Обучение представлений гетерогенных моделей в федеративном режиме: Матрешка
Проблема, рассматриваемая в данной статье, — гетерогенное федеративное обучение моделей (MHeteroFL) — возникла из-за присущих ограничений традиционного федеративного обучения (FL).
Предпосылки и академическая родословная
Происхождение и академическая родословная
Проблема, рассматриваемая в данной статье, — гетерогенное федеративное обучение моделей (MHeteroFL) — возникла из-за присущих ограничений традиционного федеративного обучения (FL). Изначально FL задумывался как метод сохранения конфиденциальности, при котором центральный сервер координирует работу нескольких владельцев данных (клиентов) для обучения единой, глобальной общей модели без прямого раскрытия локальных данных. В каждом раунде связи сервер транслирует глобальную модель, клиенты обучают ее на своих локальных данных, а затем отправляют обновленные локальные модели обратно для агрегации с целью формирования новой глобальной модели. Этот процесс повторяется до сходимости, при этом передаются только параметры модели, что обеспечивает конфиденциальность данных.
Однако эта традиционная конструкция FL столкнулась со значительными "болевыми точками" при применении в реальных сценариях, что потребовало разработки более продвинутых подходов, таких как MHeteroFL. Эти ограничения включают:
- Гетерогенность данных (не-IID данные): Локальные данные клиентов часто не соответствуют независимому и одинаково распределенному (не-IID) шаблону. Это означает, что единая глобальная модель, агрегированная из таких разнообразных локальных наборов данных, может не обеспечивать оптимальной производительности для всех клиентов. Например, у одного клиента данные могут быть сильно смещены в сторону определенного класса, а у другого — данные для других классов.
- Системная гетерогенность: Клиенты FL могут иметь совершенно разную вычислительную мощность и пропускную способность сети. Принуждение всех клиентов к обучению одной и той же, часто большой, структуры модели означает, что размер глобальной модели должен соответствовать самому слабому устройству, что приводит к субоптимальной производительности на более мощных клиентах, которые могли бы обрабатывать более крупные и сложные модели.
- Гетерогенность моделей: В практических приложениях FL, особенно когда клиентами являются предприятия, они могут обладать проприетарными моделями с уникальными архитектурами или проблемами защиты интеллектуальной собственности (ИС). Прямой обмен этими гетерогенными моделями или их структурами во время обучения FL часто неприемлем из-за защиты ИС.
Существующие методы MHeteroFL, хотя и пытаются решить эти проблемы, позволяя клиентам обучать модели с адаптированными структурами, по-прежнему страдают от ограниченных возможностей передачи знаний. Они обычно полагаются на обучающую функцию потерь для передачи знаний между клиентскими и серверными моделями, что может привести к узким местам в производительности, высоким затратам на связь и вычисления, а также к постоянному риску раскрытия частных локальных структур моделей и данных. Данная статья предлагает FedMRL для преодоления этих ограничений путем улучшения передачи знаний посредством адаптивного слияния представлений и обучения представлений с множеством перспектив, вдохновленного обучением представлений Матрешки.
Интуитивные термины предметной области
Чтобы помочь читателю с нулевым уровнем знаний понять основные концепции, здесь приведены некоторые специализированные термины из статьи, переведенные на бытовые аналогии:
- Федеративное обучение (FL): Представьте кулинарный конкурс, где несколько поваров (клиентов) готовят свои уникальные блюда (локальные модели), используя свои секретные ингредиенты (локальные данные). Вместо того чтобы делиться своими рецептами, они отправляют только краткое описание своих кулинарных техник главному судье (центральному серверу). Судья объединяет эти описания, чтобы создать общие кулинарные советы (глобальная модель) и отправляет их обратно поварам. Таким образом, каждый улучшает свое блюдо, не раскрывая своих частных рецептов.
- Гетерогенное федеративное обучение моделей (MHeteroFL): Продолжая кулинарную аналогию, представьте, что у каждого повара есть кухонное оборудование разного типа (разнообразные системные ресурсы) и он предпочитает разный стиль кухни (гетерогенные структуры моделей). MHeteroFL — это как очень гибкий главный судья, который все еще может давать полезные, индивидуальные советы каждому повару, даже если они все работают с разным оборудованием и кулинарными подходами. Судья помогает им коллективно совершенствоваться, не заставляя всех готовить одинаково или использовать одинаковое оборудование.
- Обучение представлений Матрешки (MRL): Подумайте о наборе русских матрешек. Каждая кукла — это полная, но постепенно уменьшающаяся и менее детализированная версия предыдущей. MRL — это как обучение системы генерации "вложенных" инсайтов из данных. Она может производить очень широкое, общее понимание (самая большая кукла), а также более специфические, детальные сведения (меньшие куклы внутри). Это позволяет системе использовать именно нужный уровень детализации для задачи, экономя вычислительные затраты, если требуется только общее понимание, подобно тому, как вам может понадобиться только самая большая кукла, чтобы понять, что это матрешка.
- Не-IID данные (Не-независимые и одинаково распределенные данные): Рассмотрите класс студентов, изучающих животных. Если бы данные были IID, у каждого студента был бы учебник с равным смешением картинок кошек, собак, птиц и рыб. Не-IID данные — это как если бы учебник одного студента был в основном о кошках, другого — в основном о собаках, а третьего — в основном о птицах. Их индивидуальные учебные материалы (локальные данные) распределены неравномерно и не полностью отражают весь спектр животных (глобальное распределение данных). Это затрудняет применение единого, унифицированного плана урока для всех.
Таблица обозначений
| Обозначение | Описание |
|---|---|
Определение проблемы и ограничения
Формулировка основной проблемы и дилемма
Основная проблема, рассматриваемая в данной статье, относится к области гетерогенного федеративного обучения моделей (MHeteroFL), целью которого является предоставление возможности нескольким клиентам с различными архитектурами моделей совместно обучать глобальную модель без обмена своими необработанными локальными данными.
Вход/Текущее состояние:
Традиционное федеративное обучение (FL) работает с центральным сервером, координирующим $N$ клиентов для обучения единой, общей глобальной модели. В каждом раунде связи сервер транслирует глобальную модель, клиенты обучают ее на своих локальных данных, а затем отправляют обновленные локальные модели обратно для агрегации. Этот процесс повторяется до сходимости, при этом передаются только параметры модели для сохранения конфиденциальности данных. Однако эта традиционная конструкция FL сталкивается с тремя критическими проблемами гетерогенности, распространенными в практических приложениях:
1. Гетерогенность данных (не-IID): Локальные наборы данных клиентов часто следуют не-независимым и одинаково распределенным (не-IID) шаблонам, что означает, что единая глобальная модель, агрегированная из таких разнообразных локальных данных, может работать плохо на отдельных клиентах.
2. Системная гетерогенность: Клиенты FL обладают различными вычислительными ресурсами (например, ЦП, ГП, память) и пропускной способностью сети. Требование к обучению всеми клиентами идентичной структуры модели означает, что размер глобальной модели должен быть ограничен самым слабым устройством, что приводит к субоптимальной производительности на более мощных клиентах.
3. Гетерогенность моделей: Клиенты, особенно предприятия, могут иметь проприетарные локальные модели с разнообразными, не подлежащими обмену структурами из-за проблем с интеллектуальной собственностью (ИС). Это препятствует прямому усреднению параметров или агрегации.
Существующие методы MHeteroFL пытаются решить эти проблемы, но в основном полагаются на передачу знаний между клиентскими и серверными моделями через обучающую функцию потерь. Однако этот подход приводит к ограниченному обмену знаниями, что вызывает узкие места в производительности, высокие затраты на связь и вычисления, а также потенциальные риски раскрытия частных локальных структур моделей и данных.
