प्राकृतिक वार्तालाप के लिए पैरालैंग्वेजिक्स-जागरूक भाषण-सशक्त बड़े भाषा मॉडल
प्राकृतिक वार्तालाप के लिए पैरालैंग्वेजिक्स-जागरूक भाषण-सशक्त बड़े भाषा मॉडल
पृष्ठभूमि और अकादमिक वंश
उत्पत्ति और अकादमिक वंश
इस पत्र में संबोधित समस्या टेक्स्ट-आधारित संवादात्मक AI में बड़े भाषा मॉडल (LLMs) की हालिया प्रगति और व्यापक रूप से अपनाए जाने से उत्पन्न होती है। जबकि LLMs ने टेक्स्ट को समझने, उत्पन्न करने और तर्क करने में उल्लेखनीय क्षमताएं प्रदर्शित की हैं, बोली जाने वाली बातचीत पर उनका सीधा अनुप्रयोग एक महत्वपूर्ण चुनौती बनी हुई है। मुख्य प्रेरणा LLMs की शक्तिशाली, उभरती हुई क्षमताओं—जैसे कि कुछ-शॉट इन-कॉन्टेक्स्ट लर्निंग और जटिल तर्क—को प्राकृतिक बोली जाने वाली बातचीत के क्षेत्र में विस्तारित करना है, जिससे अधिक सहज और मानव-जैसी बातचीत संभव हो सके।
ऐतिहासिक रूप से, प्रारंभिक बोली जाने वाली भाषा मॉडल (SLMs) या तो केवल भाषण डेटा पर केंद्रित थे या बहुत सरल क्रॉस-मोडल उद्देश्यों को नियोजित करते थे, जो पूर्व-प्रशिक्षित LLMs की परिष्कृत भाषाई समझ का पूरी तरह से दोहन करने में विफल रहे। अत्यधिक सक्षम टेक्स्ट-आधारित LLMs के आगमन के साथ, अकादमिक क्षेत्र ने इन मॉडलों में भाषण तौर-तरीकों को एकीकृत करने की ओर रुख किया।
पिछले दृष्टिकोणों की मौलिक सीमाएं या "दर्द बिंदु" जिन्होंने इस शोध की आवश्यकता को प्रेरित किया, उन्हें दो मुख्य प्रकारों में वर्गीकृत किया जा सकता है:
-
कैस्केडेड मॉडल: इन दृष्टिकोणों में आम तौर पर उपयोगकर्ता के भाषण को टेक्स्ट में बदलने के लिए अलग स्वचालित भाषण पहचान (ASR), एक टेक्स्ट प्रतिक्रिया उत्पन्न करने के लिए एक LLM, और फिर बोली जाने वाली प्रतिक्रिया को संश्लेषित करने के लिए एक टेक्स्ट-टू-स्पीच (TTS) प्रणाली शामिल होती है।
- भाषाई विसंगति: एक महत्वपूर्ण "दर्द बिंदु" भाषण और टेक्स्ट द्वारा जानकारी व्यक्त करने के तरीके के बीच अंतर्निहित बेमेल है। भाषण समृद्ध पैरालैंग्वेजिक्स संकेत वहन करता है जैसे भावना, स्वर और लय, जो ASR द्वारा सादे टेक्स्ट में परिवर्तित होने पर खो जाते हैं। यह भाषाई विसंगति संवाद अक्षमताओं और एक उप-इष्टतम उपयोगकर्ता अनुभव की ओर ले जाती है, क्योंकि LLM केवल अर्थ संबंधी सामग्री पर काम करता है, अक्सर महत्वपूर्ण गैर-मौखिक संदर्भ को अनदेखा करता है।
- पैरालैंग्वेजिक्स के लिए लेबल निर्भरता: कैस्केडेड मॉडल में पैरालैंग्वेजिक्स सुविधाओं को शामिल करने के लिए, स्पष्ट लेबल (जैसे, भावनाओं के लिए) अक्सर आवश्यक होते हैं। यह डेटा संग्रह को चुनौतीपूर्ण बनाता है और मॉडल को केवल उन गैर-मौखिक संकेतों तक सीमित करता है जिन्हें स्पष्ट रूप से लेबल किया जा सकता है।
- त्रुटि प्रसार: एक बड़ी कमी त्रुटियों का संचय है। ASR प्रणाली या टेक्स्ट-आधारित LLM द्वारा पेश की गई कोई भी अशुद्धि पाइपलाइन के माध्यम से फैल सकती है, जिससे कम सुसंगत या स्वाभाविक लगने वाली बोली जाने वाली प्रतिक्रियाएं हो सकती हैं।
-
एंड-टू-एंड स्पीच-ओनली या सरल क्रॉस-मोडल मॉडल: जबकि कुछ एंड-टू-एंड पाइपलाइन मौजूद हैं, वे अक्सर पूर्व-प्रशिक्षित LLMs में अंतर्निहित व्यापक ज्ञान और तर्क क्षमताओं का पूरी तरह से लाभ उठाने में विफल रहते हैं। ये मॉडल भाषण और टेक्स्ट तौर-तरीकों के बीच व्यापक, जटिल संबंधों को पकड़ने की अपनी क्षमता में सीमित हो सकते हैं, जिससे प्रासंगिक रूप से समृद्ध और प्रोसोडिक रूप से उपयुक्त बोली जाने वाली बातचीत उत्पन्न करने में उनके प्रदर्शन में बाधा आती है। लेखकों का कहना है कि पिछले मॉडल, विशिष्ट कार्यों या सरल क्रॉस-मोडल उद्देश्यों पर ध्यान केंद्रित करके, एक एकीकृत ढांचे की पेशकश की गहरी क्रॉस-मोडल समझ की क्षमता का पूरी तरह से शोषण नहीं किया।
सहज डोमेन शब्द
यहां पेपर से तीन अत्यधिक विशिष्ट डोमेन शब्द दिए गए हैं, जिन्हें शून्य-आधार पाठक के लिए सहज, रोजमर्रा की उपमाओं में अनुवादित किया गया है:
-
पैरालैंग्वेजिक्स: कल्पना कीजिए कि आप एक कहानी सुना रहे हैं। आपके द्वारा उपयोग किए जाने वाले शब्द मुख्य संदेश (अर्थशास्त्र) हैं। लेकिन जिस तरीके से आप इसे बताते हैं - आपकी आवाज का स्वर, आप कितनी तेजी से बोलते हैं, आप कहां रुकते हैं, क्या आप उत्साहित या उदास लगते हैं - वह पैरालैंग्वेजिक्स है। यह सभी गैर-शब्द ध्वनियां और मुखर गुण हैं जो आप जो कह रहे हैं उसमें अर्थ और भावना जोड़ते हैं। पैरालैंग्वेजिक्स को समझने वाला कंप्यूटर केवल "मैं ठीक हूँ" नहीं सुनता है, वह यह जानने के लिए सुनता है कि आप "मैं ठीक हूँ" कैसे कहते हैं कि क्या आप वास्तव में ठीक हैं या व्यंग्यात्मक हैं।
-
ध्वनिक इकाइयाँ / असतत भाषण प्रतिनिधित्व: एक फिल्म फिल्म के बारे में सोचें। यह गति का एक निरंतर प्रवाह है, लेकिन यह वास्तव में हजारों व्यक्तिगत, स्थिर चित्रों (फ्रेम) से बना है। ध्वनिक इकाइयाँ भाषण के लिए इन व्यक्तिगत फ्रेम की तरह हैं। एक निरंतर ध्वनि तरंग के बजाय, हम भाषण को छोटी, अलग ध्वनि "खंडों" या "टोकन" में तोड़ते हैं। इन खंडों को फिर प्रकारों के एक सीमित सेट में वर्गीकृत किया जाता है, जैसे अद्वितीय लेगो ईंटों का एक छोटा बॉक्स। इन विशिष्ट "लेगो ईंटों" का चयन और व्यवस्था करके, एक कंप्यूटर भाषण का पुनर्निर्माण कर सकता है, शब्दों और सूक्ष्म मुखर बारीकियों दोनों को पकड़ सकता है।
-
प्रोसोडी: यह भाषा का संगीत है। जब आप बोलते हैं, तो आपकी आवाज स्वाभाविक रूप से पिच में ऊपर और नीचे जाती है, आप कुछ शब्दों पर जोर देते हैं, और आप अपनी बोलने की गति को बदलते हैं। पिच, तनाव और लय के इस पैटर्न को प्रोसोडी कहा जाता है। यह वह है जो एक प्रश्न को प्रश्न की तरह बनाता है, या एक उत्साहित बयान को उत्साहित बनाता है। प्रोसोडी के बिना, सभी भाषण सपाट और रोबोटिक लगेंगे, जैसे एक कंप्यूटर एक नीरस आवाज में टेक्स्ट पढ़ रहा हो। यह उत्साह के साथ "मुझे वह प्यार है" कहने और इसे एक सपाट, प्रेरणाहीन स्वर के साथ कहने के बीच का अंतर है।
