ग्राफ़ रीइन्फोर्समेंट लर्निंग के साथ परमाणु फाइन-स्ट्रक्चर निर्धारण में तेज़ी लाना
इस पत्र में संबोधित समस्या, जिसे "टर्म विश्लेषण" के नाम से जाना जाता है, तत्वों की परमाणु संरचना को समझने की मौलिक आवश्यकता से उत्पन्न होती है। विशेष रूप से, इसमें देखे गए परमाणु स्पेक्ट्रा से ऊर्जा स्तरों की ऊर्जाओं...
पृष्ठभूमि और अकादमिक वंश
उत्पत्ति और अकादमिक वंश
इस पत्र में संबोधित समस्या, जिसे "टर्म विश्लेषण" के नाम से जाना जाता है, तत्वों की परमाणु संरचना को समझने की मौलिक आवश्यकता से उत्पन्न होती है। विशेष रूप से, इसमें देखे गए परमाणु स्पेक्ट्रा से ऊर्जा स्तरों की ऊर्जाओं और कुल इलेक्ट्रॉन कोणीय संवेगों ($J$) को निकालना और इन स्तरों को उपयुक्त टर्म प्रतीकों को निर्दिष्ट करना शामिल है। अध्ययन का यह क्षेत्र महत्वपूर्ण है क्योंकि परिणामी परमाणु डेटा, जैसे ऊर्जा स्तर और संक्रमण तरंग संख्याएँ, अनुप्रयोगों की एक विस्तृत श्रृंखला के लिए आवश्यक हैं। इनमें प्लाज्मा निदान, प्रकाश और धातु उद्योग, चुंबकीय कारावास संलयन अनुसंधान, परमाणु अनुसंधान, चिकित्सा समस्थानिक उत्पादन और खगोल विज्ञान शामिल हैं, विशेष रूप से न्यूट्रॉन स्टार विलय जैसी घटनाओं से भारी तत्वों की उत्पत्ति को समझने में।
ऐतिहासिक रूप से, टर्म विश्लेषण की प्रक्रिया एक अनुक्रमिक, जटिल निर्णय लेने वाली कार्य रही है जिसके लिए गहन परमाणु स्पेक्ट्रोस्कोपी विशेषज्ञता और व्यापक मानवीय श्रम की आवश्यकता होती है। 1970 के दशक में फूरियर ट्रांसफॉर्म (FT) स्पेक्ट्रोस्कोपिक टर्म विश्लेषण की शुरुआत के बाद से, इसका अनुप्रयोग काफी हद तक लौह-समूह तत्वों (परमाणु संख्या $Z$ 23 और 28 के बीच वाले) तक ही सीमित रहा है। चुनौती प्रेक्षणीय स्पेक्ट्रल रेखाओं (अक्सर प्रत्येक तत्व के लिए दसियों हज़ार) की विशाल संख्या से उत्पन्न होती है जो स्तरों के बीच ऊर्जा अंतर का प्रतिनिधित्व करती हैं, जिससे व्यक्तिगत ऊर्जा स्तरों का निर्धारण एक कठिन कार्य बन जाता है, जो केवल कम सटीक सैद्धांतिक भविष्यवाणियों द्वारा निर्देशित होता है।
पिछले दृष्टिकोणों की मौलिक सीमा, या "दर्द बिंदु," उनकी अत्यधिक अक्षमता और मानव विशेषज्ञों पर निर्भरता है। जबकि एक एकल परमाणु प्रजाति के लिए स्पेक्ट्रम माप और सैद्धांतिक गणना के प्रारंभिक चरण हफ्तों में पूरे किए जा सकते हैं, बाद का टर्म विश्लेषण - देखे गए डेटा से ऊर्जा स्तरों की पहचान करने का महत्वपूर्ण कदम - महीनों से वर्षों तक ले सकता है। यह मैनुअल, श्रम-गहन प्रक्रिया एक प्रमुख बाधा बन गई है, जो विभिन्न वैज्ञानिक और औद्योगिक क्षेत्रों में बढ़ती मांगों को पूरा करने के लिए आवश्यक परमाणु डेटा की तीव्र पीढ़ी को रोकती है। इसके अलावा, मौजूदा एब इनिशियो (प्रथम-सिद्धांत) गणना अक्सर केवल कुछ प्रतिशत तक ही सटीक होती है, जो उच्च स्पेक्ट्रल रिज़ॉल्यूशन की आवश्यकता वाले अनुप्रयोगों के लिए अपर्याप्त है। टर्म विश्लेषण, उनके मानवीय लागत के बावजूद, परिमाण के क्रम में उच्च सटीकता प्रदान करते हैं और सैद्धांतिक मॉडल के लिए विश्वसनीय बाधाएं प्रदान करते हैं। यह अक्षमता और अकेले सैद्धांतिक विधियों की पर्याप्त सटीकता प्रदान करने में असमर्थता लेखकों को एक स्वचालित, कृत्रिम बुद्धिमत्ता-संचालित समाधान विकसित करने के लिए प्राथमिक प्रेरणाएँ हैं।
सहज डोमेन शब्द
-
परमाणु फाइन-स्ट्रक्चर निर्धारण / टर्म विश्लेषण: कल्पना कीजिए कि आपके पास एक जटिल संगीत वाद्ययंत्र है, जैसे कि एक ग्रैंड पियानो, लेकिन आप केवल वही नोट सुन सकते हैं जो यह बजाता है, चाबियों को देख नहीं सकते या वे कैसे व्यवस्थित हैं। "परमाणु फाइन-स्ट्रक्चर निर्धारण" उस पियानो की हर एक कुंजी की सटीक स्थिति और पहचान का पता लगाना है, और वे एक-दूसरे से कैसे संबंधित हैं, केवल धुनों को सुनकर। यह देखे गए स्पेक्ट्रल "नोट्स" को परमाणु के मौलिक "कुंजियों" (ऊर्जा स्तरों) पर वापस मैप करने की प्रक्रिया है।
-
स्पेक्ट्रल रेखा / तरंग संख्या ($\sigma$): पियानो सादृश्य को जारी रखते हुए, एक "स्पेक्ट्रल रेखा" एक एकल, विशिष्ट नोट की तरह है जिसे आप सुनते हैं। जब एक परमाणु में एक इलेक्ट्रॉन उच्च ऊर्जा स्तर से निम्न स्तर पर कूदता है, तो यह एक बहुत ही विशिष्ट "पिच" पर प्रकाश उत्सर्जित करता है। "तरंग संख्या" ($\sigma$) उस पिच का सटीक माप है, जो हमें बताता है कि उस इलेक्ट्रॉन कूद में कितनी ऊर्जा जारी की गई थी। यह दो परमाणु अवस्थाओं के बीच ऊर्जा अंतर का एक प्रत्यक्ष माप है।
-
मार्कोव निर्णय प्रक्रिया (MDP): एक एमडीपी को खजाने की खोज वाले खेल के रूप में सोचें। आप ("एजेंट") एक निश्चित स्थान ("स्थिति") पर हैं, और आपके पास पथ लेने के लिए कई विकल्प हैं ("क्रियाएँ")। आपके द्वारा चुना गया प्रत्येक पथ आपको एक नए स्थान (एक नई स्थिति) पर ले जा सकता है और आपको कुछ सोना ("पुरस्कार") दे सकता है। खेल का लक्ष्य एक ऐसी रणनीति ("नीति") खोजना है जो पूरी खोज में आपके द्वारा एकत्र किए गए सोने की कुल राशि को अधिकतम करे, भले ही कुछ रास्तों पर तत्काल छोटे पुरस्कार हों लेकिन बाद में मृत अंत की ओर ले जाएं।
-
रीइन्फोर्समेंट लर्निंग (RL): यह एक रोबोट को स्पष्ट निर्देश दिए बिना खजाने की खोज वाले खेल को खेलना सिखाने जैसा है। इसके बजाय, आप रोबोट को विभिन्न पथ आज़माने देते हैं। जब उसे सोना मिलता है, तो आप उसे "अच्छा काम!" (एक सकारात्मक पुरस्कार) कहते हैं। जब वह एक मृत अंत से टकराता है, तो आप उसे "इतना अच्छा नहीं" (एक नकारात्मक पुरस्कार) कहते हैं। कई प्रयासों में, रोबोट परीक्षण और त्रुटि के माध्यम से सीखता है कि किन स्थितियों में कौन सी क्रियाएँ सबसे अधिक सोना की ओर ले जाती हैं, अंततः एक विशेषज्ञ खजाने के शिकारी बन जाती है।
-
ग्राफ़ न्यूरल नेटवर्क (GNNs): परस्पर जुड़े शहरों के एक विशाल नेटवर्क पर विचार करें, जहाँ प्रत्येक शहर की अनूठी विशेषताएँ हैं (जैसे जनसंख्या, उद्योग) और उन्हें जोड़ने वाली प्रत्येक सड़क में गुण हैं (जैसे लंबाई, यातायात)। एक जीएनएन कृत्रिम बुद्धिमत्ता का एक विशेष प्रकार है जिसे ऐसे नेटवर्क के भीतर संबंधों और विशेषताओं को समझने और उनसे सीखने के लिए डिज़ाइन किया गया है। यह एआई को समग्र संरचना और स्थानीय कनेक्शनों को "देखने" में मदद करता है, जिससे यह शहरों और सड़कों के बारे में सूचित निर्णय ले पाता है, ठीक उसी तरह जैसे यह परमाणु ऊर्जा स्तरों और स्पेक्ट्रल रेखाओं के जटिल जाल का विश्लेषण करने में मदद करता है।
संकेतन तालिका
| संकेतन | विवरण |
|---|---|
| $J$ | कुल इलेक्ट्रॉन कोणीय संवेग |
| $Z$ | परमाणु संख्या |
| $\sigma$ | तरंग संख्या |
| $\sigma_{obs}$ | प्रेक्षित तरंग संख्या |
| $\delta\sigma_{obs}$ | मानक तरंग संख्या अनिश्चितता |
| $I_{obs}$ | सापेक्ष तीव्रता |
| $S/N_{obs}$ | सिग्नल-टू-नॉइज़ अनुपात |
| $E_{obs}$ | परमाणु स्तर की प्रेक्षित ऊर्जा |
| $E_{calc}$ | परमाणु स्तर की सैद्धांतिक ऊर्जा |
| $\Delta E$ | ऊर्जा स्तर में सैद्धांतिक अनिश्चितता |
| $\Delta I$ | रेखा तीव्रता में सैद्धांतिक अनिश्चितता |
| $E_u$ | ऊपरी ऊर्जा स्तर |
| $E_l$ | निचला ऊर्जा स्तर |
| $E_0$ | जमीनी ऊर्जा स्तर (शून्य पर निश्चित) |
| $s_t$ | एमडीपी में समय $t$ पर स्थिति |
| $a_t$ | एमडीपी में समय $t$ पर की गई क्रिया |
| $r_t$ | समय $t$ पर प्राप्त पुरस्कार |
| $G_t$ | समय $t$ से संचयी छूट प्राप्त पुरस्कार |
| $\gamma$ | छूट कारक |
| $H$ | एमडीपी में परिमित क्षितिज (एपिसोड लंबाई) |
| $Q(s, a)$ | क्यू-मान (स्थिति $s$ में क्रिया $a$ लेने के लिए अपेक्षित संचयी पुरस्कार) |
| $Q_{\theta}$ | पैरामीटर $\theta$ के साथ ऑनलाइन क्यू-नेटवर्क |
| $Q_{\bar{\theta}}$ | पैरामीटर $\bar{\theta}$ के साथ लक्ष्य क्यू-नेटवर्क |
| $L$ | हानि फलन |
| $TD[n]$ | एन-स्टेप टेम्पोरल डिफरेंस त्रुटि |
| $r^{[n]}$ | एन-स्टेप रिटर्न |
| $w_m$ | न्यूनतम-वर्ग अनुकूलन में रेखा $m$ के लिए भार |
| $S_{mn}$ | रेखा $m$ को ऊर्जा स्तरों से संबंधित गुणांक मैट्रिक्स |
| $M$ | ज्ञात रेखाओं की कुल संख्या |
| $N$ | ज्ञात स्तरों की कुल संख्या |
| $D$ | क्रिया $a^{(2)}$ के लिए वरीयता स्कोर |
| $h_v$ | स्तर $v$ के लिए नोड एम्बेडिंग वेक्टर |
| $S_{agg}$ | वैश्विक ग्राफ़ स्थिति एम्बेडिंग वेक्टर |
| $V(s)$ | स्थिति-मूल्य फलन |
| $A(s, a)$ | लाभ फलन |
| MLP | मल्टी-लेयर परसेप्ट्रॉन |
| GNN | ग्राफ़ न्यूरल नेटवर्क |
| $N_c$ | सही ढंग से निर्धारित ऊर्जा स्तरों की संख्या |
| $R_{max}$ | अधिकतम संचयी पुरस्कार |
| Acc. | निर्धारित स्तरों की सटीकता |
| PER | प्राथमिकता अनुभव रीप्ले |
| MCTS | मोंटे-कार्लो ट्री सर्च |
| UCT | ट्री के लिए ऊपरी विश्वास सीमा |
समस्या परिभाषा और बाधाएँ
मुख्य समस्या सूत्रीकरण और दुविधा
इस पत्र द्वारा संबोधित मुख्य समस्या परमाणु फाइन-स्ट्रक्चर निर्धारण में तेज़ी लाना है। यह परमाणु स्पेक्ट्रोस्कोपी में एक महत्वपूर्ण कार्य है, जो प्लाज्मा निदान से लेकर खगोल भौतिकी तक विभिन्न वैज्ञानिक और औद्योगिक अनुप्रयोगों के लिए मौलिक डेटा प्रदान करता है।
इस विश्लेषण के लिए प्रारंभिक बिंदु (इनपुट/वर्तमान स्थिति) देखे गए परमाणु स्पेक्ट्रा का एक संग्रह है, जिसे "लाइन सूची" में पूर्व-संसाधित किया जाता है। इस लाइन सूची में एक दिए गए परमाणु प्रजाति के लिए लगभग $10^4$ प्रेक्षणीय स्पेक्ट्रल रेखाएँ होती हैं, जिनमें से प्रत्येक को उसकी प्रेक्षित तरंग संख्या ($\sigma_{obs}$), मानक तरंग संख्या अनिश्चितता ($\delta\sigma_{obs}$), सापेक्ष तीव्रता ($I_{obs}$), और सिग्नल-टू-नॉइज़ अनुपात ($S/N_{obs}$) द्वारा चित्रित किया जाता है। इसके अतिरिक्त, वर्तमान स्थिति में ज्ञात (अनुभवजन्य रूप से निर्धारित) ऊर्जा स्तरों और संक्रमणों का एक ग्राफ़ प्रतिनिधित्व, साथ ही सैद्धांतिक रूप से अनुमानित स्तर और रेखाएँ शामिल हैं। ये ज्ञात स्तर आमतौर पर जुड़े होते हैं, जिनकी प्रेक्षित ऊर्जाएँ ($E_{obs}$) एक निश्चित शून्य ऊर्जा जमीनी स्तर के सापेक्ष होती हैं।
