Paralinguistics-Aware Speech-Empowered Large Language Models for Natural Conversation
Recent work shows promising results in expanding the capabilities of large language models (LLM) to directly understand and synthesize speech.
Background & Academic Lineage
The Origin & Academic Lineage
The problem addressed in this paper originates from the recent advancements and widespread adoption of Large Language Models (LLMs) in text-based conversational AI. While LLMs have demonstrated remarkable capabilities in understanding, generating, and reasoning with text, their direct application to spoken dialogs has remained a significant challenge. The core motivation is to extend the powerful, emergent abilities of LLMs—such as few-shot in-context learning and complex reasoning—to the realm of natural spoken conversation, enabling more intuitive and human-like interactions.
Historically, early spoken language models (SLMs) either focused solely on speech data or employed very simple cross-modal objectives, failing to fully harness the sophisticated linguistic understanding of pretrained LLMs. With the advent of highly capable text-based LLMs, the academic field shifted towards integrating speech modalities into these models.
The fundamental limitations or "pain points" of previous approaches that necessitated this research can be categorized into two main types:
-
Cascaded Models: These approaches typically involve separate Automatic Speech Recognition (ASR) to convert user speech to text, an LLM to generate a text response, and then a Text-to-Speech (TTS) system to synthesize the spoken reply.
- Linguistic Discrepancy: A significant "pain point" is the inherent mismatch between how speech and text convey information. Speech carries rich paralinguistic cues like emotion, tone, and rhythm, which are lost when converted to plain text by ASR. This linguistic discrepancy leads to dialog inefficiencies and a sub-optimal user experience, as the LLM operates only on the semantic content, often ignoring crucial non-verbal context.
- Label Dependency for Paralinguistics: To incorporate paralinguistic features in cascaded models, explicit labels (e.g., for emotions) are often required. This makes data collection challenging and restricts the models to only those non-verbal cues that can be explicitly labeled.
- Error Propagation: A major drawback is the compounding of errors. Any inaccuracies introduced by the ASR system or the text-based LLM can propagate through the pipeline, leading to less coherent or natural-sounding spoken responses.
-
End-to-End Speech-Only or Simple Cross-Modal Models: While some end-to-end pipelines exist, they often fail to fully leverage the extensive knowledge and reasoning capabilities embedded within pretrained LLMs. These models might be limited in their ability to capture the comprehensive, intricate relationships between speech and text modalities, thereby hindering their performance in generating contextually rich and prosodically appropriate spoken dialogs. The authors highlight that previous models, by focusing on specific tasks or simple cross-modal objectives, did not fully exploit the potential for deep cross-modal understanding that a unified framework could offer.
Intuitive Domain Terms
Here are three highly specialized domain terms from the paper, translated into intuitive, everyday analogies for a zero-base reader:
-
Paralinguistics: Imagine you're telling a story. The words you use are the main message (semantics). But the way you tell it—your tone of voice, how fast you speak, where you pause, if you sound excited or sad—that's paralinguistics. It's all the non-word sounds and vocal qualities that add meaning and emotion to what you're saying. A computer that understands paralinguistics doesn't just hear "I'm fine," it hears how you say "I'm fine" to know if you're genuinely fine or being sarcastic.
-
Acoustic Units / Discrete Speech Representations: Think of a movie film. It's a continuous flow of motion, but it's actually made up of thousands of individual, still pictures (frames). Acoustic units are like these individual frames for speech. Instead of a continuous sound wave, we break speech down into tiny, distinct sound "chunks" or "tokens." These chunks are then categorized into a limited set of types, much like a small box of unique Lego bricks. By selecting and arranging these specific "Lego bricks," a computer can reconstruct speech, capturing both the words and the subtle vocal nuances.
-
Prosody: This is the music of language. When you speak, your voice naturally goes up and down in pitch, you put emphasis on certain words, and you vary your speaking speed. This pattern of pitch, stress, and rhythm is called prosody. It's what makes a question sound like a question, or an excited statement sound excited. Without prosody, all speech would sound flat and robotic, like a computer reading text in a monotone voice. It's the difference between saying "I love that" with enthusiasm and saying it with a flat, uninspired tone.
Notation Table
| Notation | Description |
|---|---|
Problem Definition & Constraints
Core Problem Formulation & The Dilemma
The core problem this paper addresses is the limitation of current Large Language Models (LLMs) in handling natural spoken dialogs in an end-to-end fashion.
Input/Current State:
Existing LLMs excel at text-based tasks, demonstrating remarkable capabilities in complex reasoning, few-shot learning, and instruction-following. However, when it comes to spoken interaction, they are typically integrated with separate Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) systems in a cascaded manner. Alternatively, some models focus solely on speech processing without leveraging the full power of LLMs.
