자연스러운 대화를 위한 파라링귀스틱 인식 음성 기반 대규모 언어 모델
Recent work shows promising results in expanding the capabilities of large language models (LLM) to directly understand and synthesize speech.
배경 및 학문적 계보
기원 및 학문적 계보
본 논문에서 다루는 문제는 텍스트 기반 대화형 AI 분야에서 최근의 발전과 광범위한 채택을 이룬 대규모 언어 모델(LLM)에서 비롯된다. LLM은 텍스트를 이해하고 생성하며 추론하는 데 있어 놀라운 능력을 보여주었지만, 음성 대화에 직접 적용하는 것은 여전히 중요한 과제로 남아 있다. 핵심 동기는 LLM의 강력하고 새롭게 등장하는 능력, 즉 소량의 데이터로 문맥 내 학습(few-shot in-context learning) 및 복잡한 추론 능력을 자연스러운 음성 대화 영역으로 확장하여 보다 직관적이고 인간과 유사한 상호작용을 가능하게 하는 것이다.
역사적으로 초기 음성 언어 모델(SLM)은 음성 데이터에만 집중하거나 매우 단순한 교차 모달(cross-modal) 목표를 사용했으며, 사전 훈련된 LLM의 정교한 언어 이해 능력을 완전히 활용하지 못했다. 고성능 텍스트 기반 LLM의 등장과 함께 학계는 음성 모달리티를 이러한 모델에 통합하는 방향으로 전환되었다.
본 연구가 필요하게 된 이전 접근 방식의 근본적인 한계 또는 "고충점(pain points)"은 크게 두 가지 유형으로 분류할 수 있다.
-
연쇄 모델(Cascaded Models): 이러한 접근 방식은 일반적으로 사용자의 음성을 텍스트로 변환하는 자동 음성 인식(ASR), 텍스트 응답을 생성하는 LLM, 그리고 음성 응답을 합성하는 음성 합성(TTS) 시스템을 별도로 포함한다.
- 언어적 불일치(Linguistic Discrepancy): 중요한 "고충점"은 음성과 텍스트가 정보를 전달하는 방식 간의 내재적 불일치이다. 음성은 감정, 톤, 리듬과 같은 풍부한 파라링귀스틱(paralinguistic) 단서를 전달하지만, ASR에 의해 일반 텍스트로 변환될 때 이러한 단서가 손실된다. 이러한 언어적 불일치는 LLM이 의미론적 내용에만 기반하여 작동하고 중요한 비언어적 맥락을 종종 무시하기 때문에 대화 비효율성과 최적이 아닌 사용자 경험으로 이어진다.
- 파라링귀스틱을 위한 레이블 의존성: 연쇄 모델에 파라링귀스틱 특징을 통합하기 위해 명시적인 레이블(예: 감정 레이블)이 종종 요구된다. 이는 데이터 수집을 어렵게 만들고 모델을 명시적으로 레이블링할 수 있는 비언어적 단서로 제한한다.
- 오류 전파(Error Propagation): 주요 단점은 오류의 누적이다. ASR 시스템이나 텍스트 기반 LLM에서 발생하는 모든 부정확성은 파이프라인을 통해 전파되어 덜 일관적이거나 자연스럽게 들리는 음성 응답으로 이어질 수 있다.
-
종단 간(End-to-End) 음성 전용 또는 단순 교차 모달 모델: 일부 종단 간 파이프라인이 존재하지만, 이들은 종종 사전 훈련된 LLM에 내재된 광범위한 지식과 추론 능력을 완전히 활용하지 못한다. 이러한 모델은 음성 및 텍스트 모달리티 간의 포괄적이고 복잡한 관계를 포착하는 능력에 제한이 있을 수 있으며, 따라서 맥락적으로 풍부하고 운율적으로 적절한 음성 대화를 생성하는 성능을 저해한다. 저자들은 이전 모델들이 특정 작업이나 단순한 교차 모달 목표에 초점을 맞춤으로써 통합 프레임워크가 제공할 수 있는 깊은 교차 모달 이해의 잠재력을 완전히 활용하지 못했다고 강조한다.
직관적인 도메인 용어
다음은 논문에서 사용된 세 가지 고도로 전문화된 도메인 용어를, 제로베이스 독자를 위한 직관적인 일상 비유로 번역한 것이다.
-
파라링귀스틱(Paralinguistics): 이야기를 하고 있다고 상상해보자. 사용하는 단어는 주요 메시지(의미론)이다. 하지만 말하는 방식—목소리 톤, 말하는 속도, 멈추는 지점, 신나 보이는지 슬퍼 보이는지—이것이 파라링귀스틱이다. 말하는 내용에 의미와 감정을 더하는 모든 비언어적 소리와 음성적 품질이다. 파라링귀스틱을 이해하는 컴퓨터는 단순히 "괜찮아"라고 듣는 것이 아니라, 당신이 진정으로 괜찮은지 아니면 비꼬는 것인지 알기 위해 "괜찮아"라고 말하는 방식을 듣는다.
-
음향 단위(Acoustic Units) / 이산 음성 표현(Discrete Speech Representations): 영화 필름을 생각해보자. 연속적인 움직임의 흐름이지만, 실제로는 수천 개의 개별적인 정지 이미지(프레임)로 구성된다. 음향 단위는 음성에 대한 이러한 개별 프레임과 같다. 연속적인 음파 대신, 음성을 작은, 구별되는 소리 "덩어리" 또는 "토큰"으로 분해한다. 이러한 덩어리는 제한된 종류의 세트로 분류되며, 마치 작은 상자의 고유한 레고 블록과 같다. 이러한 특정 "레고 블록"을 선택하고 배열함으로써 컴퓨터는 단어와 미묘한 음성적 뉘앙스를 모두 포착하여 음성을 재구성할 수 있다.
-
운율(Prosody): 이것은 언어의 음악이다. 말할 때, 목소리는 자연스럽게 음높이가 오르내리고, 특정 단어에 강조를 두고, 말하는 속도를 변화시킨다. 이러한 음높이, 강세, 리듬의 패턴을 운율이라고 한다. 이것이 질문을 질문처럼 들리게 하거나 흥분된 진술을 흥분되게 들리게 하는 것이다. 운율이 없으면 모든 음성은 단조롭고 로봇처럼 들릴 것이며, 컴퓨터가 단조로운 목소리로 텍스트를 읽는 것과 같다. 이것은 열정적으로 "정말 좋아!"라고 말하는 것과 단조롭고 영감 없는 어조로 말하는 것의 차이이다.
표기법 표
| 표기법 | 설명 |
|---|---|
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
본 논문이 다루는 핵심 문제는 현재 대규모 언어 모델(LLM)이 종단 간 방식으로 자연스러운 음성 대화를 처리하는 데 한계가 있다는 것이다.
