Встраивание траектории для обнаружения внераспределительных данных в задачах математического рассуждения
Проблема обнаружения внераспределительных (Out-of-Distribution, OOD) данных в задачах математического рассуждения для генеративных языковых моделей (ГЯМ) является относительно новой и критически важной.
Предпосылки и академическая родословная
Истоки и академическая родословная
Проблема обнаружения внераспределительных (Out-of-Distribution, OOD) данных в задачах математического рассуждения для генеративных языковых моделей (ГЯМ) является относительно новой и критически важной. Исторически алгоритмы обнаружения OOD данных в основном разрабатывались для защиты глубоких нейронных сетей от реальных данных, отклоняющихся от предположения о независимом и одинаково распределенном (i.i.d.) характере обучающих данных. Ранние исследования в этой области в значительной степени концентрировались на задачах компьютерного зрения и традиционной классификации текстов.
По мере развития ГЯМ методы обнаружения OOD данных были адаптированы для сценариев генерации текста, таких как суммаризация и перевод. Эти методы обычно полагались либо на оценку неопределенности, либо на измерение расстояний в пространстве встраиваний (embedding). Однако академическое сообщество столкнулось со значительной "болевой точкой", когда существующие подходы были применены к задачам математического рассуждения. Математическое рассуждение, являющееся сложной генеративной задачей, продемонстрировало уникальные характеристики в своем выходном пространстве, которые сделали традиционные методы, основанные на встраиваниях, неэффективными. Авторы явно заявляют, что, насколько им известно, они являются первыми, кто систематически изучил обнаружение OOD данных в задачах математического рассуждения и выявил неэффективность традиционных алгоритмов в этой специфической области. Таким образом, данная статья посвящена новой проблеме на стыке обнаружения OOD данных и математического рассуждения в контексте ГЯМ.
Фундаментальное ограничение предыдущих подходов проистекает из явления, которое авторы называют "коллапсом паттернов" (Pattern Collapse) в выходном пространстве математического рассуждения. Традиционные методы, основанные на встраиваниях, которые измеряют расстояния в статическом пространстве встраиваний (например, расстояние Махаланобиса), предполагают, что различные семантические входные данные будут отображаться в различные области пространства встраиваний. Однако в математическом рассуждении выходные данные часто являются символьными (например, числа, простые выражения) и строятся из ограниченного словаря токенов (таких как цифры 0-9 и основные математические символы). Это приводит к тому, что семантически разнообразные математические задачи порождают выходные встраивания, которые сходятся к области высокой плотности и перекрытия в латентном пространстве. Следовательно, статические расстояния между встраиваниями для распределенных (in-distribution, ID) и внераспределительных (OOD) выборок становятся неразличимыми, что делает невозможным для предыдущих методов надежное обнаружение OOD данных. Этот "коллапс паттернов" эффективно размывает границы между тем, что модель видела, а что нет, вынуждая авторов искать новый, динамический подход.
Интуитивные термины предметной области
- Внераспределительные (OOD) данные: Представьте, что вы обучили умного робота сортировать красные и зеленые яблоки. Если кто-то внезапно даст ему синюю ягоду, это будут OOD данные. Это то, с чем робот никогда не сталкивался во время обучения, и он может растеряться или сделать плохую догадку, потому что это не соответствует его выученным категориям.
- Генеративные языковые модели (ГЯМ): Думайте о ГЯМ как о высококреативном шеф-поваре, который может изобретать новые рецепты. Вы даете шеф-повару тему (например, "десерт для лета"), и он не просто выбирает из кулинарной книги; он комбинирует ингредиенты и техники, чтобы создать совершенно новое, уникальное блюдо. Аналогично, ГЯМ генерируют новый текст, а не просто извлекают существующие фразы.
- Коллапс паттернов (Pattern Collapse): Представьте себе большую художественную галерею, где каждая картина уникальна. Теперь представьте, что все эти картины были сжаты в крошечные миниатюры низкого разрешения. Многие различные картины могут выглядеть очень похоже или даже идентично в виде миниатюр, что затрудняет их различение. Это "сжатие" уникальных паттернов в общую, неразличимую форму — это то, что происходит с результатами математических рассуждений, делая их трудными для различения.
- Траектория встраивания (Embedding Trajectory): Рассмотрите сложный лабиринт с множеством уровней. Когда мышь входит в лабиринт, она оставляет след, проходя через каждый уровень. "Траектория встраивания" подобна отслеживанию этого следа для фрагмента информации, когда он проходит через каждый слой обработки нейронной сети. Она показывает не только то, где информация оказывается в итоге, но и всю последовательность преобразований, которые она претерпевает.
- Волатильность траектории (Trajectory Volatility): Продолжая аналогию с лабиринтом, "волатильность траектории" — это мера того, насколько извилист или гладок путь мыши между уровнями. Если мышь совершает резкие, большие изменения направления между уровнями, ее путь очень волатилен. Если она движется предсказуемо и плавно, ее волатильность низка. Эта "неровность" или "гладкость" пути данных через сеть может сигнализировать, является ли вход знакомым или неожиданным, внераспределительным.
Таблица обозначений
| Обозначение | Описание | Тип |
|---|---|---|
| $s$ | Данная выборка, обычно пара вход-выход. | Переменная |
| $L$ | Общее количество скрытых слоев в генеративной языковой модели. | Параметр |
| $d$ | Размерность вектора встраивания. | Параметр |
| $Y_l$ | Среднее встраивание выходной последовательности на слое $l$. | Переменная |
| $V_I(s)$ | Волатильность, независимая от размерности, для выборки $s$, отражающая локальные изменения траектории по всем размерностям. | Переменная |
| $V_J(s)$ | Волатильность, совместная по размерностям, для выборки $s$, отражающая глобальные изменения траектории с использованием L2-нормы. | Переменная |
| $\mu_l$ | Вектор среднего распределения Гаусса, подогнанного к встраиваниям распределенных (ID) данных на слое $l$. | Параметр |
| $\Sigma_l$ | Ковариационная матрица распределения Гаусса, подогнанного к встраиваниям ID данных на слое $l$. | Параметр |
| $f(Y_l)$ | Расстояние Махаланобиса среднего встраивания $Y_l$ от ID распределения Гаусса $G_l$. | Переменная |
| $S$ | Оценка волатильности траектории (TV Score) для выборки, рассчитанная как среднее разностей расстояний Махаланобиса между соседними слоями. | Переменная |
| $k$ | Порядок дифференциального сглаживания, применяемый к волатильности траектории. | Параметр |
| $\nabla^k S$ | Оценка волатильности траектории (TV Score) с $k$-порядковым дифференциальным сглаживанием. | Переменная |
Определение проблемы и ограничения
Основная постановка задачи и дилемма
Основная проблема, рассматриваемая в данной статье, заключается в точном обнаружении внераспределительных (OOD) данных в генеративных языковых моделях (ГЯМ) при выполнении задач математического рассуждения.