Desired Endpoint (Output/Goal State):
The goal is to develop a Unified Spoken Dialog Model (USDM) that can seamlessly integrate the speech modality into LLMs. This model should be capable of:
1. Directly understanding user speech, including subtle nuances and emotional states (paralinguistics), without relying on explicit ASR.
2. Generating coherent spoken responses with naturally occurring and contextually appropriate prosodic features, without relying on explicit TTS.
3. Maintaining and enhancing the LLM's powerful capabilities for dialog generation and reasoning in an end-to-end pipeline.
Missing Link/Mathematical Gap:
The exact missing link is a unified, LLM-based framework that can effectively bridge the gap between raw speech input and natural spoken responses by systematically integrating both semantic and paralinguistic information from speech into the LLM's processing. This requires a novel speech-text representation and pretraining scheme that allows the LLM to learn comprehensive cross-modal relationships and generate speech tokens that inherently carry prosodic information, rather than just semantic content. The paper aims to bridge this by proposing a "prosody-infused speech tokenization scheme" and a "generalized speech-text pretraining scheme that enhances the capture of cross-modal semantics."
The Dilemma:
Previous research has been trapped by a painful trade-off between leveraging LLM capabilities and handling speech naturally:
* Cascaded ASR/TTS vs. End-to-End Coherence: While ASR and TTS systems can be easily employed, their cascaded use leads to a "linguistic discrepancy between speech and text," causing "dialog inefficiencies and sub-optimal user experience" [10, 11]. More critically, these pipelines suffer from "error propagation inherent in the cascaded pipeline" [63], where errors in ASR or text-based dialog models compound, leading to less coherent or natural spoken responses. Furthermore, incorporating paralinguistic features (like emotion or tone) in cascaded models often requires "explicit labels," making "data collection challenging and limits the models to representing label-definable non-verbal cues" (Section 2, page 3).
* Speech-Only Models vs. LLM Reasoning: Early spoken language models (SLMs) trained solely on speech data [17, 19] lack the advanced reasoning and generative power of modern LLMs, limiting their conversational abilities. The dilemma is how to imbue speech models with LLM-like intelligence without losing the richness of the speech signal.
* Semantic vs. Paralinguistic Information in Speech Tokens: Speech tokens are typically designed to encode semantic content. The challenge is to create a discrete speech representation that not only conveys semantic information but also a significant amount of paralinguistic information (e.g., emotions, pitch variations) in a way that an LLM can effectively utilize for generating natural-sounding, contextually appropriate spoken responses.
Constraints & Failure Modes
The problem of building a paralinguistics-aware, speech-empowered LLM for natural conversation is insanely difficult due to several harsh, realistic constraints:
- Data-Driven Constraints:
- Lack of Aligned Cross-Modal Data: Creating comprehensive speech-text models requires vast amounts of high-quality, aligned speech and text data that capture diverse conversational contexts and paralinguistic features. The paper notes that its current pretraining scheme relies on "tens of thousands of hours of English data" (Section 5, page 10), indicating a significant data requirement.
- Sparsity of Labeled Paralinguistic Data: Explicit labels for paralinguistic features (like emotions or intonation) are scarce and difficult to obtain at scale, which is a major hurdle for models that depend on them (Section 2, page 3).
- Multilingual Limitations: The current model is primarily trained on English data, and its applicability to other languages with "relatively smaller amounts of speech data" is limited, posing a challenge for universal deployment (Section 5, page 10).
- Computational Constraints:
- Extreme Computational Cost for Pretraining: Training large speech-text models, especially those based on LLM architectures, demands immense computational resources. The paper states using "512 NVIDIA A100-40GB GPUs, with a global batch size of 1,024 for 8,000 iterations" (Section 4.1.1, page 7), highlighting the substantial hardware requirements.
- Memory Limits for Long Sequences: Processing interleaved speech-text sequences, particularly with a "maximum sequence length of 8,192" (Section 4.1.1, page 7), can quickly hit hardware memory limits, making it challenging to model long-range dependencies in dialog.
- Architectural & Functional Constraints:
- Maintaining LLM Reasoning Capabilities: Integrating speech into LLMs must not degrade their core reasoning and generative abilities. The model needs to effectively perform "chained reasoning over the intermediary modality" (Section 3.3, page 6).
- Generating Natural Prosody: Synthesizing speech with "naturally occurring prosodic features relevant to the given input speech" is a complex task. The model must learn to infer and generate appropriate prosody from context, which is a subtle and difficult aspect of human communication (Abstract, page 1).
- Robustness to Input Variations and Errors: The system must be robust to variations in input speech quality, accents, and potential transcription inaccuracies, especially if an intermediate text representation is used. The paper aims for an approach "more robust against transcription errors" than cascaded systems (Section 3.3, page 6).
- Cross-Modal Semantic Alignment: Ensuring that the speech and text modalities are semantically aligned and that the model can learn "cross-modal distributional semantics" is vital for coherent dialog generation (page 2).
