गणितीय तर्क में आउट-ऑफ-डिस्ट्रीब्यूशन (OOD) डिटेक्शन के लिए एम्बेडिंग ट्रेजेक्टरी
जनरेटिव लैंग्वेज मॉडल्स (GLMs) के लिए गणितीय तर्क में आउट-ऑफ-डिस्ट्रीब्यूशन (OOD) डिटेक्शन की समस्या अपेक्षाकृत नई और महत्वपूर्ण चुनौती है। ऐतिहासिक रूप से, OOD डिटेक्शन एल्गोरिदम मुख्य रूप से डीप नेटवर्क्स को...
पृष्ठभूमि और अकादमिक वंश
उत्पत्ति और अकादमिक वंश
जनरेटिव लैंग्वेज मॉडल्स (GLMs) के लिए गणितीय तर्क में आउट-ऑफ-डिस्ट्रीब्यूशन (OOD) डिटेक्शन की समस्या अपेक्षाकृत नई और महत्वपूर्ण चुनौती है। ऐतिहासिक रूप से, OOD डिटेक्शन एल्गोरिदम मुख्य रूप से डीप नेटवर्क्स को वास्तविक दुनिया के डेटा से बचाने के लिए उभरे जो प्रशिक्षण डेटा की स्वतंत्र और समान रूप से वितरित (i.i.d.) धारणा से विचलित होता है। इस क्षेत्र में प्रारंभिक शोध ने काफी हद तक विज़न और पारंपरिक टेक्स्ट क्लासिफिकेशन कार्यों पर ध्यान केंद्रित किया।
जैसे-जैसे GLMs उन्नत हुए, OOD डिटेक्शन विधियों को सारांशीकरण और अनुवाद जैसे टेक्स्ट जनरेशन परिदृश्यों के लिए अनुकूलित किया गया। ये विधियाँ आम तौर पर अनिश्चितता अनुमान या एम्बेडिंग दूरी माप पर निर्भर करती थीं। हालाँकि, जब इन मौजूदा दृष्टिकोणों को गणितीय तर्क कार्यों पर लागू किया गया तो अकादमिक क्षेत्र को एक महत्वपूर्ण "दर्द बिंदु" का सामना करना पड़ा। गणितीय तर्क, एक चुनौतीपूर्ण जनरेटिव कार्य, ने अपने आउटपुट स्पेस में अद्वितीय विशेषताओं को प्रस्तुत किया जिसने पारंपरिक एम्बेडिंग-आधारित विधियों को अप्रभावी बना दिया। लेखकों ने स्पष्ट रूप से कहा है कि, उनकी जानकारी के अनुसार, वे गणितीय तर्क में OOD डिटेक्शन का व्यवस्थित रूप से अध्ययन करने और इस विशिष्ट डोमेन में पारंपरिक एल्गोरिदम की विफलता की पहचान करने वाले पहले व्यक्ति हैं। यह पेपर इस प्रकार GLMs के संदर्भ में OOD डिटेक्शन और गणितीय तर्क के प्रतिच्छेदन पर एक नवीन समस्या का समाधान करता है।
पिछले दृष्टिकोणों की मौलिक सीमा एक ऐसी घटना से उत्पन्न होती है जिसे लेखक गणितीय तर्क के आउटपुट स्पेस में "पैटर्न कोलैप्स" कहते हैं। पारंपरिक एम्बेडिंग-आधारित विधियाँ, जो एक स्थिर एम्बेडिंग स्पेस (जैसे, महलानोबिस दूरी) में दूरियों को मापती हैं, यह मानती हैं कि अलग-अलग सिमेंटिक इनपुट एम्बेडिंग स्पेस में अलग-अलग क्षेत्रों में मैप होंगे। हालाँकि, गणितीय तर्क में, आउटपुट अक्सर प्रतीकात्मक (जैसे, संख्याएँ, सरल व्यंजक) होते हैं और टोकन की एक सीमित शब्दावली (जैसे अंक 0-9 और बुनियादी गणितीय प्रतीक) से निर्मित होते हैं। यह सिमेंटिक रूप से विविध गणितीय समस्याओं को लेटेंट स्पेस में उच्च-घनत्व, ओवरलैपिंग क्षेत्र में परिवर्तित होने वाले आउटपुट एम्बेडिंग उत्पन्न करने का कारण बनता है। परिणामस्वरूप, इन-डिस्ट्रीब्यूशन (ID) और OOD नमूनों के बीच स्थिर एम्बेडिंग दूरियाँ अविभेद्य हो जाती हैं, जिससे पिछले तरीकों के लिए विश्वसनीय रूप से OOD डेटा का पता लगाना असंभव हो जाता है। यह "पैटर्न कोलैप्स" प्रभावी रूप से मॉडल द्वारा देखी गई और जो नहीं देखी गई है, उसके बीच की रेखाओं को धुंधला कर देता है, जिससे लेखकों को एक नए, गतिशील दृष्टिकोण की तलाश करनी पड़ती है।
सहज डोमेन शब्द
- आउट-ऑफ-डिस्ट्रीब्यूशन (OOD) डेटा: कल्पना कीजिए कि आपने एक स्मार्ट रोबोट को लाल सेब और हरे सेब छाँटने के लिए प्रशिक्षित किया है। यदि कोई अचानक उसे एक नीला जामुन देता है, तो वह OOD डेटा है। यह कुछ ऐसा है जिसका रोबोट ने अपने प्रशिक्षण के दौरान कभी सामना नहीं किया है, और यह भ्रमित हो सकता है या खराब अनुमान लगा सकता है क्योंकि यह अपनी सीखी हुई श्रेणियों में फिट नहीं बैठता है।
- जनरेटिव लैंग्वेज मॉडल्स (GLMs): GLM को एक अत्यधिक रचनात्मक शेफ के रूप में सोचें जो नई रेसिपी का आविष्कार कर सकता है। आप शेफ को एक थीम (जैसे, "गर्मियों के लिए एक मिठाई") देते हैं, और वह सिर्फ एक कुकबुक से नहीं चुनता है; वह एक बिल्कुल नया, अनूठा व्यंजन बनाने के लिए सामग्री और तकनीकों को जोड़ता है। इसी तरह, GLMs नए टेक्स्ट उत्पन्न करते हैं, न कि केवल मौजूदा वाक्यांशों को पुनः प्राप्त करते हैं।
- पैटर्न कोलैप्स: कई स्तरों वाली एक बड़ी आर्ट गैलरी की कल्पना करें जहाँ प्रत्येक पेंटिंग अद्वितीय है। अब, कल्पना कीजिए कि वे सभी पेंटिंग छोटे, कम-रिज़ॉल्यूशन थंबनेल में डिजिटल रूप से संपीड़ित हो जाती हैं। कई अलग-अलग पेंटिंग अपने थंबनेल रूप में बहुत समान या यहां तक कि समान दिख सकती हैं, जिससे उन्हें अलग करना मुश्किल हो जाता है। अद्वितीय पैटर्न को एक सामान्य, अविभेद्य रूप में "स्क्विशिंग" यही वह है जो गणितीय तर्क आउटपुट में होता है, जिससे उन्हें अलग करना मुश्किल हो जाता है।
- एम्बेडिंग ट्रेजेक्टरी: कई स्तरों वाले एक जटिल भूलभुलैया पर विचार करें। जब एक चूहा भूलभुलैया में प्रवेश करता है, तो वह प्रत्येक स्तर से गुजरते हुए एक निशान छोड़ जाता है। "एम्बेडिंग ट्रेजेक्टरी" एक तंत्रिका नेटवर्क की प्रत्येक प्रसंस्करण परत से गुजरने वाली जानकारी के टुकड़े के लिए उस निशान का पता लगाने जैसा है। यह न केवल दिखाता है कि जानकारी कहाँ समाप्त होती है, बल्कि उन परिवर्तनों का पूरा क्रम भी दिखाता है जिनसे वह गुजरती है।
- ट्रेजेक्टरी अस्थिरता: भूलभुलैया सादृश्य का अनुसरण करते हुए, "ट्रेजेक्टरी अस्थिरता" स्तरों के बीच पथ कितना अनियमित या चिकना है, इसका एक माप है। यदि चूहा स्तरों के बीच दिशा में अचानक, बड़े परिवर्तन करता है, तो उसका पथ अत्यधिक अस्थिर होता है। यदि वह अनुमानित और सुचारू रूप से चलता है, तो उसकी अस्थिरता कम होती है। नेटवर्क के माध्यम से डेटा की यात्रा की यह "ऊबड़-खाबड़" या "चिकनाई" यह संकेत दे सकती है कि क्या यह परिचित या अप्रत्याशित, आउट-ऑफ-डिस्ट्रीब्यूशन इनपुट है।
संकेतन तालिका
| संकेतन | विवरण | प्रकार |
|---|---|---|
| $s$ | एक दिया गया नमूना, आमतौर पर एक इनपुट-आउटपुट जोड़ी। | चर |
| $L$ | जनरेटिव लैंग्वेज मॉडल में छिपी हुई परतों की कुल संख्या। | पैरामीटर |
| $d$ | एक एम्बेडिंग वेक्टर की आयामीता। | पैरामीटर |
| $Y_l$ | परत $l$ पर आउटपुट अनुक्रम का औसत एम्बेडिंग। | चर |
| $V_I(s)$ | नमूना $s$ के लिए आयाम-स्वतंत्र अस्थिरता, आयामों में स्थानीय ट्रेजेक्टरी परिवर्तनों को कैप्चर करना। | चर |
| $V_J(s)$ | नमूना $s$ के लिए आयाम-संयुक्त अस्थिरता, L2-नॉर्म का उपयोग करके ट्रेजेक्टरी में वैश्विक परिवर्तनों को कैप्चर करना। | चर |
| $\mu_l$ | परत $l$ पर इन-डिस्ट्रीब्यूशन (ID) एम्बेडिंग के लिए फिट किए गए गॉसियन वितरण के माध्य वेक्टर। | पैरामीटर |
| $\Sigma_l$ | परत $l$ पर ID एम्बेडिंग के लिए फिट किए गए गॉसियन वितरण का सहप्रसरण मैट्रिक्स। | पैरामीटर |
| $f(Y_l)$ | ID गॉसियन वितरण $G_l$ से औसत एम्बेडिंग $Y_l$ की महलानोबिस दूरी। | चर |
| $S$ | एक नमूने के लिए ट्रेजेक्टरी अस्थिरता (TV) स्कोर, आसन्न परतों के बीच महलानोबिस दूरी अंतर के औसत के रूप में गणना की जाती है। | चर |
| $k$ | ट्रेजेक्टरी अस्थिरता पर लागू डिफरेंशियल स्मूथिंग का क्रम। | पैरामीटर |
| $\nabla^k S$ | $k$-ऑर्डर डिफरेंशियल स्मूथिंग के साथ ट्रेजेक्टरी अस्थिरता (TV) स्कोर। | चर |
समस्या परिभाषा और बाधाएँ
मुख्य समस्या सूत्रीकरण और दुविधा
इस पेपर द्वारा संबोधित मुख्य समस्या जनरेटिव लैंग्वेज मॉडल्स (GLMs) में गणितीय तर्क कार्य करते समय आउट-ऑफ-डिस्ट्रीब्यूशन (OOD) डेटा का सटीक पता लगाना है।
