嵌入轨迹用于数学推理中的分布外检测
Real-world data deviating from the independent and identically distributed (\textit{i.i.d.}) assumption of in-distribution training data poses security threats to deep networks, thus advancing out-of-distribution...
背景与学术渊源
起源与学术渊源
生成语言模型(GLM)在数学推理中的分布外(Out-of-Distribution, OOD)检测问题,是一个相对较新且至关重要的挑战。历史上,OOD 检测算法主要出现于保护深度网络免受与训练数据独立同分布(i.i.d.)假设相悖的真实世界数据的影响。该领域的早期研究主要集中在计算机视觉和传统文本分类任务上。
随着 GLM 的发展,OOD 检测方法被应用于文本生成场景,如摘要和翻译。这些方法通常依赖于不确定性估计或嵌入距离测量。然而,当这些现有方法应用于数学推理任务时,学术界遇到了一个显著的“痛点”。数学推理是一项具有挑战性的生成任务,其输出空间具有独特的特性,使得传统的基于嵌入的方法失效。作者明确指出,据他们所知,他们是第一个系统研究 GLM 在数学推理中的 OOD 检测问题,并识别出传统算法在该特定领域失效的研究者。因此,本文在 GLM 的背景下,研究了 OOD 检测与数学推理交叉领域的一个新颖问题。
先前方法的基本局限性源于作者称之为数学推理输出空间中“模式坍塌”(Pattern Collapse)的现象。传统的基于嵌入的方法,通过测量静态嵌入空间中的距离(例如,马氏距离),假设语义不同的输入会映射到嵌入空间中不同的区域。然而,在数学推理中,输出通常是符号化的(例如,数字、简单表达式),并且由有限的词汇标记(如数字 0-9 和基本数学符号)构成。这导致语义上不同的数学问题产生收敛到高密度、重叠区域的输出嵌入,位于潜在空间中。因此,在分布内(ID)和 OOD 样本之间的静态嵌入距离变得无法区分,使得先前的方法无法可靠地检测 OOD 数据。这种“模式坍塌”有效地模糊了模型已见和未见内容之间的界限,迫使作者寻求一种新的、动态的方法。
直观领域术语
- 分布外(OOD)数据:想象一下,你训练了一个智能机器人来区分红苹果和绿苹果。如果有人突然给它一个蓝莓,那就是 OOD 数据。这是机器人训练期间从未遇到过的事物,它可能会感到困惑或做出错误的猜测,因为它不符合其学到的类别。
- 生成语言模型(GLM):将 GLM 想象成一位极富创造力的厨师,能够发明新菜谱。你给厨师一个主题(例如,“夏季甜点”),它不会仅仅从食谱书中挑选;它会结合食材和技巧来创造一道全新的、独特的菜肴。同样,GLM 生成新的文本,而不是仅仅检索现有的短语。
- 模式坍塌(Pattern Collapse):想象一个大型艺术画廊,每幅画都是独一无二的。现在,想象所有这些画都被数字压缩成微小的、低分辨率的缩略图。许多不同的画作在缩略图形式下可能看起来非常相似甚至相同,难以区分。这种将独特模式“压缩”成通用、无法区分形式的现象,正是数学推理输出中发生的情况,使得它们难以区分。
- 嵌入轨迹(Embedding Trajectory):考虑一个拥有多个层级的复杂迷宫。当一只老鼠进入迷宫时,它会随着穿越每个层级留下痕迹。“嵌入轨迹”就像追踪信息在神经网络的每个处理层中传递时的痕迹。它不仅显示了信息最终去向,还展示了它所经历的整个变换序列。
- 轨迹波动性(Trajectory Volatility):沿着迷宫的比喻,“轨迹波动性”是衡量老鼠在层级之间路径的混乱程度或平滑度的指标。如果老鼠在层级之间做出突然的、大的方向改变,它的路径波动性就很高。如果它移动得可预测且平稳,其波动性就较低。数据在网络中旅程的这种“颠簸”或“平滑”可以表明它是熟悉还是意外的、分布外的输入。
符号表
| 符号 | 描述 | 类型 |
|---|---|---|
| $s$ | 给定样本,通常是输入-输出对。 | 变量 |
| $L$ | 生成语言模型中隐藏层的总数。 | 参数 |
| $d$ | 嵌入向量的维度。 | 参数 |
| $Y_l$ | 第 $l$ 层输出序列的平均嵌入。 | 变量 |
| $V_I(s)$ | 样本 $s$ 的独立于维度的波动性,捕捉跨维度的局部轨迹变化。 | 变量 |
| $V_J(s)$ | 样本 $s$ 的联合维度波动性,使用 L2 范数捕捉轨迹的全局变化。 | 变量 |
| $\mu_l$ | 第 $l$ 层分布内(ID)嵌入的高斯分布拟合的均值向量。 | 参数 |
| $\Sigma_l$ | 第 $l$ 层分布内(ID)嵌入的高斯分布拟合的协方差矩阵。 | 参数 |
| $f(Y_l)$ | 平均嵌入 $Y_l$ 到 ID 高斯分布 $G_l$ 的马氏距离。 | 变量 |
| $S$ | 样本的轨迹波动性(TV)得分,计算为相邻层之间马氏距离差的平均值。 | 变量 |
| $k$ | 应用于轨迹波动性的微分平滑的阶数。 | 参数 |
| $\nabla^k S$ | 具有 $k$ 阶微分平滑的轨迹波动性(TV)得分。 | 变量 |
问题定义与约束
核心问题表述与困境
本文解决的核心问题是在生成语言模型(GLM)执行数学推理任务时,准确检测分布外(OOD)数据。
起点(输入/当前状态) 是一个已在分布内(ID)数据上训练过的 GLM,通常假设独立同分布(i.i.d.)数据分布。当该 GLM 遇到偏离此 i.i.d. 假设的真实世界输入(即 OOD 数据)时,其性能可能会意外下降,导致潜在有害的后果。现有的 GLM OOD 检测方法主要依赖于两种方法:不确定性估计和嵌入距离测量。虽然基于嵌入的方法对于摘要和翻译等传统语言任务已被证明有效,但它们被发现不适用于数学推理。这种不适用性源于在数学推理中观察到的两种独特现象:
1. 输入空间中的模糊聚类:跨各种领域的数学推理问题的输入嵌入表现出“模糊聚类特征”(第 2 页图 1a),使得静态嵌入难以捕捉不同数学问题之间的固有复杂性和区别。
