연합 모델 이종성 마트료시카 표현 학습
Model heterogeneous federated learning (MHeteroFL) enables FL clients to collaboratively train models with heterogeneous structures in a distributed fashion.
배경 및 학문적 계보
기원 및 학문적 계보
본 논문에서 다루는 모델 이종 연합 학습(Model Heterogeneous Federated Learning, MHeteroFL) 문제는 전통적인 연합 학습(Federated Learning, FL)의 내재적 한계에서 비롯되었다. 초기 FL은 중앙 서버가 여러 데이터 소유자(클라이언트)를 조정하여 로컬 데이터를 직접 노출하지 않고 단일의 전역 공유 모델을 학습시키는 프라이버시 보호 방법으로 구상되었다. 각 통신 라운드에서 서버는 전역 모델을 브로드캐스트하고, 클라이언트는 로컬 데이터로 이를 학습시킨 후, 업데이트된 로컬 모델을 서버로 전송하여 새로운 전역 모델을 형성하기 위해 집계한다. 이 과정은 수렴할 때까지 반복되며, 모델 파라미터만 전송되어 데이터 프라이버시를 보존한다.
그러나 이러한 전통적인 FL 설계는 실제 시나리오에 적용될 때 상당한 "고충점(pain points)"에 직면했으며, 이는 MHeteroFL과 같은 보다 발전된 접근 방식의 개발을 강제했다. 이러한 한계는 다음과 같다.
- 데이터 이종성 (Non-IID 데이터): 클라이언트의 로컬 데이터는 종종 독립적이고 동일하게 분포되지 않는(non-IID) 패턴을 따른다. 이는 이러한 다양한 로컬 데이터셋에서 집계된 단일 전역 모델이 모든 클라이언트에서 최적으로 성능을 발휘하지 못할 수 있음을 의미한다. 예를 들어, 한 클라이언트는 특정 클래스에 편중된 데이터를 가지고 있을 수 있고, 다른 클라이언트는 다른 클래스의 데이터를 가지고 있을 수 있다.
- 시스템 이종성: FL 클라이언트는 컴퓨팅 파워와 네트워크 대역폭이 매우 다를 수 있다. 모든 클라이언트에게 동일하고 종종 큰 모델 구조를 학습하도록 강제하는 것은 전역 모델 크기가 가장 약한 장치를 수용해야 함을 의미하며, 더 크고 복잡한 모델을 처리할 수 있는 더 강력한 클라이언트에서는 최적이 아닌 성능으로 이어진다.
- 모델 이종성: 실제 FL 애플리케이션, 특히 클라이언트가 기업인 경우, 고유한 아키텍처 또는 지적 재산(IP) 문제를 가진 독점 모델을 보유할 수 있다. 이러한 이종 모델이나 그 구조를 FL 학습 중에 직접 공유하는 것은 IP 보호로 인해 종종 용납되지 않는다.
기존의 MHeteroFL 방법들은 클라이언트가 맞춤형 구조를 가진 모델을 학습하도록 허용함으로써 이러한 문제를 해결하려고 시도하지만, 여전히 제한된 지식 전달 능력으로 어려움을 겪고 있다. 이들은 일반적으로 클라이언트와 서버 모델 간의 지식을 전달하기 위해 학습 손실에 의존하는데, 이는 성능 병목 현상, 높은 통신 및 계산 비용, 그리고 개인 로컬 모델 구조 및 데이터 노출의 지속적인 위험으로 이어질 수 있다. 본 논문은 Matryoshka Representation Learning에서 영감을 받은 적응형 표현 융합 및 다중 관점 표현 학습을 통해 지식 전달을 강화함으로써 이러한 한계를 극복하기 위해 FedMRL을 제안한다.
직관적인 도메인 용어
기초 독자가 핵심 개념을 이해하는 데 도움을 주기 위해, 논문의 전문 용어 몇 가지를 일상적인 비유로 번역했다.
- 연합 학습 (Federated Learning, FL): 여러 셰프(클라이언트)가 자신의 비밀 재료(로컬 데이터)를 사용하여 각자 고유한 요리(로컬 모델)를 만드는 요리 대회라고 상상해보자. 그들은 자신의 레시피를 공유하는 대신, 요리 기술에 대한 요약만 수석 심사위원(중앙 서버)에게 보낸다. 심사위원은 이러한 요약을 결합하여 일반적인 요리 조언(전역 모델)을 만들고 이를 셰프들에게 다시 보낸다. 이런 식으로 아무도 자신의 개인 레시피를 공개하지 않고 모두가 자신의 요리를 개선한다.
- 모델 이종 연합 학습 (Model Heterogeneous Federated Learning, MHeteroFL): 요리 비유를 확장하여, 각 셰프가 다른 유형의 주방 장비(다양한 시스템 리소스)를 가지고 있고 다른 스타일의 요리(이종 모델 구조)를 선호한다고 상상해보자. MHeteroFL은 모두가 다른 도구와 요리 접근 방식을 사용하고 있음에도 불구하고 각 셰프에게 여전히 유용하고 맞춤화된 조언을 제공할 수 있는 매우 유연한 수석 심사위원과 같다. 심사위원은 모두가 같은 방식으로 요리하거나 같은 장비를 사용하도록 강요하지 않으면서 집단적으로 개선하도록 돕는다.
- 마트료시카 표현 학습 (Matryoshka Representation Learning, MRL): 러시아 인형 세트를 생각해보라. 각 인형은 이전 인형의 점진적으로 작아지고 덜 상세한 버전이다. MRL은 데이터에서 "중첩된" 통찰력을 생성하는 시스템을 훈련하는 것과 같다. 매우 광범위하고 일반적인 이해(가장 큰 인형)와 더 구체적이고 세분화된 세부 정보(안쪽의 더 작은 인형)를 모두 생성할 수 있다. 이를 통해 시스템은 작업에 필요한 정확한 수준의 세부 정보를 사용할 수 있으며, 마트료시카임을 알기 위해 가장 큰 인형만 보면 되는 것처럼 계산 비용을 절약할 수 있다.
- Non-IID 데이터 (독립적이고 동일하게 분포되지 않은 데이터): 동물에 대해 배우는 학생들의 수업을 고려해보라. 데이터가 IID라면, 모든 학생은 고양이, 개, 새, 물고기 그림의 균등한 혼합이 포함된 교과서를 가질 것이다. Non-IID 데이터는 한 학생의 교과서가 주로 고양이에 관한 것이고, 다른 학생의 교과서는 주로 개에 관한 것이며, 세 번째 학생의 교과서는 주로 새에 관한 것과 같다. 그들의 개별 학습 자료(로컬 데이터)는 고르게 분포되지 않으며 전체 동물의 범위(전역 데이터 분포)를 완벽하게 나타내지 않는다. 이로 인해 단일의 통합된 수업 계획이 모든 사람에게 효과적이기가 더 어렵다.
표기법 표
| 표기법 | 설명 |
|---|---|
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
본 논문에서 다루는 핵심 문제는 모델 이종 연합 학습(MHeteroFL) 영역에 속하며, 이는 다양한 모델 아키텍처를 가진 여러 클라이언트가 원시 로컬 데이터를 공유하지 않고 전역 모델을 협력적으로 학습할 수 있도록 하는 것을 목표로 한다.
입력/현재 상태:
전통적인 연합 학습(FL)은 중앙 서버가 $N$개의 클라이언트를 조정하여 단일의 공유 전역 모델을 학습시키는 방식으로 작동한다. 각 통신 라운드에서 서버는 전역 모델을 브로드캐스트하고, 클라이언트는 로컬 데이터로 이를 학습시킨 후, 업데이트된 로컬 모델을 서버로 전송하여 집계한다. 이 과정은 수렴할 때까지 반복되며, 데이터 프라이버시를 보존하기 위해 모델 파라미터만 전송된다. 그러나 이 전통적인 FL 설계는 실제 애플리케이션에서 흔히 발생하는 세 가지 중요한 이종성 문제로 어려움을 겪는다.
1. 데이터 이종성 (Non-IID): 클라이언트의 로컬 데이터셋은 종종 독립적이고 동일하게 분포되지 않는(non-IID) 패턴을 따르므로, 이러한 다양한 로컬 데이터에서 집계된 단일 전역 모델은 개별 클라이언트에서 성능이 저하될 수 있다.
2. 시스템 이종성: FL 클라이언트는 다양한 컴퓨팅 리소스(예: CPU, GPU, 메모리)와 네트워크 대역폭을 보유하고 있다. 모든 클라이언트에게 동일한 모델 구조를 학습하도록 요구하는 것은 전역 모델 크기가 가장 약한 장치로 제한되어야 함을 의미하며, 더 강력한 클라이언트에서는 최적이 아닌 성능으로 이어진다.
3. 모델 이종성: 클라이언트, 특히 기업은 지적 재산(IP) 문제로 인해 다양하고 공유할 수 없는 구조를 가진 독점 로컬 모델을 보유할 수 있다. 이는 모델 파라미터의 직접적인 평균화 또는 집계를 방지한다.
