連合モデル異種マトリョーシュカ表現学習
Model heterogeneous federated learning (MHeteroFL) enables FL clients to collaboratively train models with heterogeneous structures in a distributed fashion.
背景と学術的系譜
起源と学術的系譜
本論文で取り組むモデル異種連合学習(Model Heterogeneous Federated Learning: MHeteroFL)という問題は、従来の連合学習(Federated Learning: FL)の固有の限界から生まれた。当初、FLは、中央サーバーが複数のデータ所有者(クライアント)を調整し、ローカルデータを直接公開することなく、単一のグローバル共有モデルをトレーニングするプライバシー保護手法として考案された。各通信ラウンドにおいて、サーバーはグローバルモデルをブロードキャストし、クライアントはローカルデータでそれをトレーニングし、更新されたローカルモデルをサーバーに送信して集約し、新しいグローバルモデルを形成する。このプロセスは収束まで繰り返され、モデルパラメータのみが送信されるため、データプライバシーが保護される。
しかし、この従来のFL設計は、現実世界のシナリオに適用する際に、多くの「ペインポイント」に直面し、MHeteroFLのようなより高度なアプローチの開発を余儀なくされた。これらの限界には以下が含まれる。
- データ異種性(Non-IIDデータ): クライアントのローカルデータは、独立かつ同一に分布しない(non-IID)パターンに従わないことが多い。これは、そのような多様なローカルデータセットから集約された単一のグローバルモデルが、すべてのクライアントで最適に機能しない可能性があることを意味する。例えば、あるクライアントのデータは特定のクラスに大きく偏っているかもしれないが、別のクライアントは異なるクラスのデータを持っているかもしれない。
- システム異種性: FLクライアントは、計算能力やネットワーク帯域幅が大きく異なる場合がある。すべてのクライアントに同じ、しばしば大きなモデル構造をトレーニングさせることは、グローバルモデルのサイズが最も弱いデバイスに合わせる必要があることを意味し、より大きな、より複雑なモデルを処理できるより強力なクライアントでのパフォーマンスが最適化されない結果となる。
- モデル異種性: 実用的なFLアプリケーション、特にクライアントが企業である場合、独自のアーキテクチャや知的財産(IP)の懸念を持つ専有モデルを保有している可能性がある。これらの異種モデルまたはその構造をFLトレーニング中に直接共有することは、IP保護のためにしばしば許容されない。
既存のMHeteroFL手法は、クライアントがカスタマイズされた構造を持つモデルをトレーニングできるようにすることでこれらの課題に対処しようとしているが、知識転送能力には依然として限界がある。それらは通常、クライアントモデルとサーバーモデル間の知識転送にトレーニング損失に依存しており、パフォーマンスのボトルネック、高い通信および計算コスト、そしてプライベートなローカルモデル構造とデータの公開のリスクが持続する可能性がある。本論文は、マトリョーシュカ表現学習(Matryoshka Representation Learning)に着想を得て、適応的表現融合と多角的表現学習を通じて知識転送を強化することにより、FedMRLを提案し、これらの限界を克服する。
直感的なドメイン用語
ゼロベースの読者がコアコンセプトを理解できるように、論文の専門用語を日常的なアナロジーに翻訳する。
- 連合学習(Federated Learning: FL): 複数のシェフ(クライアント)が、秘密の材料(ローカルデータ)を使って独自の料理(ローカルモデル)を作っている料理コンテストを想像してほしい。レシピを共有する代わりに、彼らは調理技術の要約だけをヘッドジャッジ(中央サーバー)に送る。ジャッジはこれらの要約を組み合わせて一般的な調理アドバイス(グローバルモデル)を作成し、シェフに送り返す。このようにして、誰もがプライベートなレシピを明かすことなく、料理を改善する。
- モデル異種連合学習(Model Heterogeneous Federated Learning: MHeteroFL): 料理のアナロジーを拡張して、各シェフが異なる種類のキッチン機器(多様なシステムリソース)を持ち、異なるスタイルの料理(異種モデル構造)を好むと想像してほしい。MHeteroFLは、非常に柔軟なヘッドジャッジのようなもので、全員が異なるツールや料理アプローチで作業しているにもかかわらず、各シェフに有用でカスタマイズされたアドバイスを提供できる。ジャッジは、全員に同じように料理させたり、同じ機器を使わせたりすることなく、集団的に改善するのを助ける。
- マトリョーシュカ表現学習(Matryoshka Representation Learning: MRL): ロシアの入れ子人形のセットを考えてほしい。各人形は、前の人形の完全な、しかし徐々に小さく、詳細が少ないバージョンである。MRLは、データから「入れ子状」の洞察を生成するシステムをトレーニングすることに似ている。それは非常に広範で一般的な理解(最大の人形)と、より具体的で詳細な詳細(内側のより小さい人形)を生成できる。これにより、システムはタスクに適切なレベルの詳細を使用でき、マトリョーシュカ人形であることを見るだけで十分な場合のように、計算コストを節約できる。
- Non-IIDデータ(Non-Independent and Identically Distributed Data): 動物について学んでいるクラスを考えてほしい。データがIIDであれば、すべての生徒は猫、犬、鳥、魚の写真が均等に混ざった教科書を持っているだろう。Non-IIDデータは、ある生徒の教科書が主に猫についてのもので、別の生徒の教科書が主に犬についてのもので、3番目の生徒の教科書が主に鳥についてのものであるようなものである。彼らの個々の学習教材(ローカルデータ)は均等に分布しておらず、動物(グローバルデータ分布)の全範囲を完全に表していない。これにより、単一の統一されたレッスン計画が全員に有効になるのが難しくなる。
表記テーブル
| 表記 | 説明 |
|---|---|
問題定義と制約
コア問題定式化とジレンマ
本論文で取り組むコア問題は、モデル異種連合学習(MHeteroFL)のドメイン内にあり、これは、生のローカルデータを共有することなく、多様なモデルアーキテクチャを持つ複数のクライアントがグローバルモデルを共同でトレーニングできるようにすることを目的としている。
入力/現在の状態:
従来の連合学習(FL)は、単一の共有グローバルモデルをトレーニングするためにN個のクライアントを調整する中央サーバーで動作する。各通信ラウンドにおいて、サーバーはグローバルモデルをブロードキャストし、クライアントはローカルデータでそれをトレーニングし、更新されたローカルモデルをサーバーに送信して集約する。このプロセスは収束まで繰り返され、データプライバシーを保護するためにモデルパラメータのみが送信される。しかし、この従来のFL設計は、実用的なアプリケーションに prevalent な3つの重要な異種性課題に苦しんでいる。
1. データ異種性(Non-IID): クライアントのローカルデータセットは、独立かつ同一に分布しない(non-IID)パターンに従わないことが多く、そのような多様なローカルデータから集約された単一のグローバルモデルは、個々のクライアントでパフォーマンスが低下する可能性がある。
2. システム異種性: FLクライアントは、多様な計算リソース(例:CPU、GPU、メモリ)とネットワーク帯域幅を持っている。すべてのクライアントに同一のモデル構造をトレーニングさせることは、グローバルモデルのサイズが最も弱いデバイスによって制約されることを意味し、より強力なクライアントでのパフォーマンスが最適化されない結果となる。