प्रारंभ बिंदु (इनपुट/वर्तमान स्थिति) एक GLM है जिसे इन-डिस्ट्रीब्यूशन (ID) डेटा पर प्रशिक्षित किया गया है, जो आम तौर पर एक स्वतंत्र और समान रूप से वितरित (i.i.d.) डेटा वितरण मानता है। जब इस GLM को वास्तविक दुनिया के इनपुट प्रस्तुत किए जाते हैं जो इस i.i.d. धारणा (यानी, OOD डेटा) से विचलित होते हैं, तो इसका प्रदर्शन अप्रत्याशित रूप से खराब हो सकता है, जिससे संभावित रूप से हानिकारक परिणाम हो सकते हैं। GLMs के लिए मौजूदा OOD डिटेक्शन विधियाँ मुख्य रूप से दो दृष्टिकोणों पर निर्भर करती हैं: अनिश्चितता अनुमान और एम्बेडिंग दूरी माप। जबकि एम्बेडिंग-आधारित विधियों ने सारांशीकरण और अनुवाद जैसे पारंपरिक भाषाई कार्यों के लिए प्रभावी साबित हुई हैं, वे गणितीय तर्क के लिए अव्यावहारिक पाई गई हैं। यह अव्यावहारिकता गणितीय तर्क में देखे गए दो अद्वितीय घटनाओं के कारण है:
1. इनपुट स्पेस में अस्पष्ट क्लस्टरिंग: विभिन्न डोमेन में गणितीय तर्क समस्याओं के लिए इनपुट एम्बेडिंग "अस्पष्ट क्लस्टरिंग सुविधाओं" (चित्र 1a, पृष्ठ 2) प्रदर्शित करते हैं, जिससे स्थिर एम्बेडिंग के लिए विभिन्न गणितीय प्रश्नों के बीच अंतर्निहित जटिलता और भेद को कैप्चर करना मुश्किल हो जाता है।
2. आउटपुट स्पेस में पैटर्न कोलैप्स: गणितीय तर्क के लिए आउटपुट एम्बेडिंग "उच्च-घनत्व विशेषताओं को विभिन्न डोमेन के बीच महत्वपूर्ण ओवरलैप के साथ" (चित्र 1a, पृष्ठ 2) प्रदर्शित करते हैं। यह घटना, जिसे "पैटर्न कोलैप्स" कहा जाता है, इसलिए होती है क्योंकि गणितीय आउटपुट अक्सर प्रतीकात्मक होते हैं (जैसे, अंक 0-9, विशेष प्रतीक), खोज स्थान को संपीड़ित करते हैं और गणितीय रूप से भिन्न व्यंजकों के बीच पर्याप्त टोकन साझाकरण का कारण बनते हैं। यह विविध गणितीय समस्याओं के एम्बेडिंग को एक उच्च-घनत्व क्षेत्र में परिवर्तित करने का कारण बनता है, जिससे वे पारंपरिक स्थिर एम्बेडिंग दूरी उपायों का उपयोग करके अविभेद्य हो जाते हैं।
वांछित अंतिम बिंदु (आउटपुट/लक्ष्य स्थिति) एक मजबूत, हल्का OOD डिटेक्शन एल्गोरिथम है, जिसे TV स्कोर नाम दिया गया है, जिसे विशेष रूप से गणितीय तर्क परिदृश्यों के लिए तैयार किया गया है। इस एल्गोरिथम को "पैटर्न कोलैप्स" की उपस्थिति में भी ID और OOD नमूनों के बीच प्रभावी ढंग से अंतर करना चाहिए। अंतिम लक्ष्य उच्च भेदभाव सटीकता प्राप्त करना है, जिसे एक स्कोर फ़ंक्शन $f(x, y, \theta)$ और एक थ्रेशोल्ड $\epsilon$ खोजने के रूप में औपचारिक रूप दिया गया है जो अधिकतम करता है:
$$ \max_{f} P_{(x,y)\sim P_{X,Y}}[f(x,y,\theta) < \epsilon] + P_{(x,\tilde{y})\sim P_{\tilde{X},\tilde{Y}}}[f(x,\tilde{y},\theta) > \epsilon] $$
जहां $P_{X,Y}$ इन-डिस्ट्रीब्यूशन संयुक्त डेटा वितरण है और $P_{\tilde{X},\tilde{Y}}$ आउट-ऑफ-डिस्ट्रीब्यूशन संयुक्त डेटा वितरण (समीकरण 1, पृष्ठ 3) है। इसके अलावा, विधि को उच्च-घनत्व आउटपुट सुविधाओं वाले अन्य कार्यों के लिए सामान्यीकृत किया जाना चाहिए, जैसे कि बहुविकल्पीय प्रश्न।
ठीक गायब कड़ी या गणितीय अंतर जिसे यह पेपर पुल करने का प्रयास करता है, वह "पैटर्न कोलैप्स" घटना के कारण गणितीय तर्क में स्थिर एम्बेडिंग-आधारित OOD डिटेक्शन विधियों की विफलता है। पिछले तरीके एक स्थिर इनपुट या आउटपुट स्पेस में ID एम्बेडिंग वितरण से एक नए नमूने के एम्बेडिंग के बीच महलानोबिस दूरी की गणना करते हैं (पृष्ठ 1)। हालाँकि, "पैटर्न कोलैप्स" विभिन्न गणितीय तर्क नमूनों के लिए एम्बेडिंग ट्रेजेक्टरी के अंतिम बिंदुओं को परिवर्तित करने का कारण बनता है, जिससे ये स्थिर दूरी उपाय अप्रभावी हो जाते हैं। पेपर परिकल्पना करता है कि जबकि अंतिम बिंदु ढह सकते हैं, इन अंतिम बिंदुओं तक ले जाने वाली गतिशील एम्बेडिंग ट्रेजेक्टरी ID और OOD नमूनों के बीच महत्वपूर्ण अंतर प्रदर्शित करेंगी। इसलिए गायब कड़ी इन स्थिर अंतिम बिंदु दूरियों के बजाय इन ट्रेजेक्टरी अंतरों को मापने के लिए एक तंत्र है।
दर्दनाक ट्रेड-ऑफ या दुविधा जिसमें पिछले शोधकर्ता फंस गए हैं, वह गणितीय तर्क आउटपुट की प्रतीकात्मक, उच्च-घनत्व प्रकृति और प्रभावी एम्बेडिंग-आधारित OOD डिटेक्शन की आवश्यकताओं के बीच अंतर्निहित संघर्ष है। पारंपरिक टेक्स्ट जनरेशन में, अलग-अलग सिमेंटिक अर्थ अच्छी तरह से अलग एम्बेडिंग क्लस्टर की ओर ले जाते हैं, जिससे एम्बेडिंग दूरी अच्छी तरह से काम करती है। हालाँकि, गणितीय तर्क में, उत्तरों की संक्षिप्तता और साझा टोकन शब्दावली (जैसे, अंक) विविध समस्याओं को बहुत समान आउटपुट एम्बेडिंग पर मैप करने का कारण बनती है। यह "पैटर्न कोलैप्स" का अर्थ है कि सही गणितीय उत्तर उत्पन्न करने के लिए मॉडल की क्षमता में सुधार (जो अक्सर स्केलर या सरल व्यंजक होते हैं) अनजाने में OOD डिटेक्शन विधियों पर निर्भर करने वाले अव्यक्त स्थान में विशिष्टता को नष्ट कर देता है। शोधकर्ता एक बंधन में फंस गए थे: या तो गणितीय तर्क के लिए खराब OOD डिटेक्शन स्वीकार करें या मौलिक रूप से फिर से सोचें कि ऐसे अद्वितीय आउटपुट स्पेस में OOD को कैसे परिभाषित और मापा जाता है।
बाधाएँ और विफलता मोड
गणितीय तर्क में OOD डिटेक्शन की समस्या कई कठोर, यथार्थवादी बाधाओं के कारण अविश्वसनीय रूप से कठिन है:
- डेटा-संचालित बाधा: उच्च-घनत्व आउटपुट स्पेस ("पैटर्न कोलैप्स"): यह सबसे महत्वपूर्ण बाधा है। गणितीय तर्क आउटपुट "गणितीय रूप से प्रतीकात्मक" (पृष्ठ 2) होते हैं, जिससे एक संपीड़ित खोज स्थान होता है। यह विभिन्न डोमेन के प्रश्नों के बीच ओवरलैप की संभावना को बढ़ाता है। महत्वपूर्ण रूप से, GLMs सीमित शब्दावली (अंक 0-9 और परिमित विशेष प्रतीक) का उपयोग करके गणितीय व्यंजकों को टोकन करते हैं, जिसके परिणामस्वरूप गणितीय रूप से भिन्न व्यंजकों के बीच "पर्याप्त टोकन साझाकरण" होता है (पृष्ठ 2, अनुभाग 6.2)। यह आउटपुट एम्बेडिंग को एक उच्च-घनत्व, अविभेद्य क्षेत्र में परिवर्तित करने का कारण बनता है, जिससे पारंपरिक स्थिर एम्बेडिंग दूरी विधियाँ अप्रभावी हो जाती हैं।
- डेटा-संचालित बाधा: अस्पष्ट इनपुट स्पेस क्लस्टरिंग: गणितीय तर्क के लिए इनपुट स्पेस भी "विभिन्न डोमेन में अस्पष्ट क्लस्टरिंग सुविधाओं" (पृष्ठ 2, चित्र 1a) प्रदर्शित करता है। यह इंगित करता है कि एम्बेडिंग गणितीय प्रश्नों की पूरी जटिलता को पकड़ने के लिए संघर्ष करते हैं, जिससे इनपुट पक्ष से OOD डिटेक्शन और जटिल हो जाता है।
- भौतिक बाधा: सीमित डेटा उपलब्धता: गणितीय तर्क डेटासेट "अपेक्षाकृत छोटे" (सैकड़ों या हजारों नमूने) हैं, खासकर अनुवाद या सारांशीकरण जैसे पारंपरिक NLP कार्यों के लिए उपलब्ध लाखों नमूनों की तुलना में (पृष्ठ 1, पृष्ठ 11, "सीमाएँ")। डेटा की यह कमी मजबूत मॉडल को प्रशिक्षित करना और OOD डिटेक्शन विधियों का मज़बूती से मूल्यांकन करना चुनौतीपूर्ण बनाती है, जिससे परिणामों की यादृच्छिकता बढ़ जाती है। लेखकों ने परीक्षण नमूनाकरण का उपयोग करके इसे कम किया है।
- एल्गोरिथम बाधा: ट्रेजेक्टरी अंतरों को मापना मुश्किल: जबकि स्थिर एम्बेडिंग अंतरों को महलानोबिस दूरी से मापा जा सकता है, "एक ट्रेजेक्टरी और एक ट्रेजेक्टरी क्लस्टर के बीच अंतर को मापना कम सहज है" (पृष्ठ 5)। इसके लिए परतों में एम्बेडिंग स्पेस में गतिशील परिवर्तनों को पकड़ने के लिए एक नवीन गणितीय सूत्रीकरण की आवश्यकता होती है, जिसे पेपर ट्रेजेक्टरी अस्थिरता को परिभाषित करके संबोधित करता है।