Исходная точка (Вход/Текущее состояние) — это ГЯМ, обученная на распределенных (ID) данных, обычно с предположением о независимом и одинаково распределенном (i.i.d.) характере распределения данных. Когда этой ГЯМ предъявляются реальные входные данные, отклоняющиеся от этого предположения i.i.d. (т.е. OOD данные), ее производительность может неожиданно снизиться, что приведет к потенциально вредным последствиям. Существующие методы обнаружения OOD данных для ГЯМ в основном опираются на два подхода: оценку неопределенности и измерение расстояний в пространстве встраиваний. Хотя методы, основанные на встраиваниях, оказались эффективными для традиционных лингвистических задач, таких как суммаризация и перевод, они оказались неприменимыми для математического рассуждения. Эта неприменимость обусловлена двумя уникальными явлениями, наблюдаемыми в математическом рассуждении:
1. Нечеткая кластеризация в пространстве входов: Встраивания входных данных для задач математического рассуждения в различных областях демонстрируют "нечеткие кластерные особенности" (Рисунок 1a, стр. 2), что затрудняет статическим встраиваниям захват присущей сложности и различий между различными математическими вопросами.
2. Коллапс паттернов в выходном пространстве: Выходные встраивания для математического рассуждения демонстрируют "характеристики высокой плотности со значительным перекрытием между различными областями" (Рисунок 1a, стр. 2). Это явление, названное "коллапсом паттернов", возникает потому, что математические выходные данные часто являются символьными (например, цифры 0-9, специальные символы), что сжимает пространство поиска и приводит к значительному совместному использованию токенов между математически различными выражениями. Это вызывает схождение встраиваний разнообразных математических задач к области высокой плотности, делая их неразличимыми с помощью традиционных статических мер расстояния встраиваний.
Желаемая конечная точка (Выход/Целевое состояние) — это надежный, легковесный алгоритм обнаружения OOD данных, названный TV Score, специально разработанный для сценариев математического рассуждения. Этот алгоритм должен эффективно различать ID и OOD выборки, даже при наличии "коллапса паттернов". Конечная цель — достичь высокой точности дискриминации, формализованной как поиск функции оценки $f(x, y, \theta)$ и порога $\epsilon$, максимизирующей:
$$ \max_{f} P_{(x,y)\sim P_{X,Y}}[f(x,y,\theta) < \epsilon] + P_{(x,\tilde{y})\sim P_{\tilde{X},\tilde{Y}}}[f(x,\tilde{y},\theta) > \epsilon] $$
где $P_{X,Y}$ — совместное распределение данных в пределах распределения, а $P_{\tilde{X},\tilde{Y}}$ — совместное распределение данных вне распределения (Уравнение 1, стр. 3). Кроме того, метод должен быть обобщаемым на другие задачи с выходными признаками высокой плотности, такие как вопросы с множественным выбором.
Точное недостающее звено или математический пробел, который данная статья пытается преодолеть, — это неэффективность статических методов обнаружения OOD данных на основе встраиваний в задачах математического рассуждения из-за явления "коллапса паттернов". Предыдущие методы вычисляют расстояние Махаланобиса между встраиванием новой выборки и распределением встраиваний ID в статическом входном или выходном пространстве (стр. 1). Однако "коллапс паттернов" приводит к тому, что конечные точки траекторий встраиваний для различных выборок математического рассуждения сходятся, делая эти статические меры расстояния неэффективными. Статья выдвигает гипотезу, что, хотя конечные точки могут коллапсировать, динамические траектории встраиваний, ведущие к этим конечным точкам, будут демонстрировать значительные различия между ID и OOD выборками. Таким образом, недостающее звено — это механизм для количественной оценки этих различий в траекториях, а не статических расстояний до конечных точек.
Болезненный компромисс или дилемма, в которую попали предыдущие исследователи, — это присущий конфликт между символьной природой выходных данных математического рассуждения с высокой плотностью и требованиями эффективного обнаружения OOD данных на основе встраиваний. В традиционной генерации текста различные семантические значения приводят к хорошо разделенным кластерам встраиваний, что позволяет эффективно использовать расстояние встраиваний. Однако в математическом рассуждении краткость и общий словарный запас токенов (например, цифр) ответов приводят к тому, что разнообразные задачи отображаются в очень похожие выходные встраивания. Этот "коллапс паттернов" означает, что улучшение способности модели генерировать правильные математические ответы (которые часто являются скалярными или простыми выражениями) непреднамеренно разрушает различимость в латентном пространстве, на которую полагаются методы обнаружения OOD данных. Исследователи оказались в затруднительном положении: либо принять низкое качество обнаружения OOD данных для математического рассуждения, либо фундаментально переосмыслить, как OOD определяется и измеряется в таком уникальном выходном пространстве.
Ограничения и режимы отказа
Проблема обнаружения OOD данных в задачах математического рассуждения чрезвычайно сложна из-за нескольких суровых, реалистичных ограничений:
- Ограничение, обусловленное данными: Высокоплотное выходное пространство ("Коллапс паттернов"): Это самое значительное ограничение. Выходные данные математического рассуждения являются "математически символьными" (стр. 2), что приводит к сжатому пространству поиска. Это увеличивает вероятность перекрытия между вопросами из разных областей. Важно отметить, что ГЯМ токенизируют математические выражения, используя ограниченный словарь цифр (0-9) и конечного набора специальных символов, что приводит к "значительному совместному использованию токенов" между математически различными выражениями (стр. 2, Раздел 6.2). Это вызывает схождение выходных встраиваний в область высокой плотности, неразличимую, что делает традиционные статические методы измерения расстояний встраиваний неэффективными.
- Ограничение, обусловленное данными: Нечеткая кластеризация входного пространства: Входное пространство для математического рассуждения также демонстрирует "нечеткие кластерные особенности в различных областях" (стр. 2, Рисунок 1a). Это указывает на то, что встраивания с трудом улавливают полную сложность математических вопросов, что еще больше усложняет обнаружение OOD данных со стороны входа.
- Физическое ограничение: Ограниченная доступность данных: Наборы данных для математического рассуждения "относительно малы" (сотни или тысячи выборок), особенно по сравнению с миллионами выборок, доступных для традиционных задач NLP, таких как перевод или суммаризация (стр. 1, стр. 11, "Ограничения"). Эта нехватка данных затрудняет надежное обучение моделей и оценку методов обнаружения OOD данных, увеличивая случайность результатов. Авторы смягчают это, используя выборку тестов.
- Алгоритмическое ограничение: Сложность количественной оценки различий в траекториях: Хотя статические различия встраиваний могут быть измерены с помощью расстояния Махаланобиса, "количественная оценка различия между траекторией и кластером траекторий менее интуитивна" (стр. 5). Это требует новой математической формулировки для улавливания динамических изменений в пространстве встраиваний между слоями, что решается в статье путем определения волатильности траектории.
- Алгоритмическое ограничение: Выбросы в траектории: Выбросы в траектории встраиваний могут "существенно влиять на извлечение признаков" (стр. 5). Этот шум может замаскировать истинные лежащие в основе различия между ID и OOD траекториями, требуя методов сглаживания для повышения надежности.
- Вычислительное ограничение: Размер модели и ресурсы для обучения: Метод опирается на большие ГЯМ, такие как Llama2-7B и GPT2-XL (стр. 6). Обучение этих моделей требует значительных вычислительных ресурсов (например, 4-карточная RTX 3090 для Llama2-7B, одиночная RTX 3090 для GPT2-XL, стр. 23). Хотя предложенный TV Score сам по себе "легковесен" с точки зрения собственных вычислений (миллисекунды, сложность $O(Ldn)$ или $O(Ldk)$, стр. 22), он работает поверх этих вычислительно интенсивных базовых моделей.
