수학적 추론에서의 Out-of-Distribution 탐지를 위한 임베딩 궤적
Real-world data deviating from the independent and identically distributed (\textit{i.i.d.}) assumption of in-distribution training data poses security threats to deep networks, thus advancing out-of-distribution...
배경 및 학문적 계보
기원 및 학문적 계보
생성 언어 모델(GLM)의 수학적 추론에서의 Out-of-Distribution (OOD) 탐지 문제는 비교적 새롭고 중요한 과제이다. 역사적으로 OOD 탐지 알고리즘은 주로 훈련 데이터의 독립적이고 동일하게 분포한다는(i.i.d.) 가정에서 벗어나는 실제 데이터로부터 심층 신경망을 보호하기 위해 등장했다. 이 분야의 초기 연구는 주로 비전 및 전통적인 텍스트 분류 작업에 집중되었다.
GLM이 발전함에 따라, OOD 탐지 방법은 요약 및 번역과 같은 텍스트 생성 시나리오에 맞게 조정되었다. 이러한 방법들은 일반적으로 불확실성 추정 또는 임베딩 거리 측정에 의존했다. 그러나 이러한 기존 접근 방식이 수학적 추론 작업에 적용되었을 때 학계는 상당한 "고충점(pain point)"에 직면했다. 어려운 생성 작업인 수학적 추론은 출력 공간에서 전통적인 임베딩 기반 방법을 무효화하는 고유한 특성을 나타냈다. 저자들은 자신들의 지식으로는 수학적 추론에서의 OOD 탐지를 체계적으로 연구하고 기존 알고리즘의 실패를 이 특정 영역에서 식별한 최초의 연구자라고 명시적으로 밝힌다. 따라서 이 논문은 GLM 맥락 내에서 OOD 탐지와 수학적 추론의 교차점에서 새로운 문제를 다룬다.
이전 접근 방식의 근본적인 한계는 저자들이 수학적 추론의 출력 공간에서 "패턴 붕괴(Pattern Collapse)"라고 명명한 현상에서 비롯된다. 정적 임베딩 공간(예: 마할라노비스 거리)에서의 거리를 측정하는 전통적인 임베딩 기반 방법은 서로 다른 의미론적 입력이 임베딩 공간에서 서로 다른 영역으로 매핑될 것이라고 가정한다. 그러나 수학적 추론에서는 출력이 종종 기호적(예: 숫자, 간단한 표현식)이며 제한된 토큰 어휘(0-9 숫자 및 기본 수학 기호와 같은)로 구성된다. 이로 인해 의미론적으로 다양한 수학적 문제들이 잠재 공간에서 고밀도, 중첩되는 영역으로 수렴하는 출력 임베딩을 생성한다. 결과적으로, 분포 내(ID) 및 OOD 샘플 간의 정적 임베딩 거리는 구별할 수 없게 되어 이전 방법으로는 OOD 데이터를 안정적으로 탐지하는 것이 불가능해진다. 이러한 "패턴 붕괴"는 모델이 보았던 것과 보지 못했던 것 사이의 경계를 효과적으로 흐리게 하여, 저자들이 새롭고 동적인 접근 방식을 모색하도록 강요한다.
직관적인 도메인 용어
- Out-of-Distribution (OOD) 데이터: 빨간 사과와 초록 사과를 분류하도록 훈련된 똑똑한 로봇을 상상해 보라. 누군가 갑자기 파란색 베리를 준다면, 그것은 OOD 데이터이다. 로봇이 훈련 중에 전혀 접하지 못한 것이며, 학습된 범주에 맞지 않기 때문에 혼란스러워하거나 잘못 추측할 수 있다.
- Generative Language Models (GLMs): GLM을 새로운 레시피를 발명할 수 있는 매우 창의적인 셰프로 생각하라. 셰프에게 테마(예: "여름을 위한 디저트")를 주면, 셰프는 단순히 요리책에서 고르는 것이 아니라 재료와 기술을 조합하여 완전히 새롭고 독특한 요리를 만든다. 마찬가지로, GLM은 기존 문구를 검색하는 것이 아니라 새로운 텍스트를 생성한다.
- Pattern Collapse: 각 그림이 고유한 대규모 미술관을 상상해 보라. 이제 모든 그림이 작고 저해상도 썸네일로 디지털 압축되었다고 상상해 보라. 많은 고유한 그림들이 썸네일 형태에서 매우 유사하거나 심지어 동일하게 보일 수 있어 구별하기 어렵다. 고유한 패턴이 공통적이고 구별할 수 없는 형태로 "압축"되는 것은 수학적 추론 출력에서 발생하는 것으로, 구별하기 어렵게 만든다.
- Embedding Trajectory: 여러 레벨이 있는 복잡한 미로를 고려하라. 쥐가 미로에 들어가면 각 레벨을 탐색하면서 흔적을 남긴다. "임베딩 궤적"은 정보 조각이 신경망의 각 처리 계층을 통과할 때 그 흔적을 추적하는 것과 같다. 정보가 어디에 도달하는지만 보여주는 것이 아니라, 거치는 모든 변환 시퀀스를 보여준다.
- Trajectory Volatility: 미로 비유를 따라가면, "궤적 변동성"은 레벨 간 쥐의 경로가 얼마나 불규칙하거나 부드러운지를 측정하는 것이다. 쥐가 레벨 간에 갑작스럽고 큰 방향 변화를 일으키면, 경로가 매우 변동적이다. 예측 가능하고 부드럽게 움직이면, 변동성이 낮다. 네트워크를 통한 데이터의 여정의 이러한 "울퉁불퉁함" 또는 "부드러움"은 그것이 익숙한 입력인지 아니면 예상치 못한 OOD 입력인지를 나타낼 수 있다.
표기법 표
| 표기법 | 설명 | 유형 |
|---|---|---|
| $s$ | 주어진 샘플, 일반적으로 입력-출력 쌍. | 변수 |
| $L$ | 생성 언어 모델의 총 은닉 계층 수. | 매개변수 |
| $d$ | 임베딩 벡터의 차원. | 매개변수 |
| $Y_l$ | 계층 $l$에서의 출력 시퀀스의 평균 임베딩. | 변수 |
| $V_I(s)$ | 샘플 $s$에 대한 차원 독립적 변동성, 차원 전반에 걸친 국소적 궤적 변화를 포착. | 변수 |
| $V_J(s)$ | 샘플 $s$에 대한 차원 결합 변동성, L2-norm을 사용하여 궤적의 전역적 변화를 포착. | 변수 |
| $\mu_l$ | 계층 $l$에서의 분포 내(ID) 임베딩에 맞춰진 가우시안 분포의 평균 벡터. | 매개변수 |
| $\Sigma_l$ | 계층 $l$에서의 분포 내(ID) 임베딩에 맞춰진 가우시안 분포의 공분산 행렬. | 매개변수 |
| $f(Y_l)$ | ID 가우시안 분포 $G_l$로부터의 평균 임베딩 $Y_l$의 마할라노비스 거리. | 변수 |
| $S$ | 샘플에 대한 궤적 변동성(TV) 점수, 인접 계층 간의 마할라노비스 거리 차이의 평균으로 계산됨. | 변수 |
| $k$ | 궤적 변동성에 적용되는 차분 평활화의 차수. | 매개변수 |
| $\nabla^k S$ | $k$-차 차분 평활화를 적용한 궤적 변동성(TV) 점수. | 변수 |
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
이 논문에서 다루는 핵심 문제는 생성 언어 모델(GLM)이 수학적 추론 작업을 수행할 때 발생하는 Out-of-Distribution (OOD) 데이터의 정확한 탐지이다.