3. モデル異種性: クライアント、特に企業は、知的財産(IP)の懸念により、共有できない多様で専有的なローカルモデルアーキテクチャを持っている可能性がある。これにより、直接的なパラメータ平均化や集約が不可能になる。
既存のMHeteroFL手法はこれらの課題に対処しようとしているが、主にトレーニング損失を介したクライアントモデルとサーバーモデル間の知識転送に依存している。しかし、このアプローチは、限定的な知識交換、パフォーマンスのボトルネック、高い通信および計算コスト、そしてプライベートなローカルモデル構造とデータの公開の潜在的なリスクにつながる。
望ましいエンドポイント(出力/目標状態):
本論文は、FedMRLと名付けられた新しいMHeteroFLアプローチを開発することを目指しており、これは教師あり学習タスクにおけるデータ、システム、およびモデルの異種性を効果的かつ共同で tackling することができる。目標は以下を達成することである。
1. 強化された知識転送: サーバーのグローバル均質モデルとクライアントの異種ローカルモデル間のより効果的な知識インタラクションを促進する。
2. 改善されたモデルパフォーマンス: 既存の最先端手法と比較して、優れたモデル精度を達成する。
3. 低通信および計算コスト: モデルトレーニングと更新に関連するオーバーヘッドを最小限に抑える。
4. 強力なプライバシー保護: クライアントのローカルデータと異種モデル構造が、サーバーまたは他のクライアントに公開されないことを保証する。
5. パーソナライズされた適応: 学習プロセスがローカルのNon-IIDデータ分布と多様なクライアントリソースに適応できるようにする。
欠落しているリンクまたは数学的ギャップ:
正確な欠落リンクは、プライバシーを保護する方法で、異種モデルとデータ分布を横断する知識転送のための効果的かつ効率的なメカニズムの欠如である。現在の手法が知識転送にトレーニング損失に依存していることは不十分である。FedMRLは、2つの主要なイノベーションを導入することによって、このギャップを埋めようとしている。
1. 適応的表現融合: 各ローカルデータサンプルに対して、グローバル均質小モデルとローカル異種モデルの両方の特徴抽出器が、それぞれ汎化された表現とパーソナライズされた表現を抽出する。これらは、ローカルNon-IIDデータに適応するパーソナライズされた軽量表現プロジェクター$P_k(\phi_k)$によって融合表現にスプライスされ、マッピングされる。
2. 多粒度表現学習: 融合表現は、マトリョーシュカ表現を構築するために使用される。これは、多次元かつ多粒度の埋め込み表現である。これらは、グローバル均質モデルとローカル異種モデルの両方の予測ヘッダーによって処理され、それらの結合された損失がすべてのモデルを更新するために使用される。
数学的には、本論文は以下の目的関数を最小化することを目指している(式1)。
$$
\min_{\theta, \omega_0, \dots, \omega_{N-1}, \phi_0, \dots, \phi_{N-1}} \sum_{k=0}^{N-1} l(W_k(D_k; (\theta \circ \omega_k | \phi_k)))
$$
ここで、$W_k(w_k) = (G(\theta) \circ F_k(w_k) | P_k(\phi_k))$ は、グローバル均質小モデル$G(\theta)$、クライアントのローカル異種モデル$F_k(w_k)$、およびパーソナライズされた表現プロジェクター$P_k(\phi_k)$を組み込んだクライアントkの結合モデルを表す。損失$l$は、マトリョーシュカ表現からの多角的出力に基づいて計算される。
ジレンマ:
以前の研究者を閉じ込めてきた痛みを伴うトレードオフは、低通信/計算コストと強力なプライバシー保証を同時に維持しながら、異種FLクライアント間で高いモデルパフォーマンスと効果的な知識転送を達成することとの間の固有の対立である。1つの側面を改善すると、しばしば別の側面が犠牲になる。例えば、より多くの情報(例:完全なモデルパラメータまたは詳細な中間表現)を共有すると、知識転送とパフォーマンスが向上する可能性があるが、通信コストとプライバシーリスクが大幅に増加する。逆に、プライバシーを保護しコストを削減するために共有情報を制限すると、しばしば「限定的な知識交換」と「モデルパフォーマンスのボトルネック」(ページ2、セクション1)につながり、特にNon-IIDデータでは最適化されていない精度につながる。ジレンマは、機密性の高いクライアントの詳細を公開したり、制約のあるリソースを圧倒したりすることなく、リッチで多角的な知識インタラクションを可能にする方法である。
制約と失敗モード
モデル異種連合学習の問題は、著者が直面するいくつかの厳しい現実的な壁のために、非常に困難である。
- Non-IIDデータ分布: クライアントのローカルデータは、独立かつ同一に分布しない(non-IID)ことが多く、すべてのクライアントでうまく機能する単一のグローバルモデルをトレーニングすることが困難である。これは、パーソナライズされたモデルまたは適応メカニズムを必要とし、複雑さを増す。
- 多様なクライアントシステムリソース: FLクライアントは、異なる計算能力、メモリ、およびネットワーク帯域幅で動作する。提案されたソリューションは、最も弱いデバイスで実行できるほど効率的であると同時に、より強力なデバイスの機能を活用できる必要がある。これは、モデルサイズとクライアントあたりの計算オーバーヘッドに厳密な制限を課す。
- 専有モデル構造とIP保護: クライアントは、知的財産(IP)の懸念により、直接共有または集約できない多様な専有ローカルモデルアーキテクチャを使用している可能性がある。これにより、従来の連合平均化パラメータが不可能になる。
- 限定的な知識転送効果: トレーニング損失または単純な相互学習に依存する既存のMHeteroFL手法は、しばしば「限定的な知識転送」(ページ1、要旨;ページ3、セクション2)しか達成できない。これは、最適化されていないモデルパフォーマンスと遅い収束につながる。
- 高い通信コスト: 各ラウンドでサーバーと多数のクライアント間で大きなモデルパラメータまたは広範な中間表現を送信することは、特に限られたネットワーク帯域幅で、かなりの通信コストを発生させる可能性がある。目標はこれを最小限に抑えることである。
- 高い計算オーバーヘッド: クライアントデバイスで追加のモデルまたは複雑な知識蒸留メカニズムをトレーニングすることは、かなりの計算オーバーヘッドにつながる可能性があり、リソースが制約されたクライアントにとっては望ましくない。
- 厳格なプライバシー要件: FLの基本的な原則は、ローカルデータプライバシーを保護することである。どのような手法でも、生のクライアントデータとローカルモデル構造がサーバーまたは他のクライアントに公開されないことを保証する必要がある。これを維持できないことは、重大な失敗モードである。
- 非凸最適化ランドスケープ: 異種モデルを持つ連合学習における最適化問題は、一般に非凸である。良い解、ましてやグローバルな最適解への収束を保証することは、重大な数学的課題である。本論文は、$O(1/T)$の非凸収束率(ページ1、要旨)を示す理論的分析を提供しており、これは一般的ではあるが依然として困難な側面である。
- モデルパフォーマンスのボトルネック: 効果的な知識転送がないと、クライアントモデルはパフォーマンスのボトルネックに苦しみ、うまく汎化できなかったり、高い精度を達成できなかったりする可能性がある。
- スケーラビリティの問題: ソリューションは、多数のクライアント(N)にスケーラブルであり、各通信ラウンドでのクライアント参加率(C=K/N)の変動に対して堅牢である必要がある(ページ3、セクション3)。
これらの制約は collectively に、異種モデルを持つ高パフォーマンスでプライバシーを保護し、リソース効率の良い連合学習を達成するという問題を、例外的に困難な事業にしている。
なぜこのアプローチなのか
