面向自然对话的具身智能大语言模型:融合韵律感知
Recent work shows promising results in expanding the capabilities of large language models (LLM) to directly understand and synthesize speech.
背景与学术渊源
起源与学术渊源
本文所解决的问题源于近期大语言模型(LLMs)在文本对话人工智能领域的飞速发展和广泛应用。尽管LLMs在理解、生成和推理文本方面展现出了卓越的能力,但将其直接应用于口语对话仍然是一个重大挑战。核心动机在于将LLMs强大的涌现能力——如少样本上下文学习和复杂推理——扩展到自然口语对话领域,从而实现更直观、更类人的交互。
历史上,早期的口语模型(SLMs)要么仅专注于语音数据,要么采用非常简单的跨模态目标,未能充分利用预训练LLMs精深的语言理解能力。随着高度强大的文本LLMs的出现,学术界的研究方向转向将语音模态整合到这些模型中。
先前方法存在的根本性局限或“痛点”,促使本研究的进行,可归纳为两大类:
-
级联模型(Cascaded Models):这类方法通常涉及独立的自动语音识别(ASR)将用户语音转换为文本,LLM生成文本响应,然后文本到语音(TTS)系统合成语音回复。
- 语言学差异(Linguistic Discrepancy):一个显著的“痛点”是语音和文本在传达信息方式上的固有不匹配。语音承载着丰富韵律外信息(paralinguistic cues),如情感、语调和节奏,这些信息在ASR转换为纯文本时会丢失。这种语言学差异导致对话效率低下和用户体验不佳,因为LLM仅基于语义内容进行操作,常常忽略了至关重要的非语言上下文。
- 韵律信息的标签依赖(Label Dependency for Paralinguistics):为了在级联模型中融入韵律特征,通常需要显式的标签(例如,情感标签)。这使得数据收集变得困难,并将模型限制在只能处理可显式标记的非语言线索上。
- 误差传播(Error Propagation):一个主要缺点是误差的累积。ASR系统或文本LLM引入的任何不准确之处都可能在整个流水线中传播,导致口语回复不够连贯或听起来不自然。
-
端到端纯语音或简单跨模态模型(End-to-End Speech-Only or Simple Cross-Modal Models):虽然存在一些端到端流水线,但它们往往未能充分利用预训练LLMs中嵌入的广泛知识和推理能力。这些模型在捕捉语音和文本模态之间全面、复杂的关系方面可能受限,从而阻碍了它们在生成上下文丰富且韵律恰当的口语对话方面的表现。作者们强调,先前模型通过专注于特定任务或简单的跨模态目标,未能充分挖掘统一框架可能提供的深度跨模态理解的潜力。
直观的领域术语
以下是论文中的三个高度专业化的领域术语,用面向零基础读者的直观日常类比进行翻译:
-
韵律外信息(Paralinguistics):想象你在讲一个故事。你使用的词语是主要信息(语义)。但你讲述的方式——你的声音的语调、说话的速度、停顿的位置、听起来是兴奋还是悲伤——这就是韵律外信息。它包含了所有非语言的声音和发声特质,为你说的话增加了意义和情感。一个理解韵律外信息的计算机,不仅仅听到“我很好”,它还能听到你说“我很好”的方式,从而判断你是否真的很好,还是在讽刺。
-
声学单元/离散语音表示(Acoustic Units / Discrete Speech Representations):想象一部电影。它是一个连续的动态画面流,但实际上是由成千上万个独立的静态画面(帧)组成的。声学单元就像语音的这些独立帧。我们不处理连续的声波,而是将语音分解成微小的、离散的声音“块”或“标记”。这些块然后被归类为有限的几种类型,就像一小盒独特的乐高积木。通过选择和排列这些特定的“乐高积木”,计算机可以重建语音,同时捕捉词语和细微的发声变化。
-
韵律(Prosody):这是语言的音乐。当你说话时,你的声音自然地高低起伏,你在某些词上加重音,并改变你的语速。这种音高、重音和节奏的模式被称为韵律。它使得一个问句听起来像问句,或者一个兴奋的陈述听起来很兴奋。没有韵律,所有的语音都会听起来平淡而机械,就像一台电脑用单调的声音朗读文本。它区分了充满热情地说“我喜欢那个”和用一种平淡、缺乏激情的语调说这句话。
符号表
| 符号 | 描述 |
|---|---|
问题定义与约束
核心问题表述与困境
本文所解决的核心问题是当前大语言模型(LLMs)在端到端处理自然口语对话方面的局限性。