2. 输出空间中的模式坍塌:数学推理的输出嵌入表现出“高密度特征,不同领域之间存在显著重叠”(第 2 页图 1a)。这种被称为“模式坍塌”的现象发生是因为数学输出通常是符号化的(例如,数字 0-9、特殊符号),压缩了搜索空间,并导致数学上不同的表达式之间存在大量的标记共享。这使得不同数学问题的嵌入收敛到一个高密度区域,使得使用传统的静态嵌入距离度量无法区分。
期望终点(输出/目标状态) 是一个名为 TV Score 的鲁棒、轻量级的 OOD 检测算法,专门针对数学推理场景进行定制。该算法应能有效区分 ID 和 OOD 样本,即使在存在“模式坍塌”的情况下也是如此。最终目标是实现高判别精度,形式化为找到一个得分函数 $f(x, y, \theta)$ 和一个阈值 $\epsilon$,以最大化:
$$ \max_{f} P_{(x,y)\sim P_{X,Y}}[f(x,y,\theta) < \epsilon] + P_{(x,\tilde{y})\sim P_{\tilde{X},\tilde{Y}}}[f(x,\tilde{y},\theta) > \epsilon] $$
其中 $P_{X,Y}$ 是分布内联合数据分布,而 $P_{\tilde{X},\tilde{Y}}$ 是分布外联合数据分布(第 3 页方程 1)。此外,该方法应可推广到具有高密度输出特征的其他任务,例如选择题。
本文试图弥合的确切缺失环节或数学鸿沟是由于“模式坍塌”现象,静态嵌入式 OOD 检测方法在数学推理中失效。先前的方法在静态输入或输出空间中计算新样本嵌入与 ID 嵌入分布之间的马氏距离(第 1 页)。然而,“模式坍塌”导致不同数学推理样本的嵌入轨迹终点收敛,使得这些静态距离度量无效。本文假设,虽然终点可能收敛,但导致这些终点的动态嵌入轨迹在 ID 和 OOD 样本之间会表现出显著差异。因此,缺失的环节是量化这些轨迹差异而不是静态终点距离的机制。
困扰先前研究人员的痛苦权衡或困境是数学推理输出的符号化、高密度特性与有效嵌入式 OOD 检测要求之间的固有冲突。在传统的文本生成中,不同的语义含义会导致嵌入簇分离良好,从而使嵌入距离能够很好地工作。然而,在数学推理中,答案的简洁性和共享标记词汇(例如,数字)导致不同问题映射到非常相似的输出嵌入。这种“模式坍塌”意味着提高模型生成正确数学答案的能力(通常是标量或简单表达式)会无意中破坏 OOD 检测所依赖的潜在空间中的独特性。研究人员陷入了两难境地:要么接受数学推理的 OOD 检测效果不佳,要么从根本上重新思考在这种独特的输出空间中 OOD 的定义和测量方式。
约束与失效模式
由于几个严峻的现实约束,数学推理中的 OOD 检测问题极其困难:
- 数据驱动约束:高密度输出空间(“模式坍塌”):这是最显著的约束。数学推理输出是“数学符号化的”(第 2 页),导致搜索空间压缩。这增加了来自不同领域的问答重叠的可能性。至关重要的是,GLM 使用有限的词汇表(数字 0-9 和有限的特殊符号)对数学表达式进行标记,导致数学上不同的表达式之间存在“大量的标记共享”(第 2 页,第 6.2 节)。这导致输出嵌入收敛到一个高密度、无法区分的区域,使得传统的静态嵌入距离方法无效。
- 数据驱动约束:模糊输入空间聚类:数学推理的输入空间也表现出“跨各种领域的模糊聚类特征”(第 2 页,图 1a)。这表明嵌入难以捕捉数学问题的全部复杂性,从而使从输入端进行 OOD 检测更加复杂。
- 物理约束:有限的数据可用性:数学推理数据集“相对较小”(数百或数千个样本),特别是与翻译或摘要等传统 NLP 任务可用的数百万个样本相比(第 1 页,第 11 页,“局限性”)。数据的稀缺性使得训练鲁棒模型和可靠评估 OOD 检测方法具有挑战性,增加了结果的随机性。作者通过采用测试采样来缓解这一问题。
- 算法约束:轨迹差异量化的难度:虽然静态嵌入差异可以通过马氏距离来衡量,但“量化轨迹与轨迹簇之间的差异不太直观”(第 5 页)。这需要一种新颖的数学公式来捕捉跨层嵌入空间的动态变化,本文通过定义轨迹波动性来解决这个问题。
- 算法约束:轨迹异常值:嵌入轨迹中的异常值会“显著影响特征提取”(第 5 页)。这种噪声会掩盖 ID 和 OOD 轨迹之间真实的潜在差异,因此需要平滑技术来增强鲁棒性。
- 计算约束:模型大小和训练资源:该方法依赖于 Llama2-7B 和 GPT2-XL 等大型 GLM(第 6 页)。训练这些模型需要大量的计算资源(例如,Llama2-7B 的 4 卡 RTX 3090,GPT2-XL 的单卡 RTX 3090,第 23 页)。虽然提出的 TV Score 本身在计算上是“轻量级”的(毫秒级,$O(Ldn)$ 或 $O(Ldk)$ 复杂度,第 22 页),但它运行在这些计算密集型骨干之上。
- 数据驱动约束:数据泄露的不确定性:对于 Llama2-7B 等闭源 GLM,不确定特定 OOD 数据集是否已包含在其预训练数据中(第 23 页)。这使得仅从分布角度明确声明数据集是 OOD 变得困难。作者通过将 OOD 定义为数据集“超出基础模型能力”来解决这个问题(第 23 页)。
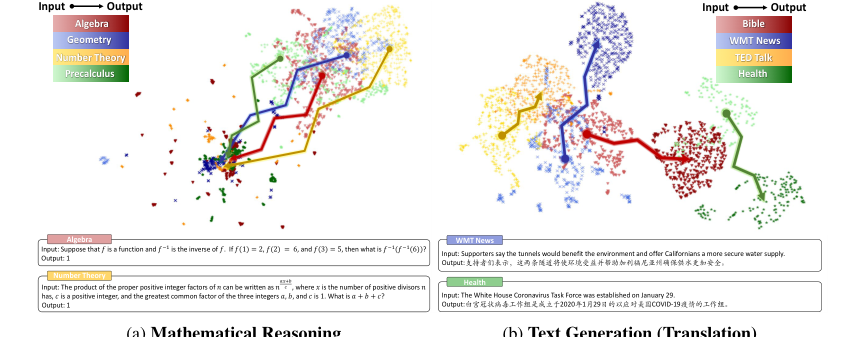 Figure 1. Embedding projection and cases of input and output spaces under mathematical reasoning and text generation scenarios. We select MATH [6] dataset for mathematical reasoning and OPUS [49] for text generation, each with four diverse domains. Different colors represent different domains, with lighter and darker shades indicating input and output. We use SimCSE [9] for sentence embeddings and UMAP [34] for dimensionality reduction. Appendix B shows detailed settings and examples
