音声認識・音声合成を意識した大規模言語モデルによる自然対話
Recent work shows promising results in expanding the capabilities of large language models (LLM) to directly understand and synthesize speech.
背景と学術的系譜
起源と学術的系譜
本稿で取り組む問題は、テキストベースの対話型AIにおける大規模言語モデル(LLM)の近年の進歩と広範な採用に端を発する。LLMはテキストの理解、生成、推論において驚異的な能力を示してきたが、音声対話への直接的な応用は依然として大きな課題であった。その根源的な動機は、LLMの持つ少数ショット学習(few-shot in-context learning)や複雑な推論といった強力な創発的能力を、自然な音声対話の領域に拡張し、より直感的で人間らしい対話を可能にすることにある。
歴史的に、初期の音声言語モデル(SLM)は音声データのみに焦点を当てるか、非常に単純なクロスモーダル目的関数を用いるにとどまり、事前学習済みLLMの洗練された言語理解能力を十分に活用できていなかった。高機能なテキストベースLLMの登場により、学術分野は音声モダリティをこれらのモデルに統合する方向へとシフトした。
本研究が必要とされる、従来のアプローチの根本的な限界または「ペインポイント」は、主に2つのタイプに分類できる。
-
カスケードモデル: これらのアプローチは通常、ユーザーの音声をテキストに変換する自動音声認識(ASR)、テキスト応答を生成するLLM、そして合成された音声応答を生成する音声合成(TTS)システムを個別に組み合わせる。
- 言語的不一致: 音声とテキストが情報を伝達する方法の間の固有の不一致が、重大な「ペインポイント」である。音声は、ASRによってプレーンテキストに変換される際に失われる感情、トーン、リズムといった豊かなパラ言語的キューを伝達する。この言語的不一致は、LLMが意味論的な内容のみに基づいて動作し、しばしば重要な非言語的コンテキストを無視するため、対話の非効率性や最適とは言えないユーザーエクスペリエンスにつながる。
- パラ言語情報のためのラベル依存性: カスケードモデルにパラ言語的特徴を組み込むためには、しばしば明示的なラベル(例:感情用)が必要となる。これによりデータ収集が困難になり、モデルは明示的にラベル付け可能な非言語的キューに限定される。
- エラー伝播: 主要な欠点は、エラーの累積である。ASRシステムまたはテキストベースLLMによって導入されたあらゆる不正確さは、パイプライン全体に伝播し、一貫性のない、あるいは不自然に聞こえる音声応答につながる可能性がある。
-
エンドツーエンド音声のみまたは単純なクロスモーダルモデル: エンドツーエンドのパイプラインは存在するものの、それらは事前学習済みLLMに埋め込まれた広範な知識と推論能力を十分に活用できていないことが多い。これらのモデルは、音声とテキストのモダリティ間の包括的かつ複雑な関係を捉える能力が限定的である可能性があり、それゆえ、コンテキストが豊かで韻律的に適切な音声対話を生成する能力を妨げている。著者らは、特定のタスクまたは単純なクロスモーダル目的関数に焦点を当てた以前のモデルは、統一されたフレームワークが提供できる深いクロスモーダル理解の可能性を十分に活用していなかったと強調している。
直感的なドメイン用語
ここでは、論文から抽出された3つの高度に専門的なドメイン用語を、ゼロベースの読者向けに直感的な日常の類推で翻訳する。
-
パラ言語(Paralinguistics): 物語を語っていると想像してほしい。使う言葉は主要なメッセージ(意味論)である。しかし、語り方――声のトーン、話す速さ、どこで間を置くか、興奮しているか悲しそうか――それがパラ言語である。それは、言葉以外の音や声質で、発言に意味と感情を加えるすべてのものである。パラ言語を理解するコンピュータは、「元気だよ」と聞くだけでなく、「元気だよ」とどのように言ったかを聞き取り、それが本当に元気なのか、それとも皮肉なのかを知ることができる。
-
音響単位 / 離散音声表現(Acoustic Units / Discrete Speech Representations): 映画のフィルムを考えてほしい。それは連続的な動きの流れだが、実際には何千もの個々の静止画像(フレーム)で構成されている。音響単位は、音声におけるこれらの個々のフレームのようなものである。連続的な音波の代わりに、音声を小さな、区別可能な音の「チャンク」または「トークン」に分解する。これらのチャンクは、少数のユニークなレゴブロックのような、限られた種類のセットに分類される。これらの特定の「レゴブロック」を選択し配置することで、コンピュータは音声の単語と微妙な声のニュアンスの両方を捉えながら、音声を再構築できる。
-
韻律(Prosody): これは言語の音楽である。話すとき、声は自然にピッチが上下し、特定の単語にアクセントを置き、話す速さを変える。このピッチ、ストレス、リズムのパターンを韻律と呼ぶ。疑問文を疑問文らしく、興奮した発言を興奮しているように聞こえさせるのはこれである。韻律がなければ、すべての音声は平坦でロボットのように、コンピュータが単調な声でテキストを読み上げるように聞こえるだろう。それは、熱意を込めて「それが大好きだ」と言うのと、平坦で活気のないトーンで言うのと違いである。
表記表
| 表記 | 説明 |
|---|---|
問題定義と制約
中核問題の定式化とジレンマ