वांछित अंतिम बिंदु (आउटपुट/लक्ष्य स्थिति) अज्ञात परमाणु ऊर्जा स्तरों के लिए प्रेक्षित ऊर्जाओं ($E_{obs}$) को सटीक रूप से निर्धारित करना है और स्पेक्ट्रल रेखाओं को वर्गीकृत करना है जो प्रयोगात्मक अनिश्चितताओं के भीतर सैद्धांतिक भविष्यवाणियों से सर्वोत्तम मेल खाती हैं। इसमें ज्ञात स्तरों के उप-ग्राफ़ का विस्तार करना शामिल है, जो अज्ञात स्तर की ऊर्जा को निर्धारित करके, लाइन सूची से कम से कम दो प्रेक्षित स्पेक्ट्रल रेखाओं की पहचान और मिलान करके एक अज्ञात स्तर को ज्ञात स्तरों से जोड़ने वाले किनारों से जुड़ा हुआ है।
ठीक लापता कड़ी या गणितीय अंतर जिसे यह पत्र पाटने का प्रयास करता है, वह कच्चे स्पेक्ट्रल लाइन डेटा और कम सटीक सैद्धांतिक भविष्यवाणियों से सटीक, अनुभवजन्य रूप से मान्य परमाणु ऊर्जा स्तरों में संक्रमण में निहित है। ऐतिहासिक रूप से, इस प्रक्रिया को "टर्म विश्लेषण" के रूप में जाना जाता है, एक अनुक्रमिक, जटिल निर्णय लेने वाली कार्य रही है जिसके लिए व्यापक मानवीय श्रम और परमाणु स्पेक्ट्रोस्कोपी विशेषज्ञता की आवश्यकता होती है, जो अक्सर एक एकल परमाणु प्रजाति के लिए महीनों से वर्षों तक चलती है। गणितीय अंतर एक स्वचालित, स्केलेबल और सटीक विधि की कमी है जो प्रेक्षित स्पेक्ट्रल लाइन अंतरों की विशाल संख्या से इन ऊर्जा स्तरों का अनुमान लगा सके, जो सैद्धांतिक लेकिन अक्सर अपूर्ण गणनाओं द्वारा निर्देशित हो। पत्र इसे एक मार्कोव निर्णय प्रक्रिया (MDP) के रूप में प्रस्तुत करता है जिसे ग्राफ़ रीइन्फोर्समेंट लर्निंग (GRL) द्वारा हल किया जाना है।
पिछले शोधकर्ताओं को फंसाने वाला दर्दनाक समझौता या दुविधा सटीकता और दक्षता के बीच कठोर विकल्प है। जबकि मानव-संचालित टर्म विश्लेषण उच्च सटीकता (एब इनिशियो गणनाओं से परिमाण के क्रम में उच्च) और विश्वसनीय सैद्धांतिक बाधाएं प्रदान करता है, यह अत्यंत धीमा और श्रम-गहन है, जो परमाणु डेटा की बढ़ती मांग को पूरा करने के लिए संघर्ष कर रहा है। इसके विपरीत, एब इनिशियो सैद्धांतिक गणनाएँ तेज़ होती हैं लेकिन आम तौर पर केवल कुछ प्रतिशत तक ही सटीक होती हैं, जो उच्च स्पेक्ट्रल रिज़ॉल्यूशन की आवश्यकता वाले अनुप्रयोगों के लिए अपर्याप्त है। दुविधा यह है कि विश्लेषण की गति में सुधार का पारंपरिक रूप से अर्थ सटीकता का त्याग करना था, या इसके विपरीत। यह पत्र प्रक्रिया को आंशिक रूप से स्वचालित करने का प्रयास करता है, जिसका लक्ष्य काफी तेज गति से मानव-स्तर की सटीकता प्राप्त करना है, जिससे डेटा मांग और विश्लेषण क्षमता के बीच की खाई को पाटा जा सके।
बाधाएँ और विफलता मोड
परमाणु फाइन-स्ट्रक्चर निर्धारण में तेज़ी लाने की समस्या कई कठोर, यथार्थवादी बाधाओं के कारण अविश्वसनीय रूप से कठिन है:
-
भौतिक और डोमेन-विशिष्ट बाधाएँ:
- डेटा मात्रा और जटिलता: प्रत्येक निम्न-आयनीकरण खुले डी- और एफ-सबशेल परमाणु प्रजातियों के लिए, लगभग $10^3$ फाइन-स्ट्रक्चर ऊर्जा स्तरों को निर्धारित करने में लगभग $10^4$ प्रेक्षणीय स्पेक्ट्रल रेखाओं का विश्लेषण शामिल होता है। प्राथमिक चुनौती "प्रेक्षित ऊर्जा अंतरों की विशाल संख्या" (धारा 1, पृष्ठ 3) से सटीक ऊर्जा स्तरों को निकालना है।
- अशुद्ध सैद्धांतिक मार्गदर्शन: मौजूदा सैद्धांतिक भविष्यवाणियाँ अक्सर "कम सटीक" (धारा 1, पृष्ठ 3) होती हैं, जो सटीक मानों के बजाय केवल एक मोटा मार्गदर्शन प्रदान करती हैं। एब इनिशियो गणनाएँ आम तौर पर केवल कुछ प्रतिशत तक ही सटीक होती हैं, जो कई अनुप्रयोगों के लिए अपर्याप्त है।
- अस्पष्टता और अनिश्चितता: निर्धारित ऊर्जा स्तरों में अक्सर "अस्पष्ट मान" (धारा 2.5, पृष्ठ 5) होते हैं। मानव विशेषज्ञों को प्रेक्षित और सैद्धांतिक रेखा तीव्रता के बीच समझौते और तरंग संख्या अनिश्चितताओं के भीतर बार-बार $E_{obs}$ मानों की स्थिरता पर विचार करना चाहिए। यह निर्णय "संक्रमण संभावनाओं में अनिश्चितताओं और स्पेक्ट्रल लाइन फिटिंग में त्रुटियों से जटिल है, विशेष रूप से व्यापक कमजोर और/या मिश्रित रेखाओं के लिए" (धारा 2.5, पृष्ठ 6)।
- सीमित प्रयोग योग्य संक्रमण: केवल विद्युत द्विध्रुवीय फाइन-स्ट्रक्चर संक्रमणों पर विचार किया जाता है, क्योंकि "उच्च क्रम मल्टीपोल संक्रमण प्रयोगशाला स्पेक्ट्रा में शायद ही कभी देखे जाते हैं" (धारा 2.2, पृष्ठ 4), विश्लेषण के लिए उपलब्ध डेटा को सीमित करते हैं।
- आउटलायर और शोर: "आउटलायर तरंग संख्याओं (जैसे, अज्ञात रेखा मिश्रण या स्पेक्ट्रल लाइन प्रोफाइल की खराब फिटिंग)" (धारा 3, पृष्ठ 8) की उपस्थिति निर्धारित ऊर्जा स्तरों में बदलाव ला सकती है, भले ही वे $\delta E$ सहनशीलता के भीतर हों।
- चुनौतीपूर्ण परिदृश्य: सबसे कठिन स्थितियाँ, जैसे "एकल-रेखा स्तर निर्धारण या असंबद्ध ज्ञात-स्तर उप-ग्राफ़ को जोड़ना, जिसमें कोई ज्ञात स्तर नहीं होने पर टर्म विश्लेषण शुरू करना" (धारा 3, पृष्ठ 8), एमडीपी जटिलता को काफी बढ़ा देती हैं और अक्सर वर्तमान दृष्टिकोणों से बाहर रखी जाती हैं।
-
कम्प्यूटेशनल और एल्गोरिथम बाधाएँ:
- कम्प्यूटेशनल व्यवहार्यता और समय क्षितिज: मानव विश्लेषण प्रक्रिया में "महीनों से वर्षों" (धारा 1, पृष्ठ 3) लगते हैं। कम्प्यूटेशनल व्यवहार्यता के लिए, एमडीपी एक परिमित क्षितिज $H$ के साथ एपिसोडिक है (धारा 2.1, पृष्ठ 4), जो एक एकल एपिसोड में निर्धारित किए जा सकने वाले अज्ञात ऊर्जा स्तरों की संख्या को सीमित करता है।
- बड़े राज्य और क्रिया स्थान: समस्या में "बड़े राज्य और क्रिया स्थान" (धारा 2.7, पृष्ठ 7) शामिल हैं, जिसके लिए फ़ंक्शन सन्निकटन के लिए गहन तंत्रिका नेटवर्क की आवश्यकता होती है। एक अज्ञात स्तर ($A^{(1)}$) का चयन करने के लिए क्रिया स्थान 0 से 200 तक हो सकता है, और रेखाओं का मिलान करने के लिए क्रिया स्थान ($A^{(2)}$) बड़े $k$ (कनेक्टिंग ज्ञात स्तरों की संख्या) के लिए $10^3$ तक पहुंच सकता है, जिसमें माध्य 10 से कम है (धारा 2.3, पृष्ठ 5)। एकल-रेखा निर्धारण की अनुमति देने से "अव्यवहार्य रूप से बड़े $A^{(1)}$" (धारा 2.3, पृष्ठ 5) होंगे।
- एमडीपी जटिलता प्रबंधन: "व्यवहार्यता और आरएल प्रदर्शन के लिए एमडीपी जटिलता को कम करना महत्वपूर्ण है" (धारा 2.6, पृष्ठ 6)। इसमें रणनीतियाँ शामिल हैं जैसे कम सिग्नल-टू-नॉइज़ अनुपात वाले ग्राफ़ किनारों को हटाना, पहले से मिलान की गई रेखाओं को बाहर करना, और स्पेक्ट्रल रेंज को सीमित करना। "कुशल अन्वेषण और स्मृति नियंत्रण" में सहायता के लिए $|A^{(2)}|$ पर एक अधिकतम सीमा लागू की जाती है (धारा 2.6, पृष्ठ 6)।
- अन्वेषण दक्षता: मोंटे-कार्लो ट्री सर्च (MCTS) में यादृच्छिक क्रिया नमूनाकरण जैसे पारंपरिक अन्वेषण विधियाँ "बड़े क्रिया स्थानों में अक्षम हैं जहाँ केवल एक क्रिया सही होती है" (धारा 4.6, पृष्ठ 11)।
- कम्प्यूटेशनल लागत: व्यापक प्रयोग, जिसमें हाइपरपैरामीटर ट्यूनिंग और मल्टी-सीड रन शामिल हैं, अत्यधिक संसाधन-गहन हैं, जिसके लिए अनुमानित $10^5$ घंटे (लगभग 11 वर्ष) एकल-कोर सीपीयू समय की आवश्यकता होती है (धारा 4.7, पृष्ठ 11)।
-
डेटा-संचालित शिक्षण बाधाएँ:
- मानव डेटा पर निर्भरता: पुरस्कार फलन "ऐतिहासिक मानव निर्णयों पर आंशिक रूप से सीखा जाता है" (सार, पृष्ठ 2) व्युत्क्रम रीइन्फोर्समेंट लर्निंग के माध्यम से, जो विशेषज्ञ-जनित एमडीपी स्थिति संक्रमणों पर निर्भर करता है।
- पुरस्कार फलन के लिए सीमित प्रशिक्षण डेटा: वरीयता स्कोर $D$ की भविष्यवाणी करने वाले एमएलपी मॉडल को अपेक्षाकृत छोटे डेटासेट पर प्रशिक्षित किया गया था जिसमें Co II से 115 विशेषज्ञ $a^{(2)}$ एमडीपी स्थिति संक्रमण और Nd III से 23 थे (धारा 4.3, पृष्ठ 9)।
- प्रशिक्षण डेटा में पूर्वाग्रह: "कमजोर रेखाएं प्रशिक्षण डेटासेट में कम प्रतिनिधित्व वाली थीं और अज्ञात रेखाएं आम तौर पर कमजोर होती हैं" (धारा 4.3, पृष्ठ 9), जो इन कम प्रमुख रेखाओं पर मॉडल के प्रदर्शन को प्रभावित कर सकती है।
- प्रारंभिक स्थिति की गुणवत्ता: "प्रारंभिक एमडीपी स्थिति" की गुणवत्ता भिन्न हो सकती है; उदाहरण के लिए, आरमैक्स एपिसोड से एनडी II डेटा को "अनंतिम" और "खराब गुणवत्ता वाले एमडीपी प्रारंभिक स्थिति" (धारा 3, पृष्ठ 8) के रूप में माना जाता है जब तक कि मानव सत्यापन न हो जाए।
यह दृष्टिकोण क्यों
विकल्प की अनिवार्यता
ग्राफ़ रीइन्फोर्समेंट लर्निंग (GRL), विशेष रूप से टर्म एनालिसिस विद ग्राफ़ डीप क्यू-नेटवर्क (TAG-DQN) का चयन, केवल एक वरीयता नहीं थी, बल्कि परमाणु फाइन-स्ट्रक्चर निर्धारण की आंतरिक प्रकृति से प्रेरित एक अनिवार्य विकल्प था। यह जटिल समस्या मौलिक रूप से ग्राफ़-संरचित डेटा पर संचालित एक अनुक्रमिक निर्णय लेने वाली कार्य है। लेखकों के लिए अहसास का "ठीक क्षण", हालांकि स्पष्ट रूप से नहीं कहा गया है, उनके समस्या सूत्रीकरण से अनुमान लगाया जा सकता है: उन्होंने विश्लेषण प्रक्रिया को ग्राफ़ के साथ एक मार्कोव निर्णय प्रक्रिया (MDP) के रूप में ढाला, जहाँ परमाणु ऊर्जा स्तर नोड होते हैं और स्पेक्ट्रल रेखाएँ किनारे होती हैं।