Желаемый конечный пункт (выход/целевое состояние):
В статье предлагается разработать новый подход MHeteroFL под названием "Федеративное обучение представлений гетерогенных моделей Матрешка" (FedMRL), который может эффективно и совместно решать проблемы гетерогенности данных, систем и моделей в задачах обучения с учителем. Цель состоит в достижении:
1. Улучшенная передача знаний: Обеспечение более эффективного взаимодействия знаний между глобальной однородной моделью сервера и гетерогенными локальными моделями клиентов.
2. Улучшенная производительность модели: Достижение превосходной точности модели по сравнению с существующими передовыми методами (SOTA).
3. Низкие затраты на связь и вычисления: Минимизация накладных расходов, связанных с обучением и обновлением моделей.
4. Надежное сохранение конфиденциальности: Обеспечение того, чтобы локальные данные клиентов и гетерогенные структуры моделей оставались нераскрытыми для сервера или других клиентов.
5. Персонализированная адаптация: Обеспечение адаптации процесса обучения к локальным не-IID распределениям данных и разнообразным ресурсам клиентов.
Отсутствующее звено или математический пробел:
Точным отсутствующим звеном является отсутствие эффективного и действенного механизма передачи знаний между гетерогенными моделями и распределениями данных с сохранением конфиденциальности. Текущая зависимость методов от обучающей функции потерь для передачи знаний недостаточна. FedMRL пытается устранить этот пробел, вводя два ключевых нововведения:
1. Адаптивное слияние представлений: Для каждого локального образца данных экстракторы признаков из небольшой глобальной однородной модели и локальной гетерогенной модели извлекают обобщенные и персонализированные представления соответственно. Затем они объединяются и отображаются в слитое представление с помощью персонализированного легковесного проектора представлений $P_k(\phi_k)$, который адаптируется к локальным не-IID данным.
2. Обучение представлений с множеством гранулярностей: Слитое представление используется для построения представлений Матрешки, которые являются многомерными и многогранулярными вложенными представлениями. Они обрабатываются предсказательными заголовками как глобальной однородной модели, так и локальной гетерогенной модели, а их комбинированные потери используются для обновления всех моделей.
Математически, статья стремится минимизировать следующую целевую функцию (Уравнение 1):
$$
\min_{\theta, \omega_0, \dots, \omega_{N-1}, \phi_0, \dots, \phi_{N-1}} \sum_{k=0}^{N-1} l(W_k(D_k; (\theta \circ \omega_k | \phi_k)))
$$
где $W_k(w_k) = (G(\theta) \circ F_k(w_k) | P_k(\phi_k))$ представляет собой комбинированную модель для клиента $k$, включающую небольшую глобальную однородную модель $G(\theta)$, локальную гетерогенную модель клиента $F_k(w_k)$ и персонализированный проектор представлений $P_k(\phi_k)$. Потери $l$ вычисляются на основе многоперспективных выходов из представлений Матрешки.
Дилемма:
Болезненный компромисс, который поставил в тупик предыдущих исследователей, — это присущий конфликт между достижением высокой производительности модели и эффективной передачей знаний между гетерогенными клиентами FL, одновременно поддерживая низкие затраты на связь/вычисления и надежные гарантии конфиденциальности. Улучшение одного аспекта часто приводит к ухудшению другого. Например, обмен большей информацией (например, полными параметрами модели или подробными промежуточными представлениями) может улучшить передачу знаний и производительность, но резко увеличит затраты на связь и риски конфиденциальности. И наоборот, ограничение передаваемой информации для защиты конфиденциальности и снижения затрат часто приводит к "ограниченному обмену знаниями" и "узким местам в производительности модели" (стр. 2, раздел 1), что приводит к субоптимальной точности, особенно на не-IID данных. Дилемма заключается в том, как обеспечить богатое, многоперспективное взаимодействие знаний без раскрытия конфиденциальной информации клиента или перегрузки ограниченных ресурсов.
Ограничения и сбои
Проблема гетерогенного федеративного обучения моделей чрезвычайно сложна из-за нескольких суровых, реалистичных стен, с которыми сталкиваются авторы:
- Распределение не-IID данных: Локальные данные клиентов часто не являются независимыми и одинаково распределенными (не-IID), что затрудняет обучение единой глобальной модели, которая хорошо работает на всех клиентах. Это требует персонализированных моделей или адаптивных механизмов, которые добавляют сложности.
- Разнообразные системные ресурсы клиентов: Клиенты FL работают с различными вычислительными мощностями, памятью и пропускной способностью сети. Любое предложенное решение должно быть достаточно эффективным для работы на самых слабых устройствах, но при этом использовать возможности более мощных. Это накладывает строгие ограничения на размер модели и вычислительные накладные расходы на клиента.
- Проприетарные структуры моделей и защита ИС: Клиенты могут использовать разнообразные, проприетарные локальные архитектуры моделей, которые нельзя напрямую обменивать или агрегировать из-за проблем с интеллектуальной собственностью. Это препятствует традиционному федеративному усреднению параметров модели.
- Ограниченная эффективность передачи знаний: Существующие методы MHeteroFL, особенно те, которые полагаются на обучающую функцию потерь или простое взаимное обучение, часто достигают только "ограниченной передачи знаний" (стр. 1, аннотация; стр. 3, раздел 2). Это приводит к субоптимальной производительности модели и медленной сходимости.
- Высокие затраты на связь: Передача больших параметров модели или обширных промежуточных представлений между сервером и многочисленными клиентами в каждом раунде может повлечь за собой значительные затраты на связь, особенно при ограниченной пропускной способности сети. Цель — минимизировать это.
- Высокие вычислительные накладные расходы: Обучение дополнительных моделей или сложных механизмов дистилляции знаний на клиентских устройствах может привести к существенным вычислительным накладным расходам, что нежелательно для клиентов с ограниченными ресурсами.
- Строгие требования к конфиденциальности: Фундаментальный принцип FL — защита конфиденциальности локальных данных. Любой метод должен гарантировать, что необработанные клиентские данные и локальные структуры моделей никогда не будут раскрыты серверу или другим клиентам. Несоблюдение этого является критическим сбоем.
- Невыпуклая оптимизационная поверхность: Оптимизационная задача в федеративном обучении с гетерогенными моделями в целом невыпукла. Гарантирование сходимости к хорошему решению, не говоря уже о глобальном оптимуме, является значительной математической проблемой. Статья предоставляет теоретический анализ, показывающий скорость невыпуклой сходимости $O(1/T)$ (стр. 1, аннотация), что является распространенным, но все еще сложным аспектом.
- Узкие места в производительности модели: Без эффективной передачи знаний клиентские модели могут страдать от узких мест в производительности, неспособности хорошо обобщаться или достигать высокой точности.
- Проблемы масштабируемости: Решение должно быть масштабируемым до большого числа клиентов ($N$) и устойчивым к различным коэффициентам участия клиентов ($C=K/N$) в каждом раунде связи (стр. 3, раздел 3).
Эти ограничения в совокупности делают задачу достижения высокопроизводительного, сохраняющего конфиденциальность и ресурсоэффективного федеративного обучения с гетерогенными моделями исключительно сложной задачей.
Почему этот подход
Неизбежность выбора
Разработка FedMRL была обусловлена присущими ограничениями существующих подходов к гетерогенному федеративному обучению моделей (MHeteroFL) при столкновении со сложными реалиями практических приложений FL. Авторы осознали, что традиционные методы "SOTA", даже адаптированные для федеративных сценариев, были недостаточны, поскольку они в основном полагались на обучающую функцию потерь для передачи знаний между клиентскими и серверными моделями. Эта зависимость привела к ряду критических недостатков: "ограниченный обмен знаниями", "узкие места в производительности модели", "высокие затраты на связь и вычисления" и значительный "риск раскрытия частных локальных структур моделей и данных" (аннотация, стр. 1).
