数学的推論における分布外検出のための埋め込み軌跡
Real-world data deviating from the independent and identically distributed (\textit{i.i.d.}) assumption of in-distribution training data poses security threats to deep networks, thus advancing out-of-distribution...
背景と学術的系譜
起源と学術的系譜
生成言語モデル(GLM)における数学的推論のための分布外(Out-of-Distribution, OOD)検出問題は、比較的新しく、かつ極めて重要な課題である。歴史的に、OOD検出アルゴリズムは主に、訓練データの独立同分布(i.i.d.)仮定から逸脱する実世界のデータからディープニューラルネットワークを保護するために出現した。この分野の初期の研究は、主にコンピュータビジョンや従来のテキスト分類タスクに集中していた。
GLMが進歩するにつれて、OOD検出手法は、要約や翻訳のようなテキスト生成シナリオに適応された。これらの手法は通常、不確実性推定または埋め込み距離測定のいずれかに依存していた。しかし、これらの既存のアプローチを数学的推論タスクに適用した際、学術界は重大な「ペインポイント」に直面した。数学的推論は、困難な生成タスクであり、その出力空間における独自の特性が、従来の埋め込みベースの手法を無効にした。著者らは、知る限り、数学的推論におけるOOD検出を体系的に研究し、この特定のドメインにおける従来のアルゴリズムの失敗を特定した最初であると明記している。したがって、本稿は、GLMの文脈におけるOOD検出と数学的推論の交差点における新規な問題に取り組むものである。
以前のアプローチの根本的な限界は、著者らが数学的推論の出力空間における「パターン崩壊」と呼ぶ現象に起因する。静的な埋め込み空間(例:マハラノビス距離)における距離を測定する従来の埋め込みベースの手法は、異なる意味論的入力が埋め込み空間の異なる領域にマッピングされると仮定している。しかし、数学的推論では、出力はしばしば記号的(例:数字、単純な式)であり、限られたトークン語彙(例:数字0-9および基本的な数学記号)から構築される。これにより、意味論的に多様な数学的問題の出力埋め込みが、潜在空間の高密度で重複する領域に収束する。結果として、分布内(ID)サンプルとOODサンプルの間の静的な埋め込み距離は区別不能になり、以前の手法ではOODデータを確実に検出することが不可能になる。「パターン崩壊」は、モデルが見たものと見ていないものの境界線を効果的に曖昧にし、著者らに新しい動的なアプローチを模索させることになった。
直感的なドメイン用語
- 分布外(OOD)データ: 赤いリンゴと緑のリンゴを分類するように訓練されたスマートロボットを想像してください。もし誰かが突然、青いベリーを与えたら、それはOODデータです。それはロボットが訓練中に一度も遭遇したことのないものであり、学習したカテゴリに適合しないため、混乱したり、誤った推測をしたりする可能性があります。
- 生成言語モデル(GLM): GLMを、新しいレシピを発明できる非常に創造的なシェフと考えてください。シェフにテーマ(例:「夏のデザート」)を与えると、彼らは単に料理本から選ぶのではなく、材料と技術を組み合わせて全く新しいユニークな料理を作成します。同様に、GLMは既存のフレーズを検索するだけでなく、新しいテキストを生成します。
- パターン崩壊: それぞれの絵画がユニークな大きな美術館を想像してください。今、それらの絵画すべてが、非常に小さな低解像度のサムネイルにデジタル圧縮されたと想像してください。多くの異なる絵画が、サムネイル形式では非常に似ていたり、同一に見えたりする可能性があり、それらを区別することが困難になります。ユニークなパターンが共通の、区別不能な形式に「押しつぶされる」ことは、数学的推論の出力で起こることであり、それらを区別することが困難になります。
- 埋め込み軌跡: 多くのレベルを持つ複雑な迷路を考えてください。ネズミが迷路に入ると、各レベルをナビゲートするにつれて痕跡を残します。埋め込み軌跡は、情報がニューラルネットワークの各処理層を通過する際のその痕跡をたどるようなものです。それは情報がどこに最終的に到達するかだけでなく、それが経験するすべての変換のシーケンスを示します。
- 軌跡の変動性: 迷路の類推に従って、軌跡の変動性は、レベル間のネズミの経路がどれほど不規則または滑らかであるかの尺度です。ネズミがレベル間で突然、大きな方向転換をする場合、その経路は非常に変動性が高いです。ネズミが予測可能かつ滑らかに移動する場合、その変動性は低いです。ネットワークを通過するデータの旅のこの「でこぼこ」または「滑らかさ」は、それが馴染みのある入力か、予期しない分布外の入力かを示す可能性があります。
記法表
| 記法 | 説明 | タイプ |
|---|---|---|
| $s$ | 与えられたサンプル、通常は入力-出力ペア。 | 変数 |
| $L$ | 生成言語モデルにおける隠れ層の総数。 | パラメータ |
| $d$ | 埋め込みベクトルの次元数。 | パラメータ |
| $Y_l$ | 層 $l$ における出力シーケンスの平均埋め込み。 | 変数 |
| $V_I(s)$ | サンプル $s$ の次元非依存変動性。次元間の局所的な軌跡変化を捉える。 | 変数 |
| $V_J(s)$ | サンプル $s$ の次元結合変動性。L2ノルムを用いた軌跡の全体的な変化を捉える。 | 変数 |
| $\mu_l$ | 層 $l$ における分布内(ID)埋め込みに適合させたガウス分布の平均ベクトル。 | パラメータ |
| $\Sigma_l$ | 層 $l$ におけるID埋め込みに適合させたガウス分布の共分散行列。 | パラメータ |
| $f(Y_l)$ | IDガウス分布 $G_l$ からの平均埋め込み $Y_l$ のマハラノビス距離。 | 変数 |
| $S$ | サンプルの軌跡変動性(TV)スコア。隣接する層間のマハラノビス距離差の平均として計算される。 | 変数 |
| $k$ | 軌跡変動性に適用される微分平滑化の次数。 | パラメータ |
| $\nabla^k S$ | $k$ 次微分平滑化を施した軌跡変動性(TV)スコア。 | 変数 |
問題定義と制約
コア問題の定式化とジレンマ
本稿で取り組む中心的な問題は、生成言語モデル(GLM)が数学的推論タスクを実行する際の、分布外(OOD)データの正確な検出である。
出発点(入力/現在の状態)は、通常、独立同分布(i.i.d.)データ分布を仮定する分布内(ID)データで訓練されたGLMである。このGLMが、このi.i.d.仮定から逸脱する実世界の入力(すなわち、OODデータ)に提示されると、そのパフォーマンスは予期せず低下する可能性があり、潜在的に有害な結果につながる。GLM向けの既存のOOD検出手法は、主に2つのアプローチに依存している:不確実性推定と埋め込み距離測定である。埋め込みベースの手法は、従来の言語タスク(要約や翻訳など)で効果的であることが証明されているが、数学的推論には適用不可能であることが判明している。この適用不可能性は、数学的推論で観察される2つの独自の現象に起因する:
1. 入力空間における曖昧なクラスタリング: 様々なドメインにわたる数学的推論問題の入力埋め込みは、「曖昧なクラスタリング特徴」(図1a、2ページ)を示し、静的な埋め込みが異なる数学的問題間の固有の複雑さと区別を捉えることを困難にする。
2. 出力空間におけるパターン崩壊: 数学的推論の出力埋め込みは、「異なるドメイン間の大きな重複を伴う高密度特性」(図1a、2ページ)を示す。この「パターン崩壊」と名付けられた現象は、数学的出力がしばしば記号的(例:数字0-9、特殊記号)であり、探索空間を圧縮し、数学的に異なる表現間でかなりのトークン共有につながるために発生する。これにより、多様な数学的問題の埋め込みが高密度領域に収束し、従来の静的な埋め込み距離測定では区別不能になる。
望ましい終点(出力/目標状態)は、数学的推論シナリオに特化して調整された、堅牢で軽量なOOD検出アルゴリズム、TVスコアである。このアルゴリズムは、「パターン崩壊」が存在する場合でも、IDサンプルとOODサンプルを効果的に区別する必要がある。最終的な目標は、高い識別精度を達成することであり、これは次式を最大化するスコア関数 $f(x, y, \theta)$ としきい値 $\epsilon$ を見つけることで形式化される:
$$ \max_{f} P_{(x,y)\sim P_{X,Y}}[f(x,y,\theta) < \epsilon] + P_{(x,\tilde{y})\sim P_{\tilde{X},\tilde{Y}}}[f(x,\tilde{y},\theta) > \epsilon] $$
ここで、$P_{X,Y}$ は分布内同時データ分布であり、$P_{\tilde{X},\tilde{Y}}$ は分布外同時データ分布である(式1、3ページ)。さらに、この手法は、多肢選択問題のような高密度出力特徴を持つ他のタスクにも一般化可能である必要がある。
本稿が橋渡ししようとしている正確な欠落リンクまたは数学的ギャップは、「パターン崩壊」現象による数学的推論における静的な埋め込みベースのOOD検出手法の失敗である。以前の手法は、静的な入力または出力空間におけるID埋め込み分布と新しいサンプルの埋め込みとの間のマハラノビス距離を計算する(1ページ)。しかし、「パターン崩壊」は、異なる数学的推論サンプルの埋め込み軌跡の終点が収束するため、これらの静的な距離測定を無効にする。本稿は、終点が崩壊する可能性がある一方で、これらの終点に至る動的な埋め込み軌跡は、IDサンプルとOODサンプルの間で顕著な違いを示すと仮説を立てている。欠落リンクはしたがって、静的な終点距離ではなく、これらの軌跡の違いを定量化するメカニズムである。
以前の研究者を閉じ込めてきた痛みを伴うトレードオフまたはジレンマは、数学的推論出力の記号的で高密度の性質と、効果的な埋め込みベースのOOD検出の要件との間の固有の対立である。従来のテキスト生成では、異なる意味論的意味がよく分離された埋め込みクラスタにつながり、埋め込み距離がうまく機能する。しかし、数学的推論では、回答の簡潔さと共有トークン語彙(例:数字)が、多様な問題が非常に類似した出力埋め込みにマッピングされる原因となる。「パターン崩壊」は、正しい数学的回答(しばしばスカラーまたは単純な式である)を生成するモデルの能力を向上させることが、意図せずOOD検出手法が依存する潜在空間の区別性を破壊することを意味する。研究者たちは、数学的推論における不十分なOOD検出を受け入れるか、またはそのようなユニークな出力空間でOODがどのように定義され測定されるかを根本的に再考するかのジレンマに陥っていた。
制約と失敗モード
数学的推論におけるOOD検出の問題は、いくつかの厳しい現実的な制約により、非常に困難である:
- データ駆動型制約: 高密度出力空間(「パターン崩壊」): これは最も重要な制約である。数学的推論の出力は「数学的に記号的」(2ページ)であり、探索空間を圧縮する。これにより、異なるドメインからの質問間の重複の可能性が高まる。特に、GLMは限られた語彙(数字0-9および有限の特殊記号)を使用して数学的表現をトークン化するため、「数学的に異なる表現間でかなりのトークン共有」(2ページ、セクション6.2)が生じる。これにより、出力埋め込みが高密度で区別不能な領域に収束し、従来の静的な埋め込み距離手法が無効になる。
- データ駆動型制約: 曖昧な入力空間クラスタリング: 数学的推論の入力空間も、「様々なドメインにわたる曖昧なクラスタリング特徴」(2ページ、図1a)を示す。これは、埋め込みが数学的問題の完全な複雑さを捉えるのに苦労していることを示しており、入力側からのOOD検出をさらに複雑にしている。
- 物理的制約: 限られたデータ可用性: 数学的推論データセットは、「比較的小さい」(数百または数千サンプル)であり、特に翻訳や要約のような従来のNLPタスクで利用可能な数百万サンプルと比較すると(1ページ、11ページ、「限界」)。このデータの不足は、堅牢なモデルを訓練し、OOD検出手法を確実に評価することを困難にし、結果のランダム性を増加させる。著者らはテストサンプリングを用いることでこれを軽減している。
- アルゴリズム的制約: 軌跡の違いの定量化の困難さ: 静的な埋め込みの違いはマハラノビス距離で測定できるが、「軌跡と軌跡クラスタの違いを定量化することは直感的ではない」(5ページ)。これには、層を横断する埋め込み空間の動的な変化を捉えるための新しい数学的定式化が必要であり、本稿では軌跡変動性を定義することによってこれを対処している。
- アルゴリズム的制約: 軌跡の外れ値: 埋め込み軌跡の外れ値は、「特徴抽出に大きな影響を与える」(5ページ)可能性がある。このノイズは、ID軌跡とOOD軌跡の間の真の基底の違いを曖昧にする可能性があり、平滑化技術を必要として堅牢性を向上させる。
- 計算的制約: モデルサイズと訓練リソース: この手法は、Llama2-7BやGPT2-XLのような大規模GLMに依存している(6ページ)。これらのモデルの訓練には、かなりの計算リソース(例:Llama2-7Bの場合は4カードRTX 3090、GPT2-XLの場合はシングルRTX 3090、23ページ)が必要である。提案されたTVスコア自体は計算(ミリ秒、$O(Ldn)$または$O(Ldk)$の複雑さ、22ページ)の点で「軽量」であるが、これらの計算集約的なバックボーンの上に動作する。
- データ駆動型制約: データ漏洩の不確実性: Llama2-7BのようなクローズドソースGLMでは、特定のOODデータセットが事前訓練データに含まれていたかどうかについて不確実性がある(23ページ)。これにより、分布的な観点からデータセットがOODであることを断定的に主張することが困難になる。著者らは、データセットが「ベースモデルの能力を超える」かどうかによってOODを定義することで、これに対処している(23ページ)。
