Парангвистически-осведомленные большие языковые модели с поддержкой речи для естественного диалога
Проблема, рассматриваемая в данной статье, проистекает из недавних достижений и широкого распространения больших языковых моделей (LLM) в области текстовых диалоговых систем.
Предпосылки и академическая родословная
Происхождение и академическая родословная
Проблема, рассматриваемая в данной статье, проистекает из недавних достижений и широкого распространения больших языковых моделей (LLM) в области текстовых диалоговых систем. Хотя LLM продемонстрировали выдающиеся возможности в понимании, генерации и обработке текста, их прямое применение к разговорной речи оставалось серьезной проблемой. Основная мотивация заключается в расширении мощных, эмерджентных способностей LLM — таких как обучение в контексте с малым числом примеров (few-shot in-context learning) и сложное рассуждение — на область естественного разговорного диалога, что позволит сделать взаимодействие более интуитивным и человекоподобным.
Исторически, ранние модели разговорной речи (SLM) либо фокусировались исключительно на речевых данных, либо использовали очень простые кросс-модальные цели, не в полной мере используя сложное лингвистическое понимание предобученных LLM. С появлением высокопроизводительных текстовых LLM академическая область сместилась в сторону интеграции речевых модальностей в эти модели.
Фундаментальные ограничения или "болевые точки" предыдущих подходов, которые обусловили необходимость данного исследования, можно разделить на два основных типа:
-
Каскадные модели: Эти подходы обычно включают в себя отдельные системы автоматического распознавания речи (ASR) для преобразования речи пользователя в текст, LLM для генерации текстового ответа и затем систему преобразования текста в речь (TTS) для синтеза устного ответа.
- Лингвистическое несоответствие: Существенной "болевой точкой" является присущее несоответствие между тем, как речь и текст передают информацию. Речь несет богатые парангвистические сигналы, такие как эмоции, тон и ритм, которые теряются при преобразовании в простой текст системой ASR. Это лингвистическое несоответствие приводит к неэффективности диалога и субоптимальному пользовательскому опыту, поскольку LLM работает только с семантическим содержанием, часто игнорируя критически важный невербальный контекст.
- Зависимость от меток для парангвистики: Для включения парангвистических признаков в каскадные модели часто требуются явные метки (например, для эмоций). Это затрудняет сбор данных и ограничивает модели только теми невербальными сигналами, которые могут быть явно размечены.
- Распространение ошибок: Основным недостатком является накопление ошибок. Любые неточности, введенные системой ASR или текстовой LLM, могут распространяться по конвейеру, приводя к менее связным или неестественно звучащим устным ответам.
-
Сквозные модели, ориентированные только на речь, или простые кросс-модальные модели: Хотя существуют некоторые сквозные конвейеры, они часто не в полной мере используют обширные знания и возможности рассуждения, встроенные в предобученные LLM. Эти модели могут быть ограничены в своей способности улавливать всеобъемлющие, сложные взаимосвязи между речевой и текстовой модальностями, тем самым снижая их производительность в генерации контекстуально богатых и просодически соответствующих разговорных диалогов. Авторы подчеркивают, что предыдущие модели, фокусируясь на конкретных задачах или простых кросс-модальных целях, не в полной мере использовали потенциал глубокого кросс-модального понимания, которое мог бы предложить унифицированный фреймворк.
Интуитивные термины предметной области
Вот три узкоспециализированных термина предметной области из статьи, переведенные в интуитивные, повседневные аналогии для читателя с нулевой базой знаний:
-
Парангвистика: Представьте, что вы рассказываете историю. Слова, которые вы используете, — это основное сообщение (семантика). Но то, как вы его рассказываете — ваш тон голоса, скорость речи, паузы, звучите ли вы взволнованно или грустно — это парангвистика. Это все несловесные звуки и вокальные качества, которые добавляют смысл и эмоции к тому, что вы говорите. Компьютер, который понимает парангвистику, не просто слышит "Я в порядке", он слышит, как вы говорите "Я в порядке", чтобы понять, действительно ли вы в порядке или саркастичны.
-
Акустические единицы / Дискретные речевые представления: Подумайте о кинофильме. Это непрерывный поток движения, но на самом деле он состоит из тысяч отдельных, неподвижных изображений (кадров). Акустические единицы подобны этим отдельным кадрам для речи. Вместо непрерывной звуковой волны мы разбиваем речь на крошечные, дискретные звуковые "кусочки" или "токены". Эти кусочки затем категоризируются в ограниченный набор типов, подобно небольшому набору уникальных кубиков Lego. Выбирая и располагая эти конкретные "кубики Lego", компьютер может реконструировать речь, улавливая как слова, так и тонкие вокальные нюансы.
-
Просодия: Это музыка языка. Когда вы говорите, ваш голос естественно повышается и понижается по высоте, вы делаете акцент на определенных словах и меняете скорость речи. Этот паттерн высоты тона, ударения и ритма называется просодией. Именно он заставляет вопрос звучать как вопрос, а взволнованное утверждение — как взволнованное. Без просодии вся речь звучала бы плоско и роботизированно, как компьютер, читающий текст монотонным голосом. Это разница между тем, чтобы сказать "Мне это очень нравится" с энтузиазмом и сказать это плоским, безжизненным тоном.
Таблица обозначений
| Обозначение | Описание |
|---|---|
Определение проблемы и ограничения
Формулировка основной проблемы и дилемма
Основная проблема, которую решает данная статья, заключается в ограничении текущих больших языковых моделей (LLM) в обработке естественного разговорного диалога в сквозном режиме.
Входное состояние / Текущее состояние:
Существующие LLM преуспевают в текстовых задачах, демонстрируя выдающиеся возможности в сложном рассуждении, обучении с малым числом примеров и следовании инструкциям. Однако, когда дело доходит до устного взаимодействия, они обычно интегрируются с отдельными системами автоматического распознавания речи (ASR) и преобразования текста в речь (TTS) в каскадном режиме. Альтернативно, некоторые модели фокусируются исключительно на обработке речи, не используя всю мощь LLM.