기존의 MHeteroFL 방법들은 이러한 문제를 해결하려고 시도하지만, 주로 학습 손실을 통해 클라이언트와 서버 모델 간의 지식을 전달하는 데 의존한다. 그러나 이 접근 방식은 제한된 지식 교환을 초래하여 성능 병목 현상, 높은 통신 및 계산 비용, 그리고 개인 로컬 모델 구조 및 데이터 노출의 잠재적 위험을 야기한다.
원하는 최종 상태 (출력/목표 상태):
본 논문은 연합 모델 이종 마트료시카 표현 학습(Federated model heterogeneous Matryoshka Representation Learning, FedMRL)이라는 새로운 MHeteroFL 접근 방식을 개발하고자 하며, 이는 지도 학습 작업에서 데이터, 시스템 및 모델 이종성을 효과적이고 공동으로 해결할 수 있다. 목표는 다음과 같다.
1. 향상된 지식 전달: 서버의 전역 동종 모델과 클라이언트의 이종 로컬 모델 간의 보다 효과적인 지식 상호 작용을 촉진한다.
2. 개선된 모델 성능: 기존의 SOTA(State-of-the-Art) 방법보다 우수한 모델 정확도를 달성한다.
3. 낮은 통신 및 계산 비용: 모델 학습 및 업데이트와 관련된 오버헤드를 최소화한다.
4. 강력한 프라이버시 보존: 클라이언트의 로컬 데이터와 이종 모델 구조가 서버나 다른 클라이언트에 노출되지 않도록 보장한다.
5. 개인화된 적응: 학습 과정이 로컬 Non-IID 데이터 분포 및 다양한 클라이언트 리소스에 적응하도록 한다.
누락된 연결 또는 수학적 격차:
정확한 누락된 연결은 프라이버시를 보존하는 방식으로 이종 모델 및 데이터 분포를 가로질러 지식을 효과적이고 효율적으로 전달할 메커니즘의 부족이다. 지식 전달을 위해 학습 손실에 의존하는 현재 방법은 불충분하다. FedMRL은 두 가지 주요 혁신을 도입하여 이 격차를 해소하려고 시도한다.
1. 적응형 표현 융합: 각 로컬 데이터 샘플에 대해, 전역 동종 소형 모델과 로컬 이종 모델의 특징 추출기가 각각 일반화된 표현과 개인화된 표현을 추출한다. 이들은 로컬 Non-IID 데이터에 적응하는 개인화된 경량 표현 프로젝터 $P_k(\phi_k)$에 의해 분할되고 매핑되어 융합된 표현으로 만들어진다.
2. 다중 세분성 표현 학습: 융합된 표현은 Matryoshka 표현을 구성하는 데 사용되며, 이는 다차원적이고 다중 세분성 임베딩 표현이다. 이들은 전역 동종 모델과 로컬 이종 모델의 예측 헤더에 의해 처리되며, 이들의 결합된 손실은 모든 모델을 업데이트하는 데 사용된다.
수학적으로, 본 논문은 다음 목적 함수(식 1)를 최소화하는 것을 목표로 한다.
$$
\min_{\theta, \omega_0, \dots, \omega_{N-1}, \phi_0, \dots, \phi_{N-1}} \sum_{k=0}^{N-1} l(W_k(D_k; (\theta \circ \omega_k | \phi_k)))
$$
여기서 $W_k(w_k) = (G(\theta) \circ F_k(w_k) | P_k(\phi_k))$는 전역 동종 소형 모델 $G(\theta)$, 클라이언트의 로컬 이종 모델 $F_k(w_k)$, 그리고 개인화된 표현 프로젝터 $P_k(\phi_k)$를 통합하는 클라이언트 $k$의 결합된 모델을 나타낸다. 손실 $l$은 Matryoshka 표현의 다중 관점 출력에 기반하여 계산된다.
딜레마:
이전 연구자들이 갇혀 있던 고통스러운 절충점은 높은 모델 성능과 이종 FL 클라이언트 간의 효과적인 지식 전달을 달성하는 것과 동시에 낮은 통신/계산 비용 및 강력한 프라이버시 보장을 유지하는 것 사이의 내재적 충돌이다. 한 측면을 개선하는 것은 종종 다른 측면을 희생시킨다. 예를 들어, 더 많은 정보(예: 전체 모델 파라미터 또는 상세한 중간 표현)를 공유하면 지식 전달과 성능을 향상시킬 수 있지만 통신 비용과 프라이버시 위험을 크게 증가시킬 것이다. 반대로, 프라이버시를 보호하고 비용을 줄이기 위해 공유되는 정보를 제한하는 것은 종종 "제한된 지식 교환"과 "모델 성능 병목 현상"(2페이지, 섹션 1)으로 이어져, 특히 Non-IID 데이터에서 최적이 아닌 정확도를 초래한다. 딜레마는 민감한 클라이언트 세부 정보를 노출하거나 제약된 리소스를 압도하지 않고 풍부하고 다중 관점의 지식 상호 작용을 가능하게 하는 방법이다.
제약 조건 및 실패 모드
모델 이종 연합 학습의 문제는 저자들이 직면하는 몇 가지 가혹하고 현실적인 벽으로 인해 믿을 수 없을 정도로 어렵다.
- Non-IID 데이터 분포: 클라이언트의 로컬 데이터는 종종 독립적이고 동일하게 분포되지 않는(non-IID) 패턴을 따르므로, 모든 클라이언트에서 잘 작동하는 단일 전역 모델을 학습하기 어렵다. 이는 개인화된 모델 또는 적응형 메커니즘을 필요로 하며, 복잡성을 더한다.
- 다양한 클라이언트 시스템 리소스: FL 클라이언트는 다양한 컴퓨팅 파워, 메모리 및 네트워크 대역폭으로 작동한다. 제안된 솔루션은 가장 약한 장치에서 실행될 만큼 효율적이어야 하며 동시에 더 강력한 장치의 기능을 활용해야 한다. 이는 모델 크기와 클라이언트당 계산 오버헤드에 엄격한 제한을 부과한다.
- 독점 모델 구조 및 IP 보호: 클라이언트는 지적 재산 문제로 인해 직접 공유하거나 집계할 수 없는 다양한 독점 로컬 모델 아키텍처를 사용할 수 있다. 이는 모델 파라미터의 전통적인 연합 평균화를 방지한다.
- 제한된 지식 전달 효과: 특히 학습 손실 또는 간단한 상호 학습에 의존하는 기존 MHeteroFL 방법은 종종 "제한된 지식 전달"(1페이지, 초록; 3페이지, 섹션 2)만 달성한다. 이는 최적이 아닌 모델 성능과 느린 수렴으로 이어진다.
- 높은 통신 비용: 각 라운드에서 서버와 수많은 클라이언트 간에 대규모 모델 파라미터 또는 광범위한 중간 표현을 전송하는 것은 제한된 네트워크 대역폭을 통해 특히 상당한 통신 비용을 발생시킬 수 있다. 목표는 이를 최소화하는 것이다.
- 높은 계산 오버헤드: 클라이언트 장치에서 추가 모델 또는 복잡한 지식 증류 메커니즘을 학습하는 것은 상당한 계산 오버헤드로 이어질 수 있으며, 이는 리소스 제약이 있는 클라이언트에게 바람직하지 않다.
- 엄격한 프라이버시 요구 사항: FL의 기본 원칙은 로컬 데이터 프라이버시를 보호하는 것이다. 모든 방법은 원시 클라이언트 데이터와 로컬 모델 구조가 서버나 다른 클라이언트에 절대 노출되지 않도록 보장해야 한다. 이를 준수하지 못하는 것은 심각한 실패 모드이다.
- 비볼록 최적화 풍경: 이종 모델을 가진 연합 학습에서의 최적화 문제는 일반적으로 비볼록하다. 좋은 해, 더구나 전역 최적해로의 수렴을 보장하는 것은 상당한 수학적 과제이다. 본 논문은 $O(1/T)$ 비볼록 수렴 속도(1페이지, 초록)를 보여주는 이론적 분석을 제공하며, 이는 일반적이지만 여전히 어려운 측면이다.
- 모델 성능 병목 현상: 효과적인 지식 전달 없이는 클라이언트 모델이 성능 병목 현상으로 고통받아 일반화가 잘 되지 않거나 높은 정확도를 달성하지 못할 수 있다.
- 확장성 문제: 솔루션은 많은 수의 클라이언트($N$)에 대해 확장 가능해야 하며 각 통신 라운드에서 클라이언트 참여율($C=K/N$)의 변화에 대해 견고해야 한다(3페이지, 섹션 3).
이러한 제약 조건들은 종합적으로 고성능, 프라이버시 보호, 리소스 효율적인 연합 학습을 이종 모델과 함께 달성하는 문제를 매우 어려운 노력으로 만든다.
