Federated Model Heterogeneous Matryoshka Representation Learning
Model heterogeneous federated learning (MHeteroFL) enables FL clients to collaboratively train models with heterogeneous structures in a distributed fashion.
Background & Academic Lineage
The Origin & Academic Lineage
The problem addressed in this paper, Model Heterogeneous Federated Learning (MHeteroFL), emerged from the inherent limitations of traditional Federated Learning (FL). Initially, FL was conceived as a privacy-preserving method where a central server coordinates multiple data owners (clients) to train a single, global shared model without directly exposing local data. In each communication round, the server broadcasts the global model, clients train it on their local data, and then send updated local models back for aggregation to form a new global model. This process repeats until convergence, with only model parameters being transmitted, thus preserving data privacy.
However, this traditional FL design faced significant "pain points" when applied to real-world scenarios, which forced the development of more advanced approaches like MHeteroFL. These limitations include:
- Data Heterogeneity (Non-IID Data): Clients' local data often do not follow an independent and identically distributed (non-IID) pattern. This means that a single global model, aggregated from such diverse local datasets, might not perform optimally across all clients. For instance, one client might have data heavily skewed towards a particular class, while another has data for different classes.
- System Heterogeneity: FL clients can have vastly different computing power and network bandwidth. Forcing all clients to train the same, often large, model structure means the global model size must accommodate the weakest device, leading to suboptimal performance on more powerful clients who could handle larger, more complex models.
- Model Heterogeneity: In practical FL applications, especially when clients are enterprises, they may possess proprietary models with unique architectures or intellectual property (IP) concerns. Directly sharing these heterogeneous models or their structures during FL training is often unacceptable due to IP protection.
Existing MHeteroFL methods, while attempting to address these challenges by allowing clients to train models with tailored structures, still suffer from limited knowledge transfer capabilities. They typically rely on training loss to transfer knowledge between client and server models, which can lead to performance bottlenecks, high communication and computation costs, and a persistent risk of exposing private local model structures and data. This paper proposes FedMRL to overcome these limitations by enhancing knowledge transfer through adaptive representation fusion and multi-perspective representation learning, inspired by Matryoshka Representation Learning.
Intuitive Domain Terms
To help a zero-base reader understand the core concepts, here are some specialized terms from the paper, translated into everyday analogies:
- Federated Learning (FL): Imagine a cooking competition where multiple chefs (clients) are making their own unique dishes (local models) using their secret ingredients (local data). Instead of sharing their recipes, they only send a summary of their cooking techniques to a head judge (central server). The judge combines these summaries to create general cooking advice (global model) and sends it back to the chefs. This way, everyone improves their dish without revealing their private recipes.
- Model Heterogeneous Federated Learning (MHeteroFL): Building on the cooking analogy, imagine each chef has a different type of kitchen equipment (diverse system resources) and prefers a different style of cuisine (heterogeneous model structures). MHeteroFL is like having a very flexible head judge who can still provide useful, tailored advice to each chef, even though they're all working with different tools and culinary approaches. The judge helps them improve collectively without forcing everyone to cook the same way or use the same equipment.
- Matryoshka Representation Learning (MRL): Think of a set of Russian nesting dolls. Each doll is a complete, but progressively smaller and less detailed, version of the one before it. MRL is like training a system to generate "nested" insights from data. It can produce a very broad, general understanding (the largest doll) and also more specific, fine-grained details (the smaller dolls inside). This allows the system to use just the right level of detail for a task, saving computational cost if only a general understanding is needed, much like you might only need to see the biggest doll to know it's a Matryoshka.
- Non-IID Data (Non-Independent and Identically Distributed Data): Consider a class of students learning about animals. If the data were IID, every student would have a textbook with an equal mix of pictures of cats, dogs, birds, and fish. Non-IID data is like one student's textbook being mostly about cats, another's mostly about dogs, and a third's primarily about birds. Their individual learning materials (local data) are not evenly distributed and don't perfectly represent the full range of animals (global data distribution). This makes it harder for a single, unified lesson plan to work for everyone.
Notation Table
| Notation | Description |
|---|---|
Problem Definition & Constraints
Core Problem Formulation & The Dilemma
The core problem addressed by this paper lies within the domain of Model Heterogeneous Federated Learning (MHeteroFL), which aims to enable multiple clients with diverse model architectures to collaboratively train a global model without sharing their raw local data.
Input/Current State:
Traditional Federated Learning (FL) operates with a central server coordinating $N$ clients to train a single, shared global model. In each communication round, the server broadcasts the global model, clients train it on their local data, and then send updated local models back for aggregation. This process repeats until convergence, with only model parameters transmitted to preserve data privacy. However, this conventional FL design struggles with three critical heterogeneity challenges prevalent in practical applications:
1. Data Heterogeneity (Non-IID): Clients' local datasets often follow non-independent and identically distributed (non-IID) patterns, meaning a single global model aggregated from such diverse local data may perform poorly on individual clients.
2. System Heterogeneity: FL clients possess varied computational resources (e.g., CPU, GPU, memory) and network bandwidth. Requiring all clients to train an identical model structure means the global model size must be constrained by the weakest device, leading to suboptimal performance on more powerful clients.
3. Model Heterogeneity: Clients, especially enterprises, may have proprietary local models with diverse, non-sharable structures due to intellectual property (IP) concerns. This prevents direct parameter averaging or aggregation.
Existing MHeteroFL methods attempt to address these challenges but primarily rely on transferring knowledge between client and server models through training loss. This approach, however, results in limited knowledge exchange, leading to performance bottlenecks, high communication and computation costs, and potential risks of exposing private local model structures and data.
Desired Endpoint (Output/Goal State):
The paper seeks to develop a novel MHeteroFL approach, named Federated model heterogeneous Matryoshka Representation Learning (FedMRL), that can effectively and jointly tackle data, system, and model heterogeneity in supervised learning tasks. The goal is to achieve:
1. Enhanced Knowledge Transfer: Facilitate more effective knowledge interaction between the server's global homogeneous model and the clients' heterogeneous local models.
2. Improved Model Performance: Achieve superior model accuracy compared to existing state-of-the-art methods.
3. Low Communication and Computational Costs: Minimize the overhead associated with model training and updates.
4. Strong Privacy Preservation: Ensure that clients' local data and heterogeneous model structures remain unexposed to the server or other clients.
