Ускорение определения тонкой структуры атомов с помощью обучения с подкреплением на графах
Проблема, рассматриваемая в данной статье, известная как "анализ термов", берет свое начало из фундаментальной потребности понять атомную структуру элементов.
Предыстория и академическая родословная
Происхождение и академическая родословная
Проблема, рассматриваемая в данной статье, известная как "анализ термов", берет свое начало из фундаментальной потребности понять атомную структуру элементов. В частности, она включает извлечение энергий и полных электронных моментов импульса ($J$) энергетических уровней из наблюдаемых атомных спектров и присвоение соответствующим термам символов этим уровням. Эта область исследований имеет решающее значение, поскольку полученные атомные данные, такие как энергетические уровни и волновые числа переходов, необходимы для широкого спектра применений. К ним относятся диагностика плазмы, металлургическая и осветительная промышленность, исследования в области магнитного удержания термоядерной плазмы, ядерные исследования, производство медицинских изотопов и астрономия, особенно в понимании происхождения тяжелых элементов в результате таких событий, как слияния нейтронных звезд.
Исторически процесс анализа термов представлял собой последовательную, сложную задачу принятия решений, требующую как глубокой экспертизы в области атомной спектроскопии, так и обширного человеческого труда. С момента внедрения анализа термов с использованием Фурье-спектроскопии в 1970-х годах его применение в основном ограничивалось элементами железной группы (элементами с атомными номерами $Z$ от 23 до 28). Сложность заключается в огромном количестве наблюдаемых спектральных линий (часто десятки тысяч для каждого элемента), которые представляют разности энергий между уровнями, что делает определение отдельных энергетических уровней трудной задачей, руководствуясь лишь менее точными теоретическими предсказаниями.
Фундаментальным ограничением или "болевой точкой" предыдущих подходов является их крайняя неэффективность и зависимость от экспертов-людей. В то время как начальные этапы измерения спектра и теоретических расчетов для одного атомного вида могут быть завершены за недели, последующий анализ термов — критический этап идентификации энергетических уровней по наблюдаемым данным — может занять месяцы или годы. Этот ручной, трудоемкий процесс стал основным узким местом, препятствующим быстрому получению атомных данных, необходимых для удовлетворения растущих потребностей в различных научных и промышленных областях. Более того, существующие расчеты ab initio (из первых принципов) часто имеют точность лишь в несколько процентов, что недостаточно для применений, требующих высокого спектрального разрешения. Анализ термов, несмотря на человеческие затраты, обеспечивает точность на порядки выше и предоставляет надежные ограничения для теоретических моделей. Эта неэффективность и неспособность теоретических методов обеспечить достаточную точность являются основными мотивами для авторов разработать автоматизированное решение на основе искусственного интеллекта.
Интуитивные термины предметной области
-
Определение тонкой структуры атома / Анализ термов: Представьте себе сложный музыкальный инструмент, например, рояль, но вы можете только слышать его звуки, не видя клавиш или их расположения. "Определение тонкой структуры атома" похоже на выяснение точного положения и идентификации каждой клавиши на этом рояле и их взаимосвязи, просто слушая мелодии. Это процесс сопоставления наблюдаемых спектральных "нот" с фундаментальными "клавишами" (энергетическими уровнями) атома.
-
Спектральная линия / Волновое число ($\sigma$): Продолжая аналогию с роялем, "спектральная линия" подобна одной, отчетливой ноте, которую вы слышите. Когда электрон в атоме переходит с более высокого энергетического уровня на более низкий, он излучает свет с очень определенной "высотой тона". "Волновое число" ($\sigma$) — это точное измерение этой высоты тона, которое говорит нам, сколько энергии было высвобождено при этом переходе электрона. Это прямое измерение разности энергий между двумя атомными состояниями.
-
Марковский процесс принятия решений (MDP): Думайте о MDP как об игре в поиск сокровищ. Вы ("агент") находитесь в определенном месте ("состояние"), и у вас есть несколько вариантов пути ("действия"). Каждый выбранный вами путь может привести вас в новое место (новое состояние) и дать вам немного золота ("вознаграждение"). Цель игры — найти стратегию ("политику"), которая максимизирует общее количество золота, собранного за всю охоту, даже если некоторые пути дают немедленные небольшие вознаграждения, но позже приводят в тупик.
-
Обучение с подкреплением (RL): Это похоже на обучение робота играть в игру поиска сокровищ без явных инструкций. Вместо этого вы позволяете роботу пробовать разные пути. Когда он находит золото, вы говорите ему "молодец!" (положительное вознаграждение). Когда он попадает в тупик, вы говорите ему "не очень хорошо" (отрицательное вознаграждение). За множество попыток робот методом проб и ошибок учится, какие действия в каких состояниях приводят к наибольшему количеству золота, в конечном итоге становясь экспертом по поиску сокровищ.
-
Графовые нейронные сети (GNN): Рассмотрите обширную сеть взаимосвязанных городов, где каждый город имеет уникальные характеристики (например, население, промышленность), а каждая соединяющая их дорога имеет свои свойства (например, длину, интенсивность движения). GNN — это особый тип искусственного интеллекта, разработанный для понимания и обучения на основе взаимосвязей и характеристик такой сети. Он помогает ИИ "видеть" общую структуру и локальные связи, позволяя ему принимать обоснованные решения о городах и дорогах, подобно тому, как он помогает анализировать сложную сеть атомных энергетических уровней и спектральных линий.
Таблица обозначений
| Обозначение | Описание |
|---|---|
| $J$ | Полный электронный момент импульса |
| $Z$ | Атомный номер |
| $\sigma$ | Волновое число |
| $\sigma_{obs}$ | Наблюдаемое волновое число |
| $\delta\sigma_{obs}$ | Стандартная неопределенность волнового числа |
| $I_{obs}$ | Относительная интенсивность |
| $S/N_{obs}$ | Отношение сигнал/шум |
| $E_{obs}$ | Наблюдаемая энергия атомного уровня |
| $E_{calc}$ | Теоретическая энергия атомного уровня |
| $\Delta E$ | Теоретическая неопределенность энергетического уровня |
| $\Delta I$ | Теоретическая неопределенность интенсивности линии |
| $E_u$ | Верхний энергетический уровень |
| $E_l$ | Нижний энергетический уровень |
| $E_0$ | Основной энергетический уровень (фиксирован на нуле) |
| $s_t$ | Состояние во время $t$ в MDP |
| $a_t$ | Действие, предпринятое во время $t$ в MDP |
| $r_t$ | Вознаграждение, полученное во время $t$ |
| $G_t$ | Кумулятивное дисконтированное вознаграждение с момента $t$ |
| $\gamma$ | Коэффициент дисконтирования |
| $H$ | Конечный горизонт (длина эпизода) в MDP |
| $Q(s, a)$ | Q-значение (ожидаемое кумулятивное вознаграждение за выполнение действия $a$ в состоянии $s$) |
| $Q_{\theta}$ | Онлайн Q-сеть с параметрами $\theta$ |
| $Q_{\bar{\theta}}$ | Целевая Q-сеть с параметрами $\bar{\theta}$ |
| $L$ | Функция потерь |
| $TD[n]$ | n-шаговая ошибка временной разности |
| $r^{[n]}$ | n-шаговый возврат |
| $w_m$ | Вес для линии $m$ в оптимизации методом наименьших квадратов |
| $S_{mn}$ | Коэффициентная матрица, связывающая энергетические уровни с линией $m$ |
| $M$ | Общее количество известных линий |
| $N$ | Общее количество известных уровней |
| $D$ | Оценка предпочтения для действия $a^{(2)}$ |
| $h_v$ | Вектор вложения узла для уровня $v$ |
| $S_{agg}$ | Вектор глобального состояния графа |
| $V(s)$ | Функция ценности состояния |
| $A(s, a)$ | Функция преимущества |
| MLP | Многослойный перцептрон |
| GNN | Графовая нейронная сеть |
| $N_c$ | Количество правильно определенных энергетических уровней |
| $R_{max}$ | Максимальное кумулятивное вознаграждение |
| Acc. | Точность определенных уровней |
| PER | Приоритетная выборка опыта |
| MCTS | Поиск по дереву Монте-Карло |
| UCT | Верхняя доверительная граница для деревьев |
Определение проблемы и ограничения
Основная постановка проблемы и дилемма
Основная проблема, рассматриваемая в данной статье, — это ускорение определения тонкой структуры атомов. Это критически важная задача в атомной спектроскопии, предоставляющая фундаментальные данные для различных научных и промышленных применений, от диагностики плазмы до астрофизики.
Отправной точкой (Входное/Текущее состояние) для этого анализа является набор наблюдаемых атомных спектров, которые предварительно обрабатываются в "список линий". Этот список линий содержит приблизительно $10^4$ наблюдаемых спектральных линий для данного атомного вида, каждая из которых характеризуется наблюдаемым волновым числом ($\sigma_{obs}$), стандартной неопределенностью волнового числа ($\delta\sigma_{obs}$), относительной интенсивностью ($I_{obs}$) и отношением сигнал/шум ($S/N_{obs}$). Кроме того, текущее состояние включает графовое представление известных (эмпирически определенных) энергетических уровней и переходов, наряду с теоретически предсказанными уровнями и линиями. Эти известные уровни обычно связаны, а их наблюдаемые энергии ($E_{obs}$) относятся к фиксированному нулевому уровню энергии.
Желаемая конечная точка (Выходное/Целевое состояние) — точное определение наблюдаемых энергий ($E_{obs}$) для неизвестных атомных энергетических уровней и классификация спектральных линий, которые наилучшим образом соответствуют теоретическим предсказаниям в пределах экспериментальных неопределенностей. Это включает расширение подграфа известных уровней путем идентификации и сопоставления по крайней мере двух наблюдаемых спектральных линий из списка линий с соответствующими ребрами, соединяющими неизвестный уровень с известными уровнями, тем самым определяя энергию неизвестного уровня.