選択の必然性
FedMRLの開発は、実用的なFLアプリケーションの複雑な現実に直面した際に、既存のモデル異種連合学習(MHeteroFL)アプローチの固有の限界によって推進された。著者は、従来の「SOTA」手法でさえ、連合設定に合わせて調整されても、クライアントとサーバーモデル間の知識転送に主にトレーニング損失に依存していたため不十分であることを認識した。この依存関係は、「限定的な知識交換」、「モデルパフォーマンスのボトルネック」、「高い通信および計算コスト」、そして「プライベートなローカルモデル構造とデータの公開のリスク」(要旨、ページ1)といった、いくつかの重要な欠点につながった。
具体的には、本論文は、従来のFL設計が3つの主要な異種性課題に苦しんでいたことを強調している。(1)データ異種性、クライアントデータがNon-IIDであること。(2)システム異種性、クライアントが多様な計算能力とネットワーク帯域幅を持ち、グローバルモデルが最も弱いデバイスに合わせることを強制すること。(3)モデル異種性、クライアントが知的財産の問題により直接共有できない専有モデルを保有していること(セクション1、ページ1-2)。MHeteroFLがこれらを tackling するために出現したにもかかわらず、適応型サブネット、知識蒸留、モデル分割、または相互学習に基づくものなど、この分野内の既存の手法でさえ、重大な欠点を示していた。例えば、FedMRLが構築される相互学習アプローチは、「2つのモデル間で限定的な知識しか転送できず、モデルパフォーマンスのボトルネックにつながる」(セクション2、ページ3)と指摘されていた。
単一のイベントとして明示的に特定されてはいないが、著者の認識の正確な瞬間は、以前のMHeteroFL手法の包括的な批判によって強く示唆されている。著者は、単純な損失ベースの蒸留を超えて、より洗練された表現レベルのインタラクションへと移行する、知識転送のための根本的に異なるメカニズムが必要であると認識した。これにより、彼らはマトリョーシュカ表現学習(MRL)[24]からインスピレーションを得るようになった。これは、モデルパフォーマンスと推論コストの最適なバランスを達成するために、表現次元を調整する方法を提供する。モデル中心または損失中心ではなく、表現中心のアプローチへのこの移行は、連合学習における異種性、プライバシー、および効率性の持続的な課題を克服するための唯一実行可能なパスとなった。
比較優位性
FedMRLは、単なるパフォーマンス指標を超えて、いくつかの構造的および機能的な利点を通じて、以前のゴールドスタンダードに対して圧倒的な質的優位性を示している。
第一に、そのコアイノベーションは適応的表現融合と多粒度表現学習にある。単一の固定表現に依存する手法とは異なり、FedMRLは汎化された表現(共有均質モデルから)とパーソナライズされた表現(クライアントの異種ローカルモデルから)の両方を抽出する。これらは、ローカルNon-IIDデータ分布に適応するために重要な、軽量でパーソナライズされたプロジェクターによって適応的に融合される(セクション3.1、ページ4)。この構造設計により、データ異種性に苦しむアプローチよりも大幅な質的飛躍となる、ローカルデータのより豊かでニュアンスのある理解が可能になる。その後のマトリョーシュカ表現の構築、つまり多次元かつ多粒度の埋め込み表現の包含は、モデルが粗い特徴と細かい特徴の両方を学習できるようにすることで、モデル学習能力をさらに強化し、より堅牢で効果的になる。これは、モデルが粗い特徴と細かい特徴の両方を学習できるようにする構造的利点である。
第二に、FedMRLは優れたプライバシー保護とリソース効率を提供する。「各クライアントのローカルモデルとデータは、トレーニング中に公開されない」(セクション2、ページ2)ことを保証する。これは、プライバシーに敏感なアプリケーションにとって重要な構造的利点である。さらに、この設計は本質的に、クライアントがローカルモデルに加えて小さな均質モデルと軽量プロジェクターのみをトレーニングするため、「低通信コスト」と「低追加計算コスト」につながる(セクション2、ページ2)。論文はメモリ複雑性を$O(N^2)$から$O(N)$に削減すると明示的に述べていないが、「小さな均質モデル」と「軽量」コンポーネントへの重点は、より大きな、より複雑なモデルや広範なデータ共有を必要とする可能性のある手法と比較して、メモリと計算フットプリントの大幅な削減を直接示唆している。
最後に、この手法のNon-IIDデータに対する堅牢性とより強力なパーソナライゼーション能力は、質的に優れている。実験は、FedProto(セクション5.3.1、5.3.2、ページ9)のようなベースラインと比較して、さまざまなNon-IID設定下でFedMRLが一貫してより高い平均テスト精度を達成することを示している。さらに、それはより強力なパーソナライゼーションを提供し、個々のクライアントの大部分(CIFAR-10で87%、CIFAR-100で99%)がFedProto(セクション5.2.2、ページ8)よりも優れたパフォーマンスを達成している。これは、多様なクライアント環境とデータ分布を処理する上での基本的な構造的利点を示している。
制約との整合性
FedMRLの設計は、異種連合学習の厳しい要件と制約と完全に整合しており、問題とソリューションの間の相乗的な「結婚」を生み出している。
- データ異種性(Non-IIDデータ): 適応的表現融合メカニズムは、これを tackling するために明示的に設計されている。パーソナライズされた表現プロジェクターは、スプライスされた汎化された表現とパーソナライズされた表現を、ローカルNon-IIDデータに適応する融合表現にマッピングする(セクション3.1、ページ4)。これにより、各クライアントのユニークなデータ分布が考慮され、Non-IID設定で一般的なパフォーマンス低下を防ぐことができる。
- システム異種性: FedMRLは、「異種ローカルモデル」と相互作用する「共有グローバル補助均質小モデル」を導入することにより、多様なクライアント機能を収容する(セクション2、ページ2)。グローバルモデルは意図的に小さく、リソースが限られたクライアントでもブロードキャストしてトレーニングできるように設計されている。クライアントは、スプライスされた表現を整合させるために、表現プロジェクターの線形層の次元を調整することもでき、ローカルシステム制約にさらに適応する(セクション3.1、ページ4)。
- モデル異種性: このフレームワークは、クライアントが「ローカルモデルに多様な構造を持つ」(セクション3.1、ページ4)ことを本質的にサポートしている。サーバーは均質小モデルとのみ相互作用し、クライアントの異種ローカルモデルをブラックボックスとして扱う。この設計は、クライアントが専有モデル構造を公開する必要がないため、知的財産の問題を尊重する。
- プライバシー保護: これはFedMRLの基盤である。「各クライアントのローカルモデルとデータは、プライバシー保護のためにトレーニング中に公開されない」(セクション2、ページ2)。均質小モデルのみが送信され、ローカルデータとモデル構造がプライベートであることを保証する。
- 通信効率: 「小さな均質モデル」(セクション2、ページ2)のみを送信することにより、FedMRLは、完全なクライアントモデルを交換する手法と比較して、通信コストを大幅に削減する。均質小モデルの表現次元$d_1$を変化させる能力は、通信オーバーヘッドの最適化をさらに可能にする(セクション5.3.3、ページ9)。
- 計算効率: クライアントは、ローカルモデルに加えて、「小さな均質モデルと軽量表現プロジェクター」(セクション2、ページ2)のみをトレーニングする必要があり、低追加計算コストが発生する。FedMRLによって達成されるより速い収束速度(図4、ページ8)は、ターゲット精度に到達するために必要な通信ラウンドが少なくなることも意味し、全体的な計算オーバーヘッドを削減する(セクション5.2.4、ページ9)。