5. Personalized Adaptation: Enable the learning process to adapt to local non-IID data distributions and diverse client resources.
Missing Link or Mathematical Gap:
The exact missing link is the lack of an effective and efficient mechanism for knowledge transfer across heterogeneous models and data distributions in a privacy-preserving manner. Current methods' reliance on training loss for knowledge transfer is insufficient. FedMRL attempts to bridge this gap by introducing two key innovations:
1. Adaptive Representation Fusion: For each local data sample, feature extractors from both a global homogeneous small model and a local heterogeneous model extract generalized and personalized representations, respectively. These are then spliced and mapped to a fused representation by a personalized lightweight representation projector $P_k(\phi_k)$ that adapts to local non-IID data.
2. Multi-Granularity Representation Learning: The fused representation is used to construct Matryoshka Representations, which are multi-dimensional and multi-granular embedded representations. These are processed by the prediction headers of both the global homogeneous model and the local heterogeneous model, with their combined losses used to update all models.
Mathematically, the paper aims to minimize the following objective function (Equation 1):
$$
\min_{\theta, \omega_0, \dots, \omega_{N-1}, \phi_0, \dots, \phi_{N-1}} \sum_{k=0}^{N-1} l(W_k(D_k; (\theta \circ \omega_k | \phi_k)))
$$
where $W_k(w_k) = (G(\theta) \circ F_k(w_k) | P_k(\phi_k))$ represents the combined model for client $k$, incorporating the global homogeneous small model $G(\theta)$, the client's local heterogeneous model $F_k(w_k)$, and the personalized representation projector $P_k(\phi_k)$. The loss $l$ is computed based on multi-perspective outputs from Matryoshka Representations.
The Dilemma:
The painful trade-off that has trapped previous researchers is the inherent conflict between achieving high model performance and effective knowledge transfer across heterogeneous FL clients, while simultaneously maintaining low communication/computation costs and strong privacy guarantees. Improving one aspect often compromises another. For instance, sharing more information (e.g., full model parameters or detailed intermediate representations) could enhance knowledge transfer and performance but would drastically increase communication costs and privacy risks. Conversely, limiting shared information to protect privacy and reduce costs often leads to "limited knowledge exchange" and "model performance bottlenecks" (Page 2, Section 1), resulting in suboptimal accuracy, especially on non-IID data. The dilemma is how to enable rich, multi-perspective knowledge interaction without exposing sensitive client details or overwhelming constrained resources.
Constraints & Failure Modes
The problem of model heterogeneous federated learning is insanely difficult due to several harsh, realistic walls that authors hit:
- Non-IID Data Distribution: Clients' local data is often non-independent and identically distributed (non-IID), making it challenging to train a single global model that performs well across all clients. This necessitates personalized models or adaptive mechanisms, which add complexity.
- Diverse Client System Resources: FL clients operate with varying computational power, memory, and network bandwidth. Any proposed solution must be efficient enough to run on the weakest devices while still leveraging the capabilities of more powerful ones. This imposes strict limits on model size and computational overhead per client.
- Proprietary Model Structures and IP Protection: Clients may use diverse, proprietary local model architectures that cannot be directly shared or aggregated due to intellectual property concerns. This prevents traditional federated averaging of model parameters.
- Limited Knowledge Transfer Effectiveness: Existing MHeteroFL methods, particularly those relying on training loss or simple mutual learning, often achieve only "limited knowledge transfer" (Page 1, Abstract; Page 3, Section 2). This leads to suboptimal model performance and slow convergence.
- High Communication Costs: Transmitting large model parameters or extensive intermediate representations between the server and numerous clients in each round can incur significant communication costs, especially over limited network bandwidths. The goal is to minimize this.
- High Computational Overhead: Training additional models or complex knowledge distillation mechanisms on client devices can lead to substantial computational overhead, which is undesirable for resource-constrained clients.
- Strict Privacy Requirements: A fundamental principle of FL is to protect local data privacy. Any method must ensure that raw client data and local model structures are never exposed to the server or other clients. Failure to uphold this is a critical failure mode.
- Non-convex Optimization Landscape: The optimization problem in federated learning with heterogeneous models is generally non-convex. Guaranteeing convergence to a good solution, let alone a global optimum, is a significant mathematical challenge. The paper provides a theoretical analysis showing an $O(1/T)$ non-convex convergence rate (Page 1, Abstract), which is a common but still challenging aspect.
- Model Performance Bottlenecks: Without effective knowledge transfer, client models can suffer from performance bottlenecks, failing to generalize well or achieve high accuracy.
- Scalability Issues: The solution must be scalable to a large number of clients ($N$) and robust to varying client participation rates ($C=K/N$) in each communication round (Page 3, Section 3).
These constraints collectively make the problem of achieving high-performance, privacy-preserving, and resource-efficient federated learning with heterogeneous models an exceptionally difficult endeavor.
Why This Approach
The Inevitability of the Choice
The development of FedMRL was driven by the inherent limitations of existing Model Heterogeneous Federated Learning (MHeteroFL) approaches when confronted with the complex realities of practical FL applications. The authors realized that traditional "SOTA" methods, even when adapted for federated settings, were insufficient because they primarily relied on training loss for knowledge transfer between client and server models. This reliance led to several critical shortcomings: "limited knowledge exchange," "model performance bottlenecks," "high communication and computation costs," and a significant "risk of exposing private local model structures and data" (Abstract, page 1).
Specifically, the paper highlights that traditional FL designs struggled with three major heterogeneity challenges: (1) Data heterogeneity, where client data is non-IID; (2) System heterogeneity, where clients have diverse computing power and network bandwidth, forcing global models to accommodate the weakest device; and (3) Model heterogeneity, where clients possess proprietary models that cannot be directly shared due to intellectual property concerns (Section 1, page 1-2). While MHeteroFL emerged to tackle these, existing methods within this field, such as those based on adaptive subnets, knowledge distillation, model splitting, or mutual learning, still exhibited critical flaws. For instance, mutual learning approaches, which FedMRL builds upon, were noted to "only transfer limited knowledge between the two models, resulting in model performance bottlenecks" (Section 2, page 3).