Точное недостающее звено или математический пробел, который эта статья пытается преодолеть, заключается в переходе от необработанных данных спектральных линий и менее точных теоретических предсказаний к точным, эмпирически подтвержденным атомным энергетическим уровням. Исторически этот процесс, известный как "анализ термов", представлял собой последовательную, сложную задачу принятия решений, требующую обширного человеческого труда и экспертизы в области атомной спектроскопии, часто занимающую месяцы или годы для одного атомного вида. Математический пробел заключается в отсутствии автоматизированного, масштабируемого и точного метода для вывода этих энергетических уровней из огромного количества наблюдаемых разностей спектральных линий, руководствуясь теоретическими, но часто неточными расчетами. Статья формулирует это как Марковский процесс принятия решений (MDP), который должен быть решен с помощью графового обучения с подкреплением (GRL).
Болезненный компромисс или дилемма, в которую попали предыдущие исследователи, — это резкий выбор между точностью и эффективностью. В то время как анализ термов, управляемый человеком, обеспечивает высокую точность (на порядки выше, чем расчеты ab initio) и надежные теоретические ограничения, он мучительно медленный и трудоемкий, с трудом удовлетворяя растущий спрос на атомные данные. И наоборот, теоретические расчеты ab initio быстры, но обычно имеют точность лишь в несколько процентов, что недостаточно для применений, требующих более высокого спектрального разрешения. Дилемма заключается в том, что повышение скорости анализа традиционно означало жертву необходимой точностью или наоборот. Эта статья стремится частично автоматизировать процесс, стремясь достичь точности на уровне человека при значительно ускоренном темпе, тем самым сокращая разрыв между спросом на данные и мощностью анализа.
Ограничения и режимы отказа
Проблема ускорения определения тонкой структуры атомов чрезвычайно сложна из-за нескольких суровых, реалистичных ограничений:
-
Физические и предметно-специфические ограничения:
- Объем и сложность данных: Для каждого низкоионизированного атома с открытыми d- и f-подоболочками определение около $10^3$ энергетических уровней тонкой структуры включает анализ примерно $10^4$ наблюдаемых спектральных линий. Основная проблема заключается в извлечении точных энергетических уровней из "огромного количества наблюдаемых разностей энергий" (Раздел 1, стр. 3).
- Неточные теоретические указания: Существующие теоретические предсказания часто "менее точны" (Раздел 1, стр. 3), предоставляя лишь грубое руководство, а не точные значения. Расчеты ab initio обычно имеют точность лишь в несколько процентов, что недостаточно для многих применений.
- Неоднозначность и неопределенность: Определенные энергетические уровни часто имеют "неоднозначные значения" (Раздел 2.5, стр. 5). Эксперты-люди должны взвешивать согласие между наблюдаемыми и теоретическими интенсивностями линий и согласованность повторяющихся значений $E_{obs}$ в пределах неопределенностей волновых чисел. Эта оценка осложняется "неопределенностями в вероятностях переходов и ошибками в подгонке спектральных линий, особенно для широко распространенных слабых и/или смешанных линий" (Раздел 2.5, стр. 6).
- Ограниченное количество используемых переходов: Рассматриваются только переходы тонкой структуры электрического диполя, поскольку "переходы более высоких мультиполей редко наблюдаются в лабораторных спектрах" (Раздел 2.2, стр. 4), что ограничивает доступные данные для анализа.
- Выбросы и шум: Наличие "выбросов волновых чисел (например, неизвестное смешивание линий или плохая подгонка профилей спектральных линий)" (Раздел 3, стр. 8) может привести к сдвигам в определенных энергетических уровнях, даже если они находятся в пределах допуска $\delta E$.
- Сложные сценарии: Наиболее трудные ситуации, такие как "определение уровней по одной линии или объединение несвязанных подграфов известных уровней, включая анализ термов, начинающийся без известных уровней" (Раздел 3, стр. 8), значительно увеличивают сложность MDP и часто опускаются в текущих подходах.
-
Вычислительные и алгоритмические ограничения:
- Вычислительная осуществимость и временной горизонт: Человеческий процесс анализа занимает "месяцы или годы" (Раздел 1, стр. 3). Для вычислительной осуществимости MDP является эпизодическим с "конечным горизонтом $H$" (Раздел 2.1, стр. 4), ограничивая количество неизвестных энергетических уровней, которые могут быть определены в одном эпизоде.
- Большие пространства состояний и действий: Проблема включает "большие пространства состояний и действий" (Раздел 2.7, стр. 7), требующие глубоких нейронных сетей для аппроксимации функций. Пространство действий для выбора неизвестного уровня ($A^{(1)}$) может варьироваться от 0 до 200, а пространство действий для сопоставления линий ($A^{(2)}$) может достигать $10^3$ для больших $k$ (количество соединяющих известных уровней), со средним значением менее 10 (Раздел 2.3, стр. 5). Разрешение определения по одной линии привело бы к "неосуществимо большим $A^{(1)}$" (Раздел 2.3, стр. 5).
- Управление сложностью MDP: "Снижение сложности MDP является ключом к осуществимости и производительности RL" (Раздел 2.6, стр. 6). Это включает стратегии, такие как удаление ребер графа с низким отношением сигнал/шум, исключение уже сопоставленных линий и ограничение спектральных диапазонов. "Максимальный предел $|A^{(2)}|$" установлен для обеспечения "эффективного исследования и контроля памяти" (Раздел 2.6, стр. 6).
- Эффективность исследования: Традиционные методы исследования, такие как случайная выборка действий в поиске по дереву Монте-Карло (MCTS), "неэффективны в больших пространствах действий, где только одно действие является правильным" (Раздел 4.6, стр. 11).
- Вычислительные затраты: Комплексные эксперименты, включая настройку гиперпараметров и запуски с несколькими начальными условиями, чрезвычайно ресурсоемки и требуют приблизительно $10^5$ часов (около 11 лет) гипотетического времени работы процессора на одном ядре (Раздел 4.7, стр. 11).
-
Ограничения, связанные с обучением на основе данных:
- Зависимость от человеческих данных: Функция вознаграждения "частично обучается на исторических решениях человека" (Аннотация, стр. 2) посредством обратного обучения с подкреплением, которое опирается на сгенерированные экспертами переходы состояний MDP.
- Ограниченные обучающие данные для функции вознаграждения: Модель MLP для прогнозирования оценки предпочтения $D$ была обучена на относительно небольшом наборе данных из 115 переходов состояний $a^{(2)}$ от экспертов для Co II и 23 для Nd III (Раздел 4.3, стр. 9).
- Смещение в обучающих данных: "Более слабые линии были недостаточно представлены в обучающем наборе данных, а неизвестные линии обычно слабее" (Раздел 4.3, стр. 9), что может повлиять на производительность модели на этих менее заметных линиях.
- Качество начального состояния: Качество "начального состояния MDP" может варьироваться; например, данные Nd II из эпизода Rmax рассматриваются как "предварительные", а "начальное состояние MDP низкого качества" (Раздел 3, стр. 8) до подтверждения человеком.
Почему этот подход
Неизбежность выбора
Выбор графового обучения с подкреплением (GRL), в частности анализа термов с использованием графовой глубокой Q-сети (TAG-DQN), был не просто предпочтением, а неизбежным выбором, обусловленным внутренней природой определения тонкой структуры атомов. Эта сложная проблема по сути является задачей последовательного принятия решений, работающей с данными, структурированными в виде графа. "Точный момент" осознания для авторов, хотя и не указан явно, может быть выведен из их постановки проблемы: они представили процедуру анализа как Марковский процесс принятия решений (MDP), включающий графы, где атомные энергетические уровни являются узлами, а спектральные линии — ребрами.
Традиционные методы "SOTA", такие как стандартные сверточные нейронные сети (CNN), базовые диффузионные модели или трансформеры, в их типичных применениях, плохо подходят для этой конкретной задачи. CNN преуспевают в данных, похожих на сетку (изображения), но испытывают трудности с нерегулярными графовыми структурами. Диффузионные модели в основном генеративны и не предназначены для последовательного принятия решений или комбинаторной оптимизации на графах. Трансформеры, хотя и мощны для последовательных данных, потребуют значительной адаптации для обработки динамического представления состояния на основе графа и последовательного процесса принятия решений, присущего анализу термов. Основная проблема заключается в том, что проблема не связана с распознаванием образов в фиксированной сетке, генерацией новых данных или простым переводом последовательностей. Вместо этого она заключается в принятии ряда взаимозависимых решений на динамически развивающемся графе для идентификации неизвестных энергетических уровней, что естественным образом соответствует сильным сторонам обучения с подкреплением на графах. Авторы явно заявляют, что "ключом к достижению масштабируемости является принятие методов, которые доказали свою успешность в этой более широкой литературе, включая декомпозицию пространства действий, ограничение допустимых действий с помощью знаний предметной области и использование графовых нейронных сетей (GNN) в качестве обучающего представления [32]", подчеркивая, что графовая структура и комбинаторная природа проблемы требовали этого специализированного подхода.
Сравнительное превосходство
Помимо простых метрик производительности, TAG-DQN предлагает качественные и структурные преимущества, которые делают его подавляюще превосходящим предыдущие золотые стандарты, которые в основном опирались на обширный человеческий труд и менее сложные алгоритмы поиска. Самым поразительным преимуществом является драматическое сокращение времени анализа: TAG-DQN может определить сотни энергетических уровней за часы, задача, которая традиционно требовала месяцев или лет человеческих усилий. Это представляет собой улучшение эффективности на порядок.