Figure 1. Embedding projection and cases of input and output spaces under mathematical reasoning and text generation scenarios. We select MATH [6] dataset for mathematical reasoning and OPUS [49] for text generation, each with four diverse domains. Different colors represent different domains, with lighter and darker shades indicating input and output. We use SimCSE [9] for sentence embeddings and UMAP [34] for dimensionality reduction. Appendix B shows detailed settings and examples
为什么选择这种方法
选择的必然性
采用基于轨迹的 TV Score 不仅仅是一种偏好,而是一种必然,这源于生成语言模型(GLM)在数学推理任务中进行分布外(OOD)检测的独特且充满挑战的特性。作者们发现,传统的“SOTA”方法,例如标准的基于嵌入的方法,在面对这一特定问题时存在一个关键的失效点。
作者们明确指出,在第 1 节中,他们意识到传统方法不足的时刻。虽然基于嵌入的方法对于摘要和翻译等传统语言任务已被证明非常有效(如 [43] 使用马氏距离 [22] 所证明的),但在数学推理中遇到了重大挑战。这是由于该领域“输出空间的高密度特征”,作者称之为“模式坍塌”。这种“模式坍塌”导致基于嵌入的方法变得不适用,如图 1 所示。核心问题是,来自不同数学领域的输出,尽管语义不同,却收敛到嵌入空间中的高密度区域,使得静态嵌入距离度量无法区分。这一认识迫使将重点从静态嵌入空间转移到动态的“嵌入轨迹”(第 2 节),因为这是捕捉分布内(ID)和 OOD 样本之间细微差别的唯一可行途径。
比较优势
除了简单的性能指标外,TV Score 方法因其在处理数学推理独特挑战方面的结构优势而表现出深远的定性优势。关键在于它能够利用嵌入在层级之间的动态变化,而不是依赖于静态的、最终层的嵌入。
“模式坍塌”现象虽然使得静态嵌入无法区分,但却产生了“样本之间显著的轨迹差异”(第 2 节,图 2)。TV Score 通过测量“轨迹波动性”来利用这一点,该波动性量化了这些动态变化。这种方法本质上对高密度输出空间问题更具鲁棒性,因为它侧重于嵌入变换的过程,而不仅仅是最终状态。
一个关键的结构优势通过“早期稳定”(Early Stabilization)现象揭示(第 2.2 节,第 3 节)。对于 ID 数据,GLM 倾向于在中后期层完成推理,导致后续层中嵌入变化幅度减小。形成鲜明对比的是,对于 OOD 数据,这种幅度持续很高,表明未能完成连贯的推理。这种独特的动态行为为 OOD 检测提供了强大而可靠的信号,而静态方法根本无法捕捉到。
此外,该方法被描述为“轻量级”(第 3 节),暗示了计算效率。可选的微分平滑技术(TV Score w/ DiSmo)通过减轻异常值对轨迹的影响,进一步增强了鲁棒性,确保了更平滑、更可靠的信号(第 3 节)。实验结果(表 1,表 2)在定量上证实了这种定性优势,显示平均 AUROC 提高了 10 个点以上,FPR95 降低了 80% 以上,即使在其他方法性能显著下降的具有挑战性的近移 OOD 情景下也是如此。
与约束的对齐
所选择的基于轨迹的方法,以 TV Score 为代表,完美地符合数学推理中 OOD 检测固有的严格约束。
- 约束:GLM 在数学推理中的 OOD 检测。 TV Score 是为此领域专门构建的,直接解决了使传统方法失效的“模式坍塌”和“高密度特征”(摘要,第 1 节)。它专门对数学推理特有的现象进行建模和测量,例如“早期稳定”(第 2.2 节)。
- 约束:克服传统基于嵌入方法的不可适用性。 TV Score 的核心动机是静态嵌入方法在数学推理中已被证明的失效(第 1 节,第 6 节)。通过转向动态嵌入轨迹,该方法直接规避了输出空间高密度所施加的限制,在这种空间中,静态嵌入失去了其判别能力(第 2 节,图 2)。
- 约束:需要轻量级解决方案。 本文明确指出 TV Score 是一个“轻量级的 OOD 检测解决方案”(第 3 节)。其计算复杂度高效,ID 分布拟合为 $O(Ldn)$,得分计算为 $O(Ldk)$,使其适用于实际的 GLM 应用(附录 D)。
- 约束:可扩展性和对其他高密度输出任务的通用性。 该方法旨在可扩展,并展示了“在细粒度检测场景中具有更大的优势”(第 5.2 节)。至关重要的是,作者们表明其可扩展到表现出“模式坍塌”特性的其他任务,例如选择题,在这些任务中,它也优于传统算法(摘要,第 5.2 节)。这证实了其超越最初数学推理重点的广泛适用性。
替代方案的拒绝
本文提供了明确的理由,解释了为何拒绝流行的替代 OOD 检测方法,主要侧重于现有方法为何在数学推理的特定环境中失效。
-
传统的静态嵌入式方法(例如,输入/输出嵌入上的马氏距离):这些方法虽然对一般文本生成有效,但被明确认为“不适用于”数学推理(第 1 节)。本文第 6 节专门讨论了“重新思考静态嵌入方法的不可适用性”,详细阐述了其失效的两个主要原因:
- 输入空间表示困境:数学推理的输入空间表现出“模糊的聚类特征”(第 6.1 节,图 1a)。如表 4 所示,语义嵌入未能准确反映数学关系。例如,数学上“分布内”的表达式可能比数学上“分布外”的表达式具有较低的余弦相似度,使得静态输入嵌入对于 OOD 检测不可靠。
- 输出空间“模式坍塌”:这是最关键的问题(第 6.2 节,图 1a)。数学推理的输出空间以高密度和跨域的显著重叠为特征。这种“模式坍塌”发生在两个层面:
- 表达式层面:数学输出通常是标量(例如,“4”),压缩了搜索空间,并增加了截然不同的数学问题之间重叠的可能性(例如,“1+3=”和“$\int x dx=$”都产生“4”)(第 6.2 节)。
- 标记层面:GLM 使用有限的数字(0-9)和特殊符号集来标记数学表达式。即使对于数学上不同的表达式,这也导致了大量的标记共享,从而在自回归预测期间在标记层面发生坍塌(第 6.2 节,表 6)。