The exact moment of realization, while not explicitly pinpointed as a single event, is strongly implied by the comprehensive critique of prior MHeteroFL methods. The authors recognized that a fundamentally different mechanism for knowledge transfer was needed—one that moved beyond simple loss-based distillation to a more sophisticated representation-level interaction. This led them to draw inspiration from Matryoshka Representation Learning (MRL) [24], which offers a way to tailor representation dimensions and achieve an optimal balance between model performance and inference costs. This shift to a representation-centric approach, rather than a model- or loss-centric one, became the only viable path to overcome the persistent challenges of heterogeneity, privacy, and efficency in federated learning.
Comparative Superiority
FedMRL demonstrates overwhelming qualitative superiority over previous gold standards through several structural and functional advantages, extending far beyond mere performance metrics.
Firstly, its core innovation lies in Adaptive Representation Fusion and Multi-Granularity Representation Learning. Unlike methods that rely on a single, fixed representation, FedMRL extracts both generalized (from a shared homogeneous model) and personalized (from a client's heterogeneous local model) representations. These are then adaptively fused by a lightweight, personalized projector, which is crucial for adapting to local non-IID data distributions (Section 3.1, page 4). This structural design allows for a richer, more nuanced understanding of local data, which is a significant qualitative leap over approaches that struggle with data heterogeneity. The subsequent construction of Matryoshka Representations, involving multi-dimensional and multi-granular embedded representations, further enhances model learning capability by enabling multi-perspective learning (Section 3.2, page 5). This is a structural advantage that allows the model to learn both coarse and fine-grained features, making it more robust and effective.
Secondly, FedMRL offers superior privacy preservation and resource efficiency. By only transmitting small homogeneous models between the server and clients, it ensures that "each client's local model and data are not exposed during training" (Section 2, page 2). This is a critical structural advantage for privacy-sensitive applications. Furthermore, this design inherently leads to "low communication costs" and "low extra computational costs" for clients, as they only train a small homogeneous model and a lightweight projector in addition to theire local model (Section 2, page 2). While the paper doesn't explicitly state a reduction from $O(N^2)$ to $O(N)$ memory complexity, the emphasis on "small homogeneous models" and "lightweight" components directly implies a significant reduction in memory and computational footprint compared to methods that might require larger, more complex models or extensive data sharing.
Finally, the method's robustness to non-IID data and stronger personalization capability are qualitatively superior. Experiments show FedMRL consistently achieves higher average test accuracy under various non-IID settings (Class and Dirichlet) compared to baselines like FedProto (Section 5.3.1, 5.3.2, page 9). Moreover, it provides stronger personalization, with a high percentage of individual clients (87% on CIFAR-10, 99% on CIFAR-100) achieving better performance than FedProto (Section 5.2.2, page 8). This indicates a fundamental structural advantage in handling diverse client environments and data distributions.
Alignment with Constraints
FedMRL's design perfectly aligns with the harsh requirements and constraints of heterogeneous federated learning, creating a synergistic "marriage" between problem and solution.
- Data Heterogeneity (non-IID data): The Adaptive Representation Fusion mechanism is explicitly designed to address this. The personalized representation projector maps spliced generalized and personalized representations to a fused representation "adapting to local non-IID data" (Section 3.1, page 4). This ensures that each client's unique data distribution is accounted for, preventing performance degradation common in non-IID settings.
- System Heterogeneity: FedMRL accommodates diverse client capabilities by introducing a "shared global auxiliary homogeneous small model" that interacts with "heterogeneous local models" (Section 2, page 2). The global model is intentionally small, allowing it to be broadcast and trained even by clients with limited resources. Clients can also adjust the linear layer dimension of their representation projector to align with the spliced representation, further adapting to local system constraints (Section 3.1, page 4).
- Model Heterogeneity: The framework inherently supports clients owning "local models with diverse structures" (Section 3.1, page 4). The server only interacts with the homogeneous small model, treating the client's heterogeneous local model as a black box. This design respects intellectual property concerns by not requiring clients to expose their proprietary model structures.
- Privacy Preservation: This is a cornerstone of FedMRL. "Each client's local model and data are not exposed during training for privacy-preservation" (Section 2, page 2). Only the small homogeneous models are transmitted, ensuring local data and model structures remain private.
- Communication Efficiency: By transmitting only the "small homogeneous models" (Section 2, page 2), FedMRL significantly reduces communication costs compared to methods that exchange full client models. The ability to vary the representation dimension $d_1$ of the homogeneous small model further allows for optimization of communication overheads (Section 5.3.3, page 9).
- Computational Efficiency: Clients only need to train a "small homogeneous model and a lightweight representation projector" in addition to their local model, incurring "low extra computational costs" (Section 2, page 2). The faster convergence speed achieved by FedMRL (Figure 4, page 8) also means fewer communication rounds are needed to reach target accuracy, thereby reducing overall computational overhead (Section 5.2.4, page 9).
- Knowledge Transfer Limitations: The dual innovations of adaptive representation fusion and multi-granularity representation learning directly tackle the "limited knowledge exchange" problem of prior methods. They facilitate "more knowledge interaction across the two models and improving model performance" by learning generalized and personalized representations from multiple perspectives (Section 2, page 3).
Rejection of Alternatives
The paper systematically identifies and rejects several categories of existing MHeteroFL approaches by highlighting their fundamental shortcomings in addressing the problem's constraints:
- MHeteroFL with Adaptive Subnets: These methods construct heterogeneous local subnets from a global model. The authors reject this approach because "in cases where clients hold black-box local models with heterogeneous structures not derived from a common global model, the server is unable to aggregate them" (Section 2, page 3). This implies a failure to handle true model heterogeneity where client models are proprietary and not simply pruned versions of a global model.
- MHeteroFL with Knowledge Distillation:
- Methods relying on a public dataset for knowledge transfer are deemed impractical because "such a suitable public dataset can be hard to find" (Section 2, page 3).
- Approaches that train a generator to synthesize a shared dataset are rejected due to the "high training costs" they incur (Section 2, page 3).
- Other methods that share intermediate information are implicitly rejected due to the risk of exposing "client local data for knowledge fusion," which can compromise privacy.
- MHeteroFL with Model Split: These methods divide models into feature extractors and predictors, sharing either one or the other. The paper rejects this strategy because it "expose[s] part of the local model structures, which might not be acceptable if the models are proprietary IPs of the clients" (Section 2, page 3). This directly conflicts with the privacy and intellectual property protection constraints.
- MHeteroFL with Mutual Learning: While FedMRL builds upon this category, it explicitly states that existing mutual learning methods (e.g., FML, FedKD, FedAPEN) are insufficient because "the mutual loss only transfers limited knowledge between the two models, resulting in model performance bottlenecks" (Section 2, page 3). FedMRL is presented as an optimization that "enhances the knowledge transfer" by moving to a representation-based approach rather than solely relying on mutual loss.