पारंपरिक "SOTA" विधियाँ जैसे मानक कनवल्शनल न्यूरल नेटवर्क (CNN), बुनियादी प्रसार मॉडल, या ट्रांसफॉर्मर, उनके विशिष्ट अनुप्रयोगों में, इस विशिष्ट चुनौती के लिए अनुपयुक्त हैं। सीएनएन ग्रिड-जैसे डेटा (छवियों) में उत्कृष्ट होते हैं लेकिन अनियमित ग्राफ़ संरचनाओं के साथ संघर्ष करते हैं। प्रसार मॉडल मुख्य रूप से जनरेटिव हैं और ग्राफ़ पर अनुक्रमिक निर्णय लेने या संयोजी अनुकूलन के लिए डिज़ाइन नहीं किए गए हैं। ट्रांसफॉर्मर, अनुक्रम डेटा के लिए शक्तिशाली होते हुए भी, टर्म विश्लेषण में निहित गतिशील, ग्राफ़-आधारित स्थिति प्रतिनिधित्व और अनुक्रमिक निर्णय लेने की प्रक्रिया को संभालने के लिए महत्वपूर्ण अनुकूलन की आवश्यकता होगी। मुख्य मुद्दा यह है कि समस्या एक निश्चित ग्रिड में पैटर्न पहचान, नया डेटा उत्पन्न करने, या सरल अनुक्रम अनुवाद के बारे में नहीं है। इसके बजाय, यह अज्ञात ऊर्जा स्तरों की पहचान करने के लिए एक गतिशील रूप से विकसित ग्राफ़ पर परस्पर निर्भर विकल्पों की एक श्रृंखला बनाने के बारे में है, एक ऐसा कार्य जो स्वाभाविक रूप से ग्राफ़ पर रीइन्फोर्समेंट लर्निंग की शक्तियों से मेल खाता है। लेखक स्पष्ट रूप से कहते हैं कि "स्केलेबिलिटी प्राप्त करने की कुंजी उन तकनीकों को अपनाना है जिन्होंने इस व्यापक साहित्य में सफलता साबित की है, जिसमें क्रिया स्थान अपघटन, डोमेन ज्ञान के माध्यम से मान्य क्रियाओं को रोकना, और सीखने के प्रतिनिधित्व के रूप में ग्राफ़ न्यूरल नेटवर्क (GNNs) का उपयोग करना [32] शामिल है," यह रेखांकित करते हुए कि समस्या की ग्राफ़ संरचना और संयोजी प्रकृति ने इस विशेष दृष्टिकोण को आवश्यक बना दिया।
तुलनात्मक श्रेष्ठता
सरल प्रदर्शन मेट्रिक्स से परे, TAG-DQN गुणात्मक और संरचनात्मक लाभ प्रदान करता है जो इसे पिछले स्वर्ण मानकों की तुलना में अत्यधिक श्रेष्ठ बनाता है, जो मुख्य रूप से व्यापक मानवीय श्रम और कम परिष्कृत खोज एल्गोरिदम पर निर्भर थे। सबसे आश्चर्यजनक लाभ विश्लेषण समय में नाटकीय कमी है: TAG-DQN घंटों में सैकड़ों ऊर्जा स्तरों को निर्धारित कर सकता है, एक ऐसा कार्य जिसके लिए पारंपरिक रूप से महीनों से वर्षों के मानवीय प्रयास की आवश्यकता होती है। यह दक्षता में परिमाण के क्रम में सुधार का प्रतिनिधित्व करता है।
संरचनात्मक रूप से, TAG-DQN की श्रेष्ठता इस क्षमता से उत्पन्न होती है:
1. ग्राफ़-संरचित डेटा को मूल रूप से संभालना: सीखने के प्रतिनिधित्व के रूप में ग्राफ़ न्यूरल नेटवर्क (GNNs) को नियोजित करके, TAG-DQN परमाणु स्तरों (नोड्स) और स्पेक्ट्रल रेखाओं (किनारों) की अंतर्निहित ग्राफ़ संरचना को सीधे संसाधित करता है। यह एक प्राकृतिक फिट है, उन विधियों के विपरीत जिन्हें ऐसे संबंधपरक डेटा को समतल या भारी पूर्व-संसाधित करने की आवश्यकता होगी, संभावित रूप से महत्वपूर्ण जानकारी खो जाएगी।
2. अनुक्रमिक निर्णय लेने को सीखना: एक रीइन्फोर्समेंट लर्निंग एजेंट के रूप में, TAG-DQN एक संचयी पुरस्कार को अधिकतम करने के लिए इष्टतम निर्णयों (अज्ञात स्तरों का चयन, स्पेक्ट्रल रेखाओं का मिलान) का एक क्रम बनाने के लिए एक नीति सीखता है। यह टर्म विश्लेषण के लिए महत्वपूर्ण है, जो एक "अनुक्रमिक, जटिल निर्णय लेने वाली कार्य" है।
3. विशेषज्ञ ज्ञान और अनिश्चितता को शामिल करना: पुरस्कार फलन व्युत्क्रम रीइन्फोर्समेंट लर्निंग के माध्यम से ऐतिहासिक मानव निर्णयों से आंशिक रूप से सीखा जाता है, जिससे मॉडल मानव विशेषज्ञों की सूक्ष्म प्राथमिकताओं और अनुमानों को पकड़ सकता है। इसके अलावा, क्रिया स्थान सैद्धांतिक और प्रयोगात्मक अनिश्चितताओं ($\Delta E$, $\Delta I$) को शामिल करता है, जिससे मॉडल यथार्थवादी भौतिक बाधाओं के भीतर काम कर सकता है।
4. दीर्घकालिक स्थिरता प्राप्त करना: मोंटे-कार्लो ट्री सर्च (MCTS) जैसे बेसलाइन खोज एल्गोरिदम की तुलना में, TAG-DQN जटिल मामलों जैसे Nd II में, विशेष रूप से सही ढंग से लेबल किए गए स्तरों के निर्धारण में बेहतर सटीकता प्रदर्शित करता है। जबकि MCTS उच्च तत्काल पुरस्कार पा सकता है, बड़े राज्य-क्रिया स्थानों में इसके उथले रोलआउट "अल्पकालिक क्रियाओं" और कम सुसंगत दीर्घकालिक परिणामों का कारण बन सकते हैं। TAG-DQN की एक नीति सीखने की क्षमता जो एपिसोड के दौरान "अवलोकन और सिद्धांत के साथ सुसंगत रहने की अधिक संभावना" वाले स्तर की पहचान की ओर ले जाती है, एक प्रमुख गुणात्मक लाभ है।
पत्र स्पष्ट रूप से $O(N^2)$ बनाम $O(N)$ के संदर्भ में स्मृति जटिलता या विशिष्ट उच्च-आयामी शोर हैंडलिंग पर पुरस्कार फलन के डिजाइन से परे चर्चा नहीं करता है, जो उच्च सिग्नल-टू-नॉइज़ अनुपात (S/N) लाइनों को प्राथमिकता देता है और खराब मापी गई लाइनों को बाहर करता है। हालांकि, GNNs और क्रिया स्थान अपघटन के माध्यम से प्राप्त स्केलेबिलिटी बड़े, उच्च-आयामी इनपुट स्थानों की चुनौती को स्पष्ट रूप से संबोधित करती है।
बाधाओं के साथ संरेखण
चुना गया TAG-DQN तरीका परमाणु फाइन-स्ट्रक्चर निर्धारण की अंतर्निहित बाधाओं और आवश्यकताओं के साथ पूरी तरह से संरेखित होता है, जो समस्या और समाधान के बीच एक मजबूत "विवाह" बनाता है।
- अनुक्रमिक निर्णय लेना: समस्या को "अनुक्रमिक, जटिल निर्णय लेने वाली कार्य" के रूप में वर्णित किया गया है। रीइन्फोर्समेंट लर्निंग, अपनी परिभाषा के अनुसार, असतत समय चरणों पर इष्टतम नीतियों को सीखने के द्वारा ऐसे समस्याओं को हल करने के लिए डिज़ाइन किया गया है।
- ग्राफ़-संरचित डेटा: परमाणु ऊर्जा स्तर और स्पेक्ट्रल रेखाएँ स्वाभाविक रूप से एक ग्राफ़ बनाती हैं, जिसमें स्तर नोड होते हैं और रेखाएँ किनारे होती हैं। GNNs, TAG-DQN का एक मुख्य घटक, विशेष रूप से ऐसे संबंधपरक डेटा को संसाधित करने और उनसे सीखने के लिए इंजीनियर किए गए हैं, जो समस्या की संरचनात्मक अखंडता को बनाए रखते हैं।
- अत्यधिक खोज स्थान: कार्य में "प्रेक्षित ऊर्जा अंतरों की विशाल संख्या" से ऊर्जा स्तरों का निर्धारण शामिल है। कुशल स्थिति प्रतिनिधित्व के लिए GNNs और बड़े राज्य-क्रिया स्थानों में सीखने के लिए DQN के संयोजन से इस विशाल संयोजी परिदृश्य को नेविगेट करने के लिए आवश्यक मशीनरी प्रदान की जाती है।
- डोमेन ज्ञान और मानव विशेषज्ञता का समावेश: टर्म विश्लेषण "स्वाभाविक रूप से अनुभवजन्य" है और मानव विशेषज्ञता पर निर्भर करता है। विधि इसे "ऐतिहासिक मानव निर्णयों पर आंशिक रूप से सीखी गई" पुरस्कार फलन का उपयोग करके संबोधित करती है, व्युत्क्रम रीइन्फोर्समेंट लर्निंग के माध्यम से, प्रभावी ढंग से विशेषज्ञ ज्ञान को एआई की निर्णय लेने की प्रक्रिया में एम्बेड करती है। डोमेन ज्ञान का उपयोग मान्य क्रियाओं को प्रतिबंधित करने और एमडीपी को सरल बनाने के लिए भी किया जाता है।
- कम्प्यूटेशनल व्यवहार्यता और स्केलेबिलिटी: एक प्रमुख बाधा मानव श्रम की "महीनों से वर्षों" की आवश्यकता है। TAG-DQN घंटों में "102 अनंतिम फाइन-स्ट्रक्चर ऊर्जा स्तरों तक" निर्धारित कर सकता है, सीधे त्वरण की आवश्यकता को संबोधित करता है। लेखक स्पष्ट रूप से "व्यवहार्यता और आरएल प्रदर्शन के लिए एमडीपी जटिलता को कम करना महत्वपूर्ण है" का भी उल्लेख करते हैं, यह बताते हुए कि वे समस्या स्थान को कैसे काटते हैं (जैसे, कम एस/एन किनारों को हटाना, स्पेक्ट्रल रेंज को सीमित करना) समाधान को प्रबंधनीय बनाने के लिए।
- अनिश्चितता हैंडलिंग: समस्या में "कम सटीक सैद्धांतिक भविष्यवाणियाँ" और प्रयोगात्मक अनिश्चितताएँ शामिल हैं। क्रिया स्थान और पुरस्कार फलन को सैद्धांतिक अनिश्चितताओं ($\Delta E$, $\Delta I$) को ध्यान में रखने और उच्च सिग्नल-टू-नॉइज़ अनुपात वाली रेखाओं को प्राथमिकता देने के लिए डिज़ाइन किया गया है, जिससे समाधान शोर डेटा के प्रति मजबूत होता है।
विकल्पों का अस्वीकरण
पत्र कुछ वैकल्पिक दृष्टिकोणों को अस्वीकार करने के लिए स्पष्ट तर्क प्रदान करता है, विशेष रूप से खोज एल्गोरिदम और सामान्य रीइन्फोर्समेंट लर्निंग प्रतिमानों के दायरे में।
- लालची खोज: लेखकों ने स्पष्ट रूप से कहा है कि "लालची खोज लगातार आरएल एजेंटों की तुलना में खराब प्रदर्शन करती है।" ऐसा इसलिए है क्योंकि लालची दृष्टिकोण, परिभाषा के अनुसार, केवल तत्काल पुरस्कारों पर विचार करते हैं और दीर्घकालिक परिणामों की योजना नहीं बना सकते हैं, जो टर्म विश्लेषण जैसे अनुक्रमिक निर्णय लेने वाले कार्य के लिए महत्वपूर्ण है जहाँ प्रारंभिक विकल्प भविष्य की संभावनाओं को प्रभावित करते हैं।
- मोंटे-कार्लो ट्री सर्च (MCTS): जबकि MCTS एक अधिक परिष्कृत खोज एल्गोरिथम है, पत्र नोट करता है कि "MCTS ने TAG-DQN की तुलना में उच्च Rmax प्राप्त किया, फिर भी TAG-DQN ने Ne की उच्च ऊपरी सीमाएँ प्राप्त कीं, विशेष रूप से Nd II मामलों में।" व्याख्या यह है कि "MCTS रोलआउट उथले थे और अल्पकालिक पुरस्कारों का पक्ष लेते थे," जिससे ट्रैजेक्टरी पुरस्कार अधिक होते थे लेकिन सही ढंग से लेबल किए गए स्तरों में सटीकता कम होती थी। यह इस समस्या के लिए इंगित करता है कि दीर्घकालिक स्थिरता और सटीकता (जो TAG-DQN ने बेहतर हासिल की) तत्काल पुरस्कार को अधिकतम करने की तुलना में अधिक महत्वपूर्ण हैं। बड़े राज्य और क्रिया स्थान गहरे MCTS रोलआउट को कम्प्यूटेशनल रूप से महंगा और शोर के लिए प्रवण बनाते हैं।
- नीति ग्रेडिएंट विधियाँ: लेखकों का कहना है, "हमने इस एल्गोरिथम वर्ग [DQN] को इसकी उच्च नमूना दक्षता के लिए नीति ग्रेडिएंट दृष्टिकोण [40] की तुलना में चुना है।" नीति ग्रेडिएंट विधियों को आम तौर पर एक प्रभावी नीति सीखने के लिए पर्यावरण के साथ अधिक इंटरैक्शन की आवश्यकता होती है, जो परमाणु डेटा विश्लेषण के जटिल, संभावित रूप से महंगे सिमुलेशन या वास्तविक दुनिया के अनुप्रयोग में एक महत्वपूर्ण कमी होगी।
