फेडरेटेड मॉडल हेटेरोजेनियस मैट्रयोश्का रिप्रेजेंटेशन लर्निंग
फेडरेटेड मॉडल हेटेरोजेनियस मैट्रयोश्का रिप्रेजेंटेशन लर्निंग
पृष्ठभूमि और अकादमिक वंश
उत्पत्ति और अकादमिक वंश
इस पत्र में संबोधित की गई समस्या, मॉडल हेटेरोजेनियस फेडरेटेड लर्निंग (MHeteroFL), पारंपरिक फेडरेटेड लर्निंग (FL) की अंतर्निहित सीमाओं से उभरी है। प्रारंभ में, FL को एक गोपनीयता-संरक्षण विधि के रूप में तैयार किया गया था, जहाँ एक केंद्रीय सर्वर कई डेटा मालिकों (क्लाइंट्स) को स्थानीय डेटा को सीधे उजागर किए बिना एक एकल, वैश्विक साझा मॉडल को प्रशिक्षित करने के लिए समन्वयित करता है। प्रत्येक संचार राउंड में, सर्वर वैश्विक मॉडल का प्रसारण करता है, क्लाइंट्स इसे अपने स्थानीय डेटा पर प्रशिक्षित करते हैं, और फिर एक नया वैश्विक मॉडल बनाने के लिए एकत्रीकरण हेतु अद्यतन स्थानीय मॉडल वापस भेजते हैं। यह प्रक्रिया अभिसरण तक दोहराई जाती है, जिसमें केवल मॉडल पैरामीटर प्रसारित किए जाते हैं, इस प्रकार डेटा गोपनीयता संरक्षित होती है।
हालांकि, MHeteroFL जैसे अधिक उन्नत दृष्टिकोणों के विकास को मजबूर करने वाले वास्तविक दुनिया के परिदृश्यों पर लागू होने पर इस पारंपरिक FL डिज़ाइन को महत्वपूर्ण "दर्द बिंदु" का सामना करना पड़ा। इन सीमाओं में शामिल हैं:
- डेटा हेटेरोजेनिटी (Non-IID डेटा): क्लाइंट्स का स्थानीय डेटा अक्सर स्वतंत्र और समान रूप से वितरित (non-IID) पैटर्न का पालन नहीं करता है। इसका मतलब है कि ऐसे विविध स्थानीय डेटासेट से एकत्रित एक एकल वैश्विक मॉडल सभी क्लाइंट्स में इष्टतम प्रदर्शन नहीं कर सकता है। उदाहरण के लिए, एक क्लाइंट के पास किसी विशेष वर्ग के प्रति भारी झुकाव वाला डेटा हो सकता है, जबकि दूसरे के पास विभिन्न वर्गों के लिए डेटा हो सकता है।
- सिस्टम हेटेरोजेनिटी: FL क्लाइंट्स में कंप्यूटिंग शक्ति और नेटवर्क बैंडविड्थ में काफी भिन्नता हो सकती है। सभी क्लाइंट्स को एक ही, अक्सर बड़े, मॉडल संरचना को प्रशिक्षित करने के लिए मजबूर करने का मतलब है कि वैश्विक मॉडल का आकार सबसे कमजोर डिवाइस को समायोजित करना चाहिए, जिससे अधिक शक्तिशाली क्लाइंट्स पर जो बड़े, अधिक जटिल मॉडल को संभाल सकते हैं, पर उप-इष्टतम प्रदर्शन होता है।
- मॉडल हेटेरोजेनिटी: व्यावहारिक FL अनुप्रयोगों में, विशेष रूप से जब क्लाइंट्स उद्यम होते हैं, तो उनके पास अद्वितीय आर्किटेक्चर या बौद्धिक संपदा (IP) चिंताओं वाले मालिकाना मॉडल हो सकते हैं। FL प्रशिक्षण के दौरान इन विषम मॉडलों या उनकी संरचनाओं को सीधे साझा करना अक्सर IP सुरक्षा के कारण अस्वीकार्य होता है।
मौजूदा MHeteroFL विधियां, क्लाइंट्स को अनुरूप संरचनाओं वाले मॉडल को प्रशिक्षित करने की अनुमति देकर इन चुनौतियों का समाधान करने का प्रयास करती हैं, फिर भी सीमित ज्ञान हस्तांतरण क्षमताओं से ग्रस्त हैं। वे आम तौर पर क्लाइंट और सर्वर मॉडल के बीच ज्ञान स्थानांतरित करने के लिए प्रशिक्षण हानि पर निर्भर करते हैं, जिससे प्रदर्शन में बाधाएं, उच्च संचार और कम्प्यूटेशनल लागत, और निजी स्थानीय मॉडल संरचनाओं और डेटा को उजागर करने का एक स्थायी जोखिम हो सकता है। यह पत्र FedMRL का प्रस्ताव करता है ताकि इन सीमाओं को मैट्रयोश्का रिप्रेजेंटेशन लर्निंग से प्रेरित अनुकूली प्रतिनिधित्व संलयन और बहु-परिप्रेक्ष्य प्रतिनिधित्व सीखने के माध्यम से ज्ञान हस्तांतरण को बढ़ाकर दूर किया जा सके।
सहज डोमेन शब्द
एक शून्य-आधारित पाठक को मुख्य अवधारणाओं को समझने में मदद करने के लिए, यहां पेपर से कुछ विशेष शब्द दिए गए हैं, जिन्हें रोजमर्रा की उपमाओं में अनुवादित किया गया है:
- फेडरेटेड लर्निंग (FL): एक कुकिंग प्रतियोगिता की कल्पना करें जहाँ कई शेफ (क्लाइंट्स) अपनी गुप्त सामग्री (स्थानीय डेटा) का उपयोग करके अपने अनूठे व्यंजन (स्थानीय मॉडल) बना रहे हैं। अपनी रेसिपी साझा करने के बजाय, वे केवल अपनी खाना पकाने की तकनीकों का सारांश मुख्य न्यायाधीश (केंद्रीय सर्वर) को भेजते हैं। न्यायाधीश इन सारांशों को मिलाकर सामान्य खाना पकाने की सलाह (वैश्विक मॉडल) बनाते हैं और इसे शेफ को वापस भेजते हैं। इस तरह, हर कोई अपनी निजी रेसिपी का खुलासा किए बिना अपने व्यंजन में सुधार करता है।
- मॉडल हेटेरोजेनियस फेडरेटेड लर्निंग (MHeteroFL): कुकिंग उपमा पर निर्माण करते हुए, कल्पना करें कि प्रत्येक शेफ के पास एक अलग प्रकार के रसोई उपकरण (विविध सिस्टम संसाधन) हैं और एक अलग शैली के व्यंजन (विषम मॉडल संरचनाएं) पसंद करते हैं। MHeteroFL एक बहुत लचीले मुख्य न्यायाधीश की तरह है जो अभी भी प्रत्येक शेफ को उपयोगी, अनुरूप सलाह प्रदान कर सकता है, भले ही वे सभी विभिन्न उपकरणों और पाक दृष्टिकोणों के साथ काम कर रहे हों। न्यायाधीश उन्हें सामूहिक रूप से सुधार करने में मदद करता है, बिना सभी को एक ही तरह से खाना पकाने या एक ही उपकरण का उपयोग करने के लिए मजबूर किए।
- मैट्रयोश्का रिप्रेजेंटेशन लर्निंग (MRL): रूसी नेस्टिंग गुड़िया के एक सेट के बारे में सोचें। प्रत्येक गुड़िया एक पूर्ण है, लेकिन उत्तरोत्तर छोटी और कम विस्तृत, पिछली वाली का संस्करण है। MRL डेटा से "नेस्टेड" अंतर्दृष्टि उत्पन्न करने के लिए एक प्रणाली को प्रशिक्षित करने जैसा है। यह एक बहुत व्यापक, सामान्य समझ (सबसे बड़ी गुड़िया) और अधिक विशिष्ट, बारीक विवरण (अंदर की छोटी गुड़िया) उत्पन्न कर सकता है। यह प्रणाली को किसी कार्य के लिए विवरण के सही स्तर का उपयोग करने की अनुमति देता है, कम्प्यूटेशनल लागत बचाता है यदि केवल एक सामान्य समझ की आवश्यकता होती है, ठीक उसी तरह जैसे आपको यह जानने के लिए केवल सबसे बड़ी गुड़िया देखने की आवश्यकता हो सकती है कि यह एक मैट्रयोश्का है।
- Non-IID डेटा (Non-Independent and Identically Distributed Data): जानवरों के बारे में सीख रहे छात्रों की कक्षा पर विचार करें। यदि डेटा IID होता, तो प्रत्येक छात्र के पास बिल्लियों, कुत्तों, पक्षियों और मछलियों के चित्रों का समान मिश्रण वाली पाठ्यपुस्तक होती। Non-IID डेटा एक छात्र की पाठ्यपुस्तक की तरह है जो ज्यादातर बिल्लियों के बारे में है, दूसरे की ज्यादातर कुत्तों के बारे में है, और तीसरे की मुख्य रूप से पक्षियों के बारे में है। उनकी व्यक्तिगत सीखने की सामग्री (स्थानीय डेटा) समान रूप से वितरित नहीं होती है और जानवरों की पूरी श्रृंखला (वैश्विक डेटा वितरण) का पूरी तरह से प्रतिनिधित्व नहीं करती है। यह सभी के लिए एक एकल, एकीकृत पाठ योजना को काम करना कठिन बनाता है।
संकेतन तालिका
| संकेतन | विवरण |
|---|---|
समस्या परिभाषा और बाधाएं
मुख्य समस्या सूत्रीकरण और दुविधा
इस पत्र द्वारा संबोधित मुख्य समस्या मॉडल हेटेरोजेनियस फेडरेटेड लर्निंग (MHeteroFL) के डोमेन में निहित है, जिसका उद्देश्य विभिन्न मॉडल आर्किटेक्चर वाले कई क्लाइंट्स को अपने कच्चे स्थानीय डेटा को साझा किए बिना एक वैश्विक मॉडल को सहयोगात्मक रूप से प्रशिक्षित करने में सक्षम बनाना है।
इनपुट/वर्तमान स्थिति:
पारंपरिक फेडरेटेड लर्निंग (FL) एक एकल, साझा वैश्विक मॉडल को प्रशिक्षित करने के लिए $N$ क्लाइंट्स को समन्वयित करने वाले एक केंद्रीय सर्वर के साथ संचालित होता है। प्रत्येक संचार राउंड में, सर्वर वैश्विक मॉडल का प्रसारण करता है, क्लाइंट्स इसे अपने स्थानीय डेटा पर प्रशिक्षित करते हैं, और फिर एकत्रीकरण के लिए अद्यतन स्थानीय मॉडल वापस भेजते हैं। यह प्रक्रिया अभिसरण तक दोहराई जाती है, जिसमें डेटा गोपनीयता को संरक्षित करने के लिए केवल मॉडल पैरामीटर प्रसारित किए जाते हैं। हालांकि, यह पारंपरिक FL डिज़ाइन व्यावहारिक अनुप्रयोगों में प्रचलित तीन महत्वपूर्ण हेटेरोजेनिटी चुनौतियों से जूझता है:
1. डेटा हेटेरोजेनिटी (Non-IID): क्लाइंट्स के स्थानीय डेटासेट अक्सर गैर-स्वतंत्र और समान रूप से वितरित (non-IID) पैटर्न का पालन करते हैं, जिसका अर्थ है कि ऐसे विविध स्थानीय डेटा से एकत्रित एक एकल वैश्विक मॉडल व्यक्तिगत क्लाइंट्स पर खराब प्रदर्शन कर सकता है।
2. सिस्टम हेटेरोजेनिटी: FL क्लाइंट्स में विविध कम्प्यूटेशनल संसाधन (जैसे, CPU, GPU, मेमोरी) और नेटवर्क बैंडविड्थ होते हैं। सभी क्लाइंट्स से एक समान मॉडल संरचना को प्रशिक्षित करने की आवश्यकता का मतलब है कि वैश्विक मॉडल का आकार सबसे कमजोर डिवाइस द्वारा सीमित होना चाहिए, जिससे अधिक शक्तिशाली क्लाइंट्स पर उप-इष्टतम प्रदर्शन होता है।