输入/当前状态:
现有的LLMs在文本任务上表现出色,在复杂推理、少样本学习和指令遵循方面展现出卓越的能力。然而,在口语交互方面,它们通常以级联的方式与独立的自动语音识别(ASR)和文本到语音(TTS)系统集成。或者,一些模型仅专注于语音处理,而未能利用LLMs的全部潜力。
期望终点(输出/目标状态):
目标是开发一个统一口语对话模型(Unified Spoken Dialog Model, USDM),能够将语音模态无缝集成到LLMs中。该模型应能够:
1. 直接理解用户语音,包括细微的语调和情感状态(韵律外信息),而无需依赖显式ASR。
2. 生成连贯的口语回复,具有自然发生的、上下文恰当的韵律特征,而无需依赖显式TTS。
3. 在端到端流水线中保持并增强LLM强大的对话生成和推理能力。
缺失环节/数学鸿沟:
确切的缺失环节是一个统一的、基于LLM的框架,该框架能够通过系统地将语音中的语义和韵律外信息整合到LLM的处理过程中,从而有效地弥合原始语音输入和自然口语回复之间的差距。这需要一种新颖的语音-文本表示和预训练方案,使LLM能够学习全面的跨模态关系,并生成本身就带有韵律信息而非仅仅语义内容的语音标记。本文旨在通过提出一个“注入韵律的语音标记化方案”和一个“增强跨模态语义捕获的通用语音-文本预训练方案”来弥合这一鸿沟。
困境:
先前研究陷入了利用LLM能力和自然处理语音之间的痛苦权衡:
* 级联ASR/TTS vs. 端到端连贯性:虽然可以轻松采用ASR和TTS系统,但它们的级联使用会导致“语音与文本之间的语言学差异”,造成“对话效率低下和用户体验不佳”[10, 11]。更关键的是,这些流水线遭受“级联流水线固有的误差传播”[63]的影响,ASR或文本对话模型的错误会累积,导致口语回复不够连贯或自然。此外,在级联模型中纳入韵律外特征(如情感或语调)通常需要“显式标签”,使得“数据收集困难,并将模型限制在表示可定义标签的非语言线索上”(第2节,第3页)。
* 纯语音模型 vs. LLM推理:仅在语音数据上训练的早期口语模型(SLMs)[17, 19]缺乏现代LLM的高级推理和生成能力,限制了它们的对话能力。困境是如何在不损失语音信号丰富性的前提下,赋予语音模型类似LLM的智能。
* 语音标记中的语义信息 vs. 韵律外信息:语音标记通常设计用于编码语义内容。挑战在于创建一种离散语音表示,它不仅传递语义信息,还传递大量的韵律外信息(例如,情感、音高变化),并且LLM能够有效地利用这些信息来生成听起来自然、上下文恰当的口语回复。
约束与失效模式
构建一个面向自然对话的具身智能、感知韵律外信息的LLM是一个极其困难的问题,原因在于存在一些严苛的现实约束:
- 数据驱动约束:
- 缺乏对齐的跨模态数据(Lack of Aligned Cross-Modal Data):创建全面的语音-文本模型需要大量高质量、对齐的语音和文本数据,这些数据需要捕捉多样化的对话上下文和韵律外特征。本文指出,其当前的预训练方案依赖于“数万小时的英语数据”(第5节,第10页),表明了巨大的数据需求。
- 标记韵律外数据稀疏(Sparsity of Labeled Paralinguistic Data):韵律外特征(如情感或语调)的显式标签稀缺且难以大规模获取,这是依赖这些标签的模型的重大障碍(第2节,第3页)。
- 多语言限制(Multilingual Limitations):当前模型主要在英语数据上训练,其在“语音数据相对较少”的其他语言上的适用性有限,对通用部署构成了挑战(第5节,第10页)。
- 计算约束:
- 预训练的极端计算成本(Extreme Computational Cost for Pretraining):训练大型语音-文本模型,特别是基于LLM架构的模型,需要巨大的计算资源。本文提到使用了“512个NVIDIA A100-40GB GPU,全局批次大小为1,024,迭代8,000次”(第4.1.1节,第7页),凸显了其巨大的硬件需求。
- 长序列的内存限制(Memory Limits for Long Sequences):处理交错的语音-文本序列,特别是“最大序列长度为8,192”(第4.1.1节,第7页),会迅速达到硬件内存限制,使得建模对话中的长程依赖关系变得困难。
- 架构与功能约束:
- 保持LLM推理能力(Maintaining LLM Reasoning Capabilities):将语音集成到LLMs中不得损害其核心推理和生成能力。模型需要有效地执行“跨中间模态的链式推理”(第3.3节,第6页)。