왜 이 접근 방식인가
선택의 불가피성
FedMRL의 개발은 실제 FL 애플리케이션의 복잡한 현실에 직면했을 때 기존 모델 이종 연합 학습(MHeteroFL) 접근 방식의 내재적 한계에 의해 주도되었다. 저자들은 전통적인 "SOTA" 방법들이 연합 설정에 맞게 조정되었음에도 불구하고, 클라이언트와 서버 모델 간의 지식 전달을 위해 주로 학습 손실에 의존했기 때문에 불충분하다는 것을 깨달았다. 이 의존성은 "제한된 지식 교환", "모델 성능 병목 현상", "높은 통신 및 계산 비용", 그리고 "개인 로컬 모델 구조 및 데이터 노출의 상당한 위험"(초록, 1페이지)과 같은 여러 가지 심각한 단점으로 이어졌다.
구체적으로, 본 논문은 전통적인 FL 설계가 세 가지 주요 이종성 문제로 어려움을 겪었다고 강조한다. (1) 클라이언트 데이터가 Non-IID인 데이터 이종성; (2) 클라이언트가 다양한 컴퓨팅 파워와 네트워크 대역폭을 가지고 있어 전역 모델이 가장 약한 장치를 수용해야 하는 시스템 이종성; (3) 클라이언트가 지적 재산 문제로 인해 직접 공유할 수 없는 독점 모델을 가지고 있는 모델 이종성(섹션 1, 1-2페이지). 이러한 문제를 해결하기 위해 MHeteroFL이 등장했지만, 적응형 서브넷, 지식 증류, 모델 분할 또는 상호 학습과 같은 이 분야의 기존 방법들도 여전히 심각한 결함을 보였다. 예를 들어, FedMRL이 기반으로 하는 상호 학습 접근 방식은 "두 모델 간에 제한된 지식만 전달하여 모델 성능 병목 현상을 초래한다"(섹션 2, 3페이지)고 언급되었다.
단일 사건으로 명시적으로 지적되지는 않았지만, 저자들이 이전 MHeteroFL 방법들에 대한 포괄적인 비판을 통해 깨달은 순간이 강력하게 암시된다. 저자들은 단순한 손실 기반 증류를 넘어선 보다 정교한 표현 수준 상호 작용으로 나아가는 근본적으로 다른 지식 전달 메커니즘이 필요하다는 것을 인식했다. 이로 인해 그들은 모델 성능과 추론 비용 간의 최적의 균형을 달성하는 방법을 제공하는 Matryoshka Representation Learning(MRL) [24]에서 영감을 얻게 되었다. 모델 또는 손실 중심이 아닌 표현 중심 접근 방식으로의 이러한 전환은 연합 학습에서 이종성, 프라이버시 및 효율성의 지속적인 문제를 극복하는 유일하게 실행 가능한 경로가 되었다.
비교 우위
FedMRL은 단순한 성능 지표를 넘어 여러 구조적 및 기능적 장점을 통해 이전의 금본위제(gold standards)에 대해 압도적인 질적 우위를 보여준다.
첫째, 핵심 혁신은 적응형 표현 융합과 다중 세분성 표현 학습에 있다. 단일의 고정된 표현에 의존하는 방법과 달리, FedMRL은 일반화된 표현(공유 동종 모델에서)과 개인화된 표현(클라이언트의 이종 로컬 모델에서)을 모두 추출한다. 이들은 로컬 Non-IID 데이터 분포에 적응하는 데 중요한 경량의 개인화된 프로젝터에 의해 적응적으로 융합된다(섹션 3.1, 4페이지). 이러한 구조적 설계는 데이터 이종성으로 어려움을 겪는 접근 방식보다 훨씬 뛰어난, 로컬 데이터에 대한 더 풍부하고 미묘한 이해를 가능하게 한다. 이후 다차원적이고 다중 세분성 임베딩 표현을 포함하는 Matryoshka 표현의 구성은 다중 관점 학습을 가능하게 하여 모델 학습 능력을 더욱 향상시킨다(섹션 3.2, 5페이지). 이것은 모델이 거칠고 미세한 특징을 모두 학습할 수 있게 하여 더 강력하고 효과적으로 만드는 구조적 이점이다.
둘째, FedMRL은 우수한 프라이버시 보존과 리소스 효율성을 제공한다. 서버와 클라이언트 간에 작은 동종 모델만 전송함으로써 "학습 중에 각 클라이언트의 로컬 모델과 데이터가 노출되지 않도록 보장한다"(섹션 2, 2페이지). 이는 프라이버시 민감 애플리케이션에 대한 중요한 구조적 이점이다. 또한, 이 설계는 클라이언트가 로컬 모델 외에 작은 동종 모델과 경량 표현 프로젝터만 학습하면 되므로 본질적으로 "낮은 통신 비용"과 "낮은 추가 계산 비용"으로 이어진다(섹션 2, 2페이지). 논문에서 메모리 복잡성을 $O(N^2)$에서 $O(N)$으로 줄인다고 명시적으로 언급하지는 않지만, "작은 동종 모델"과 "경량" 구성 요소에 대한 강조는 더 크거나 복잡한 모델 또는 광범위한 데이터 공유를 요구하는 방법과 비교하여 메모리 및 계산 발자국을 크게 줄이는 것을 직접적으로 시사한다.
마지막으로, 방법의 Non-IID 데이터에 대한 견고성과 더 강력한 개인화 기능은 질적으로 우수하다. 실험은 FedMRL이 FedProto와 같은 기준선에 비해 다양한 Non-IID 설정(클래스 및 디리클레)에서 일관되게 더 높은 평균 테스트 정확도를 달성함을 보여준다(섹션 5.3.1, 5.3.2, 9페이지). 또한, CIFAR-10에서 87%, CIFAR-100에서 99%의 개별 클라이언트가 FedProto보다 더 나은 성능을 달성하는 등 더 강력한 개인화를 제공한다(섹션 5.2.2, 8페이지). 이는 다양한 클라이언트 환경 및 데이터 분포를 처리하는 데 있어 근본적인 구조적 이점을 나타낸다.
제약 조건과의 정렬
FedMRL의 설계는 이종 연합 학습의 가혹한 요구 사항 및 제약 조건과 완벽하게 정렬되어 문제와 솔루션 간의 시너지 "결혼"을 창출한다.
- 데이터 이종성 (Non-IID 데이터): 적응형 표현 융합 메커니즘은 이를 해결하기 위해 명시적으로 설계되었다. 개인화된 표현 프로젝터는 분할된 일반화된 표현과 개인화된 표현을 "로컬 Non-IID 데이터에 적응하는" 융합된 표현으로 매핑한다(섹션 3.1, 4페이지). 이는 Non-IID 설정에서 흔히 발생하는 성능 저하를 방지하고 각 클라이언트의 고유한 데이터 분포가 고려되도록 보장한다.
- 시스템 이종성: FedMRL은 "이종 로컬 모델"과 상호 작용하는 "공유 전역 보조 동종 소형 모델"을 도입하여 다양한 클라이언트 기능을 수용한다(섹션 2, 2페이지). 전역 모델은 의도적으로 작게 만들어져 리소스가 제한된 클라이언트에서도 브로드캐스트되고 학습될 수 있다. 클라이언트는 또한 표현 프로젝터의 선형 레이어 차원을 조정하여 분할된 표현과 일치시킬 수 있으며, 이는 로컬 시스템 제약 조건에 더욱 적응한다(섹션 3.1, 4페이지).
- 모델 이종성: 이 프레임워크는 클라이언트가 "지적 재산권 문제로 인해 공유할 수 없는 다양한 구조를 가진 로컬 모델"을 소유하는 것을 본질적으로 지원한다(섹션 3.1, 4페이지). 서버는 동종 소형 모델과만 상호 작용하며 클라이언트의 이종 로컬 모델을 블랙박스로 취급한다. 이 설계는 클라이언트가 독점 모델 구조를 노출할 필요가 없으므로 지적 재산권 문제를 존중한다.
- 프라이버시 보존: 이는 FedMRL의 초석이다. "학습 중에 각 클라이언트의 로컬 모델과 데이터는 프라이버시 보존을 위해 노출되지 않는다"(섹션 2, 2페이지). 작은 동종 모델만 전송되어 로컬 데이터와 모델 구조가 프라이버시를 유지하도록 보장한다.
- 통신 효율성: "작은 동종 모델"(섹션 2, 2페이지)만 전송함으로써 FedMRL은 전체 클라이언트 모델을 교환하는 방법과 비교하여 통신 비용을 크게 줄인다. 동종 소형 모델의 표현 차원 $d_1$을 변경할 수 있는 능력은 통신 오버헤드를 최적화할 수 있게 한다(섹션 5.3.3, 9페이지).
- 계산 효율성: 클라이언트는 로컬 모델 외에 "작은 동종 모델과 경량 표현 프로젝터"만 학습하면 되므로 "낮은 추가 계산 비용"이 발생한다(섹션 2, 2페이지). FedMRL이 달성하는 더 빠른 수렴 속도(그림 4, 8페이지)는 목표 정확도에 도달하기 위해 더 적은 통신 라운드가 필요함을 의미하므로 전체 계산 오버헤드를 줄인다(섹션 5.2.4, 9페이지).