В частности, в статье подчеркивается, что традиционные конструкции FL столкнулись с тремя основными проблемами гетерогенности: (1) гетерогенность данных, когда данные клиента не-IID; (2) системная гетерогенность, когда клиенты имеют различную вычислительную мощность и пропускную способность сети, вынуждая глобальные модели учитывать самое слабое устройство; и (3) гетерогенность моделей, когда клиенты обладают проприетарными моделями, которые нельзя напрямую обменивать из-за проблем с интеллектуальной собственностью (раздел 1, стр. 1-2). Хотя MHeteroFL возник для решения этих проблем, существующие методы в этой области, такие как основанные на адаптивных подсетях, дистилляции знаний, разделении моделей или взаимном обучении, по-прежнему демонстрировали критические недостатки. Например, подходы взаимного обучения, на которых основан FedMRL, отмечались тем, что "передают лишь ограниченные знания между двумя моделями, что приводит к узким местам в производительности модели" (раздел 2, стр. 3).
Точный момент осознания, хотя и не был явно выделен как единичное событие, сильно подразумевается всесторонней критикой предыдущих методов MHeteroFL. Авторы признали, что необходим принципиально иной механизм передачи знаний — такой, который выйдет за рамки простой дистилляции на основе потерь и перейдет к более сложному взаимодействию на уровне представлений. Это побудило их черпать вдохновение из обучения представлений Матрешки (MRL) [24], которое предлагает способ настройки размерностей представлений и достижения оптимального баланса между производительностью модели и затратами на вывод. Этот переход к подходу, ориентированному на представления, а не на модели или потери, стал единственным жизнеспособным путем для преодоления постоянных проблем гетерогенности, конфиденциальности и эффективности в федеративном обучении.
Сравнительное превосходство
FedMRL демонстрирует подавляющее качественное превосходство над предыдущими золотыми стандартами благодаря ряду структурных и функциональных преимуществ, выходящих далеко за рамки простых метрик производительности.
Во-первых, его основное нововведение заключается в адаптивном слиянии представлений и обучении представлений с множеством гранулярностей. В отличие от методов, которые полагаются на одно фиксированное представление, FedMRL извлекает как обобщенные (из общей однородной модели), так и персонализированные (из локальной гетерогенной модели клиента) представления. Затем они адаптивно сливаются легковесным персонализированным проектором, что имеет решающее значение для адаптации к локальным не-IID распределениям данных (раздел 3.1, стр. 4). Эта структурная конструкция обеспечивает более богатое, более нюансированное понимание локальных данных, что является значительным качественным скачком по сравнению с подходами, которые испытывают трудности с гетерогенностью данных. Последующее построение представлений Матрешки, включающее многомерные и многогранулярные вложенные представления, еще больше повышает способность модели к обучению, позволяя осуществлять многоперспективное обучение (раздел 3.2, стр. 5). Это структурное преимущество позволяет модели изучать как грубые, так и детальные признаки, делая ее более устойчивой и эффективной.
Во-вторых, FedMRL предлагает превосходное сохранение конфиденциальности и эффективность использования ресурсов. Передавая только небольшие однородные модели между сервером и клиентами, он гарантирует, что "локальная модель и данные каждого клиента не раскрываются во время обучения" (раздел 2, стр. 2). Это критическое структурное преимущество для конфиденциальных приложений. Кроме того, эта конструкция по своей сути приводит к "низким затратам на связь" и "низким дополнительным вычислительным затратам" для клиентов, поскольку они обучают только небольшую однородную модель и легковесный проектор в дополнение к своей локальной модели (раздел 2, стр. 2). Хотя в статье явно не указано снижение сложности памяти с $O(N^2)$ до $O(N)$, акцент на "небольших однородных моделях" и "легковесных" компонентах напрямую подразумевает значительное снижение потребления памяти и вычислительных ресурсов по сравнению с методами, которые могут требовать более крупных, более сложных моделей или обширного обмена данными.
Наконец, устойчивость метода к не-IID данным и более сильная способность к персонализации качественно превосходят. Эксперименты показывают, что FedMRL последовательно достигает более высокой средней тестовой точности в различных не-IID сценариях (классовых и Дирихле) по сравнению с базовыми методами, такими как FedProto (разделы 5.3.1, 5.3.2, стр. 9). Кроме того, он обеспечивает более сильную персонализацию: высокий процент индивидуальных клиентов (87% на CIFAR-10, 99% на CIFAR-100) достигает лучшей производительности, чем FedProto (раздел 5.2.2, стр. 8). Это указывает на фундаментальное структурное преимущество в обработке разнообразных клиентских сред и распределений данных.
Соответствие ограничениям
Дизайн FedMRL идеально соответствует суровым требованиям и ограничениям гетерогенного федеративного обучения, создавая синергетический "брак" между проблемой и решением.
- Гетерогенность данных (не-IID данные): Механизм адаптивного слияния представлений специально разработан для решения этой проблемы. Персонализированный проектор представлений отображает слитые обобщенные и персонализированные представления в слитое представление, "адаптируясь к локальным не-IID данным" (раздел 3.1, стр. 4). Это гарантирует, что уникальное распределение данных каждого клиента учитывается, предотвращая деградацию производительности, распространенную в не-IID сценариях.
- Системная гетерогенность: FedMRL учитывает различные возможности клиентов, вводя "общую глобальную вспомогательную однородную небольшую модель", которая взаимодействует с "гетерогенными локальными моделями" (раздел 2, стр. 2). Глобальная модель намеренно мала, что позволяет транслировать и обучать ее даже клиентам с ограниченными ресурсами. Клиенты также могут регулировать размерность линейного слоя своего проектора представлений для согласования со слитым представлением, дополнительно адаптируясь к локальным системным ограничениям (раздел 3.1, стр. 4).
- Гетерогенность моделей: Фреймворк изначально поддерживает клиентов, владеющих "локальными моделями с разнообразными структурами" (раздел 3.1, стр. 4). Сервер взаимодействует только с однородной небольшой моделью, рассматривая гетерогенную локальную модель клиента как "черный ящик". Эта конструкция уважает проблемы интеллектуальной собственности, не требуя от клиентов раскрытия своих проприетарных структур моделей.
- Сохранение конфиденциальности: Это краеугольный камень FedMRL. "Локальная модель и данные каждого клиента не раскрываются во время обучения для сохранения конфиденциальности" (раздел 2, стр. 2). Передаются только небольшие однородные модели, гарантируя конфиденциальность локальных данных и структур моделей.
- Эффективность связи: Передавая только "небольшие однородные модели" (раздел 2, стр. 2), FedMRL значительно снижает затраты на связь по сравнению с методами, которые обмениваются полными клиентскими моделями. Возможность варьировать размерность представления $d_1$ однородной небольшой модели далее позволяет оптимизировать накладные расходы на связь (раздел 5.3.3, стр. 9).
- Вычислительная эффективность: Клиентам необходимо обучать только "небольшую однородную модель и легковесный проектор представлений" в дополнение к своей локальной модели, что влечет за собой "низкие дополнительные вычислительные затраты" (раздел 2, стр. 2). Более высокая скорость сходимости, достигнутая FedMRL (рис. 4, стр. 8), также означает, что для достижения целевой точности требуется меньше раундов связи, что снижает общие вычислительные накладные расходы (раздел 5.2.4, стр. 9).
- Ограничения передачи знаний: Двойные нововведения — адаптивное слияние представлений и обучение представлений с множеством гранулярностей — напрямую решают проблему "ограниченного обмена знаниями" предыдущих методов. Они обеспечивают "большее взаимодействие знаний между двумя моделями и улучшение производительности модели" путем изучения обобщенных и персонализированных представлений с нескольких точек зрения (раздел 2, стр. 3).