本稿が取り組む中核問題は、現在のLLMが自然な音声対話をエンドツーエンドで処理する上での限界である。
入力/現状:
既存のLLMはテキストベースのタスクに優れており、複雑な推論、少数ショット学習、指示追従において驚異的な能力を示している。しかし、音声対話に関しては、通常、カスケード方式で個別の自動音声認識(ASR)および音声合成(TTS)システムと統合されている。あるいは、一部のモデルはLLMの全能力を活用せずに、音声処理のみに焦点を当てている。
望ましい終点(出力/目標状態):
目標は、音声モダリティをLLMにシームレスに統合できる統一音声対話モデル(USDM)を開発することである。このモデルは以下を実行できる必要がある。
1. 明示的なASRに依存することなく、微妙なニュアンスや感情状態(パラ言語情報)を含むユーザーの音声を直接理解する。
2. 明示的なTTSに依存することなく、自然に発生する文脈的に適切な韻律的特徴を持つ音声応答を生成する。
3. エンドツーエンドのパイプラインで、対話生成と推論のためのLLMの強力な能力を維持・強化する。
欠落しているリンク/数学的ギャップ:
正確な欠落リンクは、意味論的およびパラ言語的情報を音声からLLMの処理に体系的に統合することにより、生の音声入力と自然な音声応答との間のギャップを効果的に橋渡しできる、LLMベースの統一フレームワークである。これには、LLMが包括的なクロスモーダル関係を学習し、意味論的な内容だけでなく韻律情報を含む音声トークンを生成できるようにする、新しい音声-テキスト表現と事前学習スキームが必要となる。本稿は、「韻律注入型音声トークン化スキーム」と「クロスモーダル意味論のキャプチャを強化する汎用音声-テキスト事前学習スキーム」を提案することで、このギャップを埋めることを目指す。
ジレンマ:
以前の研究は、LLM能力の活用と自然な音声処理との間の痛みを伴うトレードオフに囚われてきた。
* カスケードASR/TTS vs. エンドツーエンドの一貫性: ASRおよびTTSシステムは容易に採用できるが、それらのカスケード使用は「音声とテキスト間の言語的不一致」を引き起こし、「対話の非効率性および最適とは言えないユーザーエクスペリエンス」につながる[10, 11]。さらに重要なことに、これらのパイプラインは「カスケードパイプライン固有のエラー伝播」[63]に苦しみ、ASRまたはテキストベース対話モデルのエラーが累積し、一貫性のない、あるいは不自然な音声応答につながる。さらに、カスケードモデルにおけるパラ言語的特徴(感情やトーンなど)の組み込みは、しばしば「明示的なラベル」を必要とし、「データ収集を困難にし、モデルをラベル定義可能な非言語的キューに限定する」(セクション2、p.3)。
* 音声のみモデル vs. LLM推論: 音声データのみで訓練された初期の音声言語モデル(SLM)[17, 19]は、最新のLLMの高度な推論および生成能力を欠いており、対話能力を制限している。ジレンマは、音声モデルにLLMのような知能を、音声信号の豊かさを失うことなく、どのように付与するかである。
* 音声トークンにおける意味論的情報 vs. パラ言語的情報: 音声トークンは通常、意味論的な内容をエンコードするように設計されている。課題は、意味論的な情報だけでなく、LLMが自然に聞こえ、文脈的に適切な音声応答を生成するために効果的に利用できるような、かなりの量のパラ言語的情報(例:感情、ピッチ変動)をエンコードする離散音声表現を作成することである。
制約と失敗モード
自然対話のためのパラ言語認識型、音声強化型LLMの構築という問題は、いくつかの厳しい現実的な制約により、非常に困難である。
- データ駆動型制約:
- アライメントされたクロスモーダルデータの不足: 包括的な音声-テキストモデルの作成には、多様な対話コンテキストとパラ言語的特徴を捉える、高品質でアライメントされた膨大な音声とテキストのデータが必要である。論文では、現在の事前学習スキームが「数万時間の英語データ」に依存している(セクション5、p.10)と指摘しており、これはかなりのデータ要件を示唆している。
- ラベル付きパラ言語データのスパース性: パラ言語的特徴(感情やイントネーションなど)の明示的なラベルは希少であり、大規模に取得するのが困難である。これは、それらに依存するモデルにとって大きな障害となる(セクション2、p.3)。
- 多言語的限界: 現在のモデルは主に英語データで訓練されており、「比較的少量の音声データ」を持つ他の言語への適用性は限定的であり、普遍的な展開に課題を投げかけている(セクション5、p.10)。
- 計算的制約:
- 事前学習のための極端な計算コスト: 大規模な音声-テキストモデル、特にLLMアーキテクチャに基づくモデルの訓練には、莫大な計算リソースが必要となる。論文では、「512基のNVIDIA A100-40GB GPUを使用し、グローバルバッチサイズ1,024で8,000イテレーション」を行ったと述べており(セクション4.1.1、p.7)、かなりのハードウェア要件を強調している。
- 長シーケンスのためのメモリ制限: 特に「最大シーケンス長8,192」(セクション4.1.1、p.7)で、インターリーブされた音声-テキストシーケンスを処理することは、ハードウェアメモリの制限にすぐに達する可能性があり、対話における長距離依存関係のモデリングを困難にする。
- アーキテクチャおよび機能的制約:
- LLM推論能力の維持: LLMへの音声の統合は、その中核的な推論および生成能力を低下させてはならない。モデルは「中間モダリティを介した連鎖推論」を効果的に実行する必要がある(セクション3.3、p.6)。