- 지식 전달 제한: 적응형 표현 융합과 다중 세분성 표현 학습이라는 두 가지 혁신은 이전 방법의 "제한된 지식 교환" 문제를 직접적으로 해결한다. 이들은 "두 모델 간의 더 많은 지식 상호 작용을 촉진하고 모델 성능을 향상시킨다"고 말하며, 여러 관점에서 일반화된 표현과 개인화된 표현을 학습한다(섹션 2, 3페이지).
대안의 기각
본 논문은 문제의 제약 조건을 해결하는 데 있어 근본적인 단점을 강조함으로써 기존 MHeteroFL 접근 방식의 여러 범주를 체계적으로 식별하고 기각한다.
- 적응형 서브넷을 갖춘 MHeteroFL: 이러한 방법은 전역 모델에서 이종 로컬 서브넷을 구성한다. 저자들은 "클라이언트가 공통 전역 모델에서 파생되지 않은 블랙박스 로컬 모델을 보유한 경우, 서버가 이를 집계할 수 없다"(섹션 2, 3페이지)고 말하며 이 접근 방식을 기각한다. 이는 클라이언트 모델이 독점적이고 전역 모델의 단순한 가지치기 버전이 아닌 진정한 모델 이종성을 처리하지 못함을 시사한다.
- 지식 증류를 갖춘 MHeteroFL:
- 공개 데이터셋을 사용하여 지식 전달에 의존하는 방법은 "그러한 적절한 공개 데이터셋을 찾기 어려울 수 있다"(섹션 2, 3페이지)는 이유로 실용적이지 않다고 간주된다.
- 공유 데이터셋을 합성하기 위해 생성기를 훈련하는 접근 방식은 "높은 훈련 비용"을 발생시키기 때문에 기각된다(섹션 2, 3페이지).
- 중간 정보를 공유하는 다른 방법들은 "지식 융합을 위해 클라이언트 로컬 데이터를 노출"할 위험이 프라이버시를 침해할 수 있기 때문에 암묵적으로 기각된다.
- 모델 분할을 갖춘 MHeteroFL: 이러한 방법은 모델을 특징 추출기와 예측기로 나누고 둘 중 하나를 공유한다. 본 논문은 "모델이 클라이언트의 독점 IP인 경우 허용되지 않을 수 있는 로컬 모델 구조의 일부를 노출한다"(섹션 2, 3페이지)는 이유로 이 전략을 기각한다. 이는 프라이버시 및 지적 재산 보호 제약 조건과 직접적으로 충돌한다.
- 상호 학습을 갖춘 MHeteroFL: FedMRL은 이 범주를 기반으로 하지만, 기존 상호 학습 방법(예: FML, FedKD, FedAPEN)은 "상호 손실이 두 모델 간에 제한된 지식만 전달하여 모델 성능 병목 현상을 초래한다"(섹션 2, 3페이지)는 이유로 불충분하다고 명시적으로 밝힌다. FedMRL은 단순히 상호 손실에만 의존하는 것이 아니라 표현 기반 접근 방식으로 이동하여 "지식 전달을 강화한다"고 제시된다.
본 논문은 GAN, 확산 모델 또는 트랜스포머와 같은 일반 딥러닝 아키텍처의 실패를 연합 학습 접근 방식 자체의 대안으로 논의하지 않는다. 대신, 이종성, 프라이버시 및 리소스 효율성의 고유한 문제를 효과적으로 관리하지 못하는 연합 학습 패러다임의 실패를 기각하는 것이지, 근본적인 모델 아키텍처의 실패를 기각하는 것이 아니다.
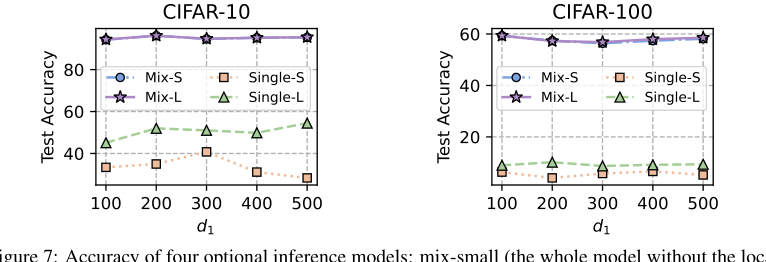 Figure 7. Accuracy of four optional inference models: mix-small (the whole model without the local header), mix-large (the whole model without the global header), single-small (the homogeneous small model), single-large (the client heterogeneous model)
Figure 7. Accuracy of four optional inference models: mix-small (the whole model without the local header), mix-large (the whole model without the global header), single-small (the homogeneous small model), single-large (the client heterogeneous model)
수학적 및 논리적 메커니즘
마스터 방정식
FedMRL 접근 방식의 절대적인 핵심은 연합 학습 설정에서 모든 참여 클라이언트에 걸친 총 손실을 최소화하는 것을 목표로 하는 목적 함수이다. 이 마스터 방정식은 전체 학습 목표를 포괄한다.
$$ \min_{\theta, \omega_0, \dots, \omega_{N-1}, \phi_0, \dots, \phi_{N-1}} \sum_{k=0}^{N-1} l(W_k(D_k; (\theta \circ \omega_k | \phi_k))) $$
항별 분석
이 마스터 방정식과 그 기본 구성 요소를 분해하여 수학적 정의, 논리적 역할 및 구성 이유를 이해해보자.
-
$\min_{\theta, \omega_0, \dots, \omega_{N-1}, \phi_0, \dots, \phi_{N-1}}$: 이것은 최적화 목표이다.
- 수학적 정의: 후속 손실 합계를 최소화하는 파라미터 세트($\theta$, $\omega_k$, $\phi_k$)를 찾는 것을 의미한다.
- 물리적/논리적 역할: 이것은 전체 FedMRL 시스템의 중심 지침이다. 학습 과정이 모든 클라이언트에 걸쳐 예측을 가능한 한 정확하게 만들기 위해 모든 관련 모델 파라미터를 조정하도록 지시한다.
- 최소화 이유: 머신러닝에서는 일반적으로 "손실" 또는 "오류" 함수를 정의하고, 목표는 이 오류를 줄이는 것이므로 최소화가 자연스러운 선택이다.
-
$\sum_{k=0}^{N-1}$: 이것은 합계 연산자이다.
- 수학적 정의: 클라이언트 $k=0$부터 $N-1$까지 각 클라이언트의 개별 손실 기여를 합산한다.
- 물리적/논리적 역할: 연합 학습에서 전체 성능은 모든 클라이언트의 집합적 측정값이다. 이 합계는 전역 목표가 모든 클라이언트의 학습 결과를 고려하도록 보장하며, 로컬 데이터를 존중하면서 공유 학습 목표를 촉진한다.
- 예를 들어 곱셈 대신 합계를 사용하는 이유: 합계는 다중 클라이언트 또는 다중 작업 설정에서 손실을 집계하는 표준 방법이다. 곱셈은 작은 손실(총계를 0으로 만듦) 또는 큰 손실(총계를 폭발시킴)에 매우 민감하여 최적화를 불안정하게 만든다. 합계는 개별 클라이언트 성능의 보다 안정적이고 해석 가능한 집계를 제공한다.
-
$l(\cdot)$: 이것은 손실 함수를 나타낸다.
- 수학적 정의: 논문(식 8)에서 언급된 바와 같이, 일반적으로 교차 엔트로피 손실 $l(y, Y_i)$이며, 이는 모델의 예측 출력 $y$와 실제 레이블 $Y_i$ 간의 불일치를 측정한다.
- 물리적/논리적 역할: 손실 함수는 모델의 예측이 주어진 입력에 대해 얼마나 "잘못되었는지"를 정량화한다. 손실이 높을수록 예측이 나쁘다는 것을 의미한다. 이는 최적화 과정이 모델 파라미터를 조정하는 신호를 제공한다.
- 교차 엔트로피를 사용하는 이유: 교차 엔트로피는 잘못된 분류를 더 심하게 처벌하고 모델이 실제 레이블 분포와 일치하는 확률을 출력하도록 장려하기 때문에 분류 작업에 널리 사용된다.
-
$W_k(D_k; (\theta \circ \omega_k | \phi_k))$: 이것은 클라이언트 $k$의 결합된 모델을 나타내며, 로컬 데이터 $D_k$에서 작동하고, 전역($\theta$), 로컬($\omega_k$), 개인화된 프로젝터($\phi_k$) 파라미터의 조합으로 매개변수화된다. 이것이 핵심 FedMRL 메커니즘이 있는 곳이다. 내부 작동 방식을 분석해보자.
-
$D_k$: 이것은 클라이언트 $k$의 로컬 데이터셋을 나타낸다.
- 수학적 정의: 입력 특징 벡터 $x_i$와 해당 실제 레이블 $Y_i$의 데이터 샘플 집합 $(x_i, Y_i)$이다.