Отклонение альтернатив
В статье систематически идентифицируются и отклоняются несколько категорий существующих подходов MHeteroFL, подчеркивая их фундаментальные недостатки в решении ограничений проблемы:
- MHeteroFL с адаптивными подсетями: Эти методы строят гетерогенные локальные подсети из глобальной модели. Авторы отклоняют этот подход, поскольку "в случаях, когда клиенты владеют локальными моделями типа "черный ящик" с гетерогенными структурами, не производными от общей глобальной модели, сервер не может их агрегировать" (раздел 2, стр. 3). Это подразумевает неспособность обрабатывать истинную гетерогенность моделей, когда клиентские модели являются проприетарными, а не просто усеченными версиями глобальной модели.
- MHeteroFL с дистилляцией знаний:
- Методы, полагающиеся на общедоступный набор данных для передачи знаний, считаются непрактичными, поскольку "такой подходящий общедоступный набор данных трудно найти" (раздел 2, стр. 3).
- Подходы, которые обучают генератор для синтеза общего набора данных, отклоняются из-за "высоких затрат на обучение", которые они влекут за собой (раздел 2, стр. 3).
- Другие методы, которые обмениваются промежуточной информацией, косвенно отклоняются из-за риска раскрытия "локальных данных клиента для слияния знаний", что может поставить под угрозу конфиденциальность.
- MHeteroFL с разделением моделей: Эти методы разделяют модели на экстракторы признаков и предикторы, обмениваясь одним или другим. Статья отклоняет эту стратегию, поскольку она "раскрывает часть локальных структур моделей, что может быть неприемлемо, если модели являются проприетарной ИС клиентов" (раздел 2, стр. 3). Это напрямую противоречит ограничениям конфиденциальности и защиты интеллектуальной собственности.
- MHeteroFL с взаимным обучением: Хотя FedMRL основан на этой категории, он явно заявляет, что существующие методы взаимного обучения (например, FML, FedKD, FedAPEN) недостаточны, поскольку "взаимные потери передают лишь ограниченные знания между двумя моделями, что приводит к узким местам в производительности модели" (раздел 2, стр. 3). FedMRL представлен как оптимизация, которая "улучшает передачу знаний", переходя к подходу, основанному на представлениях, а не исключительно полагаясь на взаимные потери.
Статья не обсуждает провал общих архитектур глубокого обучения, таких как GAN, диффузионные модели или трансформеры, в качестве альтернатив самому подходу федеративного обучения. Вместо этого она неявно включает CNN (тип архитектуры, предшествующей трансформерам) в качестве базовых моделей в своем фреймворке (Таблица 2, стр. 17). Отклонение касается парадигм федеративного обучения, которые не могут эффективно управлять уникальными проблемами гетерогенности, конфиденциальности и эффективности использования ресурсов, а не фундаментальных архитектур моделей.
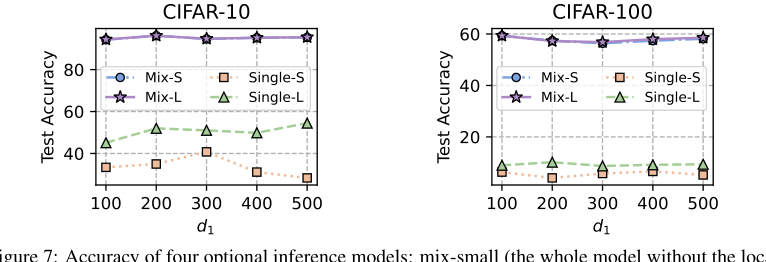 Figure 7. Accuracy of four optional inference models: mix-small (the whole model without the local header), mix-large (the whole model without the global header), single-small (the homogeneous small model), single-large (the client heterogeneous model)
Figure 7. Accuracy of four optional inference models: mix-small (the whole model without the local header), mix-large (the whole model without the global header), single-small (the homogeneous small model), single-large (the client heterogeneous model)
Математический и логический механизм
Основное уравнение
Основным ядром подхода FedMRL является его целевая функция, которая направлена на минимизацию общих потерь среди всех участвующих клиентов в федеративном обучающем сценарии. Это основное уравнение охватывает всю цель обучения:
$$ \min_{\theta, \omega_0, \dots, \omega_{N-1}, \phi_0, \dots, \phi_{N-1}} \sum_{k=0}^{N-1} l(W_k(D_k; (\theta \circ \omega_k | \phi_k))) $$
Потерпелтный разбор
Давайте разберем это основное уравнение и его основные компоненты, чтобы понять его математическое определение, логическую роль и обоснование его построения.
-
$\min_{\theta, \omega_0, \dots, \omega_{N-1}, \phi_0, \dots, \phi_{N-1}}$: Это оптимизационная цель.
- Математическое определение: Оно означает, что цель состоит в том, чтобы найти набор параметров ($\theta$, $\omega_k$, $\phi_k$), который минимизирует последующую сумму потерь.
- Физическая/логическая роль: Это центральное указание всей системы FedMRL. Оно диктует, что процесс обучения должен корректировать все соответствующие параметры модели, чтобы сделать прогнозы как можно более точными для всех клиентов.
- Почему минимизация: В машинном обучении мы обычно определяем функцию потерь или ошибки, и цель состоит в том, чтобы уменьшить эту ошибку, поэтому минимизация является естественным выбором.
-
$\sum_{k=0}^{N-1}$: Это оператор суммирования.
- Математическое определение: Он суммирует индивидуальные вклады потерь от каждого клиента, от клиента $k=0$ до $N-1$.
- Физическая/логическая роль: В федеративном обучении общая производительность является коллективной мерой всех клиентов. Это суммирование гарантирует, что глобальная цель учитывает результаты обучения каждого клиента, продвигая общую цель обучения при уважении локальных данных.
- Почему суммирование вместо, скажем, произведения: Суммирование является стандартным способом агрегации потерь в многоклиентской или многозадачной настройке. Произведение было бы очень чувствительно к малым потерям (приводя к нулю общему значению) или большим потерям (взрывая общее значение), делая оптимизацию нестабильной. Суммирование обеспечивает более стабильную и интерпретируемую агрегацию индивидуальных показателей производительности клиентов.
-
$l(\cdot)$: Это представляет собой функцию потерь.
- Математическое определение: Как указано в статье (Уравнение 8), это обычно потери кросс-энтропии, $l(y, Y_i)$, которые измеряют расхождение между предсказанным выходом модели $y$ и истинной меткой $Y_i$.
- Физическая/логическая роль: Функция потерь количественно определяет, насколько "неправильны" прогнозы модели для данного входа. Более высокие потери означают худший прогноз. Она предоставляет сигнал для оптимизационного процесса для корректировки параметров модели.
- Почему кросс-энтропия: Кросс-энтропия широко используется для задач классификации, поскольку она сильнее наказывает неправильные классификации и побуждает модель выдавать вероятности, соответствующие истинному распределению меток.
-
$W_k(D_k; (\theta \circ \omega_k | \phi_k))$: Это представляет собой комбинированную модель для клиента $k$, работающую на его локальных данных $D_k$, параметризованную комбинацией глобальных ($\theta$), локальных ($\omega_k$) и персонализированного проектора ($\phi_k$) параметров. Именно здесь находится основной механизм FedMRL. Давайте разберем его внутреннюю работу:
-
$D_k$: Это обозначает локальный набор данных клиента $k$.
- Математическое определение: Набор образцов данных $(x_i, Y_i)$, где $x_i$ — вектор входных признаков, а $Y_i$ — соответствующая истинная метка.
- Физическая/логическая роль: Это частные, локальные данные, которые каждый клиент использует для обучения. В FL крайне важно, чтобы эти данные оставались локальными и не передавались напрямую серверу или другим клиентам.
-
$\theta$: Это представляет параметры глобальной однородной небольшой модели.