The paper does not discuss the failure of general deep learning architectures like GANs, Diffusion models, or Transformers as alternatives for the federated learning approach itself. Instead, it implicitly incorporates CNNs (a type of Transformer-predecessor architecture) as the underlying models within its framework (Table 2, page 17). The rejection is of the federated learning paradigms that fail to effectively manage the unique challenges of heterogeneity, privacy, and resource efficiency, rather than the fundamental model architectures.
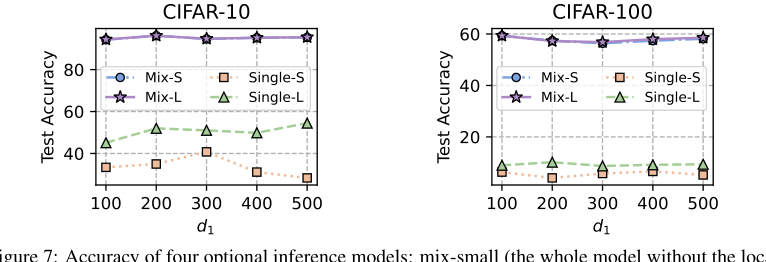 Figure 7. Accuracy of four optional inference models: mix-small (the whole model without the local header), mix-large (the whole model without the global header), single-small (the homogeneous small model), single-large (the client heterogeneous model)
Figure 7. Accuracy of four optional inference models: mix-small (the whole model without the local header), mix-large (the whole model without the global header), single-small (the homogeneous small model), single-large (the client heterogeneous model)
Mathematical & Logical Mechanism
The Master Equation
The absolute core of the FedMRL approach is its objective function, which aims to minimize the total loss across all participating clients in a federated learning setting. This master equation encapsulates the entire learning goal:
$$ \min_{\theta, \omega_0, \dots, \omega_{N-1}, \phi_0, \dots, \phi_{N-1}} \sum_{k=0}^{N-1} l(W_k(D_k; (\theta \circ \omega_k | \phi_k))) $$
Term-by-Term Autopsy
Let's dissect this master equation and its underlying components to understand its mathematical definition, logical role, and the rationale behind its construction.
-
$\min_{\theta, \omega_0, \dots, \omega_{N-1}, \phi_0, \dots, \phi_{N-1}}$: This is the optimization objective.
- Mathematical Definition: It signifies that the goal is to find the set of parameters ($\theta$, $\omega_k$, $\phi_k$) that minimizes the subsequent sum of losses.
- Physical/Logical Role: This is the central directive of the entire FedMRL system. It dictates that the learning process should adjust all relevant model parameters to make the predictions as accurate as possible across all clients.
- Why minimization: In machine learning, we typically define a "loss" or "error" function, and the objective is to reduce this error, hence minimization is the natural choice.
-
$\sum_{k=0}^{N-1}$: This is a summation operator.
- Mathematical Definition: It sums the individual loss contributions from each client, from client $k=0$ to $N-1$.
- Physical/Logical Role: In federated learning, the overall performance is a collective measure of all clients. This summation ensures that the global objective considers the learning outcomes of every client, promoting a shared learning goal while respecting local data.
- Why summation instead of, say, product: Summation is a standard way to aggregate losses in a multi-client or multi-task setting. A product would be highly sensitive to small losses (driving the total to zero) or large losses (exploding the total), making optimization unstable. Summation provides a more stable and interpretable aggregation of individual client performance.
-
$l(\cdot)$: This represents a loss function.
- Mathematical Definition: As stated in the paper (Eq. 8), this is typically a cross-entropy loss, $l(y, Y_i)$, which measures the discrepancy between a model's predicted output $y$ and the true label $Y_i$.
- Physical/Logical Role: The loss function quantifies how "wrong" the model's predictions are for a given input. A higher loss means a worse prediction. It provides the signal for the optimization process to adjust model parameters.
- Why cross-entropy: Cross-entropy is widely used for classification tasks because it penalizes incorrect classifications more heavily and encourages the model to output probabilities that match the true label distribution.
-
$W_k(D_k; (\theta \circ \omega_k | \phi_k))$: This represents the combined model for client $k$, operating on its local data $D_k$, parameterized by a combination of global ($\theta$), local ($\omega_k$), and personalized projector ($\phi_k$) parameters. This is where the core FedMRL mechanism resides. Let's break down its internal workings:
-
$D_k$: This denotes the local dataset of client $k$.
- Mathematical Definition: A set of data samples $(x_i, Y_i)$, where $x_i$ is an input feature vector and $Y_i$ is its corresponding true label.
- Physical/Logical Role: This is the private, local data that each client uses for training. It's crucial in FL that this data remains local and is not directly shared with the server or other clients.
-
$\theta$: This represents the parameters of the global homogeneous small model.
- Mathematical Definition: $\theta = \{\theta_{ex}, \theta_{hd}\}$ where $\theta_{ex}$ are the parameters for the global model's feature extractor $G_{ex}$ and $\theta_{hd}$ are for its prediction header $G_{hd}$. These are shared across all clients.
- Physical/Logical Role: This model acts as a "generalized" knowledge source. It's small and homogeneous to minimize communication costs and accommodate system heterogeneity. It provides a common baseline representation.
-
$\omega_k$: This represents the parameters of client $k$'s heterogeneous local model.
- Mathematical Definition: $\omega_k = \{\omega_{ex,k}, \omega_{hd,k}\}$ where $\omega_{ex,k}$ are parameters for client $k$'s local feature extractor $F_{ex}$ and $\omega_{hd,k}$ are for its prediction header $F_{hd}$. These are unique to each client.
- Physical/Logical Role: This model captures "personalized" knowledge adapted to client $k$'s specific data distribution and model structure. It addresses data and model heterogeneity.
-
$\phi_k$: This represents the parameters of client $k$'s personalized representation projector.
- Mathematical Definition: $\phi_k$ are the parameters of the lightweight projector $P_k$.
- Physical/Logical Role: This projector is responsible for adaptively fusing the generalized and personalized representations. It's personalized to each client to handle local non-IID data distributions effectively.
-
$\circ$ (Splicing Operator): This operator combines the outputs of the feature extractors.