संकेतन तालिका
| संकेतन | विवरण |
|---|---|
समस्या परिभाषा और बाधाएँ
मुख्य समस्या सूत्रीकरण और दुविधा
मुख्य समस्या जिसे यह पत्र संबोधित करता है, वह है वर्तमान बड़े भाषा मॉडल (LLMs) की एंड-टू-एंड फैशन में प्राकृतिक बोली जाने वाली बातचीत को संभालने की सीमा।
इनपुट/वर्तमान स्थिति:
मौजूदा LLMs टेक्स्ट-आधारित कार्यों में उत्कृष्ट हैं, जो जटिल तर्क, कुछ-शॉट सीखने और निर्देश-पालन में उल्लेखनीय क्षमताएं प्रदर्शित करते हैं। हालांकि, जब बोली जाने वाली बातचीत की बात आती है, तो उन्हें आम तौर पर कैस्केडेड तरीके से अलग स्वचालित भाषण पहचान (ASR) और टेक्स्ट-टू-स्पीच (TTS) सिस्टम के साथ एकीकृत किया जाता है। वैकल्पिक रूप से, कुछ मॉडल केवल भाषण प्रसंस्करण पर ध्यान केंद्रित करते हैं, बिना LLMs की पूरी शक्ति का लाभ उठाए।
वांछित अंतिम बिंदु (आउटपुट/लक्ष्य स्थिति):
लक्ष्य एक एकीकृत बोली जाने वाली संवाद मॉडल (USDM) विकसित करना है जो भाषण तौर-तरीकों को निर्बाध रूप से LLMs में एकीकृत कर सके। यह मॉडल निम्न में सक्षम होना चाहिए:
1. स्पष्ट ASR पर निर्भरता के बिना, सूक्ष्म बारीकियों और भावनात्मक राज्यों (पैरालैंग्वेजिक्स) सहित उपयोगकर्ता भाषण को सीधे समझना।
2. स्पष्ट TTS पर निर्भरता के बिना, स्वाभाविक रूप से होने वाली और प्रासंगिक रूप से उपयुक्त प्रोसोडिक सुविधाओं के साथ सुसंगत बोली जाने वाली प्रतिक्रियाएं उत्पन्न करना।
3. एंड-टू-एंड पाइपलाइन में संवाद पीढ़ी और तर्क के लिए LLM की शक्तिशाली क्षमताओं को बनाए रखना और बढ़ाना।
लुप्त कड़ी/गणितीय अंतर:
सटीक लुप्त कड़ी एक एकीकृत, LLM-आधारित ढांचा है जो कच्चे भाषण इनपुट और प्राकृतिक बोली जाने वाली प्रतिक्रियाओं के बीच के अंतर को प्रभावी ढंग से पाट सकता है, व्यवस्थित रूप से अर्थ संबंधी और पैरालैंग्वेजिक्स जानकारी दोनों को LLM की प्रसंस्करण में एकीकृत करके। इसके लिए एक उपन्यास भाषण-पाठ प्रतिनिधित्व और पूर्व-प्रशिक्षण योजना की आवश्यकता होती है जो LLM को व्यापक क्रॉस-मोडल संबंधों को सीखने की अनुमति देती है और भाषण टोकन उत्पन्न करती है जो केवल अर्थ संबंधी सामग्री के बजाय स्वाभाविक रूप से प्रोसोडिक जानकारी वहन करती है। पत्र का उद्देश्य "प्रोसोडी-युक्त भाषण टोकनकरण योजना" और "सामान्यीकृत भाषण-पाठ पूर्व-प्रशिक्षण योजना जो क्रॉस-मोडल अर्थशास्त्र के कैप्चर को बढ़ाती है" द्वारा इस अंतर को पाटना है।
दुविधा:
पिछला शोध LLM क्षमताओं का लाभ उठाने और भाषण को स्वाभाविक रूप से संभालने के बीच एक दर्दनाक व्यापार-बंद में फंस गया है:
* कैस्केडेड ASR/TTS बनाम एंड-टू-एंड सुसंगतता: जबकि ASR और TTS सिस्टम आसानी से नियोजित किए जा सकते हैं, उनके कैस्केडेड उपयोग से "भाषण और टेक्स्ट के बीच भाषाई विसंगति" होती है, जिससे "संवाद अक्षमताएं और उप-इष्टतम उपयोगकर्ता अनुभव" होता है [10, 11]। अधिक महत्वपूर्ण रूप से, ये पाइपलाइन "कैस्केडेड पाइपलाइन में अंतर्निहित त्रुटि प्रसार" [63] से पीड़ित हैं, जहां ASR या टेक्स्ट-आधारित संवाद मॉडल में त्रुटियां जमा हो जाती हैं, जिससे कम सुसंगत या स्वाभाविक बोली जाने वाली प्रतिक्रियाएं होती हैं। इसके अलावा, कैस्केडेड मॉडल में पैरालैंग्वेजिक्स सुविधाओं (जैसे भावना या स्वर) को शामिल करने के लिए अक्सर "स्पष्ट लेबल" की आवश्यकता होती है, जिससे "डेटा संग्रह चुनौतीपूर्ण हो जाता है और मॉडल को केवल लेबल-परिभाषित गैर-मौखिक संकेतों का प्रतिनिधित्व करने तक सीमित कर दिया जाता है" (धारा 2, पृष्ठ 3)।
* स्पीच-ओनली मॉडल बनाम LLM तर्क: केवल भाषण डेटा पर प्रशिक्षित प्रारंभिक बोली जाने वाली भाषा मॉडल (SLMs) [17, 19] में आधुनिक LLMs की उन्नत तर्क और उत्पादन क्षमता की कमी होती है, जिससे उनकी संवादात्मक क्षमताएं सीमित हो जाती हैं। दुविधा यह है कि भाषण मॉडल को LLM-जैसी बुद्धिमत्ता कैसे प्रदान की जाए, बिना भाषण संकेत की समृद्धि खोए।
* भाषण टोकन में अर्थ संबंधी बनाम पैरालैंग्वेजिक्स जानकारी: भाषण टोकन आम तौर पर अर्थ संबंधी सामग्री को एन्कोड करने के लिए डिज़ाइन किए जाते हैं। चुनौती एक असतत भाषण प्रतिनिधित्व बनाना है जो न केवल अर्थ संबंधी जानकारी प्रदान करता है, बल्कि पैरालैंग्वेजिक्स जानकारी (जैसे, भावनाएं, पिच भिन्नताएं) की एक महत्वपूर्ण मात्रा को इस तरह से भी प्रदान करता है कि एक LLM स्वाभाविक लगने वाली, प्रासंगिक रूप से उपयुक्त बोली जाने वाली प्रतिक्रियाएं उत्पन्न करने के लिए प्रभावी ढंग से उपयोग कर सके।
बाधाएँ और विफलता मोड
प्राकृतिक बातचीत के लिए पैरालैंग्वेजिक्स-जागरूक, भाषण-सशक्त LLM बनाने की समस्या कई कठोर, यथार्थवादी बाधाओं के कारण अविश्वसनीय रूप से कठिन है:
- डेटा-संचालित बाधाएँ:
- संरेखित क्रॉस-मोडल डेटा की कमी: व्यापक भाषण-पाठ मॉडल बनाने के लिए उच्च-गुणवत्ता, संरेखित भाषण और पाठ डेटा की विशाल मात्रा की आवश्यकता होती है जो विविध संवादात्मक संदर्भों और पैरालैंग्वेजिक्स सुविधाओं को कैप्चर करते हैं। पत्र नोट करता है कि इसकी वर्तमान पूर्व-प्रशिक्षण योजना "दसियों हज़ार घंटे के अंग्रेजी डेटा" (धारा 5, पृष्ठ 10) पर निर्भर करती है, जो एक महत्वपूर्ण डेटा आवश्यकता का संकेत देती है।
- लेबल वाले पैरालैंग्वेजिक्स डेटा की विरलता: पैरालैंग्वेजिक्स सुविधाओं (जैसे भावनाएं या इंटोनेशन) के लिए स्पष्ट लेबल दुर्लभ और बड़े पैमाने पर प्राप्त करना मुश्किल हैं, जो उन मॉडलों के लिए एक बड़ी बाधा है जो उन पर निर्भर करते हैं (धारा 2, पृष्ठ 3)।
- बहुभाषी सीमाएँ: वर्तमान मॉडल मुख्य रूप से अंग्रेजी डेटा पर प्रशिक्षित है, और "अपेक्षाकृत कम मात्रा में भाषण डेटा" वाली अन्य भाषाओं पर इसकी प्रयोज्यता सीमित है, जो सार्वभौमिक तैनाती के लिए एक चुनौती पेश करती है (धारा 5, पृष्ठ 10)।
- कम्प्यूटेशनल बाधाएँ:
- पूर्व-प्रशिक्षण के लिए अत्यधिक कम्प्यूटेशनल लागत: बड़े भाषण-पाठ मॉडल को प्रशिक्षित करने के लिए, विशेष रूप से LLM आर्किटेक्चर पर आधारित, भारी कम्प्यूटेशनल संसाधनों की मांग होती है। पत्र "512 NVIDIA A100-40GB GPUs का उपयोग करता है, जिसमें 1,024 के वैश्विक बैच आकार के साथ 8,000 पुनरावृति" (धारा 4.1.1, पृष्ठ 7) होती है, जो पर्याप्त हार्डवेयर आवश्यकताओं को उजागर करती है।
- लंबी अनुक्रमों के लिए मेमोरी सीमाएँ: इंटरलीव्ड भाषण-पाठ अनुक्रमों को संसाधित करना, विशेष रूप से "अधिकतम अनुक्रम लंबाई 8,192" (धारा 4.1.1, पृष्ठ 7) के साथ, जल्दी से हार्डवेयर मेमोरी सीमाओं तक पहुँच सकता है, जिससे संवाद में लंबी दूरी की निर्भरताओं को मॉडल करना चुनौतीपूर्ण हो जाता है।
- वास्तुशिल्प और कार्यात्मक बाधाएँ:
- LLM तर्क क्षमताओं को बनाए रखना: LLMs में भाषण को एकीकृत करने से उनकी मुख्य तर्क और उत्पादन क्षमताओं में गिरावट नहीं आनी चाहिए। मॉडल को प्रभावी ढंग से "मध्यवर्ती तौर-तरीकों पर श्रृंखला तर्क" (धारा 3.3, पृष्ठ 6) करने की आवश्यकता है।
- प्राकृतिक प्रोसोडी उत्पन्न करना: "दिए गए इनपुट भाषण से संबंधित स्वाभाविक रूप से होने वाली प्रोसोडिक सुविधाओं" के साथ भाषण को संश्लेषित करना एक जटिल कार्य है। मॉडल को संदर्भ से उपयुक्त प्रोसोडी का अनुमान लगाने और उत्पन्न करने के लिए सीखना चाहिए, जो मानव संचार का एक सूक्ष्म और कठिन पहलू है (सार, पृष्ठ 1)।
- इनपुट भिन्नताओं और त्रुटियों के प्रति मजबूती: सिस्टम को इनपुट भाषण गुणवत्ता, लहजे और संभावित प्रतिलेखन अशुद्धियों में भिन्नताओं के प्रति मजबूत होना चाहिए, खासकर यदि एक मध्यवर्ती पाठ प्रतिनिधित्व का उपयोग किया जाता है। पत्र "कैस्केडेड सिस्टम की तुलना में प्रतिलेखन त्रुटियों के प्रति अधिक मजबूत" दृष्टिकोण का लक्ष्य रखता है (धारा 3.3, पृष्ठ 6)।
- क्रॉस-मोडल सिमेंटिक संरेखण: यह सुनिश्चित करना कि भाषण और पाठ तौर-तरीके सिमेंटिक रूप से संरेखित हैं और मॉडल "क्रॉस-मोडल वितरण सिमेंटिक्स" सीख सकता है, सुसंगत संवाद पीढ़ी के लिए महत्वपूर्ण है (पृष्ठ 2)।
- विविध संबंधों में सामान्यीकरण: एक पूर्व-प्रशिक्षण योजना जो केवल विशिष्ट प्रकार के संबंधों (जैसे, पत्राचार या निरंतरता) पर ध्यान केंद्रित करती है, "मॉडल की क्षमताओं को केवल उन पूर्वनिर्धारित संबंधों तक सीमित कर सकती है" (धारा 3.2, पृष्ठ 5), विविध भाषण-पाठ इंटरैक्शन को संभालने की इसकी क्षमता में बाधा डालती है। मॉडल बहुमुखी होना चाहिए।
यह दृष्टिकोण क्यों
विकल्प की अनिवार्यता
लेखकों का एकीकृत बोली जाने वाली संवाद मॉडल (USDM) को बोली जाने वाली बातचीत के लिए LLM-आधारित, एंड-टू-एंड ढांचे के रूप में विकसित करने का निर्णय मौजूदा "SOTA" विधियों की अंतर्निहित सीमाओं से प्रेरित था। यह महत्वपूर्ण अहसास कि पारंपरिक दृष्टिकोण अपर्याप्त थे, कैस्केडेड सिस्टम और पिछले एंड-टू-एंड भाषण मॉडल दोनों में मौलिक दोषों का अवलोकन करने से उभरा।
विशेष रूप से, पत्र इस बात पर प्रकाश डालता है कि जबकि स्वचालित भाषण पहचान (ASR) और टेक्स्ट-टू-स्पीच (TTS) सिस्टम आसानी से नियोजित किए जा सकते हैं, उनकी अनुक्रमिक प्रकृति "भाषण और टेक्स्ट के बीच भाषाई विसंगति" का परिचय देती है जो "संवाद अक्षमताओं की ओर ले जाती है और उप-इष्टतम उपयोगकर्ता अनुभव में परिणत होती है" [10, 11]। इस कैस्केडेड दृष्टिकोण के लिए पैरालैंग्वेजिक्स सुविधाओं के लिए स्पष्ट लेबल की भी आवश्यकता होती है, जिससे डेटा संग्रह चुनौतीपूर्ण हो जाता है और मॉडल को केवल लेबल-परिभाषित गैर-मौखिक संकेतों तक सीमित कर दिया जाता है। महत्वपूर्ण रूप से, "कैस्केडेड पाइपलाइन [63] में अंतर्निहित त्रुटि प्रसार उनकी संचित त्रुटियों की संवेदनशीलता को बढ़ाता है," जिससे वास्तव में प्राकृतिक और सुसंगत बोली जाने वाली बातचीत के लिए एक अविश्वसनीय नींव बनती है।
इसके अलावा, मौजूदा LLM-आधारित भाषण मॉडल, अपनी सफलताओं के बावजूद, पैरालैंग्वेजिक्स को स्वाभाविक रूप से समझने और शामिल करने के लिए अपर्याप्त पाए गए। पहले के एंड-टू-एंड पाइपलाइन [19, 25] जो केवल भाषण-केवल प्रशिक्षण या सरल क्रॉस-मोडल उद्देश्यों पर निर्भर थे, "पूर्व-प्रशिक्षित भाषा मॉडल की क्षमताओं का पूरी तरह से उपयोग करने में विफल रहते हैं।" लेखकों ने महसूस किया कि इन गहरी समस्याओं को दूर करने और LLMs को संवादात्मक संदर्भ में उपयुक्त पैरालैंग्वेजिक्स सुविधाओं के साथ भाषण को वास्तव में समझने और उत्पन्न करने में सक्षम बनाने के लिए एक व्यापक, एकीकृत दृष्टिकोण एकमात्र व्यवहार्य समाधान था।
तुलनात्मक श्रेष्ठता
USDM मुख्य रूप से अपने एकीकृत क्रॉस-मोडल पूर्व-प्रशिक्षण और पैरालैंग्वेजिक्स जानकारी को सीधे भाषण टोकन में डालने की अपनी क्षमता के माध्यम से पिछले स्वर्ण मानकों पर गुणात्मक श्रेष्ठता प्रदर्शित करता है। यह संरचनात्मक लाभ इसे अधिक स्वाभाविक लगने वाली और सिमेंटिक रूप से सुसंगत बोली जाने वाली प्रतिक्रियाएं उत्पन्न करने की अनुमति देता है।
कैस्केडेड सिस्टम के विपरीत जो त्रुटि प्रसार और गैर-मौखिक संकेतों के लिए स्पष्ट लेबल पर निर्भरता से पीड़ित होते हैं, USDM का एंड-टू-एंड डिज़ाइन, जो शुरू से ही भाषण और टेक्स्ट तौर-तरीकों को एकीकृत करता है, स्वाभाविक रूप से इन मुद्दों को कम करता है। मॉडल की अनूठी भाषण टोकनकरण योजना, स्व-पर्यवेक्षित भाषण अभ्यावेदन (XLS-R) के के-मीन्स क्लस्टरिंग से प्राप्त, महत्वपूर्ण पैरालैंग्वेजिक्स जानकारी, जैसे भावनाएं और पिच भिन्नताएं, को समाहित करने के लिए दिखाया गया है। प्रयोगों की पुष्टि होती है कि ये ध्वनिक इकाइयाँ भावना पहचान में 60.8% सटीकता प्राप्त करती हैं, जो यादृच्छिक अनुमान से अपेक्षित 16.6% से कहीं अधिक है। पिच कंटूर को पकड़ने और पुनर्निर्माण करने की यह क्षमता (जैसा कि चित्र 2 में दिखाया गया है) प्राकृतिक प्रोसोडी उत्पन्न करने के लिए एक प्रत्यक्ष गुणात्मक लाभ है, जो अक्सर कैस्केडेड सिस्टम में टेक्स्ट-आधारित मध्यवर्ती अभ्यावेदन द्वारा खो जाती है या खराब तरीके से संभाली जाती है।