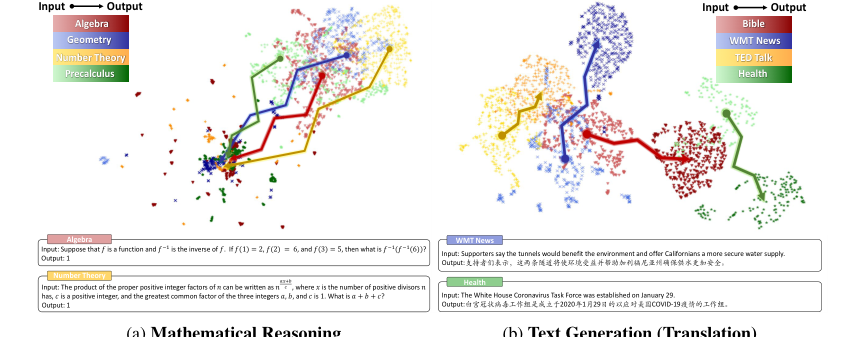 Figure 1. Embedding projection and cases of input and output spaces under mathematical reasoning and text generation scenarios. We select MATH [6] dataset for mathematical reasoning and OPUS [49] for text generation, each with four diverse domains. Different colors represent different domains, with lighter and darker shades indicating input and output. We use SimCSE [9] for sentence embeddings and UMAP [34] for dimensionality reduction. Appendix B shows detailed settings and examples
Figure 1. Embedding projection and cases of input and output spaces under mathematical reasoning and text generation scenarios. We select MATH [6] dataset for mathematical reasoning and OPUS [49] for text generation, each with four diverse domains. Different colors represent different domains, with lighter and darker shades indicating input and output. We use SimCSE [9] for sentence embeddings and UMAP [34] for dimensionality reduction. Appendix B shows detailed settings and examples
なぜこのアプローチなのか
選択の必然性
軌跡ベースのTVスコアの採用は、単なる好みではなく、生成言語モデル(GLM)における数学的推論の分布外(OOD)検出のユニークで困難な特性によって駆動される必然性であった。著者らは、従来の「SOTA」手法、特に標準的な埋め込みベースのアプローチが、この特定の課題に直面した際に、重大な失敗点であることを特定した。
著者らが従来のшел手法が不十分であると認識した正確な瞬間は、セクション1で明確に述べられている。埋め込みベースの手法は、要約や翻訳のような従来の言語タスクで非常に効果的であることが証明されていた(マハラノビス距離[22]を使用した[43]によって実証されているように)が、数学的推論では重大な課題に直面した。これは、このドメインにおける「出力空間の高密度特徴」によるものであり、著者らが「パターン崩壊」と名付けた現象である。この「パターン崩壊」は、図1に示すように、埋め込みベースの手法を適用不可能にする。根本的な問題は、意味論的に異なるにもかかわらず、多様な数学的ドメインからの出力が埋め込み空間の高密度領域に収束し、静的な埋め込み距離測定では区別不能になることである。この認識は、分布内(ID)サンプルとOODサンプルの間の微妙な違いを捉える唯一の実行可能な道であったため、静的な埋め込み空間から動的な「埋め込み軌跡」(セクション2)への焦点のシフトを強制した。
比較優位性
単純なパフォーマンスメトリックを超えて、TVスコア手法は、数学的推論のユニークな課題を処理する上での構造的利点により、深遠な定性的優位性を示す。鍵は、静的な最終層埋め込みに依存するのではなく、層を横断する埋め込みの動的な変化を活用する能力にある。
「パターン崩壊」現象は、静的な埋め込みを区別不能にする一方で、逆説的に「サンプル間の顕著な軌跡の違い」(セクション2、図2)を生み出す。TVスコアは、これらの動的なシフトを定量化する「軌跡変動性」を測定することにより、これを活用する。このアプローチは、最終状態だけでなく、埋め込み変換のプロセスに焦点を当てるため、高密度出力問題に対して本質的に堅牢である。
「早期安定化」現象(セクション2.2、セクション3)によって明らかになる重要な構造的利点がある。IDデータの場合、GLMは中間層から後期層で推論を完了する傾向があり、後続層での埋め込み変化の大きさの抑制につながる。これとは対照的に、OODデータの場合、この大きさは持続的に高く、一貫した推論の完了に失敗したことを示している。この明確な動的な挙動は、静的な手法では捉えられない、OOD検出のための強力で信頼性の高い信号を提供する。
さらに、この手法は「軽量」(セクション3)と説明されており、計算効率を示唆している。オプションの微分平滑化技術(TVスコアw/ DiSmo)は、軌跡の外れ値の影響を軽減し、より滑らかで信頼性の高い信号を保証することにより、堅牢性をさらに向上させる(セクション3)。実験結果(表1、表2)は、この定性的優位性を定量的に確認しており、困難なニアシフトOODシナリオでさえ、他のベースラインが著しいパフォーマンス低下に苦しむ場合でも、平均AUROCの10ポイント以上の改善とFPR95の顕著な80%以上の削減を示している。
制約との整合性
選択された軌跡ベースのアプローチ、TVスコアによって具体化されたものは、数学的推論におけるOOD検出に固有の厳格な制約と完全に整合している。
- 制約: 数学的推論のためのGLMにおけるOOD検出。 TVスコアは、このドメインのために特別に構築されており、従来のшел手法を失敗させる「パターン崩壊」と「高密度特徴」に直接対処している(要旨、セクション1)。特に、「早期安定化」(セクション2.2)のような、数学的推論に固有の現象をモデル化し測定する。
- 制約: 従来の埋め込みベース手法の適用不可能性の克服。 TVスコアの主な動機は、数学的推論における静的な埋め込み手法の実証された失敗である(セクション1、セクション6)。動的な埋め込み軌跡に移行することにより、この手法は、静的な埋め込みが識別力を失う出力空間の高密度によって課される限界を直接回避する(セクション2、図2)。
- 制約: 軽量ソリューションの必要性。 本稿は、TVスコアが「軽量OOD検出ソリューション」(セクション3)であると明示している。その計算複雑性は効率的であり、ID分布フィッティング用の$O(Ldn)$、スコア計算用の$O(Ldk)$の複雑さで、実世界のGLMアプリケーションに実用的である(付録D)。