- Generalization Across Diverse Relationships: A pretraining scheme that focuses only on specific types of relationships (e.g., correspondence or continuation) may "limit the model's capabilities to only those predefined relationships" (Section 3.2, page 5), hindering its ability to handle diverse speech-text interactions. The model must be versatile.
Why This Approach
The Inevitability of the Choice
The authors' decision to develop the Unified Spoken Dialog Model (USDM) as an LLM-based, end-to-end framework for spoken dialog was driven by the inherent limitations of existing "SOTA" methods. The critical realization that traditional approaches were insufficient emerged from observing the fundamental flaws in both cascaded systems and prior end-to-end speech models.
Specifically, the paper highlights that while Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) systems can be readily employed, their sequential nature introduces a "linguistic discrepancy between speech and text" that leads to "dialog inefficiencies and result in sub-optimal user experience" [10, 11]. This cascaded approach also necessitates explicit labels for paralinguistic features, making data collection challenging and restricting the models to only label-definable non-verbal cues. Crucially, the "error propagation inherent in the cascaded pipeline [63] increases their susceptibility to compounded errors," making it an unreliable foundation for truly natural and coherent spoken dialog.
Furthermore, existing LLM-based speech models, despite their successes, were found to be inadequate for generating speech, understanding, and incorporating paralinguistics naturally within spoken dialog settings. Earlier end-to-end pipelines [19, 25] that relied on speech-only training or simplistic cross-modal objectives "fail to fully utilize the capabilities of pretrained language models." The authors recognized that a comprehensive, unified approach was the only viable solution to overcome these deep-seated issues and enable LLMs to genuinely understand and generate speech with appropriate paralinguistic features in a conversational context.
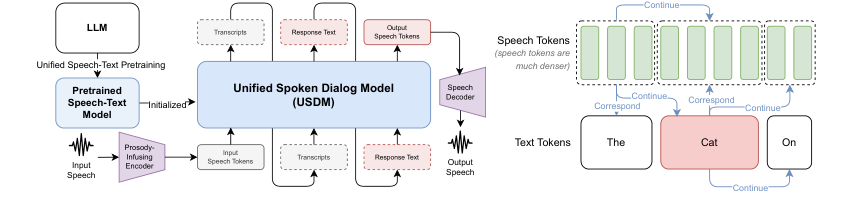 Figure 1. Overview of our spoken dialog modeling approach (Left). All possible self-supervised learning objectives from our speech-text pretraining scheme. (Right)
Figure 1. Overview of our spoken dialog modeling approach (Left). All possible self-supervised learning objectives from our speech-text pretraining scheme. (Right)
Comparative Superiority
The USDM demonstrates qualitative superiority over previous gold standards primarily through its unified cross-modal pretraining and its ability to infuse paralinguistic information directly into speech tokens. This structural advantage allows it to generate more natural-sounding and semantically coherent spoken responses.
Unlike cascaded systems that suffer from error propagation and a reliance on explicit labels for non-verbal cues, USDM's end-to-end design, which integrates speech and text modalities from the outset, inherently mitigates these issues. The model's unique speech tokenization scheme, derived from k-means clustering of self-supervised speech representations (XLS-R), is shown to contain significant paralinguistic information, such as emotions and pitch variations. Experiments confirm that these acoustic units achieve a 60.8% accuracy in emotion recognition, far surpassing the 16.6% expected from random guessing. This ability to capture and reconstruct pitch contours (as shown in Figure 2) is a direct qualitative advantage for generating natural prosody, which is often lost or poorly handled by text-based intermediate representations in cascaded systems.
Moreover, the USDM's LLM-based modeling strategy, which inserts text-related tasks between speech inputs and outputs, leverages the "chained reasoning" capabilities of the underlying LLM [6]. This makes the approach "more robust against transcription errors and better at generating contextually relevant spoken responses than if it were carried out in independent modules." This robust, contextually aware generation, particularly concerning paralinguistics, represents a significant qualitative leap. The paper's ablation studies further underscore this, showing that models lacking the comprehensive cross-modal pretraining (like the "From Scratch" model or Setup 1) perform significantly worse in terms of prosody and semantic coherence, highlighting the structual advantage of USDM's unified pretraining.
Alignment with Constraints
The chosen USDM method perfectly aligns with the problem's harsh requirements by directly addressing the need for coherent, prosody-rich spoken responses without relying on separate ASR or TTS modules. This "marriage" is evident in several key aspects:
- End-to-End Spoken Dialog Generation: The primary constraint was to move beyond cascaded systems. USDM achieves this by integrating speech and text modalities within a single LLM framework, eliminating the need for explicit ASR and TTS components during inference for dialog generation. This directly tackles the "without relying on explicit automatic speech recognition (ASR) or text-to-speech (TTS) systems" requirement.