- Ограничение, обусловленное данными: Неопределенность утечки данных: Для ГЯМ с закрытым исходным кодом, таких как Llama2-7B, существует неопределенность относительно того, были ли конкретные наборы OOD данных включены в их предварительное обучение (стр. 23). Это затрудняет однозначное объявление набора данных OOD исключительно с точки зрения распределения. Авторы решают эту проблему, определяя OOD как данные, которые "превышают возможности базовой модели" (стр. 23).
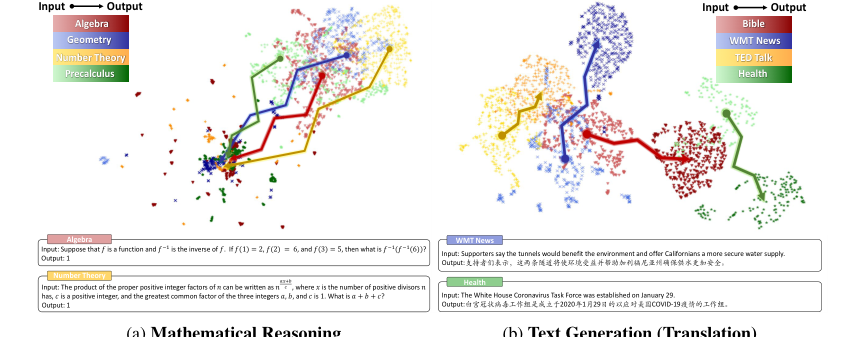 Figure 1. Embedding projection and cases of input and output spaces under mathematical reasoning and text generation scenarios. We select MATH [6] dataset for mathematical reasoning and OPUS [49] for text generation, each with four diverse domains. Different colors represent different domains, with lighter and darker shades indicating input and output. We use SimCSE [9] for sentence embeddings and UMAP [34] for dimensionality reduction. Appendix B shows detailed settings and examples
Figure 1. Embedding projection and cases of input and output spaces under mathematical reasoning and text generation scenarios. We select MATH [6] dataset for mathematical reasoning and OPUS [49] for text generation, each with four diverse domains. Different colors represent different domains, with lighter and darker shades indicating input and output. We use SimCSE [9] for sentence embeddings and UMAP [34] for dimensionality reduction. Appendix B shows detailed settings and examples
Почему такой подход
Неизбежность выбора
Принятие TV Score на основе траекторий было не просто предпочтением, а необходимостью, обусловленной уникальными и сложными характеристиками обнаружения внераспределительных (OOD) данных в задачах математического рассуждения для генеративных языковых моделей (ГЯМ). Авторы выявили критическую точку отказа в традиционных "SOTA" методах, таких как стандартные подходы на основе встраиваний, при столкновении с этой конкретной проблемой.
Точный момент, когда авторы осознали неадекватность традиционных методов, четко изложен в Разделе 1. Хотя методы на основе встраиваний оказались высокоэффективными для традиционных лингвистических задач, таких как суммаризация и перевод (как продемонстрировано в [43] с использованием расстояния Махаланобиса [22]), они столкнулись со значительными трудностями в математическом рассуждении. Это было связано с "характеристикой высокой плотности выходных пространств" в этой области, явлением, которое авторы называют "коллапсом паттернов". Этот "коллапс паттернов" делает методы на основе встраиваний неприменимыми, как показано на Рисунке 1. Основная проблема заключается в том, что выходные данные из различных математических областей, несмотря на их семантическую различность, сходятся к области высокой плотности в пространстве встраиваний, делая их неразличимыми с помощью статических мер расстояния встраиваний. Это осознание вынудило сместить фокус со статических пространств встраиваний на динамическую "траекторию встраивания" (Раздел 2), поскольку это был единственный жизнеспособный путь для улавливания тонких различий между распределенными (ID) и внераспределительными (OOD) выборками.
Сравнительное превосходство
Помимо простых метрик производительности, метод TV Score демонстрирует глубокое качественное превосходство благодаря своим структурным преимуществам в решении уникальных задач математического рассуждения. Ключ заключается в его способности использовать динамические изменения во встраиваниях между слоями, а не полагаться на статические встраивания последнего слоя.
Явление "коллапса паттернов", хотя и делает статические встраивания неразличимыми, парадоксальным образом создает "значительные различия в траекториях между выборками" (Раздел 2, Рисунок 2). TV Score использует это, измеряя "волатильность траектории", которая количественно определяет эти динамические сдвиги. Этот подход по своей сути более устойчив к проблеме выходного пространства с высокой плотностью, поскольку он фокусируется на процессе преобразования встраиваний, а не только на конечном состоянии.
Важное структурное преимущество раскрывается благодаря явлению "ранней стабилизации" (Раздел 2.2, Раздел 3). Для ID данных ГЯМ, как правило, завершают рассуждение в средних и поздних слоях, что приводит к подавлению величины изменения встраивания в последующих слоях. В резком контрасте, для OOD данных эта величина остается постоянно высокой, указывая на сбой в завершении связного рассуждения. Это отчетливое динамическое поведение обеспечивает мощный и надежный сигнал для обнаружения OOD данных, который статические методы просто не могут уловить.
Кроме того, метод описывается как "легковесный" (Раздел 3), что подразумевает вычислительную эффективность. Дополнительный метод дифференциального сглаживания (TV Score w/ DiSmo) еще больше повышает надежность, смягчая влияние выбросов в траекториях, обеспечивая более гладкий и надежный сигнал (Раздел 3). Экспериментальные результаты (Таблица 1, Таблица 2) количественно подтверждают это качественное превосходство, показывая среднее улучшение AUROC более чем на 10 пунктов и замечательное снижение FPR95 на 80%+ по сравнению с базовыми методами, даже в сложных сценариях OOD с близким сдвигом, где другие методы демонстрируют значительное снижение производительности.
Соответствие ограничениям
Выбранный подход на основе траекторий, воплощенный в TV Score, идеально соответствует строгим ограничениям, присущим обнаружению OOD данных в задачах математического рассуждения.
- Ограничение: Обнаружение OOD данных в ГЯМ для математического рассуждения. TV Score специально разработан для этой области, напрямую решая проблему "коллапса паттернов" и "характеристик высокой плотности", которые делают традиционные методы неэффективными (Аннотация, Раздел 1). Он специально моделирует и измеряет явления, уникальные для математического рассуждения, такие как "ранняя стабилизация" (Раздел 2.2).
- Ограничение: Преодоление неприменимости традиционных методов на основе встраиваний. Основной мотивацией для TV Score является продемонстрированная неэффективность статических методов на основе встраиваний в задачах математического рассуждения (Раздел 1, Раздел 6). Переходя к динамическим траекториям встраиваний, метод напрямую обходит ограничения, налагаемые высокой плотностью выходного пространства, где статические встраивания теряют свою дискриминационную способность (Раздел 2, Рисунок 2).
- Ограничение: Необходимость легковесного решения. В статье прямо указано, что TV Score является "легковесным решением для обнаружения OOD данных" (Раздел 3). Его вычислительная сложность эффективна: $O(Ldn)$ для подгонки ID распределения и $O(Ldk)$ для вычисления оценки, что делает его практичным для реальных приложений ГЯМ (Приложение D).