Желаемое конечное состояние (Выход / Целевое состояние):
Цель состоит в разработке унифицированной модели разговорного диалога (USDM), которая может беспрепятственно интегрировать речевую модальность в LLM. Эта модель должна быть способна:
1. Непосредственно понимать речь пользователя, включая тонкие нюансы и эмоциональные состояния (парангвистику), без опоры на явное ASR.
2. Генерировать связные устные ответы с естественно возникающими и контекстуально соответствующими просодическими характеристиками, без опоры на явное TTS.
3. Поддерживать и улучшать мощные возможности LLM для генерации диалога и рассуждения в сквозном конвейере.
Отсутствующее звено / Математический пробел:
Точным отсутствующим звеном является унифицированный фреймворк на основе LLM, который может эффективно преодолеть разрыв между необработанным речевым входом и естественными устными ответами путем систематической интеграции как семантической, так и парангвистической информации из речи в обработку LLM. Это требует новой схемы представления речи и предобучения, которая позволит LLM изучать всеобъемлющие кросс-модальные взаимосвязи и генерировать речевые токены, которые изначально несут просодическую информацию, а не только семантическое содержание. Статья направлена на устранение этого пробела путем предложения "схемы токенизации речи, обогащенной просодией" и "обобщенной схемы предобучения речи-текста, которая улучшает захват кросс-модальной семантики".
Дилемма:
Предыдущие исследования оказались в ловушке болезненного компромисса между использованием возможностей LLM и естественной обработкой речи:
* Каскадные ASR/TTS против сквозной связности: Хотя системы ASR и TTS могут быть легко использованы, их каскадное использование приводит к "лингвистическому несоответствию между речью и текстом", вызывая "неэффективность диалога и субоптимальный пользовательский опыт" [10, 11]. Более критично, эти конвейеры страдают от "распространения ошибок, присущего каскадному конвейеру" [63], где ошибки в ASR или текстовых диалоговых моделях накапливаются, приводя к менее связным или естественным устным ответам. Кроме того, включение парангвистических признаков (таких как эмоции или тон) в каскадные модели часто требует "явных меток", что делает "сбор данных сложным и ограничивает модели представлением невербальных сигналов, определяемых метками" (Раздел 2, стр. 3).
* Модели, ориентированные только на речь, против рассуждений LLM: Ранние модели разговорной речи (SLM), обученные исключительно на речевых данных [17, 19], не обладают продвинутыми возможностями рассуждения и генерации современных LLM, что ограничивает их диалоговые способности. Дилемма заключается в том, как наделить речевые модели интеллектом, подобным LLM, не теряя при этом богатства речевого сигнала.
* Семантическая против парангвистической информации в речевых токенах: Речевые токены обычно предназначены для кодирования семантического содержания. Задача состоит в создании дискретного речевого представления, которое не только передает семантическую информацию, но и значительный объем парангвистической информации (например, эмоции, вариации высоты тона) таким образом, чтобы LLM могла эффективно использовать ее для генерации естественно звучащих, контекстуально соответствующих устных ответов.
Ограничения и режимы отказа
Проблема создания парангвистически-осведомленной LLM с поддержкой речи для естественного диалога чрезвычайно сложна из-за нескольких жестких, реалистичных ограничений:
- Ограничения, связанные с данными:
- Недостаток выровненных кросс-модальных данных: Создание всеобъемлющих рече-текстовых моделей требует огромных объемов высококачественных, выровненных речевых и текстовых данных, которые охватывают разнообразные диалоговые контексты и парангвистические признаки. В статье отмечается, что текущая схема предобучения опирается на "десятки тысяч часов английских данных" (Раздел 5, стр. 10), что указывает на значительные требования к данным.
- Разреженность размеченных парангвистических данных: Явные метки для парангвистических признаков (таких как эмоции или интонация) редки и их трудно получить в больших масштабах, что является серьезным препятствием для моделей, которые от них зависят (Раздел 2, стр. 3).
- Многоязычные ограничения: Текущая модель в основном обучена на английских данных, и ее применимость к другим языкам с "относительно меньшим объемом речевых данных" ограничена, что создает проблему для универсального развертывания (Раздел 5, стр. 10).
- Вычислительные ограничения:
- Чрезвычайная вычислительная стоимость предобучения: Обучение больших рече-текстовых моделей, особенно основанных на архитектурах LLM, требует огромных вычислительных ресурсов. В статье указано использование "512 графических процессоров NVIDIA A100-40GB с глобальным размером пакета 1024 для 8000 итераций" (Раздел 4.1.1, стр. 7), что подчеркивает существенные аппаратные требования.
- Ограничения памяти для длинных последовательностей: Обработка чередующихся рече-текстовых последовательностей, особенно с "максимальной длиной последовательности 8192" (Раздел 4.1.1, стр. 7), может быстро достичь пределов аппаратной памяти, что затрудняет моделирование долгосрочных зависимостей в диалоге.
- Архитектурные и функциональные ограничения:
- Сохранение возможностей рассуждения LLM: Интеграция речи в LLM не должна ухудшать их основные возможности рассуждения и генерации. Модель должна эффективно выполнять "цепочечное рассуждение через промежуточную модальность" (Раздел 3.3, стр. 6).
- Генерация естественной просодии: Синтез речи с "естественно возникающими просодическими характеристиками, соответствующими данному входному речи", является сложной задачей. Модель должна научиться выводить и генерировать соответствующую просодию из контекста, что является тонким и трудным аспектом человеческого общения (Аннотация, стр. 1).