表 5 经验性地证实了这一点,表明在许多设置中,在静态嵌入上使用马氏距离产生的 AUROC 分数接近随机(约 50)。
-
不确定性估计方法(例如,最大 softmax 概率、蒙特卡洛 Dropout、序列困惑度):这些方法被包含在实验中作为基线(第 4.1 节,表 1,表 2,表 3)。虽然本文没有提供关于它们为何在数学推理中失效的详细理论分析,但与 TV Score 相比,它们持续且显著的性能不足(通常 AUROC 分数低 10+ 分,FPR95 降低 80%+)暗示了它们的不足。模式坍塌和早期稳定等独特现象并未被这些基于不确定性的方法直接解决,这些方法通常侧重于预测置信度,而不是嵌入的动态演变。
-
思维链(CoT)技术:本文将 CoT 视为一种潜在的替代方案,用于“扩展输出空间大小”并缓解“模式坍塌”(第 6.3 节)。然而,作者的结论是“尽管 CoT 扩展了输出空间大小,但输出答案本质上仍与数学推理的难度和数字相关,语义嵌入表示无法准确反映这些特征。”表 5(b) 中的经验结果表明,即使使用 CoT,使用马氏距离的检测精度仍然很差且高度可变,这表明 CoT 本身不足以解决该领域 OOD 检测的基本问题。
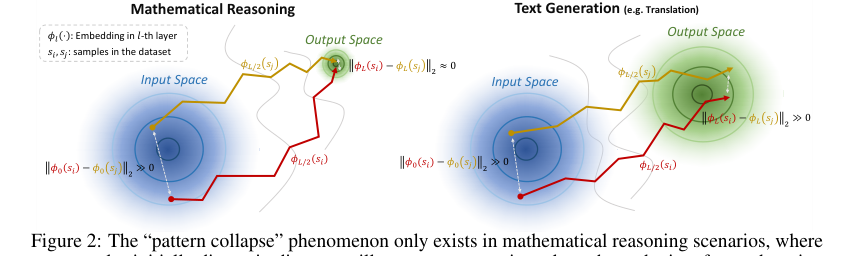 Figure 2. The “pattern collapse” phenomenon only exists in mathematical reasoning scenarios, where two samples initially distant in distance will converge approximately at the endpoint after undergoing embedding shifts, and does not occur in text generation scenarios. This produces a greater likelihood of trajectory variation under different samples in mathematical reasoning
Figure 2. The “pattern collapse” phenomenon only exists in mathematical reasoning scenarios, where two samples initially distant in distance will converge approximately at the endpoint after undergoing embedding shifts, and does not occur in text generation scenarios. This produces a greater likelihood of trajectory variation under different samples in mathematical reasoning
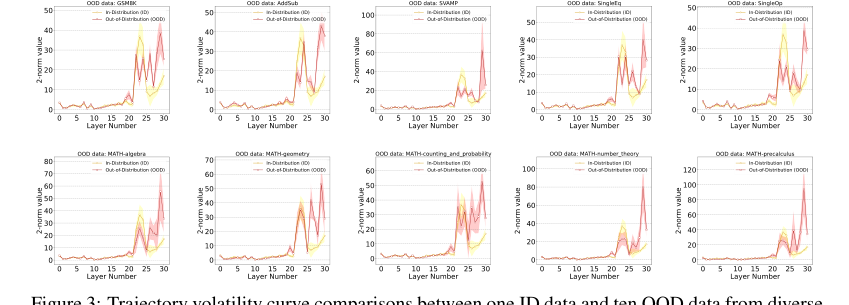 Figure 3. Trajectory volatility curve comparisons between one ID data and ten OOD data from diverse mathematical domains. Each trajectory represents the average of all samples from the corresponding datasets, with color shading being the sample standard deviation. Llama2-7B is used for the backbone
Figure 3. Trajectory volatility curve comparisons between one ID data and ten OOD data from diverse mathematical domains. Each trajectory represents the average of all samples from the corresponding datasets, with color shading being the sample standard deviation. Llama2-7B is used for the backbone
数学与逻辑机制
主方程
本文用于数学推理中分布外(OOD)检测的核心机制是轨迹波动性(TV)得分 $S$。该得分量化了样本的嵌入在生成语言模型(GLM)的层级中传播时的动态变化。TV 得分的主方程定义为:
$$ S = \frac{1}{L} \sum_{l=1}^{L} |f(y_l) - f(y_{l-1})| $$
该方程依赖于一个中间函数 $f(y_l)$,该函数计算特定层 $l$ 处嵌入的马氏距离。该函数由下式给出:
$$ f(y_l) = (y_l - \mu_l)^T (\Sigma_l)^{-1} (y_l - \mu_l) $$
逐项解剖
让我们剖析这些方程,以理解每个组件的作用:
对于 TV Score ($S$) 方程:
- $S$:
- 数学定义:给定输入样本的轨迹波动性得分。
- 物理/逻辑作用:这是作为 OOD 检测得分的最终标量值。较高的 $S$ 表明样本的嵌入轨迹在 GLM 的层级中波动性更大,这被假设是数学推理任务中 OOD 样本的区分特征。
- 为何是加法而非乘法,或积分而非求和:作者使用求和是因为 GLM 具有离散的层数($L$)。求和聚合了相邻层之间马氏距离的个体变化。选择加法是为了累积这些变化的幅度,提供“路径长度”或波动的总度量。乘法会急剧缩放得分,使其作为波动性直接度量的可解释性降低,并可能导致数值不稳定。
- $\frac{1}{L}$:
- 数学定义:$L$ 的倒数,其中 $L$ 是 GLM 中隐藏层的总数。
- 物理/逻辑作用:该项充当归一化因子。它将层级波动性之和转换为每层的平均波动性。这确保了 TV Score 在具有不同层数的模型之间或在分析不同长度的轨迹时具有可比性。