3. मॉडल हेटेरोजेनिटी: क्लाइंट्स, विशेष रूप से उद्यम, बौद्धिक संपदा (IP) चिंताओं के कारण विविध, गैर-साझा करने योग्य संरचनाओं वाले मालिकाना स्थानीय मॉडल रख सकते हैं। यह प्रत्यक्ष पैरामीटर औसत या एकत्रीकरण को रोकता है।
मौजूदा MHeteroFL विधियां इन चुनौतियों का समाधान करने का प्रयास करती हैं लेकिन मुख्य रूप से प्रशिक्षण हानि के माध्यम से क्लाइंट और सर्वर मॉडल के बीच ज्ञान स्थानांतरित करने पर निर्भर करती हैं। हालांकि, यह दृष्टिकोण सीमित ज्ञान विनिमय में परिणत होता है, जिससे प्रदर्शन में बाधाएं, उच्च संचार और कम्प्यूटेशनल लागत, और निजी स्थानीय मॉडल संरचनाओं और डेटा को उजागर करने का संभावित जोखिम होता है।
वांछित अंतिम बिंदु (आउटपुट/लक्ष्य स्थिति):
पत्र का उद्देश्य एक नवीन MHeteroFL दृष्टिकोण विकसित करना है, जिसे फेडरेटेड मॉडल हेटेरोजेनियस मैट्रयोश्का रिप्रेजेंटेशन लर्निंग (FedMRL) कहा जाता है, जो पर्यवेक्षित सीखने के कार्यों में डेटा, सिस्टम और मॉडल हेटेरोजेनिटी को प्रभावी ढंग से और संयुक्त रूप से संबोधित कर सकता है। लक्ष्य प्राप्त करना है:
1. उन्नत ज्ञान हस्तांतरण: सर्वर के वैश्विक सजातीय मॉडल और क्लाइंट्स के विषम स्थानीय मॉडल के बीच अधिक प्रभावी ज्ञान संपर्क की सुविधा प्रदान करना।
2. बेहतर मॉडल प्रदर्शन: मौजूदा अत्याधुनिक विधियों की तुलना में बेहतर मॉडल सटीकता प्राप्त करना।
3. कम संचार और कम्प्यूटेशनल लागत: मॉडल प्रशिक्षण और अद्यतनों से जुड़े ओवरहेड को कम करना।
4. मजबूत गोपनीयता संरक्षण: यह सुनिश्चित करना कि क्लाइंट्स का स्थानीय डेटा और विषम मॉडल संरचनाएं सर्वर या अन्य क्लाइंट्स को उजागर न हों।
5. व्यक्तिगत अनुकूलन: सीखने की प्रक्रिया को स्थानीय गैर-IID डेटा वितरण और विविध क्लाइंट संसाधनों के अनुकूल होने में सक्षम बनाना।
लुप्त कड़ी या गणितीय अंतर:
वास्तविक लुप्त कड़ी एक प्रभावी और कुशल तंत्र की कमी है जो गोपनीयता-संरक्षण तरीके से विषम मॉडल और डेटा वितरण में ज्ञान हस्तांतरण के लिए है। ज्ञान हस्तांतरण के लिए प्रशिक्षण हानि पर वर्तमान विधियों की निर्भरता अपर्याप्त है। FedMRL दो प्रमुख नवाचारों को पेश करके इस अंतर को पाटने का प्रयास करता है:
1. अनुकूली प्रतिनिधित्व संलयन: प्रत्येक स्थानीय डेटा नमूने के लिए, एक वैश्विक सजातीय छोटे मॉडल और एक स्थानीय विषम मॉडल दोनों के फीचर एक्सट्रैक्टर क्रमशः सामान्यीकृत और व्यक्तिगत प्रतिनिधित्व निकालते हैं। फिर इन्हें एक व्यक्तिगत हल्के प्रतिनिधित्व प्रोजेक्टर $P_k(\phi_k)$ द्वारा विभाजित और मैप किया जाता है जो स्थानीय गैर-IID डेटा के अनुकूल होता है।
2. बहु-ग्रैन्युलैरिटी प्रतिनिधित्व सीखना: संलयित प्रतिनिधित्व का उपयोग मैट्रयोश्का रिप्रेजेंटेशन बनाने के लिए किया जाता है, जो बहु-आयामी और बहु-ग्रैन्युलर एम्बेडेड प्रतिनिधित्व हैं। इन्हें वैश्विक सजातीय मॉडल और स्थानीय विषम मॉडल दोनों के भविष्यवाणी हेडर द्वारा संसाधित किया जाता है, जिनके संयुक्त नुकसान का उपयोग सभी मॉडलों को अद्यतन करने के लिए किया जाता है।
गणितीय रूप से, पत्र निम्नलिखित उद्देश्य फ़ंक्शन को कम करने का लक्ष्य रखता है (समीकरण 1):
$$
\min_{\theta, \omega_0, \dots, \omega_{N-1}, \phi_0, \dots, \phi_{N-1}} \sum_{k=0}^{N-1} l(W_k(D_k; (\theta \circ \omega_k | \phi_k)))
$$
जहां $W_k(w_k) = (G(\theta) \circ F_k(w_k) | P_k(\phi_k))$ क्लाइंट $k$ के लिए संयुक्त मॉडल का प्रतिनिधित्व करता है, जिसमें वैश्विक सजातीय छोटा मॉडल $G(\theta)$, क्लाइंट का स्थानीय विषम मॉडल $F_k(w_k)$, और व्यक्तिगत प्रतिनिधित्व प्रोजेक्टर $P_k(\phi_k)$ शामिल हैं। हानि $l$ मैट्रयोश्का रिप्रेजेंटेशन से बहु-परिप्रेक्ष्य आउटपुट के आधार पर गणना की जाती है।
दुविधा:
पिछली शोधकर्ताओं को फंसाने वाला दर्दनाक समझौता, कम संचार/कम्प्यूटेशनल लागत और मजबूत गोपनीयता गारंटी बनाए रखते हुए, विषम FL क्लाइंट्स में उच्च मॉडल प्रदर्शन और प्रभावी ज्ञान हस्तांतरण प्राप्त करने के बीच अंतर्निहित संघर्ष है। एक पहलू में सुधार अक्सर दूसरे से समझौता करता है। उदाहरण के लिए, अधिक जानकारी साझा करने (जैसे, पूर्ण मॉडल पैरामीटर या विस्तृत मध्यवर्ती प्रतिनिधित्व) से ज्ञान हस्तांतरण और प्रदर्शन में वृद्धि हो सकती है लेकिन संचार लागत और गोपनीयता जोखिमों में भारी वृद्धि होगी। इसके विपरीत, गोपनीयता की रक्षा और लागत कम करने के लिए साझा जानकारी को सीमित करने से अक्सर "सीमित ज्ञान विनिमय" और "मॉडल प्रदर्शन बाधाएं" (पृष्ठ 2, अनुभाग 1) होती हैं, जिसके परिणामस्वरूप उप-इष्टतम सटीकता होती है, विशेष रूप से गैर-IID डेटा पर। दुविधा यह है कि संवेदनशील क्लाइंट विवरणों को उजागर किए बिना या सीमित संसाधनों को अभिभूत किए बिना समृद्ध, बहु-परिप्रेक्ष्य ज्ञान संपर्क को कैसे सक्षम किया जाए।
बाधाएं और विफलता मोड
मॉडल हेटेरोजेनियस फेडरेटेड लर्निंग की समस्या कई कठोर, यथार्थवादी दीवारों के कारण अविश्वसनीय रूप से कठिन है जिनसे लेखक टकराते हैं:
- Non-IID डेटा वितरण: क्लाइंट्स का स्थानीय डेटा अक्सर गैर-स्वतंत्र और समान रूप से वितरित (non-IID) होता है, जिससे एक एकल वैश्विक मॉडल को प्रशिक्षित करना चुनौतीपूर्ण हो जाता है जो सभी क्लाइंट्स में अच्छा प्रदर्शन करता है। इसके लिए व्यक्तिगत मॉडल या अनुकूली तंत्र की आवश्यकता होती है, जो जटिलता जोड़ते हैं।
- विविध क्लाइंट सिस्टम संसाधन: FL क्लाइंट्स विभिन्न कम्प्यूटेशनल शक्ति, मेमोरी और नेटवर्क बैंडविड्थ के साथ संचालित होते हैं। किसी भी प्रस्तावित समाधान को सबसे कमजोर उपकरणों पर चलाने के लिए पर्याप्त कुशल होना चाहिए, जबकि अधिक शक्तिशाली उपकरणों की क्षमताओं का लाभ उठाना चाहिए। यह मॉडल आकार और प्रति क्लाइंट कम्प्यूटेशनल ओवरहेड पर सख्त सीमाएं लगाता है।
- मालिकाना मॉडल संरचनाएं और IP सुरक्षा: क्लाइंट्स विभिन्न, मालिकाना स्थानीय मॉडल आर्किटेक्चर का उपयोग कर सकते हैं जिन्हें बौद्धिक संपदा चिंताओं के कारण सीधे साझा या एकत्रित नहीं किया जा सकता है। यह मॉडल पैरामीटर के पारंपरिक फेडरेटेड औसत को रोकता है।
- सीमित ज्ञान हस्तांतरण प्रभावशीलता: मौजूदा MHeteroFL विधियां, विशेष रूप से प्रशिक्षण हानि या सरल पारस्परिक सीखने पर निर्भर रहने वाली, अक्सर केवल "सीमित ज्ञान हस्तांतरण" (पृष्ठ 1, सार; पृष्ठ 3, अनुभाग 2) प्राप्त करती हैं। इससे उप-इष्टतम मॉडल प्रदर्शन और धीमी अभिसरण होती है।
- उच्च संचार लागत: प्रत्येक राउंड में सर्वर और कई क्लाइंट्स के बीच बड़े मॉडल पैरामीटर या व्यापक मध्यवर्ती प्रतिनिधित्व को प्रसारित करने से महत्वपूर्ण संचार लागत लग सकती है, खासकर सीमित नेटवर्क बैंडविड्थ पर। लक्ष्य इसे कम करना है।
- उच्च कम्प्यूटेशनल ओवरहेड: क्लाइंट उपकरणों पर अतिरिक्त मॉडल या जटिल ज्ञान आसवन तंत्र को प्रशिक्षित करने से पर्याप्त कम्प्यूटेशनल ओवरहेड हो सकता है, जो संसाधन-विवश क्लाइंट्स के लिए अवांछनीय है।
- सख्त गोपनीयता आवश्यकताएं: FL का एक मौलिक सिद्धांत स्थानीय डेटा गोपनीयता की रक्षा करना है। किसी भी विधि को यह सुनिश्चित करना चाहिए कि कच्चे क्लाइंट डेटा और स्थानीय मॉडल संरचनाएं कभी भी सर्वर या अन्य क्लाइंट्स को उजागर न हों। इसका पालन करने में विफलता एक महत्वपूर्ण विफलता मोड है।
- गैर-उत्तल अनुकूलन परिदृश्य: विषम मॉडल के साथ फेडरेटेड लर्निंग में अनुकूलन समस्या आम तौर पर गैर-उत्तल होती है। एक अच्छे समाधान, वैश्विक इष्टतम को तो छोड़ ही दें, के अभिसरण की गारंटी देना एक महत्वपूर्ण गणितीय चुनौती है। पत्र एक सैद्धांतिक विश्लेषण प्रदान करता है जो $O(1/T)$ गैर-उत्तल अभिसरण दर (पृष्ठ 1, सार) दिखाता है, जो एक सामान्य लेकिन अभी भी चुनौतीपूर्ण पहलू है।
- मॉडल प्रदर्शन बाधाएं: प्रभावी ज्ञान हस्तांतरण के बिना, क्लाइंट मॉडल प्रदर्शन बाधाओं से पीड़ित हो सकते हैं, अच्छी तरह से सामान्यीकरण करने या उच्च सटीकता प्राप्त करने में विफल हो सकते हैं।
- मापनीयता मुद्दे: समाधान को बड़ी संख्या में क्लाइंट्स ($N$) और प्रत्येक संचार राउंड में विभिन्न क्लाइंट भागीदारी दरों ($C=K/N$) के लिए स्केलेबल और मजबूत होना चाहिए (पृष्ठ 3, अनुभाग 3)।
ये बाधाएं सामूहिक रूप से उच्च-प्रदर्शन, गोपनीयता-संरक्षण, और संसाधन-कुशल फेडरेटेड लर्निंग को विषम मॉडल के साथ एक असाधारण रूप से कठिन प्रयास बनाती हैं।