- Устойчивость к вариациям и ошибкам входных данных: Система должна быть устойчива к вариациям качества входной речи, акцентам и потенциальным неточностям транскрипции, особенно если используется промежуточное текстовое представление. Статья нацелена на подход, "более устойчивый к ошибкам транскрипции", чем каскадные системы (Раздел 3.3, стр. 6).
- Кросс-модальное семантическое выравнивание: Обеспечение семантического выравнивания речевой и текстовой модальностей и того, чтобы модель могла изучать "кросс-модальную распределительную семантику", жизненно важно для связной генерации диалога (стр. 2).
- Обобщение на разнообразные отношения: Схема предобучения, ориентированная только на определенные типы отношений (например, соответствие или продолжение), может "ограничить возможности модели только этими предопределенными отношениями" (Раздел 3.2, стр. 5), препятствуя ее способности обрабатывать разнообразные рече-текстовые взаимодействия. Модель должна быть универсальной.
Почему этот подход
Неизбежность выбора
Решение авторов разработать унифицированную модель разговорного диалога (USDM) как основанный на LLM, сквозной фреймворк для разговорного диалога было обусловлено присущими ограничениями существующих "SOTA" методов. Критическое осознание того, что традиционные подходы были недостаточными, возникло из наблюдения фундаментальных недостатков как каскадных систем, так и предыдущих сквозных речевых моделей.
В частности, в статье подчеркивается, что, хотя системы автоматического распознавания речи (ASR) и преобразования текста в речь (TTS) могут быть легко использованы, их последовательный характер вводит "лингвистическое несоответствие между речью и текстом", которое приводит к "неэффективности диалога и субоптимальному пользовательскому опыту" [10, 11]. Этот каскадный подход также требует явных меток для парангвистических признаков, что затрудняет сбор данных и ограничивает модели только невербальными сигналами, определяемыми метками. Критически важно, что "распространение ошибок, присущее каскадному конвейеру [63], увеличивает их подверженность накопленным ошибкам", что делает его ненадежной основой для действительно естественного и связного разговорного диалога.
Кроме того, существующие речевые модели на основе LLM, несмотря на их успехи, оказались недостаточными для естественной генерации речи, понимания и включения парангвистики в контексте разговорного диалога. Более ранние сквозные конвейеры [19, 25], которые полагались на обучение только на речи или на простые кросс-модальные цели, "не в полной мере используют возможности предобученных языковых моделей". Авторы признали, что всеобъемлющий, унифицированный подход был единственным жизнеспособным решением для преодоления этих глубоко укоренившихся проблем и предоставления LLM возможности действительно понимать и генерировать речь с соответствующими парангвистическими признаками в диалоговом контексте.
Сравнительное превосходство
USDM демонстрирует качественное превосходство над предыдущими золотыми стандартами, в первую очередь благодаря своему унифицированному кросс-модальному предобучению и способности вводить парангвистическую информацию непосредственно в речевые токены. Это структурное преимущество позволяет генерировать более естественно звучащие и семантически связные устные ответы.
В отличие от каскадных систем, которые страдают от распространения ошибок и зависимости от явных меток для невербальных сигналов, сквозная конструкция USDM, которая изначально интегрирует речевую и текстовую модальности, по своей сути устраняет эти проблемы. Уникальная схема токенизации речи модели, полученная путем кластеризации методом k-средних самообучающихся речевых представлений (XLS-R), как показано, содержит значительную парангвистическую информацию, такую как эмоции и вариации высоты тона. Эксперименты подтверждают, что эти акустические единицы достигают 60,8% точности в распознавании эмоций, что значительно превосходит ожидаемые 16,6% от случайного угадывания. Эта способность захватывать и реконструировать контуры высоты тона (как показано на Рисунке 2) является прямым качественным преимуществом для генерации естественной просодии, которая часто теряется или плохо обрабатывается текстовыми промежуточными представлениями в каскадных системах.
Кроме того, стратегия моделирования на основе LLM USDM, которая вставляет задачи, связанные с текстом, между речевыми входами и выходами, использует возможности "цепочечного рассуждения" базовой LLM [6]. Это делает подход "более устойчивым к ошибкам транскрипции и лучше генерирующим контекстуально релевантные устные ответы, чем если бы он выполнялся в независимых модулях". Эта надежная, контекстно-осведомленная генерация, особенно в отношении парангвистики, представляет собой значительный качественный скачок. Исследования по абляции в статье дополнительно подчеркивают это, показывая, что модели, которым не хватает всеобъемлющего кросс-модального предобучения (такие как модель "С нуля" или Настройка 1), значительно хуже работают с точки зрения просодии и семантической связности, подчеркивая структурное преимущество унифицированного предобучения USDM.
Соответствие ограничениям
Выбранный метод USDM идеально соответствует жестким требованиям проблемы, напрямую решая задачу связной, богатой просодией генерации устных ответов без опоры на отдельные модули ASR или TTS. Этот "брак" проявляется в нескольких ключевых аспектах:
- Сквозная генерация разговорного диалога: Основное ограничение заключалось в отказе от каскадных систем. USDM достигает этого путем интеграции речевой и текстовой модальностей в рамках единого фреймворка LLM, устраняя необходимость в явных компонентах ASR и TTS во время инференса для генерации диалога. Это напрямую решает задачу "без опоры на явное автоматическое распознавание речи (ASR) или системы преобразования текста в речь (TTS)".
- Естественно возникающие просодические характеристики: Основным требованием было генерировать ответы с естественной просодией. Уникальная "схема токенизации речи, обогащенной просодией" USDM специально разработана для этой цели. Демонстрируя, что акустические единицы захватывают эмоциональные сигналы и вариации высоты тона (Раздел 3.1, Рисунок 2), метод гарантирует, что невербальные характеристики, критически важные для естественного диалога, сохраняются и генерируются. Это прямое и эффективное соответствие.