- अन्य डीप लर्निंग आर्किटेक्चर (निहित अस्वीकरण): स्पष्ट रूप से यह नहीं कहा गया है कि GANs, प्रसार मॉडल, या मानक CNNs/ट्रांसफॉर्मर असफल रहे, GNNs और RL का चुनाव अंतर्निहित रूप से मुख्य समस्या के लिए इन्हें अस्वीकार करता है। समस्या छवि निर्माण, अनुक्रम अनुवाद, या ग्रिड-जैसे डेटा पर सरल वर्गीकरण नहीं है। स्तरों और रेखाओं के परमाणु की अंतर्निहित ग्राफ़ संरचना, अनुक्रमिक निर्णय लेने की प्रकृति के साथ मिलकर, GRL को सबसे उपयुक्त और प्रभावी प्रतिमान बनाती है। इन अन्य विधियों को उनकी आर्किटेक्चर में फिट करने के लिए समस्या के महत्वपूर्ण, शायद अप्राकृतिक, पुनः-फ्रेमिंग की आवश्यकता होगी, जिससे संभवतः उप-इष्टतम प्रदर्शन या बढ़ी हुई जटिलता होगी।
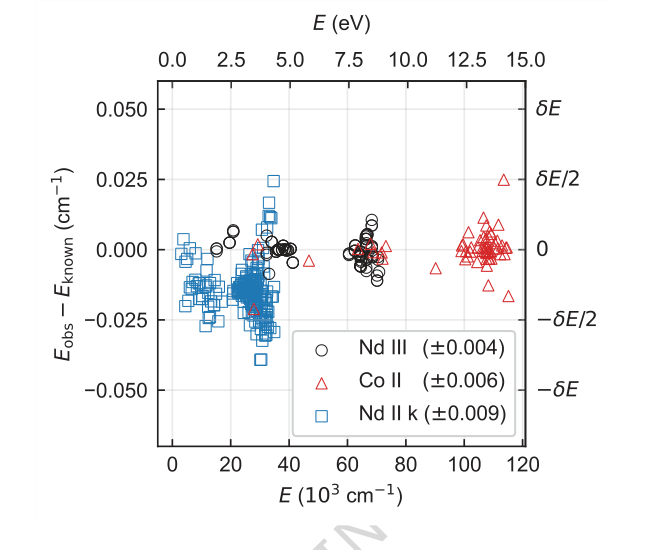 Figure 4. Difference between energy levels determined from a single seed and their known (ac- cepted) values for each species. Only levels contributing to Nc are shown. Energy differences for Nd III, Co II, and Nd II k are shown in circles, triangles, and squares, respectively. The root-mean-square energy differences are given in parentheses in the legend. Typical energy level uncertainty by FT spectroscopy is of order 0.001 cm−1. The offset and higher spread of Nd II k energies are expected and within uncertainties as their known values were derived by lower-precision grating spectroscopy [4]
Figure 4. Difference between energy levels determined from a single seed and their known (ac- cepted) values for each species. Only levels contributing to Nc are shown. Energy differences for Nd III, Co II, and Nd II k are shown in circles, triangles, and squares, respectively. The root-mean-square energy differences are given in parentheses in the legend. Typical energy level uncertainty by FT spectroscopy is of order 0.001 cm−1. The offset and higher spread of Nd II k energies are expected and within uncertainties as their known values were derived by lower-precision grating spectroscopy [4]
गणितीय और तार्किक तंत्र
मास्टर समीकरण
इस पत्र के तंत्र का मूल दो मौलिक समीकरणों के इर्द-गिर्द घूमता है: मार्कोव निर्णय प्रक्रिया (MDP) के लिए उद्देश्य फलन जिसे एजेंट अधिकतम करने का लक्ष्य रखता है, और अंतर्निहित तंत्रिका नेटवर्क के सीखने को चलाने वाला हानि फलन। इसके अतिरिक्त, ऊर्जा स्तरों को निर्धारित करने के लिए एक महत्वपूर्ण गणना स्थिति अद्यतन तंत्र का एक अभिन्न अंग बनाती है।
रीइन्फोर्समेंट लर्निंग एजेंट का प्राथमिक उद्देश्य परिमित क्षितिज $H$ पर अपेक्षित संचयी छूट प्राप्त पुरस्कार को अधिकतम करना है:
$$ E[G_t] = E\left[\sum_{k=0}^{H} \gamma^k r_{t+k}\right] \quad (1) $$
यह समीकरण परिभाषित करता है कि एजेंट क्या हासिल करने की कोशिश कर रहा है: परमाणु फाइन-स्ट्रक्चर को निर्धारित करने के लिए इष्टतम निर्णयों का एक क्रम बनाना जो भविष्य के पुरस्कारों का उच्चतम संभव योग की ओर ले जाता है, जहाँ पहले प्राप्त पुरस्कार बाद में प्राप्त होने वाले पुरस्कारों की तुलना में अधिक मूल्यवान होते हैं।
डीप क्यू-नेटवर्क (DQN) एजेंट के लिए सीखने की प्रक्रिया को एक हानि फलन को कम करके संचालित किया जाता है, विशेष रूप से वर्ग एन-स्टेप टेम्पोरल डिफरेंस (TD) त्रुटि:
$$ L = [TD[n]]^2 = \left[r^{[n]} + \gamma^n Q_{\bar{\theta}}(s_{t+n}, \text{argmax}_{a_{t+n}} Q_{\theta}(s_{t+n}, a_{t+n})) – Q_{\theta}(s_t, a_t)\right]^2 \quad (15) $$
यह हानि फलन तंत्रिका नेटवर्क को क्रियाओं की "गुणवत्ता" का सटीक अनुमान लगाने के लिए निर्देशित करता है, यह सुनिश्चित करता है कि इसके अनुमान वास्तविक भविष्य के पुरस्कारों के साथ संरेखित हों।
अंत में, एक महत्वपूर्ण गणना जो स्थिति अद्यतनों को रेखांकित करती है, विशेष रूप से प्रेक्षित ऊर्जा स्तरों ($E_{obs}$) का निर्धारण, भारित न्यूनतम-वर्ग न्यूनीकरण के माध्यम से किया जाता है:
$$ E_{obs} = \text{argmin}_{E_n} \sum_{m=0}^{M-1} w_m \left( \sum_{n=0}^{N-1} S_{mn}E_n - \sigma_m \right)^2 \quad (9) $$
यह समीकरण है कि कैसे सिस्टम प्रेक्षित स्पेक्ट्रल रेखाओं के आधार पर ज्ञात स्तरों के ऊर्जा मानों को परिष्कृत करता है, जिससे यह "गणितीय इंजन" का एक केंद्रीय घटक बन जाता है जो परमाणु डेटा को संसाधित और अद्यतन करता है।
टर्म-दर-टर्म ऑटोप्सी
आइए इन समीकरणों में से प्रत्येक को उनके व्यक्तिगत घटकों और उनकी भूमिकाओं को समझने के लिए विच्छेदित करें।
समीकरण (1): अपेक्षित संचयी छूट प्राप्त पुरस्कार
- $E[G_t]$: यह समय चरण $t$ से शुरू होने वाले अपेक्षित संचयी छूट प्राप्त पुरस्कार का प्रतिनिधित्व करता है।
- गणितीय परिभाषा: कई संभावित प्रक्षेपवक्रों पर $G_t$ का औसत मान।
- भौतिक/तार्किक भूमिका: यह रीइन्फोर्समेंट लर्निंग एजेंट का अंतिम उद्देश्य फलन है। एजेंट की नीति को इस मात्रा को अधिकतम करने वाली क्रियाओं को चुनने के लिए डिज़ाइन किया गया है, प्रभावी ढंग से परमाणु फाइन-स्ट्रक्चर को निर्धारित करने के लिए निर्णयों का सबसे अच्छा क्रम खोजना।
- $E[\cdot]$: यह अपेक्षा ऑपरेटर है।
- गणितीय परिभाषा: एक यादृच्छिक चर का औसत मान परिकलित करता है।
- भौतिक/तार्किक भूमिका: रीइन्फोर्समेंट लर्निंग में, एजेंट को सटीक भविष्य के पुरस्कारों या स्थिति संक्रमणों का नियतात्मक रूप से पता नहीं होता है। यह ऑपरेटर अंतर्निहित अनिश्चितता को ध्यान में रखता है, यह सुनिश्चित करता है कि एजेंट औसत परिणाम के लिए अनुकूलित हो।
- $G_t$: यह समय $t$ से संचयी छूट प्राप्त पुरस्कार है।
- गणितीय परिभाषा: भविष्य के सभी पुरस्कारों का योग, प्रत्येक को $\gamma$ के कारक से छूट दी जाती है जो भविष्य में चरणों की संख्या की शक्ति तक बढ़ जाती है।
- भौतिक/तार्किक भूमिका: यह समय $t$ से शुरू होने वाले कार्यों और स्थितियों के एक विशेष क्रम की कुल "अच्छाई" को मापता है।
- $\sum_{k=0}^{H} \gamma^k r_{t+k}$: यह छूट प्राप्त भविष्य के पुरस्कारों का योग है।
- गणितीय परिभाषा: एक परिमित योग जहाँ प्रत्येक पुरस्कार $r_{t+k}$ को $\gamma^k$ से गुणा किया जाता है।
- भौतिक/तार्किक भूमिका: यह भविष्य के समय चरणों $t+k$ पर प्राप्त पुरस्कारों को एकत्रित करता है, दूर के पुरस्कारों की तुलना में तत्काल पुरस्कारों को अधिक मूल्यवान बनाने के लिए छूट लागू करता है। योग का उपयोग किया जाता है क्योंकि कुल पुरस्कार व्यक्तिगत पुरस्कारों का संचय है।
- $\gamma$: यह छूट कारक है।
- गणितीय परिभाषा: 0 और 1 (समावेशी) के बीच एक स्केलर मान, $\gamma \in [0, 1]$।
- भौतिक/तार्किक भूमिका: यह तत्काल पुरस्कारों बनाम भविष्य के पुरस्कारों के महत्व को संतुलित करता है। 0 के करीब एक $\gamma$ एजेंट को "अल्पकालिक" बनाता है, तत्काल लाभ पर ध्यान केंद्रित करता है, जबकि 1 के करीब एक $\gamma$ इसे "दूरदर्शी" बनाता है, दीर्घकालिक परिणामों पर विचार करता है। लेखकों ने योग के लिए जोड़ का चुनाव किया क्योंकि कुल मूल्य व्यक्तिगत पुरस्कारों का संचय है।
- $k$: यह समय $t$ के सापेक्ष समय चरण सूचकांक है।
- गणितीय परिभाषा: एक पूर्णांक जो समय $t$ से भविष्य में चरणों की संख्या का प्रतिनिधित्व करता है।
- भौतिक/तार्किक भूमिका: यह ट्रैक करता है कि किसी विशेष पुरस्कार $r_{t+k}$ को कितनी दूर भविष्य में प्राप्त किया जाता है, जो छूट के लिए $\gamma$ की शक्ति निर्धारित करता है।
- $r_{t+k}$: यह समय $t+k$ पर प्राप्त पुरस्कार है।
- गणितीय परिभाषा: एक स्केलर मान जो एक क्रिया करने के बाद पर्यावरण से तत्काल प्रतिक्रिया का प्रतिनिधित्व करता है।
- भौतिक/तार्किक भूमिका: इस पत्र में, पुरस्कारों को निर्धारित ऊर्जा स्तरों में विश्वास को दर्शाने के लिए डिज़ाइन किया गया है, सिद्धांत और अवलोकनों के साथ समझौते, और भविष्य के स्तर निर्धारण को सक्षम करने की क्षमता (समीकरण 6 और 7)।
समीकरण (15): TAG-DQN के लिए हानि फलन
- $L$: यह हानि फलन है।
- गणितीय परिभाषा: अनुमानित क्यू-मानों और लक्ष्य क्यू-मानों के बीच त्रुटि को मापने वाला एक स्केलर मान।
- भौतिक/तार्किक भूमिका: प्रशिक्षण का लक्ष्य इस हानि को कम करना है, जो बदले में क्यू-नेटवर्क के अनुमानों को अधिक सटीक बनाता है।
- $[TD[n]]^2$: यह वर्ग एन-स्टेप टेम्पोरल डिफरेंस (TD) त्रुटि है।
- गणितीय परिभाषा: एन-स्टेप रिटर्न (भविष्य के पुरस्कार का एक अनुमान) और वर्तमान क्यू-मान अनुमान के बीच अंतर का वर्ग।
- भौतिक/तार्किक भूमिका: त्रुटि को वर्ग करने से यह सुनिश्चित होता है कि सकारात्मक और नकारात्मक दोनों त्रुटियाँ हानि में योगदान करती हैं और बड़ी त्रुटियों को अधिक दंडित करती हैं, जिससे अभिसरण को बढ़ावा मिलता है।
- $r^{[n]}$: यह एन-स्टेप रिटर्न है।
- गणितीय परिभाषा: पहले $n$ पुरस्कारों का योग, छूट प्राप्त, क्यू-मान अनुमान द्वारा $n$ चरणों के बाद पहुंचे राज्य में छूट प्राप्त।
- भौतिक/तार्किक भूमिका: यह क्यू-मान अनुमान से बूटस्ट्रैपिंग से पहले एक छोटी क्षितिज पर वास्तविक पुरस्कारों को शामिल करके, एक एकल-चरण रिटर्न की तुलना में एक अधिक स्थिर और कम पक्षपाती अनुमान प्रदान करता है।
- $\gamma^n$: यह छूट कारक है जो $n$ की शक्ति तक बढ़ाया गया है।
- गणितीय परिभाषा: छूट कारक $\gamma$ को $n$ बार स्वयं से गुणा किया जाता है।
- भौतिक/तार्किक भूमिका: यह स्थिति $s_{t+n}$ पर भविष्य के क्यू-मान अनुमान को समय $t$ तक वापस छूट देता है, $n$ चरणों पर प्राप्त पुरस्कारों के साथ इसके मूल्य को संरेखित करता है।
- $Q_{\bar{\theta}}(s_{t+n}, \text{argmax}_{a_{t+n}} Q_{\theta}(s_{t+n}, a_{t+n}))$: यह लक्ष्य क्यू-मान है।