- 制約: 他の高密度出力タスクへのスケーラビリティと一般化可能性。 この手法はスケーラブルになるように設計されており、「ファイングレイン検出シナリオでより大きな利点」(セクション5.2)を示す。特に重要なのは、著者らが、多肢選択問題のような「パターン崩壊」特性を示す他のタスクへの拡張性を示しており、そこでも従来のアルゴリズムを上回っていることである(要旨、セクション5.2)。これは、最初の数学的推論の焦点を超えた広範な適用可能性を確認するものである。
代替案の却下
本稿は、主に数学的推論の特定の文脈で既存の手法が失敗する理由に焦点を当て、人気のある代替OOD検出アプローチを却下する明確な理由を提供している。
-
従来の静的埋め込みベース手法(例:入力/出力埋め込みのマハラノビス距離): これらの手法は、一般的なテキスト生成には効果的であるが、数学的推論には明確に「適用不可能」とされている(セクション1)。本稿は、セクション6を「静的埋め込み手法の適用不可能性の再考」に費やし、その失敗の2つの主な理由を詳述している:
- 入力空間表現のジレンマ: 数学的推論の入力空間は「曖昧なクラスタリング特徴」(セクション6.1、図1a)を示す。表4に示すように、意味論的埋め込みは数学的関係を正確に反映しない。例えば、数学的に「分布内」の表現は、数学的に「分布外」の表現よりも低いコサイン類似度を持つ可能性があり、静的な入力埋め込みはOOD検出には信頼できない。
- 出力空間の「パターン崩壊」: これは最も重要な問題である(セクション6.2、図1a)。数学的推論の出力空間は、高密度とドメイン間の大きな重複を特徴とする。この「パターン崩壊」は2つのレベルで発生する:
- 表現レベル: 数学的出力はしばしばスカラー(例:「4」)であり、探索空間を圧縮し、非常に異なる数学的問題間の重複の可能性を高める(例:「1+3=」と「$\int x dx=$」の両方が「4」を生成する)(セクション6.2)。
- トークンレベル: GLMは、数字(0-9)と特殊記号の限られたセットを使用して数学的表現をトークン化する。これにより、数学的に異なる表現であっても、かなりのトークン共有が生じ、自己回帰予測中のトークンレベルでの崩壊を引き起こす(セクション6.2、表6)。
表5は、この却下を経験的に確認しており、静的な埋め込み上のマハラノビス距離が、多くの設定でほぼランダムなAUROCスコア(約50)を生成することを示している。
-
不確実性推定手法(例:最大ソフトマックス確率、モンテカルロドロップアウト、シーケンスパープレキシティ): これらの手法は、実験(セクション4.1、表1、表2、表3)でベースラインとして含まれている。本稿は、それらが数学的推論に失敗する理由の詳細な理論的分析を提供していないが、TVスコアと比較して一貫して著しく低いパフォーマンス(しばしば10+ AUROCポイントおよび80%+ FPR95削減)は、それらの不十分さを示唆している。これらの不確実性ベースの手法は、埋め込みの動的な進化ではなく、予測信頼性に焦点を当てることが多いが、「パターン崩壊」や「早期安定化」のような独自の現象には直接対処していない。
-
思考連鎖(CoT)手法: 本稿は、「出力空間のサイズを拡大」し、「パターン崩壊」を軽減するための代替案としてCoTを検討している(セクション6.3)。しかし、著者らは、「CoTが出力空間のサイズを拡大するにもかかわらず、出力される回答は依然として数学的推論の難易度と数字に本質的に関連しており、意味論的埋め込み表現はこれらの特徴を正確に反映できない」と結論付けている。表5(b)の経験的結果は、CoTを使用しても、マハラノビス距離を使用した検出精度が依然として低く、変動が大きいことを示しており、CoTだけではこのドメインにおけるOOD検出の根本的な問題を解決するには不十分であることを示唆している。
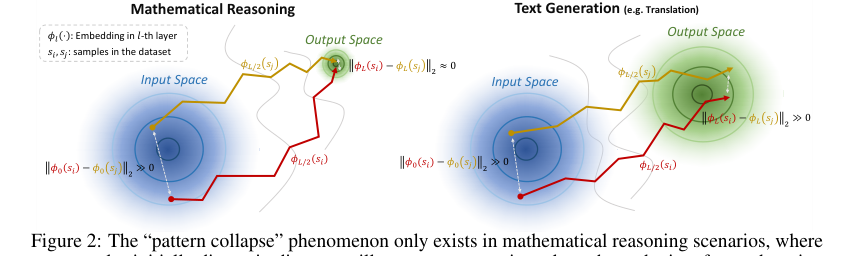 Figure 2. The “pattern collapse” phenomenon only exists in mathematical reasoning scenarios, where two samples initially distant in distance will converge approximately at the endpoint after undergoing embedding shifts, and does not occur in text generation scenarios. This produces a greater likelihood of trajectory variation under different samples in mathematical reasoning
Figure 2. The “pattern collapse” phenomenon only exists in mathematical reasoning scenarios, where two samples initially distant in distance will converge approximately at the endpoint after undergoing embedding shifts, and does not occur in text generation scenarios. This produces a greater likelihood of trajectory variation under different samples in mathematical reasoning
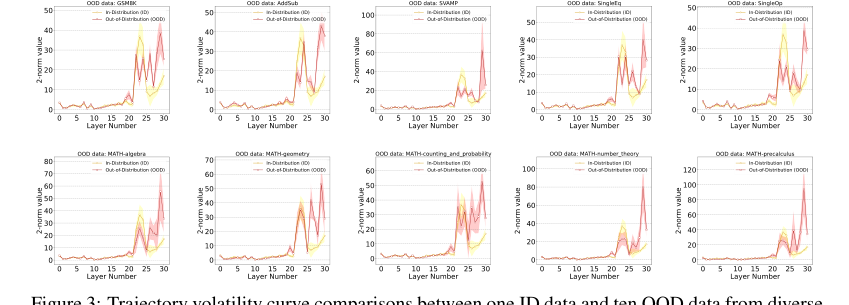 Figure 3. Trajectory volatility curve comparisons between one ID data and ten OOD data from diverse mathematical domains. Each trajectory represents the average of all samples from the corresponding datasets, with color shading being the sample standard deviation. Llama2-7B is used for the backbone
Figure 3. Trajectory volatility curve comparisons between one ID data and ten OOD data from diverse mathematical domains. Each trajectory represents the average of all samples from the corresponding datasets, with color shading being the sample standard deviation. Llama2-7B is used for the backbone
数学的・論理的メカニズム
マスター方程式