यह दृष्टिकोण क्यों
पसंद की अनिवार्यता
FedMRL का विकास व्यावहारिक FL अनुप्रयोगों की जटिल वास्तविकताओं का सामना करने पर मौजूदा मॉडल हेटेरोजेनियस फेडरेटेड लर्निंग (MHeteroFL) दृष्टिकोणों की अंतर्निहित सीमाओं से प्रेरित था। लेखकों ने महसूस किया कि पारंपरिक "SOTA" विधियां, यहां तक कि फेडरेटेड सेटिंग्स के लिए अनुकूलित होने पर भी, अपर्याप्त थीं क्योंकि वे मुख्य रूप से क्लाइंट और सर्वर मॉडल के बीच ज्ञान हस्तांतरण के लिए प्रशिक्षण हानि पर निर्भर करती थीं। इस निर्भरता से कई महत्वपूर्ण कमियां हुईं: "सीमित ज्ञान विनिमय," "मॉडल प्रदर्शन बाधाएं," "उच्च संचार और कम्प्यूटेशनल लागत," और "निजी स्थानीय मॉडल संरचनाओं और डेटा को उजागर करने का एक महत्वपूर्ण जोखिम" (सार, पृष्ठ 1)।
विशेष रूप से, पत्र इस बात पर प्रकाश डालता है कि पारंपरिक FL डिज़ाइन तीन प्रमुख हेटेरोजेनिटी चुनौतियों से जूझते थे: (1) डेटा हेटेरोजेनिटी, जहां क्लाइंट डेटा गैर-IID है; (2) सिस्टम हेटेरोजेनिटी, जहां क्लाइंट्स के पास विविध कम्प्यूटेशनल शक्ति और नेटवर्क बैंडविड्थ है, जिससे वैश्विक मॉडल को सबसे कमजोर डिवाइस को समायोजित करने के लिए मजबूर होना पड़ता है; और (3) मॉडल हेटेरोजेनिटी, जहां क्लाइंट्स के पास मालिकाना मॉडल होते हैं जिन्हें बौद्धिक संपदा चिंताओं के कारण सीधे साझा नहीं किया जा सकता है (अनुभाग 1, पृष्ठ 1-2)। जबकि MHeteroFL इन पर काबू पाने के लिए उभरा, इस क्षेत्र के भीतर मौजूदा विधियां, जैसे कि अनुकूली सबनेट, ज्ञान आसवन, मॉडल विभाजन, या पारस्परिक सीखने पर आधारित, अभी भी महत्वपूर्ण खामियां प्रदर्शित करती हैं। उदाहरण के लिए, पारस्परिक सीखने के दृष्टिकोण, जिन पर FedMRL आधारित है, को "दो मॉडलों के बीच केवल सीमित ज्ञान स्थानांतरित करने" के रूप में नोट किया गया था, जिसके परिणामस्वरूप "मॉडल प्रदर्शन बाधाएं" (अनुभाग 2, पृष्ठ 3) हुईं।
वास्तविक अहसास का क्षण, हालांकि स्पष्ट रूप से एक एकल घटना के रूप में इंगित नहीं किया गया है, पिछले MHeteroFL विधियों की व्यापक आलोचना से दृढ़ता से निहित है। लेखकों ने महसूस किया कि ज्ञान हस्तांतरण के लिए एक मौलिक रूप से भिन्न तंत्र की आवश्यकता थी - एक जो सरल हानि-आधारित आसवन से अधिक परिष्कृत प्रतिनिधित्व-स्तरीय संपर्क की ओर बढ़ता है। इसने उन्हें मैट्रयोश्का रिप्रेजेंटेशन लर्निंग (MRL) [24] से प्रेरणा लेने के लिए प्रेरित किया, जो मॉडल प्रदर्शन और अनुमान लागत के बीच एक इष्टतम संतुलन प्राप्त करने के लिए प्रतिनिधित्व आयामों को अनुकूलित करने का एक तरीका प्रदान करता है। प्रतिनिधित्व-केंद्रित दृष्टिकोण पर यह बदलाव, मॉडल- या हानि-केंद्रित दृष्टिकोण के बजाय, फेडरेटेड लर्निंग में हेटेरोजेनिटी, गोपनीयता और दक्षता की लगातार चुनौतियों को दूर करने का एकमात्र व्यवहार्य मार्ग बन गया।
तुलनात्मक श्रेष्ठता
FedMRL कई संरचनात्मक और कार्यात्मक लाभों के माध्यम से पिछले स्वर्ण मानकों पर भारी गुणात्मक श्रेष्ठता प्रदर्शित करता है, जो केवल प्रदर्शन मेट्रिक्स से परे है।
सबसे पहले, इसका मुख्य नवाचार अनुकूली प्रतिनिधित्व संलयन और बहु-ग्रैन्युलैरिटी प्रतिनिधित्व सीखना में निहित है। एकल, निश्चित प्रतिनिधित्व पर निर्भर रहने वाली विधियों के विपरीत, FedMRL सामान्यीकृत (एक साझा सजातीय मॉडल से) और व्यक्तिगत (क्लाइंट के विषम स्थानीय मॉडल से) प्रतिनिधित्व निकालता है। इन्हें फिर एक हल्के, व्यक्तिगत प्रोजेक्टर द्वारा अनुकूली रूप से संलयित किया जाता है, जो स्थानीय गैर-IID डेटा वितरण के अनुकूल होने के लिए महत्वपूर्ण है (अनुभाग 3.1, पृष्ठ 4)। यह संरचनात्मक डिजाइन स्थानीय डेटा की एक समृद्ध, अधिक सूक्ष्म समझ की अनुमति देता है, जो उन दृष्टिकोणों पर एक महत्वपूर्ण गुणात्मक छलांग है जो डेटा हेटेरोजेनिटी से जूझते हैं। मैट्रयोश्का रिप्रेजेंटेशन का बाद का निर्माण, जिसमें बहु-आयामी और बहु-ग्रैन्युलर एम्बेडेड प्रतिनिधित्व शामिल हैं, बहु-परिप्रेक्ष्य सीखने को सक्षम करके मॉडल सीखने की क्षमता को और बढ़ाता है (अनुभाग 3.2, पृष्ठ 5)। यह एक संरचनात्मक लाभ है जो मॉडल को मोटे और बारीक दोनों तरह की सुविधाओं को सीखने की अनुमति देता है, जिससे यह अधिक मजबूत और प्रभावी होता है।
दूसरे, FedMRL बेहतर गोपनीयता संरक्षण और संसाधन दक्षता प्रदान करता है। सर्वर और क्लाइंट्स के बीच केवल छोटे सजातीय मॉडल प्रसारित करके, यह सुनिश्चित करता है कि "प्रशिक्षण के दौरान प्रत्येक क्लाइंट के स्थानीय मॉडल और डेटा का खुलासा नहीं किया जाता है" (अनुभाग 2, पृष्ठ 2)। यह गोपनीयता-संवेदनशील अनुप्रयोगों के लिए एक महत्वपूर्ण संरचनात्मक लाभ है। इसके अलावा, यह डिजाइन स्वाभाविक रूप से "कम संचार लागत" और क्लाइंट्स के लिए "कम अतिरिक्त कम्प्यूटेशनल लागत" की ओर ले जाता है, क्योंकि वे अपने स्थानीय मॉडल के अलावा केवल एक छोटा सजातीय मॉडल और एक हल्का प्रतिनिधित्व प्रोजेक्टर प्रशिक्षित करते हैं (अनुभाग 2, पृष्ठ 2)। यद्यपि पत्र स्पष्ट रूप से $O(N^2)$ से $O(N)$ मेमोरी जटिलता में कमी नहीं बताता है, "छोटे सजातीय मॉडल" और "हल्के" घटकों पर जोर सीधे उन विधियों की तुलना में मेमोरी और कम्प्यूटेशनल फुटप्रिंट में महत्वपूर्ण कमी का संकेत देता है जिन्हें बड़े, अधिक जटिल मॉडल या व्यापक डेटा साझाकरण की आवश्यकता हो सकती है।
अंत में, विधि की गैर-IID डेटा के प्रति मजबूती और मजबूत वैयक्तिकरण क्षमता गुणात्मक रूप से बेहतर हैं। प्रयोगों से पता चलता है कि FedMRL विभिन्न गैर-IID सेटिंग्स (वर्ग और डिริचलेट) के तहत बेसलाइन जैसे FedProto (अनुभाग 5.3.1, 5.3.2, पृष्ठ 9) की तुलना में लगातार उच्च औसत परीक्षण सटीकता प्राप्त करता है। इसके अलावा, यह मजबूत वैयक्तिकरण प्रदान करता है, जिसमें व्यक्तिगत क्लाइंट्स का एक उच्च प्रतिशत (CIFAR-10 पर 87%, CIFAR-100 पर 99%) FedProto की तुलना में बेहतर प्रदर्शन प्राप्त करता है (अनुभाग 5.2.2, पृष्ठ 8)। यह विविध क्लाइंट वातावरण और डेटा वितरण को संभालने में एक मौलिक संरचनात्मक लाभ का संकेत देता है।
बाधाओं के साथ संरेखण
FedMRL का डिजाइन हेटेरोजेनियस फेडरेटेड लर्निंग की कठोर आवश्यकताओं और बाधाओं के साथ पूरी तरह से संरेखित होता है, जिससे समस्या और समाधान के बीच एक सहक्रियात्मक "विवाह" बनता है।
- डेटा हेटेरोजेनिटी (non-IID डेटा): अनुकूली प्रतिनिधित्व संलयन तंत्र विशेष रूप से इसे संबोधित करने के लिए डिज़ाइन किया गया है। व्यक्तिगत प्रतिनिधित्व प्रोजेक्टर विभाजित सामान्यीकृत और व्यक्तिगत प्रतिनिधित्व को एक संलयित प्रतिनिधित्व में मैप करता है "स्थानीय गैर-IID डेटा के अनुकूल" (अनुभाग 3.1, पृष्ठ 4)। यह सुनिश्चित करता है कि प्रत्येक क्लाइंट के अद्वितीय डेटा वितरण को ध्यान में रखा जाता है, जिससे गैर-IID सेटिंग्स में सामान्य प्रदर्शन गिरावट को रोका जा सके।
- सिस्टम हेटेरोजेनिटी: FedMRL "विषम स्थानीय मॉडल" के साथ बातचीत करने वाले एक "साझा वैश्विक सहायक सजातीय छोटे मॉडल" का परिचय देकर विविध क्लाइंट क्षमताओं को समायोजित करता है (अनुभाग 2, पृष्ठ 2)। वैश्विक मॉडल जानबूझकर छोटा है, जिससे इसे प्रसारित करना और सीमित संसाधनों वाले क्लाइंट्स द्वारा भी प्रशिक्षित करना संभव हो जाता है। क्लाइंट्स प्रतिनिधित्व प्रोजेक्टर के रैखिक परत आयाम को विभाजित प्रतिनिधित्व के साथ संरेखित करने के लिए समायोजित कर सकते हैं, जो स्थानीय सिस्टम बाधाओं के अनुकूल होता है (अनुभाग 3.1, पृष्ठ 4)।
- मॉडल हेटेरोजेनिटी: ढांचा स्वाभाविक रूप से क्लाइंट्स को "विविध संरचनाओं वाले स्थानीय मॉडल" रखने का समर्थन करता है (अनुभाग 3.1, पृष्ठ 4)। सर्वर केवल सजातीय छोटे मॉडल के साथ बातचीत करता है, क्लाइंट के विषम स्थानीय मॉडल को एक ब्लैक बॉक्स के रूप में मानता है। यह डिजाइन क्लाइंट्स से अपने मालिकाना मॉडल संरचनाओं को उजागर करने की आवश्यकता के बिना बौद्धिक संपदा चिंताओं का सम्मान करता है।
- गोपनीयता संरक्षण: यह FedMRL का एक आधारशिला है। "प्रशिक्षण के दौरान गोपनीयता-संरक्षण के लिए प्रत्येक क्लाइंट के स्थानीय मॉडल और डेटा का खुलासा नहीं किया जाता है" (अनुभाग 2, पृष्ठ 2)। केवल छोटे सजातीय मॉडल प्रसारित किए जाते हैं, यह सुनिश्चित करते हुए कि स्थानीय डेटा और मॉडल संरचनाएं निजी रहें।