- गणितीय परिभाषा: स्थिति $s_{t+n}$ का क्यू-मान और वह क्रिया जो उस स्थिति में क्यू-मान को अधिकतम करती है, जैसा कि लक्ष्य नेटवर्क $Q_{\bar{\theta}}$ द्वारा अनुमानित किया गया है।
- भौतिक/तार्किक भूमिका: यह पद एक स्थिर लक्ष्य प्रदान करता है जिससे ऑनलाइन नेटवर्क सीख सकता है। एक अलग लक्ष्य नेटवर्क के साथ विलंबित अद्यतनों ($\bar{\theta}$) का उपयोग करके, यह क्यू-मान अनुमानों को एक गतिशील लक्ष्य का पीछा करने से रोकता है, जो प्रशिक्षण में अस्थिरता का कारण बन सकता है। $\text{argmax}$ भाग यह सुनिश्चित करता है कि लक्ष्य वर्तमान ऑनलाइन नेटवर्क की समझ के अनुसार, अगली स्थिति से सर्वोत्तम संभव क्रिया के मूल्य को दर्शाता है।
- $Q_{\theta}(s_t, a_t)$: यह वर्तमान क्यू-मान अनुमान है।
- गणितीय परिभाषा: वर्तमान स्थिति-क्रिया जोड़ी $(s_t, a_t)$ का क्यू-मान, जैसा कि ऑनलाइन नेटवर्क $Q_{\theta}$ द्वारा अनुमानित किया गया है।
- भौतिक/तार्किक भूमिका: यह वह मान है जिसका नेटवर्क वर्तमान में स्थिति $s_t$ में क्रिया $a_t$ लेने के लिए अनुमान लगा रहा है। हानि फलन का लक्ष्य $\theta$ को समायोजित करना है ताकि यह अनुमान लक्ष्य क्यू-मान से मेल खाए।
- $s_t$: यह समय $t$ पर स्थिति है।
- गणितीय परिभाषा: समय $t$ पर पर्यावरण का एक प्रतिनिधित्व, जिसमें ग्राफ़ नोड और किनारा सुविधाएँ शामिल हैं (समीकरण 2 और 3)।
- भौतिक/तार्किक भूमिका: यह टर्म विश्लेषण की वर्तमान प्रगति के बारे में सभी प्रासंगिक जानकारी को समाहित करता है, जैसे ज्ञात/अज्ञात स्तर, प्रेक्षित स्पेक्ट्रल रेखाएँ, और सैद्धांतिक गणनाएँ।
- $a_t$: यह समय $t$ पर की गई क्रिया है।
- गणितीय परिभाषा: एजेंट द्वारा की गई एक असतत पसंद, या तो एक अज्ञात स्तर ($a^{(1)}$) का चयन करना या ऊर्जा निर्धारित करने के लिए रेखाओं का मिलान करना ($a^{(2)}$)।
- भौतिक/तार्किक भूमिका: यह टर्म विश्लेषण प्रक्रिया में एजेंट के निर्णय का प्रतिनिधित्व करता है।
- $\theta$: ये ऑनलाइन क्यू-नेटवर्क के पैरामीटर हैं।
- गणितीय परिभाषा: तंत्रिका नेटवर्क के भार और पूर्वाग्रह जो वर्तमान में क्यू-मानों का अनुमान लगाते हैं।
- भौतिक/तार्किक भूमिका: ये वे पैरामीटर हैं जिन्हें एजेंट की नीति को बेहतर बनाने के लिए प्रशिक्षण के दौरान सक्रिय रूप से अद्यतन किया जाता है।
- $\bar{\theta}$: ये लक्ष्य क्यू-नेटवर्क के पैरामीटर हैं।
- गणितीय परिभाषा: क्यू-नेटवर्क की एक प्रति के भार और पूर्वाग्रह, कम बार या सुचारू रूप से अद्यतन किए जाते हैं।
- भौतिक/तार्किक भूमिका: सीखने की प्रक्रिया की स्थिरता के लिए क्यू-मानों के लक्ष्य के रूप में एक स्थिर संदर्भ प्रदान करता है।
- $\text{argmax}_{a_{t+n}} Q_{\theta}(s_{t+n}, a_{t+n})$: यह ऑपरेटर स्थिति $s_{t+n}$ में क्यू-मान को अधिकतम करने वाली क्रिया को ढूंढता है।
- गणितीय परिभाषा: ऑनलाइन नेटवर्क मापदंडों $\theta$ का उपयोग करके स्थिति $s_{t+n}$ के लिए उच्चतम क्यू-मान प्राप्त करने वाली क्रिया $a_{t+n}$ लौटाता है।
- भौतिक/तार्किक भूमिका: यह डबल DQN का एक प्रमुख घटक है, जहाँ ऑनलाइन नेटवर्क लक्ष्य मान गणना के लिए क्रिया का चयन करता है, लेकिन लक्ष्य नेटवर्क इसके मूल्य का मूल्यांकन करता है। यह क्यू-सीखने में अति-अनुमान पूर्वाग्रह को कम करने में मदद करता है।
समीकरण (9): स्तर ऊर्जा अनुकूलन
- $E_{obs}$: यह स्तरों की प्रेक्षित ऊर्जाओं का प्रतिनिधित्व करता है।
- गणितीय परिभाषा: $N$ ज्ञात स्तरों के लिए ऊर्जा मान $E_n$ का एक वेक्टर।
- भौतिक/तार्किक भूमिका: ये अनुभवजन्य रूप से निर्धारित ऊर्जा स्तर हैं जिन्हें टर्म विश्लेषण स्थापित करने का लक्ष्य रखता है।
- $\text{argmin}_{E_n}$: यह न्यूनतमीकरण ऑपरेटर है।
- गणितीय परिभाषा: $E_n$ के मानों को ढूंढता है जो बाद के व्यंजक को न्यूनतम करते हैं।
- भौतिक/तार्किक भूमिका: यह दर्शाता है कि प्रेक्षित ऊर्जा स्तरों को प्रेक्षित स्पेक्ट्रल रेखाओं को सर्वोत्तम रूप से फिट करने वाले ऊर्जा स्तरों के सेट को ढूंढकर निर्धारित किया जाता है, विसंगतियों को न्यूनतम करता है।
- $\sum_{m=0}^{M-1} w_m \left( \sum_{n=0}^{N-1} S_{mn}E_n - \sigma_m \right)^2$: यह भारित वर्ग अवशिष्टों का योग है।
- गणितीय परिभाषा: सभी $M$ ज्ञात रेखाओं पर एक योग, जहाँ प्रत्येक पद एक अनुमानित तरंग संख्या और एक प्रेक्षित तरंग संख्या के बीच वर्ग अंतर है, जिसे $w_m$ द्वारा भारित किया गया है।
- भौतिक/तार्किक भूमिका: यह न्यूनतम-वर्ग अनुकूलन के लिए उद्देश्य फलन है। यह वर्तमान ऊर्जा स्तरों के सेट और प्रेक्षित स्पेक्ट्रल रेखाओं के बीच समग्र असहमति को मापता है। इस योग को न्यूनतम करने का अर्थ है ऊर्जा स्तरों को खोजना जो प्रेक्षित स्पेक्ट्रम की सर्वोत्तम व्याख्या करते हैं। योग का उपयोग किया जाता है क्योंकि कुल त्रुटि व्यक्तिगत रेखाओं से त्रुटियों का एक समुच्चय है।
- $M$: यह ज्ञात रेखाओं की कुल संख्या है।
- गणितीय परिभाषा: ज्ञात ऊर्जा स्तरों के बीच संक्रमणों से मेल खाने वाली स्पेक्ट्रल रेखाओं की एक पूर्णांक गणना।
- भौतिक/तार्किक भूमिका: ऊर्जा स्तरों को सीमित करने के लिए उपलब्ध अनुभवजन्य डेटा की मात्रा का प्रतिनिधित्व करता है।
- $N$: यह ज्ञात स्तरों की कुल संख्या है।
- गणितीय परिभाषा: उन ऊर्जा स्तरों की संख्या जिनके मानों को अनुकूलित किया जा रहा है।
- भौतिक/तार्किक भूमिका: उन परमाणु ऊर्जा अवस्थाओं की संख्या का प्रतिनिधित्व करता है जिनके मानों को परिष्कृत किया जा रहा है।
- $w_m$: यह रेखा $m$ के लिए भार है।
- गणितीय परिभाषा: $w_m = (\delta\sigma_m)^{-2}$, रेखा $m$ के लिए तरंग संख्या अनिश्चितता के व्युत्क्रम वर्ग।
- भौतिक/तार्किक भूमिका: यह अधिक सटीक रूप से मापी गई स्पेक्ट्रल रेखाओं (जिनमें छोटी $\delta\sigma_m$ होती है) को उच्च महत्व और उच्च अनिश्चितता वाली रेखाओं को कम महत्व प्रदान करता है। यह सुनिश्चित करता है कि विश्वसनीय डेटा निर्धारित ऊर्जा स्तरों पर अधिक प्रभाव डाले। व्युत्क्रम वर्ग भारित न्यूनतम वर्गों में एक मानक विकल्प है, जहाँ भार माप त्रुटि के विचरण के व्युत्क्रम के समानुपाती होते हैं।
- $\left( \sum_{n=0}^{N-1} S_{mn}E_n - \sigma_m \right)^2$: यह रेखा $m$ के लिए वर्ग अंतर (अवशिष्ट) है।
- गणितीय परिभाषा: वर्तमान ऊर्जा स्तरों द्वारा अनुमानित तरंग संख्या और रेखा $m$ के लिए प्रेक्षित तरंग संख्या के बीच अंतर का वर्ग।
- भौतिक/तार्किक भूमिका: यह मापता है कि वर्तमान ऊर्जा स्तरों का सेट एक विशिष्ट प्रेक्षित स्पेक्ट्रल रेखा की कितनी अच्छी तरह व्याख्या करता है। वर्ग करने से सकारात्मक मान सुनिश्चित होते हैं और बड़े विचलन को अधिक दंडित किया जाता है।
- $S_{mn}$: यह गुणांक है जो ऊर्जा स्तरों और रेखा $m$ के बीच संबंध को परिभाषित करता है।
- गणितीय परिभाषा: एक मैट्रिक्स तत्व जो 1 है यदि स्तर $n$ संक्रमण $m$ का ऊपरी स्तर है, -1 यदि स्तर $n$ संक्रमण $m$ का निचला स्तर है, और अन्यथा 0 है।
- भौतिक/तार्किक भूमिका: यह गुणांक मौलिक संबंध को एन्कोड करता है कि एक स्पेक्ट्रल रेखा की तरंग संख्या ($\sigma_m$) ऊपरी ($E_u$) और निचली ($E_l$) ऊर्जा स्तरों के बीच का अंतर है जो संक्रमण में शामिल हैं: $\sigma_m = E_u - E_l$।
- $E_n$: यह स्तर $n$ की ऊर्जा है।
- गणितीय परिभाषा: एक विशिष्ट परमाणु स्तर की ऊर्जा का प्रतिनिधित्व करने वाला एक स्केलर मान।
- भौतिक/तार्किक भूमिका: ये अज्ञात पैरामीटर हैं जिन्हें अनुकूलन प्रक्रिया निर्धारित करने का लक्ष्य रखती है।
- $\sigma_m$: यह रेखा $m$ के लिए प्रेक्षित तरंग संख्या है।
- गणितीय परिभाषा: एक मापा गया स्केलर मान जो एक स्पेक्ट्रल रेखा की तरंग संख्या का प्रतिनिधित्व करता है।
- भौतिक/तार्किक भूमिका: यह स्पेक्ट्रल लाइन सूची से अनुभवजन्य इनपुट डेटा है जिसे ऊर्जा स्तरों का पालन करना चाहिए।
चरण-दर-चरण प्रवाह
परमाणु विश्लेषण को एक गतिशील असेंबली लाइन के रूप में कल्पना करें, जहाँ परमाणु स्तर निर्धारण की वर्तमान स्थिति का प्रतिनिधित्व करने वाला एक अमूर्त डेटा बिंदु संचालन की एक श्रृंखला से गुजरता है।
-
प्रारंभिक स्थिति इनपुट: प्रक्रिया एक प्रारंभिक ग्राफ़ स्थिति $s_t$ के साथ शुरू होती है। यह स्थिति एक समृद्ध डेटा संरचना है, एक ग्राफ़ $G=(V, E)$, जहाँ नोड $V$ परमाणु ऊर्जा स्तर हैं (कुछ ज्ञात, कुछ अज्ञात) और किनारे $E$ संभावित या प्रेक्षित स्पेक्ट्रल रेखाएँ (संक्रमण) हैं। प्रत्येक नोड और किनारे में सुविधाओं का एक सेट होता है (जैसे, सैद्धांतिक ऊर्जा, प्रेक्षित तरंग संख्या, अनिश्चितता, "ज्ञात" या "चयनित" के लिए बाइनरी फ़्लैग)। इसके साथ, एक व्यापक स्पेक्ट्रल लाइन सूची है जिसमें सभी प्रेक्षित संक्रमण शामिल हैं।
-
क्रिया $a^{(1)}$: स्तर चयन: एजेंट पहले $a^{(1)}$ प्रकार की क्रिया करता है। यह उन सभी अज्ञात स्तरों का सर्वेक्षण करता है जिनके पास ज्ञात स्तरों से कम से कम दो संभावित कनेक्शन (किनारे) हैं। इस पूल से, एजेंट निर्धारण के लिए ध्यान केंद्रित करने के लिए एक विशिष्ट अज्ञात स्तर का चयन करता है। यह चयन एजेंट के सीखे हुए क्यू-मानों पर आधारित है, जो उस स्तर को चुनने के दीर्घकालिक पुरस्कार का अनुमान लगाते हैं। एक बार चयनित होने के बाद, इस नोड के लिए एक "चयनित" फ़्लैग चालू कर दिया जाता है ताकि यह इंगित किया जा सके कि यह वर्तमान लक्ष्य है।
-
क्रिया $a^{(2)}$: रेखा मिलान और ऊर्जा परिकल्पना: इसके बाद, एजेंट $a^{(2)}$ प्रकार की क्रिया निष्पादित करता है। "चयनित" अज्ञात स्तर के लिए, यह ज्ञात स्तरों से जुड़ने वाले सभी संभावित किनारों पर विचार करता है। ऐसे प्रत्येक किनारे के लिए, यह पूरी स्पेक्ट्रल लाइन सूची (जिसमें $10^4$ लाइनें हो सकती हैं) को फ़िल्टर करके उम्मीदवार प्रेक्षित रेखाओं को ढूंढता है। यह फ़िल्टरिंग सख्त है:
- तरंग संख्या मिलान: एक प्रेक्षित तरंग संख्या $\sigma_{obs}$ एक सैद्धांतिक सीमा $[\sigma_{calc} \pm \Delta E]$ के भीतर होनी चाहिए, जहाँ $\sigma_{calc}$ संक्रमण के लिए सैद्धांतिक तरंग संख्या है और $\Delta E$ ऊर्जा अनिश्चितता है।
- तीव्रता मिलान: प्रेक्षित तीव्रता $I_{obs}$ एक सैद्धांतिक सीमा $[I_{calc} \pm \Delta I]$ के भीतर होनी चाहिए।
- उम्मीदवार $E_{obs}$ उत्पादन: प्रत्येक फ़िल्टर की गई रेखा के लिए, एक उम्मीदवार प्रेक्षित ऊर्जा $E_{obs}$ अज्ञात स्तर के लिए जुड़े हुए स्तर की ज्ञात ऊर्जा से रेखा की तरंग संख्या को जोड़कर या घटाकर गणना की जाती है (यह इस बात पर निर्भर करता है कि चयनित स्तर ऊपरी है या निचला)।
- समेकन: चूंकि कई रेखाएँ अज्ञात स्तर के लिए समान ऊर्जा का सुझाव दे सकती हैं, उम्मीदवारों को समूहीकृत किया जाता है, और केवल $E_{obs}$ मान जो एक छोटी सहनशीलता $\delta E$ के भीतर दोहराए जाते हैं, उन्हें माना जाता है। एजेंट तब इन समेकित $E_{obs}$ मानों में से एक को चुनता है (या यदि कोई उपयुक्त उम्मीदवार नहीं हैं तो "कोई-ऑप" नहीं)।
-
स्थिति संक्रमण और ग्राफ़ अद्यतन: एक बार जब $E_{obs}$ मान को $a^{(2)}$ के माध्यम से चयनित स्तर के लिए चुना जाता है, तो ग्राफ़ स्थिति $s_t$ नियतात्मक रूप से एक नई स्थिति $s_{t+1}$ में परिवर्तित हो जाती है:
- "चयनित" अज्ञात स्तर अब एक "ज्ञात" स्तर बन जाता है, और इसकी $E_{obs}$ सुविधा को चुने हुए मान के साथ अद्यतन किया जाता है।
- मिलान किए गए स्पेक्ट्रल रेखाओं के अनुरूप किनारे भी "ज्ञात" किनारे बन जाते हैं, और उनकी सुविधाओं (जैसे, $\sigma_{obs}$, $I_{obs}$) को लाइन सूची से अद्यतन किया जाता है। इन मिलान की गई रेखाओं को फिर इस एपिसोड में भविष्य के $a^{(2)}$ विचारों से बाहर रखा जाता है।
- वैश्विक पुनः-अनुकूलन: महत्वपूर्ण रूप से, एक नया स्तर निर्धारित होने के बाद, सभी वर्तमान ज्ञात स्तरों (नए निर्धारित स्तर सहित) की प्रेक्षित ऊर्जाएँ $E_{obs}$ भारित न्यूनतम-वर्ग न्यूनीकरण (समीकरण 9) का उपयोग करके पुनः-अनुकूलित की जाती हैं। यह पूरे ज्ञात स्तर प्रणाली में स्थिरता सुनिश्चित करता है। जमीनी ऊर्जा स्तर $E_0$ को संदर्भ के रूप में शून्य पर निश्चित किया गया है।
-
पुरस्कार गणना: नई स्थिति $s_{t+1}$ और की गई क्रियाओं के आधार पर, एक पुरस्कार $r_t$ की गणना की जाती है। यह पुरस्कार एक समग्र है, जो निर्धारित स्तर में विश्वास, सिद्धांत के साथ इसके समझौते, और भविष्य के निर्धारण को सक्षम करने की इसकी क्षमता को दर्शाता है। $a^{(1)}$ के लिए, यह कनेक्टिंग रेखाओं के सिग्नल-टू-नॉइज़ अनुपात (समीकरण 6) पर आधारित है। $a^{(2)}$ के लिए, इसमें एक सीखा हुआ वरीयता स्कोर $D$ (समीकरण 7) शामिल है, जो मानव विशेषज्ञ निर्णयों से प्राप्त होता है।
-
अनुभव भंडारण: टपल $(s_t, a_t, r_t, s_{t+1})$ - पुरानी स्थिति, की गई क्रिया, प्राप्त पुरस्कार, और नई स्थिति का प्रतिनिधित्व - एक रीप्ले बफर में संग्रहीत किया जाता है। यह बफर एक स्मृति के रूप में कार्य करता है, पिछले अनुभवों को जमा करता है।
-
पुनरावृति: प्रक्रिया फिर चरण 2 पर वापस लूप करती है, जिसमें एजेंट एक और अज्ञात स्तर का चयन करता है या वर्तमान स्तर को परिष्कृत करना जारी रखता है, जब तक कि एक परिमित क्षितिज $H$ तक नहीं पहुंच जाता या कोई और मान्य क्रिया नहीं की जा सकती।
यह पूरी श्रृंखला अमूर्त गणित को एक चलती यांत्रिक असेंबली लाइन की तरह महसूस कराती है, जहाँ कच्चे स्पेक्ट्रल डेटा को लगातार परिष्कृत और परमाणु ऊर्जा स्तरों के एक बढ़ते, स्व-सुसंगत मॉडल में एकीकृत किया जाता है।
अनुकूलन गतिशीलता
TAG-DQN तंत्र मुख्य रूप से टेम्पोरल डिफरेंस (TD) त्रुटि को कम करके गहन रीइन्फोर्समेंट लर्निंग तकनीकों के एक परिष्कृत परस्पर क्रिया के माध्यम से सीखता है और अभिसरण करता है। यह इस प्रकार काम करता है:
-
ग्राफ़ प्रतिनिधित्व सीखना: नींव एक ग्राफ़ न्यूरल नेटवर्क (GNN) है। जब एक ग्राफ़ स्थिति $s_t$ (ज्ञात/अज्ञात स्तरों और रेखाओं की वर्तमान स्थिति का प्रतिनिधित्व) प्रस्तुत की जाती है, तो GNN अपने नोड्स (स्तर) और किनारों (रेखाओं) और उनकी संबंधित सुविधाओं (जैसे, $E_{calc}$, $\sigma_{obs}$, $I_{obs}$) को संसाधित करता है। यह प्रत्येक स्तर $v$ के लिए समृद्ध, प्रासंगिक नोड एम्बेडिंग वैक्टर $h_v$ सीखने के लिए मल्टी-हेड ग्राफ़ अटेंशन परतों का उपयोग करता है। ये एम्बेडिंग प्रत्येक नोड के स्थानीय पड़ोस की संरचनात्मक और फीचर जानकारी को कैप्चर करते हैं। एक वैश्विक ग्राफ़ स्थिति एम्बेडिंग वेक्टर $S_{agg}$ को इन नोड एम्बेडिंग को बस औसत करके प्राप्त किया जाता है (समीकरण 11)। यह $S_{agg}$ प्रभावी ढंग से पूरी ग्राफ़ की वर्तमान स्थिति को सारांशित करता है।
-
क्यू-मान अनुमान (डुएलिंग DQN): सीखे गए ग्राफ़ एम्बेडिंग को फिर क्यू-मानों का अनुमान लगाने के लिए मल्टी-लेयर परसेप्ट्रॉन (MLPs) में फीड किया जाता है। आर्किटेक्चर एक डुएलिंग DQN डिज़ाइन का उपयोग करता है, जो स्थिति-मूल्य फलन $V(s)$ और लाभ फलन $A(s, a)$ के अनुमान को अलग करता है।
- क्रिया प्रकार $a^{(1)}$ (एक अज्ञात स्तर का चयन) के लिए, प्रत्येक मान्य स्तर विकल्प के लिए क्यू-मान का अनुमान वैश्विक $S_{agg}$ (स्थिति-मूल्य के लिए) को चुने हुए स्तर के नोड एम्बेडिंग (लाभ के लिए) के साथ जोड़कर लगाया जाता है, जैसा कि समीकरण (12) में दिखाया गया है।
- क्रिया प्रकार $a^{(2)}$ (ऊर्जा निर्धारित करने के लिए रेखाओं का मिलान) के लिए, क्यू-मान का अनुमान समान रूप से लगाया जाता है, लेकिन लाभ फलन $A(s,a)$ की गणना स्थिति-क्रिया मान और स्थिति मान के बीच अंतर लेकर की जाती है, जैसा कि समीकरण (13) में दिखाया गया है। यह पृथक्करण नेटवर्क को यह सीखने में मदद करता है कि कौन सी स्थितियाँ क्रियाओं के स्वतंत्र रूप से मूल्यवान हैं, जिससे दक्षता में सुधार होता है।
-
नीति और अन्वेषण: एजेंट की नीति अनुमानित क्यू-मानों के संबंध में लालची है। प्रत्येक चरण में, यह उस क्रिया (या तो $a^{(1)}$ या $a^{(2)}$) का चयन करता है जिसका अनुमानित क्यू-मान उच्चतम होता है। अन्वेषण के लिए, पारंपरिक एप्सिलॉन-लालची विधि के बजाय, लेखक शोर नेटवर्क का उपयोग करते हैं। इसका मतलब है कि शोर सीधे एमएलपी आउटपुट परतों के भार में जोड़ा जाता है, जिससे एजेंट को स्पष्ट $\epsilon$ पैरामीटर की आवश्यकता के बिना स्वाभाविक रूप से विभिन्न क्रियाओं का पता लगाने के लिए प्रोत्साहित किया जाता है। शोर सीखा और समय के साथ अनुकूलित किया जाता है, जिससे जटिल वातावरण में अधिक कुशल अन्वेषण की अनुमति मिलती है।
-
अनुभव से सीखना (रीप्ले बफर और एन-स्टेप रिटर्न): सीखने के लिए, एजेंट केवल अपने सबसे हाल के अनुभव का उपयोग नहीं करता है। इसके बजाय, यह पिछले अनुभवों (स्थिति, क्रिया, पुरस्कार, अगली स्थिति टपल) को एक रीप्ले बफर में संग्रहीत करता है। प्रशिक्षण के दौरान, इन अनुभवों के बैचों को बेतरतीब ढंग से बफर से नमूना लिया जाता है। यह सीखने की प्रक्रिया को स्थिर करने वाले लगातार अनुभवों के बीच सहसंबंधों को तोड़ता है। हानि गणना (समीकरण 15) एन-स्टेप रिटर्न ($r^{[n]}$) का उपयोग करती है, जिसका अर्थ है कि तत्काल पुरस्कार $r_t$ और अगली स्थिति $s_{t+1}$ के क्यू-मान पर विचार करने के बजाय, यह $n$ चरणों तक भविष्य को देखता है। यह क्यू-मान अनुमान से बूटस्ट्रैपिंग से पहले एक छोटी प्रक्षेपवक्र पर वास्तविक पुरस्कारों को शामिल करके सीखने के लिए एक अधिक सटीक लक्ष्य प्रदान करता है।
-
स्थिरता के लिए लक्ष्य नेटवर्क: क्यू-सीखने में एक प्रमुख चुनौती यह है कि लक्ष्य मान (जिसका नेटवर्क अनुमान लगाने की कोशिश कर रहा है) उसी नेटवर्क पर निर्भर करता है जिसे अद्यतन किया जा रहा है, जिससे अस्थिरता होती है। इसे संबोधित करने के लिए, TAG-DQN एक लक्ष्य नेटवर्क $Q_{\bar{\theta}}$ का उपयोग करता है। यह ऑनलाइन क्यू-नेटवर्क ($Q_{\theta}$) की एक अलग प्रति है जिसके पैरामीटर $\theta$ की तुलना में $\bar{\theta}$ बहुत धीरे-धीरे अद्यतन किए जाते हैं। विशेष रूप से, $\bar{\theta}$ को प्रत्येक चरण में ऑनलाइन नेटवर्क के मापदंडों के एक छोटे से अंश को लक्ष्य नेटवर्क मापदंडों में मिश्रित करके नरम-अद्यतन (समीकरण 14) किया जाता है। यह ऑनलाइन नेटवर्क के सीखने के लिए एक स्थिर लक्ष्य बनाता है, जिससे दोलन और विचलन को रोका जा सके। डबल DQN का उपयोग इसे और परिष्कृत करता है, लक्ष्य मान गणना के लिए ऑनलाइन नेटवर्क का उपयोग करके, लेकिन इसके मूल्य का मूल्यांकन करने के लिए लक्ष्य नेटवर्क का उपयोग करके, जो क्यू-मान अति-अनुमान पूर्वाग्रह को कम करने में मदद करता है।
-
पुरस्कार फलन सीखना (व्युत्क्रम रीइन्फोर्समेंट लर्निंग): एक अनूठा पहलू यह है कि क्रिया $a^{(2)}$ (वरीयता स्कोर $D$) के लिए पुरस्कार फलन को हाथ से कोडित नहीं किया गया है। इसके बजाय, यह ऐतिहासिक मानव विशेषज्ञ निर्णयों से सीखा जाता है व्युत्क्रम रीइन्फोर्समेंट लर्निंग के एक रूप का उपयोग करके। एक साधारण मल्टी-लेयर परसेप्ट्रॉन (MLP) को उम्मीदवार रेखाओं की सुविधाओं से $D$ की भविष्यवाणी करने के लिए प्रशिक्षित किया जाता है (समीकरण 8)। यह MLP विशेषज्ञ-जनित एमडीपी स्थिति संक्रमणों पर प्रशिक्षित किया जाता है, जहाँ मानव विकल्पों को सकारात्मक उदाहरणों के रूप में लेबल किया जाता है। यह मॉडल को मानव विशेषज्ञों के सूक्ष्म निर्णय को पकड़ने की अनुमति देता है कि एक विशेष रेखा मिलान की "अच्छाई" क्या है, जिससे हानि परिदृश्य को उन क्रियाओं के पक्ष में आकार मिलता है जो विशेषज्ञ अंतर्ज्ञान के साथ संरेखित होती हैं।