- Ограничение: Масштабируемость и обобщаемость на другие задачи с высокоплотными выходами. Метод разработан для масштабируемости и демонстрирует "большие преимущества в сценариях точной дискриминации" (Раздел 5.2). Важно отметить, что авторы показывают его расширяемость на другие задачи, демонстрирующие свойство "коллапса паттернов", такие как вопросы с множественным выбором, где он также превосходит традиционные алгоритмы (Аннотация, Раздел 5.2). Это подтверждает его широкую применимость за пределами первоначальной направленности на математическое рассуждение.
Отклонение альтернатив
В статье представлены четкие обоснования для отклонения популярных альтернативных подходов к обнаружению OOD данных, в основном сосредоточенные на том, почему существующие методы неэффективны в специфическом контексте математического рассуждения.
-
Традиционные статические методы на основе встраиваний (например, расстояние Махаланобиса на входных/выходных встраиваниях): Эти методы, хотя и эффективны для общей генерации текста, явно признаны "неприменимыми" для математического рассуждения (Раздел 1). Статья посвящает Раздел 6 "Переосмыслению неприменимости статических методов на основе встраиваний", подробно описывая две основные причины их неэффективности:
- Дилемма представления входного пространства: Математические выражения во входном пространстве демонстрируют "нечеткие кластерные особенности" (Раздел 6.1, Рисунок 1a). Семантические встраивания, как показано в Таблице 4, не точно отражают математические отношения. Например, математически "распределенное" выражение может иметь более низкое косинусное сходство, чем математически "внераспределительное", что делает статические входные встраивания ненадежными для обнаружения OOD данных.
- "Коллапс паттернов" в выходном пространстве: Это наиболее критическая проблема (Раздел 6.2, Рисунок 1a). Выходное пространство математического рассуждения характеризуется высокой плотностью и значительным перекрытием между областями. Этот "коллапс паттернов" происходит на двух уровнях:
- Уровень выражений: Математические выходные данные часто являются скалярными (например, "4"), что сжимает пространство поиска и увеличивает вероятность перекрытия между совершенно разными математическими вопросами (например, "1+3=" и "$\int x dx=$" оба дают "4") (Раздел 6.2).
- Уровень токенов: ГЯМ токенизируют математические выражения, используя ограниченный набор цифр (0-9) и специальных символов. Это приводит к значительному совместному использованию токенов даже для математически различных выражений, вызывая коллапс на уровне токенов во время авторегрессивного предсказания (Раздел 6.2, Таблица 6).
Таблица 5 эмпирически подтверждает это отклонение, показывая, что расстояние Махаланобиса на статических встраиваниях дает почти случайные значения AUROC (около 50) во многих настройках.
-
Методы оценки неопределенности (например, максимальная вероятность максимума, Монте-Карло Dropout, перплексия последовательности): Эти методы включены в качестве базовых в экспериментах (Раздел 4.1, Таблица 1, Таблица 2, Таблица 3). Хотя в статье не приводится подробного теоретического анализа причин их неэффективности для математического рассуждения, их постоянная и значительная недопроизводительность по сравнению с TV Score (часто на 10+ пунктов AUROC и снижение FPR95 на 80%+) подразумевает их неадекватность. Уникальные явления "коллапса паттернов" и "ранней стабилизации" не затрагиваются напрямую этими методами, основанными на неопределенности, которые обычно фокусируются на уверенности предсказания, а не на динамической эволюции встраиваний.
-
Техники "цепочки рассуждений" (Chain-of-Thought, CoT): В статье CoT рассматривается как потенциальная альтернатива для "расширения размера выходного пространства" и смягчения "коллапса паттернов" (Раздел 6.3). Однако авторы приходят к выводу, что "несмотря на то, что CoT расширяет размер выходного пространства, выходной ответ по-прежнему существенно связан со сложностью и цифрами математического рассуждения, а представление семантических встраиваний не может точно отразить эти особенности". Эмпирические результаты в Таблице 5(b) показывают, что даже с CoT точность обнаружения с использованием расстояния Махаланобиса остается низкой и сильно варьируется, что указывает на то, что сам по себе CoT недостаточен для решения фундаментальных проблем обнаружения OOD данных в этой области.
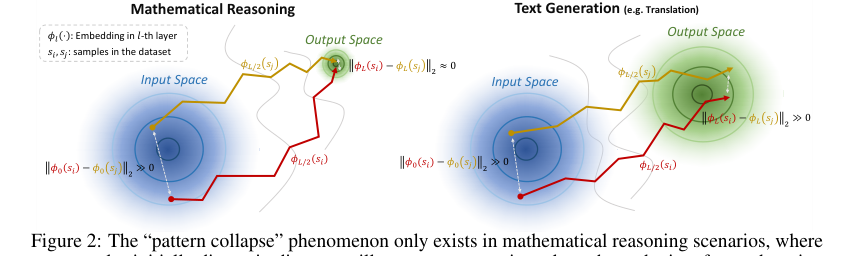 Figure 2. The “pattern collapse” phenomenon only exists in mathematical reasoning scenarios, where two samples initially distant in distance will converge approximately at the endpoint after undergoing embedding shifts, and does not occur in text generation scenarios. This produces a greater likelihood of trajectory variation under different samples in mathematical reasoning
Figure 2. The “pattern collapse” phenomenon only exists in mathematical reasoning scenarios, where two samples initially distant in distance will converge approximately at the endpoint after undergoing embedding shifts, and does not occur in text generation scenarios. This produces a greater likelihood of trajectory variation under different samples in mathematical reasoning
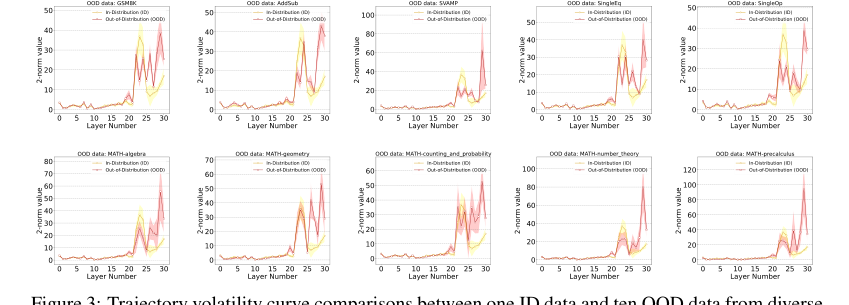 Figure 3. Trajectory volatility curve comparisons between one ID data and ten OOD data from diverse mathematical domains. Each trajectory represents the average of all samples from the corresponding datasets, with color shading being the sample standard deviation. Llama2-7B is used for the backbone
Figure 3. Trajectory volatility curve comparisons between one ID data and ten OOD data from diverse mathematical domains. Each trajectory represents the average of all samples from the corresponding datasets, with color shading being the sample standard deviation. Llama2-7B is used for the backbone
Математический и логический механизм
Основное уравнение
Ядром механизма обнаружения внераспределительных (OOD) данных в математическом рассуждении в данной статье является оценка волатильности траектории (Trajectory Volatility, TV Score), $S$. Эта оценка количественно определяет динамические изменения встраивания выборки по мере ее распространения через слои генеративной языковой модели (ГЯМ). Основное уравнение для TV Score определяется как:
$$ S = \frac{1}{L} \sum_{l=1}^{L} |f(y_l) - f(y_{l-1})| $$
Это уравнение опирается на промежуточную функцию $f(y_l)$, которая вычисляет расстояние Махаланобиса встраивания на определенном слое $l$. Эта функция задается как:
$$ f(y_l) = (y_l - \mu_l)^T (\Sigma_l)^{-1} (y_l - \mu_l) $$
Послойный разбор
Давайте разберем эти уравнения, чтобы понять роль каждого компонента:
Для уравнения TV Score ($S$):
- $S$:
- Математическое определение: Оценка волатильности траектории для данной входной выборки.