- Связные устные ответы: Модель использует мощные возможности рассуждения предобученной большой языковой модели (Mistral-7B). Вводя промежуточный этап генерации текста, вдохновленный рассуждением по цепочке мыслей, USDM гарантирует, что семантическая связность диалога поддерживается и даже улучшается. Это позволяет LLM генерировать "семантически связные диалоговые ответы" при работе в речевой области, выполняя требование связного вывода.
- Унифицированная кросс-модальная семантика: Предложенная "унифицированная схема предобучения речи-текста" способствует изучению "кросс-модальной распределительной семантики", которая "жизненно важна для наделения LLM способностью генерировать связную речь в моделировании разговорного диалога". Это всеобъемлющее предобучение, охватывающее различные отношения речь-текст, гарантирует, что модель может обрабатывать сложные взаимодействия и генерировать контекстуально соответствующие ответы, напрямую решая потребность в надежном и связном диалоге.
Отклонение альтернатив
Статья предоставляет четкое обоснование для отклонения двух основных категорий альтернативных подходов: каскадных систем и более простых сквозных моделей, которым не хватает всеобъемлющего кросс-модального предобучения.
-
Каскадные системы ASR + LLM + TTS:
- Обоснование: Авторы явно заявляют, что каскадные модели, несмотря на использование мощных отдельных компонентов, таких как
whisper-large-v3для ASR, страдают от "лингвистического несоответствия между речью и текстом" и "распространения ошибок, присущего каскадному конвейеру" [10, 11, 63]. Это приводит к "субоптимальному пользовательскому опыту" и ограничивает способность включать невербальные сигналы без явных, трудно собираемых меток. - Эмпирические доказательства: Базовая модель "Каскадная", хотя и достигает более низкого WER ASR, последовательно показывает худшие результаты, чем USDM, в тестах человеческих предпочтений по общему качеству, P-MOS (естественность просодии) и семантическим метрикам (METEOR, ROUGE-L, предпочтение GPT-4) (Таблицы 1 и 2). Это демонстрирует, что архитектурные ограничения каскадных систем перевешивают сильные стороны их отдельных компонентов для сквозного разговорного диалога.
- Обоснование: Авторы явно заявляют, что каскадные модели, несмотря на использование мощных отдельных компонентов, таких как
-
Сквозные модели с ограниченным предобучением (например, "С нуля" или специфические настройки предобучения):
- Обоснование: В статье утверждается, что "сквозные конвейеры [19, 25], которые фокусируются исключительно на обучении только на речи или используют простые кросс-модальные цели для предобучения речи-текста, не в полной мере используют возможности предобученных языковых моделей". Модель "С нуля", которая является USDM без обширного предобучения речи-текста, "склонна упускать из виду связующий текст и генерирует устный ответ, который не соответствует предварительно сгенерированному письменному ответу, тем самым негативно влияя на ее производительность". Это подчеркивает, что простого дообучения LLM на данных разговорного диалога недостаточно; модель должна изучать глубокие кросс-модальные взаимосвязи во время предобучения.
- Эмпирические доказательства: Базовая модель "С нуля" демонстрирует значительно более высокие показатели WER для TTS и STT (58,1% и 64,0% соответственно), гораздо более низкие оценки MOS и P-MOS, а также плохую семантическую производительность по сравнению с USDM (Таблицы 1 и 2). Кроме того, исследования по абляции схем предобучения (Раздел 4.2.1, Таблица 3, Таблица 9) показывают, что настройки (например, Настройка 1, Настройка 2, Настройка 3), которые моделируют только отношения продолжения или соответствия, или используют фиксированный шаблон, дают более высокую перплексию (PPL) и худшую производительность в последующем разговорном диалоге (например, Настройка 1 имеет значительно более высокие показатели WER для STT и TTS). Это подтверждает, что всеобъемлющая, унифицированная стратегия предобучения полезна, а более простые, менее интегрированные сквозные подходы недостаточны.
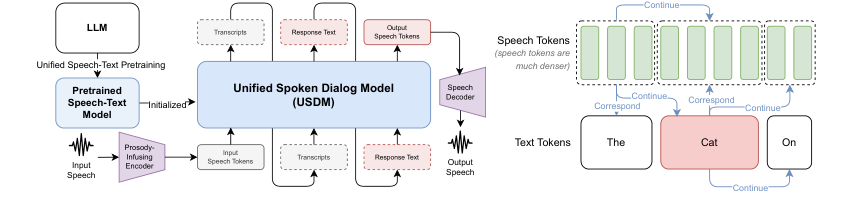 Figure 1. Overview of our spoken dialog modeling approach (Left). All possible self-supervised learning objectives from our speech-text pretraining scheme. (Right)
Figure 1. Overview of our spoken dialog modeling approach (Left). All possible self-supervised learning objectives from our speech-text pretraining scheme. (Right)
Математический и логический механизм
Основное уравнение
Абсолютно ключевым уравнением, которое лежит в основе данной статьи, особенно для унифицированного предобучения речи-текста и последующего дообучения, является функция целевой функции отрицательного логарифма правдоподобия. Эта функция направляет модель на изучение условной вероятности следующего токена при заданных предыдущих токенах авторегрессионным образом. Она формально представлена как:
$$L(\theta) = -\sum_{j=1}^{||D||} \sum_{k=1}^{||I_j||} \log p(i_{k,j}|i_{ Давайте разберем это уравнение и рассмотрим каждый компонент: $L(\theta)$: $\theta$: $\sum_{j=1}^{||D||}$: $\sum_{k=1}^{||I_j||}$: $\log p(i_{k,j}|i_{ $i_{k,j}$: $i_{ Представьте себе один абстрактный набор данных, который в данном контексте является чередующейся рече-текстовой выборкой $I_j$. Проследим его путь через математический движок: Прием последовательности: Вся чередующаяся последовательность $I_j$, состоящая из смеси токенов акустических единиц, текстовых токенов и специальных управляющих токенов (таких как Встраивание токенов: Каждый отдельный токен $i_{k,j}$ в $I_j$ сначала преобразуется в плотный числовой вектор, известный как встраивание (embedding). Для существующих текстовых токенов используются встраивания предобученной LLM. Для вновь введенных токенов речевых единиц и специальных токенов используются их инициализированные веса встраивания. Эти встраивания преобразуют