입력/현재 상태:
기존 LLM은 텍스트 기반 작업에서 뛰어나 복잡한 추론, 소량 데이터 학습, 지시 따르기 등에서 놀라운 능력을 보여준다. 그러나 음성 상호작용에 관해서는 일반적으로 연쇄적인 방식으로 별도의 자동 음성 인식(ASR) 및 음성 합성(TTS) 시스템과 통합된다. 또는 일부 모델은 LLM의 전체적인 힘을 활용하지 않고 음성 처리에만 집중한다.
원하는 최종 상태(출력/목표 상태):
목표는 음성 모달리티를 LLM에 원활하게 통합할 수 있는 통합 음성 대화 모델(Unified Spoken Dialog Model, USDM)을 개발하는 것이다. 이 모델은 다음을 수행할 수 있어야 한다.
1. 명시적인 ASR에 의존하지 않고, 미묘한 뉘앙스와 감정 상태(파라링귀스틱)를 포함한 사용자 음성을 직접 이해한다.
2. 명시적인 TTS에 의존하지 않고, 자연스럽게 발생하는 맥락적으로 적절한 운율 특징을 가진 일관된 음성 응답을 생성한다.
3. 종단 간 파이프라인에서 LLM의 강력한 대화 생성 및 추론 능력을 유지하고 향상시킨다.
누락된 연결/수학적 격차:
정확한 누락된 연결은 음성 입력에서 자연스러운 음성 응답으로의 격차를 효과적으로 해소하여 LLM의 처리 과정에 음성의 의미론적 및 파라링귀스틱 정보를 체계적으로 통합하는 통합 LLM 기반 프레임워크이다. 이를 위해서는 LLM이 포괄적인 교차 모달 관계를 학습하고 단순한 의미론적 내용뿐만 아니라 운율 정보를 내재적으로 전달하는 음성 토큰을 생성할 수 있도록 하는 새로운 음성-텍스트 표현 및 사전 훈련 체계가 필요하다. 본 논문은 "운율이 주입된 음성 토큰화 방식"과 "교차 모달 의미론 포착을 향상시키는 일반화된 음성-텍스트 사전 훈련 방식"을 제안함으로써 이 격차를 해소하고자 한다.
딜레마:
이전 연구는 LLM 능력 활용과 음성을 자연스럽게 처리하는 것 사이의 고통스러운 절충안에 갇혀 있었다.
* 연쇄 ASR/TTS 대 종단 간 일관성: ASR 및 TTS 시스템은 쉽게 사용될 수 있지만, 연쇄적인 사용은 "음성과 텍스트 간의 언어적 불일치"를 초래하여 "대화 비효율성과 최적이 아닌 사용자 경험"을 야기한다 [10, 11]. 더 중요하게는, 이러한 파이프라인은 "연쇄 파이프라인에 내재된 오류 전파" [63]로 고통받으며, ASR 또는 텍스트 기반 대화 모델의 오류가 누적되어 덜 일관적이거나 자연스러운 음성 응답으로 이어진다. 또한, 연쇄 모델에서 파라링귀스틱 특징(감정 또는 톤과 같은)을 통합하려면 종종 "명시적인 레이블"이 필요하며, 이는 "데이터 수집을 어렵게 만들고 모델을 레이블 정의 가능한 비언어적 단서로 제한한다" (섹션 2, 3페이지).
* 음성 전용 모델 대 LLM 추론: 음성 데이터로만 훈련된 초기 음성 언어 모델(SLM) [17, 19]은 최신 LLM의 고급 추론 및 생성 능력이 부족하여 대화 능력이 제한된다. 딜레마는 음성 모델에 LLM과 같은 지능을 부여하면서 음성 신호의 풍부함을 잃지 않는 방법이다.
* 음성 토큰에서의 의미론적 대 파라링귀스틱 정보: 음성 토큰은 일반적으로 의미론적 내용을 인코딩하도록 설계된다. 과제는 의미론적 정보뿐만 아니라 상당한 양의 파라링귀스틱 정보(예: 감정, 음높이 변화)를 LLM이 효과적으로 활용하여 자연스럽게 들리고 맥락적으로 적절한 음성 응답을 생성할 수 있는 방식으로 인코딩하는 이산 음성 표현을 만드는 것이다.
제약 조건 및 실패 모드
자연스러운 대화를 위한 파라링귀스틱 인식 음성 기반 LLM 구축 문제는 몇 가지 가혹하고 현실적인 제약 조건으로 인해 매우 어렵다.
- 데이터 기반 제약 조건:
- 정렬된 교차 모달 데이터 부족: 포괄적인 음성-텍스트 모델을 만들기 위해서는 다양한 대화 맥락과 파라링귀스틱 특징을 포착하는 고품질의 정렬된 음성 및 텍스트 데이터가 방대하게 필요하다. 본 논문은 현재 사전 훈련 체계가 "수만 시간의 영어 데이터"에 의존한다고 언급하며 (섹션 5, 10페이지), 상당한 데이터 요구 사항을 나타낸다.
- 레이블링된 파라링귀스틱 데이터의 희소성: 파라링귀스틱 특징(감정 또는 억양과 같은)에 대한 명시적인 레이블은 희소하고 대규모로 얻기 어렵기 때문에 이에 의존하는 모델에 주요 장애물이 된다 (섹션 2, 3페이지).
- 다국어 제한: 현재 모델은 주로 영어 데이터로 훈련되었으며, "상대적으로 적은 양의 음성 데이터"를 가진 다른 언어에 대한 적용 가능성이 제한되어 보편적인 배포에 어려움을 제기한다 (섹션 5, 10페이지).
- 계산 제약 조건:
- 사전 훈련을 위한 극심한 계산 비용: 대규모 음성-텍스트 모델, 특히 LLM 아키텍처 기반 모델을 훈련하는 데는 막대한 계산 자원이 필요하다. 본 논문은 "512개의 NVIDIA A100-40GB GPU를 사용하여 1,024의 전역 배치 크기로 8,000번의 반복"을 사용했다고 명시하며 (섹션 4.1.1, 7페이지), 상당한 하드웨어 요구 사항을 강조한다.
- 긴 시퀀스에 대한 메모리 한계: 특히 "최대 시퀀스 길이 8,192" (섹션 4.1.1, 7페이지)를 가진 인터리브된 음성-텍스트 시퀀스를 처리하는 것은 하드웨어 메모리 한계에 빠르게 도달할 수 있어 대화에서 장거리 의존성을 모델링하기 어렵게 만든다.
- 아키텍처 및 기능 제약 조건:
- LLM 추론 능력 유지: 음성을 LLM에 통합하는 것은 핵심 추론 및 생성 능력을 저하시켜서는 안 된다. 모델은 "중간 모달리티에 대한 연쇄 추론"을 효과적으로 수행해야 한다 (섹션 3.3, 6페이지).