- $\sum_{l=1}^{L}$:
- 数学定义:求和算子,从第一层($l=1$)迭代到最后一层($L$)。
- 物理/逻辑作用:该算子聚合了来自相邻层之间每个过渡的个体波动性贡献。它将样本表示通过模型深度时马氏距离“跳跃”或“移动”的量相加。
- $| \cdot |$:
- 数学定义:绝对值函数。
- 物理/逻辑作用:这确保只考虑相邻层之间马氏距离差的幅度,而不考虑其方向(即距离是增加还是减少)。重点完全在于变化的程度,这对于测量波动性至关重要。
- $f(y_l)$:
- 数学定义:第 $l$ 层平均嵌入 $y_l$ 的马氏距离。
- 物理/逻辑作用:该项量化了样本在第 $l$ 层的嵌入距离 ID 样本在该层典型分布的“远近”。它将高维嵌入转换为一个单一的标量值,表示其在该特定层的“ID-性”。
- $f(y_{l-1})$:
- 数学定义:紧邻第 $l$ 层之前的层 $l-1$ 的平均嵌入 $y_{l-1}$ 的马氏距离。
- 物理/逻辑作用:与 $f(y_l)$ 类似,但用于前一层。差值 $|f(y_l) - f(y_{l-1})|$ 特别测量了当样本表示从第 $l-1$ 层演变到第 $l$ 层时,“ID-性”变化的幅度。
对于马氏距离 ($f(y_l)$) 方程:
- $y_l$:
- 数学定义:第 $l$ 层输出序列的平均嵌入。它是一个 $d$ 维向量,计算方式为 $y_l = \frac{1}{T} \sum_{t=1}^{T} h_t^l$,其中 $h_t^l$ 是第 $l$ 层第 $t$ 个标记的输出嵌入,而 $T$ 是标记的数量。
- 物理/逻辑作用:该向量代表了 GLM 内部特定深度处整个输出序列的聚合语义和数学信息。它是样本在第 $l$ 层输出表示的“状态”。
- $\mu_l$:
- 数学定义:第 $l$ 层所有分布内(ID)样本嵌入拟合的高斯分布 $G_l = N(\mu_l, \Sigma_l)$ 的均值向量。它也是一个 $d$ 维向量。
- 物理/逻辑作用:该向量代表了第 $l$ 层 ID 样本的“中心”或“典型”嵌入。它作为该特定层“正常”的参考点。
- $(y_l - \mu_l)$:
- 数学定义:样本嵌入 $y_l$ 与第 $l$ 层平均 ID 嵌入 $\mu_l$ 之间差值的向量。
- 物理/逻辑作用:这是偏差向量,指示当前样本的嵌入在第 $l$ 层偏离平均 ID 嵌入的程度。
- $(\cdot)^T$:
- 数学定义:转置算子。
- 物理/逻辑作用:在此上下文中,它将列向量 $(y_l - \mu_l)$ 转换为行向量,这对于马氏距离二次形式中的矩阵乘法是必需的。
- $(\Sigma_l)^{-1}$:
- 数学定义:协方差矩阵 $\Sigma_l$ 的逆。$\Sigma_l$ 是第 $l$ 层所有分布内(ID)样本嵌入拟合的高斯分布 $G_l = N(\mu_l, \Sigma_l)$ 的协方差矩阵。它是一个 $d \times d$ 矩阵。
- 物理/逻辑作用:这是马氏距离的一个关键组成部分。它考虑了第 $l$ 层 ID 嵌入空间维度之间的相关性和方差。通过求逆,距离度量有效地“白化”了数据,对特征空间中不同的尺度和旋转进行了归一化。这使得距离比简单的欧氏距离更能反映 ID 数据分布的实际几何形状。
- $(\cdot)^T (\cdot)^{-1} (\cdot)$:
- 数学定义:二次形式,特别是马氏距离的平方。
- 物理/逻辑作用:整个表达式计算马氏距离的平方。它以标准差的单位衡量 $y_l$ 和 $\mu_l$ 之间的距离,有效地对 ID 数据云的分布和方向进行了归一化。这提供了一种衡量嵌入在第 $l$ 层下“可能性”的稳健度量。
分步流程
想象一个单一的、抽象的数据点——我们称之为“查询样本”$s$——进入 OOD 检测管道。这是它在数学引擎中的旅程:
- 初始嵌入生成:查询样本 $s$(例如,一个数学问题)被输入到一个预训练的生成语言模型(GLM)中。GLM 处理输入并生成输出序列(例如,数学解)。
- 层级输出嵌入:当 GLM 生成输出序列时,其内部层会产生标记嵌入。对于输出序列中的每个标记 $T$,从 $L$ 个隐藏层($l=1, \dots, L$)中的每一个层提取一个 $d$ 维嵌入向量 $h_t^l$。
- 句子级聚合:对于每一层 $l$,输出序列中的所有 $T$ 个标记嵌入 $h_t^l$ 被平均,形成一个单一的、代表性的 $d$ 维向量 $y_l$。这个 $y_l$ 封装了该特定层处的整体输出表示。此步骤有效地追踪了样本在 GLM 层级中的“嵌入轨迹”:$y_1 \to y_2 \to \dots \to y_L$。
- ID 分布参考:在处理查询样本之前,系统已经建立了一个“正常”参考。这包括收集一组已知的分布内(ID)样本,将它们通过相同的 GLM,并计算它们的层级平均嵌入。对于每一层 $l$,一个高斯分布 $G_l = N(\mu_l, \Sigma_l)$ 被拟合到这些 ID 嵌入。这意味着均值向量 $\mu_l$ 和协方差矩阵 $\Sigma_l$ 是统计估计的,刻画了每个层级典型的 ID 嵌入空间。
- 马氏距离映射:现在,对于我们查询样本的轨迹,在每一层 $l$,其平均嵌入 $y_l$ 使用马氏距离公式映射到一个标量值 $f(y_l)$。此计算使用该特定层预先计算的 ID 均值 $\mu_l$ 和协方差 $\Sigma_l$。此步骤将复杂的 $d$ 维嵌入转换为一个简单的标量,指示其在该层有多“ID-like”,同时考虑了 ID 数据云的形状。
- 波动性测量:然后,系统查看连续层之间此“ID-性”变化的幅度。对于每一对相邻层 $(l-1, l)$,计算绝对差值 $|f(y_l) - f(y_{l-1})|$。这衡量了当样本表示从一层移动到下一层时,马氏距离变化的幅度。
- TV Score 聚合:所有这些层级波动性幅度被加起来,然后除以总层数 $L$,得到最终的轨迹波动性得分 $S$。这个 $S$ 是一个单一的、平均的度量,表示样本在 GLM 的潜在空间中的旅程中,“ID-性”波动的程度。
- OOD 分类:最后,将查询样本计算出的 TV Score $S$ 与预定义的阈值 $\epsilon$ 进行比较。如果 $S$ 超过 $\epsilon$,则将样本标记为分布外;否则,将其视为分布内。根本假设是,OOD 样本,尤其是在数学推理中,将表现出更高的轨迹波动性,这源于“模式坍塌”等现象。