- 知識転送の限界: 適応的表現融合と多粒度表現学習の二重のイノベーションは、以前の手法の「限定的な知識交換」問題を直接 tackling する。「2つのモデル間の知識インタラクションを促進し、モデルパフォーマンスを向上させる」ことで、複数の視点から汎化された表現とパーソナライズされた表現を学習する(セクション2、ページ3)。
代替案の却下
本論文は、問題の制約に対処する上での根本的な欠点を強調することにより、既存のMHeteroFLアプローチのいくつかのカテゴリを体系的に特定し、却下している。
- 適応型サブネットを持つMHeteroFL: これらの手法は、グローバルモデルから異種ローカルサブネットを構築する。著者は、「クライアントが共通のグローバルモデルから派生していないブラックボックスローカルモデルを保有している場合、サーバーはそれらを集約できない」(セクション2、ページ3)ため、このアプローチを却下する。これは、クライアントモデルが専有的であり、グローバルモデルの単なる枝刈りバージョンではない、真のモデル異種性を処理できないことを意味する。
- 知識蒸留を持つMHeteroFL:
- 公開データセットを知識転送に使用する手法は、「そのような適切な公開データセットを見つけるのが難しい」(セクション2、ページ3)ため、非実用的と見なされる。
- 共有データセットを合成するためにジェネレーターをトレーニングするアプローチは、「高いトレーニングコスト」(セクション2、ページ3)がかかるため却下される。
- 中間情報を共有する他の手法は、「クライアントローカルデータを知識融合のために公開する」リスクがあるため、プライバシーが侵害される可能性があるため、暗黙的に却下される。
- モデル分割を持つMHeteroFL: これらの手法は、モデルを特徴抽出器と予測器に分割し、いずれか一方を共有する。本論文は、「モデルがクライアントの専有IPである場合、受け入れられない可能性があるローカルモデル構造の一部を公開する」(セクション2、ページ3)ため、この戦略を却下する。これは、プライバシーと知的財産保護の制約に直接矛盾する。
- 相互学習を持つMHeteroFL: FedMRLはこのカテゴリに基づいて構築されているが、既存の相互学習手法(例:FML、FedKD、FedAPEN)は、「相互損失は2つのモデル間で限定的な知識しか転送できず、モデルパフォーマンスのボトルネックにつながる」(セクション2、ページ3)ため不十分であると明示的に述べている。FedMRLは、単に相互損失に依存するのではなく、表現ベースのアプローチに移行することにより、「知識転送を強化する」最適化として提示されている。
本論文は、GAN、拡散モデル、またはTransformerのような一般的な深層学習アーキテクチャの失敗を、連合学習アプローチ自体の代替案として議論していない。代わりに、それは暗黙的にCNN(Transformerの先行アーキテクチャの一種)をそのフレームワーク内の基盤モデルとして組み込んでいる(表2、ページ17)。却下は、異種性、プライバシー、およびリソース効率のユニークな課題を効果的に管理できない連合学習パラダイムに対するものであり、基本的なモデルアーキテクチャに対するものではない。
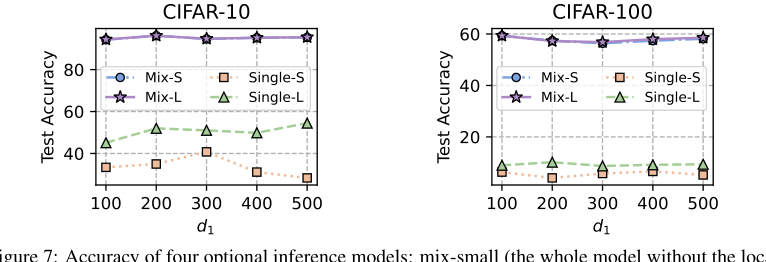 Figure 7. Accuracy of four optional inference models: mix-small (the whole model without the local header), mix-large (the whole model without the global header), single-small (the homogeneous small model), single-large (the client heterogeneous model)
Figure 7. Accuracy of four optional inference models: mix-small (the whole model without the local header), mix-large (the whole model without the global header), single-small (the homogeneous small model), single-large (the client heterogeneous model)
数学的・論理的メカニズム
マスター方程式
FedMRLアプローチの絶対的なコアは、連合学習設定におけるすべての参加クライアントの合計損失を最小化することを目的とする目的関数である。このマスター方程式は、学習全体の目標をカプセル化している。
$$ \min_{\theta, \omega_0, \dots, \omega_{N-1}, \phi_0, \dots, \phi_{N-1}} \sum_{k=0}^{N-1} l(W_k(D_k; (\theta \circ \omega_k | \phi_k))) $$
用語ごとの解剖
このマスター方程式とその基盤となるコンポーネントを分解して、その数学的定義、論理的役割、およびその構築の根拠を理解しよう。
-
$\min_{\theta, \omega_0, \dots, \omega_{N-1}, \phi_0, \dots, \phi_{N-1}}$: これは最適化目的である。
- 数学的定義: 後続の損失の合計を最小化するパラメータのセット($\theta$、$\omega_k$、$\phi_k$)を見つけることが目標であることを意味する。
- 物理的/論理的役割: これはFedMRLシステム全体の中心的な指示である。学習プロセスが、すべてのクライアントで予測を可能な限り正確にするために、関連するすべてのモデルパラメータを調整することを指示する。
- なぜ最小化なのか: 機械学習では、通常、「損失」または「誤差」関数を定義し、この誤差を削減することが目標であるため、最小化が自然な選択である。
-
$\sum_{k=0}^{N-1}$: これは合計演算子である。
- 数学的定義: クライアント$k=0$から$N-1$までの各クライアントからの個々の損失貢献を合計することを意味する。
- 物理的/論理的役割: 連合学習では、全体的なパフォーマンスはすべてのクライアントの集合的な測定値である。この合計は、グローバルな学習目標を促進しながらローカルデータを尊重するために、グローバルな目的がすべてのクライアントの学習結果を考慮することを保証する。
- なぜ合計なのか(例えば積ではなく): 合計は、マルチクライアントまたはマルチタスク設定で損失を集約する標準的な方法である。積は、小さな損失(合計をゼロに駆動する)または大きな損失(合計を爆発させる)に非常に敏感であり、最適化を不安定にするだろう。合計は、個々のクライアントパフォーマンスのより安定した解釈可能な集約を提供する。
-
$l(\cdot)$: これは損失関数を表す。
- 数学的定義: 論文(式8)で述べられているように、これは通常、モデルの予測出力$y$と真のラベル$Y_i$との間の不一致を測定するクロスエントロピー損失、$l(y, Y_i)$である。
- 物理的/論理的役割: 損失関数は、モデルの予測が与えられた入力に対してどれだけ「間違っている」かを定量化する。損失が高いほど、予測は悪い。これは、モデルパラメータを調整するための最適化プロセスに信号を提供する。
- なぜクロスエントロピーなのか: クロスエントロピーは、誤った分類をより重く罰し、モデルが真のラベル分布に一致する確率を出力するように奨励するため、分類タスクで広く使用されている。
-
$W_k(D_k; (\theta \circ \omega_k | \phi_k))$: これは、クライアントkの結合モデルを表し、そのローカルデータ$D_k$上で動作し、グローバル($\theta$)、ローカル($\omega_k$)、およびパーソナライズされたプロジェクター($\phi_k$)パラメータの組み合わせによってパラメータ化される。FedMRLのコアメカニズムが reside する場所である。その内部動作を分解してみよう。