- संचार दक्षता: केवल "छोटे सजातीय मॉडल" (अनुभाग 2, पृष्ठ 2) प्रसारित करके, FedMRL पूर्ण क्लाइंट मॉडल का आदान-प्रदान करने वाली विधियों की तुलना में संचार लागत को काफी कम करता है। सजातीय छोटे मॉडल के रैखिक परत आयाम $d_1$ को भिन्न करने की क्षमता संचार ओवरहेड के अनुकूलन की भी अनुमति देती है (अनुभाग 5.3.3, पृष्ठ 9)।
- कम्प्यूटेशनल दक्षता: क्लाइंट्स को अपने स्थानीय मॉडल के अलावा केवल एक "छोटा सजातीय मॉडल और एक हल्का प्रतिनिधित्व प्रोजेक्टर" (अनुभाग 2, पृष्ठ 2) प्रशिक्षित करने की आवश्यकता होती है, जिससे "कम अतिरिक्त कम्प्यूटेशनल लागत" लगती है। FedMRL द्वारा प्राप्त तेज अभिसरण गति (चित्र 4, पृष्ठ 8) का मतलब यह भी है कि लक्ष्य सटीकता तक पहुंचने के लिए कम संचार राउंड की आवश्यकता होती है, जिससे समग्र कम्प्यूटेशनल ओवरहेड कम हो जाता है (अनुभाग 5.2.4, पृष्ठ 9)।
- ज्ञान हस्तांतरण सीमाएं: अनुकूली प्रतिनिधित्व संलयन और बहु-ग्रैन्युलैरिटी प्रतिनिधित्व सीखने के दोहरे नवाचार सीधे पिछली विधियों की "सीमित ज्ञान विनिमय" समस्या को संबोधित करते हैं। वे "दो मॉडलों के बीच अधिक ज्ञान संपर्क की सुविधा प्रदान करते हैं और मॉडल प्रदर्शन में सुधार करते हैं" बहु-परिप्रेक्ष्य से सामान्यीकृत और व्यक्तिगत प्रतिनिधित्व सीखकर (अनुभाग 2, पृष्ठ 3)।
विकल्पों का अस्वीकरण
पत्र व्यवस्थित रूप से मौजूदा MHeteroFL दृष्टिकोणों की श्रेणियों की पहचान करता है और उन्हें अस्वीकार करता है, उनकी मूलभूत कमियों को उजागर करता है जो समस्या की बाधाओं को संबोधित करने में हैं:
- अनुकूली सबनेट के साथ MHeteroFL: ये विधियां एक वैश्विक मॉडल से विषम स्थानीय सबनेट का निर्माण करती हैं। लेखक इस दृष्टिकोण को अस्वीकार करते हैं क्योंकि "उन मामलों में जहां क्लाइंट्स सामान्य वैश्विक मॉडल से प्राप्त नहीं होने वाली विषम संरचनाओं वाले ब्लैक-बॉक्स स्थानीय मॉडल रखते हैं, सर्वर उन्हें एकत्रित करने में असमर्थ है" (अनुभाग 2, पृष्ठ 3)। इसका तात्पर्य है कि वास्तविक मॉडल हेटेरोजेनिटी को संभालने में विफलता जहां क्लाइंट मॉडल मालिकाना हैं और वैश्विक मॉडल के छंटे हुए संस्करण नहीं हैं।
- ज्ञान आसवन के साथ MHeteroFL:
- ज्ञान हस्तांतरण के लिए एक सार्वजनिक डेटासेट पर निर्भर रहने वाली विधियों को अव्यावहारिक माना जाता है क्योंकि "ऐसा उपयुक्त सार्वजनिक डेटासेट खोजना मुश्किल हो सकता है" (अनुभाग 2, पृष्ठ 3)।
- एक साझा डेटासेट को संश्लेषित करने के लिए एक जनरेटर को प्रशिक्षित करने वाले दृष्टिकोणों को "उच्च प्रशिक्षण लागत" के कारण अस्वीकार कर दिया जाता है (अनुभाग 2, पृष्ठ 3)।
- अन्य विधियां जो मध्यवर्ती जानकारी साझा करती हैं, उन्हें ज्ञान संलयन के लिए "क्लाइंट स्थानीय डेटा को उजागर करने" के जोखिम के कारण अप्रत्यक्ष रूप से अस्वीकार कर दिया जाता है, जो गोपनीयता से समझौता कर सकता है।
- मॉडल विभाजन के साथ MHeteroFL: ये विधियां मॉडल को फीचर एक्सट्रैक्टर और भविष्यवक्ता में विभाजित करती हैं, या तो एक या दूसरे को साझा करती हैं। पत्र इस रणनीति को अस्वीकार करता है क्योंकि यह "स्थानीय मॉडल संरचनाओं के हिस्से को उजागर करता है, जो स्वीकार्य नहीं हो सकता है यदि मॉडल क्लाइंट्स के मालिकाना आईपी हैं" (अनुभाग 2, पृष्ठ 3)। यह सीधे गोपनीयता और बौद्धिक संपदा संरक्षण बाधाओं का खंडन करता है।
- पारस्परिक सीखने के साथ MHeteroFL: यद्यपि FedMRL इस श्रेणी पर आधारित है, यह स्पष्ट रूप से बताता है कि मौजूदा पारस्परिक सीखने की विधियां (जैसे, FML, FedKD, FedAPEN) अपर्याप्त हैं क्योंकि "पारस्परिक हानि केवल दो मॉडलों के बीच सीमित ज्ञान स्थानांतरित करती है, जिसके परिणामस्वरूप मॉडल प्रदर्शन बाधाएं होती हैं" (अनुभाग 2, पृष्ठ 3)। FedMRL को एक अनुकूलन के रूप में प्रस्तुत किया गया है जो केवल पारस्परिक हानि पर निर्भर रहने के बजाय प्रतिनिधित्व-आधारित दृष्टिकोण पर जाकर "ज्ञान हस्तांतरण को बढ़ाता है"।
पत्र सामान्य डीप लर्निंग आर्किटेक्चर जैसे GANs, डिफ्यूजन मॉडल, या ट्रांसफॉर्मर की विफलता पर चर्चा नहीं करता है, जो फेडरेटेड लर्निंग दृष्टिकोण के रूप में वैकल्पिक हैं। इसके बजाय, यह अप्रत्यक्ष रूप से CNNs (एक प्रकार का ट्रांसफॉर्मर-पूर्व आर्किटेक्चर) को अपने ढांचे के भीतर अंतर्निहित मॉडल के रूप में शामिल करता है (तालिका 2, पृष्ठ 17)। अस्वीकरण उन फेडरेटेड लर्निंग प्रतिमानों के लिए है जो हेटेरोजेनिटी, गोपनीयता और संसाधन दक्षता की अनूठी चुनौतियों को प्रभावी ढंग से प्रबंधित करने में विफल रहते हैं, न कि मौलिक मॉडल आर्किटेक्चर के लिए।
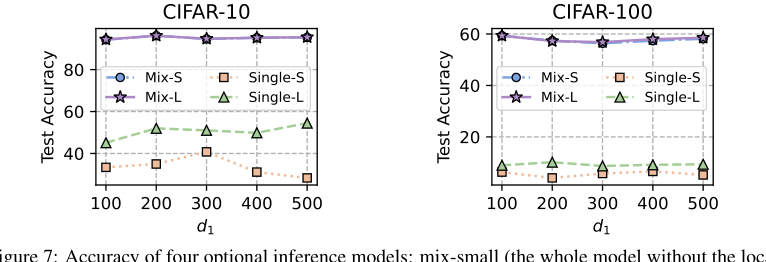 Figure 7. Accuracy of four optional inference models: mix-small (the whole model without the local header), mix-large (the whole model without the global header), single-small (the homogeneous small model), single-large (the client heterogeneous model)
Figure 7. Accuracy of four optional inference models: mix-small (the whole model without the local header), mix-large (the whole model without the global header), single-small (the homogeneous small model), single-large (the client heterogeneous model)
गणितीय और तार्किक तंत्र
मास्टर समीकरण
FedMRL दृष्टिकोण का पूर्ण मूल इसका उद्देश्य फ़ंक्शन है, जो फेडरेटेड लर्निंग सेटिंग में सभी भाग लेने वाले क्लाइंट्स में कुल हानि को कम करने का लक्ष्य रखता है। यह मास्टर समीकरण पूरे सीखने के लक्ष्य को समाहित करता है:
$$ \min_{\theta, \omega_0, \dots, \omega_{N-1}, \phi_0, \dots, \phi_{N-1}} \sum_{k=0}^{N-1} l(W_k(D_k; (\theta \circ \omega_k | \phi_k))) $$
पद-दर-पद विच्छेदन
आइए इसके गणितीय परिभाषा, तार्किक भूमिका और इसके निर्माण के पीछे के तर्क को समझने के लिए इस मास्टर समीकरण और इसके अंतर्निहित घटकों को विच्छेदित करें।
-
$\min_{\theta, \omega_0, \dots, \omega_{N-1}, \phi_0, \dots, \phi_{N-1}}$: यह अनुकूलन उद्देश्य है।
- गणितीय परिभाषा: यह दर्शाता है कि लक्ष्य उन मापदंडों के सेट ($\theta$, $\omega_k$, $\phi_k$) को खोजना है जो हानियों के बाद के योग को कम करते हैं।
- भौतिक/तार्किक भूमिका: यह पूरे FedMRL प्रणाली का केंद्रीय निर्देश है। यह निर्देशित करता है कि सीखने की प्रक्रिया को सभी प्रासंगिक मॉडल मापदंडों को समायोजित करना चाहिए ताकि सभी क्लाइंट्स में भविष्यवाणियां यथासंभव सटीक हों।
- न्यूनतमीकरण क्यों: मशीन लर्निंग में, हम आम तौर पर एक "हानि" या "त्रुटि" फ़ंक्शन को परिभाषित करते हैं, और उद्देश्य इस त्रुटि को कम करना है, इसलिए न्यूनतम एक प्राकृतिक विकल्प है।
-
$\sum_{k=0}^{N-1}$: यह एक योग ऑपरेटर है।
- गणितीय परिभाषा: यह क्लाइंट $k=0$ से $N-1$ तक, प्रत्येक क्लाइंट से व्यक्तिगत हानि योगदानों का योग करता है।
- भौतिक/तार्किक भूमिका: फेडरेटेड लर्निंग में, समग्र प्रदर्शन सभी क्लाइंट्स का एक सामूहिक माप है। यह योग सुनिश्चित करता है कि वैश्विक उद्देश्य प्रत्येक क्लाइंट के सीखने के परिणामों पर विचार करता है, स्थानीय डेटा का सम्मान करते हुए एक साझा सीखने के लक्ष्य को बढ़ावा देता है।
- क्यों योग के बजाय, जैसे, उत्पाद: योग एक बहु-क्लाइंट या बहु-कार्य सेटिंग में हानियों को एकत्रित करने का एक मानक तरीका है। एक उत्पाद छोटे नुकसानों (कुल को शून्य तक ले जाना) या बड़े नुकसानों (कुल को विस्फोट करना) के प्रति अत्यधिक संवेदनशील होगा, जिससे अनुकूलन अस्थिर हो जाएगा। योग व्यक्तिगत क्लाइंट प्रदर्शन के स्थिर और व्याख्यात्मक एकत्रीकरण प्रदान करता है।
-
$l(\cdot)$: यह एक हानि फ़ंक्शन का प्रतिनिधित्व करता है।
- गणितीय परिभाषा: जैसा कि पत्र (समीकरण 8) में कहा गया है, यह आम तौर पर एक क्रॉस-एंट्रॉपी हानि है, $l(y, Y_i)$, जो मॉडल के अनुमानित आउटपुट $y$ और सत्य लेबल $Y_i$ के बीच विसंगति को मापता है।
- भौतिक/तार्किक भूमिका: हानि फ़ंक्शन यह मापता है कि किसी दिए गए इनपुट के लिए मॉडल की भविष्यवाणियां कितनी "गलत" हैं। उच्च हानि का मतलब एक खराब भविष्यवाणी है। यह मॉडल मापदंडों को समायोजित करने के लिए अनुकूलन प्रक्रिया के लिए संकेत प्रदान करता है।