- 生成自然韵律(Generating Natural Prosody):合成具有“与给定输入语音相关的自然发生的韵律特征”的语音是一项复杂任务。模型必须学会从上下文中推断并生成恰当的韵律,这是人类交流中一个微妙且困难的方面(摘要,第1页)。
- 对输入变化和错误的鲁棒性(Robustness to Input Variations and Errors):系统必须对输入语音质量、口音和潜在的转录不准确性等变化具有鲁棒性,特别是如果使用了中间文本表示。本文旨在实现一种“比级联系统更鲁棒,不易受转录错误影响”的方法(第3.3节,第6页)。
- 跨模态语义对齐(Cross-Modal Semantic Alignment):确保语音和文本模态在语义上对齐,并且模型能够学习“跨模态分布语义”,这对于连贯的对话生成至关重要(第2页)。
- 跨越多样化关系的泛化能力(Generalization Across Diverse Relationships):一个仅关注特定类型关系的预训练方案(例如,对应或延续)可能会“将模型的性能限制在仅预定义的那些关系上”(第3.2节,第5页),阻碍其处理多样化语音-文本交互的能力。模型必须是多功能的。
为何选择此方法
选择的必然性
作者们决定开发统一口语对话模型(USDM)作为一种基于LLM的端到端口语对话框架,这是由现有“SOTA”方法固有的局限性所驱动的。在观察到级联系统和先前端到端语音模型的基本缺陷后,他们关键地认识到传统方法是不够的。
具体而言,本文强调,尽管自动语音识别(ASR)和文本到语音(TTS)系统可以方便地使用,但它们的顺序性质引入了“语音与文本之间的语言学差异”,导致“对话效率低下,并导致用户体验不佳”[10, 11]。这种级联方法还要求为韵律外特征提供显式标签,使得数据收集困难,并将模型限制在只能处理可定义标签的非语言线索上。至关重要的是,“级联流水线固有的误差传播[63]增加了其对累积错误的敏感性”,使其成为真正自然连贯的口语对话不可靠的基础。
此外,现有的基于LLM的语音模型,尽管取得了成功,但被发现不足以在口语对话环境中自然地生成语音、理解和整合韵律外信息。早期依赖纯语音训练或简单跨模态目标的端到端流水线[19, 25]“未能充分利用预训练语言模型的能力”。作者们认识到,一个全面、统一的方法是克服这些根深蒂固问题的唯一可行解决方案,并使LLMs能够真正理解和生成具有适当韵律外特征的语音,并将其用于对话情境。
比较优势
USDM主要通过其统一的跨模态预训练以及将韵律外信息直接注入语音标记的能力,展现出优于先前黄金标准的定性优势。这种结构优势使其能够生成更自然、语义更连贯的口语回复。
与遭受误差传播和依赖显式标签来获取非语言线索的级联系统不同,USDM的端到端设计从一开始就集成了语音和文本模态,从根本上缓解了这些问题。该模型独特的语音标记化方案,源自自监督语音表示(XLS-R)的k-means聚类,已被证明包含显著的韵律外信息,如情感和音高变化。实验证实,这些声学单元在情感识别方面达到了60.8%的准确率,远超随机猜测预期的16.6%。这种捕捉和重建音高轮廓的能力(如图2所示)是生成自然韵律的直接定性优势,而这在级联系统中通常会因基于文本的中间表示而丢失或处理不当。
此外,USDM的基于LLM的建模策略,通过在语音输入和输出之间插入与文本相关的任务,利用了底层LLM的“链式推理”能力[6]。这使得该方法“比在独立模块中进行更鲁棒,不易受转录错误影响,并且更擅长生成上下文相关的口语回复”。这种鲁棒的、上下文感知的生成,特别是在韵律外信息方面,代表了质的飞跃。本文的消融研究进一步强调了这一点,表明缺乏全面跨模态预训练的模型(如“从头开始”模型或设置1)在韵律和语义连贯性方面表现明显较差,凸显了USDM统一预训练的结构优势。
与约束的对齐
所选的USDM方法通过直接解决在不依赖独立ASR或TTS模块的情况下生成连贯、富含韵律的口语回复的需求,完美地契合了问题的严苛要求。这种“结合”在几个关键方面显而易见:
- 端到端口语对话生成(End-to-End Spoken Dialog Generation):主要约束是超越级联系统。USDM通过在单个LLM框架内集成语音和文本模态来实现这一点,消除了对话生成过程中对显式ASR和TTS组件的依赖。这直接解决了“无需依赖显式自动语音识别(ASR)或文本到语音(TTS)系统”的要求。