इसके अलावा, USDM की LLM-आधारित मॉडलिंग रणनीति, जो भाषण इनपुट और आउटपुट के बीच टेक्स्ट-संबंधित कार्यों को सम्मिलित करती है, अंतर्निहित LLM की "श्रृंखला तर्क" क्षमताओं का लाभ उठाती है [6]। यह दृष्टिकोण को "प्रतिलेखन त्रुटियों के खिलाफ अधिक मजबूत और स्वतंत्र मॉड्यूल में किए जाने की तुलना में प्रासंगिक रूप से प्रासंगिक बोली जाने वाली प्रतिक्रियाएं उत्पन्न करने में बेहतर" बनाता है। यह मजबूत, प्रासंगिक रूप से जागरूक पीढ़ी, विशेष रूप से पैरालैंग्वेजिक्स के संबंध में, एक महत्वपूर्ण गुणात्मक छलांग का प्रतिनिधित्व करती है। पेपर के एब्लेशन अध्ययन इसे और रेखांकित करते हैं, यह दिखाते हुए कि व्यापक क्रॉस-मोडल पूर्व-प्रशिक्षण (जैसे "स्क्रैच से" मॉडल या सेटअप 1) की कमी वाले मॉडल प्रोसोडी और सिमेंटिक सुसंगतता के मामले में काफी खराब प्रदर्शन करते हैं, जो USDM के एकीकृत पूर्व-प्रशिक्षण के संरचनात्मक लाभ को उजागर करते हैं।
बाधाओं के साथ संरेखण
चुना गया USDM विधि सुसंगत, प्रोसोडी-समृद्ध बोली जाने वाली प्रतिक्रियाओं की आवश्यकता को सीधे संबोधित करके समस्या की कठोर आवश्यकताओं के साथ पूरी तरह से संरेखित होती है, बिना अलग ASR या TTS मॉड्यूल पर निर्भर हुए। यह "विवाह" कई प्रमुख पहलुओं में स्पष्ट है:
- एंड-टू-एंड बोली जाने वाली संवाद पीढ़ी: प्राथमिक बाधा कैस्केडेड सिस्टम से परे जाना था। USDM इसे एक एकल LLM ढांचे के भीतर भाषण और टेक्स्ट तौर-तरीकों को एकीकृत करके प्राप्त करता है, जिससे अनुमान के दौरान स्पष्ट ASR और TTS घटकों की आवश्यकता समाप्त हो जाती है। यह सीधे "स्पष्ट स्वचालित भाषण पहचान (ASR) या टेक्स्ट-टू-स्पीच (TTS) सिस्टम पर निर्भरता के बिना" आवश्यकता को संबोधित करता है।
- स्वाभाविक रूप से होने वाली प्रोसोडिक विशेषताएं: प्राकृतिक प्रोसोडी के साथ प्रतिक्रियाएं उत्पन्न करना एक मुख्य आवश्यकता थी। USDM की अनूठी "प्रोसोडी-युक्त भाषण टोकनकरण योजना" विशेष रूप से इसके लिए डिज़ाइन की गई है। यह प्रदर्शित करके कि ध्वनिक इकाइयाँ भावनात्मक संकेतों और पिच भिन्नताओं को कैप्चर करती हैं (धारा 3.1, चित्र 2), विधि सुनिश्चित करती है कि प्राकृतिक बातचीत के लिए महत्वपूर्ण गैर-मौखिक विशेषताओं को संरक्षित और उत्पन्न किया जाता है। यह एक प्रत्यक्ष और प्रभावी संरेखण है।
- सुसंगत बोली जाने वाली प्रतिक्रियाएं: मॉडल एक पूर्व-प्रशिक्षित बड़े भाषा मॉडल (Mistral-7B) की शक्तिशाली तर्क क्षमताओं का लाभ उठाता है। मध्यवर्ती पाठ पीढ़ी चरण का परिचय देकर, जो चेन-ऑफ-थॉट तर्क से प्रेरित है, USDM सुनिश्चित करता है कि संवाद की सिमेंटिक सुसंगतता बनी रहे और यहां तक कि बढ़ी भी हो। यह LLM को भाषण डोमेन में काम करते हुए "सिमेंटिक रूप से सुसंगत संवाद प्रतिक्रियाएं" उत्पन्न करने की अनुमति देता है, जिससे सुसंगत आउटपुट की आवश्यकता पूरी होती है।
- एकीकृत क्रॉस-मोडल सिमेंटिक्स: प्रस्तावित "एकीकृत भाषण-पाठ पूर्व-प्रशिक्षण योजना" "क्रॉस-मोडल वितरण सिमेंटिक्स" सीखने को बढ़ावा देती है, जो "LLMs को बोली जाने वाली संवाद मॉडलिंग में सुसंगत भाषण उत्पन्न करने की क्षमता से लैस करने के लिए महत्वपूर्ण है।" यह व्यापक पूर्व-प्रशिक्षण, विभिन्न भाषण-पाठ संबंधों को कवर करते हुए, यह सुनिश्चित करता है कि मॉडल जटिल इंटरैक्शन को संभाल सकता है और प्रासंगिक रूप से उपयुक्त प्रतिक्रियाएं उत्पन्न कर सकता है, जिससे मजबूत और सुसंगत संवाद की आवश्यकता सीधे संबोधित होती है।
विकल्पों का अस्वीकरण
पेपर दो मुख्य श्रेणियों के वैकल्पिक दृष्टिकोणों को अस्वीकार करने के लिए स्पष्ट तर्क प्रदान करता है: कैस्केडेड सिस्टम और व्यापक क्रॉस-मोडल पूर्व-प्रशिक्षण की कमी वाले सरल एंड-टू-एंड मॉडल।
-
कैस्केडेड ASR + LLM + TTS सिस्टम:
- तर्क: लेखकों ने स्पष्ट रूप से कहा है कि कैस्केडेड मॉडल,
whisper-large-v3जैसे शक्तिशाली व्यक्तिगत घटकों का उपयोग करने के बावजूद, "भाषण और टेक्स्ट के बीच भाषाई विसंगति" और "कैस्केडेड पाइपलाइन [10, 11, 63] में अंतर्निहित त्रुटि प्रसार" से पीड़ित हैं। इससे "उप-इष्टतम उपयोगकर्ता अनुभव" होता है और स्पष्ट, एकत्र करने में मुश्किल लेबल के बिना गैर-मौखिक संकेतों को शामिल करने की क्षमता सीमित हो जाती है। - अनुभवजन्य साक्ष्य: "कैस्केडेड" बेसलाइन, एक निम्न ASR WER प्राप्त करने के बावजूद, समग्र गुणवत्ता, P-MOS (प्रोसोडी स्वाभाविकता), और सिमेंटिक मेट्रिक्स (METEOR, ROUGE-L, GPT-4 वरीयता) के लिए मानव वरीयता परीक्षणों में लगातार USDM से खराब प्रदर्शन करती है (तालिका 1 और 2)। यह दर्शाता है कि कैस्केडेड सिस्टम की वास्तुशिल्प सीमाएं बोली जाने वाली बातचीत के लिए उनके व्यक्तिगत घटकों की ताकत से अधिक हैं।
- तर्क: लेखकों ने स्पष्ट रूप से कहा है कि कैस्केडेड मॉडल,
-
सीमित पूर्व-प्रशिक्षण वाले एंड-टू-एंड मॉडल (जैसे, "स्क्रैच से" या विशिष्ट पूर्व-प्रशिक्षण सेटअप):
- तर्क: पेपर का तर्क है कि "केवल भाषण-केवल प्रशिक्षण या भाषण-पाठ पूर्व-प्रशिक्षण के लिए सरल क्रॉस-मोडल उद्देश्यों का लाभ उठाने पर ध्यान केंद्रित करने वाले एंड-टू-एंड पाइपलाइन [19, 25] पूर्व-प्रशिक्षित भाषा मॉडल की क्षमताओं का पूरी तरह से उपयोग करने में विफल रहते हैं।" "स्क्रैच से" मॉडल, जिसमें यह एकीकृत पूर्व-प्रशिक्षण नहीं है, "ब्रिजिंग टेक्स्ट को अनदेखा करने की प्रवृत्ति रखता है और एक बोली जाने वाली प्रतिक्रिया उत्पन्न करता है जो पूर्व-जनित लिखित प्रतिक्रिया से मेल नहीं खाती है, इस प्रकार इसके प्रदर्शन पर नकारात्मक प्रभाव पड़ता है।" यह इस बात पर प्रकाश डालता है कि केवल बोली जाने वाली संवाद डेटा पर LLM को फाइन-ट्यून करना पर्याप्त नहीं है; मॉडल को पूर्व-प्रशिक्षण के दौरान गहरे क्रॉस-मोडल संबंधों को सीखने की आवश्यकता है।