- 自然な韻律の生成: 「入力音声に関連する自然に発生する韻律的特徴」を持つ音声を合成することは、複雑なタスクである。モデルは、文脈から適切な韻律を推測して生成する方法を学習する必要があり、これは人間コミュニケーションの微妙で困難な側面である(アブストラクト、p.1)。
- 入力変動およびエラーに対する堅牢性: システムは、特に中間テキスト表現が使用される場合、入力音声品質、アクセント、および潜在的な文字起こし不正確さの変動に対して堅牢でなければならない。論文は、カスケードシステムよりも「文字起こしエラーに対してより堅牢」なアプローチを目指している(セクション3.3、p.6)。
- クロスモーダル意味論的アライメント: 音声とテキストのモダリティが意味論的にアライメントされ、モデルが「クロスモーダル分布意味論」を学習できることを保証することは、一貫した対話生成に不可欠である(p.2)。
- 多様な関係性における汎化: 特定の種類の関係性(例:対応または継続)に焦点を当てた事前学習スキームは、「モデルの能力を定義済みの関係性のみに限定する」可能性があり(セクション3.2、p.5)、多様な音声-テキスト対話の処理能力を妨げる。モデルは多用途でなければならない。
なぜこのアプローチなのか
選択の必然性
著者らが統一音声対話モデル(USDM)を音声対話のためのLLMベースのエンドツーエンドフレームワークとして開発するという決定は、既存の「SOTA」手法の固有の限界によって推進された。従来の「アプローチが不十分である」という根本的な認識は、カスケードシステムと以前のエンドツーエンド音声モデルの両方の根本的な欠陥を観察することから生じた。
具体的には、論文では、自動音声認識(ASR)および音声合成(TTS)システムは容易に採用できるものの、それらの逐次的な性質は「音声とテキスト間の言語的不一致」を導入し、「対話の非効率性につながり、最適とは言えないユーザーエクスペリエンスをもたらす」[10, 11]と強調している。このカスケードアプローチは、パラ言語的特徴のための明示的なラベルも必要とし、データ収集を困難にし、モデルをラベル定義可能な非言語的キューに限定する。決定的に、「カスケードパイプライン固有のエラー伝播[63]は、エラーの累積に対する脆弱性を高める」ため、真に自然で一貫した音声対話の信頼できる基盤とはなり得ない。
さらに、成功にもかかわらず、既存のLLMベース音声モデルは、音声対話設定においてパラ言語情報を自然に生成、理解、組み込むのに不十分であることが判明した。音声のみのトレーニングまたは単純なクロスモーダル目的関数に依存する以前のエンドツーエンドパイプライン[19, 25]は、「事前学習済み言語モデルの能力を十分に活用できていない」。著者らは、これらの根深い問題を克服し、LLMが対話コンテキストにおいて適切なパラ言語的特徴を持つ音声を真に理解し生成できるようにするためには、包括的で統一されたアプローチが唯一実行可能な解決策であると認識した。
比較優位性
USDMは、その統一されたクロスモーダル事前学習と、パラ言語情報を直接音声トークンに注入する能力により、以前のゴールドスタンダードに対して質的な優位性を示す。この構造的な利点により、より自然に聞こえ、意味論的に一貫した音声応答を生成できる。
エラー伝播と非言語的キューの明示的なラベルへの依存に苦しむカスケードシステムとは異なり、当初から音声とテキストのモダリティを統合するUSDMのエンドツーエンド設計は、本質的にこれらの問題を軽減する。k-meansクラスタリングによる自己教師あり音声表現(XLS-R)から派生したモデル独自の音声トークン化スキームは、感情やピッチ変動といった実質的なパラ言語情報を含んでいることが示されている。実験では、これらの音響単位が感情認識において60.8%の精度を達成し、ランダム推測で期待される16.6%をはるかに上回ることが確認されている。ピッチコンターを捉え再構築するこの能力(図2に示す)は、カスケードシステムにおけるテキストベースの中間表現ではしばしば失われたり、うまく処理されなかったりする自然な韻律を生成するための直接的な質的利点である。
さらに、音声入力と出力の間にテキスト関連タスクを挿入するLLMベースのモデリング戦略は、「連鎖推論」能力を活用する[6]。これにより、アプローチは「独立したモジュールで行われるよりも、文字起こしエラーに対してより堅牢で、文脈的に関連性の高い音声応答を生成するのに優れている」。この堅牢で文脈を意識した生成、特にパラ言語性に関するものは、重要な質的飛躍を表す。論文のアブレーション研究はさらにこれを強調しており、包括的なクロスモーダル事前学習を欠くモデル(「From Scratch」モデルまたはセットアップ1など)が、韻律と意味論的一貫性の点で著しく劣っていることを示しており、USDMの統一事前学習の構造的利点を強調している。
制約との整合性
選択されたUSDM手法は、個別のASRまたはTTSモジュールに依存することなく、一貫性があり、韻律が豊かな音声応答の必要性に直接対処することで、問題の厳しい要件に完全に適合する。この「結婚」は、いくつかの重要な側面で明らかである。
- エンドツーエンド音声対話生成: 主要な制約は、カスケードシステムを超えて移行することであった。USDMは、単一のLLMフレームワーク内で音声とテキストのモダリティを統合することにより、これを達成し、対話生成中の明示的なASRおよびTTSコンポーネントの必要性を排除する。これは、「明示的な自動音声認識(ASR)または音声合成(TTS)システムに依存することなく」という要件に直接対応する。