- क्रॉस-एंट्रॉपी क्यों: क्रॉस-एंट्रॉपी का उपयोग वर्गीकरण कार्यों के लिए व्यापक रूप से किया जाता है क्योंकि यह गलत वर्गीकरणों को अधिक भारी दंडित करता है और मॉडल को ऐसी संभावनाएँ आउटपुट करने के लिए प्रोत्साहित करता है जो सत्य लेबल वितरण से मेल खाती हैं।
-
$W_k(D_k; (\theta \circ \omega_k | \phi_k))$: यह क्लाइंट $k$ के लिए संयुक्त मॉडल का प्रतिनिधित्व करता है, जो इसके स्थानीय डेटा $D_k$ पर संचालित होता है, जो वैश्विक ($\theta$), स्थानीय ($\omega_k$), और व्यक्तिगत प्रोजेक्टर ($\phi_k$) मापदंडों के संयोजन द्वारा पैरामीट्रिज्ड होता है। यहीं पर मुख्य FedMRL तंत्र निहित है। आइए इसके आंतरिक कामकाज को तोड़ें:
-
$D_k$: यह क्लाइंट $k$ के स्थानीय डेटासेट को दर्शाता है।
- गणितीय परिभाषा: डेटा नमूनों का एक सेट $(x_i, Y_i)$, जहां $x_i$ एक इनपुट फीचर वेक्टर है और $Y_i$ इसका संबंधित सत्य लेबल है।
- भौतिक/तार्किक भूमिका: यह वह निजी, स्थानीय डेटा है जिसका उपयोग प्रत्येक क्लाइंट प्रशिक्षण के लिए करता है। FL में यह महत्वपूर्ण है कि यह डेटा स्थानीय रहे और सीधे सर्वर या अन्य क्लाइंट्स के साथ साझा न किया जाए।
-
$\theta$: यह वैश्विक सजातीय छोटे मॉडल के मापदंडों का प्रतिनिधित्व करता है।
- गणितीय परिभाषा: $\theta = \{\theta_{ex}, \theta_{hd}\}$ जहां $\theta_{ex}$ वैश्विक मॉडल के फीचर एक्सट्रैक्टर $G_{ex}$ के लिए पैरामीटर हैं और $\theta_{hd}$ इसके भविष्यवाणी हेडर $G_{hd}$ के लिए हैं। ये सभी क्लाइंट्स में साझा किए जाते हैं।
- भौतिक/तार्किक भूमिका: यह मॉडल एक "सामान्यीकृत" ज्ञान स्रोत के रूप में कार्य करता है। यह संचार लागत को कम करने और सिस्टम हेटेरोजेनिटी को समायोजित करने के लिए छोटा और सजातीय है। यह एक सामान्य आधार रेखा प्रतिनिधित्व प्रदान करता है।
-
$\omega_k$: यह क्लाइंट $k$ के विषम स्थानीय मॉडल के मापदंडों का प्रतिनिधित्व करता है।
- गणितीय परिभाषा: $\omega_k = \{\omega_{ex,k}, \omega_{hd,k}\}$ जहां $\omega_{ex,k}$ क्लाइंट $k$ के स्थानीय फीचर एक्सट्रैक्टर $F_{ex}$ के लिए पैरामीटर हैं और $\omega_{hd,k}$ इसके भविष्यवाणी हेडर $F_{hd}$ के लिए हैं। ये प्रत्येक क्लाइंट के लिए अद्वितीय हैं।
- भौतिक/तार्किक भूमिका: यह मॉडल क्लाइंट $k$ के विशिष्ट डेटा वितरण और मॉडल संरचना के अनुकूल "व्यक्तिगत" ज्ञान को कैप्चर करता है। यह डेटा और मॉडल हेटेरोजेनिटी को संबोधित करता है।
-
$\phi_k$: यह क्लाइंट $k$ के व्यक्तिगत प्रतिनिधित्व प्रोजेक्टर के मापदंडों का प्रतिनिधित्व करता है।
- गणितीय परिभाषा: $\phi_k$ हल्के प्रोजेक्टर $P_k$ के पैरामीटर हैं।
- भौतिक/तार्किक भूमिका: यह प्रोजेक्टर सामान्यीकृत और व्यक्तिगत प्रतिनिधित्व को अनुकूली रूप से संलयित करने के लिए जिम्मेदार है। यह प्रभावी ढंग से स्थानीय गैर-IID डेटा वितरण को संभालने के लिए प्रत्येक क्लाइंट के लिए व्यक्तिगत है।
-
$\circ$ (स्प्लिसिंग ऑपरेटर): यह ऑपरेटर फीचर एक्सट्रैक्टर के आउटपुट को जोड़ता है।
- गणितीय परिभाषा: समीकरण (3) के अनुसार, $R_i = R_k^g \circ R_k^f$, जहां $R_k^g = G_{ex}(x_i; \theta_{ex,t-1})$ वैश्विक मॉडल के फीचर एक्सट्रैक्टर से सामान्यीकृत प्रतिनिधित्व है और $R_k^f = F_{ex}(x_i; \omega_{ex,t-1})$ स्थानीय मॉडल के फीचर एक्सट्रैक्टर से व्यक्तिगत प्रतिनिधित्व है। स्प्लिसिंग में आम तौर पर फीचर वैक्टर को जोड़ना शामिल होता है।
- भौतिक/तार्किक भूमिका: यह ऑपरेशन सामान्यीकृत ज्ञान (सामान्य ज्ञान) को व्यक्तिगत ज्ञान (क्लाइंट-विशिष्ट ज्ञान) के साथ एक समृद्ध प्रतिनिधित्व में विलय करता है।
- जोड़ने के बजाय स्प्लिसिंग क्यों: स्प्लिसिंग (संयोजन) दोनों स्रोतों से अलग-अलग अर्थ संबंधी जानकारी को संरक्षित करता है। यदि हम जोड़ते या गुणा करते, तो जानकारी खो सकती थी या मिश्रित हो सकती थी, खासकर यदि फीचर स्पेस में अलग-अलग पैमाने या अर्थ हों। स्प्लिसिंग बाद के प्रोजेक्टर को इन अलग-अलग दृष्टिकोणों को सर्वोत्तम रूप से संयोजित करना सीखने की अनुमति देता है। पत्र नोट करता है कि यह "सापेक्ष अर्थ संबंधी स्थान की स्थिति बनाए रख सकता है।"
-
$|$ (मैट्रयोश्का रिप्रेजेंटेशन लर्निंग): यह प्रतीक बहु-आयामी, बहु-ग्रैन्युलर मैट्रयोश्का रिप्रेजेंटेशन लर्निंग प्रक्रिया का वैचारिक रूप से प्रतिनिधित्व करता है।
- गणितीय परिभाषा: स्प्लिस किए गए प्रतिनिधित्व $R_i$ को एक संलयित प्रतिनिधित्व $R_i = P_k(R_i; \phi_{k,t-1})$ (समीकरण 4) में प्रोजेक्ट करने के बाद, इसे दो एम्बेडेड प्रतिनिधित्वों में विभाजित किया जाता है: $R_i^{lc} = R_i^{1:d_1}$ (कम-आयाम, मोटे-ग्रैन्युलैरिटी) और $R_i^{hf} = R_i^{1:d_2}$ (उच्च-आयाम, बारीक-ग्रैन्युलैरिटी) (समीकरण 5)। फिर इन्हें अलग-अलग भविष्यवाणी हेडर में फीड किया जाता है: $y_i^{lc} = G_{hd}(R_i^{lc}; \theta_{hd,t-1})$ (समीकरण 6) और $y_i^{F_k} = F_{hd}(R_i^{hf}; \omega_{hd,t-1})$ (समीकरण 7)।
- भौतिक/तार्किक भूमिका: यह तंत्र मैट्रयोश्का गुड़िया से प्रेरित है, जहां छोटी गुड़िया बड़ी गुड़िया के अंदर नेस्टेड होती हैं। यहां, इसका मतलब विभिन्न ग्रैन्युलैरिटी और आयामों पर प्रतिनिधित्व निकालना है। यह मॉडल को कई दृष्टिकोणों से सीखने की अनुमति देता है, मोटे और बारीक दोनों तरह की जानकारी को कैप्चर करता है, जो मॉडल की सीखने की क्षमता और मजबूती को बढ़ाता है। वैश्विक हेडर मोटे प्रतिनिधित्व का उपयोग करता है, जबकि स्थानीय हेडर बारीक-ग्रैन्युलर वाले का उपयोग करता है।
- विभाजन और अलग हेडर क्यों: यह डिजाइन "बहु-परिप्रेक्ष्य प्रतिनिधित्व सीखना" को सक्षम बनाता है। विभिन्न ग्रैन्युलैरिटी के प्रतिनिधित्व को संसाधित करने वाले विभिन्न हेडर होने से, मॉडल अधिक मजबूत और व्यापक सुविधाएँ सीख सकता है। यह एक वस्तु को दूर से देखने जैसा है ताकि सामान्य आकार मिल सके, और फिर विवरण देखने के लिए करीब से, दोनों बेहतर समझ में योगदान करते हैं।
-
$m_i^{lc} \cdot l_i^{lc} + m_i^{F_k} \cdot l_i^{F_k}$ (भारित हानि योग): यह क्लाइंट $k$ पर एक डेटा बिंदु $i$ के लिए अंतिम संयुक्त हानि है।
- गणितीय परिभाषा: $l_i = m_i^{lc} \cdot l_i^{lc} + m_i^{F_k} \cdot l_i^{F_k}$ (समीकरण 9), जहां $l_i^{lc}$ वैश्विक मॉडल के हेडर से हानि है और $l_i^{F_k}$ स्थानीय मॉडल के हेडर से हानि है (समीकरण 8)। $m_i^{lc}$ और $m_i^{F_k}$ महत्व भार हैं, जो डिफ़ॉल्ट रूप से 1 पर सेट होते हैं।
- भौतिक/तार्किक भूमिका: यह सामान्यीकृत (वैश्विक) और व्यक्तिगत (स्थानीय) दोनों दृष्टिकोणों से सीखने के संकेतों को जोड़ता है। इन हानियों को भारित करके, सिस्टम प्रत्येक सीखने की शाखा के प्रभाव को संतुलित कर सकता है। भार को 1 पर सेट करने से सुनिश्चित होता है कि दोनों मॉडल समग्र सीखने में समान रूप से योगदान करते हैं।
- जोड़ क्यों: समग्र योग के समान, भारित हानियों को जोड़ना कई सीखने के उद्देश्यों को संयोजित करने का एक मानक तरीका है। यह प्रत्येक घटक से संतुलित योगदान की अनुमति देता है, मॉडल को एक इष्टतम स्थिति की ओर निर्देशित करता है जो मोटे और बारीक दोनों तरह के सीखने के लक्ष्यों को पूरा करता है।
-
चरण-दर-चरण प्रवाह
क्लाइंट $k$ पर FedMRL प्रणाली में प्रवेश करने वाले एक एकल डेटा बिंदु, एक छवि $x_i$ को उसके सत्य लेबल $Y_i$ के साथ कल्पना करें। यहाँ इसकी यात्रा है:
-
फ़ीचर निष्कर्षण: इनपुट छवि $x_i$ पहले समानांतर में दो अलग-अलग फीचर एक्सट्रैक्टर में प्रवेश करती है।
- वैश्विक सजातीय मॉडल का फीचर एक्सट्रैक्टर $G_{ex}$ ($\theta_{ex}$ मापदंडों के साथ) एक सामान्यीकृत प्रतिनिधित्व $R_k^g$ उत्पन्न करने के लिए $x_i$ को संसाधित करता है। यह छवि की एक सामान्य, सामान्य समझ प्राप्त करने जैसा है।
- साथ ही, क्लाइंट $k$ के स्थानीय विषम मॉडल का फीचर एक्सट्रैक्टर $F_{ex}$ ($\omega_{ex,k}$ मापदंडों के साथ) एक व्यक्तिगत प्रतिनिधित्व $R_k^f$ उत्पन्न करने के लिए $x_i$ को संसाधित करता है। यह क्लाइंट-विशिष्ट विवरण या बारीकियों को कैप्चर करता है।
-
प्रतिनिधित्व स्प्लिसिंग: दो प्रतिनिधित्व, $R_k^g$ और $R_k^f$, फिर एक संयुक्त प्रतिनिधित्व $R_i$ बनाने के लिए "स्प्लिस" (संयोजित) किए जाते हैं। यह कदम सुनिश्चित करता है कि सामान्य और व्यक्तिगत दोनों जानकारी अगल-बगल संरक्षित रहे।
-