Структурно превосходство TAG-DQN обусловлено его способностью:
1. Обрабатывать графовые данные нативно: Используя графовые нейронные сети (GNN) в качестве обучающего представления, TAG-DQN напрямую обрабатывает присущую графовую структуру атомных уровней (узлы) и спектральных линий (ребра). Это естественное соответствие, в отличие от методов, которые потребовали бы сглаживания или сильной предварительной обработки таких реляционных данных, потенциально теряя важную информацию.
2. Обучаться последовательному принятию решений: Как агент обучения с подкреплением, TAG-DQN изучает политику для принятия последовательности оптимальных решений (выбор неизвестных уровней, сопоставление спектральных линий) для максимизации кумулятивного вознаграждения. Это критически важно для анализа термов, который является "последовательной, сложной задачей принятия решений".
3. Включать экспертные знания и неопределенность: Функция вознаграждения частично обучается на исторических решениях человека посредством обратного обучения с подкреплением, что позволяет модели улавливать тонкие предпочтения и эвристики экспертов-людей. Кроме того, пространство действий включает теоретические и экспериментальные неопределенности ($\Delta E$, $\Delta I$), что позволяет модели работать в рамках реалистичных физических ограничений.
4. Достигать долгосрочной согласованности: По сравнению с базовыми алгоритмами поиска, такими как поиск по дереву Монте-Карло (MCTS), TAG-DQN демонстрирует превосходную точность в определении правильно помеченных уровней, особенно в сложных случаях, таких как Nd II. В то время как MCTS может находить более высокие немедленные вознаграждения, его неглубокие прогоны в больших пространствах состояний и действий могут приводить к "близоруким действиям" и менее согласованным долгосрочным результатам. Способность TAG-DQN изучать политику, которая учитывает долгосрочные последствия своих решений, приводя к тому, что идентификаторы уровней "более вероятно останутся согласованными с наблюдениями и теорией на протяжении всего эпизода", является ключевым качественным преимуществом.
Статья явно не обсуждает сложность памяти в терминах $O(N^2)$ против $O(N)$ или специфическую обработку высокоразмерного шума, кроме как в дизайне функции вознаграждения для приоритезации линий с высоким отношением сигнал/шум (S/N) и исключения плохо измеренных. Однако масштабируемость, достигнутая благодаря GNN и декомпозиции пространства действий, косвенно решает проблему больших, высокоразмерных входных пространств.
Соответствие ограничениям
Выбранный метод TAG-DQN идеально соответствует присущим ограничениям и требованиям определения тонкой структуры атомов, образуя прочный "союз" между проблемой и решением.
- Последовательное принятие решений: Проблема описывается как "последовательная, сложная задача принятия решений". Обучение с подкреплением по самому своему определению предназначено для решения таких задач путем изучения оптимальных политик на дискретных временных шагах.
- Графовые данные: Атомные энергетические уровни и спектральные линии естественным образом образуют граф, где уровни являются узлами, а линии — ребрами. GNN, являющиеся основным компонентом TAG-DQN, специально разработаны для обработки и обучения на таких реляционных данных, сохраняя структурную целостность проблемы.
- Огромное пространство поиска: Задача включает определение энергетических уровней из "огромного количества наблюдаемых разностей энергий". Комбинация GNN для эффективного представления состояний и DQN для обучения в больших пространствах состояний и действий предоставляет необходимый механизм для навигации по этому огромному комбинаторному ландшафту.
- Включение знаний предметной области и экспертных знаний человека: Анализ термов является "по своей сути эмпирическим" и опирается на человеческий опыт. Метод решает эту проблему, используя функции вознаграждения, "частично обученные на исторических решениях человека" посредством обратного обучения с подкреплением, эффективно встраивая экспертные знания в процесс принятия решений ИИ. Знания предметной области также используются для ограничения допустимых действий и упрощения MDP.
- Вычислительная осуществимость и масштабируемость: Основным ограничением является "месяцы или годы" человеческого труда. TAG-DQN достигает "до 102 предварительных энергетических уровней тонкой структуры... за часы", напрямую решая проблему ускорения. Авторы также явно упоминают "Снижение сложности MDP является ключом к осуществимости и производительности RL", подробно описывая, как они обрезают пространство проблемы (например, удаляя ребра с низким S/N, ограничивая спектральные диапазоны), чтобы сделать решение решаемым.
- Обработка неопределенностей: Проблема включает "менее точные теоретические предсказания" и экспериментальные неопределенности. Пространство действий и функция вознаграждения разработаны для учета теоретических неопределенностей ($\Delta E$, $\Delta I$) и приоритезации линий с высоким отношением сигнал/шум, что делает решение устойчивым к зашумленным данным.
Отклонение альтернатив
Статья предоставляет четкое обоснование для отклонения определенных альтернативных подходов, особенно в области алгоритмов поиска и общих парадигм обучения с подкреплением.
- Жадный поиск: Авторы явно заявляют, что "Жадный поиск последовательно уступал по производительности агентам RL". Это связано с тем, что жадные подходы по определению максимизируют только немедленные вознаграждения и не могут планировать долгосрочные последствия, что критически важно для задачи последовательного принятия решений, такой как анализ термов, где ранние выборы влияют на будущие возможности.
- Поиск по дереву Монте-Карло (MCTS): Хотя MCTS является более сложным алгоритмом поиска, статья отмечает, что "MCTS достиг более высокого Rmax по сравнению с TAG-DQN, однако TAG-DQN достиг более высоких верхних границ Ne, особенно в случаях Nd II". Интерпретация заключается в том, что "прогоны MCTS были неглубокими и отдавали предпочтение краткосрочным вознаграждениям", что привело к более высоким вознаграждениям по траектории, но к более низкой точности правильно помеченных уровней. Это подчеркивает, что для данной проблемы долгосрочная согласованность и точность (которые TAG-DQN достигал лучше) важнее максимизации немедленного вознаграждения. Большие пространства состояний и действий делают глубокие прогоны MCTS вычислительно дорогими и подверженными шуму.
- Методы градиента политики: Авторы заявляют: "Мы выбрали этот класс алгоритмов [DQN] из-за его более высокой эффективности выборки по сравнению с подходами градиента политики [40]". Методы градиента политики обычно требуют большего взаимодействия со средой для изучения эффективной политики, что было бы значительным недостатком в сложной, потенциально дорогостоящей симуляции или реальном применении анализа атомных данных.
- Другие архитектуры глубокого обучения (неявное отклонение): Хотя явно не заявляется, что GAN, диффузионные модели или стандартные CNN/трансформеры провалились, выбор GNN и RL неявно отклоняет их для основной проблемы. Проблема не связана с генерацией изображений, переводом последовательностей или простой классификацией на данных, похожих на сетку. Присущая графовая структура атомных уровней и линий в сочетании с природой последовательного принятия решений делает GRL наиболее подходящей и эффективной парадигмой. Эти другие методы потребовали бы значительного, возможно, неестественного переосмысления проблемы для соответствия их архитектурам, что, вероятно, привело бы к субоптимальной производительности или повышенной сложности.
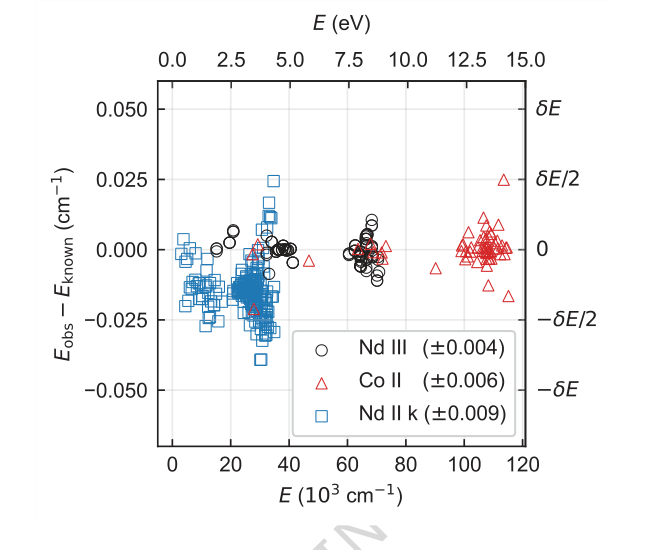 Figure 4. Difference between energy levels determined from a single seed and their known (ac- cepted) values for each species. Only levels contributing to Nc are shown. Energy differences for Nd III, Co II, and Nd II k are shown in circles, triangles, and squares, respectively. The root-mean-square energy differences are given in parentheses in the legend. Typical energy level uncertainty by FT spectroscopy is of order 0.001 cm−1. The offset and higher spread of Nd II k energies are expected and within uncertainties as their known values were derived by lower-precision grating spectroscopy [4]
Figure 4. Difference between energy levels determined from a single seed and their known (ac- cepted) values for each species. Only levels contributing to Nc are shown. Energy differences for Nd III, Co II, and Nd II k are shown in circles, triangles, and squares, respectively. The root-mean-square energy differences are given in parentheses in the legend. Typical energy level uncertainty by FT spectroscopy is of order 0.001 cm−1. The offset and higher spread of Nd II k energies are expected and within uncertainties as their known values were derived by lower-precision grating spectroscopy [4]
Математический и логический механизм
Главное уравнение
Основной механизм данной статьи вращается вокруг двух фундаментальных уравнений: целевой функции для Марковского процесса принятия решений (MDP), которую агент стремится максимизировать, и функции потерь, которая управляет обучением базовой нейронной сети. Кроме того, неотъемлемой частью механизма обновления состояния является критический расчет для определения энергетических уровней.
Основная цель агента обучения с подкреплением — максимизировать ожидаемое кумулятивное дисконтированное вознаграждение за конечный горизонт $H$:
$$ E[G_t] = E\left[\sum_{k=0}^{H} \gamma^k r_{t+k}\right] \quad (1) $$
Это уравнение определяет, чего пытается достичь агент: принять последовательность решений, которые приведут к максимально возможной сумме будущих вознаграждений, где вознаграждения, полученные раньше, ценятся выше, чем полученные позже.