- Математическое определение: $\theta = \{\theta_{ex}, \theta_{hd}\}$, где $\theta_{ex}$ — параметры экстрактора признаков глобальной модели $G_{ex}$, а $\theta_{hd}$ — параметры ее предсказательного заголовка $G_{hd}$. Они общие для всех клиентов.
- Физическая/логическая роль: Эта модель действует как источник "обобщенных" знаний. Она мала и однородна, чтобы минимизировать затраты на связь и учитывать системную гетерогенность. Она предоставляет общий базовый уровень представления.
-
$\omega_k$: Это представляет параметры гетерогенной локальной модели клиента $k$.
- Математическое определение: $\omega_k = \{\omega_{ex,k}, \omega_{hd,k}\}$, где $\omega_{ex,k}$ — параметры экстрактора признаков локальной модели клиента $k$ $F_{ex}$, а $\omega_{hd,k}$ — параметры ее предсказательного заголовка $F_{hd}$. Они уникальны для каждого клиента.
- Физическая/логическая роль: Эта модель захватывает "персонализированные" знания, адаптированные к конкретному распределению данных и структуре модели клиента $k$. Она решает проблемы гетерогенности данных и моделей.
-
$\phi_k$: Это представляет параметры персонализированного проектора представлений клиента $k$.
- Математическое определение: $\phi_k$ — это параметры легковесного проектора $P_k$.
- Физическая/логическая роль: Этот проектор отвечает за адаптивное слияние обобщенных и персонализированных представлений. Он персонализирован для каждого клиента, чтобы эффективно обрабатывать локальные не-IID распределения данных.
-
$\circ$ (Оператор слияния): Этот оператор объединяет выходы экстракторов признаков.
- Математическое определение: Согласно Уравнению (3), $R_i = R_k^g \circ R_k^f$, где $R_k^g = G_{ex}(x_i; \theta_{ex,t-1})$ — обобщенное представление из экстрактора признаков глобальной модели, а $R_k^f = F_{ex}(x_i; \omega_{ex,t-1})$ — персонализированное представление из экстрактора признаков локальной модели. Слияние обычно означает конкатенацию векторов признаков.
- Физическая/логическая роль: Эта операция объединяет обобщенные признаки (общие знания) с персонализированными признаками (специфические для клиента знания) в единое, более богатое представление.
- Почему слияние вместо сложения или умножения: Слияние (конкатенация) сохраняет различное семантическое содержание из обоих источников. Если бы мы складывали или умножали, информация могла бы смешаться или потеряться, особенно если признаки имеют разные масштабы или значения. Слияние позволяет последующему проектору научиться наилучшим образом комбинировать эти различные перспективы. В статье отмечается, что это "может сохранять относительное положение семантического пространства".
-
$|$ (Обучение представлений Матрешки): Этот символ концептуально представляет многомерное, многогранулярное обучение представлений Матрешки.
- Математическое определение: После того как слитое представление $R_i$ проецируется в слитое представление $R_i = P_k(R_i; \phi_{k,t-1})$ (Уравнение 4), оно затем разделяется на два вложенных представления: $R_i^{lc} = R_i^{1:d_1}$ (низкая размерность, грубая гранулярность) и $R_i^{hf} = R_i^{1:d_2}$ (высокая размерность, тонкая гранулярность) (Уравнение 5). Затем они подаются в отдельные предсказательные заголовки: $y_i^{lc} = G_{hd}(R_i^{lc}; \theta_{hd,t-1})$ (Уравнение 6) и $y_i^{F_k} = F_{hd}(R_i^{hf}; \omega_{hd,t-1})$ (Уравнение 7).
- Физическая/логическая роль: Этот механизм вдохновлен матрешками, где меньшие куклы вложены в большие. Здесь это означает извлечение представлений с различной гранулярностью и размерностью. Это позволяет модели учиться с множеством перспектив, захватывая как грубую, так и детальную информацию, что повышает способность модели к обучению и ее устойчивость. Глобальный заголовок использует грубое представление, а локальный заголовок — тонкозернистое.
- Почему разделение и отдельные заголовки: Эта конструкция обеспечивает "многоперспективное обучение представлений". Имея разные заголовки, обрабатывающие разные гранулярности слитого представления, модель может изучать более надежные и полные признаки. Это похоже на то, как смотреть на объект издалека, чтобы получить общую форму, а затем вблизи, чтобы увидеть детали, оба вносят вклад в лучшее понимание.
-
$m_i^{lc} \cdot l_i^{lc} + m_i^{F_k} \cdot l_i^{F_k}$ (Взвешенная сумма потерь): Это окончательные комбинированные потери для одного образца данных $i$ в клиенте $k$.
- Математическое определение: $l_i = m_i^{lc} \cdot l_i^{lc} + m_i^{F_k} \cdot l_i^{F_k}$ (Уравнение 9), где $l_i^{lc}$ — потери от заголовка глобальной модели, а $l_i^{F_k}$ — потери от заголовка локальной модели (Уравнение 8). $m_i^{lc}$ и $m_i^{F_k}$ — весовые коэффициенты важности, обычно устанавливаемые равными 1 по умолчанию.
- Физическая/логическая роль: Это объединяет сигналы обучения как из обобщенной (глобальной), так и из персонализированной (локальной) перспектив. Взвешивая эти потери, система может сбалансировать влияние каждой ветви обучения. Установка весов равными 1 гарантирует, что обе модели вносят равный вклад в общее обучение.
- Почему сложение: Подобно общему суммированию, сложение взвешенных потерь является стандартным способом объединения нескольких целей обучения. Это позволяет сбалансированно вносить вклад от каждого компонента, направляя модель к оптимальному состоянию, которое удовлетворяет как грубым, так и детальным целям обучения.
-
Пошаговый поток
Представьте, что один образец данных, изображение $x_i$ с его истинной меткой $Y_i$, поступает в систему FedMRL на клиенте $k$. Вот его путь:
-
Извлечение признаков: Входное изображение $x_i$ сначала параллельно поступает в два различных экстрактора признаков.
- Экстрактор признаков глобальной однородной модели $G_{ex}$ (с параметрами $\theta_{ex}$) обрабатывает $x_i$, чтобы получить обобщенное представление $R_k^g$. Это похоже на получение общего, общепринятого понимания изображения.
- Одновременно экстрактор признаков локальной гетерогенной модели клиента $k$ $F_{ex}$ (с параметрами $\omega_{ex,k}$) обрабатывает $x_i$, чтобы получить персонализированное представление $R_k^f$. Это захватывает специфические для клиента детали или нюансы.
-
Слияние представлений: Два представления, $R_k^g$ и $R_k^f$, затем "сливаются" (конкатенируются) для формирования комбинированного представления $R_i$. Этот шаг гарантирует, что как общая, так и персонализированная информация сохраняются рядом.
-
Адаптивное слияние представлений: Слитое представление $R_i$ затем подается в персонализированный легковесный проектор представлений клиента $k$ $P_k$ (с параметрами $\phi_k$). Этот проектор отображает слитое представление в слитое представление $R_i$. Здесь система адаптирует комбинированные знания к уникальному распределению данных клиента.
-
Разделение представлений Матрешки: Слитое представление $R_i$ затем концептуально разделяется на две части, подобно открытию матрешки для раскрытия меньшей.
- Представление низкой размерности, грубой гранулярности $R_i^{lc}$ извлекается из начального сегмента $R_i$.
- Представление высокой размерности, тонкой гранулярности $R_i^{hf}$ извлекается из большего сегмента $R_i$.
-
Многоперспективное предсказание: Эти два представления Матрешки затем передаются в соответствующие предсказательные заголовки:
- $R_i^{lc}$ поступает в предсказательный заголовок глобальной однородной модели $G_{hd}$ (с параметрами $\theta_{hd}$) для получения грубого предсказания $y_i^{lc}$.