अनुकूली प्रतिनिधित्व संलयन: स्प्लिस किए गए प्रतिनिधित्व $R_i$ को फिर क्लाइंट $k$ के व्यक्तिगत हल्के प्रतिनिधित्व प्रोजेक्टर $P_k$ ($\phi_k$ मापदंडों के साथ) में फीड किया जाता है। यह प्रोजेक्टर स्प्लिस किए गए प्रतिनिधित्व को एक संलयित प्रतिनिधित्व $R_i$ में मैप करता है। यहीं पर सिस्टम संयुक्त ज्ञान को क्लाइंट के अद्वितीय डेटा वितरण के अनुकूल बनाता है।
-
मैट्रयोश्का प्रतिनिधित्व विभाजन: संलयित प्रतिनिधित्व $R_i$ को फिर वैचारिक रूप से दो भागों में विभाजित किया जाता है, जैसे कि एक छोटी गुड़िया को प्रकट करने के लिए मैट्रयोश्का गुड़िया खोलना।
- $R_i$ के प्रारंभिक खंड से एक कम-आयाम, मोटे-ग्रैन्युलैरिटी प्रतिनिधित्व $R_i^{lc}$ निकाला जाता है।
- $R_i$ के एक बड़े खंड से एक उच्च-आयाम, बारीक-ग्रैन्युलैरिटी प्रतिनिधित्व $R_i^{hf}$ निकाला जाता है।
-
बहु-परिप्रेक्ष्य भविष्यवाणी: इन दो मैट्रयोश्का प्रतिनिधित्वों को फिर उनके संबंधित भविष्यवाणी हेडर में पारित किया जाता है:
- $R_i^{lc}$ वैश्विक सजातीय मॉडल के भविष्यवाणी हेडर $G_{hd}$ ($\theta_{hd}$ मापदंडों के साथ) में मोटे भविष्यवाणी $y_i^{lc}$ उत्पन्न करने के लिए जाता है।
- $R_i^{hf}$ क्लाइंट $k$ के स्थानीय विषम मॉडल के भविष्यवाणी हेडर $F_{hd}$ ($\omega_{hd,k}$ मापदंडों के साथ) में बारीक-ग्रैन्युलर भविष्यवाणी $y_i^{F_k}$ उत्पन्न करने के लिए जाता है।
-
हानि गणना: प्रत्येक भविष्यवाणी के लिए, सत्य लेबल $Y_i$ के विरुद्ध एक हानि की गणना की जाती है:
- $l_i^{lc}$ मोटे भविष्यवाणी $y_i^{lc}$ के लिए हानि है।
- $l_i^{F_k}$ बारीक-ग्रैन्युलर भविष्यवाणी $y_i^{F_k}$ के लिए हानि है।
-
भारित हानि एकत्रीकरण: अंत में, इन दो व्यक्तिगत हानियों को एक एकल कुल हानि $l_i$ में डेटा बिंदु $x_i$ के लिए एक भारित योग द्वारा संयोजित किया जाता है। डिफ़ॉल्ट रूप से, दोनों हानियां समान रूप से योगदान करती हैं। यह $l_i$ समग्र उद्देश्य फ़ंक्शन में योगदान करने वाला मान है।
यह पूरी प्रक्रिया बैच में सभी डेटा बिंदुओं के लिए दोहराई जाती है, और बैच के लिए औसत हानि का उपयोग अनुकूलन के लिए किया जाता है।
अनुकूलन गतिशीलता
FedMRL तंत्र ग्रेडिएंट डिसेंट की प्रक्रिया के माध्यम से पुनरावृत्त रूप से अपने मापदंडों को सीखता और अद्यतन करता है, जिसका लक्ष्य वैश्विक उद्देश्य फ़ंक्शन को कम करना है।
-
ग्रेडिएंट गणना: क्लाइंट $k$ पर डेटा बिंदुओं के बैच के लिए भारित हानि $l_i$ की गणना के बाद, क्लाइंट $k$ के मॉडल में शामिल सभी मापदंडों के संबंध में इस हानि के ग्रेडिएंट की गणना की जाती है:
- $\nabla l_i$ $\theta$ (वैश्विक मॉडल मापदंडों) के संबंध में।
- $\nabla l_i$ $\omega_k$ (क्लाइंट $k$ के स्थानीय मॉडल मापदंडों) के संबंध में।
- $\nabla l_i$ $\phi_k$ (क्लाइंट $k$ के व्यक्तिगत प्रतिनिधित्व प्रोजेक्टर मापदंडों) के संबंध में।
-
स्थानीय पैरामीटर अद्यतन: प्रत्येक क्लाइंट $k$ फिर इन ग्रेडिएंट्स और पूर्वनिर्धारित सीखने की दरों ($\eta_\theta, \eta_\omega, \eta_\phi$) का उपयोग करके अपने स्थानीय मापदंडों ($\omega_k$ और $\phi_k$) और वैश्विक मॉडल मापदंडों ($\theta$) की अपनी प्रति को अद्यतन करता है। यह एक मानक ग्रेडिएंट डिसेंट चरण है:
$$ \theta^t \leftarrow \theta^{t-1} - \eta_\theta \nabla l_i \\ \omega_k^t \leftarrow \omega_k^{t-1} - \eta_\omega \nabla l_i \\ \phi_k^t \leftarrow \phi_k^{t-1} - \eta_\phi \nabla l_i $$
ये अद्यतन स्थानीय रूप से प्रत्येक क्लाइंट पर होते हैं, जो मॉडलों को उनके विशिष्ट डेटा और सीखने के उद्देश्यों के अनुकूल बनाते हैं। पत्र स्थिर अभिसरण के लिए डिफ़ॉल्ट रूप से $\eta_\theta = \eta_\omega = \eta_\phi$ सेट करने का उल्लेख करता है। -
सर्वर एकत्रीकरण: एक स्थानीय प्रशिक्षण राउंड (जिसमें कई स्थानीय युग शामिल हो सकते हैं) के बाद, प्रत्येक भाग लेने वाला क्लाइंट अपने अद्यतन सजातीय छोटे मॉडल मापदंडों (यानी, अपने अद्यतन $\theta$ मापदंडों) को केंद्रीय सर्वर पर अपलोड करता है। सर्वर तब नए, समेकित वैश्विक मॉडल $\theta^t$ का उत्पादन करने के लिए भाग लेने वाले सभी क्लाइंट्स से इन अद्यतन वैश्विक मॉडल मापदंडों को एकत्रित करता है। यह एकत्रीकरण आम तौर पर प्राप्त मापदंडों का औसत होता है। स्थानीय विषम मॉडल पैरामीटर $\omega_k$ और प्रोजेक्टर पैरामीटर $\phi_k$ क्लाइंट पर बने रहते हैं और सर्वर को प्रसारित नहीं किए जाते हैं, जिससे गोपनीयता संरक्षित होती है।
-
प्रसारण और पुनरावृति: नव एकत्रित वैश्विक मॉडल $\theta^t$ को फिर अगले संचार राउंड के लिए सभी क्लाइंट्स को वापस प्रसारित किया जाता है। स्थानीय प्रशिक्षण, पैरामीटर अपलोड, सर्वर एकत्रीकरण, और वैश्विक मॉडल प्रसारण का यह चक्र एक निर्दिष्ट संख्या में राउंड के लिए या अभिसरण तक दोहराया जाता है।
हानि परिदृश्य और अभिसरण: FedMRL के लिए समग्र हानि परिदृश्य गैर-उत्तल है, जो डीप लर्निंग मॉडल के लिए विशिष्ट है। पुनरावृत्त ग्रेडिएंट डिसेंट चरण इस परिदृश्य को नेविगेट करते हैं, एक न्यूनतम खोजने का लक्ष्य रखते हैं। पत्र में सैद्धांतिक विश्लेषण से पता चलता है कि FedMRL $O(1/T)$ गैर-उत्तल अभिसरण दर प्राप्त करता है, जहां $T$ संचार राउंड की कुल संख्या है। इसका मतलब है कि जैसे-जैसे राउंड की संख्या बढ़ती है, स्थानीय प्रशिक्षण पूरे मॉडल के औसत ग्रेडिएंट घटता है, यह दर्शाता है कि मॉडल वास्तव में समय के साथ सीख रहा है और अभिसरण कर रहा है। इस अभिसरण के लिए शर्तें सीखने की दरों और पैरामीटर भिन्नताओं और ग्रेडिएंट भिन्नताओं की सीमितता पर निर्भर करती हैं, जैसा कि लेम्मा और प्रमेयों में विस्तृत है। अनुकूली प्रतिनिधित्व संलयन और बहु-ग्रैन्युलैरिटी प्रतिनिधित्व सीखने को इस हानि परिदृश्य को इस तरह से आकार देने के लिए डिज़ाइन किया गया है जो अधिक प्रभावी ज्ञान हस्तांतरण की सुविधा प्रदान करता है और बेहतर न्यूनतम खोजने के लिए मॉडल की क्षमता में सुधार करता है, जिससे बेहतर प्रदर्शन होता है।
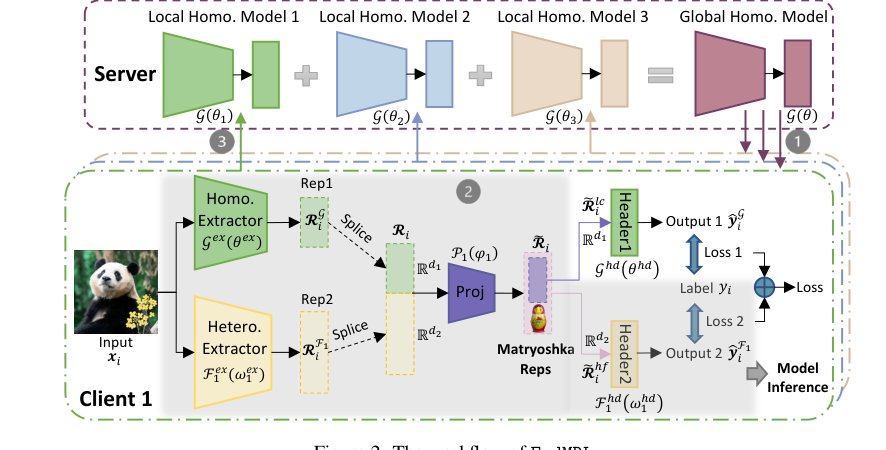 Figure 2. The workflow of FedMRL
Figure 2. The workflow of FedMRL
परिणाम, सीमाएं और निष्कर्ष
प्रयोगात्मक डिजाइन और बेसलाइन
FedMRL के गणितीय दावों और व्यावहारिक प्रभावशीलता को कठोरता से मान्य करने के लिए, लेखकों ने एक व्यापक प्रयोगात्मक सेटअप तैयार किया। प्रस्तावित FedMRL दृष्टिकोण को Pytorch का उपयोग करके लागू किया गया था और सात अत्याधुनिक MHeteroFL विधियों के मुकाबले बेंचमार्क किया गया था। ये प्रयोग चार NVIDIA GeForce 3090 GPUs के एक मजबूत हार्डवेयर कॉन्फ़िगरेशन पर किए गए थे, जिनमें से प्रत्येक में 24GB मेमोरी थी।
FedMRL के मुकाबले जिन "पीड़ितों" (बेसलाइन मॉडल) को खड़ा किया गया था, वे चार श्रेणियों में आते हैं:
1. स्टैंडअलोन: क्लाइंट्स स्थानीय डेटा पर स्वतंत्र रूप से मॉडल प्रशिक्षित करते हैं।
2. सार्वजनिक डेटा के बिना ज्ञान आसवन: FD [21] और FedProto [43] जैसी विधियां।
3. मॉडल विभाजन: LG-FedAvg [27] द्वारा दर्शाया गया।
4. पारस्परिक सीखना: FML [41], FedKD [45], और FedAPEN [37] सहित।
FL छवि वर्गीकरण के लिए दो व्यापक रूप से उपयोग किए जाने वाले बेंचमार्क डेटासेट का उपयोग किया गया था: CIFAR-10 (60,000 32x32 रंगीन छवियां, 10 वर्ग) और CIFAR-100 (60,000 32x32 रंगीन छवियां, 100 वर्ग)। दोनों के लिए, 50,000 छवियों का उपयोग प्रशिक्षण के लिए और 10,000 का उपयोग परीक्षण के लिए किया गया था। यथार्थवादी फेडरेटेड वातावरण का अनुकरण करने के लिए, दो प्रकार के Non-IID (गैर-स्वतंत्र और समान रूप से वितरित) डेटा वितरण का निर्माण किया गया था:
* Non-IID (वर्ग): क्लाइंट्स को सीमित संख्या में वर्ग (CIFAR-10 के लिए 2, CIFAR-100 के लिए 10) सौंपे गए थे, जिसमें कम वर्ग अधिक Non-IIDness का संकेत देते हैं।
* Non-IID (डिริचलेट): डेटा वितरण को नियंत्रित करने के लिए एक डिริचलेट($\alpha$) फ़ंक्शन का उपयोग किया गया था, जहां एक छोटा $\alpha$ अधिक स्पष्ट Non-IIDness का संकेत देता है।
मूल्यांकन में मॉडल-होमोजेनियस (सभी क्लाइंट्स CNN-1 का उपयोग करते हैं) और मॉडल-हेटेरोजेनियस (क्लाइंट्स CNN-1 से CNN-5 का मिश्रण उपयोग करते हैं) FL परिदृश्यों दोनों को शामिल किया गया था। FedMRL के प्रतिनिधित्व प्रोजेक्टर एक साधारण एक-परत रैखिक मॉडल था। मॉडल-होमोजेनियस सेटिंग्स के लिए, FedMRL ने अपने सजातीय वैश्विक छोटे मॉडल के लिए CNN-1 का उपयोग किया, लेकिन क्लाइंट के $d_2$ की तुलना में एक छोटे प्रतिनिधित्व आयाम $d_1$ के साथ। मॉडल-हेटेरोजेनियस सेटिंग्स में, FedMRL ने अपने वैश्विक घटक के लिए सबसे छोटे CNN-5 मॉडल का उपयोग किया, फिर से एक कम $d_1$ के साथ।