-
$D_k$: これはクライアントkのローカルデータセットを表す。
- 数学的定義: 入力特徴ベクトル$x_i$とその対応する真のラベル$Y_i$のデータサンプルセット。
- 物理的/論理的役割: これは、各クライアントがトレーニングに使用するプライベートなローカルデータである。FLにおいて、このデータがローカルに残り、サーバーまたは他のクライアントと直接共有されないことが重要である。
-
$\theta$: これはグローバル均質小モデルのパラメータを表す。
- 数学的定義: $\theta = \{\theta_{ex}, \theta_{hd}\}$ここで、$\theta_{ex}$はグローバルモデルの特徴抽出器$G_{ex}$のパラメータ、$\theta_{hd}$は予測ヘッダー$G_{hd}$のパラメータである。これらはすべてのクライアントで共有される。
- 物理的/論理的役割: このモデルは「汎化された」知識源として機能する。通信コストを最小限に抑え、システム異種性を収容するために、小さく均質である。一般的なベースライン表現を提供する。
-
$\omega_k$: これはクライアントkの異種ローカルモデルのパラメータを表す。
- 数学的定義: $\omega_k = \{\omega_{ex,k}, \omega_{hd,k}\}$ここで、$\omega_{ex,k}$はクライアントkのローカル特徴抽出器$F_{ex}$のパラメータ、$\omega_{hd,k}$は予測ヘッダー$F_{hd}$のパラメータである。これらは各クライアントに固有である。
- 物理的/論理的役割: このモデルは、クライアントkの特定のデータ分布とモデル構造に適応した「パーソナライズされた」知識をキャプチャする。データおよびモデルの異種性に対処する。
-
$\phi_k$: これはクライアントkのパーソナライズされた表現プロジェクターのパラメータを表す。
- 数学的定義: $\phi_k$は軽量プロジェクター$P_k$のパラメータである。
- 物理的/論理的役割: このプロジェクターは、汎化された表現とパーソナライズされた表現を適応的に融合する責任がある。ローカルNon-IIDデータ分布を効果的に処理するために、各クライアントにパーソナライズされている。
-
$\circ$ (スプライシング演算子): この演算子は、特徴抽出器の出力を組み合わせる。
- 数学的定義: 式(3)によると、$R_i = R_k^g \circ R_k^f$ここで、$R_k^g = G_{ex}(x_i; \theta_{ex,t-1})$はグローバルモデルの特徴抽出器からの汎化された表現、$R_k^f = F_{ex}(x_i; \omega_{ex,t-1})$はローカルモデルの特徴抽出器からのパーソナライズされた表現である。スプライシングは通常、特徴ベクトルを連結することを意味する。
- 物理的/論理的役割: このステップは、汎用的な知識とクライアント固有の知識の両方から得られた表現を、単一の、より豊かな表現にマージすることを保証する。
- なぜ加算や乗算ではなくスプライシングなのか: スプライシング(連結)は、両方のソースからの明確な意味論的情報を保持する。加算または乗算を行った場合、特に特徴空間が異なるスケールや意味を持っている場合、情報がブレンドされたり失われたりする可能性がある。スプライシングにより、後続のプロジェクターがこれらの異なる視点を最良の方法で組み合わせる方法を学習できるようになる。論文はそれが「相対的な意味論的空間位置を維持できる」と述べている。
-
$|$ (マトリョーシュカ表現学習): このシンボルは、概念的に多次元、多粒度のマトリョーシュカ表現学習プロセスを表す。
- 数学的定義: スプライスされた表現$R_i$がプロジェクター$P_k$によって融合表現$R_i = P_k(R_i; \phi_{k,t-1})$(式4)にマッピングされた後、それは2つの埋め込み表現に分割される。$R_i^{lc} = R_i^{1:d_1}$(低次元、粗粒度)および$R_i^{hf} = R_i^{1:d_2}$(高次元、細粒度)(式5)。これらはその後、別々の予測ヘッダーにフィードされる。$y_i^{lc} = G_{hd}(R_i^{lc}; \theta_{hd,t-1})$(式6)および$y_i^{F_k} = F_{hd}(R_i^{hf}; \omega_{hd,t-1})$(式7)。
- 物理的/論理的役割: このメカニズムは、より小さい人形がより大きい人形の中にネストされているマトリョーシュカ人形に触発されている。ここでは、異なる粒度と次元で表現を抽出することを意味する。これにより、モデルは複数の視点から学習できるようになり、粗い情報と細かい情報の両方をキャプチャでき、モデル学習能力と堅牢性が向上する。グローバルヘッダーは粗い表現を使用し、ローカルヘッダーは細かい表現を使用する。
- なぜ分割と別々のヘッダーなのか: この設計により、「多角的表現学習」が可能になる。異なるヘッダーが融合表現の異なる粒度を処理することで、モデルはより堅牢で包括的な特徴を学習できる。それは、全体的な形状を把握するために遠くから物体を見ることと、詳細を見るために近くから見ることのようで、両方ともより良い理解に貢献する。
-
$m_i^{lc} \cdot l_i^{lc} + m_i^{F_k} \cdot l_i^{F_k}$ (重み付き損失合計): これは、クライアントkの単一データポイントiの最終的な結合損失である。
- 数学的定義: $l_i = m_i^{lc} \cdot l_i^{lc} + m_i^{F_k} \cdot l_i^{F_k}$(式9)、ここで、$l_i^{lc}$はグローバルモデルのヘッダーからの損失、$l_i^{F_k}$はローカルモデルのヘッダーからの損失(式8)である。$m_i^{lc}$と$m_i^{F_k}$は重要度重みであり、デフォルトで1に設定されることが多い。
- 物理的/論理的役割: これは、汎化された(グローバル)およびパーソナライズされた(ローカル)両方の視点からの学習信号を組み合わせる。これらの損失に重みを付けることで、システムは各学習ブランチの影響のバランスをとることができる。重みを1に設定すると、両方のモデルが全体的な学習に等しく貢献することが保証される。
- なぜ加算なのか: 全体的な合計と同様に、重み付き損失を加算することは、複数の学習目的を組み合わせる標準的な方法である。これにより、各コンポーネントからのバランスの取れた貢献が可能になり、粗い学習目標と細かい学習目標の両方を満たす最適な状態にモデルを導くことができる。
-
ステップバイステップフロー
クライアントkでFedMRLシステムに入力される真のラベル$Y_i$を持つ画像$x_i$という単一のデータポイントを想像してほしい。その旅は次のとおりである。
-
特徴抽出: 入力画像$x_i$は、まず並列に2つの異なる特徴抽出器に入力される。
- グローバル均質モデルの特徴抽出器 $G_{ex}$(パラメータ$\theta_{ex}$付き)は、$x_i$を処理して汎化された表現 $R_k^g$を生成する。これは、画像に関する一般的で共通の理解を得るようなものである。
- 同時に、クライアントkのローカル異種モデルの特徴抽出器 $F_{ex}$(パラメータ$\omega_{ex,k}$付き)は、$x_i$を処理してパーソナライズされた表現 $R_k^f$を生成する。これは、クライアント固有の詳細やニュアンスをキャプチャする。
-
表現スプライシング: 2つの表現、$R_k^g$と$R_k^f$は、次に「スプライス」(連結)されて、結合された表現$R_i$を形成する。このステップは、一般的およびパーソナライズされた両方の情報が並んで保持されることを保証する。
-
適応的表現融合: スプライスされた表現$R_i$は、次にクライアントkのパーソナライズされた軽量表現プロジェクター $P_k$(パラメータ$\phi_k$付き)に入力される。このプロジェクターは、スプライスされた表現を融合表現 $R_i$にマッピングする。これは、システムが結合された知識をクライアントのユニークなデータ分布に適応させる場所である。