- 물리적/논리적 역할: 이것은 각 클라이언트가 학습에 사용하는 개인 로컬 데이터이다. FL에서 이 데이터가 로컬로 유지되고 서버나 다른 클라이언트와 직접 공유되지 않는 것이 중요하다.
-
$\theta$: 이것은 전역 동종 소형 모델의 파라미터를 나타낸다.
- 수학적 정의: $\theta = \{\theta_{ex}, \theta_{hd}\}$이며, 여기서 $\theta_{ex}$는 전역 모델의 특징 추출기 $G_{ex}$의 파라미터이고 $\theta_{hd}$는 예측 헤더 $G_{hd}$의 파라미터이다. 이들은 모든 클라이언트에서 공유된다.
- 물리적/논리적 역할: 이 모델은 "일반화된" 지식 소스 역할을 한다. 통신 비용을 최소화하고 시스템 이종성을 수용하기 위해 작고 동종이다. 일반적인 기준선 표현을 제공한다.
-
$\omega_k$: 이것은 클라이언트 $k$의 이종 로컬 모델의 파라미터를 나타낸다.
- 수학적 정의: $\omega_k = \{\omega_{ex,k}, \omega_{hd,k}\}$이며, 여기서 $\omega_{ex,k}$는 클라이언트 $k$의 로컬 특징 추출기 $F_{ex}$의 파라미터이고 $\omega_{hd,k}$는 예측 헤더 $F_{hd}$의 파라미터이다. 이들은 각 클라이언트에 고유하다.
- 물리적/논리적 역할: 이 모델은 클라이언트 $k$의 특정 데이터 분포 및 모델 구조에 맞춰진 "개인화된" 지식을 포착한다. 데이터 및 모델 이종성을 해결한다.
-
$\phi_k$: 이것은 클라이언트 $k$의 개인화된 표현 프로젝터의 파라미터를 나타낸다.
- 수학적 정의: $\phi_k$는 경량 프로젝터 $P_k$의 파라미터이다.
- 물리적/논리적 역할: 이 프로젝터는 일반화된 표현과 개인화된 표현을 적응적으로 융합하는 역할을 한다. 로컬 Non-IID 데이터 분포를 효과적으로 처리하기 위해 각 클라이언트에 개인화되어 있다.
-
$\circ$ (스플라이싱 연산자): 이 연산자는 특징 추출기의 출력을 결합한다.
- 수학적 정의: 식 (3)에 따라, $R_i = R_k^g \circ R_k^f$이며, 여기서 $R_k^g = G_{ex}(x_i; \theta_{ex,t-1})$는 전역 모델 특징 추출기의 일반화된 표현이고 $R_k^f = F_{ex}(x_i; \omega_{ex,t-1})$는 로컬 모델 특징 추출기의 개인화된 표현이다. 스플라이싱은 일반적으로 특징 벡터를 연결하는 것을 의미한다.
- 물리적/논리적 역할: 이 연산은 일반화된 특징(공통 지식)과 개인화된 특징(클라이언트별 지식)을 하나의 더 풍부한 표현으로 병합한다.
- 덧셈이나 곱셈 대신 스플라이싱을 사용하는 이유: 스플라이싱(연결)은 두 소스의 별도의 의미론적 정보를 보존한다. 덧셈이나 곱셈을 하면, 특징 공간이 다른 스케일이나 의미를 가질 경우 정보가 혼합되거나 손실될 수 있다. 스플라이싱은 후속 프로젝터가 이러한 별도의 관점을 최적으로 결합하는 방법을 학습할 수 있도록 한다. 논문은 이것이 "상대적인 의미론적 공간 위치를 유지할 수 있다"고 언급한다.
-
$|$ (마트료시카 표현 학습): 이 기호는 개념적으로 다차원적이고 다중 세분성인 마트료시카 표현 학습 과정을 나타낸다.
- 수학적 정의: 스플라이스된 표현 $R_i$가 프로젝터 $R_i = P_k(R_i; \phi_{k,t-1})$(식 4)로 매핑된 후, 두 개의 임베딩 표현으로 분할된다: $R_i^{lc} = R_i^{1:d_1}$ (저차원, 거친 세분성) 및 $R_i^{hf} = R_i^{1:d_2}$ (고차원, 미세 세분성)(식 5). 이들은 별도의 예측 헤더에 공급된다: $y_i^{lc} = G_{hd}(R_i^{lc}; \theta_{hd,t-1})$(식 6) 및 $y_i^{F_k} = F_{hd}(R_i^{hf}; \omega_{hd,t-1})$(식 7).
- 물리적/논리적 역할: 이 메커니즘은 작은 인형이 더 큰 인형 안에 중첩된 마트료시카 인형에서 영감을 받았다. 여기서는 다른 세분성 및 차원에서 표현을 추출하는 것을 의미한다. 이를 통해 모델은 여러 관점에서 학습할 수 있으며, 거친 정보와 미세한 정보를 모두 포착하여 모델 학습 능력과 견고성을 향상시킨다. 전역 헤더는 거친 표현을 사용하고 로컬 헤더는 미세한 표현을 사용한다.
- 분할 및 별도 헤더를 사용하는 이유: 이 설계는 "다중 관점 표현 학습"을 가능하게 한다. 다른 헤더가 융합된 표현의 다른 세분성을 처리함으로써 모델은 더 강력하고 포괄적인 특징을 학습할 수 있다. 멀리서 물체를 보아 일반적인 모양을 파악하고, 가까이서 세부 사항을 보는 것과 같으며, 둘 다 더 나은 이해에 기여한다.
-
$m_i^{lc} \cdot l_i^{lc} + m_i^{F_k} \cdot l_i^{F_k}$ (가중 손실 합계): 이것은 클라이언트 $k$의 데이터 포인트 $i$에 대한 최종 결합된 손실이다.
- 수학적 정의: $l_i = m_i^{lc} \cdot l_i^{lc} + m_i^{F_k} \cdot l_i^{F_k}$ (식 9)이며, 여기서 $l_i^{lc}$는 전역 모델 헤더의 손실이고 $l_i^{F_k}$는 로컬 모델 헤더의 손실이다(식 8). $m_i^{lc}$와 $m_i^{F_k}$는 일반적으로 기본값으로 1로 설정되는 중요도 가중치이다.
- 물리적/논리적 역할: 이것은 일반화된(전역) 및 개인화된(로컬) 관점 모두에서 학습 신호를 결합한다. 이러한 손실에 가중치를 부여함으로써 시스템은 각 학습 분기의 영향을 균형 있게 조절할 수 있다. 가중치를 1로 설정하면 두 모델이 전체 학습에 동등하게 기여하도록 보장한다.
- 덧셈을 사용하는 이유: 전체 합계와 유사하게, 가중치 손실을 더하는 것은 여러 학습 목표를 결합하는 표준 방법이다. 이를 통해 각 구성 요소의 균형 잡힌 기여를 허용하여 거친 학습 목표와 미세한 학습 목표 모두를 만족시키는 최적 상태로 모델을 안내한다.
-
단계별 흐름
클라이언트 $k$에서 FedMRL 시스템으로 실제 레이블 $Y_i$와 함께 이미지 $x_i$라는 단일 데이터 포인트가 들어온다고 가정해보자. 다음은 그 여정이다.
-
특징 추출: 입력 이미지 $x_i$는 먼저 병렬로 두 개의 별도 특징 추출기에 들어간다.
- 전역 동종 모델의 특징 추출기 $G_{ex}$ (파라미터 $\theta_{ex}$ 포함)는 $x_i$를 처리하여 일반화된 표현 $R_k^g$을 생성한다. 이것은 이미지에 대한 일반적이고 공통적인 이해를 얻는 것과 같다.
- 동시에, 클라이언트 $k$의 로컬 이종 모델의 특징 추출기 $F_{ex}$ (파라미터 $\omega_{ex,k}$ 포함)는 $x_i$를 처리하여 개인화된 표현 $R_k^f$을 생성한다. 이것은 클라이언트별 세부 정보나 뉘앙스를 포착한다.
-
표현 스플라이싱: 두 표현 $R_k^g$와 $R_k^f$는 "스플라이스"(연결)되어 결합된 표현 $R_i$를 형성한다. 이 단계는 일반적인 정보와 개인화된 정보 모두가 나란히 보존되도록 보장한다.
-
적응형 표현 융합: 스플라이스된 표현 $R_i$는 클라이언트 $k$의 개인화된 경량 표현 프로젝터 $P_k$ (파라미터 $\phi_k$ 포함)에 공급된다. 이 프로젝터는 스플라이스된 표현을 융합된 표현 $R_i$로 매핑한다. 이것은 시스템이 결합된 지식을 클라이언트의 고유한 데이터 분포에 적응시키는 곳이다.
-
마트료시카 표현 분할: 융합된 표현 $R_i$는 개념적으로 두 부분으로 분할된다. 마치 마트료시카 인형을 열어 더 작은 인형을 드러내는 것과 같다.