- 自然に発生する韻律的特徴: 中核的な要件は、自然な韻律を持つ応答を生成することであった。USDM独自の「韻律注入型音声トークン化スキーム」は、まさにこの目的のために設計されている。音響単位が感情的なキューとピッチ変動を捉えることを実証することにより(セクション3.1、図2)、この手法は、自然な対話に不可欠な非言語的特徴が保持され、生成されることを保証する。これは直接的かつ効果的な整合性である。
- 一貫した音声応答: モデルは、事前学習済み大規模言語モデル(Mistral-7B)の強力な推論能力を活用する。連鎖思考推論に着想を得た中間テキスト生成ステップを導入することにより、USDMは対話の意味論的一貫性が維持され、さらには強化されることを保証する。これにより、LLMは音声ドメインで動作しながら「意味論的に一貫した対話応答」を生成でき、一貫した出力の要件を満たす。
- 統一されたクロスモーダル意味論: 提案された「統一音声-テキスト事前学習スキーム」は、「対話モデリングにおける音声の生成能力に意味論的一貫性を付与するために不可欠な」クロスモーダル分布意味論の学習を促進する。多様な音声-テキスト関係性をカバーするこの包括的な事前学習は、モデルが複雑な対話を処理し、文脈的に適切な応答を生成できることを保証し、堅牢で一貫した対話の必要性に直接対応する。
代替案の却下
論文は、カスケードシステムと包括的なクロスモーダル事前学習を欠く単純なエンドツーエンドモデルという、2つの主要な代替アプローチのカテゴリーを却下する明確な理由を提供している。
-
カスケードASR + LLM + TTSシステム:
- 理由: 著者らは、
whisper-large-v3のような強力な個々のコンポーネントをASRに使用しても、カスケードモデルは「音声とテキスト間の言語的不一致」および「カスケードパイプライン固有のエラー伝播」に苦しむと明示的に述べている[10, 11, 63]。これは「最適とは言えないユーザーエクスペリエンス」につながり、明示的で収集が困難なラベルなしでは非言語的キューを組み込む能力を制限する。 - 経験的証拠: 「Cascaded」ベースラインは、ASR WERが低いにもかかわらず、全体的な品質、P-MOS(韻律の自然さ)、および意味論的メトリクス(METEOR、ROUGE-L、GPT-4選好度)において、USDMよりも一貫して劣っている(表1および表2)。これは、カスケードシステムのアーキテクチャ上の限界が、エンドツーエンド音声対話における個々のコンポーネントの強みを上回ることを示している。
- 理由: 著者らは、
-
限定的な事前学習を持つエンドツーエンドモデル(例:「From Scratch」または特定の事前学習セットアップ):
- 理由: 論文では、「音声のみのトレーニングに焦点を当てた、または音声-テキスト事前学習のための単純なクロスモーダル目的関数を活用したエンドツーエンドパイプライン[19, 25]は、事前学習済み言語モデルの能力を十分に活用できていない」と主張している。「From Scratch」モデルは、USDMから広範な音声-テキスト事前学習を除いたものであり、「ブリッジングテキストを見落としがちで、生成された書き起こし応答に対応しない音声応答を生成するため、そのパフォーマンスに悪影響を与える」。これは、単に音声対話データでLLMをファインチューニングするだけでは不十分であり、モデルは事前学習中に深いクロスモーダル関係を学習する必要があることを強調している。
- 経験的証拠: 「From Scratch」ベースラインは、USDMと比較して著しく高いSTTおよびTTS WER(それぞれ58.1%および64.0%)、はるかに低いMOSおよびP-MOSスコア、および劣った意味論的パフォーマンスを示す(表1および表2)。さらに、事前学習スキームのアブレーション研究(セクション4.2.1、表3、表9)では、継続または対応関係のみをモデル化する、または固定テンプレートを使用するセットアップ(例:セットアップ1は著しく高いSTTおよびTTS WERを持つ)は、より高いパープレキシティ(PPL)と劣った下流音声対話パフォーマンスをもたらすことが示されている。これは、包括的な統一事前学習戦略が有益であり、より単純で統合性の低いエンドツーエンドアプローチは不十分であることを確認している。
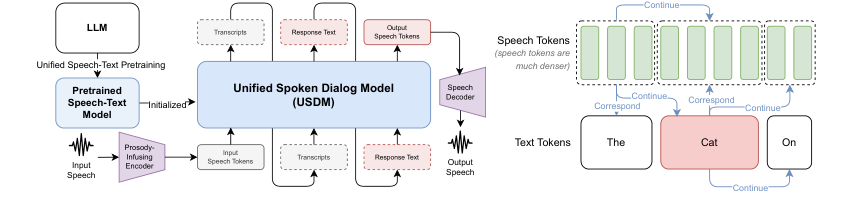 Figure 1. Overview of our spoken dialog modeling approach (Left). All possible self-supervised learning objectives from our speech-text pretraining scheme. (Right)
Figure 1. Overview of our spoken dialog modeling approach (Left). All possible self-supervised learning objectives from our speech-text pretraining scheme. (Right)
数学的・論理的メカニズム
マスター方程式
この論文の、特に統一音声-テキスト事前学習および後続のファインチューニングを推進する絶対的な中心方程式は、負の対数尤度目的関数である。この関数は、モデルが自己回帰的に先行するトークンを与えられた次のトークンの条件付き確率を学習するように導く。これは形式的に次のように表される。