Процесс обучения агента глубокой Q-сети (DQN) управляется минимизацией функции потерь, в частности, квадратичной ошибки временной разности (TD) по n шагам:
$$ L = [TD[n]]^2 = \left[r^{[n]} + \gamma^n Q_{\bar{\theta}}(s_{t+n}, \text{argmax}_{a_{t+n}} Q_{\theta}(s_{t+n}, a_{t+n})) – Q_{\theta}(s_t, a_t)\right]^2 \quad (15) $$
Эта функция потерь направляет нейронную сеть к точному прогнозированию "качества" действий, гарантируя, что ее оценки соответствуют фактическим будущим вознаграждениям.
Наконец, критический расчет, который лежит в основе обновлений состояний, особенно определения наблюдаемых энергетических уровней ($E_{obs}$), выполняется путем минимизации методом взвешенных наименьших квадратов:
$$ E_{obs} = \text{argmin}_{E_n} \sum_{m=0}^{M-1} w_m \left( \sum_{n=0}^{N-1} S_{mn}E_n - \sigma_m \right)^2 \quad (9) $$
Это уравнение показывает, как система уточняет значения энергии известных уровней на основе наблюдаемых спектральных линий, что делает его центральным компонентом "математического двигателя", который обрабатывает и обновляет атомные данные.
Пошаговый разбор
Давайте разберем каждое из этих уравнений, чтобы понять их отдельные компоненты и их роль.
Уравнение (1): Ожидаемое кумулятивное дисконтированное вознаграждение
- $E[G_t]$: Это ожидаемое кумулятивное дисконтированное вознаграждение, начиная с временного шага $t$.
- Математическое определение: Среднее значение $G_t$ по многим возможным траекториям.
- Физическая/логическая роль: Это конечная целевая функция для агента обучения с подкреплением. Политика агента разработана для выбора действий, максимизирующих это количество, эффективно находя наилучшую последовательность решений для определения тонких структур атомов.
- $E[\cdot]$: Это оператор математического ожидания.
- Математическое определение: Вычисляет среднее значение случайной величины.
- Физическая/логическая роль: В обучении с подкреплением агент не знает точных будущих вознаграждений или переходов состояний детерминированным образом. Этот оператор учитывает присущую неопределенность среды, гарантируя, что агент оптимизирует средний результат.
- $G_t$: Это кумулятивное дисконтированное вознаграждение с момента $t$.
- Математическое определение: Сумма всех будущих вознаграждений, каждое из которых дисконтируется фактором $\gamma$, возведенным в степень количества шагов в будущее.
- Физическая/логическая роль: Оно количественно определяет общую "хорошесть" определенной последовательности действий и состояний, начиная с момента $t$.
- $\sum_{k=0}^{H} \gamma^k r_{t+k}$: Это сумма дисконтированных будущих вознаграждений.
- Математическое определение: Конечная сумма, где каждое вознаграждение $r_{t+k}$ умножается на $\gamma^k$.
- Физическая/логическая роль: Оно агрегирует вознаграждения, полученные на будущих временных шагах $t+k$, применяя дисконтирование, чтобы сделать немедленные вознаграждения более ценными, чем отдаленные. Суммирование используется, поскольку общее вознаграждение является накоплением отдельных вознаграждений.
- $\gamma$: Это коэффициент дисконтирования.
- Математическое определение: Скалярное значение от 0 до 1 (включительно), $\gamma \in [0, 1]$.
- Физическая/логическая роль: Оно балансирует важность немедленных и будущих вознаграждений. $\gamma$, близкое к 0, делает агента "близоруким", фокусирующимся на немедленных выгодах, в то время как $\gamma$, близкое к 1, делает его "дальновидным", учитывающим долгосрочные последствия. Авторы выбрали сложение для суммы, поскольку общее значение является накоплением отдельных вознаграждений.
- $k$: Это индекс временного шага относительно $t$.
- Математическое определение: Целое число, представляющее количество шагов в будущее от момента $t$.
- Физическая/логическая роль: Оно отслеживает, насколько далеко в будущее получено конкретное вознаграждение $r_{t+k}$, что определяет степень, в которую $\gamma$ возводится для дисконтирования.
- $r_{t+k}$: Это вознаграждение, полученное в момент времени $t+k$.
- Математическое определение: Скалярное значение, представляющее немедленную обратную связь от среды после выполнения действия.
- Физическая/логическая роль: В данной статье вознаграждения разработаны для отражения уверенности в определенных энергетических уровнях, согласия с теорией и наблюдениями, а также способности обеспечить будущие определения уровней (уравнения 6 и 7).
Уравнение (15): Функция потерь для TAG-DQN
- $L$: Это функция потерь.
- Математическое определение: Скалярное значение, количественно определяющее ошибку между прогнозируемыми Q-значениями и целевыми Q-значениями.
- Физическая/логическая роль: Цель обучения — минимизировать эту потерю, что, в свою очередь, делает прогнозы Q-сети более точными.
- $[TD[n]]^2$: Это квадратичная ошибка временной разности (TD) по n шагам.
- Математическое определение: Квадрат разности между n-шаговым возвратом (оценкой будущего вознаграждения) и текущим прогнозом Q-значения.
- Физическая/логическая роль: Возведение ошибки в квадрат гарантирует, что как положительные, так и отрицательные ошибки вносят вклад в потери, и сильнее наказывает большие ошибки, способствуя сходимости.
- $r^{[n]}$: Это n-шаговый возврат.
- Математическое определение: Сумма первых $n$ вознаграждений, дисконтированных, плюс дисконтированное Q-значение состояния, достигнутого после $n$ шагов.
- Физическая/логическая роль: Он обеспечивает более стабильную и менее смещенную оценку истинной ценности по сравнению с одношаговым возвратом, включая фактические вознаграждения за короткий горизонт перед бутстрэппингом из оценки Q-значения.
- $\gamma^n$: Это коэффициент дисконтирования, возведенный в степень $n$.
- Математическое определение: Коэффициент дисконтирования $\gamma$, умноженный сам на себя $n$ раз.
- Физическая/логическая роль: Он дисконтирует оценку будущего Q-значения в состоянии $s_{t+n}$ обратно ко времени $t$, приводя его значение в соответствие с вознаграждениями, полученными за $n$ шагов.
- $Q_{\bar{\theta}}(s_{t+n}, \text{argmax}_{a_{t+n}} Q_{\theta}(s_{t+n}, a_{t+n}))$: Это целевое Q-значение.
- Математическое определение: Q-значение состояния $s_{t+n}$ и действия, которое максимизирует Q-значение в этом состоянии, как предсказано целевой сетью $Q_{\bar{\theta}}$.
- Физическая/логическая роль: Этот член обеспечивает стабильную цель для обучения онлайн-сети. Используя отдельную целевую сеть с отложенными обновлениями ($\bar{\theta}$), он предотвращает преследование оценок Q-значений движущейся цели, что может привести к нестабильности обучения. Часть $\text{argmax}$ гарантирует, что цель отражает ценность наилучшего возможного действия из следующего состояния, согласно текущему пониманию онлайн-сети.
- $Q_{\theta}(s_t, a_t)$: Это текущий прогноз Q-значения.
- Математическое определение: Q-значение текущей пары состояние-действие $(s_t, a_t)$, как предсказано онлайн-сетью $Q_{\theta}$.
- Физическая/логическая роль: Это значение, которое сеть в настоящее время прогнозирует за выполнение действия $a_t$ в состоянии $s_t$. Функция потерь направлена на корректировку $\theta$ таким образом, чтобы этот прогноз соответствовал целевому Q-значению.
- $s_t$: Это состояние во время $t$.
- Математическое определение: Представление среды во время $t$, включая узлы графа и признаки ребер (уравнения 2 и 3).
- Физическая/логическая роль: Оно содержит всю релевантную информацию о текущем прогрессе анализа термов, такую как известные/неизвестные уровни, наблюдаемые спектральные линии и теоретические расчеты.
- $a_t$: Это действие, предпринятое во время $t$.
- Математическое определение: Дискретный выбор, сделанный агентом, либо выбор неизвестного уровня ($a^{(1)}$), либо сопоставление линий для определения его энергии ($a^{(2)}$).
- Физическая/логическая роль: Оно представляет собой решение агента в процессе анализа термов.
- $\theta$: Это параметры онлайн Q-сети.
- Математическое определение: Веса и смещения нейронной сети, которая в настоящее время прогнозирует Q-значения.
- Физическая/логическая роль: Это параметры, которые активно обновляются во время обучения для улучшения политики агента.
- $\bar{\theta}$: Это параметры целевой Q-сети.
- Математическое определение: Веса и смещения копии Q-сети, обновляемые реже или плавно.
- Физическая/логическая роль: Обеспечивает стабильную ссылку для целевых Q-значений, что имеет решающее значение для стабильности процесса обучения.
- $\text{argmax}_{a_{t+n}} Q_{\theta}(s_{t+n}, a_{t+n})$: Этот оператор находит действие, максимизирующее Q-значение в состоянии $s_{t+n}$ согласно онлайн-сети.
- Математическое определение: Возвращает действие $a_{t+n}$, которое дает наивысшее Q-значение для состояния $s_{t+n}$ с использованием параметров онлайн-сети $\theta$.
- Физическая/логическая роль: Это ключевой компонент Double DQN, где онлайн-сеть выбирает действие для расчета целевого значения, но целевая сеть оценивает его ценность. Это помогает смягчить смещение переоценки в Q-обучении.
Уравнение (9): Оптимизация энергии уровней
- $E_{obs}$: Это наблюдаемые энергии уровней.
- Математическое определение: Вектор значений энергии $E_n$ для $N$ известных уровней.
- Физическая/логическая роль: Это эмпирически определенные энергетические уровни, которые анализ термов стремится установить.