-
マトリョーシュカ表現分割: 融合表現$R_i$は、次に概念的に2つの部分に分割される。マトリョーシュカ人形を開いてより小さい人形を明らかにするように。
- 低次元、粗粒度の表現 $R_i^{lc}$は、$R_i$の初期セグメントから抽出される。
- 高次元、細粒度の表現 $R_i^{hf}$は、$R_i$のより大きなセグメントから抽出される。
-
多角的予測: これらの2つのマトリョーシュカ表現は、次にそれぞれの予測ヘッダーに渡される。
- $R_i^{lc}$は、グローバル均質モデルの予測ヘッダー $G_{hd}$(パラメータ$\theta_{hd}$付き)に渡され、粗い予測 $y_i^{lc}$を生成する。
- $R_i^{hf}$は、クライアントkのローカル異種モデルの予測ヘッダー $F_{hd}$(パラメータ$\omega_{hd,k}$付き)に渡され、細かい予測 $y_i^{F_k}$を生成する。
-
損失計算: 各予測について、真のラベル$Y_i$に対する損失が計算される。
- $l_i^{lc}$は、粗い予測$y_i^{lc}$の損失である。
- $l_i^{F_k}$は、細かい予測$y_i^{F_k}$の損失である。
-
重み付き損失集約: 最後に、これらの2つの個々の損失は、重み付き合計によって、データポイント$x_i$の単一の合計損失$l_i$に結合される。デフォルトでは、両方の損失が等しく寄与する。この$l_i$は、全体的な目的関数に貢献する値である。
このプロセス全体がバッチ内のすべてのデータポイントに対して繰り返され、バッチの平均損失が最適化に使用される。
最適化ダイナミクス
FedMRLメカニズムは、勾配降下法を通じてパラメータを反復的に学習および更新し、グローバル目的関数を最小化することを目指す。
-
勾配計算: クライアントkでデータポイントのバッチに対して重み付き損失$l_i$が計算された後、この損失の勾配は、クライアントkのモデルに関与するすべてのパラメータに対して計算される。
- $\nabla l_i$ 対 $\theta$(グローバルモデルパラメータ)。
- $\nabla l_i$ 対 $\omega_k$(クライアントkのローカルモデルパラメータ)。
- $\nabla l_i$ 対 $\phi_k$(クライアントkのパーソナライズされた表現プロジェクターパラメータ)。
-
ローカルパラメータ更新: 各クライアントkは、これらの勾配と事前に定義された学習率($\eta_\theta$、$\eta_\omega$、$\eta_\phi$)を使用して、ローカルパラメータ($\omega_k$および$\phi_k$)とグローバルモデルパラメータのコピー($\theta$)を更新する。これは標準的な勾配降下ステップである。
$$ \theta^t \leftarrow \theta^{t-1} - \eta_\theta \nabla l_i \\ \omega_k^t \leftarrow \omega_k^{t-1} - \eta_\omega \nabla l_i \\ \phi_k^t \leftarrow \phi_k^{t-1} - \eta_\phi \nabla l_i $$
これらの更新は各クライアントでローカルに発生し、モデルを特定のデータと学習目標に適応させる。論文では、安定した収束のためにデフォルトで$\eta_\theta = \eta_\omega = \eta_\phi$を設定することに言及している。 -
サーバー集約: ローカルトレーニングラウンド(複数のローカルエポックを含む場合がある)の後、参加している各クライアントは、更新された均質小モデルパラメータ(つまり、更新された$\theta$パラメータ)を中央サーバーにアップロードする。サーバーは、参加しているすべてのクライアントからのこれらの更新されたグローバルモデルパラメータを集約して、新しい統合グローバルモデル$\theta^t$を生成する。この集約は通常、受信したパラメータの平均である。ローカル異種モデルパラメータ$\omega_k$とプロジェクターパラメータ$\phi_k$はクライアント上に残り、サーバーに送信されないため、プライバシーが保護される。
-
ブロードキャストと反復: 新しく集約されたグローバルモデル$\theta^t$は、次の通信ラウンドのためにすべてのクライアントにブロードキャストされる。このローカルトレーニング、パラメータアップロード、サーバー集約、およびグローバルモデルブロードキャストのサイクルは、指定されたラウンド数または収束まで繰り返される。
損失ランドスケープと収束: FedMRLの全体的な損失ランドスケープは非凸であり、これは深層学習モデルでは一般的である。反復勾配降下ステップは、このランドスケープをナビゲートし、最小値を見つけようとする。論文のセクション4の理論的分析は、FedMRLが$O(1/T)$の非凸収束率を達成することを示しており、ここで$T$は通信ラウンドの総数である。これは、ラウンド数が増加するにつれて、ローカルトレーニング全体モデルの平均勾配が減少することを示しており、モデルが実際に学習し、時間とともに収束していることを示唆している。この収束の条件は、学習率とパラメータ変動および勾配分散の有界性によって異なり、補題と定理で詳細に説明されている。適応的表現融合と多粒度表現学習は、この損失ランドスケープを、より効果的な知識転送を促進し、モデルがより良い最小値を見つける能力を向上させるように形成するように設計されており、パフォーマンスの向上につながる。
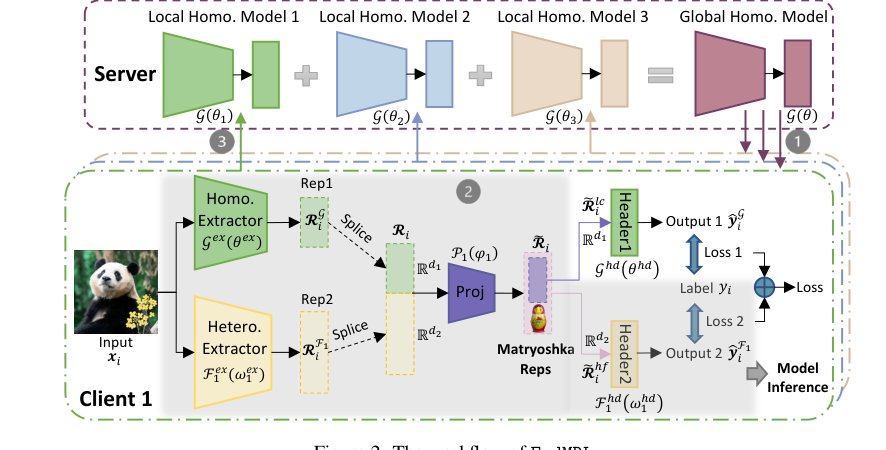 Figure 2. The workflow of FedMRL
Figure 2. The workflow of FedMRL
結果、限界、および結論
実験設計とベースライン
FedMRLの数学的主張と実用的な有効性を厳密に検証するために、著者は包括的な実験セットアップを設計した。提案されたFedMRLアプローチはPytorchを使用して実装され、7つの最先端MHeteroFL手法と比較ベンチマークされた。これらの実験は、それぞれ24GBのメモリを搭載した4つのNVIDIA GeForce 3090 GPUで構成される堅牢なハードウェア構成で実施された。
FedMRLと比較された「犠牲者」(ベースラインモデル)は、4つのカテゴリに分類された。
1. スタンドアロン: クライアントはローカルデータでモデルを独立してトレーニングする。
2. 公開データなしの知識蒸留: FD [21]およびFedProto [43]のような手法。
3. モデル分割: LG-FedAvg [27]で表される。
4. 相互学習: FML [41]、FedKD [45]、およびFedAPEN [37]を含む。
FL画像分類のための2つの広く使用されているベンチマークデータセットが採用された。CIFAR-10(60,000個の32x32カラー画像、10クラス)およびCIFAR-100(60,000個の32x32カラー画像、100クラス)。両方の場合、50,000枚の画像がトレーニングに使用され、10,000枚がテストに使用された。現実的な連合環境をシミュレートするために、2種類のNon-IID(独立かつ同一に分布しない)データ分布が構築された。
* Non-IID(クラス): クライアントには少数のクラス(CIFAR-10で2、CIFAR-100で10)が割り当てられ、クラス数が少ないほどNon-IID性が高くなる。
* Non-IID(ディリクレ): ディリクレ($\alpha$)関数を使用してデータ分布を制御し、$\alpha$が小さいほどNon-IID性が顕著になる。