- $R_i$의 초기 부분에서 저차원, 거친 세분성 표현 $R_i^{lc}$이 추출된다.
- $R_i$의 더 큰 부분에서 고차원, 미세 세분성 표현 $R_i^{hf}$이 추출된다.
-
다중 관점 예측: 이 두 마트료시카 표현은 해당 예측 헤더에 전달된다.
- $R_i^{lc}$는 전역 동종 모델의 예측 헤더 $G_{hd}$ (파라미터 $\theta_{hd}$ 포함)로 가서 거친 예측 $y_i^{lc}$을 생성한다.
- $R_i^{hf}$는 클라이언트 $k$의 로컬 이종 모델의 예측 헤더 $F_{hd}$ (파라미터 $\omega_{hd,k}$ 포함)로 가서 미세 세분성 예측 $y_i^{F_k}$을 생성한다.
-
손실 계산: 각 예측에 대해 실제 레이블 $Y_i$에 대한 손실이 계산된다.
- $l_i^{lc}$는 거친 예측 $y_i^{lc}$에 대한 손실이다.
- $l_i^{F_k}$는 미세 세분성 예측 $y_i^{F_k}$에 대한 손실이다.
-
가중 손실 집계: 마지막으로, 이 두 가지 개별 손실은 가중 합계를 통해 데이터 포인트 $x_i$에 대한 단일 총 손실 $l_i$로 결합된다. 기본적으로 두 손실 모두 동등하게 기여한다. 이 $l_i$는 전체 목적 함수에 기여하는 값이다.
이 전체 과정은 배치 내의 모든 데이터 포인트에 대해 반복되며, 배치에 대한 평균 손실은 최적화에 사용된다.
최적화 역학
FedMRL 메커니즘은 목적 함수를 최소화하기 위해 기울기 하강 과정을 통해 반복적으로 파라미터를 학습하고 업데이트한다.
-
기울기 계산: 클라이언트 $k$에서 데이터 포인트 배치에 대한 가중치 손실 $l_i$가 계산된 후, 이 손실의 기울기가 클라이언트 $k$의 모델에 관련된 모든 파라미터에 대해 계산된다.
- $\theta$ (전역 모델 파라미터)에 대한 $\nabla l_i$.
- $\omega_k$ (클라이언트 $k$의 로컬 모델 파라미터)에 대한 $\nabla l_i$.
- $\phi_k$ (클라이언트 $k$의 개인화된 표현 프로젝터 파라미터)에 대한 $\nabla l_i$.
-
로컬 파라미터 업데이트: 각 클라이언트 $k$는 이러한 기울기와 미리 정의된 학습률($\eta_\theta, \eta_\omega, \eta_\phi$)을 사용하여 로컬 파라미터($\omega_k$ 및 $\phi_k$)와 전역 모델 파라미터($\theta$)의 복사본을 업데이트한다. 이것은 표준 기울기 하강 단계이다.
$$ \theta^t \leftarrow \theta^{t-1} - \eta_\theta \nabla l_i \\ \omega_k^t \leftarrow \omega_k^{t-1} - \eta_\omega \nabla l_i \\ \phi_k^t \leftarrow \phi_k^{t-1} - \eta_\phi \nabla l_i $$
이러한 업데이트는 각 클라이언트에서 로컬로 발생하며, 모델을 특정 데이터와 학습 목표에 맞게 조정한다. 논문에서는 안정적인 수렴을 위해 기본적으로 $\eta_\theta = \eta_\omega = \eta_\phi$로 설정한다고 언급한다. -
서버 집계: 로컬 학습 라운드(여러 로컬 에포크를 포함할 수 있음) 후, 참여하는 각 클라이언트는 업데이트된 동종 소형 모델 파라미터(즉, 업데이트된 $\theta$ 파라미터)를 중앙 서버에 업로드한다. 서버는 참여하는 모든 클라이언트로부터 이러한 업데이트된 전역 모델 파라미터를 집계하여 새로운 통합 전역 모델 $\theta^t$를 생성한다. 이 집계는 일반적으로 수신된 파라미터의 평균이다. 로컬 이종 모델 파라미터 $\omega_k$와 프로젝터 파라미터 $\phi_k$는 클라이언트에 남아 있으며 서버로 전송되지 않아 프라이버시를 보존한다.
-
브로드캐스트 및 반복: 새로 집계된 전역 모델 $\theta^t$는 다음 통신 라운드를 위해 모든 클라이언트에 다시 브로드캐스트된다. 이 로컬 학습, 파라미터 업로드, 서버 집계 및 전역 모델 브로드캐스트 주기는 지정된 라운드 수 또는 수렴할 때까지 반복된다.
손실 풍경 및 수렴: FedMRL의 전체 손실 풍경은 딥러닝 모델의 경우 일반적인 비볼록이다. 반복적인 기울기 하강 단계는 이 풍경을 탐색하며 최소값을 찾으려고 한다. 논문의 섹션 4에 있는 이론적 분석은 FedMRL이 $O(1/T)$ 비볼록 수렴 속도를 달성함을 보여주며, 여기서 $T$는 총 통신 라운드 수이다. 이는 라운드 수가 증가함에 따라 로컬 학습 전체 모델의 평균 기울기가 감소함을 의미하며, 이는 모델이 실제로 학습하고 시간이 지남에 따라 수렴하고 있음을 나타낸다. 이 수렴 조건은 학습률과 파라미터 변동 및 기울기 분산의 경계에 따라 달라지며, 이는 보조 정리 및 정리에 자세히 설명되어 있다. 적응형 표현 융합 및 다중 세분성 표현 학습은 이 손실 풍경을 더 효과적인 지식 전달을 촉진하고 모델이 더 나은 최소값을 찾는 능력을 향상시키는 방식으로 형성하도록 설계되어 우수한 성능으로 이어진다.
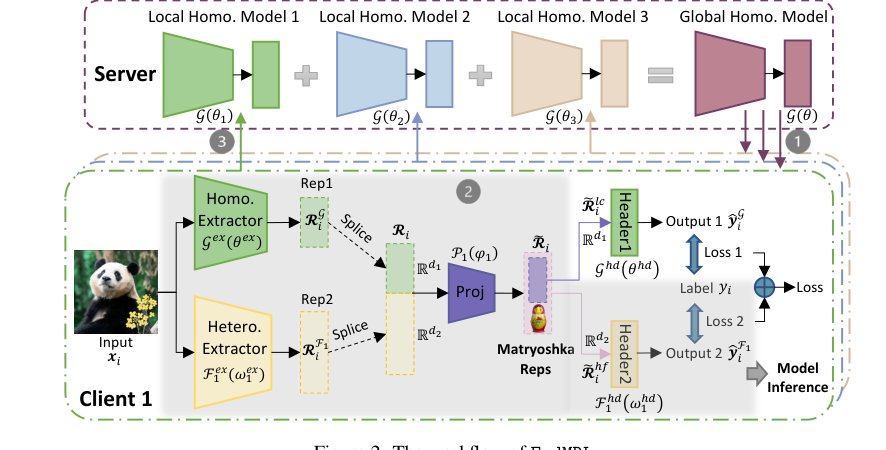 Figure 2. The workflow of FedMRL
Figure 2. The workflow of FedMRL
결과, 한계 및 결론
실험 설계 및 기준선
FedMRL의 수학적 주장과 실제 효능을 엄격하게 검증하기 위해 저자들은 포괄적인 실험 설계를 구축했다. 제안된 FedMRL 접근 방식은 Pytorch를 사용하여 구현되었으며 7가지 최첨단 MHeteroFL 방법과 비교되었다. 이러한 실험은 24GB 메모리를 갖춘 4개의 NVIDIA GeForce 3090 GPU로 구성된 강력한 하드웨어 구성에서 수행되었다.
FedMRL과 비교된 "희생자"(기준선 모델)는 네 가지 범주로 나뉘었다.
1. 독립형: 클라이언트는 로컬 데이터에서 독립적으로 모델을 학습시킨다.
2. 공개 데이터 없는 지식 증류: FD [21] 및 FedProto [43]와 같은 방법.
3. 모델 분할: LG-FedAvg [27]로 대표된다.
4. 상호 학습: FML [41], FedKD [45], FedAPEN [37] 포함.
FL 이미지 분류를 위한 두 가지 널리 사용되는 벤치마크 데이터셋이 사용되었다. CIFAR-10 (60,000개의 32x32 컬러 이미지, 10개 클래스) 및 CIFAR-100 (60,000개의 32x32 컬러 이미지, 100개 클래스). 둘 다 50,000개의 이미지가 학습에 사용되었고 10,000개가 테스트에 사용되었다. 현실적인 연합 환경을 시뮬레이션하기 위해 두 가지 유형의 Non-IID(독립적이고 동일하게 분포되지 않은) 데이터 분포가 구성되었다.
* Non-IID (클래스): 클라이언트에게 제한된 수의 클래스(CIFAR-10의 경우 2개, CIFAR-100의 경우 10개)가 할당되었으며, 클래스 수가 적을수록 Non-IID성이 높아진다.