$$L(\theta) = -\sum_{j=1}^{||D||} \sum_{k=1}^{||I_j||} \log p(i_{k,j}|i_{ この方程式を分解し、各コンポーネントを検討しよう。 $L(\theta)$: $\theta$: $\sum_{j=1}^{||D||}$: $\sum_{k=1}^{||I_j||}$: $\log p(i_{k,j}|i_{ $i_{k,j}$: $i_{ ここでは、単一の抽象的なデータポイント、この文脈ではインターリーブされた音声-テキストサンプル$I_j$を想像してみよう。その旅を数学的エンジンを通して追ってみよう。 シーケンスの取り込み: 音響ユニットトークン、テキストトークン、および特殊制御トークン( トークン埋め込み: $I_j$内の各個々のトークン$i_{k,j}$は、まず埋め込みと呼ばれる密な数値ベクトルに変換される。既存のテキストトークンの場合、事前学習済みLLMの埋め込みが使用される。新しく導入された音声ユニットトークンおよび特殊トークンの場合、それらの再初期化された埋め込み重みが使用される。これらの埋め込みは、離散トークンを連続的な高次元空間に変換し、そこで意味論的およびパラ言語的情報を処理できる。 コンテキストエンコーディング(LLM): 埋め込みシーケンスは、モデルの中核である大規模言語モデル(この場合はMistral-7B)に渡される。これは通常、Transformerベースのアーキテクチャである。シーケンスの各ポジション$k$について、モデルは先行するトークン$i_{ 次トークン確率予測: 各ステップ$k$で、$i_{ 単一トークンの損失計算: システムは次に、グラウンドトゥルース入力シーケンスのその位置にあった実際のトークン$i_{k,j}$を見る。モデルがその正しいトークンに割り当てた確率を予測分布から取得する。この確率の負の対数、$-\log p(i_{k,j}|i_{ シーケンス損失集計: このトークンレベルの損失計算は、$I_j$のシーケンス全体内のすべてのトークン$k$に対して繰り返される。これらの個々のトークン損失はすべて合計され、$I_j$という特定のサンプル全体の損失が得られる。 データセット損失集計: 最後に、このプロセス全体(ステップ1~6)は、データセット$D$内のすべてのサンプル$I_j$に対して繰り返される。すべての個々のサンプル損失は合計され、バッチ全体またはデータセット全体の総損失$L(\theta)$が得られる。この$L(\theta)$は、モデルの全体的なパフォーマンスを定量化する単一の数値である。 このメカニズムは、主にAdamオプティマイザを使用した勾配降下法によって駆動される反復プロセスを通じて学習、更新、収束する。 損失ランドスケープ: 損失関数$L(\theta)$は、各点が特定のモデルパラメータ$\theta$のセットとその関連する損失値に対応する高次元の「損失ランドスケープ」を定義する。このランドスケープは一般に非凸であり、多くの局所的最小値と鞍点を持つ。最適化の目標は、このランドスケープをナビゲートして、$L(\theta)$を最小化するパラメータ$\theta$のセットを見つけることである。負の対数尤度目的関数は、正しい次のトークンに対する確率が高いパラメータがより低い損失値につながるように、本質的にこのランドスケープを形成する。 勾配計算(誤差逆伝播): モデルを順伝播させてバッチの$L(\theta)$を計算した後、$\theta$内のすべての単一パラメータに対するこの損失の勾配が計算される。これは、誤差逆伝播アルゴリズムを使用して効率的に行われる。これらの勾配、$\nabla_\theta L(\theta)$は、損失ランドスケープにおける最も急な上昇の方向を示す。損失を最小化するには、パラメータを勾配とは逆の方向に移動させる必要がある。 パラメータ更新(Adamオプティマイザ): 論文ではAdamオプティマイザが使用されていると述べている。Adamは、パラメータごとの学習率を維持する適応的学習率最適化アルゴリズムである。各パラメータについて、それは以下を計算する。 学習率スケジューリング: 論文では「線形学習率スケジューリング」に言及している。これは通常、学習率$\alpha$が特定の開始値から始まり、線形にウォームアップし、その後トレーニング中に線形に減衰することを意味する。このスケジューリング戦略は、モデルがトレーニングの早い段階で大きな更新を行い、損失ランドスケープを迅速に探索し、その後、過剰なオーバーシュートなしに微調整して良好な最小値に落ち着くのを助ける。 収束: 順伝播、損失計算、勾配計算、およびパラメータ更新の繰り返しを通じて、モデルのパラメータ$\theta$は徐々に調整される。損失$L(\theta)$は時間とともに減少し、モデルがインターリーブされた音声-テキストシーケンスの次のトークンを予測するのが上手くなっていることを示す。プロセスは、損失が安定した最小値に収束するか、事前に定義されたトレーニングエポック数が達成されるまで続く。モデルは効果的に入力音声とテキストのコンテキストを、確率的な次の音声またはテキストトークンにマッピングする方法を学習し、それによって一貫性があり韻律的な音声対話応答を生成する能力を獲得する。クロスモーダル事前学習は特にここで重要であり、モデルがモダリティ固有の局所的最小値に陥るのを防ぎ、シームレスな遷移と理解を促進するように損失ランドスケープが形成されることを保証する。 我々の実験的検証は、DailyTalkデータセット[70]を中心に展開された。