数学的推論における分布外(OOD)検出のための本稿のメカニズムの中核は、軌跡変動性(TV)スコア、$S$ である。このスコアは、生成言語モデル(GLM)の層を通過する際のサンプルの埋め込みの動的な変化を定量化する。TVスコアのマスター方程式は次のように定義される:
$$ S = \frac{1}{L} \sum_{l=1}^{L} |f(y_l) - f(y_{l-1})| $$
この方程式は、特定の層 $l$ における埋め込みのマハラノビス距離を計算する中間関数、$f(y_l)$ に依存する。この関数は次のように与えられる:
$$ f(y_l) = (y_l - \mu_l)^T (\Sigma_l)^{-1} (y_l - \mu_l) $$
項ごとの解剖
これらの式を分解して、各コンポーネントの役割を理解しよう:
TVスコア($S$)の方程式について:
- $S$:
- 数学的定義: 与えられた入力サンプルの軌跡変動性スコア。
- 物理的/論理的役割: これは、OOD検出スコアとして機能する最終的なスカラー値である。$S$ が高いほど、数学的推論タスクにおけるOODサンプルの特徴であると仮定される、GLMの層を横断するサンプルの埋め込み軌跡の変動性が大きいことを示す。
- なぜ加算なのか、乗算や積分ではなく和なのか: 著者らは、GLMが層の数 ($L$) が離散的であるため、和を使用している。和は、隣接する層間のマハラノビス距離の個々の変化を合計する。加算は、これらの変化の大きさを累積するために選択され、「パス長」または変動性の総測定値を提供する。乗算はスコアを劇的にスケールアップし、変動性の直接的な尺度としての解釈を困難にし、数値的不安定性を引き起こす可能性がある。
- $\frac{1}{L}$:
- 数学的定義: $L$(GLMの隠れ層の総数)の逆数。
- 物理的/論理的役割: この項は正規化係数として機能する。層ごとの変動性の合計を層あたりの平均変動性に変換する。これにより、TVスコアは、層数が異なるモデル間や、異なる長さの軌跡を分析する際に比較可能になる。
- $\sum_{l=1}^{L}$:
- 数学的定義: 和演算子。最初の層($l=1$)から最後の層($L$)まで反復する。
- 物理的/論理的役割: この演算子は、隣接する層間の各遷移からの個々の変動性寄与を合計する。サンプルの表現がモデルの深さを通過するにつれて、マハラノビス距離がどれだけ「ジャンプ」または「シフト」するかを合計する。
- $| \cdot |$:
- 数学的定義: 絶対値関数。
- 物理的/論理的役割: 隣接する層間のマハラノビス距離の差の大きさのみを考慮し、その方向(距離が増加したか減少したか)は考慮しないことを保証する。焦点は、変動性を測定する中心である変化の程度にのみある。
- $f(y_l)$:
- 数学的定義: 層 $l$ における平均埋め込み $y_l$ のマハラノビス距離。
- 物理的/論理的役割: この項は、層 $l$ におけるサンプルの埋め込みが、その同じ層における分布内(ID)サンプルの典型的な分布からどれだけ「離れている」かを定量化する。これは、高次元埋め込みを、その特定の層における「IDらしさ」を表す単一のスカラー値に変換する。
- $f(y_{l-1})$:
- 数学的定義: 層 $l$ の直前の層における平均埋め込み $y_{l-1}$ のマハラノビス距離。
- 物理的/論理的役割: $f(y_l)$ と同様だが、前の層に対して。差 $|f(y_l) - f(y_{l-1})|$ は、サンプルの表現が層 $l-1$ から層 $l$ へ進化するにつれて、マハラノビス距離の「IDらしさ」の変化を具体的に測定する。
マハラノビス距離($f(y_l)$)の方程式について:
- $y_l$:
- 数学的定義: 層 $l$ における出力シーケンスのトークンの平均埋め込み。これは $d$ 次元ベクトルであり、$y_l = \frac{1}{T} \sum_{t=1}^{T} h_t^l$ として計算される。ここで、$h_t^l$ は層 $l$ における $t$ 番目のトークンの出力埋め込みであり、$T$ はトークンの数である。
- 物理的/論理的役割: このベクトルは、GLM内の特定の深さにおける出力シーケンス全体の集約された意味論的および数学的情報を表す。これは、特定の層におけるサンプル出力表現の「状態」である。
- $\mu_l$:
- 数学的定義: 層 $l$ におけるすべての分布内(ID)サンプル埋め込みに適合させたガウス分布 $G_l = N(\mu_l, \Sigma_l)$ の平均ベクトル。これも $d$ 次元ベクトルである。
- 物理的/論理的役割: このベクトルは、層 $l$ におけるIDサンプルの「中心」または「典型的」な埋め込みを表す。これは、その特定の層で「正常」と見なされるものの参照点として機能する。
- $(y_l - \mu_l)$:
- 数学的定義: 層 $l$ におけるサンプルの埋め込み $y_l$ とID平均埋め込み $\mu_l$ との差を表すベクトル。
- 物理的/論理的役割: これは偏差ベクトルであり、層 $l$ における現在のサンプルの埋め込みがID平均埋め込みからどれだけ逸脱しているかを示す。
- $(\cdot)^T$:
- 数学的定義: 転置演算子。
- 物理的/論理的役割: この文脈では、列ベクトル $(y_l - \mu_l)$ を行ベクトルに変換し、マハラノビス距離の二次形式における行列乗算に必要となる。
- $(\Sigma_l)^{-1}$:
- 数学的定義: 共分散行列 $\Sigma_l$ の逆行列。$\Sigma_l$ は、層 $l$ におけるすべての分布内(ID)サンプル埋め込みに適合させたガウス分布 $G_l = N(\mu_l, \Sigma_l)$ の共分散行列である。これは $d \times d$ 行列である。
- 物理的/論理的役割: これはマハラノビス距離の重要なコンポーネントである。層 $l$ におけるID埋め込み空間の次元間の相関と分散を考慮する。それを逆転させることにより、距離尺度は、特徴空間における異なるスケールと回転に対してデータを効果的に「ホワイトニング」する。これにより、IDデータ分布の実際の形状に対してより意味のある「距離」尺度が得られ、ユークリッド距離よりも堅牢になる。
- $(\cdot)^T (\cdot)^{-1} (\cdot)$:
- 数学的定義: 二次形式、特に二乗マハラノビス距離。
- 物理的/論理的役割: この式全体が二乗マハラノビス距離を計算する。これは、$y_l$ と $\mu_l$ の間の距離を標準偏差の単位で測定し、IDデータクラウドの広がりと向きを効果的に正規化する。これにより、各層におけるID分布の下での埋め込みの「ありえなさ」の堅牢な尺度が得られる。
ステップバイステップの流れ
単一の抽象的なデータポイント、ここでは「クエリサンプル」$s$ がOOD検出パイプラインに入力されると想像してください。これは、数学的エンジンを通過するその旅です:
- 初期埋め込み生成: クエリサンプル $s$(例:数学的問題)が、事前訓練された生成言語モデル(GLM)に入力される。GLMは入力を処理し、出力シーケンス(例:数学的解)を生成する。
- 層ごとの出力埋め込み: GLMが出力シーケンスを生成するにつれて、その内部層はトークン埋め込みを生成する。出力シーケンスの各トークン $T$ に対して、$d$ 次元埋め込みベクトル $h_t^l$ が $L$ 個の隠れ層($l=1, \dots, L$)のそれぞれから抽出される。
- 文レベル集約: 各層 $l$ について、出力シーケンスのすべてのトークン埋め込み $h_t^l$ が平均化され、単一の代表的な $d$ 次元ベクトル $y_l$ が形成される。この $y_l$ は、特定の層における出力の全体的な表現をカプセル化する。このステップは、GLMの層を横断するサンプルの「埋め込み軌跡」を効果的にたどる:$y_1 \to y_2 \to \dots \to y_L$。
- ID分布参照: クエリサンプルの処理に先立ち、システムはすでに「正常」な参照を確立している。これには、既知の分布内(ID)サンプルの大きなセットを収集し、それらを同じGLMに通し、層ごとの平均埋め込みを計算することが含まれる。各層 $l$ について、これらのID埋め込みに適合させたガウス分布 $G_l = N(\mu_l, \Sigma_l)$ が計算される。これは、各層における典型的なID埋め込み空間を特徴づける、平均ベクトル $\mu_l$ と共分散行列 $\Sigma_l$ が統計的に推定されることを意味する。
- マハラノビス距離マッピング: 次に、クエリサンプルの軌跡について、各層 $l$ で、その平均埋め込み $y_l$ がマハラノビス距離式を使用してスカラー値 $f(y_l)$ にマッピングされる。この計算は、その特定の層の、事前に計算されたID平均 $\mu_l$ と共分散 $\Sigma_l$ を使用する。このステップは、複雑な $d$ 次元埋め込みを、その層における「IDらしさ」をどれだけ「IDらしい」かを示す単純なスカラーに変換する。
- 変動性測定: 次に、システムは、隣接する層間のこの「IDらしさ」の変化を見る。隣接する層のペア $(l-1, l)$ ごとに、絶対差 $|f(y_l) - f(y_{l-1})|$ が計算される。これは、サンプルの表現が次の層へ移動するにつれて、マハラノビス距離のシフトの大きさを測定する。
- TVスコア集約: これらの層ごとの変動性の大きさすべてが合計され、最終的な軌跡変動性スコア $S$ を得るために、層の総数 $L$ で割られる。この $S$ は、GLMの潜在空間での旅を通して、サンプルの「IDらしさ」がどれだけ変動するかを平均化した単一の尺度である。
- OOD分類: 最後に、クエリサンプルの計算されたTVスコア $S$ が、事前に定義されたしきい値 $\epsilon$ と比較される。$S$ が $\epsilon$ を超える場合、サンプルは分布外としてフラグが立てられ、そうでなければ分布内と見なされる。根本的な仮説は、特に数学的推論において、OODサンプルは「パターン崩壊」のような現象により、より高い軌跡変動性を示すということである。
最適化ダイナミクス
本稿で提案されている軌跡変動性(TV)スコアメカニズム自体は、勾配ベースの最適化や学習を経るモデルではなく、事後検出手法であることに注意することが重要である。損失関数を最小化するわけでもなく、バックプロパゲーションを通じて自身のパラメータを反復的に更新するわけでもない。
代わりに、メカニズムの「学習」または「適応」は、2つの異なる段階で発生する:
- 事前訓練された生成言語モデル(GLM): システムのコアは、事前訓練されたGLM(例:Llama2-7BまたはGPT2-XL)に依存している。このGLMは、広大な量のデータ(分布内数学的推論問題を含む)で別途訓練されている。この事前訓練段階中に、GLMは一貫性があり、数学的に健全な出力を生成することを学習し、その過程で、その層を横断する内部埋め込み表現を開発する。このTVスコア手法が適用されるとき、このGLMの重みとパラメータは固定されている。埋め込み $y_l$ は、単にこの静的な事前訓練済みモデルの出力である。
- 分布内(ID)参照フィッティング: TVスコア手法に固有の唯一の「フィッティング」または「学習」は、各層 $l$ のガウス分布 $G_l = N(\mu_l, \Sigma_l)$ の一度限りの統計的推定である。
- 平均($\mu_l$): 各層について、$\mu_l$ は、その層で収集されたすべてのIDサンプル埋め込みの経験的平均として計算される。
- 共分散($\Sigma_l$): 同様に、$\Sigma_l$ は、その層におけるこれらのIDサンプル埋め込みの経験的共分散行列である。
これらのパラメータ($\mu_l, \Sigma_l$)は、指定された分布内訓練データセットから一度だけ計算される。その後、固定され、各層における「正常」な埋め込みを構成するための静的な「参照」として機能する。$\mu_l$ と $\Sigma_l$ の初期計算を超える、それらを決定するための反復更新や勾配は存在しない。
OOD検出の最終ステップは、計算されたTVスコア $S$ をしきい値 $\epsilon$ と比較することを含む。このしきい値は通常、検証セットで経験的に決定される。例えば、AUROCやFPR95のようなメトリックを最適化することによって(セクション4.2で言及されている)。このしきい値選択は、損失ランドスケープを形成したり、モデル状態を更新したりするような、反復学習プロセスではなく、ハイパーパラメータチューニングの一種である。
本質的に、TVスコアメカニズムは、事前訓練済みGLMの固定された学習済み表現と、統計的に定義されたIDデータ参照を活用する統計的スコアリング関数である。それ自体は、勾配降下法または同様の最適化ダイナミクスを通じて学習、更新、または収束しない。
結果、限界、結論
実験設計とベースライン
著者らは、数学的推論における生成言語モデル(GLM)の分布外(OOD)検出に焦点を当てた、包括的な実験セットアップを考案し、数学的主張を厳密に検証した。評価は、オフライン検出とオンライン検出の2つの主要なシナリオに分かれた。
オフライン検出の場合、与えられたリストからのサンプルがOODであるかどうかを分類することが目標であった。採用された主要なメトリックは、AUROC(ROC曲線下面積)とFPR95(95%真陽性率における偽陽性率)であった。オンライン検出の場合、タスクは、新しいサンプルがOODであるかどうかを直接決定するために最適な分類しきい値を計算することを含んだ。
提案されたTVスコアと比較して、厳密に比較された「犠牲者」(ベースラインモデル)は、GLMにおけるOOD検出手法が少ないため、5つの訓練不要な手法であった:
1. 最大ソフトマックス確率(Prob.) [12]
2. モンテカルロドロップアウト [8]
3. シーケンスパープレキシティ [3]
4. 入力埋め込み [43]
5. 出力埋め込み [43]