дискретные токены в непрерывное, высокоразмерное пространство, где может обрабатываться семантическая и парангвистическая информация. Контекстное кодирование (LLM): Последовательность встраиваний затем пропускается через ядро модели: большую языковую модель (в данном случае Mistral-7B), которая обычно представляет собой архитектуру на основе Transformer. Для каждой позиции $k$ в последовательности модель обрабатывает предшествующие токены $i_{ Предсказание вероятности следующего токена: На каждом шаге $k$, на основе контекстного представления $i_{ Расчет потерь для одного токена: Затем система смотрит на фактический токен $i_{k,j}$, который произошел на этой позиции в истинной входной последовательности. Она извлекает вероятность, которую модель присвоила этому правильному токену из предсказанного распределения. Отрицательный логарифм этой вероятности, $-\log p(i_{k,j}|i_{ Агрегация потерь последовательности: Этот расчет потерь на уровне токенов повторяется для каждого токена $k$ во всей последовательности $I_j$. Все эти индивидуальные потери токенов суммируются, чтобы получить общие потери для конкретной выборки $I_j$. Агрегация потерь набора данных: Наконец, весь этот процесс (шаги 1-6) повторяется для каждой выборки $I_j$ в наборе данных $D$. Все индивидуальные потери выборок суммируются, чтобы получить общие потери $L(\theta)$ для всего пакета или набора данных. Это $L(\theta)$ является единым числовым значением, которое количественно определяет общую производительность модели. Механизм обучается, обновляется и сходится в основном через итеративный процесс, управляемый градиентным спуском, в частности, с использованием оптимизатора Adam. Ландшафт потерь: Функция потерь $L(\theta)$ определяет многомерный "ландшафт потерь", где каждая точка соответствует определенному набору параметров модели $\theta$ и его соответствующему значению потерь. Этот ландшафт, как правило, невыпуклый, то есть он имеет много локальных минимумов и седловых точек. Цель оптимизации — перемещаться по этому ландшафту, чтобы найти набор параметров $\theta$, который минимизирует $L(\theta)$. Целевая функция отрицательного логарифма правдоподобия по своей сути формирует этот ландшафт таким образом, что параметры, ведущие к более высоким вероятностям для правильных следующих токенов, приводят к более низким значениям потерь. Вычисление градиента (обратное распространение ошибки): После прямого прохода через модель, который вычисляет $L(\theta)$ для пакета обучающих данных, вычисляются градиенты этой функции потерь по отношению к каждому отдельному параметру в $\theta$. Это делается эффективно с использованием алгоритма обратного распространения ошибки. Эти градиенты, $\nabla_\theta L(\theta)$, указывают направление самого крутого подъема в ландшафте потерь. Чтобы минимизировать потери, параметры должны перемещаться в противоположном направлении градиента. Обновление параметров (оптимизатор Adam): В статье указано, что используется оптимизатор Adam. Adam — это алгоритм оптимизации с адаптивной скоростью обучения, который поддерживает скорости обучения для каждого параметра. Для каждого параметра он вычисляет: Планирование скорости обучения: В статье упоминается "линейное планирование скорости обучения". Это обычно означает, что скорость обучения $\alpha$ начинается с определенного значения, может линейно увеличиваться, а затем линейно уменьшается в течение всего обучения. Эта стратегия планирования помогает модели делать большие обновления в начале обучения, чтобы быстро исследовать ландшафт потерь, а затем более точные, мелкие обновления позже, чтобы точно настроить параметры и достичь хорошего минимума, не перескакивая. Сходимость: Путем многократных итераций прямого прохода, расчета потерь, вычисления градиентов и обновлений параметров параметры модели $\theta$ постепенно настраиваются. Потери $L(\theta)$ со временем уменьшаются, указывая на то, что модель становится лучше в предсказании следующих токенов в чередующихся рече-текстовых последовательностях. Процесс продолжается до тех пор, пока потери не сойдутся к стабильному минимуму, или не будет достигнуто заданное количество эпох обучения. Модель эффективно учится отображать входные речевые и текстовые контексты на вероятные следующие речевые или текстовые токены, тем самым приобретая способность генерировать связные и просодические устные ответы. Кросс-модальное предобучение особенно важно здесь, поскольку оно гарантирует, что ландшафт потерь сформирован для обеспечения беспрепятственных переходов и понимания между речевой и текстовой модальностями, предотвращая застревание модели в локальных минимумах, специфичных для модальности. Наша экспериментальная проверка была сосредоточена на наборе данных DailyTalk [70], коллекции из 20 часов данных разговорного диалога, с частотой дискретизации 22 050 Гц, с участием одного мужского и одного женского голоса. Этот набор данных был предварительно обработан для одноходового разговорного диалога, в результате чего было получено 20 117 обучающих выборок и 1058 тестовых выборок. Унифицированная модель разговорного диалога (USDM) была спроектирована с модулем преобразования речи в единицы, использующим официальный чекпойнт XLS-R [64] и квантователь с $k=10000$ [33], обученный на 436K часах многоязычных речевых данных. Для речевого декодера мы использовали модель unit-Voicebox на основе архитектуры Voicebox [66], обученную на 54k часах данных ASR из английских подмножеств Multilingual LibriSpeech [71] и GigaSpeech [72]. Этот unit-Voicebox был разработан для использования эталонной речи из предыдущего хода для нулевого выстрела (zero-shot) реконструкции, обеспечивая согласованность голоса в многоходовых диалогах. Основной большой языковой моделью (LLM) был Mistral-7B [67]. Наш этап предобучения включал 512 графических процессоров NVIDIA A100-40GB, глобальный размер пакета 1024 