- Физическая/логическая роль: Это окончательное скалярное значение, которое служит оценкой для обнаружения OOD. Более высокое значение $S$ указывает на большую волатильность траектории встраивания выборки по слоям ГЯМ, что, как предполагается, является отличительной чертой OOD выборок в задачах математического рассуждения.
- Почему сложение вместо умножения или интеграл вместо суммирования: Авторы используют суммирование, поскольку ГЯМ имеет дискретное количество слоев ($L$). Суммирование агрегирует индивидуальные изменения в расстоянии Махаланобиса между соседними слоями. Сложение выбрано для накопления величин этих изменений, обеспечивая общую меру "длины пути" или флуктуации. Умножение резко увеличило бы оценку, сделав ее менее интерпретируемой как прямая мера волатильности и потенциально приведя к числовой нестабильности.
- $\frac{1}{L}$:
- Математическое определение: Обратное значение $L$, где $L$ — общее количество скрытых слоев в ГЯМ.
- Физическая/логическая роль: Этот член действует как нормализующий множитель. Он преобразует сумму послойных волатильностей в среднюю волатильность на слой. Это гарантирует, что TV Score будет сопоставим между моделями с разным количеством слоев или при анализе траекторий разной длины.
- $\sum_{l=1}^{L}$:
- Математическое определение: Оператор суммирования, итерирующий от первого слоя ($l=1$) до последнего слоя ($L$).
- Физическая/логическая роль: Этот оператор агрегирует индивидуальные вклады волатильности от каждого перехода между соседними слоями. Он суммирует, насколько "прыгает" или "сдвигается" расстояние Махаланобиса по мере продвижения представления выборки через глубину модели.
- $| \cdot |$:
- Математическое определение: Функция абсолютного значения.
- Физическая/логическая роль: Это гарантирует, что учитывается только величина разницы в расстоянии Махаланобиса между соседними слоями, а не ее направление (т.е. увеличилось или уменьшилось расстояние). Фокус исключительно на степени изменения, что является центральным для измерения волатильности.
- $f(y_l)$:
- Математическое определение: Расстояние Махаланобиса среднего встраивания $y_l$ на слое $l$.
- Физическая/логическая роль: Этот член количественно определяет, насколько "далеко" встраивание выборки на слое $l$ находится от типичного распределения выборок в пределах распределения (ID) на том же слое. Он преобразует высокоразмерное встраивание в одно скалярное значение, представляющее его "ID-подобность" на данном слое.
- $f(y_{l-1})$:
- Математическое определение: Расстояние Махаланобиса среднего встраивания $y_{l-1}$ на слое, непосредственно предшествующем слою $l$.
- Физическая/логическая роль: Аналогично $f(y_l)$, но для предыдущего слоя. Разница $|f(y_l) - f(y_{l-1})|$ конкретно измеряет изменение "ID-подобности" по мере эволюции представления выборки от слоя $l-1$ к слою $l$.
Для уравнения расстояния Махаланобиса ($f(y_l)$):
- $y_l$:
- Математическое определение: Среднее встраивание токенов выходной последовательности на слое $l$. Это $d$-мерный вектор, вычисляемый как $y_l = \frac{1}{T} \sum_{t=1}^{T} h_t^l$, где $h_t^l$ — это выходное встраивание $t$-го токена на слое $l$, а $T$ — количество токенов.
- Физическая/логическая роль: Этот вектор представляет собой агрегированную семантическую и математическую информацию всей выходной последовательности на определенной глубине в ГЯМ. Это "состояние" выходного представления выборки на слое $l$.
- $\mu_l$:
- Математическое определение: Вектор среднего распределения Гаусса $G_l = N(\mu_l, \Sigma_l)$, которое было подогнано к встраиваниям всех выборок ID на слое $l$. Это также $d$-мерный вектор.
- Физическая/логическая роль: Этот вектор представляет собой "центр" или "типичное" встраивание для выборки ID на слое $l$. Он служит точкой отсчета для того, что считается "нормальным" на данном слое.
- $(y_l - \mu_l)$:
- Математическое определение: Вектор, представляющий разницу между встраиванием выборки $y_l$ и средним встраиванием ID $\mu_l$ на слое $l$.
- Физическая/логическая роль: Это вектор отклонения, указывающий, насколько встраивание текущей выборки отклоняется от среднего встраивания ID на слое $l$.
- $(\cdot)^T$:
- Математическое определение: Оператор транспонирования.
- Физическая/логическая роль: В данном контексте он преобразует вектор-столбец $(y_l - \mu_l)$ в вектор-строку, что необходимо для матричного умножения в квадратичной форме расстояния Махаланобиса.
- $(\Sigma_l)^{-1}$:
- Математическое определение: Обратная матрица ковариационной матрицы $\Sigma_l$. $\Sigma_l$ — это ковариационная матрица распределения Гаусса $G_l = N(\mu_l, \Sigma_l)$, подогнанного к встраиваниям всех выборок ID на слое $l$. Это матрица размера $d \times d$.
- Физическая/логическая роль: Это критически важный компонент расстояния Махаланобиса. Он учитывает корреляции и дисперсии между размерностями пространства встраиваний ID на слое $l$. Инвертируя его, метрика расстояния эффективно "отбеливает" данные, нормализуя различные масштабы и повороты в пространстве признаков. Это делает расстояние более устойчивым к фактической геометрии распределения данных ID, обеспечивая более осмысленную меру "расстояния", чем просто евклидово расстояние.
- $(\cdot)^T (\cdot)^{-1} (\cdot)$:
- Математическое определение: Квадратичная форма, в частности, квадрат расстояния Махаланобиса.
- Физическая/логическая роль: Все это выражение вычисляет квадрат расстояния Махаланобиса. Оно измеряет расстояние между $y_l$ и $\mu_l$ в единицах стандартных отклонений, эффективно нормализуя разброс и ориентацию облака данных ID. Это обеспечивает надежную меру того, насколько "маловероятно" встраивание в соответствии с распределением ID на слое $l$.
Пошаговый поток
Представим себе единую, абстрактную точку данных — назовем ее "запросной выборкой" $s$ — входящую в конвейер обнаружения OOD. Вот ее путь через математический механизм:
- Генерация начального встраивания: Запросная выборка $s$ (например, математическая задача) подается в предварительно обученную генеративную языковую модель (ГЯМ). ГЯМ обрабатывает входные данные и генерирует выходную последовательность (например, математическое решение).
- Послойные выходные встраивания: По мере генерации выходной последовательности ГЯМ, ее внутренние слои производят встраивания токенов. Для каждого из $T$ токенов в выходной последовательности из каждого из $L$ скрытых слоев ($l=1, \dots, L$) извлекается $d$-мерный вектор встраивания $h_t^l$.