- एल्गोरिथम बाधा: ट्रेजेक्टरी आउटलायर्स: एम्बेडिंग ट्रेजेक्टरी में आउटलायर्स "फ़ीचर निष्कर्षण पर महत्वपूर्ण प्रभाव डाल सकते हैं" (पृष्ठ 5)। यह शोर ID और OOD ट्रेजेक्टरी के बीच वास्तविक अंतर्निहित अंतरों को अस्पष्ट कर सकता है, जिसके लिए मजबूती बढ़ाने के लिए स्मूथिंग तकनीकों की आवश्यकता होती है।
- कम्प्यूटेशनल बाधा: मॉडल आकार और प्रशिक्षण संसाधन: विधि Llama2-7B और GPT2-XL (पृष्ठ 6) जैसे बड़े GLMs पर निर्भर करती है। इन मॉडलों को प्रशिक्षित करने के लिए महत्वपूर्ण कम्प्यूटेशनल संसाधनों (जैसे, Llama2-7B के लिए 4-कार्ड RTX 3090, GPT2-XL के लिए सिंगल RTX 3090, पृष्ठ 23) की आवश्यकता होती है। जबकि प्रस्तावित TV स्कोर स्वयं अपने कम्प्यूटेशन (मिलीसेकंड, $O(Ldn)$ या $O(Ldk)$ जटिलता, पृष्ठ 22) के मामले में "हल्का" है, यह इन कम्प्यूटेशनल रूप से गहन बैकबोन के शीर्ष पर संचालित होता है।
- डेटा-संचालित बाधा: डेटा रिसाव की अनिश्चितता: Llama2-7B जैसे क्लोज्ड-सोर्स GLMs के लिए, इस बात की अनिश्चितता है कि क्या विशिष्ट OOD डेटासेट को उनके प्री-ट्रेनिंग डेटा में शामिल किया गया हो सकता है (पृष्ठ 23)। इससे केवल वितरण परिप्रेक्ष्य से किसी डेटासेट को निश्चित रूप से OOD घोषित करना मुश्किल हो जाता है। लेखक इसे इस आधार पर OOD को परिभाषित करके संबोधित करते हैं कि डेटासेट "बेस मॉडल की क्षमताओं से अधिक है" (पृष्ठ 23)।
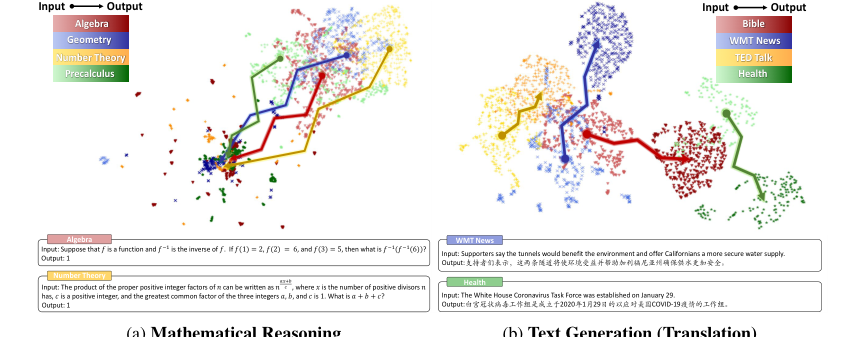 Figure 1. Embedding projection and cases of input and output spaces under mathematical reasoning and text generation scenarios. We select MATH [6] dataset for mathematical reasoning and OPUS [49] for text generation, each with four diverse domains. Different colors represent different domains, with lighter and darker shades indicating input and output. We use SimCSE [9] for sentence embeddings and UMAP [34] for dimensionality reduction. Appendix B shows detailed settings and examples
Figure 1. Embedding projection and cases of input and output spaces under mathematical reasoning and text generation scenarios. We select MATH [6] dataset for mathematical reasoning and OPUS [49] for text generation, each with four diverse domains. Different colors represent different domains, with lighter and darker shades indicating input and output. We use SimCSE [9] for sentence embeddings and UMAP [34] for dimensionality reduction. Appendix B shows detailed settings and examples
यह दृष्टिकोण क्यों
चुनाव की अनिवार्यता
ट्रेजेक्टरी-आधारित TV स्कोर को अपनाना केवल एक प्राथमिकता नहीं बल्कि एक आवश्यकता थी, जो जनरेटिव लैंग्वेज मॉडल्स (GLMs) के लिए गणितीय तर्क कार्यों में आउट-ऑफ-डिस्ट्रीब्यूशन (OOD) डिटेक्शन की अद्वितीय और चुनौतीपूर्ण विशेषताओं से प्रेरित थी। लेखकों ने इस विशिष्ट समस्या का सामना करते समय पारंपरिक "SOTA" विधियों, जैसे मानक एम्बेडिंग-आधारित दृष्टिकोणों में एक महत्वपूर्ण विफलता बिंदु की पहचान की।
जिस क्षण लेखकों को एहसास हुआ कि पारंपरिक विधियाँ अपर्याप्त थीं, वह अनुभाग 1 में स्पष्ट रूप से बताया गया है। जबकि एम्बेडिंग-आधारित विधियाँ सारांशीकरण और अनुवाद जैसे पारंपरिक भाषाई कार्यों के लिए अत्यधिक प्रभावी साबित हुई थीं (जैसा कि महलानोबिस दूरी [22] का उपयोग करके [43] द्वारा प्रदर्शित किया गया है), उन्हें गणितीय तर्क में महत्वपूर्ण चुनौतियों का सामना करना पड़ा। यह इस डोमेन में "आउटपुट स्पेस की उच्च-घनत्व विशेषता" के कारण था, जिसे लेखकों ने "पैटर्न कोलैप्स" कहा। यह "पैटर्न कोलैप्स" एम्बेडिंग-आधारित विधियों को अव्यावहारिक बना देता है, जैसा कि चित्र 1 में दर्शाया गया है। मुख्य समस्या यह है कि विभिन्न गणितीय डोमेन से आउटपुट, सिमेंटिक रूप से अलग होने के बावजूद, एम्बेडिंग स्पेस में एक उच्च-घनत्व क्षेत्र में परिवर्तित हो जाते हैं, जिससे वे स्थिर एम्बेडिंग दूरी उपायों द्वारा अविभेद्य हो जाते हैं। इस अहसास ने स्थिर एम्बेडिंग स्पेस से गतिशील "एम्बेडिंग ट्रेजेक्टरी" (अनुभाग 2) पर ध्यान केंद्रित करने के लिए मजबूर किया, क्योंकि यह इन-डिस्ट्रीब्यूशन (ID) और OOD नमूनों के बीच सूक्ष्म अंतर को पकड़ने का एकमात्र व्यवहार्य मार्ग था।
तुलनात्मक श्रेष्ठता
सरल प्रदर्शन मेट्रिक्स से परे, TV स्कोर विधि गणितीय तर्क की अनूठी चुनौतियों को संभालने में अपनी संरचनात्मक लाभों के कारण गहन गुणात्मक श्रेष्ठता प्रदर्शित करती है। कुंजी स्थिर, अंतिम-परत एम्बेडिंग पर निर्भर रहने के बजाय परतों में एम्बेडिंग में गतिशील परिवर्तनों का लाभ उठाने की इसकी क्षमता में निहित है।
"पैटर्न कोलैप्स" घटना, जबकि स्थिर एम्बेडिंग को अविभेद्य बनाती है, विरोधाभासी रूप से "नमूनों के बीच महत्वपूर्ण ट्रेजेक्टरी अंतर" (अनुभाग 2, चित्र 2) बनाती है। TV स्कोर इसे "ट्रेजेक्टरी अस्थिरता" को मापकर भुनाने का काम करता है, जो इन गतिशील बदलावों को मापता है। यह दृष्टिकोण आउटपुट स्पेस की उच्च घनत्व की समस्या के प्रति स्वाभाविक रूप से अधिक मजबूत है क्योंकि यह केवल अंतिम स्थिति के बजाय एम्बेडिंग परिवर्तन की प्रक्रिया पर केंद्रित है।
एक महत्वपूर्ण संरचनात्मक लाभ "प्रारंभिक स्थिरीकरण" घटना (अनुभाग 2.2, अनुभाग 3) द्वारा प्रकट होता है। ID डेटा के लिए, GLMs बाद की परतों में एम्बेडिंग परिवर्तन परिमाण के दमन की ओर ले जाते हुए, मध्य-से-देर परतों में अपने तर्क को पूरा करते हैं। इसके विपरीत, OOD डेटा के लिए, यह परिमाण लगातार उच्च बना रहता है, जो सुसंगत तर्क को पूरा करने में विफलता का संकेत देता है। यह विशिष्ट गतिशील व्यवहार एक शक्तिशाली और विश्वसनीय संकेत प्रदान करता है जो स्थिर विधियाँ बस कैप्चर नहीं कर सकती हैं।
इसके अलावा, विधि को "हल्का" (अनुभाग 3) के रूप में वर्णित किया गया है, जो कम्प्यूटेशनल दक्षता का अर्थ है। वैकल्पिक डिफरेंशियल स्मूथिंग तकनीक (TV स्कोर w/ DiSmo) आउटलायर्स के प्रभाव को कम करके मजबूती को और बढ़ाती है, जिससे एक चिकना और अधिक विश्वसनीय संकेत सुनिश्चित होता है (अनुभाग 3)। प्रयोगात्मक परिणाम (तालिका 1, तालिका 2) मात्रात्मक रूप से इस गुणात्मक श्रेष्ठता की पुष्टि करते हैं, जो AUROC में औसतन 10 अंकों से अधिक के सुधार और FPR95 में 80% से अधिक की कमी दिखाते हैं, यहां तक कि चुनौतीपूर्ण निकट-शिफ्ट OOD परिदृश्यों में भी जहां अन्य विधियों को महत्वपूर्ण प्रदर्शन गिरावट का सामना करना पड़ता है।
बाधाओं के साथ संरेखण
चुना गया ट्रेजेक्टरी-आधारित दृष्टिकोण, TV स्कोर द्वारा सन्निहित, गणितीय तर्क में OOD डिटेक्शन में निहित कठोर बाधाओं के साथ पूरी तरह से संरेखित होता है।
- बाधा: गणितीय तर्क के लिए GLMs में OOD डिटेक्शन। TV स्कोर इस डोमेन के लिए विशेष रूप से बनाया गया है, जो सीधे "पैटर्न कोलैप्स" और "उच्च-घनत्व सुविधाओं" को संबोधित करता है जो पारंपरिक विधियों को विफल करते हैं (सार, अनुभाग 1)। यह विशेष रूप से गणितीय तर्क के लिए अद्वितीय घटनाओं को मॉडल और मापता है, जैसे "प्रारंभिक स्थिरीकरण" (अनुभाग 2.2)।
- बाधा: पारंपरिक एम्बेडिंग-आधारित विधियों की अव्यावहारिकता को दूर करना। TV स्कोर के लिए मुख्य प्रेरणा गणितीय तर्क में स्थिर एम्बेडिंग विधियों की प्रदर्शित विफलता है (अनुभाग 1, अनुभाग 6)। गतिशील एम्बेडिंग ट्रेजेक्टरी पर जाकर, विधि सीधे आउटपुट स्पेस के उच्च घनत्व द्वारा लगाई गई सीमाओं को दरकिनार करती है, जहां स्थिर एम्बेडिंग अपनी भेदभाव शक्ति खो देते हैं (अनुभाग 2, चित्र 2)।