* Non-IID (디리클레): 디리클레($\alpha$) 함수가 데이터 분포를 제어하는 데 사용되었으며, 여기서 $\alpha$ 값이 작을수록 Non-IID성이 더 두드러진다.
실험은 모델 동종(모든 클라이언트가 CNN-1 사용) 및 모델 이종(클라이언트가 CNN-1에서 CNN-5까지 혼합 사용) FL 시나리오 모두에서 수행되었다. FedMRL의 표현 프로젝터는 간단한 단일 계층 선형 모델이었다. 모델 동종 설정의 경우, FedMRL은 동종 전역 소형 모델로 CNN-1을 사용했지만, 클라이언트의 $d_2$보다 작은 표현 차원 $d_1$을 사용했다. 모델 이종 설정의 경우, FedMRL은 전역 구성 요소로 가장 작은 CNN-5 모델을 사용했으며, 역시 감소된 $d_1$을 사용했다.
성능은 세 가지 중요한 측면에서 평가되었다.
* 모델 정확도: 모든 클라이언트에 대한 평균 테스트 정확도.
* 통신 비용: 목표 평균 정확도에 도달하기 위해 서버와 한 클라이언트 간에 전송된 총 파라미터 수로 측정되며, 라운드당 파라미터와 라운드 수를 모두 고려한다.
* 계산 오버헤드: 목표 평균 정확도에 도달하기 위해 클라이언트당 총 FLOP(부동 소수점 연산)으로 측정되며, 라운드당 FLOP와 라운드 수를 모두 고려한다.
학습 전략에는 배치 크기, 에포크, 통신 라운드 및 학습률을 포함한 모든 알고리즘에 대한 광범위한 하이퍼파라미터 튜닝이 포함되었다. 결정적으로, FedMRL의 고유한 하이퍼파라미터인 $d_1$(동종 소형 모델의 표현 차원)는 최적의 절충점을 찾기 위해 100에서 500까지 다양하게 조정되었다. 실험은 모델 동종 및 모델 이종 시나리오 모두에 대해 세 가지 다른 FL 설정(N=10, C=100%; N=50, C=20%; N=100, C=10%)에서 수행되었다. 저자들은 각 실험 설정에 대해 세 번의 시도에 대한 평균 결과를 보고했다.
증거가 증명하는 것
실험 증거는 FedMRL의 핵심 메커니즘—적응형 개인화 표현 융합 및 다중 세분성 표현 학습—이 실제로 효과적으로 작동하여 우수한 성능으로 이어진다는 결정적이고 부인할 수 없는 증거를 제공한다.
우수한 모델 정확도:
* FedMRL은 모델 이종(표 1) 및 모델 동종(표 3, 부록 C.2) FL 설정 모두에서 모든 7가지 최첨단 기준선보다 일관되게 우수했다.
* 최고의 전체 기준선보다 최대 8.48%, 최고의 동일 범주(상호 학습 기반) 기준선보다 최대 24.94%의 평균 테스트 정확도 향상을 달성했다.
* 그림 3(왼쪽 6개 플롯)은 다양한 클라이언트 및 참여율 설정에서 최고의 기준선(FedProto)과 비교하여 FedMRL의 더 빠른 수렴 속도와 더 높은 최종 평균 테스트 정확도를 시각적으로 확인시켜 준다.
향상된 개인화:
* 그림 3(오른쪽 2개 플롯)은 FedMRL과 FedProto 간의 개별 클라이언트 테스트 정확도 차이를 보여준다. CIFAR-10에서 클라이언트의 87%와 CIFAR-100에서 99%가 FedMRL로 더 나은 성능을 달성했다. 이것은 FedMRL의 우수한 개인화 기능에 대한 강력한 증거이며, 이는 적응형 개인화 다중 세분성 표현 학습 설계에 직접적으로 기인한다.
효율성 향상:
* 통신 비용: FedMRL은 전체 동종 소형 모델을 전송하여 FedProto(로컬 본 클래스 평균 표현만 전송)보다 라운드당 더 높은 통신 비용을 발생시키지만, 그림 4(왼쪽)는 FedMRL이 목표 정확도에 도달하기 위해 더 적은 통신 라운드가 필요하여 더 빠른 수렴으로 이어진다는 것을 보여준다. 또한, 더 작은 표현 차원($d_1$)을 고려할 때, FedMRL은 더 큰 표현 차원을 사용하는 다른 상호 학습 기반 기준선(FML, FedKD, FedAPEN)보다 더 높은 통신 효율성을 달성한다.
* 계산 오버헤드: 추가 동종 소형 모델과 경량 표현 프로젝터를 학습하는 라운드당 오버헤드에도 불구하고, 그림 4(오른쪽)는 FedMRL이 FedProto보다 더 낮은 총 계산 비용을 발생시킨다는 것을 보여준다. 이것은 더 빠른 수렴의 직접적인 결과이며, 더 적은 전체 학습 라운드가 필요하다.
Non-IID 데이터에 대한 견고성:
* 클래스 기반 Non-IID성: 그림 5(왼쪽 2개 플롯)는 클라이언트당 클래스 수가 감소함에 따라(Non-IID성 증가) FedMRL이 FedProto보다 높은 평균 테스트 정확도를 유지하며 FedMRL의 견고성을 명확하게 보여준다.
* 디리클레 기반 Non-IID성: 그림 5(오른쪽 2개 플롯)는 테스트된 모든 $\alpha$ 값에 걸쳐 FedMRL이 FedProto를 상당히 능가하며, 데이터 이종성의 다양한 정도에 대한 견고성을 입증하면서 이러한 견고성을 더욱 검증한다.
메커니즘 검증을 위한 민감도 및 제거 연구:
* $d_1$에 대한 민감도: 그림 6(왼쪽 2개 플롯)은 더 작은 $d_1$ 값(동종 소형 모델의 표현 차원)이 더 높은 평균 테스트 정확도와 감소된 통신/계산 오버헤드로 이어진다는 것을 보여준다. 이는 $d_1$이 최적의 절충점을 달성하는 데 중요함을 강조한다.
* 제거 연구: 그림 6(오른쪽 2개 플롯)은 마트료시카 표현 학습(MRL) 구성 요소의 유용성을 결정적으로 입증한다. MRL이 없는 FedMRL보다 MRL이 있는 FedMRL이 일관되게 우수하여 다중 세분성 표현 학습이 MHeteroFL의 중요한 설계 요소임을 확인시켜 준다. $d_1$이 증가함에 따라 정확도 격차가 줄어든다는 관찰은 전역 및 로컬 헤더가 점점 더 겹치는 표현을 학습할 때 MRL의 이점이 줄어든다는 것을 시사한다.
추론 모델 유연성:
* 부록 C.3 및 그림 7은 "mix-small"(로컬 헤더 없는 전체 모델) 및 "mix-large"(전역 헤더 없는 전체 모델) 추론 모델이 유사하고 높은 정확도를 달성하며, 단일 동종 또는 이종 모델보다 훨씬 우수함을 보여준다. 이는 사용자가 특정 추론 비용 요구 사항에 따라 선택할 수 있는 실용적인 유연성을 제공한다.
한계 및 향후 방향
FedMRL은 모델 이종 연합 학습에서 상당한 발전을 보여주지만, 현재의 한계를 인정하고 향후 개발을 위한 경로를 고려하는 것이 중요하다.
현재 한계:
저자들이 식별한 주요 한계는 마트료시카 표현 내의 다중 세분성 임베딩 표현에 있다. 이러한 표현은 현재 전역 소형 모델의 헤더와 로컬 클라이언트 모델의 헤더 모두에 의해 처리된다. 전역 헤더가 단일 선형 레이어만 포함하더라도, 이 이중 처리는 여전히 저장 비용, 통신 오버헤드 및 전역 헤더의 학습 오버헤드에 기여한다. 이는 FedMRL이 수렴을 가속화하여 전반적인 효율성을 향상시키지만, 이러한 다중 세분성 표현을 처리하는 전역 모델과 관련된 리소스 소비를 최적화할 여지가 여전히 있음을 시사한다.
향후 방향 및 논의 주제:
-
다중 세분성 처리 간소화: 본 논문은 향후 작업에서 보다 발전된 마트료시카 표현 학습 방법(MRL-E) [24]을 채택할 것을 명시적으로 제안한다. 이는 전역 헤더를 완전히 제거하고 다중 세분성 마트료시카 표현을 처리하기 위해 로컬 모델 헤더에만 의존하는 것을 포함할 것이다. 이는 모델 성능과 저장, 통신 및 계산 비용 간의 더 나은 절충점으로 이어질 수 있다.