- 자연스러운 운율 생성: "주어진 입력 음성과 관련된 자연스럽게 발생하는 운율 특징"을 가진 음성을 합성하는 것은 복잡한 작업이다. 모델은 인간 의사소통의 미묘하고 어려운 측면인 적절한 운율을 맥락에서 추론하고 생성하는 방법을 배워야 한다 (초록, 1페이지).
- 입력 변형 및 오류에 대한 견고성: 시스템은 입력 음성 품질, 악센트 및 잠재적인 전사 오류의 변형에 대해 견고해야 하며, 특히 중간 텍스트 표현이 사용되는 경우 더욱 그렇다. 본 논문은 연쇄 시스템보다 "전사 오류에 더 견고한" 접근 방식을 목표로 한다 (섹션 3.3, 6페이지).
- 교차 모달 의미론적 정렬: 음성 및 텍스트 모달리티가 의미론적으로 정렬되고 모델이 "교차 모달 분포 의미론"을 학습할 수 있도록 보장하는 것은 일관된 대화 생성을 위해 필수적이다 (2페이지).
- 다양한 관계에 걸친 일반화: 특정 유형의 관계(예: 대응 또는 연속)에만 초점을 맞춘 사전 훈련 체계는 "모델의 능력을 미리 정의된 해당 관계에만 제한할 수 있다" (섹션 3.2, 5페이지), 다양한 음성-텍스트 상호작용을 처리하는 능력을 저해한다. 모델은 다재다능해야 한다.
왜 이 접근 방식인가
선택의 불가피성
저자들이 음성 대화를 위한 LLM 기반 종단 간 프레임워크인 통합 음성 대화 모델(USDM)을 개발하기로 결정한 것은 기존 "SOTA" 방법의 내재적 한계에 의해 주도되었다. 전통적인 접근 방식이 불충분하다는 결정적인 깨달음은 연쇄 시스템과 이전 종단 간 음성 모델 모두의 근본적인 결함을 관찰하면서 나왔다.
구체적으로, 본 논문은 자동 음성 인식(ASR) 및 음성 합성(TTS) 시스템을 쉽게 사용할 수 있지만, 순차적인 특성은 "음성과 텍스트 간의 언어적 불일치"를 초래하여 "대화 비효율성을 야기하고 최적이 아닌 사용자 경험을 초래한다" [10, 11]고 강조한다. 이러한 연쇄 접근 방식은 또한 파라링귀스틱 특징에 대한 명시적인 레이블을 필요로 하여 데이터 수집을 어렵게 하고 모델을 레이블 정의 가능한 비언어적 단서로만 제한한다. 결정적으로, "연쇄 파이프라인에 내재된 오류 전파 [63]는 오류 누적에 대한 취약성을 증가시킨다"는 점은 진정으로 자연스럽고 일관된 음성 대화를 위한 신뢰할 수 있는 기반이 되지 못하게 한다.
더욱이, 성공에도 불구하고 기존 LLM 기반 음성 모델은 파라링귀스틱을 자연스럽게 통합하고 음성 대화 설정에서 음성을 생성하고 이해하는 데 부적합한 것으로 밝혀졌다. 음성 전용 훈련이나 단순한 교차 모달 목표에 의존하는 이전 종단 간 파이프라인 [19, 25]은 "사전 훈련된 언어 모델의 능력을 완전히 활용하지 못한다." 저자들은 이러한 깊은 문제를 극복하고 LLM이 대화 맥락에서 적절한 파라링귀스틱 특징을 가진 음성을 진정으로 이해하고 생성할 수 있도록 하기 위해서는 포괄적이고 통합된 접근 방식이 유일하게 실행 가능한 해결책이라는 것을 인식했다.
비교 우위
USDM은 통합 교차 모달 사전 훈련과 파라링귀스틱 정보를 음성 토큰에 직접 주입하는 능력 덕분에 이전의 황금 표준에 비해 질적으로 우수함을 보여준다. 이러한 구조적 이점은 보다 자연스럽게 들리고 의미론적으로 일관된 음성 응답을 생성할 수 있게 한다.
오류 전파와 비언어적 단서에 대한 명시적 레이블 의존성으로 고통받는 연쇄 시스템과 달리, 처음부터 음성 및 텍스트 모달리티를 통합하는 USDM의 종단 간 설계는 본질적으로 이러한 문제를 완화한다. 자기 지도 음성 표현(XLS-R)의 k-평균 클러스터링에서 파생된 이 모델의 고유한 음성 토큰화 방식은 감정 및 음높이 변화와 같은 상당한 파라링귀스틱 정보를 포함하는 것으로 나타났다. 실험 결과는 이러한 음향 단위가 감정 인식에서 60.8%의 정확도를 달성하여 무작위 추측에서 예상되는 16.6%를 훨씬 능가한다는 것을 확인시켜 준다. 음높이 윤곽을 포착하고 재구성하는 이러한 능력(그림 2 참조)은 연쇄 시스템에서 텍스트 기반 중간 표현으로 인해 종종 손실되거나 제대로 처리되지 못하는 자연스러운 운율을 생성하는 데 직접적인 질적 이점이다.
더욱이, 음성 입력과 출력 사이에 텍스트 관련 작업을 삽입하는 USDM의 LLM 기반 모델링 전략은 기본 LLM의 "연쇄 추론" 능력을 활용한다 [6]. 이는 이 접근 방식을 "독립 모듈에서 수행되는 것보다 전사 오류에 더 견고하고 맥락적으로 관련성 있는 음성 응답을 생성하는 데 더 뛰어나게" 만든다. 특히 파라링귀스틱과 관련하여 이러한 견고하고 맥락을 인식하는 생성은 상당한 질적 도약을 나타낸다. 본 논문의 축소 분석(ablation studies)은 이러한 점을 더욱 강조하며, 포괄적인 교차 모달 사전 훈련이 없는 모델(예: "From Scratch" 모델 또는 설정 1)이 운율 및 의미론적 일관성 측면에서 현저히 낮은 성능을 보임을 보여주며, USDM의 통합 사전 훈련의 구조적 이점을 강조한다.
제약 조건과의 정렬
선택된 USDM 방법은 별도의 ASR 또는 TTS 모듈에 의존하지 않고 일관되고 운율이 풍부한 음성 응답의 필요성을 직접 해결함으로써 문제의 가혹한 요구 사항과 완벽하게 일치한다. 이러한 "결합"은 몇 가지 핵심 측면에서 분명하다.