- 自然发生的韵律特征(Naturally Occurring Prosodic Features):核心要求是生成具有自然韵律的回复。USDM独特的“注入韵律的语音标记化方案”正是为此而设计的。通过证明声学单元能够捕捉情感线索和音高变化(第3.1节,图2),该方法确保了自然对话中至关重要的非语言特征得以保留和生成。这是一个直接有效的对齐。
- 连贯的口语回复(Coherent Spoken Responses):该模型利用了预训练大语言模型(Mistral-7B)强大的推理能力。通过引入中间文本生成步骤,借鉴了思维链推理的启发,USDM确保了对话的语义连贯性得到维持甚至增强。这使得LLM在语音领域操作时能够生成“语义连贯的对话回复”,满足了连贯输出的要求。
- 统一的跨模态语义(Unified Cross-Modal Semantics):提出的“统一语音-文本预训练方案”促进了“跨模态分布语义”的学习,这“对于赋予LLMs在口语对话建模中生成连贯语音的能力至关重要”。这种全面的预训练,涵盖了各种语音-文本关系,确保模型能够处理复杂的交互并生成上下文恰当的回复,直接满足了对鲁棒和连贯对话的需求。
替代方案的拒绝
本文为拒绝两大类替代方案提供了清晰的理由:级联系统和缺乏全面跨模态预训练的更简单的端到端模型。
-
级联ASR + LLM + TTS系统:
- 理由:作者们明确指出,级联模型尽管使用了像
whisper-large-v3这样的强大独立组件进行ASR,但它们遭受“语音与文本之间的语言学差异”和“级联流水线固有的误差传播”[10, 11, 63]的影响。这导致了“用户体验不佳”,并限制了在没有显式、难以收集的标签的情况下整合非语言线索的能力。 - 实证证据:虽然“级联”基线在ASR WER方面取得了较低的成绩,但在整体质量、P-MOS(韵律自然度)以及语义指标(METEOR、ROUGE-L、GPT-4偏好度)方面,在人类偏好测试中始终表现不如USDM(表1和表2)。这表明,对于端到端口语对话而言,级联系统的架构限制超过了其独立组件的优势。
- 理由:作者们明确指出,级联模型尽管使用了像
-
预训练有限的端到端模型(例如,“从头开始”或特定预训练设置):
- 理由:本文认为,“仅专注于纯语音训练或利用简单的跨模态目标进行语音-文本预训练的端到端流水线[19, 25]未能充分利用预训练语言模型的能力。”“从头开始”模型,即USDM在没有广泛语音-文本预训练的情况下,在口语对话数据上直接微调预训练的Mistral-7B,表现不佳。“倾向于忽略桥接文本,并生成与预先生成的书面回复不对应的口语回复,从而对其性能产生负面影响。”这凸显了仅仅在口语对话数据上微调LLM是不够的;模型需要在预训练期间学习深层的跨模态关系。
- 实证证据:“从头开始”基线在STT和TTS WER方面表现明显更差(分别为58.1%和64.0%),MOS和P-MOS得分也低得多,并且在语义性能方面不如USDM(表1和表2)。此外,关于预训练方案的消融研究(第4.2.1节,表3,表9)表明,仅建模延续或对应关系,或使用固定模板的设置(例如,设置1,设置2,设置3)会产生更高的困惑度(PPL)和更差的下游口语对话性能(例如,设置1的STT和TTS WER显著更高)。这证实了全面的、统一的预训练策略是有益的,而更简单、集成度较低的端到端方法则不足。
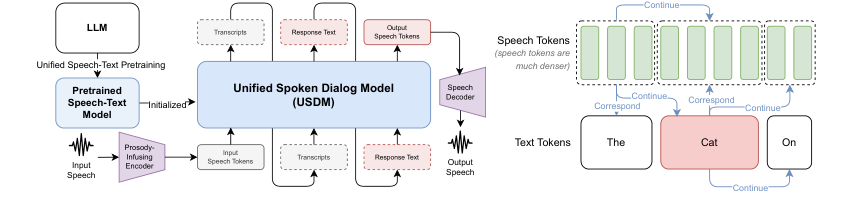 Figure 1. Overview of our spoken dialog modeling approach (Left). All possible self-supervised learning objectives from our speech-text pretraining scheme. (Right)
Figure 1. Overview of our spoken dialog modeling approach (Left). All possible self-supervised learning objectives from our speech-text pretraining scheme. (Right)
数学与逻辑机制
核心方程
驱动本文的核心方程,特别是对于统一的语音-文本预训练和后续微调,是负对数似然目标函数。该函数指导模型以自回归方式学习给定先前标记的下一个标记的条件概率。其形式如下:
$$L(\theta) = -\sum_{j=1}^{||D||} \sum_{k=1}^{||I_j||} \log p(i_{k,j}|i_{ 让我们将这个方程分解并检查每个组件: $L(\theta)$: $\theta$: $\sum_{j=1}^{||D||}$: $\sum_{k=1}^{||I_j||}$: $\log p(i_{k,j}|i_{ $i_{k,j}$: $i_{ 想象一个抽象的数据点,在本文的上下文中,它是一个交错的语音-文本样本$I_j$。让我们追踪它在数学引擎中的旅程: 序列输入(Sequence Ingestion):整个交错序列$I_j$,包含混合的声学单元标记、文本标记和特殊控制标记(如 标记嵌入(Token Embedding):$I_j$中的每个单独标记$i_{k,j}$首先被转换为一个密集的数值向量,称为嵌入。对于现有的文本标记,使用预训练LLM的嵌入。对于新引入的语音单元标记和特殊标记,则使用其重新初始化的嵌入权重。这些嵌入将离散标记转换为连续的高维空间,其中语义和韵律外信息可以被处理。 上下文编码(LLM)(Contextual Encoding (LLM)):嵌入序列随后被传递到模型的核心:一个大型语言模型(在本例中为Mistral-7B),它通常是一个基于Transformer的架构。对于序列中的每个位置$k$,模型处理先前的标记$i_{ 下一个标记概率预测(Next Token Probability Prediction):在每个步骤$k$,基于$i_{ 单个标记的损失计算(Loss Calculation for a Single Token):系统随后查看真实输入序列中该位置实际发生的标记$i_{k,j}$。它检索模型从预测分布中分配给该正确标记的概率。计算该概率的负对数,$-\log p(i_{k,j}|i_{ 序列损失聚合(Sequence Loss Aggregation):此标记级损失计算对序列$I_j$中的每个标记$k$重复进行。所有这些单独的标记损失被加起来,得到该特定样本$I_j$的总损失。 数据集损失聚合(Dataset Loss Aggregation):最后,这个整个过程(步骤1-6)对数据集$D$中的每个样本$I_j$重复进行。所有单独的样本损失被加起来,得到整个批次或数据集的总损失$L(\theta)$。这个$L(\theta)$是量化模型整体性能的单一数值。 该机制主要通过梯度下降驱动的迭代过程来学习、更新和收敛,特别是使用Adam优化器。 损失景观(Loss Landscape):损失函数$L(\theta)$定义了一个高维“损失景观”,其中每个点对应于一组特定的模型参数$\theta$及其相关的损失值。这个景观通常是非凸的,意味着它有许多局部最小值和鞍点。优化的目标是导航这个景观,找到最小化$L(\theta)$的参数集$\theta$。负对数似然目标函数自然地塑造了这个景观,使得导致正确下一个标记更高概率的参数产生更低的损失值。 梯度计算(反向传播)(Gradient Computation (Backpropagation)):在模型进行前向传播计算一批训练数据的$L(\theta)$后,计算该损失相对于$\theta$中每个参数的梯度。这是使用反向传播算法高效完成的。这些梯度,$\nabla_\theta L(\theta)$,指示了损失景观中最陡峭的上升方向。为了最小化损失,参数必须朝着与梯度相反的方向移动。 参数更新(Adam优化器)(Parameter Updates (Adam Optimizer)):本文提到使用了Adam优化器。Adam是一种自适应学习率优化算法,它维护每个参数的学习率。对于每个参数,它计算: 学习率调度(Learning Rate Scheduling):本文提到了“线性学习率调度”。这通常意味着学习率$\alpha$从某个值开始,可能线性预热,然后在训练过程中线性衰减。这种调度策略有助于模型在训练早期进行较大的更新以快速探索损失景观,然后在后期进行较小、更精确的更新,以进行微调并稳定在良好的最小值,而不会过冲。 收敛(Convergence):通过重复前向传播、损失计算、梯度计算和参数更新的迭代,模型参数$\theta$被逐渐调整。损失$L(\theta)$随时间下降,表明模型在预测交错语音-文本序列中的下一个标记方面变得越来越好。该过程一直持续到损失收敛到稳定最小值,或达到预定的训练周期数。模型有效地学会将输入的语音和文本上下文映射到可能的下一个语音或文本标记,从而获得生成连贯且具有韵律的口语对话回复的能力。跨模态预训练在这里尤为重要,因为它确保了损失景观的形状能够促进模态之间的无缝过渡和理解,防止模型陷入模态特定的局部最小值。 