-
अनुकूलन एल्गोरिथम: नेटवर्क पैरामीटर $\theta$ को एडम ऑप्टिमाइज़र का उपयोग करके अनुकूलित किया जाता है, जो एक लोकप्रिय स्टोकेस्टिक ग्रेडिएंट डिसेंट विधि है जो डीप लर्निंग कार्यों में अपनी दक्षता और अच्छे प्रदर्शन के लिए जानी जाती है। यह पुनरावृत्ति अनुकूलन प्रक्रिया क्यू-मान अनुमानों की सटीकता को बेहतर बनाने के लिए भार और पूर्वाग्रहों को समायोजित करती है और, परिणामस्वरूप, एजेंट की नीति को।
संक्षेप में, अनुकूलन गतिशीलता में एक निरंतर चक्र शामिल होता है: एजेंट पर्यावरण में कार्य करता है, अनुभव एकत्र करता है, इसे संग्रहीत करता है, और फिर सावधानीपूर्वक निर्मित हानि फलन को कम करके इस अनुभव के बैचों से सीखता है। यह सीखने की प्रक्रिया लक्ष्य नेटवर्क, एन-स्टेप रिटर्न और डुएलिंग आर्किटेक्चर जैसी तकनीकों द्वारा स्थिर की जाती है, जबकि अन्वेषण शोर नेटवर्क द्वारा नियंत्रित किया जाता है। मानव विशेषज्ञता से प्राप्त सीखा हुआ पुरस्कार फलन, एजेंट को भौतिक रूप से सार्थक समाधानों की ओर और मार्गदर्शन करता है, जिससे हानि परिदृश्य विशेषज्ञ प्राथमिकताओं और अनिश्चितताओं को दर्शाता है। यह पुनरावृत्ति परिष्करण एजेंट को एक ऐसी नीति में अभिसरण करने की अनुमति देता है जो परमाणु फाइन-स्ट्रक्चर को कुशलतापूर्वक और सटीक रूप से निर्धारित करती है।
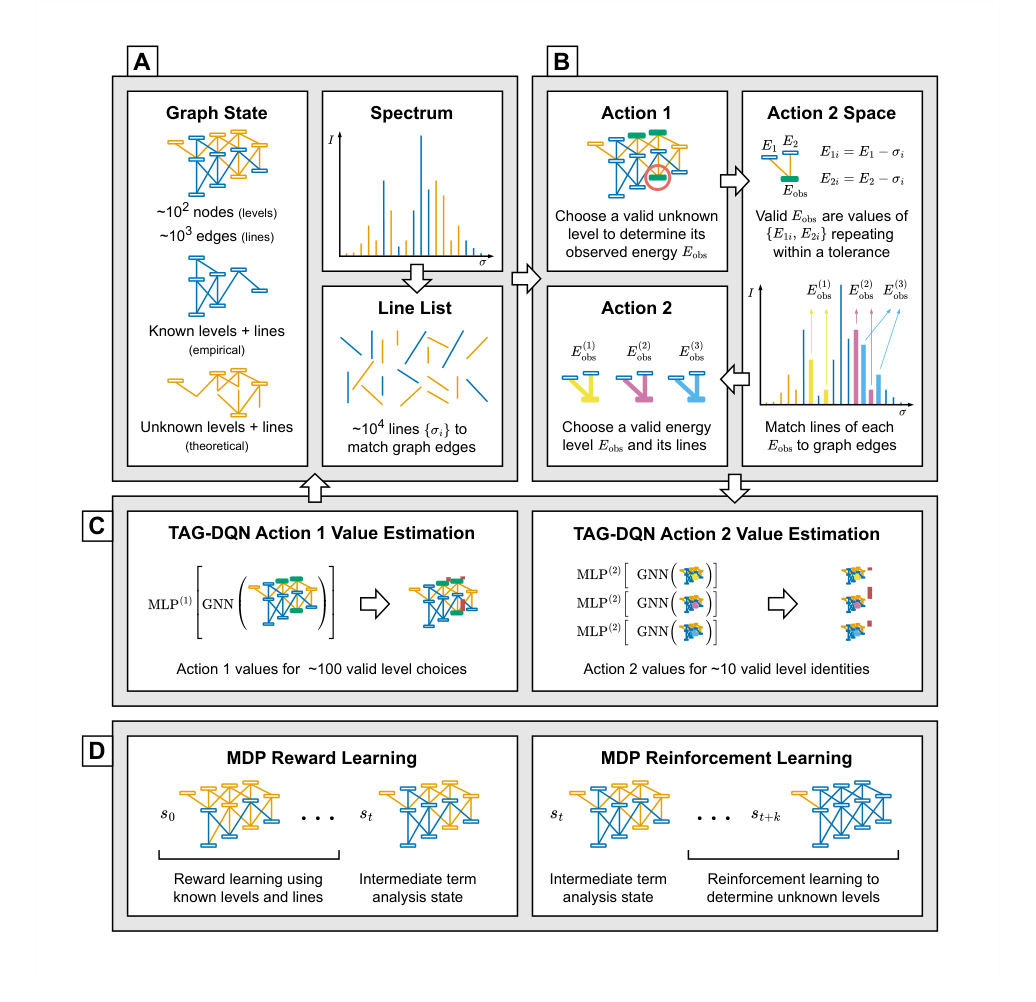 Figure 1. Illustration of the MDP environment and TAG-DQN. A The term analysis state is represented as a graph with node and edge features, alongside the spectral line list. B Actions alternate between two regimes; each pair of actions leads to the determination of the observed energy Eobs for one level by matching at least two lines from the line list to unknown edges in the graph. C TAG-DQN employs a GNN to embed graph representations, which are inputs for multilayer perceptrons (MLPs) estimating Q-values for each action (vertical bars); the highest Q-value action advances the MDP to the next state. D Given a term analysis state st, the MDP trajectory leading to st involving known levels is used for reward learning, while RL with the learned reward function guides the discovery of unknown levels in future states st+k
Figure 1. Illustration of the MDP environment and TAG-DQN. A The term analysis state is represented as a graph with node and edge features, alongside the spectral line list. B Actions alternate between two regimes; each pair of actions leads to the determination of the observed energy Eobs for one level by matching at least two lines from the line list to unknown edges in the graph. C TAG-DQN employs a GNN to embed graph representations, which are inputs for multilayer perceptrons (MLPs) estimating Q-values for each action (vertical bars); the highest Q-value action advances the MDP to the next state. D Given a term analysis state st, the MDP trajectory leading to st involving known levels is used for reward learning, while RL with the learned reward function guides the discovery of unknown levels in future states st+k
परिणाम, सीमाएँ और निष्कर्ष
प्रयोगात्मक डिजाइन और बेसलाइन
अपने गणितीय दावों को कठोरता से मान्य करने के लिए, लेखकों ने TAG-DQN के अपने टर्म एनालिसिस को दो बेसलाइन मॉडल के साथ तुलना करने वाले प्रयोगों की एक श्रृंखला तैयार की: एक लालची खोज एजेंट और एक मानक मोंटे-कार्लो ट्री सर्च (MCTS) एजेंट, जिसने ट्री के लिए ऊपरी विश्वास सीमा (UCT) रणनीति का उपयोग किया। मुख्य विचार यह प्रदर्शित करना था कि TAG-DQN परमाणु फाइन-स्ट्रक्चर निर्धारण के जटिल, अनुक्रमिक निर्णय लेने वाले कार्य को प्रभावी ढंग से स्वचालित और तेज कर सकता है।
प्रयोगात्मक सेटअप में चार अलग-अलग मार्कोव निर्णय प्रक्रिया (MDP) वातावरण शामिल थे, जिनमें से प्रत्येक को Co II, Nd III, और Nd II के दो वेरिएंट (Nd II u एब इनिशियो गणनाओं के लिए और Nd II k कोवान कोड गणनाओं के लिए) के वास्तविक दुनिया के परमाणु टर्म विश्लेषण से प्राप्त किया गया था। इन वातावरणों को वास्तविक टर्म विश्लेषण की चुनौतियों को दर्शाने के लिए सावधानीपूर्वक निर्मित किया गया था, जिसमें मौजूदा फूरियर ट्रांसफॉर्म (FT) स्पेक्ट्रल लाइन सूचियों और सैद्धांतिक गणनाओं का उपयोग किया गया था। उदाहरण के लिए, Co II वातावरण को संशोधित प्रकाशित डेटा से 141 ज्ञात स्तरों के साथ शुरू किया गया था, जबकि Nd III ने 40 स्तरों का उपयोग किया। Nd II वातावरण छह जमीनी टर्म स्तरों, पांच 6K स्तरों और 11 संक्रमणों के साथ शुरू हुए, जो उनकी सैद्धांतिक गणना विधियों में भिन्न थे।
निष्पक्ष और मजबूत तुलना सुनिश्चित करने के लिए, TAG-DQN और MCTS का मूल्यांकन 25 विभिन्न यादृच्छिक बीजों पर किया गया, जिसमें औसत प्रदर्शन और 95% विश्वास अंतराल की रिपोर्ट की गई। लालची खोज, जो नियतात्मक थी, एक बार चलाई गई थी। प्रदर्शन को तीन प्रमुख मेट्रिक्स का उपयोग करके मापा गया:
1. $R_{max}$: एमडीपी एपिसोड की लंबाई $H$ के भीतर एक एजेंट द्वारा प्राप्त अधिकतम संचयी पुरस्कार।
2. $N_c$: $R_{max}$ एपिसोड में सही ढंग से निर्धारित ऊर्जा स्तरों की संख्या, जहाँ एक स्तर को सही माना जाता था यदि उसकी प्रेक्षित ऊर्जा ($E_{obs}$) पहले प्रकाशित ऊर्जा स्तर ($E_{known}$) से $\pm \delta E$ के भीतर थी।
3. सटीकता (Acc.): $R_{max}$ एपिसोड में निर्धारित स्तरों की कुल संख्या के लिए $N_c$ का अनुपात।
व्यवहार्यता और आरएल प्रदर्शन को बढ़ाने के लिए एमडीपी वातावरण को सावधानीपूर्वक सरल बनाया गया था। इसमें कम सिग्नल-टू-नॉइज़ अनुपात ($S/N_{calc} < 2$) वाले ग्राफ़ किनारों को काटना, लाइन सूची प्रविष्टियों को बाहर करना जो पहले से मेल खाती थीं, ऊर्जा अनुकूलन के दौरान प्रारंभिक ज्ञात स्तरों को ठीक करना, और स्पेक्ट्रल रेंज को सीमित करना शामिल था। कुशल अन्वेषण और स्मृति प्रबंधन में सहायता के लिए रेखाओं का मिलान करने के लिए क्रिया स्थान ($|A^{(2)}|$) पर एक अधिकतम सीमा भी लगाई गई थी। एपिसोड की लंबाई $H$ प्रति प्रजाति भिन्न थी (जैसे, Nd III और Co II के लिए $H=128$, Nd II u के लिए $H=64$, Nd II k के लिए $H=512$) कम्प्यूटेशनल लागत और एजेंट की दीर्घकालिक परिणामों को सीखने की क्षमता के बीच संतुलन बनाने के लिए।
इसके अलावा, TAG-DQN के समग्र प्रदर्शन के लिए कौन से आर्किटेक्चरल घटक सबसे महत्वपूर्ण थे, यह इंगित करने के लिए Nd III वातावरण पर एब्लेशन अध्ययन किए गए थे।
साक्ष्य क्या साबित करता है
प्रायोगिक परिणाम सम्मोहक प्रमाण प्रदान करते हैं कि TAG-DQN परमाणु फाइन-स्ट्रक्चर निर्धारण को महत्वपूर्ण रूप से तेज कर सकता है, एक ऐसा कार्य जिसके लिए पारंपरिक रूप से महीनों से वर्षों के मानवीय प्रयास की आवश्यकता होती है। सिस्टम कुछ घंटों में सैकड़ों ऊर्जा स्तरों की पहचान और निर्धारण करने में सक्षम था।
विशेष रूप से, TAG-DQN का मुख्य तंत्र, जो टर्म विश्लेषण को ग्राफ़ रीइन्फोर्समेंट लर्निंग के साथ हल की जाने वाली मार्कोव निर्णय प्रक्रिया के रूप में प्रस्तुत करता है, जिसमें मानव निर्णयों से आंशिक रूप से सीखा गया पुरस्कार फलन होता है, स्पष्ट रूप से वास्तविकता में काम करता है। निश्चित प्रमाण उच्च समझौते दरों में निहित है: Co II के लिए 95% और Nd II और Nd III के लिए 54% और 87% के बीच। यह सटीकता का स्तर, समय के एक अंश में प्राप्त, विधि की प्रभावशीलता का एक मजबूत संकेतक है।
बेसलाइन मॉडल (तालिका 2) के मुकाबले, TAG-DQN ने सभी मेट्रिक्स पर लगातार लालची खोज एजेंट से बेहतर प्रदर्शन किया। इससे भी महत्वपूर्ण बात यह है कि इसने पांच में से तीन केस स्टडी में $N_c$ (सही ढंग से निर्धारित ऊर्जा स्तरों की संख्या) के मामले में MCTS एजेंट से बेहतर प्रदर्शन दिखाया। जबकि MCTS ने कभी-कभी उच्च अधिकतम संचयी पुरस्कार ($R_{max}$) प्राप्त किया, TAG-DQN ने लगातार $N_c$ के लिए उच्च ऊपरी सीमाएँ प्राप्त कीं, विशेष रूप से Nd II मामलों में। यह बताता है कि TAG-DQN ऐसे स्तर की पहचान चुनने में बेहतर था जो एपिसोड के दौरान अवलोकनों और सिद्धांत के साथ सुसंगत रहे, जबकि MCTS के उथले रोलआउट समग्र सटीकता की कीमत पर अल्पकालिक पुरस्कारों का पक्ष ले सकते थे। Nd II k के लिए, TAG-DQN ने MCTS (130 $\pm$ 11) की तुलना में काफी अधिक संख्या में स्तरों (169 $\pm$ 10) को सही ढंग से लेबल किया, जिससे यह व्याख्या और मजबूत हुई।
सीखने के वक्र (चित्र 2A, B) स्पष्ट रूप से संचयी पुरस्कार और सही ढंग से निर्धारित ऊर्जा स्तरों ($N_c$) की संख्या के बीच संरेखण को दर्शाते हैं, यह इंगित करते हुए कि सीखा हुआ पुरस्कार फलन एजेंट को सटीक स्तर निर्धारण की ओर प्रभावी ढंग से निर्देशित करता है। बोल्ट्ज़मान प्लॉट (चित्र 2C) ने पुष्टि की कि TAG-DQN विभिन्न इलेक्ट्रॉन विन्यासों में स्तरों को निर्धारित कर सकता है और यह कि बोल्ट्ज़मान स्तर की आबादी के आधार पर इसकी रेखा तीव्रता फ़िल्टरिंग, समस्याग्रस्त रेखाओं को बाहर करने में प्रभावी थी।