- बाधा: एक हल्के समाधान की आवश्यकता। पेपर स्पष्ट रूप से बताता है कि TV स्कोर एक "हल्का OOD डिटेक्शन समाधान" है (अनुभाग 3)। इसकी कम्प्यूटेशनल जटिलता कुशल है, जिसमें ID वितरण फिटिंग के लिए $O(Ldn)$ और स्कोर गणना के लिए $O(Ldk)$ है, जिससे यह वास्तविक दुनिया के GLM अनुप्रयोगों के लिए व्यावहारिक है (परिशिष्ट D)।
- बाधा: अन्य उच्च-घनत्व आउटपुट कार्यों के लिए स्केलेबिलिटी और सामान्यीकरण। विधि को स्केलेबल होने के लिए डिज़ाइन किया गया है और यह "फाइन-ग्रेन्ड डिटेक्शन परिदृश्यों में बड़े फायदे" (अनुभाग 5.2) प्रदर्शित करती है। महत्वपूर्ण रूप से, लेखक इसे "पैटर्न कोलैप्स" गुण प्रदर्शित करने वाले अन्य कार्यों, जैसे बहुविकल्पीय प्रश्न, के लिए इसकी विस्तारशीलता दिखाते हैं, जहां यह पारंपरिक एल्गोरिदम से भी बेहतर प्रदर्शन करता है (सार, अनुभाग 5.2)। यह प्रारंभिक गणितीय तर्क फोकस से परे इसकी व्यापक प्रयोज्यता की पुष्टि करता है।
विकल्पों का अस्वीकरण
पेपर स्पष्ट कारण प्रदान करता है कि लोकप्रिय वैकल्पिक OOD डिटेक्शन दृष्टिकोणों को क्यों अस्वीकार किया जाए, मुख्य रूप से इस बात पर ध्यान केंद्रित किया जाए कि मौजूदा विधियाँ गणितीय तर्क के विशिष्ट संदर्भ में क्यों विफल होती हैं।
-
पारंपरिक स्थिर एम्बेडिंग-आधारित विधियाँ (जैसे, इनपुट/आउटपुट एम्बेडिंग पर महलानोबिस दूरी): ये विधियाँ, सामान्य टेक्स्ट जनरेशन के लिए प्रभावी होने के बावजूद, गणितीय तर्क के लिए स्पष्ट रूप से "अव्यावहारिक" मानी जाती हैं (अनुभाग 1)। पेपर "स्थिर एम्बेडिंग विधियों की अव्यावहारिकता पर पुनर्विचार" के लिए अनुभाग 6 समर्पित करता है, जो उनकी विफलता के दो मुख्य कारणों का विवरण देता है:
- इनपुट स्पेस प्रतिनिधित्व दुविधा: इनपुट स्पेस में गणितीय व्यंजक "अस्पष्ट क्लस्टरिंग सुविधाओं" (अनुभाग 6.1, चित्र 1a) प्रदर्शित करते हैं। तालिका 4 में दिखाए गए सिमेंटिक एम्बेडिंग, गणितीय संबंधों को सटीक रूप से प्रतिबिंबित नहीं करते हैं। उदाहरण के लिए, एक गणितीय रूप से "इन-डिस्ट्रीब्यूशन" व्यंजक में एक गणितीय रूप से "आउट-ऑफ-डिस्ट्रीब्यूशन" व्यंजक की तुलना में कम कोसाइन समानता हो सकती है, जिससे OOD डिटेक्शन के लिए स्थिर इनपुट एम्बेडिंग अविश्वसनीय हो जाते हैं।
- आउटपुट स्पेस "पैटर्न कोलैप्स": यह सबसे महत्वपूर्ण मुद्दा है (अनुभाग 6.2, चित्र 1a)। गणितीय तर्क का आउटपुट स्पेस उच्च घनत्व और डोमेन के बीच महत्वपूर्ण ओवरलैप की विशेषता है। यह "पैटर्न कोलैप्स" दो स्तरों पर होता है:
- अभिव्यक्ति स्तर: गणितीय आउटपुट अक्सर स्केलर होते हैं (जैसे, "4"), खोज स्थान को संपीड़ित करते हैं और विभिन्न गणितीय प्रश्नों के बीच ओवरलैप की संभावना को बढ़ाते हैं (जैसे, "1+3=" और "$\int x dx=$" दोनों "4" उत्पन्न करते हैं) (अनुभाग 6.2)।
- टोकन स्तर: GLMs अंकों (0-9) और विशेष प्रतीकों के सीमित सेट का उपयोग करके गणितीय व्यंजकों को टोकन करते हैं। यह गणितीय रूप से भिन्न व्यंजकों के लिए भी पर्याप्त टोकन साझाकरण की ओर ले जाता है, जिससे ऑटोरेग्रेसिव भविष्यवाणी के दौरान टोकन स्तर पर कोलैप्स होता है (अनुभाग 6.2, तालिका 6)।
तालिका 5 अनुभवजन्य रूप से इस अस्वीकरण की पुष्टि करती है, यह दिखाते हुए कि स्थिर एम्बेडिंग पर महलानोबिस दूरी कई सेटिंग्स में लगभग यादृच्छिक AUROC स्कोर (लगभग 50) उत्पन्न करती है।
-
अनिश्चितता अनुमान विधियाँ (जैसे, अधिकतम सॉफ्टमैक्स संभाव्यता, मोंटे कार्लो ड्रॉपआउट, अनुक्रम परिपूर्णता): इन विधियों को प्रयोगों (अनुभाग 4.1, तालिका 1, तालिका 2, तालिका 3) में बेसलाइन के रूप में शामिल किया गया है। जबकि पेपर क्यों वे गणितीय तर्क के लिए विफल होते हैं, इसका विस्तृत सैद्धांतिक विश्लेषण प्रदान नहीं करता है, उनका लगातार और महत्वपूर्ण रूप से खराब प्रदर्शन TV स्कोर की तुलना में (अक्सर 10+ AUROC अंक और 80%+ FPR95 कमी से) उनकी अपर्याप्तता का अर्थ है। "पैटर्न कोलैप्स" और "प्रारंभिक स्थिरीकरण" की अनूठी घटनाएं इन अनिश्चितता-आधारित दृष्टिकोणों द्वारा सीधे संबोधित नहीं की जाती हैं, जो आम तौर पर भविष्य कहनेवाला आत्मविश्वास पर ध्यान केंद्रित करते हैं न कि एम्बेडिंग के गतिशील विकास पर।
-
चेन-ऑफ-थॉट (CoT) तकनीकें: पेपर CoT को "आउटपुट स्पेस आकार का विस्तार" और "पैटर्न कोलैप्स" को कम करने के लिए एक संभावित विकल्प के रूप में मानता है (अनुभाग 6.3)। हालाँकि, लेखकों का निष्कर्ष है कि "भले ही CoT आउटपुट स्पेस आकार का विस्तार करता है, आउटपुट उत्तर अभी भी गणितीय तर्क की कठिनाई और अंकों से अनिवार्य रूप से संबंधित है, और सिमेंटिक एम्बेडिंग प्रतिनिधित्व इन सुविधाओं को सटीक रूप से प्रतिबिंबित नहीं कर सकता है।" तालिका 5(b) में अनुभवजन्य परिणाम दिखाते हैं कि CoT के साथ भी, महलानोबिस दूरी का उपयोग करके पता लगाने की सटीकता खराब और अत्यधिक परिवर्तनशील बनी हुई है, यह दर्शाता है कि इस डोमेन में OOD के लिए मौलिक मुद्दों को हल करने के लिए CoT अकेले अपर्याप्त है।
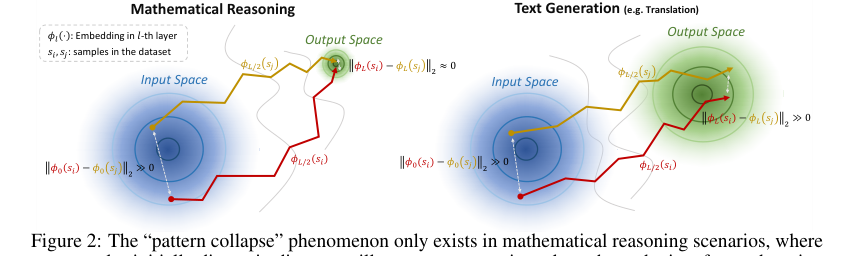 Figure 2. The “pattern collapse” phenomenon only exists in mathematical reasoning scenarios, where two samples initially distant in distance will converge approximately at the endpoint after undergoing embedding shifts, and does not occur in text generation scenarios. This produces a greater likelihood of trajectory variation under different samples in mathematical reasoning
Figure 2. The “pattern collapse” phenomenon only exists in mathematical reasoning scenarios, where two samples initially distant in distance will converge approximately at the endpoint after undergoing embedding shifts, and does not occur in text generation scenarios. This produces a greater likelihood of trajectory variation under different samples in mathematical reasoning
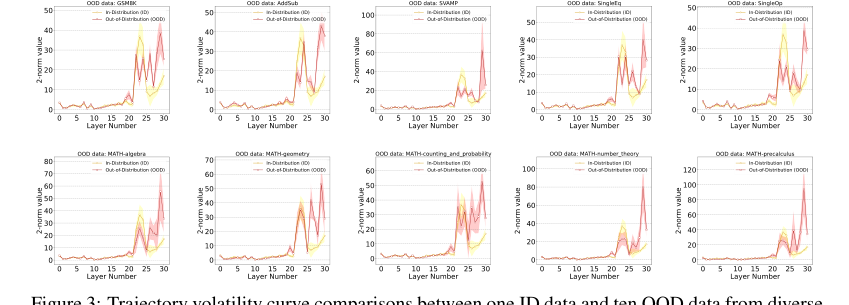 Figure 3. Trajectory volatility curve comparisons between one ID data and ten OOD data from diverse mathematical domains. Each trajectory represents the average of all samples from the corresponding datasets, with color shading being the sample standard deviation. Llama2-7B is used for the backbone
Figure 3. Trajectory volatility curve comparisons between one ID data and ten OOD data from diverse mathematical domains. Each trajectory represents the average of all samples from the corresponding datasets, with color shading being the sample standard deviation. Llama2-7B is used for the backbone
गणितीय और तार्किक तंत्र
मास्टर समीकरण
गणितीय तर्क में आउट-ऑफ-डिस्ट्रीब्यूशन (OOD) डिटेक्शन के लिए इस पेपर के तंत्र का मूल ट्रेजेक्टरी अस्थिरता (TV) स्कोर, $S$ है। यह स्कोर जनरेटिव लैंग्वेज मॉडल (GLM) की परतों के माध्यम से फैलने पर एक नमूने के एम्बेडिंग में गतिशील परिवर्तनों को मापता है। TV स्कोर के लिए मास्टर समीकरण को इस प्रकार परिभाषित किया गया है:
$$ S = \frac{1}{L} \sum_{l=1}^{L} |f(y_l) - f(y_{l-1})| $$