и 8000 итераций примерно на 87 000 часах английских данных ASR (включая Multilingual LibriSpeech, People's Speech, GigaSpeech, Common Voice и Voxpopuli) с максимальной длиной последовательности 8192. Дообучение на DailyTalk проводилось в течение 5 эпох с глобальным размером пакета 64, используя линейное планирование скорости обучения с пиковой скоростью обучения $2 \cdot 10^{-5}$. Вокодер BigVGAN [74] использовался для всего синтеза речи. Чтобы безжалостно доказать наши математические утверждения, мы противопоставили USDM трем "жертвам" — базовым моделям: Наша стратегия оценки сочетала как человеческие, так и автоматизированные метрики. Человеческие оценки проводились через Amazon Mechanical Turk и включали: Автоматизированные оценки включали тест предпочтений на основе GPT-4 [1] (с использованием Доказательства однозначно подтверждают, что наша унифицированная модель разговорного диалога (USDM) эффективно интегрирует парангвистическую информацию и генерирует превосходные устные ответы по сравнению с сильными базовыми моделями, в значительной степени благодаря своему новому предобучению и дообучению. Основной механизм использования токенов речи, обогащенных просодией, был строго проверен. В задаче распознавания эмоций с использованием акустических единиц на наборе данных CREMA-D [65] наш 3-слойный трансформерный классификатор эмоций достиг точности 60,8%. Это значительный скачок по сравнению с 16,6%, ожидаемыми от случайного угадывания, предоставляя неоспоримые доказательства того, что эти акустические единицы, которые традиционно считались в основном кодирующими семантическую информацию, также содержат богатые эмоциональные сигналы. Кроме того, наша модель реконструкции единиц в речь, обученная на 54 000 часах речевых данных, продемонстрировала, что, хотя тембр и абсолютная высота тона реконструированной речи могут отличаться от оригинала, вариация высоты тона тесно отражала истинные данные (Рисунок 2). Это неопровержимое доказательство того, что наши речевые токены успешно захватывают критически важные невербальные характеристики, такие как контуры высоты тона. Превосходство USDM в генерации естественных и связных устных ответов последовательно демонстрировалось в различных оценках: Исследования по абляции предоставили критически важные сведения об эффективности наших проектных решений: Несмотря на значительные достижения, представленные USDM, существует несколько присущих ограничений и захватывающих направлений для будущего развития. Во-первых, наше исследование наборов данных и моделей для этапа предобучения было несколько ограничено. Хотя мы продемонстрировали эффективность нашей схемы с Mistral-7B и определенным набором данных ASR, не совсем ясно, какие источники данных наиболее важны для оптимальной производительности, и насколько хорошо наша схема предобучения обобщается на другие LLM, кроме Mistral-7B. Будущая работа должна включать более систематическое исследование разнообразных наборов данных и архитектур LLM для выявления наиболее значимых комбинаций. Во-вторых, текущая архитектура USDM полагается на подход кросс-модальной цепочки: входная речь сначала транскрибируется в текст, затем генерируется текстовый ответ, и, наконец, этот текст синтезируется в устный вывод. Хотя эта стратегия "связующего текста" эффективно использует возможности рассуждения LLM, она вводит промежуточный этап. Перспективным направлением будущей работы является разработка модели разговорного диалога, способной напрямую генерировать устные ответы из входного разговорного диалога без этой явной кросс-модальной цепочки. Это оптимизировало бы конвейер и потенциально уменьшило бы распространение ошибок, предлагая поистине сквозной опыт "речь-в-речь". В-третьих, текущая схема предобучения в основном основана на десятках тысяч часов английских данных. Это представляет собой явное ограничение при применении USDM к другим языкам, особенно к тем, которые имеют относительно меньшие ресурсы речевых данных. Расширение нашей модели для поддержки более широкого спектра языков, помимо английского, является критически важным следующим шагом для повышения ее глобальной применимости и полезности. Это, вероятно, потребует изучения многоязычных стратегий предобучения и адаптации компонентов токенизации речи и декодирования для разнообразных лингвистических особенностей. Наконец, наш анализ динамики обучения для каждой задачи (Рисунок 7, справа) показал, что увеличение количества параметров дообучения, особенно с LoRA, иногда может приводить к ухудшению производительности задачи "единица-в-текст", предполагая потенциальное переобучение. Для решения этой проблемы будущие исследования могут изучить стратегии для смягчения переобучения в задаче "единица-в-текст". Это может включать динамическое изменение весов потерь для каждой задачи в конвейере или внедрение подходов к обучению по учебному плану, где модель постепенно подвергается более сложным задачам. Помимо этих конкретных моментов, более широкие последствия этой работы открывают несколько тем для обсуждения. Как мы можем дальше использовать продемонстрированную способность акустических единиц захватывать парангвистические признаки для создания более эмпатичных и контекстно-осведомленных диалоговых агентов? Можем ли мы разработать надежные механизмы для обеспечения этичного развертывания таких высококачественных моделей синтеза речи, предотвращая злоупотребления в сценариях, таких как голосовой фишинг, при максимизации положительного воздействия на общество, например, предоставление доступных альтернатив связи для людей с нарушениями чтения или письма? Кроме того, исследование изоморфизмов нашего подхода к предобучению с другими задачами "речь-текст", такими как перевод речи или резюмирование, может открыть еще более широкие области применения и укрепить основу для поистине мультимодальных LLM.Покомпонентный разбор.