- अनुभवजन्य साक्ष्य: "स्क्रैच से" बेसलाइन काफी उच्च STT और TTS WERs (क्रमशः 58.1% और 64.0%) प्रदर्शित करती है, बहुत कम MOS और P-MOS स्कोर, और USDM की तुलना में खराब सिमेंटिक प्रदर्शन (तालिका 1 और 2)। इसके अलावा, पूर्व-प्रशिक्षण योजनाओं पर एब्लेशन अध्ययन (धारा 4.2.1, तालिका 3, तालिका 9) से पता चलता है कि ऐसे सेटअप (जैसे, सेटअप 1, सेटअप 2, सेटअप 3) जो केवल निरंतरता या पत्राचार संबंधों को मॉडल करते हैं, या एक निश्चित टेम्पलेट का उपयोग करते हैं, उच्च पप्लेक्सिटी (PPL) और खराब डाउनस्ट्रीम बोली जाने वाली संवाद प्रदर्शन (जैसे, सेटअप 1 में काफी उच्च STT और TTS WERs हैं) उत्पन्न करते हैं। यह पुष्टि करता है कि एक व्यापक, एकीकृत पूर्व-प्रशिक्षण रणनीति फायदेमंद है और सरल, कम एकीकृत एंड-टू-एंड दृष्टिकोण अपर्याप्त हैं।
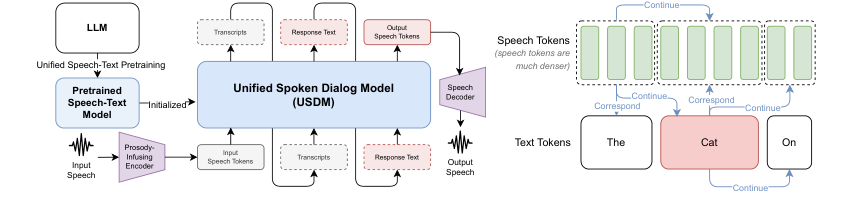 Figure 1. Overview of our spoken dialog modeling approach (Left). All possible self-supervised learning objectives from our speech-text pretraining scheme. (Right)
Figure 1. Overview of our spoken dialog modeling approach (Left). All possible self-supervised learning objectives from our speech-text pretraining scheme. (Right)
गणितीय और तार्किक तंत्र
मास्टर समीकरण
इस पत्र को शक्ति प्रदान करने वाला पूर्ण कोर समीकरण, विशेष रूप से एकीकृत भाषण-पाठ पूर्व-प्रशिक्षण और बाद के फाइन-ट्यूनिंग के लिए, नकारात्मक लॉग-संभावना उद्देश्य फ़ंक्शन है। यह फ़ंक्शन मॉडल को एक ऑटोरेग्रेसिव तरीके से अनुक्रम में पिछले टोकन दिए जाने पर अगले टोकन की सशर्त संभावना सीखने के लिए निर्देशित करता है। इसे औपचारिक रूप से इस प्रकार प्रस्तुत किया गया है:
$$L(\theta) = -\sum_{j=1}^{||D||} \sum_{k=1}^{||I_j||} \log p(i_{k,j}|i_{ आइए इस समीकरण को तोड़ें और प्रत्येक घटक की जांच करें: $L(\theta)$: $\theta$: $\sum_{j=1}^{||D||}$: $\sum_{k=1}^{||I_j||}$: $\log p(i_{k,j}|i_{ $i_{k,j}$: $i_{ एक एकल सार डेटा बिंदु की कल्पना करें, जो इस संदर्भ में एक इंटरलीव्ड भाषण-पाठ नमूना $I_j$ है। आइए इसके गणितीय इंजन के माध्यम से इसकी यात्रा का पता लगाएं: अनुक्रम अंतर्ग्रहण: संपूर्ण इंटरलीव्ड अनुक्रम $I_j$, जिसमें ध्वनिक इकाई टोकन, पाठ टोकन और विशेष नियंत्रण टोकन (जैसे टोकन एम्बेडिंग: $I_j$ के भीतर प्रत्येक व्यक्तिगत टोकन $i_{k,j}$ को पहले एक घने संख्यात्मक वेक्टर में परिवर्तित किया जाता है, जिसे एम्बेडिंग के रूप में जाना जाता है। मौजूदा पाठ टोकन के लिए, पूर्व-प्रशिक्षित LLM के एम्बेडिंग का उपयोग किया जाता है। नए पेश किए गए भाषण इकाई टोकन और विशेष टोकन के लिए, उनके पुन: आरंभ किए गए एम्बेडिंग भार का उपयोग किया जाता है। ये एम्बेडिंग असतत टोकन को एक सतत, उच्च-आयामी स्थान में परिवर्तित करते हैं जहां अर्थ संबंधी और पैरालैंग्वेजिक्स जानकारी को संसाधित किया जा सकता है। प्रासंगिक एन्कोडिंग (LLM): एम्बेडिंग के अनुक्रम को फिर मॉडल के कोर से गुजारा जाता है: एक बड़ा भाषा मॉडल (इस मामले में Mistral-7B), जो आम तौर पर एक ट्रांसफार्मर-आधारित वास्तुकला है। अनुक्रम में प्रत्येक स्थिति $k$ के लिए, मॉडल पूर्ववर्ती टोकन $i_{ अगला टोकन संभाव्यता भविष्यवाणी: प्रत्येक चरण $k$ पर, $i_{ एकल टोकन के लिए हानि गणना: सिस्टम फिर वास्तविक टोकन $i_{k,j}$ को देखता है जो ग्राउंड-ट्रूथ इनपुट अनुक्रम में उस स्थिति में हुआ था। यह मॉडल द्वारा अनुमानित वितरण से इस सही टोकन को सौंपी गई संभावना को पुनः प्राप्त करता है। इस सही संभावना का नकारात्मक लघुगणक, $-\log p(i_{k,j}|i_{ अनुक्रम हानि एकत्रीकरण: यह टोकन-स्तरीय हानि गणना $I_j$ में प्रत्येक टोकन $k$ के लिए दोहराई जाती है। सभी व्यक्तिगत टोकन हानियों को उस विशेष नमूना $I_j$ के लिए कुल हानि प्राप्त करने के लिए जोड़ा जाता है। डेटासेट हानि एकत्रीकरण: अंत में, यह पूरी प्रक्रिया (चरण 1-6) डेटासेट $D$ में प्रत्येक नमूना $I_j$ के लिए दोहराई जाती है। सभी व्यक्तिगत नमूना हानियों को कुल हानि $L(\theta)$ प्राप्त करने के लिए एक साथ जोड़ा जाता है। यह $L(\theta)$ एकल संख्यात्मक मान है जो मॉडल के समग्र प्रदर्शन को मापता है। तंत्र मुख्य रूप से ग्रेडिएंट डिसेंट द्वारा संचालित एक पुनरावृत्त प्रक्रिया के माध्यम से सीखता है, अपडेट करता है और अभिसरण करता है, विशेष रूप से एडम ऑप्टिमाइज़र का उपयोग करता है। हानि परिदृश्य: हानि फ़ंक्शन $L(\theta)$ एक उच्च-आयामी "हानि परिदृश्य" को परिभाषित करता है जहां प्रत्येक बिंदु मॉडल मापदंडों $\theta$ के एक विशिष्ट सेट और उसके संबंधित हानि मान से मेल खाता है। यह परिदृश्य आम तौर पर गैर-उत्तल होता है, जिसका अर्थ है कि इसमें कई स्थानीय न्यूनतम और काठी बिंदु होते हैं। अनुकूलन का लक्ष्य $L(\theta)$ को कम करने वाले मापदंडों का एक सेट खोजने के लिए इस परिदृश्य को नेविगेट करना है। नकारात्मक लॉग-संभावना उद्देश्य स्वाभाविक रूप से इस परिदृश्य को आकार देता है ताकि सही अगले टोकन के लिए उच्च संभावनाओं की ओर ले जाने वाले पैरामीटर कम हानि मानों में परिणामित हों। ग्रेडिएंट गणना (बैकप्रॉपैगेशन): प्रशिक्षण डेटा के एक बैच के लिए $L(\theta)$ की गणना करने वाले फॉरवर्ड पास के बाद, $\theta$ में प्रत्येक एकल पैरामीटर के संबंध में इस हानि के ग्रेडिएंट की गणना की जाती है। यह बैकप्रॉपैगेशन एल्गोरिथम का उपयोग करके कुशलतापूर्वक किया जाता है। ये ग्रेडिएंट, $\nabla_\theta L(\theta)$, हानि परिदृश्य में सबसे खड़ी चढ़ाई की दिशा को इंगित करते हैं। हानि को कम करने के लिए, मापदंडों को ग्रेडिएंट की विपरीत दिशा में ले जाया जाना चाहिए। पैरामीटर अपडेट (एडम ऑप्टिमाइज़र): पेपर बताता है कि एडम ऑप्टिमाइज़र का उपयोग किया जाता है। एडम एक अनुकूली सीखने की दर अनुकूलन एल्गोरिथम है जो प्रति-पैरामीटर सीखने की दर बनाए रखता है। प्रत्येक पैरामीटर के लिए, यह गणना करता है: सीखने की दर शेड्यूलिंग: पेपर "रैखिक सीखने की दर शेड्यूलिंग" का उल्लेख करता है। इसका आम तौर पर मतलब है कि सीखने की दर $\alpha$ एक निश्चित मान से शुरू होती है, रैखिक रूप से गर्म हो सकती है, और फिर प्रशिक्षण के दौरान रैखिक रूप से घट जाती है। यह