यह समीकरण एक मध्यवर्ती फ़ंक्शन, $f(y_l)$ पर निर्भर करता है, जो एक विशिष्ट परत $l$ पर एम्बेडिंग की महलानोबिस दूरी की गणना करता है। यह फ़ंक्शन इस प्रकार दिया गया है:
$$ f(y_l) = (y_l - \mu_l)^T (\Sigma_l)^{-1} (y_l - \mu_l) $$
पद-दर-पद विच्छेदन
आइए प्रत्येक घटक की भूमिका को समझने के लिए इन समीकरणों का विश्लेषण करें:
TV स्कोर ($S$) समीकरण के लिए:
- $S$:
- गणितीय परिभाषा: एक दिए गए इनपुट नमूने के लिए ट्रेजेक्टरी अस्थिरता स्कोर।
- भौतिक/तार्किक भूमिका: यह अंतिम स्केलर मान है जो OOD डिटेक्शन स्कोर के रूप में कार्य करता है। एक उच्च $S$ गणितीय तर्क कार्यों में OOD नमूनों की एक विशिष्ट विशेषता होने की परिकल्पना की गई GLM की परतों में एम्बेडिंग ट्रेजेक्टरी में अधिक अस्थिरता का संकेत देता है।
- जोड़ के बजाय गुणा क्यों, या एक अभिन्न के बजाय एक योग क्यों: लेखक योग का उपयोग करते हैं क्योंकि GLM में परतों की एक असतत संख्या ($L$) होती है। योग आसन्न परतों के बीच महलानोबिस दूरी में व्यक्तिगत परिवर्तनों को एकत्रित करता है। कुल "पथ लंबाई" या उतार-चढ़ाव के माप प्रदान करने के लिए परिवर्तनों के परिमाण को जमा करने के लिए जोड़ चुना जाता है। गुणा स्कोर को बहुत अधिक बढ़ा देगा, जिससे यह अस्थिरता के प्रत्यक्ष माप के रूप में कम व्याख्यात्मक हो जाएगा और संभावित रूप से संख्यात्मक अस्थिरता हो सकती है।
- $\frac{1}{L}$:
- गणितीय परिभाषा: $L$, GLM में छिपी हुई परतों की कुल संख्या, का व्युत्क्रम।
- भौतिक/तार्किक भूमिका: यह पद एक सामान्यीकरण कारक के रूप में कार्य करता है। यह परत-वार अस्थिरता के योग को प्रति परत औसत अस्थिरता में परिवर्तित करता है। यह सुनिश्चित करता है कि TV स्कोर विभिन्न परतों की संख्या वाले मॉडल में या विभिन्न लंबाई की ट्रेजेक्टरी का विश्लेषण करते समय तुलनीय हो।
- $\sum_{l=1}^{L}$:
- गणितीय परिभाषा: योग ऑपरेटर, पहली परत ($l=1$) से अंतिम परत ($L$) तक पुनरावृति।
- भौतिक/तार्किक भूमिका: यह ऑपरेटर आसन्न परतों के बीच प्रत्येक संक्रमण से व्यक्तिगत अस्थिरता योगदान को एकत्रित करता है। यह इस बात का योग करता है कि नमूने का प्रतिनिधित्व मॉडल की गहराई से गुजरने पर महलानोबिस दूरी कितनी "कूदती" या "स्थानांतरित" होती है।
- $| \cdot |$:
- गणितीय परिभाषा: निरपेक्ष मान फ़ंक्शन।
- भौतिक/तार्किक भूमिका: यह सुनिश्चित करता है कि केवल आसन्न परतों के बीच महलानोबिस दूरी के अंतर के परिमाण पर विचार किया जाए, न कि इसकी दिशा (यानी, दूरी बढ़ी या घटी)। ध्यान पूरी तरह से परिवर्तन की सीमा पर है, जो अस्थिरता को मापने के लिए केंद्रीय है।
- $f(y_l)$:
- गणितीय परिभाषा: परत $l$ पर औसत एम्बेडिंग $y_l$ की महलानोबिस दूरी।
- भौतिक/तार्किक भूमिका: यह पद मापता है कि परत $l$ पर नमूने के एम्बेडिंग उस विशिष्ट परत पर ID नमूनों के विशिष्ट वितरण से कितनी "दूर" है। यह एक उच्च-आयामी एम्बेडिंग को एक एकल स्केलर मान में बदलता है जो उस विशिष्ट परत पर इसकी "ID-नेस" का प्रतिनिधित्व करता है।
- $f(y_{l-1})$:
- गणितीय परिभाषा: परत $l$ से ठीक पहले की परत में औसत एम्बेडिंग $y_{l-1}$ की महलानोबिस दूरी।
- भौतिक/तार्किक भूमिका: $f(y_l)$ के समान, लेकिन पिछली परत के लिए। अंतर $|f(y_l) - f(y_{l-1})|$ विशेष रूप से मापता है कि नमूने के प्रतिनिधित्व के परत $l-1$ से परत $l$ तक विकसित होने पर "ID-ness" में परिवर्तन कितना है।
महालानोबिस दूरी ($f(y_l)$) समीकरण के लिए:
- $y_l$:
- गणितीय परिभाषा: परत $l$ पर आउटपुट अनुक्रम टोकन का औसत एम्बेडिंग। यह एक $d$-आयामी वेक्टर है, जिसकी गणना $y_l = \frac{1}{T} \sum_{t=1}^{T} h_t^l$ के रूप में की जाती है, जहां $h_t^l$ परत $l$ पर $t$-वें टोकन का आउटपुट एम्बेडिंग है और $T$ टोकन की संख्या है।
- भौतिक/तार्किक भूमिका: यह वेक्टर GLM के भीतर एक विशेष गहराई पर पूरे आउटपुट अनुक्रम के समग्र सिमेंटिक और गणितीय जानकारी का प्रतिनिधित्व करता है। यह मॉडल की परतों के माध्यम से नमूने के आउटपुट प्रतिनिधित्व की "स्थिति" है।
- $\mu_l$:
- गणितीय परिभाषा: परत $l$ पर सभी इन-डिस्ट्रीब्यूशन (ID) नमूना एम्बेडिंग के लिए फिट किए गए गॉसियन वितरण $G_l = N(\mu_l, \Sigma_l)$ का माध्य वेक्टर। यह भी एक $d$-आयामी वेक्टर है।
- भौतिक/तार्किक भूमिका: यह वेक्टर परत $l$ पर एक ID नमूने के लिए "केंद्र" या "विशिष्ट" एम्बेडिंग का प्रतिनिधित्व करता है। यह उस विशिष्ट परत पर "सामान्य" क्या माना जाता है, उसके लिए संदर्भ बिंदु के रूप में कार्य करता है।
- $(y_l - \mu_l)$:
- गणितीय परिभाषा: परत $l$ पर नमूने के एम्बेडिंग $y_l$ और औसत ID एम्बेडिंग $\mu_l$ के बीच अंतर का प्रतिनिधित्व करने वाला एक वेक्टर।
- भौतिक/तार्किक भूमिका: यह विचलन वेक्टर है, जो इंगित करता है कि वर्तमान नमूने का एम्बेडिंग परत $l$ पर औसत ID एम्बेडिंग से कितना विचलित होता है।
- $(\cdot)^T$:
- गणितीय परिभाषा: ट्रांसपोज़ ऑपरेटर।
- भौतिक/तार्किक भूमिका: इस संदर्भ में, यह कॉलम वेक्टर $(y_l - \mu_l)$ को एक पंक्ति वेक्टर में बदलता है, जो महलानोबिस दूरी के द्विघात रूप में मैट्रिक्स गुणन के लिए आवश्यक है।
- $(\Sigma_l)^{-1}$:
- गणितीय परिभाषा: सहप्रसरण मैट्रिक्स $\Sigma_l$ का व्युत्क्रम। $\Sigma_l$ परत $l$ पर सभी इन-डिस्ट्रीब्यूशन (ID) नमूना एम्बेडिंग के लिए फिट किए गए गॉसियन वितरण $G_l = N(\mu_l, \Sigma_l)$ का सहप्रसरण मैट्रिक्स है। यह एक $d \times d$ मैट्रिक्स है।
- भौतिक/तार्किक भूमिका: यह महलानोबिस दूरी का एक महत्वपूर्ण घटक है। यह परत $l$ पर ID एम्बेडिंग स्पेस के आयामों के बीच सहसंबंधों और विविधताओं को ध्यान में रखता है। इसे व्युत्क्रम करके, दूरी मीट्रिक प्रभावी रूप से डेटा को "सफेद" करता है, फीचर स्पेस में विभिन्न पैमानों और रोटेशन के लिए सामान्यीकरण करता है। यह ID डेटा वितरण के वास्तविक ज्यामिति के लिए एक अधिक सार्थक "दूरी" माप प्रदान करता है।
- $(\cdot)^T (\cdot)^{-1} (\cdot)$:
- गणितीय परिभाषा: द्विघात रूप, विशेष रूप से, वर्ग महलानोबिस दूरी।
- भौतिक/तार्किक भूमिका: यह पूरा व्यंजक वर्ग महलानोबिस दूरी की गणना करता है। यह $y_l$ और $\mu_l$ के बीच की दूरी को मानक विचलन की इकाइयों में मापता है, प्रभावी रूप से ID डेटा क्लाउड के प्रसार और अभिविन्यास के लिए सामान्यीकरण करता है। यह परत $l$ पर ID वितरण के तहत एक एम्बेडिंग कितना "असंभावित" है, इसका एक मजबूत माप प्रदान करता है।
चरण-दर-चरण प्रवाह
एक एकल, अमूर्त डेटा बिंदु की कल्पना करें - इसे "क्वेरी नमूना" $s$ कहें - OOD डिटेक्शन पाइपलाइन में प्रवेश कर रहा है। यहाँ गणितीय इंजन के माध्यम से इसकी यात्रा है:
- प्रारंभिक एम्बेडिंग जनरेशन: क्वेरी नमूना $s$ (जैसे, एक गणितीय समस्या) एक पूर्व-प्रशिक्षित जनरेटिव लैंग्वेज मॉडल (GLM) में फीड किया जाता है। GLM इनपुट को संसाधित करता है और एक आउटपुट अनुक्रम (जैसे, गणितीय समाधान) उत्पन्न करता है।
- परत-वार आउटपुट एम्बेडिंग: जैसे ही GLM आउटपुट अनुक्रम उत्पन्न करता है, इसकी आंतरिक परतें टोकन एम्बेडिंग उत्पन्न करती हैं। आउटपुट अनुक्रम के प्रत्येक $T$ टोकन के लिए, $d$-आयामी एम्बेडिंग वेक्टर $h_t^l$ को $L$ छिपी हुई परतों ($l=1, \dots, L$) में से प्रत्येक से निकाला जाता है।