- Naturally Occuring Prosodic Features: A core requirement was to generate responses with natural prosody. USDM's unique "prosody-infused speech tokenization scheme" is specifically designed for this. By demonstrating that the acoustic units capture emotional cues and pitch variations (Section 3.1, Figure 2), the method ensures that non-verbal characteristics crucial for natural conversation are preserved and generated. This is a direct and effective alignment.
- Coherent Spoken Responses: The model leverages the powerful reasoning capabilities of a pretrained Large Language Model (Mistral-7B). By introducing an intermediate text generation step, inspired by chain-of-thought reasoning, USDM ensures that the semantic coherence of the dialog is maintained and even enhanced. This allows the LLM to generate "semantically coherent dialog responses" while operating in the speech domain, fulfilling the requirement for coherent output.
- Unified Cross-Modal Semantics: The proposed "unified speech-text pretraining scheme" promotes learning "cross-modal distributional semantics," which is "vital for imbuing LLMs with the ability to generate coherent speeches in spoken dialog modeling." This comprehensive pretraining, covering various speech-text relationships, ensures the model can handle complex interactions and generate contextually appropriate responses, directly addressing the need for robust and coherent dialog.
Rejection of Alternatives
The paper provides clear reasoning for rejecting two main categories of alternative approaches: cascaded systems and simpler end-to-end models lacking comprehensive cross-modal pretraining.
-
Cascaded ASR + LLM + TTS Systems:
- Reasoning: The authors explicitly state that cascaded models, despite using powerful individual components like
whisper-large-v3for ASR, suffer from "linguistic discrepancy between speech and text" and "error propagation inherent in the cascaded pipeline" [10, 11, 63]. This leads to "sub-optimal user experience" and limits the ability to incorporate non-verbal cues without explicit, hard-to-collect labels. - Empirical Evidence: The "Cascaded" baseline, while achieving a lower ASR WER, consistently performs worse than USDM in human preference tests for overall quality, P-MOS (prosody naturalness), and semantic metrics (METEOR, ROUGE-L, GPT-4 preference) (Tables 1 and 2). This demonstrates that the architectural limitations of cascaded systems outweigh the strengths of their individual components for end-to-end spoken dialog.
- Reasoning: The authors explicitly state that cascaded models, despite using powerful individual components like
-
End-to-End Models with Limited Pretraining (e.g., "From Scratch" or specific pretraining setups):
- Reasoning: The paper argues that "end-to-end pipelines [19, 25] that focus solely on speech-only training or leverage simple cross-modal objectives for speech-text pretraining fail to fully utilize the capabilities of pretrained language models." The "From Scratch" model, which is USDM without the extensive speech-text pretraining, "tends to overlook the bridging text and generates a spoken response that does not correspond to the pre-generated written response, thus negatively impacting its performance." This highlights that simply fine-tuning an LLM on spoken dialog data is not enough; the model needs to learn deep cross-modal relationships during pretraining.
- Empirical Evidence: The "From Scratch" baseline exhibits significantly higher STT and TTS WERs (58.1% and 64.0% respectively), much lower MOS and P-MOS scores, and poor semantic performance compared to USDM (Tables 1 and 2). Furthermore, ablation studies on pretraining schemes (Section 4.2.1, Table 3, Table 9) show that setups (e.g., Setup 1, Setup 2, Setup 3) that only model continuation or correspondence relationships, or use a fixed template, yield higher perplexity (PPL) and worse downstream spoken dialog performance (e.g., Setup 1 has significantly higher STT and TTS WERs). This confirms that a comprehensive, unified pretraining strategy is benefical and simpler, less integrated end-to-end approaches are insufficient.