我们的实验验证集中在DailyTalk数据集[70]上,该数据集包含20小时的口语对话数据,采样率为22,050 Hz,由一名男性和一名女性说话人组成。该数据集被预处理为单轮口语对话,产生了20,117个训练样本和1,058个测试样本。 统一口语对话模型(USDM)的架构包括一个语音到单元模块,使用了XLS-R[64]的官方检查点和一个具有$k=10,000$个单元的量化器[33],该模块在436K小时的多语言语音数据上进行了训练。对于语音解码器,我们采用了基于Voicebox架构[66]的单元-Voicebox模型,该模型在来自英语子集的多语言LibriSpeech[71]和GigaSpeech[72]的54k小时ASR数据上进行了训练。该单元-Voicebox被设计为使用前一轮的参考语音进行零样本重建,确保多轮对话中的声音一致性。核心大型语言模型(LLM)是Mistral-7B[67]。我们的预训练阶段使用了512个NVIDIA A100-40GB GPU,全局批次大小为1,024,迭代8,000次,覆盖约87,000小时的英语ASR数据(包括Multilingual LibriSpeech、People's Speech、GigaSpeech、Common Voice和Voxpopuli),最大序列长度为8,192。在DailyTalk上的微调进行了5个epoch,全局批次大小为64,使用线性学习率调度,峰值学习率为$2 \cdot 10^{-5}$。BigVGAN[74]声码器用于所有语音合成。 为了严苛地证明我们的数学主张,我们将USDM与三个“受害者”基线模型进行了比较: 我们的评估策略结合了人类和自动化指标。人类评估通过Amazon Mechanical Turk进行,包括: 自动化评估包括基于GPT-4的偏好测试[1](使用 证据明确证明,我们的统一口语对话模型(USDM)有效地整合了韵律外信息,并生成了优于强大基线的口语回复,这主要归功于其新颖的预训练和微调策略。 利用注入韵律的语音标记的核心机制得到了严格验证。在使用CREMA-D数据集[65]的声学单元进行情感识别任务时,我们基于3层Transformer的情感分类器达到了60.8%的准确率。这比随机猜测预期的16.6%有了显著的飞跃,提供了无可辩驳的证据表明,这些声学单元,传统上认为主要编码语义信息,也包含了丰富的情感线索。此外,我们的单元到语音重建模型,在54,000小时语音数据上训练,表明虽然重建语音的音色和绝对音高可能与原始语音不同,但音高变化密切反映了真实情况(图2)。这是我们语音标记成功捕捉音高轮廓等关键非语言特征的硬性证据。 USDM在生成自然连贯的口语回复方面的优越性在多项评估中得到了一致证明: 消融研究提供了对我们设计选择有效性的关键见解: 尽管USDM取得了显著的进步,但仍存在一些固有的局限性和令人兴奋的未来发展方向。 首先,我们对预训练阶段数据集和模型的探索相对有限。虽然我们已经展示了该方案与Mistral-7B和特定ASR数据集的有效性,但尚不完全清楚哪些数据源对最佳性能最关键,也未完全确定我们的预训练方案在多大程度上能泛化到Mistral-7B以外的其他LLM。未来的工作应更系统地研究多样化数据集和LLM架构,以确定最具影响力的组合。 其次,当前的USDM架构依赖于一种跨模态链式方法:语音输入首先被转录为文本,然后生成文本回复,最后将文本合成为语音输出。虽然这种“桥接文本”策略有效地利用了LLM的推理能力,但它引入了一个中间步骤。一个有前途的未来方向是开发一个能够直接从输入口语对话生成口语回复,而无需这种显式跨模态链式的口语对话模型。这将简化流水线并可能减少误差传播,提供真正的端到端语音到语音体验。 第三,当前的预训练方案主要基于数万小时的英语数据。当将USDM应用于其他语言时,特别是那些语音数据资源相对较少的语言,这构成了一个明显的限制。将我们的模型扩展到支持更多样化的语言,而不仅仅是英语,是提高其全球适用性和实用性的关键下一步。这可能需要探索多语言预训练策略,并调整语音标记化和解码组件以适应不同的语言特征。 最后,我们对每项任务的动态训练分析(图7,右侧)表明,增加微调参数的数量,特别是使用LoRA时,有时会导致单元到文本任务性能下降,这表明可能存在过拟合。为了解决这个问题,未来的研究可以探索减轻单元到文本任务过拟合的策略。这可能包括动态调整流水线中各项任务的损失权重,或实施课程学习方法,让模型逐步接触更复杂的任务。 除了这些具体点之外,这项工作的更广泛意义还开启了几个讨论话题。我们如何进一步利用声学单元捕捉韵律外特征的已证明能力,以构建更具同理心和上下文感知的对话代理?我们能否开发鲁棒的机制来确保此类高质量语音合成模型的道德部署,防止在语音网络钓鱼等场景中滥用,同时最大化其社会效益,例如为有读写困难的个体提供可访问的沟通替代方案?此外,研究我们预训练方法的同构性与其他语音-文本任务(如语音翻译或摘要)的同构性,可能会解锁更广泛的应用,并为真正多模态的LLM奠定坚实的基础。 一种生成式序列建模框架,它学习不同模态离散表示之间的全面关系,以产生上下文丰富的输出。逐项剖析