- 종단 간 음성 대화 생성: 주요 제약 조건은 연쇄 시스템을 넘어서는 것이었다. USDM은 단일 LLM 프레임워크 내에서 음성 및 텍스트 모달리티를 통합함으로써 이를 달성하며, 대화 생성 시 추론을 위한 명시적인 ASR 및 TTS 구성 요소의 필요성을 제거한다. 이는 "명시적인 자동 음성 인식(ASR) 또는 음성 합성(TTS) 시스템에 의존하지 않고"라는 요구 사항을 직접적으로 해결한다.
- 자연스럽게 발생하는 운율 특징: 핵심 요구 사항은 자연스러운 운율을 가진 응답을 생성하는 것이었다. USDM의 고유한 "운율이 주입된 음성 토큰화 방식"은 이를 위해 특별히 설계되었다. 음향 단위가 감정 단서와 음높이 변화를 포착한다는 것을 입증함으로써 (섹션 3.1, 그림 2), 이 방법은 자연스러운 대화에 중요한 비언어적 특징이 보존되고 생성되도록 보장한다. 이것은 직접적이고 효과적인 정렬이다.
- 일관된 음성 응답: 이 모델은 사전 훈련된 대규모 언어 모델(Mistral-7B)의 강력한 추론 능력을 활용한다. 중간 텍스트 생성 단계를 도입함으로써, 연쇄 사고 추론에서 영감을 받아 USDM은 대화의 의미론적 일관성이 유지되고 심지어 향상되도록 보장한다. 이를 통해 LLM은 음성 도메인에서 작동하면서 "의미론적으로 일관된 대화 응답"을 생성할 수 있으며, 일관된 출력 요구 사항을 충족한다.
- 통합 교차 모달 의미론: 제안된 "통합 음성-텍스트 사전 훈련 방식"은 "음성 대화 모델링에서 일관된 음성 생성을 위한 LLM의 능력을 부여하는 데 필수적인" "교차 모달 분포 의미론"을 학습하도록 촉진한다. 다양한 음성-텍스트 관계를 포괄하는 이 포괄적인 사전 훈련은 모델이 복잡한 상호작용을 처리하고 맥락적으로 적절한 응답을 생성할 수 있도록 보장하여 견고하고 일관된 대화의 필요성을 직접적으로 해결한다.
대안의 거부
본 논문은 연쇄 시스템과 포괄적인 교차 모달 사전 훈련이 부족한 단순한 종단 간 모델이라는 두 가지 주요 대안 접근 방식을 거부하는 명확한 이유를 제공한다.
-
연쇄 ASR + LLM + TTS 시스템:
- 이유: 저자들은
whisper-large-v3와 같은 강력한 개별 구성 요소를 ASR에 사용하더라도 연쇄 모델이 "음성과 텍스트 간의 언어적 불일치"와 "연쇄 파이프라인에 내재된 오류 전파"로 고통받는다고 명시적으로 언급한다 [10, 11, 63]. 이는 "최적이 아닌 사용자 경험"으로 이어지며, 명시적이고 수집하기 어려운 레이블 없이는 비언어적 단서를 통합하는 능력을 제한한다. - 경험적 증거: "Cascaded" 기준선은 낮은 ASR WER를 달성했지만, 전체 품질, P-MOS(운율 자연스러움), 의미론적 지표(METEOR, ROUGE-L, GPT-4 선호도)에 대한 인간 선호도 테스트에서 USDM보다 일관되게 낮은 성능을 보였다 (표 1 및 2). 이는 연쇄 시스템의 아키텍처적 한계가 종단 간 음성 대화에 대한 개별 구성 요소의 강점을 능가한다는 것을 보여준다.
- 이유: 저자들은
-
제한된 사전 훈련을 가진 종단 간 모델 (예: "From Scratch" 또는 특정 사전 훈련 설정):
- 이유: 본 논문은 "음성 전용 훈련에만 초점을 맞추거나 음성-텍스트 사전 훈련을 위한 단순한 교차 모달 목표를 활용하는 종단 간 파이프라인 [19, 25]은 사전 훈련된 언어 모델의 능력을 완전히 활용하지 못한다"고 주장한다. USDM이 아닌 "From Scratch" 모델은 사전 훈련된 Mistral-7B를 음성 대화 데이터에 직접 미세 조정했으며, "중간 텍스트를 간과하고 사전 생성된 서면 응답에 해당하지 않는 음성 응답을 생성하는 경향이 있어 성능에 부정적인 영향을 미친다." 이는 단순히 음성 대화 데이터에 LLM을 미세 조정하는 것만으로는 충분하지 않으며, 모델이 사전 훈련 중에 깊은 교차 모달 관계를 학습해야 함을 강조한다.
- 경험적 증거: "From Scratch" 기준선은 USDM에 비해 현저히 높은 STT 및 TTS WER(각각 58.1% 및 64.0%), 훨씬 낮은 MOS 및 P-MOS 점수, 그리고 낮은 의미론적 성능을 보였다 (표 1 및 2). 또한, 사전 훈련 체계에 대한 축소 분석(섹션 4.2.1, 표 3, 표 9)은 연속 또는 대응 관계만 모델링하거나 고정 템플릿을 사용하는 설정(예: 설정 1은 현저히 높은 STT 및 TTS WER를 가짐)이 더 높은 복잡도(PPL)와 더 낮은 종단 간 음성 대화 성능을 초래함을 보여준다. 이는 포괄적인 통합 사전 훈련 전략이 유익하며 단순하고 덜 통합된 종단 간 접근 방식은 불충분하다는 것을 확인시켜 준다.
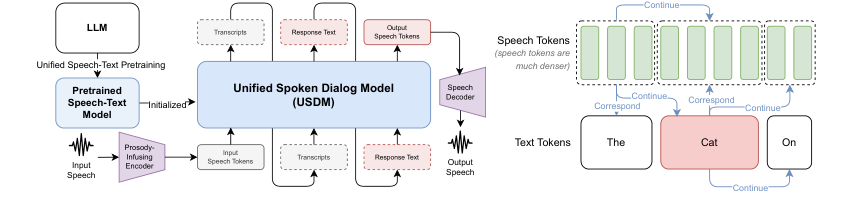 Figure 1. Overview of our spoken dialog modeling approach (Left). All possible self-supervised learning objectives from our speech-text pretraining scheme. (Right)
Figure 1. Overview of our spoken dialog modeling approach (Left). All possible self-supervised learning objectives from our speech-text pretraining scheme. (Right)
수학적 및 논리적 메커니즘
마스터 방정식
이 논문의 핵심을 이루는, 특히 통합 음성-텍스트 사전 훈련 및 후속 미세 조정을 위한 핵심 방정식은 음의 로그-가능도 목적 함수이다. 이 함수는 모델이 자기회귀 방식으로 이전 토큰이 주어졌을 때 다음 토큰의 조건부 확률을 학습하도록 안내한다. 공식적으로 다음과 같이 표현된다.