- $R_i^{hf}$ поступает в предсказательный заголовок локальной гетерогенной модели клиента $k$ $F_{hd}$ (с параметрами $\omega_{hd,k}$) для получения тонкозернистого предсказания $y_i^{F_k}$.
-
Расчет потерь: Для каждого предсказания рассчитывается потери относительно истинной метки $Y_i$:
- $l_i^{lc}$ — потери для грубого предсказания $y_i^{lc}$.
- $l_i^{F_k}$ — потери для тонкозернистого предсказания $y_i^{F_k}$.
-
Взвешенная агрегация потерь: Наконец, эти две индивидуальные потери объединяются в общие потери $l_i$ для образца данных $x_i$ путем взвешенной суммы. По умолчанию обе потери вносят равный вклад. Это $l_i$ — значение, которое вносит вклад в общую целевую функцию.
Этот весь процесс повторяется для всех точек данных в пакете, и средние потери для пакета используются для оптимизации.
Динамика оптимизации
Механизм FedMRL обучается и обновляет свои параметры итеративно посредством процесса градиентного спуска, стремясь минимизировать глобальную целевую функцию.
-
Вычисление градиента: После расчета взвешенных потерь $l_i$ для пакета образцов данных на клиенте $k$ вычисляются градиенты этих потерь по отношению ко всем параметрам, задействованным в модели клиента $k$:
- $\nabla l_i$ по отношению к $\theta$ (параметры глобальной модели).
- $\nabla l_i$ по отношению к $\omega_k$ (параметры локальной модели клиента $k$).
- $\nabla l_i$ по отношению к $\phi_k$ (параметры персонализированного проектора представлений клиента $k$).
-
Локальное обновление параметров: Каждый клиент $k$ затем обновляет свои локальные параметры ($\omega_k$ и $\phi_k$) и свою копию параметров глобальной модели ($\theta$), используя эти градиенты и предопределенные скорости обучения ($\eta_\theta, \eta_\omega, \eta_\phi$). Это стандартный шаг градиентного спуска:
$$ \theta^t \leftarrow \theta^{t-1} - \eta_\theta \nabla l_i \\ \omega_k^t \leftarrow \omega_k^{t-1} - \eta_\omega \nabla l_i \\ \phi_k^t \leftarrow \phi_k^{t-1} - \eta_\phi \nabla l_i $$
Эти обновления происходят локально на каждом клиенте, адаптируя модели к их специфическим данным и целям обучения. В статье упоминается установка $\eta_\theta = \eta_\omega = \eta_\phi$ по умолчанию для стабильной сходимости. -
Серверная агрегация: После раунда локального обучения (который может включать несколько локальных эпох) каждый участвующий клиент загружает свои обновленные параметры однородной небольшой модели (т. е. свои обновленные параметры $\theta$) на центральный сервер. Затем сервер агрегирует эти обновленные параметры глобальной модели от всех участвующих клиентов, чтобы сформировать новую, консолидированную глобальную модель $\theta^t$. Эта агрегация обычно представляет собой усреднение полученных параметров. Параметры локальной гетерогенной модели $\omega_k$ и параметры проектора $\phi_k$ остаются на клиенте и не передаются серверу, сохраняя конфиденциальность.
-
Трансляция и итерация: Недавно агрегированная глобальная модель $\theta^t$ затем транслируется обратно всем клиентам для следующего раунда связи. Этот цикл локального обучения, загрузки параметров, серверной агрегации и трансляции глобальной модели повторяется в течение заданного числа раундов или до сходимости.
Поверхность потерь и сходимость: Общая поверхность потерь для FedMRL является невыпуклой, что типично для моделей глубокого обучения. Итеративные шаги градиентного спуска перемещаются по этой поверхности, стремясь найти минимум. Теоретический анализ в разделе 4 статьи демонстрирует, что FedMRL достигает скорости невыпуклой сходимости $O(1/T)$, где $T$ — общее число раундов связи. Это означает, что по мере увеличения числа раундов средний градиент всей локальной обучающей модели уменьшается, указывая на то, что модель действительно обучается и сходится со временем. Условия этой сходимости зависят от скоростей обучения и ограниченности вариаций параметров и дисперсий градиентов, как подробно описано в леммах и теоремах. Адаптивное слияние представлений и обучение представлений с множеством гранулярностей разработаны для формирования этой поверхности потерь таким образом, чтобы обеспечить более эффективную передачу знаний и улучшить способность модели находить лучшие минимумы, что приводит к превосходной производительности.
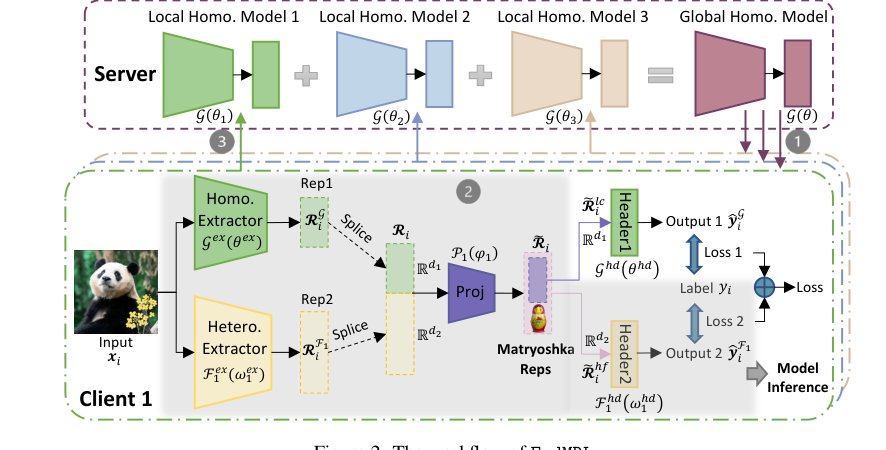 Figure 2. The workflow of FedMRL
Figure 2. The workflow of FedMRL
Результаты, ограничения и заключение
Экспериментальный дизайн и базовые методы
Для строгого подтверждения математических утверждений и практической эффективности FedMRL авторы разработали комплексную экспериментальную установку. Предложенный подход FedMRL был реализован с использованием Pytorch и протестирован против семи передовых методов MHeteroFL. Эти эксперименты проводились на надежной аппаратной конфигурации, состоящей из четырех графических процессоров NVIDIA GeForce 3090, каждый из которых оснащен 24 ГБ памяти.
"Жертвы" (базовые модели), против которых был протестирован FedMRL, делились на четыре категории:
1. Автономные: Клиенты независимо обучают модели на локальных данных.
2. Дистилляция знаний без общедоступных данных: Методы, такие как FD [21] и FedProto [43].
3. Разделение моделей: Представлено LG-FedAvg [27].
4. Взаимное обучение: Включая FML [41], FedKD [45] и FedAPEN [37].
Были использованы два широко используемых эталонных набора данных для классификации изображений FL: CIFAR-10 (60 000 цветных изображений размером 32x32, 10 классов) и CIFAR-100 (60 000 цветных изображений размером 32x32, 100 классов). Для обоих было использовано 50 000 изображений для обучения и 10 000 для тестирования. Для имитации реалистичных федеративных сред были построены два типа не-IID (не-независимых и одинаково распределенных) распределений данных:
* Не-IID (Классовое): Клиентам было назначено ограниченное количество классов (2 для CIFAR-10, 10 для CIFAR-100), причем меньшее количество классов указывало на более высокую степень не-IID.
* Не-IID (Дирихле): Функция Дирихле($\alpha$) использовалась для управления распределением данных, где меньшее $\alpha$ означало более выраженную не-IID.
Оценка охватывала как однородные по моделям (все клиенты используют CNN-1), так и гетерогенные по моделям (клиенты используют смесь CNN-1 до CNN-5) сценарии FL. Проектор представлений FedMRL представлял собой простую однослойную линейную модель. В однородных по моделям сценариях FedMRL использовал CNN-1 для своей однородной глобальной небольшой модели, но с меньшей размерностью представления $d_1$ по сравнению с $d_2$ клиента. В гетерогенных по моделям сценариях FedMRL использовал самую маленькую модель CNN-5 для своего глобального компонента, опять же с уменьшенным $d_1$.