これは、22,050 Hzでサンプリングされた20時間の音声対話データで、1人の男性と1人の女性話者が含まれる。このデータセットは、シングルターンの音声対話用に前処理され、20,117のトレーニングサンプルと1,058のテストサンプルが得られた。 統一音声対話モデル(USDM)は、XLS-R[64]の公式チェックポイントと、436K時間の多言語音声データで訓練された$k=10,000$の量子化器[33]を使用した音声-ユニットモジュールで構築された。音声デコーダーには、Multilingual LibriSpeech[71]およびGigaSpeech[72]の英語サブセットから54k時間のASRデータで訓練されたVoiceboxアーキテクチャ[66]に基づくユニットVoiceboxモデルを採用した。このユニットVoiceboxは、マルチターンの対話で一貫した音声を保証するために、ゼロショット再構築のために先行ターンの参照音声を使用するように設計された。中核となる大規模言語モデル(LLM)はMistral-7B[67]であった。我々の事前学習フェーズは、512基のNVIDIA A100-40GB GPU、グローバルバッチサイズ1,024、約87,000時間の英語ASRデータ(Multilingual LibriSpeech、People's Speech、GigaSpeech、Common Voice、Voxpopuliを含む)での8,000イテレーション、最大シーケンス長8,192を伴った。DailyTalkでのファインチューニングは、ピーク学習率$2 \cdot 10^{-5}$の線形学習率スケジューリングを使用して、グローバルバッチサイズ64で5エポック実施された。BigVGAN[74]ボコーダーがすべての音声合成に使用された。 我々の数学的主張を徹底的に証明するために、USDMを3つの「犠牲」ベースラインモデルと対比させた。 我々の評価戦略は、人間と自動メトリクスの両方を組み合わせた。人間による評価はAmazon Mechanical Turkを通じて実施され、以下が含まれた。 自動評価には、文字起こしされた応答の意味論的適切性を評価するためのGPT-4ベースの選好度テスト[1]( 証拠は、我々の統一音声対話モデル(USDM)が、その新しい事前学習およびファインチューニング戦略のおかげで、強力なベースラインと比較して、パラ言語情報を効果的に統合し、優れた音声応答を生成することを断定的に証明している。 韻律注入型音声トークンの活用という中核メカニズムは、厳密に検証された。CREMA-Dデータセット[65]の音響単位を使用した感情認識タスクでは、我々の3層トランスフォーマーベースの感情分類器は60.8%の精度を達成した。これは、ランダム推測で期待される16.6%から大幅な進歩であり、伝統的に主に意味論的情報をエンコードすると考えられていたこれらの音響単位が、豊かな感情的なキューも含むという否定できない証拠を提供する。さらに、54,000時間の音声データで訓練された我々のユニット-音声再構築モデルは、再構築された音声の音色と絶対ピッチはオリジナルとは異なる可能性があるものの、ピッチ変動はグラウンドトゥルースに密接に似ていた(図2)ことを示した。これは、我々の音声トークンがピッチコンターのような重要な非言語的特徴を効果的に捉えていることを示すハードな証拠である。 USDMの自然で一貫した音声応答生成における優位性は、複数の評価で一貫して実証された。 アブレーション研究は、我々の設計選択の効果に関する重要な洞察を提供した。 USDMが提示する顕著な進歩にもかかわらず、いくつかの固有の限界とエキサイティングな開発の方向性が存在する。 第一に、事前学習フェーズのためのデータセットとモデルの探求は、ある程度限定的であった。我々はMistral-7Bと特定のASRデータセットでのスキームの有効性を示してきたが、最適なパフォーマンスのために最も重要なデータソースが何であるか、また我々の事前学習スキームがMistral-7B以外の他のLLMにどれほどうまく汎化するかは、完全には明らかではない。将来の研究では、最も影響力のある組み合わせを特定するために、多様なデータセットとLLMアーキテクチャのより体系的な調査を含むべきである。 第二に、現在のUSDMアーキテクチャはクロスモーダル連鎖アプローチに依存している。音声入力はまずテキストに文字起こしされ、次にテキスト応答が生成され、最後にこのテキストが音声出力に合成される。この「ブリッジングテキスト」戦略はLLMの推論能力を効果的に活用するが、中間ステップを導入する。有望な将来の方向性は、この明示的なクロスモーダル連鎖なしに、入力音声対話から直接音声応答を生成できる音声対話モデルを開発することである。これにより、パイプラインが合理化され、エラー伝播が削減される可能性があり、真のエンドツーエンド音声-音声体験が提供される。 第三に、現在の事前学習スキームは、主に数万時間の英語データに基づいている。これは、USDMを他の言語、特に音声データリソースが比較的小さい言語に適用する際に明確な限界をもたらす。モデルをより多様な言語に対応できるようにすることは、グローバルな適用性と有用性を向上させるための重要な次のステップである。これには、多言語事前学習戦略の探求と、多様な言語的特徴のための音声トークン化およびデコーディングコンポーネントの適応が含まれる可能性が高い。 最後に、我々のタスクごとの動的分析(図7、右)は、LoRAを使用したファインチューニングパラメータの増加が、ユニット-テキストタスクパフォーマンスの低下につながる可能性があることを示唆しており、過学習の可能性を示唆している。