$$L(\theta) = -\sum_{j=1}^{||D||} \sum_{k=1}^{||I_j||} \log p(i_{k,j}|i_{ 이 방정식을 분해하고 각 구성 요소를 살펴보자. $L(\theta)$: $\theta$: $\sum_{j=1}^{||D||}$: $\sum_{k=1}^{||I_j||}$: $\log p(i_{k,j}|i_{ $i_{k,j}$: $i_{ 하나의 추상적인 데이터 포인트, 즉 이 맥락에서 인터리브된 음성-텍스트 샘플 $I_j$를 상상해보자. 이것이 수학적 엔진을 통해 어떻게 진행되는지 추적해보자. 시퀀스 수집: 음향 단위 토큰, 텍스트 토큰 및 특수 제어 토큰(예: 토큰 임베딩: $I_j$ 내의 각 개별 토큰 $i_{k,j}$는 먼저 임베딩이라고 하는 밀집된 숫자 벡터로 변환된다. 기존 텍스트 토큰의 경우 사전 훈련된 LLM의 임베딩이 사용된다. 새로 도입된 음성 단위 토큰 및 특수 토큰의 경우, 재초기화된 임베딩 가중치가 사용된다. 이러한 임베딩은 이산 토큰을 연속적인 고차원 공간으로 변환하여 의미론적 및 파라링귀스틱 정보를 처리할 수 있게 한다. 맥락 인코딩 (LLM): 임베딩 시퀀스는 모델의 핵심인 대규모 언어 모델(이 경우 Mistral-7B)을 통과한다. 이것은 일반적으로 트랜스포머 기반 아키텍처이다. 시퀀스의 각 위치 $k$에 대해 모델은 이전 토큰 $i_{ 다음 토큰 확률 예측: 각 단계 $k$에서 $i_{ 단일 토큰에 대한 손실 계산: 시스템은 그런 다음 실제 입력 시퀀스의 해당 위치에서 발생한 실제 토큰 $i_{k,j}$를 살펴본다. 모델이 예측 분포에서 이 올바른 토큰에 할당한 확률을 검색한다. 이 확률의 음수 로그, $-\log p(i_{k,j}|i_{ 시퀀스 손실 집계: 이 토큰 수준 손실 계산은 전체 시퀀스 $I_j$ 내의 모든 토큰 $k$에 대해 반복된다. 이러한 개별 토큰 손실은 모두 합산되어 해당 샘플 $I_j$에 대한 총 손실을 얻는다. 데이터셋 손실 집계: 마지막으로, 이 전체 프로세스(단계 1-6)는 데이터셋 $D$의 모든 샘플 $I_j$에 대해 반복된다. 모든 개별 샘플 손실은 합산되어 전체 배치 또는 데이터셋에 대한 총 손실 $L(\theta)$를 생성한다. 이 $L(\theta)$는 모델의 전반적인 성능을 정량화하는 단일 숫자 값이다. 메커니즘은 주로 Adam 옵티마이저를 사용하는 기울기 하강 기반의 반복적인 프로세스를 통해 학습, 업데이트 및 수렴한다. 손실 지형: 손실 함수 $L(\theta)$는 각 지점이 특정 모델 매개변수 $\theta$ 세트와 해당 손실 값에 해당하는 고차원 "손실 지형"을 정의한다. 이 지형은 일반적으로 비볼록(non-convex)하여 많은 지역 최소값과 안장점을 가진다. 최적화의 목표는 $L(\theta)$를 최소화하는 매개변수 $\theta$ 세트를 찾기 위해 이 지형을 탐색하는 것이다. 음수 로그 가능도 목적 함수는 본질적으로 올바른 다음 토큰에 대한 더 높은 확률을 초래하는 매개변수가 더 낮은 손실 값을 갖도록 이 지형을 형성한다. 기울기 계산 (역전파): 모델을 통한 순방향 패스가 배치 학습 데이터에 대한 $L(\theta)$를 계산한 후, 이 손실의 모든 단일 매개변수에 대한 기울기가 계산된다. 이는 역전파 알고리즘을 사용하여 효율적으로 수행된다. 이러한 기울기, $\nabla_\theta L(\theta)$는 손실 지형에서 가장 가파른 상승 방향을 나타낸다. 손실을 최소화하려면 매개변수를 기울기의 반대 방향으로 이동해야 한다. 매개변수 업데이트 (Adam 옵티마이저): 본 논문에서는 Adam 옵티마이저를 사용한다고 명시한다. Adam은 매개변수별 학습률을 유지하는 적응형 학습률 최적화 알고리즘이다. 각 매개변수에 대해 다음을 계산한다. 학습률 스케줄링: 본 논문에서는 "선형 학습률 스케줄링"을 언급한다. 이는 일반적으로 학습률 $\alpha$가 특정 값에서 시작하여 선형적으로 증가한 다음 훈련 과정 동안 선형적으로 감소함을 의미한다. 이러한 스케줄링 전략은 모델이 훈련 초기에 더 큰 업데이트를 수행하여 손실 지형을 빠르게 탐색하고, 나중에 더 작고 정밀한 업데이트를 수행하여 매개변수를 미세 조정하고 과도하게 지나치지 않고 좋은 최소값에 정착하도록 돕는다. 수렴: 순방향 패스, 손실 계산, 기울기 계산 및 매개변수 업데이트의 반복을 통해 모델의 매개변수 $\theta$는 점진적으로 조정된다. 손실 $L(\theta)$는 시간이 지남에 따라 감소하며, 이는 모델이 인터리브된 음성-텍스트 시퀀스에서 다음 토큰을 예측하는 데 더 나아지고 있음을 나타낸다. 손실이 안정적인 최소값으로 수렴하거나 미리 정의된 훈련 에포크 수가 완료될 때까지 프로세스가 계속된다. 모델은 효과적으로 입력 음성 및 텍스트 맥락을 확률적 다음 음성 또는 텍스트 토큰에 매핑하는 방법을 학습하여 일관되고 운율적인 음성 대화 응답을 생성하는 능력을 습득한다. 특히 교차 모달 사전 훈련은 모델이 모달리티 간의 원활한 전환과 이해를 촉진하도록 손실 지형을 형성하여 모델이 모달리티별 지역 최소값에 갇히는 것을 방지하는 데 중요하다. 우리의 실험적 검증은 22,050 Hz로 샘플링된 20시간 분량의 음성 대화 데이터 모음인 DailyTalk 데이터셋 [70]에 집중되었으며, 한 명의 남성 및 한 명의 여성 화자가 포함되었다. 이 데이터셋은 단일 턴 음성 대화를 위해 전처리되어 20,117개의 훈련 샘플과 1,058개의 테스트 샘플을 생성했다. 통합 음성 대화 모델(USDM)은 436K 시간의 다국어 음성 데이터로 훈련된 XLS-R [64]의 공식 체크포인트와 $k=10,000$ [33]의 양자화기를 사용하는 음성-단위 모듈을 사용하여 설계되었다. 음성 디코더의 경우, 우리는 Multilingual LibriSpeech [71] 및 GigaSpeech [72]의 영어 하위 집합에서 54k 시간의 ASR 데이터로 훈련된 Voicebox 아키텍처 [66]를 기반으로 하는 unit-Voicebox 모델을 사용했다. 