- वाक्य-स्तर एकत्रीकरण: प्रत्येक परत $l$ के लिए, आउटपुट अनुक्रम से सभी $T$ टोकन एम्बेडिंग $h_t^l$ को एक एकल, प्रतिनिधि $d$-आयामी वेक्टर $y_l$ बनाने के लिए औसत किया जाता है। यह $y_l$ उस विशिष्ट परत पर समग्र आउटपुट प्रतिनिधित्व को समाहित करता है। यह चरण प्रभावी रूप से GLM की परतों के माध्यम से नमूने के लिए एक "एम्बेडिंग ट्रेजेक्टरी" का पता लगाता है: $y_1 \to y_2 \to \dots \to y_L$ ।
- ID वितरण संदर्भ: क्वेरी नमूने को संसाधित करने से पहले, सिस्टम ने पहले ही एक "सामान्य" संदर्भ स्थापित कर लिया है। इसमें ज्ञात इन-डिस्ट्रीब्यूशन (ID) नमूनों का एक बड़ा सेट एकत्र करना, उन्हें उसी GLM के माध्यम से पास करना और उनकी परत-वार औसत एम्बेडिंग की गणना करना शामिल है। प्रत्येक परत $l$ के लिए, इन ID एम्बेडिंग के लिए एक गॉसियन वितरण $G_l = N(\mu_l, \Sigma_l)$ फिट किया जाता है। इसका मतलब है कि माध्य वेक्टर $\mu_l$ और सहप्रसरण मैट्रिक्स $\Sigma_l$ सांख्यिकीय रूप से अनुमानित हैं, जो प्रत्येक परत पर विशिष्ट ID एम्बेडिंग स्पेस को चित्रित करते हैं।
- महालानोबिस दूरी मैपिंग: अब, हमारे क्वेरी नमूने की ट्रेजेक्टरी के लिए, प्रत्येक परत $l$ पर, इसके औसत एम्बेडिंग $y_l$ को महलानोबिस दूरी सूत्र का उपयोग करके एक स्केलर मान $f(y_l)$ पर मैप किया जाता है। यह गणना उस विशिष्ट परत के लिए पूर्व-गणना किए गए ID माध्य $\mu_l$ और सहप्रसरण $\Sigma_l$ का उपयोग करती है। यह चरण जटिल $d$-आयामी एम्बेडिंग को एक सरल स्केलर में बदल देता है जो इंगित करता है कि यह उस परत पर कितना "ID-जैसा" है, ID डेटा क्लाउड के आकार को ध्यान में रखते हुए।
- अस्थिरता माप: फिर सिस्टम क्रमिक परतों के बीच इस "ID-likeness" में परिवर्तन को देखता है। प्रत्येक आसन्न परत जोड़ी $(l-1, l)$ के लिए, निरपेक्ष अंतर $|f(y_l) - f(y_{l-1})|$ की गणना की जाती है। यह मापता है कि नमूने के प्रतिनिधित्व के परत $l-1$ से परत $l$ तक जाने पर महलानोबिस दूरी में बदलाव का परिमाण कितना है।
- TV स्कोर एकत्रीकरण: इन सभी परत-वार अस्थिरता परिमाणों को जोड़ा जाता है और फिर अंतिम ट्रेजेक्टरी अस्थिरता स्कोर $S$ प्राप्त करने के लिए कुल परतों $L$ से विभाजित किया जाता है। यह $S$ एक एकल, औसत माप है कि GLM के अव्यक्त स्थान में अपनी यात्रा के दौरान नमूने की "ID-likeness" कितनी उतार-चढ़ाव करती है।
- OOD वर्गीकरण: अंत में, क्वेरी नमूने के लिए गणना किए गए TV स्कोर $S$ की तुलना एक पूर्व-निर्धारित थ्रेशोल्ड $\epsilon$ से की जाती है। यदि $S$, $\epsilon$ से अधिक है, तो नमूने को आउट-ऑफ-डिस्ट्रीब्यूशन के रूप में फ़्लैग किया जाता है; अन्यथा, इसे इन-डिस्ट्रीब्यूशन माना जाता है। अंतर्निहित परिकल्पना यह है कि OOD नमूने, विशेष रूप से गणितीय तर्क में, "पैटर्न कोलैप्स" जैसी घटनाओं के कारण उच्च ट्रेजेक्टरी अस्थिरता प्रदर्शित करेंगे।
अनुकूलन गतिशीलता
यह स्पष्ट करना महत्वपूर्ण है कि ट्रेजेक्टरी अस्थिरता (TV) स्कोर तंत्र स्वयं, जैसा कि इस पेपर में प्रस्तावित है, एक पोस्ट-हॉक डिटेक्शन विधि है न कि एक मॉडल जो पारंपरिक ग्रेडिएंट-आधारित अनुकूलन या सीखने से गुजरता है। इसमें एक हानि फ़ंक्शन नहीं है जिसे न्यूनतम किया जाता है, न ही यह बैकप्रॉपैगेशन के माध्यम से अपने स्वयं के मापदंडों को पुनरावृत्त रूप से अपडेट करता है।
इसके बजाय, तंत्र की "सीखने" या "अनुकूलन" दो अलग-अलग चरणों में होता है:
- पूर्व-प्रशिक्षित जनरेटिव लैंग्वेज मॉडल (GLM): सिस्टम का मूल एक पूर्व-प्रशिक्षित GLM (जैसे, Llama2-7B या GPT2-XL) पर निर्भर करता है। इस GLM को अलग से विशाल मात्रा में डेटा पर प्रशिक्षित किया जाता है, जिसमें इन-डिस्ट्रीब्यूशन गणितीय तर्क समस्याएं शामिल हैं। इस प्री-ट्रेनिंग चरण के दौरान, GLM सुसंगत और गणितीय रूप से ध्वनि आउटपुट उत्पन्न करना सीखता है, और ऐसा करते हुए, यह अपनी परतों में अपने आंतरिक एम्बेडिंग प्रतिनिधित्व विकसित करता है। इस TV स्कोर विधि को लागू करते समय इस GLM के भार और पैरामीटर निश्चित होते हैं। एम्बेडिंग $y_l$ बस इस स्थिर, पूर्व-प्रशिक्षित मॉडल के आउटपुट होते हैं।
- इन-डिस्ट्रीब्यूशन (ID) संदर्भ फिटिंग: TV स्कोर विधि के लिए एकमात्र "फिटिंग" या "सीखने" प्रत्येक परत $l$ के लिए गॉसियन वितरण $G_l = N(\mu_l, \Sigma_l)$ के एक बार के सांख्यिकीय अनुमान का है।
- माध्य ($\mu_l$): प्रत्येक परत के लिए, $\mu_l$ की गणना उस परत पर एकत्र किए गए सभी ID नमूना एम्बेडिंग के अनुभवजन्य माध्य के रूप में की जाती है।
- सहप्रसरण ($\Sigma_l$): इसी तरह, $\Sigma_l$ उस परत पर इन ID नमूना एम्बेडिंग का अनुभवजन्य सहप्रसरण मैट्रिक्स है।
ये पैरामीटर ($\mu_l, \Sigma_l$) एक बार इन-डिस्ट्रीब्यूशन प्रशिक्षण डेटा के एक नामित सेट से गणना की जाती हैं। वे फिर निश्चित हो जाते हैं और प्रत्येक परत पर "सामान्य" एम्बेडिंग क्या है, उसके लिए स्थिर "संदर्भ" के रूप में कार्य करते हैं। $\mu_l$ और $\Sigma_l$ के प्रारंभिक गणना से परे उन्हें निर्धारित करने में कोई पुनरावृत्त अपडेट या ग्रेडिएंट शामिल नहीं हैं।
OOD डिटेक्शन का अंतिम चरण परिकलित TV स्कोर $S$ की थ्रेशोल्ड $\epsilon$ से तुलना करना है। यह थ्रेशोल्ड आम तौर पर एक सत्यापन सेट पर अनुभवजन्य रूप से निर्धारित किया जाता है, उदाहरण के लिए, AUROC या FPR95 जैसे मेट्रिक्स को अनुकूलित करके (जैसा कि अनुभाग 4.2 में उल्लेख किया गया है)। यह थ्रेशोल्ड चयन हाइपरपैरामीटर ट्यूनिंग का एक रूप है, न कि एक पुनरावृत्त सीखने की प्रक्रिया जो हानि परिदृश्य को आकार देती है या मॉडल राज्यों को अपडेट करती है।
संक्षेप में, TV स्कोर तंत्र एक सांख्यिकीय स्कोरिंग फ़ंक्शन है जो एक पूर्व-प्रशिक्षित GLM के निश्चित, सीखे हुए प्रतिनिधित्व और ID डेटा के लिए सांख्यिकीय रूप से परिभाषित संदर्भ का लाभ उठाता है। यह स्वयं ग्रेडिएंट डिसेंट या समान अनुकूलन गतिशीलता के माध्यम से नहीं सीखता है, अपडेट करता है, या अभिसरण करता है।
परिणाम, सीमाएँ और निष्कर्ष
प्रयोगात्मक डिजाइन और बेसलाइन
अपने गणितीय दावों को कठोरता से मान्य करने के लिए, लेखकों ने जनरेटिव लैंग्वेज मॉडल्स (GLMs) के लिए गणितीय तर्क में आउट-ऑफ-डिस्ट्रीब्यूशन (OOD) डिटेक्शन पर ध्यान केंद्रित करते हुए एक व्यापक प्रयोगात्मक सेटअप तैयार किया। मूल्यांकन को दो प्राथमिक परिदृश्यों में विभाजित किया गया था: ऑफलाइन डिटेक्शन और ऑनलाइन डिटेक्शन।
ऑफलाइन डिटेक्शन के लिए, लक्ष्य नमूनों की एक दी गई सूची OOD थी या नहीं, यह वर्गीकृत करना था। प्रमुख मेट्रिक्स जो नियोजित किए गए थे वे AUROC (एरिया अंडर द रिसीवर ऑपरेटिंग कैरेक्टरिस्टिक कर्व) और FPR95 (95% ट्रू पॉजिटिव रेट पर फाल्स पॉजिटिव रेट) थे। ऑनलाइन डिटेक्शन के लिए, कार्य नए नमूनों के लिए OOD थे या नहीं, यह सीधे निर्धारित करने के लिए एक इष्टतम वर्गीकरण थ्रेशोल्ड की गणना करना था, भेदभाव सटीकता और मजबूती (नमूना भिन्नता के रूप में मापा जाता है) का उपयोग करना।
प्रस्तावित TV स्कोर की क्रूरता से तुलना की गई पांच प्रशिक्षण-मुक्त विधियों के खिलाफ "पीड़ित" (बेसलाइन मॉडल) थे, जिन्हें GLMs पर OOD डिटेक्शन विधियों की कमी के कारण चुना गया था:
1. मैक्सिमम सॉफ्टमैक्स प्रोबेबिलिटी (Prob.) [12]
2. मोंटे-कार्लो ड्रॉपआउट [8]
3. सीक्वेंस पर्प्लेक्सिटी [3]
4. इनपुट एम्बेडिंग [43]
5. आउटपुट एम्बेडिंग [43]
प्रयोगात्मक डिजाइन ने इन-डिस्ट्रीब्यूशन (ID) डेटासेट के रूप में MultiArith [44] का उपयोग किया, जिसमें अंकगणित तर्क पर गणित शब्द समस्याएं शामिल थीं। OOD डेटा के लिए, दो अलग-अलग परिदृश्यों पर विचार किया गया:
* फार-शिफ्ट OOD: इसमें MATH डेटासेट [11] शामिल था, जिसमें पांच विविध गणितीय डोमेन (बीजगणित, ज्यामिति, गणना और संभाव्यता, संख्या सिद्धांत, और प्रीकैलकुलस) शामिल थे। ये समस्याएं कॉलेज स्तर की कठिनाई की हैं, जो MultiArith के प्राथमिक विद्यालय स्तर के विपरीत हैं, जो एक महत्वपूर्ण वितरण शिफ्ट सुनिश्चित करती हैं।
* नियर-शिफ्ट OOD: इसमें पांच अंकगणित तर्क डेटासेट (GSM8K [6], SVAMP [39], AddSub [13], SingleEq [18], और SingleOp [18]) शामिल थे। जबकि ये भी गणित शब्द समस्याएं हैं, उन्हें MultiArith की तुलना में विभिन्न तर्क चरणों और ज्ञान बिंदुओं की आवश्यकता होती है, जो एक अधिक सूक्ष्म वितरण शिफ्ट का प्रतिनिधित्व करते हैं।
ID डेटा (MultiArith) को प्रशिक्षण के लिए 360 नमूनों और परीक्षण के लिए 240 नमूनों में विभाजित किया गया था। छोटे परीक्षण सेट से यादृच्छिकता को कम करने के लिए, 1000 के परीक्षण नमूना आकार का उपयोग किया गया था, जो सकारात्मक (OOD) और नकारात्मक (ID) नमूनों की संतुलित संख्या सुनिश्चित करता है। बैकबोन GLMs Llama2-7B [50] और GPT2-XL (1.5B) [5] का उपयोग किया गया था, जिन्हें MultiArith ID प्रशिक्षण सेट पर प्रशिक्षित किया गया था। OOD डेटासेट चयन की तर्कसंगतता को इस बात की पुष्टि करके कठोरता से जांचा गया था कि ये डेटासेट बेस मॉडल की क्षमताओं से अधिक थे, उन पर बहुत कम सटीकता प्रदर्शित करते थे, इस प्रकार मॉडल प्रदर्शन के दृष्टिकोण से उनकी OOD स्थिति को मान्य करते थे। TV स्कोर के लिए डिफरेंशियल स्मूथिंग (TV स्कोर w/ DiSmo) के साथ, स्मूथिंग ऑर्डर $k$ को 1 से 5 तक बदला गया था, और सर्वश्रेष्ठ प्रदर्शन की सूचना दी गई थी।
साक्ष्य क्या साबित करते हैं
प्रयोगात्मक परिणाम निर्णायक, निर्विवाद प्रमाण प्रदान करते हैं कि ट्रेजेक्टरी अस्थिरता का मूल तंत्र गणितीय तर्क में ID और OOD नमूनों को प्रभावी ढंग से अलग करता है, जो पारंपरिक एल्गोरिदम से काफी बेहतर प्रदर्शन करता है।
ऑफलाइन डिटेक्शन में, TV स्कोर ने उल्लेखनीय श्रेष्ठता प्रदर्शित की:
* फार-शिफ्ट OOD: हमारे तरीके ने 98.76 (Llama2-7B) और 93.47 (GPT2-XL) का औसत AUROC प्राप्त किया, जो इष्टतम बेसलाइन से 10 अंकों से अधिक है। और भी आश्चर्यजनक रूप से, FPR95 मीट्रिक 5.21 (Llama2-7B) और 9.89 (GPT2-XL) था, जो सर्वश्रेष्ठ बेसलाइन की तुलना में 80% से अधिक की कमी का प्रतिनिधित्व करता है। यह स्पष्ट रूप से इंगित करता है कि गतिशील एम्बेडिंग ट्रेजेक्टरी का विश्लेषण करके, मॉडल विभिन्न गणितीय डोमेन से नमूनों को मज़बूती से पहचान सकता है।
* नियर-शिफ्ट OOD: इस अधिक चुनौतीपूर्ण परिदृश्य में भी, जहां बेसलाइन ने महत्वपूर्ण प्रदर्शन गिरावट (AUROC 60 से नीचे, FPR95 80 से ऊपर) का अनुभव किया, हमारे तरीके ने उत्कृष्ट प्रदर्शन बनाए रखा, जिसमें AUROC स्कोर 90 से ऊपर और FPR95 30 से नीचे था। यह साबित करता है कि TV स्कोर की अधिक अनुकूलन क्षमता और मजबूती सूक्ष्म वितरण शिफ्टों के लिए है।
मॉडल विश्लेषण ने आगे दिलचस्प घटनाओं का खुलासा किया: GPT2-XL ने फार- और नियर-शिफ्ट दोनों सेटिंग्स में अधिक स्थिर प्रदर्शन प्रदर्शित किया, जबकि Llama2-7B ने नियर-शिफ्ट सेटिंग में बेसलाइन के लिए अधिक स्पष्ट गिरावट दिखाई। डिफरेंशियल स्मूथिंग तकनीक (DiSmo) विशेष रूप से GPT2-XL पर प्रभावी थी, जो सुझाव देती है कि यह छोटे मॉडल के अव्यक्त स्थानों में विषम सीखने की प्रवृत्तियों को कम करने में मदद करती है। महत्वपूर्ण रूप से, हमारे तरीके ने लगभग सभी महत्व परीक्षणों को पास किया, जो एम्बेडिंग-आधारित बेसलाइन के विपरीत है, जिनमें नमूना त्रुटि के प्रति उच्च संवेदनशीलता दिखाई गई।
ऑनलाइन डिटेक्शन के लिए, TV स्कोर ने फार-शिफ्ट और नियर-शिफ्ट OOD दोनों परिदृश्यों में एम्बेडिंग-आधारित विधियों पर औसतन 20-पॉइंट सटीकता सुधार प्राप्त किया, जिसमें कुछ डेटासेट 40 अंकों से अधिक सुधार दिखाते हैं। यह मजबूत मजबूती, कम नमूना भिन्नता में परिलक्षित होती है, जिसका अर्थ है कि इष्टतम OOD वर्गीकरण थ्रेशोल्ड को वास्तविक दुनिया के परिदृश्यों में अधिक लगातार पाया जा सकता है, जिससे अनियंत्रित डेटा अधिग्रहण से जोखिम कम हो जाते हैं।
डिटेक्शन से परे, TV स्कोर OOD गुणवत्ता अनुमान के लिए भी प्रभावी साबित हुआ। बाइनरी मैचिंग गुणवत्ता मीट्रिक के साथ सहसंबंध को मापते समय, हमारे तरीके ने Llama2-7B के लिए SOTA बेसलाइन पर 100% तक सुधार (केंडल सहसंबंध) और 100% (फार-शिफ्ट) / 30% (नियर-शिफ्ट) सुधार (स्पीयरमैन सहसंबंध) दिखाया। यह कठोर साक्ष्य इंगित करता है कि TV स्कोर न केवल ID/OOD को अलग करता है, बल्कि उत्पन्न गणितीय तर्क की गुणवत्ता और सटीकता को भी सटीक रूप से दर्शाता है।
अंत में, विधि की सामान्यीकरण क्षमता MMLU बहुविकल्पीय प्रश्न डेटासेट पर प्रदर्शित की गई थी, एक ऐसा कार्य जो "पैटर्न कोलैप्स" की विशेषता भी है। हमारे TV स्कोर ने इस सेटिंग में सभी पारंपरिक एल्गोरिदम को बेहतर प्रदर्शन किया, स्केलेबिलिटी और फाइन-ग्रेन्ड डिटेक्शन परिदृश्यों में फायदे प्रदर्शित किए, विशेष रूप से जहां पारंपरिक एम्बेडिंग-आधारित विधियों को संघर्ष करना पड़ा।
सीमाएँ और भविष्य की दिशाएँ
जबकि TV स्कोर गणितीय तर्क के लिए OOD डिटेक्शन में महत्वपूर्ण प्रगति प्रदर्शित करता है, अंतर्निहित सीमाओं को स्वीकार करना और भविष्य के विकास के लिए रास्ते पर विचार करना महत्वपूर्ण है।
लेखकों द्वारा उजागर की गई प्राथमिक सीमा गणितीय तर्क के लिए उपलब्ध डेटासेट का अपेक्षाकृत छोटा आकार है। पारंपरिक भाषाई कार्यों के विपरीत जिनमें लाखों नमूने होते हैं, गणितीय तर्क डेटासेट आम तौर पर सैकड़ों या हजारों में होते हैं। यह कमी मॉडल को मज़बूती से प्रशिक्षित करना और उनका मूल्यांकन करना चुनौतीपूर्ण बनाती है। लेखकों ने यादृच्छिकता को कम करने और छोटे पैमाने पर परीक्षण में डेटा असंतुलन को कम करने के लिए परीक्षण नमूनाकरण का उपयोग करके इसे संबोधित किया, लेकिन डेटा उपलब्धता का मौलिक मुद्दा बना हुआ है। एक और अवलोकन यह था कि डिफरेंशियल स्मूथिंग (DiSmo) का प्रदर्शन विभिन्न सेटिंग्स में उतार-चढ़ाव करता था, और अत्यधिक स्मूथिंग (जैसे, $k > 2$) उपयोगी फ़ीचर जानकारी के नुकसान का कारण बन सकती है, जिससे डिटेक्शन सटीकता कम हो जाती है।
आगे देखते हुए, इस कार्य से कई भविष्य की दिशाएँ उभरती हैं, जो विकास के लिए विविध दृष्टिकोण प्रदान करती हैं:
- गणितीय तर्क में डेटा की कमी को संबोधित करना: गणितीय तर्क डेटा को एकत्र करने और लेबल करने में कठिनाई को देखते हुए, भविष्य के शोध में गणितीय व्यंजकों के लिए विशेष रूप से अधिक उन्नत डेटा संवर्धन तकनीकों का पता लगाया जा सकता है। क्या सिंथेटिक डेटा जनरेशन, शायद औपचारिक गणितीय गुणों या प्रमेय प्रूवर्स द्वारा निर्देशित, एक स्केलेबल समाधान प्रदान कर सकता है? व्यापक ID डेटासेट पर कम निर्भर रहने वाले कुछ-शॉट या शून्य-शॉट OOD डिटेक्शन विधियों की जांच करना भी मूल्यवान होगा।
- "पैटर्न कोलैप्स" की समझ को गहरा करना: पेपर "पैटर्न कोलैप्स" को एक महत्वपूर्ण घटना के रूप में पहचानता है। इसके मूल कारणों की गहरी सैद्धांतिक और अनुभवजन्य जांच, वर्तमान टोकन और अभिव्यक्ति स्तर विश्लेषण से परे, नवीन शमन रणनीतियों को जन्म दे सकती है। क्या हम GLM आर्किटेक्चर या प्रशिक्षण उद्देश्यों को डिजाइन कर सकते हैं जो प्रतीकात्मक डोमेन में पैटर्न कोलैप्स के लिए स्वाभाविक रूप से अधिक प्रतिरोधी हों?