शेड्यूलिंग रणनीति मॉडल को हानि परिदृश्य का तेजी से पता लगाने के लिए प्रशिक्षण की शुरुआत में बड़े अपडेट करने में मदद करती है, और फिर बाद में ठीक-ट्यूनिंग मापदंडों और एक अच्छे न्यूनतम में बसने के लिए छोटे, अधिक सटीक अपडेट करती है बिना ओवरशूट किए। अभिसरण: फॉरवर्ड पास, हानि गणना, ग्रेडिएंट गणना और पैरामीटर अपडेट के बार-बार पुनरावृत्तियों के माध्यम से, मॉडल के पैरामीटर $\theta$ को धीरे-धीरे समायोजित किया जाता है। हानि $L(\theta)$ समय के साथ घट जाती है, यह दर्शाता है कि मॉडल इंटरलीव्ड भाषण-पाठ अनुक्रमों में अगले टोकन की भविष्यवाणी करने में बेहतर हो रहा है। प्रक्रिया तब तक जारी रहती है जब तक कि हानि एक स्थिर न्यूनतम पर अभिसरण न हो जाए, या प्रशिक्षण युगों की एक पूर्वनिर्धारित संख्या तक न पहुंच जाए। मॉडल प्रभावी ढंग से इनपुट भाषण और पाठ संदर्भों को संभावित अगले भाषण या पाठ टोकन पर मैप करना सीखता है, इस प्रकार सुसंगत और प्रोसोडिक बोली जाने वाली संवाद प्रतिक्रियाएं उत्पन्न करने की क्षमता प्राप्त करता है। क्रॉस-मोडल पूर्व-प्रशिक्षण यहां विशेष रूप से महत्वपूर्ण है, क्योंकि यह सुनिश्चित करता है कि हानि परिदृश्य भाषण और पाठ तौर-तरीकों के बीच निर्बाध संक्रमण और समझ को सुविधाजनक बनाने के लिए आकार दिया गया है, जिससे मॉडल को तौर-तरीका-विशिष्ट स्थानीय न्यूनतम में फंसने से रोका जा सके। हमारे प्रयोगात्मक सत्यापन दैनिक वार्तालाप (DailyTalk) डेटासेट [70] पर केंद्रित थे, जो 20 घंटे के बोली जाने वाली संवाद डेटा का एक संग्रह है, जिसे 22,050 हर्ट्ज पर नमूना किया गया है, जिसमें एक पुरुष और एक महिला वक्ता शामिल हैं। इस डेटासेट को एकल-बारी बोली जाने वाली बातचीत के लिए पूर्व-संसाधित किया गया था, जिससे 20,117 प्रशिक्षण नमूने और 1,058 परीक्षण नमूने प्राप्त हुए। एकीकृत बोली जाने वाली संवाद मॉडल (USDM) को XLS-R [64] के एक आधिकारिक चेकपॉइंट का उपयोग करके एक भाषण-से-इकाई मॉड्यूल के साथ आर्किटेक्ट किया गया था और 436K घंटे के बहुभाषी भाषण डेटा पर प्रशिक्षित $k=10,000$ [33] के साथ एक क्वांटाइज़र का उपयोग किया गया था। भाषण डिकोडर के लिए, हमने वॉयसबॉक्स आर्किटेक्चर [66] पर आधारित एक यूनिट-वॉयसबॉक्स मॉडल का उपयोग किया, जिसे मल्टीलिंगुअल लिब्रिसपीच [71] और गिगास्पीच [72] के अंग्रेजी उपसमूहों से 54k घंटे के ASR डेटा पर प्रशिक्षित किया गया था। यह यूनिट-वॉयसबॉक्स बहु-बारी बातचीत में सुसंगत आवाज सुनिश्चित करने के लिए शून्य-शॉट पुनर्निर्माण के लिए पिछली बारी से संदर्भ भाषण का उपयोग करने के लिए डिज़ाइन किया गया था। मुख्य बड़े भाषा मॉडल (LLM) Mistral-7B [67] था। हमारे पूर्व-प्रशिक्षण चरण में 512 NVIDIA A100-40GB GPUs, 1,024 का वैश्विक बैच आकार, और लगभग 87,000 घंटे के अंग्रेजी ASR डेटा (मल्टीलिंगुअल लिब्रिसपीच, पीपल्स स्पीच, गिगास्पीच, कॉमन वॉयस, और वोक्सपोपुली सहित) पर 8,000 पुनरावृति शामिल थी, जिसमें 8,192 की अधिकतम अनुक्रम लंबाई थी। DailyTalk पर फाइन-ट्यूनिंग 5 युगों के लिए $2 \cdot 10^{-5}$ की शिखर सीखने की दर के साथ रैखिक सीखने की दर शेड्यूलिंग का उपयोग करके 64 के वैश्विक बैच आकार के साथ की गई थी। सभी भाषण संश्लेषण के लिए BigVGAN [74] वोकोडर का उपयोग किया गया था। हमारे गणितीय दावों को क्रूरतापूर्वक साबित करने के लिए, हमने USDM को तीन "पीड़ित" बेसलाइन मॉडल के खिलाफ खड़ा किया: हमारे मूल्यांकन रणनीति में मानव और स्वचालित दोनों मेट्रिक्स का संयोजन शामिल था। मानव मूल्यांकन अमेज़ॅन मैकेनिकल तुर्क के माध्यम से आयोजित किए गए थे, जिसमें शामिल थे: स्वचालित मूल्यांकन में सिमेंटिक उपयुक्तता का आकलन करने के लिए एक GPT-4-आधारित वरीयता परीक्षण [1] ( साक्ष्य निश्चित रूप से साबित करते हैं कि हमारा एकीकृत बोली जाने वाली संवाद मॉडल (USDM) पैरालैंग्वेजिक्स जानकारी को प्रभावी ढंग से एकीकृत करता है और अपने उपन्यास पूर्व-प्रशिक्षण और फाइन-ट्यूनिंग रणनीतियों के कारण मजबूत बेसलाइन की तुलना में बेहतर बोली जाने वाली प्रतिक्रियाएं उत्पन्न करता है। प्रोसोडी-युक्त भाषण टोकन का लाभ उठाने के मुख्य तंत्र को कठोरता से मान्य किया गया था। CREMA-D डेटासेट [65] पर ध्वनिक इकाइयों का उपयोग करके एक भावना पहचान कार्य में, हमारे 3-परत ट्रांसफार्मर-आधारित भावना क्लासिफायर ने 60.8% की सटीकता प्राप्त की। यह यादृच्छिक अनुमान से अपेक्षित 16.6% से एक महत्वपूर्ण छलांग है, जो अकाट्य प्रमाण प्रदान करता है कि ये ध्वनिक इकाइयाँ, जिन्हें पारंपरिक रूप से मुख्य रूप से सिमेंटिक जानकारी को एन्कोड करने के लिए सोचा जाता है, में समृद्ध भावनात्मक संकेत भी होते हैं। इसके अलावा, 54,000 घंटे के भाषण डेटा पर प्रशिक्षित हमारे यूनिट-टू-स्पीच पुनर्निर्माण मॉडल ने प्रदर्शित किया कि जबकि पुनर्निर्मित भाषण की टिम्बर और पूर्ण पिच मूल से भिन्न हो सकती है, पिच भिन्नता ग्राउंड ट्रुथ को बारीकी से दर्शाती है (चित्र 2)। यह एक ठोस प्रमाण है कि हमारे भाषण टोकन सफलतापूर्वक पिच कंटूर जैसी महत्वपूर्ण गैर-मौखिक विशेषताओं को कैप्चर करते हैं। USDM की प्राकृतिक और सुसंगत बोली जाने वाली प्रतिक्रियाएं उत्पन्न करने में श्रेष्ठता लगातार कई मूल्यांकनों में प्रदर्शित की गई थी: एब्लेशन अध्ययन ने हमारी डिजाइन पसंदों की प्रभावशीलता में महत्वपूर्ण अंतर्दृष्टि प्रदान की: USDM द्वारा प्रस्तुत महत्वपूर्ण प्रगति के बावजूद, कई अंतर्निहित सीमाएँ और भविष्य के विकास के लिए रोमांचक रास्ते हैं। सबसे पहले, पूर्व-प्रशिक्षण चरण के लिए डेटासेट और मॉडल की हमारी खोज कुछ हद तक सीमित रही है। जबकि हमने Mistral-7B और ASR डेटा के एक विशिष्ट सेट के साथ अपनी योजना की प्रभावशीलता दिखाई है, यह पूरी तरह से स्पष्ट नहीं है कि कौन से डेटा स्रोत इष्टतम प्रदर्शन के लिए सबसे महत्वपूर्ण हैं, न ही यह कि हमारी पूर्व-प्रशिक्षण योजना Mistral-7B से परे अन्य LLMs के लिए कितनी अच्छी तरह सामान्यीकृत