- $\text{argmin}_{E_n}$: Это оператор минимизации.
- Математическое определение: Находит значения $E_n$, которые минимизируют последующее выражение.
- Физическая/логическая роль: Оно означает, что наблюдаемые энергетические уровни определяются путем поиска набора энергий, который наилучшим образом соответствует наблюдаемым спектральным линиям, минимизируя расхождения.
- $\sum_{m=0}^{M-1} w_m \left( \sum_{n=0}^{N-1} S_{mn}E_n - \sigma_m \right)^2$: Это взвешенная сумма квадратичных остатков.
- Математическое определение: Сумма по всем $M$ известным линиям, где каждый член представляет собой квадрат разности между предсказанным волновым числом и наблюдаемым волновым числом для линии $m$.
- Физическая/логическая роль: Это целевая функция для оптимизации методом наименьших квадратов. Она количественно определяет общее несоответствие между текущим набором энергетических уровней и наблюдаемым спектром. Минимизация этой суммы означает поиск энергетических уровней, которые наилучшим образом объясняют наблюдаемый спектр. Суммирование используется, поскольку общая ошибка является агрегатом ошибок от отдельных линий.
- $M$: Это общее количество известных линий.
- Математическое определение: Целочисленное количество спектральных линий, которые были сопоставлены с переходами между известными энергетическими уровнями.
- Физическая/логическая роль: Представляет объем эмпирических данных, доступных для ограничения энергетических уровней.
- $N$: Это общее количество известных уровней.
- Математическое определение: Целочисленное количество энергетических уровней, значения которых оптимизируются.
- Физическая/логическая роль: Представляет количество атомных состояний, значения которых уточняются.
- $w_m$: Это вес для линии $m$.
- Математическое определение: $w_m = (\delta\sigma_m)^{-2}$, обратный квадрат неопределенности волнового числа для линии $m$.
- Физическая/логическая роль: Он присваивает более высокую важность более точно измеренным спектральным линиям (с меньшим $\delta\sigma_m$) и меньшую важность линиям с более высокой неопределенностью. Это гарантирует, что надежные данные имеют большее влияние на определенные энергетические уровни. Обратный квадрат является стандартным выбором в методе взвешенных наименьших квадратов, где веса обратно пропорциональны дисперсии ошибки измерения.
- $\left( \sum_{n=0}^{N-1} S_{mn}E_n - \sigma_m \right)^2$: Это квадрат разности (остатка) для линии $m$.
- Математическое определение: Квадрат разности между волновым числом, предсказанным текущими энергетическими уровнями, и наблюдаемым волновым числом для линии $m$.
- Физическая/логическая роль: Он измеряет, насколько хорошо текущий набор энергетических уровней объясняет конкретную наблюдаемую спектральную линию. Возведение в квадрат обеспечивает положительные значения и сильнее наказывает большие отклонения.
- $S_{mn}$: Это коэффициент, определяющий связь между энергетическими уровнями и линией $m$.
- Математическое определение: Элемент матрицы, который равен 1, если уровень $n$ является верхним уровнем перехода $m$, -1, если уровень $n$ является нижним уровнем перехода $m$, и 0 в противном случае.
- Физическая/логическая роль: Этот коэффициент кодирует фундаментальную связь, что волновое число спектральной линии ($\sigma_m$) является разностью между верхним ($E_u$) и нижним ($E_l$) энергетическими уровнями, участвующими в переходе: $\sigma_m = E_u - E_l$.
- $E_n$: Это энергия уровня $n$.
- Математическое определение: Скалярное значение, представляющее энергию конкретного атомного уровня.
- Физическая/логическая роль: Это неизвестные параметры, которые процесс оптимизации стремится определить.
- $\sigma_m$: Это наблюдаемое волновое число для линии $m$.
- Математическое определение: Измеренное скалярное значение, представляющее волновое число спектральной линии.
- Физическая/логическая роль: Это эмпирические входные данные из списка спектральных линий, которым должны соответствовать энергетические уровни.
Пошаговый поток
Представьте анализ термов как динамичную сборочную линию, где абстрактная точка данных, представляющая текущее состояние определения атомных уровней, проходит через ряд операций.
-
Ввод начального состояния: Процесс начинается с начального состояния графа $s_t$. Это состояние представляет собой богатую структуру данных, граф $G=(V, E)$, где узлы $V$ — это атомные энергетические уровни (некоторые известные, некоторые неизвестные), а ребра $E$ — это потенциальные или наблюдаемые спектральные линии (переходы). Каждый узел и ребро несут набор признаков (например, теоретические энергии, наблюдаемые волновые числа, неопределенности, бинарные флаги "известный" или "выбранный"). Наряду с этим существует полный список спектральных линий, содержащий все наблюдаемые переходы.
-
Действие $a^{(1)}$: Выбор уровня: Агент сначала выполняет действие типа $a^{(1)}$. Он просматривает все в настоящее время неизвестные уровни, которые имеют по крайней мере два потенциальных соединения (ребра) с известными уровнями. Из этого пула агент выбирает один конкретный неизвестный уровень для фокусировки определения. Этот выбор основан на изученных Q-значениях агента, которые оценивают долгосрочное вознаграждение за выбор этого уровня. После выбора флаг "выбранный" для этого узла переключается, чтобы указать, что это текущая цель.
-
Действие $a^{(2)}$: Сопоставление линий и гипотеза энергии: Затем агент выполняет действие типа $a^{(2)}$. Для "выбранного" неизвестного уровня он рассматривает все возможные ребра, соединяющие его с известными уровнями. Для каждого такого ребра он фильтрует полный список спектральных линий (который может содержать $10^4$ линий), чтобы найти кандидаты наблюдаемых линий. Эта фильтрация строгая:
- Соответствие волнового числа: Наблюдаемое волновое число $\sigma_{obs}$ должно находиться в теоретическом диапазоне $[\sigma_{calc} \pm \Delta E]$, где $\sigma_{calc}$ — теоретическое волновое число для перехода, а $\Delta E$ — неопределенность энергии.
- Соответствие интенсивности: Наблюдаемая интенсивность $I_{obs}$ должна находиться в теоретическом диапазоне $[I_{calc} \pm \Delta I]$.
- Генерация кандидатов $E_{obs}$: Для каждой отфильтрованной линии вычисляется кандидат наблюдаемой энергии $E_{obs}$ для выбранного неизвестного уровня путем добавления или вычитания волнового числа линии из известной энергии связанного уровня (в зависимости от того, является ли выбранный уровень верхним или нижним).
- Консолидация: Поскольку несколько линий могут указывать на одну и ту же энергию для неизвестного уровня, кандидаты группируются, и только $E_{obs}$, которые повторяются в пределах небольшого допуска $\delta E$, считаются. Затем агент выбирает одно из этих консолидированных значений $E_{obs}$ (или "бездействует", если подходящих кандидатов нет).
-
Переход состояния и обновление графа: После выбора значения $E_{obs}$ для выбранного уровня (через $a^{(2)}$) состояние графа $s_t$ детерминированно переходит в новое состояние $s_{t+1}$:
- "Выбранный" неизвестный уровень теперь становится "известным" уровнем, и его признак $E_{obs}$ обновляется выбранным значением.
- Ребра, соответствующие сопоставленным спектральным линиям, также становятся "известными" ребрами, и их признаки (например, $\sigma_{obs}$, $I_{obs}$) обновляются из списка линий. Эти сопоставленные линии затем исключаются из будущих рассмотрений $a^{(2)}$ в этом эпизоде.
- Глобальная повторная оптимизация: Важно отметить, что после определения нового уровня наблюдаемые энергии $E_{obs}$ всех текущих известных уровней (включая вновь определенный) повторно оптимизируются с использованием минимизации методом взвешенных наименьших квадратов (Уравнение 9). Это обеспечивает согласованность всей известной системы уровней. Основной энергетический уровень $E_0$ фиксируется на нуле в качестве эталона.
-
Расчет вознаграждения: На основе нового состояния $s_{t+1}$ и предпринятых действий вычисляется вознаграждение $r_t$. Это вознаграждение является составным и отражает уверенность в определенном уровне, его соответствие теории и его потенциал для обеспечения будущих определений. Для $a^{(1)}$ оно основано на отношении сигнал/шум соединяющих линий (Уравнение 6). Для $a^{(2)}$ оно включает изученную оценку предпочтения $D$ (Уравнение 7), которая выводится из решений экспертов-людей.
-
Хранение опыта: Кортеж $(s_t, a_t, r_t, s_{t+1})$ — представляющий старое состояние, предпринятое действие, полученное вознаграждение и новое состояние — сохраняется в буфере повторного воспроизведения. Этот буфер действует как память, накапливая прошлый опыт.
-
Итерация: Затем процесс возвращается к шагу 2, где агент выбирает другой неизвестный уровень или продолжает уточнять текущий, пока не будет достигнут конечный горизонт $H$ или не станет возможным предпринять больше допустимых действий.
Эта вся последовательность делает абстрактную математику похожей на движущуюся механическую сборочную линию, где необработанные спектральные данные постоянно уточняются и интегрируются в растущую, самосогласованную модель атомных энергетических уровней.
Динамика оптимизации
Механизм TAG-DQN обучается и сходится благодаря сложному взаимодействию методов глубокого обучения с подкреплением, в основном управляемого минимизацией ошибки временной разности (TD). Вот как это работает:
-
Обучение представлений графа: Основой является графовая нейронная сеть (GNN). Когда представляется состояние графа $s_t$ (представляющее текущий набор известных/неизвестных уровней и линий), GNN обрабатывает его узлы (уровни) и ребра (линии) и связанные с ними признаки (например, $E_{calc}$, $\sigma_{obs}$, $I_{obs}$). Он использует многоголовые слои графового внимания для изучения богатых, контекстуальных векторов вложений узлов $h_v$ для каждого узла $v$. Эти вложения захватывают структурную и признаковую информацию локального окружения вокруг каждого узла. Затем глобальный вектор состояния графа $S_{agg}$ получается простым усреднением этих вложений узлов (Уравнение 11). Этот $S_{agg}$ эффективно суммирует текущее состояние всего графа.