実験設計では、算術推論に関する数学的単語問題を含むMultiArith [44] を分布内(ID)データセットとして使用した。OODデータについては、2つの異なるシナリオが考慮された:
* 遠距離シフトOOD: これには、代数、幾何学、数え上げと確率、数論、および微積分学の5つの多様な数学的ドメインを含むMATHデータセット [11] が含まれた。これらの問題は大学レベルの難易度であり、MultiArithの初等レベルとは対照的であり、著しい分布シフトを保証する。
* 近距離シフトOOD: これには、5つの算術推論データセット(GSM8K [6]、SVAMP [39]、AddSub [13]、SingleEq [18]、SingleOp [18])が含まれた。これらも数学的単語問題であるが、MultiArithとは異なる推論ステップと知識ポイントを必要とし、より微妙な分布シフトを表す。
IDデータ(MultiArith)は、訓練用に360サンプル、テスト用に240サンプルに分割された。小規模テストセットからのランダム性を軽減するため、1000のテストサンプリングサイズが使用され、陽性(OOD)サンプルと陰性(ID)サンプルのバランスの取れた数が保証された。バックボーンGLMはLlama2-7B [50] とGPT2-XL(1.5B)[5] が使用され、MultiArith ID訓練セットで訓練された。OODデータセット選択の合理性は、これらのデータセットがベースモデルの能力を超えており、それらに対する精度が非常に低いことを確認することで厳密にチェックされ、それによってそれらのOODステータスをモデルパフォーマンスの観点から検証した。TVスコアに微分平滑化(TVスコアw/ DiSmo)を適用した場合、平滑化次数 $k$ は1から5まで変化させ、最良のパフォーマンスが報告された。
証拠が証明すること
実験結果は、軌跡変動性のコアメカニズムが数学的推論におけるIDおよびOODサンプルを効果的に区別し、従来のアルゴリズムを大幅に上回ることを、決定的で否定できない証拠を提供する。
オフライン検出において、TVスコアは驚異的な優位性を示した:
* 遠距離シフトOOD: 我々の手法は、平均AUROC 98.76(Llama2-7B)および93.47(GPT2-XL)を達成し、最適なベースラインを10ポイント以上上回った。さらに顕著なのは、FPR95メトリックが5.21(Llama2-7B)および9.89(GPT2-XL)であり、これは最良のベースラインと比較して80%以上の削減を表す。これは、動的な埋め込み軌跡を分析することにより、モデルが著しく異なる数学的ドメインからのサンプルを堅牢に識別できることを明確に示している。
* 近距離シフトOOD: このより困難なシナリオでさえ、ベースラインが著しいパフォーマンス低下(AUROC 60未満、FPR95 80超)に苦しんだにもかかわらず、我々の手法は優れたパフォーマンスを維持し、AUROCスコアは90超、FPR95は30未満であった。これは、TVスコアのより大きな適応性と堅牢性が、微妙な分布シフトに対しても有効であることを証明している。
モデル分析は、さらに興味深い現象を明らかにした:GPT2-XLは、遠距離および近距離シフト設定全体でより安定したパフォーマンスを示した一方、Llama2-7Bは、近距離シフト設定でベースラインのパフォーマンス低下がより顕著であった。微分平滑化技術(DiSmo)は、特にGPT2-XLで効果的であり、より小さなモデルの潜在空間における異常な学習傾向を軽減するのに役立つことが示唆された。特に重要なのは、我々の手法は、埋め込みベースのベースラインとは異なり、サンプリング誤差に対するサンプリング誤差への感受性が高いのに対し、ほとんどすべての有意性検定をパスしたことである。
オンライン検出において、TVスコアは、遠距離および近距離シフトOOD設定の両方で、埋め込みベースの手法と比較して平均20ポイントの精度向上を達成し、一部のデータセットでは40ポイント以上の向上を示した。より低いサンプリング分散に反映されるこのより強い堅牢性は、現実世界のシナリオで最適なOOD分類しきい値をより一貫して見つけることができることを意味し、制御不能なデータ取得からのリスクを低減する。
検出を超えて、TVスコアはOOD品質推定にも効果的であることが証明された。バイナリマッチング品質メトリックとの相関を測定すると、我々の手法はLlama2-7BにおいてKendall相関で最大100%の改善、Spearman相関で最大100%(遠距離シフト)/ 30%(近距離シフト)の改善をベースラインSOTAと比較して示した。この経験的証拠は、TVスコアがID/OODを区別するだけでなく、生成された数学的推論の品質と精度を正確に反映することを示唆している。
最後に、この手法の一般化可能性は、MMLU多肢選択問題データセットで実証された。このタスクも「パターン崩壊」を特徴とする。我々のTVスコアは、この設定で従来のアルゴリズムすべてを上回り、特に従来の埋め込みベースの手法が苦労したファイングレイン検出シナリオでのスケーラビリティと利点を示した。
限界と将来の方向性
TVスコアは数学的推論におけるOOD検出において著しい進歩を示しているが、固有の限界を認識し、将来の開発の方向性を考慮することは重要である。
著者らによって強調されている主な限界は、数学的推論で利用可能なデータセットのサイズが比較的小さいことである。従来の言語タスクは数百万のサンプルを誇るが、数学的推論データセットは通常、数百または数千の範囲である。この希少性は、モデルを堅牢に訓練および評価することを困難にする。著者らは、ランダム性を軽減し、小規模テストでのデータ不均衡を緩和するためにテストサンプリングを採用することでこれを対処したが、データの可用性という根本的な問題は残っている。また、微分平滑化(DiSmo)のパフォーマンスが異なる設定で変動し、過度の平滑化(例:$k > 2$)が有用な特徴情報の損失につながり、検出精度を低下させる可能性があることも観察された。
将来に向けて、この作品からいくつかの将来の方向性が現れており、進化のための多様な視点を提供している:
- 数学的推論におけるデータ希少性の対処: 数学的推論データの収集とラベリングが困難であることを考えると、将来の研究では、数学的表現に特別に調整された、より高度なデータ拡張技術を探求できる可能性がある。形式的な数学的プロパティまたは定理証明器によってガイドされる合成データ生成は、スケーラブルなソリューションを提供できるだろうか?広範なIDデータセットにあまり依存しない、少数ショットまたはゼロショットOOD検出手法を調査することも価値があるだろう。
- 「パターン崩壊」の理解の深化: 本稿は「パターン崩壊」を重要な現象として特定している。その根本原因の、現在のトークンおよび表現レベルの分析を超えた、より深い理論的および経験的な調査は、新しい緩和戦略につながる可能性がある。シンボリックドメインにおけるパターン崩壊に対して本質的により耐性のあるGLMアーキテクチャまたは訓練目的を設計できるだろうか?