Mathematical & Logical Mechanism
The Master Equation
The absolute core equation that powers this paper, particularly for the unified speech-text pretraining and subsequent fine-tuning, is the negative log-likelihood objective function. This function guides the model to learn the conditional probability of the next token given the preceding tokens in an autoregressive manner. It is formally presented as:
$$L(\theta) = -\sum_{j=1}^{||D||} \sum_{k=1}^{||I_j||} \log p(i_{k,j}|i_{ Let's tear this equation apart and examine each component: $L(\theta)$: $\theta$: $\sum_{j=1}^{||D||}$: $\sum_{k=1}^{||I_j||}$: $\log p(i_{k,j}|i_{ $i_{k,j}$: $i_{ Imagine a single abstract data point, which in this context is an interleaved speech-text sample $I_j$. Let's trace its journey through the mathematical engine: Sequence Ingestion: The entire interleaved sequence $I_j$, comprising a mix of acoustic unit tokens, text tokens, and special control tokens (like Token Embedding: Each individual token $i_{k,j}$ within $I_j$ is first converted into a dense numerical vector, known as an embedding. For existing text tokens, the pretrained LLM's embeddings are used. For the newly introduced speech unit tokens and special tokens, their reinitialized embedding weights are utilized. These embeddings transform discrete tokens into a continuous, high-dimensional space where semantic and paralinguistic information can be processed. Contextual Encoding (LLM): The sequence of embeddings is then passed through the core of the model: a large language model (Mistral-7B in this case), which is typically a Transformer-based architecture. For each position $k$ in the sequence, the model processes the preceding tokens $i_{ Next Token Probability Prediction: At each step $k$, based on the contextual representation of $i_{ Loss Calculation for a Single Token: The system then looks at the actual token $i_{k,j}$ that occured at that position in the ground-truth input sequence. It retrieves the probability that the model assigned to this correct token from the predicted distribution. The negative logarithm of this probability, $-\log p(i_{k,j}|i_{ Sequence Loss Aggregation: This token-level loss calculation is repeated for every token $k$ in the entire sequence $I_j$. All these individual token losses are summed up to get the total loss for that particular sample $I_j$. Dataset Loss Aggregation: Finally, this entire process (steps 1-6) is repeated for every sample $I_j$ in the dataset $D$. All the individual sample losses are summed together to yield the grand total loss $L(\theta)$ for the entire batch or dataset. This $L(\theta)$ is the single numerical value that quantifies the model's overall performance. The mechanism learns, updates, and converges primarily through an iterative process driven by gradient descent, specifically using the Adam optimizer. Loss Landscape: The loss function $L(\theta)$ defines a high-dimensional "loss landscape" where each point corresponds to a specific set of model parameters $\theta$ and its associated loss value. This landscape is generally non-convex, meaning it has many local minima and saddle points. The goal of optimization is to navigate this landscape to find a set of parameters $\theta$ that minimizes $L(\theta)$. The negative log-likelihood objective inherently shapes this landscape such that parameters leading to higher probabilities for correct next tokens result in lower loss values. Gradient Computation (Backpropagation): After a forward pass through the model calculates $L(\theta)$ for a batch of training data, the gradients of this loss with respect to every single parameter in $\theta$ are computed. This is done efficiently using the backpropagation algorithm. These gradients, $\nabla_\theta L(\theta)$, indicate the direction of the steepest ascent in the loss landscape. To minimize the loss, the parameters must be moved in the opposite direction of the gradient. Parameter Updates (Adam Optimizer): The paper states that the Adam optimizer is used. Adam is an adaptive learning rate optimization algorithm that maintains per-parameter learning rates. For each parameter, it calculates: Learning Rate Scheduling: The paper mentions "linear learning rate scheduling." This typically means the learning rate $\alpha$ starts at a certain value, might warm up linearly, and then decays linearly over the course of training. This scheduling strategy helps the model make larger updates early in training to quickly explore the loss landscape, and then smaller, more precise updates later to fine-tune the parameters and settle into a good minimum without overshooting. Convergence: Through repeated iterations of forward pass, loss calculation, gradient computation, and parameter updates, the model's parameters $\theta$ are gradually adjusted. The loss $L(\theta)$ decreases over time, indicating that the model is becoming better at predicting the next tokens in the interleaved speech-text sequences. The process continues until the loss converges to a stable minimum, or a predefined number of training epochs is reached. The model effectively learns to map input speech and text contexts to probable next speech or text tokens, thereby acquiring the ability to generate coherent and prosodic spoken dialog responses. The cross-modal pretraining is particularly important here, as it ensures the loss landscape is shaped to facilitate seamless transitions and understanding between speech and text modalities, preventing the model from getting stuck in modality-specific local minima. Our experimental validation centered on the DailyTalk dataset [70], a collection of 20 hours of spoken dialog data, sampled at 22,050 Hz, featuring one male and one female speaker. This dataset was preprocessed for single-turn spoken dialog, yielding 20,117 training samples and 1,058 test samples. The Unified Spoken Dialog Model (USDM) was architected with a speech-to-unit module utilizing an official checkpoint of XLS-R [64] and a quantizer with $k=10,000$ [33], trained on 436K hours of multilingual speech data. For the speech decoder, we employed a unit-Voicebox model based on the Voicebox architecture [66], trained on 54k hours of ASR data from the English subsets of Multilingual LibriSpeech [71] and GigaSpeech [72]. This unit-Voicebox was designed to use reference speech from the preceding turn for zero-shot reconstruction, ensuring consistent voice in multi-turn dialogs. The core Large Language Model (LLM) was Mistral-7B [67]. Our pretraining phase involved 512 NVIDIA A100-40GB GPUs, a global batch size of 1,024, and 