Производительность оценивалась по трем критическим аспектам:
* Точность модели: Средняя тестовая точность всех клиентов.
* Затраты на связь: Измеряются общим количеством параметров, переданных между сервером и одним клиентом для достижения целевой средней точности, с учетом как параметров за раунд, так и количества раундов.
* Вычислительные накладные расходы: Измеряются общим количеством операций с плавающей запятой (FLOPs) на клиента для достижения целевой средней точности, с учетом FLOPs за раунд и количества раундов.
Стратегия обучения включала обширную настройку гиперпараметров для всех алгоритмов, включая размер пакета, эпохи, раунды связи и скорости обучения. Важно отметить, что уникальный гиперпараметр FedMRL, $d_1$ (размерность представления однородной небольшой глобальной модели), варьировался от 100 до 500 для поиска оптимального компромисса. Эксперименты проводились в трех различных настройках FL (N=10, C=100%; N=50, C=20%; N=100, C=10%) как для однородных, так и для гетерогенных моделей. Авторы сообщили средние результаты трех испытаний для каждой экспериментальной настройки.
Что доказывают доказательства
Экспериментальные данные предоставляют окончательные, неоспоримые доказательства того, что основной механизм FedMRL — адаптивное персонализированное слияние представлений и обучение представлений с множеством гранулярностей — эффективно работает на практике, приводя к превосходной производительности.
Превосходная точность модели:
* FedMRL последовательно превосходил все семь передовых базовых методов как в гетерогенных по моделям (Таблица 1), так и в однородных по моделям (Таблица 3, Приложение C.2) сценариях FL.
* Он достиг впечатляющего улучшения средней тестовой точности до 8,48% по сравнению с лучшим общим базовым методом и до 24,94% по сравнению с лучшим базовым методом той же категории (основанным на взаимном обучении).
* Рисунок 3 (левые шесть графиков) визуально подтверждает более быструю сходимость FedMRL и более высокую конечную среднюю тестовую точность по сравнению с лучшим базовым методом (FedProto) при различных настройках клиентов и коэффициентов участия.
Улучшенная персонализация:
* Рисунок 3 (правые два графика) иллюстрирует разницу в тестовой точности индивидуальных клиентов между FedMRL и FedProto. Замечательные 87% клиентов на CIFAR-10 и 99% на CIFAR-100 достигли лучшей производительности с FedMRL. Это убедительное доказательство превосходной способности FedMRL к персонализации, напрямую связанной с его адаптивным персонализированным обучением представлений с множеством гранулярностей.
Улучшенная эффективность:
* Затраты на связь: Хотя FedMRL передает полную однородную небольшую модель, что влечет за собой более высокие затраты на связь за раунд, чем FedProto (который отправляет только локальные представления увиденных классов), Рисунок 4 (слева) показывает, что FedMRL требует меньше раундов связи для достижения целевой точности, что приводит к более быстрой сходимости. Кроме того, при рассмотрении необязательной меньшей размерности представления ($d_1$) FedMRL достигает более высокой эффективности связи, чем другие базовые методы взаимного обучения (FML, FedKD, FedAPEN), которые используют большие размерности представления.
* Вычислительные накладные расходы: Несмотря на накладные расходы за раунд, связанные с обучением дополнительной однородной небольшой модели и легковесного проектора представлений, Рисунок 4 (справа) демонстрирует, что FedMRL несет более низкие общие вычислительные затраты, чем FedProto. Это прямое следствие его более быстрой сходимости, требующей меньшего общего числа раундов обучения.
Устойчивость к не-IID данным:
* Не-IID по классам: Рисунок 5 (левые два графика) ясно показывает устойчивость FedMRL, поддерживая более высокую среднюю тестовую точность, чем FedProto, даже по мере уменьшения количества классов на клиента (увеличение не-IID).
* Не-IID по Дирихле: Рисунок 5 (правые два графика) далее подтверждает эту устойчивость, причем FedMRL значительно превосходит FedProto по всем протестированным значениям $\alpha$, демонстрируя его устойчивость к различным степеням гетерогенности данных.
Валидация механизма посредством анализа чувствительности и абляционного исследования:
* Чувствительность к $d_1$: Анализ Рисунка 6 (левые два графика) показывает, что меньшие значения $d_1$ (размерность представления однородной небольшой модели) часто приводят к более высокой средней тестовой точности и снижению накладных расходов на связь/вычисления. Это подчеркивает важность $d_1$ для достижения оптимального компромисса.
* Абляционное исследование: Рисунок 6 (правые два графика) окончательно доказывает полезность компонента обучения представлений Матрешки (MRL). FedMRL с MRL последовательно превосходил FedMRL без MRL, подтверждая, что обучение представлений с множеством гранулярностей является критически важным элементом дизайна для MHeteroFL. Наблюдение, что разрыв в точности уменьшается по мере увеличения $d_1$, предполагает, что когда глобальные и локальные заголовки изучают все более перекрывающиеся представления, преимущества MRL уменьшаются.
Гибкость модели вывода:
* Приложение C.3 и Рисунок 7 показывают, что модели вывода "mix-small" (вся модель без локального заголовка) и "mix-large" (вся модель без глобального заголовка) достигают схожей, высокой точности, значительно превосходящей отдельные однородные или гетерогенные модели. Это обеспечивает практическую гибкость для пользователей в выборе в зависимости от их конкретных требований к затратам на вывод.
Ограничения и будущие направления
Хотя FedMRL представляет собой значительный прогресс в гетерогенном федеративном обучении моделей, важно признать его текущие ограничения и рассмотреть направления для будущего развития.
Текущие ограничения:
Основное ограничение, выявленное авторами, заключается в многогранулярных вложенных представлениях в рамках представлений Матрешки. Эти представления в настоящее время обрабатываются как заголовком глобальной небольшой модели, так и заголовком локальной клиентской модели. Хотя глобальный заголовок может включать только один линейный слой, эта двойная обработка по-прежнему способствует увеличению затрат на хранение, накладных расходов на связь и накладных расходов на обучение для глобального заголовка. Это подразумевает, что, хотя FedMRL улучшает общую эффективность за счет ускорения сходимости, все еще есть возможности для оптимизации потребления ресурсов, связанного с обработкой этих многогранулярных представлений глобальной моделью.
Будущие направления и темы для обсуждения:
-
Оптимизация обработки с множеством гранулярностей: В статье предлагается использовать более продвинутый метод обучения представлений Матрешки (MRL-E) [24] в будущей работе. Это потребует полного удаления глобального заголовка и полагания исключительно на локальный заголовок модели для обработки многогранулярных представлений Матрешки. Это может привести к лучшему компромиссу между производительностью модели и затратами на хранение, связь и вычисления.
- Обсуждение: Как такой сдвиг может повлиять на аспект "глобальных знаний" федеративного обучения? Не рискует ли опора исключительно на локальные заголовки для многогранулярной обработки размыть преимущества общей глобальной модели, или механизм адаптивного слияния представлений может достаточно компенсировать это? Какие архитектурные изменения потребуются в локальном заголовке модели для обработки этой возросшей ответственности без существенного увеличения локальной вычислительной нагрузки?
-
Динамическая оптимизация $d_1$: Анализ чувствительности показал, что меньшие значения $d_1$ (размерность представления однородной небольшой модели) часто приводят к более высокой точности и снижению накладных расходов.
- Обсуждение: Может ли $d_1$ динамически оптимизироваться в процессе обучения FL, возможно, на основе специфических характеристик данных клиента или метрик сходимости? Можно ли использовать подход обучения с подкреплением для изучения оптимального $d_1$ для различных клиентов или раундов связи, вместо того чтобы полагаться на фиксированный, предварительно настроенный гиперпараметр?