步骤流程
<|correspond|>或<|continue|>),被输入到系统中。该序列代表了口语对话或语音-文本对的一个片段。优化动力学
这些估计随后进行偏差校正。Adam的参数更新规则是:
$$\theta_{t+1} = \theta_t - \alpha \frac{\hat{m}_t}{\sqrt{\hat{v}_t} + \epsilon}$$
其中$\theta_t$是时间步$t$时的参数向量,$\alpha$是学习率(例如,单元-Voicebox训练为$10^{-4}$,预训练/微调为$2 \cdot 10^{-5}$),$\hat{m}_t$和$\hat{v}_t$是偏差校正后的一阶和二阶矩估计,$\epsilon$是一个小的常数,以防止除以零。这种自适应性使得Adam能够有效地处理稀疏梯度和不同尺度的参数,帮助模型更快、更鲁棒地收敛。结果、局限性与结论
实验设计与基线
1. 从头开始(From Scratch):该模型与USDM几乎相同,但关键是缺乏统一的语音-文本预训练。它使用与USDM相同的超参数,直接在口语对话数据上微调了预训练的Mistral-7B。该基线旨在隔离我们新颖预训练方案的影响。
2. 级联(Cascaded):该方法采用了独立的、现成的自动语音识别(ASR)和文本到语音(TTS)系统。具体来说,它使用了whisper-large-v3[78](在5M小时语音数据上训练)进行ASR,以及一个Voicebox模型(使用文本输入训练,类似于我们的单元-Voicebox)进行TTS。LLM(Mistral-7B)在口语对话数据的转录文本上进行了微调。该基线代表了口语对话的传统、模块化方法。
3. SpeechGPT [25]:我们使用了SpeechGPT-7B-cm的官方实现和检查点,这是一个最先进的预训练语音-文本模型,在DailyTalk上进行了微调,以进行公平比较。
- 整体偏好测试(Overall Preference Tests):150名评估员比较了USDM的口语回复与基线回复,考虑了自然度、韵律和语义连贯性,针对50个随机选择的口语对话。此项成本约200美元。
- 韵律平均意见得分(Prosody Mean Opinion Score, P-MOS):198名评估员在5分制量表上对韵律自然度进行评分,给定真实的文本回复。此项成本约250美元。
- 平均意见得分(Mean Opinion Score, MOS):176名评估员在5分制量表上对音频质量和自然度进行评分,仅给定回复文本和口语回复。此项成本也约250美元。gpt-4-0125-preview)来评估转录回复的语义适当性,以及诸如METEOR和ROUGE-L分数(用于语义内容)以及词错误率(WER)(用于语音到文本(STT WER)和文本到语音(TTS WER)组件)等定量指标。消融研究进一步剖析了我们统一预训练和微调方案的贡献,使用了LibriSpeech上的困惑度(PPL)以及DailyTalk上的上述对话指标。证据证明了什么
- 人类偏好:在全面的人类偏好测试中,USDM的偏好度与真实情况相似,并且显著优于所有基线(根据Wilcoxon符号秩检验的p值<0.05)。这是其整体质量和用户体验的有力指标。
- 韵律自然度:在P-MOS评估中,USDM优于所有基线(p值<0.05),展示了其生成具有自然韵律的语音的卓越能力。它显著优于级联模型,后者尽管使用了显式标签,但在韵律方面仍存在困难,这凸显了USDM有效、隐式地整合韵律外特征的能力。
- 语义连贯性:在定量指标(METEOR和ROUGE-L)和基于GPT-4的偏好测试(p值<0.05)中,我们的模型在语义适当性方面优于基线。这证实了USDM生成与输入语音语义连贯且高度匹配的回复的能力。
- 统一预训练:我们提出的统一语音-文本预训练方案,它同时建模对应和延续关系,在所有模态和序列类型上实现了卓越的平均困惑度(PPL)(表3,表9)。这明确证明了全面的预训练策略对于LLM学习多样化的语音-文本交互至关重要,而不是专门针对有限的关系。缺乏这种预训练的“从头开始”模型,在TTS和STT WER方面表现显著更差(分别为64.0%和58.1%),并且语义性能较差,凸显了跨模态预训练的关键作用。