优化动力学
需要澄清的是,本文提出的轨迹波动性(TV)得分机制本身是一种事后检测方法,而不是一种经过传统梯度下降优化或学习的模型。它没有需要最小化的损失函数,也没有通过反向传播迭代更新其自身参数。
相反,该机制的“学习”或“适应”发生在两个不同的阶段:
- 预训练的生成语言模型(GLM):系统的核心依赖于预训练的 GLM(例如,Llama2-7B 或 GPT2-XL)。该 GLM 在海量数据上单独训练,包括分布内数学推理问题。在此预训练阶段,GLM 学会生成连贯且在数学上合理的输出,并在这样做时,它发展了其跨层级的内部嵌入表示。当应用 TV Score 方法时,此 GLM 的权重和参数是固定的。嵌入 $y_l$ 仅仅是这个静态、预训练模型的输出。
- 分布内(ID)参考拟合:TV Score 方法特有的唯一“拟合”或“学习”是高斯分布 $G_l = N(\mu_l, \Sigma_l)$ 的一次性统计估计,为每一层 $l$ 进行。
- 均值($\mu_l$):对于每一层,$\mu_l$ 计算为该层收集的所有 ID 样本嵌入的经验均值。
- 协方差($\Sigma_l$):类似地,$\Sigma_l$ 是该层 ID 样本嵌入的经验协方差矩阵。
这些参数($\mu_l, \Sigma_l$)一次性从指定的分布内训练数据集中计算得出。然后将它们固定下来,作为每一层“正常”嵌入的静态“参考”。除了初始计算外,确定 $\mu_l$ 和 $\Sigma_l$ 没有涉及迭代更新或梯度。
OOD 检测的最后一步涉及将计算出的 TV Score $S$ 与阈值 $\epsilon$ 进行比较。该阈值通常在验证集上经验确定,例如,通过优化 AUROC 或 FPR95 等指标(如第 4.2 节所述)。这种阈值选择是一种超参数调整,而不是塑造损失景观或更新模型状态的迭代学习过程。
本质上,TV Score 机制是一个统计评分函数,它利用预训练 GLM 的固定、学习表示以及 ID 数据的统计定义参考。它本身不通过梯度下降或类似的优化动力学进行学习、更新或收敛。
结果、局限性与结论
实验设计与基线
为了严格验证其数学主张,作者们设计了一个全面的实验设置,重点关注生成语言模型(GLM)在数学推理中的分布外(OOD)检测。评估分为两个主要场景:离线检测和在线检测。
对于离线检测,目标是分类给定列表中的样本是否为 OOD。采用的关键指标是 AUROC(接收者操作特征曲线下面积)和 FPR95(95% 真阳性率下的假阳性率)。对于在线检测,任务涉及计算最佳分类阈值,以直接确定新样本是否为 OOD,使用判别精度和鲁棒性(以采样方差衡量)。
与 TV Score 进行无情比较的“受害者”(基线模型)是五种无需训练的方法,选择它们是因为 GLM 上 OOD 检测方法的稀缺性:
1. 最大 Softmax 概率(Prob.) [12]
2. 蒙特卡洛 Dropout [8]
3. 序列困惑度 [3]
4. 输入嵌入 [43]
5. 输出嵌入 [43]
实验设计使用 MultiArith [44] 作为分布内(ID)数据集,包含算术推理的数学应用题。对于 OOD 数据,考虑了两种不同的场景:
* 远移 OOD:这包括 MATH 数据集 [11],涵盖五个不同的数学领域(代数、几何、计数与概率、数论和预微积分)。这些问题是大学难度,与 MultiArith 的小学水平形成对比,确保了显著的分布偏移。
* 近移 OOD:这包括五个算术推理数据集(GSM8K [6]、SVAMP [39]、AddSub [13]、SingleEq [18] 和 SingleOp [18])。虽然也是数学应用题,但它们需要与 MultiArith 不同的推理步骤和知识点,代表了更微妙的分布偏移。
ID 数据(MultiArith)被分为 360 个样本用于训练,240 个样本用于测试。为了减轻小测试集的随机性,使用了 1000 个测试采样大小,确保了正样本(OOD)和负样本(ID)数量的平衡。骨干 GLM 使用的是 Llama2-7B [50] 和 GPT2-XL (1.5B) [5],在 MultiArith ID 训练集上进行训练。OOD 数据集选择的合理性通过确认这些数据集超出了基础模型的能力,在它们上的准确率非常低来严格检查,从而从模型性能的角度验证了它们的 OOD 状态。对于带有微分平滑的 TV Score(TV Score w/ DiSmo),平滑阶数 $k$ 在 1 到 5 之间变化,并报告了最佳性能。
证据证明了什么
实验结果提供了决定性的、无可辩驳的证据,表明轨迹波动性的核心机制有效地区分了数学推理中的 ID 和 OOD 样本,并且性能大大优于传统算法。
在离线检测中,TV Score 表现出卓越的优势:
* 远移 OOD:我们的方法在 AUROC 上达到了平均 98.76(Llama2-7B)和 93.47(GPT2-XL),比最佳基线高出 10 多个点。更引人注目的是,FPR95 指标为 5.21(Llama2-7B)和 9.89(GPT2-XL),与最佳基线相比降低了 80% 以上。这清楚地表明,通过分析动态嵌入轨迹,模型可以稳健地识别来自显著不同数学领域的样本。
* 近移 OOD:即使在这种更具挑战性的场景下,基线性能也显著下降(AUROC 低于 60,FPR95 高于 80),我们的方法仍然保持了出色的性能,AUROC 分数高于 90,FPR95 低于 30。这证明了 TV Score 对细微分布偏移的更大适应性和鲁棒性。
模型分析进一步揭示了有趣的现象:GPT2-XL 在远移和近移场景下表现出更稳定的性能,而 Llama2-7B 在近移场景下,基线的性能下降更为明显。微分平滑技术(DiSmo)在 GPT2-XL 上尤其有效,这表明它有助于减轻较小模型潜在空间中的异常学习趋势。至关重要的是,我们的方法几乎通过了所有显著性检验,而基于嵌入的基线则显示出对采样误差更强的敏感性。
对于在线检测,在远移和近移 OOD 情景下,TV Score 的平均准确率比基于嵌入的方法提高了 20 个点,某些数据集的提高幅度超过 40 个点。这种更强的鲁棒性(体现在较低的采样方差中)意味着在现实场景中可以更一致地找到最佳 OOD 分类阈值,从而降低不可控数据获取带来的风险。