시작점 (입력/현재 상태)은 분포 내(ID) 데이터로 훈련된 GLM이며, 일반적으로 독립적이고 동일하게 분포하는(i.i.d.) 데이터 분포를 가정한다. 이 GLM이 i.i.d. 가정에서 벗어나는 실제 입력(즉, OOD 데이터)을 받으면 성능이 예상치 못하게 저하될 수 있으며, 잠재적으로 해로운 결과를 초래할 수 있다. GLM에 대한 기존 OOD 탐지 방법은 주로 두 가지 접근 방식에 의존한다: 불확실성 추정 및 임베딩 거리 측정. 임베딩 기반 방법은 요약 및 번역과 같은 전통적인 언어 작업에 효과적인 것으로 입증되었지만, 수학적 추론에는 적용 불가능한 것으로 밝혀졌다. 이러한 적용 불가능성은 수학적 추론에서 관찰되는 두 가지 고유한 현상에서 비롯된다:
1. 입력 공간에서의 모호한 클러스터링: 다양한 도메인의 수학적 추론 문제에 대한 입력 임베딩은 "모호한 클러스터링 특징"(그림 1a, 2페이지)을 나타내어, 정적 임베딩이 다양한 수학적 질문 간의 고유한 복잡성과 구분을 포착하기 어렵게 만든다.
2. 출력 공간에서의 패턴 붕괴: 수학적 추론의 출력 임베딩은 "상당한 중첩을 가진 고밀도 특징"(그림 1a, 2페이지)을 나타낸다. "패턴 붕괴"라고 명명된 이 현상은 수학적 출력이 종종 기호적(예: 0-9 숫자, 특수 기호)이어서 검색 공간을 압축하고 수학적으로 다른 표현 간에 상당한 토큰 공유를 초래하기 때문에 발생한다. 이로 인해 다양한 수학적 문제의 임베딩이 고밀도 영역으로 수렴하여 전통적인 정적 임베딩 거리 측정으로는 구별할 수 없게 된다.
원하는 종착점 (출력/목표 상태)은 TV Score라는, 수학적 추론 시나리오에 특화된 강력하고 경량화된 OOD 탐지 알고리즘이다. 이 알고리즘은 "패턴 붕괴"가 존재하는 경우에도 ID 및 OOD 샘플을 효과적으로 구별해야 한다. 궁극적인 목표는 다음을 최대화하는 점수 함수 $f(x, y, \theta)$와 임계값 $\epsilon$을 찾는 것이다:
$$ \max_{f} P_{(x,y)\sim P_{X,Y}}[f(x,y,\theta) < \epsilon] + P_{(x,\tilde{y})\sim P_{\tilde{X},\tilde{Y}}}[f(x,\tilde{y},\theta) > \epsilon] $$
여기서 $P_{X,Y}$는 분포 내 결합 데이터 분포이고 $P_{\tilde{X},\tilde{Y}}$는 분포 외 결합 데이터 분포이다(방정식 1, 3페이지). 또한, 이 방법은 다중 선택 문제와 같이 출력 특징이 고밀도인 다른 작업에도 일반화될 수 있어야 한다.
이 논문이 연결하고자 하는 정확한 누락된 연결 또는 수학적 격차는 "패턴 붕괴" 현상으로 인해 수학적 추론에서 정적 임베딩 기반 OOD 탐지 방법의 실패이다. 이전 방법들은 정적 입력 또는 출력 공간에서 새로운 샘플의 임베딩과 ID 임베딩 분포 간의 마할라노비스 거리를 계산했다(1페이지). 그러나 "패턴 붕괴"는 다양한 수학적 추론 샘플의 임베딩 궤적의 끝점이 수렴하게 하여 이러한 정적 거리 측정값을 무효화한다. 이 논문은 끝점이 붕괴될 수 있지만, 이러한 끝점으로 이어지는 동적 임베딩 궤적은 ID 및 OOD 샘플 간에 상당한 차이를 나타낼 것이라고 가정한다. 따라서 누락된 연결은 정적 끝점 거리보다는 이러한 궤적 차이를 정량화하는 메커니즘이다.
이전 연구자들을 가두었던 고통스러운 절충 또는 딜레마는 수학적 추론 출력의 기호적이고 고밀도인 특성과 효과적인 임베딩 기반 OOD 탐지의 요구 사항 간의 내재된 충돌이다. 전통적인 텍스트 생성에서 서로 다른 의미론적 의미는 잘 분리된 임베딩 클러스터를 초래하여 임베딩 거리가 잘 작동하도록 한다. 그러나 수학적 추론에서는 답변의 간결성과 공유된 토큰 어휘(예: 숫자)가 다양한 문제가 매우 유사한 출력 임베딩으로 매핑되도록 한다. 이러한 "패턴 붕괴"는 올바른 수학적 답변(종종 스칼라 또는 간단한 표현식)을 생성하는 모델의 능력을 향상시키는 것이 의도치 않게 OOD 탐지 방법이 의존하는 잠재 공간의 구별성을 파괴한다는 것을 의미한다. 연구자들은 수학적 추론에 대한 OOD 탐지 성능 저하를 받아들이거나, 이러한 고유한 출력 공간에서 OOD가 어떻게 정의되고 측정되는지 근본적으로 재고해야 하는 딜레마에 빠졌다.
제약 조건 및 실패 모드
수학적 추론에서의 OOD 탐지 문제는 다음과 같은 몇 가지 가혹하고 현실적인 제약 조건으로 인해 매우 어렵다:
- 데이터 기반 제약: 고밀도 출력 공간 ("패턴 붕괴"): 이것이 가장 중요한 제약이다. 수학적 추론 출력은 "수학적으로 기호적"(2페이지)이어서 압축된 검색 공간을 초래한다. 이는 서로 다른 도메인의 질문 간에 중첩될 가능성을 높인다. 결정적으로, GLM은 제한된 어휘(0-9 숫자 및 유한한 특수 기호)를 사용하여 수학적 표현을 토큰화하므로, 수학적으로 다른 표현 간에 "상당한 토큰 공유"가 발생한다(2페이지, 6.2절). 이로 인해 출력 임베딩이 고밀도, 구별할 수 없는 영역으로 수렴하여 전통적인 정적 임베딩 거리 방법이 무효화된다.
- 데이터 기반 제약: 모호한 입력 공간 클러스터링: 수학적 추론의 입력 공간 또한 "다양한 도메인에 걸친 모호한 클러스터링 특징"(2페이지, 그림 1a)을 나타낸다. 이는 임베딩이 수학적 질문의 전체 복잡성을 포착하는 데 어려움을 겪고 있음을 나타내며, 입력 측면에서 OOD 탐지를 더욱 복잡하게 만든다.
- 물리적 제약: 제한된 데이터 가용성: 수학적 추론 데이터셋은 "비교적 작다"(수백 또는 수천 개의 샘플), 특히 번역 또는 요약과 같은 전통적인 NLP 작업에 사용 가능한 수백만 개의 샘플에 비해(1페이지, 11페이지, "제한 사항"). 이러한 데이터 부족은 강력한 모델을 훈련하고 OOD 탐지 방법을 안정적으로 평가하기 어렵게 만들어 결과의 무작위성을 증가시킨다. 저자들은 테스트 샘플링을 통해 이를 완화한다.
- 알고리즘 제약: 궤적 차이 정량화의 어려움: 정적 임베딩 차이는 마할라노비스 거리로 측정할 수 있지만, "궤적과 궤적 클러스터 간의 차이를 정량화하는 것은 덜 직관적이다"(5페이지). 이를 위해서는 계층 전반에 걸친 임베딩 공간의 동적 변화를 포착하기 위한 새로운 수학적 공식화가 필요하며, 이는 논문에서 궤적 변동성을 정의함으로써 해결된다.
- 알고리즘 제약: 궤적 이상치: 임베딩 궤적의 이상치는 "특징 추출에 상당한 영향을 미칠 수 있다"(5페이지). 이러한 노이즈는 ID 및 OOD 궤적 간의 실제 근본적인 차이를 가릴 수 있으므로, 견고성을 향상시키기 위한 평활화 기술이 필요하다.
- 계산 제약: 모델 크기 및 훈련 리소스: 이 방법은 Llama2-7B 및 GPT2-XL(6페이지)과 같은 대규모 GLM에 의존한다. 이러한 모델을 훈련하려면 상당한 계산 리소스(예: Llama2-7B의 경우 4개 카드 RTX 3090, GPT2-XL의 경우 단일 RTX 3090, 23페이지)가 필요하다. 제안된 TV Score 자체는 계산 측면에서 "경량"(수 밀리초, $O(Ldn)$ 또는 $O(Ldk)$ 복잡성, 22페이지)이지만, 이러한 계산 집약적인 백본 위에 작동한다.