評価は、モデル均質(すべてのクライアントがCNN-1を使用)とモデル異種(クライアントがCNN-1からCNN-5の混合を使用)の両方のFLシナリオをカバーした。FedMRLの表現プロジェクターは単純な1層線形モデルであった。モデル均質設定では、FedMRLはCNN-1を均質グローバル小モデルとして使用したが、クライアントの$d_2$よりも小さい表現次元$d_1$であった。モデル異種設定では、FedMRLは最小のCNN-5モデルをグローバルコンポーネントとして使用し、同様に削減された$d_1$であった。
パフォーマンスは、3つの重要な側面で評価された。
* モデル精度: すべてのクライアントの平均テスト精度。
* 通信コスト: 目標平均精度に到達するためにサーバーと1つのクライアント間で送信される総パラメータ数で測定され、ラウンドあたりのパラメータ数とラウンド数を考慮する。
* 計算オーバーヘッド: 目標平均精度に到達するためにクライアントあたりの総FLOPs(浮動小数点演算)で測定され、ラウンドあたりのFLOPsとラウンド数を考慮する。
トレーニング戦略には、バッチサイズ、エポック、通信ラウンド、学習率を含む、すべてのアルゴリズムの広範なハイパーパラメータチューニングが含まれた。 FedMRLのユニークなハイパーパラメータである$d_1$(均質グローバル小モデルの表現次元)は、最適なトレードオフを見つけるために100から500まで変化させた。実験は、モデル均質およびモデル異種シナリオの両方で、3つの異なるFL設定(N=10、C=100%;N=50、C=20%;N=100、C=10%)で実施された。著者は、各実験設定の3回の試行の平均結果を報告した。
証拠が証明すること
実験的証拠は、FedMRLのコアメカニズム—適応的パーソナライズ表現融合と多粒度表現学習—が現実世界で効果的に機能し、パフォーマンスの向上につながるという、決定的で否定できない証拠を提供する。
優れたモデル精度:
* FedMRLは、モデル異種(表1)およびモデル均質(表3、付録C.2)FL設定の両方で、すべての7つの最先端ベースラインを一貫して上回った。
* それは、最高の全体的なベースラインを最大8.48%、最高の同カテゴリー(相互学習ベース)ベースラインを最大24.94%上回る、平均テスト精度の印象的な改善を達成した。
* 図3(左側の6つのプロット)は、さまざまなクライアントと参加率設定下で、FedMRLのより速い収束速度とより高い最終平均テスト精度を視覚的に確認している。
強化されたパーソナライゼーション:
* 図3(右側の2つのプロット)は、FedMRLとFedProtoの間の個々のクライアントテスト精度の違いを示している。驚くべきことに、クライアントの87%(CIFAR-10)と99%(CIFAR-100)がFedMRLでより優れたパフォーマンスを達成した。これは、FedMRLの適応的パーソナライズ多粒度表現学習設計に直接起因する、FedMRLの優れたパーソナライゼーション能力の強力な証拠である。
効率の向上:
* 通信コスト: FedMRLは完全な均質小モデルを送信するため、FedProto(ローカルで見たクラスの平均表現のみを送信する)よりもラウンドあたりの通信コストが高くなるが、図4(左)は、FedMRLがターゲット精度に到達するためにより少ない通信ラウンドを必要とし、収束を速めることを示している。さらに、オプションのより小さい表現次元($d_1$)を考慮すると、FedMRLは、より大きい表現次元を使用する他の相互学習ベースのベースライン(FML、FedKD、FedAPEN)よりも高い通信効率を達成する。
* 計算オーバーヘッド: 追加の均質小モデルと軽量表現プロジェクターをトレーニングするラウンドあたりのオーバーヘッドにもかかわらず、図4(右)は、FedMRLがFedProtoよりも低い総計算コストを発生させることを示している。これは、より少ない全体的なトレーニングラウンドを必要とする、より速い収束の結果である。
Non-IIDデータに対する堅牢性:
* クラスベースのNon-IID性: 図5(左側の2つのプロット)は、クライアントあたりのクラス数が減少しても(Non-IID性が増加しても)、FedMRLがFedProtoよりも高い平均テスト精度を維持するというFedMRLの堅牢性を明確に示している。
* ディリクレベースのNon-IID性: 図5(右側の2つのプロット)は、FedMRLがテストされたすべての$\alpha$値でFedProtoを大幅に上回ることで、この堅牢性をさらに検証しており、データ異種性のさまざまな程度に対するその回復力を示している。
感度分析とアブレーションスタディによるメカニズム検証:
* $d_1$への感度: 図6(左側の2つのプロット)は、より小さい$d_1$値(均質小モデルの表現次元)がより高い平均テスト精度と通信/計算オーバーヘッドの削減につながることを明らかにしている。これは、$d_1$が最適なトレードオフを達成する上で重要であることを強調している。
* アブレーションスタディ: 図6(右側の2つのプロット)は、マトリョーシュカ表現学習(MRL)コンポーネントの有用性を決定的に証明している。MRLなしのFedMRLは、MRLありのFedMRLよりも一貫してパフォーマンスが悪く、多粒度表現学習がMHeteroFLの重要な設計要素であることを確認している。$d_1$が増加するにつれて精度ギャップが縮小するという観察は、グローバルヘッダーとローカルヘッダーがますます重複する表現を学習する場合、MRLの利点が減少することを示唆している。
推論モデルの柔軟性:
* 付録C.3と図7は、「mix-small」(ローカルヘッダーなしの全体モデル)と「mix-large」(グローバルヘッダーなしの全体モデル)の推論モデルが、単一の均質または異種モデルを大幅に上回る、同様の高い精度を達成することを示している。これは、ユーザーが特定の推論コスト要件に基づいて選択できる実用的な柔軟性を提供する。
限界と将来の方向性
FedMRLはモデル異種連合学習における重要な進歩を示しているが、現在の限界を認識し、将来の開発の方向性を検討することが重要である。
現在の限界:
著者が特定した主な限界は、マトリョーシュカ表現内の多粒度埋め込み表現にある。これらの表現は現在、グローバル小モデルのヘッダーとローカルクライアントモデルのヘッダーの両方によって処理されている。グローバルヘッダーは単一の線形層のみを含む場合があるが、この二重処理はストレージコスト、通信オーバーヘッド、およびグローバルヘッダーのトレーニングオーバーヘッドの増加に依然として寄与している。これは、FedMRLが収束を加速することによって全体的な効率を改善する一方で、これらの多粒度表現を処理するグローバルモデルに関連するリソース消費を最適化する余地がまだあることを示唆している。
将来の方向性と議論のトピック:
-
多粒度処理の合理化: 本論文は、将来の研究でより高度なマトリョーシュカ表現学習手法(MRL-E)[24]を採用することを明確に示唆している。これにより、グローバルヘッダーを完全に削除し、多粒度マトリョーシュカ表現を処理するためにローカルモデルヘッダーのみに依存するようになる。これにより、モデルパフォーマンスとストレージ、通信、および計算コストの間のより良いトレードオフが得られる可能性がある。
- 議論: このような移行は、連合学習の「グローバル知識」の側面にどのように影響するだろうか?多粒度処理の責任をローカルヘッダーのみに依存すると、共有グローバルモデルの利点が希薄化するリスクがあるか、それとも適応的表現融合メカニズムが十分に補償できるか?ローカル計算負荷を大幅に増加させることなく、この増加した責任を処理するために、ローカルモデルヘッダーにどのようなアーキテクチャ変更が必要になるだろうか?
-
動的な$d_1$最適化: 感度分析は、より小さい$d_1$値(均質小モデルの表現次元)がしばしばより良い精度と効率につながることを示している。
- 議論: $d_1$は、クライアント固有のデータ特性または収束メトリックに基づいて、FLトレーニングプロセス中に動的に最適化できるか?固定された、事前に調整されたハイパーパラメータに依存するのではなく、さまざまなクライアントまたは通信ラウンドに最適な$d_1$を学習するために、強化学習アプローチを使用できるか?