除了检测之外,TV Score 在OOD 质量估计方面也表现出色。在衡量与二元匹配质量指标的相关性时,我们的方法在 Llama2-7B 上比 SOTA 基线显示出高达 100% 的 Kendall 相关性提高,以及高达 100%(远移)/ 30%(近移)的 Spearman 相关性提高。这些确凿的证据表明,TV Score 不仅区分 ID/OOD,而且还能准确反映生成数学推理的质量和精度。
最后,该方法的通用性在 MMLU 选择题数据集上得到了证明,该任务也以“模式坍塌”为特征。我们的 TV Score 在此场景下优于所有传统算法,在细粒度检测场景中显示出可扩展性和优势,特别是在传统基于嵌入的方法遇到困难的情况下。
局限性与未来方向
虽然 TV Score 在数学推理的 OOD 检测方面取得了显著进展,但承认其固有的局限性并考虑未来发展的方向至关重要。
作者们强调的主要局限性是数学推理可用数据集的规模相对较小。与拥有数百万样本的传统语言任务不同,数学推理数据集通常只有数百或数千个。这种稀缺性使得训练和评估模型具有鲁棒性变得困难。作者们通过采用测试采样来减少随机性并缓解小规模测试中的数据不平衡问题,但数据可用性的根本问题仍然存在。另一个观察是,微分平滑(DiSmo)的性能在不同设置下有所波动,过度的平滑(例如,$k > 2$)可能会导致有用的特征信息丢失,从而降低检测精度。
展望未来,这项工作催生了几个未来方向,为演变提供了不同的视角:
- 解决数学推理中的数据稀缺问题:鉴于收集和标记大规模数学推理数据的困难,未来的研究可以探索专门针对数学表达式的更高级数据增强技术。能否通过形式数学属性或定理证明器引导的合成数据生成,提供可扩展的解决方案?研究对 ID 数据集依赖性较低的少样本或零样本 OOD 检测方法也将是有价值的。
- 深化对“模式坍塌”的理解:本文将“模式坍塌”确定为一个关键现象。对其根本原因进行更深入的理论和经验研究,超越当前的标记和表达式层面分析,可能会带来新颖的缓解策略。我们能否设计出在结构上更能抵抗符号域中模式坍塌的 GLM 架构或训练目标?
- 扩展到其他符号 AI 任务的通用性:成功扩展到选择题是一个有希望的迹象。这表明 TV Score 可能适用于更广泛的符号 AI 任务,这些任务具有受限的输出空间并表现出“模式坍塌”,例如代码生成、逻辑推理或结构化预测。未来的工作可以系统地识别和验证其他此类领域,可能导致符号 AI 的统一 OOD 检测框架。
- 改进轨迹波动性度量:当前的 TV Score 使用独立于维度和联合维度的波动性。探索更复杂的嵌入轨迹动态度量,例如曲率、挠率,甚至根据样本特征动态调整 $k$ 的自适应平滑技术,可能会产生更精细、更鲁棒的 OOD 检测。
- 混合 OOD 检测方法:虽然基于嵌入的方法,特别是轨迹波动性,在此背景下已被证明更优,但将它们与不确定性估计技术(例如,贝叶斯神经网络、集成方法)相结合,可能会产生更鲁棒的混合 OOD 检测器。这种方法可以利用这两种范例的优势,提供对 OOD 性质更全面的评估。
- 大型模型的计算效率:随着 GLM 的规模和层数不断增加,拟合 ID 分布($O(Ldn)$)和得分计算($O(Ldk)$)的计算复杂度可能会成为瓶颈。未来的工作可以专注于优化这些操作,可能通过近似技术、硬件加速或更高效的嵌入分布统计建模。
- 模式坍塌和轨迹波动性的理论保证:本文提供了经验证据和理论直觉。开发关于为什么数学推理中会发生“模式坍塌”以及为什么轨迹波动性是 OOD 样本可靠信号的更严格的理论保证,将加强这种方法的根基。这可能涉及形式化这些现象成立的条件,并证明 TV Score 有效性的界限。
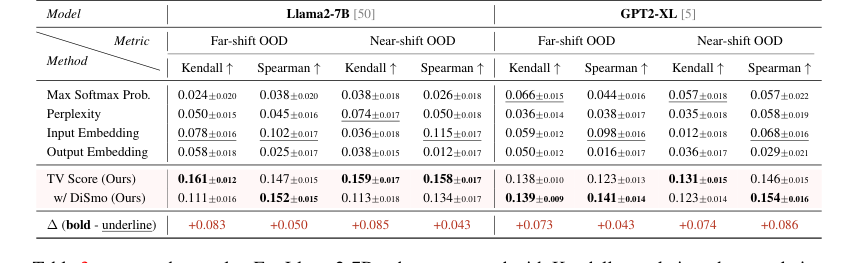 Table 3. presents the results. For Llama2-7B, when compared with Kendall correlation, the correlation improvement of TV scores over SOTA baselines reaches up to 100% under both far-shift and near-shift OOD settings. Compared with Spearman correlation, TV scores demonstrate a correlation enhancement over SOTA baselines by up to 100% under far-shift OOD setting and 30% under near-shift OOD setting. GPT2-XL also demonstrates excellent performance. These findings indicate that our TV scores not only facilitate the binary discrimination of ID and OOD samples but also substantially reflect the quality and precision of generated mathematical reasoning
Table 3. presents the results. For Llama2-7B, when compared with Kendall correlation, the correlation improvement of TV scores over SOTA baselines reaches up to 100% under both far-shift and near-shift OOD settings. Compared with Spearman correlation, TV scores demonstrate a correlation enhancement over SOTA baselines by up to 100% under far-shift OOD setting and 30% under near-shift OOD setting. GPT2-XL also demonstrates excellent performance. These findings indicate that our TV scores not only facilitate the binary discrimination of ID and OOD samples but also substantially reflect the quality and precision of generated mathematical reasoning