-
Оценка Q-значений (Duelling DQN): Полученные графовые вложения затем подаются в многослойные перцептроны (MLP) для оценки Q-значений. Архитектура использует дизайн Duelling DQN, который разделяет оценку функции ценности состояния $V(s)$ и функции преимущества $A(s, a)$.
- Для типа действия $a^{(1)}$ (выбор неизвестного уровня) Q-значение для каждого допустимого выбора уровня оценивается путем объединения глобального $S_{agg}$ (для ценности состояния) с вложением узла выбранного уровня (для преимущества), как показано в Уравнении (12).
- Для типа действия $a^{(2)}$ (сопоставление линий для определения энергии) Q-значение оценивается аналогично, но функция преимущества $A(s,a)$ вычисляется путем взятия разности между ценностью состояния-действия и ценностью состояния, как показано в Уравнении (13). Это разделение помогает сети изучать, какие состояния ценны независимо от предпринятых действий, повышая эффективность.
-
Политика и исследование: Политика агента является жадной по отношению к оцененным Q-значениям. На каждом шаге он выбирает действие (либо $a^{(1)}$, либо $a^{(2)}$), которое имеет наивысшее прогнозируемое Q-значение. Для исследования, вместо традиционного метода эпсилон-жадного, авторы используют шумные сети. Это означает, что шум добавляется непосредственно к весам выходных слоев MLP, побуждая агента естественным образом исследовать разные действия без явного параметра $\epsilon$. Шум изучается и адаптируется со временем, обеспечивая более эффективное исследование в сложных средах.
-
Обучение на опыте (Буфер повторного воспроизведения и n-шаговые возвраты): Чтобы учиться, агент не просто использует свой самый последний опыт. Вместо этого он сохраняет прошлый опыт (кортежи состояние, действие, вознаграждение, следующее состояние) в буфере повторного воспроизведения. Во время обучения случайным образом выбираются пакеты этого опыта из буфера. Это нарушает корреляции между последовательными опытами, стабилизируя процесс обучения. Расчет потерь (Уравнение 15) использует n-шаговые возвраты ($r^{[n]}$), что означает, что вместо рассмотрения только немедленного вознаграждения $r_t$ и Q-значения следующего состояния $s_{t+1}$, он смотрит на $n$ шагов вперед. Это обеспечивает более точную цель для обучения, включая фактические вознаграждения за короткую траекторию перед бутстрэппингом из оценки Q-значения.
-
Целевая сеть для стабильности: Ключевая проблема в Q-обучении заключается в том, что целевое значение (что сеть пытается предсказать) зависит от той же сети, которая обновляется, что приводит к нестабильности. Для решения этой проблемы TAG-DQN использует целевую сеть $Q_{\bar{\theta}}$. Это отдельная копия онлайн Q-сети ($Q_{\theta}$), параметры которой $\bar{\theta}$ обновляются гораздо медленнее, чем $\theta$. В частности, $\bar{\theta}$ мягко обновляется (Уравнение 14) путем смешивания небольшой доли параметров онлайн-сети с параметрами целевой сети на каждом шаге. Это создает стабильную цель для обучения онлайн-сети, предотвращая колебания и расхождение. Использование Double DQN дополнительно уточняет это, используя онлайн-сеть для выбора наилучшего действия для следующего состояния, но целевую сеть для оценки его ценности, что помогает смягчить смещение переоценки.
-
Обучение функции вознаграждения (Обратное обучение с подкреплением): Уникальный аспект заключается в том, что функция вознаграждения для действия $a^{(2)}$ (оценка предпочтения $D$) не закодирована вручную. Вместо этого она обучается на исторических решениях экспертов-людей с использованием формы обратного обучения с подкреплением. Простой многослойный перцептрон (MLP) обучается прогнозировать $D$ на основе признаков кандидатов линий (Уравнение 8). Этот MLP обучается на сгенерированных экспертами переходах состояний MDP, где решения человека помечены как положительные примеры. Это позволяет системе неявно улавливать тонкие суждения экспертов-людей относительно "хорошести" конкретного сопоставления линий, формируя ландшафт потерь для благоприятствования действиям, соответствующим интуиции экспертов.
-
Алгоритм оптимизации: Параметры сети $\theta$ оптимизируются с использованием оптимизатора Adam, популярного метода стохастического градиентного спуска, известного своей эффективностью и хорошей производительностью в задачах глубокого обучения. Этот итеративный процесс оптимизации корректирует веса и смещения GNN и MLP для минимизации функции потерь, тем самым повышая точность прогнозов Q-значений и, как следствие, политики агента.
По сути, динамика оптимизации включает непрерывный цикл: агент действует в среде, собирает опыт, сохраняет его, а затем учится на пакетах этого опыта, минимизируя тщательно сконструированную функцию потерь. Этот процесс обучения стабилизируется такими методами, как целевые сети, n-шаговые возвраты и дуэльные архитектуры, в то время как исследование обрабатывается шумными сетями. Изученная функция вознаграждения, полученная из экспертных знаний человека, дополнительно направляет агента к физически осмысленным решениям, формируя ландшафт потерь для отражения предпочтений и неопределенностей экспертов. Эта итеративная доработка позволяет агенту сходиться к политике, которая эффективно и точно определяет тонкие структуры атомов.
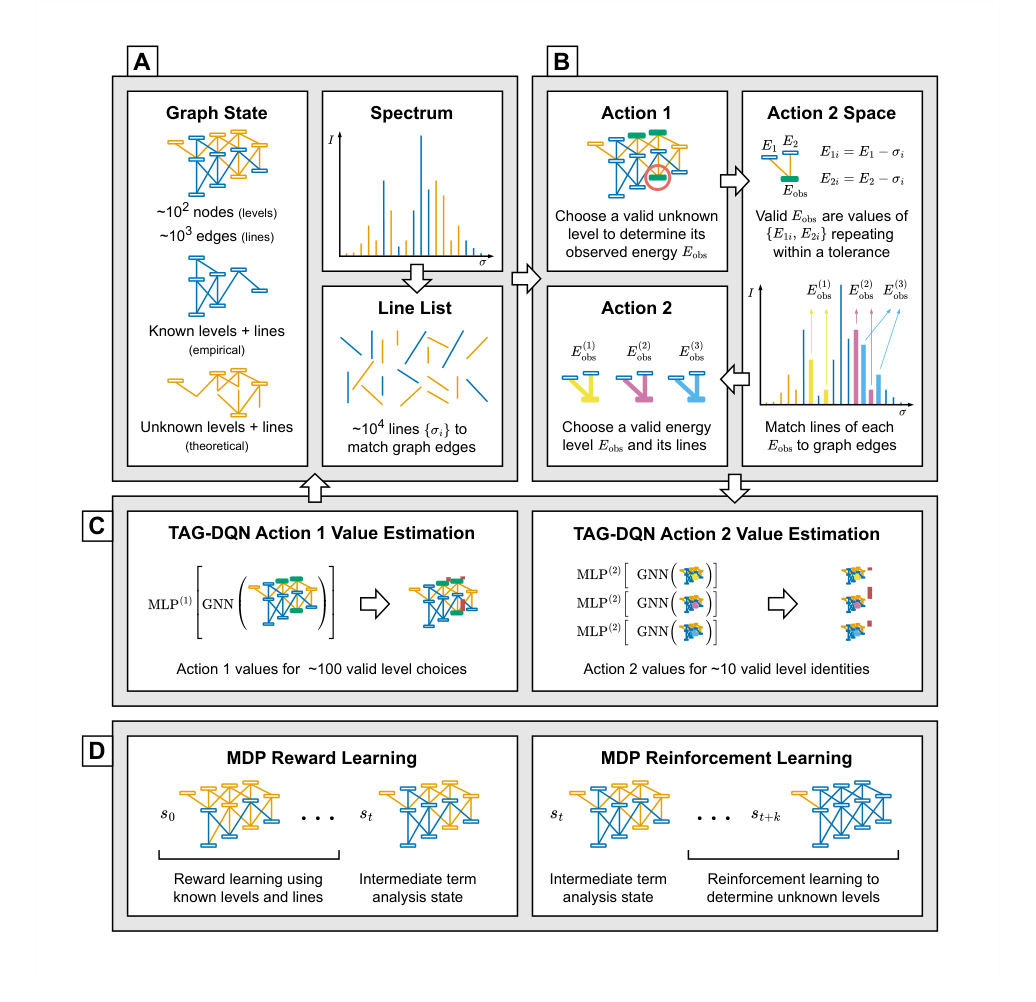 Figure 1. Illustration of the MDP environment and TAG-DQN. A The term analysis state is represented as a graph with node and edge features, alongside the spectral line list. B Actions alternate between two regimes; each pair of actions leads to the determination of the observed energy Eobs for one level by matching at least two lines from the line list to unknown edges in the graph. C TAG-DQN employs a GNN to embed graph representations, which are inputs for multilayer perceptrons (MLPs) estimating Q-values for each action (vertical bars); the highest Q-value action advances the MDP to the next state. D Given a term analysis state st, the MDP trajectory leading to st involving known levels is used for reward learning, while RL with the learned reward function guides the discovery of unknown levels in future states st+k
Figure 1. Illustration of the MDP environment and TAG-DQN. A The term analysis state is represented as a graph with node and edge features, alongside the spectral line list. B Actions alternate between two regimes; each pair of actions leads to the determination of the observed energy Eobs for one level by matching at least two lines from the line list to unknown edges in the graph. C TAG-DQN employs a GNN to embed graph representations, which are inputs for multilayer perceptrons (MLPs) estimating Q-values for each action (vertical bars); the highest Q-value action advances the MDP to the next state. D Given a term analysis state st, the MDP trajectory leading to st involving known levels is used for reward learning, while RL with the learned reward function guides the discovery of unknown levels in future states st+k
Результаты, ограничения и заключение
Экспериментальный дизайн и базовые модели
Для строгой проверки своих математических утверждений авторы разработали серию экспериментов, сравнивающих их анализ термов с графовой глубокой Q-сетью (TAG-DQN) с двумя базовыми моделями: жадным поисковым агентом и стандартным поисковым агентом по дереву Монте-Карло (MCTS), который использовал стратегию Верхней доверительной границы для деревьев (UCT). Основная идея заключалась в демонстрации того, что TAG-DQN может эффективно автоматизировать и ускорить сложную задачу последовательного принятия решений по определению тонкой структуры атомов.