이 unit-Voicebox는 다중 턴 대화에서 일관된 목소리를 보장하기 위해 제로샷 재구성을 위해 이전 턴의 참조 음성을 사용하도록 설계되었다. 핵심 대규모 언어 모델(LLM)은 Mistral-7B [67]였다. 우리의 사전 훈련 단계는 512개의 NVIDIA A100-40GB GPU, 1,024의 전역 배치 크기, 약 87,000 시간의 영어 ASR 데이터(Multilingual LibriSpeech, People's Speech, GigaSpeech, Common Voice 및 Voxpopuli 포함)에 대한 8,000번의 반복, 최대 시퀀스 길이 8,192를 포함했다. DailyTalk에 대한 미세 조정은 2 $\cdot 10^{-5}$의 피크 학습률을 가진 선형 학습률 스케줄링을 사용하여 5 에포크 동안 수행되었다. BigVGAN [74] 보코더는 모든 음성 합성에 사용되었다. 우리의 수학적 주장을 철저히 증명하기 위해 우리는 USDM을 세 가지 "피해자" 기준선 모델과 비교했다. 우리의 평가 전략은 인간 및 자동화된 지표를 결합했다. 인간 평가는 Amazon Mechanical Turk을 통해 수행되었으며 다음을 포함했다. 자동 평가에는 전사된 응답의 의미론적 적절성을 평가하기 위한 GPT-4 기반 선호도 테스트 [1] ( 증거는 우리의 통합 음성 대화 모델(USDM)이 파라링귀스틱 정보를 효과적으로 통합하고, 주로 새로운 사전 훈련 및 미세 조정 전략 덕분에 강력한 기준선에 비해 우수한 음성 응답을 생성한다는 것을 확실하게 증명한다. 파라링귀스틱이 주입된 음성 토큰을 활용하는 핵심 메커니즘은 엄격하게 검증되었다. CREMA-D 데이터셋 [65]의 음향 단위에 대한 감정 인식 작업에서 우리의 3계층 트랜스포머 기반 감정 분류기는 60.8%의 정확도를 달성했다. 이는 무작위 추측에서 예상되는 16.6%에서 상당한 도약으로, 전통적으로 주로 의미론적 정보를 인코딩한다고 생각되었던 이러한 음향 단위에도 풍부한 감정 단서가 포함되어 있다는 부인할 수 없는 증거를 제공한다. 또한, 54,000 시간의 음성 데이터로 훈련된 우리의 단위-음성 재구성 모델은 재구성된 음성의 음색과 절대 음높이가 원본과 다를 수 있지만, 음높이 변화는 정답과 밀접하게 일치함을 보여주었다 (그림 2). 이것은 우리의 음성 토큰이 음높이 윤곽과 같은 중요한 비언어적 특징을 성공적으로 포착한다는 것을 보여주는 증거이다. USDM의 자연스럽고 일관된 음성 응답 생성에서의 우수성은 여러 평가에서 일관되게 입증되었다. 축소 분석은 설계 선택의 효과에 대한 중요한 통찰력을 제공했다. USDM이 제시하는 상당한 발전에도 불구하고, 몇 가지 내재된 한계와 흥미로운 개발 기회가 있다. 첫째, 사전 훈련 단계에 대한 데이터셋 및 모델 탐색은 다소 제한적이었다. 우리는 Mistral-7B 및 특정 ASR 데이터 세트로 우리의 체계의 효과를 보여주었지만, 어떤 데이터 소스가 최적의 성능에 가장 중요한지, 그리고 우리의 사전 훈련 체계가 Mistral-7B를 넘어서는 다른 LLM에 얼마나 잘 일반화될지는 완전히 명확하지 않다. 향후 연구에서는 가장 영향력 있는 조합을 식별하기 위해 다양한 데이터셋 및 LLM 아키텍처에 대한 보다 체계적인 조사가 포함되어야 한다. 둘째, 현재 USDM 아키텍처는 교차 모달 체인 접근 방식에 의존한다: 음성 입력은 먼저 텍스트로 전사되고, 텍스트 응답이 생성되며, 마지막으로 이 텍스트가 음성 출력으로 합성된다. 이 "브릿지 텍스트" 전략은 LLM의 추론 능력을 효과적으로 활용하지만, 중간 단계를 도입한다. 유망한 미래 방향은 이 명시적인 교차 모달 체인 없이 입력 음성 대화에서 직접 음성 응답을 생성할 수 있는 음성 대화 모델을 개발하는 것이다. 이는 파이프라인을 간소화하고 잠재적으로 오류 전파를 줄여 진정한 종단 간 음성-음성 경험을 제공할 것이다. 셋째, 현재 사전 훈련 체계는 주로 영어 데이터 수만 시간 기반이다. 이는 USDM을 다른 언어, 특히 음성 데이터 리소스가 상대적으로 적은 언어에 적용할 때 명확한 한계를 제시한다. 모델을 더 다양한 언어를 지원하도록 확장하는 것은 글로벌 적용 가능성과 유용성을 향상시키기 위한 중요한 다음 단계이다. 이는 다국어 사전 훈련 전략을 탐색하고 음성 토큰화 및 디코딩 구성 요소를 다양한 언어적 특징에 맞게 조정하는 것을 포함할 가능성이 높다. 마지막으로, 우리의 작업별 훈련 동적 분석(그림 7, 오른쪽)은 LoRA를 사용하여 미세 조정 매개변수 수를 늘리는 것이 때때로 단위-텍스트 작업 성능 저하로 이어질 수 있음을 나타내며, 이는 잠재적인 과적합을 시사한다. 이를 해결하기 위해 향후 연구에서는 파이프라인 내 각 작업에 대한 손실 가중치를 동적으로 변경하거나 모델이 점진적으로 더 복잡한 작업에 노출되는 커리큘럼 학습 접근 방식을 구현하는 것과 같은 과적합을 완화하는 전략을 탐색할 수 있다. 이러한 특정 사항 외에도, 이 작업의 광범위한 의미는 여러 논의 주제를 열어준다. 음향 단위가 파라링귀스틱 특징을 포착하는 입증된 능력을 더 잘 활용하여 보다 공감적이고 맥락을 인식하는 대화 에이전트를 구축하는 방법은 무엇인가? 음성 피싱과 같은 시나리오에서 오용을 방지하면서 긍정적인 사회적 영향을 극대화하기 위해 이러한 고품질 음성 합성 모델의 윤리적 배포를 보장하는 견고한 메커니즘을 개발할 수 있는가? 또한, 우리의 사전 훈련 접근 방식과 다른 음성-텍스트 작업(예: 음성 번역 또는 요약) 간의 동형성(isomorphism)을 조사하면 훨씬 더 넓은 응용 분야를 열고 진정한 다중 모달 LLM의 기반을 공고히 할 수 있다.항별 분석
단계별 흐름
<|correspond|> 또는 <|continue|>)의 혼합으로 구성된 전체 인터리브된 시퀀스 $I_j$가 시스템에 공급된다. 이 시퀀스는 음성 대화 세그먼트 또는 음성-텍스트 쌍을 나타낸다.최적화 역학
이러한 추정치는 편향 보정된다. Adam의 매개변수 업데이트 규칙은 다음과 같다.