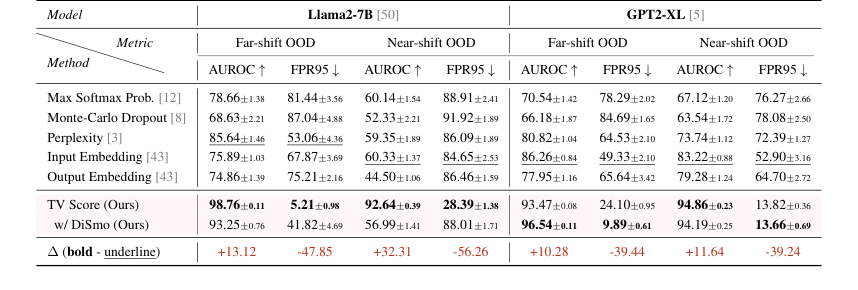 Table 1. AUROC and FPR95 results of the Offline Detection scenario. Underline and bold denote SOTA among all baselines and all methods, respectively. We report the average results under each setting in the main text, results of each dataset are shown in Table 11 and 12 (Appendix F)
Table 1. AUROC and FPR95 results of the Offline Detection scenario. Underline and bold denote SOTA among all baselines and all methods, respectively. We report the average results under each setting in the main text, results of each dataset are shown in Table 11 and 12 (Appendix F)
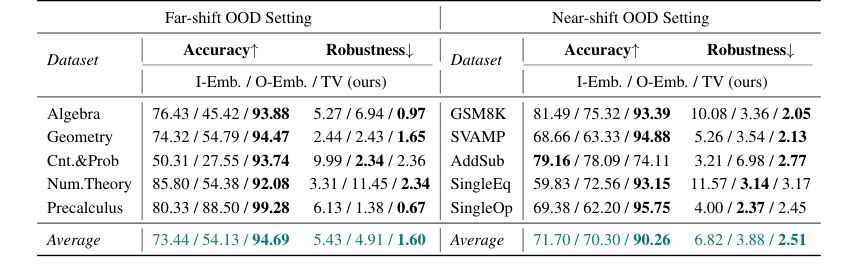 Table 2. presents the results in Llama2-7B. Compared to the embedding-based methods, our TV score obtains about an average of 20-point accuracy improvement in both far-shift OOD and near-shift OOD settings, and on some datasets, such as Cnt.&Prob, our TV score achieves more than 40 points of improvement. These all imply that TV Score can perform online discrimination of OOD samples more accurately. In addition, our TV score also possesses stronger robustness, which means that in real scenarios, we can find the optimal threshold more consistently in the face of different accessible ID and OOD data, reducing the potential riskiness due to uncontrollable data acquisition
Table 2. presents the results in Llama2-7B. Compared to the embedding-based methods, our TV score obtains about an average of 20-point accuracy improvement in both far-shift OOD and near-shift OOD settings, and on some datasets, such as Cnt.&Prob, our TV score achieves more than 40 points of improvement. These all imply that TV Score can perform online discrimination of OOD samples more accurately. In addition, our TV score also possesses stronger robustness, which means that in real scenarios, we can find the optimal threshold more consistently in the face of different accessible ID and OOD data, reducing the potential riskiness due to uncontrollable data acquisition
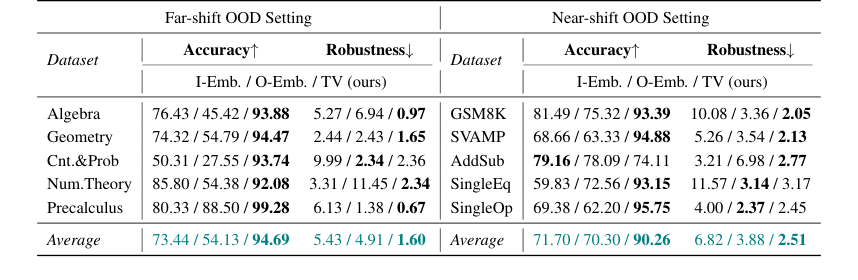 Table 2. Accuracy and Robustness results of the Online Detection scenario. We mainly compare our method with embedding-based methods, and bold denotes the best among these methods
Table 2. Accuracy and Robustness results of the Online Detection scenario. We mainly compare our method with embedding-based methods, and bold denotes the best among these methods
与其他领域的同构性
结构骨架
本文的核心数学和逻辑机制是一种方法,它量化深度神经网络层级中嵌入轨迹的波动性,以识别偏离预期分布的样本。