होगी। भविष्य के काम में सबसे प्रभावशाली संयोजनों की पहचान करने के लिए विविध डेटासेट और LLM आर्किटेक्चर की अधिक व्यवस्थित जांच शामिल होनी चाहिए। दूसरे, वर्तमान USDM वास्तुकला एक क्रॉस-मोडल चेनिंग दृष्टिकोण पर निर्भर करती है: भाषण इनपुट को पहले टेक्स्ट में प्रतिलेखित किया जाता है, फिर एक टेक्स्ट प्रतिक्रिया उत्पन्न की जाती है, और अंत में, इस टेक्स्ट को बोली जाने वाली आउटपुट में संश्लेषित किया जाता है। जबकि यह "ब्रिजिंग टेक्स्ट" रणनीति प्रभावी ढंग से LLM की तर्क क्षमताओं का लाभ उठाती है, यह एक मध्यवर्ती कदम पेश करती है। एक आशाजनक भविष्य की दिशा एक बोली जाने वाली संवाद मॉडल विकसित करना है जो इस स्पष्ट क्रॉस-मोडल चेनिंग के बिना इनपुट बोली जाने वाली बातचीत से सीधे बोली जाने वाली प्रतिक्रियाएं उत्पन्न करने में सक्षम हो। यह पाइपलाइन को सुव्यवस्थित करेगा और संभावित रूप से त्रुटि प्रसार को कम करेगा, एक सच्चा एंड-टू-एंड भाषण-से-भाषण अनुभव प्रदान करेगा। तीसरे, वर्तमान पूर्व-प्रशिक्षण योजना मुख्य रूप से अंग्रेजी डेटा के दसियों हज़ार घंटों पर आधारित है। यह अन्य भाषाओं में USDM लागू करते समय एक स्पष्ट सीमा प्रस्तुत करता है, खासकर उन भाषाओं में जिनकी तुलना में भाषण डेटा संसाधन कम हैं। मॉडल को अंग्रेजी से परे विभिन्न प्रकार की भाषाओं का समर्थन करने के लिए विस्तारित करना एक महत्वपूर्ण अगला कदम है ताकि इसकी वैश्विक प्रयोज्यता और उपयोगिता को बढ़ाया जा सके। इसमें संभवतः बहुभाषी पूर्व-प्रशिक्षण रणनीतियों की खोज और विविध भाषाई सुविधाओं के लिए भाषण टोकनकरण और डिकोडिंग घटकों को अनुकूलित करना शामिल होगा। अंत में, हमारे प्रति-कार्य प्रशिक्षण गतिशील विश्लेषण (चित्र 7, दाएं) ने संकेत दिया कि फाइन-ट्यूनिंग मापदंडों की संख्या में वृद्धि, विशेष रूप से LoRA के साथ, कभी-कभी इकाई-से-पाठ कार्य प्रदर्शन में गिरावट का कारण बन सकती है, जो संभावित ओवरफिटिंग का सुझाव देती है। इसे संबोधित करने के लिए, भविष्य के शोध पाइपलाइन के भीतर प्रत्येक कार्य के लिए हानि भार को गतिशील रूप से बदलने या पाठ्यक्रम सीखने के दृष्टिकोण को लागू करने जैसी रणनीतियों का पता लगा सकते हैं, जहां मॉडल को धीरे-धीरे अधिक जटिल कार्यों के संपर्क में लाया जाता है। इन विशिष्ट बिंदुओं से परे, इस काम के व्यापक निहितार्थ कई चर्चा विषयों को खोलते हैं। हम पैरालैंग्वेजिक्स सुविधाओं को पकड़ने के लिए ध्वनिक इकाइयों की प्रदर्शित क्षमता का लाभ उठाकर अधिक सहानुभूतिपूर्ण और संदर्भ-जागरूक संवादात्मक एजेंट कैसे बना सकते हैं? क्या हम आवाज फ़िशिंग जैसे परिदृश्यों में दुरुपयोग को रोकते हुए, पढ़ने या लिखने में कठिनाई वाले व्यक्तियों के लिए सुलभ संचार विकल्प प्रदान करने जैसे सकारात्मक सामाजिक प्रभावों को अधिकतम करते हुए, ऐसे उच्च-गुणवत्ता वाले भाषण संश्लेषण मॉडल की नैतिक तैनाती सुनिश्चित करने के लिए मजबूत तंत्र विकसित कर सकते हैं? इसके अलावा, अन्य भाषण-पाठ कार्यों, जैसे भाषण अनुवाद या सारांश के लिए हमारे पूर्व-प्रशिक्षण दृष्टिकोण की समरूपता की जांच, और भी व्यापक अनुप्रयोगों को खोल सकती है और वास्तव में बहुविध LLMs के लिए नींव को मजबूत कर सकती है।पद-दर-पद विच्छेदन।
चरण-दर-चरण प्रवाह
<|correspond|> या <|continue|>) का मिश्रण शामिल है, को सिस्टम में फीड किया जाता है। यह अनुक्रम बोली जाने वाली बातचीत या भाषण-पाठ जोड़ी के एक खंड का प्रतिनिधित्व करता है।अनुकूलन गतिशीलता
इन अनुमानों को फिर पूर्वाग्रह-सुधार किया जाता है। एडम के लिए पैरामीटर अद्यतन नियम है:
$$\theta_{t+1} = \theta_t - \alpha \frac{\hat{m}_t}{\sqrt{\hat{v}_t} + \epsilon}$$
जहां $\theta_t$ समय चरण $t$ पर पैरामीटर वेक्टर है, $\alpha$ सीखने की दर है (जैसे, यूनिट-वॉयसबॉक्स प्रशिक्षण के लिए $10^{-4}$, पूर्व-प्रशिक्षण/फाइन-ट्यूनिंग के लिए $2 \cdot 10^{-5}$), $\hat{m}_t$ और $\hat{v}_t$ पूर्वाग्रह-सुधारित पहले और दूसरे क्षण अनुमान हैं, और $\epsilon$ शून्य से विभाजन को रोकने के लिए एक छोटा स्थिरांक है। यह अनुकूली प्रकृति एडम को विरल ग्रेडिएंट्स और पैरामीटरों के विभिन्न पैमानों को प्रभावी ढंग से संभालने की अनुमति देती है, जिससे मॉडल को तेजी से और अधिक मजबूती से अभिसरण करने में मदद मिलती है।परिणाम, सीमाएँ और निष्कर्ष
प्रयोगात्मक डिजाइन और बेसलाइन
1. स्क्रैच से: यह मॉडल USDM के लगभग समान था लेकिन महत्वपूर्ण रूप से एकीकृत भाषण-पाठ पूर्व-प्रशिक्षण का अभाव था। इसने USDM के समान हाइपरपैरामीटर का उपयोग करके, बोली जाने वाली संवाद डेटा पर पूर्व-प्रशिक्षित Mistral-7B को सीधे फाइन-ट्यून किया। इस बेसलाइन को हमारे उपन्यास पूर्व-प्रशिक्षण योजना के प्रभाव को अलग करने के लिए डिज़ाइन किया गया था।
2. कैस्केडेड: इस दृष्टिकोण ने अलग, ऑफ-द-शेल्फ स्वचालित भाषण पहचान (ASR) और टेक्स्ट-टू-स्पीच (TTS) सिस्टम का उपयोग किया। विशेष रूप से, इसने ASR के लिए whisper-large-v3 [78] (5M घंटे के भाषण डेटा पर प्रशिक्षित) और TTS के लिए वॉयसबॉक्स मॉडल (टेक्स्ट इनपुट के साथ प्रशिक्षित, हमारे यूनिट-वॉयसबॉक्स के समान) का उपयोग किया। LLM (Mistral-7B) को बोली जाने वाली संवाद डेटा के ट्रांसक्रिप्ट पर फाइन-ट्यून किया गया था। यह बेसलाइन बोली जाने वाली बातचीत के लिए पारंपरिक, मॉड्यूलर दृष्टिकोण का प्रतिनिधित्व करती थी।
3. SpeechGPT [25]: हमने SpeechGPT-7B-cm के आधिकारिक कार्यान्वयन और चेकपॉइंट का उपयोग किया, जो एक अत्याधुनिक पूर्व-प्रशिक्षित भाषण-पाठ मॉडल है, जिसे उचित तुलना के लिए DailyTalk पर फाइन-ट्यून किया गया था।
- समग्र वरीयता परीक्षण: 150 मूल्यांकनकर्ताओं ने बेसलाइन की तुलना में USDM की बोली जाने वाली प्रतिक्रियाओं की तुलना की, जिसमें 50 यादृच्छिक रूप से चयनित बोली जाने वाली बातचीत के लिए स्वाभाविकता, प्रोसोडी और सिमेंटिक सुसंगतता पर विचार किया गया। इसमें लगभग USD 200 का खर्च आया।