- 데이터 기반 제약: 데이터 누출의 불확실성: Llama2-7B와 같은 폐쇄 소스 GLM의 경우, 특정 OOD 데이터셋이 사전 훈련 데이터에 포함되었는지 여부에 대한 불확실성이 있다(23페이지). 이로 인해 분포적 관점에서 데이터셋이 OOD임을 명확하게 주장하기 어렵다. 저자들은 OOD를 데이터셋이 "기본 모델의 능력을 초과하는지 여부"로 정의함으로써 이를 해결한다(23페이지).
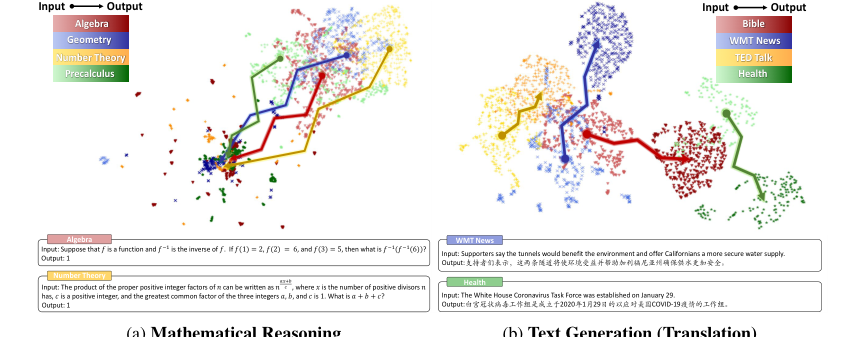 Figure 1. Embedding projection and cases of input and output spaces under mathematical reasoning and text generation scenarios. We select MATH [6] dataset for mathematical reasoning and OPUS [49] for text generation, each with four diverse domains. Different colors represent different domains, with lighter and darker shades indicating input and output. We use SimCSE [9] for sentence embeddings and UMAP [34] for dimensionality reduction. Appendix B shows detailed settings and examples
Figure 1. Embedding projection and cases of input and output spaces under mathematical reasoning and text generation scenarios. We select MATH [6] dataset for mathematical reasoning and OPUS [49] for text generation, each with four diverse domains. Different colors represent different domains, with lighter and darker shades indicating input and output. We use SimCSE [9] for sentence embeddings and UMAP [34] for dimensionality reduction. Appendix B shows detailed settings and examples
왜 이 접근 방식인가
선택의 불가피성
궤적 기반 TV Score의 채택은 단순히 선호도가 아니라, 생성 언어 모델(GLM)의 수학적 추론 작업에서 Out-of-Distribution (OOD) 탐지의 고유하고 어려운 특성에 의해 주도된 필연성이었다. 저자들은 이 특정 문제에 직면했을 때 전통적인 "SOTA" 방법, 예를 들어 표준 임베딩 기반 접근 방식의 결정적인 실패 지점을 식별했다.
저자들이 전통적인 방법이 불충분하다는 것을 깨달은 정확한 순간은 섹션 1에 명확하게 설명되어 있다. 임베딩 기반 방법은 요약 및 번역과 같은 전통적인 언어 작업에 매우 효과적이었지만([43]에서 마할라노비스 거리 [22] 사용), 수학적 추론에서는 상당한 어려움에 직면했다. 이는 이 영역의 "출력 공간의 고밀도 특징" 때문이며, 저자들이 "패턴 붕괴"라고 명명한 현상이다. 이 "패턴 붕괴"는 그림 1에 설명된 대로 임베딩 기반 방법을 적용 불가능하게 만든다. 핵심 문제는 의미론적으로 다른 다양한 수학적 도메인의 출력들이 임베딩 공간에서 고밀도 영역으로 수렴하여 정적 임베딩 거리 측정으로는 구별할 수 없게 된다는 것이다. 이러한 깨달음은 분포 내(ID) 및 OOD 샘플 간의 미묘한 차이를 포착할 수 있는 유일한 실행 가능한 경로였기 때문에, 정적 임베딩 공간에서 동적 "임베딩 궤적"(섹션 2)으로 초점을 전환하도록 강요했다.
비교 우위
단순한 성능 지표를 넘어, TV Score 방법은 수학적 추론의 고유한 과제를 처리하는 구조적 이점으로 인해 심오한 질적 우수성을 보여준다. 핵심은 최종 계층 임베딩에만 의존하는 것이 아니라, 계층 전반에 걸친 임베딩의 동적 변화를 활용하는 능력에 있다.
"패턴 붕괴" 현상은 정적 임베딩을 구별할 수 없게 만들지만, 역설적으로 "샘플 간의 상당한 궤적 차이"(섹션 2, 그림 2)를 생성한다. TV Score는 이러한 동적 변화를 정량화하는 "궤적 변동성"을 측정함으로써 이를 활용한다. 이 접근 방식은 최종 상태뿐만 아니라 프로세스에 초점을 맞추기 때문에 고밀도 출력 공간 문제에 본질적으로 더 강력하다.
"조기 안정화"(섹션 2.2, 섹션 3) 현상에 의해 밝혀진 중요한 구조적 이점이 있다. ID 데이터의 경우, GLM은 중간-후반 계층에서 추론을 완료하는 경향이 있어 후속 계층에서 임베딩 변화 크기가 억제된다. 이와 극명하게 대조적으로, OOD 데이터의 경우 이 크기는 지속적으로 높게 유지되어 일관된 추론 완료 실패를 나타낸다. 이러한 뚜렷한 동적 행동은 정적 방법으로는 단순히 포착할 수 없는 강력하고 신뢰할 수 있는 OOD 탐지 신호를 제공한다.
또한, 이 방법은 "경량"(섹션 3)으로 설명되어 계산 효율성을 시사한다. 선택적인 차분 평활화 기술(TV Score w/ DiSmo)은 궤적의 이상치 영향을 완화하여 더 부드럽고 신뢰할 수 있는 신호를 보장함으로써 견고성을 더욱 향상시킨다(섹션 3). 실험 결과(표 1, 표 2)는 이러한 질적 우수성을 정량적으로 확인하며, 다른 기준선이 심각한 성능 저하를 겪는 어려운 근접 이동 OOD 시나리오에서도 AUROC 개선이 평균 10포인트 이상이고 FPR95가 80% 이상 감소했음을 보여준다.
제약 조건과의 정렬
TV Score로 구현된 선택된 궤적 기반 접근 방식은 수학적 추론에서의 OOD 탐지에 내재된 엄격한 제약 조건과 완벽하게 일치한다.
- 제약 조건: 수학적 추론을 위한 GLM에서의 OOD 탐지. TV Score는 이 도메인을 위해 특별히 제작되었으며, 전통적인 방법을 실패하게 만드는 "패턴 붕괴" 및 "고밀도 특징"을 직접적으로 다룬다(초록, 섹션 1). 특히 "조기 안정화"(섹션 2.2)와 같은 수학적 추론 고유의 현상을 모델링하고 측정한다.
- 제약 조건: 전통적인 임베딩 기반 방법의 적용 불가능성 극복. TV Score의 핵심 동기는 수학적 추론에서 정적 임베딩 방법의 입증된 실패이다(섹션 1, 섹션 6). 동적 임베딩 궤적으로 전환함으로써, 이 방법은 정적 임베딩이 판별력을 잃는 출력 공간의 고밀도로 인해 부과되는 한계를 직접적으로 우회한다(섹션 2, 그림 2).
- 제약 조건: 경량 솔루션의 필요성. 이 논문은 TV Score가 "경량 OOD 탐지 솔루션"(섹션 3)이라고 명시적으로 밝힌다. 계산 복잡성이 효율적이어서 ID 분포 적합성($O(Ldn)$) 및 점수 계산($O(Ldk)$)에 실용적이다(부록 D).