प्रदर्शन का मूल्यांकन तीन महत्वपूर्ण पहलुओं पर किया गया था:
* मॉडल सटीकता: सभी क्लाइंट्स में औसत परीक्षण सटीकता।
* संचार लागत: सर्वर और एक क्लाइंट के बीच लक्ष्य औसत सटीकता तक पहुंचने के लिए प्रेषित मापदंडों की कुल संख्या से मापा जाता है, जिसमें प्रति राउंड मापदंडों और राउंड की संख्या दोनों पर विचार किया जाता है।
* कम्प्यूटेशनल ओवरहेड: लक्ष्य औसत सटीकता तक पहुंचने के लिए प्रति क्लाइंट कुल FLOPs (फ्लोटिंग-पॉइंट ऑपरेशंस) से मापा जाता है, जिसमें प्रति राउंड FLOPs और राउंड की संख्या दोनों पर विचार किया जाता है।
प्रशिक्षण रणनीति में सभी एल्गोरिदम के लिए व्यापक हाइपरपैरामीटर ट्यूनिंग शामिल थी, जिसमें बैच आकार, युग, संचार राउंड और सीखने की दरें शामिल हैं। महत्वपूर्ण रूप से, FedMRL के अद्वितीय हाइपरपैरामीटर, $d_1$ (सजातीय वैश्विक छोटे मॉडल का प्रतिनिधित्व आयाम), को इष्टतम ट्रेड-ऑफ खोजने के लिए 100 से 500 तक भिन्न किया गया था। प्रयोग मॉडल-होमोजेनियस और मॉडल-हेटेरोजेनियस परिदृश्यों दोनों के लिए तीन अलग-अलग FL सेटिंग्स (N=10, C=100%; N=50, C=20%; N=100, C=10%) के तहत किए गए थे। लेखकों ने प्रत्येक प्रयोगात्मक सेटिंग के लिए तीन परीक्षणों पर औसत परिणाम की सूचना दी।
साक्ष्य क्या साबित करते हैं
प्रायोगिक साक्ष्य निश्चित, निर्विवाद प्रमाण प्रदान करते हैं कि FedMRL का मुख्य तंत्र - अनुकूली व्यक्तिगत प्रतिनिधित्व संलयन और बहु-ग्रैन्युलैरिटी प्रतिनिधित्व सीखना - वास्तव में वास्तविकता में प्रभावी ढंग से काम करता है, जिससे बेहतर प्रदर्शन होता है।
बेहतर मॉडल सटीकता:
* FedMRL ने मॉडल-हेटेरोजेनियस (तालिका 1) और मॉडल-होमोजेनियस (तालिका 3, परिशिष्ट C.2) FL सेटिंग्स दोनों में सभी सात अत्याधुनिक बेसलाइन को लगातार बेहतर प्रदर्शन किया।
* इसने सर्वश्रेष्ठ समग्र बेसलाइन पर 8.48% तक और सर्वश्रेष्ठ समान-श्रेणी (पारस्परिक सीखने-आधारित) बेसलाइन पर 24.94% तक औसत परीक्षण सटीकता में प्रभावशाली सुधार हासिल किया।
* चित्र 3 (बाएं छह प्लॉट) विभिन्न क्लाइंट और भागीदारी दर सेटिंग्स के तहत सर्वश्रेष्ठ बेसलाइन (FedProto) की तुलना में FedMRL की तेज अभिसरण गति और उच्च अंतिम औसत परीक्षण सटीकता की पुष्टि करता है।
उन्नत वैयक्तिकरण:
* चित्र 3 (दाएं दो प्लॉट) FedMRL और FedProto के बीच व्यक्तिगत क्लाइंट परीक्षण सटीकता अंतर को दर्शाते हैं। CIFAR-10 पर 87% क्लाइंट्स और CIFAR-100 पर 99% ने FedMRL के साथ बेहतर प्रदर्शन हासिल किया। यह FedMRL की बेहतर वैयक्तिकरण क्षमता का एक मजबूत प्रमाण है, जो सीधे इसके अनुकूली व्यक्तिगत बहु-ग्रैन्युलैरिटी प्रतिनिधित्व सीखने के डिजाइन के लिए जिम्मेदार है।
बेहतर दक्षता:
* संचार लागत: यद्यपि FedMRL पूर्ण सजातीय छोटे मॉडल को प्रसारित करता है, जिससे FedProto (जो केवल स्थानीय देखी गई-वर्ग औसत प्रतिनिधित्व भेजता है) की तुलना में प्रति राउंड उच्च संचार लागत आती है, चित्र 4 (बाएं) से पता चलता है कि FedMRL को लक्ष्य सटीकता तक पहुंचने के लिए कम संचार राउंड की आवश्यकता होती है, जिससे तेज अभिसरण होता है। इसके अलावा, जब एक वैकल्पिक छोटे प्रतिनिधित्व आयाम ($d_1$) पर विचार किया जाता है, तो FedMRL उन अन्य पारस्परिक सीखने-आधारित बेसलाइन (FML, FedKD, FedAPEN) की तुलना में उच्च संचार दक्षता प्राप्त करता है जो बड़े प्रतिनिधित्व आयामों का उपयोग करते हैं।
* कम्प्यूटेशनल ओवरहेड: एक अतिरिक्त सजातीय छोटे मॉडल और एक हल्के प्रतिनिधित्व प्रोजेक्टर को प्रशिक्षित करने के प्रति राउंड ओवरहेड के बावजूद, चित्र 4 (दाएं) प्रदर्शित करता है कि FedMRL FedProto की तुलना में कम कुल कम्प्यूटेशनल लागत का कारण बनता है। यह इसके तेज अभिसरण का एक सीधा परिणाम है, जिसके लिए कम समग्र प्रशिक्षण राउंड की आवश्यकता होती है।
Non-IID डेटा के प्रति मजबूती:
* वर्ग-आधारित Non-IIDness: चित्र 5 (बाएं दो प्लॉट) स्पष्ट रूप से FedMRL की मजबूती को दर्शाता है, यहां तक कि प्रति क्लाइंट वर्गों की संख्या कम होने पर भी (Non-IIDness में वृद्धि) FedProto की तुलना में उच्च औसत परीक्षण सटीकता बनाए रखता है।
* डिริचलेट-आधारित Non-IIDness: चित्र 5 (दाएं दो प्लॉट) इस मजबूती को और मान्य करता है, जिसमें FedMRL परीक्षण किए गए सभी $\alpha$ मानों पर FedProto से काफी बेहतर प्रदर्शन करता है, जो डेटा हेटेरोजेनिटी की विभिन्न डिग्री के प्रति इसके लचीलेपन को प्रदर्शित करता है।
तंत्र संवेदनशीलता और एब्लेशन अध्ययन के माध्यम से मान्य:
* $d_1$ के प्रति संवेदनशीलता: चित्र 6 (बाएं दो प्लॉट) से पता चलता है कि छोटे $d_1$ मान (सजातीय छोटे मॉडल का प्रतिनिधित्व आयाम) अक्सर उच्च औसत परीक्षण सटीकता और कम संचार/कम्प्यूटेशनल ओवरहेड की ओर ले जाते हैं। यह ट्रेड-ऑफ को प्राप्त करने में $d_1$ के महत्व को उजागर करता है।
* एब्लेशन अध्ययन: चित्र 6 (दाएं दो प्लॉट) निश्चित रूप से मैट्रयोश्का रिप्रेजेंटेशन लर्निंग (MRL) घटक की उपयोगिता को साबित करते हैं। MRL के बिना FedMRL की तुलना में MRL के साथ FedMRL लगातार बेहतर प्रदर्शन करता है, यह पुष्टि करता है कि बहु-ग्रैन्युलैरिटी प्रतिनिधित्व सीखना MHeteroFL के लिए एक महत्वपूर्ण डिजाइन तत्व है। यह अवलोकन कि सटीकता का अंतर $d_1$ बढ़ने पर कम हो जाता है, यह बताता है कि जब वैश्विक और स्थानीय हेडर तेजी से ओवरलैपिंग प्रतिनिधित्व सीखते हैं, तो MRL के लाभ कम हो जाते हैं।
अनुमान मॉडल लचीलापन:
* परिशिष्ट C.3 और चित्र 7 दिखाते हैं कि "मिक्स-स्मॉल" (स्थानीय हेडर के बिना पूरा मॉडल) और "मिक्स-लार्ज" (वैश्विक हेडर के बिना पूरा मॉडल) अनुमान मॉडल समान, उच्च सटीकता प्राप्त करते हैं, जो एकल सजातीय या विषम मॉडल से काफी बेहतर प्रदर्शन करते हैं। यह उपयोगकर्ताओं के लिए उनकी विशिष्ट अनुमान लागत आवश्यकताओं के आधार पर चुनने के लिए व्यावहारिक लचीलापन प्रदान करता है।
सीमाएं और भविष्य की दिशाएं
यद्यपि FedMRL मॉडल-हेटेरोजेनियस फेडरेटेड लर्निंग में एक महत्वपूर्ण प्रगति प्रस्तुत करता है, इसकी वर्तमान सीमाओं को स्वीकार करना और भविष्य के विकास के लिए रास्ते पर विचार करना महत्वपूर्ण है।
वर्तमान सीमाएं:
लेखकों द्वारा पहचानी गई प्राथमिक सीमा मैट्रयोश्का रिप्रेजेंटेशन के भीतर बहु-ग्रैन्युलैरिटी एम्बेडेड प्रतिनिधित्व में निहित है। ये प्रतिनिधित्व वर्तमान में दोनों वैश्विक छोटे मॉडल के हेडर और स्थानीय क्लाइंट मॉडल के हेडर द्वारा संसाधित किए जाते हैं। यद्यपि वैश्विक हेडर में केवल एक रैखिक परत शामिल हो सकती है, यह दोहरा प्रसंस्करण अभी भी भंडारण लागत, संचार ओवरहेड और वैश्विक हेडर के लिए प्रशिक्षण ओवरहेड में योगदान देता है। इसका तात्पर्य है कि यद्यपि FedMRL अभिसरण को तेज करके समग्र दक्षता में सुधार करता है, फिर भी बहु-ग्रैन्युलर प्रतिनिधित्व के वैश्विक मॉडल के प्रसंस्करण से जुड़े संसाधन खपत को अनुकूलित करने के लिए जगह है।
भविष्य की दिशाएं और चर्चा विषय:
-
बहु-ग्रैन्युलैरिटी प्रसंस्करण को सुव्यवस्थित करना: पत्र स्पष्ट रूप से भविष्य के काम में एक अधिक उन्नत मैट्रयोश्का रिप्रेजेंटेशन लर्निंग विधि (MRL-E) [24] अपनाने का सुझाव देता है। इसमें पूरी तरह से वैश्विक हेडर को हटाना और बहु-ग्रैन्युलर मैट्रयोश्का रिप्रेजेंटेशन को संसाधित करने के लिए पूरी तरह से स्थानीय मॉडल हेडर पर निर्भर रहना शामिल होगा। इससे मॉडल प्रदर्शन और भंडारण, संचार और कम्प्यूटेशनल की लागतों के बीच एक बेहतर ट्रेड-ऑफ हो सकता है।
- चर्चा: क्या इस तरह के बदलाव फेडरेटेड लर्निंग के "वैश्विक ज्ञान" पहलू को प्रभावित कर सकते हैं? क्या केवल स्थानीय हेडर पर बहु-ग्रैन्युलर प्रसंस्करण के लिए निर्भर रहने से साझा वैश्विक मॉडल के लाभों का क्षरण हो सकता है, या क्या अनुकूली प्रतिनिधित्व संलयन तंत्र पर्याप्त रूप से क्षतिपूर्ति कर सकता है? स्थानीय कम्प्यूटेशनल बोझ को महत्वपूर्ण रूप से बढ़ाए बिना इस बढ़ी हुई जिम्मेदारी को संभालने के लिए स्थानीय मॉडल हेडर में क्या वास्तुशिल्प परिवर्तन की आवश्यकता होगी?
