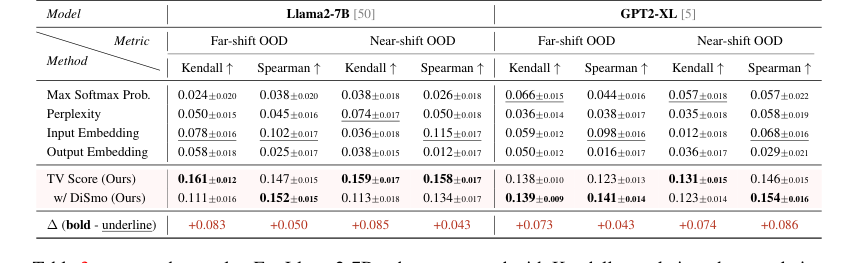 Table 3. presents the results. For Llama2-7B, when compared with Kendall correlation, the correlation improvement of TV scores over SOTA baselines reaches up to 100% under both far-shift and near-shift OOD settings. Compared with Spearman correlation, TV scores demonstrate a correlation enhancement over SOTA baselines by up to 100% under far-shift OOD setting and 30% under near-shift OOD setting. GPT2-XL also demonstrates excellent performance. These findings indicate that our TV scores not only facilitate the binary discrimination of ID and OOD samples but also substantially reflect the quality and precision of generated mathematical reasoning
Table 3. presents the results. For Llama2-7B, when compared with Kendall correlation, the correlation improvement of TV scores over SOTA baselines reaches up to 100% under both far-shift and near-shift OOD settings. Compared with Spearman correlation, TV scores demonstrate a correlation enhancement over SOTA baselines by up to 100% under far-shift OOD setting and 30% under near-shift OOD setting. GPT2-XL also demonstrates excellent performance. These findings indicate that our TV scores not only facilitate the binary discrimination of ID and OOD samples but also substantially reflect the quality and precision of generated mathematical reasoning
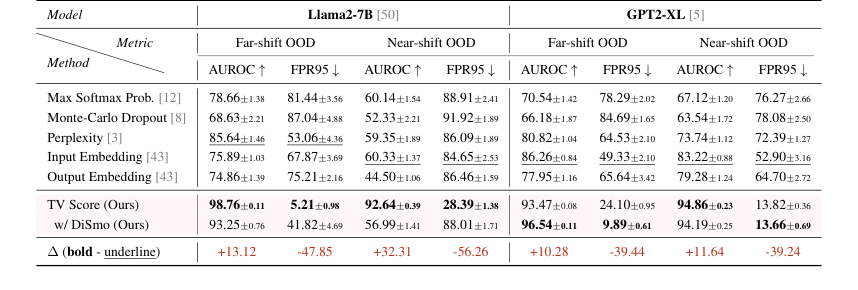 Table 1. AUROC and FPR95 results of the Offline Detection scenario. Underline and bold denote SOTA among all baselines and all methods, respectively. We report the average results under each setting in the main text, results of each dataset are shown in Table 11 and 12 (Appendix F)
Table 1. AUROC and FPR95 results of the Offline Detection scenario. Underline and bold denote SOTA among all baselines and all methods, respectively. We report the average results under each setting in the main text, results of each dataset are shown in Table 11 and 12 (Appendix F)
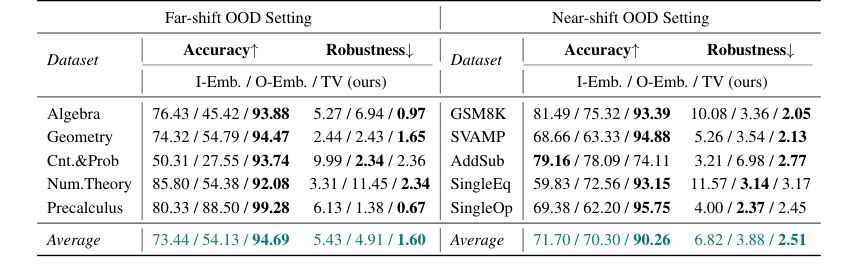 Table 2. presents the results in Llama2-7B. Compared to the embedding-based methods, our TV score obtains about an average of 20-point accuracy improvement in both far-shift OOD and near-shift OOD settings, and on some datasets, such as Cnt.&Prob, our TV score achieves more than 40 points of improvement. These all imply that TV Score can perform online discrimination of OOD samples more accurately. In addition, our TV score also possesses stronger robustness, which means that in real scenarios, we can find the optimal threshold more consistently in the face of different accessible ID and OOD data, reducing the potential riskiness due to uncontrollable data acquisition
Table 2. presents the results in Llama2-7B. Compared to the embedding-based methods, our TV score obtains about an average of 20-point accuracy improvement in both far-shift OOD and near-shift OOD settings, and on some datasets, such as Cnt.&Prob, our TV score achieves more than 40 points of improvement. These all imply that TV Score can perform online discrimination of OOD samples more accurately. In addition, our TV score also possesses stronger robustness, which means that in real scenarios, we can find the optimal threshold more consistently in the face of different accessible ID and OOD data, reducing the potential riskiness due to uncontrollable data acquisition
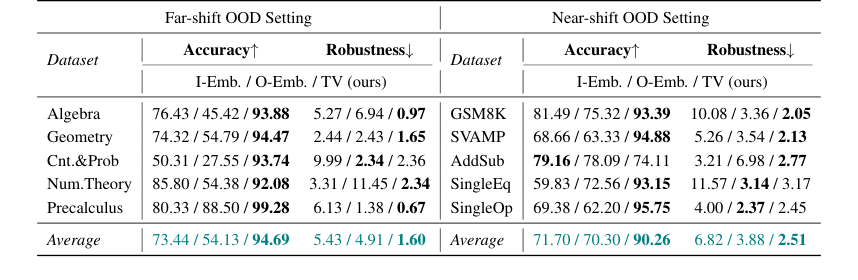 Table 2. Accuracy and Robustness results of the Online Detection scenario. We mainly compare our method with embedding-based methods, and bold denotes the best among these methods
Table 2. Accuracy and Robustness results of the Online Detection scenario. We mainly compare our method with embedding-based methods, and bold denotes the best among these methods