$$\theta_{t+1} = \theta_t - \alpha \frac{\hat{m}_t}{\sqrt{\hat{v}_t} + \epsilon}$$
여기서 $\theta_t$는 시간 단계 $t$에서의 매개변수 벡터이고, $\alpha$는 학습률(예: unit-Voicebox 훈련의 경우 $10^{-4}$, 사전 훈련/미세 조정의 경우 $2 \cdot 10^{-5}$)이며, $\hat{m}_t$ 및 $\hat{v}_t$는 편향 보정된 1차 및 2차 모멘트 추정치이고, $\epsilon$은 0으로 나누는 것을 방지하기 위한 작은 상수이다. 이러한 적응적 특성은 Adam이 희소 기울기와 다양한 규모의 매개변수를 효과적으로 처리할 수 있게 하여 모델이 더 빠르고 견고하게 수렴하도록 돕는다.결과, 한계 및 결론
실험 설계 및 기준선
1. From Scratch: 이 모델은 USDM과 거의 동일했지만 결정적으로 통합 음성-텍스트 사전 훈련이 부족했다. 이것은 USDM과 동일한 하이퍼파라미터를 사용하여 사전 훈련된 Mistral-7B를 음성 대화 데이터에 직접 미세 조정했다. 이 기준선은 우리의 새로운 사전 훈련 체계의 영향을 분리하도록 설계되었다.
2. Cascaded: 이 접근 방식은 별도의 기성 자동 음성 인식(ASR) 및 음성 합성(TTS) 시스템을 사용했다. 구체적으로 ASR에는 whisper-large-v3 78을 사용했고 TTS에는 Voicebox 모델(우리의 unit-Voicebox와 유사하게 텍스트 입력으로 훈련됨)을 사용했다. LLM(Mistral-7B)은 음성 대화 데이터의 전사본에 미세 조정되었다. 이 기준선은 음성 대화에 대한 전통적인 모듈식 접근 방식을 나타냈다.
3. SpeechGPT [25]: 우리는 공정한 비교를 위해 DailyTalk에 미세 조정된 최첨단 사전 훈련 음성-텍스트 모델인 SpeechGPT-7B-cm의 공식 구현 및 체크포인트를 사용했다.
- 전체 선호도 테스트: 150명의 평가자가 USDM의 음성 응답을 기준선과 비교하여 자연스러움, 운율 및 의미론적 일관성을 고려하여 무작위로 선택된 50개의 음성 대화에 대해 평가했다. 이는 약 200달러가 소요되었다.
- 운율 평균 의견 점수 (P-MOS): 198명의 평가자가 정답 텍스트 응답이 주어졌을 때 5점 척도로 운율 자연스러움을 평가했다. 이는 약 250달러가 소요되었다.
- 평균 의견 점수 (MOS): 176명의 평가자가 응답 텍스트와 음성 응답만 주어졌을 때 오디오 품질과 자연스러움을 5점 척도로 평가했다. 이 역시 약 250달러가 소요되었다.gpt-4-0125-preview 사용)과 의미론적 내용에 대한 METEOR 및 ROUGE-L 점수, 그리고 음성-텍스트(STT WER) 및 텍스트-음성(TTS WER) 구성 요소 모두에 대한 단어 오류율(WER)과 같은 정량적 지표가 포함되었다. 축소 분석은 LibriSpeech에 대한 복잡도(PPL) 및 DailyTalk에 대한 앞서 언급한 대화 지표를 사용하여 우리의 통합 사전 훈련 및 미세 조정 체계의 기여를 추가로 분석했다.증거가 증명하는 것
- 인간 선호도: 포괄적인 인간 선호도 테스트에서 USDM은 정답과 유사하게 선호되었으며 모든 기준선을 현저히 능가했다 (Wilcoxon 부호 순위 검정에서 p-값 < 0.05). 이것은 전반적인 품질과 사용자 경험에 대한 강력한 지표이다.
- 운율 자연스러움: USDM은 P-MOS 평가에서 모든 기준선을 능가했다 (p-값 < 0.05), 자연스러운 운율을 가진 음성을 생성하는 탁월한 능력을 보여주었다. 특히 명시적인 레이블을 사용했음에도 운율에 어려움을 겪었던 연쇄 모델을 능가했는데, 이는 USDM의 효과적이고 암묵적인 파라링귀스틱 특징 통합을 강조한다.
- 의미론적 일관성: 우리 모델은 의미론적 적절성에 대한 정량적 지표(METEOR 및 ROUGE-L)와 GPT-4 기반 선호도 테스트(p-값 < 0.05) 모두에서 기준선을 능가했다. 이는 USDM이 입력 음성과 잘 정렬된 의미론적으로 일관된 응답을 생성하는 능력을 확인시켜 준다.
- 통합 사전 훈련: 대응 및 연속 관계를 모두 모델링하는 우리의 제안된 통합 음성-텍스트 사전 훈련 체계는 모든 모달리티 및 시퀀스 유형에 걸쳐 우수한 평균 복잡도(PPL)를 달성했다 (표 3, 표 9). 이것은 LLM이 제한된 관계에 특화되기보다는 다양한 음성-텍스트 상호작용을 학습하기 위해 포괄적인 사전 훈련 전략이 필수적임을 결정적으로 증명했다. 이 사전 훈련이 없는 "From Scratch" 모델은 현저히 더 나쁜 TTS 및 STT WER(각각 64.0% 및 58.1%)과 낮은 의미론적 성능을 보였으며, 교차 모달 사전 훈련의 중요한 역할을 강조했다.