-
गतिशील $d_1$ अनुकूलन: संवेदनशीलता विश्लेषण से पता चला है कि छोटे $d_1$ मान (सजातीय छोटे मॉडल का प्रतिनिधित्व आयाम) अक्सर बेहतर सटीकता और दक्षता की ओर ले जाते हैं।
- चर्चा: क्या $d_1$ को FL प्रशिक्षण प्रक्रिया के दौरान गतिशील रूप से अनुकूलित किया जा सकता है, शायद क्लाइंट-विशिष्ट डेटा विशेषताओं या अभिसरण मेट्रिक्स के आधार पर? क्या क्लाइंट्स या संचार राउंड के लिए इष्टतम $d_1$ सीखने के लिए एक सुदृढीकरण सीखने के दृष्टिकोण का उपयोग किया जा सकता है, बजाय एक निश्चित, पूर्व-ट्यून किए गए हाइपरपैरामीटर पर निर्भर रहने के?
-
अनसुपरवाइज्ड/सेल्फ-सुपरवाइज्ड कार्यों तक विस्तार: वर्तमान FedMRL दृष्टिकोण पर्यवेक्षित सीखने के कार्यों के लिए डिज़ाइन किया गया है।
- चर्चा: सीमित लेबल वाले डेटा वाले परिदृश्यों के लिए तेजी से प्रासंगिक अनसुपरवाइज्ड या सेल्फ-सुपरवाइज्ड फेडरेटेड लर्निंग तक अनुकूली प्रतिनिधित्व संलयन और बहु-ग्रैन्युलैरिटी प्रतिनिधित्व सीखने के सिद्धांतों को कैसे बढ़ाया जा सकता है? ऐसे परिदृश्यों में हानि फ़ंक्शन और ज्ञान हस्तांतरण तंत्र के लिए क्या संशोधन आवश्यक होंगे?
-
एडवर्सेरियल हमलों और डेटा पॉइज़निंग के प्रति मजबूती: यद्यपि पत्र गोपनीयता संरक्षण का उल्लेख करता है, यह दुर्भावनापूर्ण हमलों के खिलाफ मजबूती का स्पष्ट रूप से विवरण नहीं देता है।
- चर्चा: बढ़ी हुई ज्ञान हस्तांतरण और व्यक्तिगत प्रतिनिधित्व को देखते हुए, FedMRL का आर्किटेक्चर डेटा पॉइज़निंग या मॉडल व्युत्क्रमण हमलों का स्वाभाविक रूप से प्रतिरोध कैसे कर सकता है या कमजोर हो सकता है? क्या अतिरिक्त गोपनीयता-संरक्षण तंत्र (जैसे, विभेदक गोपनीयता, सुरक्षित एकत्रीकरण) को FedMRL के साथ एकीकृत किया जा सकता है ताकि इसके प्रदर्शन या दक्षता लाभों से महत्वपूर्ण रूप से समझौता किए बिना इसकी सुरक्षा को और मजबूत किया जा सके?
-
अत्यधिक बड़े N और विविध C के लिए मापनीयता: प्रयोगों को N=100 क्लाइंट्स तक के साथ किया गया था।
- चर्चा: FedMRL हजारों या लाखों क्लाइंट्स वाले फेडरेटेड नेटवर्क के लिए कैसे मापेगा, विशेष रूप से विभिन्न क्लाइंट भागीदारी दरों (C) और रुक-रुक कर क्लाइंट उपलब्धता को ध्यान में रखते हुए? क्या ऐसे बड़े पैमाने पर परिनियोजन में दक्षता बनाए रखने के लिए एकत्रीकरण रणनीति या संचार प्रोटोकॉल के लिए और अनुकूलन की आवश्यकता है?
-
छवि वर्गीकरण से परे: वर्तमान सत्यापन छवि वर्गीकरण डेटासेट पर है।
- चर्चा: FedMRL अन्य डेटा तौर-तरीकों और कार्यों, जैसे प्राकृतिक भाषा प्रसंस्करण, समय-श्रृंखला विश्लेषण, या चिकित्सा इमेजिंग के लिए कितनी अच्छी तरह सामान्यीकृत होगा? क्या बहु-ग्रैन्युलैरिटी प्रतिनिधित्व की "मैट्रयोश्का" अवधारणा सीधे अनुवादित होगी, या फीचर निष्कर्षण और संलयन के लिए डोमेन-विशिष्ट अनुकूलन की आवश्यकता होगी?
ये चर्चा बिंदु FedMRL की मूलभूत अंतर्दृष्टि का लाभ उठाने और फेडरेटेड लर्निंग के क्षेत्र में व्यापक चुनौतियों का समाधान करने और नई संभावनाओं को खोलने के लिए विकसित करने के बारे में महत्वपूर्ण सोच को उत्तेजित करने का लक्ष्य रखते हैं।
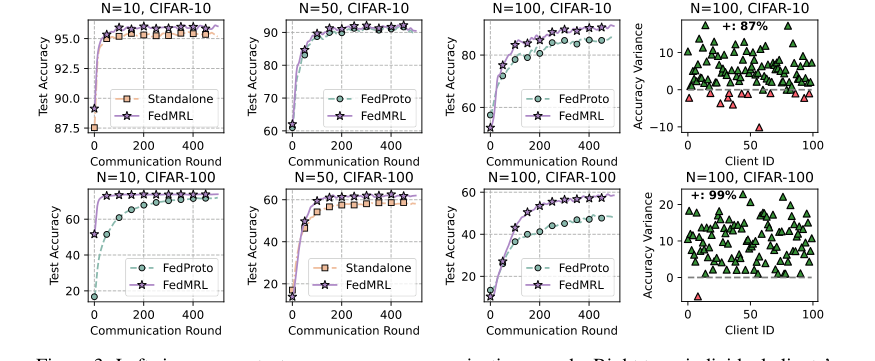 Figure 3. Left six: average test accuracy vs. communication rounds. Right two: individual clients’ test accuracy (%) differences (FedMRL - FedProto)
Figure 3. Left six: average test accuracy vs. communication rounds. Right two: individual clients’ test accuracy (%) differences (FedMRL - FedProto)
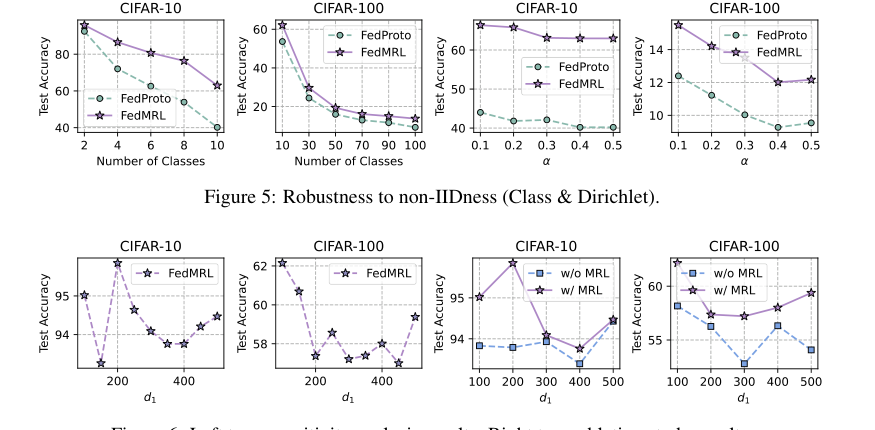 Figure 6. Left two: sensitivity analysis results. Right two: ablation study results
Figure 6. Left two: sensitivity analysis results. Right two: ablation study results
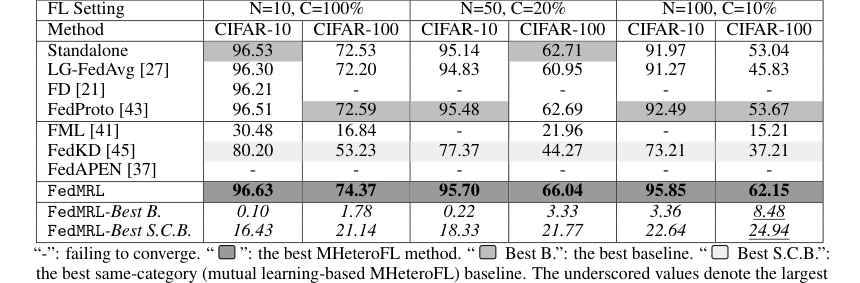 Table 1. and Table 3 (Appendix C.2) show that FedMRL consistently outperforms all baselines under both model-heterogeneous or homogeneous settings. It achieves up to a 8.48% improvement in average test accuracy compared with the best baseline under each setting. Furthermore, it achieves up to a 24.94% average test accuracy improvement than the best same-category (i.e., mutual learning- based MHeteroFL) baseline under each setting. These results demonstrate the superiority of FedMRL
Table 1. and Table 3 (Appendix C.2) show that FedMRL consistently outperforms all baselines under both model-heterogeneous or homogeneous settings. It achieves up to a 8.48% improvement in average test accuracy compared with the best baseline under each setting. Furthermore, it achieves up to a 24.94% average test accuracy improvement than the best same-category (i.e., mutual learning- based MHeteroFL) baseline under each setting. These results demonstrate the superiority of FedMRL
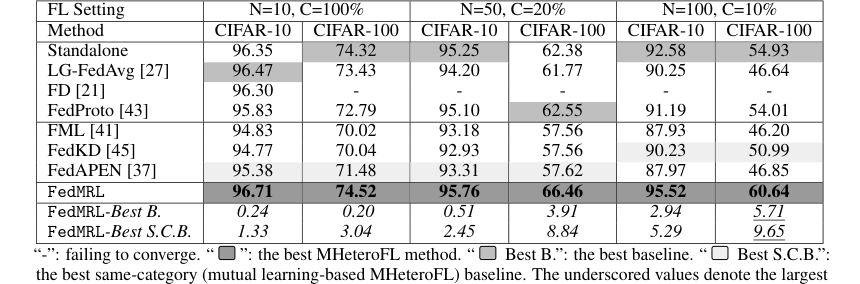 Table 3. presents the results of FedMRL and baselines in model-homogeneous FL scenarios
Table 3. presents the results of FedMRL and baselines in model-homogeneous FL scenarios