- 제약 조건: 확장성 및 기타 고밀도 출력 작업에 대한 일반화 가능성. 이 방법은 확장 가능하도록 설계되었으며 "미세한 탐지 시나리오에서 더 큰 이점"(섹션 5.2)을 보여준다. 결정적으로, 저자들은 이 방법이 다중 선택 문제와 같이 "패턴 붕괴" 속성을 나타내는 다른 작업에도 확장 가능함을 보여주며, 여기서도 전통적인 알고리즘을 능가한다(초록, 섹션 5.2). 이는 초기 수학적 추론 초점을 넘어 광범위한 적용 가능성을 확인한다.
대안의 기각
이 논문은 주로 수학적 추론의 특정 맥락에서 기존 방법이 실패하는 이유에 초점을 맞춰 인기 있는 대안 OOD 탐지 접근 방식을 기각하는 명확한 이유를 제공한다.
-
전통적인 정적 임베딩 기반 방법 (예: 입력/출력 임베딩에 대한 마할라노비스 거리): 일반적인 텍스트 생성에는 효과적이지만, 수학적 추론에는 명시적으로 "적용 불가능"(섹션 1)하다고 간주된다. 이 논문은 섹션 6을 "정적 임베딩 방법의 적용 불가능성 재고"에 할애하며, 실패의 두 가지 주요 이유를 자세히 설명한다:
- 입력 공간 표현 딜레마: 수학적 표현은 입력 공간에서 "모호한 클러스터링 특징"(섹션 6.1, 그림 1a)을 나타낸다. 표 5에서 볼 수 있듯이 의미론적 임베딩은 수학적 관계를 정확하게 반영하지 못한다. 예를 들어, 수학적으로 "분포 내"인 표현이 수학적으로 "분포 외"인 표현보다 낮은 코사인 유사도를 가질 수 있어, 정적 입력 임베딩은 OOD 탐지에 신뢰할 수 없다.
- 출력 공간 "패턴 붕괴": 이것이 가장 중요한 문제이다(섹션 6.2, 그림 1a). 수학적 추론의 출력 공간은 고밀도와 다양한 도메인 간의 상당한 중첩으로 특징지어진다. 이러한 "패턴 붕괴"는 두 가지 수준에서 발생한다:
- 표현 수준: 수학적 출력은 종종 스칼라(예: "4")이어서 검색 공간을 압축하고 매우 다른 수학적 질문 간의 중첩 가능성을 높인다(예: "1+3="과 "$\int x dx=$" 모두 "4"를 생성함)(섹션 6.2).
- 토큰 수준: GLM은 0-9 숫자와 특수 기호의 제한된 집합을 사용하여 수학적 표현을 토큰화한다. 이는 수학적으로 다른 표현에서도 상당한 토큰 공유를 초래하여, 자동 회귀 예측 중에 토큰 수준에서 붕괴를 일으킨다(섹션 6.2, 표 6).
표 5는 경험적으로 이러한 기각을 확인하며, 정적 임베딩에 대한 마할라노비스 거리가 많은 설정에서 거의 무작위 AUROC 점수(약 50)를 산출함을 보여준다.
-
불확실성 추정 방법 (예: 최대 소프트맥스 확률, 몬테카를로 드롭아웃, 시퀀스 복잡도): 이러한 방법들은 실험에서 기준선으로 포함된다(섹션 4.1, 표 1, 표 2, 표 3). 이 논문은 그것들이 수학적 추론에 실패하는 이유에 대한 자세한 이론적 분석을 제공하지는 않지만, TV Score에 비해 지속적이고 상당한 성능 저하(종종 10+ AUROC 포인트 및 80%+ FPR95 감소)는 그것들의 부적절함을 암시한다. "패턴 붕괴" 및 "조기 안정화"의 고유한 현상은 예측 신뢰도에 초점을 맞추고 임베딩의 동적 진화에는 초점을 맞추지 않는 이러한 불확실성 기반 접근 방식에 의해 직접적으로 다루어지지 않는다.
-
사고 연쇄 (CoT) 기법: 이 논문은 "출력 공간 크기를 확장"하고 "패턴 붕괴"를 완화하기 위한 잠재적 대안으로 CoT를 고려한다(섹션 6.3). 그러나 저자들은 "CoT가 출력 공간 크기를 확장함에도 불구하고, 출력 답변은 여전히 수학적 추론의 난이도 및 숫자에 본질적으로 관련되어 있으며, 의미론적 임베딩 표현은 이러한 특징을 정확하게 반영할 수 없다"고 결론짓는다. 표 5(b)의 경험적 결과는 CoT를 사용하더라도 마할라노비스 거리를 사용한 탐지 정확도가 여전히 낮고 매우 가변적이어서, CoT만으로는 이 영역에서 OOD 탐지를 위한 근본적인 문제를 해결하기에 불충분함을 나타낸다.
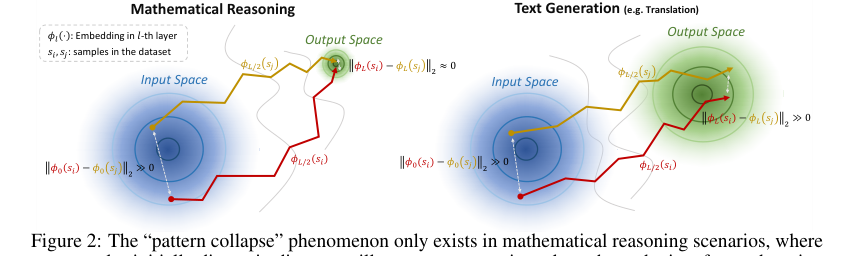 Figure 2. The “pattern collapse” phenomenon only exists in mathematical reasoning scenarios, where two samples initially distant in distance will converge approximately at the endpoint after undergoing embedding shifts, and does not occur in text generation scenarios. This produces a greater likelihood of trajectory variation under different samples in mathematical reasoning
Figure 2. The “pattern collapse” phenomenon only exists in mathematical reasoning scenarios, where two samples initially distant in distance will converge approximately at the endpoint after undergoing embedding shifts, and does not occur in text generation scenarios. This produces a greater likelihood of trajectory variation under different samples in mathematical reasoning
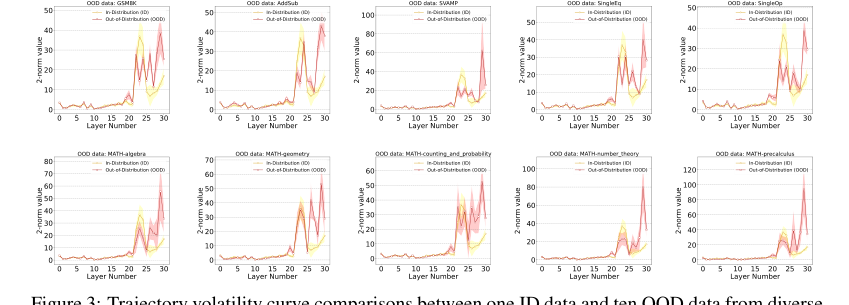 Figure 3. Trajectory volatility curve comparisons between one ID data and ten OOD data from diverse mathematical domains. Each trajectory represents the average of all samples from the corresponding datasets, with color shading being the sample standard deviation. Llama2-7B is used for the backbone
Figure 3. Trajectory volatility curve comparisons between one ID data and ten OOD data from diverse mathematical domains. Each trajectory represents the average of all samples from the corresponding datasets, with color shading being the sample standard deviation. Llama2-7B is used for the backbone
수학적 및 논리적 메커니즘
마스터 방정식
수학적 추론에서 Out-of-Distribution (OOD) 탐지를 위한 이 논문의 메커니즘의 핵심은 생성 언어 모델(GLM)의 계층을 통해 샘플의 임베딩이 전파될 때 동적 변화를 정량화하는 궤적 변동성(TV) 점수, $S$이다. TV 점수에 대한 마스터 방정식은 다음과 같이 정의된다:
$$ S = \frac{1}{L} \sum_{l=1}^{L} |f(y_l) - f(y_{l-1})| $$
이 방정식은 특정 계층 $l$에서의 임베딩의 마할라노비스 거리를 계산하는 중간 함수, $f(y_l)$에 의존한다. 이 함수는 다음과 같이 주어진다:
$$ f(y_l) = (y_l - \mu_l)^T (\Sigma_l)^{-1} (y_l - \mu_l) $$
항별 분석
이 방정식들을 분해하여 각 구성 요소의 역할을 이해해 보자:
TV 점수 ($S$) 방정식의 경우:
- $S$:
- 수학적 정의: 주어진 입력 샘플에 대한 궤적 변동성 점수.