- Mathematical Definition: As per Eq. (3), $R_i = R_k^g \circ R_k^f$, where $R_k^g = G_{ex}(x_i; \theta_{ex,t-1})$ is the generalized representation from the global model's feature extractor and $R_k^f = F_{ex}(x_i; \omega_{ex,t-1})$ is the personalized representation from the local model's feature extractor. Splicing typically means concatenating the feature vectors.
- Physical/Logical Role: This operation merges the generalized features (common knowledge) with the personalized features (client-specific knowledge) into a single, richer representation.
- Why splicing instead of addition or multiplication: Splicing (concatenation) preserves the distinct semantic information from both sources. If we were to add or multiply, the information might blend or be lost, especially if the feature spaces have different scales or meanings. Splicing allows the subsequent projector to learn how to best combine these distinct perspectives. The paper notes it "can keep the relative semantic space positions."
-
$|$ (Matryoshka Representation Learning): This symbol conceptually represents the multi-dimensional, multi-granular Matryoshka Representation Learning process.
- Mathematical Definition: After the spliced representation $R_i$ is projected to a fused representation $R_i = P_k(R_i; \phi_{k,t-1})$ (Eq. 4), it is then split into two embedded representations: $R_i^{lc} = R_i^{1:d_1}$ (low-dimension, coarse-granularity) and $R_i^{hf} = R_i^{1:d_2}$ (high-dimension, fine-granularity) (Eq. 5). These are then fed into separate prediction headers: $y_i^{lc} = G_{hd}(R_i^{lc}; \theta_{hd,t-1})$ (Eq. 6) and $y_i^{F_k} = F_{hd}(R_i^{hf}; \omega_{hd,t-1})$ (Eq. 7).
- Physical/Logical Role: This mechanism is inspired by Matryoshka dolls, where smaller dolls are nested within larger ones. Here, it means extracting representations at different granularities and dimensions. This allows the model to learn from multiple perspectives, capturing both coarse and fine-grained information, which enhances the model's learning capability and robustness. The global header uses the coarse representation, while the local header uses the fine-grained one.
- Why splitting and separate headers: This design enables "multi-perspective representation learning." By having different headers process different granularities of the fused representation, the model can learn more robust and comprehensive features. It's like looking at an object from afar to get the general shape, and then up close to see the details, both contributing to a better understanding.
-
$m_i^{lc} \cdot l_i^{lc} + m_i^{F_k} \cdot l_i^{F_k}$ (Weighted Loss Sum): This is the final combined loss for a single data point $i$ at client $k$.
- Mathematical Definition: $l_i = m_i^{lc} \cdot l_i^{lc} + m_i^{F_k} \cdot l_i^{F_k}$ (Eq. 9), where $l_i^{lc}$ is the loss from the global model's header and $l_i^{F_k}$ is the loss from the local model's header (Eq. 8). $m_i^{lc}$ and $m_i^{F_k}$ are importance weights, typically set to 1 by default.
- Physical/Logical Role: This combines the learning signals from both the generalized (global) and personalized (local) perspectives. By weighting these losses, the system can balance the influence of each learning branch. Setting weights to 1 ensures both models contribute equally to the overall learning.
- Why addition: Similar to the overall summation, adding weighted losses is a standard way to combine multiple learning objectives. It allows for a balanced contribution from each component, guiding the model towards an optimal state that satisfies both coarse and fine-grained learning goals.
-
Step-by-Step Flow
Imagine a single data point, an image $x_i$ with its true label $Y_i$, entering the FedMRL system at client $k$. Here's its journey:
-
Feature Extraction: The input image $x_i$ first enters two distinct feature extractors in parallel.
- The global homogeneous model's feature extractor $G_{ex}$ (with parameters $\theta_{ex}$) processes $x_i$ to produce a generalized representation $R_k^g$. This is like getting a general, common understanding of the image.
- Simultaneously, the client $k$'s local heterogeneous model's feature extractor $F_{ex}$ (with parameters $\omega_{ex,k}$) processes $x_i$ to produce a personalized representation $R_k^f$. This captures client-specific details or nuances.
-
Representation Splicing: The two representations, $R_k^g$ and $R_k^f$, are then "spliced" together (concatenated) to form a combined representation $R_i$. This step ensures that both the general and personalized information are preserved side-by-side.
-
Adaptive Representation Fusion: The spliced representation $R_i$ is then fed into client $k$'s personalized lightweight representation projector $P_k$ (with parameters $\phi_k$). This projector maps the spliced representation into a fused representation $R_i$. This is where the system adapts the combined knowledge to the client's unique data distribution.
-
Matryoshka Representation Splitting: The fused representation $R_i$ is then conceptually split into two parts, like opening a Matryoshka doll to reveal a smaller one.
- A low-dimension, coarse-granularity representation $R_i^{lc}$ is extracted from the initial segment of $R_i$.
- A high-dimension, fine-granularity representation $R_i^{hf}$ is extracted from a larger segment of $R_i$.
-
Multi-Perspective Prediction: These two Matryoshka representations are then passed to their respective prediction headers:
- $R_i^{lc}$ goes to the global homogeneous model's prediction header $G_{hd}$ (with parameters $\theta_{hd}$) to produce a coarse prediction $y_i^{lc}$.
- $R_i^{hf}$ goes to the client $k$'s local heterogeneous model's prediction header $F_{hd}$ (with parameters $\omega_{hd,k}$) to produce a fine-grained prediction $y_i^{F_k}$.
-
Loss Calculation: For each prediction, a loss is computed against the true label $Y_i$:
- $l_i^{lc}$ is the loss for the coarse prediction $y_i^{lc}$.
- $l_i^{F_k}$ is the loss for the fine-grained prediction $y_i^{F_k}$.
-
Weighted Loss Aggregation: Finally, these two individual losses are combined into a single total loss $l_i$ for the data point $x_i$ by a weighted sum. By default, both losses contribute equally. This $l_i$ is the value that contributes to the overall objective function.