-
教師なし/自己教師ありタスクへの拡張: 現在のFedMRLアプローチは、教師あり学習タスク向けに設計されている。
- 議論: ラベル付きデータが限られているシナリオでますます関連性が高まっている、教師なしまたは自己教師あり連合学習に、適応的表現融合と多粒度表現学習の原則をどのように拡張できるか?そのような設定での損失関数と知識転送メカニズムにはどのような変更が必要になるだろうか?
-
敵対的攻撃とデータポイズニングに対する堅牢性: 本論文はプライバシー保護に言及しているが、悪意のある攻撃に対する堅牢性については明示的に詳述していない。
- 議論: 強化された知識転送とパーソナライズされた表現を考慮すると、FedMRLのアーキテクチャは、データポイズニングやモデル逆襲攻撃にどのように固有に抵抗したり脆弱になったりするか?パフォーマンスや効率の向上を大幅に損なうことなく、セキュリティをさらに強化するために、FedMRLと統合できる追加のプライバシー保護メカニズム(例:差分プライバシー、セキュア集約)は何だろうか?
-
極めて大規模なNと多様なCへのスケーラビリティ: 実験は最大N=100クライアントで実施された。
- 議論: FedMRLは、特にさまざまなクライアント参加率(C)と断続的なクライアント可用性を考慮して、数千または数百万のクライアントを持つ連合ネットワークにどのようにスケーリングするか?そのような大規模展開で効率を維持するために、集約戦略または通信プロトコルにさらなる最適化が必要か?
-
画像分類以外の分野: 現在の検証は画像分類データセットに基づいている。
- 議論: FedMRLは、自然言語処理、時系列分析、または医療画像などの他のデータモダリティやタスクにどの程度一般化できるか?「マトリョーシュカ」の多粒度表現の概念は直接翻訳されるか、それとも特徴抽出と融合にはドメイン固有の適応が必要になるだろうか?
これらの議論ポイントは、FedMRLの基本的な洞察をどのように活用し、進化させて、連合学習分野におけるより広範な課題に対処し、新しい可能性を解き放つかを刺激することを目的としている。
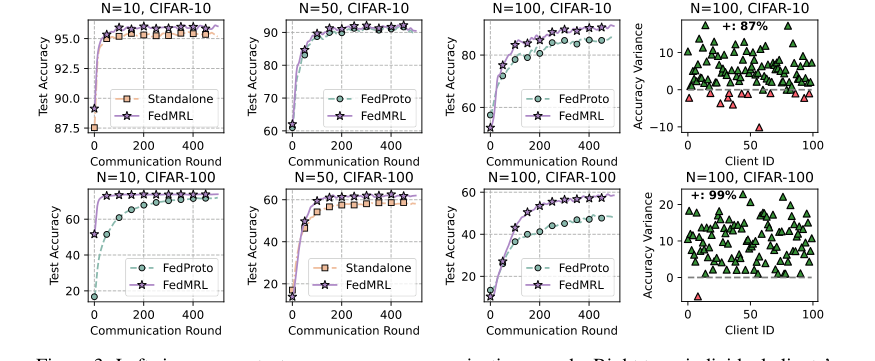 Figure 3. Left six: average test accuracy vs. communication rounds. Right two: individual clients’ test accuracy (%) differences (FedMRL - FedProto)
Figure 3. Left six: average test accuracy vs. communication rounds. Right two: individual clients’ test accuracy (%) differences (FedMRL - FedProto)
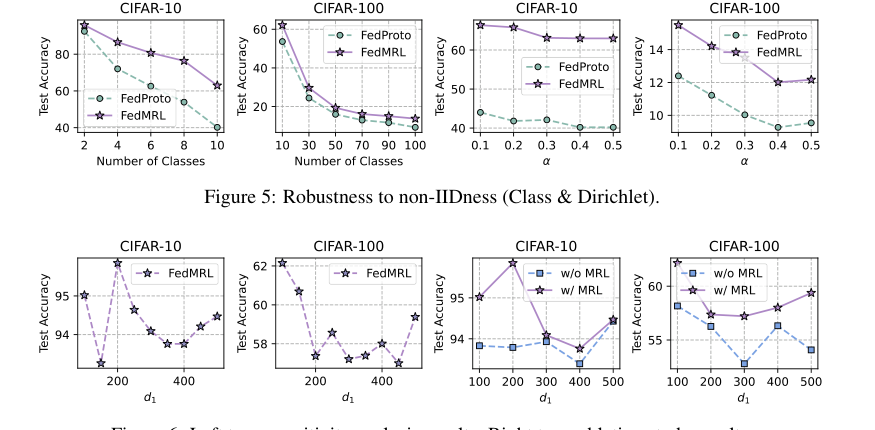 Figure 6. Left two: sensitivity analysis results. Right two: ablation study results
Figure 6. Left two: sensitivity analysis results. Right two: ablation study results
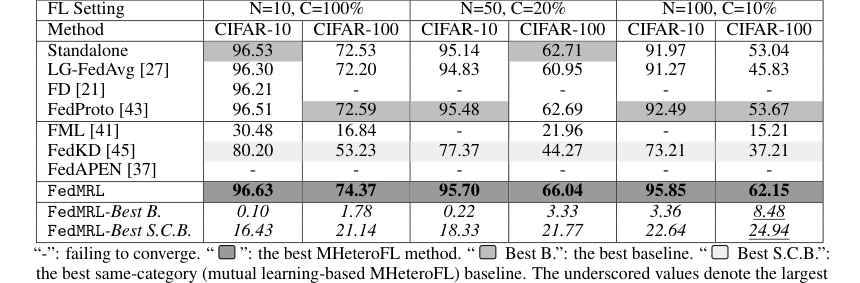 Table 1. and Table 3 (Appendix C.2) show that FedMRL consistently outperforms all baselines under both model-heterogeneous or homogeneous settings. It achieves up to a 8.48% improvement in average test accuracy compared with the best baseline under each setting. Furthermore, it achieves up to a 24.94% average test accuracy improvement than the best same-category (i.e., mutual learning- based MHeteroFL) baseline under each setting. These results demonstrate the superiority of FedMRL
Table 1. and Table 3 (Appendix C.2) show that FedMRL consistently outperforms all baselines under both model-heterogeneous or homogeneous settings. It achieves up to a 8.48% improvement in average test accuracy compared with the best baseline under each setting. Furthermore, it achieves up to a 24.94% average test accuracy improvement than the best same-category (i.e., mutual learning- based MHeteroFL) baseline under each setting. These results demonstrate the superiority of FedMRL
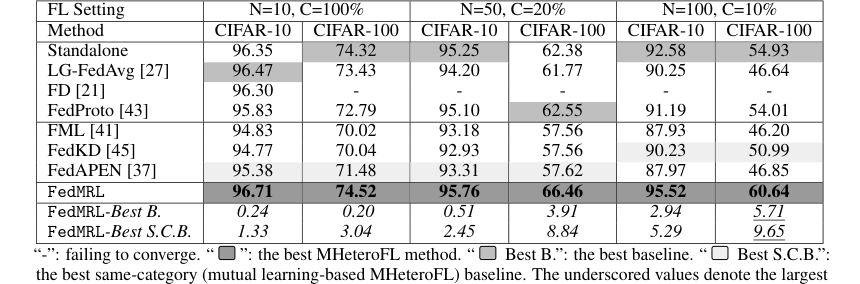 Table 3. presents the results of FedMRL and baselines in model-homogeneous FL scenarios
Table 3. presents the results of FedMRL and baselines in model-homogeneous FL scenarios
他の分野との同型性
構造的骨格
本論文のソリューションの核心は、堅牢でプライバシーを保護する知識転送を、分散システムで多様な、プライベートな、異種なコンポーネント間で促進するために、複数のソース(モデル)からの情報を異なる粒度のレベルで分解および再結合するメカニズムである。