これを解決するために、将来の研究では、ユニット-テキストタスクにおける過学習を軽減する戦略を探求できる。これには、パイプライン内の各タスクの損失重みを動的に変更したり、モデルが徐々に複雑なタスクにさらされるカリキュラム学習アプローチを実装したりすることが含まれる可能性がある。 これらの特定の点を超えて、この作品のより広範な意味は、いくつかの議論のトピックを開く。パラ言語的特徴を捉える実証された能力を、より共感的で文脈を意識した対話エージェントを構築するために、どのようにさらに活用できるか?音声フィッシングのようなシナリオでの誤用を防ぎつつ、読み書きに困難を抱える人々のためのアクセス可能なコミュニケーション代替手段を提供するなど、社会的な影響を最大化するために、このような高品質な音声合成モデルの倫理的な展開を保証するための堅牢なメカニズムを開発できるか?さらに、我々の事前学習アプローチと他の音声-テキストタスク(音声翻訳や要約など)との間の同型性を調査することは、さらに広範なアプリケーションを解き放ち、真にマルチモーダルなLLMの基盤を固める可能性がある。項ごとの解剖
ステップバイステップの流れ
<|correspond|>または<|continue|>など)の混合からなる、インターリーブされたシーケンス$I_j$全体がシステムに供給される。このシーケンスは、音声対話のセグメントまたは音声-テキストペアを表す。最適化ダイナミクス
これらの推定値は、バイアス補正される。Adamのパラメータ更新ルールは次のとおりである。
$$\theta_{t+1} = \theta_t - \alpha \frac{\hat{m}_t}{\sqrt{\hat{v}_t} + \epsilon}$$
ここで、$\theta_t$はタイムステップ$t$におけるパラメータベクトル、$\alpha$は学習率(例:ユニットVoiceboxトレーニングでは$10^{-4}$、事前学習/ファインチューニングでは$2 \cdot 10^{-5}$)、$\hat{m}_t$および$\hat{v}_t$はバイアス補正された第一および第二モーメント推定値、$\epsilon$はゼロ除算を防ぐための小さな定数である。この適応的な性質により、Adamはスパースな勾配と異なるスケールのパラメータを効果的に処理でき、モデルがより速く、より堅牢に収束するのを助ける。結果、限界、結論
実験設計とベースライン
1. From Scratch: このモデルはUSDMとほぼ同一であったが、決定的に統一音声-テキスト事前学習を欠いていた。事前学習済みMistral-7Bを、USDMと同じハイパーパラメータを使用して、音声対話データに直接ファインチューニングした。このベースラインは、我々の新しい事前学習スキームの影響を分離するように設計された。
2. Cascaded: このアプローチは、個別の市販の自動音声認識(ASR)および音声合成(TTS)システムを採用した。具体的には、ASRにはwhisper-large-v3[78](5M時間の音声データで訓練済み)、TTSにはVoiceboxモデル(我々のユニットVoiceboxと同様にテキスト入力で訓練済み)を使用した。LLM(Mistral-7B)は、音声対話データの文字起こしでファインチューニングされた。このベースラインは、音声対話への伝統的なモジュラーアプローチを表していた。
3. SpeechGPT [25]: 公正な比較のために、最先端の事前学習済み音声-テキストモデルであるSpeechGPT-7B-cmの公式実装とチェックポイントを使用し、DailyTalkでファインチューニングした。
- 全体的な選好度テスト: 150人の評価者が、ランダムに選択された50の音声対話について、自然さ、韻律、意味論的一貫性を考慮して、USDMの音声応答をベースラインと比較した。これは約200米ドルかかった。
- 韻律平均評価スコア(P-MOS): 198人の評価者が、グラウンドトゥルースのテキスト応答を与えられた状態で、5点スケールで韻律の自然さを評価した。これは約250米ドルかかった。
- 平均評価スコア(MOS): 176人の評価者が、応答テキストと音声応答のみを与えられた状態で、5点スケールで音声品質と自然さを評価した。これも約250米ドルかかった。gpt-4-0125-previewを使用)、および意味論的内容のMETEORおよびROUGE-Lスコア、およびテキストから音声への(STT)および音声からテキストへの(TTS)コンポーネントの単語誤り率(WER)といった定量的メトリクスが含まれた。アブレーション研究は、パープレキシティ(PPL)をLibriSpeechで、および前述の対話メトリクスをDailyTalkで、統一事前学習とファインチューニングスキームの貢献をさらに解剖した。証拠が証明すること
- 人間による選好度: 包括的な人間による選好度テストでは、USDMはグラウンドトゥルースと同程度に選好され、すべてのベースラインを大幅に上回った(Wilcoxon符号順位検定によるp値<0.05)。これは、全体的な品質とユーザーエクスペリエンスの強力な指標である。
- 韻律の自然さ: USDMは、P-MOS評価ですべてのベースラインを上回った(p値<0.05)。これは、自然な韻律を持つ音声を生成する卓越した能力を示している。特に、明示的なラベルを使用しても韻律に苦労したカスケードモデルを上回っており、USDMの効果的で暗黙的なパラ言語的特徴の組み込みを強調している。