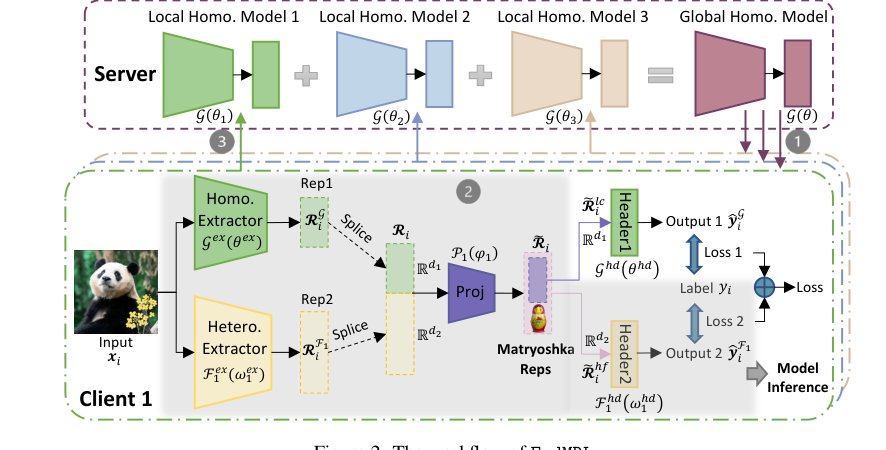 Figure 2. The workflow of FedMRL
Figure 2. The workflow of FedMRL
This entire process is repeated for all data points in a batch, and the average loss for the batch is used for optimization.
Optimization Dynamics
The FedMRL mechanism learns and updates its parameters iteratively through a process of gradient descent, aiming to minimize the global objective function.
-
Gradient Computation: After the weighted loss $l_i$ is calculated for a batch of data points at client $k$, the gradients of this loss are computed with respect to all the parameters involved in client $k$'s model:
- $\nabla l_i$ with respect to $\theta$ (global model parameters).
- $\nabla l_i$ with respect to $\omega_k$ (client $k$'s local model parameters).
- $\nabla l_i$ with respect to $\phi_k$ (client $k$'s personalized representation projector parameters).
-
Local Parameter Update: Each client $k$ then updates its local parameters ($\omega_k$ and $\phi_k$) and its copy of the global model parameters ($\theta$) using these gradients and predefined learning rates ($\eta_\theta, \eta_\omega, \eta_\phi$). This is a standard gradient descent step:
$$ \theta^t \leftarrow \theta^{t-1} - \eta_\theta \nabla l_i \\ \omega_k^t \leftarrow \omega_k^{t-1} - \eta_\omega \nabla l_i \\ \phi_k^t \leftarrow \phi_k^{t-1} - \eta_\phi \nabla l_i $$
These updates happen locally on each client, adapting the models to their specific data and learning objectives. The paper mentions setting $\eta_\theta = \eta_\omega = \eta_\phi$ by default for stable convergence. -
Server Aggregation: After a local training round (which may involve multiple local epochs), each participating client uploads its updated homogeneous small model parameters (i.e., its updated $\theta$ parameters) to the central server. The server then aggregates these updated global model parameters from all participating clients to produce a new, consolidated global model $\theta^t$. This aggregation is typically an average of the received parameters. The local heterogeneous model parameters $\omega_k$ and projector parameters $\phi_k$ remain on the client and are not transmitted to the server, preserving privacy.
-
Broadcast and Iteration: The newly aggregated global model $\theta^t$ is then broadcast back to all clients for the next communication round. This cycle of local training, parameter upload, server aggregation, and global model broadcast repeats for a specified number of rounds or until convergence.
Loss Landscape and Convergence: The overall loss landscape for FedMRL is non-convex, which is typical for deep learning models. The iterative gradient descent steps navigate this landscape, seeking to find a minimum. The theoretical analysis in Section 4 of the paper demonstrates that FedMRL achieves an $O(1/T)$ non-convex convergence rate, where $T$ is the total number of communication rounds. This means that as the number of rounds increases, the average gradient of the local training whole model decreases, indicating that the model is indeed learning and converging over time. The conditions for this convergence depend on the learning rates and the boundedness of parameter variations and gradient variances, as detailed in the lemmas and theorems. The adaptive representation fusion and multi-granularity representation learning are designed to shape this loss landscape in a way that facilitates more effective knowledge transfer and improves the model's ability to find better minima, leading to superior performance.
Results, Limitations & Conclusion
Experimental Design & Baselines
To rigorously validate FedMRL's mathematical claims and practical efficacy, the authors architected a comprehensive experimental setup. The proposed FedMRL approach was implemented using Pytorch and benchmarked against seven state-of-the-art MHeteroFL methods. These experiments were conducted on a robust hardware configuration comprising four NVIDIA GeForce 3090 GPUs, each equipped with 24GB of memory.
The "victims" (baseline models) against which FedMRL was pitted fell into four categories:
1. Standalone: Clients train models independently on local data.
2. Knowledge Distillation Without Public Data: Methods like FD [21] and FedProto [43].
3. Model Split: Represented by LG-FedAvg [27].
4. Mutual Learning: Including FML [41], FedKD [45], and FedAPEN [37].
Two widely-used benchmark datasets for FL image classification were employed: CIFAR-10 (60,000 32x32 color images, 10 classes) and CIFAR-100 (60,000 32x32 color images, 100 classes). For both, 50,000 images were used for training and 10,000 for testing. To simulate realistic federated environments, two types of non-IID (non-independent and identically distributed) data distributions were constructed:
* Non-IID (Class): Clients were assigned a limited number of classes (2 for CIFAR-10, 10 for CIFAR-100), with fewer classes indicating higher non-IIDness.
* Non-IID (Dirichlet): A Dirichlet($\alpha$) function was used to control the data distribution, where a smaller $\alpha$ signifies more pronounced non-IIDness.
The evaluation covered both model-homogeneous (all clients use CNN-1) and model-heterogeneous (clients use a mix of CNN-1 to CNN-5) FL scenarios. FedMRL's representation projector was a simple one-layer linear model. For model-homogeneous settings, FedMRL used a CNN-1 for its homogeneous global small model, but with a smaller representation dimension $d_1$ compared to the client's $d_2$. In model-heterogeneous settings, FedMRL used the smallest CNN-5 model for its global component, again with a reduced $d_1$.
Performance was assessed across three critical aspects:
* Model Accuracy: Average test accuracy across all clients.
* Communication Cost: Measured by the total number of parameters transmitted between the server and one client to reach a target average accuracy, considering both parameters per round and the number of rounds.
* Computation Overhead: Measured by the total FLOPs (floating-point operations) per client to reach a target average accuracy, considering FLOPs per round and the number of rounds.