Пошаговый поток
<|correspond|> или <|continue|>), подается в систему. Эта последовательность представляет собой сегмент разговорного диалога или пару речь-текст.Динамика оптимизации
Эти оценки затем корректируются по смещению. Правило обновления параметров для Adam:
$$\theta_{t+1} = \theta_t - \alpha \frac{\hat{m}_t}{\sqrt{\hat{v}_t} + \epsilon}$$
где $\theta_t$ — вектор параметров в момент времени $t$, $\alpha$ — скорость обучения (например, $10^{-4}$ для обучения unit-Voicebox, $2 \cdot 10^{-5}$ для предобучения/дообучения), $\hat{m}_t$ и $\hat{v}_t$ — скорректированные по смещению оценки первого и второго моментов, а $\epsilon$ — небольшая константа для предотвращения деления на ноль. Эта адаптивная природа позволяет Adam обрабатывать разреженные градиенты и параметры разных масштабов эффективно, помогая модели сходиться быстрее и более надежно.Результаты, ограничения и заключение
Экспериментальный дизайн и базовые модели
1. С нуля: Эта модель была почти идентична USDM, но, что критически важно, не имела унифицированного предобучения речи-текста. Она дообучила предобученную Mistral-7B напрямую на данных разговорного диалога с использованием тех же гиперпараметров, что и USDM. Эта базовая модель была разработана для изоляции влияния нашей новой схемы предобучения.
2. Каскадная: Этот подход использовал отдельные, готовые системы автоматического распознавания речи (ASR) и преобразования текста в речь (TTS). В частности, он использовал whisper-large-v3 [78] (обученный на 5M часах речевых данных) для ASR и модель Voicebox (обученную на текстовом входе, аналогично нашему unit-Voicebox) для TTS. LLM (Mistral-7B) была дообучена на транскрипциях данных разговорного диалога. Эта базовая модель представляла собой традиционный, модульный подход к разговорному диалогу.
3. SpeechGPT [25]: Мы использовали официальные реализации и чекпойнты SpeechGPT-7B-cm, передовой предобученной рече-текстовой модели, дообученной на DailyTalk для справедливого сравнения.
- Тесты общего предпочтения: 150 оценщиков сравнивали устные ответы USDM с базовыми моделями, учитывая естественность, просодию и семантическую связность для 50 случайно выбранных разговорных диалогов. Это стоило около 200 долларов США.
- Средняя оценка просодии (P-MOS): 198 оценщиков оценивали естественность просодии по 5-балльной шкале, имея истинные текстовые ответы. Это стоило около 250 долларов США.
- Средняя оценка (MOS): 176 оценщиков оценивали качество и естественность аудио по 5-балльной шкале, имея только текст ответа и устный ответ. Это также стоило около 250 долларов США.gpt-4-0125-preview) для оценки семантической адекватности транскрибированных ответов, а также количественные метрики, такие как оценки METEOR и ROUGE-L для семантического содержания и частота ошибок по словам (WER) как для компонента "речь-в-текст" (STT WER), так и для компонента "текст-в-речь" (TTS WER). Исследования по абляции далее детализировали вклад наших схем унифицированного предобучения и дообучения, используя перплексию (PPL) на LibriSpeech и вышеупомянутые диалоговые метрики на DailyTalk.Что доказывают доказательства
- Человеческие предпочтения: В комплексных тестах человеческих предпочтений USDM была предпочтительна аналогично истинным данным и значительно превосходила все базовые модели (p-значение < 0,05 по критерию знаковых рангов Уилкоксона). Это является сильным показателем ее общего качества и пользовательского опыта.
- Естественность просодии: USDM превзошла все базовые модели в оценках P-MOS (p-значение < 0,05), демонстрируя свою исключительную способность генерировать речь с естественной просодией. Она заметно превзошла каскадную модель, которая испытывала трудности с просодией, несмотря на использование явных меток, подчеркивая эффективное, неявное включение парангвистических признаков USDM.
- Семантическая связность: Наша модель превзошла базовые модели как по количественным метрикам (METEOR и ROUGE-L), так и по тесту предпочтений на основе GPT-4 (p-значение < 0,05) для семантической адекватности. Это подтверждает способность USDM генерировать семантически связные ответы, которые хорошо согласуются с входной речью.
- Унифицированное предобучение: Наша предложенная унифицированная схема предобучения речи-текста, которая моделирует как отношения соответствия, так и продолжения, достигла превосходной средней перплексии (PPL) по всем модальностям и типам последовательностей (Таблица 3, Таблица 9). Это окончательно доказало, что всеобъемлющая стратегия предобучения необходима для того, чтобы LLM изучала разнообразные рече-текстовые взаимодействия, а не специализировалась на ограниченных отношениях. Модель "С нуля", которой не хватало этого предобучения, показала значительно худшие показатели WER для TTS и STT (64,0% и 58,1% соответственно) и плохую семантическую производительность, подчеркивая критическую роль кросс-модального предобучения.
- Моделирование промежуточного текста: Схема дообучения, которая использует промежуточный текст в качестве моста (вход речи -> транскрипция текста -> генерация текстового ответа -> синтез устного ответа), оказалась высокоэффективной. Прямая модель "речь-в-речь" (S1 -> S2) показала значительно худшие результаты по показателям METEOR и ROUGE-L (Таблица 3), подтверждая, что использование возможностей рассуждения предобученной LLM через текстовую модальность является полезным.