-
Расширение на задачи без учителя/самообучения: Текущий подход FedMRL разработан для задач обучения с учителем.
- Обсуждение: Как принципы адаптивного слияния представлений и обучения представлений с множеством гранулярностей могут быть распространены на федеративное обучение без учителя или самообучения, которые становятся все более актуальными для сценариев с ограниченными размеченными данными? Какие модификации потребуются для функций потерь и механизмов передачи знаний в таких условиях?
-
Устойчивость к антагонистическим атакам и отравлению данных: Хотя в статье упоминается защита конфиденциальности, она явно не детализирует устойчивость к злонамеренным атакам.
- Обсуждение: Учитывая улучшенную передачу знаний и персонализированные представления, как архитектура FedMRL может изначально сопротивляться или быть уязвимой к атакам отравления данных или инверсии модели? Какие дополнительные механизмы сохранения конфиденциальности (например, дифференциальная конфиденциальность, безопасная агрегация) могут быть интегрированы с FedMRL для дальнейшего усиления его безопасности без существенного компромисса его производительности или эффективности?
-
Масштабируемость до чрезвычайно большого N и разнообразного C: Эксперименты проводились с участием до N=100 клиентов.
- Обсуждение: Как FedMRL будет масштабироваться до федеративных сетей с тысячами или даже миллионами клиентов, особенно с учетом различных коэффициентов участия клиентов (C) и прерывистой доступности клиентов? Требуются ли дальнейшие оптимизации для стратегии агрегации или протоколов связи для поддержания эффективности в таких крупномасштабных развертываниях?
-
За пределами классификации изображений: Текущая валидация проводится на наборах данных для классификации изображений.
- Обсуждение: Насколько хорошо FedMRL обобщится на другие модальности данных и задачи, такие как обработка естественного языка, анализ временных рядов или медицинская визуализация? Перенесется ли концепция "Матрешки" многогранулярных представлений напрямую, или потребуются доменно-специфические адаптации для извлечения признаков и слияния?
Эти темы для обсуждения направлены на стимулирование критического мышления о том, как фундаментальные идеи FedMRL могут быть использованы и развиты для решения более широких проблем и открытия новых возможностей в области федеративного обучения.
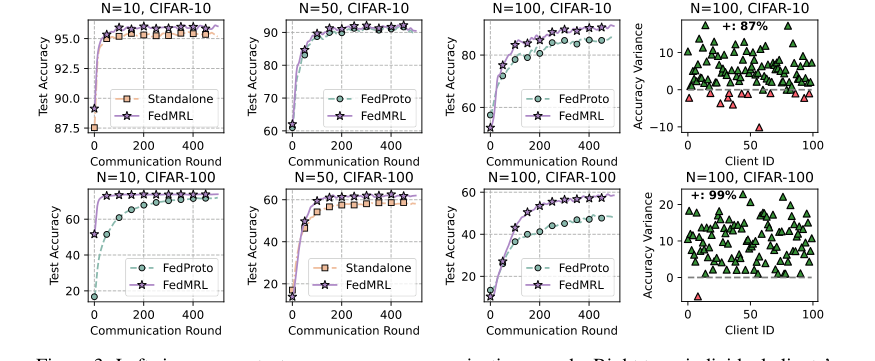 Figure 3. Left six: average test accuracy vs. communication rounds. Right two: individual clients’ test accuracy (%) differences (FedMRL - FedProto)
Figure 3. Left six: average test accuracy vs. communication rounds. Right two: individual clients’ test accuracy (%) differences (FedMRL - FedProto)
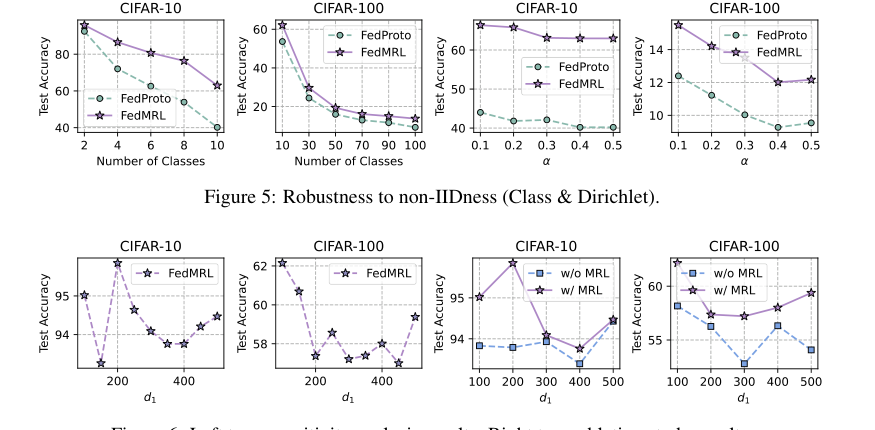 Figure 6. Left two: sensitivity analysis results. Right two: ablation study results
Figure 6. Left two: sensitivity analysis results. Right two: ablation study results
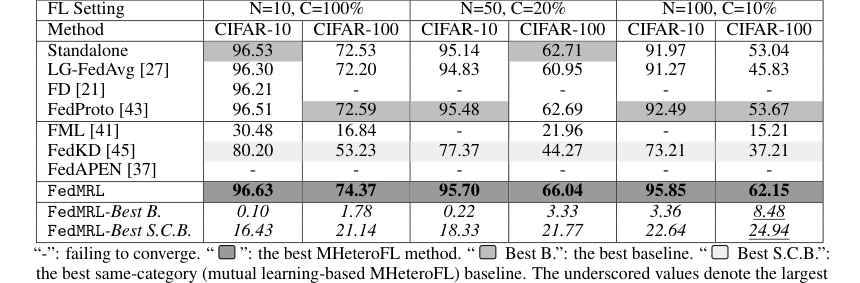 Table 1. and Table 3 (Appendix C.2) show that FedMRL consistently outperforms all baselines under both model-heterogeneous or homogeneous settings. It achieves up to a 8.48% improvement in average test accuracy compared with the best baseline under each setting. Furthermore, it achieves up to a 24.94% average test accuracy improvement than the best same-category (i.e., mutual learning- based MHeteroFL) baseline under each setting. These results demonstrate the superiority of FedMRL
Table 1. and Table 3 (Appendix C.2) show that FedMRL consistently outperforms all baselines under both model-heterogeneous or homogeneous settings. It achieves up to a 8.48% improvement in average test accuracy compared with the best baseline under each setting. Furthermore, it achieves up to a 24.94% average test accuracy improvement than the best same-category (i.e., mutual learning- based MHeteroFL) baseline under each setting. These results demonstrate the superiority of FedMRL
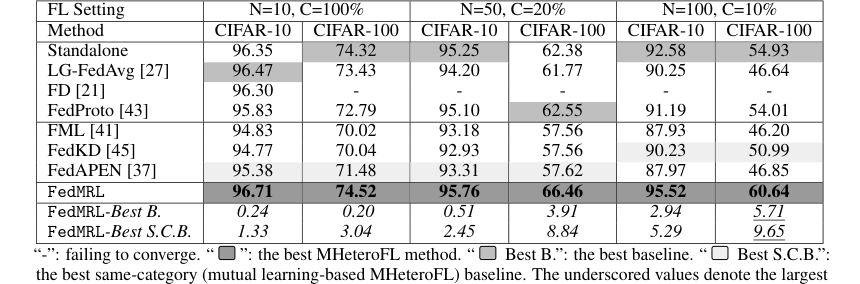 Table 3. presents the results of FedMRL and baselines in model-homogeneous FL scenarios
Table 3. presents the results of FedMRL and baselines in model-homogeneous FL scenarios