- 중간 텍스트 모델링: 중간 텍스트를 브릿지로 사용하는 미세 조정 체계(음성 입력 -> 텍스트 전사 -> 텍스트 응답 생성 -> 음성 응답 합성)는 매우 효과적인 것으로 나타났다. 직접적인 음성-음성 모델(S1 -> S2)은 METEOR 및 ROUGE-L 점수에서 현저히 낮은 성능을 보였다 (표 3). 이는 텍스트 모달리티를 통한 LLM의 추론 능력 활용이 유익하다는 것을 확인시켜 준다.
- 입력 모달리티 활용: 주의 맵(그림 4)은 USDM이 생성한 응답이 입력 음성과 전사된 텍스트 모두에 주의를 기울인다는 것을 보여주었다. 이러한 시각적 증거는 우리 모델이 두 모달리티의 정보를 효과적으로 통합하여 더 견고하고 의미론적으로 일관된 출력을 생성한다는 것을 확인시켜 준다. 또한, 모델이 생성한 입력 전사를 정답 전사로 대체하면 METEOR 및 ROUGE-L 점수가 향상되어 (각각 13.6 대 13.1 및 16.2 대 15.7), USDM의 단위-텍스트 변환 정확도를 향상시키는 것이 의미론적 일관성을 직접적으로 향상시킨다는 것을 입증했다.한계 및 향후 방향
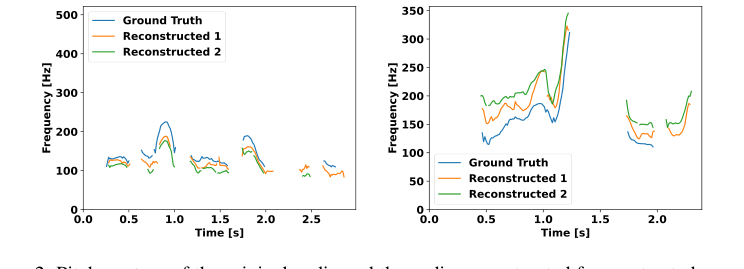 Figure 2. Pitch contour of the original audio and the audio reconstructed from extracted acoustic units. Due to the stochastic nature of the reconstruction model, we attempt reconstruction twice, demonstrating that the pitch variation closely mirrors the ground truth
Figure 2. Pitch contour of the original audio and the audio reconstructed from extracted acoustic units. Due to the stochastic nature of the reconstruction model, we attempt reconstruction twice, demonstrating that the pitch variation closely mirrors the ground truth
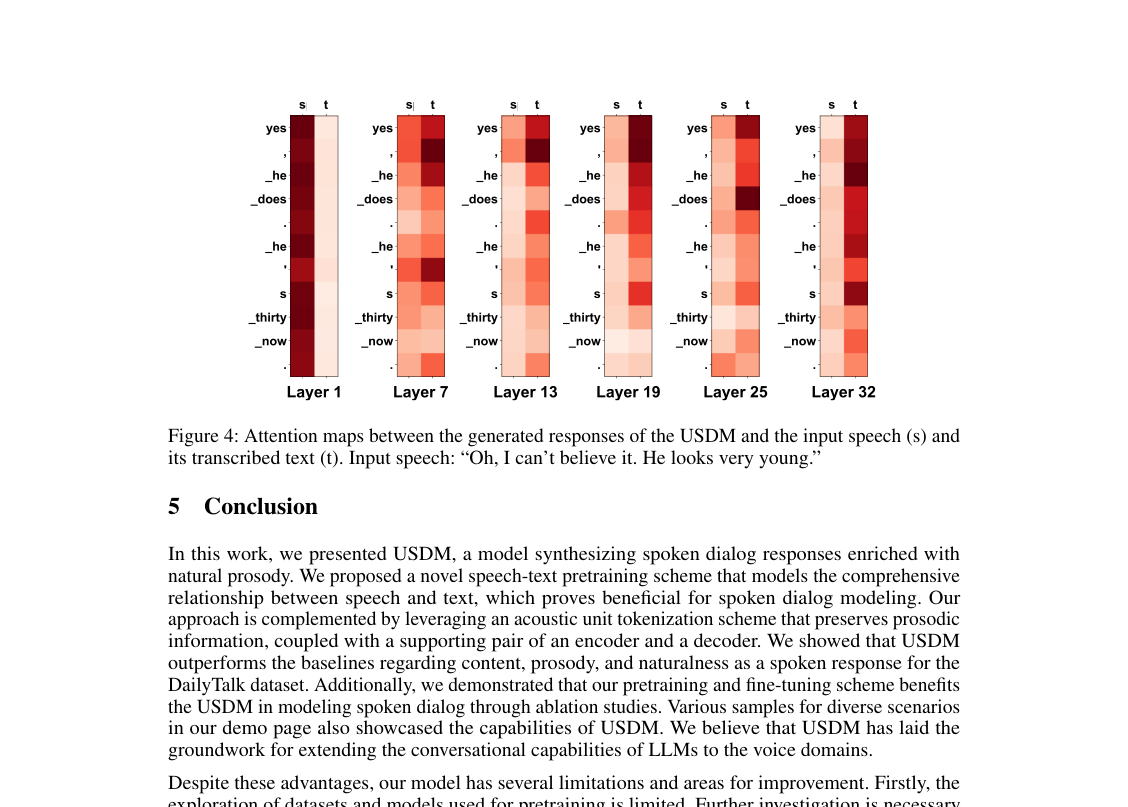 Figure 4. Attention maps between the generated responses of the USDM and the input speech (s) and its transcribed text (t). Input speech: “Oh, I can’t believe it. He looks very young.”
Figure 4. Attention maps between the generated responses of the USDM and the input speech (s) and its transcribed text (t). Input speech: “Oh, I can’t believe it. He looks very young.”
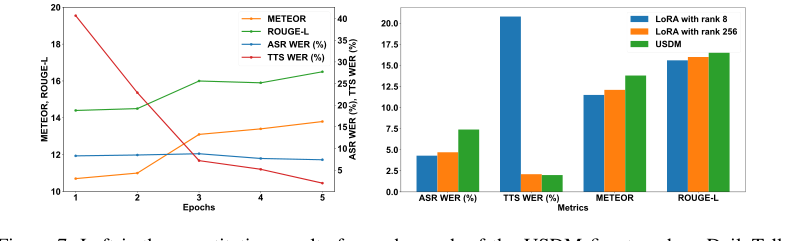 Figure 7. Left is the quantitative results for each epoch of the USDM fine-tuned on DailyTalk. The figure on the right illustrates the performance of the Spoken Dialog Model when trained with Low-Rank Adaptation (LoRA) versus full fine-tuning
Figure 7. Left is the quantitative results for each epoch of the USDM fine-tuned on DailyTalk. The figure on the right illustrates the performance of the Spoken Dialog Model when trained with Low-Rank Adaptation (LoRA) versus full fine-tuning