The training strategy involved extensive hyperparameter tuning for all algorithms, including batch size, epochs, communication rounds, and learning rates. Crucially, FedMRL's unique hyperparameter, $d_1$ (the representation dimension of the homogeneous global small model), was varied from 100 to 500 to find the optimal trade-off. Experiments were conducted under three distinct FL settings (N=10, C=100%; N=50, C=20%; N=100, C=10%) for both model-homogeneous and model-heterogeneous scenarios. The authors reported average results over three trials for each experimental setting.
What the Evidence Proves
The experimental evidence provides definitive, undeniable proof that FedMRL's core mechanism—adaptive personalized representation fusion and multi-granularity representation learning—works effectively in reality, leading to superior perfomance.
Superior Model Accuracy:
* FedMRL consistantly outperformed all seven state-of-the-art baselines across both model-heterogeneous (Table 1) and model-homogeneous (Table 3, Appendix C.2) FL settings.
* It achieved an impressive improvement in average test accuracy of up to 8.48% over the best overall baseline and up to 24.94% over the best same-category (mutual learning-based) baseline.
* Figure 3 (left six plots) visually confirms FedMRL's faster convergence speed and higher final average test accuracy compared to the best baseline (FedProto) under various client and participation rate settings.
Enhanced Personalization:
* Figure 3 (right two plots) illustrates the individual client test accuracy differences between FedMRL and FedProto. A remarkable 87% of clients on CIFAR-10 and 99% on CIFAR-100 achieved better performance with FedMRL. This is strong evidence of FedMRL's superior personalization capability, directly attributable to its adaptive personalized multi-granularity representation learning design.
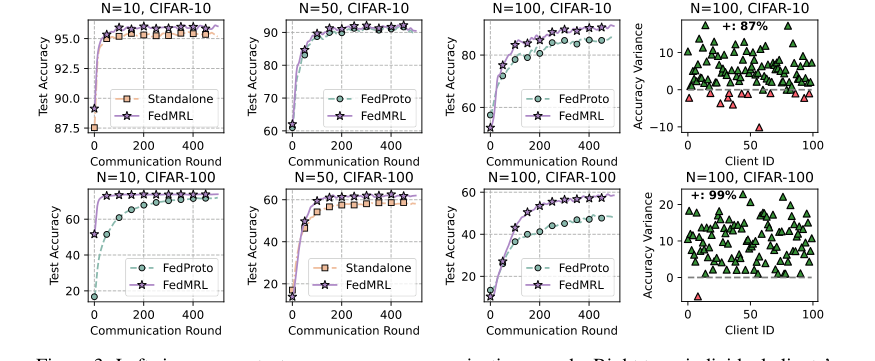 Figure 3. Left six: average test accuracy vs. communication rounds. Right two: individual clients’ test accuracy (%) differences (FedMRL - FedProto)
Figure 3. Left six: average test accuracy vs. communication rounds. Right two: individual clients’ test accuracy (%) differences (FedMRL - FedProto)
Improved Efficiency:
* Communication Cost: While FedMRL transmits the full homogeneous small model, incurring higher communication costs per round than FedProto (which only sends local seen-class average representations), Figure 4 (left) shows that FedMRL requires fewer communication rounds to reach target accuracy, leading to faster convergence. Furthermore, when considering an optional smaller representation dimension ($d_1$), FedMRL achieves higher communication efficiency than other mutual learning-based baselines (FML, FedKD, FedAPEN) that use larger representation dimensions.
* Computation Overhead: Despite the per-round overhead of training an additional homogeneous small model and a lightweight representation projector, Figure 4 (right) demonstrates that FedMRL incurs lower total computation costs than FedProto. This is a direct consequence of its faster convergence, requiring fewer overall training rounds.
Robustness to Non-IID Data:
* Class-based Non-IIDness: Figure 5 (left two plots) clearly shows FedMRL's robustness, maintaining higher average test accuracy than FedProto even as the number of classes per client decreases (increasing non-IIDness).
* Dirichlet-based Non-IIDness: Figure 5 (right two plots) further validates this robustness, with FedMRL significantly outperforming FedProto across all tested $\alpha$ values, demonstrating its resilience to varying degrees of data heterogeneity.
Mechanism Validation through Sensitivity and Ablation Studies:
* Sensitivity to $d_1$: Figure 6 (left two plots) reveals that smaller $d_1$ values (representation dimension of the homogeneous small model) lead to higher average test accuracy and reduced communication/computation overheads. This highlights the importance of $d_1$ in achieving an optimal trade-off.
* Ablation Study: Figure 6 (right two plots) definitively proves the utility of the Matryoshka Representation Learning (MRL) component. FedMRL with MRL consistently outperformed FedMRL without MRL, confirming that multi-granularity representation learning is a crucial design element for MHeteroFL. The observation that the accuracy gap diminishes as $d_1$ increases suggests that when global and local headers learn increasingly overlapping representations, the benefits of MRL are reduced.
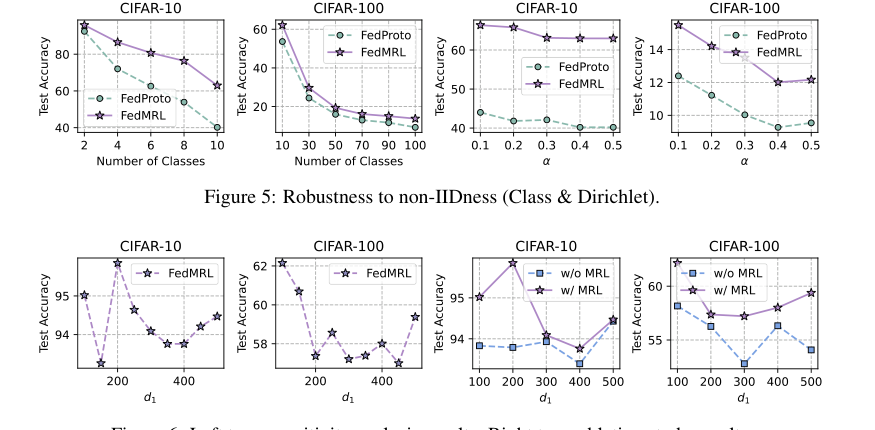 Figure 6. Left two: sensitivity analysis results. Right two: ablation study results
Figure 6. Left two: sensitivity analysis results. Right two: ablation study results
Inference Model Flexibility:
* Appendix C.3 and Figure 7 show that "mix-small" (whole model without local header) and "mix-large" (whole model without global header) inference models achieve similar, high accuracy, significantly outperforming single homogeneous or heterogeneous models. This offers practical flexibility for users to choose based on thier specific inference cost requirements.