- 中间文本建模:事实证明,使用中间文本作为桥梁的微调方案(语音输入 -> 文本转录 -> 文本回复生成 -> 语音回复合成)非常有效。直接的语音到语音模型(S1 -> S2)在METEOR和ROUGE-L分数方面表现显著更差(表3),证实了通过文本模态利用预训练LLM的推理能力是有益的。
- 输入模态利用:注意力图(图4)显示,USDM生成的回复同时关注输入语音及其转录文本。这一视觉证据证实了我们的模型有效地整合了来自两种模态的信息,从而产生了更鲁棒、语义更连贯的输出。此外,用真实文本替换模型生成的输入转录提高了METEOR和ROUGE-L分数(分别为13.6 vs 13.1和16.2 vs 15.7),这表明增强USDM中单元到文本转换的准确性直接提高了语义连贯性。局限性与未来方向
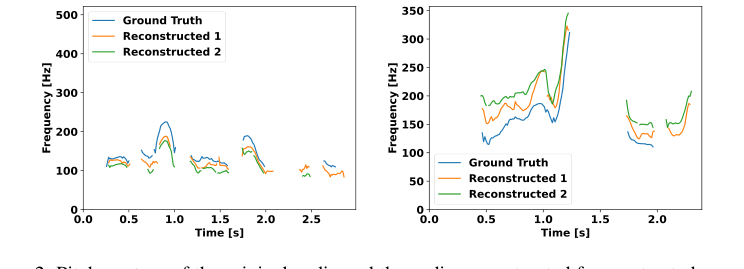 Figure 2. Pitch contour of the original audio and the audio reconstructed from extracted acoustic units. Due to the stochastic nature of the reconstruction model, we attempt reconstruction twice, demonstrating that the pitch variation closely mirrors the ground truth
Figure 2. Pitch contour of the original audio and the audio reconstructed from extracted acoustic units. Due to the stochastic nature of the reconstruction model, we attempt reconstruction twice, demonstrating that the pitch variation closely mirrors the ground truth
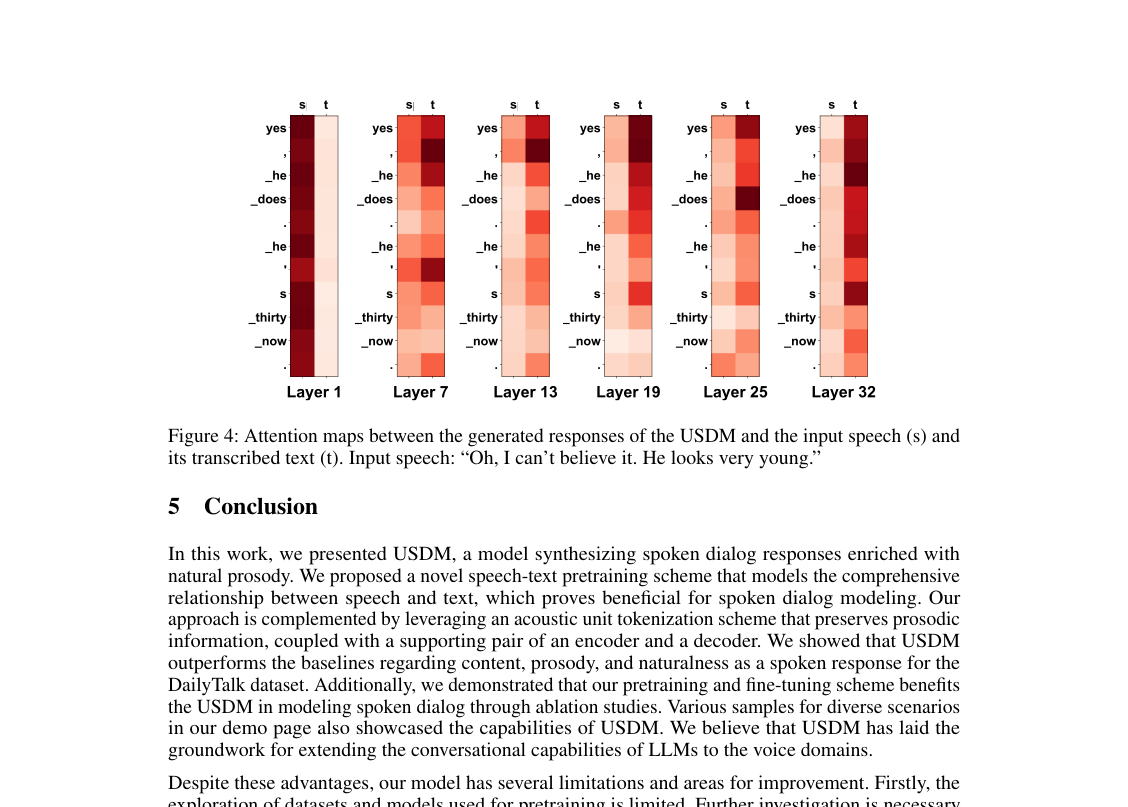 Figure 4. Attention maps between the generated responses of the USDM and the input speech (s) and its transcribed text (t). Input speech: “Oh, I can’t believe it. He looks very young.”
Figure 4. Attention maps between the generated responses of the USDM and the input speech (s) and its transcribed text (t). Input speech: “Oh, I can’t believe it. He looks very young.”
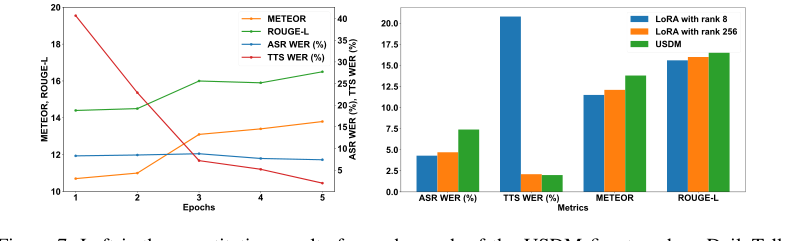 Figure 7. Left is the quantitative results for each epoch of the USDM fine-tuned on DailyTalk. The figure on the right illustrates the performance of the Spoken Dialog Model when trained with Low-Rank Adaptation (LoRA) versus full fine-tuning
Figure 7. Left is the quantitative results for each epoch of the USDM fine-tuned on DailyTalk. The figure on the right illustrates the performance of the Spoken Dialog Model when trained with Low-Rank Adaptation (LoRA) versus full fine-tuning
与其他领域的同构性
结构骨架