- 물리적/논리적 역할: 이것은 OOD 탐지 점수로 사용되는 최종 스칼라 값이다. 높은 $S$는 수학적 추론 작업에서 OOD 샘플의 구별 특징으로 가정되는 GLM의 계층 전반에 걸친 샘플 임베딩의 더 큰 변동성을 나타낸다.
- 왜 곱셈 대신 덧셈, 또는 적분 대신 합계를 사용하는가: 저자들은 GLM이 이산적인 수의 계층($L$)을 가지고 있기 때문에 합계를 사용한다. 합계는 인접 계층 간의 마할라노비스 거리의 개별 변화를 집계한다. 덧셈은 이러한 변화의 크기를 축적하여 "경로 길이" 또는 변동성의 총량을 제공하기 위해 선택된다. 곱셈은 점수를 크게 확장하여 변동성의 직접적인 측정으로 해석하기 어렵게 만들고 잠재적으로 수치적 불안정성을 초래할 수 있다.
- $\frac{1}{L}$:
- 수학적 정의: $L$의 역수, 여기서 $L$은 GLM의 총 은닉 계층 수이다.
- 물리적/논리적 역할: 이 항은 정규화 계수 역할을 한다. 계층별 변동성의 합계를 계층당 평균 변동성으로 변환한다. 이를 통해 TV 점수는 계층 수가 다른 모델 간 또는 다양한 길이의 궤적을 분석할 때 비교 가능하게 된다.
- $\sum_{l=1}^{L}$:
- 수학적 정의: 합계 연산자, 첫 번째 계층($l=1$)부터 마지막 계층($L$)까지 반복된다.
- 물리적/논리적 역할: 이 연산자는 각 인접 계층 간 전환에서 발생하는 개별 변동성 기여를 집계한다. 샘플의 표현이 모델의 깊이를 통과함에 따라 마할라노비스 거리가 "점프"하거나 "이동"하는 양을 합산한다.
- $| \cdot |$:
- 수학적 정의: 절대값 함수.
- 물리적/논리적 역할: 이 함수는 인접 계층 간의 마할라노비스 거리 차이의 크기만 고려하고 방향(즉, 거리가 증가했는지 감소했는지)은 고려하지 않도록 한다. 초점은 변동성 측정의 핵심인 변화의 정도에만 맞춰진다.
- $f(y_l)$:
- 수학적 정의: 계층 $l$에서의 평균 임베딩 $y_l$의 마할라노비스 거리.
- 물리적/논리적 역할: 이 항은 계층 $l$에서의 샘플 임베딩이 해당 계층의 ID 샘플의 일반적인 분포로부터 얼마나 "멀리" 떨어져 있는지를 정량화한다. 고차원 임베딩을 해당 특정 계층에서의 "ID-ness"를 나타내는 단일 스칼라 값으로 변환한다.
- $f(y_{l-1})$:
- 수학적 정의: 계층 $l$ 바로 이전 계층에서의 평균 임베딩 $y_{l-1}$의 마할라노비스 거리.
- 물리적/논리적 역할: $f(y_l)$과 유사하지만 이전 계층에 대한 것이다. $|f(y_l) - f(y_{l-1})|$의 차이는 샘플의 표현이 계층 $l-1$에서 계층 $l$로 이동함에 따라 "ID-ness"의 변화를 구체적으로 측정한다.
마할라노비스 거리 ($f(y_l)$) 방정식의 경우:
- $y_l$:
- 수학적 정의: 계층 $l$에서의 출력 시퀀스 토큰의 평균 임베딩. 이는 $T$가 계층 $l$에서의 $t$-번째 토큰의 출력 임베딩일 때 $y_l = \frac{1}{T} \sum_{t=1}^{T} h_t^l$로 계산되는 $d$차원 벡터이다.
- 물리적/논리적 역할: 이 벡터는 GLM 내부의 특정 깊이에서 전체 출력 시퀀스의 집계된 의미론적 및 수학적 정보를 나타낸다. 이는 계층 $l$에서의 샘플 출력 표현의 "상태"이다.
- $\mu_l$:
- 수학적 정의: 계층 $l$에서 모든 분포 내(ID) 샘플 임베딩에 맞춰진 가우시안 분포 $G_l = N(\mu_l, \Sigma_l)$의 평균 벡터. 이는 $d$차원 벡터이기도 하다.
- 물리적/논리적 역할: 이 벡터는 계층 $l$에서의 ID 샘플의 "중심" 또는 "일반적인" 임베딩을 나타낸다. 이는 해당 특정 계층에서 "정상"으로 간주되는 것에 대한 참조점을 제공한다.
- $(y_l - \mu_l)$:
- 수학적 정의: 계층 $l$에서 샘플의 임베딩 $y_l$과 ID 평균 임베딩 $\mu_l$ 간의 차이를 나타내는 벡터.
- 물리적/논리적 역할: 이것은 편차 벡터로, 계층 $l$에서 현재 샘플의 임베딩이 ID 평균 임베딩에서 얼마나 벗어나는지를 나타낸다.
- $(\cdot)^T$:
- 수학적 정의: 전치 연산자.
- 물리적/논리적 역할: 이 맥락에서 열 벡터 $(y_l - \mu_l)$를 행 벡터로 변환하여 마할라노비스 거리의 이차 형식에서 행렬 곱셈에 필요하다.
- $(\Sigma_l)^{-1}$:
- 수학적 정의: 공분산 행렬 $\Sigma_l$의 역행렬. $\Sigma_l$은 계층 $l$에서 모든 분포 내(ID) 샘플 임베딩에 맞춰진 가우시안 분포 $G_l = N(\mu_l, \Sigma_l)$의 공분산 행렬이다. 이는 $d \times d$ 행렬이다.
- 물리적/논리적 역할: 이것은 마할라노비스 거리의 중요한 구성 요소이다. 이는 계층 $l$에서의 ID 임베딩 공간의 차원 간의 상관 관계와 분산을 고려한다. 이를 역행렬화함으로써 거리 측정은 데이터의 "화이트닝"을 효과적으로 수행하여 특징 공간에서 다른 스케일과 회전을 정규화한다. 이는 단순한 유클리드 거리보다 더 의미 있는 "거리" 측정값을 제공하여 ID 데이터 분포의 실제 기하학에 대한 거리를 더욱 견고하게 만든다.
- $(\cdot)^T (\cdot)^{-1} (\cdot)$:
- 수학적 정의: 이차 형식, 특히 제곱 마할라노비스 거리.
- 물리적/논리적 역할: 이 전체 표현은 제곱 마할라노비스 거리를 계산한다. 이는 $y_l$과 $\mu_l$ 간의 거리를 표준 편차 단위로 측정하여, ID 데이터 구름의 확산과 방향을 정규화한다. 이는 해당 특정 계층에서 임베딩이 ID 분포 하에서 얼마나 "가능성이 낮은지"를 나타내는 견고한 측정값을 제공한다.
단계별 흐름
단일 추상 데이터 포인트, 즉 "쿼리 샘플" $s$가 OOD 탐지 파이프라인에 들어가는 과정을 상상해 보자. 다음은 수학 엔진을 통한 여정이다:
- 초기 임베딩 생성: 쿼리 샘플 $s$(예: 수학 문제)는 사전 훈련된 생성 언어 모델(GLM)에 공급된다. GLM은 입력을 처리하고 출력 시퀀스(예: 수학적 해결책)를 생성한다.
- 계층별 출력 임베딩: GLM이 출력 시퀀스를 생성함에 따라, 내부 계층은 토큰 임베딩을 생성한다. 출력 시퀀스의 각 $T$ 토큰에 대해, $L$개의 은닉 계층($l=1, \dots, L$) 각각에서 $d$차원 임베딩 벡터 $h_t^l$이 추출된다.