- 意味論的一貫性: 我々のモデルは、意味論的適切性に関する定量メトリクス(METEORおよびROUGE-L)とGPT-4ベースの選好度テスト(p値<0.05)の両方でベースラインを上回った。これは、USDMが一貫した意味論的応答を生成し、入力音声とよくアライメントされる能力を確認するものである。
- 統一事前学習: 対応関係と継続関係の両方をモデル化する我々の提案された統一音声-テキスト事前学習スキームは、すべてのモダリティとシーケンスタイプにわたる優れた平均パープレキシティ(PPL)を達成した(表3、表9)。これは、包括的な事前学習戦略が、LLMが限定的な関係性に特化するのではなく、多様な音声-テキスト対話を学習するために不可欠であることを決定的に証明した。この事前学習を欠く「From Scratch」モデルは、著しく劣ったTTSおよびSTT WER(それぞれ64.0%および58.1%)と劣った意味論的パフォーマンスを示し、クロスモーダル事前学習の重要な役割を強調した。
- 中間テキストモデリング: 中間テキストをブリッジとして使用するファインチューニングスキーム(音声入力 -> テキスト文字起こし -> テキスト応答生成 -> 音声応答合成)は非常に効果的であることが示された。直接的な音声-音声モデル(S1 -> S2)は、METEORおよびROUGE-Lスコアで著しく劣ったパフォーマンスを示し(表3)、テキストモダリティを介してLLMの推論能力を活用することが有益であることを確認した。
- 入力モダリティの活用: アテンションマップ(図4)は、USDMの生成された応答が入力音声とその文字起こしテキストの両方に注意を払っていることを明らかにした。この視覚的な証拠は、我々のモデルが両方のモダリティからの情報を効果的に統合し、より堅牢で意味論的に一貫した出力を生成していることを確認する。さらに、モデル生成の入力文字起こしをグラウンドトゥルース文字起こしに置き換えることは、METEORおよびROUGE-Lスコアを改善し(それぞれ13.6 vs 13.1および16.2 vs 15.7)、USDMにおけるユニット-テキスト変換の精度の向上は意味論的一貫性を直接向上させることを実証した。限界と将来の方向性
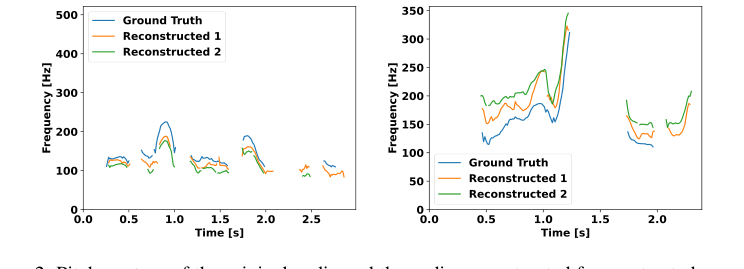 Figure 2. Pitch contour of the original audio and the audio reconstructed from extracted acoustic units. Due to the stochastic nature of the reconstruction model, we attempt reconstruction twice, demonstrating that the pitch variation closely mirrors the ground truth
Figure 2. Pitch contour of the original audio and the audio reconstructed from extracted acoustic units. Due to the stochastic nature of the reconstruction model, we attempt reconstruction twice, demonstrating that the pitch variation closely mirrors the ground truth
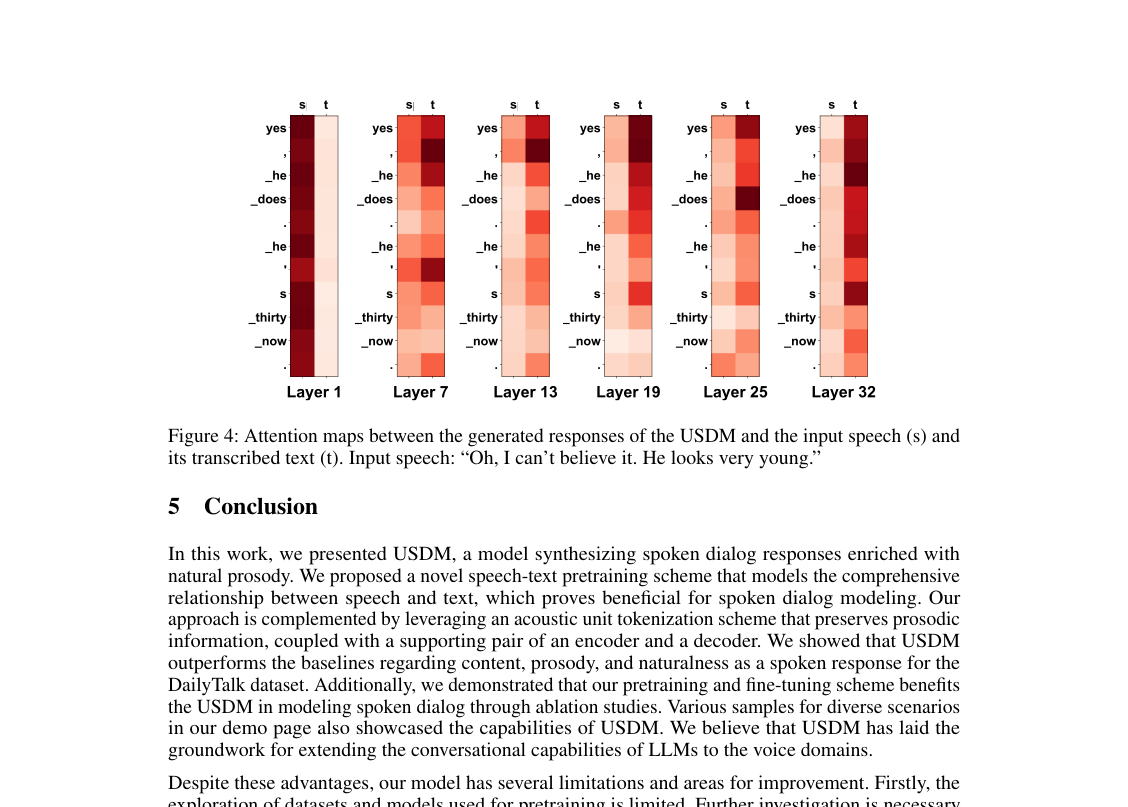 Figure 4. Attention maps between the generated responses of the USDM and the input speech (s) and its transcribed text (t). Input speech: “Oh, I can’t believe it. He looks very young.”
Figure 4. Attention maps between the generated responses of the USDM and the input speech (s) and its transcribed text (t). Input speech: “Oh, I can’t believe it. He looks very young.”
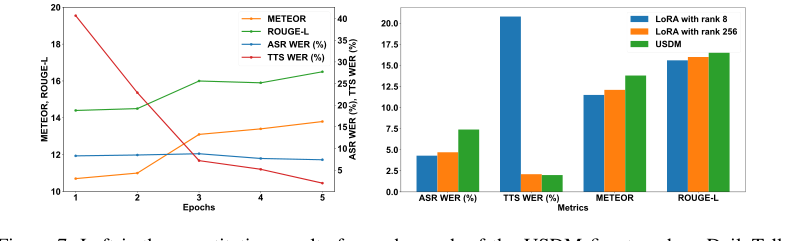 Figure 7. Left is the quantitative results for each epoch of the USDM fine-tuned on DailyTalk. The figure on the right illustrates the performance of the Spoken Dialog Model when trained with Low-Rank Adaptation (LoRA) versus full fine-tuning
Figure 7. Left is the quantitative results for each epoch of the USDM fine-tuned on DailyTalk. The figure on the right illustrates the performance of the Spoken Dialog Model when trained with Low-Rank Adaptation (LoRA) versus full fine-tuning