एब्लेशन अध्ययन (चित्र 3) ने TAG-DQN के आर्किटेक्चर में महत्वपूर्ण अंतर्दृष्टि प्रदान की। उन्होंने खुलासा किया कि अधिकांश DQN एक्सटेंशन ने प्रदर्शन में सकारात्मक योगदान दिया, जिसमें डुएलिंग नेटवर्क आर्किटेक्चर और अन्वेषण के लिए शोर नेटवर्क विशेष रूप से महत्वपूर्ण थे। यह संभवतः समस्या में निहित बड़े क्रिया स्थानों के कारण है। दिलचस्प बात यह है कि प्राथमिकता अनुभव रीप्ले (PER) ने प्रदर्शन को थोड़ा कम कर दिया, संभवतः इसलिए कि बफर आकार और प्रशिक्षण चरण इस विशिष्ट वातावरण में PER के लाभों के लिए इष्टतम रूप से स्केल नहीं किए गए थे। ऊर्जा स्तर अंतर (चित्र 4) ने विधि की सटीकता का और समर्थन किया, यह दिखाते हुए कि जबकि निर्धारित स्तरों का एक छोटा सा अंश स्वीकृत मानों से विचलित हुआ, ये विचलन आम तौर पर प्रयोगात्मक अनिश्चितता $\delta E$ के भीतर थे (जैसे, Nd III के लिए $\pm 0.004$ सेमी$^{-1}$, Co II के लिए $\pm 0.006$ सेमी$^{-1}$, Nd II k के लिए $\pm 0.009$ सेमी$^{-1}$), जो अधिकांश अनुप्रयोगों के लिए नगण्य हैं।
सीमाएँ और भविष्य की दिशाएँ
जबकि TAG-DQN दृष्टिकोण परमाणु फाइन-स्ट्रक्चर निर्धारण को स्वचालित करने में एक महत्वपूर्ण कदम का प्रतिनिधित्व करता है, इसकी वर्तमान सीमाओं को स्वीकार करना और भविष्य के विकास के लिए रास्ते पर विचार करना महत्वपूर्ण है।
एक प्राथमिक सीमा यह है कि वर्तमान विधि, अपनी प्रभावशाली गति के बावजूद, अभी भी मानव विशेषज्ञों और परमाणु संरचना गणनाओं पर निर्भरता की तुलना में कम सटीकता प्रदर्शित करती है। निर्धारित स्तरों, विशेष रूप से Nd II k जैसे मामलों के लिए, को अनंतिम माना जाता है और अंतिम प्रकाशन से पहले मानव सत्यापन की आवश्यकता होती है। इसके अलावा, वर्तमान ढाँचा अभी तक टर्म विश्लेषण में सबसे चुनौतीपूर्ण परिदृश्यों से नहीं निपटता है, जैसे कि एकल-रेखा स्तरों का निर्धारण, असंबद्ध ज्ञात-स्तर उप-ग्राफ़ को जोड़ना, या पूरी तरह से अज्ञात स्थिति से विश्लेषण शुरू करना। ये स्थितियाँ एमडीपी जटिलता को काफी बढ़ा देंगी और महत्वपूर्ण पुन: डिजाइन की आवश्यकता होगी। पुरस्कार फलन, वर्तमान में मुख्य रूप से Co II डेटा पर प्रशिक्षित है, विभिन्न परमाणु प्रजातियों और स्थितियों में इसके सामान्यीकरण में सुधार के लिए एक अधिक विविध और व्यापक प्रशिक्षण डेटासेट से लाभान्वित हो सकता है।
आगे देखते हुए, कई आशाजनक दिशाएँ इन निष्कर्षों को और विकसित कर सकती हैं:
- एमडीपी स्थिति और क्रिया स्थान को समृद्ध करना: वर्तमान एमडीपी को अधिक दानेदार जानकारी को शामिल करने के लिए विस्तारित किया जा सकता है। उदाहरण के लिए, कच्चे स्पेक्ट्रम और रेखा प्रोफ़ाइल विश्लेषण को सीधे एमडीपी में एकीकृत करने से एजेंट को समस्थानिक शिफ्ट, हाइपरफाइन संरचना और विभिन्न स्पेक्ट्रा के बीच तुलना जैसे अतिरिक्त कारकों पर विचार करने की अनुमति मिलेगी। तरंग फलन के बारे में जानकारी, जैसे कि अग्रणी विन्यास लेबल, इलेक्ट्रॉन संभाव्यता घनत्व, और विशिष्ट समता और जे मानों के भीतर स्थानीय स्तर घनत्व, रेखा प्रोफाइल और तीव्रता पर एजेंट के निर्णयों को भी सूचित कर सकती है, जिससे संभावित रूप से अधिक मजबूत और सटीक स्तर निर्धारण हो सकता है।
- अधिक मजबूत पुरस्कार फलन विकसित करना: जैसा कि उल्लेख किया गया है, सीमित डेटासेट पर निर्भर वर्तमान पुरस्कार फलन एक बाधा है। भविष्य के काम को विभिन्न परमाणु प्रजातियों के लाइन सूचियों और एमडीपी की एक विशाल सरणी का उपयोग करके एक अधिक सामान्यीकृत पुरस्कार फलन को प्रशिक्षित करने पर ध्यान केंद्रित करना चाहिए। यह एजेंट की नई स्थितियों को संभालने की क्षमता को बढ़ाएगा और समग्र प्रदर्शन में सुधार करेगा।
- मानव-इन-द-लूप एकीकरण: लेखक एक सहयोगात्मक दृष्टिकोण की परिकल्पना करते हैं जहाँ एआई का आउटपुट एक मध्यवर्ती कदम के रूप में कार्य करता है। एक एपिसोड की अंतिम एमडीपी स्थिति मानव विशेषज्ञों के लिए स्पेक्ट्रम का निरीक्षण करने, गलत तरीके से निर्धारित स्तरों को काटने, अर्ध-अनुभवजन्य गणनाओं को परिष्कृत करने और पुरस्कार फलन को पुनः प्रशिक्षित करने के लिए एक नया प्रारंभिक स्थिति बन सकती है। यह पुनरावृत्ति मानव-एआई सहयोग दोनों की ताकत का लाभ उठा सकता है, जिसमें एआई श्रमसाध्य प्रारंभिक पहचान को संभालता है और मानव विशेषज्ञ महत्वपूर्ण सत्यापन और शोधन प्रदान करता है।
- जटिल परिदृश्यों को संबोधित करना: भविष्य के शोध को वर्तमान में छोड़ी गई चुनौतीपूर्ण स्थितियों को संभालने के लिए एमडीपी को फिर से डिजाइन करने पर ध्यान केंद्रित करना चाहिए। इसमें बढ़ी हुई जटिलता को प्रबंधित करने के लिए नवीन ग्राफ़ अभ्यावेदन या क्रिया स्थान अपघटन शामिल हो सकते हैं, जो टर्म विश्लेषण के सबसे कठिन पहलुओं को भी स्वचालित करने की क्षमता को अनलॉक कर सकते हैं।
- अन्य प्रयोगात्मक विधियों तक विस्तार: यह दृष्टिकोण स्वाभाविक रूप से लचीला है और इसे अन्य प्रयोगात्मक विधियों, जैसे ग्रेटिंग स्पेक्ट्रोस्कोपी, को पर्यावरण मापदंडों जैसे $\delta E$, $\Delta I$, और पुरस्कार फलन में मामूली समायोजन के साथ अनुकूलित किया जा सकता है। यह विभिन्न स्पेक्ट्रोस्कोपिक तकनीकों में ग्राफ़ रीइन्फोर्समेंट लर्निंग की प्रयोज्यता का विस्तार करेगा।
- कम्प्यूटेशनल दक्षता और अवसंरचना: जबकि TAG-DQN एकल-बीज रनों के लिए सामान्य हार्डवेयर पर चल सकता है, व्यापक हाइपरपैरामीटर ट्यूनिंग और मल्टी-सीड मूल्यांकन सहित व्यापक प्रयोगों के लिए महत्वपूर्ण कम्प्यूटेशनल संसाधनों की आवश्यकता होती है। भविष्य के काम में व्यापक अनुसंधान के लिए आवश्यक कम्प्यूटेशनल लागत और समय को कम करने के लिए अधिक कुशल हाइपरपैरामीटर अनुकूलन तकनीकों या वितरित कंप्यूटिंग फ्रेमवर्क का पता लगाया जा सकता है।
अंततः, यह कार्य डेटा- और श्रम-गहन क्षेत्रों में वैज्ञानिक खोज में सहायता करने में ग्राफ़ रीइन्फोर्समेंट लर्निंग और सामान्य रूप से एआई की क्षमता का एक प्रमाण है। प्रस्तावित प्रगति तेजी से परमाणु भौतिकी अनुसंधान के एक नए युग का मार्ग प्रशस्त कर सकती है, जो परमाणु डेटा की मांग और इसके निर्धारण की वर्तमान दक्षता के बीच की खाई को पाटा जा सके।
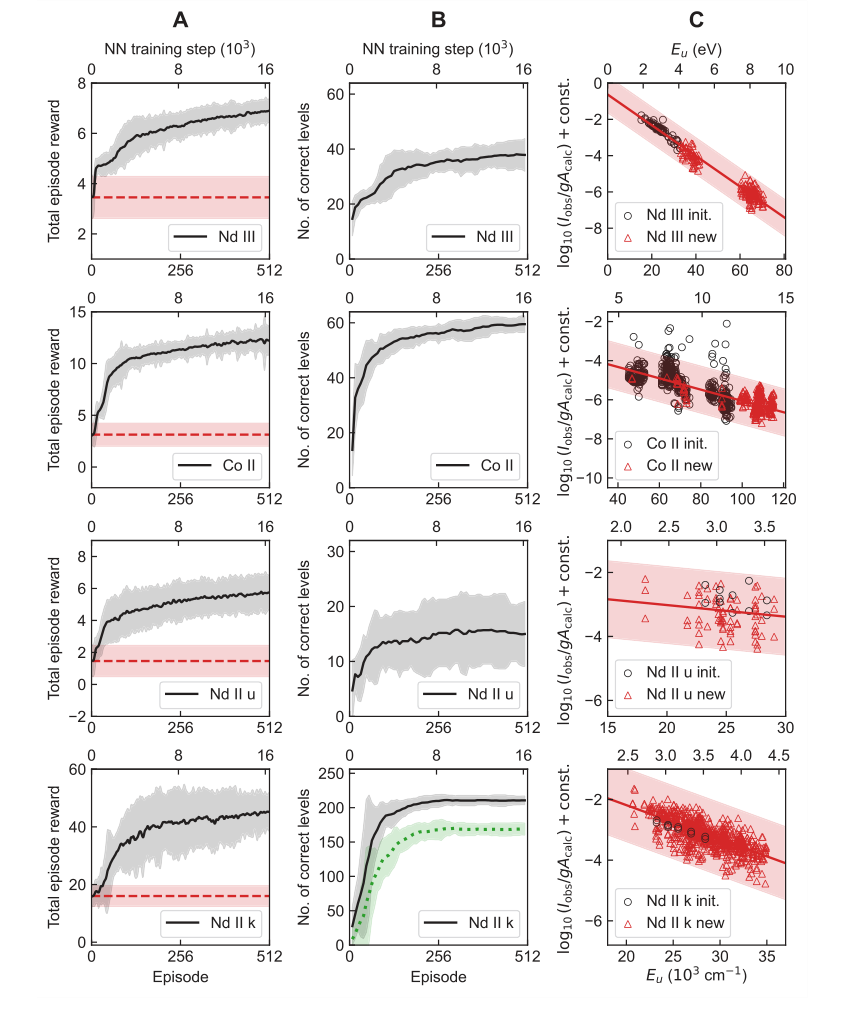 Figure 2. Learning results of TAG-DQN agent in the four case studies of Table 1. A Average learning curves, i.e., mean cumulative rewards obtained as a function of neural network (NN) training steps. The dashed horizontal lines show reward obtained during the pre-training episodes and correspond to rewards obtained by choosing actions in the MDP uniformly at random. The shaded regions show ±2 standard deviations across 25 random seeds. B Average Nc of the final state of the most recent maximum reward episode. The dotted curve for Nd II k shows the number of correct levels that also match human chosen level labels, and the y-axes limits are H
Figure 2. Learning results of TAG-DQN agent in the four case studies of Table 1. A Average learning curves, i.e., mean cumulative rewards obtained as a function of neural network (NN) training steps. The dashed horizontal lines show reward obtained during the pre-training episodes and correspond to rewards obtained by choosing actions in the MDP uniformly at random. The shaded regions show ±2 standard deviations across 25 random seeds. B Average Nc of the final state of the most recent maximum reward episode. The dotted curve for Nd II k shows the number of correct levels that also match human chosen level labels, and the y-axes limits are H
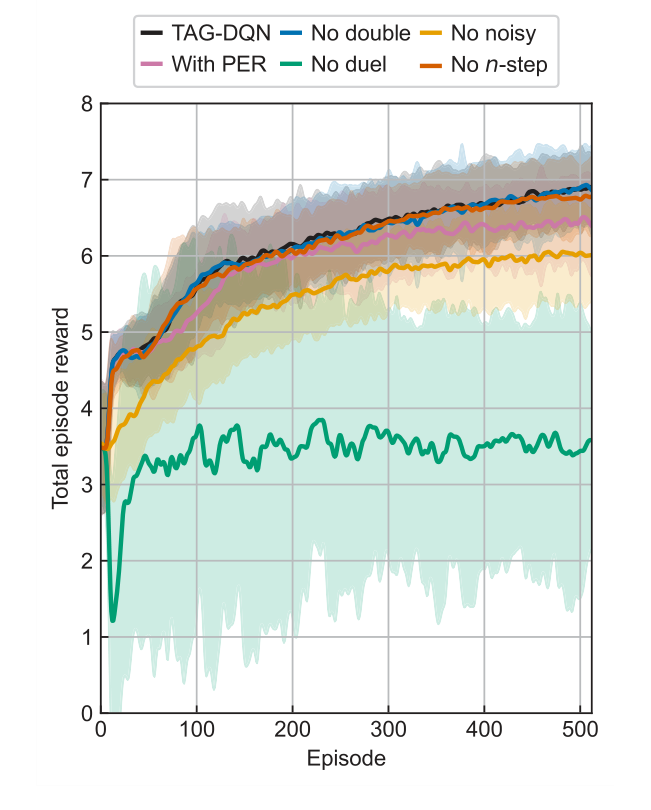 Figure 3. Learning curves of TAG-DQN (black) and its variants in the Nd III environment. Average total episode reward during training of TAG-DQN and its designs with or without particular deep Q-network extensions: without double Q-learning (blue), without noisy networks for exploration (yellow), with prioritised experience replay (PER, pink), without duelling deep Q-network (green), and without multi(n)-step return (orange). Shaded regions show ±2 standard deviations across 16 seeds. The duelling extension and noisy networks for exploration are key for TAG-DQN, while using PER reduced performance slightly
Figure 3. Learning curves of TAG-DQN (black) and its variants in the Nd III environment. Average total episode reward during training of TAG-DQN and its designs with or without particular deep Q-network extensions: without double Q-learning (blue), without noisy networks for exploration (yellow), with prioritised experience replay (PER, pink), without duelling deep Q-network (green), and without multi(n)-step return (orange). Shaded regions show ±2 standard deviations across 16 seeds. The duelling extension and noisy networks for exploration are key for TAG-DQN, while using PER reduced performance slightly
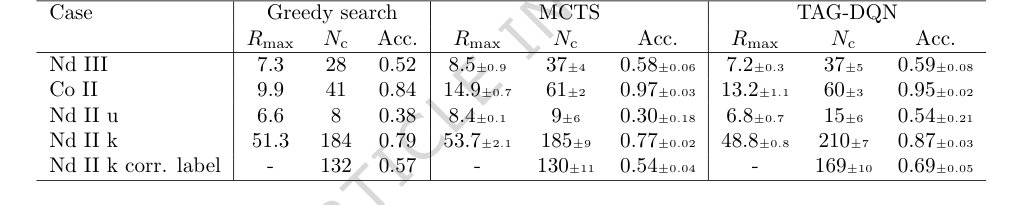 Table 2. Results and comparisons with benchmark agents. TAG-DQN matches MCTS performance as judged by downstream metrics in 2/5 cases and outperforms it in 3/5 cases, while Greedy search is worse overall
Table 2. Results and comparisons with benchmark agents. TAG-DQN matches MCTS performance as judged by downstream metrics in 2/5 cases and outperforms it in 3/5 cases, while Greedy search is worse overall
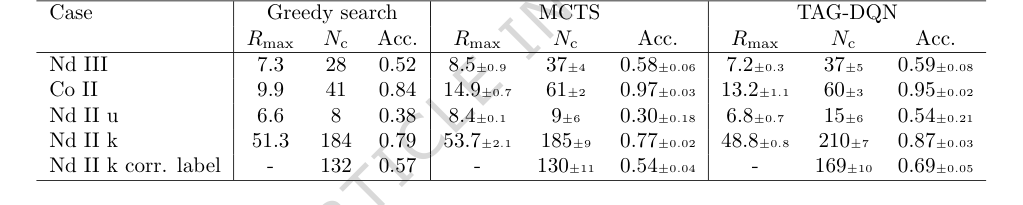 Table 1. Key term analysis MDP environment parameters
Table 1. Key term analysis MDP environment parameters