- Использование входной модальности: Карты внимания (Рисунок 4) показали, что сгенерированные ответы USDM обращают внимание как на входную речь, так и на ее транскрибированный текст. Эти визуальные доказательства подтверждают, что наша модель эффективно интегрирует информацию из обеих модальностей, что приводит к более надежным и семантически связным выводам. Более того, замена сгенерированной моделью входной транскрипции на истинную транскрипцию улучшила показатели METEOR и ROUGE-L (13,6 против 13,1 и 16,2 против 15,7 соответственно), демонстрируя, что улучшение точности преобразования единиц в текст в USDM напрямую повышает семантическую связность.Ограничения и будущие направления
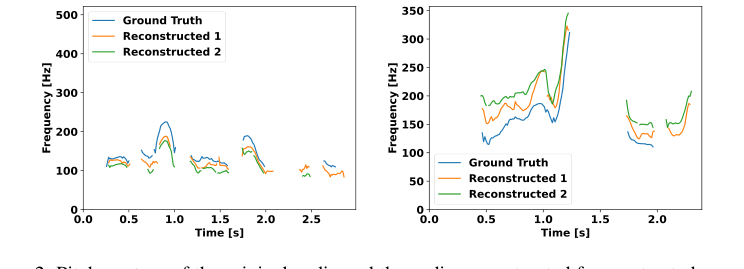 Figure 2. Pitch contour of the original audio and the audio reconstructed from extracted acoustic units. Due to the stochastic nature of the reconstruction model, we attempt reconstruction twice, demonstrating that the pitch variation closely mirrors the ground truth
Figure 2. Pitch contour of the original audio and the audio reconstructed from extracted acoustic units. Due to the stochastic nature of the reconstruction model, we attempt reconstruction twice, demonstrating that the pitch variation closely mirrors the ground truth
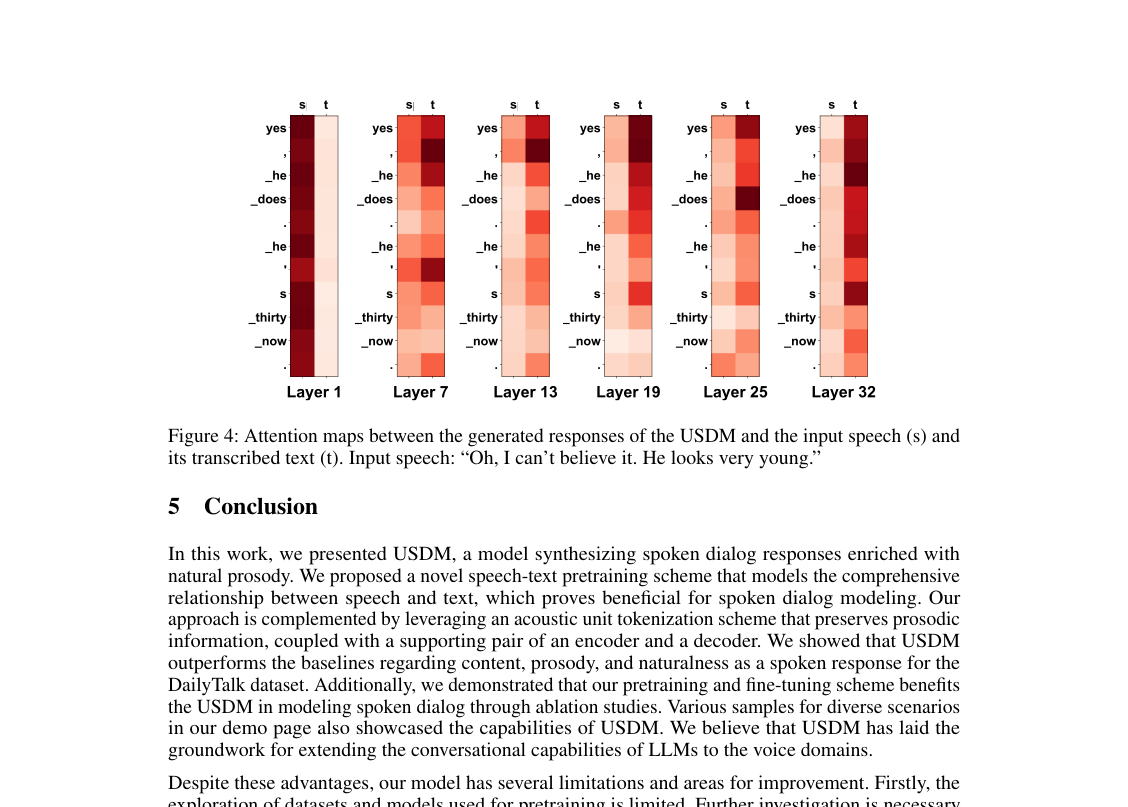 Figure 4. Attention maps between the generated responses of the USDM and the input speech (s) and its transcribed text (t). Input speech: “Oh, I can’t believe it. He looks very young.”
Figure 4. Attention maps between the generated responses of the USDM and the input speech (s) and its transcribed text (t). Input speech: “Oh, I can’t believe it. He looks very young.”
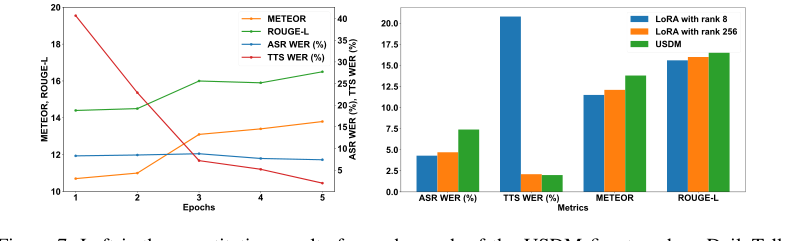 Figure 7. Left is the quantitative results for each epoch of the USDM fine-tuned on DailyTalk. The figure on the right illustrates the performance of the Spoken Dialog Model when trained with Low-Rank Adaptation (LoRA) versus full fine-tuning
Figure 7. Left is the quantitative results for each epoch of the USDM fine-tuned on DailyTalk. The figure on the right illustrates the performance of the Spoken Dialog Model when trained with Low-Rank Adaptation (LoRA) versus full fine-tuning