- Агрегация на уровне предложений: Для каждого слоя $l$ все $T$ векторных встраиваний токенов $h_t^l$ из выходной последовательности усредняются для формирования единого, репрезентативного $d$-мерного вектора $y_l$. Этот $y_l$ инкапсулирует общее выходное представление на данном конкретном слое. Этот шаг эффективно отслеживает "траекторию встраивания" для выборки через слои ГЯМ: $y_1 \to y_2 \to \dots \to y_L$.
- Эталонное распределение ID: Перед обработкой запроснй выборки система уже установила "нормальный" эталон. Это включает сбор большого набора известных распределенных (ID) выборок, пропуск их через ту же ГЯМ и вычисление их послойных средних встраиваний. Для каждого слоя $l$ к этим встраиваниям ID подгоняется распределение Гаусса $G_l = N(\mu_l, \Sigma_l)$. Это означает, что вектор среднего $\mu_l$ и ковариационная матрица $\Sigma_l$ статистически оцениваются, характеризуя типичное пространство встраиваний ID на каждом слое.
- Отображение расстоянием Махаланобиса: Теперь для траектории запроснй выборки на каждом слое $l$ ее среднее встраивание $y_l$ отображается в скалярное значение $f(y_l)$ с использованием формулы расстояния Махаланобиса. Этот расчет использует предварительно вычисленные средние $\mu_l$ и ковариации $\Sigma_l$ ID для данного конкретного слоя. Этот шаг преобразует сложное $d$-мерное встраивание в более простое скалярное значение, указывающее, насколько оно "ID-подобно" на данном слое, учитывая форму облака данных ID.
- Измерение волатильности: Затем система рассматривает изменение этой "ID-подобности" между последовательными слоями. Для каждой смежной пары слоев $(l-1, l)$ вычисляется абсолютная разница $|f(y_l) - f(y_{l-1})|$. Это измеряет величину сдвига в расстоянии Махаланобиса при переходе представления выборки от слоя $l-1$ к слою $l$.
- Агрегация TV Score: Все эти послойные величины волатильности суммируются, а затем делятся на общее количество слоев $L$ для получения окончательной оценки волатильности траектории $S$. Этот $S$ является единой, усредненной мерой того, насколько "ID-подобность" выборки колеблется на протяжении ее пути в ГЯМ.
- Классификация OOD: Наконец, вычисленная TV Score $S$ для запроснй выборки сравнивается с предопределенным порогом $\epsilon$. Если $S$ превышает $\epsilon$, выборка помечается как внераспределительная (Out-of-Distribution); в противном случае она считается распределенной (In-Distribution). Основная гипотеза заключается в том, что OOD выборки, особенно в задачах математического рассуждения, будут демонстрировать более высокую волатильность траектории из-за таких явлений, как "коллапс паттернов".
Динамика оптимизации
Важно уточнить, что сам механизм Trajectory Volatility (TV) Score, предложенный в данной статье, является методом постобработки для обнаружения, а не моделью, которая подвергается традиционной оптимизации на основе градиентов или обучению. У него нет функции потерь, которую нужно минимизировать, и он не обновляет свои собственные параметры итеративно посредством обратного распространения ошибки.
Вместо этого "обучение" или "адаптация" механизма происходит в двух различных этапах:
- Предварительно обученная генеративная языковая модель (ГЯМ): Ядром системы является предварительно обученная ГЯМ (например, Llama2-7B или GPT2-XL). Эта ГЯМ отдельно обучается на огромных объемах данных, включая распределенные задачи математического рассуждения. Во время этого этапа предварительного обучения ГЯМ учится генерировать связные и математически корректные выходные данные, и при этом она развивает свои внутренние представления встраиваний по своим слоям. Веса и параметры этой ГЯМ фиксированы при применении метода TV Score. Встраивания $y_l$ являются просто выходными данными этой статической, предварительно обученной модели.
- Подгонка эталонного распределения (ID): Единственная "подгонка" или "обучение", специфичное для метода TV Score, — это однократная статистическая оценка распределений Гаусса $G_l = N(\mu_l, \Sigma_l)$ для каждого слоя $l$.
- Среднее ($\mu_l$): Для каждого слоя $\mu_l$ вычисляется как эмпирическое среднее всех выборок встраиваний ID, собранных на этом слое.
- Ковариация ($\Sigma_l$): Аналогично, $\Sigma_l$ является эмпирической ковариационной матрицей этих встраиваний ID на слое $l$.
Эти параметры ($\mu_l, \Sigma_l$) вычисляются один раз из назначенного набора данных ID. Затем они фиксируются и служат статическим "эталоном" для того, что представляет собой "нормальное" встраивание на каждом слое. Нет итеративных обновлений или градиентов, участвующих в определении $\mu_l$ и $\Sigma_l$, кроме их первоначального вычисления.
Заключительный этап обнаружения OOD включает сравнение вычисленной TV Score $S$ с порогом $\epsilon$. Этот порог обычно определяется эмпирически на валидационном наборе, например, путем оптимизации таких метрик, как AUROC или FPR95 (как упомянуто в Разделе 4.2). Этот выбор порога является формой настройки гиперпараметров, а не итеративным процессом обучения, который формирует ландшафт потерь или обновляет состояния модели.
По сути, механизм TV Score — это статистическая функция оценки, которая использует фиксированные, выученные представления предварительно обученной ГЯМ и статистически определенный эталон для данных ID. Он сам по себе не обучается, не обновляется и не сходится посредством градиентного спуска или аналогичной динамики оптимизации.
Результаты, ограничения и заключение
Экспериментальный дизайн и базовые методы
Для строгого подтверждения своих математических утверждений авторы разработали комплексную экспериментальную установку, ориентированную на обнаружение внераспределительных (OOD) данных в генеративных языковых моделях (ГЯМ) для математического рассуждения. Оценка была разделена на два основных сценария: офлайн-обнаружение и онлайн-обнаружение.
Для офлайн-обнаружения целью было классифицировать, являются ли выборки из данного списка OOD. Основными использованными метриками были AUROC (площадь под кривой рабочей характеристики приемника) и FPR95 (частота ложных срабатываний при 95% частоте истинных срабатываний). Для онлайн-обнаружения задача заключалась в вычислении оптимального порога классификации для прямого определения, являются ли новые выборки OOD, с использованием точности дискриминации и надежности (измеренной как дисперсия выборки).
"Жертвами" (базовыми моделями), против которых безжалостно сравнивался предложенный TV Score, были пять методов без обучения, выбранных из-за нехватки методов обнаружения OOD данных на ГЯМ:
1. Максимальная вероятность максимума (Prob.) [12]
2. Монте-Карло Dropout [8]
3. Перплексия последовательности [3]
4. Встраивание входа [43]
5. Выходное встраивание [43]
В экспериментальном дизайне использовался MultiArith [44] в качестве набора данных в пределах распределения (ID), включающего задачи на арифметическое рассуждение в виде текстовых задач. Для OOD данных рассматривались два различных сценария:
* OOD с большим сдвигом (Far-shift OOD): Это включало набор данных MATH [11], охватывающий пять различных математических областей (алгебра, геометрия, комбинаторика и теория вероятностей, теория чисел и прекалькулус). Эти задачи имеют сложность уровня колледжа, в отличие от элементарного уровня MultiArith, что обеспечивает значительный сдвиг распределения.