- 문장 수준 집계: 각 계층 $l$에 대해, 출력 시퀀스의 모든 $T$ 토큰 임베딩 $h_t^l$은 평균화되어 단일의 대표적인 $d$차원 벡터 $y_l$을 형성한다. 이 $y_l$은 특정 계층에서의 전체 출력 표현을 포함한다. 이 단계는 샘플의 "임베딩 궤적"을 GLM의 계층을 통해 효과적으로 추적한다: $y_1 \to y_2 \to \dots \to y_L$.
- ID 분포 참조: 쿼리 샘플을 처리하기 전에, 시스템은 이미 "정상" 참조를 설정했다. 여기에는 알려진 분포 내(ID) 샘플 세트를 수집하고, 동일한 GLM을 통해 통과시키고, 계층별 평균 임베딩을 계산하는 것이 포함된다. 각 계층 $l$에 대해, 이 ID 임베딩에 맞춰진 가우시안 분포 $G_l = N(\mu_l, \Sigma_l)$가 피팅된다. 이는 통계적으로 추정된 평균 벡터 $\mu_l$ 및 공분산 행렬 $\Sigma_l$을 의미하며, 각 계층에서의 일반적인 ID 임베딩 공간을 특징짓는다.
- 마할라노비스 거리 매핑: 이제 쿼리 샘플의 궤적에 대해, 각 계층 $l$에서 평균 임베딩 $y_l$은 마할라노비스 거리 공식을 사용하여 스칼라 값 $f(y_l)$로 매핑된다. 이 계산은 해당 특정 계층의 사전 계산된 ID 평균 $\mu_l$ 및 공분산 $\Sigma_l$을 사용한다. 이 단계는 복잡한 $d$차원 임베딩을 해당 계층에서의 "ID 유사성"을 나타내는 더 간단한 스칼라로 변환하며, ID 데이터 구름의 모양을 고려한다.
- 변동성 측정: 시스템은 이제 연속 계층 간의 이 "ID 유사성"의 변화를 살펴본다. 각 인접 계층 쌍 $(l-1, l)$에 대해, 절대값 차이 $|f(y_l) - f(y_{l-1})|$가 계산된다. 이는 샘플의 표현이 계층 $l-1$에서 계층 $l$로 이동함에 따라 마할라노비스 거리의 변화 크기를 측정한다.
- TV 점수 집계: 이러한 모든 계층별 변동성 크기는 합산된 다음 총 계층 수 $L$로 나누어 최종 궤적 변동성 점수 $S$를 얻는다. 이 $S$는 샘플의 "ID 유사성"이 GLM의 잠재 공간에서의 여정 동안 얼마나 변동하는지에 대한 단일의 평균 측정값이다.
- OOD 분류: 마지막으로, 쿼리 샘플에 대해 계산된 TV 점수 $S$는 미리 정의된 임계값 $\epsilon$과 비교된다. $S$가 $\epsilon$을 초과하면 샘플은 Out-of-Distribution으로 플래그가 지정되고, 그렇지 않으면 In-Distribution으로 간주된다. 근본적인 가설은 OOD 샘플, 특히 수학적 추론에서 "패턴 붕괴"와 같은 현상으로 인해 더 높은 궤적 변동성을 나타낼 것이라는 것이다.
최적화 역학
이 논문의 궤적 변동성(TV) 점수 메커니즘 자체는 전통적인 기울기 기반 최적화 또는 학습을 거치는 모델이 아니라 사후 탐지 방법임을 명확히 해야 한다. 손실 함수를 최소화하거나 자체 매개변수를 역전파를 통해 반복적으로 업데이트하지 않는다.
대신, 메커니즘의 "학습" 또는 "적응"은 두 가지 별개의 단계에서 발생한다:
- 사전 훈련된 생성 언어 모델 (GLM): 시스템의 핵심은 사전 훈련된 GLM(예: Llama2-7B 또는 GPT2-XL)에 의존한다. 이 GLM은 방대한 양의 데이터(분포 내 수학적 추론 문제 포함)로 별도로 훈련된다. 이 사전 훈련 단계 동안, GLM은 일관되고 수학적으로 건전한 출력을 생성하는 방법을 학습하며, 이를 통해 계층 전반에 걸친 임베딩 표현을 개발한다. 이 GLM의 가중치와 매개변수는 TV Score 방법이 적용될 때 고정된다. 임베딩 $y_l$은 단순히 이 정적, 사전 훈련된 모델의 출력이다.
- 분포 내 (ID) 참조 피팅: TV Score 방법에 대한 유일한 "피팅" 또는 "학습"은 각 계층 $l$에 대한 가우시안 분포 $G_l = N(\mu_l, \Sigma_l)$의 일회성 통계적 추정이다.
- 평균 ($\mu_l$): 각 계층에 대해, $\mu_l$은 해당 계층에서 수집된 모든 ID 샘플 임베딩의 경험적 평균으로 계산된다.
- 공분산 ($\Sigma_l$): 마찬가지로, $\Sigma_l$은 해당 계층에서의 이러한 ID 샘플 임베딩의 경험적 공분산 행렬이다.
이러한 매개변수($\mu_l, \Sigma_l$)는 지정된 분포 내 훈련 데이터 세트에서 한 번 계산된다. 그런 다음 고정되어 각 계층에서의 "정상" 임베딩을 구성하는 정적 "참조" 역할을 한다. $\mu_l$ 및 $\Sigma_l$을 결정하는 데 초기 계산을 넘어서는 반복 업데이트나 기울기는 없다.
최종 OOD 탐지 단계는 계산된 TV 점수 $S$를 임계값 $\epsilon$과 비교하는 것을 포함한다. 이 임계값은 일반적으로 검증 세트에서 경험적으로 결정된다. 예를 들어, AUROC 또는 FPR95와 같은 지표를 최적화한다(섹션 4.2 참조). 이 임계값 선택은 손실 환경을 형성하거나 모델 상태를 업데이트하는 반복 학습 프로세스가 아니라 일종의 하이퍼파라미터 튜닝이다.
본질적으로 TV Score 메커니즘은 사전 훈련된 GLM의 고정된 학습된 표현과 ID 데이터에 대한 통계적으로 정의된 참조를 활용하는 통계적 점수 함수이다. 자체적으로 기울기 하강 또는 유사한 최적화 역학을 통해 학습, 업데이트 또는 수렴하지 않는다.
결과, 제한 사항 및 결론
실험 설계 및 기준선
수학적 주장을 엄격하게 검증하기 위해, 저자들은 생성 언어 모델(GLM)의 수학적 추론에서의 OOD 탐지에 초점을 맞춘 포괄적인 실험 설계를 구성했다. 평가는 오프라인 탐지와 온라인 탐지의 두 가지 주요 시나리오로 나뉘었다.
오프라인 탐지의 경우, 주어진 목록의 샘플이 OOD인지 여부를 분류하는 것이 목표였다. 사용된 주요 지표는 AUROC(수신자 작동 특성 곡선 아래 면적) 및 FPR95(95% 참 양성률에서의 거짓 양성률)였다. 온라인 탐지의 경우, 새로운 샘플이 OOD인지 여부를 직접 결정하기 위한 최적의 분류 임계값을 계산하는 작업이었으며, 판별 정확도와 견고성(샘플링 분산으로 측정)을 사용했다.
제안된 TV Score와 "무자비하게" 비교된 기준선 모델은 5가지 훈련 없는 방법으로, GLM에 대한 OOD 탐지 방법이 부족하기 때문에 선택되었다:
1. 최대 소프트맥스 확률 (Prob.) [12]
2. 몬테카를로 드롭아웃 [8]
3. 시퀀스 복잡도 [3]
4. 입력 임베딩 [43]
5. 출력 임베딩 [43]
실험 설계는 분포 내(ID) 데이터셋으로 MultiArith [44]를 사용했으며, 산술 추론에 대한 수학 단어 문제를 포함했다. OOD 데이터의 경우, 두 가지 뚜렷한 시나리오가 고려되었다:
* 원거리 이동 OOD: 여기에는 대수학, 기하학, 조합 및 확률, 정수론, 미적분학 전의 5가지 다양한 수학 도메인을 포함하는 MATH 데이터셋 [11]이 포함되었다. 이 문제들은 대학 수준의 난이도를 가지며 MultiArith의 초등 수준과 대조되어 상당한 분포 이동을 보장한다.