- 他のシンボリックAIタスクへの一般化可能性の拡大: 多肢選択問題への成功した拡張は有望である。これは、TVスコアが、出力空間が制約されており、「パターン崩壊」を示すコード生成、論理推論、または構造化予測のような、より広範なシンボリックAIタスクに適用可能であることを示唆している。将来の研究では、他のそのようなドメインを体系的に特定および検証し、シンボリックAIのための統一されたOOD検出フレームワークにつながる可能性がある。
- 軌跡変動性尺度の洗練: 現在のTVスコアは、次元非依存および次元結合変動性を使用している。埋め込み軌跡ダイナミクスのより洗練された尺度、例えば曲率、捩率、またはサンプル特性に基づいて動的に$k$を調整する適応的平滑化技術でさえ探求することは、潜在的によりきめ細かく、より堅牢なOOD検出をもたらす可能性がある。
- ハイブリッドOOD検出アプローチ: 埋め込みベースの手法、特に軌跡変動性は、この文脈で優れていることが証明されているが、それらを不確実性推定技術(例:ベイズニューラルネットワーク、アンサンブル手法)と統合することにより、より堅牢なハイブリッドOOD検出器が得られる可能性がある。そのようなアプローチは、両方のパラダイムの強みを活用し、OOD性に関するより包括的な評価を提供する可能性がある。
- 大規模モデルの計算効率: GLMのサイズと層数が増え続けるにつれて、ID分布フィッティング($O(Ldn)$)とスコア計算($O(Ldk)$)の計算複雑性はボトルネックになる可能性がある。将来の研究では、近似技術、ハードウェアアクセラレーション、または埋め込み分布のより効率的な統計モデリングを通じて、これらの操作を最適化することに焦点を当てる可能性がある。
- パターン崩壊と軌跡変動性に対する理論的保証: 本稿は経験的証拠と理論的直観を提供する。数学的推論における「パターン崩壊」が発生する理由と、軌跡変動性がOODサンプルの信頼できる信号である理由について、より厳密な理論的保証を開発することは、このアプローチの基盤を強化するだろう。これには、これらの現象が成り立つ条件を形式化し、TVスコアの有効性の境界を証明することが含まれる可能性がある。
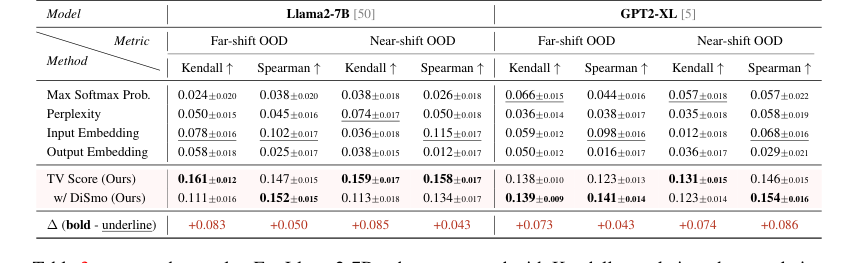 Table 3. presents the results. For Llama2-7B, when compared with Kendall correlation, the correlation improvement of TV scores over SOTA baselines reaches up to 100% under both far-shift and near-shift OOD settings. Compared with Spearman correlation, TV scores demonstrate a correlation enhancement over SOTA baselines by up to 100% under far-shift OOD setting and 30% under near-shift OOD setting. GPT2-XL also demonstrates excellent performance. These findings indicate that our TV scores not only facilitate the binary discrimination of ID and OOD samples but also substantially reflect the quality and precision of generated mathematical reasoning
Table 3. presents the results. For Llama2-7B, when compared with Kendall correlation, the correlation improvement of TV scores over SOTA baselines reaches up to 100% under both far-shift and near-shift OOD settings. Compared with Spearman correlation, TV scores demonstrate a correlation enhancement over SOTA baselines by up to 100% under far-shift OOD setting and 30% under near-shift OOD setting. GPT2-XL also demonstrates excellent performance. These findings indicate that our TV scores not only facilitate the binary discrimination of ID and OOD samples but also substantially reflect the quality and precision of generated mathematical reasoning
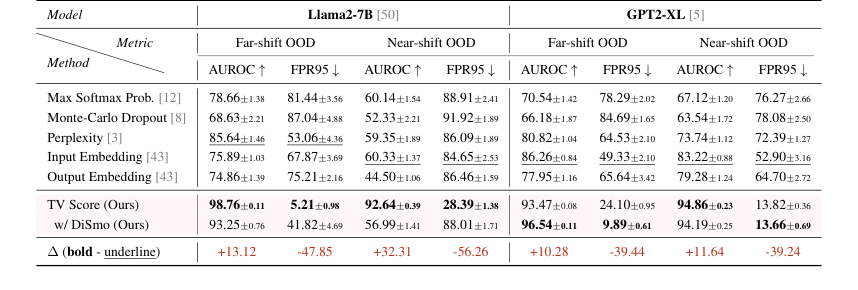 Table 1. AUROC and FPR95 results of the Offline Detection scenario. Underline and bold denote SOTA among all baselines and all methods, respectively. We report the average results under each setting in the main text, results of each dataset are shown in Table 11 and 12 (Appendix F)
Table 1. AUROC and FPR95 results of the Offline Detection scenario. Underline and bold denote SOTA among all baselines and all methods, respectively. We report the average results under each setting in the main text, results of each dataset are shown in Table 11 and 12 (Appendix F)
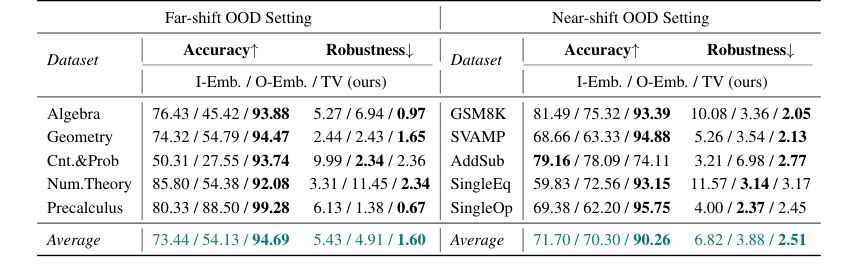 Table 2. presents the results in Llama2-7B. Compared to the embedding-based methods, our TV score obtains about an average of 20-point accuracy improvement in both far-shift OOD and near-shift OOD settings, and on some datasets, such as Cnt.&Prob, our TV score achieves more than 40 points of improvement. These all imply that TV Score can perform online discrimination of OOD samples more accurately. In addition, our TV score also possesses stronger robustness, which means that in real scenarios, we can find the optimal threshold more consistently in the face of different accessible ID and OOD data, reducing the potential riskiness due to uncontrollable data acquisition
Table 2. presents the results in Llama2-7B. Compared to the embedding-based methods, our TV score obtains about an average of 20-point accuracy improvement in both far-shift OOD and near-shift OOD settings, and on some datasets, such as Cnt.&Prob, our TV score achieves more than 40 points of improvement. These all imply that TV Score can perform online discrimination of OOD samples more accurately. In addition, our TV score also possesses stronger robustness, which means that in real scenarios, we can find the optimal threshold more consistently in the face of different accessible ID and OOD data, reducing the potential riskiness due to uncontrollable data acquisition
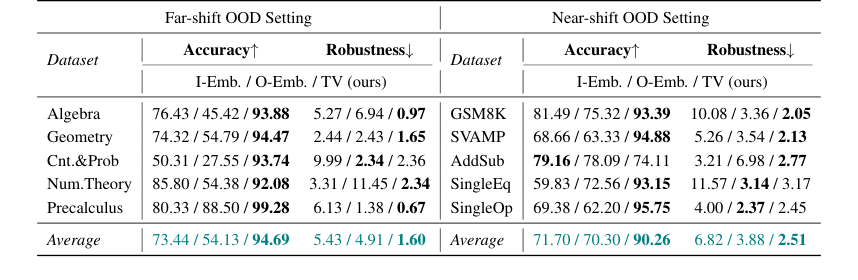 Table 2. Accuracy and Robustness results of the Online Detection scenario. We mainly compare our method with embedding-based methods, and bold denotes the best among these methods
Table 2. Accuracy and Robustness results of the Online Detection scenario. We mainly compare our method with embedding-based methods, and bold denotes the best among these methods