Экспериментальная установка включала четыре различных среды Марковского процесса принятия решений (MDP), каждая из которых была получена из реальных анализов атомных термов Co II, Nd III и двух вариантов Nd II (Nd II u для расчетов ab initio и Nd II k для расчетов по коду Кована). Эти среды были тщательно сконструированы для отражения проблем реального анализа термов, используя существующие списки спектральных линий Фурье-трансформации (FT) и теоретические расчеты. Например, среда Co II была инициализирована 141 известным уровнем из пересмотренных опубликованных данных, в то время как Nd III использовал 40 уровней. Среды Nd II начинались с шести уровней основного терма, пяти уровней 6K и 11 переходов, различающихся методами теоретических расчетов.
Для обеспечения справедливого и надежного сравнения TAG-DQN и MCTS оценивались по 25 различным случайным начальным условиям, с отчетами о средней производительности и 95% доверительных интервалах. Жадный поиск, будучи детерминированным, проводился один раз. Производительность измерялась с использованием трех ключевых метрик:
1. $R_{max}$: Максимальное кумулятивное вознаграждение, достигнутое агентом в эпизоде MDP длиной $H$.
2. $N_c$: Количество правильно определенных энергетических уровней в эпизоде $R_{max}$, где уровень считался правильным, если его наблюдаемая энергия ($E_{obs}$) находилась в пределах $\pm \delta E$ от ранее опубликованного энергетического уровня ($E_{known}$).
3. Точность (Acc.): Определяется как отношение $N_c$ к общему количеству уровней, определенных в эпизоде $R_{max}$.
Среды MDP были тщательно упрощены для повышения осуществимости и производительности RL. Это включало обрезку ребер графа с низким отношением сигнал/шум ($S/N_{calc} < 2$), исключение записей из списка линий, которые уже были сопоставлены, фиксацию начальных известных уровней во время оптимизации энергии и ограничение спектральных диапазонов. Максимальный предел пространства действий для сопоставления линий ($|A^{(2)}|$) также был установлен для обеспечения эффективного исследования и управления памятью. Длина эпизода $H$ варьировалась для каждого вида (например, $H=128$ для Nd III и Co II, $H=64$ для Nd II u, $H=512$ для Nd II k) для балансировки вычислительных затрат и способности агента изучать долгосрочные последствия.
Кроме того, были проведены абляционные исследования на среде Nd III для анализа вклада различных расширений глубокой Q-сети (таких как двойное Q-обучение, приоритетная выборка опыта, дуэлинг, многошаговые возвраты и шумные сети для исследования) в общую производительность TAG-DQN. Это позволило исследователям точно определить, какие компоненты архитектуры были наиболее важны для успешной работы модели.
Что доказывают доказательства
Экспериментальные результаты предоставляют убедительные доказательства того, что TAG-DQN может значительно ускорить определение тонкой структуры атомов, задачу, которая традиционно требовала месяцев или лет человеческих усилий. Система смогла идентифицировать и определить сотни энергетических уровней за несколько часов.
В частности, основной механизм TAG-DQN, который рассматривает анализ термов как Марковский процесс принятия решений, решаемый с помощью графового обучения с подкреплением с функцией вознаграждения, частично обученной на решениях человека, продемонстрировал свою работоспособность на практике. Окончательным доказательством является высокая степень согласия с опубликованными значениями: 95% для Co II и от 54% до 87% для Nd II и Nd III. Такой уровень точности, достигнутый за долю времени, является сильным показателем эффективности метода.
По сравнению с базовыми моделями (Таблица 2), TAG-DQN последовательно превосходил жадный поисковый агент по всем метрикам. Более важно, что он показал превосходную производительность по сравнению с агентом MCTS по показателю $N_c$ (количество правильно определенных энергетических уровней) в трех из пяти случаев. В то время как MCTS иногда достигал более высокого максимального кумулятивного вознаграждения ($R_{max}$), TAG-DQN последовательно достигал более высоких верхних границ для $N_c$, особенно в случаях Nd II. Это предполагает, что TAG-DQN лучше выбирал идентификаторы уровней, которые оставались согласованными с наблюдениями и теорией на протяжении всего эпизода, в то время как неглубокие прогоны MCTS могли отдавать предпочтение краткосрочным вознаграждениям в ущерб общей точности. Для Nd II k TAG-DQN правильно определил значительно большее количество уровней (169 $\pm$ 10) по сравнению с MCTS (130 $\pm$ 11), что еще больше подтверждает эту интерпретацию.
Кривые обучения (Рисунок 2A, B) наглядно иллюстрируют соответствие между кумулятивным вознаграждением и количеством правильно определенных уровней ($N_c$), указывая на то, что изученная функция вознаграждения эффективно направляет агента к точным определениям уровней. Графики Больцмана (Рисунок 2C) подтвердили, что TAG-DQN может определять уровни в различных электронных конфигурациях и что его фильтрация интенсивности линий, основанная на населенностях уровней Больцмана, была эффективной в исключении проблемных линий.
Абляционные исследования (Рисунок 3) предоставили важные сведения об архитектуре TAG-DQN. Они показали, что большинство расширений DQN положительно влияли на производительность, причем архитектуры дуэльных сетей и шумные сети для исследования были особенно критичны. Вероятно, это связано с большими пространствами действий, присущими проблеме. Интересно, что приоритетная выборка опыта (PER) немного снизила производительность, возможно, потому, что размер буфера и шаги обучения не были оптимально масштабированы для преимуществ PER в этой конкретной среде. Разности энергетических уровней (Рисунок 4) далее подтвердили точность метода, показав, что, хотя небольшая доля определенных уровней отклонялась от принятых значений, эти отклонения, как правило, находились в пределах экспериментальной неопределенности $\delta E$ (например, $\pm 0.004$ см$^{-1}$ для Nd III, $\pm 0.006$ см$^{-1}$ для Co II, $\pm 0.009$ см$^{-1}$ для Nd II k), что делает их незначительными для большинства применений.
Ограничения и будущие направления
Хотя подход TAG-DQN знаменует собой значительный прогресс в автоматизации определения тонкой структуры атомов, важно признать его текущие ограничения и рассмотреть пути для будущих разработок.
Одним из основных ограничений является то, что текущий метод, несмотря на свою впечатляющую скорость, по-прежнему демонстрирует сниженную точность по сравнению с экспертами-людьми и опирается на расчеты атомной структуры. Определенные уровни, особенно в случаях, подобных Nd II k, считаются предварительными и требуют проверки человеком перед окончательной публикацией. Более того, текущая структура еще не решает наиболее сложные сценарии в анализе термов, такие как определение уровней по одной линии, соединение несвязанных подграфов известных уровней или инициирование анализов из полностью неизвестного состояния. Эти ситуации значительно увеличат сложность MDP и потребуют существенного перепроектирования. Функция вознаграждения, в настоящее время обученная преимущественно на данных Co II, могла бы выиграть от более разнообразного и обширного обучающего набора данных для улучшения ее обобщения на различные атомные виды и условия.
Заглядывая вперед, несколько перспективных направлений могут далее развить эти выводы:
- Обогащение пространства состояний и действий MDP: Текущий MDP может быть расширен для включения более детальной информации. Например, интеграция необработанного спектра и анализа профилей линий непосредственно в MDP позволила бы агенту учитывать дополнительные факторы, такие как изотопические сдвиги, сверхтонкая структура и сравнения между различными спектрами. Информация о волновой функции, такая как ведущие метки конфигураций, плотность электронов и локальная плотность уровней в пределах определенных четности и J-значений, также могла бы информировать решения агента о профилях и интенсивностях линий, потенциально приводя к более надежным и точным определениям уровней.
- Разработка более надежной функции вознаграждения: Как отмечалось, зависимость текущей функции вознаграждения от ограниченного набора данных является ограничением. Будущая работа должна быть сосредоточена на обучении более обобщенной функции вознаграждения с использованием огромного массива списков линий и MDP от различных атомных видов. Это улучшит способность агента обрабатывать новые ситуации и повысит общую производительность.
- Интеграция с участием человека: Авторы предполагают совместный подход, где вывод ИИ служит промежуточным шагом. Конечное состояние MDP эпизода может стать новым начальным состоянием для экспертов-людей, чтобы они могли проверить спектр, обрезать некорректно определенные уровни, уточнить полуэмпирические расчеты и переобучить функцию вознаграждения. Это итеративное сотрудничество человека и ИИ могло бы использовать сильные стороны обоих, при этом ИИ обрабатывает трудоемкую первоначальную идентификацию, а эксперт-человек обеспечивает критическую проверку и уточнение.
- Решение сложных сценариев: Будущие исследования должны быть сосредоточены на перепроектировании MDP для обработки в настоящее время опущенных сложных ситуаций. Это может потребовать новых графовых представлений или декомпозиций пространства действий для управления повышенной сложностью, потенциально открывая возможность автоматизировать даже самые сложные аспекты анализа термов.