* 근거리 이동 OOD: 여기에는 5가지 산술 추론 데이터셋(GSM8K [6], SVAMP [39], AddSub [13], SingleEq [18], SingleOp [18])이 포함되었다. 이들도 수학 단어 문제이지만, MultiArith와 비교하여 다른 추론 단계와 지식이 필요하며, 더 미묘한 분포 이동을 나타낸다.
ID 데이터(MultiArith)는 훈련용 360개 샘플과 테스트용 240개 샘플로 분할되었다. 소규모 테스트 세트의 무작위성을 완화하기 위해 1000개의 테스트 샘플 크기가 사용되어 양성(OOD) 및 음성(ID) 샘플의 균형 잡힌 수를 보장했다. 백본 GLM은 Llama2-7B [50] 및 GPT2-XL (1.5B) [5]를 사용했으며, MultiArith ID 훈련 세트로 훈련되었다. OOD 데이터셋 선택의 합리성은 이러한 데이터셋이 기본 모델의 능력을 초과하고 낮은 정확도를 나타내어 OOD 상태를 모델 성능 관점에서 검증함으로써 확인되었다. 차분 평활화(TV Score w/ DiSmo)가 있는 TV Score의 경우, 평활화 차수 $k$는 1에서 5까지 다양했으며 최적의 성능이 보고되었다.
증거가 증명하는 것
실험 결과는 궤적 변동성의 핵심 메커니즘이 수학적 추론에서 ID 및 OOD 샘플을 효과적으로 구별하며, 전통적인 알고리즘을 실질적으로 능가한다는 결정적이고 부인할 수 없는 증거를 제공한다.
오프라인 탐지에서 TV Score는 놀라운 우수성을 보여주었다:
* 원거리 이동 OOD: 우리 방법은 평균 AUROC 98.76 (Llama2-7B) 및 93.47 (GPT2-XL)을 달성하여 최적 기준선을 10포인트 이상 능가했다. 더욱 놀라운 것은 FPR95 지표가 5.21 (Llama2-7B) 및 9.89 (GPT2-XL)로, 최고 기준선에 비해 80% 이상 감소했다는 것이다. 이는 동적 임베딩 궤적을 분석함으로써 모델이 상당히 다른 수학적 도메인의 샘플을 안정적으로 식별할 수 있음을 명확하게 나타낸다.
* 근거리 이동 OOD: 이 더 어려운 시나리오에서도 기준선이 상당한 성능 저하(AUROC 60 미만, FPR95 80 초과)를 겪었음에도 불구하고, 우리 방법은 AUROC 점수 90 이상 및 FPR95 30 미만으로 우수한 성능을 유지했다. 이는 TV Score의 더 큰 적응성과 견고성이 미묘한 분포 이동에 대한 것임을 증명한다.
모델 분석은 또한 흥미로운 현상을 드러냈다: GPT2-XL은 원거리 및 근거리 이동 설정 전반에 걸쳐 더 안정적인 성능을 보인 반면, Llama2-7B는 근거리 이동 설정에서 기준선에 대해 더 두드러진 성능 저하를 보였다. 차분 평활화 기술(DiSmo)은 특히 GPT2-XL에서 효과적이었으며, 이는 더 작은 모델의 잠재 공간에서 이상 학습 경향을 완화하는 데 도움이 된다는 것을 시사한다. 결정적으로, 우리 방법은 임베딩 기반 기준선과 달리 샘플링 오류에 대한 민감도가 높아 거의 모든 유의성 테스트를 통과했다.
온라인 탐지의 경우, TV Score는 원거리 및 근거리 이동 OOD 설정 모두에서 임베딩 기반 방법에 비해 평균 20포인트의 정확도 향상을 달성했으며, 일부 데이터셋에서는 40포인트 이상의 향상을 보였다. 낮은 샘플링 분산으로 반영된 이러한 더 강력한 견고성은 실제 시나리오에서 더 일관되게 최적의 OOD 분류 임계값을 찾을 수 있음을 의미하며, 제어 불가능한 데이터 획득으로 인한 위험을 줄인다.
탐지를 넘어, TV Score는 OOD 품질 추정에도 효과적이었다. 이진 매칭 품질 지표와의 상관 관계를 측정할 때, 우리 방법은 Llama2-7B에 대해 SOTA 기준선보다 최대 100%의 Kendall 상관 관계 향상과 최대 100%(원거리 이동) / 30%(근거리 이동)의 Spearman 상관 관계 향상을 보여주었다. 이러한 강력한 증거는 TV 점수가 ID/OOD를 구별할 뿐만 아니라 생성된 수학적 추론의 품질과 정확성을 정확하게 반영함을 나타낸다.
마지막으로, 방법의 일반화 가능성은 "패턴 붕괴" 속성을 특징으로 하는 작업인 다중 선택 질문 데이터셋인 MMLU에서 입증되었다. 우리 TV Score는 이 설정에서 모든 전통적인 알고리즘을 능가했으며, 특히 전통적인 임베딩 기반 방법이 어려움을 겪었던 미세한 탐지 시나리오에서 확장성과 이점을 보여주었다.
제한 사항 및 향후 방향
TV Score는 수학적 추론에서의 OOD 탐지에 상당한 발전을 보여주지만, 내재된 제한 사항을 인식하고 향후 개발 방향을 고려하는 것이 중요하다.
저자들이 강조한 주요 제한 사항은 수학적 추론에 사용할 수 있는 데이터셋의 상대적으로 작은 크기이다. 전통적인 언어 작업은 수백만 개의 샘플을 자랑하지만, 수학적 추론 데이터셋은 일반적으로 수백 또는 수천 개이다. 이러한 부족은 모델을 안정적으로 훈련하고 평가하기 어렵게 만든다. 저자들은 무작위성을 줄이고 소규모 테스트에서의 데이터 불균형을 완화하기 위해 테스트 샘플링을 사용하여 이를 해결했지만, 데이터 가용성의 근본적인 문제는 남아 있다. 또 다른 관찰은 차분 평활화(DiSmo)의 성능이 다양한 설정에서 변동했으며, 과도한 평활화(예: $k > 2$)는 유용한 특징 정보의 손실을 초래하여 탐지 정확도를 감소시킬 수 있다는 것이다.
앞으로 이 작업에서 몇 가지 향후 방향이 나타나며, 진화를 위한 다양한 관점을 제공한다:
- 수학적 추론에서의 데이터 부족 해결: 수학적 표현에 특화된 고급 데이터 증강 기술을 탐색할 수 있다. 형식적인 수학적 속성 또는 정리 증명기를 통해 안내되는 합성 데이터 생성이 확장 가능한 솔루션을 제공할 수 있을까? 광범위한 ID 데이터셋에 덜 의존하는 소수샷 또는 제로샷 OOD 탐지 방법을 조사하는 것도 가치가 있을 것이다.
- "패턴 붕괴"에 대한 이해 심화: 이 논문은 "패턴 붕괴"를 중요한 현상으로 식별한다. 현재 토큰 및 표현 수준 분석을 넘어서는 근본 원인에 대한 더 깊은 이론적 및 경험적 조사는 새로운 완화 전략으로 이어질 수 있다. 이러한 패턴 붕괴에 본질적으로 더 강한 GLM 아키텍처 또는 훈련 목표를 설계할 수 있을까?
- 기타 기호 AI 작업으로의 일반화 확장: 다중 선택 질문으로의 성공적인 확장은 유망하다. 이는 TV Score가 출력 공간이 제한되고 "패턴 붕괴"를 나타내는 코드 생성, 논리적 추론 또는 구조화된 예측과 같은 더 넓은 범위의 기호 AI 작업에 적용될 수 있음을 시사한다. 향후 연구는 이러한 도메인을 체계적으로 식별하고 검증하여 초기 수학적 추론 초점을 넘어선 통합 OOD 탐지 프레임워크로 이어질 수 있다.