8,000 iterations over approximately 87,000 hours of English ASR data (including Multilingual LibriSpeech, People's Speech, GigaSpeech, Common Voice, and Voxpopuli), with a maximum sequence length of 8,192. Fine-tuning on DailyTalk was conducted for 5 epochs with a global batch size of 64, using linear learning rate scheduling with a peak learning rate of $2 \cdot 10^{-5}$. The BigVGAN [74] vocoder was used for all speech synthesis. To ruthlessly prove our mathematical claims, we pitted USDM against three "victim" baseline models: Our evaluation strategy combined both human and automated metrics. Human evaluations were conducted via Amazon Mechanical Turk, involving: Automated evaluations included a GPT-4-based preference test [1] (using The evidence definitively proves that our Unified Spoken Dialog Model (USDM) effectively integrates paralinguistic information and generates superior spoken responses compared to strong baselines, largely due to its novel pretraining and fine-tuning strategies. The core mechanism of leveraging prosody-infused speech tokens was rigorously validated. In an emotion recognition task using acoustic units on the CREMA-D dataset [65], our 3-layer transformer-based emotion classifier achieved an accuracy of 60.8%. This is a significant leap from the 16.6% expected from random guessing, providing undeniable evidence that these acoustic units, traditionally thought to primarily encode semantic information, also contain rich emotional cues. Furthermore, our unit-to-speech reconstruction model, trained on 54,000 hours of speech data, demonstrated that while the timbre and absolute pitch of reconstructed speech might differ from the original, the pitch variation closely mirrored the ground truth (Figure 2). This is hard evidence that our speech tokens successfully capture crucial non-verbal characteristics like pitch contours. USDM's superiority in generating natural and coherent spoken responses was consistently demonstrated across multiple evaluations: Ablation studies provided crucial insights into the effectiveness of our design choices: Despite the significant advancements USDM presents, there are several inherent limitations and exciting avenues for future development. Firstly, our exploration of datasets and models for the pretraining phase has been somewhat limited. While we've shown the efficacy of our scheme with Mistral-7B and a specific set of ASR data, it's not entirely clear which data sources are most crucial for optimal performance, nor how well our pretraining scheme would generalize to other LLMs beyond Mistral-7B. Future work should involve a more systematic investigation into diverse datasets and LLM architectures to identify the most impactful combinations. Secondly, the current USDM architecture relies on a cross-modal chaining approach: speech input is first transcribed to text, then a text response is generated, and finally, this text is synthesized into spoken output. While this "bridging text" strategy effectively leverages the LLM's reasoning capabilities, it introduces an intermediary step. A promising future direction is to develop a spoken dialog model capable of directly generating spoken responses from input spoken dialog without this explicit cross-modal chaining. This would streamline the pipeline and potentially reduce error propagation, offering a truly end-to-end speech-to-speech experience. Thirdly, the current pretraining scheme is predominantly based on tens of thousands of hours of English data. This presents a clear limitation when applying USDM to other languages, especially those with comparatively smaller speech data resources. Expanding our model to support a wider variety of languages, beyond just English, is a critical next step to enhance its global applicability and utility. This would likely involve exploring multilingual pretraining strategies and adapting the speech tokenization and decoding components for diverse linguistic features. Finally, our per-task training dynamic analysis (Figure 7, right) indicated that increasing the number of fine-tuning parameters, particularly with LoRA, can sometimes lead to a deterioration in the unit-to-text task performance, suggesting potential overfitting. To address this, future research could explore strategies to mitigate overfitting in the unit-to-text task. This might involve dynamically varying the loss weights for each task within the pipeline or implementing curriculum learning approaches, where the model is gradually exposed to more complex tasks. Beyond these specific points, the broader implications of this work open up several discussion topics. How can we further leverage the demonstrated ability of acoustic units to capture paralinguistic features to build more empathetic and context-aware conversational agents? Can we develop robust mechanisms to ensure the ethical deployment of such high-quality speech synthesis models, preventing misuse in scenarios like voice phishing while maximizing positive societal impacts, such as providing accessible communication alternatives for individuals with reading or writing difficulties? Furthermore, investigating the isomorphisms of our pretraining approach with other speech-text tasks, such as speech translation or summarization, could unlock even wider applications and solidify the foundation for truly multimodal LLMs.Term-by-Term Autopsy.
Step-by-Step Flow
<|correspond|> or <|continue|>), is fed into the system. This sequence represents a segment of a spoken dialog or a speech-text pair.Optimization Dynamics
These estimates are then bias-corrected. The parameter update rule for Adam is:
$$\theta_{t+1} = \theta_t - \alpha \frac{\hat{m}_t}{\sqrt{\hat{v}_t} + \epsilon}$$
where $\theta_t$ is the parameter vector at time step $t$, $\alpha$ is the learning rate (e.g., $10^{-4}$ for unit-Voicebox training, $2 \cdot 10^{-5}$ for pretraining/fine-tuning), $\hat{m}_t$ and $\hat{v}_t$ are the bias-corrected first and second moment estimates, and $\epsilon$ is a small constant to prevent division by zero. This adaptive nature allows Adam to handle sparse gradients and different scales of parameters effectively, helping the model converge faster and more robustly.Results, Limitations & Conclusion
Experimental Design & Baselines
1. From Scratch: This model was nearly identical to USDM but crucially lacked the unified speech-text pretraining. It fine-tuned the pretrained Mistral-7B directly on spoken dialog data using the same hyperparameters as USDM. This baseline was designed to isolate the impact of our novel pretraining scheme.