* OOD с близким сдвигом (Near-shift OOD): Это включало пять наборов данных для арифметического рассуждения (GSM8K [6], SVAMP [39], AddSub [13], SingleEq [18] и SingleOp [18]). Хотя это также текстовые задачи по математике, они требуют различных шагов рассуждения и точек знаний по сравнению с MultiArith, представляя более тонкий сдвиг распределения.
Данные ID (MultiArith) были разделены на 360 выборок для обучения и 240 для тестирования. Чтобы уменьшить случайность из-за небольшого тестового набора, использовался размер выборки тестов 1000, обеспечивая сбалансированное количество положительных (OOD) и отрицательных (ID) выборок. В качестве базовых ГЯМ использовались Llama2-7B [50] и GPT2-XL (1.5B) [5], обученные на наборе данных ID MultiArith. Рациональность выбора наборов данных OOD была тщательно проверена путем подтверждения того, что эти наборы данных превышают возможности базовых моделей, демонстрируя на них очень низкую точность, тем самым подтверждая их статус OOD с точки зрения производительности модели. Для TV Score с дифференциальным сглаживанием (TV Score w/ DiSmo) порядок сглаживания $k$ варьировался от 1 до 5, и сообщалось о наилучшей производительности.
Что доказывают свидетельства
Экспериментальные результаты предоставляют окончательные, неоспоримые доказательства того, что основной механизм волатильности траектории эффективно различает ID и OOD выборки в задачах математического рассуждения, значительно превосходя традиционные алгоритмы.
В офлайн-обнаружении TV Score продемонстрировал замечательное превосходство:
* OOD с большим сдвигом: Наш метод достиг среднего AUROC 98.76 (Llama2-7B) и 93.47 (GPT2-XL), превзойдя оптимальный базовый метод более чем на 10 пунктов. Более поразительно, что метрика FPR95 составила 5.21 (Llama2-7B) и 9.89 (GPT2-XL), что представляет собой сокращение более чем на 80% по сравнению с лучшим базовым методом. Это ясно указывает на то, что, анализируя динамическую траекторию встраивания, модель может надежно идентифицировать выборки из значительно отличающихся математических областей.
* OOD с близким сдвигом: Даже в этом более сложном сценарии, где базовые методы показали значительное снижение производительности (AUROC ниже 60, FPR95 выше 80), наш метод сохранил отличную производительность, с показателями AUROC выше 90 и FPR95 ниже 30. Это доказывает большую адаптивность и надежность TV Score к тонким сдвигам распределения.
Анализ моделей далее выявил интересные явления: GPT2-XL демонстрировал более стабильную производительность в сценариях с большим и близким сдвигом, в то время как Llama2-7B показал более выраженное снижение производительности базовых методов в сценарии с близким сдвигом. Метод дифференциального сглаживания (DiSmo) был особенно эффективен на GPT2-XL, предполагая, что он помогает смягчить аномальные тенденции обучения в латентных пространствах меньших моделей. Важно отметить, что наш метод прошел почти все тесты на значимость, в отличие от базовых методов на основе встраиваний, которые показали более высокую подверженность ошибкам выборки.
Для онлайн-обнаружения TV Score достиг среднего улучшения точности на 20 пунктов по сравнению с методами на основе встраиваний в сценариях как с большим, так и с близким сдвигом OOD, причем некоторые наборы данных показали улучшение более чем на 40 пунктов. Эта более высокая надежность, отраженная в более низкой дисперсии выборки, означает, что оптимальный порог классификации OOD может быть найден более последовательно в реальных сценариях, снижая риски от неконтролируемого приобретения данных.
Помимо обнаружения, TV Score также оказался эффективным для оценки качества OOD. При измерении корреляции с бинарной метрикой качества соответствия наш метод показал улучшение корреляции Кендалла до 100% и улучшение корреляции Спирмена до 100% (большой сдвиг) / 30% (близкий сдвиг) для Llama2-7B по сравнению с SOTA базовыми методами. Эти неопровержимые доказательства указывают на то, что TV Score не только различает ID/OOD, но и точно отражает качество и точность генерируемых математических рассуждений.
Наконец, обобщаемость метода была продемонстрирована на наборе данных MMLU с вопросами множественного выбора, задаче, также характеризующейся "коллапсом паттернов". Наш TV Score превзошел все традиционные алгоритмы в этом сценарии, демонстрируя масштабируемость и преимущества в сценариях точной дискриминации, особенно там, где традиционные методы на основе встраиваний испытывали трудности.
Ограничения и будущие направления
Хотя TV Score демонстрирует значительные достижения в обнаружении OOD данных для математического рассуждения, важно признать присущие ограничения и рассмотреть направления для дальнейшего развития.
Основное ограничение, выделенное авторами, — это относительно небольшой размер наборов данных, доступных для математического рассуждения. В отличие от традиционных лингвистических задач, которые могут похвастаться миллионами выборок, наборы данных для математического рассуждения обычно насчитывают сотни или тысячи. Эта нехватка затрудняет надежное обучение и оценку моделей. Авторы решили эту проблему, используя выборку тестов для уменьшения случайности и смягчения несбалансированности данных в мелкомасштабном тестировании, но фундаментальная проблема доступности данных остается. Другое наблюдение заключалось в том, что производительность дифференциального сглаживания (DiSmo) колебалась в различных настройках, и чрезмерное сглаживание (например, $k > 2$) могло привести к потере полезной информации признаков, снижая точность обнаружения.
Заглядывая вперед, из этой работы вытекает несколько будущих направлений, предлагающих различные перспективы для эволюции:
- Решение проблемы нехватки данных в математическом рассуждении: Учитывая трудности с сбором и маркировкой крупномасштабных данных для математического рассуждения, будущие исследования могли бы изучить более продвинутые методы аугментации данных, специально разработанные для математических выражений. Могут ли синтетические данные, возможно, управляемые формальными математическими свойствами или доказателями теорем, обеспечить масштабируемое решение? Исследование методов обнаружения OOD данных в режиме обучения с несколькими примерами (few-shot) или без примеров (zero-shot), которые в меньшей степени зависят от обширных наборов данных ID, также было бы ценным.
- Углубление понимания "коллапса паттернов": Статья определяет "коллапс паттернов" как критическое явление. Более глубокое теоретическое и эмпирическое исследование его коренных причин, помимо текущего анализа на уровне токенов и выражений, может привести к новым стратегиям смягчения. Можем ли мы спроектировать архитектуры ГЯМ или цели обучения, которые по своей сути более устойчивы к коллапсу паттернов в символьных доменах?
- Расширение обобщаемости на другие задачи символьного ИИ: Успешное расширение на вопросы с множественным выбором является многообещающим. Это предполагает, что TV Score может быть применим к более широкому спектру задач символьного ИИ, где выходные пространства ограничены и демонстрируют "коллапс паттернов", таких как генерация кода, логический вывод или структурированное предсказание. Будущие работы могли бы систематически выявлять и проверять другие подобные области, потенциально приводя к унифицированной системе обнаружения OOD для символьного ИИ.
- Уточнение мер волатильности траекторий: Текущий TV Score использует волатильность, независимую от размерности и совместную по размерностям. Исследование более сложных мер динамики траекторий встраиваний, таких как кривизна, кручение или даже адаптивные методы сглаживания, которые динамически настраивают $k$ на основе характеристик выборки, потенциально может привести к еще более точной и надежной детекции OOD.