- अन्य प्रतीकात्मक AI कार्यों के लिए सामान्यीकरण का विस्तार करना: बहुविकल्पीय प्रश्नों तक सफल विस्तार आशाजनक है। यह बताता है कि TV स्कोर प्रतीकात्मक AI कार्यों की एक विस्तृत श्रृंखला पर लागू हो सकता है जहां आउटपुट स्पेस सीमित हैं और "पैटर्न कोलैप्स" प्रदर्शित करते हैं, जैसे कोड जनरेशन, तार्किक अनुमान, या संरचित भविष्यवाणी। भविष्य के काम व्यवस्थित रूप से ऐसे अन्य डोमेन की पहचान और सत्यापन कर सकते हैं, जिससे प्रतीकात्मक AI के लिए एक एकीकृत OOD डिटेक्शन फ्रेमवर्क बन सकता है।
- ट्रेजेक्टरी अस्थिरता उपायों को परिष्कृत करना: वर्तमान TV स्कोर आयाम-स्वतंत्र और आयाम-संयुक्त अस्थिरता का उपयोग करता है। एम्बेडिंग ट्रेजेक्टरी की अधिक परिष्कृत उपायों की खोज, जैसे वक्रता, मरोड़, या यहां तक कि अनुकूली स्मूथिंग तकनीक जो नमूना विशेषताओं के आधार पर गतिशील रूप से $k$ को समायोजित करती है, संभावित रूप से और भी अधिक फाइन-ग्रेन्ड और मजबूत OOD डिटेक्शन प्रदान कर सकती है।
- हाइब्रिड OOD डिटेक्शन दृष्टिकोण: जबकि एम्बेडिंग-आधारित विधियाँ, विशेष रूप से ट्रेजेक्टरी अस्थिरता, इस संदर्भ में बेहतर साबित हुई हैं, अनिश्चितता अनुमान तकनीकों (जैसे, बायेसियन न्यूरल नेटवर्क, एन्सेम्बल विधियाँ) के साथ उन्हें एकीकृत करने से अधिक मजबूत हाइब्रिड OOD डिटेक्टर बन सकते हैं। ऐसा दृष्टिकोण दोनों प्रतिमानों की शक्तियों का लाभ उठा सकता है, OODness का अधिक व्यापक मूल्यांकन प्रदान कर सकता है।
- बड़े मॉडल के लिए कम्प्यूटेशनल दक्षता: जैसे-जैसे GLMs आकार और परत गणना में बढ़ते रहेंगे, ID वितरण ($O(Ldn)$) और स्कोर गणना ($O(Ldk)$) को फिट करने की कम्प्यूटेशनल जटिलता एक बाधा बन सकती है। भविष्य के काम इन ऑपरेशनों को अनुकूलित करने पर ध्यान केंद्रित कर सकते हैं, शायद सन्निकटन तकनीकों, हार्डवेयर त्वरण, या एम्बेडिंग वितरणों के अधिक कुशल सांख्यिकीय मॉडलिंग के माध्यम से।
- पैटर्न कोलैप्स और ट्रेजेक्टरी अस्थिरता के लिए सैद्धांतिक गारंटी: पेपर अनुभवजन्य साक्ष्य और सैद्धांतिक अंतर्दृष्टि प्रदान करता है। गणितीय तर्क में "पैटर्न कोलैप्स" क्यों होता है और ट्रेजेक्टरी अस्थिरता OOD नमूनों के लिए एक विश्वसनीय संकेत क्यों है, इसके लिए अधिक कठोर सैद्धांतिक गारंटी विकसित करने से इस दृष्टिकोण की नींव मजबूत होगी। इसमें उन स्थितियों को औपचारिक बनाना शामिल हो सकता है जिनके तहत ये घटनाएं होती हैं और TV स्कोर की प्रभावशीलता पर सीमाएं साबित होती हैं।
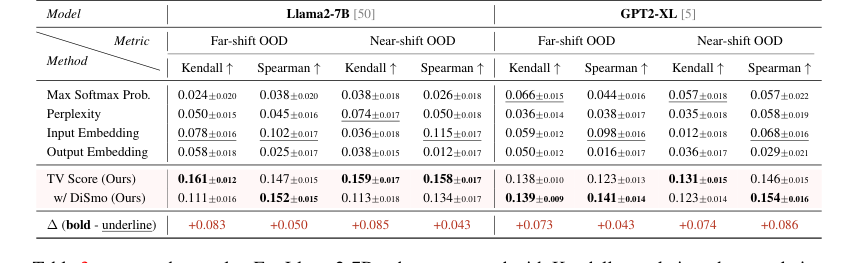 Table 3. presents the results. For Llama2-7B, when compared with Kendall correlation, the correlation improvement of TV scores over SOTA baselines reaches up to 100% under both far-shift and near-shift OOD settings. Compared with Spearman correlation, TV scores demonstrate a correlation enhancement over SOTA baselines by up to 100% under far-shift OOD setting and 30% under near-shift OOD setting. GPT2-XL also demonstrates excellent performance. These findings indicate that our TV scores not only facilitate the binary discrimination of ID and OOD samples but also substantially reflect the quality and precision of generated mathematical reasoning
Table 3. presents the results. For Llama2-7B, when compared with Kendall correlation, the correlation improvement of TV scores over SOTA baselines reaches up to 100% under both far-shift and near-shift OOD settings. Compared with Spearman correlation, TV scores demonstrate a correlation enhancement over SOTA baselines by up to 100% under far-shift OOD setting and 30% under near-shift OOD setting. GPT2-XL also demonstrates excellent performance. These findings indicate that our TV scores not only facilitate the binary discrimination of ID and OOD samples but also substantially reflect the quality and precision of generated mathematical reasoning
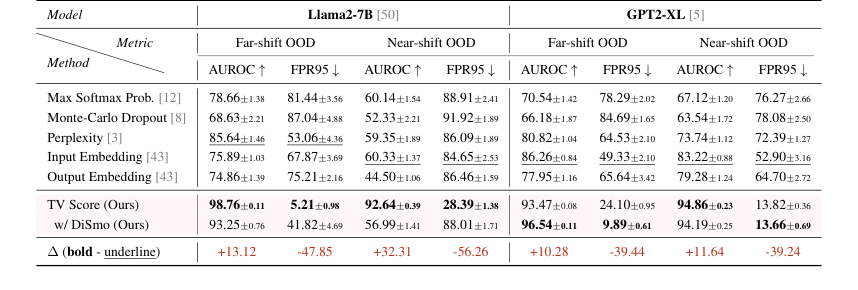 Table 1. AUROC and FPR95 results of the Offline Detection scenario. Underline and bold denote SOTA among all baselines and all methods, respectively. We report the average results under each setting in the main text, results of each dataset are shown in Table 11 and 12 (Appendix F)
Table 1. AUROC and FPR95 results of the Offline Detection scenario. Underline and bold denote SOTA among all baselines and all methods, respectively. We report the average results under each setting in the main text, results of each dataset are shown in Table 11 and 12 (Appendix F)
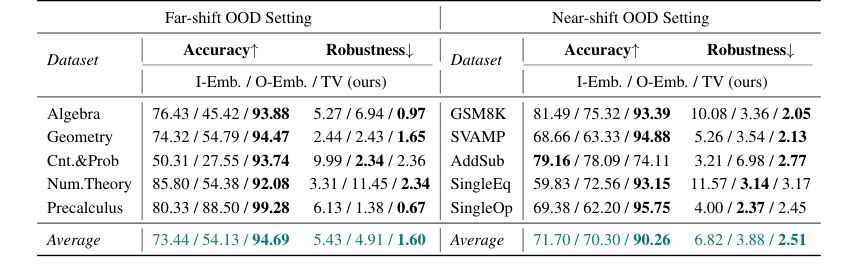 Table 2. presents the results in Llama2-7B. Compared to the embedding-based methods, our TV score obtains about an average of 20-point accuracy improvement in both far-shift OOD and near-shift OOD settings, and on some datasets, such as Cnt.&Prob, our TV score achieves more than 40 points of improvement. These all imply that TV Score can perform online discrimination of OOD samples more accurately. In addition, our TV score also possesses stronger robustness, which means that in real scenarios, we can find the optimal threshold more consistently in the face of different accessible ID and OOD data, reducing the potential riskiness due to uncontrollable data acquisition
Table 2. presents the results in Llama2-7B. Compared to the embedding-based methods, our TV score obtains about an average of 20-point accuracy improvement in both far-shift OOD and near-shift OOD settings, and on some datasets, such as Cnt.&Prob, our TV score achieves more than 40 points of improvement. These all imply that TV Score can perform online discrimination of OOD samples more accurately. In addition, our TV score also possesses stronger robustness, which means that in real scenarios, we can find the optimal threshold more consistently in the face of different accessible ID and OOD data, reducing the potential riskiness due to uncontrollable data acquisition
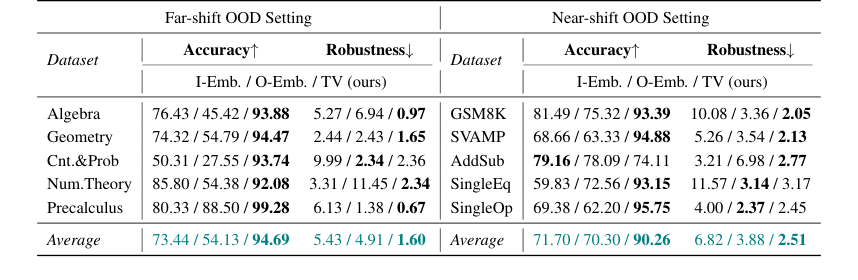 Table 2. Accuracy and Robustness results of the Online Detection scenario. We mainly compare our method with embedding-based methods, and bold denotes the best among these methods
Table 2. Accuracy and Robustness results of the Online Detection scenario. We mainly compare our method with embedding-based methods, and bold denotes the best among these methods