2. Cascaded: This approach employed separate, off-the-shelf Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) systems. Specifically, it used whisper-large-v3 [78] (trained on 5M hours of speech data) for ASR and a Voicebox model (trained with text input, similar to our unit-Voicebox) for TTS. The LLM (Mistral-7B) was fine-tuned on the transcripts of the spoken dialog data. This baseline represented the traditional, modular approach to spoken dialog.
3. SpeechGPT [25]: We utilized the official implementations and checkpoints of SpeechGPT-7B-cm, a state-of-the-art pretrained speech-text model, fine-tuned on DailyTalk for a fair comparison.
- Overall Preference Tests: 150 evaluators compared USDM's spoken responses against baselines, considering naturalness, prosody, and semantic coherence for 50 randomly selected spoken dialogs. This cost approximately USD 200.
- Prosody Mean Opinion Score (P-MOS): 198 evaluators rated prosody naturalness on a 5-point scale, given ground truth text responses. This cost around USD 250.
- Mean Opinion Score (MOS): 176 evaluators rated audio quality and naturalness on a 5-point scale, given only the response text and spoken response. This also cost approximately USD 250.gpt-4-0125-preview) to assess semantic appropriateness of transcribed responses, and quantitative metrics such as METEOR and ROUGE-L scores for semantic content, and Word Error Rate (WER) for both speech-to-text (STT WER) and text-to-speech (TTS WER) components. Ablation studies further dissected the contributions of our unified pretraining and fine-tuning schemes, using Perplexity (PPL) on LibriSpeech and the aforementioned dialog metrics on DailyTalk.What the Evidence Proves
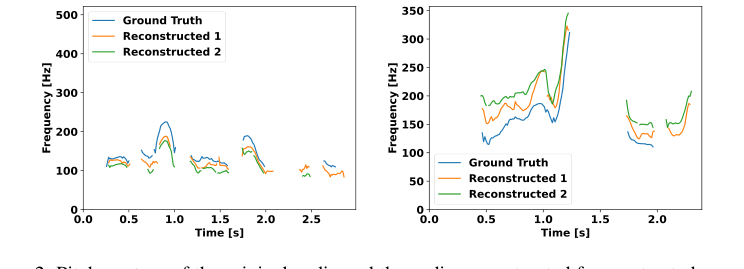 Figure 2. Pitch contour of the original audio and the audio reconstructed from extracted acoustic units. Due to the stochastic nature of the reconstruction model, we attempt reconstruction twice, demonstrating that the pitch variation closely mirrors the ground truth
Figure 2. Pitch contour of the original audio and the audio reconstructed from extracted acoustic units. Due to the stochastic nature of the reconstruction model, we attempt reconstruction twice, demonstrating that the pitch variation closely mirrors the ground truth
- Human Preference: In comprehensive human preference tests, USDM was preferred similarly to the Ground Truth and significantly outperformed all baselines (p-value < 0.05 from the Wilcoxon signed-rank test). This is a strong indicator of its overall quality and user experience.
- Prosody Naturalness: USDM surpassed all baselines in P-MOS evaluations (p-value < 0.05), showcasing its exceptional ability to generate speech with natural prosody. It notably outperformed the Cascaded model, which struggled with prosody despite using explicit labels, highlighting USDM's effective, implicit incorporation of paralinguistic features.
- Semantic Coherence: Our model outperformed baselines in both quantitative metrics (METEOR and ROUGE-L) and the GPT-4-based preference test (p-value < 0.05) for semantic appropriateness. This confirms USDM's capability to generate semantically coherent responses that are well-aligned with the input speech.
- Unified Pretraining: Our proposed unified speech-text pretraining scheme, which models both correspondence and continuation relationships, achieved superior average Perplexity (PPL) across all modalities and sequence types (Table 3, Table 9). This definitively proved that a comprehensive pretraining strategy is essential for the LLM to learn diverse speech-text interactions, rather than specializing in limited relationships. The "From Scratch" model, lacking this pretraining, exhibited significantly worse TTS and STT WERs (64.0% and 58.1% respectively) and poor semantic performance, underscoring the critical role of cross-modal pretraining.
- Intermediate Text Modeling: The fine-tuning scheme that uses intermediate text as a bridge (speech input -> text transcription -> text response generation -> speech response synthesis) was shown to be highly effective. A direct speech-to-speech model (S1 -> S2) performed significantly worse in METEOR and ROUGE-L scores (Table 3), confirming that leveraging the pretrained LLM's reasoning capabilities through the text modality is beneficial.