- प्रोसोडी मीन ओपिनियन स्कोर (P-MOS): 198 मूल्यांकनकर्ताओं ने 5-बिंदु पैमाने पर प्रोसोडी स्वाभाविकता को रेट किया, जिसमें ग्राउंड ट्रुथ टेक्स्ट प्रतिक्रियाएं दी गईं। इसमें लगभग USD 250 का खर्च आया।
- मीन ओपिनियन स्कोर (MOS): 176 मूल्यांकनकर्ताओं ने 5-बिंदु पैमाने पर ऑडियो गुणवत्ता और स्वाभाविकता को रेट किया, जिसमें केवल प्रतिक्रिया टेक्स्ट और बोली जाने वाली प्रतिक्रिया दी गई थी। इसमें भी लगभग USD 250 का खर्च आया।gpt-4-0125-preview का उपयोग करके), और सिमेंटिक सामग्री के लिए METEOR और ROUGE-L स्कोर जैसे मात्रात्मक मेट्रिक्स, और भाषण-से-पाठ (STT WER) और टेक्स्ट-टू-स्पीच (TTS WER) दोनों घटकों के लिए वर्ड एरर रेट (WER) शामिल थे। एब्लेशन अध्ययन ने हमारे एकीकृत पूर्व-प्रशिक्षण और फाइन-ट्यूनिंग योजनाओं के योगदान को और अलग किया, लिब्रिसपीच पर पप्लेक्सिटी (PPL) और DailyTalk पर उपरोक्त संवाद मेट्रिक्स का उपयोग किया।साक्ष्य क्या साबित करते हैं
- मानव वरीयता: व्यापक मानव वरीयता परीक्षणों में, USDM को ग्राउंड ट्रुथ के समान पसंद किया गया था और सभी बेसलाइन से काफी बेहतर प्रदर्शन किया (विल्कोक्सन साइन्ड-रैंक टेस्ट से पी-वैल्यू < 0.05)। यह इसकी समग्र गुणवत्ता और उपयोगकर्ता अनुभव का एक मजबूत संकेतक है।
- प्रोसोडी स्वाभाविकता: USDM ने P-MOS मूल्यांकन में सभी बेसलाइन को पार कर लिया (पी-वैल्यू < 0.05), जो प्राकृतिक प्रोसोडी के साथ भाषण उत्पन्न करने की इसकी असाधारण क्षमता को प्रदर्शित करता है। इसने विशेष रूप से कैस्केडेड मॉडल को बेहतर प्रदर्शन किया, जिसने स्पष्ट लेबल के बावजूद प्रोसोडी के साथ संघर्ष किया, जो पैरालैंग्वेजिक्स की USDM की प्रभावी, अंतर्निहित समावेशिता को उजागर करता है।
- सिमेंटिक सुसंगतता: हमारे मॉडल ने मात्रात्मक मेट्रिक्स (METEOR और ROUGE-L) और सिमेंटिक उपयुक्तता के लिए GPT-4-आधारित वरीयता परीक्षण (पी-वैल्यू < 0.05) दोनों में बेसलाइन को बेहतर प्रदर्शन किया। यह USDM की सिमेंटिक रूप से सुसंगत प्रतिक्रियाएं उत्पन्न करने की क्षमता की पुष्टि करता है जो इनपुट भाषण के साथ अच्छी तरह से संरेखित होती हैं।
- एकीकृत पूर्व-प्रशिक्षण: हमारा प्रस्तावित एकीकृत भाषण-पाठ पूर्व-प्रशिक्षण योजना, जो पत्राचार और निरंतरता दोनों संबंधों को मॉडल करता है, ने सभी तौर-तरीकों और अनुक्रम प्रकारों में श्रेष्ठ औसत पप्लेक्सिटी (PPL) प्राप्त किया (तालिका 3, तालिका 9)। इसने निश्चित रूप से साबित कर दिया कि एक व्यापक पूर्व-प्रशिक्षण रणनीति LLM के लिए विविध भाषण-पाठ इंटरैक्शन सीखने के लिए आवश्यक है, न कि सीमित संबंधों में विशेषज्ञता के बजाय। "स्क्रैच से" मॉडल, इस पूर्व-प्रशिक्षण के अभाव में, काफी खराब TTS और STT WERs (क्रमशः 64.0% और 58.1%) और खराब सिमेंटिक प्रदर्शन प्रदर्शित किया, जो क्रॉस-मोडल पूर्व-प्रशिक्षण की महत्वपूर्ण भूमिका को रेखांकित करता है।
- मध्यवर्ती पाठ मॉडलिंग: मध्यवर्ती पाठ को एक पुल के रूप में उपयोग करने वाली फाइन-ट्यूनिंग योजना (भाषण इनपुट -> पाठ प्रतिलेखन -> पाठ प्रतिक्रिया पीढ़ी -> भाषण प्रतिक्रिया संश्लेषण) अत्यधिक प्रभावी साबित हुई। एक प्रत्यक्ष भाषण-से-भाषण मॉडल (S1 -> S2) ने METEOR और ROUGE-L स्कोर (तालिका 3) में काफी खराब प्रदर्शन किया, जिससे यह पुष्टि हुई कि पाठ तौर-तरीके के माध्यम से पूर्व-प्रशिक्षित LLM की तर्क क्षमताओं का लाभ उठाना फायदेमंद है।
- इनपुट तौर-तरीका उपयोग: ध्यान मानचित्र (चित्र 4) से पता चला है कि USDM की उत्पन्न प्रतिक्रियाएं इनपुट भाषण और उसके प्रतिलेखित पाठ दोनों पर ध्यान केंद्रित करती हैं। यह दृश्य साक्ष्य पुष्टि करता है कि हमारा मॉडल प्रभावी ढंग से दोनों तौर-तरीकों से जानकारी को एकीकृत करता है, जिससे अधिक मजबूत और सिमेंटिक रूप से सुसंगत आउटपुट प्राप्त होते हैं। इसके अलावा, मॉडल-जनित इनपुट प्रतिलेख को ग्राउंड ट्रुथ प्रतिलेख से बदलने से METEOR और ROUGE-L स्कोर में सुधार हुआ (क्रमशः 13.6 बनाम 13.1 और 16.2 बनाम 15.7), यह प्रदर्शित करते हुए कि USDM में इकाई-से-पाठ रूपांतरण की सटीकता को बढ़ाना सीधे सिमेंटिक सुसंगतता को बढ़ावा देता है।सीमाएँ और भविष्य की दिशाएँ
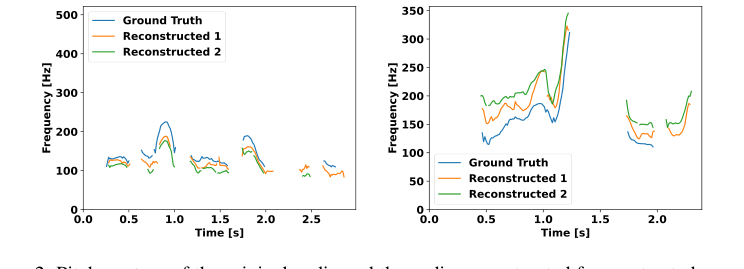 Figure 2. Pitch contour of the original audio and the audio reconstructed from extracted acoustic units. Due to the stochastic nature of the reconstruction model, we attempt reconstruction twice, demonstrating that the pitch variation closely mirrors the ground truth
Figure 2. Pitch contour of the original audio and the audio reconstructed from extracted acoustic units. Due to the stochastic nature of the reconstruction model, we attempt reconstruction twice, demonstrating that the pitch variation closely mirrors the ground truth
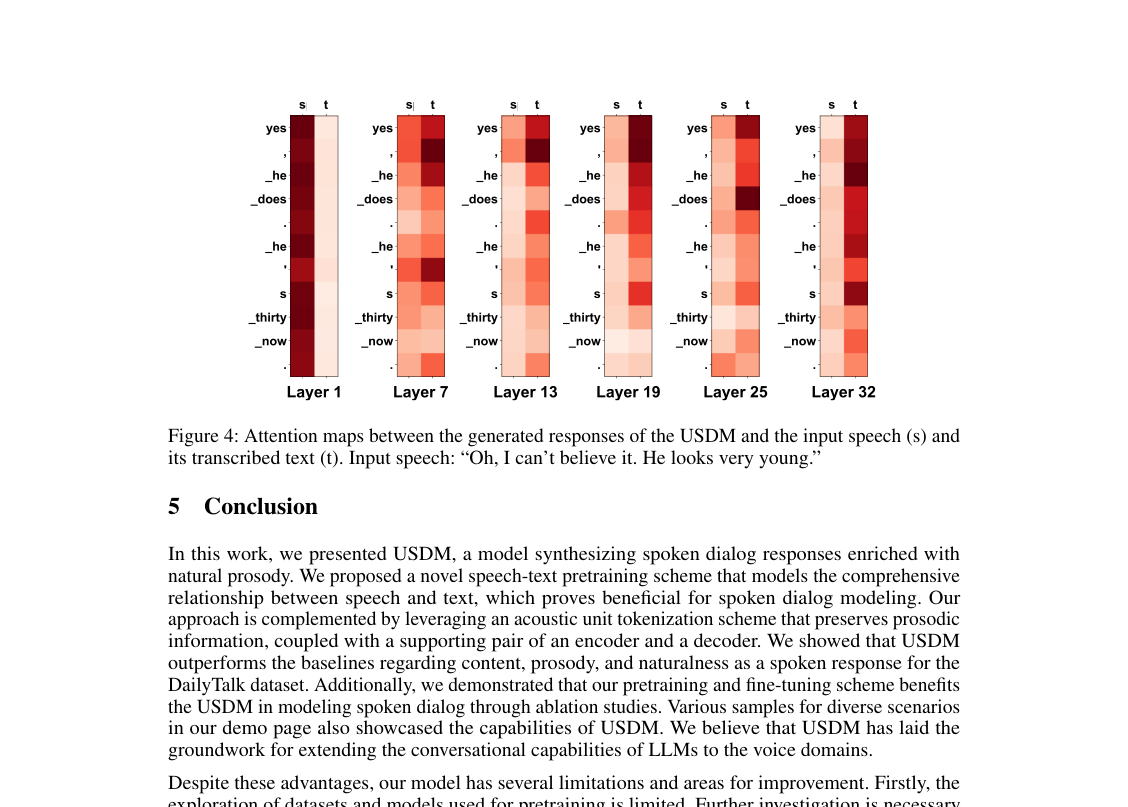 Figure 4. Attention maps between the generated responses of the USDM and the input speech (s) and its transcribed text (t). Input speech: “Oh, I can’t believe it. He looks very young.”
Figure 4. Attention maps between the generated responses of the USDM and the input speech (s) and its transcribed text (t). Input speech: “Oh, I can’t believe it. He looks very young.”
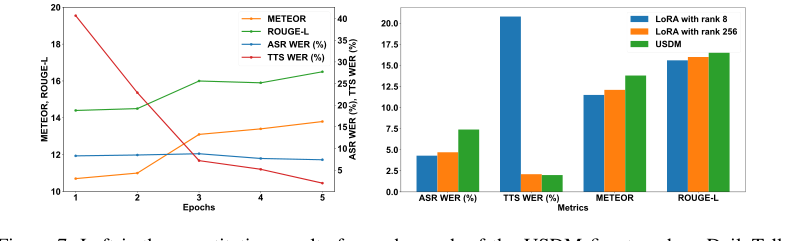 Figure 7. Left is the quantitative results for each epoch of the USDM fine-tuned on DailyTalk. The figure on the right illustrates the performance of the Spoken Dialog Model when trained with Low-Rank Adaptation (LoRA) versus full fine-tuning
Figure 7. Left is the quantitative results for each epoch of the USDM fine-tuned on DailyTalk. The figure on the right illustrates the performance of the Spoken Dialog Model when trained with Low-Rank Adaptation (LoRA) versus full fine-tuning