- Расширение на другие экспериментальные методы: Подход является гибким по своей природе и может быть адаптирован к другим экспериментальным методам, таким как дифракционная спектроскопия, с незначительными корректировками параметров среды, такими как $\delta E$, $\Delta I$, и функция вознаграждения. Это расширит применимость графового обучения с подкреплением в различных спектроскопических методах.
- Вычислительная эффективность и инфраструктура: В то время как TAG-DQN может работать на обычном оборудовании для однократных запусков, комплексные эксперименты, включающие обширную настройку гиперпараметров и оценки с несколькими начальными условиями, требуют значительных вычислительных ресурсов. Будущая работа могла бы изучить более эффективные методы оптимизации гиперпараметров или распределенные вычислительные фреймворки для сокращения вычислительных затрат и времени, необходимых для обширных исследований.
В конечном счете, эта работа является свидетельством потенциала графового обучения с подкреплением и ИИ в целом для содействия научным открытиям, особенно в областях, требующих больших объемов данных и трудоемких процессов. Предложенные усовершенствования могут проложить путь к новой эре ускоренных исследований в области атомной физики, сокращая разрыв между спросом на атомные данные и текущей эффективностью их определения.
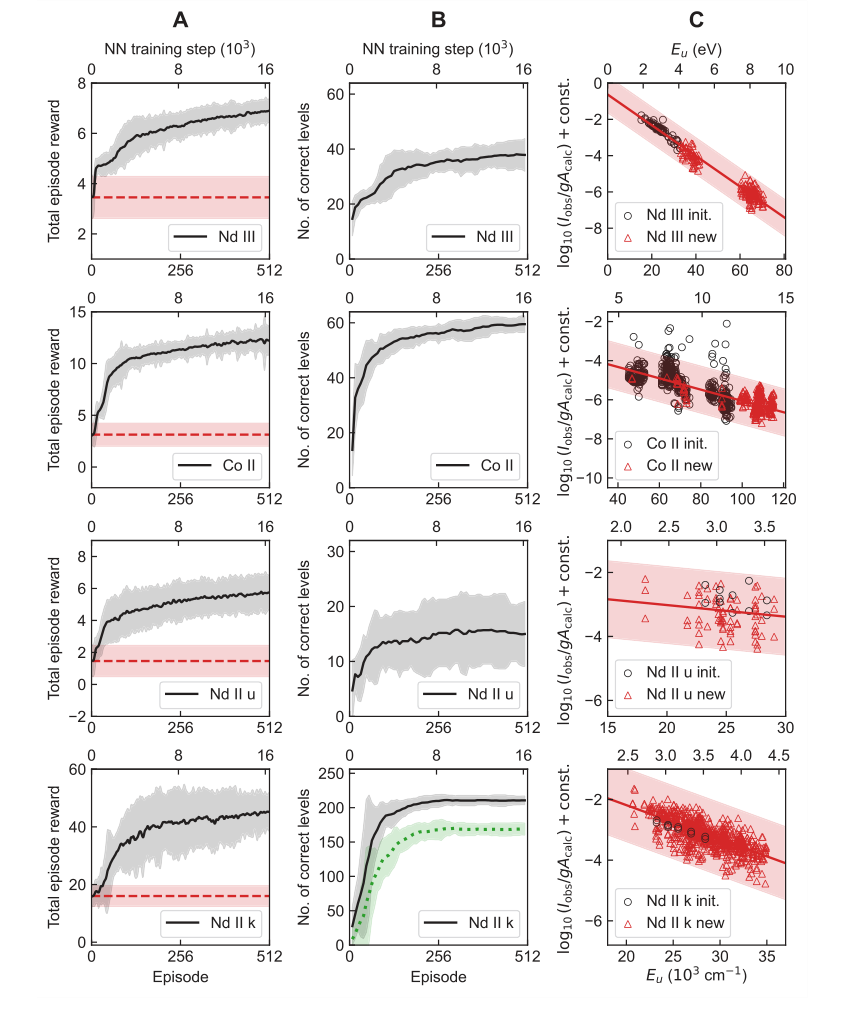 Figure 2. Learning results of TAG-DQN agent in the four case studies of Table 1. A Average learning curves, i.e., mean cumulative rewards obtained as a function of neural network (NN) training steps. The dashed horizontal lines show reward obtained during the pre-training episodes and correspond to rewards obtained by choosing actions in the MDP uniformly at random. The shaded regions show ±2 standard deviations across 25 random seeds. B Average Nc of the final state of the most recent maximum reward episode. The dotted curve for Nd II k shows the number of correct levels that also match human chosen level labels, and the y-axes limits are H
Figure 2. Learning results of TAG-DQN agent in the four case studies of Table 1. A Average learning curves, i.e., mean cumulative rewards obtained as a function of neural network (NN) training steps. The dashed horizontal lines show reward obtained during the pre-training episodes and correspond to rewards obtained by choosing actions in the MDP uniformly at random. The shaded regions show ±2 standard deviations across 25 random seeds. B Average Nc of the final state of the most recent maximum reward episode. The dotted curve for Nd II k shows the number of correct levels that also match human chosen level labels, and the y-axes limits are H
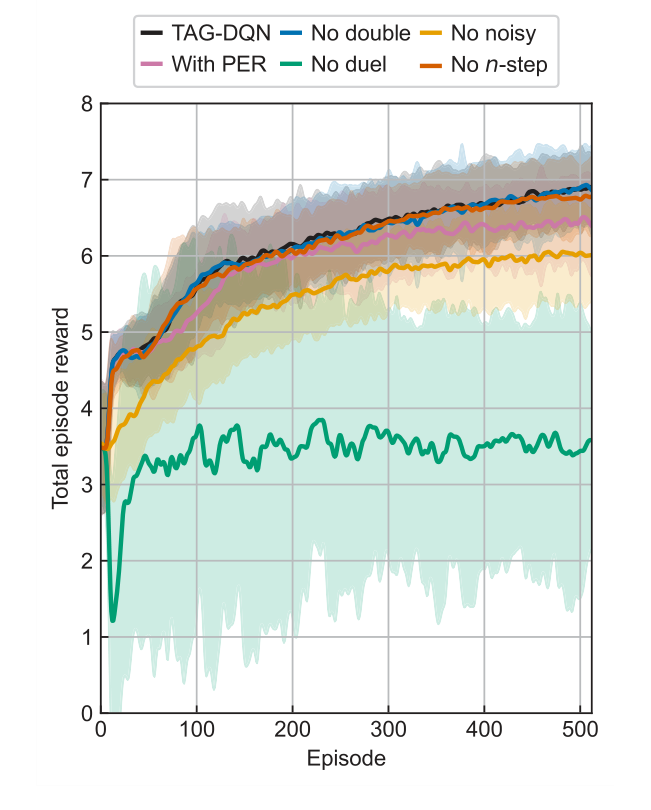 Figure 3. Learning curves of TAG-DQN (black) and its variants in the Nd III environment. Average total episode reward during training of TAG-DQN and its designs with or without particular deep Q-network extensions: without double Q-learning (blue), without noisy networks for exploration (yellow), with prioritised experience replay (PER, pink), without duelling deep Q-network (green), and without multi(n)-step return (orange). Shaded regions show ±2 standard deviations across 16 seeds. The duelling extension and noisy networks for exploration are key for TAG-DQN, while using PER reduced performance slightly
Figure 3. Learning curves of TAG-DQN (black) and its variants in the Nd III environment. Average total episode reward during training of TAG-DQN and its designs with or without particular deep Q-network extensions: without double Q-learning (blue), without noisy networks for exploration (yellow), with prioritised experience replay (PER, pink), without duelling deep Q-network (green), and without multi(n)-step return (orange). Shaded regions show ±2 standard deviations across 16 seeds. The duelling extension and noisy networks for exploration are key for TAG-DQN, while using PER reduced performance slightly
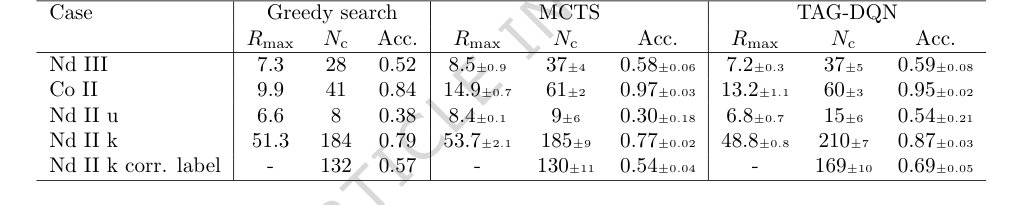 Table 2. Results and comparisons with benchmark agents. TAG-DQN matches MCTS performance as judged by downstream metrics in 2/5 cases and outperforms it in 3/5 cases, while Greedy search is worse overall
Table 2. Results and comparisons with benchmark agents. TAG-DQN matches MCTS performance as judged by downstream metrics in 2/5 cases and outperforms it in 3/5 cases, while Greedy search is worse overall
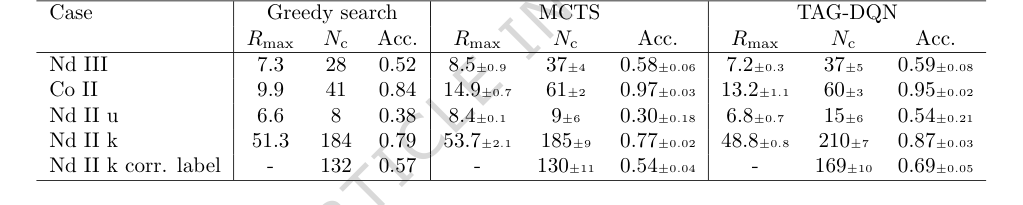 Table 1. Key term analysis MDP environment parameters
Table 1. Key term analysis MDP environment parameters