Limitations & Future Directions
While FedMRL presents a significant advancement in model-heterogeneous federated learning, it's important to acknowledge its current limitations and consider avenues for future development.
Current Limitations:
The primary limitation identified by the authors lies in the multi-granularity embedded representations within Matryoshka Representations. These representations are currently processed by both the global small model's header and the local client model's header. Although the global header might only involve a single linear layer, this dual processing still contributes to increased storage costs, communication overhead, and training overhead for the global header. This implies that while FedMRL improves overall efficiency by accelerating convergence, there's still room to optimize the resource consumption associated with the global model's processing of these multi-granular representations.
Future Directions & Discussion Topics:
-
Streamlining Multi-Granularity Processing: The paper explicitly suggests adopting a more advanced Matryoshka Representation Learning method (MRL-E) [24] in future work. This would involve removing the global header entirely and relying solely on the local model header to process multi-granularity Matryoshka Representations. This could lead to a better trade-off between model performance and the costs of storage, communication, and computation.
- Discussion: How might such a shift impact the "global knowledge" aspect of federated learning? Would relying solely on local headers for multi-granularity processing risk diluting the benefits of a shared global model, or could the adaptive representation fusion mechanism sufficiently compensate? What architectural changes would be needed in the local model header to handle this increased responsibility without significantly increasing local computational burden?
-
Dynamic $d_1$ Optimization: The sensitivity analysis showed that smaller $d_1$ values (representation dimension of the homogeneous small model) often lead to better accuracy and efficiency.
- Discussion: Can $d_1$ be dynamically optimized during the FL training process, perhaps based on client-specific data characteristics or convergence metrics? Could a reinforcement learning approach be used to learn the optimal $d_1$ for different clients or communication rounds, rather than relying on a fixed, pre-tuned hyperparameter?
-
Extending to Unsupervised/Self-Supervised Tasks: The current FedMRL approach is designed for supervised learning tasks.
- Discussion: How could the principles of adaptive representation fusion and multi-granularity representation learning be extended to unsupervised or self-supervised federated learning, which are increasingly relevant for scenarios with limited labeled data? What modifications would be necessary for the loss functions and knowledge transfer mechanisms in such settings?
-
Robustness to Adversarial Attacks and Data Poisoning: While the paper mentions privacy protection, it doesn't explicitly detail robustness against malicious attacks.
- Discussion: Given the enhanced knowledge transfer and personalized representations, how might FedMRL's architecture inherently resist or be vulnerable to data poisoning or model inversion attacks? What additional privacy-preserving mechanisms (e.g., differential privacy, secure aggregation) could be integrated with FedMRL to further bolster its security without significantly compromising its performance or efficiency gains?
-
Scalability to Extremely Large N and Diverse C: The experiments were conducted with up to N=100 clients.
- Discussion: How would FedMRL scale to federated networks with thousands or even millions of clients, especially considering varying client participation rates (C) and intermittent client availability? Are there further optimizations needed for the aggregation strategy or communication protocols to maintain efficiency in such large-scale deployments?
-
Beyond Image Classification: The current validation is on image classification datasets.
- Discussion: How well would FedMRL generalize to other data modalities and tasks, such as natural language processing, time-series analysis, or medical imaging? Would the "Matryoshka" concept of multi-granularity representations translate directly, or would domain-specific adaptations be required for feature extraction and fusion?
These discussion points aim to stimulate critical thinking about how FedMRL's foundational insights can be leveraged and evolved to address broader challenges and unlock new possibilities in the field of federated learning.
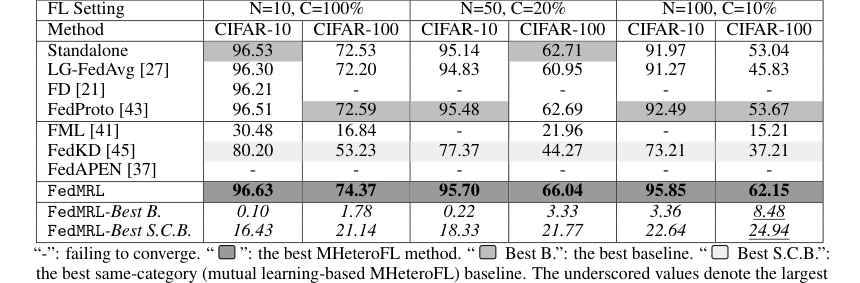 Table 1. and Table 3 (Appendix C.2) show that FedMRL consistently outperforms all baselines under both model-heterogeneous or homogeneous settings. It achieves up to a 8.48% improvement in average test accuracy compared with the best baseline under each setting. Furthermore, it achieves up to a 24.94% average test accuracy improvement than the best same-category (i.e., mutual learning- based MHeteroFL) baseline under each setting. These results demonstrate the superiority of FedMRL
Table 1. and Table 3 (Appendix C.2) show that FedMRL consistently outperforms all baselines under both model-heterogeneous or homogeneous settings. It achieves up to a 8.48% improvement in average test accuracy compared with the best baseline under each setting. Furthermore, it achieves up to a 24.94% average test accuracy improvement than the best same-category (i.e., mutual learning- based MHeteroFL) baseline under each setting. These results demonstrate the superiority of FedMRL
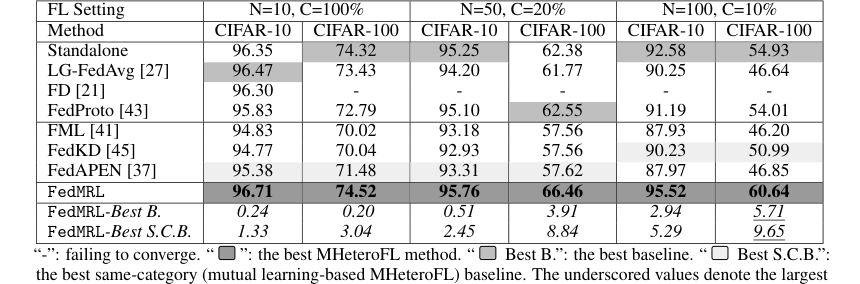 Table 3. presents the results of FedMRL and baselines in model-homogeneous FL scenarios
Table 3. presents the results of FedMRL and baselines in model-homogeneous FL scenarios