- 궤적 변동성 측정 개선: 현재 TV Score는 차원 독립적 및 차원 결합 변동성을 사용한다. 임베딩 궤적 역학의 더 정교한 측정, 예를 들어 곡률, 비틀림 또는 샘플 특성에 따라 $k$를 동적으로 조정하는 적응형 평활화 기술을 탐색하면 잠재적으로 더 미세하고 더 강력한 OOD 탐지가 가능할 수 있다.
- 하이브리드 OOD 탐지 접근 방식: 임베딩 기반 방법, 특히 궤적 변동성이 이 맥락에서 우수함이 입증되었지만, 이를 불확실성 추정 기술(예: 베이즈 신경망, 앙상블 방법)과 통합하면 더 강력한 하이브리드 OOD 탐지기가 될 수 있다. 이러한 접근 방식은 두 패러다임의 강점을 활용하여 OOD성에 대한 더 포괄적인 평가를 제공할 수 있다.
- 대규모 모델에 대한 계산 효율성: GLM의 크기와 계층 수가 계속 증가함에 따라 ID 분포 적합성($O(Ldn)$) 및 점수 계산($O(Ldk)$)의 계산 복잡성이 병목 현상이 될 수 있다. 향후 연구는 근사 기술, 하드웨어 가속 또는 임베딩 분포에 대한 더 효율적인 통계 모델링을 통해 이러한 연산을 최적화하는 데 초점을 맞출 수 있다.
- 패턴 붕괴 및 궤적 변동성에 대한 이론적 보장: 이 논문은 경험적 증거와 이론적 직관을 제공한다. 수학적 추론에서 "패턴 붕괴"가 발생하는 이유와 궤적 변동성이 OOD 샘플에 대한 신뢰할 수 있는 신호인 이유에 대한 더 엄격한 이론적 보장을 개발하면 이 접근 방식의 기초가 강화될 것이다. 여기에는 이러한 현상이 발생하는 조건을 형식화하고 TV Score의 효과에 대한 경계를 증명하는 것이 포함될 수 있다.
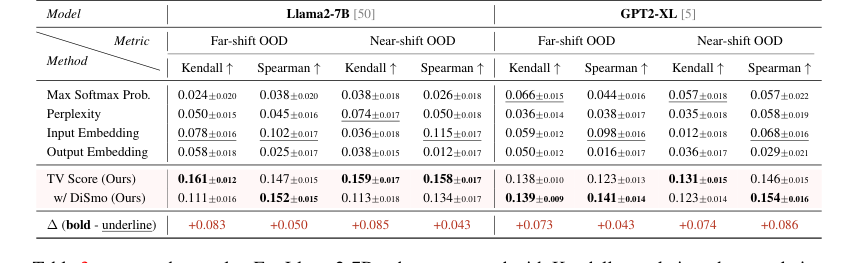 Table 3. presents the results. For Llama2-7B, when compared with Kendall correlation, the correlation improvement of TV scores over SOTA baselines reaches up to 100% under both far-shift and near-shift OOD settings. Compared with Spearman correlation, TV scores demonstrate a correlation enhancement over SOTA baselines by up to 100% under far-shift OOD setting and 30% under near-shift OOD setting. GPT2-XL also demonstrates excellent performance. These findings indicate that our TV scores not only facilitate the binary discrimination of ID and OOD samples but also substantially reflect the quality and precision of generated mathematical reasoning
Table 3. presents the results. For Llama2-7B, when compared with Kendall correlation, the correlation improvement of TV scores over SOTA baselines reaches up to 100% under both far-shift and near-shift OOD settings. Compared with Spearman correlation, TV scores demonstrate a correlation enhancement over SOTA baselines by up to 100% under far-shift OOD setting and 30% under near-shift OOD setting. GPT2-XL also demonstrates excellent performance. These findings indicate that our TV scores not only facilitate the binary discrimination of ID and OOD samples but also substantially reflect the quality and precision of generated mathematical reasoning
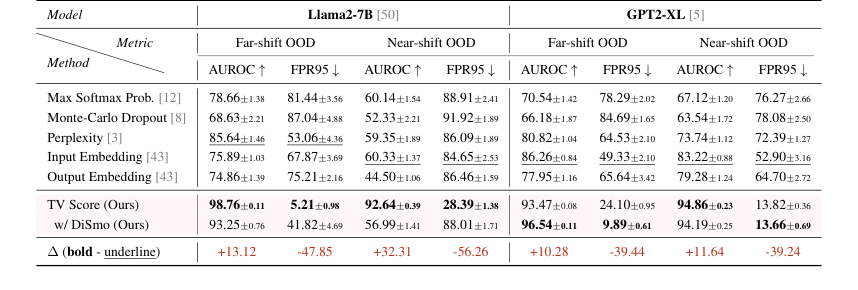 Table 1. AUROC and FPR95 results of the Offline Detection scenario. Underline and bold denote SOTA among all baselines and all methods, respectively. We report the average results under each setting in the main text, results of each dataset are shown in Table 11 and 12 (Appendix F)
Table 1. AUROC and FPR95 results of the Offline Detection scenario. Underline and bold denote SOTA among all baselines and all methods, respectively. We report the average results under each setting in the main text, results of each dataset are shown in Table 11 and 12 (Appendix F)
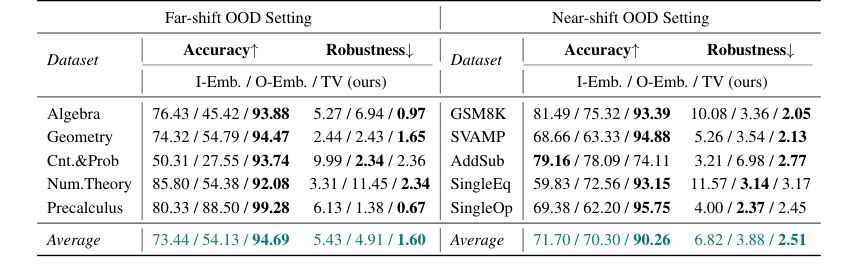 Table 2. presents the results in Llama2-7B. Compared to the embedding-based methods, our TV score obtains about an average of 20-point accuracy improvement in both far-shift OOD and near-shift OOD settings, and on some datasets, such as Cnt.&Prob, our TV score achieves more than 40 points of improvement. These all imply that TV Score can perform online discrimination of OOD samples more accurately. In addition, our TV score also possesses stronger robustness, which means that in real scenarios, we can find the optimal threshold more consistently in the face of different accessible ID and OOD data, reducing the potential riskiness due to uncontrollable data acquisition
Table 2. presents the results in Llama2-7B. Compared to the embedding-based methods, our TV score obtains about an average of 20-point accuracy improvement in both far-shift OOD and near-shift OOD settings, and on some datasets, such as Cnt.&Prob, our TV score achieves more than 40 points of improvement. These all imply that TV Score can perform online discrimination of OOD samples more accurately. In addition, our TV score also possesses stronger robustness, which means that in real scenarios, we can find the optimal threshold more consistently in the face of different accessible ID and OOD data, reducing the potential riskiness due to uncontrollable data acquisition
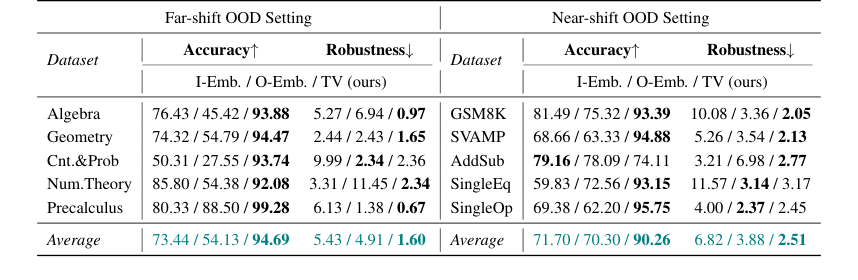 Table 2. Accuracy and Robustness results of the Online Detection scenario. We mainly compare our method with embedding-based methods, and bold denotes the best among these methods
Table 2. Accuracy and Robustness results of the Online Detection scenario. We mainly compare our method with embedding-based methods, and bold denotes the best among these methods