- Input Modality Utilization: Attention maps (Figure 4) revealed that USDM's generated responses attend to both the input speech and its transcribed text. This visual evidence confirms that our model effectively integrates information from both modalities, leading to more robust and semantically coherent outputs. Further, substituting the model-generated input transcript with the ground truth transcript improved METEOR and ROUGE-L scores (13.6 vs 13.1 and 16.2 vs 15.7, respectively), demonstrating that enhancing the accuracy of the unit-to-text conversion in USDM directly boosts semantic coherence.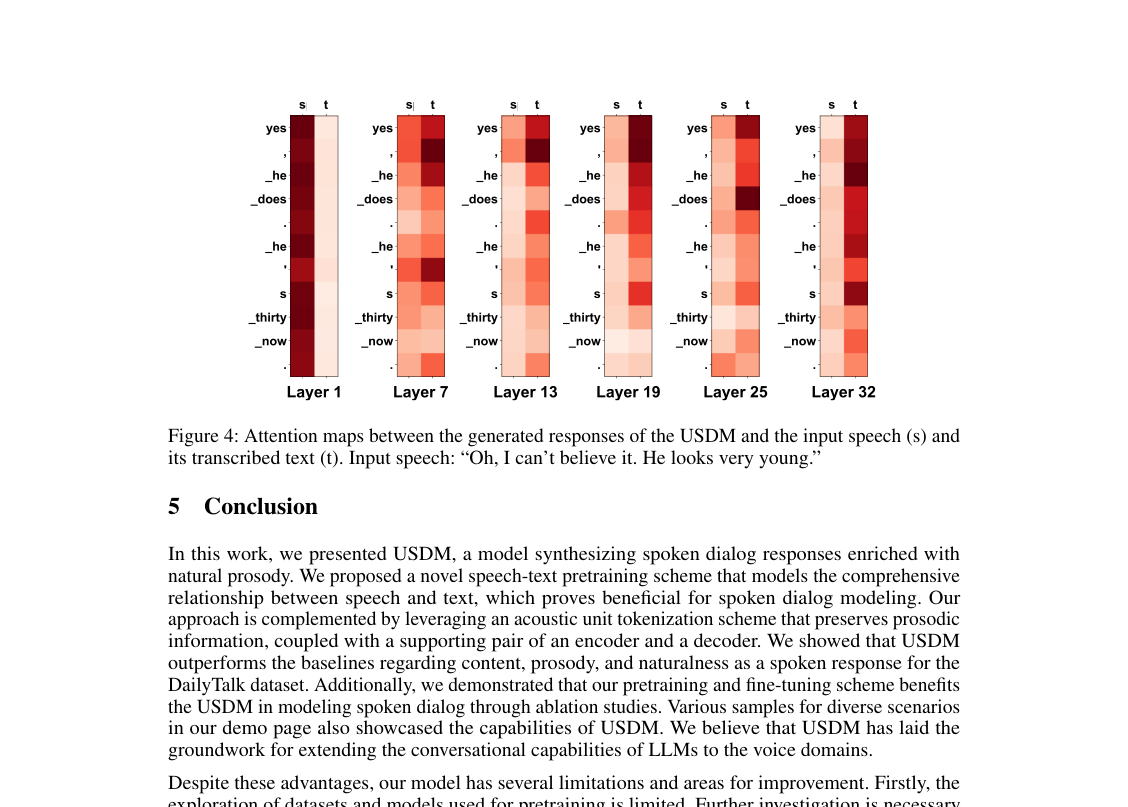 Figure 4. Attention maps between the generated responses of the USDM and the input speech (s) and its transcribed text (t). Input speech: “Oh, I can’t believe it. He looks very young.”
Figure 4. Attention maps between the generated responses of the USDM and the input speech (s) and its transcribed text (t). Input speech: “Oh, I can’t believe it. He looks very young.”
Limitations & Future Directions
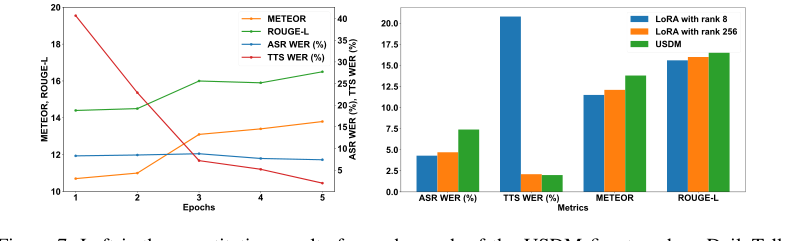 Figure 7. Left is the quantitative results for each epoch of the USDM fine-tuned on DailyTalk. The figure on the right illustrates the performance of the Spoken Dialog Model when trained with Low-Rank Adaptation (LoRA) versus full fine-tuning
Figure 7. Left is the quantitative results for each epoch of the USDM fine-tuned on DailyTalk. The figure on the right illustrates the performance of the Spoken Dialog Model when trained with Low-Rank Adaptation (LoRA) versus full fine-tuning