- 논의: 이러한 변화는 연합 학습의 "전역 지식" 측면에 어떤 영향을 미칠 수 있는가? 다중 세분성 처리를 전적으로 로컬 헤더에 의존하는 것이 공유 전역 모델의 이점을 희석시킬 위험이 있는가, 아니면 적응형 표현 융합 메커니즘이 충분히 보상할 수 있는가? 로컬 계산 부담을 크게 늘리지 않고 이러한 증가된 책임을 처리하기 위해 헤더 아키텍처에 어떤 수정이 필요할까?
-
동적 $d_1$ 최적화: 민감도 분석은 더 작은 $d_1$ 값(동종 소형 모델의 표현 차원)이 종종 더 나은 정확도와 효율성을 초래한다는 것을 보여주었다.
- 논의: $d_1$을 FL 학습 과정 중에 동적으로 최적화할 수 있는가, 아마도 클라이언트별 데이터 특성 또는 수렴 지표에 따라? 고정되고 사전 조정된 하이퍼파라미터에 의존하는 대신, 다양한 클라이언트 또는 통신 라운드에 대한 최적의 $d_1$을 학습하기 위해 강화 학습 접근 방식을 사용할 수 있는가?
-
비지도/자기 지도 작업으로 확장: 현재 FedMRL 접근 방식은 지도 학습 작업에 대해 설계되었다.
- 논의: 레이블이 지정된 데이터가 제한된 시나리오에서 점점 더 관련성이 높아지고 있는 비지도 또는 자기 지도 연합 학습에 적응형 표현 융합 및 다중 세분성 표현 학습의 원칙을 어떻게 확장할 수 있는가? 그러한 설정에서 손실 함수 및 지식 전달 메커니즘에 어떤 수정이 필요할까?
-
적대적 공격 및 데이터 오염에 대한 견고성: 본 논문은 프라이버시 보호를 언급하지만, 악의적인 공격에 대한 견고성을 명시적으로 자세히 설명하지는 않는다.
- 논의: 향상된 지식 전달 및 개인화된 표현을 고려할 때, FedMRL의 아키텍처는 데이터 오염 또는 모델 역전 공격에 본질적으로 어떻게 저항하거나 취약할 수 있는가? 성능이나 효율성 이점을 크게 손상시키지 않고 프라이버시를 더욱 강화하기 위해 다른 프라이버시 보호 메커니즘(예: 차등 프라이버시, 보안 집계)을 FedMRL과 통합할 수 있는가?
-
매우 큰 N 및 다양한 C에 대한 확장성: 실험은 최대 N=100명의 클라이언트를 대상으로 수행되었다.
- 논의: FedMRL은 수천 또는 수백만 명의 클라이언트를 가진 연합 네트워크에 어떻게 확장될 수 있는가, 특히 다양한 클라이언트 참여율(C)과 간헐적인 클라이언트 가용성을 고려할 때? 이러한 대규모 배포에서 효율성을 유지하기 위해 집계 전략 또는 통신 프로토콜에 추가적인 최적화가 필요한가?
-
이미지 분류를 넘어서: 현재 검증은 이미지 분류 데이터셋에 대한 것이다.
- 논의: FedMRL은 자연어 처리, 시계열 분석 또는 의료 영상과 같은 다른 데이터 모달리티 및 작업으로 얼마나 잘 일반화될까? "마트료시카" 개념인 다중 세분성 표현이 직접적으로 적용될까, 아니면 특징 추출 및 융합을 위해 도메인별 조정이 필요할까?
이러한 논의 지점들은 FedMRL의 기초적인 통찰력을 활용하고 연합 학습 분야의 더 넓은 도전 과제를 해결하고 새로운 가능성을 열기 위해 어떻게 발전시킬 수 있는지에 대한 비판적 사고를 자극하는 것을 목표로 한다.
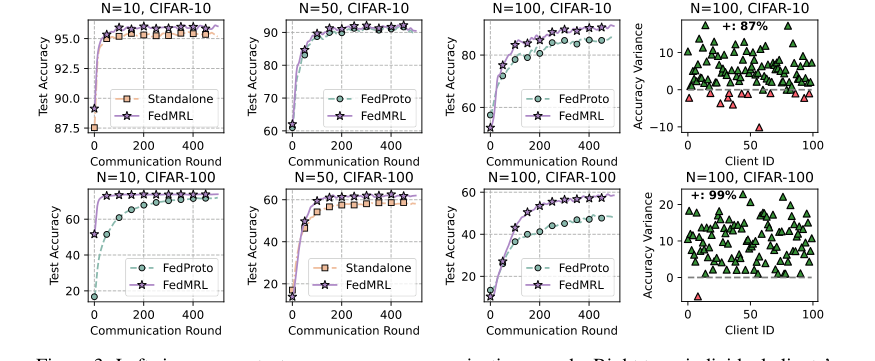 Figure 3. Left six: average test accuracy vs. communication rounds. Right two: individual clients’ test accuracy (%) differences (FedMRL - FedProto)
Figure 3. Left six: average test accuracy vs. communication rounds. Right two: individual clients’ test accuracy (%) differences (FedMRL - FedProto)
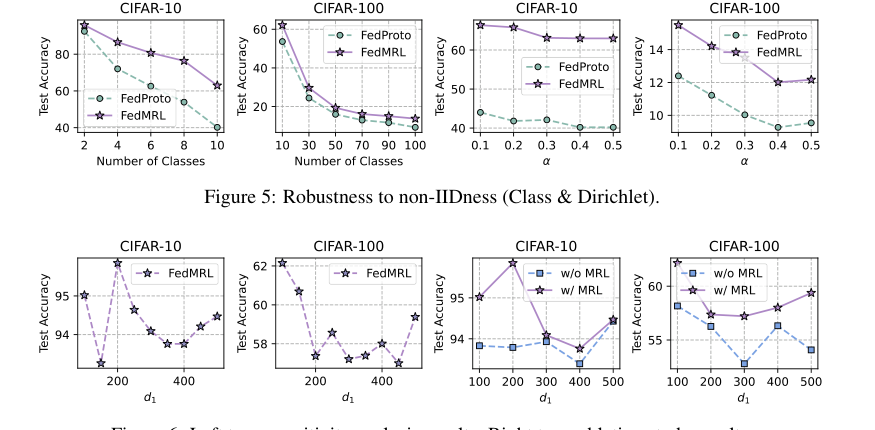 Figure 6. Left two: sensitivity analysis results. Right two: ablation study results
Figure 6. Left two: sensitivity analysis results. Right two: ablation study results
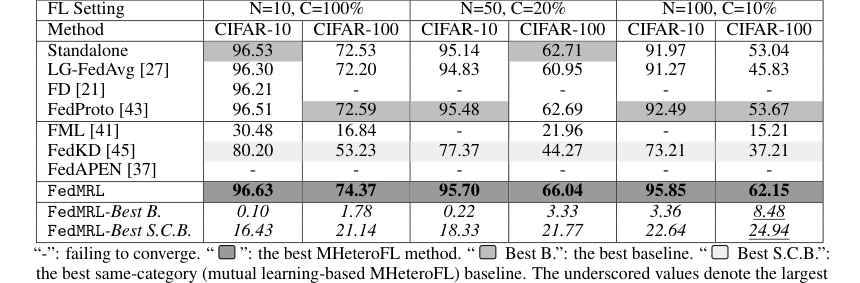 Table 1. and Table 3 (Appendix C.2) show that FedMRL consistently outperforms all baselines under both model-heterogeneous or homogeneous settings. It achieves up to a 8.48% improvement in average test accuracy compared with the best baseline under each setting. Furthermore, it achieves up to a 24.94% average test accuracy improvement than the best same-category (i.e., mutual learning- based MHeteroFL) baseline under each setting. These results demonstrate the superiority of FedMRL
Table 1. and Table 3 (Appendix C.2) show that FedMRL consistently outperforms all baselines under both model-heterogeneous or homogeneous settings. It achieves up to a 8.48% improvement in average test accuracy compared with the best baseline under each setting. Furthermore, it achieves up to a 24.94% average test accuracy improvement than the best same-category (i.e., mutual learning- based MHeteroFL) baseline under each setting. These results demonstrate the superiority of FedMRL
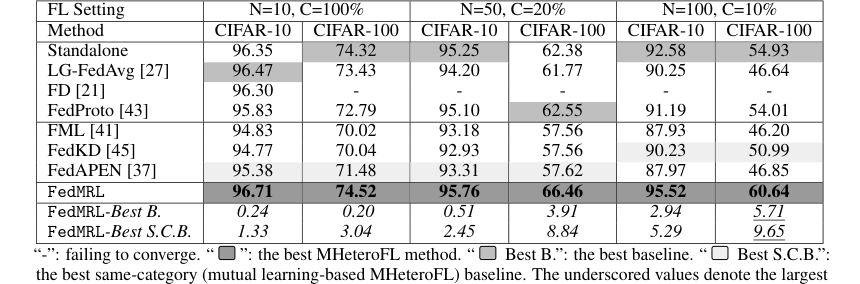 Table 3. presents the results of FedMRL and baselines in model-homogeneous FL scenarios
Table 3. presents the results of FedMRL and baselines in model-homogeneous FL scenarios