- Гибридные подходы к обнаружению OOD: Хотя методы на основе встраиваний, особенно волатильность траекторий, доказали свое превосходство в этом контексте, их интеграция с методами оценки неопределенности (например, байесовские нейронные сети, ансамблевые методы) может привести к более надежным гибридным детекторам OOD. Такой подход мог бы использовать сильные стороны обеих парадигм, обеспечивая более полную оценку OOD.
- Вычислительная эффективность для больших моделей: Поскольку ГЯМ продолжают расти по размеру и количеству слоев, вычислительная сложность подгонки ID распределений ($O(Ldn)$) и вычисления оценки ($O(Ldk)$) может стать узким местом. Будущие работы могли бы сосредоточиться на оптимизации этих операций, возможно, посредством аппроксимационных методов, аппаратного ускорения или более эффективного статистического моделирования распределений встраиваний.
- Теоретические гарантии для коллапса паттернов и волатильности траекторий: Статья предоставляет эмпирические доказательства и теоретическую интуицию. Разработка более строгих теоретических гарантий того, почему "коллапс паттернов" происходит в математическом рассуждении и почему волатильность траекторий является надежным сигналом для выборок OOD, укрепит основу этого подхода. Это может включать формализацию условий, при которых эти явления имеют место, и доказательство границ эффективности TV Score.
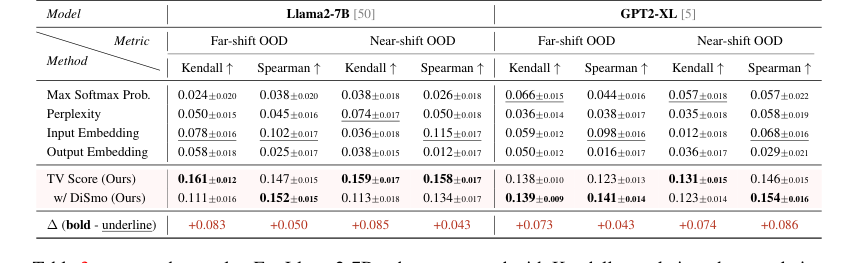 Table 3. presents the results. For Llama2-7B, when compared with Kendall correlation, the correlation improvement of TV scores over SOTA baselines reaches up to 100% under both far-shift and near-shift OOD settings. Compared with Spearman correlation, TV scores demonstrate a correlation enhancement over SOTA baselines by up to 100% under far-shift OOD setting and 30% under near-shift OOD setting. GPT2-XL also demonstrates excellent performance. These findings indicate that our TV scores not only facilitate the binary discrimination of ID and OOD samples but also substantially reflect the quality and precision of generated mathematical reasoning
Table 3. presents the results. For Llama2-7B, when compared with Kendall correlation, the correlation improvement of TV scores over SOTA baselines reaches up to 100% under both far-shift and near-shift OOD settings. Compared with Spearman correlation, TV scores demonstrate a correlation enhancement over SOTA baselines by up to 100% under far-shift OOD setting and 30% under near-shift OOD setting. GPT2-XL also demonstrates excellent performance. These findings indicate that our TV scores not only facilitate the binary discrimination of ID and OOD samples but also substantially reflect the quality and precision of generated mathematical reasoning
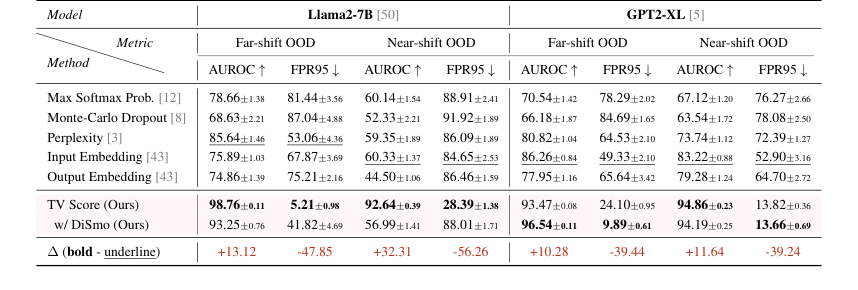 Table 1. AUROC and FPR95 results of the Offline Detection scenario. Underline and bold denote SOTA among all baselines and all methods, respectively. We report the average results under each setting in the main text, results of each dataset are shown in Table 11 and 12 (Appendix F)
Table 1. AUROC and FPR95 results of the Offline Detection scenario. Underline and bold denote SOTA among all baselines and all methods, respectively. We report the average results under each setting in the main text, results of each dataset are shown in Table 11 and 12 (Appendix F)
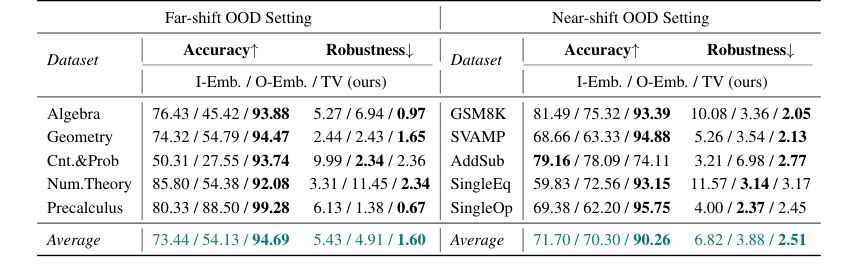 Table 2. presents the results in Llama2-7B. Compared to the embedding-based methods, our TV score obtains about an average of 20-point accuracy improvement in both far-shift OOD and near-shift OOD settings, and on some datasets, such as Cnt.&Prob, our TV score achieves more than 40 points of improvement. These all imply that TV Score can perform online discrimination of OOD samples more accurately. In addition, our TV score also possesses stronger robustness, which means that in real scenarios, we can find the optimal threshold more consistently in the face of different accessible ID and OOD data, reducing the potential riskiness due to uncontrollable data acquisition
Table 2. presents the results in Llama2-7B. Compared to the embedding-based methods, our TV score obtains about an average of 20-point accuracy improvement in both far-shift OOD and near-shift OOD settings, and on some datasets, such as Cnt.&Prob, our TV score achieves more than 40 points of improvement. These all imply that TV Score can perform online discrimination of OOD samples more accurately. In addition, our TV score also possesses stronger robustness, which means that in real scenarios, we can find the optimal threshold more consistently in the face of different accessible ID and OOD data, reducing the potential riskiness due to uncontrollable data acquisition
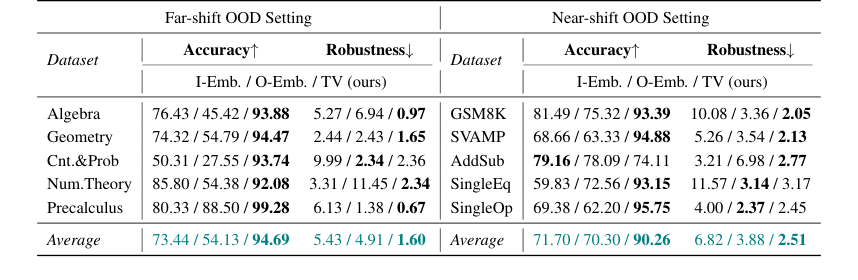 Table 2. Accuracy and Robustness results of the Online Detection scenario. We mainly compare our method with embedding-based methods, and bold denotes the best among these methods
Table 2. Accuracy and Robustness results of the Online Detection scenario. We mainly compare our method with embedding-based methods, and bold denotes the best among these methods